1. Introduction
Fractional calculus generalizes calculus by allowing differentiation and integration to arbitrary real orders. This framework provides a powerful tool for modeling memory effects, long-range interactions, and anomalous diffusion—phenomena commonly observed in scientific and engineering applications. Unlike classical integer-order models, which assume purely local and instantaneous interactions, fractional-order models naturally incorporate non-locality and history dependence. This feature allows them to more accurately represent real-world processes such as viscoelasticity, dielectric polarization, electrochemical reactions, and subdiffusion in disordered media [
1,
2,
3]. Moreover, fractional-order models often require fewer parameters to match or exceed the accuracy of classical models in representing complex dynamics, making them both efficient and descriptive [
4].
The key advantage of FDs over classical derivatives lies in their capacity to capture hereditary characteristics and long-range temporal correlations, which are particularly relevant in biological systems [
5], control systems [
6], and viscoelastic materials [
3]. For instance, traditional damping models use exponential kernels that decay too quickly to accurately capture certain relaxation behaviors. In contrast, fractional models employ power-law kernels, enabling them to describe slower and more realistic decay rates [
7].
Among the various definitions of FDs, the Caputo FD is particularly popular due to its compatibility with classical initial and boundary conditions, which allows seamless integration with standard numerical and analytical techniques for solving fractional differential equations. Unlike the Riemann–Liouville FD, the Caputo FD defines the FD of a constant as zero, simplifying the mathematical treatment of steady-state solutions and improving the applicability of collocation methods. A prominent example of its application is the Bagley–Torvik equation, a well-known fractional differential equation involving a Caputo derivative of order 1.5. This equation models the motion of a rigid plate immersed in a viscous fluid, where the FD term represents a damping force that depends on the history of the plate’s motion. Such damping—referred to as fractional or viscoelastic damping—is commonly used to model materials exhibiting memory effects.
Recent advances in finite-time stability analysis for fractional systems (e.g., [
8]) underscore the growing demand for robust numerical methods. In particular, the numerical approximation of FDs and the solution to equations such as the Bagley–Torvik equation remain active and challenging areas of research. These developments highlight the necessity of stable, efficient, and highly accurate numerical methods capable of capturing the complex dynamics inherent in fractional-order models. Several numerical studies have demonstrated that classical methods struggle to maintain accuracy or stability when adapted to fractional settings due to the singular kernel behavior of fractional integrals, especially near the origin [
9]. Hence, developing dedicated fractional methods that respect the non-local structure of the problem is crucial for realistic simulations. In the following, we mention some of the key contributions to the numerical solution to the Bagley–Torvik equation using the Caputo FD:
Spectral Methods: Saw and Kumar [
10] proposed a Chebyshev collocation scheme for solving the fractional Bagley–Torvik equation. The Caputo FD was handled through a system of algebraic equations formed using Chebyshev polynomials and specific collocation points. Ji et al. [
11] presented a numerical solution using SC polynomials. The Caputo derivative was expressed using an operational matrix of FDs, and the fractional-order differential equation was reduced to a system of algebraic equations that was solved using Newton’s method. Hou et al. [
12] solved the Bagley–Torvik equation by converting the differential equation into a Volterra integral equation, which was then solved using Jacobi collocation. Ji and Hou [
13] applied Laguerre polynomials to approximate the solution to the Bagley–Torvik equation. The Laplace transform was first used to convert the problem into an algebraic equation, and then, Laguerre polynomials were used for numerical inversion.
Wavelet-Based Methods: Kaur et al. [
14] developed a hybrid numerical method using non-dyadic wavelets for solving the Bagley–Torvik equation. Dincel [
15] employed sine–cosine wavelets to approximate the solution to the Bagley–Torvik equation, where the Caputo FD was computed using the operational matrix of fractional integration. Rabiei and Razzaghi [
16] introduced a wavelet-based technique, utilizing the Riemann–Liouville integral operator to transform the fractional Bagley–Torvik equation into algebraic equations.
Operational Matrix Methods: Abd-Elhameed and Youssri [
17] formulated an operational matrix of FDs in the Caputo sense using Lucas polynomials, and applied Tau and collocation methods to solve the Bagley–Torvik equation. Youssri [
18] introduced an operational matrix approach using Fermat polynomials for solving the fractional Bagley–Torvik equation in the Caputo sense. A spectral tau method was employed to transform the problem into algebraic equations.
Galerkin Methods: Izadi and Negar [
19] used a local discontinuous Galerkin scheme with upwind fluxes for solving the Bagley–Torvik equation. The Caputo derivative was approximated by discretizing elementwise systems. Chen [
20] proposed a fast multiscale Galerkin algorithm using orthogonal functions with vanishing moments.
Spline and Finite Difference Methods: Tamilselvan et al. [
21] used a second-order spline approximation for the Caputo FD and a central difference scheme for the second-order derivative term in solving the Bagley–Torvik equation.
Artificial Intelligence-Based Methods: Verma and Kumar [
22] employed an artificial neural network method with Legendre polynomials to approximate the solution to the Bagley–Torvik equation, where the Caputo derivative was handled through an optimization-based training process.
This work introduces a novel framework for approximating Caputo FDs of any positive orders using an SGPS method. Unlike traditional approaches, our method employs a strategic change of variables to transform the Caputo FD into a scaled integral of the mth-derivative of the Lagrange interpolating polynomial, where m is the ceiling of the fractional order . This transformation mitigates the singularity inherent in the Caputo derivative near zero, thereby improving numerical stability and accuracy. The numerical approximation of the Caputo FD is finally furnished by linking the mth-derivative of SG polynomials with another set of SG polynomials of lower degrees and higher parameter values whose integration can be recovered within excellent accuracies using SG quadratures. By employing orthogonal collocation and SG quadratures in barycentric form, we achieve a highly accurate, computationally efficient, and stable scheme for solving fractional differential equations under optimal parameter settings compared to classical PS methods. Furthermore, we provide a rigorous error analysis showing that the SGPS method is convergent when implemented within a semi-analytic framework, where all necessary integrals are computed analytically, and is conditionally convergent with an exponential rate of convergence for sufficiently smooth functions when performed using finite-precision arithmetic. This exponential convergence generally leads to superior accuracy compared to existing wavelet-based, operational matrix, and finite difference methods. We conduct rigorous error and convergence analyses to derive the total truncation error bound of the method and study its asymptotic behavior within double-precision arithmetic. The SGPS is highly flexible in the sense that the SG parameters associated with SG interpolation and quadratures allow for flexibility in adjusting the method to suit different types of problems. These parameters influence the clustering of collocation and quadrature points and can be tuned for optimal performance. A key contribution of this work is the development of the FSGIM. This matrix facilitates the direct computation of Caputo FDs through efficient matrix–vector multiplications. Notably, the FSGIM is constant for a given set of points and parameter values. This allows for pre-computation and storage, significantly accelerating the execution of the SGPS method. The SGPS method avoids the need for extended precision arithmetic, as it remains within the limits of double-precision computations, making it computationally efficient compared to methods that require high-precision arithmetic. The current approach is designed to handle any positive fractional order , making it more flexible than some existing methods that are constrained to specific fractional orders. Unlike Chebyshev polynomials (fixed clustering) or wavelets (local support), SG polynomials offer tunable clustering via their index , optimizing accuracy for smooth solutions, while their derivative properties enable efficient FD computation, surpassing finite difference methods in convergence rate. The efficacy of our approach is demonstrated through its application to Caputo fractional TPBVPs of the Bagley–Torvik type, where it outperforms existing numerical schemes. The method’s framework supports extension to multidimensional and time-dependent fractional PDEs through the tensor products of FSGIMs. By integrating interpolation and integration into a cohesive SG polynomial-based approach, it provides a unified solution framework for fractional differential equations.
The remainder of this paper is structured as follows.
Section 2 introduces the SGPS method, providing a detailed exposition of its theoretical framework and numerical implementation. The computational complexity of the derived FSGIM is discussed in
Section 3. A comprehensive error analysis of the method is carried out in
Section 4, establishing its convergence properties and providing insights into its accuracy. In
Section 5, we demonstrate the effectiveness of the SGPS method through a case study, focusing on its application to Caputo fractional TPBVPs of the Bagley–Torvik type.
Section 6 presents a series of numerical examples, demonstrating the superior performance of the SGPS method in comparison to existing techniques.
Section 7 conducts a sensitivity analysis to investigate the impact of the SG parameters on the numerical stability of the SGPS method, providing practical insights into parameter selection for relatively small interpolation and quadrature mesh sizes. Finally,
Section 8 concludes the paper with a summary of our key findings and a discussion of potential future research directions.
Table 1 and the list of acronyms display the symbols and acronyms used in the paper and their meanings. A pseudocode for the SGPS method to solve Bagley–Torvik TPBVPs is provided in
Appendix A.
Appendix B supports the error analysis conducted in
Section 4 by providing rigorous mathematical justifications for the asymptotic order of some key terms in the error bound.
2. The SGPS Method
This section introduces the SGPS method for approximating Caputo FDs. Readers interested in obtaining a deeper understanding of Gegenbauer and SG polynomials, as well as their associated quadratures, are encouraged to consult [
23,
24,
25,
26].
Let
, and consider the following SGPS interpolant of
f:
where
is the
nth-degree Lagrange interpolating polynomial in modal form defined by
and
are the normalization factors for SG polynomials and the Christoffel numbers associated with their quadratures, respectively,
and
(cf. Equations (2.6), (2.7), (2.10), and (2.12) in [
23]). The matrix form of Equation (
2) can be stated as
Equation (
1) allows us to approximate the Caputo FD of
f:
To accurately evaluate
, we apply the following
m-dependent change of variables:
which reduces
to a scalar multiple of the integral of the
mth-derivative of
f on the fixed interval
, denoted by
, and defined by
It is easy here to show that the value of
will always lie in the range
. Combining Equations (
4) and (
5) gives
where
denotes the
mth-derivative of
. Substituting Equation (
3) into Equation (
6) yields
where
denotes the
mth-derivative of
.
To efficiently evaluate Caputo FDs at arbitrary points
, Formula (
7) can be applied iteratively within a loop. While direct implementation using a loop over the vector’s elements of
is possible, employing matrix operations is highly recommended for substantial performance gains. To this end, notice first that Equation (
3) can be rewritten at
as
Equation (
8) together with (
6) yield:
where
With simple algebraic manipulation, we can further show that Equation (
9) can be rewritten as
where
We refer to the
matrix
as
“the αth-order FSGIM,” which approximates Caputo FD at the points
using an
nth-degree SG interpolant. We also refer to
as the
“αth-order FSGIM Generator” for an obvious reason. Although the implementation of Formula (
10) is straightforward, Formula (
9) is slightly more stable numerically, with fewer arithmetic operations, particularly because it avoids constructing a diagonal matrix and directly applies elementwise multiplication after the matrix–vector product. Note that for
, Formulas (
9) and (
10) reduce to (
7).
It remains now to show how to compute
effectively. Notice first that although the integrand is defined in terms of a polynomial in
x, the integrand itself is not a polynomial in
y, since
is not an integer for
. Therefore, when trying to evaluate the integral symbolically, the process can be very challenging and slow. Numerical integration, on the other hand, is often more practical for such integrals because it can achieve any specified accuracy by evaluating the integrand at discrete points without requiring closed-form antiderivatives or algebraic complications. Our reliable tool for this task is the SGIM; cf. [
23,
25] and the references therein. The SGIM utilizes the barycentric representation of shifted Lagrange interpolating polynomials and their associated barycentric weights to approximate definite integrals effectively through matrix–vector multiplications. The SGPS quadratures constructed by these operations extend the classical Gegenbauer quadrature methods and can improve their performance in terms of convergence speed and numerical stability. An efficient way to construct the SGIM is to premultiply the corresponding GIM by half, rather than shifting the quadrature nodes, weights, and Lagrange polynomials to the target domain
, as shown earlier in [
23]. In the current work, we only need the GIRV,
, which extends the applicability of the barycentric GIM to include the boundary point 1 (cf. [
24] Algorithm 6 or 7). The associated SGIRV,
, can be directly generated through the formula
Given that the construction of
is independent of the SGPS interpolant (
1), we can define
using any set of SGG quadrature nodes
. This flexibility enables us to improve the accuracy of the required integrals without being constrained by the resolution of the interpolation grid. With this strategy, the SGIRV provides a convenient way to approximate the required integral through the following matrix–vector multiplication:
. We refer to a quadrature of the form (
12) as the
-SGPS quadrature. A remarkable property of Gegenbauer polynomials (and their shifted counterparts) is that their derivatives are essentially other Gegenbauer polynomials, albeit with different degrees and parameters, as shown by the following theorem.
Theorem 1. The mth-derivatives of the nth-degree, λ-indexed, Gegenbauer and SG polynomials are given bywhere, and . Proof. Let
be the
nth-degree,
-indexed Gegenbauer polynomial standardized by Szegö [
27]. We shall first prove that
where
denotes the
mth-derivative of
. To this end, we shall use the well-known derivative formula of this polynomial given by the following recurrence relation:
We will prove Equation (
15) through mathematical induction on
m. The base case
holds true due to the given recurrence relation for the first derivative. Assume now that Equation (
15) holds true for
, where
k is an arbitrary integer such that
. That is,
We need to show that it also holds true for
. Differentiating both sides of the induction hypothesis with respect to
x gives
This shows that if the formula holds for
, it also holds for
. Through mathematical induction, Equation (
15) holds true for all integers
. Formula ([
28] (A.5)) and the fact that
immediately show that
from which Equation (13a) is derived. Formula (13b) follows from (13a) through successive application of the Chain Rule. □
Equations (12) and (13b) bring to light the sought formula
where
.
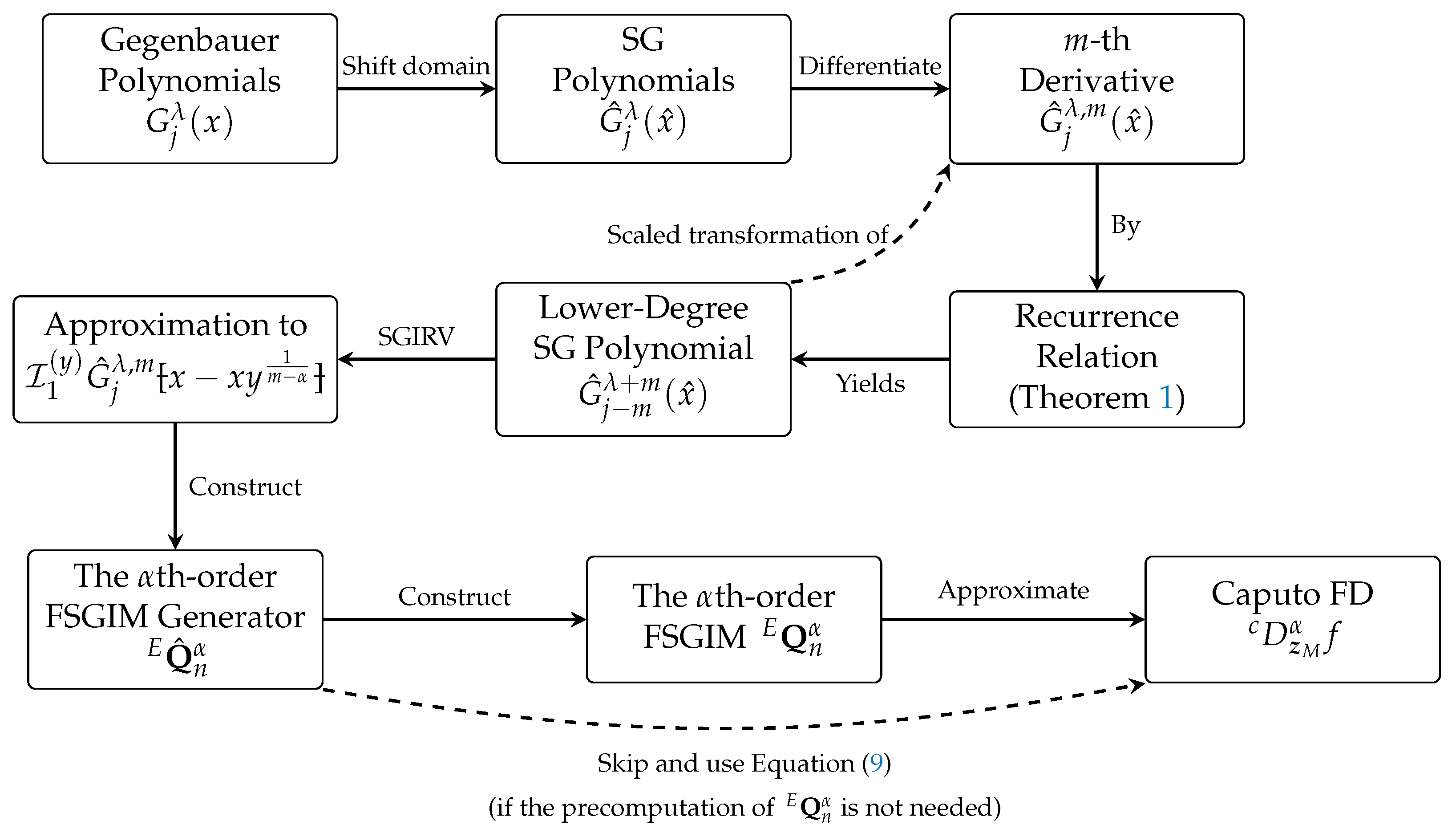
Figure 1 illustrates the key polynomial transformations in the SGPS method, where lower-degree SG polynomials serve as scaled transformations of the derivative terms. We denote the approximate
th-order Caputo FD of a function at point
x, computed using Equation (
16) in conjunction with either Equations (
9) or (
10), as
. It is interesting to notice here that the quadrature nodes involved in the computations of the necessary integrals (
16), which are required for the construction of the FSGIM
, are independent of the SGG points associated with the SGPS interpolant (
1), and therefore, any set of SGG quadrature nodes can be used. This flexibility allows for improving the accuracy of the required integrals without being constrained by the resolution of the interpolation grid.
Figure 2 illustrates the logarithmic absolute errors of Caputo FD approximations for
. These approximations utilize SG interpolants of varying parameters but consistent degrees, in conjunction with a
-SGPS quadrature. The exact Caputo FD of
is given below:
In all plots of
Figure 2, the rapid convergence of the PS approximations is evident. Given that the SG interpolants share the same polynomial degree as the power function, and since
, the interpolation error vanishes, as we demonstrate later with Theorem 2 in
Section 4. Consequently, the quadrature error becomes the dominant component. Theorem 4 in
Section 4 further indicates that the quadrature error vanishes for
, which elucidates the high accuracy achieved by the SGPS method in all four plots when
n is sufficiently less than
in many cases, leading to a near-machine epsilon level of the total error. While the error analysis in
Section 4 predicts the collapse of the total error when
under exact arithmetic, the limitations of finite-digit arithmetic often prevent this, frequently necessitating an increase in
by one unit or more, especially when varying
, for effective total error collapse. In Subplot 1, with
, an
nth-degree SG interpolant sufficiently approximates the Caputo FD of the power function
to within machine precision for
. The error curves exhibit plateaus in this range, with slight fluctuations for specific
values, attributed to accumulated round-off errors as the approximation approaches machine precision. For
, the total error becomes predominantly the quadrature error and remains relatively stable around
. Notably, the error profiles remain consistent for
despite variations in
. Altering
while keeping
constant can significantly impact the error, as shown in the upper right plot. Specifically, the error generally decreases with decreasing
values, with the exception of
, where the error reaches its minimum. The lower left plot demonstrates the exponential decay of the error with increasing values of
, with the error decreasing by approximately two orders of magnitude for every two-unit increase in
. The lower right plot presents a comparison between the SGPS method and MATLAB’s “integral” function, employing the tolerance parameters RelTol = AbsTol
. The SGPS method achieves near-machine-precision accuracy with the parameter values
and
, outperforming MATLAB’s integral function by nearly two orders of magnitude in certain cases. The method achieves near-machine-epsilon precision with relatively coarse grids, demonstrating notable stability through consistent error trends.
Figure 3 further shows the logarithmic absolute errors of the Caputo FD approximations of the function
using SG interpolants of various parameters and a
-SGPS quadrature. The exact Caputo FD of
is given below:
The figure illustrates the rapid convergence of the proposed PS approximations. Specifically, across the parameter range
, the logarithmic absolute errors exhibit a consistent decrease as the degree of the Gegenbauer interpolant increases. This trend underscores the improved accuracy of higher-degree interpolants in approximating the Caputo FD up to a defined precision threshold. For lower degrees (
n), the error reduction is more enunciated as
decreases, indicating that other members of the SG polynomial family, associated with negative
values, exhibit superior convergence rates in these cases. For higher degrees (
n), the errors converge to a stable accuracy level irrespective of the
value, highlighting the robustness of higher-degree interpolants in accurately approximating the Caputo FD. The near-linear error profiles observed in the plots confirm the exponential convergence of the PS approximations, with convergence rates modulated by the parameter selections, as detailed in
Section 4.
4. Error Analysis
The following theorem defines the truncation error of the
th-order SGPS quadrature (
10) associated with the
th-order FSGIM
in closed form.
Theorem 2. Let , and suppose that is approximated by the SGPS interpolant (1). Also, assume that the integralsare computed exactly . Then, such that the truncation error, , in the Caputo FD approximation (7) is given bywhere Proof. The Lagrange interpolation error associated with the SGPS interpolation (
1) is given below:
where
is the leading coefficient of the
nth-degree,
-indexed SG polynomial (cf. Equation (4.12) in [
23]). Applying Caputo FD on both sides of the equation gives the truncation error associated with Formula (
7) in the following form:
The proof is established by substituting Formula (13b) into (19). □
For the theoretical truncation error in Equation (
18), we assume that the integrals in Equation (
17) are evaluated exactly. In practice, however, these integrals are approximated using SGPS quadratures, with the corresponding quadrature errors analyzed in Theorems 4 and 5, as discussed later in this section.
The following theorem marks the truncation error bound associated with Theorem 2.
Theorem 3. Suppose that the assumptions of Theorem 2 hold true. Then, the truncation error is asymptotically bounded above bywhere and Proof. Since
, Equation (4.29a) in [
23] shows that
. Thus,
according to the Mean Value Theorem for Integrals. Notice also that
. Combining this elementary inequality with the sharp inequalities of the Gamma function ([
25] Inequality (96)) implies that
where
. The required asymptotic Formula (
20) is derived by combining the asymptotic Formula (
22) with In Equation (
21). □
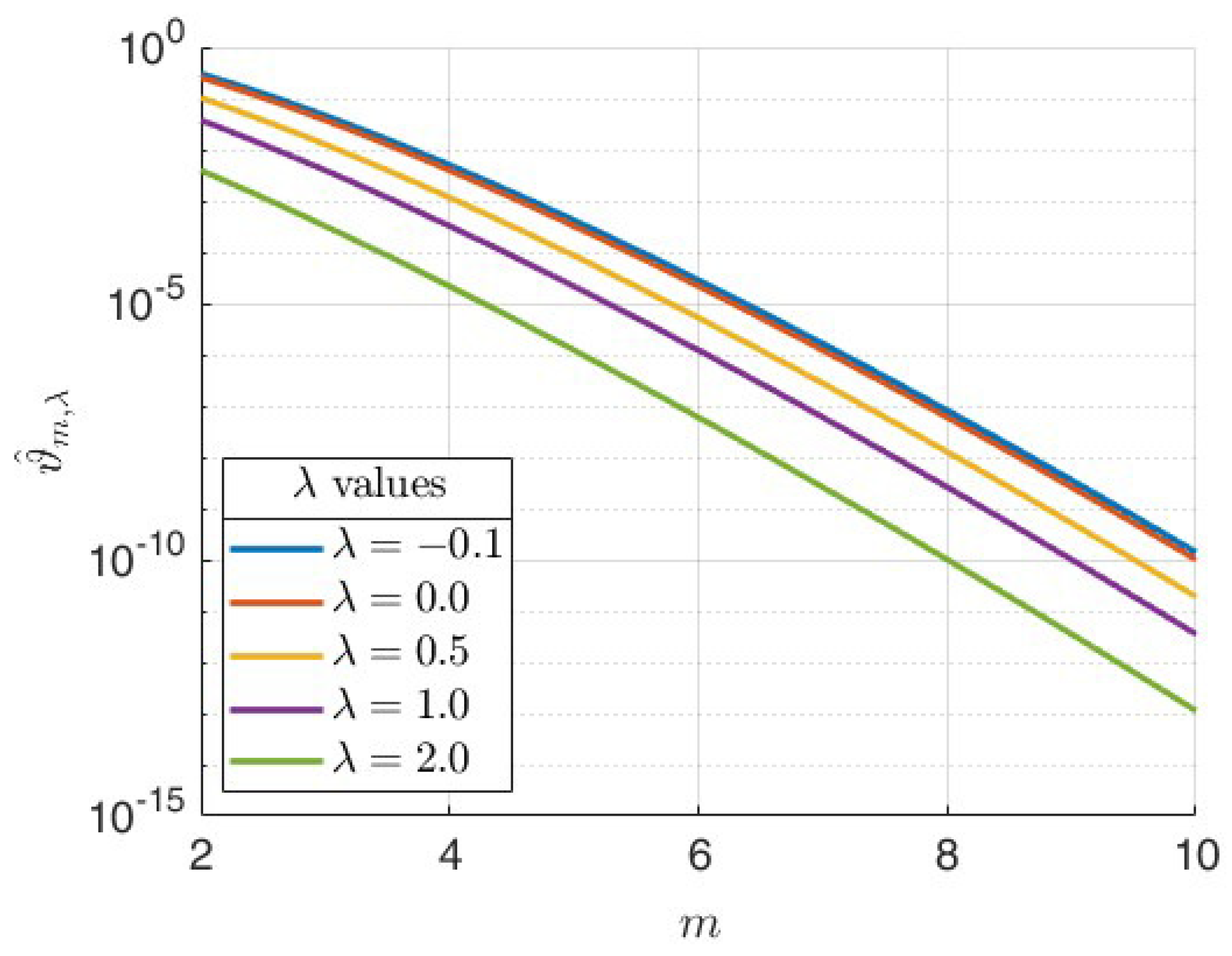
Since the dominant term in the asymptotic bound (
20) is
, the truncation error exhibits exponential decay as
. Notice also that increasing
while keeping
fixed and keeping
n sufficiently large leads to an increase in
m, which, in turn, affects two factors: (i) the polynomial term
grows, which slightly slows convergence, and (ii) the prefactor
, which decreases exponentially, reducing the error; cf.
Figure 4. Despite the polynomial growth of the former factor, the exponential decay term
dominates. Now, let us consider the effect of changing
while keeping
fixed and
n large enough. If we increase
gradually, the term
will exhibit exponential decay, and the prefactor
will also decrease exponentially, further reducing the error. The polynomial term
, on the other hand, will increase, slightly increasing the error. Although the polynomial term
grows and slightly increases the error, the dominant exponential decay effects from both
and the prefactor
ensure that the truncation error decreases significantly as
increases. Hence, increasing
leads to faster decay of the truncation error. This analysis shows that for
, increasing
slightly increases the error bound due to polynomial growth but does not affect exponential convergence. Furthermore, increasing
generally improves convergence, since the exponential decay dominates the polynomial growth. In fact, one can see this last remark from two other viewpoints:
- (i)
, and the truncation error accordingly.
- (ii)
, as
. Consequently, the integrals (
17) collapse
, indicating faster convergence rates in the Caputo FD approximation (
7).
In all cases, choosing a sufficiently large n ensures overall exponential convergence. It is important to note that these observations are based on the asymptotic behavior of the error upper bound as , assuming the SGPS quadrature is computed exactly.
Beyond the convergence considerations mentioned above, we highlight two important numerical stability issues related to this analysis:
- (i)
A small buffer parameter
is often introduced to offset the instability of the SG interpolation near
, where SG polynomials grow rapidly for increasing orders [
23].
- (ii)
As
increases, the SGG nodes
cluster more toward the center of the interval. This means that the SGPS interpolation rule (
1) relies more on extrapolation than interpolation, making it more sensitive to perturbations in the function values and amplifying numerical errors. This consideration reveals that, although increasing
theoretically improves the convergence rate, it can introduce numerical instability due to increased extrapolation effects. Therefore, when selecting
, one must balance convergence speed against numerical stability considerations to ensure accurate interpolation computations. This aligns well with the widely accepted understanding that, for sufficiently smooth functions and sufficiently large spectral expansion terms, the truncated expansion in the SC quadrature (corresponding to
) is optimal in the
-norm for definite integral approximations; cf. [
28] and the references therein.
In the following, we study the truncation error of the quadrature Formula (
16) and how its outcomes add up to the above analysis.
Theorem 4. Let , and assume that is interpolated by the SG polynomials with respect to the variable y at the SGG nodes . Then, such that the truncation error, , in the quadrature approximation (16) is given by Proof. Theorem 4.1 in [
23] immediately shows that
according to the Chain Rule. The error bound (23) is accomplished by substituting Formula (13b) into (24). The proof is completed by further realizing that
. □
The truncation error analysis of the quadrature approximation (
16) hinges on understanding the interplay between the parameters
and
. While Theorem 4 provides an exact error expression, the next theorem establishes a rigorous asymptotic upper bound, revealing how the error scales with these parameters.
Theorem 5. Let the assumptions of Theorem 4 hold true. Then, the truncation error, , in the quadrature approximation (16) is bounded above by, wherewhere is a constant dependent on , and is a constant dependent on , and . Proof. Lemma 5.1 in [
26] shows that
where
is a constant dependent on
. Therefore,
since
. Moreover, Formula (
14) and the definition of
(see p.g. 103 of [
26]) show that
The proof is established by applying the sharp inequalities of the Gamma function (Inequality (96) of [
25]) to (
27). □
When , the analysis of Theorem 5 bifurcates into the following two essential cases:
Given
, the quadrature truncation error in Theorem 5 converges when
, under the conditions that
and Condition (28) are met, or if
and Condition (31) are satisfied. In the special case when
, the quadrature truncation error totally collapses due to Theorem 4. In all cases, the parameter
always serves as a decay accelerator, whereas
functions as a decay brake. Notably, the observed slower convergence rate with increasing
aligns well with the earlier finding in [
28] that selecting relatively large positive values of
causes the Gegenbauer weight function associated with the GIM to diminish rapidly near the boundaries
. This effect shifts the focus of the Gegenbauer quadrature toward the central region of the interval, increasing sensitivity to errors and making the quadrature more extrapolatory. Extensive prior research by the author on the application of Gegenbauer and SG polynomials for interpolation and collocation informs the selection of the Gegenbauer index
within the interval
designated as the “Gegenbauer parameter collocation interval of choice” in [
29]. Specifically, investigations utilizing GG, SG, flipped-GG-Radau, and related nodal sets demonstrate that these configurations yield optimal numerical performance within this interval, consistently producing stable and accurate schemes for problems with smooth solutions; cf. [
26,
28,
29] and the references therein, for example.
The following theorem provides an upper bound for the asymptotic total error, encompassing both the series truncation error and the quadrature approximation error in light of Theorems 3 and 5.
Theorem 6 (Asymptotic total truncation error bound).
Let , and suppose that the assumptions of Theorems 2 and 4 hold true. Then, the total truncation error, denoted by , arising from both the series truncation (1) and the quadrature approximation (16), is asymptotically bounded above by:, where, and are constants with the definitions and properties outlined in Theorems 3 and 5, as well as in Equation (26). Proof. The total truncation error is the sum of the truncation error associated with Caputo FD approximation (
7),
, and the accumulated truncation errors associated with the quadrature approximation (
16), for
, arising from Formula (
7):
where
is the truncation error associated with the quadrature approximation (
16)
, and
and
are the normalization factors for Gegenbauer polynomials and the Christoffel numbers associated with their quadratures. The key upper bounds on these latter factors were recently derived in Lemmas B.1 and B.2 of [
30]:
where
. By combining these results with Equation (
26), we can bound the total truncation error by
where
. Since the
j-dependent polynomial factor
is maximized at
by Lemma A2, the proof is accomplished by applying the asymptotic inequality (25) to (33) after replacing
j with
n. □
Under the assumptions of Theorem 6, exponential error decay dominates the overall error behavior if
, provided that
and Condition (
28) hold, or if
and Condition (31) are satisfied. In the special case when
, the total truncation error reduces to pure interpolation error, as the quadrature truncation error vanishes. The rigorous asymptotic analysis presented in this section leads to the following practical guideline for selecting
and
:
Rule of Thumb(Selection of λ and Parameters). and :
Remark 2. The recommended range (34) for is derived by combining two key observations:
Polynomial term growth prevention: To control the quadrature truncation error bound:
Choose such thatfor . Choose such thatfor .
Stability and accuracy: The Gegenbauer index should lie within the interval to ensure higher stability and accuracy.
Since , the inequalities and hold. To maintain stability (as indicated by Observation 2), we enforce .
Remark 3. It is important to note that the observations made in this section rely on asymptotic results . However, since the integrand is smooth when , the SG quadrature often achieves high accuracy with relatively few nodes. Smooth integrands may exhibit spectral convergence before asymptotic effects takes place, as we demonstrate later in Section 6. Remark 4. The truncation errors in the SGPS method’s quadrature strategy are not negligible in general but can be made negligible by choosing a sufficiently large , especially when , as demonstrated in this section. Aliasing errors, while less severe than in Fourier-based methods on equi-spaced grids, can still arise in the SGPS method due to undersampling in interpolation or quadrature, particularly for non-smooth functions or when n and are not sufficiently large. These errors are mitigated by the use of non-equispaced SGG nodes, barycentric forms, and the flexibility to increase independently of n. To ensure robustness, we may (i) increase for complex integrands or higher fractional orders α, (ii) follow this study’s guidelines for λ and to optimize node clustering and stability, (iii) monitor solution smoothness and consider adaptive methods for non-smooth cases, and (iv) utilize the precomputable FSGIM to efficiently test the convergence of the SGPS method for different values. The numerical simulations in Section 6 suggest that, for smooth problems, these errors are already well controlled, with modest n and , achieving near-machine precision. However, for more challenging problems, careful parameter tuning and validation are essential to minimize error accumulation. Remark 5. The SGPS method assumes sufficient smoothness of the solution to exploit the rapid convergence properties of PS approximations. For less smooth functions, alternative specialized methods may be more appropriate. In particular, filtering techniques (e.g., modal filtering) can be integrated to dampen spurious high-frequency oscillations without significantly degrading the overall accuracy. Adaptive interpolation strategies, such as local refinement near singularities or moving-node approaches, may also be employed to capture localized features more accurately. Furthermore, domain decomposition techniques, where the computational domain is partitioned into subdomains with potentially different resolutions or spectral parameters, offer another viable pathway to accommodate irregularities while preserving the advantages of SGPS approximations within each smooth subregion.
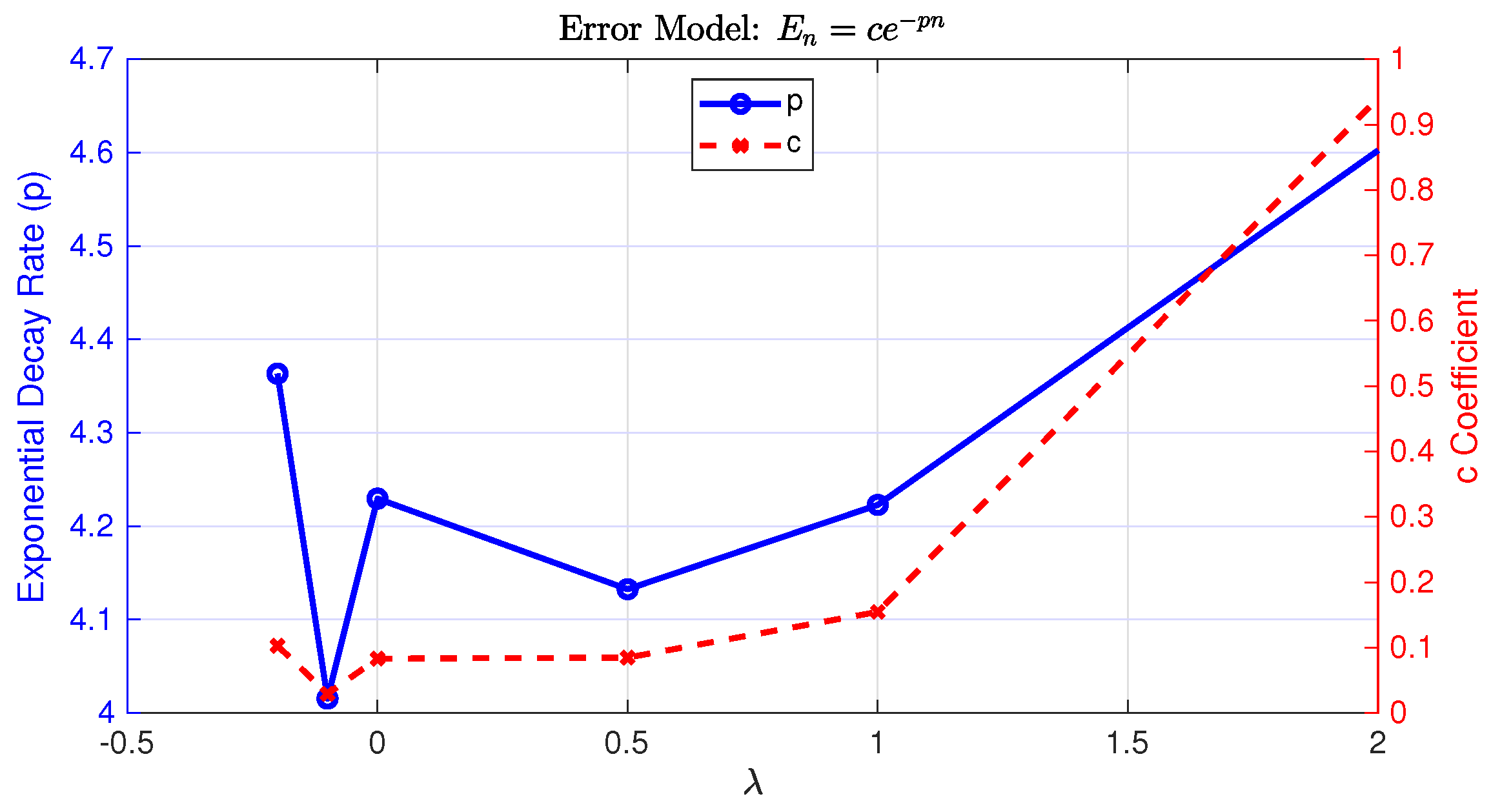
To provide empirical support for our theoretical claims on the convergence rate of the SGPS method, we analyze the error in computing the Caputo FD as a function of the number of interpolation points for various parameter values. We estimate the rate of convergence based on a semi-log regression of the error. Specifically, we assume that the error follows an exponential decay model of the form
, where
p is the exponential decay rate and
c is a positive constant. Taking the natural logarithm of this expression yields
. We can estimate
p by performing a linear regression of
against
n. The magnitude of the slope of the resulting line provides an estimate for the decay rate
p. As an illustration, reconsider Test Function
, previously examined in
Section 2, with its error plots shown in
Figure 3. Under the same data settings,
Figure 5 depicts the variation in the estimated exponential decay rate (
p) and coefficient (
c) with respect to
. The decay rate
p remains relatively consistent across different
values, fluctuating slightly between 4 and 4.6, indicating that the SGPS method sustains a stable exponential convergence rate under variations in
. The coefficient
c varies smoothly between approximately 0.1 and 1, reflecting a stable baseline magnitude of the approximation error. The bounded variation in
c further suggests that the method’s accuracy is largely insensitive to the choice of
within the considered range.
5. Case Study: Caputo Fractional TPBVP of the Bagley–Torvik Type
In this section, we consider the application of the proposed method on the following Caputo fractional TPBVP of the Bagley–Torvik type, defined as follows: 353035
with the given Dirichlet boundary conditions
where
, and
. With the derived numerical instrument for approximating Caputo FDs, determining an accurate numerical solution to the TPBVP is rather straightforward. Indeed, collocating System (35a) at the SGG set
in conjunction with Equation (
10) yields 363536
Since
and
, according to the properties of SG polynomials, substituting the boundary conditions (35b) into Equation (
1) gives the following system of equations:
Therefore, the linear system described by Equations (36a), (36b) and (36c) can now be compactly written in the following form:
where
is the collocation matrix, and
The solution to the linear system (37) provides the approximate solution values at the SGG points. The solution values at any non-collocated point in
can further be estimated with excellent accuracy via the interpolation Formula (
1).
When
, Caputo FD reduces to the classical integer-order derivative of the same order. In this case, we can use the first-order GDM in barycentric form,
, of Elgindy and Dahy [
31]. This matrix enables the approximation of the function’s derivative at the GG nodes using the function values at those nodes by employing matrix–vector multiplication. The entries of the differentiation matrix are computed based on the barycentric weights and GG nodes. The associated differentiation formula exhibits high accuracy, often exhibiting exponential convergence for smooth functions. This rapid convergence is a hallmark of PS methods and makes the GDM highly accurate for approximating derivatives. Furthermore, the utilization of barycentric forms improves the numerical stability of the differentiation matrix and leads to efficient computations. Using the properties of PS differentiation matrices, higher-order differentiation matrices can be readily generated through successive multiplication by the first-order GDM:
The SGDM of any order
, based on the SGG point set
, can be generated directly from
using the following formula:
Figure 6 outlines the complete solution workflow for applying the SGPS method to Bagley–Torvik TPBVPs. The process begins with constructing the FSGIMs and, when necessary, the SGDM for integer orders. These are used to discretize the governing fractional differential equations via collocation at SGG nodes. The resulting system is assembled into a linear algebraic system, which is solved to obtain the numerical solution at collocation points. Finally, the global numerical solution is recovered by interpolating these discrete values using the SGPS interpolant.
6. Numerical Examples
In this section, we present numerical experiments conducted on a personal laptop equipped with an AMD Ryzen 7 4800H processor (2.9 GHz, 8 cores/16 threads) and 16GB of RAM, and running Windows 11. All simulations were performed using MATLAB R2023b. The accuracy of the computed solutions was assessed using absolute errors and maximum absolute errors, which provide quantitative measures of the pointwise and worst-case discrepancies between the exact and numerical solutions, respectively.
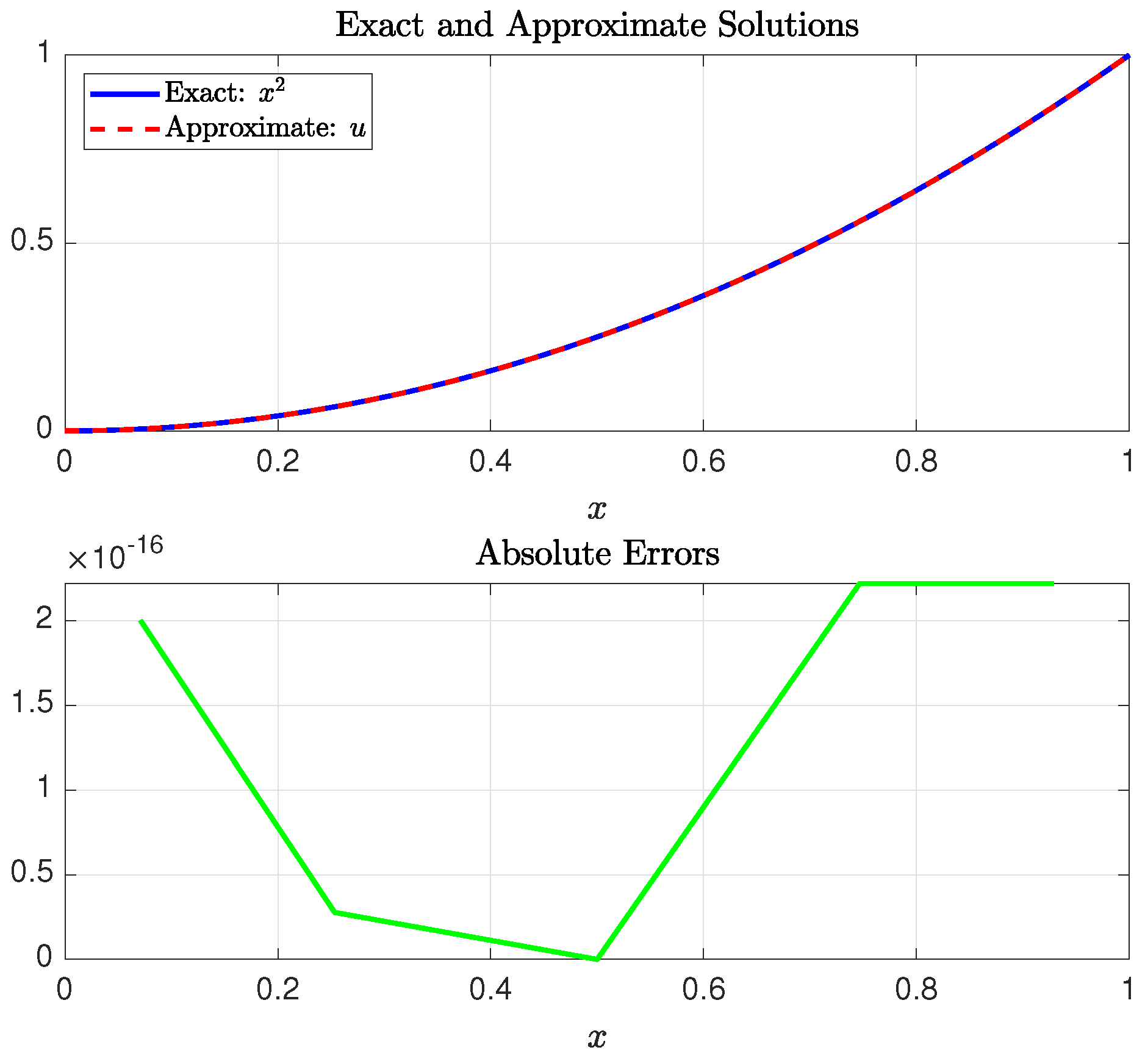
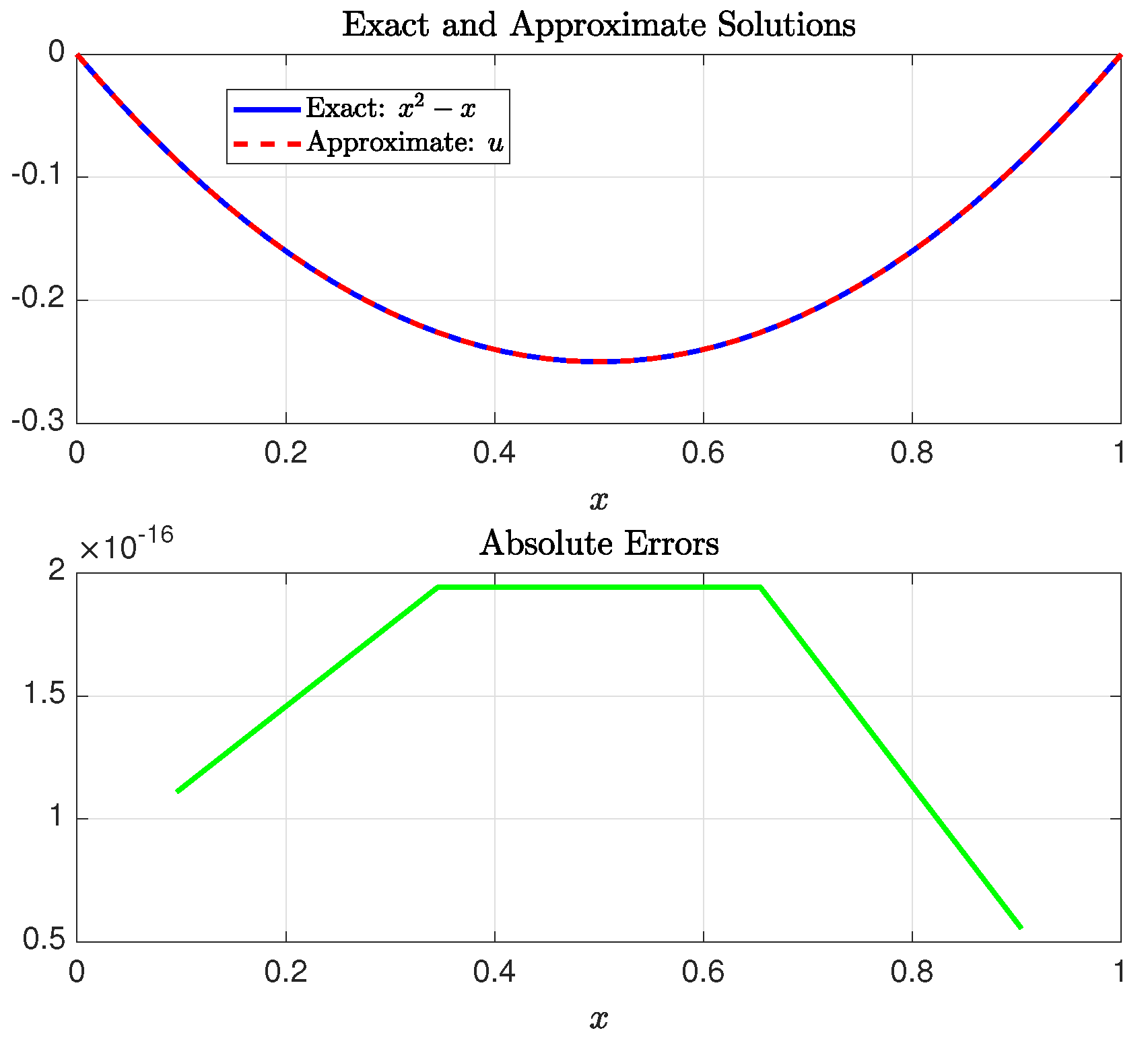
Example 1. Consider the Caputo fractional TPBVP of the Bagley–Torvik typewith the given Dirichlet boundary conditions The exact solution is
. This problem was solved by Al-Mdallal et al. [
32] using a method that combines conjugating collocation, spline analysis, and the shooting technique. Their reported error norm was
; cf. [
33]. Later, Batool et al. [
33] addressed the same problem using integral operational matrices based on Chelyshkov polynomials, transforming the problem into solvable Sylvester-type equations. They reported an error norm of
, obtained using approximate solution terms with significantly more than 16 digits of precision. Specifically, the three terms used to derive this error included 32, 47, and 47 digits after the decimal point, indicating that the method utilizes extended or arbitrary-precision arithmetic, rather than being constrained to standard double precision. For a more fair comparison, since all components of our computational algorithm adhere to double-precision representations and computations, we recalculated their approximate solution using Equation (92) of [
33] on the MATLAB platform with double-precision arithmetic. Our results indicate that the maximum absolute error in their approximate solution, evaluated at 50 equally spaced points in
, was approximately
. The SGPS method produced this same result using the parameters
and
. The elapsed time required to run the SGPS method was
s.
Figure 7 illustrates the exact solution, the approximate solution obtained using the SGPS method, and the absolute errors at the SGG collocation points.
Example 2. Consider the Caputo fractional TPBVP of the Bagley–Torvik typewith the given Dirichlet boundary conditions The exact solution is
. Yüzbaşı [
34] solved this problem using a numerical technique based on collocation points, matrix operations, and a generalized form of Bessel functions of the first kind. The maximum absolute error reported in [
34] (at
) was
. Our SGPS method produced near-exact solution values within a maximum absolute error of
using
; cf.
Figure 8. The elapsed time required to run the SGPS method was
s.
Example 3. Consider the Caputo fractional TPBVP of the Bagley–Torvik typewith the given Dirichlet boundary conditions The exact solution is
. Our SGPS method produced near-exact solution values within a maximum absolute error of
using
and
; cf.
Figure 9. The elapsed time required to run the SGPS method was
s.
7. Sensitivity Analysis of SG Parameters and
Optimizing the performance of the SGPS method requires a thorough understanding of how the Gegenbauer parameters
and
influence numerical stability and accuracy. These parameters govern the clustering of collocation and quadrature points, directly affecting the condition number of the collocation matrix
and the overall robustness of the method. In this section, we present a sensitivity analysis to quantify the impact of varying
and
on the stability of the SGPS method, as measured by the condition number
. The analysis specifically examines the behavior of the method when solving the Caputo Fractional TPBVP of the Bagley–Torvik Type with smaller interpolation and quadrature mesh sizes. The numerical examples from
Section 6 serve as the basis for this analysis, and the results are visualized using surface plots, contour plots, and semilogarithmic plots to illustrate the condition number’s behavior across the parameter space.
Figure 10 illustrates the influence of varying the parameters
and
on the condition number of collocation matrix
associated with Example 1. Higher condition numbers indicate increased sensitivity to perturbations in the input data, potentially leading to instability in the numerical solution. The results show that
and
, the condition number is influenced by
; as
increases, the condition number tends to grow linearly. Conversely, the condition number exhibits minimal sensitivity to changes in
within the range specified by the “Rule of Thumb.” This suggests that the stability of the method for low-degree SG interpolants and small quadrature mesh sizes is primarily dependent on the appropriate selection of
. Specifically, choosing a
that is relatively large and positive can compromise stability. Conversely, the figure indicates that
values closer to
(while maintaining a sufficient distance to prevent excessive growth in SG polynomial values), combined with
values within the interval
, particularly near its endpoints, yield lower condition numbers. We notice, however, that
remains in the order of
for
, indicating that the SGPS method is numerically stable for this range of parameters. Moreover, for double-precision arithmetic, this observation implies a potential loss of two significant digits in the worst case. However, the actual error observed in the numerical experiments is much smaller, indicating that the method is highly accurate in practice.
Figure 11 and
Figure 12 present further sensitivity analyses of the SGPS method’s numerical stability for Examples 2 and 3. The condition number in both examples is in the order of 10 for the parameter range considered (up to nearly 2), indicating high numerical stability for that parameter range. These figures consistently indicate that stability is influenced by
and
, but minimally impacted by
.
The sensitivity analysis conducted in this section reveals an important decoupling in parameter effects: while
primarily governs the numerical stability through its linear relationship with the condition number of the collocation matrix,
predominantly controls the accuracy of Caputo FD approximations, as seen earlier in
Figure 2 and
Figure 3, without significantly affecting system conditioning. This decoupling allows for the independent optimization of stability and accuracy. In particular, we can select
to ensure well-conditioned systems while tuning
to achieve the desired precision in derivative computations. The recommended parameter ranges (
) provide a practical balance. Negative values of
and
close to
can improve stability and accuracy when using smaller interpolation and quadrature grids, while excellent quadrature accuracy is often achieved at
. This separation of concerns simplifies parameter selection and enables robust implementations across diverse problem configurations.
8. Conclusions and Discussion
This study pioneers a unified SGPS framework that seamlessly integrates interpolation and integration for approximating higher-order Caputo FDs and solving TPBVPs of the Bagley–Torvik type, offering significant advancements in numerical methods for fractional differential equations through the following: (i) The development of FSGIMs that accurately and efficiently approximate Caputo FDs at any random set of points using SG quadratures generalizes traditional PS differentiation matrices to the fractional-order setting, which we consider a significant theoretical advancement. (ii) The use of FSGIMs allows for pre-computation and storage, significantly accelerating the execution of the SGPS method. (iii) The method applies an innovative change of variables that transforms the Caputo FD into a scaled integral of an integer-order derivative. This transformation simplifies computations, facilitates error analysis, and mitigates singularities in the Caputo FD near zero, which improves both stability and accuracy. (iv) The method can produce approximations withing near-full machine precision at an exponential rate using relatively coarse mesh grids. (v) The method generally improves numerical stability and attempts to avoid issues related to ill conditioning in classical PS differentiation matrices by using SG quadratures in barycentric form. (vi) The proposed methodology can be extended to multidimensional fractional problems, making it a strong candidate for future research in high-dimensional fractional differential equations. (vii) Unlike traditional methods that treat interpolation and integration separately, the current method unifies these operations into a cohesive framework using SG polynomials. Numerical experiments validated the superior accuracy of the proposed method over existing techniques, achieving near-machine precision results in many cases. The current study also highlighted critical guidelines for selecting the parameters
and
to optimize the performance of the SGPS method
. In particular, for large interpolation and quadrature mesh sizes, and for high-precision computations,
should be selected within the range
, while
should be adjusted to satisfy
. This ensures a balance between convergence speed and numerical stability. For general-purpose computations, setting
(corresponding to the SC interpolant and quadrature) is recommended, as it provides optimal
-norm accuracy for smooth functions. The analysis also revealed that increasing
accelerates theoretical convergence but may introduce numerical instability due to extrapolation effects, while larger
values can slow convergence.
and
, the sensitivity analysis in this study reveals that the conditioning of the linear system of equations produced by the SGPS method when treating a Caputo Fractional TPBVP of the Bagley–Torvik Type increases approximately linearly with
. This indicates that smaller values of
in this case can lead to improved numerical stability. In particular, it is advisable to choose negative
values, especially in the neighborhood of
, as evidenced by the numerical simulations, but not too close to
, to avoid the rapid growth of SG polynomials. The conditioning of the linear system is less sensitive to variations in
compared to
and
, with minimal effect on stability. However, to maintain accuracy, it is still recommended to keep
within the recommended interval
, with excellent quadrature accuracy often attained at
. These insights ensure robust and efficient implementations of the SGPS method across diverse problem settings. The SGPS method’s computational efficiency is further underscored by its predictable runtime and storage costs, as summarized in
Table 2. For practitioners, these estimates provide clear guidelines for resource allocation. The table also highlights recommended parameter ranges to balance accuracy and stability.
The current work assumes sufficient smoothness of the solution to achieve exponential convergence. For fractional problems involving weakly singular or non-smooth solutions, where derivatives may be unbounded, future research may investigate adaptive techniques—such as graded meshes or hybrid spectral–finite element approaches—to extend the method’s applicability. The robust approximation of Caputo derivatives achieved by the SGPS method creates opportunities for modeling viscoelasticity in smart materials, anomalous transport in heterogeneous media, and non-local dynamics in control theory. Future directions could include adaptive parameter tuning to capture singularities in viscoelastic models or coupling the method with machine learning to optimize fractional-order controllers. These applications would improve the method’s interdisciplinary relevance while preserving its mathematical rigor. Additionally, the SGPS approach could be extended to multidimensional fractional problems, where tensor products of one-dimensional FSGIMs can be employed. The inherent parallelizability of FSGIM matrix–vector operations makes the method particularly suitable for GPU acceleration or distributed computing. For time-dependent fractional PDEs, like fractional diffusion equations, the SGPS method can employ the FSGIM for spatial discretization, transforming the problem into a system of ODEs in time. Standard time-stepping schemes, such as Runge–Kutta or fractional linear multistep methods, can then be applied. The precomputation and reuse of the FSGIM for spatial discretization at each time step can yield significant efficiency gains in time-marching schemes.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}