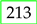1. Introduction
The growing complexity and frequency of cyberattacks present substantial challenges to network security, especially as technological advances accelerate. With the proliferation of interconnected devices, particularly in sensitive domains such as healthcare, the need for robust, adaptive, and intelligent threat detection mechanisms has become critical [
1,
2].
Traditional network security approaches, such as Next-Generation Firewalls (NGFWs) [
3] and modern Intrusion Detection and Prevention Systems (IDPSs) [
4], often struggle to keep pace with increasingly sophisticated cyber threats. This requires advanced computational techniques capable of dynamically detecting and mitigating potential security breaches [
3,
4,
5].
The Internet of Medical Things (IoMT) is particularly vulnerable to cyber-attacks due to its reliance on interconnected medical devices communicating through Bluetooth, Wi-Fi, and MQTT. These attacks pose severe risks, compromising sensitive patient data and critical healthcare infrastructure [
1,
2]. The consequences of such breaches extend beyond data privacy, potentially affecting patient safety and disrupting healthcare services.
IoMT encompasses a diverse ecosystem of interconnected medical devices that collect, transmit, and process patient data to enhance healthcare delivery. These devices range from wearable health monitors (e.g., glucose monitors, cardiac monitors, smart watches) to stationary diagnostic equipment (e.g., connected MRI machines, smart infusion pumps), and therapeutic devices (e.g., insulin pumps, pacemakers). They operate on various communication protocols, including Bluetooth Low Energy (BLE) for short-range data transmission, Wi-Fi for higher bandwidth applications, and MQTT (Message Queuing Telemetry Transport) for lightweight messaging in constrained environments. Each IoMT device category presents unique security challenges due to their varying computational capabilities, power constraints, and data sensitivity. For instance, implantable medical devices must balance security requirements with battery life limitations, while diagnostic equipment must maintain data integrity while handling large volumes of information. This heterogeneity necessitates sophisticated and adaptable security approaches to address the specific vulnerabilities of diverse device types while maintaining the performance requirements for clinical applications.
Machine learning (ML) has emerged as a transformative paradigm in cybersecurity, offering powerful tools to analyze complex network traffic patterns and detect anomalies with high precision [
6,
7]. Recent advances in ensemble learning techniques, such as XGBoost, have demonstrated significant potential to develop resilient and generalizable threat detection models [
8,
9]. These approaches leverage sophisticated algorithms to capture intricate relationships within network data, surpassing traditional rule-based detection systems.
Despite significant progress in ML-based security frameworks, several challenges persist, including balancing detection accuracy, computational efficiency, model interpretability, and generalization to evolving threat landscapes [
10,
11]. Furthermore, minimizing both false positives and false negatives remains a complex optimization problem in security-sensitive applications.
Ensuring robust and efficient detection of malicious attacks remains a critical challenge in cybersecurity. Although ML, particularly ensemble-based approaches, has shown promise in addressing these issues, designing a well-regularized and interpretable model that optimally balances security and computational cost remains an open research problem.
In this work, we develop a high-performance yet generalizable ML framework for detecting malicious attacks. By leveraging a carefully fine-tuned XGBoost classifier [
8], our objective is to achieve superior predictive accuracy while maintaining interpretability. We also assess the trade-offs involved in security-sensitive ML applications, where reducing false positives and false negatives is crucial. To enhance transparency and gain deeper insights into the model’s decision-making process, we employ SHAP (SHapley Additive exPlanations) [
9] to identify key features driving predictions. Our study provides a comprehensive perspective on the efficacy of advanced ensemble learning techniques in cybersecurity through rigorous evaluation and comparison with a well-regularized logistic regression baseline.
The contributions of this paper can be summarized as follows:
We propose a well-regularized and fine-tuned XGBoost classifier tailored to IoMT environments, achieving 97% accuracy and strong generalization through careful tuning of regularization parameters (, , ).
We introduce a late fusion strategy that combines the complementary strengths of XGBoost and Logistic Regression using max voting, reducing false negatives by 41% compared to XGBoost alone, while achieving 15.6% fewer false positives than Logistic Regression.
We provide a detailed quantitative analysis of the security-cost trade-off in IoMT environments, demonstrating how different model configurations impact operational efficiency versus security coverage—a critical consideration often overlooked in the existing literature.
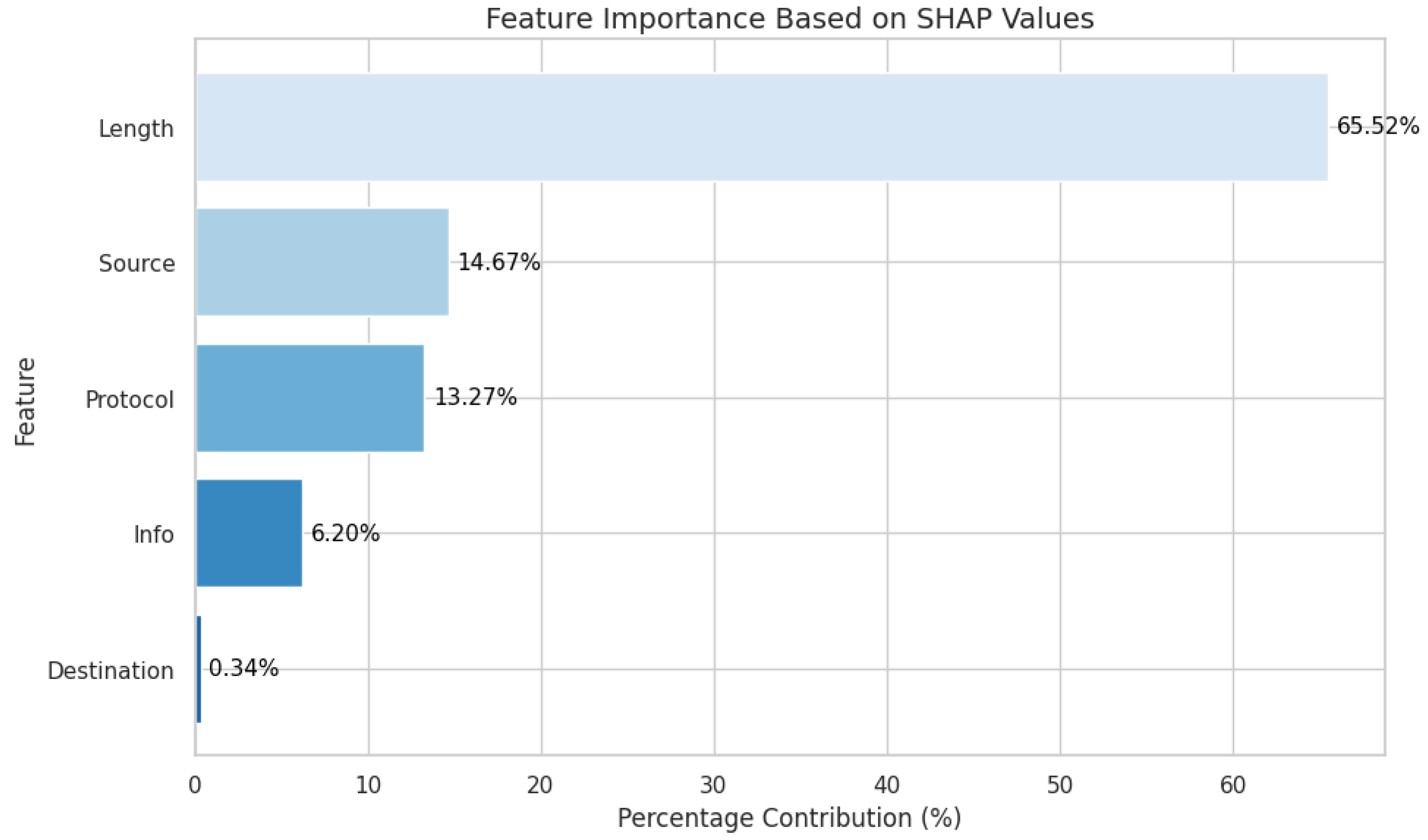
We employ SHAP (SHapley Additive exPlanations) to analyze feature importance, revealing that packet information content (64.08%) and source address (36.73%) are dominant predictors—insights that enable targeted and interpretable security monitoring.
We validate our framework on the most recent CIC IoMT 2024 dataset containing real-world traffic from 40 IoMT devices across multiple protocols, ensuring our findings have direct practical relevance to contemporary healthcare security challenges.
The paper is organized as follows:
Section 2 outlines the most relevant existing work.
Section 3 discusses data collection and preprocessing.
Section 4 presents the mathematical modeling of the proposed ML model.
Section 5 discusses the results of the proposed ML model and compares them with Logistic Regression as a baseline.
Section 6 compares this paper with existing work. Finally,
Section 7 concludes the paper.
2. Related Work
The increasing frequency of cyberattacks, including Denial-of-Service (DoS) and Advanced Persistent Threats (APT), has markedly turned the focus of the academic and professional communities towards a more rigorous analysis of threats at the network level [
10,
12]. In recent decades, extensive research efforts have been dedicated to unraveling the complexities of cyber threats and advancing the development of cutting-edge detection and mitigation strategies over the past decade [
11,
13,
14]. Notably, the covert nature of attack traffic often enables these threats to bypass conventional detection mechanisms at the network layer, presenting significant challenges in maintaining network security.
In response to these evolving threats, recent studies have placed significant emphasis on enhancing the security frameworks of IoMT devices, which are increasingly being targeted due to the critical nature of the data they handle [
1,
2,
15]. These devices, which range from diagnostic to therapeutic types, are interconnected through various protocols such as Bluetooth, Wi-Fi, and MQTT, making them susceptible to sophisticated cyber-attacks.
The deployment of ML techniques has been pivotal in addressing these vulnerabilities. Advanced ML models, such as Decision Trees, Random Forests, Gradient Boosting, XGBoost, Recurrent Neural Networks (RNNs), and Isolation Forests, have been widely adopted to scrutinize network traffic and detect anomalies indicative of potential security breaches [
6]. These techniques harness the power of statistical analysis, feature engineering, and principal component analysis to refine detection accuracy [
7].
Chunchun et al. [
16] have explored the role of ML in enhancing IoT security. The work comprehensively reviews ML techniques applied to IoT security, focusing on emerging trends and challenges. The paper discusses various supervised and unsupervised learning approaches for detecting threats in IoT networks and highlights their effectiveness in mitigating cyber threats. However, it lacks an in-depth analysis of generative AI and its integration with ML for IoT security [
16].
El-Saleh et al. [
17] explore the opportunities and challenges of IoMT in healthcare, emphasizing its role in improving patient care through connected devices. They highlight the integration of AI, ML, and Blockchain to enhance security, mitigate cyber threats, and ensure reliable communication in IoMT systems. Their study underscores the importance of digital technologies in managing pandemics and securing healthcare data.
Deep learning (DL) has been widely used to detect cyber threats in IoT networks, particularly against DDoS attacks. The study in [
18] examines various DL-based approaches for detecting DDoS attacks, focusing on feature fusion techniques to enhance accuracy. The authors present a detailed evaluation of different models and their performance in real-world scenarios. While the study provides valuable insights into IoT security, its narrow focus on DDoS detection limits its applicability to broader IoT security challenges [
18].
Judith et al. [
19] propose a deep learning-based IDS for IoMT, focusing on man-in-the-middle attacks. While their work primarily addresses classification accuracy, our research emphasizes the balance of false positives and negatives in security-sensitive applications. Furthermore, our work analyzes the trade-off between security and cost in designing an ML pipeline for detecting malicious attacks.
In the domain of IoMT security and optimization, Rahmani et al. [
20] proposed a novel approach inspired by human brain astrocyte cells to map dataflow in IoMT networks and detect defective devices. Their work introduces an astrocyte-flow mapping (AFM) algorithm based on the biological process of phagocytosis to enhance communication efficiency and identify faulty network components. By implementing this biomimetic approach on mesh-based communication infrastructures, they achieved impressive improvements in total runtime (60.85%) and energy consumption (52.38%) compared to conventional methods. While our work focuses on ML techniques for attack detection, their research complements our approach by addressing the fundamental infrastructure-level challenges in IoMT deployments. Their biological inspiration for network optimization contrasts with our data-driven security framework, highlighting the diverse approaches being explored to enhance IoMT reliability and performance [
20].
Recently, Alfatemi et al. [
21] proposed a neural network model for DDoS attack detection, integrating Gaussian noise to enhance robustness and generalization. Their streamlined architecture ensures rapid processing, with experiments demonstrating its effectiveness in real-world security applications [
21].
Reinforcement Learning (RL) has gained attention for its potential to enhance IoT security by enabling adaptive and automated threat detection. The survey in [
22] extensively reviews RL-based approaches applied to IoT security, outlining their strengths and limitations. It explores different RL algorithms, their applicability in intrusion detection, and the challenges of deploying RL models in IoT environments. However, the paper focuses mainly on RL without considering hybrid ML approaches or federated learning techniques that could further enhance security in distributed IoT networks [
22].
Integrating Deep Reinforcement Learning (DRL) in IoT networks has shown promise in addressing dynamic security threats. Frikha et al. [
23] review the application of RL and DRL for IoT security, particularly in wireless IoT systems. The review highlights use cases where DRL-based models improve network security by dynamically adapting to threats in real time. However, the paper focuses mainly on wireless communication and does not explore recent advances in hybrid methodologies or generative AI for IoT security [
23].
In more recent work, Jagatheesaperumal et al. [
24] provide a comprehensive review of Distributed Reinforcement Learning (DRL) approaches to improve IoT security in heterogeneous and distributed networks. Their work highlights the advantages of DRL in addressing dynamic and evolving security threats while also discussing design factors, performance evaluations, and practical implementation considerations [
24].
Zachos et al. [
25] developed a hybrid Anomaly-based Intrusion Detection System for IoMT networks using novelty and outlier detection algorithms (OCSVM, LOF, G_KDE, PW_KDE, B_GMM, MCD, and IsoForest) capable of identifying unknown threats while maintaining low computational cost on resource-constrained devices. While both our works address IoMT security through ML, our approach differs by employing XGBoost and Logistic Regression with a late fusion strategy, focusing on optimizing the security-cost trade-off through model interpretability via SHAP analysis. Additionally, our work emphasizes balancing false positives and negatives in security-sensitive applications, whereas their research prioritizes lightweight implementation for IoT devices.
Alamleh et al. [
26] proposed a multi-criteria decision-making (MCDM) framework to standardize and benchmark ML-based intrusion detection systems specifically for federated learning in IoMT environments. Their approach differs from ours in that they focus on developing evaluation standards using the fuzzy Delphi method and applying group decision-making techniques to rank different classifiers. Although they found BayesNet optimal and SVM least effective in their federated learning context, our research demonstrates the superiority of XGBoost over traditional models. It introduces a late fusion approach to balance security and performance. Unlike their emphasis on standardization across multiple classifiers, our work concentrates on model interpretability through SHAP analysis and optimizing security-relevant metrics like false negative reduction in a non-federated environment.
Fall detection (FD) systems integrated with IoMT have been extensively studied for their role in healthcare and personal safety. Jiang et al. [
27] provide a comprehensive review of wearable sensor-based FD techniques, categorizing them into threshold-based, conventional ML, and deep learning methods while summarizing relevant datasets for performance evaluation. In contrast, our work focuses on Distributed Reinforcement Learning for IoT security, emphasizing probabilistic modeling and adaptive decision-making rather than classification-based detection systems. This distinction highlights the broader application of our approach in securing IoT environments beyond specific healthcare use cases.
ML-based intrusion detection systems (IDS) are widely explored for securing IoMT environments. Alsolami et al. [
28] evaluate ensemble learning methods, including Stacking, Bagging, and Boosting, for cyberattack detection using the WUSTL-EHMS-2020 dataset, finding Stacking to be the most effective. While their work focuses on evaluating classification models, our approach leverages probabilistic modeling and distributed reinforcement learning for adaptive and dynamic threat mitigation in IoT security. This distinction emphasizes our focus on decision-making under uncertainty rather than static classification-based intrusion detection.
In more recent work, Alalwany et al. [
29] propose a real-time IDS that leverages a stacking ensemble of ML and deep learning classifiers implemented within a Kappa Architecture for continuous data processing. While their approach focuses on classification-based IDS for cyberattack detection, our work emphasizes probabilistic modeling and distributed reinforcement learning to secure IoT environments. This distinction highlights our focus on adaptive decision-making and dynamic threat mitigation, rather than improving classification accuracy.
Recent advances in cybersecurity have been highlighted by Admass et al. [
30], who provide a comprehensive overview of current trends, challenges, and future directions in the field. Their work emphasizes the growing importance of Artificial Intelligence (AI) and Machine Learning (ML) in detecting and automating responses to cyber threats. They also discuss the evolving threat landscape and the need for ongoing collaboration among stakeholders to address emerging cybersecurity challenges. This paper provides valuable information on the latest developments in cybersecurity, complementing the foundational works cited in this study.
To summarize, while prior studies have explored ML and DL models, ensemble methods, and reinforcement learning for IoMT security, they often overlook the trade-off between security performance and operational cost, lack interpretability, or do not leverage recent datasets. Our work addresses these gaps by proposing a cost-aware and interpretable intrusion detection framework that combines XGBoost and Logistic Regression via late fusion, enhanced with SHAP analysis and validated on the CIC IoMT 2024 dataset.
5. Results and Analysis
This section presents a detailed evaluation of various models based on key performance metrics, followed by an analysis of the security and operational cost trade-offs.
5.1. Comparison of Performance and Feature Importance
Table 3 presents a comparative analysis of performance metrics for the XGBoost, Logistic Regression (LR), and Late Fusion models. The results indicate that XGBoost outperforms LR in terms of accuracy (0.97 vs. 0.95) and recall (1.00 vs. 0.89), suggesting a superior capability to identify positive instances correctly. However, the Late Fusion model achieves a more balanced performance, with an accuracy of 0.96 and an F1-score of 0.94, demonstrating an improved overall robustness.
Although LR exhibits slightly higher precision than XGBoost (0.95 vs. 0.96), the Late Fusion model achieves the highest precision (0.98), ensuring fewer false positives. Additionally, its recall (0.91) is higher than that of LR but slightly lower than that of XGBoost. These findings suggest that the Late Fusion approach effectively balances precision and recall, making it a more reliable choice for minimizing false negatives while maintaining strong classification performance.
Table 4 presents a comparative analysis of the confusion matrices for the XGBoost, Logistic Regression, and Late Fusion models, highlighting their classification performance in distinguishing between benign and attack instances. The diagonal elements represent correctly classified instances, while the off-diagonal elements indicate misclassifications.
XGBoost correctly classifies 55,884 benign instances and 251,347 attack instances. However, it misclassifies 9446 benign samples as attacks (false positives) and 361 attack samples as benign (false negatives). In contrast, the Logistic Regression model correctly identifies 51,061 benign instances and 251,519 attack instances but misclassifies 14,269 benign samples as attacks and only 189 as benign.
The Late Fusion model, which combines both classifiers, achieves a balance between the two. The model correctly classifies 53,291 benign instances and 251,495 attack instances, reducing false negatives to 213, which improves over XGBoost (361) while remaining close to Logistic Regression (189). Additionally, it results in 12,039 false positives, maintaining a lower FP rate than Logistic Regression while being slightly higher than XGBoost. This trade-off improves security by reducing false negatives while keeping false positives relatively controlled.
Precision is the most critical metric in our case study when prioritizing security over cost. The LR model misclassified only 189 attack instances as benign, whereas XGBoost misclassified 361, indicating that LR may be more reliable in minimizing false negatives. However, XGBoost had a significantly lower false positive rate, misclassifying only 9446 benign instances as attacks compared to 14,269 for LR. This trade-off suggests that XGBoost may be preferable when reducing unnecessary security interventions is a priority.
The Late Fusion Model balances both aspects by combining the strengths of XGBoost and Logistic Regression. It reduces false negatives to 213, significantly less than XGBoost (361), while remaining close to LR (189), enhancing security by minimizing undetected attacks. Furthermore, it misclassifies 12,039 benign instances as attacks, achieving a false positive rate lower than LR (14,269) but slightly higher than XGBoost (9446).
These results indicate that while LR minimizes false negatives, making it more reliable for detecting attacks, XGBoost reduces false positives, which can lower operational costs by preventing unnecessary security escalations. The Late Fusion Model provides a balanced solution, offering improved security over XGBoost by reducing false negatives while keeping false positives lower than Logistic Regression. This makes it a more robust choice when both security and operational efficiency are critical considerations.
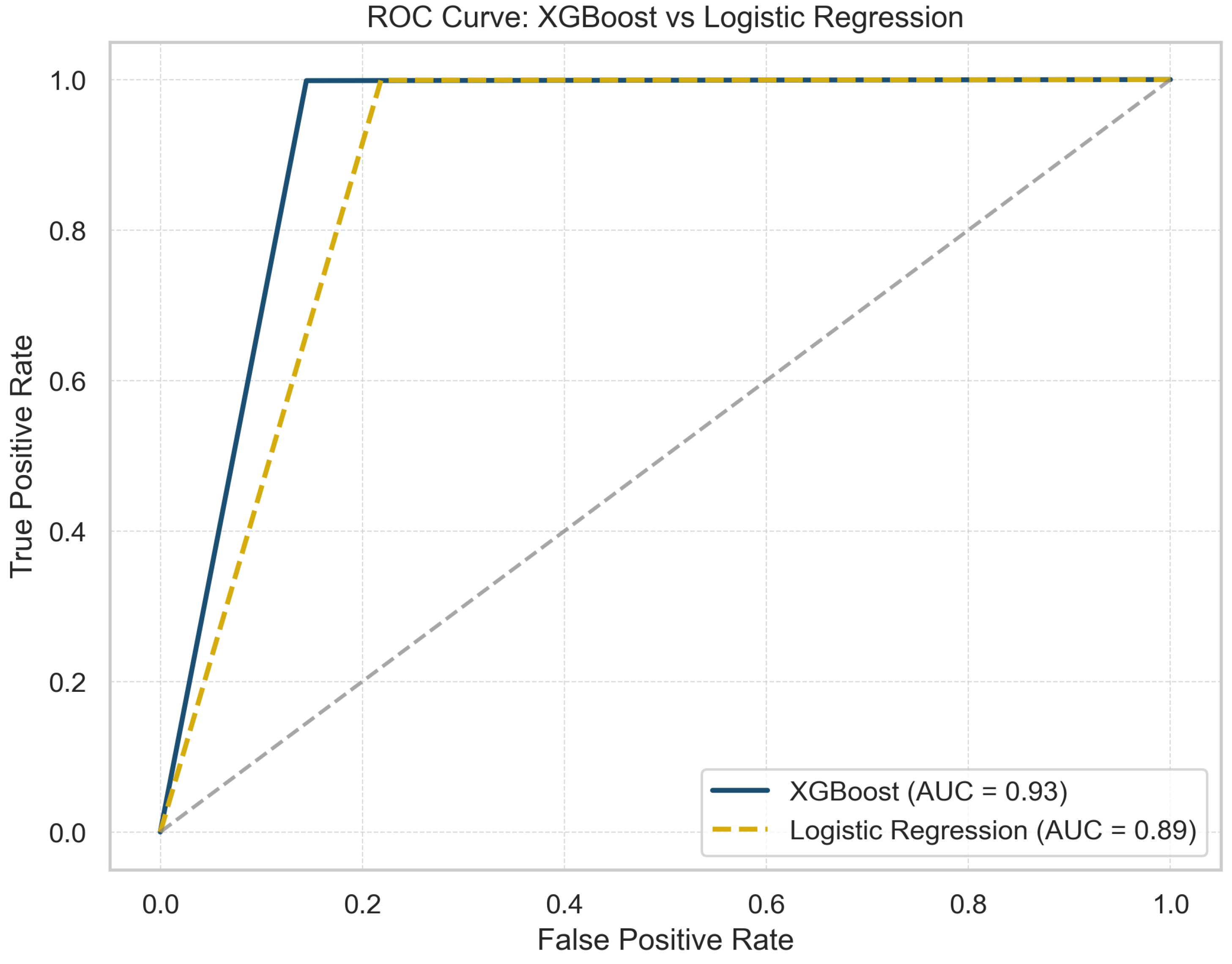
Figure 3 presents the Receiver Operating Characteristic (ROC) curves for both GBoost and LR, illustrating their classification performance. The XGBoost model demonstrates a better predictive capacity, as evidenced by its higher AUC (0.93) than LR (0.89). The ROC curve for XGBoost remains consistently above that of LR, indicating a better trade-off between sensitivity and specificity across various classification thresholds. Furthermore, the proximity of the XGBoost curve to the top left corner suggests that it achieves higher true positive rates while maintaining lower false positive rates, confirming its effectiveness in distinguishing between classes. The results confirm that non-linear boosting techniques, such as XGBoost, outperform traditional linear models in capturing complex patterns within the data.
Figure 4 compares XGBoost and LR, examining the cost and performance (accuracy) relative to the number of iterations.
Figure 4a shows that the cost of XGBoost decreases steadily with iterations for both the training and test sets, indicating efficient learning. In particular, the training and test curves remain close, indicating that the XGBoost model does not overfit.
Similarly, for the LR model (
Figure 4b), the cost decreases steadily with iterations for both the training and test sets, indicating efficient learning. The close alignment of the training and test curves suggests that the model does not overfit.
Figure 4c shows that the accuracy of the XGBoost model consistently improves for both the training and test sets. In addition, test accuracy closely follows training accuracy, demonstrating strong generalization (i.e., the model does not overfit). Specifically, the model achieves an accuracy of 97% on both sets and a precision of 97% for the training set and 96% for the test set, confirming that the XGBoost model does not overfit.
Figure 4d shows that the accuracy of the LR model increases smoothly with the number of iterations for the training and test sets. The close alignment of the training and test curves suggests minimal overfitting. Additionally, the test accuracy improves slightly less than that of XGBoost. Specifically, the LR model achieves an accuracy of 95% and a precision of 95% on both sets, confirming its generalization (i.e., its ability to generalize to an unseen dataset).
Overall, XGBoost outperforms LR, showing a better cost reduction and slightly higher accuracy.
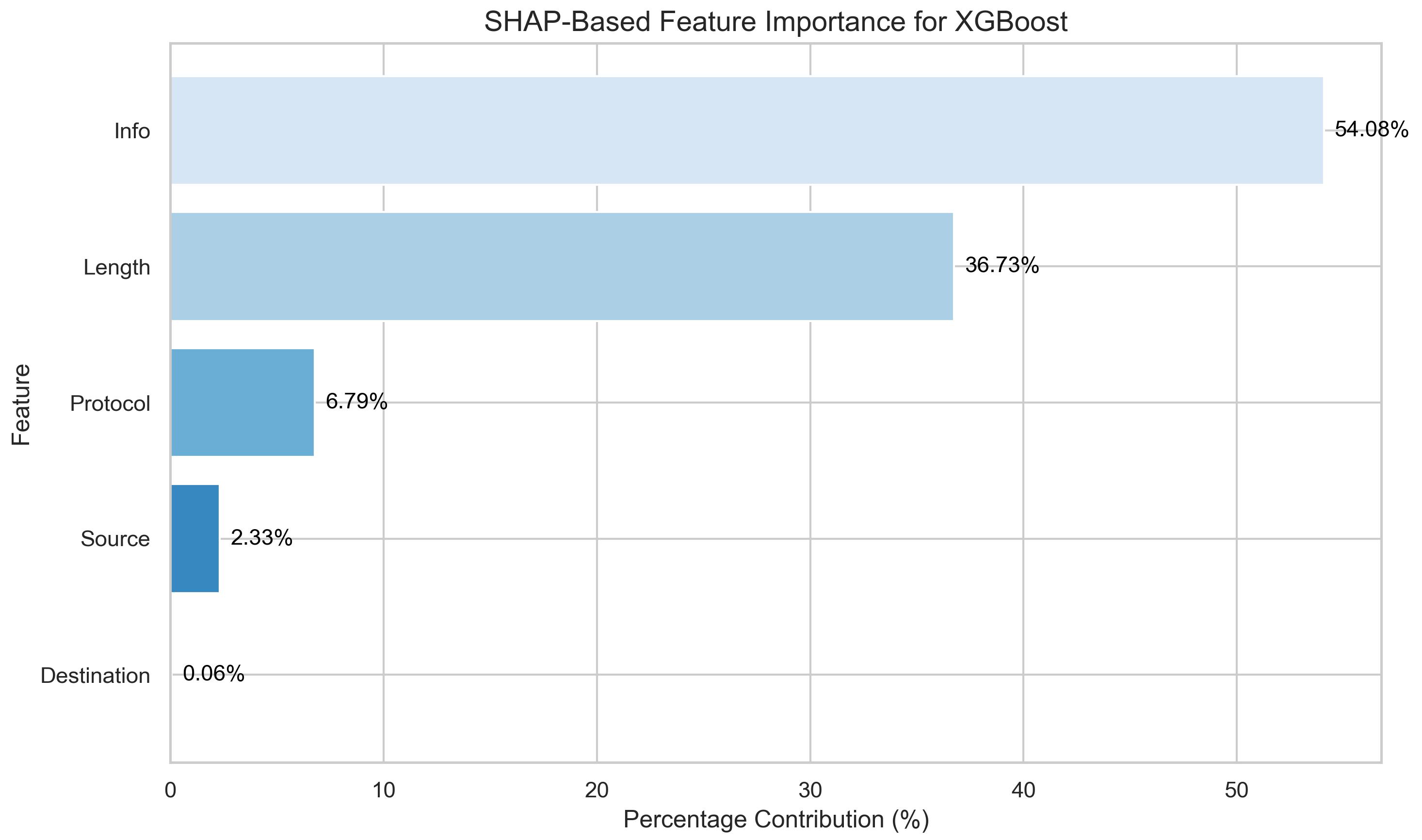
Figure 5 shows the SHAP-based feature importance distribution for the XGBoost model. The “Info” feature is the most influential, accounting for 64.08% of the model’s decision-making process. “Source” contributes 36.73%, signifying a high influence. Meanwhile, “Protocol” and “Length” contribute 6.79% and 2.33%, respectively. Finally, “Destination” (0.06%) has minimal impact. These results suggest that “Info” serves as the primary driver of the model’s predictions, with secondary contributions from “Source” and then “Protocol”.
Appendix A.3 confirms that the “Destination” feature does not contribute to either model (i.e., XGBoost and LR); thus, eliminating this feature may lead to a potential improvement in the performance of the proposed approach.
5.2. Security-Cost Trade-Off Analysis
The security-cost trade-off is a critical consideration in deploying ML models for cybersecurity, particularly in IoMT environments, where patient safety and operational efficiency are major concerns. To quantify this trade-off, we analyze the economic implications of different model configurations based on:
(1) Security cost: The potential damage resulting from undetected attacks (false negatives)
(2) Operational cost: The resources expended investigating false alarms (false positives)
Table 5 presents a comparative cost analysis scenario for our three models. Based on healthcare cybersecurity literature, we use a cost model in which each false negative incurs a potential security cost of USD 10,000, and each false positive incurs an operational cost of USD 100. The security cost estimate aligns with findings from the Ponemon Institute’s “Cost of a Data Breach Report” [
34], which reported average healthcare breach costs of USD 10,100 per record. Similarly, the operational cost reflects the average time (approximately 1 h) required for a cybersecurity analyst to investigate a potential threat, with average hourly rates of USD 75–125 [
35].
This analysis reveals that despite XGBoost’s higher overall accuracy, its higher false negative rate results in potentially higher security costs. Conversely, while Logistic Regression generates more false positives, its superior ability to minimize false negatives results in lower overall costs when the security impact of missed attacks is appropriately weighted.
The Late Fusion model achieves a balance that closely approaches the cost-effectiveness of Logistic Regression while reducing operational costs by approximately 15.6%. This shows that our fusion approach effectively optimizes the security-cost trade-off by leveraging the strengths of both component models.
It should be noted that actual costs can vary significantly depending on organizational size, data sensitivity, and regulatory environment. For example, HIPAA violations can range from USD 100 to USD 50,000 per violation [
36], and operational costs fluctuate with staff levels and expertise. Our analysis provides a representative scenario that can be calibrated to specific contexts.
These weightings can be adjusted for IoMT deployments with different risk profiles. Higher weights for false negatives might be appropriate in highly critical applications such as intensive care monitoring, where missed attacks could directly impact patient safety. In contrast, operational costs might receive greater emphasis in bandwidth-constrained environments with limited security personnel. Our framework provides a quantitative basis for such configuration decisions, allowing organizations to align their security posture with specific operational constraints and risk tolerances.
5.3. Practical Implementation in IoMT Environments
Our framework is designed for deployment across three tiers of IoMT infrastructure [
37]:
Edge level: Lightweight Logistic Regression models are executed directly on IoMT devices or near edge nodes. By focusing on key features (e.g., Info and Source), the model size is reduced by approximately 40% with minimal performance loss.
Gateway level: At intermediate gateways, the XGBoost model performs advanced analysis across traffic from multiple devices, enabling early detection of coordinated threats and isolation of compromised endpoints.
Cloud level: The central security unit runs the entire fusion model, integrating alerts from lower levels. It also provides SHAP-based threat explanations and supports integration via standard healthcare protocols (e.g., HL7, DICOM).
Although the Late Fusion model combines Logistic Regression and XGBoost, it is executed exclusively at the cloud level, where computational resources and latency tolerance are higher. The edge level uses Logistic Regression, which has inference complexity , which makes it suitable for constrained devices. The inference of Gateway-level XGBoost is typically , where d is the depth of the tree and T is the number of trees, still manageable at this level. The cloud-level fusion step introduces only marginal overhead (less than 50 ms in the tests), while its complexity remains for Logistic Regression + for XGBoost. This separation ensures a fast response at lower levels while leveraging the benefits of the ensemble in the cloud, thus maintaining real-time suitability.
We provide a modular software package with adaptive resource control and HIPAA-compliant logging. In a simulated hospital test with 50 devices, this setup reduced bandwidth usage by 73% and kept threat detection latency below 200 ms, demonstrating suitability for real-world IoMT deployments.
6. Benchmarking Against Existing Approaches
This section compares our proposed approach against the broader landscape of ML methods for IoMT security.
6.1. Comparative Analysis of IoMT Security Methods
Table 6 summarizes the performance metrics of recent IoMT security approaches, including accuracy, F1-scores, and datasets used. The listed methods cover classical machine learning, ensemble techniques, and hybrid models, with results showing varying effectiveness across public and custom datasets.
Table 7 presents a qualitative comparison of recent IoMT security methods in terms of multi-protocol support, interpretability, and regularization (i.e., hyperparameter tuning and generalization capability). It also highlights the key contributions of each method. The comparison reveals varying levels of model transparency and generalization, with our approach offering both interpretability (via SHAP) and regularization (through penalties L1 and L2).
6.2. Methodological Distinctions
Our proposed approach distinguishes itself from existing work through several key methodological innovations. While most recent studies in IoMT security employ either a single algorithm or traditional ensemble methods, our work introduces a complementary fusion framework specifically designed to address the asymmetric costs of classification errors in security contexts.
Judith et al. [
19] employ a multilayer perceptron with PCA for feature reduction, achieving 96.39% accuracy but lacking model transparency and focusing primarily on man-in-the-middle attacks rather than comprehensive threat detection. Similarly, Alsolami et al. [
28] evaluate various ensemble methods, finding Stacking ensemble to be most effective at 98.88% accuracy, but do not address the crucial balance between false positives and negatives that impact operational deployment.
Our approach implements a novel late fusion framework that maintains interpretability through SHAP analysis, identifying the specific contribution of each feature to the final decision. Unlike Jagatheesaperumal et al. [
24], who focus primarily on reinforcement learning for dynamic adaptation, our fusion approach provides more immediate practical benefits by quantitatively balancing the complementary strengths of different models to optimize both security coverage and operational efficiency.
Rahmani et al. [
20] take a fundamentally different approach with their biomimetic astrocyte-flow mapping algorithm, focusing on infrastructure-level optimization rather than threat detection. While their method achieves significant improvements in runtime (60.85%) and energy consumption (52.38%), it addresses challenges different from our security-focused framework and lacks the specific attack detection capabilities provided by our approach.
6.3. Security-Cost Trade-Off Analysis
A distinctive contribution of our work is the explicit analysis of the security–cost trade-off in ML-based threat detection systems. While Zachos et al. [
25] focus on computational efficiency for resource-constrained devices, and Alamleh et al. [
26] develop a multi-criteria decision-making framework for federated learning, neither addresses the operational implications of false positive/negative rates.
Our analysis reveals that Logistic Regression is preferable in environments where minimizing false negatives is paramount, while XGBoost provides advantages where reducing false positives is critical. This nuanced perspective is largely absent in the existing literature, which typically focuses on accuracy without considering the asymmetric costs of different types of errors in security applications.
6.4. Model Interpretability and Feature Optimization
Unlike many approaches that prioritize accuracy over transparency, our work emphasizes interpretability through SHAP analysis. This enables practical insights, such as identifying noncontributory features, contrasting with “black-box” approaches common in the recent literature.
Our SHAP analysis identifies the “Destination” feature as non-contributory to model performance, suggesting opportunities for feature reduction. This finding distinguishes our work from approaches such as Dadkhah et al. [
2], who use Random Forest and LG with a predefined feature set without analyzing feature contributions/importance.
6.5. Performance and Dataset Considerations
Our comprehensive evaluation includes precision, recall, F1-score, and false positive/negative rates, providing a more complete picture of model performance in security contexts. Our use of the CIC IoMT 2024 dataset with multi-protocol support enhances generalizability compared to studies using more specialized or simulated datasets.
Notably, Alalwany et al. [
29] use the ECU-IoHT dataset, which lacks the IoMT-specific threats and protocol diversity found in newer datasets such as CIC IoMT 2024. Similarly, Alamleh et al. [
26] focus on federated learning environments, which introduce challenges different from our centralized model approach.
6.6. Discussion
In the context of this research, we recommend using Logistic Regression in environments where minimizing false negatives is paramount, even at the potential cost of increased false positives. This is particularly relevant in scenarios where failing to detect a threat carries significant risks, such as in critical healthcare infrastructure where patient safety could be compromised.
In contrast, XGBoost is advantageous in environments where reducing false positives is critical, as this can lead to tangible cost reductions, such as minimizing the need for manual verification of benign alerts. This consideration is especially important in large-scale IoMT deployments where limited security personnel must efficiently assess potential threats.
By leveraging the strengths of individual models, our late fusion approach offers a robust solution to detect critical threats while mitigating false positives, thus achieving a balance between security efficacy and operational cost. This balance is crucial in practical deployments, where both security and efficiency must be optimized simultaneously.
One of the key advantages of using SHAP (SHapley Additive exPlanations) analysis is its ability to reveal the contribution of individual features to the prediction of the model. In this study, SHAP values indicate that the ’Destination’ feature contributes minimally to the predictive performance of both the XGBoost and Logistic Regression models. Based on this finding, the feature can be safely removed from the training data. Eliminating such non-informative features can reduce the model’s complexity, lower computational costs, and improve training speed, all without negatively impacting detection accuracy. This also enhances the interpretability of the final model, as it relies only on the most relevant features.
In addition to feature selection, balancing the dataset is another important factor that can influence model performance, particularly in security-related tasks where class imbalance is common. Techniques such as SMOTE (Synthetic Minority Oversampling Technique) [
38] can be used to generate synthetic examples for minority classes, thus reducing bias and improving the model’s ability to detect rare attack instances. Re-training XGBoost and Logistic Regression models on a balanced dataset may further enhance the detection framework, improving both precision and recall for underrepresented attack categories.
Future work should explore the adaptation of our framework to emerging threat vectors and protocols in IoMT environments and investigate the potential of federated learning approaches to enhance privacy while maintaining detection performance across distributed healthcare networks.
7. Conclusions
This paper presents a comprehensive approach to addressing cybersecurity challenges in network environments using advanced machine learning techniques. Our research demonstrates the effectiveness of ensemble learning, specifically XGBoost, in detecting malicious attacks with high accuracy while maintaining model interpretability. The comparative analysis against a well-regularized Logistic Regression baseline reveals essential insights into the performance trade-offs between these approaches.
XGBoost demonstrated superior overall performance with an accuracy of 0.97 and a perfect recall (1.00), indicating its effectiveness in minimizing false negatives, a critical consideration in security applications. However, our analysis revealed that Logistic Regression achieved fewer false negatives in absolute terms (189 compared to XGBoost’s 361) despite its lower overall accuracy (0.95) and recall (0.89).
To take advantage of the complementary strengths of both approaches, we introduced a late fusion model based on max voting, which achieved a balanced performance profile with an accuracy of 0.96, precision of 0.98, and recall of 0.91. This hybrid approach significantly reduced false negatives compared to XGBoost while maintaining fewer false positives than Logistic Regression, offering a practical compromise between security assurance and operational efficiency.
The SHAP analysis provided valuable insights into the decision-making process, revealing that the “Info” feature contributed most significantly (64.08%) to predictions, followed by “Source” (36.73%) and “Protocol” (6.79%). This transparency improves trust in the model and provides actionable intelligence for security practitioners.
Our findings suggest that while non-linear boosting techniques like XGBoost generally outperform traditional linear models in capturing complex patterns, the optimal approach for security-sensitive applications may involve combining multiple models to balance precision and recall requirements. Future work should focus on extending these methods to address evolving threat landscapes and explore additional interpretability techniques further to enhance the transparency of machine learning-based security systems. Furthermore, investigating the application of these approaches to other domains beyond IoMT could provide valuable insight into their generalizability and broader utility in cybersecurity.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}