
A Hybrid Vector Autoregressive Model for Accurate Macroeconomic Forecasting: An Application to the U.S. Economy

 ,
,  ,
,  , and
, and
Abstract
1. Introduction
2. Literature Review
3. Methodology
3.1. Formulation of the Forecasting Models
3.2. Sparse Structure of the VAR Model
3.3. SCAD-VAR Hybrid
3.4. Statistical Loss Functions
4. Case Study Forecasting Results
5. Discussion
6. Concluding Remarks
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Dědeček, R.; Dudzich, V. Exploring the limitations of GDP per capita as an indicator of economic development: A cross-country perspective. Rev. Econ. Perspect. 2022, 22, 193–217. [Google Scholar] [CrossRef]
- Zhang, S.; Li, X.; Zhang, C.; Luo, J.; Cheng, C.; Ge, W. Measurement of factor mismatch in industrial enterprises with labor skills heterogeneity. J. Bus. Res. 2023, 158, 113643. [Google Scholar] [CrossRef]
- Ren, Y.; Zhang, J.; Wang, X. How does data factor utilization stimulate corporate total factor productivity: A discussion of the productivity paradox. Int. Rev. Econ. Financ. 2024, 96, 103681. [Google Scholar] [CrossRef]
- Ma, Q.; Zhang, Y.; Hu, F.; Zhou, H. Can the energy conservation and emission reduction demonstration city policy enhance urban domestic waste control? Evidence from 283 cities in China. Cities 2024, 154, 105323. [Google Scholar] [CrossRef]
- Nneamaka, N.T. Prospects of Oil Palm Wine and Raphia Palm Wine in South East, Nigeria. Prospects 2019, 9, 31–35. [Google Scholar]
- Xi, X.; Xi, B.; Miao, C.; Yu, R.; Xie, J.; Xiang, R.; Hu, F. Factors influencing technological innovation efficiency in the Chinese video game industry: Applying the meta-frontier approach. Technol. Forecast. Soc. Change 2022, 178, 121574. [Google Scholar] [CrossRef]
- Zhao, S.; Zhang, L.; An, H.; Peng, L.; Zhou, H.; Hu, F. Has China’s low-carbon strategy pushed forward the digital transformation of manufacturing enterprises? Evidence from the low-carbon city pilot policy. Environ. Impact Assess. Rev. 2023, 102, 107184. [Google Scholar] [CrossRef]
- Chen, Q.; Han, Y.; Huang, Y.; Jiang, G.J. Jump Risk Implicit in Options Market. J. Financ. Econom. 2025, 23, nbaf002. [Google Scholar] [CrossRef]
- Chaudhary, S.K.; Xiumin, L. Analysis of the determinants of inflation in Nepal. Am. J. Econ. 2018, 8, 209–212. [Google Scholar]
- Shi, J.; Liu, C.; Liu, J. Hypergraph-Based Model for Modeling Multi-Agent Q-Learning Dynamics in Public Goods Games. IEEE Trans. Netw. Sci. Eng. 2024, 11, 6169–6179. [Google Scholar] [CrossRef]
- Amaral, A.; Dyhoum, T.E.; Abdou, H.A.; Aljohani, H.M. Modeling for the relationship between monetary policy and GDP in the USA using statistical methods. Mathematics 2022, 10, 4137. [Google Scholar] [CrossRef]
- Zhang, X.; Yang, X.; He, Q. Multi-scale systemic risk and spillover networks of commodity markets in the bullish and bearish regimes. N. Am. J. Econ. Financ. 2022, 62, 101766. [Google Scholar] [CrossRef]
- Zhao, S.; Zhang, L.; Peng, L.; Zhou, H.; Hu, F. Enterprise pollution reduction through digital transformation? Evidence from Chinese manufacturing enterprises. Technol. Soc. 2024, 77, 102520. [Google Scholar] [CrossRef]
- Wei, M.; Xiong, Y.; Sun, B. Spatial effects of urban economic activities on airports’ passenger throughputs: A case study of thirteen cities and nine airports in the Beijing-Tianjin-Hebei region, China. J. Air Transp. Manag. 2025, 125, 102765. [Google Scholar] [CrossRef]
- Shah, Z.; Abbas, G.; Khan, F. Deep learning in financial time series forecasting. Expert Syst. Appl. 2022, 207, 117033. [Google Scholar] [CrossRef]
- Zhang, S.; Roller, S.; Goyal, N.; Artetxe, M.; Chen, M.; Chen, S.; Zettlemoyer, L. Opt: Open pre-trained transformer language models. arXiv 2022, arXiv:2205.01068. [Google Scholar]
- Chang, X.; Gao, H.; Li, W. Discontinuous Distribution of Test Statistics Around Significance Thresholds in Empirical Accounting Studies. J. Account. Res. 2025, 63, 165–206. [Google Scholar] [CrossRef]
- Dong, X.; Yu, M. Time-varying effects of macro shocks on cross-border capital flows in China’s bond market. Int. Rev. Econ. Financ. 2024, 96, 103720. [Google Scholar] [CrossRef]
- Li, L.; Xia, Y.; Ren, S.; Yang, X. Homogeneity Pursuit in the Functional-Coefficient Quantile Regression Model for Panel Data with Censored Data. Stud. Nonlinear Dyn. Econom. 2024. [Google Scholar] [CrossRef]
- Kotchoni, R.; Leroux, M.; Stevanovic, D. Macroeconomic forecast accuracy in a data-rich environment. J. Appl. Econom. 2019, 34, 1050–1072. [Google Scholar] [CrossRef]
- Castle, J.L.; Doornik, J.A.; Hendry, D.F. Improving models and forecasts after equilibrium-mean shifts. Int. J. Forecast. 2024, 40, 1085–1100. [Google Scholar] [CrossRef]
- Luciani, M. Large-Dimensional Dynamic Factor Models in Real-Time: A Survey. Technical Report 2511872, SSRN. 2014. Available online: https://ssrn.com/abstract=2511872 (accessed on 25 May 2024).
- Swanson, N.R.; Xiong, W. Big data analytics in economics: What have we learned so far, and where should we go from here? Can. J. Econ. 2018, 51, 695–746. [Google Scholar] [CrossRef]
- Diebold, F.X.; Shin, M. Machine learning for regularized survey forecast combination: Partially-egalitarian lasso and its derivatives. Int. J. Forecast. 2019, 35, 1679–1691. [Google Scholar] [CrossRef]
- Swanson, N.R.; Xiong, W.; Yang, X. Predicting interest rates using shrinkage methods, real-time diffusion indexes, and model combinations. J. Appl. Econom. 2020, 35, 587–613. [Google Scholar] [CrossRef]
- Muhammadullah, S.; Urooj, A.; Khan, F.; Alshahrani, M.N.; Alqawba, M.; Al-Marzouki, S. Comparison of Weighted Lag Adaptive LASSO with Autometrics for Covariate Selection and Forecasting Using Time-Series Data. Complexity 2022, 2022, 2649205. [Google Scholar] [CrossRef]
- Giannone, D.; Lenza, M.; Primiceri, G.E. Economic Predictions with Big Data: The Illusion of Sparsity; Technical Report 847; Federal Reserve Bank of New York: New York, NY, USA, 2018. [Google Scholar]
- Nakajima, Y.; Sueishi, N. Forecasting the Japanese macroeconomy using high-dimensional data. Jpn. Econ. Rev. 2022, 73, 299–324. [Google Scholar] [CrossRef]
- Medeiros, M.C.; Vasconcelos, G.F.; Veiga, A.; Zilberman, E. Supplementary material for forecasting inflation in a data-rich environment: The benefits of machine learning methods. J. Bus. Econ. Stat. 2021, 39, 98–119. [Google Scholar] [CrossRef]
- Ng, S.; Bai, J. Selecting instrumental variables in a data rich environment. J. Time Ser. Econom. 2009, 1, 4. [Google Scholar] [CrossRef]
- Nakamura, E. Inflation forecasting using a neural network. Econ. Lett. 2005, 86, 373–378. [Google Scholar] [CrossRef]
- Shintani, M. Nonlinear forecasting analysis using diffusion indexes: An application to Japan. J. Money Credit. Bank. 2005, 37, 517–538. [Google Scholar] [CrossRef]
- Smalter Hall, A.; Cook, T.R. Macroeconomic Indicator Forecasting with Deep Neural Networks; Technical Report 17-11; Federal Reserve Bank of Kansas City: Kansas City, MO, USA, 2017. [Google Scholar]
- Lunde, A.; Torkar, M. Including news data in forecasting macro economic performance of China. Comput. Manag. Sci. 2020, 17, 585–611. [Google Scholar] [CrossRef]
- Ang, A.; Hodrick, R.J.; Xing, Y.; Zhang, X. The cross-section of volatility and expected returns. J. Financ. 2006, 61, 259–299. [Google Scholar] [CrossRef]
- Brave, S.A.; Butters, R.A.; Justiniano, A. Forecasting economic activity with mixed frequency BVARs. Int. J. Forecast. 2019, 35, 1692–1707. [Google Scholar] [CrossRef]
- Hauzenberger, N.; Huber, F.; Koop, G.; Onorante, L. Fast and flexible Bayesian inference in time-varying parameter regression models. J. Bus. Econ. Stat. 2023, 40, 1904–1918. [Google Scholar] [CrossRef]
- Kamble, V.R.; Koop, G.; Korobilis, D. Bayesian shrinkage in VAR models. J. Time Ser. Anal. 2010, 31, 89–104. [Google Scholar]
- Giannone, D.; Reichlin, L.; Small, D. Nowcasting: The real-time informational content of macroeconomic data. J. Monet. Econ. 2008, 55, 665–676. [Google Scholar] [CrossRef]
- Yiu, M.S.; Chow, K.K. Nowcasting Chinese GDP: Information content of economic and financial data. China Econ. J. 2010, 3, 223–240. [Google Scholar] [CrossRef]
- Estrella, A.; Hardouvelis, G.A. The term structure as a predictor of real economic activity. J. Financ. 1991, 46, 555–576. [Google Scholar] [CrossRef]
- Bernard, H.; Gerlach, S. Does the term structure predict recessions? The international evidence. Int. J. Financ. Econ. 1998, 3, 195–215. [Google Scholar]
- Koop, G.M. Forecasting with medium and large Bayesian VARs. J. Appl. Econom. 2013, 28, 177–203. [Google Scholar] [CrossRef]
- Schorfheide, F.; Song, D. Real-time forecasting with a mixed-frequency VAR. J. Bus. Econ. Stat. 2015, 33, 366–380. [Google Scholar] [CrossRef]
- Yang, X.; Han, Q.; Ni, J.; Li, L. Research on the Expansion of Deposit Insurance Pricing Model Based on the Merton Option Pricing Framework. Comput. Econ. 2025. [Google Scholar] [CrossRef]
- Sims, C.A. Macroeconomics and reality. Econometrica 1980, 48, 1–48. [Google Scholar] [CrossRef]
- Litterman, R.B. Techniques of Forecasting Using Vector Autoregressions; Technical Report 115; Federal Reserve Bank of Minneapolis: Minneapolis, MN, USA, 1979. [Google Scholar]
- Bernanke, B.S.; Boivin, J.; Eliasz, P. Measuring the effects of monetary policy: A factor-augmented vector autoregressive (FAVAR) approach. Q. J. Econ. 2005, 120, 387–422. [Google Scholar]
- Davis, R.A.; Zang, P.; Zheng, T. Reduced-rank covariance estimation in vector autoregressive modeling. arXiv 2014, arXiv:1412.2183. [Google Scholar]
- Hsu, N.J.; Hung, H.L.; Chang, Y.M. Subset selection for vector autoregressive processes using lasso. Comput. Stat. Data Anal. 2008, 52, 3645–3657. [Google Scholar] [CrossRef]
- Aydin, A.D.; Cavdar, S.C. Comparison of prediction performances of artificial neural network (ANN) and vector autoregressive (VAR) Models. Procedia Econ. Financ. 2015, 30, 3–14. [Google Scholar] [CrossRef]
- Marcellino, M. Forecast pooling for European macroeconomic variables. Oxf. Bull. Econ. Stat. 2004, 66, 91–112. [Google Scholar] [CrossRef]
- Yan, L.; Zhang, H.T.; Goncalves, J.; Xiao, Y.; Wang, M.; Guo, Y.; Yuan, Y. An interpretable mortality prediction model for COVID-19 patients. Nat. Mach. Intell. 2020, 2, 283–288. [Google Scholar] [CrossRef]
- Fokin, N.; Polbin, A. Forecasting Russia’s Key Macroeconomic Indicators with the VAR-LASSO Model. Russ. J. Money Financ. 2019, 78, 67–93. [Google Scholar] [CrossRef]
- Li, J.; Chen, W. Forecasting macroeconomic time series: LASSO-based approaches and their forecast combinations with dynamic factor models. Int. J. Forecast. 2014, 30, 996–1015. [Google Scholar] [CrossRef]
- Cavalcante, L.; Bessa, R.J.; Reis, M.; Browell, J. LASSO vector autoregression structures for very short-term wind power forecasting. Wind Energy 2017, 20, 657–675. [Google Scholar] [CrossRef]
- Araujo, G.S.; Gaglianone, W.P. Machine learning methods for inflation forecasting in Brazil: New contenders versus classical models. Lat. Am. J. Cent. Bank. 2023, 4, 100087. [Google Scholar] [CrossRef]
- Masini, R.P.; Medeiros, M.C.; Mendes, E.F. Machine learning advances for time series forecasting. J. Econ. Surv. 2023, 37, 76–111. [Google Scholar] [CrossRef]
- Goulet Coulombe, P.; Leroux, M.; Stevanovic, D.; Surprenant, S. How is machine learning useful for macroeconomic forecasting? J. Appl. Econom. 2022, 37, 920–964. [Google Scholar] [CrossRef]
- Khan, A.; Khan, N.; Shafiq, M. The economic impact of COVID-19 from a global perspective. Contemp. Econ. 2021, 15, 64–75. [Google Scholar] [CrossRef]
- Gujarati, D.N. Basic Econometrics, 4th ed.; McGraw-Hill Companies: New York, NY, USA, 2014. [Google Scholar]
- Franses, P.H. Time Series Models for Business and Economic Forecasting; Cambridge University Press: Cambridge, UK, 1998. [Google Scholar]
- Gonzales, S.M.; Iftikhar, H.; López-Gonzales, J.L. Analysis and forecasting of electricity prices using an improved time series ensemble approach: An application to the Peruvian electricity market. AIMS Math. 2024, 9, 21952–21971. [Google Scholar] [CrossRef]
- Iftikhar, H.; Bibi, N.; Canas Rodrigues, P.; López-Gonzales, J.L. Multiple novel decomposition techniques for time series forecasting: Application to monthly forecasting of electricity consumption in Pakistan. Energies 2023, 16, 2579. [Google Scholar] [CrossRef]
- Cuba, W.M.; Huaman Alfaro, J.C.; Iftikhar, H.; López-Gonzales, J.L. Modeling and analysis of monkeypox outbreak using a new time series ensemble technique. Axioms 2024, 13, 554. [Google Scholar] [CrossRef]
- Nicholson, W.B.; Wilms, I.; Bien, J.; Matteson, D.S. High dimensional forecasting via interpretable vector autoregression. J. Mach. Learn. Res. 2020, 21, 6690–6741. [Google Scholar]
- Tibshirani, R. Regression shrinkage and selection via the lasso. J. R. Stat. Soc. Ser. B 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Khan, F.; Tarimer, I.; Alwageed, H.S.; Karadağ, B.C.; Fayaz, M.; Abdusalomov, A.B.; Cho, Y.I. Effect of feature selection on the accuracy of music popularity classification using machine learning algorithms. Electronics 2022, 11, 3518. [Google Scholar] [CrossRef]
- Zou, H.; Hastie, T. Regularization and variable selection via the elastic net. J. R. Stat. Soc. Ser. B 2005, 67, 301–320. [Google Scholar] [CrossRef]
- Fan, J.; Li, R. Variable selection via nonconcave penalized likelihood and its oracle properties. J. Am. Stat. Assoc. 2001, 96, 1348–1360. [Google Scholar] [CrossRef]
- Lu, Z.; Pu, H.; Wang, F.; Hu, Z.; Wang, L. The expressive power of neural networks: A view from the width. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Jan, F.; Iftikhar, H.; Tahir, M.; Khan, M. Forecasting day-ahead electric power prices with functional data analysis. Front. Energy Res. 2025, 13, 1477248. [Google Scholar] [CrossRef]
- Iftikhar, H.; Turpo-Chaparro, J.E.; Canas Rodrigues, P.; López-Gonzales, J.L. Forecasting day-ahead electricity prices for the Italian electricity market using a new decomposition—Combination technique. Energies 2023, 16, 6669. [Google Scholar] [CrossRef]
- Quispe, F.; Salcedo, E.; Iftikhar, H.; Zafar, A.; Khan, M.; Turpo-Chaparro, J.E.; Rodrigues, P.C.; López-Gonzales, J.L. Multi-step ahead ozone level forecasting using a component-based technique: A case study in Lima, Peru. AIMS Environ. Sci. 2024, 11, 401–425. [Google Scholar] [CrossRef]
- Iftikhar, H.; Khan, M.; Turpo-Chaparro, J.E.; Rodrigues, P.C.; Lopez-Gonzales, J.L. Forecasting stock prices using a novel filtering-combination technique: Application to the Pakistan stock exchange. AIMS Math. 2024, 9, 3264–3289. [Google Scholar] [CrossRef]
- Qureshi, M.; Iftikhar, H.; Rodrigues, P.C.; Rehman, M.Z.; Salar, S.A. Statistical modeling to improve time series forecasting using machine learning, time series, and hybrid models: A case study of bitcoin price forecasting. Mathematics 2024, 12, 3666. [Google Scholar] [CrossRef]
- Khan, F.; Muhammadullah, S.; Sharif, A.; Lee, C.C. The role of green energy stock market in forecasting China’s crude oil market: An application of IIS approach and sparse regression models. Energy Econ. 2024, 130, 107269. [Google Scholar] [CrossRef]
- Iftikhar, H.; Khan, F.; Rodrigues, P.C.; Alharbi, A.A.; Allohibi, J. Forecasting of Inflation Based on Univariate and Multivariate Time Series Models: An Empirical Application. Mathematics 2025, 13, 1121. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
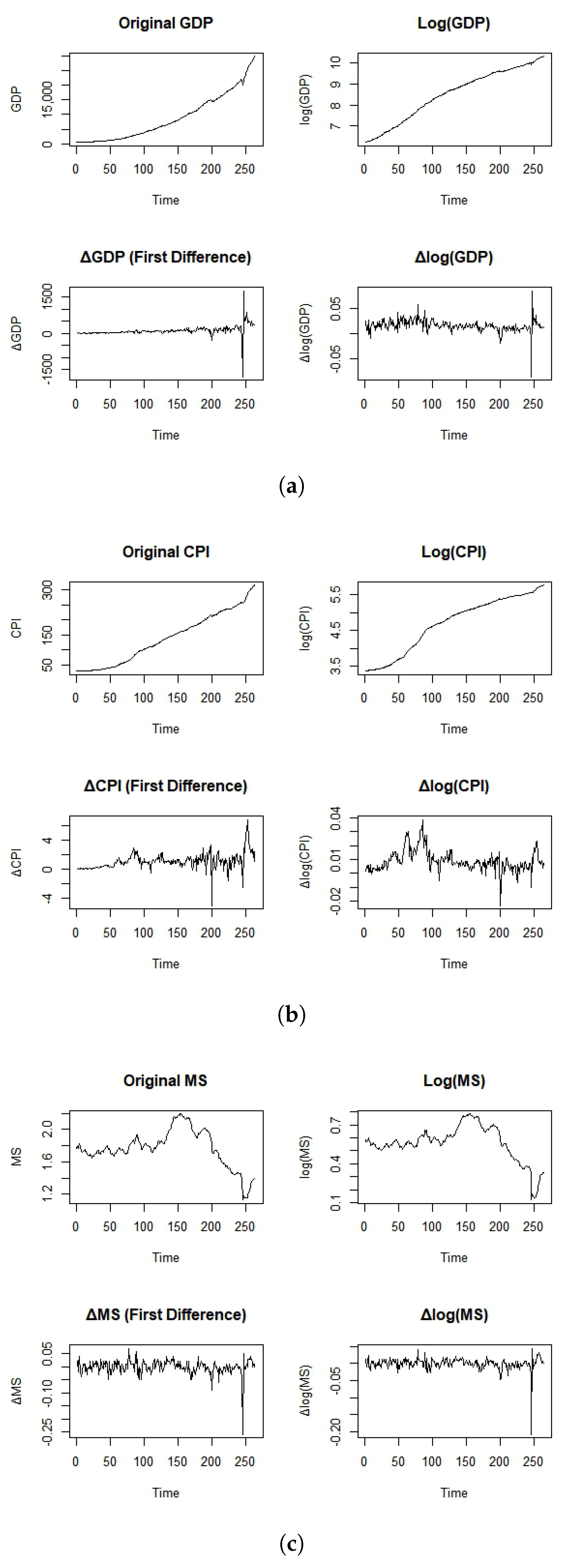
| Series | Mean | Median | Variance | CV | Min | Max | Skewness | Kurtosis | ADF Stat (p-Val) |
|---|---|---|---|---|---|---|---|---|---|
| GDP | 8769.9 | 6760.7 | 9.86 × 107 | 0.113 | 243.1 | 27,000.0 | 0.70 | 2.36 | −1.78 (0.71) |
| log (GDP) | 8.76 | 8.82 | 0.501 | 0.08 | 5.49 | 10.21 | −0.28 | 2.17 | −2.36 (0.40) |
| GDP | 177.5 | 141.3 | 1.05 × 105 | 1.83 | −642.5 | 1011.8 | 0.89 | 4.51 | −3.91 (0.01) |
| log (GDP) | 0.019 | 0.018 | 0.0002 | 0.74 | −0.067 | 0.089 | −0.02 | 2.83 | −3.66 (0.03) |
| CPI | 110.5 | 109.9 | 1535.6 | 0.35 | 23.5 | 303.3 | 0.93 | 2.66 | −1.94 (0.62) |
| log (CPI) | 4.57 | 4.70 | 0.396 | 0.14 | 3.16 | 5.71 | −0.22 | 2.13 | −2.81 (0.22) |
| CPI | 1.48 | 1.40 | 3.46 | 1.26 | −2.15 | 6.73 | 0.31 | 3.39 | −3.25 (0.08) |
| log (CPI) | 0.0129 | 0.0126 | 0.0003 | 1.36 | −0.029 | 0.034 | −0.10 | 2.57 | −3.01 (0.12) |
| MS | 3134.3 | 2063.8 | 1.22 × 107 | 1.12 | 139.9 | 9870.0 | 0.64 | 2.06 | −1.55 (0.79) |
| log(MS) | 7.63 | 7.63 | 0.540 | 0.096 | 4.94 | 9.20 | −0.10 | 1.79 | −2.49 (0.33) |
| MS | 98.4 | 83.0 | 6.57 × 104 | 2.6 | −1366.0 | 964.3 | −0.51 | 4.47 | −4.73 (0.00) |
| log (MS) | 0.013 | 0.013 | 0.0002 | 1.09 | −0.067 | 0.067 | −0.13 | 2.60 | −4.58 (0.00) |
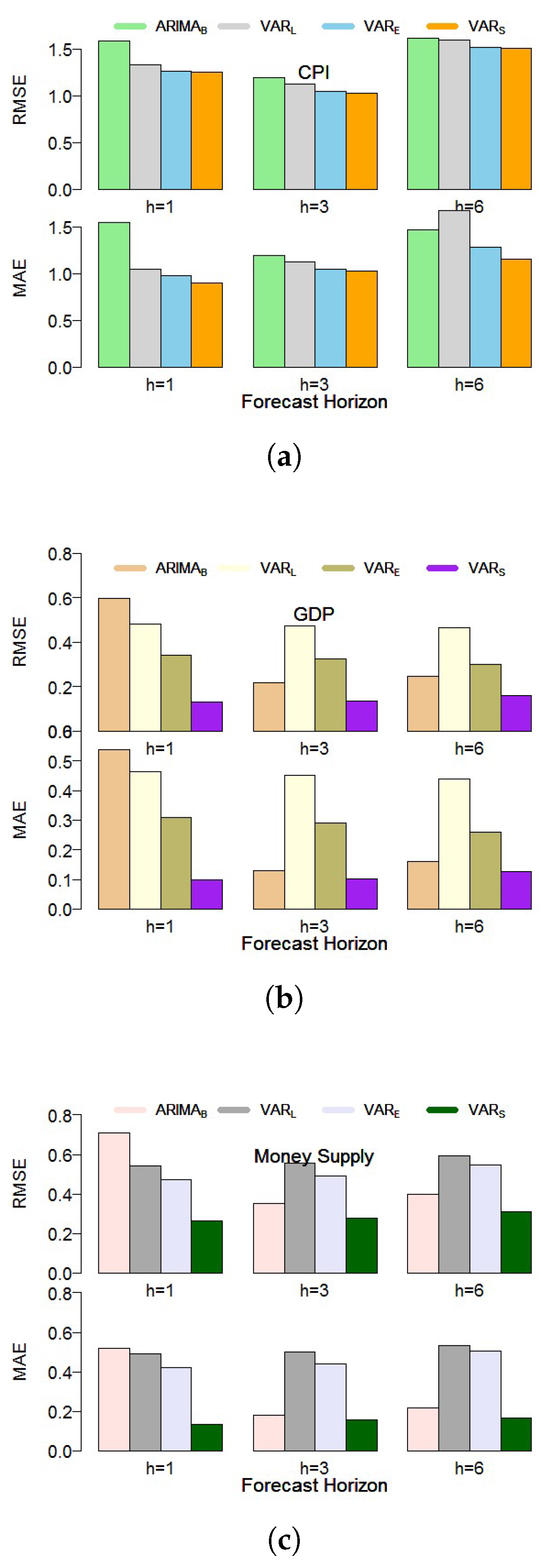
| Variable | GDP | CPI | MS | ||||
|---|---|---|---|---|---|---|---|
| Forecast Horizons | Methods | RMSE | MAE | RMSE | MAE | RMSE | MAE |
| 0.596 | 0.538 | 1.589 | 1.547 | 0.711 | 0.518 | ||
| 0.482 | 0.463 | 1.335 | 1.05 | 0.54 | 0.489 | ||
| 0.34 | 0.308 | 1.266 | 0.979 | 0.473 | 0.422 | ||
| 0.132 | 0.1 | 1.253 | 0.902 | 0.262 | 0.135 | ||
| 0.219 | 0.129 | 1.426 | 1.19 | 0.35 | 0.181 | ||
| 0.472 | 0.451 | 1.413 | 1.126 | 0.556 | 0.501 | ||
| 0.327 | 0.291 | 1.335 | 1.044 | 0.493 | 0.44 | ||
| 0.137 | 0.102 | 1.417 | 1.026 | 0.279 | 0.156 | ||
| 0.249 | 0.159 | 1.615 | 1.464 | 0.398 | 0.219 | ||
| 0.467 | 0.439 | 1.6 | 1.672 | 0.594 | 0.531 | ||
| 0.302 | 0.259 | 1.513 | 1.282 | 0.548 | 0.505 | ||
| 0.159 | 0.128 | 1.509 | 1.159 | 0.311 | 0.165 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khan, F.; Iftikhar, H.; Khan, I.; Rodrigues, P.C.; Alharbi, A.A.; Allohibi, J. A Hybrid Vector Autoregressive Model for Accurate Macroeconomic Forecasting: An Application to the U.S. Economy. Mathematics 2025, 13, 1706. https://doi.org/10.3390/math13111706
Khan F, Iftikhar H, Khan I, Rodrigues PC, Alharbi AA, Allohibi J. A Hybrid Vector Autoregressive Model for Accurate Macroeconomic Forecasting: An Application to the U.S. Economy. Mathematics. 2025; 13(11):1706. https://doi.org/10.3390/math13111706
Chicago/Turabian StyleKhan, Faridoon, Hasnain Iftikhar, Imran Khan, Paulo Canas Rodrigues, Abdulmajeed Atiah Alharbi, and Jeza Allohibi. 2025. "A Hybrid Vector Autoregressive Model for Accurate Macroeconomic Forecasting: An Application to the U.S. Economy" Mathematics 13, no. 11: 1706. https://doi.org/10.3390/math13111706
APA StyleKhan, F., Iftikhar, H., Khan, I., Rodrigues, P. C., Alharbi, A. A., & Allohibi, J. (2025). A Hybrid Vector Autoregressive Model for Accurate Macroeconomic Forecasting: An Application to the U.S. Economy. Mathematics, 13(11), 1706. https://doi.org/10.3390/math13111706