
Information-Theoretic Sequential Framework to Elicit Dynamic High-Order Interactions in High-Dimensional Network Processes

 , , , ,
, , , ,  ,
,  and
and
Abstract
1. Introduction
2. Sequential Method for Quantifying Higher-Order Interactions
2.1. Sequential Procedure Outline
- 1.
- Given the set , first identify the triplet that exhibits the highest level of redundancy or synergy according to a predefined metric.
- 2.
- Expand the selected triplet iteratively by adding one process at a time, ensuring that its inclusion results in the maximal statistically significant increase in the overall redundancy or synergy of the joint multiplet according to the chosen metric. Repeat this until no additional inclusion produces a statistically significant increase in redundancy or synergy.
2.2. Linear Parametric Estimation of Higher-Order Interaction Information Measures
3. Simulation Studies
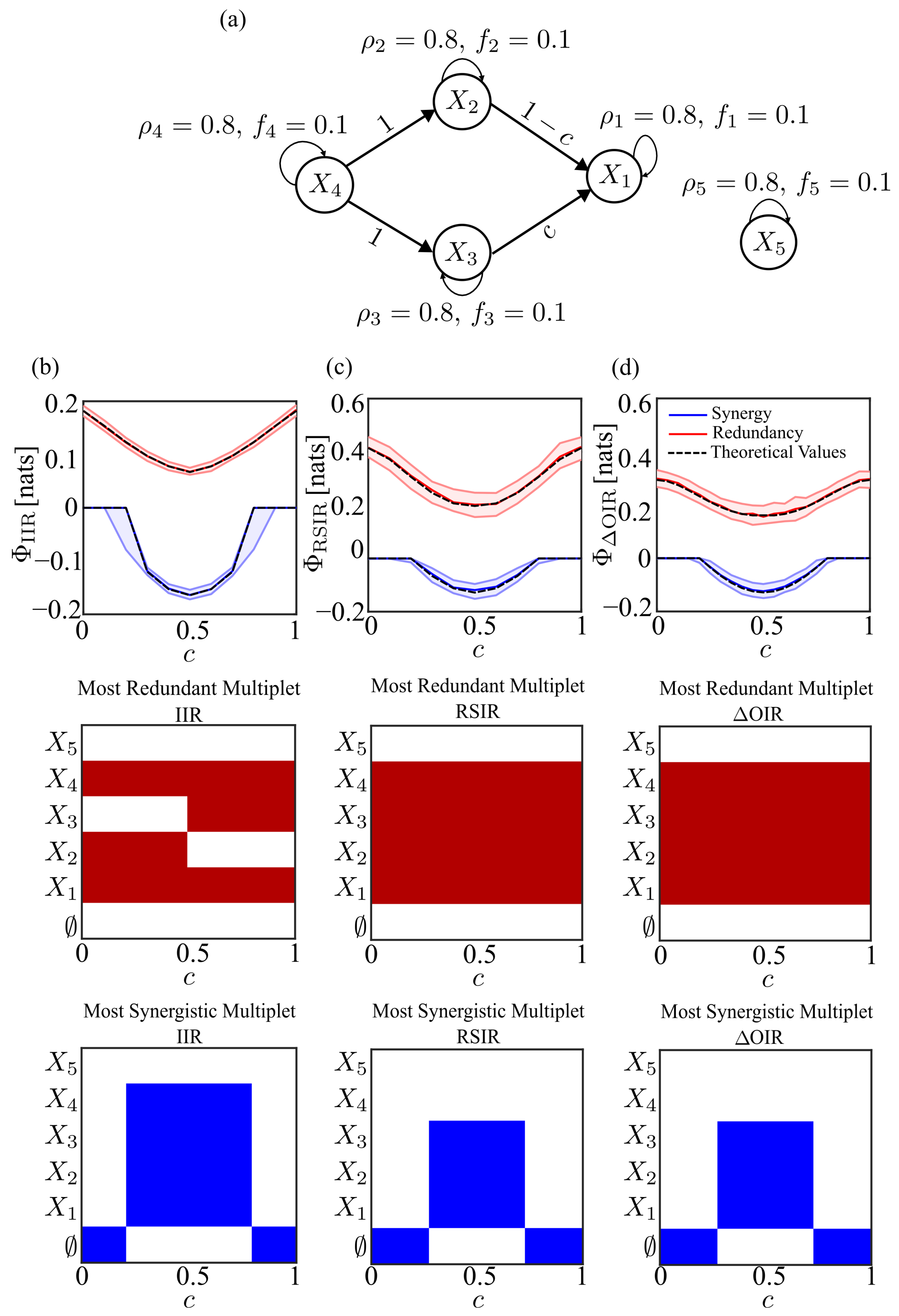
3.1. Five-Dimensional VAR Model
3.2. Randomly Connected Networks
4. Application to a Climate Network
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Bashan, A.; Bartsch, R.P.; Kantelhardt, J.W.; Havlin, S.; Ivanov, P.C. Network physiology reveals relations between network topology and physiological function. Nat. Commun. 2012, 3, 702. [Google Scholar] [CrossRef] [PubMed]
- Bassett, D.S.; Sporns, O. Network neuroscience. Nat. Neurosci. 2017, 20, 353–364. [Google Scholar] [CrossRef] [PubMed]
- Battiston, F.; Cencetti, G.; Iacopini, I.; Latora, V.; Lucas, M.; Patania, A.; Young, J.G.; Petri, G. Networks beyond pairwise interactions: Structure and dynamics. Phys. Rep. 2020, 874, 1–92. [Google Scholar] [CrossRef]
- Battiston, F.; Amico, E.; Barrat, A.; Bianconi, G.; de Arruda, G.F.; Franceschiello, B.; Iacopini, I.; Kéfi, S.; Latora, V.; Moreno, Y.; et al. The physics of higher-order interactions in complex systems. Nat. Phys. 2021, 17, 1093–1098. [Google Scholar] [CrossRef]
- Bianconi, G. Higher-Order Networks: An Introduction to Simplicial Complexes; Cambridge University Press: Cambridge, UK, 2021; p. 140. [Google Scholar] [CrossRef]
- Antonacci, Y.; Barà, C.; Sparacino, L.; Pirovano, I.; Mastropietro, A.; Rizzo, G.; Faes, L. Spectral Information Dynamics of Cortical Signals Uncover the Hierarchical Organization of the Human Brain’s Motor Network. IEEE Trans. Biomed. Eng. 2024, 72, 1655–1664. [Google Scholar] [CrossRef] [PubMed]
- Antonacci, Y.; Minati, L.; Nuzzi, D.; Mijatovic, G.; Pernice, R.; Marinazzo, D.; Stramaglia, S.; Faes, L. Measuring high-order interactions in rhythmic processes through multivariate spectral information decomposition. IEEE Access 2021, 9, 149486–149505. [Google Scholar] [CrossRef]
- Bardoscia, M.; Barucca, P.; Battiston, S.; Caccioli, F.; Cimini, G.; Garlaschelli, D.; Saracco, F.; Squartini, T.; Caldarelli, G. The physics of financial networks. Nat. Rev. Phys. 2021, 3, 490–507. [Google Scholar] [CrossRef]
- Mijatovic, G.; Antonacci, Y.; Javorka, M.; Marinazzo, D.; Stramaglia, S.; Faes, L. Network Representation of Higher-Order Interactions Based on Information Dynamics. IEEE Trans. Netw. Sci. Eng. 2025, 12, 1872–1884. [Google Scholar] [CrossRef]
- Faes, L.; Mijatovic, G.; Antonacci, Y.; Pernice, R.; Bara, C.; Sparacino, L.; Sammartino, M.; Porta, A.; Marinazzo, D.; Stramaglia, S. A New Framework for the Time-and Frequency-Domain Assessment of High-Order Interactions in Networks of Random Processes. IEEE Trans. Signal Process. 2022, 70, 5766–5777. [Google Scholar] [CrossRef]
- Leung, L.Y.; North, G.R. Information theory and climate prediction. J. Clim. 1990, 3, 5–14. [Google Scholar] [CrossRef]
- Williams, P.L.; Beer, R.D. Nonnegative Decomposition of Multivariate Information. arXiv 2010, arXiv:1004.2515. [Google Scholar]
- James, R.G.; Ellison, C.J.; Crutchfield, J.P. Anatomy of a bit: Information in a time series observation. Chaos Interdiscip. J. Nonlinear Sci. 2011, 21, 037109. [Google Scholar] [CrossRef] [PubMed]
- Stramaglia, S.; Cortes, J.M.; Marinazzo, D. Synergy and redundancy in the Granger causal analysis of dynamical networks. New J. Phys. 2014, 16, 105003. [Google Scholar] [CrossRef]
- Barrett, A.B. Exploration of synergistic and redundant information sharing in static and dynamical Gaussian systems. Phys. Rev. E 2015, 91, 052802. [Google Scholar] [CrossRef]
- Finn, C.; Lizier, J.T. Pointwise partial information decomposition using the specificity and ambiguity lattices. Entropy 2018, 20, 297. [Google Scholar] [CrossRef] [PubMed]
- Wibral, M.; Priesemann, V.; Kay, J.W.; Lizier, J.T.; Phillips, W.A. Partial information decomposition as a unified approach to the specification of neural goal functions. Brain Cogn. 2017, 112, 25–38. [Google Scholar] [CrossRef]
- Rosas, F.; Ntranos, V.; Ellison, C.J.; Pollin, S.; Verhelst, M. Understanding interdependency through complex information sharing. Entropy 2016, 18, 38. [Google Scholar] [CrossRef]
- Ince, R.A.A. The Partial Entropy Decomposition: Decomposing multivariate entropy and mutual information via pointwise common surprisal. arXiv 2017, arXiv:1702.01591. [Google Scholar]
- Rosas, F.E.; Mediano, P.A.; Gastpar, M.; Jensen, H.J. Quantifying high-order interdependencies via multivariate extensions of the mutual information. Phys. Rev. E 2019, 100, 032305. [Google Scholar] [CrossRef]
- Rosas, F.E.; Mediano, P.A.M.; Jensen, H.J.; Seth, A.K.; Barrett, A.B.; Carhart-Harris, R.L.; Bor, D. Reconciling emergences: An information-theoretic approach to identify causal emergence in multivariate data. PLoS Comput. Biol. 2020, 16, e1008289. [Google Scholar] [CrossRef]
- Mediano, P.A.; Rosas, F.E.; Bor, D.; Seth, A.K.; Barrett, A.B. The strength of weak integrated information theory. Trends Cogn. Sci. 2022, 26, 646–655. [Google Scholar] [CrossRef] [PubMed]
- Stramaglia, S.; Faes, L.; Cortes, J.M.; Marinazzo, D. Disentangling high-order effects in the transfer entropy. Phys. Rev. Res. 2024, 6, L032007. [Google Scholar] [CrossRef]
- Schreiber, T. Measuring information transfer. Phys. Rev. Lett. 2000, 85, 461–464. [Google Scholar] [CrossRef] [PubMed]
- Ontivero-Ortega, M.; Faes, L.; Cortes, J.M.; Marinazzo, D.; Stramaglia, S. Assessing high-order effects in feature importance via predictability decomposition. Phys. Rev. E 2025, 111, L033301. [Google Scholar] [CrossRef]
- McGill, W. Multivariate information transmission. Trans. IRE Prof. Group Inf. Theory 1954, 4, 93–111. [Google Scholar] [CrossRef]
- Timme, N.; Alford, W.; Flecker, B.; Beggs, J.M. Synergy, redundancy, and multivariate information measures: An experimentalist’s perspective. J. Comput. Neurosci. 2014, 36, 119–140. [Google Scholar] [CrossRef]
- Timmermann, A.; An, S.I.; Kug, J.S.; Jin, F.F.; Cai, W.; Capotondi, A.; Cobb, K.; Lengaigne, M.; McPhaden, M.J.; Stuecker, M.F.; et al. El Niño–Southern Oscillation complexity. Nature 2018, 559, 535–545. [Google Scholar] [CrossRef]
- McPhaden, M.J.; Zebiak, S.E.; Glantz, M.H. ENSO as an Integrating Concept in Earth Science. Science 2006, 314, 1740–1745. [Google Scholar] [CrossRef] [PubMed]
- Silini, R.; Tirabassi, G.; Barreiro, M.; Ferranti, L.; Masoller, C. Assessing causal dependencies in climatic indices. Clim. Dyn. 2023, 61, 79–89. [Google Scholar] [CrossRef]
- Chechik, G.; Globerson, A.; Anderson, M.; Young, E.; Nelken, I.; Tishby, N. Group redundancy measures reveal redundancy reduction in the auditory pathway. In Advances in Neural Information Processing Systems 14: Proceedings of the 2001 Conference; MIT Press: Cambridge, MA, USA, 2001. [Google Scholar] [CrossRef]
- Duncan, T.E. On the calculation of mutual information. SIAM J. Appl. Math. 1970, 19, 215–220. [Google Scholar] [CrossRef]
- Rosas, F.E.; Mediano, P.A.; Gastpar, M. Characterising Directed and Undirected Metrics of High-Order Interdependence. In Proceedings of the 2024 IEEE International Symposium on Information Theory Workshops (ISIT-W), Athens, Greece, 7–12 July 2024; pp. 1–6. [Google Scholar] [CrossRef]
- Mijatovic, G.; Sparacino, L.; Antonacci, Y.; Javorka, M.; Marinazzo, D.; Stramaglia, S.; Faes, L. Assessing High-Order Links in Cardiovascular and Respiratory Networks via Static and Dynamic Information Measures. IEEE Open J. Eng. Med. Biol. 2024, 5, 846–858. [Google Scholar] [CrossRef] [PubMed]
- Lütkepohl, H. New Introduction to Multiple Time Series Analysis; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2005. [Google Scholar] [CrossRef]
- Akaike, H. A new look at the statistical model identification. IEEE Trans. Autom. Control 1974, 19, 716–723. [Google Scholar] [CrossRef]
- Barnett, L.; Seth, A.K. The MVGC multivariate Granger causality toolbox: A new approach to Granger-causal inference. J. Neurosci. Methods 2014, 223, 50–68. [Google Scholar] [CrossRef] [PubMed]
- Faes, L.; Montalto, A.; Nollo, G.; Marinazzo, D. Information decomposition of short-term cardiovascular and cardiorespiratory variability. In Proceedings of the Computing in Cardiology 2013, Zaragoza, Spain, 22–25 September 2013; pp. 113–116. [Google Scholar]
- Barnett, L.; Seth, A.K. Granger causality for state-space models. Phys. Rev. E-Stat. Nonlinear Soft Matter Phys. 2015, 91, 040101. [Google Scholar] [CrossRef]
- Hannan, E.; Deistler, M. The Statistical Theory of Linear Systems; Classics in Applied Mathematics; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 1988. [Google Scholar] [CrossRef]
- Barnett, L.; Seth, A.K. Dynamical independence: Discovering emergent macroscopic processes in complex dynamical systems. Phys. Rev. E 2023, 108, 014304. [Google Scholar] [CrossRef]
- Theiler, J.; Eubank, S.; Longtin, A.; Galdrikian, B.; Farmer, J.D. Testing for nonlinearity in time series: The method of surrogate data. Phys. D Nonlinear Phenom. 1992, 58, 77–94. [Google Scholar] [CrossRef]
- Schreiber, T.; Schmitz, A. Improved surrogate data for nonlinearity tests. Phys. Rev. Lett. 1996, 77, 635. [Google Scholar] [CrossRef]
- Pinto, H.; Lazic, I.; Antonacci, Y.; Pernice, R.; Gu, D.; Barà, C.; Faes, L.; Rocha, A.P. Testing dynamic correlations and nonlinearity in bivariate time series through information measures and surrogate data analysis. Front. Netw. Physiol. 2024, 4, 1385421. [Google Scholar] [CrossRef]
- Lancaster, G.; Iatsenko, D.; Pidde, A.; Ticcinelli, V.; Stefanovska, A. Surrogate data for hypothesis testing of physical systems. Phys. Rep. 2018, 748, 1–60. [Google Scholar] [CrossRef]
- Anzolin, A.; Toppi, J.; Petti, M.; Cincotti, F.; Astolfi, L. Seed-g: Simulated eeg data generator for testing connectivity algorithms. Sensors 2021, 21, 3632. [Google Scholar] [CrossRef]
- Tsonis, A.A.; Swanson, K.L.; Roebber, P.J. What Do Networks Have to Do with Climate? Bull. Am. Meteorol. Soc. 2006, 87, 585–596. [Google Scholar] [CrossRef]
- Runge, J. Causal network reconstruction from time series: From theoretical assumptions to practical estimation. Chaos 2018, 28, 075310. [Google Scholar] [CrossRef] [PubMed]
- Mosedale, T.J.; Stephenson, D.B.; Collins, M.; Mills, T.C. Granger Causality of Coupled Climate Processes: Ocean Feedback on the North Atlantic Oscillation. J. Clim. 2006, 19, 1182–1194. [Google Scholar] [CrossRef]
- Runge, J.; Heitzig, J.; Marwan, N.; Kurths, J. Quantifying causal coupling strength: A lag-specific measure for multivariate time series related to transfer entropy. Phys. Rev. E-Stat. Nonlinear Soft Matter Phys. 2012, 86, 061121. [Google Scholar] [CrossRef] [PubMed]
- Dickey, D.A.; Fuller, W.A. Distribution of the Estimators for Autoregressive Time Series With a Unit Root. J. Am. Stat. Assoc. 1979, 74, 427–431. [Google Scholar] [CrossRef]
- Lilliefors, H.W. On the Kolmogorov-Smirnov Test for Normality with Mean and Variance Unknown. J. Am. Stat. Assoc. 1967, 62, 399–402. [Google Scholar] [CrossRef]
- Hosking, J.R.M. The Multivariate Portmanteau Statistic. J. Am. Stat. Assoc. 1980, 75, 602–608. [Google Scholar] [CrossRef]
- Faes, L.; Sparacino, L.; Mijatovic, G.; Antonacci, Y.; Ricci, L.; Marinazzo, D.; Stramaglia, S. Partial Information Rate Decomposition. arXiv 2025, arXiv:2502.04550. [Google Scholar]
- Smith, S.R.; Brolley, J.; O’Brien, J.J.; Tartaglione, C.A. ENSO’s impact on regional U.S. hurricane activity. J. Clim. 2007, 20, 1404–1414. [Google Scholar] [CrossRef]
- Rodríguez-Fonseca, B.; Suárez-Moreno, R.; Ayarzagüena, B.; López-Parages, J.; Gómara, I.; Villamayor, J.; Mohino, E.; Losada, T.; Castaño-Tierno, A. A review of ENSO influence on the North Atlantic. A non-stationary signal. Atmosphere 2016, 7, 87. [Google Scholar] [CrossRef]
- Kraskov, A.; Stögbauer, H.; Grassberger, P. Estimating mutual information. Phys. Rev. E 2004, 69, 66138. [Google Scholar] [CrossRef] [PubMed]
- Varley, T.F.; Pope, M.; Faskowitz, J.; Sporns, O. Multivariate information theory uncovers synergistic subsystems of the human cerebral cortex. Commun. Biol. 2023, 6, 451. [Google Scholar] [CrossRef] [PubMed]
- Catrambone, V.; Valenza, G. Functional Brain-Heart Interplay: From Physiology to Advanced Methodology of Signal Processing and Modeling; Springer International Publishing: Berlin/Heidelberg, Germany, 2021; pp. 1–236. [Google Scholar] [CrossRef]
- Candia-Rivera, D. Brain-heart interactions in the neurobiology of consciousness. Curr. Res. Neurobiol. 2022, 3, 100050. [Google Scholar] [CrossRef] [PubMed]
- Candia-Rivera, D.; Faes, L.; Fallani, F.d.V.; Chavez, M. Measures and Models of Brain-Heart Interactions. IEEE Rev. Biomed. Eng. 2025; early access. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
| Measure/Target | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Density 0.1 | Redundancy | 0.0391 | 0.0710 | 0.0783 | 0.0783 | 0.0690 | 0.0783 | 0.2430 | 0 | 0.2430 | 0.0835 | 0.0975 | 0.2430 | 0 | |
| 0.0932 | 0.2589 | 0.0783 | 0.0783 | 0.2574 | 0.0783 | 0.2126 | 0.1174 | 0.2126 | 0.2482 | 0.3154 | 0.2126 | 0.1174 | |||
| 0.0783 | 0.2209 | 0.0783 | 0.0783 | 0.2206 | 0.0783 | 0.2126 | 0.1025 | 0.2126 | 0.2118 | 0.2252 | 0.2126 | 0.1025 | |||
| Synergy | −0.0026 | −0.0968 | −0.0457 | −0.0169 | −0.0419 | −0.0150 | −0.0296 | −0.0968 | −0.0457 | −0.0440 | −0.0968 | −0.0457 | 0 | ||
| −0.0377 | −0.0968 | −0.0457 | −0.0169 | −0.0419 | −0.0150 | −0.0296 | −0.0968 | −0.0457 | −0.0440 | −0.0968 | −0.0457 | −0.0227 | |||
| −0.0348 | −0.0968 | −0.0457 | −0.0169 | −0.0419 | −0.0150 | −0.0296 | −0.0968 | −0.0457 | −0.0440 | −0.0968 | −0.0457 | −0.0208 | |||
| Density 0.3 | Redundancy | 0.2544 | 0.2624 | 0.1728 | 0.3388 | 0.3388 | 0.2514 | 0.1921 | 0.2781 | 0.2091 | 0.3102 | 0.3388 | 0.2564 | 0.2395 | |
| 1.7048 | 1.7048 | 1.6904 | 1.7048 | 1.7048 | 1.7048 | 1.7843 | 1.7048 | 1.6856 | 1.7048 | 1.7048 | 1.7048 | 1.7048 | |||
| 0.3912 | 0.4293 | 0.4472 | 0.3609 | 0.3609 | 0.3819 | 0.3739 | 0.3982 | 0.3787 | 0.3895 | 0.3609 | 0.3848 | 0.4211 | |||
| Synergy | 0 | 0 | 0 | 0 | −0.1368 | 0 | −0.1368 | 0 | 0 | 0 | 0 | −0.1368 | 0 | ||
| 0 | 0 | 0 | 0 | −0.0533 | 0 | −0.0533 | 0 | 0 | 0 | 0 | −0.0533 | 0 | |||
| 0 | 0 | 0 | 0 | −0.0533 | 0 | −0.0533 | 0 | 0 | 0 | 0 | −0.0533 | 0 |
| Measure\Target | Sahel | NAO | NP | GMT | HURR | AMO | SOI | TSA | QBO | PDO | NINO34 | NTA | AIR | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Redundancy | 0.0090 | 0.0194 | 0.0162 | 0.0188 | 0.0069 | 0.0194 | 0.0188 | 0.0083 | 0.0034 | 0.0185 | 0.0188 | 0.0204 | 0.0165 | |
| 0.0514 | 0.0194 | 0.0492 | 0.0485 | 0.0213 | 0.0194 | 0.0485 | 0.0499 | 0.0591 | 0.0581 | 0.0485 | 0.0194 | 0.0636 | ||
| 0.0178 | 0.0194 | 0.0237 | 0.0237 | 0.0188 | 0.0194 | 0.0237 | 0.0205 | 0.0277 | 0.0288 | 0.0237 | 0.0194 | 0.0198 | ||
| Synergy | −0.0029 | −0.0023 | −0.0029 | −0.0021 | −0.0007 | −0.0012 | −0.0033 | −0.0037 | −0.0021 | −0.0022 | −0.0037 | −0.0023 | −0.0037 | |
| −0.0022 | −0.0021 | −0.0022 | −0.0021 | −0.0007 | −0.0012 | −0.0024 | −0.0025 | −0.0021 | −0.0022 | −0.0025 | −0.0021 | −0.0025 | ||
| −0.0022 | −0.0021 | −0.0022 | −0.0021 | −0.0007 | −0.0012 | −0.0024 | −0.0025 | −0.0021 | −0.0022 | −0.0025 | −0.0021 | −0.0025 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pinto, H.; Antonacci, Y.; Mijatovic, G.; Sparacino, L.; Stramaglia, S.; Faes, L.; Rocha, A.P. Information-Theoretic Sequential Framework to Elicit Dynamic High-Order Interactions in High-Dimensional Network Processes. Mathematics 2025, 13, 2081. https://doi.org/10.3390/math13132081
Pinto H, Antonacci Y, Mijatovic G, Sparacino L, Stramaglia S, Faes L, Rocha AP. Information-Theoretic Sequential Framework to Elicit Dynamic High-Order Interactions in High-Dimensional Network Processes. Mathematics. 2025; 13(13):2081. https://doi.org/10.3390/math13132081
Chicago/Turabian StylePinto, Helder, Yuri Antonacci, Gorana Mijatovic, Laura Sparacino, Sebastiano Stramaglia, Luca Faes, and Ana Paula Rocha. 2025. "Information-Theoretic Sequential Framework to Elicit Dynamic High-Order Interactions in High-Dimensional Network Processes" Mathematics 13, no. 13: 2081. https://doi.org/10.3390/math13132081
APA StylePinto, H., Antonacci, Y., Mijatovic, G., Sparacino, L., Stramaglia, S., Faes, L., & Rocha, A. P. (2025). Information-Theoretic Sequential Framework to Elicit Dynamic High-Order Interactions in High-Dimensional Network Processes. Mathematics, 13(13), 2081. https://doi.org/10.3390/math13132081