
Self-Supervised Feature Disentanglement for Deepfake Detection


Abstract
1. Introduction
- 1.
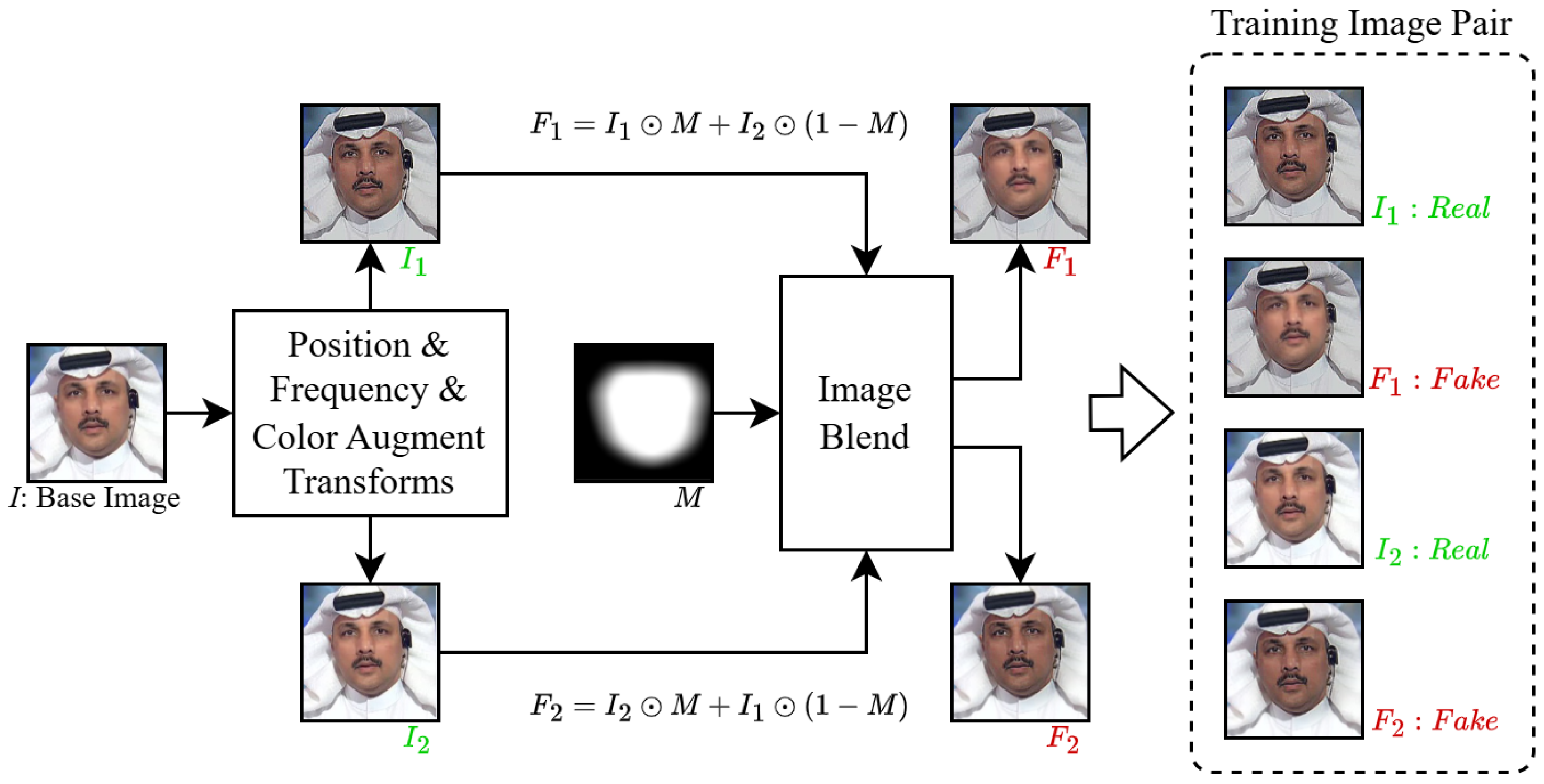
- Self-supervised sample construction with controlled disentanglement guidance: While existing works like the adjustable forgery synthesizer (AFS) [4] focus on generating pseudo-samples through image blending, our approach introduces explicit guidance for feature disentanglement via controlled blending ratios and spatial constraints. Unlike AFS, which lacks systematic mechanisms to enforce feature separability, our method strategically simulates diverse manipulation patterns by mixing authentic image patches with forged regions under strict spatial-temporal constraints. This ensures that the generated pseudo-samples effectively promote learning disentangled feature representations, overcoming the vague guidance issue in prior self-supervised sample construction.
- 2.
- Adversarially constrained feature disentanglement network architecture: Inspired by mutual information maximization strategies in [5], our dual branch network design goes beyond previous feature extraction frameworks by introducing adversarial training constraints to enforce strict feature independence between content features (e.g., identity, scene context) and forgery-related artifacts (e.g., high-frequency noise, edge discrepancies). Unlike study [5], which mainly relies on mutual information estimation without explicit adversarial regularization, our architecture significantly enhances cross-domain adaptability through adversarial minimization of feature interdependencies. This adversarial constraint mechanism represents a novel improvement in ensuring the disentangled features are discriminative and domain-invariant.
- 3.
- Generative conditional decoding validation mechanism extended: Building on the unlearning memory mechanism (UMM) in [3], which was initially applied to discriminative tasks, our work innovatively extends UMM to generative scenarios through a conditional decoding validation mechanism. Using content features as primary input and forgery patterns as conditional vectors, with reconstruction quality as disentanglement validity criteria, our approach introduces a feedback loop where failed reconstructions trigger network optimization via backward feature redundancy analysis. This generative validation framework addresses the limitation of previous UMM-based methods that lacked effective validation mechanisms for feature disentanglement in generative tasks, providing a more comprehensive solution for ensuring the quality of disentangled features.
2. Related Work
2.1. Primitive Detection Methods
2.2. Generalization-Oriented Deepfake Detection Approaches
2.3. Self-Supervised Learning-Based Detection Methods
3. Methods
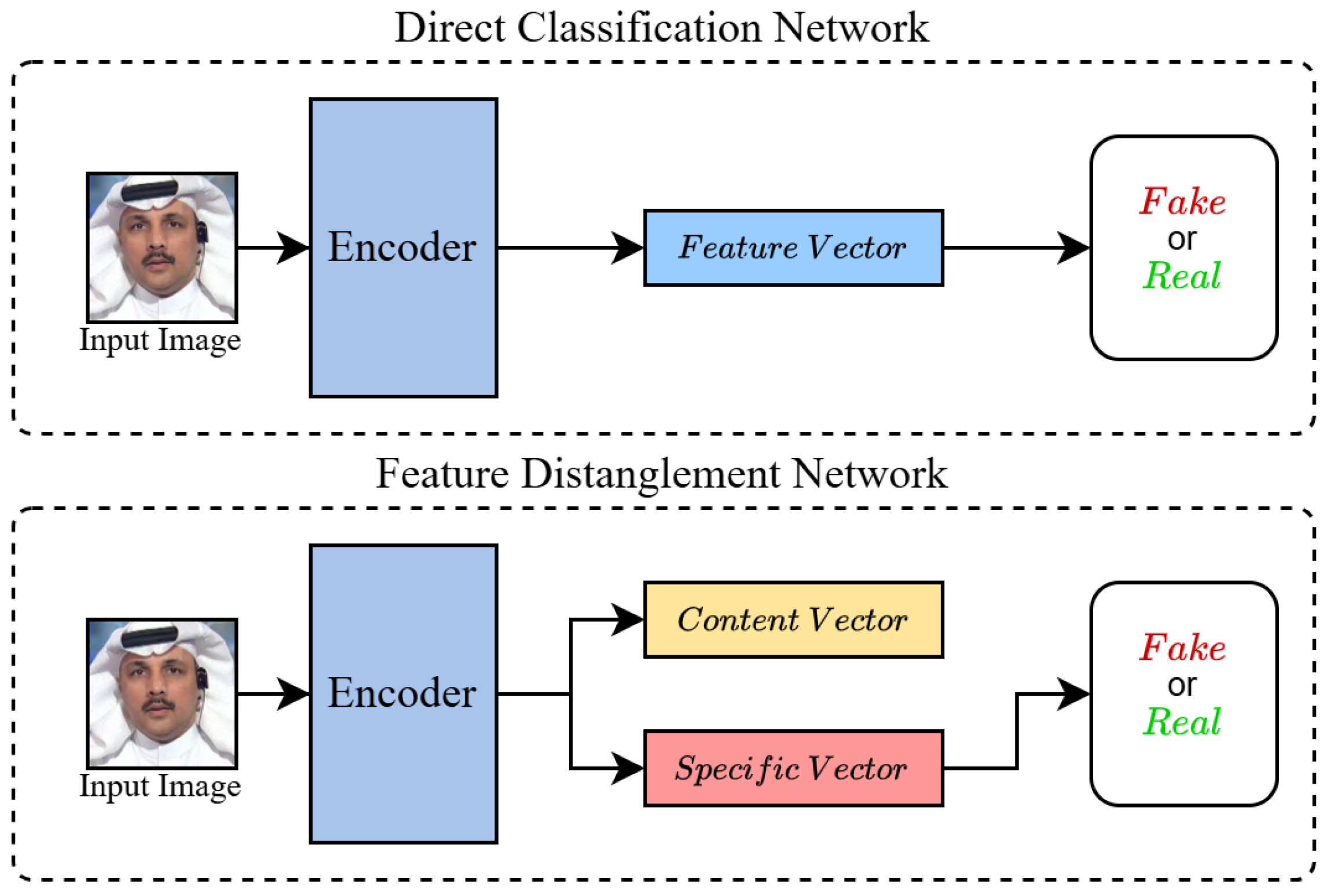
3.1. Motivation
3.2. Architecture Summary
3.3. Self-Supervised Forged Image Synthesis
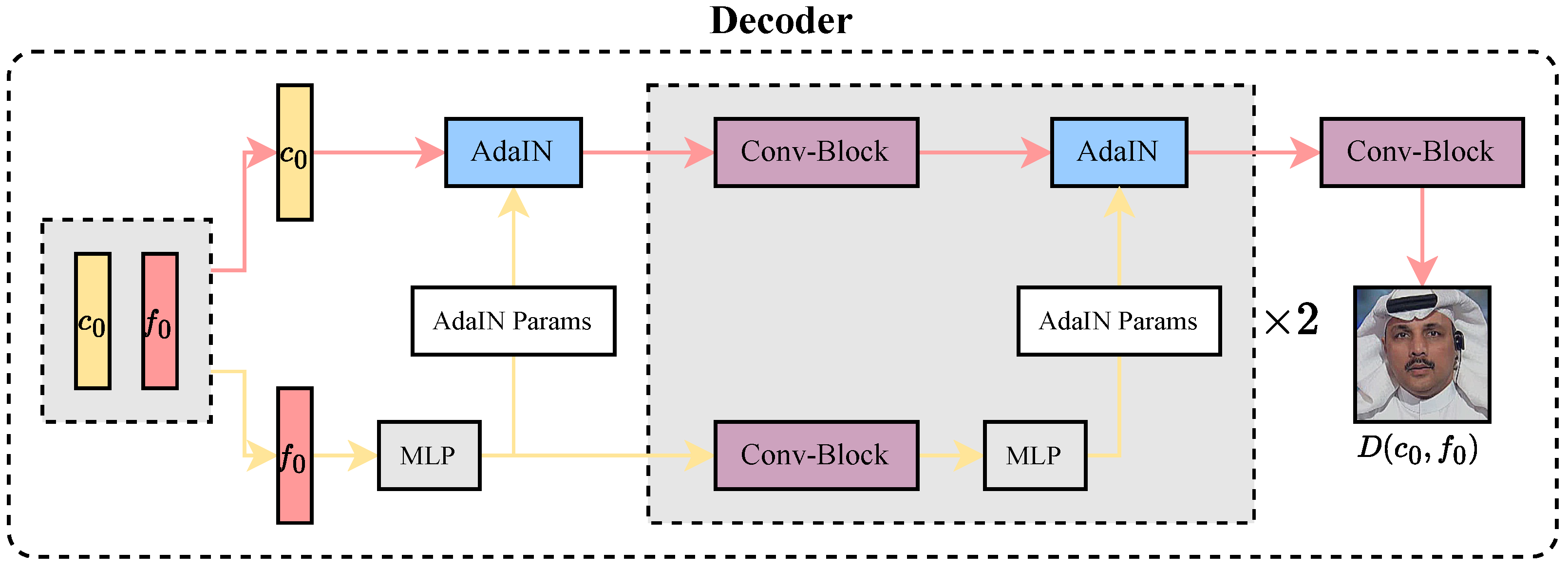
3.4. Feature Disentanglement Network
3.5. Objective Function
4. Experiments
4.1. Experimental Settings
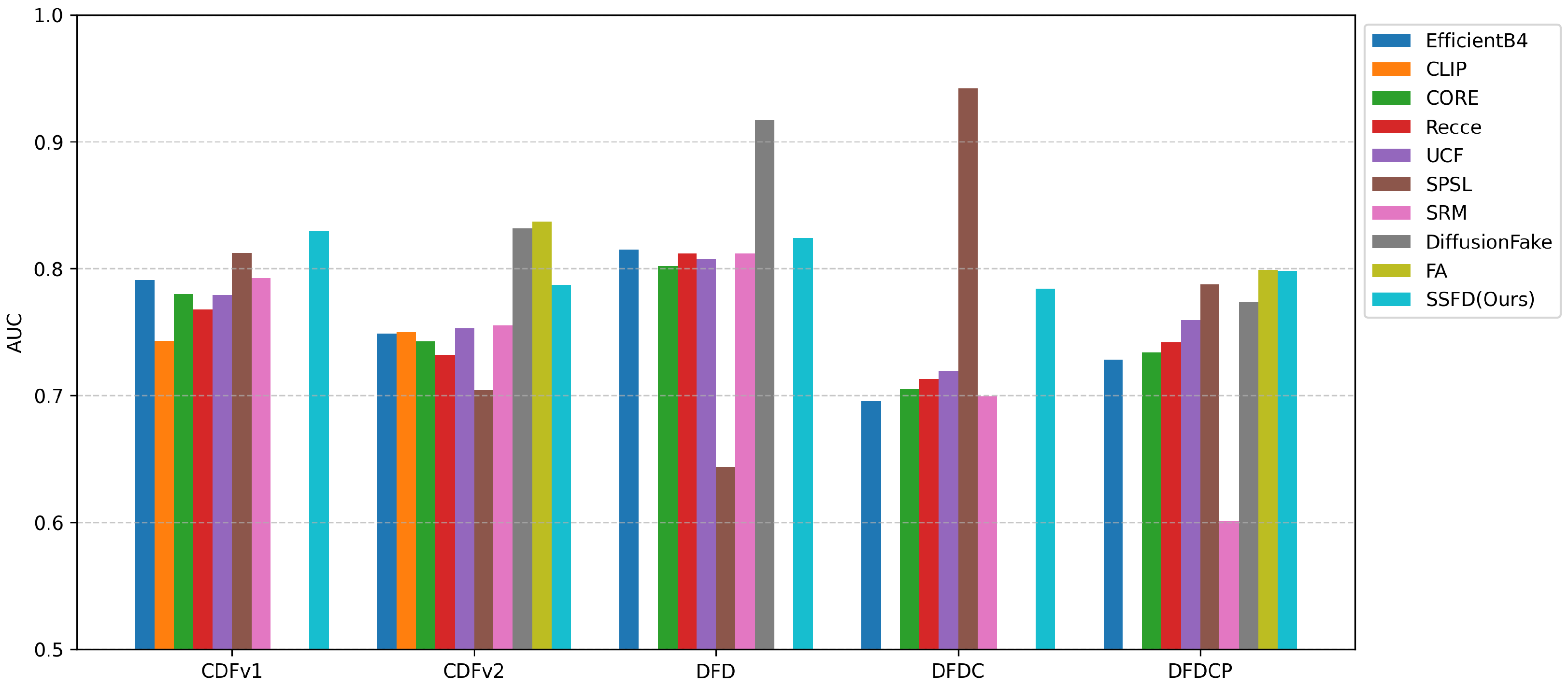
4.2. Generalization Evaluation
4.3. Ablation Study
4.3.1. Effects of Self-Supervised Forged Image
4.3.2. Effects of Conditional Decoder
4.3.3. Choice of Encoder Architectures
4.3.4. Effects of Hyper-Parameter
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Yan, Z.; Zhang, Y.; Fan, Y.; Wu, B. UCF: Uncovering Common Features for Generalizable Deepfake Detection. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 2–3 October 2023; pp. 22355–22366. [Google Scholar]
- Qiang, W.; Song, Z.; Gu, Z.; Li, J.; Zheng, C.; Sun, F.; Xiong, H. On the Generalization and Causal Explanation in Self-Supervised Learning. arXiv 2024, arXiv:2410.00772. [Google Scholar] [CrossRef]
- Chen, H.; Lin, Y.; Li, B.; Tan, S. Learning Features of Intra-Consistency and Inter-Diversity: Keys Toward Generalizable Deepfake Detection. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 1468–1480. [Google Scholar] [CrossRef]
- Ba, Z.; Liu, Q.; Liu, Z.; Wu, S.; Lin, F.; Lu, L.; Ren, K. Exposing the Deception: Uncovering More Forgery Clues for Deepfake Detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024. [Google Scholar]
- Nguyen, H.H.; Yamagishi, J.; Echizen, I. Exploring Self-Supervised Vision Transformers for Deepfake Detection: A Comparative Analysis. In Proceedings of the 2024 IEEE International Joint Conference on Biometrics (IJCB), Buffalo, NY, USA, 15–18 September 2024; pp. 1–10. [Google Scholar]
- Amerini, I.; Ballan, L.; Caldelli, R.; Del Bimbo, A.; Serra, G. A sift-based forensic method for copy–move attack detection and transformation recovery. IEEE Trans. Inf. Forensics Secur. 2011, 6, 1099–1110. [Google Scholar] [CrossRef]
- De Carvalho, T.J.; Riess, C.; Angelopoulou, E.; Pedrini, H.; de Rezende Rocha, A. Exposing digital image forgeries by illumination color classification. IEEE Trans. Inf. Forensics Secur. 2013, 8, 1182–1194. [Google Scholar] [CrossRef]
- Lukas, J.; Fridrich, J.; Goljan, M. Detecting digital image forgeries using sensor pattern noise. In Proceedings of the SPIE, the International Society for Optical Engineering, San Diego, CA, USA, 13–17 August 2006; Society of Photo-Optical Instrumentation Engineers: Bellingham, DC, USA, 2006; p. 60720Y–1. [Google Scholar]
- Chierchia, G.; Parrilli, S.; Poggi, G.; Verdoliva, L.; Sansone, C. PRNU-based detection of small-size image forgeries. In Proceedings of the 2011 17th International Conference on Digital Signal Processing (DSP), Corfu, Greece, 6–8 July 2011; pp. 1–6. [Google Scholar]
- Wen, D.; Han, H.; Jain, A.K. Face spoof detection with image distortion analysis. IEEE Trans. Inf. Forensics Secur. 2015, 10, 746–761. [Google Scholar] [CrossRef]
- Pei, G.; Zhang, J.; Hu, M.; Zhang, Z.; Wang, C.; Wu, Y.; Zhai, G.; Yang, J.; Shen, C.; Tao, D. Deepfake generation and detection: A benchmark and survey. arXiv 2024, arXiv:2403.17881. [Google Scholar]
- Afchar, D.; Nozick, V.; Yamagishi, J.; Echizen, I. Mesonet: A compact facial video forgery detection network. In Proceedings of the 2018 IEEE International Workshop on Information Forensics and Security (WIFS), Hong Kong, 11–13 December 2018; pp. 1–7. [Google Scholar]
- Nguyen, H.H.; Yamagishi, J.; Echizen, I. Capsule-forensics: Using capsule networks to detect forged images and videos. In Proceedings of the ICASSP 2019–2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 2307–2311. [Google Scholar]
- Rossler, A.; Cozzolino, D.; Verdoliva, L.; Riess, C.; Thies, J.; Nießner, M. Faceforensics++: Learning to detect manipulated facial images. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1–11. [Google Scholar]
- Qian, Y.; Yin, G.; Sheng, L.; Chen, Z.; Shao, J. Thinking in frequency: Face forgery detection by mining frequency-aware clues. In Proceedings of the European Conference on Computer Vision; Springer: London, UK, 2020; pp. 86–103. [Google Scholar]
- Frank, J.; Eisenhofer, T.; Schönherr, L.; Fischer, A.; Kolossa, D.; Holz, T. Leveraging frequency analysis for deep fake image recognition. In Proceedings of the International Conference on Machine Learning, Vienna, Austria, 12–18 July 2020; PMLR: New York, NY, USA, 2020; pp. 3247–3258. [Google Scholar]
- Agarwal, S.; Farid, H.; Gu, Y.; He, M.; Nagano, K.; Li, H. Protecting world leaders against deep fakes. In Proceedings of the CVPR Workshops, Long Beach, CA, USA, 16–20 June 2019; Volume 1. [Google Scholar]
- Amerini, I.; Galteri, L.; Caldelli, R.; Del Bimbo, A. Deepfake video detection through optical flow based cnn. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Güera, D.; Delp, E.J. Deepfake video detection using recurrent neural networks. In Proceedings of the 2018 15th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Auckland, New Zealand, 27–30 November 2018; pp. 1–6. [Google Scholar]
- Sabir, E.; Cheng, J.; Jaiswal, A.; AbdAlmageed, W.; Masi, I.; Natarajan, P. Recurrent convolutional strategies for face manipulation detection in videos. Interfaces 2019, 3, 80–87. [Google Scholar]
- Luo, Y.; Zhang, Y.; Yan, J.; Liu, W. Generalizing face forgery detection with high-frequency features. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 16317–16326. [Google Scholar]
- Cao, J.; Ma, C.; Yao, T.; Chen, S.; Ding, S.; Yang, X. End-to-end reconstruction-classification learning for face forgery detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 4113–4122. [Google Scholar]
- Shiohara, K.; Yamasaki, T. Detecting deepfakes with self-blended images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 18720–18729. [Google Scholar]
- Chen, L.; Zhang, Y.; Song, Y.; Liu, L.; Wang, J. Self-supervised learning of adversarial example: Towards good generalizations for deepfake detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 18710–18719. [Google Scholar]
- Yu, Y.; Ni, R.; Yang, S.; Ni, Y.; Zhao, Y.; Kot, A.C. Mining Generalized Multi-timescale Inconsistency for Detecting Deepfake Videos. Int. J. Comput. Vis. 2024, 133, 1532–1548. [Google Scholar] [CrossRef]
- Yu, P.; Fei, J.; Gao, H.; Feng, X.; Xia, Z.; Chang, C.H. Unlocking the Capabilities of Vision-Language Models for Generalizable and Explainable Deepfake Detection. arXiv 2025, arXiv:2503.14853. [Google Scholar]
- Li, L.; Bao, J.; Zhang, T.; Yang, H.; Chen, D.; Wen, F.; Guo, B. Face X-ray for more general face forgery detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5001–5010. [Google Scholar]
- Yan, Z.; Luo, Y.; Lyu, S.; Liu, Q.; Wu, B. Transcending forgery specificity with latent space augmentation for generalizable deepfake detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 8984–8994. [Google Scholar]
- Cui, X.; Li, Y.; Luo, A.; Zhou, J.; Dong, J. Forensics Adapter: Adapting CLIP for Generalizable Face Forgery Detection. arXiv 2024, arXiv:2411.19715. [Google Scholar]
- Haliassos, A.; Mira, R.; Petridis, S.; Pantic, M. Leveraging real talking faces via self-supervision for robust forgery detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 14950–14962. [Google Scholar]
- Zhang, D.; Xiao, Z.; Li, S.; Lin, F.; Li, J.; Ge, S. Learning Natural Consistency Representation for Face Forgery Video Detection. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024. [Google Scholar]
- Sun, K.; Chen, S.; Yao, T.; Liu, H.; Sun, X.; Ding, S.; Ji, R. DiffusionFake: Enhancing Generalization in Deepfake Detection via Guided Stable Diffusion. arXiv 2024, arXiv:2410.04372. [Google Scholar]
- Xu, J.; Liu, X.; Lin, W.; Shang, W.; Wang, Y. Localization and detection of deepfake videos based on self-blending method. Sci. Rep. 2025, 15, 3927. [Google Scholar] [CrossRef] [PubMed]
- Huang, X.; Belongie, S. Arbitrary style transfer in real-time with adaptive instance normalization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1501–1510. [Google Scholar]
- Deepfakes. 2021. Available online: https://github.com/deepfakes/faceswap (accessed on 30 May 2025).
- Thies, J.; Zollhöfer, M.; Stamminger, M.; Theobalt, C.; Nießner, M. Face2Face: Real-Time Face Capture and Reenactment of RGB Videos. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2387–2395. [Google Scholar]
- Faceswap. 2021. Available online: https://github.com/MarekKowalski/FaceSwap (accessed on 25 May 2025).
- Thies, J.; Zollhöfer, M.; Nießner, M. Deferred neural rendering: Image synthesis using neural textures. ACM Trans. Graph. 2019, 38, 1–12. [Google Scholar] [CrossRef]
- Li, Y.; Yang, X.; Sun, P.; Qi, H.; Lyu, S. Celeb-df: A large-scale challenging dataset for deepfake forensics. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3207–3216. [Google Scholar]
- Contributing Data to Deepfake Detection Research. 2021. Available online: https://ai.googleblog.com/2019/09/contributing-data-to-deepfake-detection.html (accessed on 23 May 2025).
- Dolhansky, B.; Bitton, J.; Pflaum, B.; Lu, J.; Howes, R.; Wang, M.; Ferrer, C.C. The deepfake detection challenge (dfdc) dataset. arXiv 2020, arXiv:2006.07397. [Google Scholar]
- Dolhansky, B.; Howes, R.; Pflaum, B.; Baram, N.; Ferrer, C.C. The deepfake detection challenge (dfdc) preview dataset. arXiv 2019, arXiv:1910.08854. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; PMLR: New York, NY, USA, 2019; pp. 6105–6114. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Foret, P.; Kleiner, A.; Mobahi, H.; Neyshabur, B. Sharpness-aware minimization for efficiently improving generalization. arXiv 2020, arXiv:2010.01412. [Google Scholar]
- Yan, Z.; Zhang, Y.; Yuan, X.; Lyu, S.; Wu, B. DeepfakeBench: A Comprehensive Benchmark of Deepfake Detection. arXiv 2023, arXiv:2307.01426. [Google Scholar]
- Wang, S.Y.; Wang, O.; Zhang, R.; Owens, A.; Efros, A.A. CNN-generated images are surprisingly easy to spot... for now. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8695–8704. [Google Scholar]
- Ojha, U.; Li, Y.; Lee, Y.J. Towards Universal Fake Image Detectors that Generalize Across Generative Models. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 24480–24489. [Google Scholar]
- Ni, Y.; Meng, D.; Yu, C.; Quan, C.; Ren, D.; Zhao, Y. Core: Consistent representation learning for face forgery detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12–21. [Google Scholar]
- Liu, H.; Li, X.; Zhou, W.; Chen, Y.; He, Y.; Xue, H.; Zhang, W.; Yu, N. Spatial-phase shallow learning: Rethinking face forgery detection in frequency domain. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 772–781. [Google Scholar]
- Wang, Y.; Yu, K.; Chen, C.; Hu, X.; Peng, S. Dynamic graph learning with content-guided spatial-frequency relation reasoning for deepfake detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7278–7287. [Google Scholar]
- Yu, P.; Fei, J.; Xia, Z.; Zhou, Z.; Weng, J. Improving generalization by commonality learning in face forgery detection. IEEE Trans. Inf. Forensics Secur. 2022, 17, 547–558. [Google Scholar] [CrossRef]
- Masi, I.; Killekar, A.; Mascarenhas, R.M.; Gurudatt, S.P.; AbdAlmageed, W. Two-branch recurrent network for isolating deepfakes in videos. In Proceedings of the Computer vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; proceedings, Part VII 16. Springer: London, UK, 2020; pp. 667–684. [Google Scholar]
- Gu, Q.; Chen, S.; Yao, T.; Chen, Y.; Ding, S.; Yi, R. Exploiting fine-grained face forgery clues via progressive enhancement learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 22 February–1 March 2022; Volume 36, pp. 735–743. [Google Scholar]
- Zhao, H.; Zhou, W.; Chen, D.; Wei, T.; Zhang, W.; Yu, N. Multi-attentional deepfake detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 2185–2194. [Google Scholar]
- Chen, S.; Yao, T.; Chen, Y.; Ding, S.; Li, J.; Ji, R. Local relation learning for face forgery detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 2–9 February 2021; Volume 35, pp. 1081–1088. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2016; pp. 1800–1807. [Google Scholar]
- Liang, J.; Shi, H.; Deng, W. Exploring disentangled content information for face forgery detection. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: London, UK, 2022; pp. 128–145. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Published | Limitations |
|---|---|---|
| SRM [22] | CVPR’21 | For some forgery methods that do not produce obvious high-frequency feature differences, the detection effect may be limited. |
| Recce [23] | CVPR’22 | The computational complexity of the model may be high, and the processing efficiency for large-scale datasets needs to be improved. |
| SBI [24] | CVPR’22 | The synthetic data may have a different distribution from real data, affecting the model’s generalization ability in real-world scenarios. |
| SLADD [25] | CVPR’22 | The process of generating adversarial samples may be complex, and the quality of the generated samples may affect the detection results. |
| UCF [2] | CVPR’23 | The training process of the model may be complex and require a large amount of computational resources and time. |
| MDIM [26] | IJCV’24 | May not be able to adapt to and accurately detect some dynamically changing forgery techniques. |
| LVLMs [27] | arXiv’25 | Require a large amount of labeled data and computational resources for fine-tuning, and the interpretability of the model is relatively poor. |
| Dataset | Methods | Fake | Real Videos | Repositories |
|---|---|---|---|---|
| FF++ [15] | 4 | 4000 | 1000 | github.com/ondyari/FaceForensics, accessed on 25 May 2025 |
| DFD [41] | 5 | 3068 | 363 | github.com/ondyari/FaceForensics, accessed on 30 May 2025 |
| CDF [40] | 1 | 5639 | 590 | celeb-deepfakeforensics, accessed on 17 April 2025 |
| DFDCP [43] | 2 | 1131 | 4113 | ai.meta.com/datasets/dfdc, accessed on 30 May 2025 |
| DFDC [42] | 8 | 124 K | deepfake-detection-challenge, accessed on 20 May 2025 | |
| Detector | Backbone | Cross Domain Evaluation | |||||
|---|---|---|---|---|---|---|---|
| CDFv1 | CDFv2 | DFD | DFDC | DFDCP | Avg. | ||
| CNN-Aug [48] | ResNet | 0.7420 | 0.7027 | 0.6464 | 0.6361 | 0.6170 | 0.6688 |
| EfficientB4 [44] | EfficientB4 | 0.7909 | 0.7487 | 0.8148 | 0.6955 | 0.7283 | 0.7556 |
| CLIP [49] | ViT | 0.743 | 0.750 | - | - | - | - |
| CORE [50] | Xception | 0.7798 | 0.7428 | 0.8018 | 0.7049 | 0.7341 | 0.7526 |
| Recce [23] | Designed | 0.7677 | 0.7319 | 0.8119 | 0.7133 | 0.7419 | 0.7533 |
| UCF [2] | Xception | 0.7793 | 0.7527 | 0.8074 | 0.7191 | 0.7594 | 0.7635 |
| SPSL [51] | Xception | 0.8122 | 0.7040 | 0.6437 | 0.9424 | 0.7875 | 0.7779 |
| SRM [22] | Xception | 0.7926 | 0.7552 | 0.8120 | 0.6995 | 0.6014 | 0.7321 |
| DiffusionFake [33] | EfficientB4 | - | 0.8317 | 0.9171 | - | 0.7735 | - |
| FA [30] | ViT | - | 0.837 | - | - | 0.799 | - |
| SSFD(Ours) | EfficientB4 | 0.8296 | 0.7872 | 0.8243 | 0.7841 | 0.7982 | 0.8046 |
| Model | Training Set | CDFv2 | DFDC |
|---|---|---|---|
| Two-branch [54] | FF++ | 0.734 | 0.734 |
| PEL [55] | FF++ | 0.692 | 0.633 |
| MADD [56] | FF++ | 0.674 | - |
| Local-relation [57] | FF++ | 0.783 | 0.765 |
| CFFs [53] | FF++ | 0.742 | 0.721 |
| SFDG [52] | FF++ | 0.758 | 0.736 |
| UCF [2] | FF++ | 0.7527 | 0.7191 |
| SSFD(Ours) | FF++ | 0.7872 | 0.7841 |
| Training Datasets | Methods | Testing AUC | ||
|---|---|---|---|---|
| CDFv2 | DFD | DFDC | ||
| FF++ | Xception [58] | 0.672 | 0.727 | 0.651 |
| Liang et al. [59] | 0.706 | 0.829 | 0.700 | |
| UCF [2] | 0.752 | 0.807 | 0.719 | |
| SSFD (ours) | 0.787 | 0.824 | 0.784 | |
| Training Datasets | Methods | Testing AUC | ||
|---|---|---|---|---|
| CDFv2 | DFD | DFDC | ||
| FF++ | SSFD (Ours) | 0.7745 | 0.8124 | 0.7683 |
| SSFD (Ours) + SBI | 0.7872 | 0.8243 | 0.7841 | |
| Training Datasets | Methods | Testing AUC | ||
|---|---|---|---|---|
| CDFv2 | DFD | DFDC | ||
| FF++ | SSFD (Ours) | 0.7545 | 0.8024 | 0.7483 |
| SSFD (Ours) + CD | 0.7872 | 0.8243 | 0.7841 | |
| Training Dataset | Methods | Testing AUC | |||
|---|---|---|---|---|---|
| CDFv2 | DFD | DFDC | Avg. | ||
| FF++ | Xception [58] | 0.737 | 0.816 | 0.708 | 0.754 |
| Ours (Xception) | 0.753 | 0.821 | 0.744 | 0.773 | |
| EfficientB4 [44] | 0.749 | 0.815 | 0.696 | 0.753 | |
| Ours (EfficientB4) | 0.787 | 0.824 | 0.784 | 0.799 | |
| Training Dataset | Testing AUC | ||||
|---|---|---|---|---|---|
| CDFv2 | DFD | DFDC | Avg. | ||
| FF++ | 0.1 | 0.763 | 0.824 | 0.772 | 0.786 |
| 0.3 | 0.787 | 0.818 | 0.784 | 0.796 | |
| 0.5 | 0.758 | 0.809 | 0.762 | 0.776 | |
| 0.7 | 0.741 | 0.786 | 0.755 | 0.761 | |
| 1.0 | 0.724 | 0.773 | 0.736 | 0.744 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yan, B.; Liu, P.; Yang, Y.; Guo, Y. Self-Supervised Feature Disentanglement for Deepfake Detection. Mathematics 2025, 13, 2024. https://doi.org/10.3390/math13122024
Yan B, Liu P, Yang Y, Guo Y. Self-Supervised Feature Disentanglement for Deepfake Detection. Mathematics. 2025; 13(12):2024. https://doi.org/10.3390/math13122024
Chicago/Turabian StyleYan, Bo, Pan Liu, Yumin Yang, and Yanming Guo. 2025. "Self-Supervised Feature Disentanglement for Deepfake Detection" Mathematics 13, no. 12: 2024. https://doi.org/10.3390/math13122024
APA StyleYan, B., Liu, P., Yang, Y., & Guo, Y. (2025). Self-Supervised Feature Disentanglement for Deepfake Detection. Mathematics, 13(12), 2024. https://doi.org/10.3390/math13122024