1. Introduction
Large language models (LLMs) now underpin state-of-the-art systems across many natural language processing (NLP) tasks, generating text that is both coherent and fluent. However, LLMs are also prone to hallucinations—content that is not supported by either their pre-trained knowledge or the user-supplied context. In high-stakes settings such as medicine or law, an ungrounded answer can cause tangible harm, for example by suggesting an incorrect diagnosis or an invalid legal argument.
Existing attempts to curb hallucinations fall into three broad groups: (1) prompt-based methods, (2) fine-tuning approaches, and (3) decoding-time methods, which update the model itself—most notably reinforcement learning from human feedback (RLHF) [
1]. Prompt-based approaches reshape the input so that the model is better primed to use external information. Chain-of-thought (CoT) [
2] guides step-by-step reasoning, while tree-of-thought (ToT) [
3] explores multiple reasoning paths in parallel. These methods, however, leave the model’s internal representations untouched, so hallucinations can persist whenever complex reasoning or knowledge conflicts are involved. RLHF fine-tuning can substantially improve factuality but requires costly human annotation and extensive additional computation, which can be prohibitive for many real-world deployments.
More recently, the focus has shifted to decoding-time interventions. Context-contrast methods create an explicit “context-free” baseline and down-weight tokens that are not bolstered by the new evidence. Context-aware decoding (CAD) [
4] compares the probabilities with and without context; Delta [
5] masks random spans to build the baseline; and dynamic contrastive decoding (DVD) [
6] updates the contrast dynamically during retrieval-augmented generation. While effective, these techniques are layer-agnostic: they operate only on the final logits and therefore cannot see where in the network the context is actually integrated.
A complementary line of work exploits the network’s internal hierarchy. Inter-layer methods such as DoLa (decoding by contrasting layers) [
7] identify the layer whose distribution diverges most from the final layer and boost tokens that emerge there. END (cross-layer entropy-enhanced decoding) [
8] goes further by measuring how sharply each token’s probability concentrates across successive layers and amplifying low-entropy tokens. However, because both DoLa and END rely solely on internal activations, they lack a context-free baseline and cannot tell whether a probability gain reflects genuinely new evidence or merely an internal redistribution of prior knowledge.
Thus, context-contrast methods (CAD, Delta, DVD) and inter-layer methods (DoLa, END) attack hallucination from different angles, but neither family balances fresh context against entrenched priors at the layer level. In this paper we introduce layer-aware contextual decoding (LACD), which unifies the two perspectives: it computes a context-free baseline and reasons over layer-wise token distributions, dynamically re-weighting tokens so that newly provided evidence is integrated without erasing reliable pre-trained knowledge.
Our contributions are threefold. First, we propose LACD, the first plug-in decoder that jointly contrasts context-free and context-provided logits at multiple layers. Second, without any fine-tuning, LACD consistently reduces hallucination on HotPotQA and SQuAD and surpasses strong decoding baselines such as CAD and DoLa. Third, we analyze where and how context is integrated in large models, revealing a stable performance plateau that guides practical hyper-parameter choices.
The remainder of this paper is organized as follows:
Section 2 surveys prior work;
Section 3 details the LACD algorithm;
Section 4 describes datasets, evaluation, and implementation;
Section 5 reports empirical results;
Section 6 discusses limitations and future work; and finally,
Section 7 concludes.
2. Relative Works
2.1. Hallucination
With the advancement of large language models (LLMs), hallucination has emerged as an important research topic. Hallucination refers to information generated by LLMs without a factual basis and is commonly categorized into intrinsic hallucination, which contradicts the given context, and extrinsic hallucination, which introduces facts that cannot be verified from the context [
9]. Intrinsic errors are often observed in tasks like abstractive summarization, where the model may invert or fabricate details already present in the source document, whereas extrinsic errors occur when the model supplements plausible yet unverifiable knowledge—an issue that becomes acute in open-domain question answering. Recent analyses further subdivide intrinsic hallucinations into instruction-inconsistency, logic-inconsistency, and context-inconsistency, highlighting that each subtype stems from different attention failures within the model pipeline [
10]. This phenomenon significantly limits the application of LLMs in domains requiring high reliability, such as summarization, question answering (QA), legal, and medical data processing [
11].
The causes of hallucination are broadly categorized into three types [
10]. First, conflicts between a model’s prior knowledge and the input context can cause hallucination. LLMs have strong prior knowledge learned from vast amounts of web data, making them prone to generating unrealistic responses when encountering conflicting new information. Second, insufficient input context can lead to hallucination. When inadequate information is provided, the model attempts to fill in incomplete data based on learned patterns, potentially resulting in hallucination. Third, limitations in decoding strategies are responsible. Due to the probabilistic nature of autoregressive text generation, LLMs can assign non-negligible probabilities to tokens lacking factual grounding, particularly under ambiguous or conflicting contexts.
Various studies have been conducted to address this issue, notably proposing methods such as CAD and DoLa. These approaches aim to mitigate hallucination by fully utilizing the model’s existing pretrained capabilities, thus reducing hallucination without the need for additional fine-tuning.
2.2. CAD
Another recent approach proposed to address hallucinations caused by conflicts between context and prior knowledge in large language models (LLMs) is context-aware decoding (CAD).
CAD employs a decoding strategy that contrasts the probability distributions predicted by the model in “context-provided” and “context-free” states, allowing contextual information to effectively override the model’s prior knowledge. Specifically, it leverages the concept of pointwise mutual information (PMI) to reweight the probability distribution by assigning higher weights to tokens whose probabilities significantly increase when context is provided.
This approach encourages pretrained models to actively incorporate newly provided contexts without additional fine-tuning, effectively mitigating hallucinations in tasks such as summarization and QA. Notably, CAD has shown particular effectiveness in knowledge-conflict scenarios—such as when updated information contradicts outdated knowledge stored in the model—enabling accurate context-based responses.
Empirical evaluations using summarization datasets such as CNN-DM [
12] and XSUM [
13], as well as knowledge conflict tasks like NQ-Swap [
14] and MemoTrap [
15], have demonstrated significant improvements in ROUGE-L, accuracy, and factuality metrics. These results illustrate that CAD effectively reduces hallucinations and enhances factuality simply by strengthening the emphasis on contextual information during decoding, without retraining model parameters.
CAD computes pointwise mutual information only from the final-layer probabilities, treating the network as a single black box; because it never contrasts context-provided and context-free representations at intermediate layers, it lacks any layer-wise comparison. This absence of hierarchical insight forces CAD to apply one global correction, which can over- or under-adjust individual tokens and leaves the balance between new context and prior knowledge uncontrolled.
2.3. DoLa
DoLa has been proposed as an approach to mitigate hallucinations by exploiting differences in logit distributions between internal layers of large language models. Unlike traditional contrastive decoding, which utilizes differences in probability distributions between two separate models, DoLa compares token distributions derived from intermediate layers (early exit) and the final layer within a single model. Using Jensen–Shannon divergence (JSD) [
16], DoLa dynamically identifies the layer with the greatest distributional shift and leverages this difference to prioritize the selection of factual tokens.
This method emphasizes factual knowledge already embedded in the model, thus enhancing factuality and reliability during generation without external knowledge or additional fine-tuning. When applied to large language models such as LLaMA [
17] or GPT-4 [
18], DoLa has been reported to effectively produce accurate knowledge-based responses and reduce hallucinations. Evaluations across various benchmarks, including TruthfulQA [
19], FACTOR [
20], StrategyQA [
21], and GSM8K [
22], have shown significant improvements in factual reasoning performance, demonstrating the capability of DoLa to more effectively utilize the model’s internal information without additional computation or training.
DoLa selects a single “peak’’ layer purely by its divergence from the final layer, without examining how that layer responds to the external context. As a result, the chosen layer may capture stylistic or length-related shifts rather than genuine contextual information, and, lacking a context-free baseline, DoLa cannot tell whether the divergence stems from new context or an internal redistribution of prior knowledge.
Both CAD and DoLa are plug-in decoding strategies that require no extra fine-tuning and rely solely on a single pre-trained model. However, they differ in three key respects: (i) granularity: CAD applies a global PMI adjustment at the final layer, whereas DoLa selects a single pivot layer based on JSD; (ii) context handling: CAD explicitly contrasts context-provided and context-free probabilities, while DoLa never uses a context-free baseline; (iii) knowledge utilization: CAD may under-use prior knowledge by over-amplifying context, whereas DoLa can ignore new context when the JSD peak is not context-driven. Our proposed LACD inherits the plug-in property but combines layer-wise context scores with dynamic weighting, thereby mitigating both the final-layer bias of CAD and the single-layer bias of DoLa.
3. Methodology
3.1. Background
Large-scale language models consist of an embedding layer,
N Transformer (LLM) [
23] layers, and an affine layer for final prediction. The input token sequence is first converted into a vector sequence by the embedding layer. As these vectors pass through each Transformer layer, they progressively integrate semantic and contextual information. Let
be the output of the
i-th Transformer layer, and let
be the output of the final (
N-th) layer, which most strongly reflects the model’s learned knowledge. The affine layer then predicts the probability distribution for the next token as follows:
In this formulation, t denotes the current time step for which the token is to be predicted, with prediction based on tokens generated up to time step . The model leverages the previous tokens (i.e., all tokens preceding time step t) to predict the probability distribution for the next token .
The weight matrix projects the hidden vector into the vocabulary dimension. This projection results in a logit vector of dimension , which is subsequently transformed by the softmax function to yield the probability distribution across all possible tokens in the vocabulary.
3.2. Contextual Conflicts with Pre-Trained Knowledge
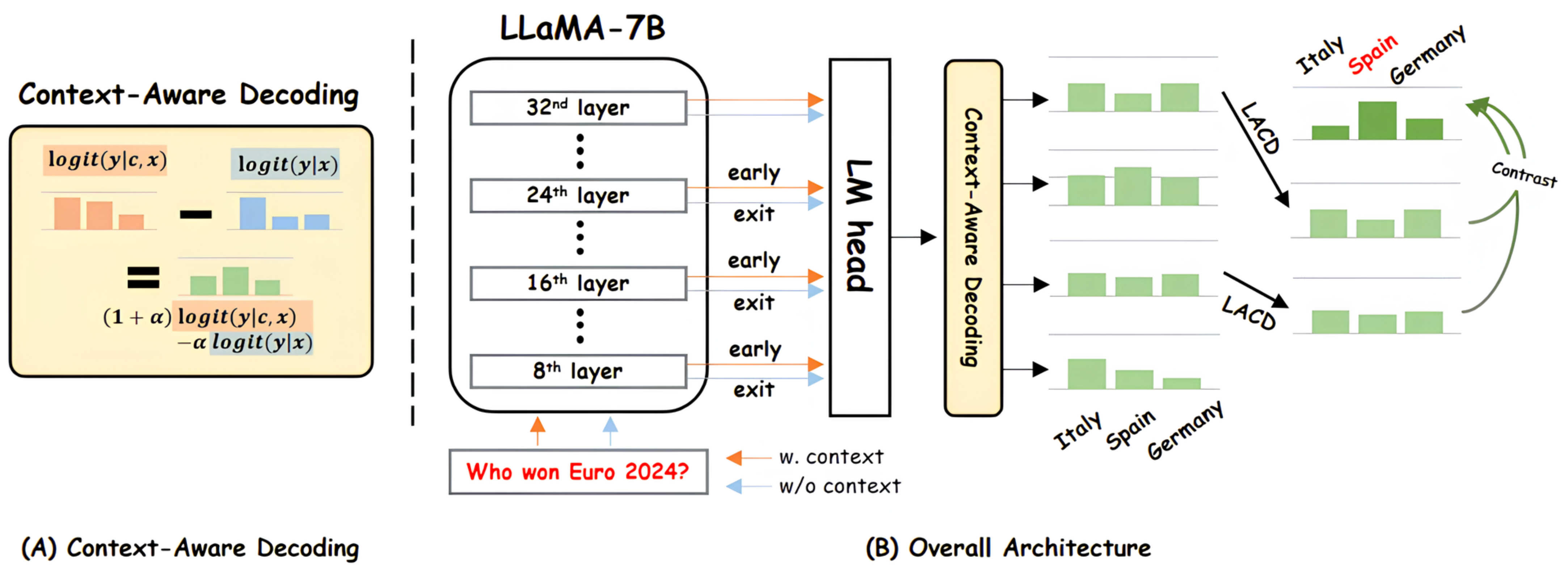
Figure 1A illustrates the contrast decoding process for handling potential conflicts between context and pre-trained knowledge. Given a context
c and an input query
x, the language model generates an answer
y. Formally, this can be written as:
However, when provided context c falls outside the scope of the model’s pre-trained data or conflicts with previously learned knowledge, the model may inadequately incorporate c, defaulting excessively to outdated or conflicting pre-trained information. For example, if the question is “Which country most recently won the Euro?” and the context states “Spain won the 2024 UEFA European Championship”, the model might still produce the incorrect answer “Italy”, based on its older learned data.
To address this issue, we propose combining the probability distribution that reflects the given context with one that primarily relies on pre-trained knowledge, in a contrastive fashion. In the
i-th layer early exit, the adjusted distribution can be defined as:
Equation (
3) can be derived from point-wise mutual information (PMI) in three algebraic steps.
Step 1: PMI definition. For a token
and the context
c, PMI is
Step 2: Scaling and exponentiation. Introducing a hyper-parameter
that controls the strength of contextual influence and exponentiating Equation (
4) gives
Step 3: Forming the unnormalized contrastive distribution. Multiplying Equation (
5) by the context-conditional probability yields
where the superscript
indicates that the two probabilities are obtained from the early-exit logits of the
i-th layer via the softmax projection in Equation (
8).
Step 4: Renormalization. Finally, normalizing Equation (
6) over the vocabulary
gives a valid distribution,
thereby recovering Equation (
3).
Through this contrastive adjustment, the model reconciles pre-trained knowledge with newly provided context, reducing erroneous predictions and improving factual consistency.
3.3. Early Exit Mechanisms for Improved Context Integration
Figure 1B shows the entire decoding pipeline, within which an early exit branch taps the
i-th-layer hidden state
of LLaMA-7B and projects it through the shared output matrix
W to obtain an interim next-token distribution:
This approach aims to mitigate the issue of excessive reliance on pre-trained knowledge—which can lead to overlooking newly provided information—by identifying the point at which the newly given question or input has already been sufficiently incorporated within the model’s internal layers. In doing so, it helps control potential hallucinations or biases that may become more pronounced in the final layers.
Subsequently, by performing contrast decoding between the probability distributions obtained from the selected intermediate (i-th) layer and the final (N-th) layer, the model verifies whether the tokens, whose probabilities sharply increase in the higher layers, align with the information the model is better understanding while processing the given input. Early exit is utilized to pinpoint the point at which the model sufficiently integrates the new information.
We want to use the early exit mechanism to focus on how the model has utilized the given information and which layers have successfully understood it. Therefore, we conduct the context-conflict across all layers. From there, we perform contrast decoding by dynamic layer selection to choose the most relevant layer that best represents the information the model has integrated.
3.4. Appropriate Layer Selection
Large language models, built on the Transformer architecture, process input information progressively through multiple layers. In this process, the lower layers typically capture relatively general patterns (e.g., syntactic features), while the upper layers focus on more nuanced semantic content (e.g., factual knowledge) [
24]. Using these layer-wise shifts in information, we propose a decoding strategy that highlights the newly provided context. Specifically, by analyzing output probability distributions at selected layers, adjustments are made whenever the model’s pre-trained knowledge neglects or misrepresents the given context.
3.4.1. Dynamic Layer Selection
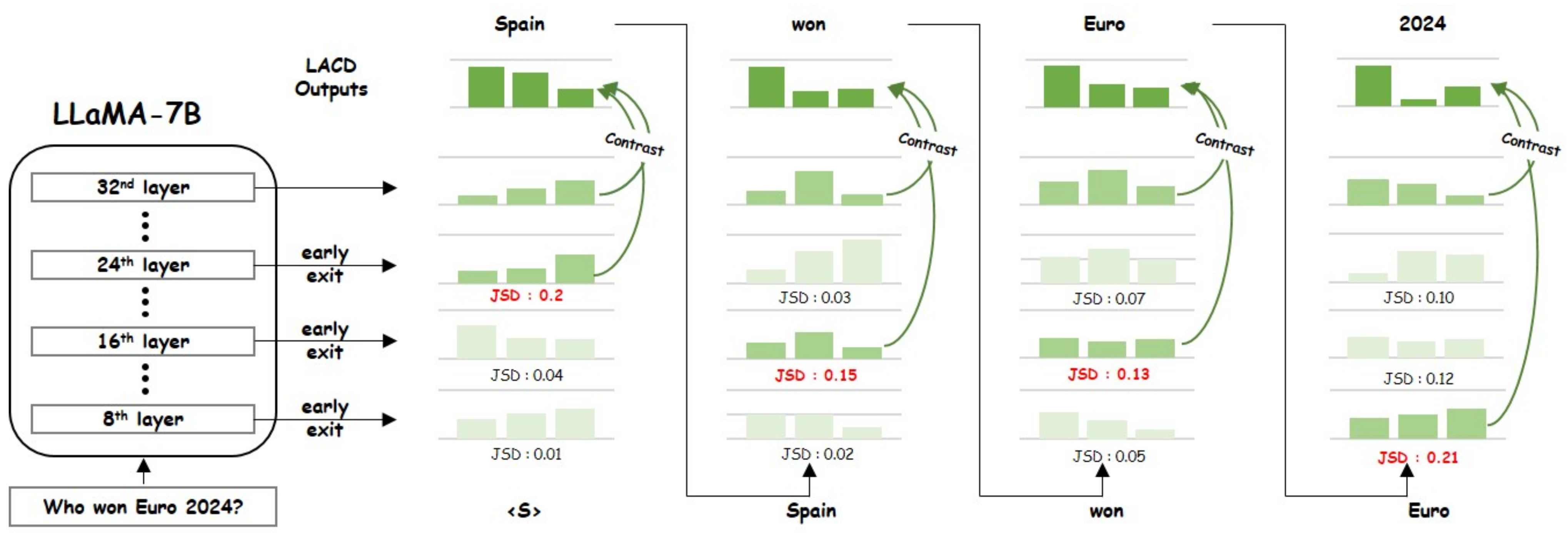
As illustrated in
Figure 2, Transformer-based language models produce their final output at the top-most layer, where semantic and pre-trained knowledge are synthesized to generate a response. By contrast, the lower layers contain comparatively simpler syntactic features or initial predictions and are therefore likely to be less influenced by newly provided context. To exploit this property, we compare the probability distributions of these lower layers with that of the final layer, and then dynamically select the intermediate layer whose distribution differs the most. Specifically, if a token has a low probability in a lower layer but a high probability in the final layer, it likely reflects a strong influence from newly provided context. By identifying such tokens—through comparison with the final layer—and leveraging them, we can generate more reliable outputs.
3.4.2. Comparison via JSD
To compare the output probability distributions of each candidate layer with that of the final layer, we employ the Jensen–Shannon divergence (JSD) [
16]. JSD is a symmetric measure of the difference between two probability distributions, defined as:
where
M is the average of the two distributions:
and
is the Kullback–Leibler divergence [
25], a non-symmetric measure of distributional difference. In our framework, the selected layer is the one whose distribution
P exhibits the highest JSD relative to the final-layer distribution
Q, indicating that context information has begun to be effectively integrated.
3.4.3. Contrast Decoding Between the Final Layer and the Selected Layer
Figure 2 also depicts how contrast decoding is applied between the final (
N-th) layer and the selected layer identified in the previous step. Specifically,
where
denotes the adjusted distribution from the final layer and
the adjusted distribution from the selected (intermediate) layer. By partially compensating the final layer’s distribution with
times the selected-layer distribution, this approach suppresses tokens overly influenced by pre-trained knowledge and preserves the newly incorporated context captured earlier. Finally, the next token is selected via
By choosing the intermediate layer that best reflects newly provided information and contrasting it with the final layer, the model more thoroughly retains contextual cues, mitigating hallucinations or biases that could arise from excessive reliance on pre-trained knowledge.
4. Experiments
4.1. Datasets
In this paper, we evaluate our proposed method on three QA datasets: the distractor set of the HotPotQA [
26] validation dataset, SQuAD [
27]. HotPotQA is a large-scale question-answering (QA) dataset based on Wikipedia paragraphs, specifically designed to require multi-hop reasoning. We use the distractor set to assess our model’s ability to handle complex contextual information and multi-step inference. The Stanford Question Answering Dataset (SQuAD) is a widely used QA benchmark consisting of questions and answers derived from Wikipedia paragraphs, making it suitable for evaluating reading comprehension and single-paragraph answer extraction.
4.2. Experimental Setup
We evaluate our decoding method on three Meta-AI backbones—LLaMA-1 7B [
17], LLaMA-2 7B [
28], and LLaMA 3.2 1B [
29]. Each model is loaded as is, and only the inference procedure is modified, so no additional fine-tuning influences the results. The context weight
was chosen by a coarse grid search (step 0.1, range 0.1–0.9) on the full validation set of each dataset. This search yields
for
HotPotQA and
for
SQuAD. Shifting either value by
changes EM/F1 by less than 0.6, indicating limited sensitivity. Decoding starts from the
Transformer layer, and the layer-reweighting coefficient is fixed at
. Exact match (EM) and F1 are reported to capture both strict correctness and partial-overlap quality of generated answers. All experiments were conducted on a single workstation with two NVIDIA RTX 4090 GPUs (24 GB each) without distributed training or model-parallel inference. Experiments were run with Python 3.10, PyTorch 2.6.0, Transformers 4.28.1
4.3. Prompt Construction and Few-Shot Examples
In our research, we perform the question-answering task using only few-shot prompts, without applying any additional fine-tuning to the pre-trained model. To this end, we prepare six question–answer examples in a demo-text format in advance. Sample questions (e.g., “Is Mars called the Red Planet?”) mainly involve relatively simple general knowledge, while the corresponding answers (for example, “yes” or “Mount Everest”) are clearly defined to guide the model effectively.
In
Table 1, we provide a concrete example of how prompts are constructed and how a few-shot setup can be presented. In particular, when contextual information is needed, it can be included in the format “Supporting information: …” to encourage the model to leverage that additional context. Conversely, the “no-context” setting simply connects the preprepared few-shot examples with the question in a straightforward QA format; in this case, the model relies solely on its pre-trained knowledge and the demonstration examples to infer an answer. By preparing these two variations, we can compare the model’s output depending on whether additional context is provided or not.
5. Results and Analysis
5.1. Main Results
Table 2 presents exact match (EM) and F1 on
HotPotQA and
SQuAD for three publicly released Meta backbones—LLaMA-1 7B, LLaMA-2 7B, and LLaMA 3.2 1B. Removing retrieved passages (Baseline (w/o context)) leaves the models almost powerless (e.g., 2.23/4.33 EM/F1 on LLaMA-1 for HotPotQA); adding the same passages (Baseline (w. context)) therefore boosts performance to 38.84/52.91, highlighting the importance of context.
Compared with other approaches, DoLa and CAD show complementary strengths: CAD yields the highest EM on HotPotQA for LLaMA-1 (39.08), while DoLa attains the best F1 (56.50); on SQuAD, CAD is clearly stronger (30.12 EM/45.29 F1). Our LACD decoder surpasses both in every setting: for LLaMA-1, it achieves 41.01 EM/56.84 F1 on HotPotQA and 31.62 EM/48.60 F1 on SQuAD, improving over the strongest baseline by up to +1.93 EM and +3.31 F1. Consistent gains are maintained on LLaMA-2 (30.51/44.86 on HotPotQA; 40.60/56.20 on SQuAD) and on the smaller LlaMA 3.2 1B backbone (27.18/45.46 on HotPotQA; 21.55/40.28 on SQuAD).
Overall, these results confirm that the proposed layer-aware context reweighting achieves reliable improvements across datasets and model generations without any additional fine-tuning.
5.2. Experimental Results for Start Layer Selection
We introduce a start layer parameter to reduce the computational overhead of comparing all layers in the model. Specifically, instead of evaluating contrastive decoding at every layer, the model begins from a chosen start layer and only compares layers above that threshold. By varying this start layer from L2 to L30, we observe how performance shifts as the model leverages earlier vs. later layers.
Figure 3 illustrates the EM and F1 scores on HotPotQA for different start layers. The scores remain relatively stable until around the 18th layer, after which a noticeable drop occurs. This trend is consistent with our prior observations that earlier layers capture vital contextual information and are thus pivotal for accurate question answering. Once the model begins contrastive decoding from too deep a layer (e.g., L20 or beyond), it effectively bypasses some of the crucial context alignment happening in earlier layers. Consequently, it relies on representations that are already more task- or semantics-focused, rather than continuing to refine the overarching contextual cues.
These findings align with our hypothesis that later Transformer layers, though informative semantically, do not necessarily reintroduce essential context for multi-hop QA. By starting at deeper layers, the model risks omitting the context-building steps, leading to a decrease in both EM and F1. In practical terms, setting the start layer too high reduces the effectiveness of contrastive decoding, suggesting an optimal trade-off between computation and performance around the mid-to-lower layers.
5.3. Experimental Results of the Contrast-Decoding Layer Coefficient
In this experiment, we examine how varying the contrast-decoding coefficient
affects the performance of the proposed LACD method.
Table 3 summarizes the results on the HotPotQA dataset in terms of exact match and F1 score.
As shown in the table, the performance across different values forms a broad plateau. Specifically, the highest EM score (41.01) is achieved at , accompanied by an F1 score of 56.84. Neighboring values exhibit only marginal differences: at , EM slightly decreases to 40.99 with F1 at 56.81, and at , EM decreases slightly to 40.96, although the F1 score peaks at 56.85.
Even at the extremes ( and 0.70), performance differences remain minimal, with EM dropping slightly to 40.95 and 40.94, respectively, and F1 scores remaining similarly stable.
Because EM and F1 scores vary by less than 0.1 within the tested range (), we consider not as a finely tuned optimum but rather as a robust midpoint on this stable performance plateau. Values significantly lower or higher than 0.50 slightly shift the balance between intermediate- and final-layer logits, resulting in minor but consistent decreases in performance.
5.4. Ablation Study
Layer selection strategy. To investigate the effectiveness of our proposed dynamic layer selection strategy, we conducted an ablation study comparing our Jensen–Shannon divergence (JSD)-based approach against static layer selection at different depths of the model.
Table 4 presents the results of this comparison on the HotPotQA dataset.
The results clearly demonstrate that our dynamic layer selection strategy outperforms all static layer configurations. When examining static layer selection, we observe an interesting pattern: performance initially improves slightly from layer 12 (40.70% EM, 56.66% F1) to layer 16 (40.73% EM, 56.62% F1), suggesting that middle layers contain rich semantic representations useful for question answering. However, performance degrades dramatically as we move to deeper layers, with layer 20 showing significant F1 score degradation (37.70%), and layers 24 and 28 exhibiting catastrophic performance drops (23.98% and 17.21% F1, respectively).
This performance pattern confirms our hypothesis that different layers capture different aspects of knowledge and context representation. Shallow to middle layers (12–16) contain rich semantic representations beneficial for question answering, whereas exclusive reliance on deeper layers can lead to over-specialization and reduced performance on complex QA tasks.
We also tested KL divergence as an alternative dynamic layer selection metric, achieving 40.05% EM and 55.31% F1. This result is lower than our proposed JSD-based approach (41.01% EM, 56.84% F1), likely because KL divergence, as an asymmetric metric, is more sensitive to sparse or noisy distributions and thus provides less stable layer selection.
Our JSD-based dynamic layer selection approach, which achieves 41.01% EM and 56.84% F1, successfully addresses this limitation by adaptively choosing the most appropriate layer representations based on the specific input query and context. The dynamic selection enables the model to leverage the most relevant knowledge representation for each instance, effectively combining the strengths of different layers and avoiding the limitations of any single fixed layer.
The superiority of our approach becomes particularly evident when comparing against deeper layers (20, 24, and 28), where static selection performance drops precipitously. This suggests that our method effectively mitigates the potential negative impacts of less suitable layer representations while capitalizing on the most informative ones, resulting in more robust QA performance across diverse query types.
Effect of the
Parameter on HotPotQA and SQuAD. We examined how the context weighting parameter
affects model performance in each dataset.
Figure 4 illustrates how tuning
impacts model performance on each dataset. Our analysis showed that tuning
leads to different outcomes: in one dataset, a higher
tended to be more beneficial, whereas in the other dataset, a moderate or lower setting resulted in better overall performance. This finding suggests that each dataset’s unique characteristics require distinct parameter configurations, underscoring the importance of carefully calibrating
for optimal results.
Latency Analysis of Layer Selection Strategies. To better assess the deployment cost of each decoder, we measured end-to-end inference latency (
Table 5). Approaches that must compute two forward passes—one with context and one without—and then contrast the resulting logits (LACD and CAD) incur noticeably higher latency than single-pass decoders such as DOLA or the context-aware baseline. Concretely, LACD (0.5289 s/sample) and CAD (0.4956 s/sample) are roughly twice as slow as DOLA (0.2740 s/sample) and the baseline (0.2377 s/sample). This overhead is dominated by the second forward pass and the subsequent element-wise contrast operation, revealing a clear trade-off between the richer context modelling of two-pass decoders and the efficiency of single-pass alternatives. For latency-critical applications, the additional accuracy delivered by LACD and CAD must therefore be weighed against their larger computational footprint.
6. Discussion
Our experimental results demonstrate that incorporating contextual information and carefully adjusting decoding strategies can effectively reduce hallucinations, while improving both factual correctness and linguistic quality. The substantial performance gap between the “no-context” and “with-context” baselines on HotPotQA and SQuAD highlights the importance of newly provided context. This finding corroborates previous studies on knowledge conflicts and contextual deficits in large language models [
14,
15], reinforcing our working hypothesis that an LLM’s strong reliance on pre-trained knowledge must be suitably balanced with new context to prevent outdated or conflicting information from undermining generated responses.
Dynamic layer selection. Our experiments confirm that our JSD-based dynamic layer selection strategy significantly outperforms static selection approaches. The dramatic performance degradation with static selection at deeper layers (e.g., layers 20, 24, and 28) suggests that different layers capture distinct aspects of knowledge representation. As shown in our ablation study, shallow to middle layers (12–16) contain rich semantic representations beneficial for question answering, whereas exclusive reliance on deeper layers can lead to over-specialization and reduced performance. The start layer experiment further indicates that performance remains stable until around layer 18, after which scores drop noticeably. This pattern supports the conclusion that earlier layers capture crucial contextual information necessary for accurate responses, and omitting these layers in decoding diminishes the model’s overall effectiveness.
Contrast-decoding coefficients. The analysis of the contrast-decoding coefficient () reveals that moderate values (around 0.5) generally achieve stronger EM and F1, implying that a balanced weighting of final-layer and lower-layer distributions is optimal. Excessively large may override newly provided context, while overly small risks neglecting valuable higher-level semantic knowledge embedded in later layers. Our observed performance peak at thus supports the notion that an appropriate “middle ground” is required to integrate context effectively without forfeiting essential pre-trained information.
Latency and practical trade-offs. An important finding from our latency analysis (
Section 5.4,
Table 5) is that logits-based methods such as our proposed LACD and CAD incur higher inference latency—roughly double the time compared to heuristic-based methods like DOLA or the context-aware baseline. This latency increase primarily arises from the additional divergence calculations inherent in logits-based approaches. While the enhanced accuracy from logits-based methods is clear, this computational overhead presents practical considerations for latency-sensitive applications, emphasizing the necessity of balancing representational power with inference efficiency.
Comparison with related approaches. Both CAD and DoLa, which mitigate hallucinations by leveraging pre-trained capabilities [
4,
7], showed modest gains over the context-inclusive baseline. In contrast, our proposed LACD framework demonstrated a more pronounced improvement, indicating that fine-grained control over how context is integrated—and how internal knowledge is adjusted—can further boost response accuracy. On HotPotQA, LACD reached 41.01% EM and 56.84% F1, surpassing both the baseline and other methods. On SQuAD, LACD achieved 31.62% EM and 48.60% F1, substantially higher than CAD’s 30.12% EM and 45.29% F1. These results underscore the value of explicitly modeling the interplay between new contextual cues and learned representations, rather than relying solely on end-to-end pre-trained or fine-tuned strategies.
Limitations and future directions. Although our experiments offer promising insights, they are limited to QA tasks focusing on HotPotQA and SQuAD. Future work could investigate the proposed methods across broader domains such as summarization or specialized fields like biomedicine, where hallucination risks have particularly significant implications. Another direction is to study how dynamic layer selection and contrast decoding can be extended to different model architectures (e.g., encoder–decoder or mixture-of-experts). Additionally, exploring automated ways to adapt or the start layer per query—based on uncertainty estimates or user feedback—might yield an even more robust and adaptive system. Extending the evaluation to larger backbones (e.g., 70 B parameters) and mixture-of-experts (MoE) architectures will require multi-GPU resources that are currently beyond our budget; we plan to explore these settings when they become available. Because LACD operates purely on per-layer logits produced after expert aggregation, it should transfer to MoE models without modifying their routing mechanism.
Overall, our findings reinforce that hallucinations are best mitigated through balanced approaches that merge newly provided contextual cues with a model’s extensive but occasionally outdated or conflicting pre-trained knowledge. By employing selective layer usage and finely tuned contrast decoding, one can attain more reliable, context-appropriate generation in large language models.
7. Conclusions
In this paper, we proposed LACD, which integrates dynamic layer selection and contrast decoding to mitigate hallucinations in large language models. Our experiments reveal that excluding context severely degrades performance (e.g., EM dropping to around 2.23%), whereas incorporating additional information and selectively balancing pre-trained knowledge with newly provided context results in substantial gains in both accuracy and output quality.
Through variations in the contrast-decoding coefficient and adjustments to the starting layer, we demonstrated that strategically balancing focus between lower-layer and final-layer representations effectively mitigates hallucinated content and enhances exact match (EM) performance.
We also clearly identified a practical trade-off between computational complexity and inference latency. Methods relying on logits-based divergence calculations, such as our proposed LACD approach, exhibited approximately twice the latency compared to heuristic approaches. This insight is crucial for applying these methods in real-world scenarios, especially those demanding low latency.
In future work, we plan to extend this approach to broader tasks such as summarization, domain-specific applications (e.g., medical or legal contexts), and multi-hop reasoning, further validating its generality and robustness. Additionally, an automated mechanism to adapt and the start layer on a per-query basis—potentially guided by user feedback or uncertainty estimates—could offer more flexible, context-sensitive generation in real-world scenarios.
Author Contributions
Conceptualization, S.Y., G.K., and S.K.; formal analysis, S.Y.; methodology, S.Y., G.K., and S.K.; software, S.Y. and G.K.; validation, S.Y.; visualization, S.Y.; writing—original draft preparation, S.Y.; writing—review and editing, G.K. and S.K.; supervision, G.K.; project administration, S.K.; resources, S.K.; funding acquisition, S.K. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by a National Research Foundation of Korea (NRF) grant funded by the Korean government (MSIT) (No. 2022R1A2C1005316) and in part by Gachon University’s research fund of 2024 (GCU-202400460001).
Data Availability Statement
Conflicts of Interest
The authors declare no conflicts of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results.
References
- Ouyang, L.; Wu, J.; Jiang, X.; Almeida, D.; Wainwright, C.; Mishkin, P.; Zhang, C.; Agarwal, S.; Slama, K.; Ray, A.; et al. Training language models to follow instructions with human feedback. arXiv 2022, arXiv:2203.02155. [Google Scholar]
- Wei, J.; Wang, X.; Schuurmans, D.; Bosma, M.; Ichter, B.; Xia, F.; Chi, E.; Le, Q.V.; Zhou, D. Chain-of-thought prompting elicits reasoning in large language models. Adv. Neural Inf. Process. Syst. 2022, 35, 24824–24837. [Google Scholar]
- Yao, S.; Yu, D.; Zhao, J.; Shafran, I.; Griffiths, T.; Cao, Y.; Narasimhan, K. Tree of thoughts: Deliberate problem solving with large language models. Adv. Neural Inf. Process. Syst. 2023, 36, 11809–11822. [Google Scholar]
- Shi, W.; Han, X.; Lewis, M.; Tsvetkov, Y.; Zettlemoyer, L.; Yih, W.t. Trusting your evidence: Hallucinate less with context-aware decoding. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers), Mexico City, Mexico, 16–21 June 2024; pp. 783–791. [Google Scholar]
- Chen, R.; Wang, X.; Liu, H. Delta: Dynamic Prompt Masking for Context-Aware Decoding. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, Miami, FL, USA, 12–16 November 2024; pp. 1234–1246. [Google Scholar]
- Zhao, L.; Gupta, A.; Lee, K. Dynamic Contrastive Decoding for Retrieval-Augmented Generation. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, Miami, FL, USA, 12–16 November 2024; pp. 2345–2357. [Google Scholar]
- Chuang, Y.S.; Xie, Y.; Luo, H.; Kim, Y.; Glass, J.; He, P. Dola: Decoding by contrasting layers improves factuality in large language models. arXiv 2023, arXiv:2309.03883. [Google Scholar]
- Wu, J.; Shen, Y.; Liu, S.; Tang, Y.; Song, S.; Wang, X.; Cai, L. Improve Decoding Factuality by Token-wise Cross-Layer Entropy of Large Language Models. In Proceedings of the Findings of the Association for Computational Linguistics (NAACL 2025), Albuquerque, NM, USA, 29 April–4 May 2025. [Google Scholar]
- Ji, Z.; Lee, N.; Frieske, R.; Yu, T.; Su, D.; Xu, Y.; Ishii, E.; Bang, Y.J.; Madotto, A.; Fung, P. Survey of hallucination in natural language generation. ACM Comput. Surv. 2023, 55, 1–38. [Google Scholar] [CrossRef]
- Huang, L.; Yu, W.; Ma, W.; Zhong, W.; Feng, Z.; Wang, H.; Chen, Q.; Peng, W.; Feng, X.; Qin, B.; et al. A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions. ACM Trans. Inf. Syst. 2025, 43, 1–55. [Google Scholar] [CrossRef]
- Tonmoy, S.; Zaman, S.; Jain, V.; Rani, A.; Rawte, V.; Chadha, A.; Das, A. A comprehensive survey of hallucination mitigation techniques in large language models. arXiv 2024, arXiv:2401.01313. [Google Scholar]
- Nallapati, R.; Zhou, B.; Nogueira dos santos, C.; Gulcehre, C.; Xiang, B. Abstractive text summarization using sequence-to-sequence rnns and beyond. arXiv 2016, arXiv:1602.06023. [Google Scholar]
- Narayan, S.; Cohen, S.B.; Lapata, M. Don’t give me the details, just the summary! topic-aware convolutional neural networks for extreme summarization. arXiv 2018, arXiv:1808.08745. [Google Scholar]
- Longpre, S.; Perisetla, K.; Chen, A.; Ramesh, N.; DuBois, C.; Singh, S. Entity-based knowledge conflicts in question answering. arXiv 2021, arXiv:2109.05052. [Google Scholar]
- Liu, A.; Liu, J. The MemoTrap Dataset. 2023. Available online: https://github.com/liujch1998/memo-trap (accessed on 28 May 2025).
- Lin, J. Divergence measures based on the Shannon entropy. IEEE Trans. Inf. Theory 1991, 37, 145–151. [Google Scholar] [CrossRef]
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. Llama: Open and efficient foundation language models. arXiv 2023, arXiv:2302.13971. [Google Scholar]
- Achiam, J.; Adler, S.; Agarwal, S.; Ahmad, L.; Akkaya, I.; Aleman, F.L.; Almeida, D.; Altenschmidt, J.; Altman, S.; Anadkat, S.; et al. Gpt-4 technical report. arXiv 2023, arXiv:2303.08774. [Google Scholar]
- Lin, S.; Hilton, J.; Evans, O. Truthfulqa: Measuring how models mimic human falsehoods. arXiv 2021, arXiv:2109.07958. [Google Scholar]
- Gao, L.; Biderman, S.; Black, S.; Golding, L.; Hoppe, T.; Foster, C.; Phang, J.; He, H.; Thite, A.; Nabeshima, N.; et al. The pile: An 800gb dataset of diverse text for language modeling. arXiv 2020, arXiv:2101.00027. [Google Scholar]
- Geva, M.; Khashabi, D.; Segal, E.; Khot, T.; Roth, D.; Berant, J. Did aristotle use a laptop? a question answering benchmark with implicit reasoning strategies. Trans. Assoc. Comput. Linguist. 2021, 9, 346–361. [Google Scholar] [CrossRef]
- Cobbe, K.; Kosaraju, V.; Bavarian, M.; Chen, M.; Jun, H.; Kaiser, L.; Plappert, M.; Tworek, J.; Hilton, J.; Nakano, R.; et al. Training verifiers to solve math word problems. arXiv 2021, arXiv:2110.14168. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Tenney, I.; Das, D.; Pavlick, E. BERT rediscovers the classical NLP pipeline. arXiv 2019, arXiv:1905.05950. [Google Scholar]
- Kullback, S.; Leibler, R.A. On Information and Sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Yang, Z.; Qi, P.; Zhang, S.; Bengio, Y.; Cohen, W.W.; Salakhutdinov, R.; Manning, C.D. HotpotQA: A dataset for diverse, explainable multi-hop question answering. arXiv 2018, arXiv:1809.09600. [Google Scholar]
- Rajpurkar, P.; Zhang, J.; Lopyrev, K.; Liang, P. Squad: 100,000+ questions for machine comprehension of text. arXiv 2016, arXiv:1606.05250. [Google Scholar]
- Touvron, H.; Martin, L.; Stone, K.; Albert, P.; Almahairi, A.; Babaei, Y.; Bashlykov, N.; Batra, S.; Bhargava, P.; Bhosale, S.; et al. Llama 2: Open foundation and fine-tuned chat models. arXiv 2023, arXiv:2307.09288. [Google Scholar]
- Grattafiori, A.; Dubey, A.; Jauhri, A.; Pandey, A.; Kadian, A.; Al-Dahle, A.; Letman, A.; Mathur, A.; Schelten, A.; Vaughan, A.; et al. The llama 3 herd of models. arXiv 2024, arXiv:2407.21783. [Google Scholar]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).







{kind=link}
{kind=link}
{kind=link}
{kind=link}