
Leveraging Attribute Interaction and Self-Training for Graph Alignment via Optimal Transport


Abstract
1. Introduction
- We propose an unsupervised learning approach for graph alignment under the framework of Gromov–Wasserstein distance and optimal transport. Compared to existing OT-based methods, deeper graph structures and node information are incorporated in the design of the intra-graph cost, meanwhile, linear transformation of node attributes is integrated into cost design to facilitate attribute interaction across dimensions. It is proved to have more expressive power while sharing the convergence results. Moreover, we introduce a cost normalization layer to enhance the stability of model training.
- Inspired by the global interaction properties of nodes reflected in the intra-graph cost, by selecting high-confidence matched node pairs as pseudo-labels, we propose a self-training strategy that not only enhances our model but also improves the accuracy of other OT-based methods.
- Extensive experimental results demonstrate PORTRAIT’s outstanding performance, achieving a 5% improvement in Hits@1, while also exhibiting remarkable efficiency and robustness.
2. Preliminary
2.1. Problem Definition
2.2. State-of-the-Art Methods
2.2.1. Unsupervised Graph Alignment
- GAlign [22]: The model incorporates the idea of data augmentation into the learning objective to obtain high-quality node embeddings. In particular, it encourages the node embeddings () of each GNN layer k to retain graph structures, as well as to be robust upon graph perturbation. Afterward, the alignment refinement procedure augments the original graph by first choosing the confident node matchings and then increasing the weight of their adjacency edges. This serves as an effective unsupervised heuristic to iteratively match node pairs.
- GTCAlign [23]: Arguably having the best accuracy among embedding-based solutions, it simplifies the idea of GAlign with the following observation. First, it uses a GNN with randomized parameters for node embedding computation, as it is intricate to design an embedding-based objective that directly corresponds to the goal of node alignment. Second, the iterative learning process is empowered by graph augmentation, i.e., to adjust edge weights according to confident predictions. By normalizing the node embeddings to length 1, the learning process gradually decreases the cosine angle between confident node matchings.
- GWL [15]: Xu et al. [15] present a graph matching framework by combining the graph-based optimal transport and node embedding learning. It predicts an alignment matrix following Definition 2. Given the learnable node representations and , GWL minimizes a combination of the Wasserstein discrepancy and the Gromov–Wasserstein discrepancy (GWD), while the latter shares similar ideas with graph matching. Specifically, the objective for the Wasserstein discrepancy is , where is a function to measure the distance based on two node embeddings. The loss corresponding to the Gromov–Wasserstein discrepancy is defined aswhere the form of follows GWD:
- SLOTAlign [14]: As the state-of-the-art unsupervised method, SLOTAlign improves existing GWD-based approaches (e.g., [15,32]) with a more careful design of the intra-graph costs and . It introduces the module of multi-view structure modeling which incorporates graph structure, node features, and multi-hop information via an attribute propagation procedure. Then, it uses a few learnable parameters (with additional constraints) to compute the intra-graph cost from the weighted sum of the above information. Next, SLOTAlign adopts a similar procedure as GWL to learn the alignment matrix by minimizing GWD (see Equation (5)).
2.2.2. Supervised Graph Alignment
3. Our Approach
3.1. Model Overview
| Algorithm 1: PORTRAIT. |
Input: Two attributed graphs and with , , , and Output: The set of predicted node matchings // Algorithm 2 ; // Algorithm 3 ;
// Algorithm 4 ; return; |
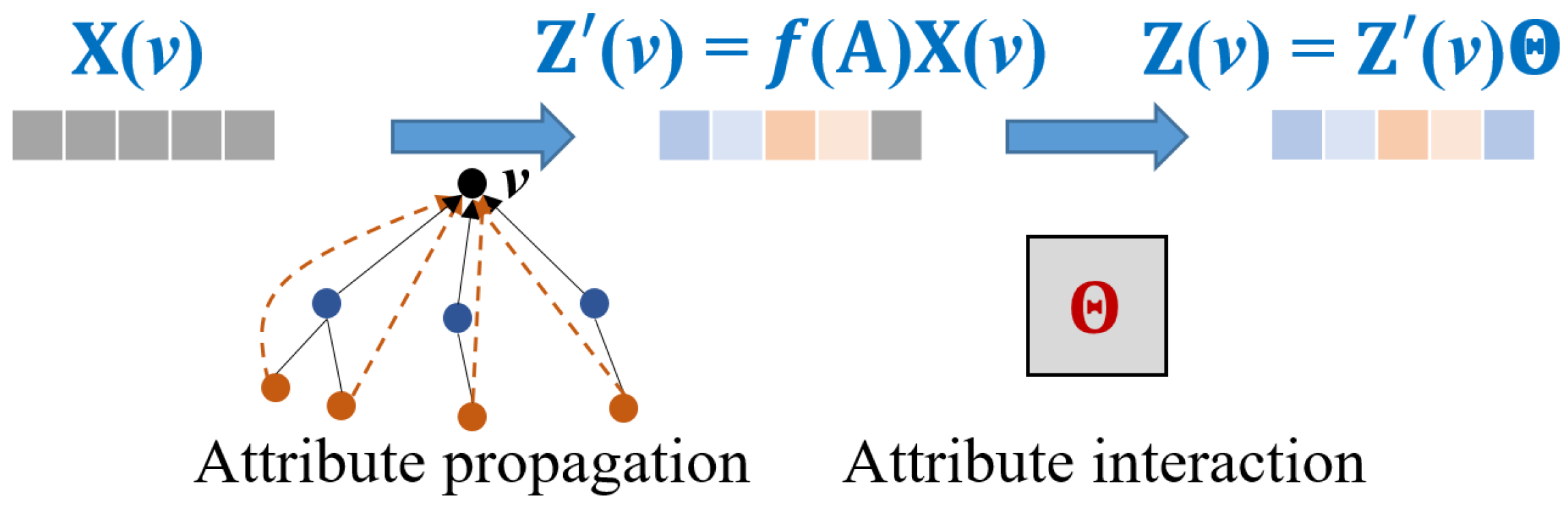
3.2. Attribute Propagation and Interaction
| Algorithm 2: AttrProp&Interact. |
Input: Adjacency matrix and node attributes Output: Node representation // Attribute Propagation ; // Attribute Interaction ; return ; |
3.3. Unsupervised Gromov–Wasserstein Learning
3.3.1. Cost Computation
- Intra-graph cost computation. We adopt the multi-view modeling of intra-graph cost, which considers graph structure , node attributes , and a joint modeling of them via node representation :where and denote the intra-graph cost matrix of and , respectively. Here, we use to represent the learnable coefficients. Compared to [14], we compute through both attribute propagation and interaction (see Section 3.2), while simultaneously aggregating node representations from different convolutional layers to capture both local and global information, which enhances the model’s expressiveness (as demonstrated in Theorem 1). Specifically, it has the following concrete form:
- Inter-graph cost computation. Given intra-graph cost matrices and , this step follows the definition of Gromow–Wasserstein discrepancy (Equation (6)). We denote by the -sized inter-graph cost matrix.
- Cost normalization. It has been observed that the Sinkhorn algorithm [25] invoked by the GW learning process might have numerical instability issues [35]. We observe that most terms are far less than 1 in practice. As the average value of is , the inter-graph cost for most node pairs are of very small values. We find that this phenomenon deteriorates the stability of GW learning. Hence, we employ a cost normalization module to rescale the inter-graph cost. Let and , we have
3.3.2. Learning Algorithm
| Algorithm 3: Unsuper-GW. |
 |
- Relaxing the constraints on . Through our empirical study, we find that the constraints on (as in [14]) and (see Theorem 2) can be relaxed. That is, we do not force the non-negativity of parameters nor constrain that the (column-wise) summation equals 1. Please note that the theoretical analysis only guarantees convergence of the algorithm to a critical point, which aligns with the existing studies [14,15].
3.4. Self-Training Phase
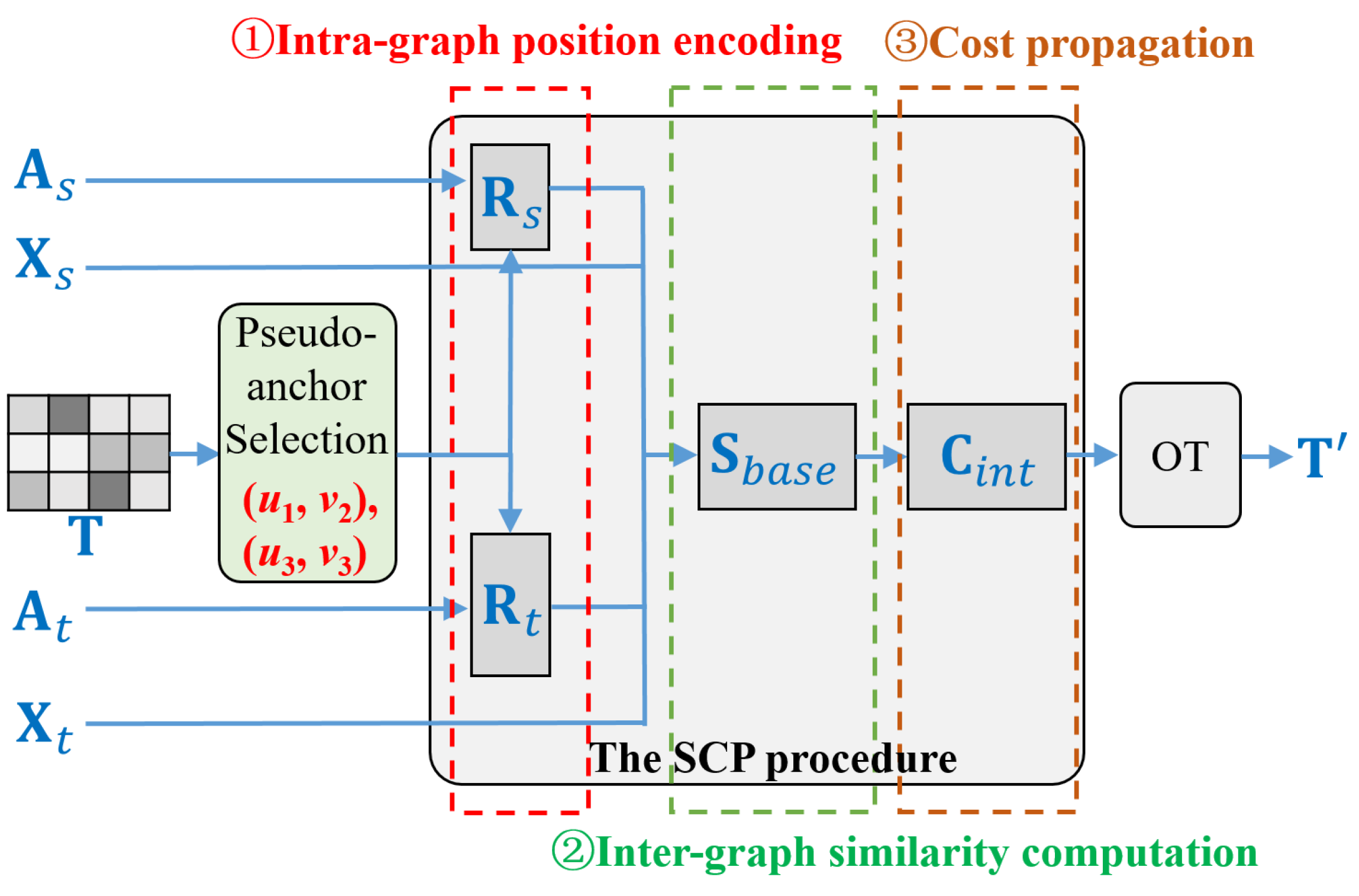
3.4.1. Pseudo-Anchor Selection
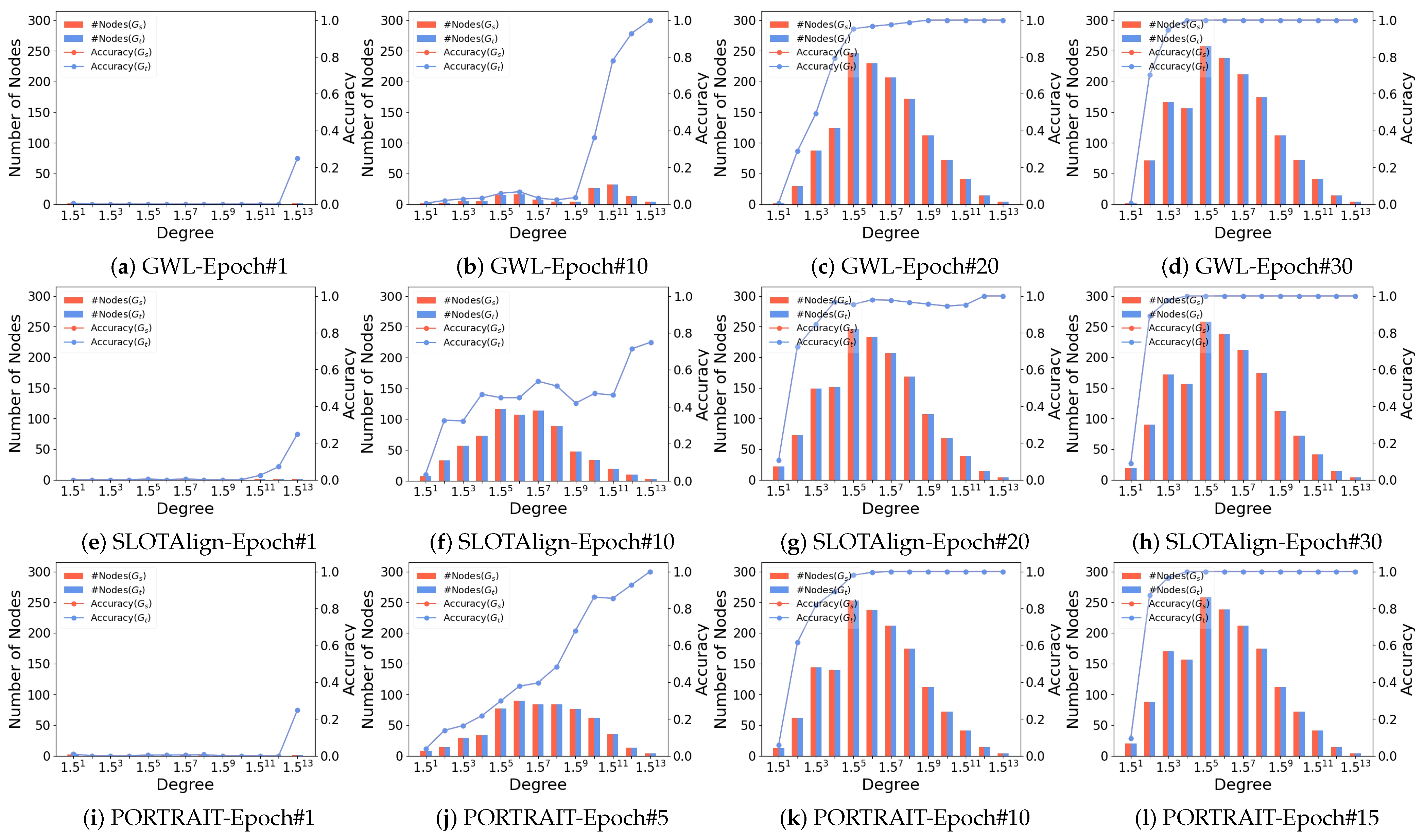
- Motivation. As mentioned above, when using Gromov–Wasserstein distance (GWD) to model the graph alignment problem, represents the intra-graph cost, , which is crucial for determining the matching accuracy [14], as it captures the relationships between nodes within a single graph. In this context, for a graph with n nodes, we can categorize the nodes into those that are easy to match and those that are more challenging to align. A natural question that arises is how to define which nodes are more likely to be matched accurately. Since represents the dependencies between nodes, a fundamental metric node degree can provide insight. Nodes with higher degree can access more information across the graph, capturing dependencies with multiple other nodes, which aligns well with role in representing overall intra-graph relationships. Conversely, nodes with a lower degree are relatively less capable of modeling inter-node relationships, making them harder to align accurately.
3.4.2. Similarity-Based Cost Propagation (SCP)
3.4.3. Learning Algorithm
| Algorithm 4: Self-training. |
Input: The alignment matrix obtained from the unsupervised step, the ratio of pseudo-anchors q Output: The refined alignment matrix Sort by descending order of and select the top- node pairs as pseudo-anchors; Replacing the original transport cost in PARROT [12] with SCP to obtain a refined alignment matrix ; return ; |
3.5. Complexity Analysis
4. Experimental Analysis
4.1. Experimental Setup
- Baselines: We include representative embedding-based methods WAlign [17], GAlign [22], and GTCAlign [23], and use GWL and SLOTAlign as the OT-based competitors because they achieve state-of-the-art performance on the aforementioned datasets according to [14,15]. We do not include [32,39,40] as baselines since they are significantly outperformed by GWL and SLOTAlign [14] and thus are not comparable with ours. We also omit [29,30] as they are limited to graphs with no larger than one hundred nodes. For all baselines, we run the code provided by the authors with the default configuration.
- Evaluation Metrics: We evaluate the performance of all models using the well-adopted metric Hits@k with . Hits@k indicates whether the ground truth correspondence of a node occurs in the top-k predictions ordered by the alignment probability. In particular, we put emphasis on Hits@1 because it reflects the percentage of matching that is correctly found.
- Hyperparameter Settings: For PORTRAIT, the learning rate of is the same as SLOTAlign [14], while the learning rate of is set to 0.01. In the self-training phase, we fix the ratio of pseudo-anchors q as , (in Equation (7)) as 0.1, as , and as , following [12]. We set the number of layers (i.e., K) of the attribute propagation step as 2. For the similarity-based cost propagation, we set the temperature parameter to 10.
4.2. Evaluation of Model Accuracy
- Ablation Study: Different variants of PORTRAIT are evaluated in terms of prediction accuracy (see Table 3), where the self-training phase (denoted as ST), the attributed interaction stage (denoted as ), and cost normalization (denoted as Norm) are deactivated. For PORTRAIT w/o ST + Norm, we train it following a similar procedure with SLOTAlign [14]. Particularly, we first train and alternatively and then solely update with hundreds of iterations. It can be concluded that all three modules contribute significant accuracy improvement on Douban and ACM-DBLP while helping our model to achieve the best performance on PPI. It also indicates the necessity of attribute interaction in improving model capability.
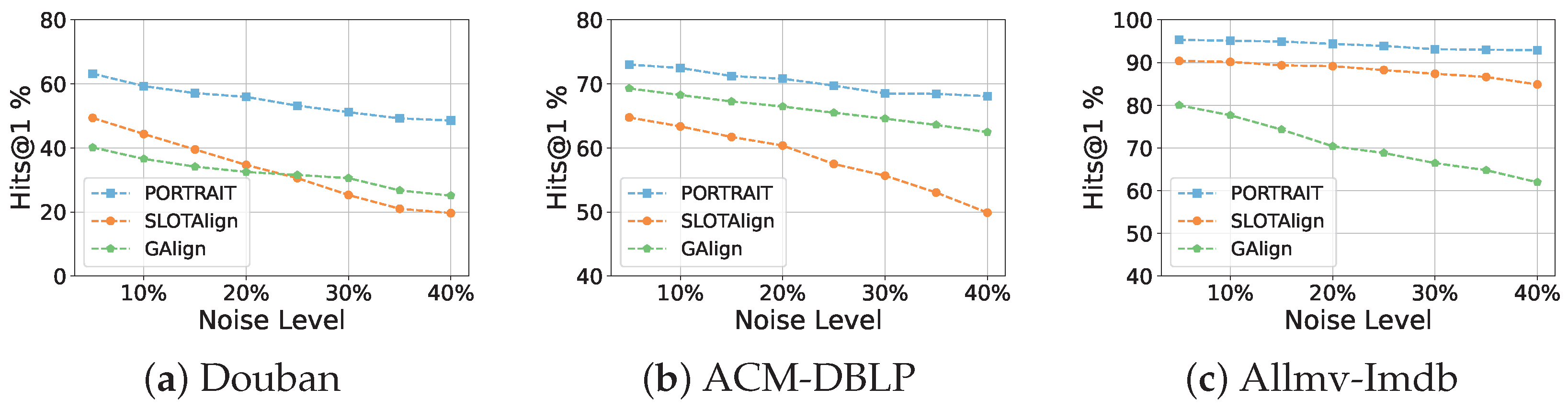
- Robustness Analysis: To validate the robustness of our proposed model, we conduct comprehensive experiments involving edge perturbations (ranging from 10% to 40% noise ratios) across three real-world datasets. For comparative analysis, we selected two representative baseline methods: GAlign as the embedding-based approach, and SLOTAlign as the optimal transport-based method. As illustrated in Figure 6, our model demonstrates consistently superior robustness across all noise levels, exhibiting significantly smaller performance degradation compared to baseline methods. Particularly noteworthy is the observation that at 30% noise contamination, a substantial perturbation level, our model maintains prediction accuracy comparable to that achieved by competing methods under noise-free conditions.
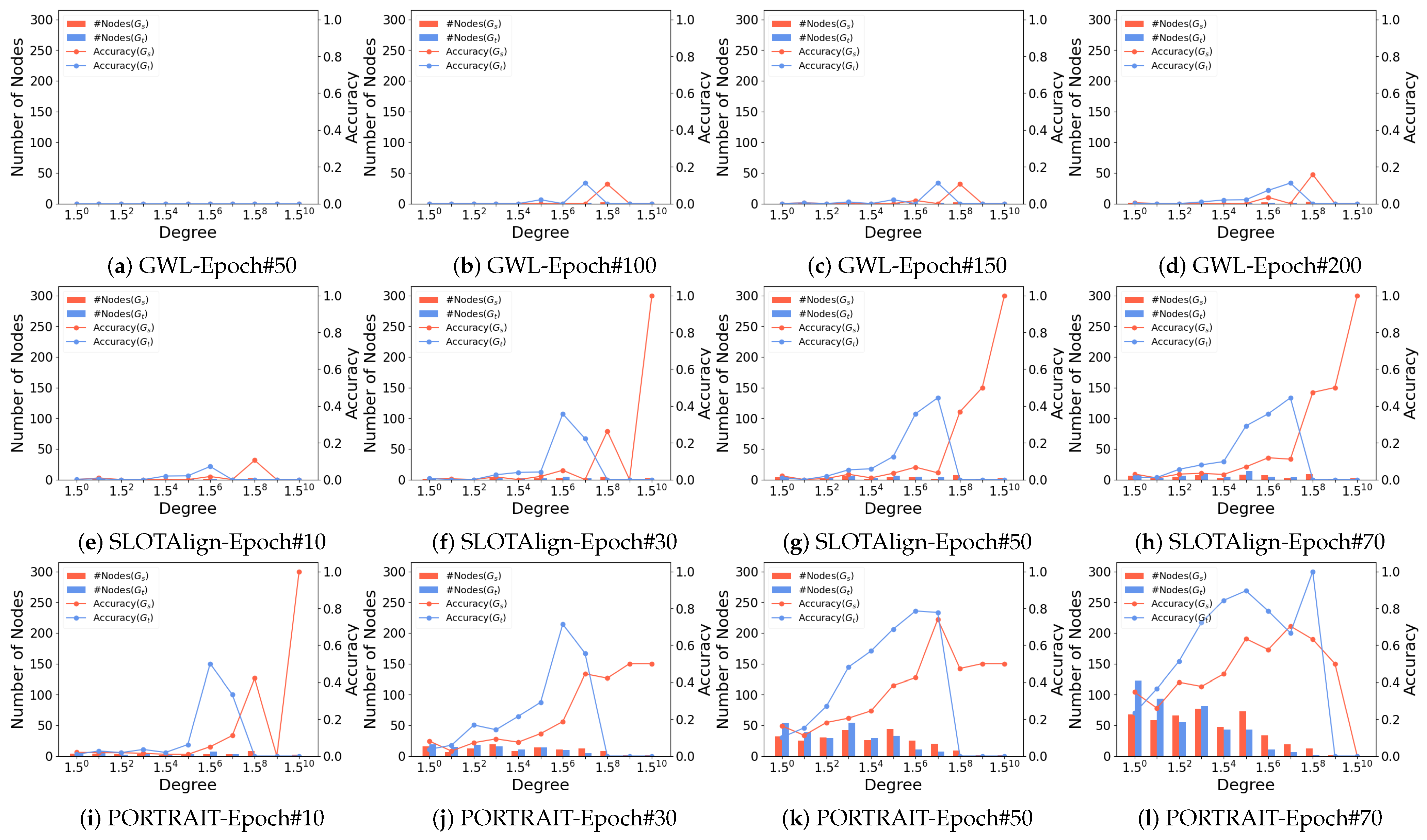
- Parameter Sensitivity: We study the effects of hyperparameters on model accuracy, including the number of layers K in the attribute propagation step, the ratio of the pseudo-anchors, and the temperature parameter in the SCP module on the two real datasets. We use Hits@1 as the evaluation metric. The results are presented in Figure 7. By analyzing the impact of attribute propagation layers, a subtle decline in performance on the Douban dataset is noticeable with the increasing value of K. We speculate that this decline may be attributed to a certain degree of oversmoothing, potentially caused by the heightened number of layers. Interestingly, as the pseudo-anchor ratio increases, the model’s performance initially improves, followed by a slight decline. We attribute this phenomenon to higher confidence (92%) in pseudo-anchors within a smaller range; as the ratio grows, additional noise is introduced, which diminishes performance. Meanwhile, we observe a slight improvement in performance on the ACM-DBLP dataset as the temperature coefficient increases. In general, our model exhibits consistent robustness to variations of hyperparameters, highlighting the stability of our proposed approach.
- Efficiency Comparison: To evaluate the computational efficiency of our model, we measure the runtime to convergence across three datasets. As shown by Figure 8 and Figure 9, our framework achieves significantly faster convergence on real-world datasets compared to baseline methods. This advantage becomes particularly pronounced on larger-scale datasets (e.g., ACM-DBLP), which we attribute to the model’s enhanced expressive power, which enables faster convergence with fewer epochs, and the matrix multiplication in Gromov–Wasserstein learning process could fully leverage the computing power of GPUs. For the synthetic dataset PPI, all methods achieve comparable efficiency.
4.3. Properties of OT-Based Methods
5. Other Related Work
6. Conclusions and Limitation
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Cao, X.; Yu, Y. Joint User Modeling Across Aligned Heterogeneous Sites Using Neural Networks. In Proceedings of the Machine Learning and Knowledge Discovery in Databases—European Conference, ECML PKDD 2017, Skopje, Republic of Macedonia, 18–22 September 2017. Part I. [Google Scholar]
- Farseev, A.; Nie, L.; Akbari, M.; Chua, T. Harvesting Multiple Sources for User Profile Learning: A Big Data Study. In Proceedings of the 5th ACM on International Conference on Multimedia Retrieval, Shanghai, China, 23–26 June 2015. [Google Scholar]
- Fey, M.; Lenssen, J.E.; Morris, C.; Masci, J.; Kriege, N.M. Deep graph matching consensus. arXiv 2020, arXiv:2001.09621. [Google Scholar]
- Feng, S.; Shen, D.; Nie, T.; Kou, Y.; Yu, G. A generation probability based percolation network alignment method. World Wide Web 2021, 24, 1511–1531. [Google Scholar] [CrossRef]
- Ni, J.; Tong, H.; Fan, W.; Zhang, X. Inside the atoms: Ranking on a network of networks. In Proceedings of the The 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’14, New York, NY, USA, 24–27 August 2014. [Google Scholar]
- Kazemi, E.; Hassani, S.H.; Grossglauser, M.; Modarres, H.P. PROPER: Global protein interaction network alignment through percolation matching. BMC Bioinform. 2016, 17, 1–16. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Ding, H.; Chen, D.; Xu, J. Novel Geometric Approach for Global Alignment of PPI Networks. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Tang, J.; Zhang, J.; Yao, L.; Li, J.; Zhang, L.; Su, Z. ArnetMiner: Extraction and mining of academic social networks. In Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Las Vegas, NV, USA, 24–27 August 2008. [Google Scholar]
- Zhang, S.; Tong, H.; Jin, L.; Xia, Y.; Guo, Y. Balancing Consistency and Disparity in Network Alignment. In Proceedings of the KDD ’21: The 27th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Singapore, 14–18 August 2021. [Google Scholar]
- Li, Y.; Chen, L.; Liu, C.; Zhou, R.; Li, J. Generative adversarial network for unsupervised multi-lingual knowledge graph entity alignment. World Wide Web 2023, 26, 2265–2290. [Google Scholar] [CrossRef]
- Shu, Y.; Zhang, J.; Huang, G.; Chi, C.H.; He, J. Entity alignment via graph neural networks: A component-level study. World Wide Web 2023, 26, 4069–4092. [Google Scholar] [CrossRef]
- Zeng, Z.; Zhang, S.; Xia, Y.; Tong, H. PARROT: Position-Aware Regularized Optimal Transport for Network Alignment. In Proceedings of the ACM Web Conference 2023, WWW 2023, Austin, TX, USA, 30 April–4 May 2023. [Google Scholar]
- Yan, Y.; Zhang, S.; Tong, H. BRIGHT: A Bridging Algorithm for Network Alignment. In Proceedings of the WWW ’21: The Web Conference 2021, Ljubljana, Slovenia, 19–23 April 2021; Leskovec, J., Grobelnik, M., Najork, M., Tang, J., Zia, L., Eds.; 2021. [Google Scholar]
- Tang, J.; Zhang, W.; Li, J.; Zhao, K.; Tsung, F.; Li, J. Robust Attributed Graph Alignment via Joint Structure Learning and Optimal Transport. In Proceedings of the 39th IEEE International Conference on Data Engineering, ICDE 2023, Anaheim, CA, USA, 3–7 April 2023. [Google Scholar]
- Xu, H.; Luo, D.; Zha, H.; Carin, L. Gromov-Wasserstein Learning for Graph Matching and Node Embedding. In Proceedings of the 36th International Conference on Machine Learning, ICML 2019, Long Beach, CA, USA, 9–15 June 2019; Chaudhuri, K., Salakhutdinov, R., Eds.; 2019. [Google Scholar]
- Wang, H.; Hu, R.; Zhang, Y.; Qin, L.; Wang, W.; Zhang, W. Neural Subgraph Counting with Wasserstein Estimator. In Proceedings of the SIGMOD ’22: International Conference on Management of Data, Philadelphia, PA, USA, 12–17 June 2022. [Google Scholar]
- Gao, J.; Huang, X.; Li, J. Unsupervised Graph Alignment with Wasserstein Distance Discriminator. In Proceedings of the KDD ’21: The 27th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Singapore, 14–18 August 2021. [Google Scholar]
- Yan, Y.; Liu, L.; Ban, Y.; Jing, B.; Tong, H. Dynamic Knowledge Graph Alignment. In Proceedings of the Thirty-Fifth AAAI Conference on Artificial Intelligence, AAAI 2021, Thirty-Third Conference on Innovative Applications of Artificial Intelligence, IAAI 2021, The Eleventh Symposium on Educational Advances in Artificial Intelligence, EAAI 2021, Virtual Event, 2–9 February 2021. [Google Scholar]
- Liu, L.; Cheung, W.K.; Li, X.; Liao, L. Aligning Users across Social Networks Using Network Embedding. In Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence, IJCAI 2016, New York, NY, USA, 9–15 July 2016. [Google Scholar]
- Chu, X.; Fan, X.; Yao, D.; Zhu, Z.; Huang, J.; Bi, J. Cross-Network Embedding for Multi-Network Alignment. In Proceedings of the World Wide Web Conference, WWW 2019, San Francisco, CA, USA, 13–17 May 2019. [Google Scholar]
- Zhang, S.; Tong, H.; Xia, Y.; Xiong, L.; Xu, J. NetTrans: Neural Cross-Network Transformation. In Proceedings of the KDD ’20: The 26th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, San Diego, CA, USA, 23–27 August 2020. [Google Scholar]
- Trung, H.T.; Van Vinh, T.; Tam, N.T.; Yin, H.; Weidlich, M.; Hung, N.Q.V. Adaptive network alignment with unsupervised and multi-order convolutional networks. In Proceedings of the 2020 IEEE 36th International Conference on Data Engineering (ICDE), Dallas, TX, USA, 20–24 April 2020; pp. 85–96. [Google Scholar]
- Wang, C.; Jiang, P.; Zhang, X.; Wang, P.; Qin, T.; Guan, X. GTCAlign: Global Topology Consistency-based Graph Alignment. IEEE Trans. Knowl. Data Eng. 2023, 36, 2009–2025. [Google Scholar] [CrossRef]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein Generative Adversarial Networks. In Proceedings of the 34th International Conference on Machine Learning, ICML 2017, Sydney, NSW, Australia, 6–11 August 2017. [Google Scholar]
- Cuturi, M. Sinkhorn Distances: Lightspeed Computation of Optimal Transport. In Proceedings of the Advances in Neural Information Processing Systems 26: 27th Annual Conference on Neural Information Processing Systems 2013, Lake Tahoe, NV, USA, 5–8 December 2013. [Google Scholar]
- Villani, C. Optimal Transport: Old and New; Springer: Berlin/Heidelberg, Germany, 2009; Volume 338. [Google Scholar]
- Mémoli, F. Gromov—Wasserstein distances and the metric approach to object matching. Found. Comput. Math. 2011, 11, 417–487. [Google Scholar] [CrossRef]
- Wu, F.; de Souza, A.H., Jr.; Zhang, T.; Fifty, C.; Yu, T.; Weinberger, K.Q. Simplifying Graph Convolutional Networks. In Proceedings of the 36th International Conference on Machine Learning, ICML, Long Beach, CA, USA, 9–15 June 2019. [Google Scholar]
- Maretic, H.P.; Gheche, M.E.; Chierchia, G.; Frossard, P. GOT: An Optimal Transport framework for Graph comparison. In Proceedings of the Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Maretic, H.P.; Gheche, M.E.; Chierchia, G.; Frossard, P. fGOT: Graph Distances Based on Filters and Optimal Transport. In Proceedings of the Thirty-Sixth AAAI Conference on Artificial Intelligence, AAAI 2022, Thirty-Fourth Conference on Innovative Applications of Artificial Intelligence, IAAI 2022, The Twelveth Symposium on Educational Advances in Artificial Intelligence, EAAI, Virtual Event, 22 February–1 March 2022. [Google Scholar]
- Xie, Y.; Wang, X.; Wang, R.; Zha, H. A Fast Proximal Point Method for Computing Exact Wasserstein Distance. In Proceedings of the Thirty-Fifth Conference on Uncertainty in Artificial Intelligence, UAI 2019, Tel Aviv, Israel, 22–25 July 2019; Globerson, A., Silva, R., Eds.; [Google Scholar]
- Vayer, T.; Courty, N.; Tavenard, R.; Chapel, L.; Flamary, R. Optimal Transport for structured data with application on graphs. In Proceedings of the 36th International Conference on Machine Learning, ICML 2019, Long Beach, CA, USA, 9–15 June 2019. [Google Scholar]
- Zhang, S.; Tong, H. FINAL: Fast Attributed Network Alignment. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016. [Google Scholar]
- Page, L.; Brin, S.; Motwani, R.; Winograd, T. The Pagerank Citation Ranking: Bring Order to the Web; Technical Report; Stanford University: Stanford, CA, USA, 1998. [Google Scholar]
- Peyré, G.; Cuturi, M. Computational optimal transport: With applications to data science. Found. Trends® Mach. Learn. 2019, 11, 355–607. [Google Scholar] [CrossRef]
- Bolte, J.; Sabach, S.; Teboulle, M. Proximal alternating linearized minimization for nonconvex and nonsmooth problems. Math. Program. 2014, 146, 459–494. [Google Scholar] [CrossRef]
- Zhang, S.; Tong, H. Attributed Network Alignment: Problem Definitions and Fast Solutions. IEEE Trans. Knowl. Data Eng. 2019, 31, 1680–1692. [Google Scholar] [CrossRef]
- Zitnik, M.; Leskovec, J. Predicting multicellular function through multi-layer tissue networks. Bioinformatics 2017, 33, i190–i198. [Google Scholar] [CrossRef] [PubMed]
- Heimann, M.; Shen, H.; Safavi, T.; Koutra, D. REGAL: Representation Learning-based Graph Alignment. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, CIKM 2018, Torino, Italy, 22–26 October 2018. [Google Scholar]
- Wang, Z.; Lv, Q.; Lan, X.; Zhang, Y. Cross-lingual Knowledge Graph Alignment via Graph Convolutional Networks. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018. [Google Scholar]
- Chen, M.; Tian, Y.; Yang, M.; Zaniolo, C. Multilingual Knowledge Graph Embeddings for Cross-lingual Knowledge Alignment. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, IJCAI 2017, Melbourne, Australia, 19–25 August 2017. [Google Scholar]
- Nassar, H.; Veldt, N.; Mohammadi, S.; Grama, A.; Gleich, D.F. Low Rank Spectral Network Alignment. In Proceedings of the 2018 World Wide Web Conference on World Wide Web, WWW 2018, Lyon, France, 23–27 April 2018. [Google Scholar]
- Pei, S.; Yu, L.; Hoehndorf, R.; Zhang, X. Semi-Supervised Entity Alignment via Knowledge Graph Embedding with Awareness of Degree Difference. In Proceedings of the World Wide Web Conference, WWW 2019, San Francisco, CA, USA, 13–17 May 2019. [Google Scholar]
- Pei, S.; Yu, L.; Zhang, X. Improving Cross-lingual Entity Alignment via Optimal Transport. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, IJCAI 2019, Macao, China, 10–16 August 2019. [Google Scholar]
- Zhang, S.; Tong, H.; Maciejewski, R.; Eliassi-Rad, T. Multilevel network alignment. In Proceedings of the World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 2344–2354. [Google Scholar]
- Chen, M.; Tian, Y.; Chang, K.; Skiena, S.; Zaniolo, C. Co-training Embeddings of Knowledge Graphs and Entity Descriptions for Cross-lingual Entity Alignment. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, IJCAI 2018, Stockholm, Sweden, 13–19 July 2018. [Google Scholar]
- Li, C.; Wang, S.; Wang, H.; Liang, Y.; Yu, P.S.; Li, Z.; Wang, W. Partially Shared Adversarial Learning For Semi-supervised Multi-platform User Identity Linkage. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, CIKM 2019, Beijing, China, 3–7 November 2019. [Google Scholar]
- Su, S.; Sun, L.; Zhang, Z.; Li, G.; Qu, J. MASTER: Across Multiple social networks, integrate Attribute and STructure Embedding for Reconciliation. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, IJCAI 2018, Stockholm, Sweden, 13–19 July 2018. [Google Scholar]
- Sun, Z.; Hu, W.; Li, C. Cross-Lingual Entity Alignment via Joint Attribute-Preserving Embedding. In Proceedings of the The Semantic Web-ISWC 2017-6th International Semantic Web Conference, Vienna, Austria, 21–25 October 2017. Part I. [Google Scholar]
- Yasar, A.; Çatalyürek, Ü.V. An Iterative Global Structure-Assisted Labeled Network Aligner. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD 2018, London, UK, 19–23 August 2018. [Google Scholar]
- Chen, S.; Lin, Y.; Liu, Y.; Ouyang, Y.; Guo, Z.; Zou, L. Enhancing robust semi-supervised graph alignment via adaptive optimal transport. World Wide Web 2025, 28, 22. [Google Scholar] [CrossRef]
- Chen, S.; Liu, Y.; Zou, L.; Wang, Z.; Lin, Y.; Chen, Y.; Pan, A. Combining Optimal Transport and Embedding-Based Approaches for More Expressiveness in Unsupervised Graph Alignment. arXiv 2024, arXiv:2406.13216. [Google Scholar]
- Sun, Z.; Hu, W.; Zhang, Q.; Qu, Y. Bootstrapping Entity Alignment with Knowledge Graph Embedding. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, IJCAI 2018, Stockholm, Sweden, 13–19 July 2018. [Google Scholar]
- Zeng, W.; Zhao, X.; Tan, Z.; Tang, J.; Cheng, X. Matching Knowledge Graphs in Entity Embedding Spaces: An Experimental Study. IEEE Trans. Knowl. Data Eng. 2023, 35, 12770–12784. [Google Scholar] [CrossRef]
- Zeng, K.; Li, C.; Hou, L.; Li, J.; Feng, L. A comprehensive survey of entity alignment for knowledge graphs. AI Open 2021, 2, 1–13. [Google Scholar] [CrossRef]
- Koutra, D.; Tong, H.; Lubensky, D.M. BIG-ALIGN: Fast Bipartite Graph Alignment. In Proceedings of the 2013 IEEE 13th International Conference on Data Mining, Dallas, TX, USA, 7–10 December 2013. [Google Scholar]
- Zhan, Q.; Zhang, J.; Yu, P.S. Integrated anchor and social link predictions across multiple social networks. Knowl. Inf. Syst. 2019, 60, 303–326. [Google Scholar] [CrossRef]
- Singh, R.; Xu, J.; Berger, B. Global alignment of multiple protein interaction networks with application to functional orthology detection. Proc. Natl. Acad. Sci. USA 2008, 105, 12763–12768. [Google Scholar] [CrossRef] [PubMed]
- Pei, S.; Yu, L.; Yu, G.; Zhang, X. Graph Alignment with Noisy Supervision. In Proceedings of the WWW ’22: The ACM Web Conference 2022, Lyon, France, 25–29 April 2022. [Google Scholar]
- Li, M.; Yu, J.; Li, T.; Meng, C. Importance Sparsification for Sinkhorn Algorithm. CoRR 2023. [Google Scholar] [CrossRef]
- Li, M.; Yu, J.; Xu, H.; Meng, C. Efficient Approximation of Gromov-Wasserstein Distance using Importance Sparsification. CoRR 2022. [Google Scholar] [CrossRef]
- Klicpera, J.; Lienen, M.; Günnemann, S. Scalable Optimal Transport in High Dimensions for Graph Distances, Embedding Alignment, and More. In Proceedings of the 38th International Conference on Machine Learning, ICML 2021, Virtual Event, 18–24 July 2021; Meila, M., Zhang, T., Eds.; [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Description |
|---|---|
| The two attributed graphs to be aligned | |
| The adjacency matrices of and | |
| The node attributes | |
| The number of nodes in and () | |
| The intra-graph cost matrices for and | |
| The inter-graph cost matrix (of size ) | |
| The alignment matrix |
| Dataset | Features | Answers | ||
|---|---|---|---|---|
| Douban [33] | 1118 | 3022 | 538 | 1118 |
| 3906 | ||||
| ACM-DBLP [37] | 9872 | 17 | 6325 | |
| 9916 | ||||
| PPI [38] | 1767 | 50 | 1767 | |
| 1767 | ||||
| Allmv-Imdb [22] | 5713 | 14 | 5174 | |
| 6011 |
| Douban Online–Offline | ACM-DBLP | PPI | Allmv-Imdb | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Model | Hits@1 | Hits@5 | Hits@10 | Hits@1 | Hits@5 | Hits@10 | Hits@1 | Hits@5 | Hits@10 | Hits@1 | Hits@5 | Hits@10 |
| WAlign | 39.45 | 62.25 | 71.47 | 63.43 | 83.18 | 86.58 | 88.51 | 92.98 | 93.87 | 52.59 | 70.94 | 76.53 |
| GAlign | 45.24 | 67.77 | 78.13 | 70.17 | 86.98 | 91.25 | 89.07 | 90.28 | 94.04 | 82.14 | 86.35 | 90.03 |
| GTCAlign | 60.91 | 76.77 | 82.18 | 60.83 | 75.52 | 80.11 | 89.25 | 92.81 | 94.07 | 84.73 | 89.92 | 91.37 |
| GWL | 3.49 | 8.32 | 9.93 | 56.36 | 77.09 | 82.18 | 86.76 | 88.06 | 88.62 | 87.82 | 92.31 | 93.83 |
| GWL + ST | 10.55 | 23.61 | 30.59 | 64.18 | 85.31 | 89.69 | 89.24 | 93.09 | 93.99 | 90.12 | 93.53 | 94.07 |
| SLOTAlign | 51.43 | 73.43 | 77.73 | 65.63 | 85.84 | 87.76 | 89.30 | 92.53 | 93.49 | 90.60 | 92.75 | 93.12 |
| SLOTAlign + ST | 55.18 | 78.03 | 82.86 | 69.88 | 88.62 | 91.28 | 89.36 | 93.01 | 94.03 | 92.07 | 93.81 | 94.26 |
| PORTRAIT | 63.32 | 86.40 | 90.87 | 73.45 | 90.13 | 93.50 | 89.75 | 93.04 | 94.17 | 95.33 | 96.27 | 96.72 |
| PORTRAIT w/o ST | 58.68 | 78.35 | 83.54 | 69.05 | 87.04 | 90.61 | 89.36 | 92.64 | 93.66 | 93.75 | 94.79 | 95.26 |
| PORTRAIT w/o ST+ | 50.45 | 68.25 | 72.90 | 66.22 | 84.96 | 87.32 | 89.25 | 92.30 | 93.06 | 89.98 | 93.01 | 93.79 |
| PORTRAIT w/o ST+Norm | 45.61 | 63.95 | 68.92 | 63.54 | 81.14 | 84.62 | 85.74 | 89.59 | 90.72 | 87.96 | 92.77 | 93.91 |
| Douban Online–Offline | ACM-DBLP | PPI | Allmv-Imdb | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Model | Hits@1 | Hits@5 | Hits@10 | Hits@1 | Hits@5 | Hits@10 | Hits@1 | Hits@5 | Hits@10 | Hits@1 | Hits@5 | Hits@10 |
| PORTRAIT | 63.42 | 86.40 | 90.87 | 73.45 | 90.13 | 93.50 | 89.75 | 93.04 | 94.17 | 95.33 | 96.27 | 96.72 |
| PORTRAIT w/degree-based | 62.25 | 86.25 | 90.78 | 72.66 | 89.66 | 93.35 | 89.58 | 93.03 | 94.13 | 95.12 | 96.18 | 96.39 |
| PORTRAIT w/PARROT | 58.32 | 81.92 | 86.35 | 70.68 | 89.16 | 92.88 | 89.60 | 92.92 | 94.11 | 94.33 | 95.29 | 95.61 |
| Douban Online–Offline | ACM-DBLP | |||
|---|---|---|---|---|
| Set of Nodes | ||||
| Top 10% | ||||
| Top 30% | ||||
| All | ||||
| Last 70% | ||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, S.; Lin, Y.; Zeng, Z.; Xue, M. Leveraging Attribute Interaction and Self-Training for Graph Alignment via Optimal Transport. Mathematics 2025, 13, 1971. https://doi.org/10.3390/math13121971
Chen S, Lin Y, Zeng Z, Xue M. Leveraging Attribute Interaction and Self-Training for Graph Alignment via Optimal Transport. Mathematics. 2025; 13(12):1971. https://doi.org/10.3390/math13121971
Chicago/Turabian StyleChen, Songyang, Youfang Lin, Ziyuan Zeng, and Mengyang Xue. 2025. "Leveraging Attribute Interaction and Self-Training for Graph Alignment via Optimal Transport" Mathematics 13, no. 12: 1971. https://doi.org/10.3390/math13121971
APA StyleChen, S., Lin, Y., Zeng, Z., & Xue, M. (2025). Leveraging Attribute Interaction and Self-Training for Graph Alignment via Optimal Transport. Mathematics, 13(12), 1971. https://doi.org/10.3390/math13121971