1. Introduction
The rapid development of the Artificial Intelligence of Things (AIoT) has led to substantial advancements in human action recognition, particularly in resource-constrained environments such as smart homes, healthcare systems, and intelligent surveillance [
1]. The integration of cloud–edge–terminal (CET) devices has emerged as a powerful architecture to offload computational tasks and improve data processing efficiency [
2,
3]. However, applying deep learning models directly to terminal devices is limited by their restricted computational power, energy resources, and storage capacities [
4].
To address these constraints, the cloud–edge–end collaborative framework has been proposed, enabling each system layer to contribute to the overall learning process [
5]. On the terminal side, lightweight models are deployed to allow for rapid inference and decision-making. The edge side aggregates and optimizes intermediate models, acting as a bridge between the cloud and terminal devices, while the cloud provides a centralized platform for model retraining, fine-tuning, and global optimization [
6].
Distributed sensing systems for human action recognition are often affected by class imbalance, where certain action categories dominate the training data while others are underrepresented [
7,
8]. This imbalance can degrade the performance of traditional learning algorithms by skewing the model toward the majority classes. Various techniques, such as the synthetic minority over-sampling technique (SMOTE) [
9], adaptive boosting (AdaBoost), and loss function modification methods like focal loss [
10] and gradient harmonized mechanisms (GHMs), have been explored to address class imbalance.
However, these approaches primarily focus on improving model robustness within a single layer of the CET framework and often overlook the collaborative nature of cloud, edge, and terminal devices. Moreover, deploying large models on terminal devices remains a challenge due to their resource limitations [
11].
To overcome these challenges, we propose a novel learning framework that integrates model compression techniques—such as distillation, pruning, and quantization—to facilitate efficient knowledge transfer across cloud, edge, and terminal devices [
12,
13]. Our approach incorporates a monitoring mechanism to dynamically adjust the loss function based on the detected class imbalance, thereby enhancing the performance of the collaborative learning framework.
We propose a novel framework that combines few-shot learning with multimodal data fusion for robust beam selection under data-limited conditions. By leveraging complementary features from RGB images, radar signals, and LiDAR data, the model effectively captures spatiotemporal features, enabling efficient and adaptive communication.
The multimodal fusion approach increases the model’s robustness against environmental noise and variability. By combining few-shot learning with multimodal inputs, the proposed method can quickly adapt to new scenarios, maintaining high accuracy in dynamic communication environments.
By reducing dependence on large-scale labeled datasets, the proposed framework enhances computational efficiency, enabling real-time beam selection to meet the low-latency requirements of mmWave communication systems.
Notation 1. Throughout this paper, we denote the cloud and edge model parameters as and , respectively. The loss function includes the classification cross-entropy loss , the knowledge distillation loss , and a regularization term used for model compression via pruning and quantization. The weights λ and γ control the importance of distillation and regularization in the joint objective. For each edge node i, we define resource constraints as storage budget , delay budget , and communication cost limit . Model compression parameters include the pruning ratio ρ and the quantization bit-width b. Finally, E denotes the number of participating edge devices.
2. Related Work
Cloud-edge collaborative systems have garnered increasing attention due to their ability to improve computational efficiency and reduce latency [
14]. These systems rely on a hierarchical architecture in which computational tasks are distributed across cloud servers, edge devices, and end devices, enabling real-time processing and efficient resource utilization. The cloud layer typically provides extensive computational resources, making it suitable for large-scale model training, global optimization, and knowledge aggregation. In contrast, the edge layer facilitates localized data processing, model aggregation, and communication between the cloud and end devices. Finally, end devices, constrained by limited computational power, benefit from lightweight models optimized for fast inference and low power consumption.
Federated learning (FL) is a prominent paradigm for enabling collaborative learning across distributed devices while preserving data privacy by keeping raw data localized and transmitting only model updates [
15]. For the FL framework, each participant trains a local model using its private data and uploads the model’s gradients or parameters to a central server for aggregation. This iterative process continues until the global model converges. FL has demonstrated success in various applications such as image classification, speech recognition, and recommendation systems [
16]. However, traditional FL methods often assume uniformly distributed data, which is rarely the case in real-world applications, where data heterogeneity and class imbalance are common [
17]. While effective for privacy, standard FL struggles with significant data imbalance across clients and lacks inherent mechanisms for model compression needed for resource-constrained edge/end devices.
Ficili et al. explored integration approaches for IoT, cloud/edge computing, and AI, emphasizing challenges and strategies for seamless integration of these technologies to achieve pervasive ambient intelligence [
18]. In cloud–edge–end collaborative systems, class imbalance is exacerbated by the hierarchical nature, where data collected by edge and terminal devices may be skewed toward certain categories. For instance, surveillance systems in different locations may capture human actions with varying frequencies, leading to biased training datasets. Additionally, the limited computational capacity of terminal devices prevents the direct application of complex methods [
1].
To mitigate class imbalance, several methods have been proposed, including data-level approaches like over-sampling and under-sampling, and algorithm-level approaches that modify the learning process to emphasize minority classes [
19]. Data-level methods balance the dataset by generating synthetic samples for underrepresented classes or reducing the number of samples from overrepresented classes. The most popular technique in this category is SMOTE and its variants, such as Borderline-SMOTE and SMOTEBoost, which generate synthetic samples by interpolating between existing minority class samples [
20]. Although effective, these methods can be computationally expensive and may introduce noise when applied to complex data distributions.
Algorithm-level methods modify the training process to address class imbalance. Ensemble-based techniques like EasyEnsemble and BalanceCascade aim to improve classification performance by combining multiple classifiers trained on rebalanced datasets [
21]. However, the computational cost associated with training multiple classifiers makes these methods unsuitable for resource-constrained devices. Moreover, ensemble methods may not generalize well when deployed in real-world cloud–edge–end architectures due to the mismatch between local and global models.
Loss function modifications, such as focal loss and gradient harmonized mechanisms (GHMs), enhance the learning process by reducing the impact of easily classified samples and emphasizing hard-to-classify ones. While these approaches help with class imbalance within a single model, they do not consider the collaborative nature of cloud–edge–end systems.
Existing collaborative learning approaches for such environments also face significant limitations when deploying complex models to resource-constrained edge and terminal devices. Moreover, traditional solutions fail to address the challenges of model compression and efficient knowledge transfer, which are critical for deploying lightweight models on resource-constrained terminal devices. Techniques like knowledge distillation, pruning, and quantization have been shown to reduce model size and improve inference speed without significantly compromising performance [
12,
13]. However, integrating these techniques into a cloud–edge collaborative framework presents challenges related to joint optimization, balancing accuracy with limited computational resources, communication bandwidth, and inference accuracy. Recent studies have further demonstrated the integration of cloud–edge architectures in intelligent systems [
5,
6,
18]. For example, Ficili et al. [
18] proposed a multi-layer AIoT architecture, while Krishnamurthy et al. [
6] applied reinforcement learning for fog computing resource optimization.
Our proposed framework tackles these challenges by incorporating model compression techniques within the cloud–edge system. By addressing the integration of these techniques, the framework aims to overcome the identified gaps in existing solutions. Using knowledge distillation, pruning, and quantization, our approach facilitates efficient knowledge transfer from the cloud to edge and terminal devices, improving recognition accuracy while minimizing computational costs. Additionally, we introduce a monitoring mechanism that dynamically detects class imbalance and adjusts the loss function accordingly. The integration of these techniques provides a robust solution for real-time human action recognition in distributed environments.
3. Motivation
Human action recognition has attracted significant attention in recent years due to its wide range of applications, including surveillance, smart healthcare, human–computer interaction, and sports analysis. With the advent of Artificial Intelligence of Things (AIoT), collaborative learning frameworks involving cloud, edge, and terminal devices have been developed to enhance computational efficiency and improve recognition accuracy. However, existing methods face several critical challenges:
Resource constraints: Terminal devices often have limited computational power, memory, and battery life, making it difficult to deploy large-scale deep learning models directly on these devices.
Data distribution imbalance: Human action data collected from distributed devices is often unbalanced, with some actions being significantly under-represented. This issue severely impacts the training process, causing models to be biased towards majority classes.
Communication overhead: Collaborative learning requires frequent communication between cloud, edge, and terminal devices. High communication costs can reduce the efficiency and scalability of the framework.
To address these challenges in the context of efficient and robust human action recognition, we propose a cloud–edge collaborative learning framework that integrates model compression techniques, including knowledge distillation, pruning, and quantization. The framework aims to optimize the trade-off between accuracy, computational efficiency, and communication costs. Specifically, we formulate the optimization problem as follows:
where
is the cross-entropy loss, representing classification accuracy.
indicates knowledge distillation loss, which measures the divergence between the student model (edge) and the teacher model (cloud).
represents the regularization term, representing the model compression achieved by pruning and quantization.
denotes the hyperparameter, controlling the impact of knowledge distillation.
is the hyperparameter controlling the strength of the regularization term.
indicate the parameters of the edge model and cloud model, respectively.
The optimization goal is to minimize the overall loss by balancing classification accuracy, knowledge distillation, and model compression. The proposed approach effectively reduces computational resource consumption and communication overhead while preserving high recognition accuracy.
4. System Model
4.1. Wireless Signal Model
Conventional device-free gesture recognition methods using WiFi signals typically extract broad statistical or signal-based features from channel state information (CSI). However, variations in user posture, movement direction, and complex indoor propagation can distort the extracted features, making gesture classification less robust and precise.
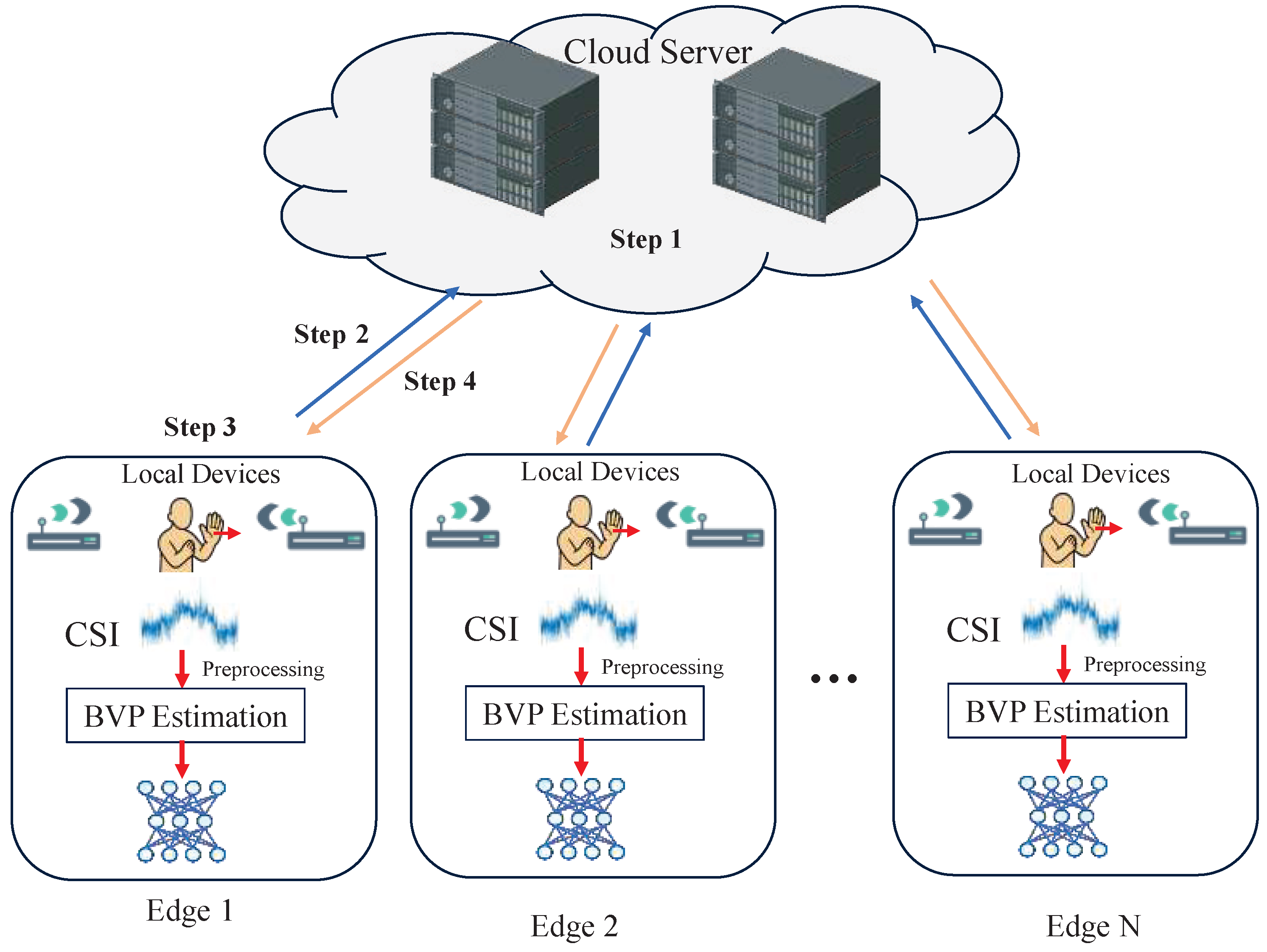
As shown in
Figure 1, the overall process of wireless-based action detection begins with capturing incoming signals and processing the CSI to analyze the propagation environment. The refined CSI data are then used to detect and interpret user actions. Initially, a wireless receiver captures the signal and computes the CSI, reflecting how the environment influences signal propagation. Subsequent preprocessing extracts features like amplitude, phase, and time delay, which are sensitive to human movement. These features serve as inputs for classification models that associate signal patterns with specific activities, enabling applications such as smart environment interaction and human behavior monitoring. Recognition performance hinges on CSI fidelity, feature representation, and model effectiveness.
The CSI at time instance
t and frequency bin
f describes the cumulative effect of multipath propagation in indoor settings:
where
K is the total number of propagation paths,
and
denote the complex attenuation and delay of the
k-th path, respectively, and
accounts for residual phase distortions from system imperfections like frequency offsets. Equation (
2) describes the CSI as a frequency–domain representation of multipath propagation, capturing the cumulative impact of
K signal paths.
By representing the phase in terms of the Doppler effect, the CSI can be rewritten as:
where
refers to the aggregated static signal components, and
denotes the set of dynamic paths affected by motion. Equation (
3) reformulates the CSI to separate static and dynamic Doppler-influenced components.
To remove irrelevant noise and random phase drift, differential CSI between antennas on the same NIC is computed, and further denoising removes static clutter. Short-time Fourier transform (STFT) is then applied to derive energy patterns over time and Doppler frequency. Each resulting frame forms a Doppler spectrum—a matrix of size , with Q time samples and R transmitter–receiver links.
When a person moves, the variation in position of different limbs induces distinct Doppler shifts. These shifts combine into a composite Doppler signature, reflecting not only gestures but also broader motion. However, for gesture isolation, only hand-related velocities—described by the body-centric velocity profile (BVP)—are considered. BVP can be estimated using multi-link Doppler information.
Let the position of the sender and receiver for link
j be denoted by
and
, respectively. The velocity vector
of a moving body point contributes a Doppler component
on link
j, modeled as:
where
depend on the geometrical alignment of the transmitter and receiver:
where
is the Doppler coefficient and
denotes the Euclidean norm. Equation (
5) defines the Doppler shift on each link as a function of the moving body point’s velocity and transceiver geometry.
To map the Doppler spectrum of link
j to motion, a projection matrix
is introduced:
where
G is the count of Doppler bins and
M is a resolution parameter. The Doppler signature
for link
j relates to BVP via:
where
is an attenuation coefficient due to signal loss. Finally, the velocity profile
is inferred by solving the following optimization:
where
is a divergence metric, and the
-norm term encourages sparsity, controlled by parameter
.
4.2. Scenario Modeling
To support scalable, low-latency, and accurate human action recognition, we propose a two-tier hierarchical collaborative framework consisting of cloud servers and distributed edge devices. In this architecture, the edge nodes represent on-site devices, while the cloud provides centralized computation and long-term knowledge storage. This architecture enables efficient division of labor, where the cloud handles global model optimization and the edge performs real-time inference and localized updates.
Collaborative Learning and Optimization Framework
Let denote the global model at the cloud, and let be the local model running on the i-th edge device.
In the cloud side, the cloud aggregates information from multiple edge nodes to perform global training and refinement. It serves as the knowledge source in a distillation framework and generates model updates for deployment. The loss function at the cloud includes both prediction accuracy and regularization for global consistency:
where
is the knowledge distillation loss,
is a regularization term,
E is the number of edge nodes, and
reflects the trust level or sample volume of edge node
i. Equation (
9) defines the cloud-side loss function, which combines knowledge distillation and regularization.
On the edge side, each edge node performs localized training and inference using data collected on-site. To reduce computation and communication costs, edge models are optimized with lightweight constraints via pruning and quantization. The local training objective is:
where
is the cross-entropy loss and
and
are weighting factors for knowledge distillation and compression regularization, respectively.
Edge models are further compressed to reduce latency and memory requirements:
where
denotes the pruning ratio for node
i, and
b is the quantization bit-width.
The total optimization problem of the cloud–edge system is defined as:
where
represent the storage, real-time delay, and communication budget constraints for edge device
i. In our experiments, we consider a range of
, representing small- to moderately sized deployment scenarios, to evaluate the scalability and effectiveness of the proposed optimization framework.
In the proposed cloud–edge collaborative framework, the model lifecycle begins with the cloud training a global model using a large-scale labeled dataset or through self-supervised pretraining. This global model serves as a knowledge-rich teacher model, which is subsequently compressed via pruning and quantization to generate lightweight student models for deployment on edge devices. After deployment, each edge model performs localized training using on-device data to adapt to its specific environment while preserving generalization capabilities through knowledge distillation from the cloud model. Periodically, edge devices transmit local model updates—either in the form of gradients or entire model parameters—back to the cloud, where they are aggregated and used to refine the global model . The updated global model is then re-distilled and redistributed to edge devices, enabling continual learning and adaptation across the system. This cyclical update mechanism ensures that the global model maintains robustness and adaptability, while edge models remain lightweight and responsive to local variations in human activity patterns.
This scenario modeling approach ensures that the edge devices remain lightweight and adaptive, while the cloud continues to learn a more generalized model. The use of joint loss optimization, compression-aware training, and knowledge distillation forms the core of robust cloud–edge collaboration for human action recognition.
To better accommodate real-world deployment scenarios, future versions of the optimization framework can be extended in two important directions. First, uncertainty in system parameters—such as fluctuating network latency, device availability, or energy status—can be modeled using robust or fuzzy optimization techniques. This would improve the resilience of the learning process to dynamic environments. Second, a multi-objective formulation can be introduced to simultaneously optimize recognition accuracy, communication efficiency, and energy consumption. Pareto-based approaches or scalarization methods could be used to explore trade-offs among these objectives and guide the system toward balanced performance under competing resource constraints.
4.3. Proposed Architecture
The proposed cloud–edge collaborative learning architecture is designed to achieve accurate, efficient, and low-latency human action recognition by integrating model compression, knowledge distillation, and federated optimization into a unified hierarchical framework. At the core of the system lies a global model
trained on the cloud using large-scale datasets. Once trained, this model undergoes structured model compression techniques—including network pruning and parameter quantization—to generate lightweight variants that are suitable for deployment on edge devices. Mathematically, for a given compression ratio
and quantization level
b, the compressed edge model
is obtained as:
where
E is the total number of edge devices and
is the pruning ratio tailored to edge node
i’s resource constraints.
To preserve the representational power of the original cloud model within these compressed variants, knowledge distillation is employed during deployment. The cloud model
serves as a teacher, and each edge model
acts as a student. For a given input
x and soft label distribution
, the student is trained to minimize the divergence between its output
and the teacher’s output using the distillation loss:
where
is the softmax function and
T is the temperature parameter controlling the softness of predicted distributions. This allows the student model to learn finer-grained decision boundaries and internal representations, even under tight parameter budgets.
The architecture also integrates a federated optimization strategy to support decentralized learning and privacy preservation. During system operation, each edge device updates its local model
using real-time, device-specific data. These updates are periodically transmitted to the cloud for aggregation into the global model
. The global model is then refined using weighted averaging:
where
is the size of the local dataset on edge device
i, and
is the local model parameter at training round
t. After aggregation, the updated global model is re-distilled and re-compressed, and the process repeats, forming a closed-loop iterative training cycle that adapts to environmental dynamics and usage patterns.
The resulting architecture not only ensures model compactness and inference efficiency at the edge but also maintains global knowledge consistency and robustness through periodic cloud-level aggregation and distillation. This enables the scalable deployment of intelligent sensing systems across heterogeneous environments with diverse computational and communication resources.
4.4. Algorithm Training Procedure
The training procedure of the proposed cloud–edge collaborative framework follows a cyclic optimization process that balances centralized intelligence with distributed adaptability. The process begins with the cloud server initializing the global model through pretraining on a large labeled dataset or synthetic data generation. This global model is then compressed via pruning and quantization to generate edge-deployable variants , which are dispatched to distributed edge nodes. Each edge device performs local training using real-time or user-specific data, adjusting its model parameters via standard gradient descent or local SGD. This local training incorporates both supervised learning and knowledge distillation from the cloud model, ensuring that the edge models preserve the global feature abstraction capacity despite local task heterogeneity.
After a defined number of local update steps, each edge device uploads either the full model or its parameter gradients back to the cloud. The cloud server aggregates these edge models through a federated averaging approach, optionally applying regularization and global constraints. The updated global model is then distilled and compressed again for the next iteration of deployment. This cyclic pipeline ensures continual learning, personalized adaptation at the edge, and model robustness across heterogeneous environments.
The training process is structured into four key stages: cloud-side compression, edge deployment and local training, parameter aggregation, and global model refinement. These steps are detailed below in Algorithm 1.
| Algorithm 1: Cloud-Edge Collaborative Training Procedure |
![Mathematics 13 01753 i001]() |
5. Experiment Results
5.1. Experimental Setup
To assess the performance of the proposed training framework under cloud–edge conditions, we conducted a series of experiments using the Widar3.0 dataset [
1], which includes six types of hand or body gestures: Push&Pull, Sweep, Clap, Slide, Draw-Zigzag, and Draw-N. The Widar3.0 dataset is a publicly available benchmark commonly used for WiFi-based gesture and action recognition tasks. It has been validated in several peer-reviewed studies such as [
1], making it a reliable foundation for our experiments. The full dataset contains 7498 labeled instances, which were randomly divided into training and testing partitions with a ratio of 8:2. This results in 6000 samples allocated for model training and the remaining 1498 samples allocated for testing.
Because the collection duration and signal length may vary across samples, the raw BVP data extracted from WiFi signals exhibit inconsistent temporal dimensions. To address this, each BVP instance is zero-padded and reshaped into a standardized 3D tensor of dimensions , thereby enabling uniform processing across the entire dataset.
Prior to training, all BVP tensors
v are normalized on a per-sample basis using min-max scaling, ensuring that the input values fall within the interval
. For each communication round, every edge device performs 50 epochs of local training using its available data. The batch size is fixed at 256, and the learning rate is initialized at
. All experiments are implemented in PyTorch 2.6 and executed on a computing platform equipped with an NVIDIA GeForce RTX 4090 GPU. Details regarding the dataset composition, preprocessing steps, and hyperparameter settings are summarized in
Table 1.
5.2. Experimental Results
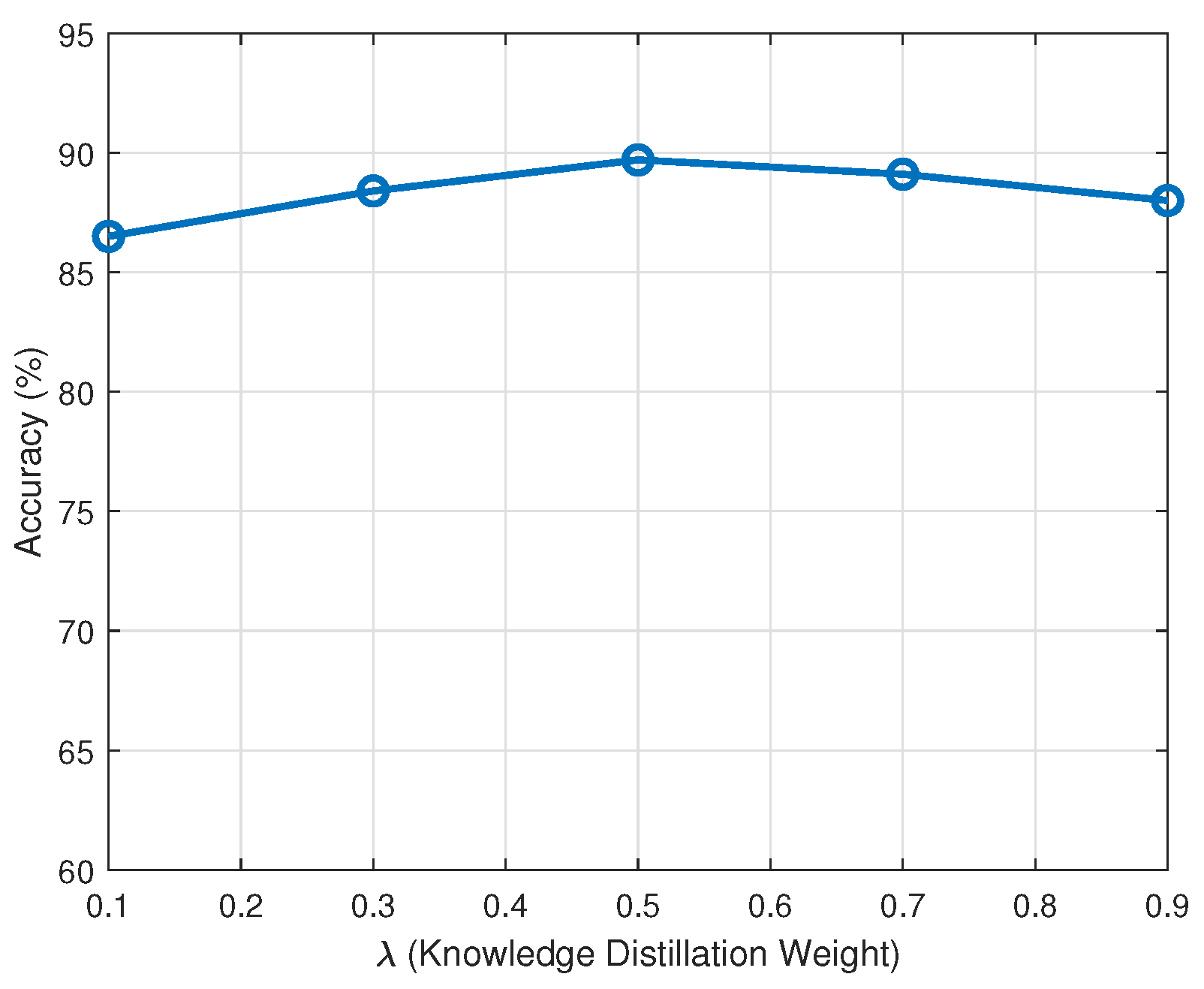
The parameter
controls the influence of the teacher model during distillation. As shown in
Figure 2, increasing
from 0.1 to 0.5 improves accuracy by encouraging the edge models to better mimic the cloud (teacher) model. Beyond 0.5, the accuracy plateaus and slightly decreases, indicating that an over-reliance on the teacher model can reduce the edge model’s ability to adapt to local data nuances. Therefore,
= 0.5 is an optimal trade-off point balancing generalization and local adaptation.
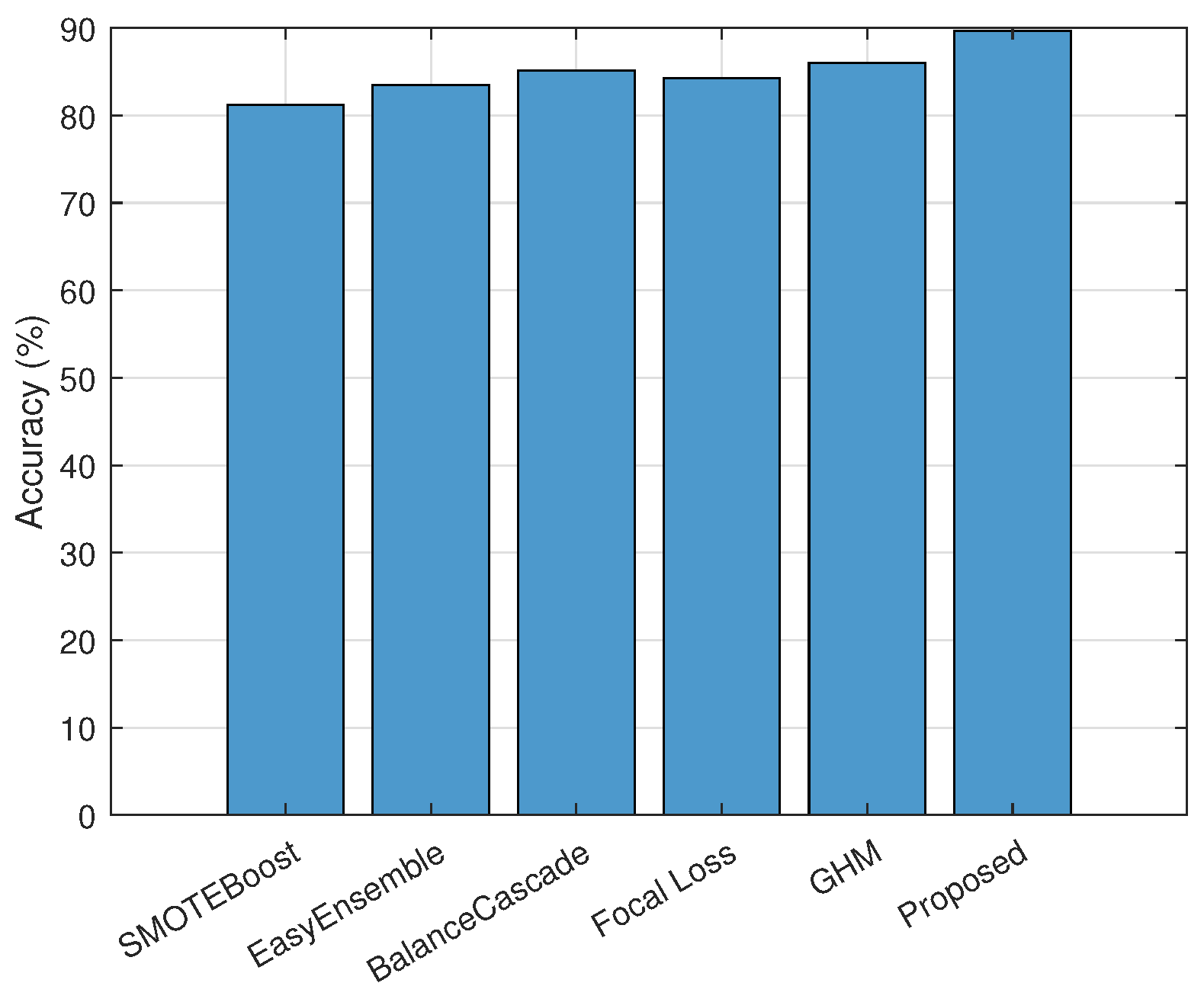
To thoroughly evaluate the effectiveness of the proposed cloud–edge collaborative learning framework, a series of experiments were conducted. The evaluation focused on multiple aspects, including recognition accuracy, model robustness, compression efficiency, knowledge distillation performance, and communication overhead. The proposed method was benchmarked against several competitive baselines, including SMOTEBoost, EasyEnsemble, BalanceCascade, Focal Loss, and the GHM. Performance metrics used for assessment comprised classification accuracy.
The classification performance across different learning approaches is evaluated. As illustrated in
Figure 3, the proposed framework achieved an accuracy of 89.7%, outperforming all baselines. Traditional ensemble methods such as EasyEnsemble and BalanceCascade demonstrated moderate effectiveness due to their ability to handle class imbalance, while SMOTEBoost and focal Loss partially mitigated data skew. However, their performance was constrained by the absence of global coordination and compression-aware optimization. The superior accuracy of the proposed approach is attributed to its hierarchical optimization scheme, integrated model compression, and knowledge distillation components, which enhance generalization under imbalanced data distributions.
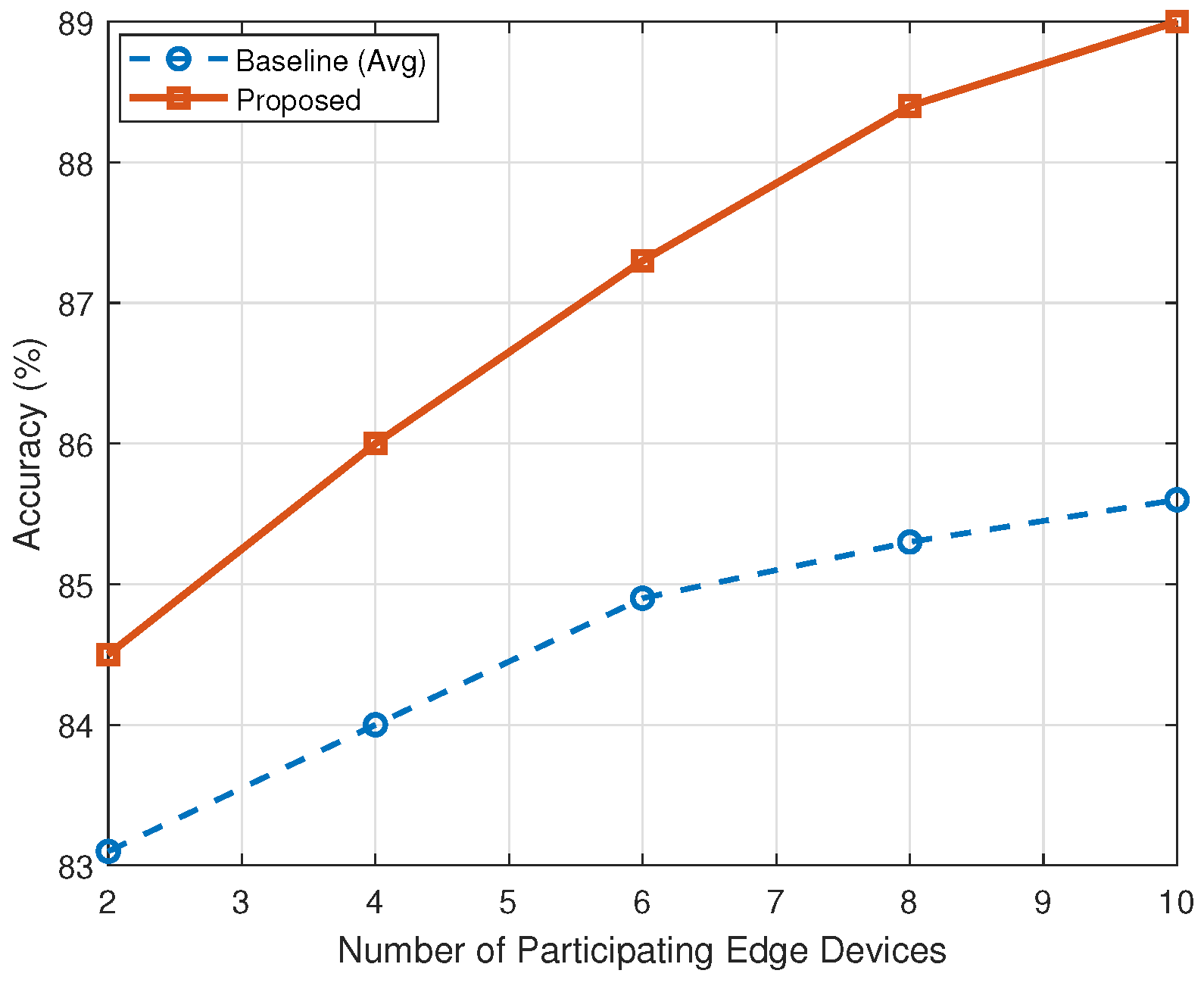
We also explored how the number of participating edge devices influences recognition performance. As shown in
Figure 4, increasing the number of edge nodes resulted in consistent performance improvements for both the proposed method and the baseline. However, the proposed framework exhibited a steeper accuracy gain, reaching 89.0% with 10 participating devices, compared with 85.6% for the baseline. This suggests that the proposed method better exploits distributed data diversity, largely due to its federated aggregation mechanism and consistent knowledge transfer from the cloud model.
Figure 5 illustrates the effect of varying compression ratios—defined as the proportion of model parameters retained after pruning and quantization—on classification performance. While aggressive compression led to significant performance degradation in conventional models, the proposed framework maintained a high accuracy range of 81.5–89.0% across all compression levels. This robustness is attributed to regularization-aware training and cloud-guided distillation, which preserve critical model features even under severe parameter reductions. The results affirm the feasibility of deploying lightweight models on edge devices without compromising accuracy.
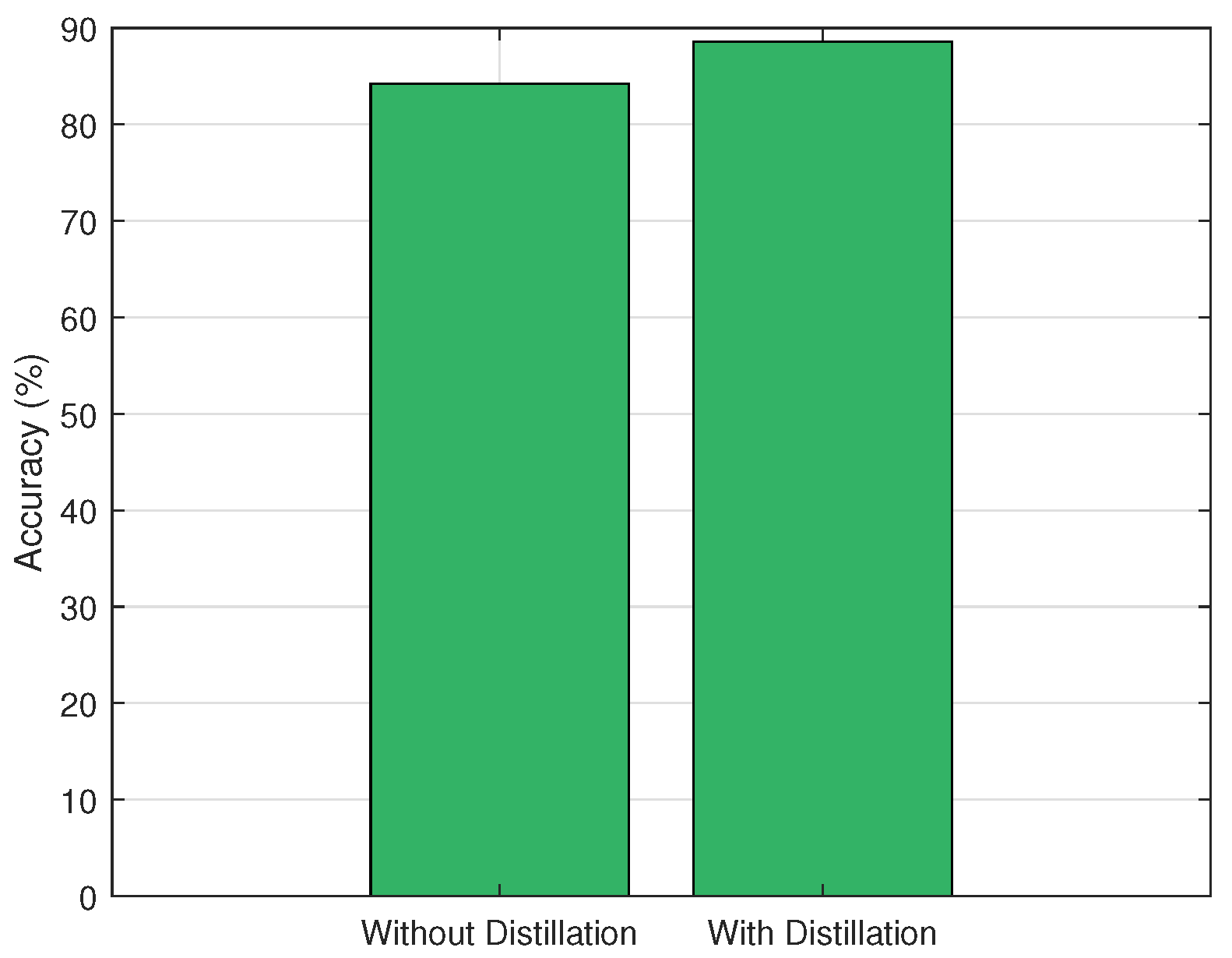
Additionally, the impact of knowledge distillation on model performance was assessed. As depicted in
Figure 6, edge models trained without distillation achieved an accuracy of only 84.2%, whereas incorporating distillation from the cloud model improved performance to 88.6%. This 4.4% gain underscores the critical role of the teacher–student paradigm in enabling compact edge models to approximate the decision boundaries of more complex cloud models, thereby enhancing inference quality under resource constraints.
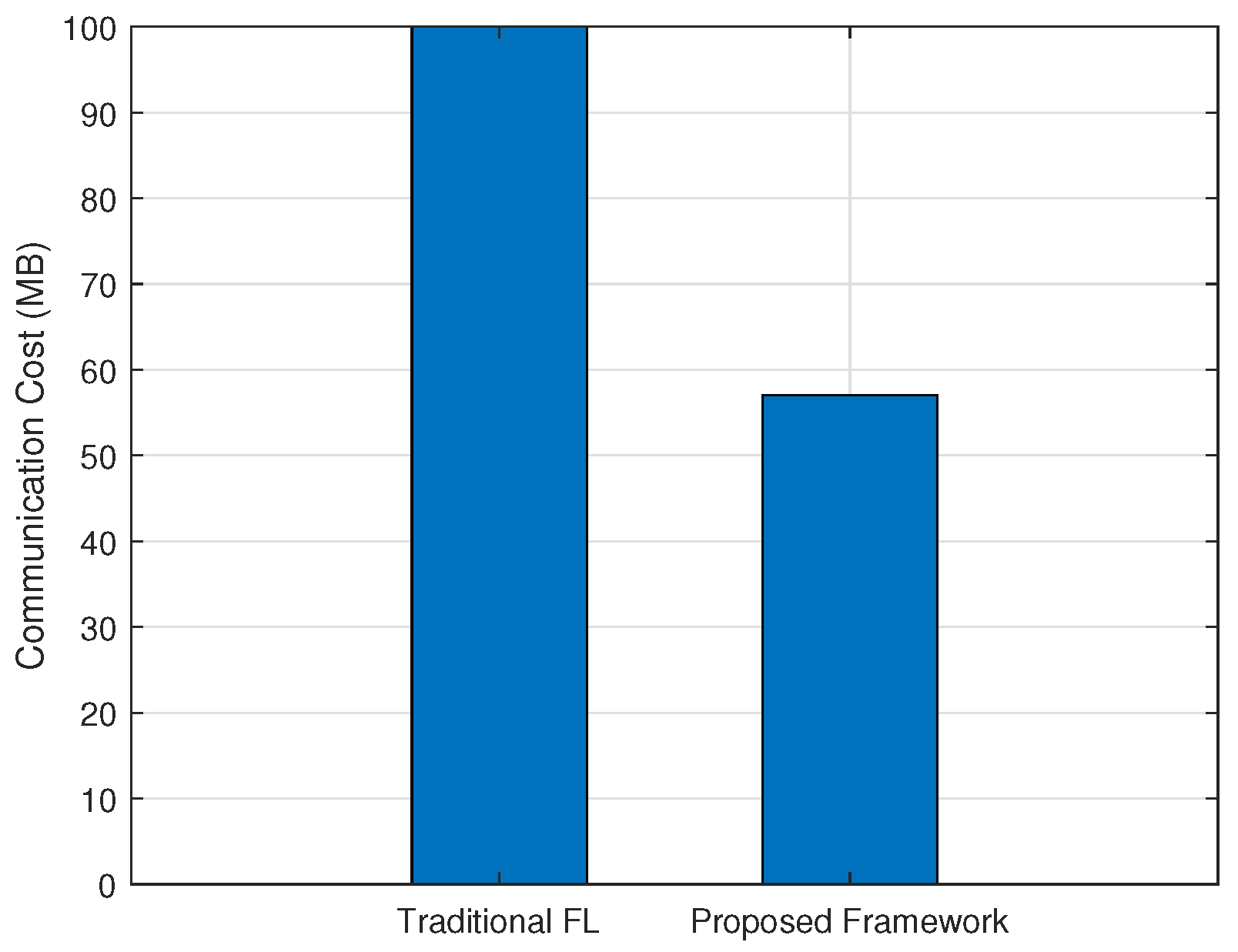
The final experiment compared the communication cost of the proposed method with that of standard federated learning frameworks. As shown in
Figure 7, the proposed approach significantly reduced communication overhead per round from 100 MB to 57 MB—a 43% reduction. This improvement results from selective update transmission, intermediate feature compression, and parameter sparsification. These results demonstrate the practicality of the proposed method in bandwidth-constrained or latency-sensitive environments such as IoT systems and mobile edge networks.
Overall, the experimental results convincingly validate the effectiveness of the proposed cloud–edge collaborative learning framework. It consistently outperforms existing methods in terms of accuracy and robustness while also offering efficient compression, effective knowledge distillation, and reduced communication cost. The joint design of compression-aware training and cloud-assisted optimization provides a promising solution for real-time human activity recognition in edge-intelligent applications.
6. Conclusions
This paper proposes a cloud–edge collaborative learning framework for human action recognition that effectively addresses challenges related to computational efficiency, model accuracy, and communication overhead. By integrating model compression techniques—namely knowledge distillation, pruning, and quantization—the framework achieves substantial reductions in resource consumption while maintaining high recognition accuracy. Experimental results demonstrate that the proposed method attains an accuracy of 89.7%, surpassing baseline approaches by up to 4.4%. Furthermore, communication costs per round are reduced by 43%, decreasing from 100 MB to 57 MB. The framework exhibits robust performance in scenarios involving up to 10 edge devices, with consistent accuracy improvements observed as the number of devices increases. These findings underscore the system’s effectiveness in enabling real-time human action recognition with minimal computational demands, rendering it well suited for deployment in bandwidth-constrained and resource-limited settings. Nonetheless, these promising results motivate further investigation into large-scale and dynamic deployment scenarios. Although the framework demonstrates robustness up to 10 edge nodes, scaling to larger systems or highly heterogeneous environments may introduce new challenges. As the number of nodes increases, communication synchronization overhead and edge-to-cloud latency may degrade performance. Additionally, edge devices with highly diverse hardware capabilities and data distributions could complicate model consistency and fairness.
Although the framework demonstrates robustness with up to 10 edge nodes, scaling to larger or highly heterogeneous systems may introduce new challenges. Increasing the number of nodes can lead to heightened communication synchronization overhead and greater edge-to-cloud latency, potentially degrading performance. Additionally, heterogeneity in hardware capabilities and data distributions across edge devices may complicate maintaining model consistency and fairness. Despite its advantages, the proposed framework has several limitations. First, it assumes stable cloud–edge connectivity, which may not be guaranteed in mobile or low-connectivity environments. Second, while model compression preserves most of the accuracy, aggressive pruning or quantization can still cause noticeable performance degradation. Finally, the current evaluation is confined to WiFi-based action recognition; thus, future work should validate the framework across diverse data modalities and broader task domains to assess its generalizability. Expanding evaluations to larger-scale, more dynamic deployments will be essential to address challenges arising from varying data types and network conditions.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}