
Research on E-Commerce Inventory Sales Forecasting Model Based on ARIMA and LSTM Algorithm



Abstract
1. Introduction
- Strategic Differentiation of Forecasting Targets: We precisely define and separate forecasting objectives: “inventory” represents overall monthly stocking requirements (reflecting replenishment cycles and storage capacity planning), while “sales” denote daily total shipments (capturing volatile customer demand). This delineation is crucial for tailoring models to the distinct temporal characteristics and business implications of each metric.
- Application of a Complementary Dual-Model Strategy: To effectively model these differentiated targets, we strategically apply ARIMA models for their proficiency in capturing seasonality and trends in relatively stable monthly inventory data, and LSTM networks for their strength in handling non-linear, high-frequency fluctuations inherent in daily sales data. This tailored combination is shown to yield significant improvements in forecasting accuracy.
- Demonstration of Practical Value for Warehouse Operations: Beyond theoretical model optimization, this research underscores the practical utility of the framework. Through multi-dimensional evaluation metrics, we provide a quantitative basis for enhanced warehouse planning decisions, including optimizing category-specific warehouse layouts, reducing inventory holding costs, and improving supply chain responsiveness.
2. Materials and Methods
2.1. ARIMA Model
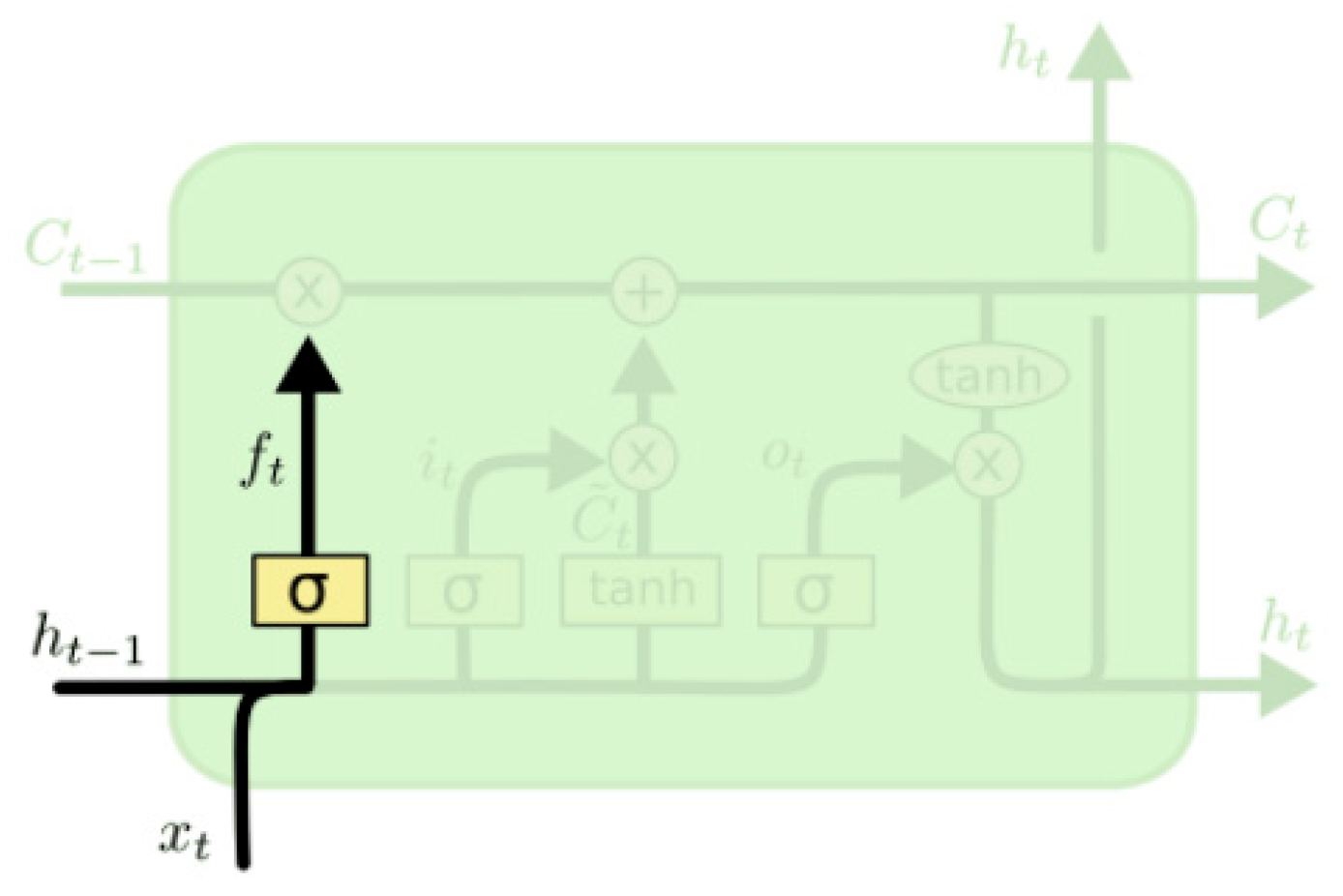
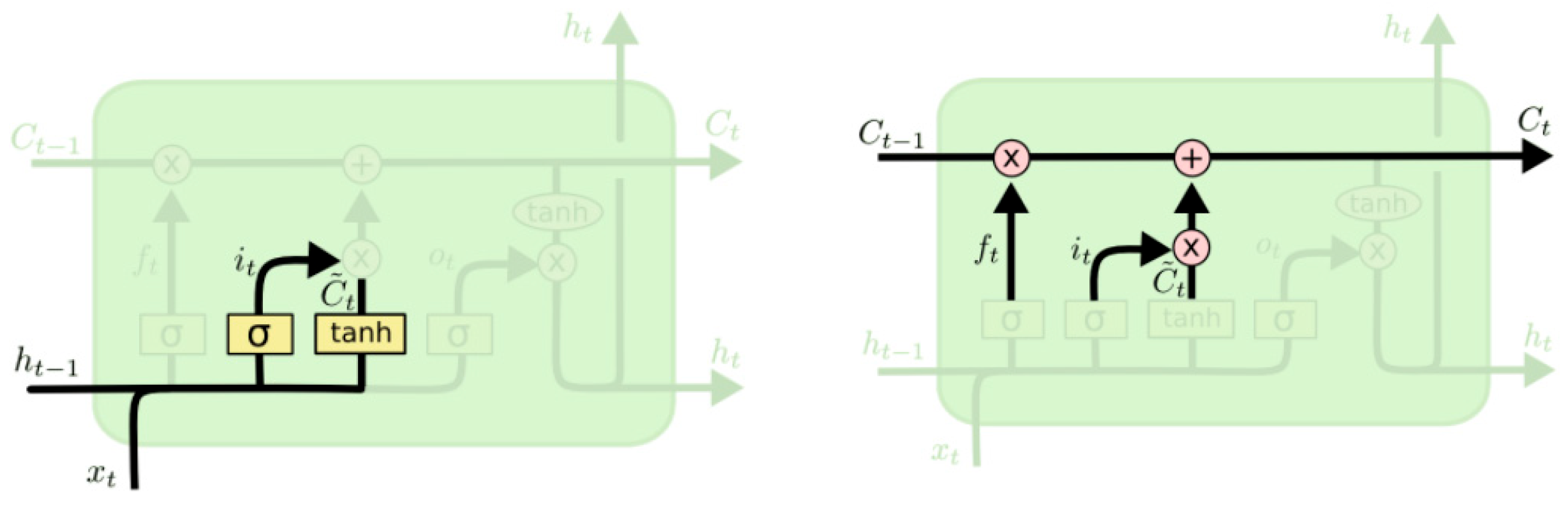
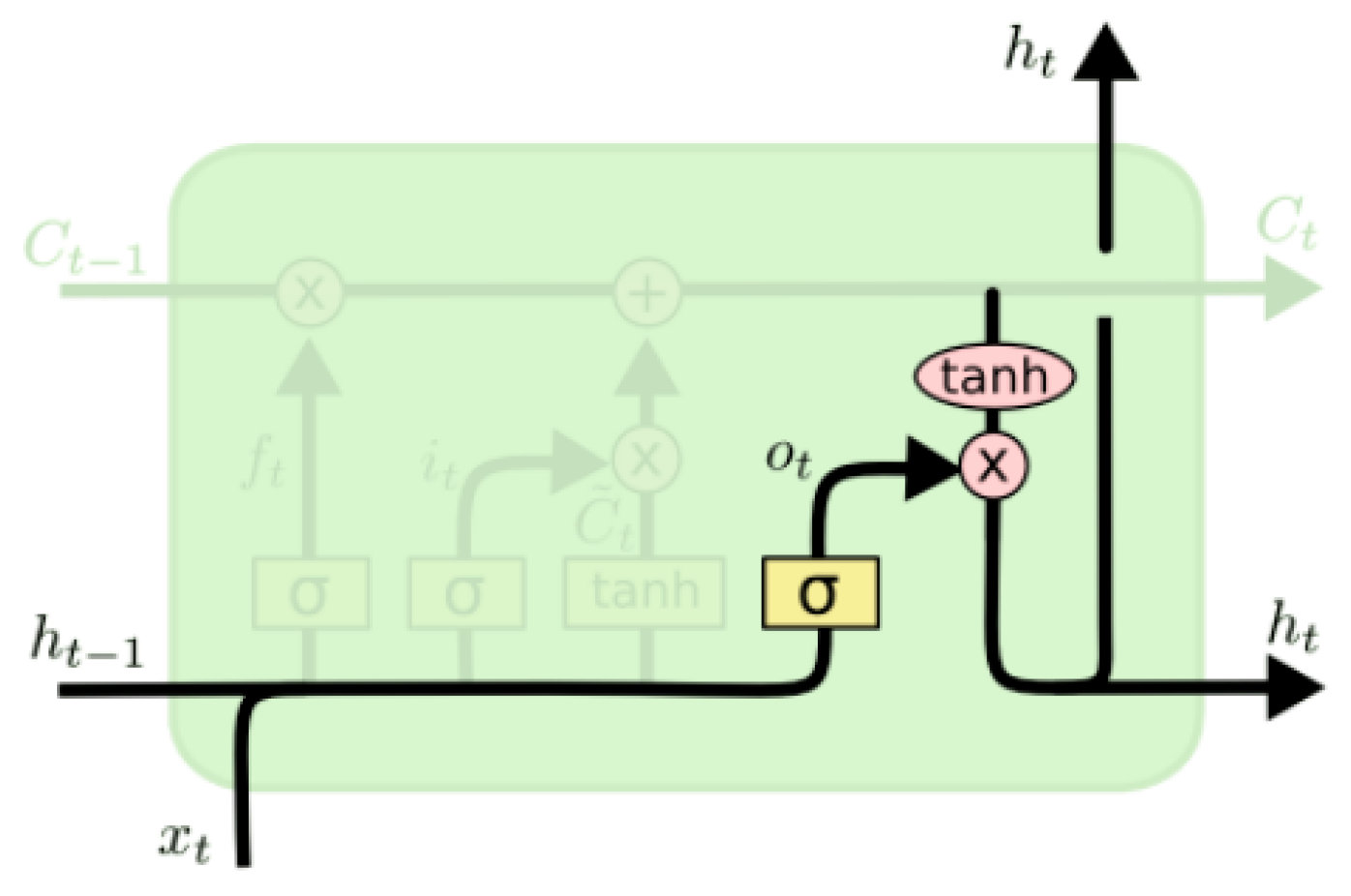
2.2. LSTM Model
3. Experimental Results and Analysis
3.1. Experimental Environment and Data Set
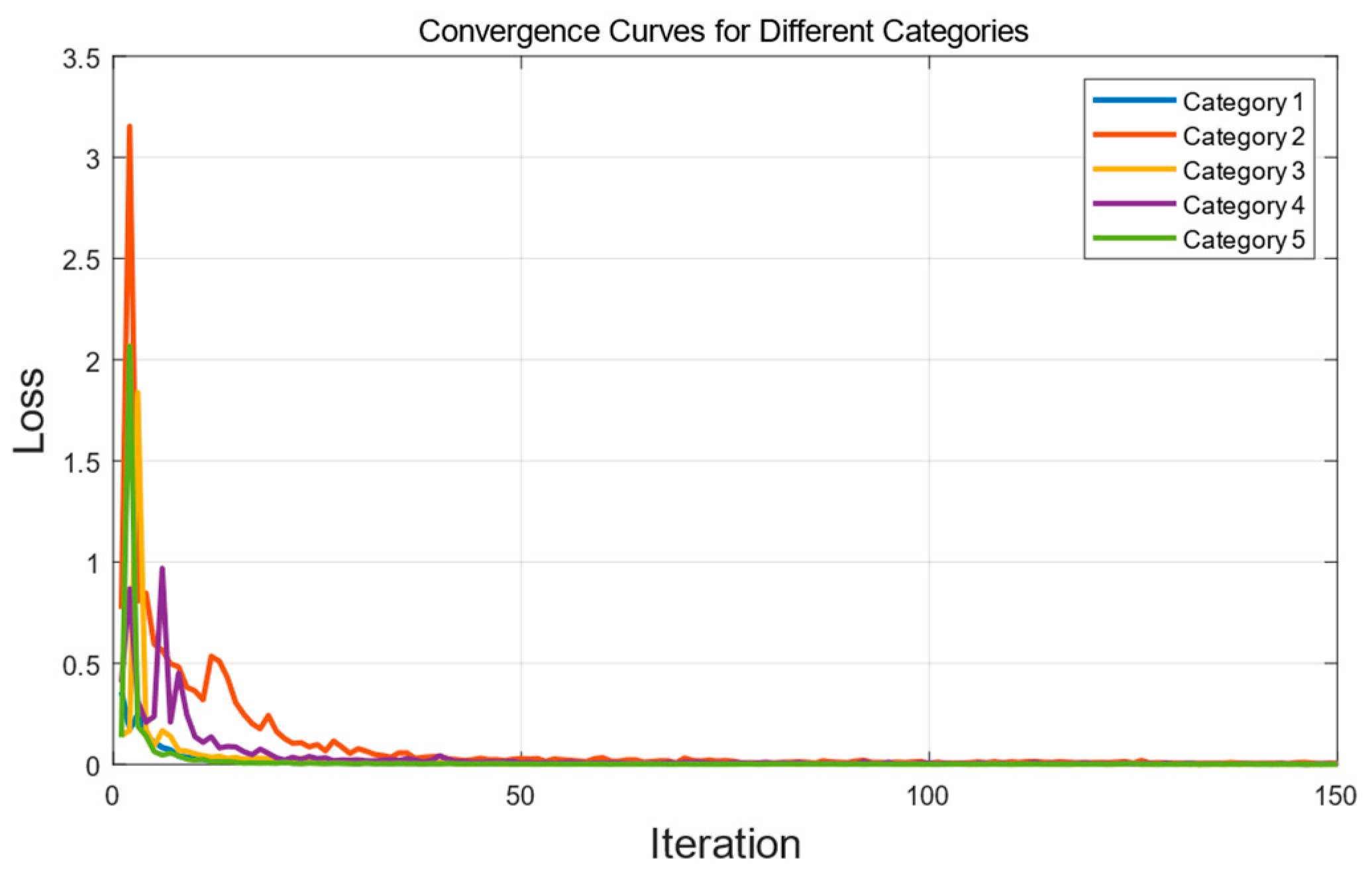
3.2. Model Convergence
3.3. Inventory Forecast Results Based on the ARIMA Algorithm
3.4. Sales Forecast Results Based on the LSTM Network
3.5. Visualization of Sales Performance Tiers
- High-Volume Tiers (Class 5–6): These elite categories, despite constituting only approximately 15% of the total number of product categories, are forecasted to drive a disproportionately large share of sales, accounting for roughly 30% of the total predicted sales volume. These tiers often encompass fast-moving consumer goods (FMCGs) or high-demand seasonal items, representing critical revenue drivers.
- Mid-Range Tiers (Class 3–4): This segment demonstrates moderate yet consistent sales performance. Collectively, these categories are predicted to contribute approximately 40% of the total sales volume, forming the stable core of the sales distribution.
- Low-Volume Tiers (Class 1–2): These categories are the most numerous, representing nearly 45% of all product types. However, their combined contribution to overall sales is forecasted to be relatively modest, at approximately 30%. This highlights a long-tail phenomenon, where a large number of products contribute individually small amounts to the total sales.
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Huang, Z.; Ji, Q.; Chen, D. Research on intelligent logistics warehousing system in the Internet of things. Autom. Instrum. 2011, 32, 12–15. [Google Scholar]
- Wang, X.; Zhang, Q. Construction of fresh agricultural products cold chain logistics system based on Internet of things: Framework, mechanism and path. J. Nanjing Agric. Univ. (Soc. Sci. Ed.) 2016, 16, 31–41+163. [Google Scholar]
- Tulli, S.K.C. Warehouse Layout Optimization: Techniques for Improved Order Fulfillment Efficiency. Int. J. Acta Inform. 2023, 2, 138–168. [Google Scholar]
- Islam, M.R.; Ali, S.M.; Fathollahi-Fard, A.M.; Kabir, G. A novel particle swarm optimization-based grey model for the prediction of warehouse performance. J. Comput. Des. Eng. 2021, 8, 705–727. [Google Scholar] [CrossRef]
- Singh, K.; Booma, P.M.; Eaganathan, U. E-Commerce System for Sale Prediction Using Machine Learning Technique. J. Phys. Conf. Ser. 2020, 1712, 012042. [Google Scholar] [CrossRef]
- Feng, Y.; Chen, Z.; Wu, X. Smart Warehouse Management Using IoT and Big Data Analytics. IEEE Trans. Ind. Inform. 2023, 19, 4321–4332. [Google Scholar]
- Raizada, S.; Saini, J.R. Comparative analysis of supervised machine learning techniques for sales forecasting. Int. J. Adv. Comput. Sci. Appl. 2021, 12, 102–110. [Google Scholar] [CrossRef]
- Zhang, X.; He, Y.; Wang, L. Research and analysis of e-commerce sales forecasting based on integrated learning. J. Change Univ. 2024, 34, 1–7. [Google Scholar]
- Chai, F.; Zhang, L.; Su, J.; Li, F.; Gao, M.; Lv, F.; Zhang, B.; Zhan, C. Research on prediction of agricultural equipment inventory based on deep learning. Comput. Eng. Softw. 2023, 44, 21–25. [Google Scholar]
- Huang, Y.; Liang, F.; Fan, C.; Song, Z. Application of improved particle swarm optimization algorithm in inventory forecasting. J. Northwest. Polytech. Univ. 2023, 41, 428–438. [Google Scholar] [CrossRef]
- Wang, W.; Tang, R.; Li, C.; Liu, P.; Luo, L. A BP neural network model optimized by mind evolutionary algorithm for predicting the ocean wave heights. Ocean Eng. 2018, 162, 98–107. [Google Scholar] [CrossRef]
- Chafak, T.; Nur, S.; Cenk, G.; Okan, O. Short term load forecasting based on ARIMA and ANN approaches. Energy Rep. 2023, 9, 550–557. [Google Scholar]
- Tian, Z.; Yu, X.; Feng, G. Short-term wind speed prediction model based on long short-term memory network with feature extraction. Earth. Sci. Inform. 2025, 18, 333. [Google Scholar] [CrossRef]
- Gu, Y.H.; Jin, D.; Yin, H.; Zheng, R.; Piao, X.; Yoo, S.J. Forecasting agricultural commodity prices using dual input attention LSTM. Agriculture 2022, 12, 256. [Google Scholar] [CrossRef]
- Han, M.; Wang, Q. Adaptive Graph Convolution Neural Differential Equation for Spatio-Temporal Time Series Prediction. IEEE Trans. Knowl. Data Eng. 2025, 37, 3193–3204. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| July | August | September | |
|---|---|---|---|
| category 1 | 6076 | 6119 | 6174 |
| category 31 | 0 | 0 | 0 |
| category 61 | 240,564 | 240,564 | 240,564 |
| category 91 | 3824 | 951 | 0 |
| category 121 | 73,618 | 73,618 | 73,618 |
| category 151 | 100,857 | 129,028 | 110,154 |
| category 181 | 379 | 763 | 433 |
| category 211 | 8211 | 8560 | 8498 |
| category 241 | 58,047 | 58,047 | 58,047 |
| category 271 | 15,108 | 15,108 | 15,108 |
| category 301 | 2528 | 2635 | 2644 |
| category 331 | 39,559 | 25,879 | 12,198 |
| 1 July | 11 July | 21 July | 31 July | 11 August | 21 August | 31 August | 11 September | 21 September | |
|---|---|---|---|---|---|---|---|---|---|
| Category 1 | 28 | 33 | 23 | 21 | 32 | 25 | 22 | 27 | 27 |
| Category 31 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Category 61 | 2119 | 1939 | 3693 | 1825 | 1701 | 4236 | 1754 | 1830 | 3987 |
| Category 91 | 1 | 4 | 1 | 2 | 4 | 0 | 0 | 7 | 1 |
| Category 121 | 992 | 948 | 2352 | 886 | 904 | 2322 | 912 | 781 | 1236 |
| Category 151 | 2059 | 2772 | 1873 | 1499 | 4076 | 1646 | 3708 | 1368 | 3738 |
| Category 181 | 4 | 2 | 4 | 4 | 12 | 3 | 1 | 11 | 2 |
| Category 211 | 31 | 18 | 23 | 10 | 24 | 21 | 10 | 24 | 21 |
| Category 241 | 806 | 1012 | 878 | 909 | 1031 | 911 | 970 | 1069 | 970 |
| Category 271 | 246 | 171 | 414 | 157 | 165 | 347 | 159 | 214 | 171 |
| Category 301 | 53 | 27 | 26 | 22 | 18 | 28 | 12 | 87 | 23 |
| Category 331 | 791 | 367 | 569 | 451 | 874 | 412 | 518 | 857 | 388 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, C.; Wang, J. Research on E-Commerce Inventory Sales Forecasting Model Based on ARIMA and LSTM Algorithm. Mathematics 2025, 13, 1838. https://doi.org/10.3390/math13111838
Wang C, Wang J. Research on E-Commerce Inventory Sales Forecasting Model Based on ARIMA and LSTM Algorithm. Mathematics. 2025; 13(11):1838. https://doi.org/10.3390/math13111838
Chicago/Turabian StyleWang, Chenyang, and Junsheng Wang. 2025. "Research on E-Commerce Inventory Sales Forecasting Model Based on ARIMA and LSTM Algorithm" Mathematics 13, no. 11: 1838. https://doi.org/10.3390/math13111838
APA StyleWang, C., & Wang, J. (2025). Research on E-Commerce Inventory Sales Forecasting Model Based on ARIMA and LSTM Algorithm. Mathematics, 13(11), 1838. https://doi.org/10.3390/math13111838