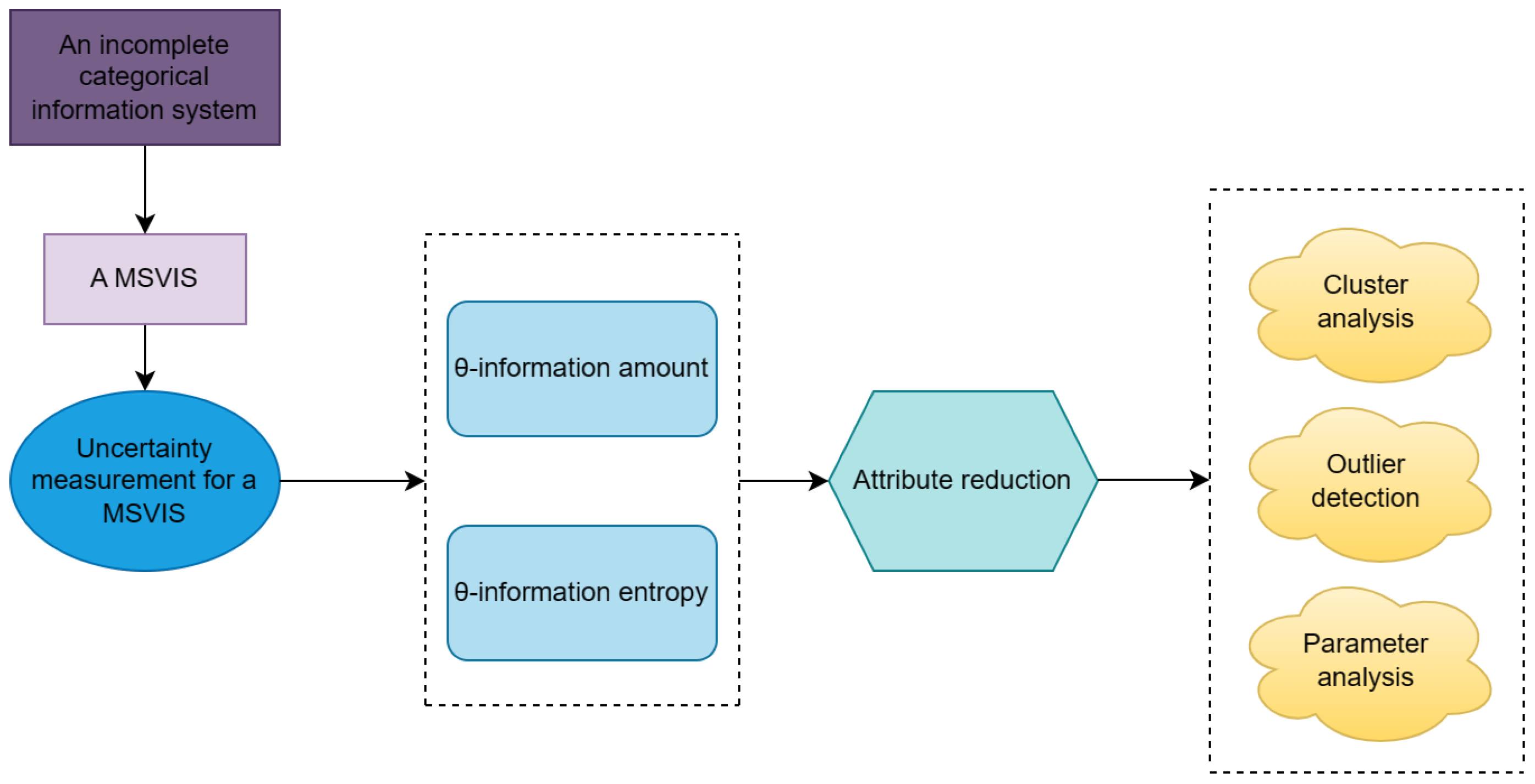
1.1. Research Background
Data with missing information values, also called missing data, are a common occurrence in datasets for various reasons. Simple approaches like listwise deletion handle missing data by removing incomplete records. Despite their simplicity, such methods risk losing valuable information and introducing bias. Moreover, it could result in bias sometimes [
1]. Data imputation is a statistical method that fills the missing values by applying reasonable rules. Common imputation techniques include mean substitution and regression imputation [
1]. Despite their utility, imputation methods also carry the risk of inducing bias [
2].
On the other hand, mathematical models such granular computing (GrC) [
3] and rough set theory (RST) [
4] are effective tools for dealing with uncertainty. GrC is a significant methodology in artificial intelligence. It has its unique theory, which tries to obtain a granular structure representation of a problem. Providing a basic conceptual framework, GrC is broadly researched in pattern recognition [
5] and data mining [
6]. As a realistic approach of GrC, RST provides a mathematical tool to handle uncertainty, such as imprecision, inconsistency, and incomplete information [
7,
8]. An information system (IS) was also presented by Pawlak [
4]. The vast majority of applications of RST are bound with an IS.
In RST, a dataset with missing information values is usually represented by an incomplete information system (IIS). An SVIS represents each missing information value under an attribute with all possible values, and each information value that is not missing with a set of its original value. Thus, an SVIS can be obtained from an IIS. As an effective way of handling missing information values, SVIS has drawn great attention from researchers. For instance, Chen et al. [
9] investigated the attribute reduction of an SVIS based on a tolerance relation. Dai et al. [
8] investigated UMs in an SVIS. Furthermore, an SVIS with missing information values is also studied. Xie et al. [
10] investigated the UMs for an incomplete probability SVIS. Chen et al. [
11] presented UMs for an incomplete SVIS by using Gaussian kernel.
Feature selection, also known as attribute reduction in RST, is used to reduce redundant attributes and the complexity of calculation for high-dimensional data while improving or maintaining the algorithm performance of a particular task. UM holds particular relevance in the context of attribute reduction within an information system. Zhang et al. [
12] investigated UM for categorical data using fuzzy information structures and applied it to attribute reduction. Gao et al. [
13] studied a monotonic UM for attribute reduction based on granular maximum decision entropy.
An SVIS is a valuable tool for handling datasets with missing information values. Specifically, an SVIS approach involves replacing the missing information values of an attribute with a set comprising all the possible values that could exist under the same attribute. Meanwhile, the existing information values are substituted with a set containing the original values. By employing this technique, a dataset containing missing information values can be converted into an SVIS, enabling the application of further processes such as calculating the Jaccard distance within the framework of an SVIS.
The study on attribute reduction in an SVIS are abundant. Just to name a few, Peng et al. [
14] delved into uncertainty measurement-based feature selection for set-valued data. Singh et al. [
15] explored attribute selection in an SVIS based on a fuzzy similarity. Zhang et al. [
16] studied attribute reduction for set-valued data based on D-S evidence theory. Liu et al. [
17] proposed an incremental attribute reduction method for set-valued decision information system with variable attribute sets. Lang et al. [
18] studied an incremental approach to attribute reduction of a dynamic SVIS.
However, the straightforward replacement of missing information with all possible values in an SVIS can be considered overly simplistic and may result in some loss of information. This approach fails to consider the potential variations in the occurrence frequency of different attribute values, leading to a lack of differentiation between values that may occur more frequently than others and should thus be treated distinctively.
An MSVIS has been developed to enhance the functionality of an SVIS [
19,
20,
21]. In the MSVIS framework, the information values associated with an attribute in a dataset are organized as multisets, which allow elements to be repeated. Within an MSVIS, each missing information value is represented by a multiset, ensuring that the frequency of each value is maintained. Information values that are not missing are depicted by multisets that are equivalent to traditional sets containing only the original value.
This approach enables an MSVIS to accurately capture the frequency distribution of information values within the dataset, addressing one of the limitations of an SVIS related to potential information loss arising from oversimplified imputation strategies. By preserving the frequency information associated with each value, an MSVIS provides a more nuanced representation of the dataset, enhancing the robustness and accuracy of data analysis processes.
Despite the benefits of an MSVIS, research on attribute reduction in an MSVIS is relatively scarce compared to the extensive body of research focused on an SVIS. Huang et al. [
22] developed a supervised feature-selection method for multiset-valued data using fuzzy conditional information entropy, while Li et al. [
23] proposed a semi-supervised approach to attribute reduction for partially labelled multiset-valued data.
Recent advancements in unsupervised attribute reduction have primarily focused on improving computational efficiency and scalability. For instance, Feng et al. [
24] proposed a dynamic attribute reduction algorithm using relative neighborhood discernibility, achieving incremental updates for evolving datasets. While their method demonstrates efficiency in handling object additions, it neglects the critical role of frequency distributions in multiset-valued data: a gap that leads to information loss in scenarios like dynamic feature evolution or missing value imputation. Similarly, He et al. [
25] introduced uncertainty measures for partially labeled categorical data, yet their semi-supervised framework still relies on partial labels and predefined thresholds, limiting applicability in fully unsupervised environments. Zonoozi et al. [
26] proposed an unsupervised adversarial domain adaptation framework using variational auto-encoders (VAEs) to align feature distributions across domains. While it validates the robustness of domain-invariant feature learning, it neglects frequency semantics in missing data. Chen et al. [
27] introduced an ensemble regression method that assigns weights to base models based on relative error rates. Although effective for continuous targets, their approach relies on predefined error metrics and ignores the intrinsic frequency distributions in multiset-valued data.
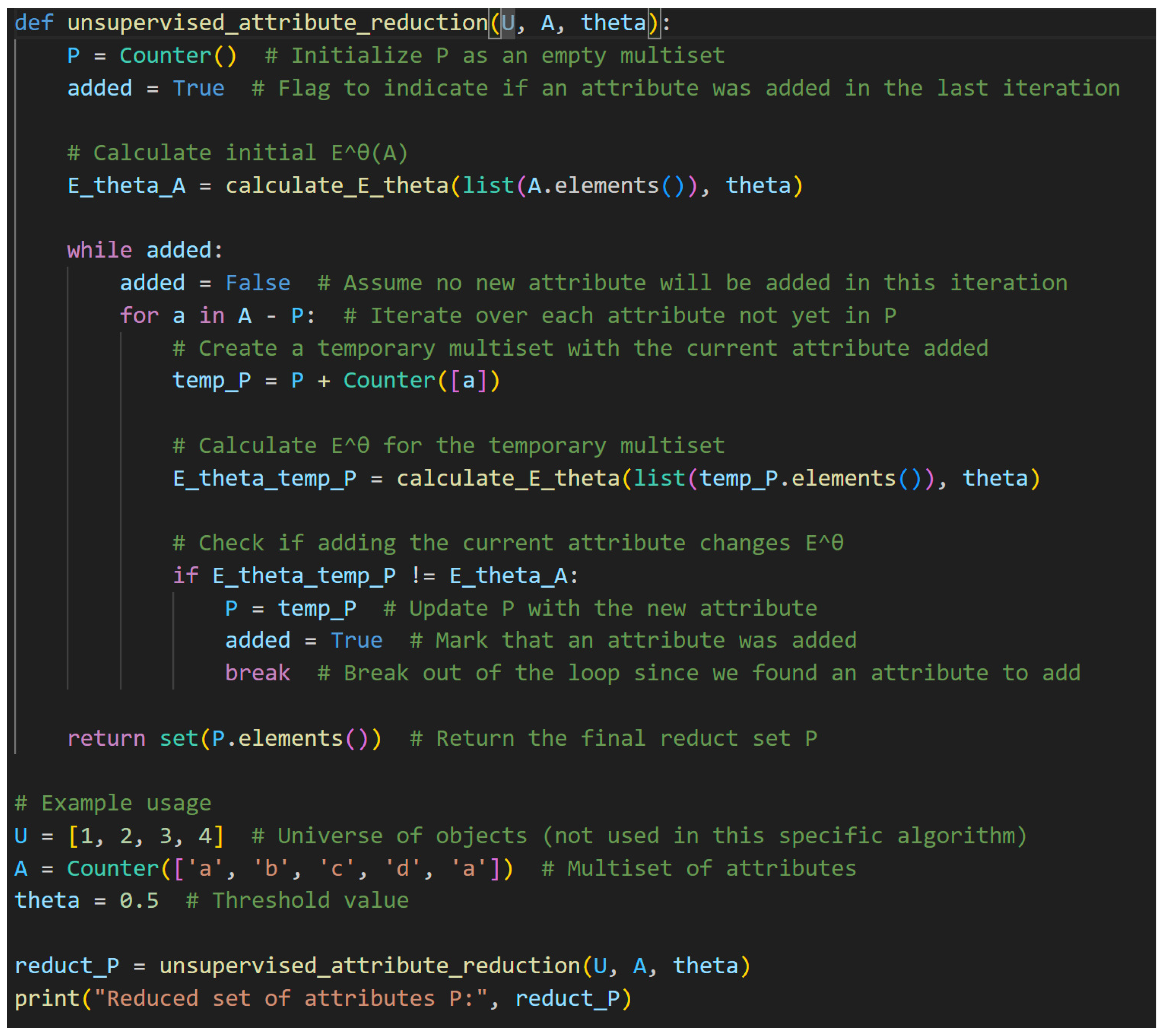
To bridge these gaps, we propose the multiset-valued information system (MSVIS) framework in unsupervised attribute reduction, which uniquely integrates frequency-sensitive uncertainty measurement for missing data with granular computing principles. Unlike conventional SVIS-based methods (e.g., uniform set imputation), an MSVIS explicitly preserves frequency distributions (e.g., 2/S,3/M) through multisets, enabling dynamic adjustments via -tolerance relations. Building on this, this paper uses an MSVIS to represent a dataset with missing information values and builds a UM-based attribute reduction method within it.
Attribute reduction and missing data processing have been researched mainly as two separate data preprocess topics, and related work has been focused on attribute reduction in an SVIS. This paper combines them together, that is, the task of attribute reduction for missing data. The proposed method offers several advantages. Firstly, unlike some data imputation methods, it does not presume any data distribution and is totally based on data itself. Secondly, unlike the approaches proposed by Huang et al. [
22] and Li et al. [
23], which necessitate the presence of decision attributes in a dataset, the method introduced in this paper does not require decision attributes, thereby expanding its applicability across a broader range of datasets. Lastly, the method proposed in this paper is user-friendly and easy to implement, ensuring accessibility and facilitating its practical application in diverse research and application scenarios.
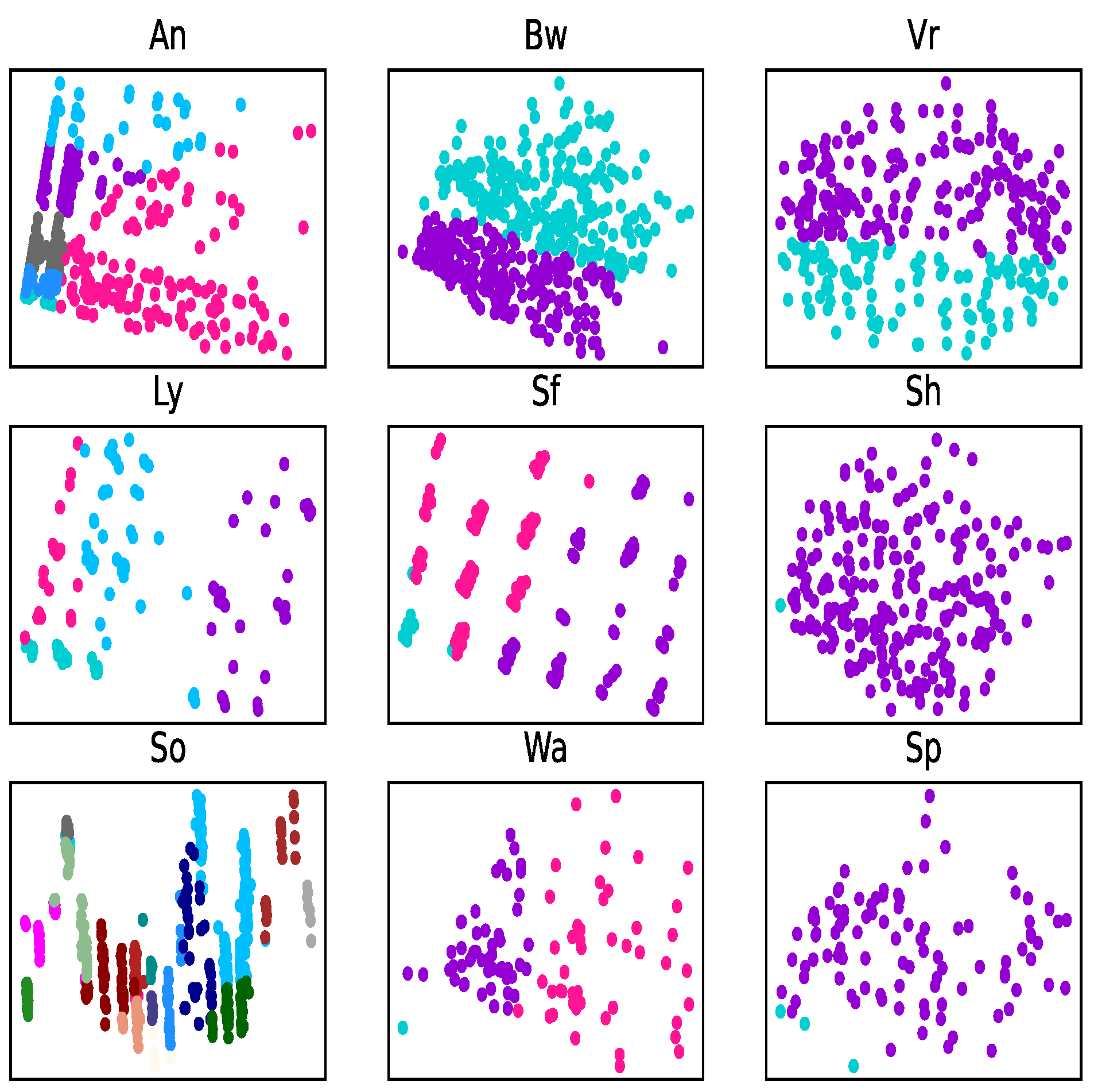
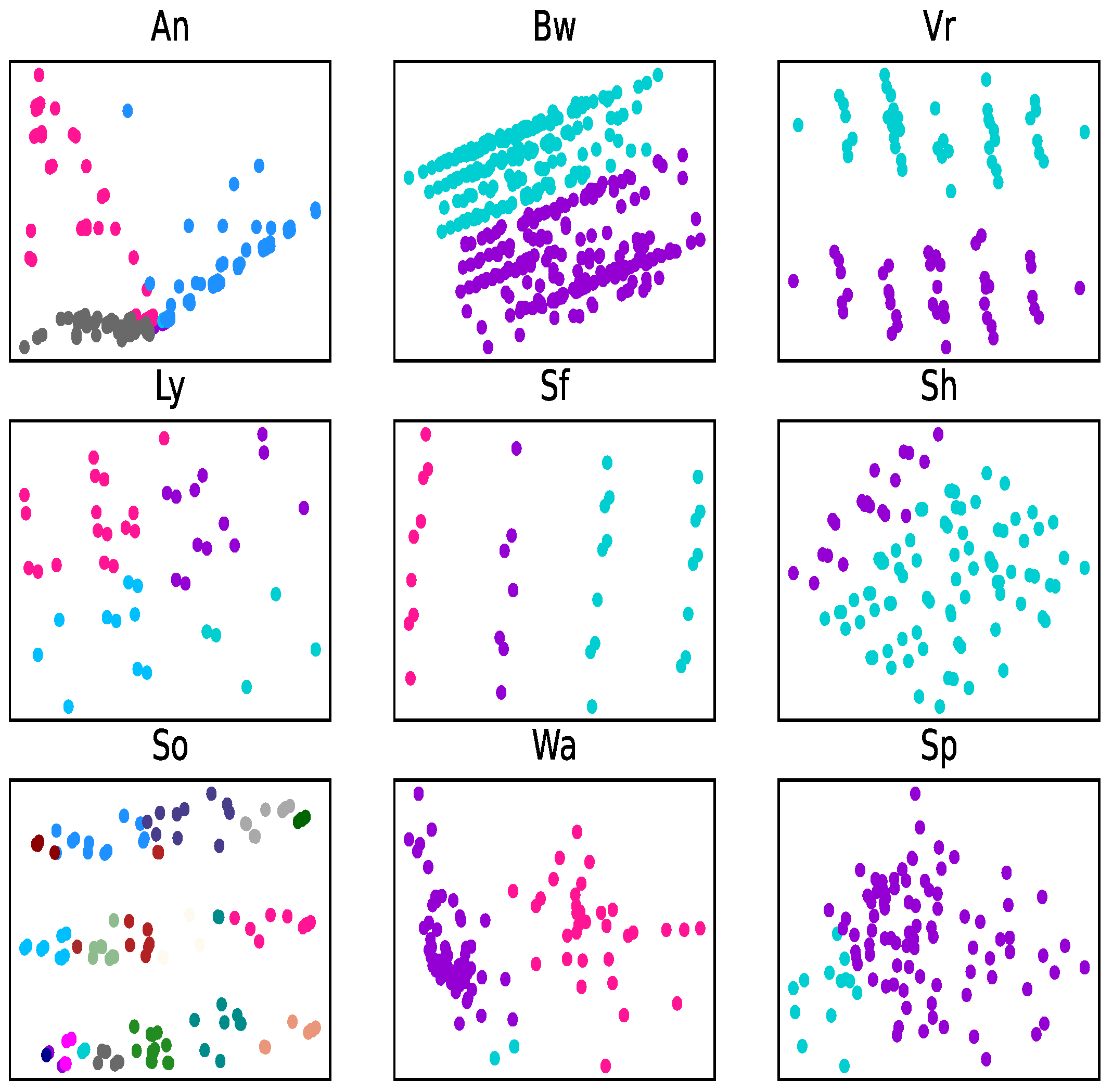
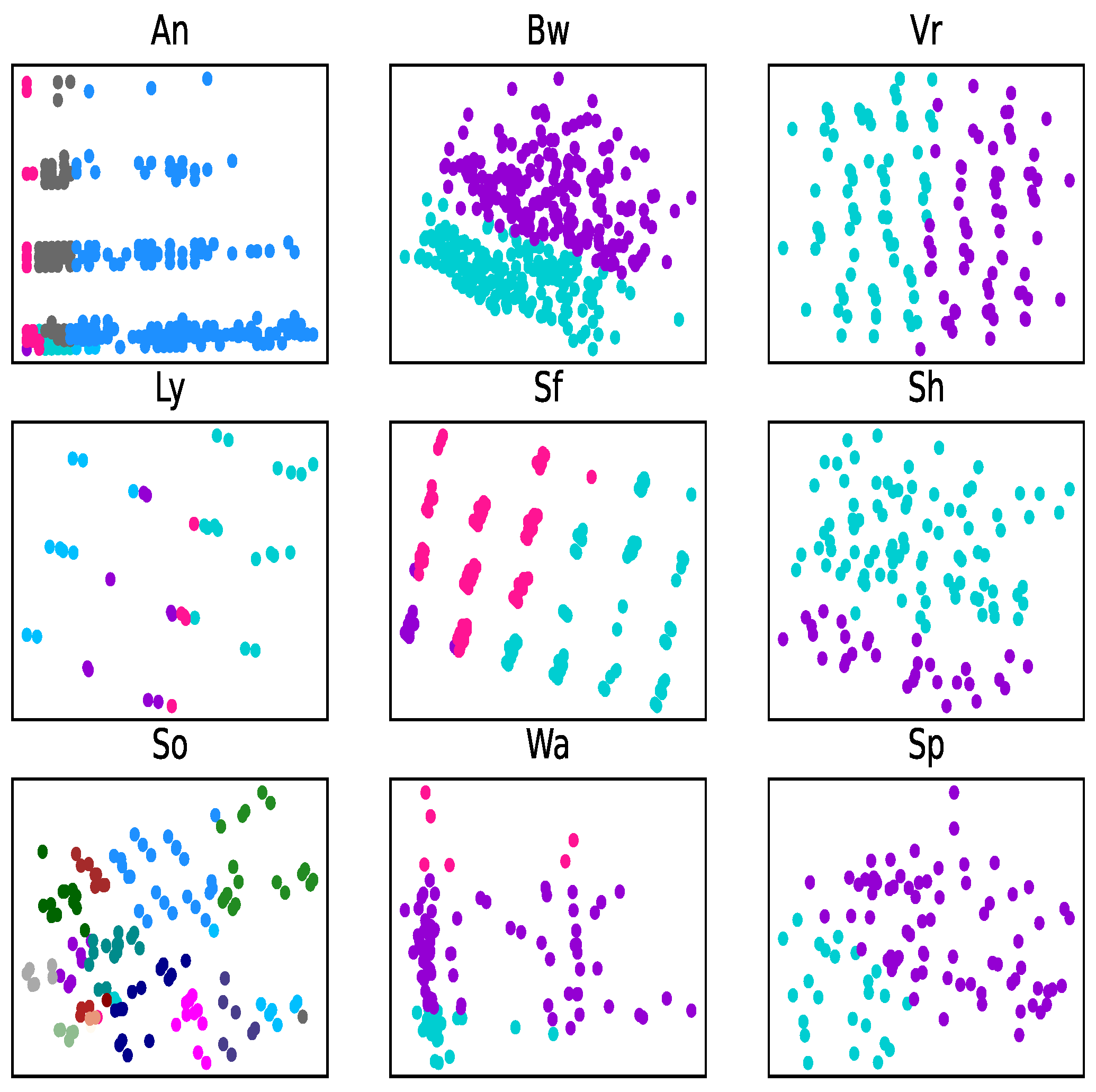
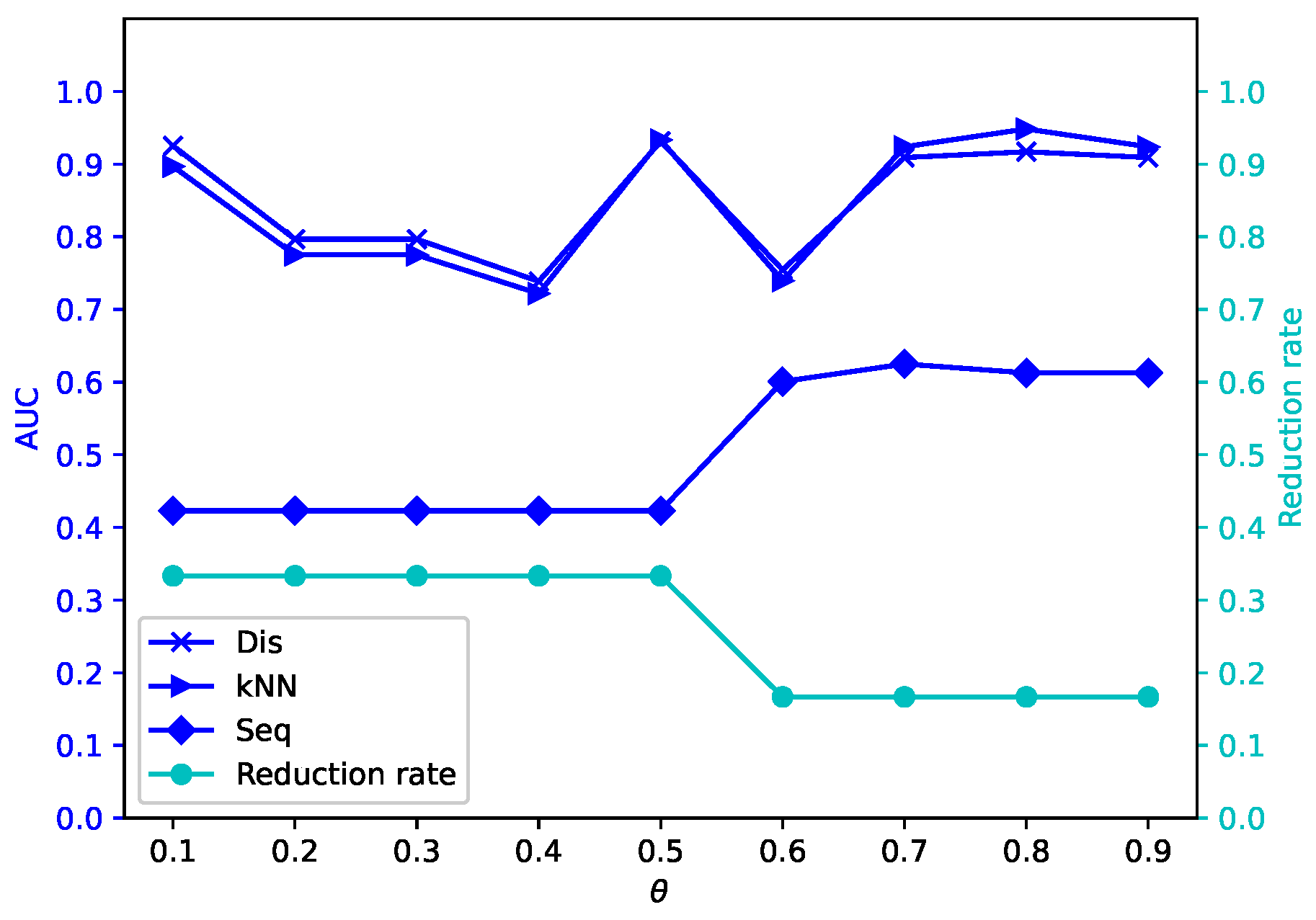
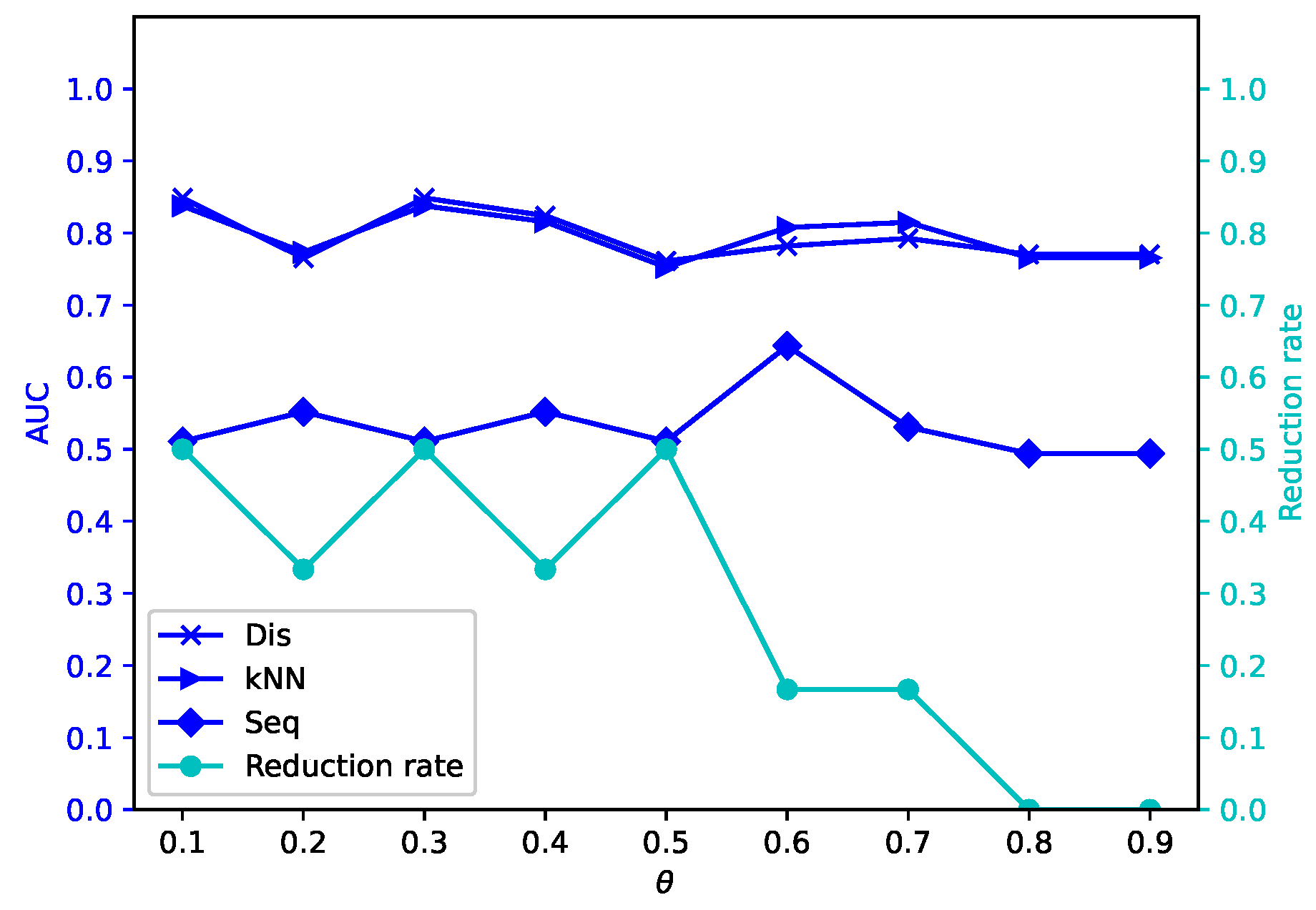
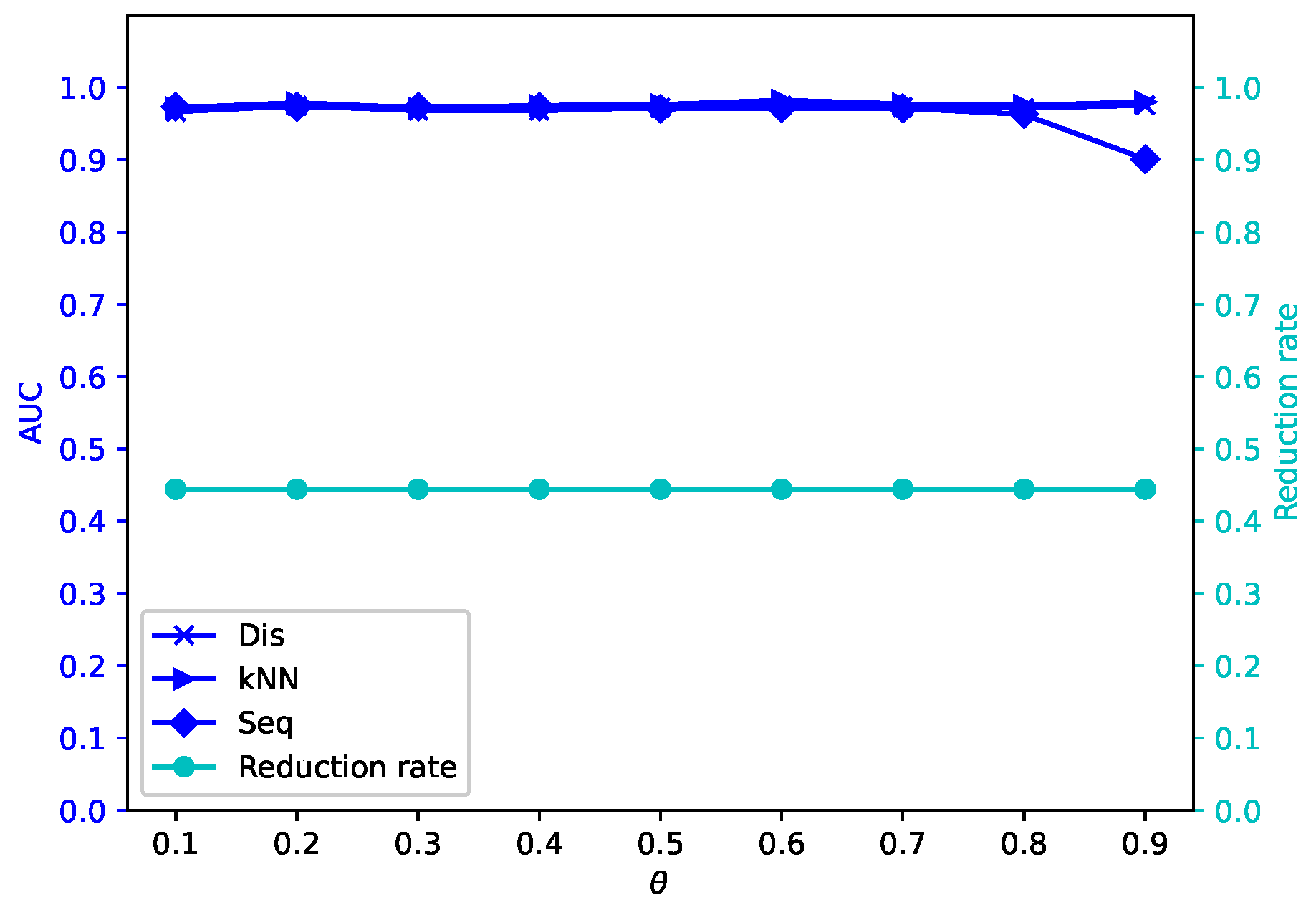
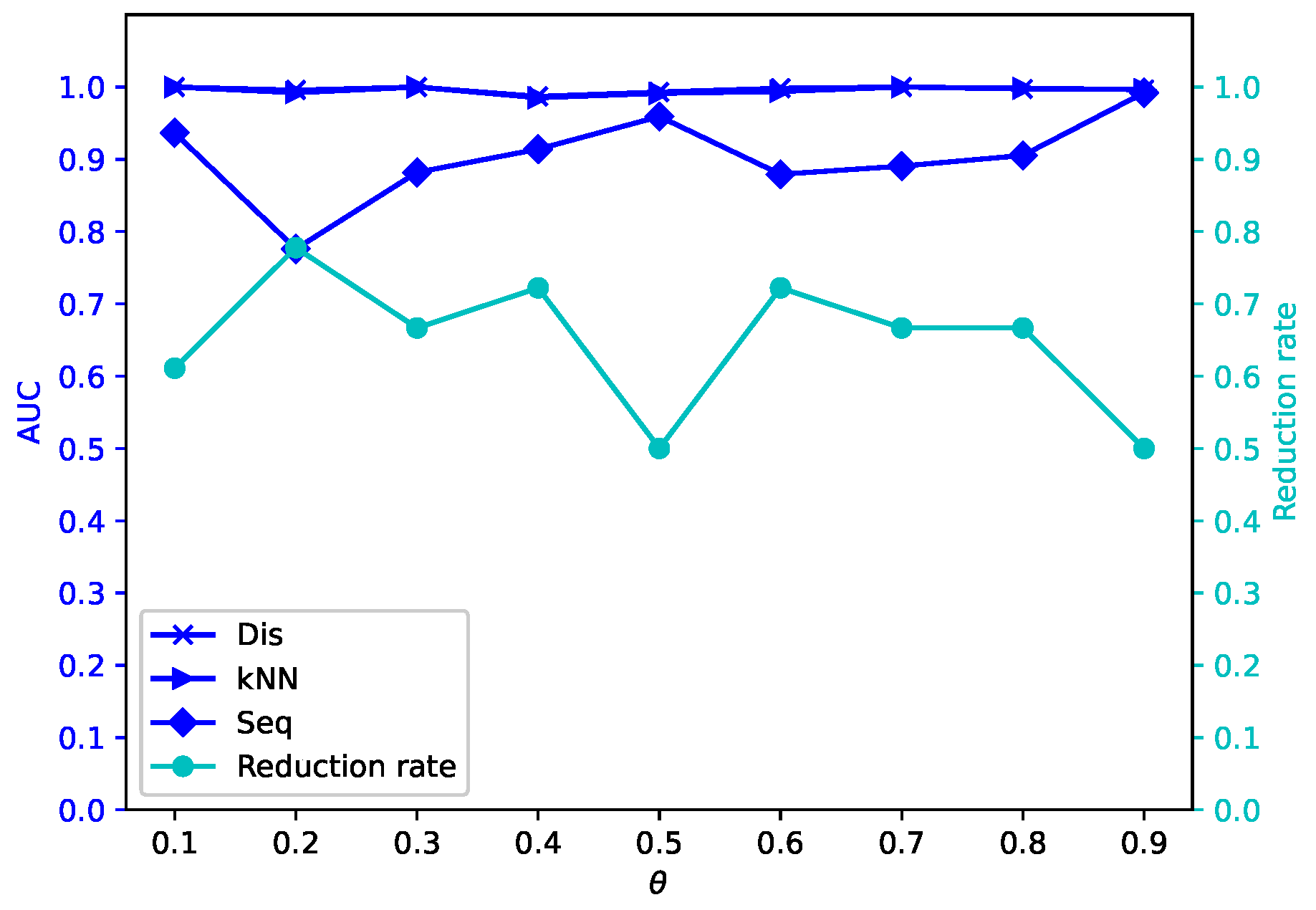
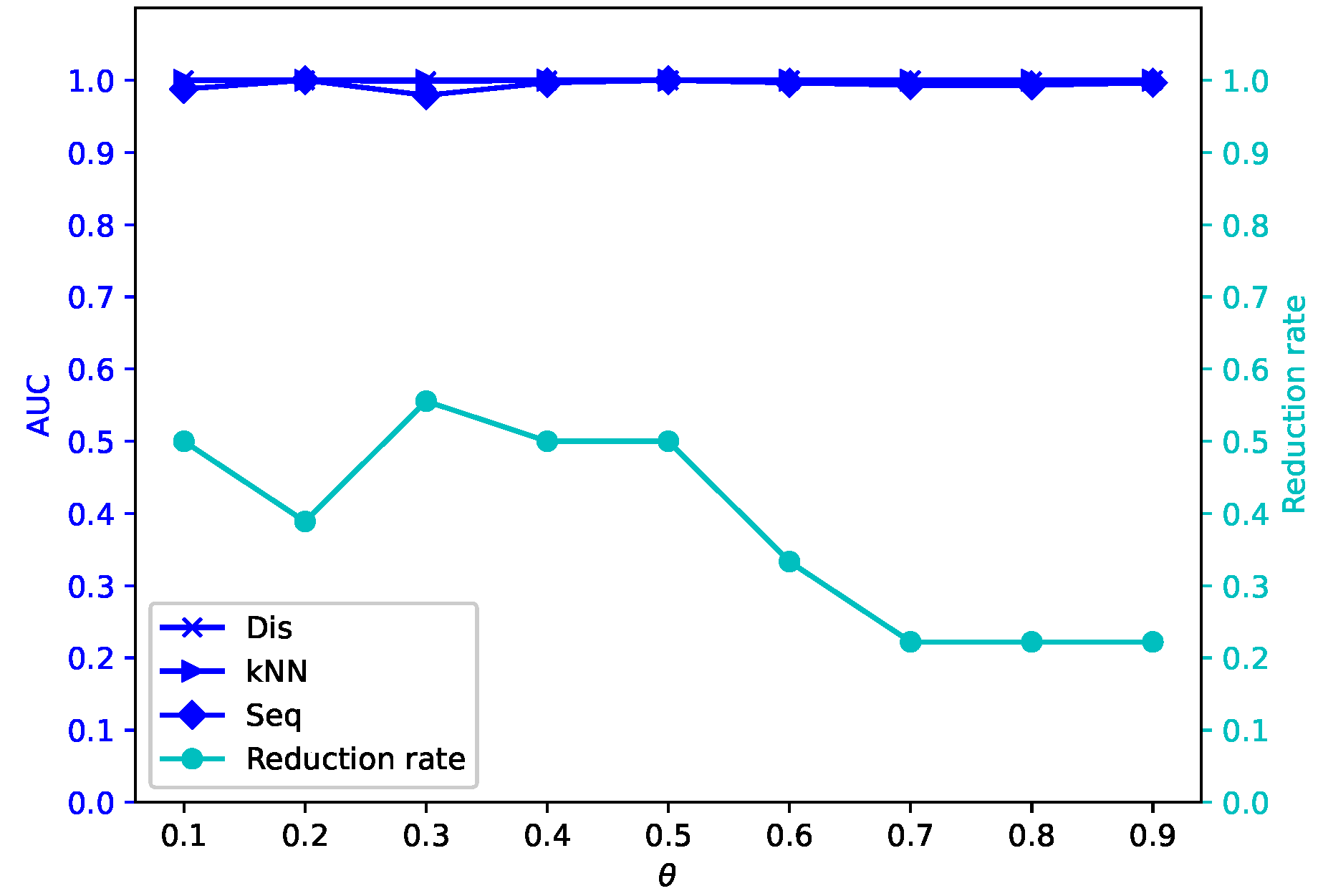
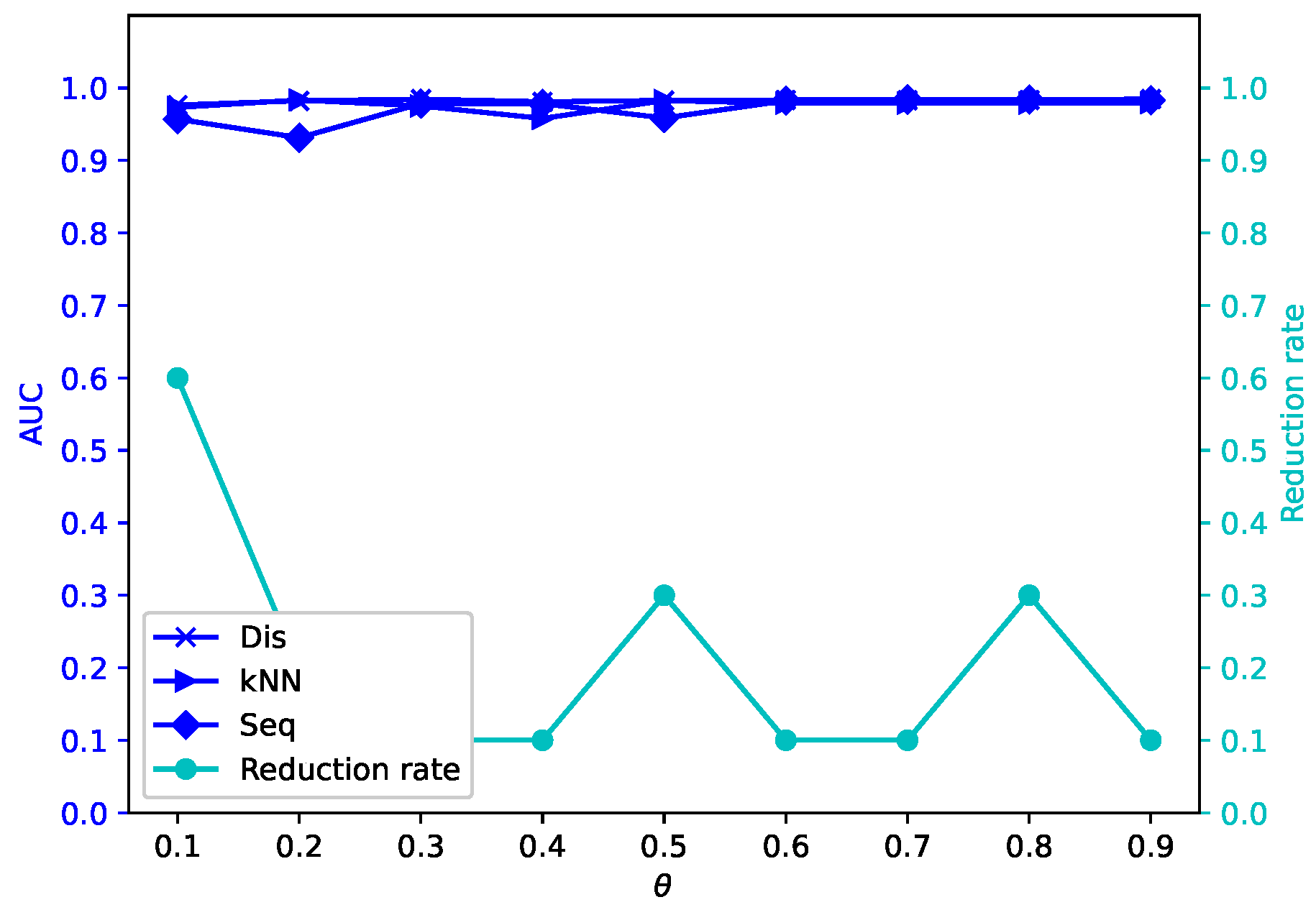
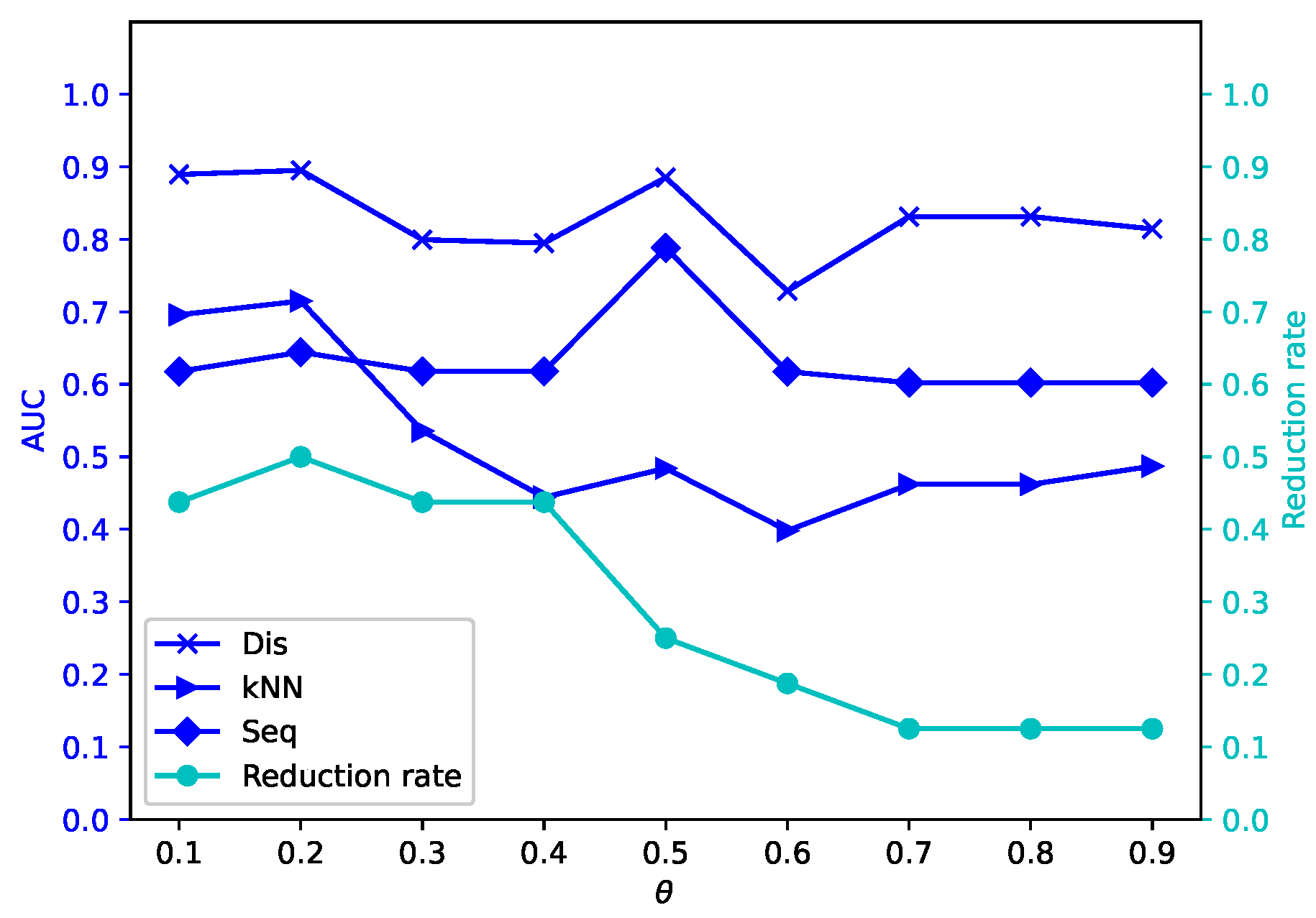
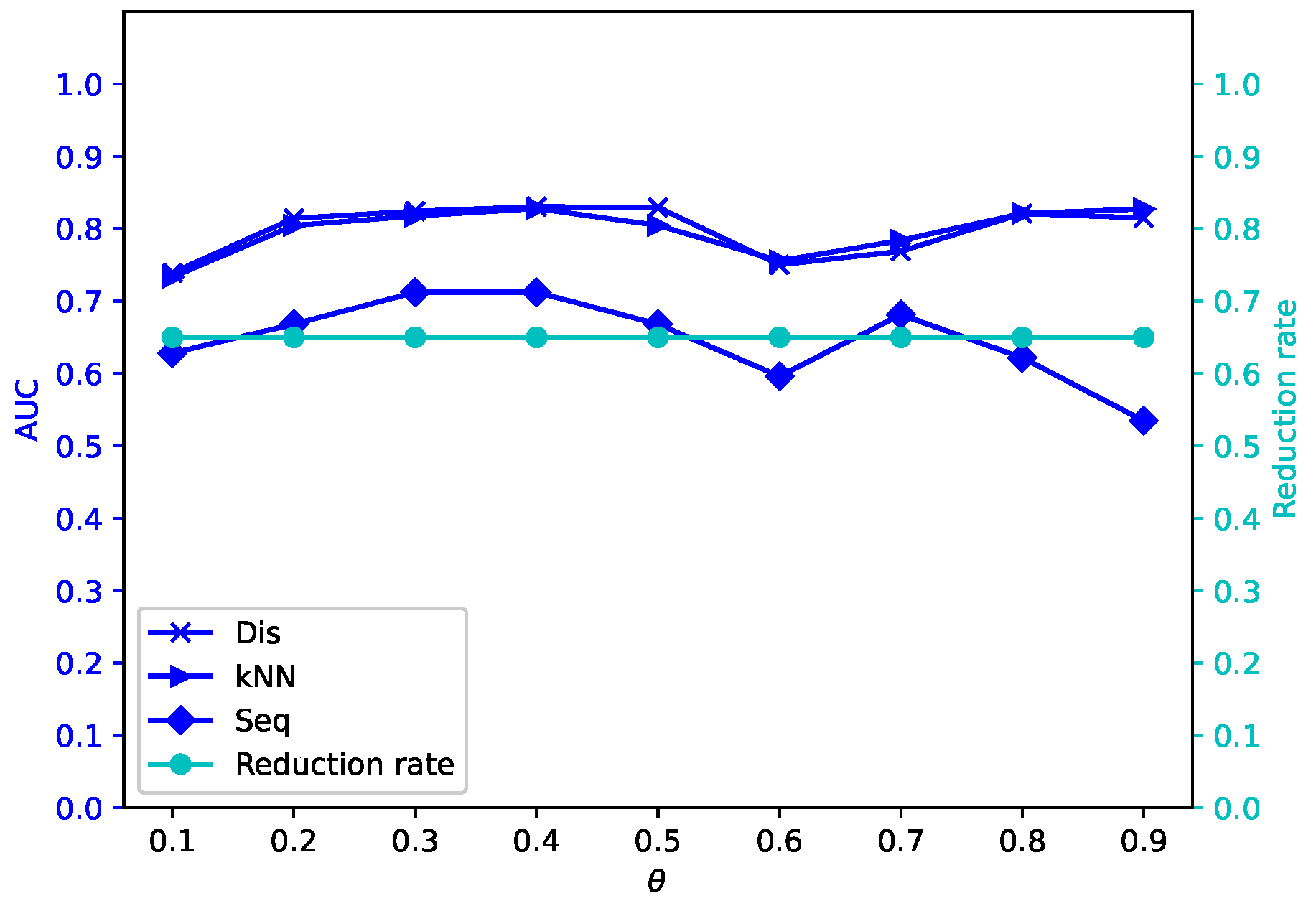
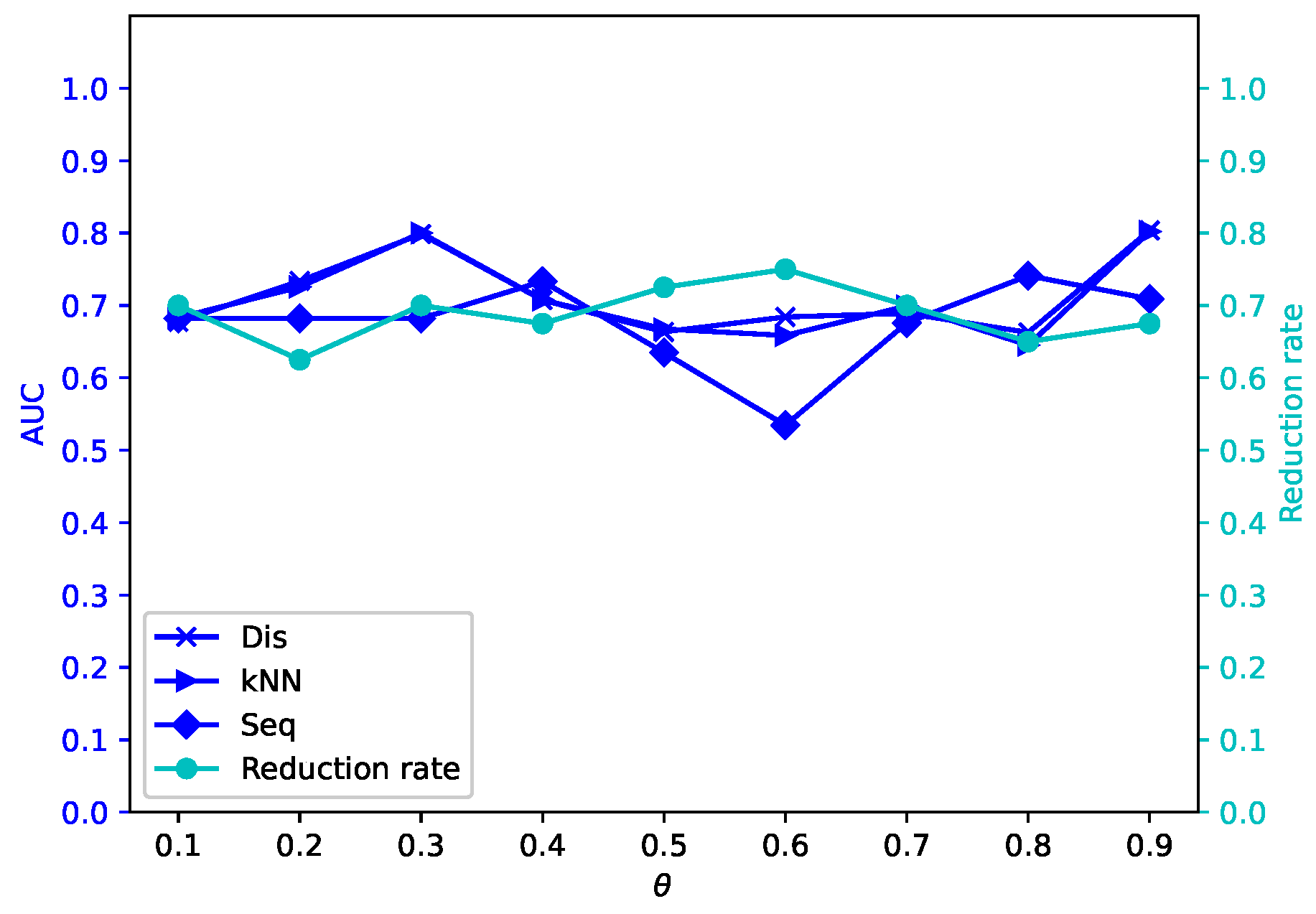
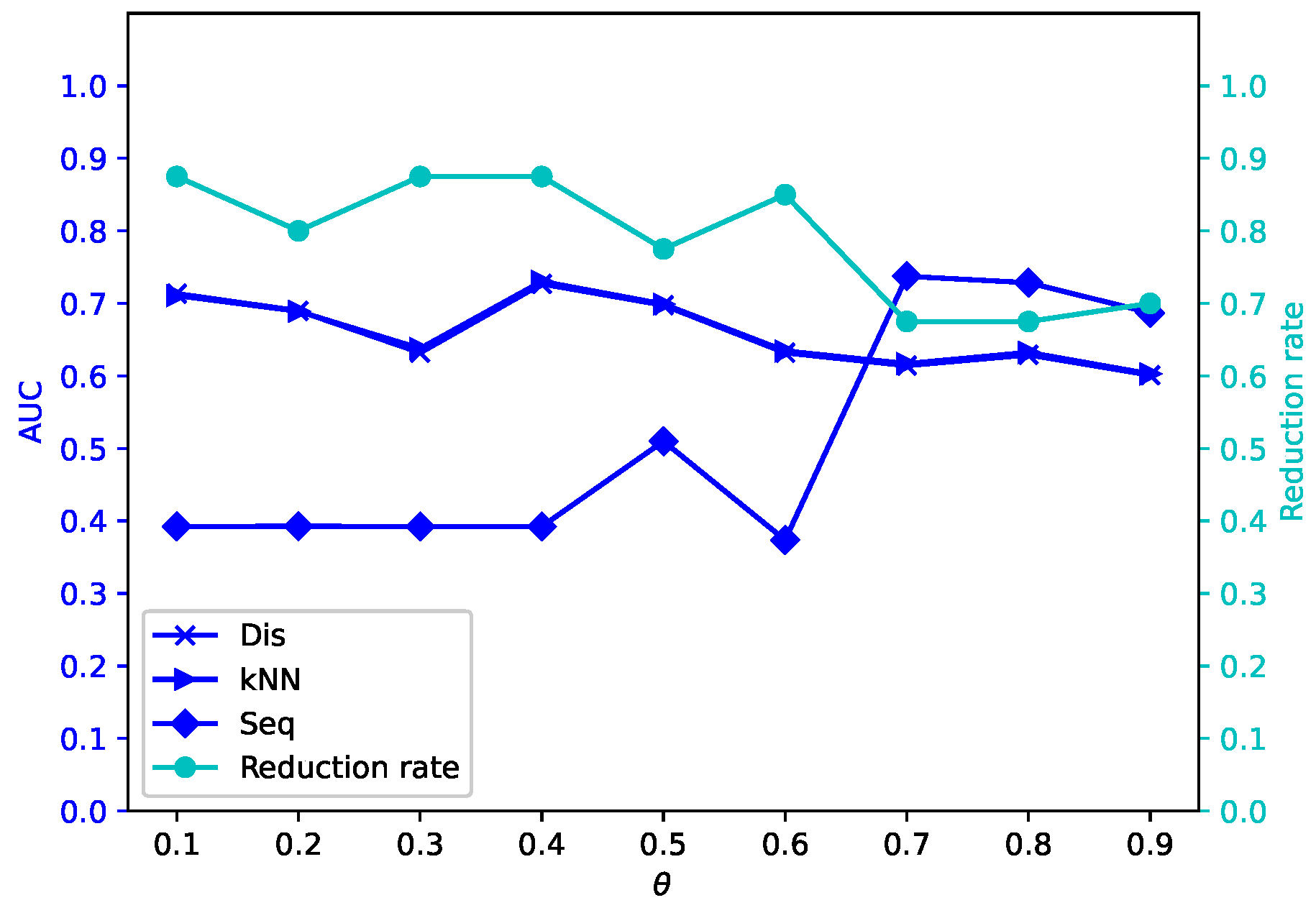
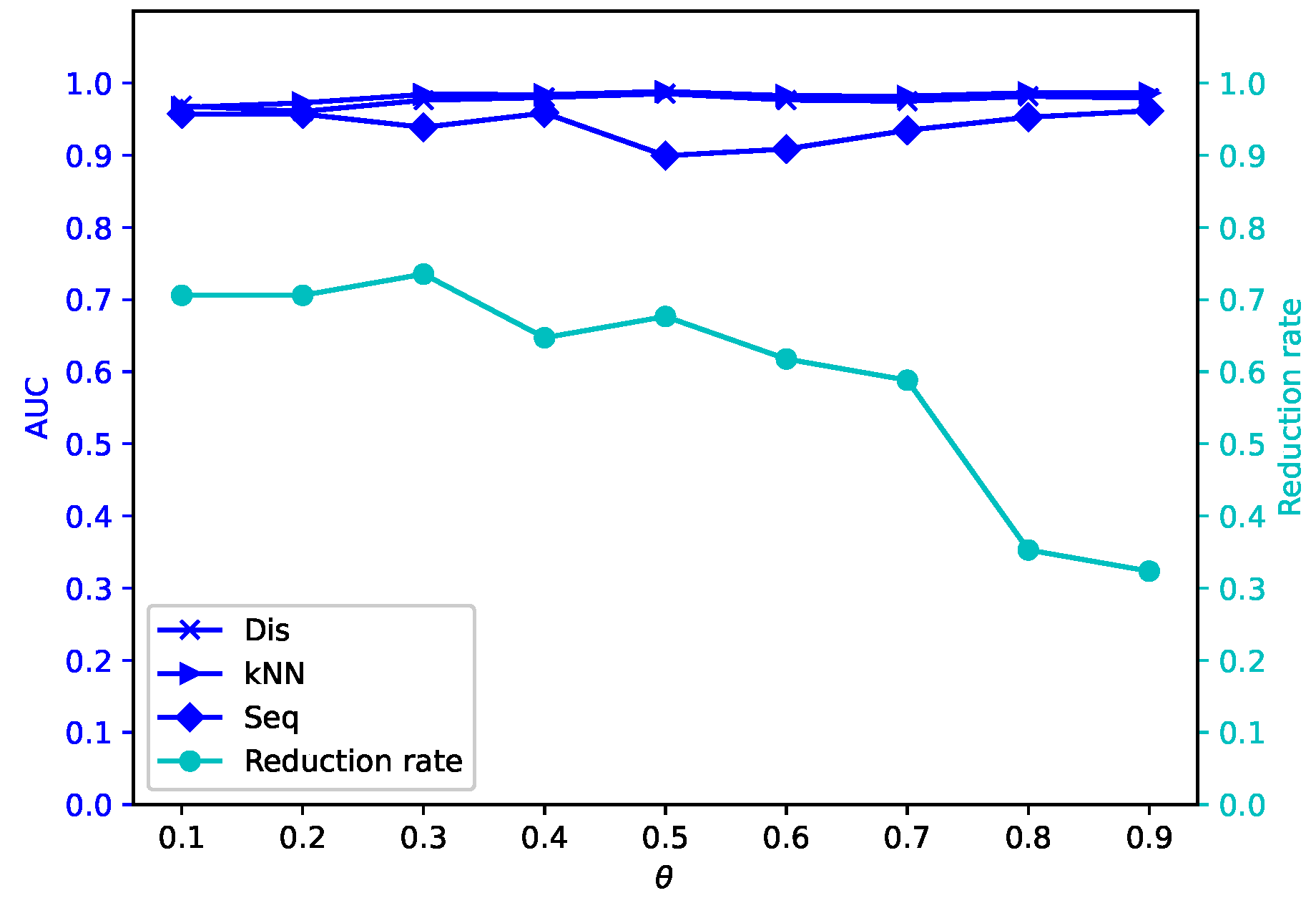
Different attribute reduction algorithms are compared. Particularly, the proposed attribute reduction algorithms are conducted in both MSVIS and SVIS and then are compared. Parameter analysis is also conducted to see the influence of the parameters. The experimental results show the effectiveness and superiority of the proposed algorithms.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}