1. Introduction
The mean-variance (MV) portfolio selection model, introduced by [
1], has been widely utilized in both academic research and investment practice. However, a drawback of the MV formulation is its symmetric nature, which penalizes both gains and losses equally. To address this issue, various risk measures have been introduced into the portfolio optimization framework. The concept of a
coherent risk measure [
2], along with its extension, the
convex risk measure [
3], has laid down fundamental principles for defining more reasonable risk measures. Along with the development of modern risk measures, the mean-risk portfolio optimization models have been extensively studied under the frameworks of static and dynamic portfolio optimizations (e.g., [
4,
5,
6,
7,
8,
9,
10,
11]). Recently, researchers (e.g., [
12,
13,
14]) have also demonstrated the successful application of the downside risk-based models in portfolio insurance management. Among these studies, one particular direction focuses on the portfolio optimization model with multiple hybrid risk measures (e.g., [
10,
11,
15,
16,
17]). This line of research is motivated by the fact that, in cases where the distribution of portfolio returns is asymmetrical and non-Gaussian, solely minimizing variance is insufficient for effectively managing downside risk.
This paper adopts a similar approach to previous studies, exploring the dynamic mean-risk portfolio decision model by integrating both the mean-variance (MV) formulation and the
spectral risk measure (SRM). Building on the foundational work of [
18], SRM calculates risk as a weighted average of the quantiles of the return (or wealth) distribution. When the weighting function, also referred to as the spectrum, satisfies certain mild conditions, SRM qualifies as a coherent risk measure, as demonstrated by [
9,
18]. While SRM represents a specific case within the broader spectrum of risk measures, such as the distortion risk measure or weighted VaR [
7,
9], it possesses several advantageous properties, including convexity, tractability, and flexibility when selecting the spectrum function. The power of distortion functions to capture nuanced risk preferences is further highlighted by their use in other advanced frameworks, such as distributionally robust optimization under distorted expectations [
19]. These attributes make SRM a particularly suitable choice for constructing portfolio optimization models.
In this study, we propose a novel hybrid portfolio optimization model that integrates multiple risk measures, specifically the dynamic SRM-MV portfolio optimization model. The integration of SRM into the dynamic MV framework is significant for several reasons. First, it enhances the ability to shape the distribution of terminal wealth, particularly by strengthening the management of downside risk in the loss domain. Recent research by [
20] highlights that the terminal wealth distribution under a dynamic MV policy may exhibit a long tail in the loss domain, underscoring the importance of incorporating downside risk measures to control tail risk. Second, the inclusion of SRM diminishes the dominance of variance in the objective function, thereby alleviating the conservatism associated with variance-based risk management within the gains domain. This hybrid approach not only improves the robustness of portfolio optimization but also aligns more closely with real-world risk management needs.
On the other hand, in the traditional multi-period portfolio selection model, the focus is primarily on the risk and return associated with terminal wealth. However, in real-world investment scenarios, investors are also concerned with the performance of the portfolio during intermediate periods within the investment horizon. To address this, intertemporal risk–reward restrictions have been introduced in the mean-variance (MV) portfolio selection framework. These restrictions focus on the intermediate expected values and variances in the portfolio, thereby enabling investors to impose constraints that help mitigate significant variations in portfolio performance. This approach is particularly beneficial for institutional investors with evolving risk management needs, as it allows them to dynamically manage both tail risk and overall portfolio volatility. The problem of controlling intermediate portfolio behavior, whether in terms of returns or variance, was first explored by [
21]. They proposed a solution using the embedding method introduced by [
22]. However, the computational complexity of this approach posed challenges for practical implementation. To address this, [
23] developed a novel mean-field framework. This framework provides an efficient modeling tool and offers a semi-analytical solution scheme, significantly simplifying the process of tackling such problems. Their work represents a significant advancement in multi-period portfolio optimization, bridging the gap between theoretical models and practical applications. The trend of embedding intertemporal risk controls within multi-period mean-variance frameworks has continued, with models incorporating, for example, intertemporal variances directly in the objective function [
24], or featuring intertemporal constraints as explored by [
25].
Although some research has studied the portfolio optimization model with hybrid risk measures or the intertemporal risk–reward restriction, the current literature provides little insight on a model including both of these features. Our work meet this challenge. Our contribution is threefold. First, we introduce a novel formulation that combines SRMs with variance measures across multiple time periods, allowing investors to manage both tail risk and overall portfolio volatility dynamically. The flexibility of our model enables investors to specify time-varying risk preferences through the spectral function, making it particularly suitable for institutional investors with evolving risk management requirements. Second, we develop an efficient solution methodology based on the Progressive Hedging Algorithm (PHA), enhanced with specialized reformulations for handling linkage objectives and constraints. Our theoretical analysis provides strong convergence guarantees, demonstrating that the algorithm achieves a q-linear convergence rate under mild conditions. Third, the numerical results validate the effectiveness of our approach, showing that the intertemporal weighting scheme provides more consistent risk management across the investment horizon compared to terminal-focused strategies. Particularly noteworthy is the superior performance in terms of downside risk protection, as evidenced by improved Sortino and Omega ratios. These findings have significant practical implications for portfolio managers seeking to implement dynamic risk-management strategies that account for both intermediate and terminal objectives.
The remainder of this paper is organized as follows: Review of the Related Literature reviews the relevant literature on portfolio optimization, risk measures, and solution methodologies.
Section 2 presents our mathematical formulation of the multi-period portfolio optimization problem incorporating intertemporal spectral risk measures.
Section 3 develops our solution methodology based on the Progressive Hedging Algorithm and establishes its theoretical properties.
Section 4 provides comprehensive numerical experiments that demonstrate the effectiveness of our approach and compare different weighting schemes. Finally,
Section 5 concludes with a discussion of implications and future research directions.
For notational clarity, we adopt the following conventions throughout this paper: bold lowercase letters (e.g., , ) denote vectors, while bold uppercase letters (e.g., , ) represent matrices. Scalar quantities are indicated by non-bold letters (e.g., , r). The transpose of a vector or matrix is denoted by a superscript ⊤ (e.g., , ). We use to represent the Frobenius inner product of two matrices, defined as , where denotes the trace operator. For vectors, represents the standard inner product. The Euclidean norm of a vector is denoted by , and the Frobenius norm of a matrix by . We use to denote the set of real numbers, for n-dimensional real vector space, and for the space of real matrices. The expectation operator is denoted by , and probability by .
3. Methodology
In this section, we apply the Progressive Hedging Algorithm (PHA) in combination with linkage objective and constraint reformulation techniques to solve the problem , which incorporates the intertemporal SRMs.
3.1. Scenario-Based Decomposition and Progressive Hedging Algorithm
Let
be the set of
N empirical realizations, which is
, where
is the
i-th realization. Let the objective function be
, which is defined as
where
. Let the feasible policy set be
, which is defined as
Moreover, the multi-stage decisions should be
nonanticipative; that is, decisions at each stage should be based only on information available up to that point in time, without knowledge of future random outcomes or events. Let
be the nonanticipativity action space. Hence, the problem
can be rewritten as
PHA operates by decomposing the original stochastic optimization problem into a set of deterministic subproblems, each corresponding to a specific scenario
. These subproblems are then solved iteratively, and their solutions are aggregated to converge towards a globally optimal solution. Formally, the original problem is decomposed into
N scenario-based subproblems, each of which can be expressed as:
To ensure convergence to a solution that is both feasible and optimal for the original stochastic problem, PHA incorporates penalty terms that progressively enforce consensus among scenario-specific decisions. Let
represent the dual variables (also referred to as the price system), where
, and
is the orthogonal complement of
. Consequently, the
N scenario-based subproblems that PHA solves in each iteration can be formulated as:
Following the resolution of these
N scenario-based subproblems, PHA aggregates the obtained solutions
and updates both the primal and dual variables. The complete procedure for PHA is summarized in Algorithm 1. For further details and the corresponding proof, refer to [
36].
| Algorithm 1 Original progressive hedging. |
- Require:
Initial primal–dual pair , penalty parameter - Ensure:
Optimal solution - 1:
Set iteration - 2:
repeat - 3:
// Scenario decomposition - 4:
for all do - 5:
- 6:
end for - 7:
// Update primal and dual variables - 8:
▹ Project onto subspace - 9:
▹ Project onto subspace - 10:
- 11:
until convergence - 12:
return solution
|
The standard PHA framework outlined in Algorithm 1 is effective for problems where the objective function and constraints are scenario-separable. However, our problem includes terms like and , and the constraint , which inherently link decisions across different scenarios. These “linkage” terms violate the separability assumption crucial for the direct application of PHA. Therefore, modifications are necessary to handle these interdependencies.
3.2. Reformulation of Linkage Objectives
We begin by reformulating intertemporal SRMs. Let the summation of intertemporal SRM be ISRM:
Let us introduce the function
, which serves as a key component in our reformulation:
where
represents the scenario of random variables capturing the uncertainty in our model,
for
, and the coefficients
are defined as
.
is a matrix of auxiliary variables, with each
representing a vector of these variables for a specific time period
t.
represents the positive part function.
This formulation leverages the known representation of CVaR as the solution to an optimization problem [
26] and the relationship between SRM and CVaR (as shown in
Appendix A, Lemma A1). It allows us to express the intertemporal SRM in terms of a minimization problem over the auxiliary variables
, as we will demonstrate in the subsequent theorem.
Theorem 1. The ISRM can be expressed as the minimum of the function over the auxiliary variables :Minimize the ISRM associated with over all is equivalent to minimize over all :For the optimal solution , each element is equal to the VaR at level for the loss at time t: The detailed proof is provided in
Appendix A. Theorem 1 establishes the equivalence between minimizing ISRM and minimizing the function
in a continuous probability space. For practical implementation within our scenario-based framework, we need to work with the discrete empirical distribution derived from the scenarios. This leads to a discrete approximation of the function
.
Let us assume we have collected
N such realizations. We can then formulate a discrete approximation of the ISRM by sampling from the probability distribution of
:
These discretized formulations offer computationally tractable approximations of the ISRM. Furthermore, these discretizations facilitate the decomposition of the objective function into scenario-based sub-objectives, rendering them amenable to the PHA framework.
Utilizing the function
, we can reformulate the original problem as:
which can be subsequently decomposed into scenario-based sub-objectives:
This decomposition property is crucial for the efficient application of PHA to our multi-period portfolio optimization problem
.
Despite this increased separability, a challenge persists regarding the requirement for to remain consistent across all scenarios . Specifically, is subject to the nonanticipativity constraint. Hence, we treat it as an additional first-stage decision variable. Consequently, must converge to a constant value to satisfy the nonanticipativity condition. The intricacies of projecting onto the nonanticipativity subspace and updating its corresponding dual variables are delineated in Algorithm 2.
3.3. Reformulation of Linkage Constraints
Having successfully decomposed the linkage objective function into scenario-specific components through the reformulation utilizing , we now address the linkage constraint . This constraint is classified as a linkage constraint due to its incorporation of the expectation over all scenarios, thereby coupling decisions across different realizations. Such coupling precludes straightforward scenario-based decomposition.
To address the linkage constraint, one approach involves employing augmented Lagrangian relaxation techniques. This method entails introducing a Lagrange multiplier associated with the constraint and incorporating it into the objective function. Subsequently, the linkage constraint can be decomposed using the methodology presented in
Section 3.2. However, the direct integration of PHA with Lagrangian methods results in a nested iterative process. The outer iteration involves updating the Lagrangian multiplier, while the inner iteration comprises the PHA update steps with a fixed Lagrangian multiplier. To ensure global convergence, it becomes necessary to iterate the PHA steps until convergence for each outer iteration, which is computationally inefficient. Although some research has attempted to consolidate the nested iterative process into a single iteration [
43], the guarantee of convergence to optimality and the associated convergence rate remain challenging to theoretically establish.
To address the linkage constraint without resorting to Lagrangian multipliers, we propose an alternative approach that introduces auxiliary variables and modifies the nonanticipativity subspace. We begin by reformulating the linkage constraint as follows:
This constraint can be equivalently expressed using auxiliary variables:
where
and
is a vector of auxiliary variables.
Therefore, the feasible set
can be modified to
, which are defined as:
The auxiliary variables represent the deviation of the scenario-specific wealth realization from the target mean . The constraint ensures that the expected deviation is zero, thereby satisfying the original linkage constraint .
This constraint on
is handled within the PHA projection step. The projection onto the augmented nonanticipativity space is modified due to the introduction of the additional constraint
. Let
denote the optimal results obtained from all scenarios
, and let
represent the associated dual variables. The projection of
onto the augmented nonanticipativity space
is given by:
while the update of the dual variables is expressed as:
The integration of these modifications with PHA is delineated in Algorithm 2.
This reformulation allows us to decompose the linkage constraint into scenario-specific components while maintaining the overall expectation constraint through the auxiliary variables. By incorporating these auxiliary variables into the PHA framework, we can effectively handle the linkage constraint without introducing nested iterations, thereby improving computational efficiency.
3.4. Algorithm for Problem
Having developed methods to reformulate both the linkage objectives (
Section 3.2) and the linkage constraints (
Section 3.3) into forms compatible with scenario decomposition, we can now integrate these techniques into the Progressive Hedging Algorithm. This leads to a modified PHA specifically designed to solve problem
in this section. Specifically, we integrate the scenario-decomposition approach of the original PHA outlined in
Section 3.1 with the techniques developed for addressing linkage objectives and constraints, as detailed in
Section 3.2 and
Section 3.3, respectively. This integration results in a unified algorithmic framework tailored to efficiently solve our multi-period portfolio optimization problem with intertemporal SRMs.
To implement the modified PHA for problem , we consider several sets of variables that require iterative calculation. The algorithm operates on three primal–dual pairs: (, ), (, ), and (, ). Here, represents the original decision variables of the portfolio optimization problem, denotes the auxiliary variables introduced to decompose the linkage objective, and comprises the auxiliary variables used to decompose the linkage constraint. Their respective dual variables are represented by , , and . For notational convenience, we define enlarged primal and dual variables as and , respectively.
Algorithm 2 presents a detailed exposition of the modified PHA tailored for problem
, which yields an optimal solution that respects both the nonanticipativity constraints and the linkage constraints of the original problem. The initial conditions for the dual variables
and
ensure they lie within the appropriate subspace orthogonal to the nonanticipativity constraints imposed on
and
, respectively.
| Algorithm 2 Modified Progressive Hedging Algorithm for problem . |
- Require:
Initial primal–dual pairs: - 1:
(, ), where and ; - 2:
(, ), where , where are constants and ; - 3:
(, ), where with and with , where are constants; - 4:
penalty parameter . - Ensure:
Optimal solution - 5:
Set iteration - 6:
repeat - 7:
// Scenario decomposition - 8:
- 9:
end for - 10:
// Update primal variables - 11:
- 12:
- 13:
- 14:
// Update dual variables - 15:
- 16:
- 17:
- 18:
- 19:
until convergence - 20:
return solution
|
Having presented the modified PHA (Algorithm 2) designed to solve problem
, we now turn to its theoretical validation. A crucial aspect of any iterative optimization algorithm is ensuring that it reliably converges to a correct solution. The following theorem formally establishes this convergence guarantee for our proposed method and characterizes the speed at which it approaches the optimum. The detailed proof is provided in
Appendix B.
Theorem 2. (Convergence guarantee and convergence rate) Let be the sequence generated by Algorithm 2 from any initial point . The sequence converges to an optimal solution of problem . The convergence occurs at a q-linear rate with respect to the norm defined as:where is the penalty parameter used in the algorithm. Specifically, there exists a constant such that for all :with strict inequality holding unless . Remark 1. The q-linear convergence rate implies that the distance to the optimal solution decreases by at least a fixed fraction in each iteration, which is a strong form of convergence. The strict inequality in the convergence rate, unless at the optimal point, ensures that the algorithm makes progress in each iteration until the optimal solution is reached.
Theorem 2 provides a theoretical guarantee for the overall convergence of Algorithm 2. It is worth noting, however, that the practical speed of convergence, quantified by the q-linear rate q, is influenced by several parameters related to the problem formulation and the algorithm itself. A crucial factor is the PHA penalty parameter r; selecting an appropriate value is key, as it must balance enhancing the strong convexity of the subproblems (favoring faster convergence) against potentially slowing the propagation of information through the dual variable updates.
Furthermore, the objective function weights, particularly the variance weight , impact the problem’s conditioning. Larger values of strengthen the quadratic term in the objective, which can improve the strong convexity with respect to the allocation variables and thus potentially decrease q (i.e., accelerate convergence). The SRM weights also contribute to the objective landscape. Additionally, the inherent structure, including dimensionality () and asset return characteristics, along with the nature of the feasible sets , affects the overall conditioning and convergence behavior. While convergence is guaranteed, practical implementation often involves tuning r to achieve efficient performance for a specific problem instance.
An important consideration related to the problem formulation is the choice of the spectral function . While Theorem 2 guarantees q-linear convergence for any valid spectral function (including step functions), the specific form of can affect the practical convergence speed by altering the complexity of the scenario subproblems solved in Step 4 of Algorithm 2. Specifically:
If
is a single-step function (corresponding to CVaR at a specific quantile level, e.g., [
49,
50]), the SRM reformulation
requires only one auxiliary variable
per time period
t. This significantly simplifies the scenario subproblem, potentially leading to faster computation within each PHA iteration.
If is a step function with K steps(), the reformulation involves K auxiliary variables per time t. The subproblem complexity is intermediate between the CVaR case and the general case analyzed.
If is a more general function approximated by an N-step function(as implicitly achieved in our discretization and reformulation), the subproblem involves N auxiliary variables per time t, representing the most complex case considered here.
Therefore, using simpler spectral functions (like step functions with fewer steps) can reduce the computational burden per iteration, potentially leading to faster overall convergence in practice. This presents a possible trade-off between the flexibility of the spectral risk measure used and the computational efficiency of the algorithm. While convergence is guaranteed, practical implementation often involves tuning r and considering the structure of to achieve efficient performance for a specific problem instance.
Moreover, the practical performance of the algorithm heavily depends on the efficiency with which the scenario-specific subproblems (Step 4 in Algorithm 2) can be solved in each iteration. We now turn our attention to the structure of these subproblems and investigate possibilities for obtaining analytical or semi-analytical solutions under certain conditions.
While these convex subproblems can generally be solved numerically, deriving an analytical solution, even under simplifying assumptions, provides valuable insight into the structure of the problem and can potentially lead to faster implementations. We now consider the specific case where there are no explicit constraints (like non-negativity or budget limits) imposed on the portfolio allocation decisions
within the set
. The following theorem presents the resulting analytical expression for the optimal solution
of the scenario subproblem under this condition. The detailed proof is provided in
Appendix C.
Theorem 3. Suppose there are no restrictions on how assets can be allocated in the portfolio . In that case, the optimal solution for the scenario-based subproblem can be expressed as:where , with the i-th element defined as if , and otherwise. is a matrix defined as: However, it is important to note that this solution is not explicitly solvable in a single step. The expressions for and exhibit a mutual dependence through the indicator terms . This interdependence arises because the optimal portfolio allocation affects the wealth , which in turn influences the optimal risk thresholds . Conversely, the risk thresholds determine which scenarios are considered in the tail risk calculations, thereby impacting the optimal portfolio allocation . This circular relationship between and creates a complex optimization landscape. It precludes the possibility of obtaining a closed-form solution through direct algebraic manipulation. Instead, this interdependence necessitates a more sophisticated approach to find the optimal solution.
Fortunately, the sequence is monotonically increasing for each t, a property that stems from representing the VaR at progressively higher confidence levels. This monotonicity allows us to employ an efficient binary search algorithm to determine the optimal values. Leveraging this property, we can characterize as a binary sequence: a contiguous series of ones followed by a contiguous series of zeros. Consequently, our task reduces to finding the transition point between these two series. This can be achieved by iteratively updating and while employing binary search to efficiently locate the transition point in the indicator sequence for each t. This approach significantly reduces the computational complexity compared to exhaustively evaluating all possible combinations of and , thereby providing an efficient method to solve the scenario-based subproblem.
4. Numerical Results
To assess the effectiveness of our proposed approach, we conducted some numerical experiments using a multi-period portfolio optimization problem incorporating intertemporal spectral risk measures. The portfolio optimization problem is defined over a three-period time horizon (), with a risk-free rate of . The portfolio consists of two risky assets, characterized by risk–return pairs . This setup yields 4 scenarios per time period, resulting in a total of scenarios across the full horizon. We set targeted mean returns for each time period .
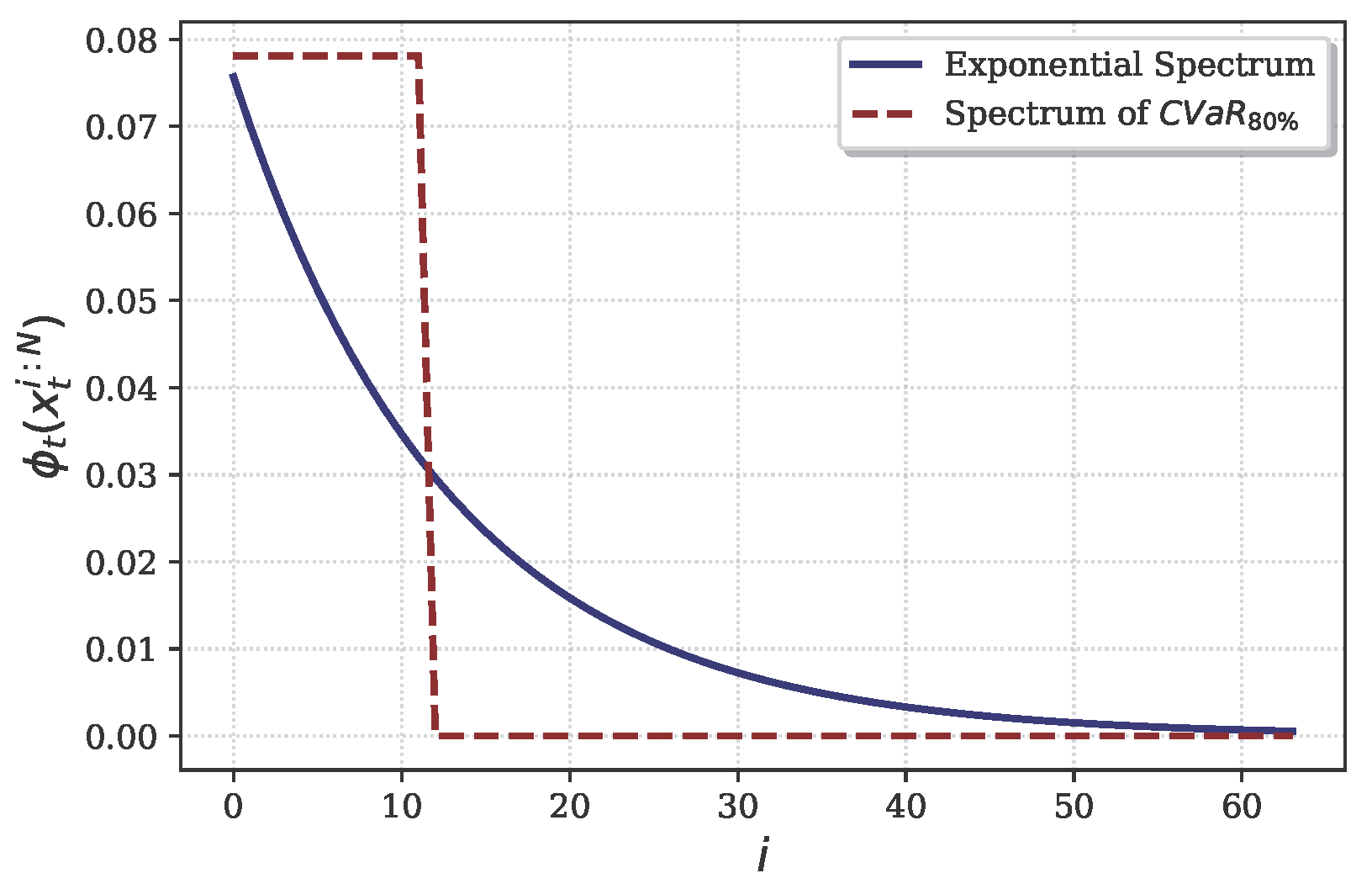
For the spectral risk measure, we employed an exponential spectrum defined as
, where
. This spectrum, illustrated in
Figure 2, provides a nuanced representation of risk preferences across different probability levels, assigning greater weight to extreme losses. The function exhibits a high initial value for extreme losses and decreases exponentially as the loss magnitude diminishes, reflecting a risk-averse attitude. This configuration emphasizes severe, low-probability losses over more frequent, moderate ones. For comparison, we also plotted the CVaR spectrum with an
quantile, represented by a step function in
Figure 2. While CVaR assigns uniform weight to the worst
of outcomes and zero to others, our exponential spectrum offers a more gradual transition. This approach facilitates a comprehensive risk assessment across all potential outcomes while maintaining an emphasis on tail risk.
We solved this optimization problem using the Progressive Hedging Algorithm, which was implemented with a step size of for updating dual variables, a maximum of 200 iterations, and a convergence tolerance of . Two distinct weighting schemes for the spectral risk measures and variance terms were explored to evaluate their impact on portfolio performance.
We compare the performance of two distinct weighting schemes: an intertemporal scheme that considers risk (SRM and variance) across all time periods and a terminal scheme that focuses solely on the risk at the final period. The first scheme, referred to as the “intertemporal weights” scheme, assigns equal importance to all time periods, setting and for each . The second scheme, referred to as the “terminal weights” scheme, focuses exclusively on the final period by setting and , while nullifying the weights for intermediate periods ( for ). The relatively large value of compared to was chosen to balance the scales between the variance and SRM terms in the objective function, as the variance term tends to be smaller in magnitude than the SRM term.
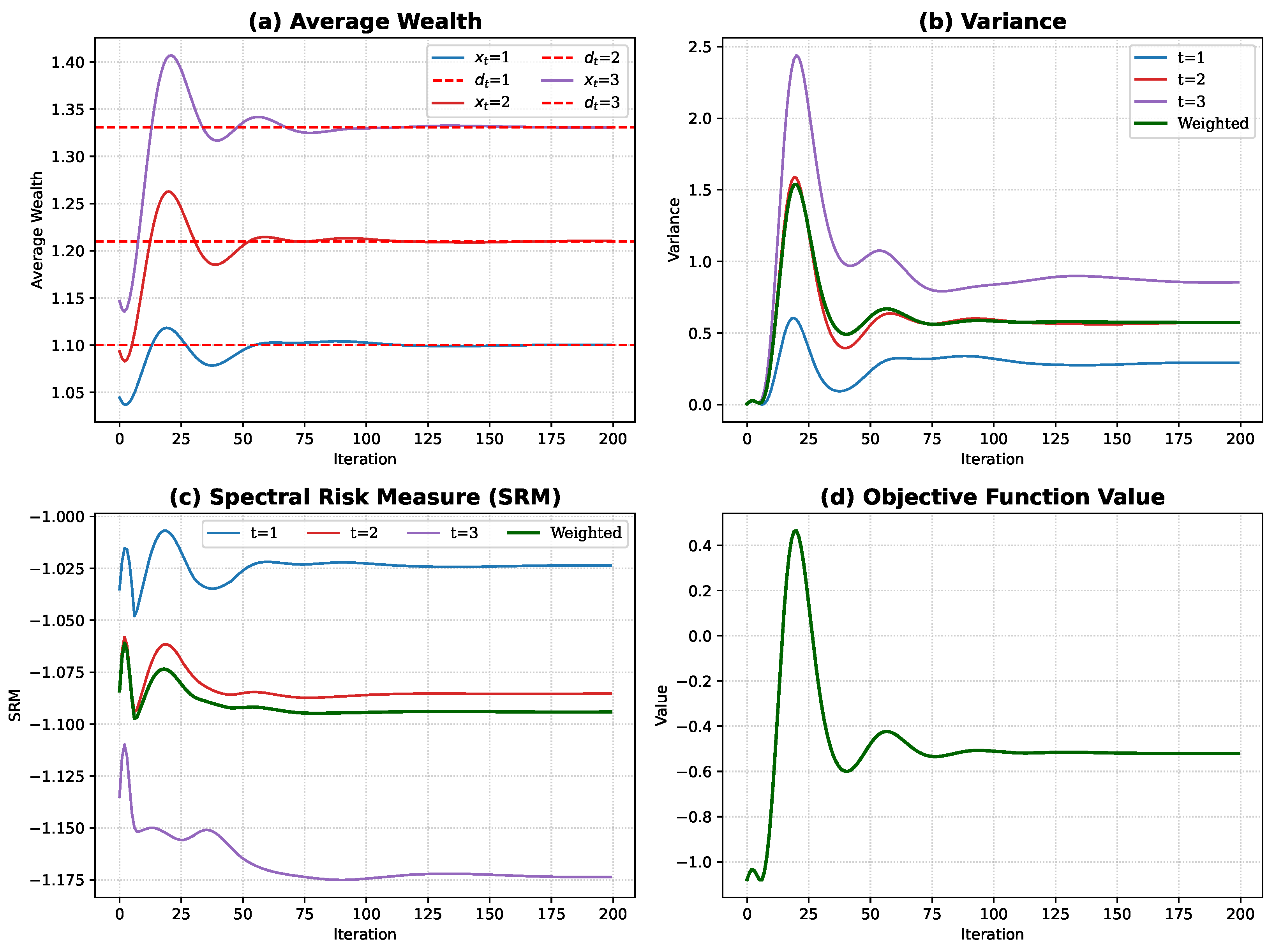
Figure 3 and
Figure 4 demonstrate the convergence behavior of the PHA for intertemporal weighting schemes.
Figure 3 tracks several performance metrics—average wealth, variance, SRM, and objective function value—which all stabilize after approximately 100 iterations. More importantly,
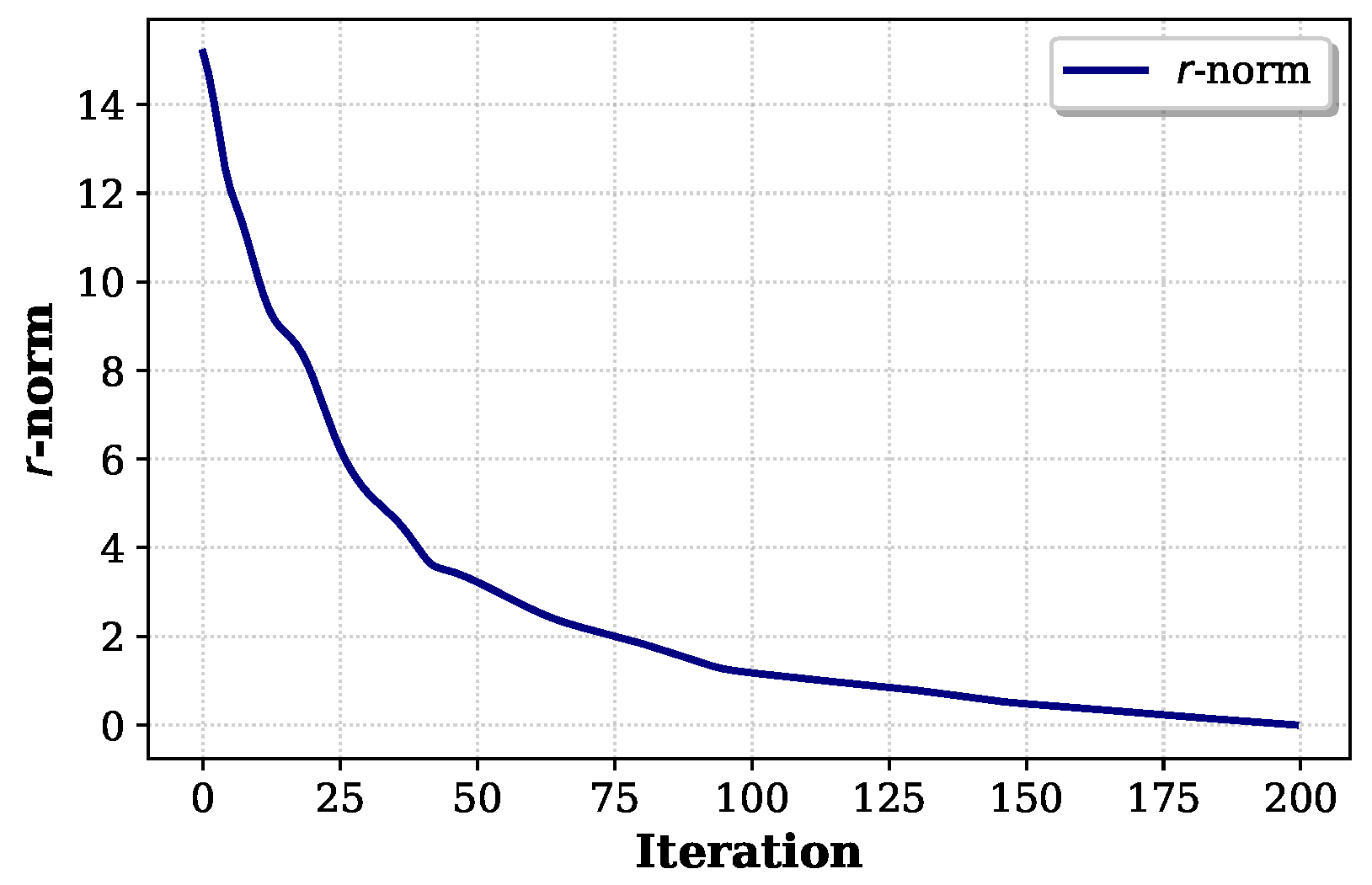
Figure 4 shows the monotonic decrease in the
r-norm, which measures the combined distance of primal and dual variables from their optimal values. The strictly decreasing pattern of the
r-norm confirms the
q-linear convergence rate established in Theorem 2. The empirical evidence of both the metric stabilization and the r-norm’s monotonic decrease validates the theoretical convergence properties of our modified PHA in solving the multi-period portfolio optimization problem with intertemporal risk measures.
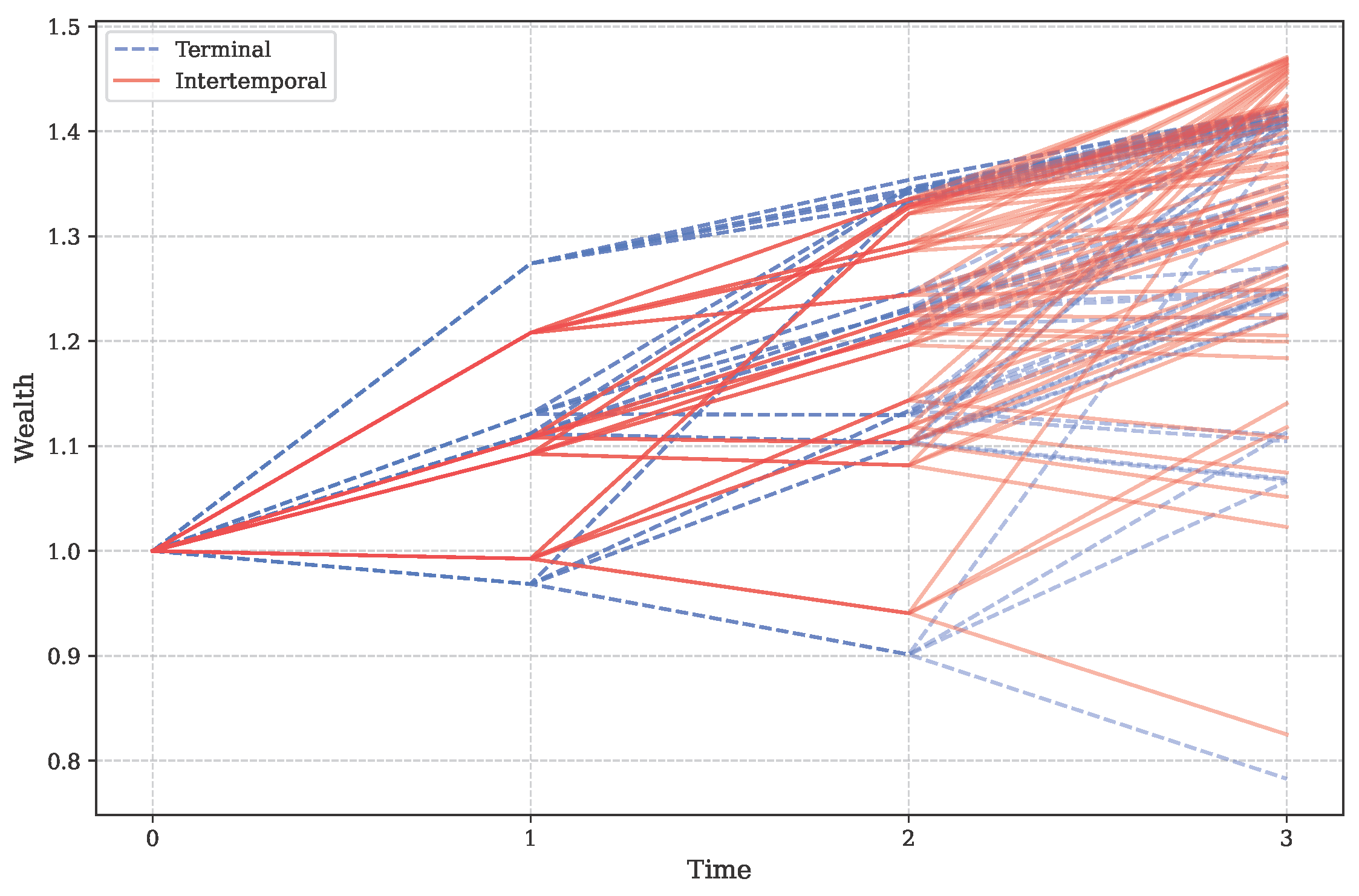
Figure 5 illustrates the wealth trajectories across all scenarios for both the intertemporal and terminal weighting schemes over the three-period investment horizon. The intertemporal scheme exhibits a tighter clustering of wealth trajectories, especially in the intermediate period (
). This tighter clustering suggests that the intertemporal approach provides more consistent wealth outcomes across different scenarios, indicating better risk management throughout the investment horizon. In contrast, the terminal weighting scheme shows a wider dispersion of wealth trajectories, particularly in the intermediate periods. This increased variability likely stems from the scheme’s focus on optimizing only the final period’s risk, allowing for greater fluctuations in earlier periods.
The observed tighter clustering of wealth trajectories under the intertemporal scheme (
Figure 5), suggesting more consistent wealth outcomes, aligns with findings in other dynamic asset allocation studies, where strategies considering intermediate performance often lead to reduced path diversity and smoother wealth accumulation. For instance, [
24] noted that incorporating intermediate variance controls in a multi-period setting, albeit with different risk measures, helped stabilize portfolio performance across scenarios.
While the trajectory plots offer a useful visual comparison, a more rigorous evaluation requires examining quantitative performance and risk metrics. More measure metrics are shown in
Table 1. The intertemporal weighting scheme outperforms the terminal scheme in terms of the overall objective function value. This suggests that considering risk across all time periods leads to a more optimal solution according to our defined criteria. The intertemporal approach also achieves better time-weighted SRM and time-weighted variance scores.
Looking at the time-specific metrics, we observe that the intertemporal scheme generally provides better risk management in the earlier periods () across various measures, including variance, SRM, skewness, kurtosis, and VaR. This is consistent with its design to consider risk throughout the investment horizon. The terminal scheme, however, shows slightly better performance in some metrics for the final period (), such as variance and SRM, aligning with its focus on terminal risk.
In terms of risk-adjusted return measures, we consider three widely used ratios: the Sharpe ratio, the Sortino ratio, and the Omega ratio. The Sharpe ratio measures excess return per unit of total risk, providing a general measure of risk-adjusted performance. The Sortino ratio is similar but focuses on downside risk, penalizing only returns below a target threshold. The Omega ratio offers a comprehensive view by considering the entire return distribution, weighing potential gains against losses. In our analysis, the intertemporal scheme demonstrates superior performance in Sortino and Omega ratios across all time periods, indicating better downside risk management. The Sharpe ratios are comparable, with the intertemporal scheme showing an advantage in earlier periods and the terminal scheme slightly outperforming in the final period.
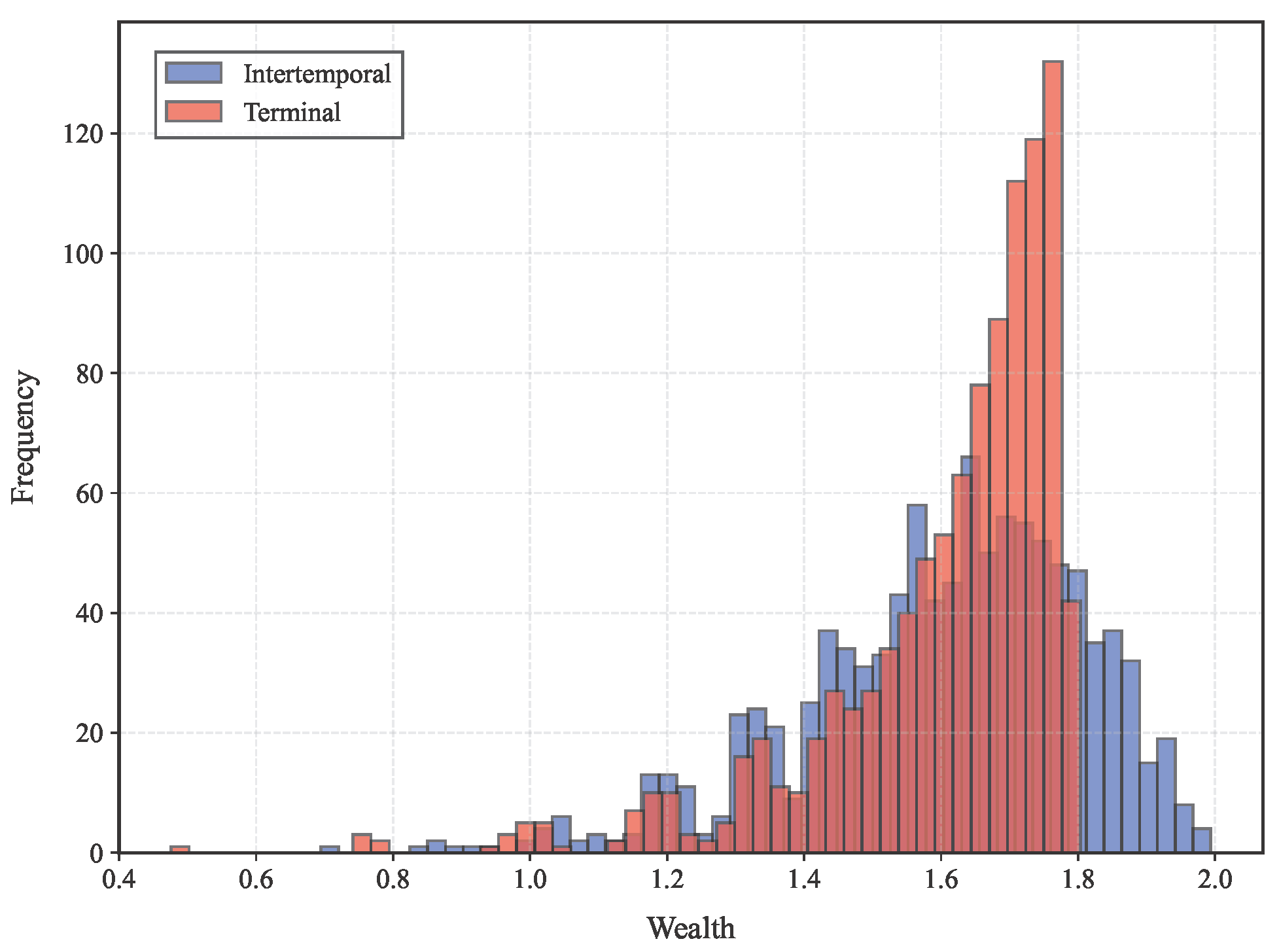
Moreover, we extend the time horizon to 5 periods, resulting in
scenarios.
Figure 6 presents the distribution of terminal wealth under both the intertemporal and terminal schemes. The terminal scheme exhibits a leptokurtic (high-kurtosis) distribution with heavy tails, indicating a higher probability of extreme outcomes that may be undesirable for risk-averse investors. In contrast, the intertemporal scheme yields a more balanced wealth distribution with moderate tails and lower kurtosis, which better aligns with typical investor preferences for stable and predictable investment outcomes.
Overall, these results suggest that the intertemporal weighting scheme provides more consistent risk management across the entire investment horizon, leading to generally better performance metrics, especially in earlier periods. The terminal scheme, while focusing on and slightly outperforming in some final period metrics, appears to sacrifice some risk management in earlier periods.
5. Conclusions
This paper presents a comprehensive framework for multi-period portfolio optimization incorporating intertemporal spectral risk measures. Our approach makes several significant contributions to the literature on dynamic portfolio management and risk measurement.
First, we introduced a novel multi-period portfolio optimization model that integrates SRMs with variance measures across all time periods. This formulation fills an important gap by explicitly considering both types of risk in an intertemporal fashion. Second, we propose an efficient solution methodology based on a modified Progressive Hedging Algorithm, enhanced with specialized reformulations for handling linkage objectives and constraints.Third, our research provides strong theoretical underpinnings and empirical validation. We have established the q-linear convergence rate of our modified PHA under mild conditions, offering a solid theoretical foundation for its computational efficiency. Furthermore, comprehensive numerical experiments have validated the model’s effectiveness, demonstrating that an intertemporal focus on risk leads to superior downside risk protection—as evidenced by improved Sortino and Omega ratios—and more balanced terminal wealth distributions compared to traditional terminal-focused strategies.
The framework and findings of this research carry several practical implications for portfolio managers, institutional investors, financial advisors, and, potentially, financial regulators. The proposed model serves as a practical tool for investors to implement more sophisticated dynamic risk-management strategies. By considering both tail risk and volatility at each period, managers can better navigate uncertain market conditions and tailor strategies to achieve more consistent performance throughout the investment horizon, rather than focusing solely on terminal outcomes.
The ability to specify time-varying risk preferences via the spectral function allows investment strategies to be precisely aligned with evolving institutional needs or individual investor life-cycle considerations, such as a pension fund gradually de-risking its portfolio as it approaches its liability horizon.
Critically, our numerical results strongly suggest that incorporating ISRMs leads to better protection against significant losses, which is crucial for risk-averse investors, endowments, and any entity with strict drawdown limits or capital preservation mandates. Furthermore, many investors are concerned with performance and risk exposure during intermediate periods; our intertemporal approach directly addresses this by optimizing risk–return characteristics throughout the investment journey, leading to smoother wealth paths and increased confidence in meeting ongoing obligations. This allows for more informed decision-making in the design and management of complex financial products like structured products or target-date funds that require a nuanced approach to risk evolution.
In essence, our approach empowers investment professionals with a flexible and robust methodology to proactively manage multifaceted risks across time, leading to potentially more stable and desirable investment outcomes.
Moreover, the framework developed in this paper opens several promising directions for future research. These include the incorporation of transaction costs and market frictions, and the extension to robust optimization frameworks, for instance, to handle uncertainty in the spectral function itself. A crucial area for future investigation involves a comprehensive analysis of the model’s sensitivity to key assumptions—such as those related to market behavior and investor preferences—and its robustness under a wider range of market conditions. This could include evaluating alternative scenario generation methods that capture diverse market dynamics, and exploring the impact of varying investor preference parameters, like different spectral functions or risk aversion weights, or even extending to models where these preferences are endogenously determined or strategically designed [
53]. Further research could also focus on adaptation to other complex market dynamics. Additionally, the methodological advances presented here may find applications beyond portfolio optimization, potentially benefiting other areas of financial risk management and dynamic decision-making under uncertainty.
In conclusion, our work provides both theoretical insights and practical tools for implementing dynamic risk-management strategies that effectively balance multiple objectives across time. The framework’s flexibility and computational tractability make it particularly valuable for institutional investors and asset managers seeking to implement sophisticated risk-management strategies in practice.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}