


Exploring the Entropy-Based Classification of Time Series Using Visibility Graphs from Chaotic Maps

 ,
,  ,
,  ,
,  and
and 
Abstract
1. Introduction
- A concept for comparing the efficiency of classifying chaotic time series using entropy-based features is presented. The developed methodology can be used in classification problems for financial, biological, and medical signals.
- A new characteristic for assessing the global efficiency of entropy (GEFMCC) is presented. GEFMCC is calculated based on synthetic databases generated by four chaotic mappings.
- The Python package for GEFMCC calculation is developed.
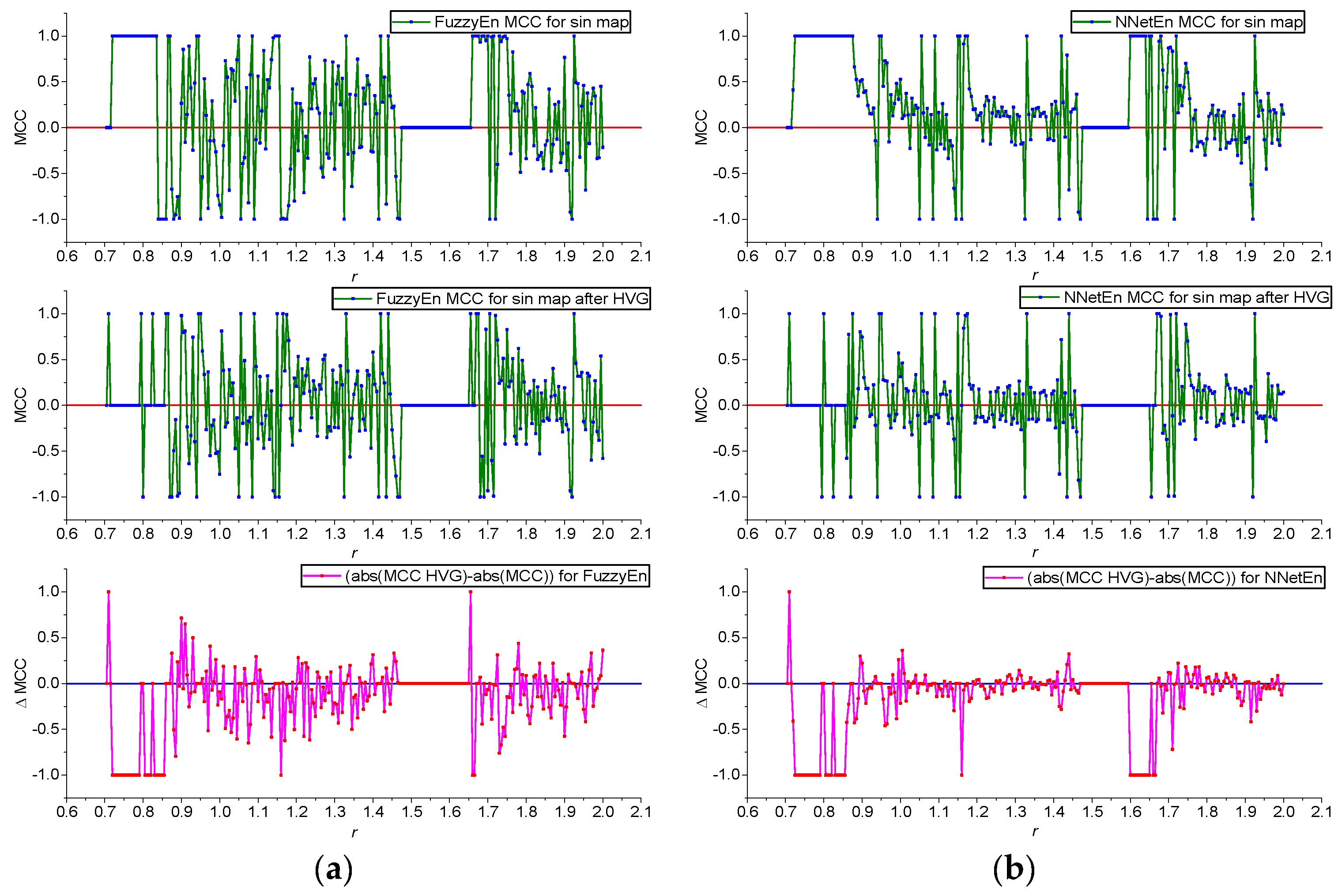
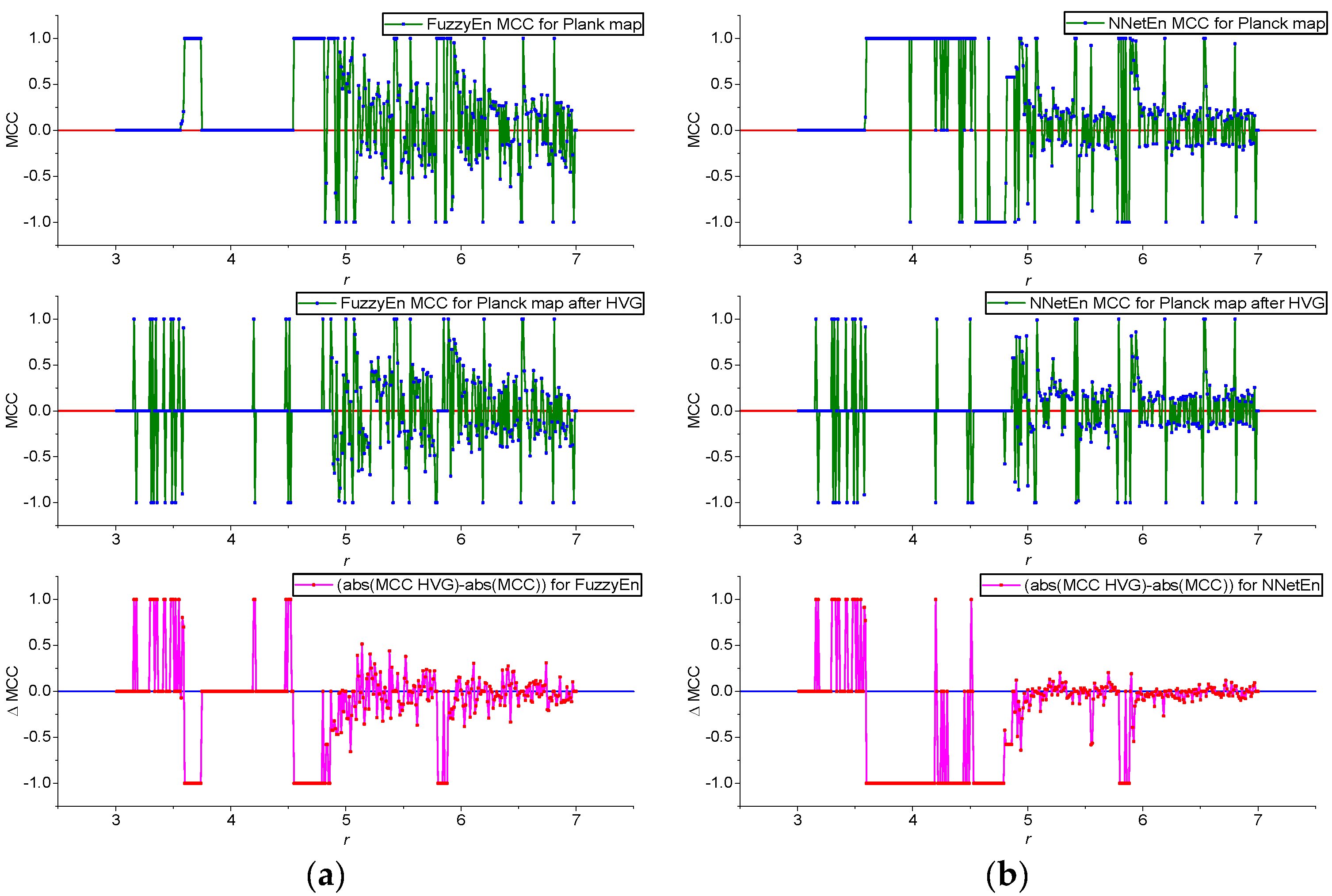
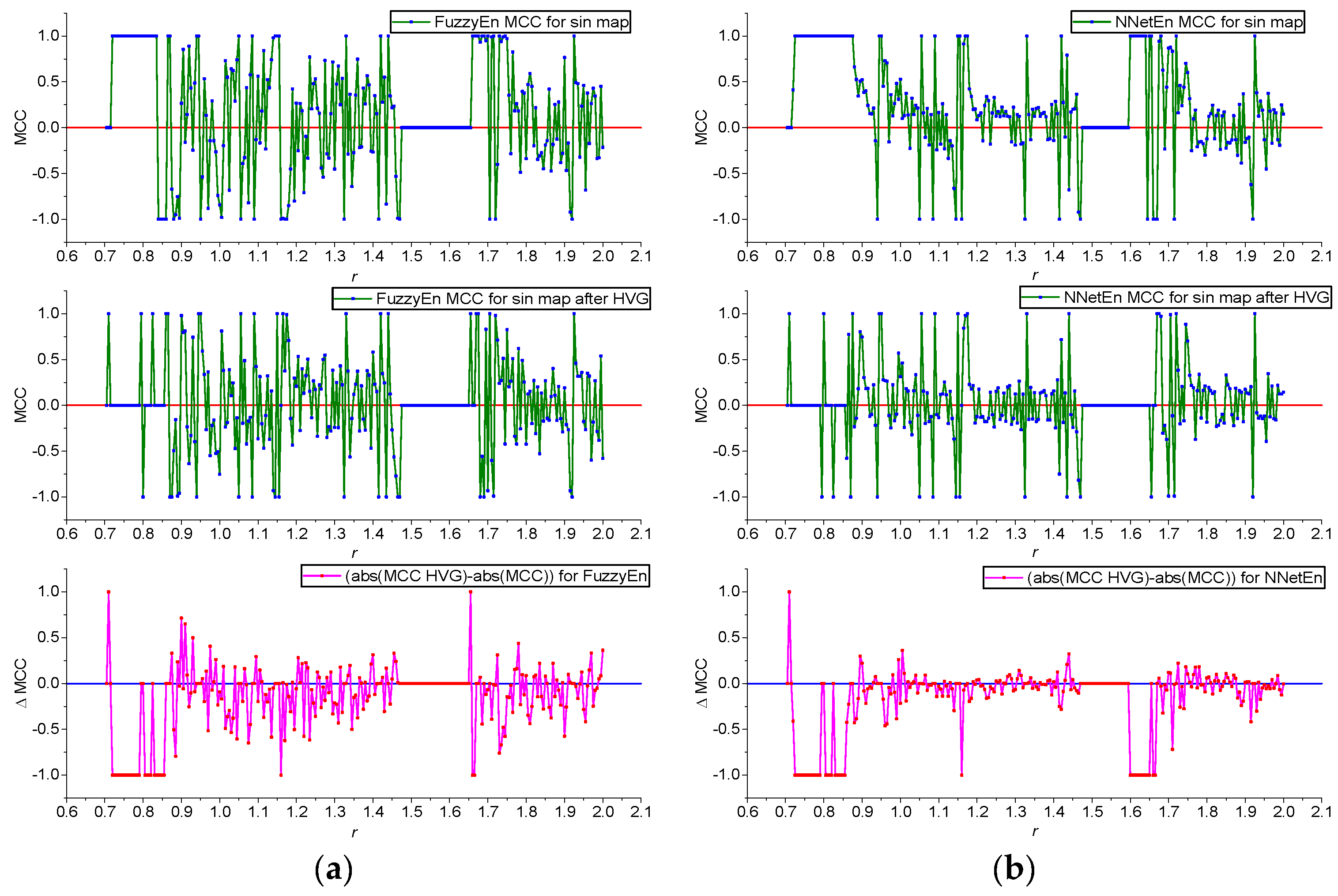
- A comparison of the effectiveness of FuzzyEn (m = 1, r = 0.2∙d, r2 = 3, τ = 1) and NNetEn (D1, 1, M3, Ep5, Acc) was investigated. FuzzyEn is shown to have improved GEFMCC in the classification task compared to NNetEn. At the same time, there are local areas of the time series dynamics in which the classification efficiency NNetEn is higher than FuzzyEn. The Matthews correlation coefficient was used to evaluate binary classification.
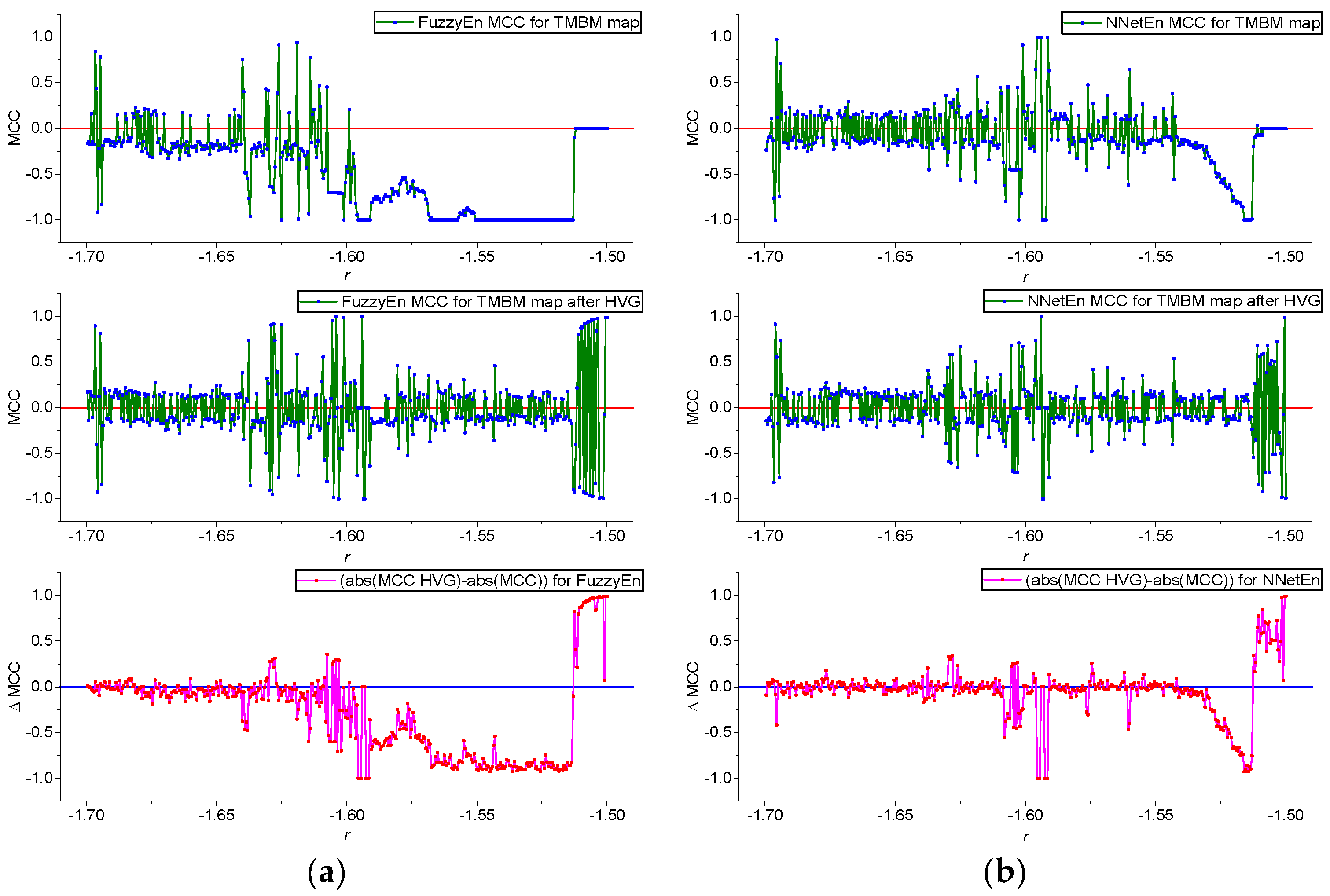
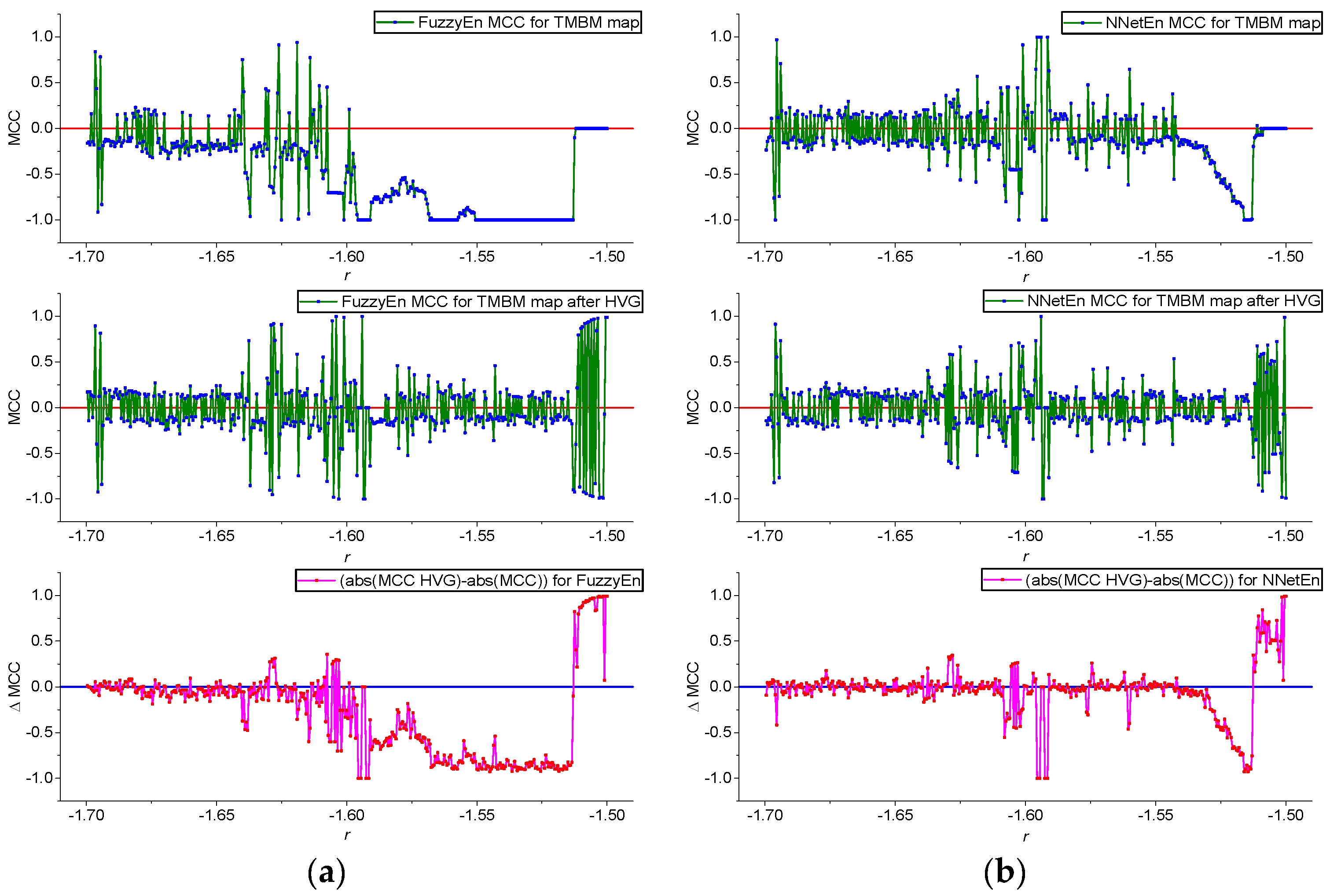
- The results of using HVG are shown. GEFMCC decreases after HVG time series transformation, but there are local areas of time series dynamics in which the classification efficiency increases after HVG.
2. Materials and Methods
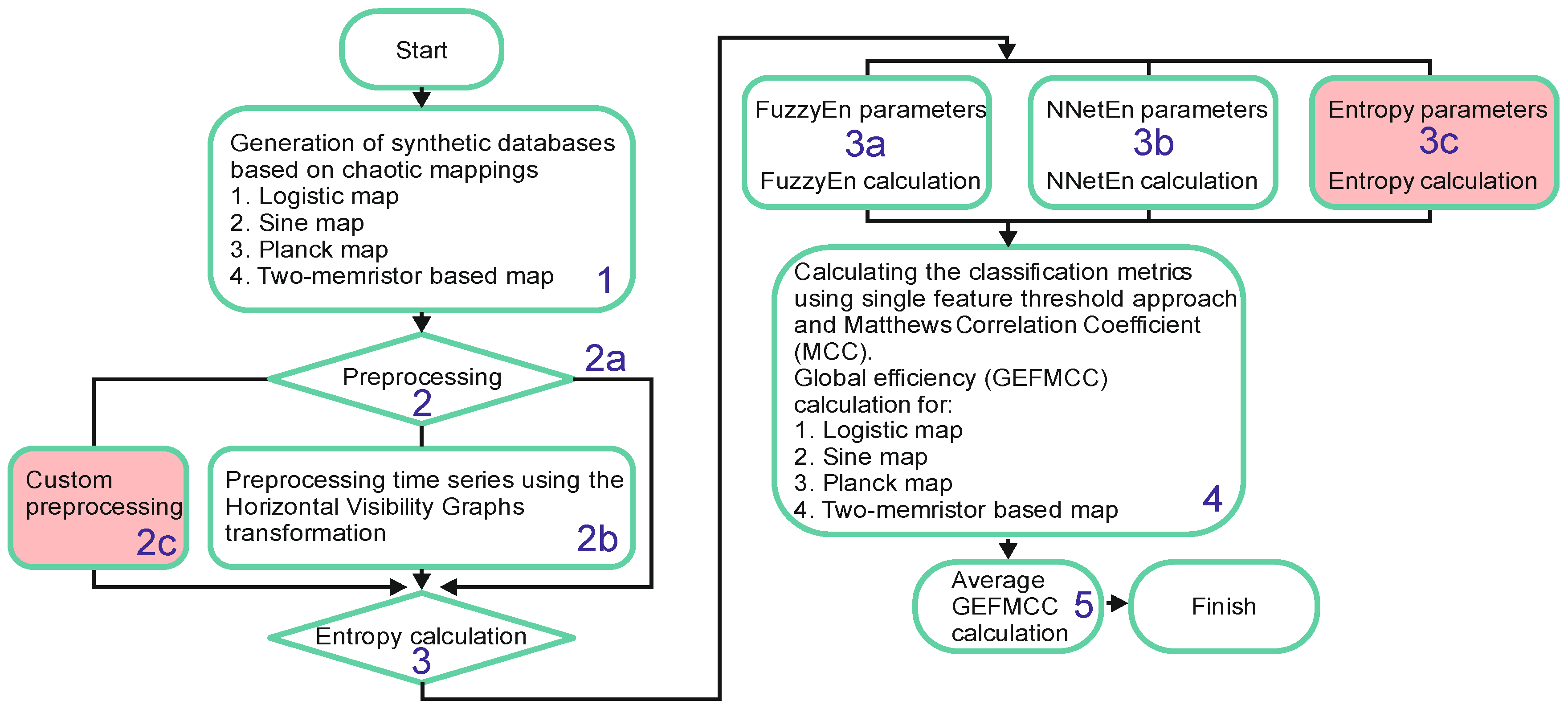
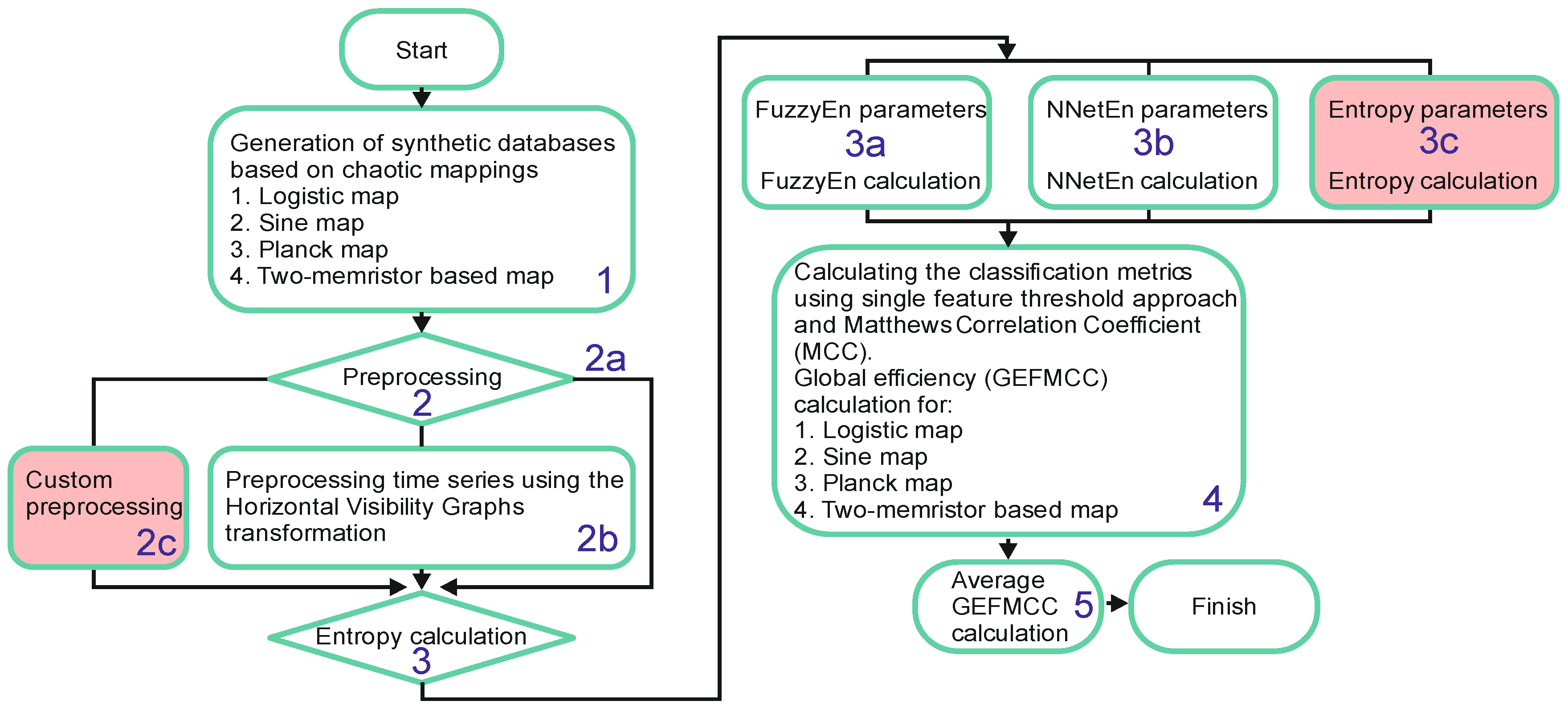
2.1. The Workflow Diagram of the Proposed Method
2.2. Generation of Synthetic Time Series (Stage 1)
- 2.
- Sine map [45]:
- 3.
- Planck map [45]:
- 4.
- Two-memristor-based map (TMBM) [46]:
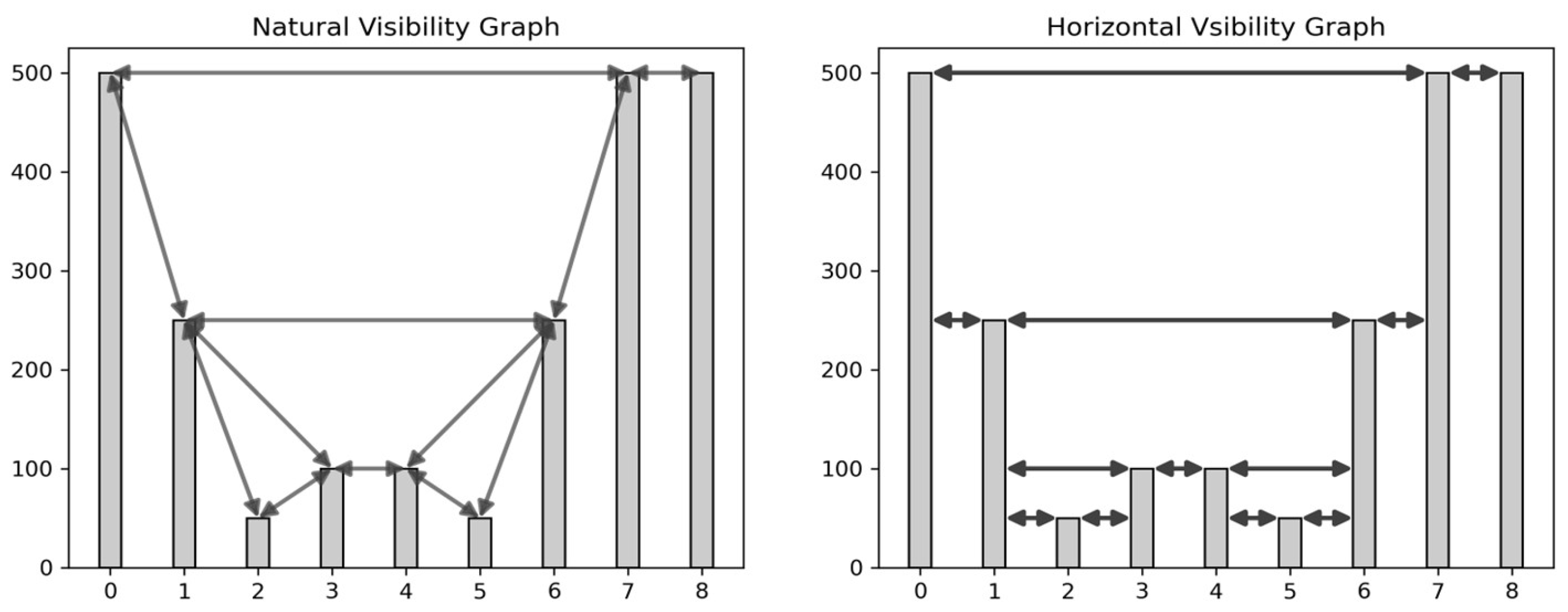
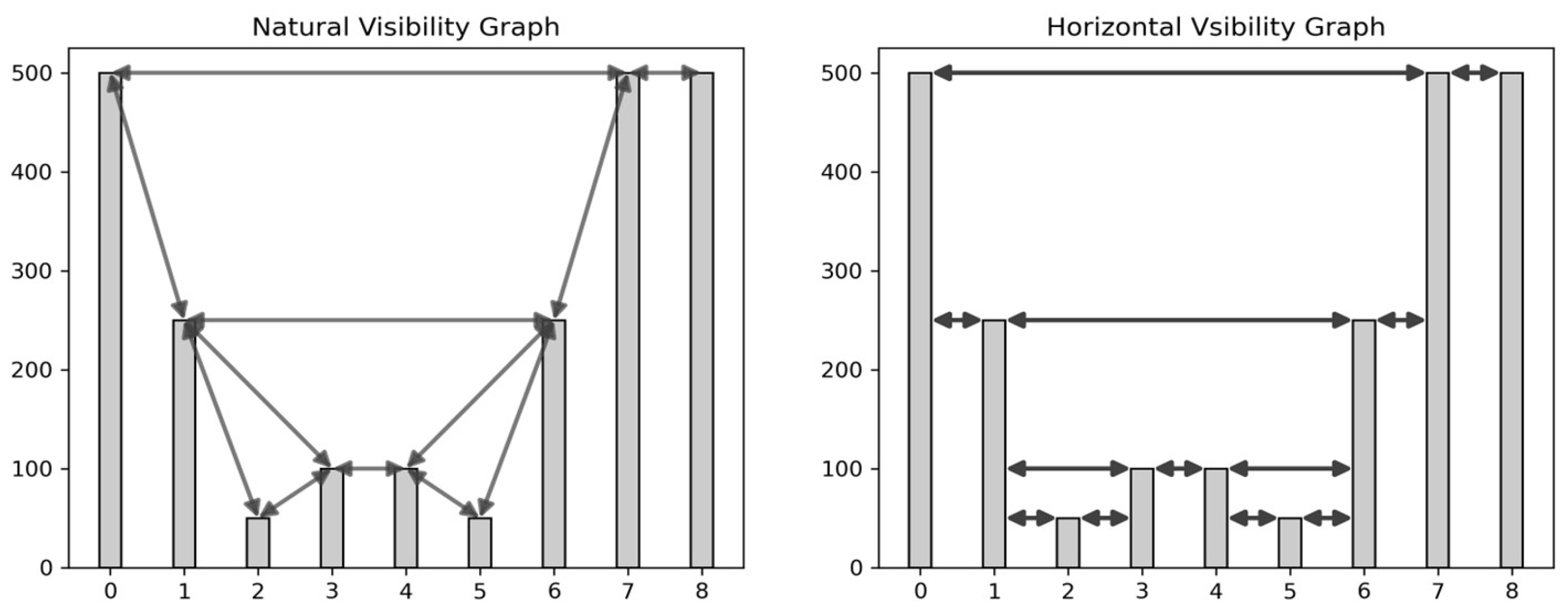
2.3. Natural and Horizontal Visibility Graphs (Stage 2b)
2.4. FuzzyEn Calculation (Stage 3a)
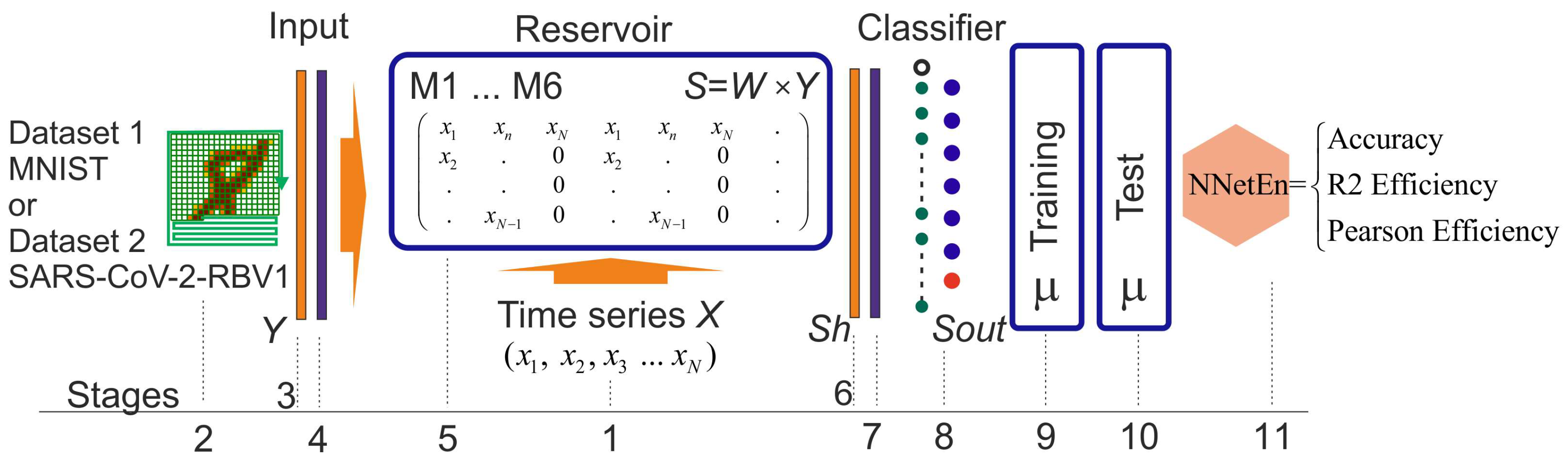
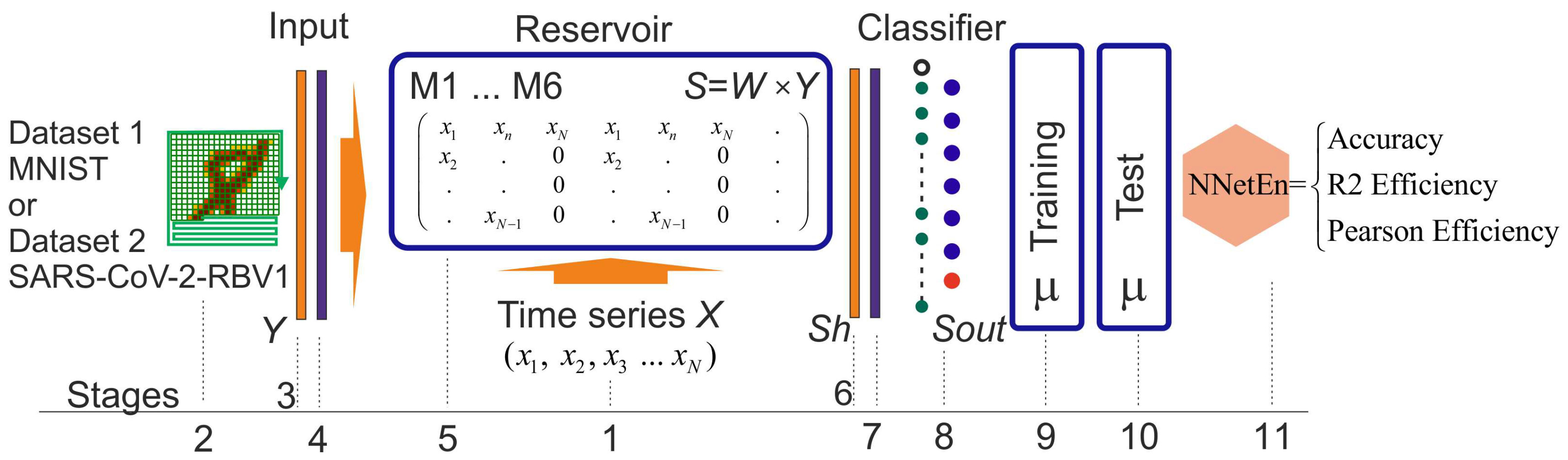
2.5. NNetEn Calculation (Stage 3b)
2.6. Time Series Classification Metrics (Stages 4)
2.7. Calculation of the Average GEFMCC Value (Stage 5)
2.8. Python Package for GEFMCC Calculation
| Listing 1. An example configuration of the Python script and function global_map_generator. |
| > > > import map_generate ….. > > > base_config = { ‘config_gen’: { ‘log_map’: { ‘N_ser’: 100, ‘N_el’: 300, ‘h1’: 3.4, ‘h2’: 4, ‘h_step’: 0.002, ‘n_ignor’: 1000, ‘x0’: 0.1 }, ….. }, ‘config_entropy’: { ‘use_chaotic_map’: ‘log_map’, ‘type_entropy’: ‘fuzzy’, ‘process’: 20, ‘transform’: ‘hvg’, ‘fuzzyen_params’: { ‘fuzzy_m’: 1, ‘fuzzy_r1’: 0.2, ‘fuzzy_r2’: 3, ‘fuzzy_t’: 1 }, ‘nneten_params’: { …. }, } …… > > > map_generate.global_map_generator(base_config) |
| Listing 2. Command to transformation HVG. |
| > > > from transform import generate_hvg_series …. > > > time_series = generate_hvg_series(data) |
- Data—unprocessed time series.
| Listing 3. An example of Python function global_calculate_entropy for entropy calculation. |
| > > > import entropy …. > > > entropy.global_calculate_entropy(base_config) |
- base_config (see Listing 1).
| Listing 4. Command to classify using a single-feature threshold approach. |
| > > > import classification …. > > > classification.global_calculate_gefmcc(base_config) |
- base_config (see Listing 1).
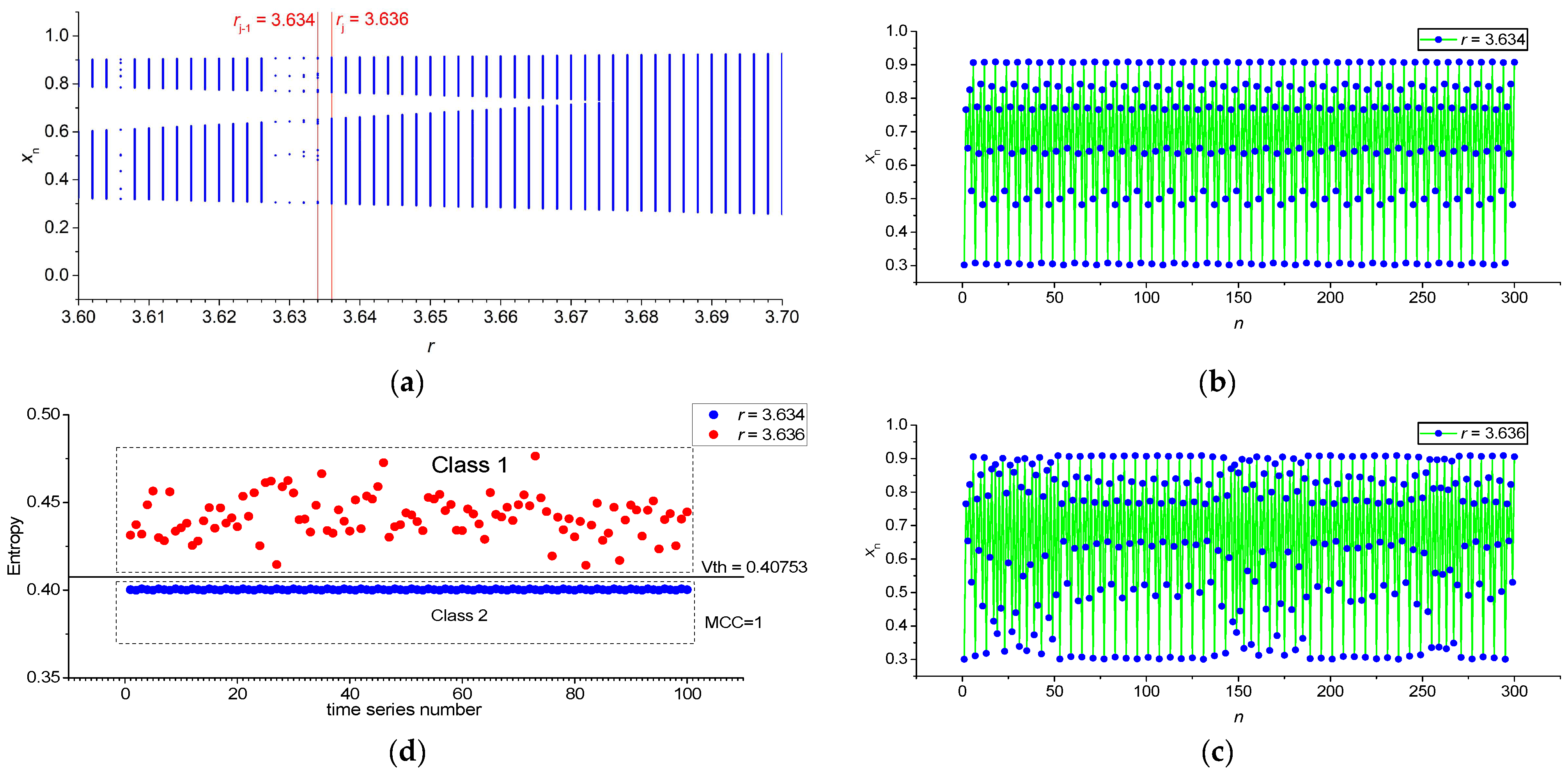
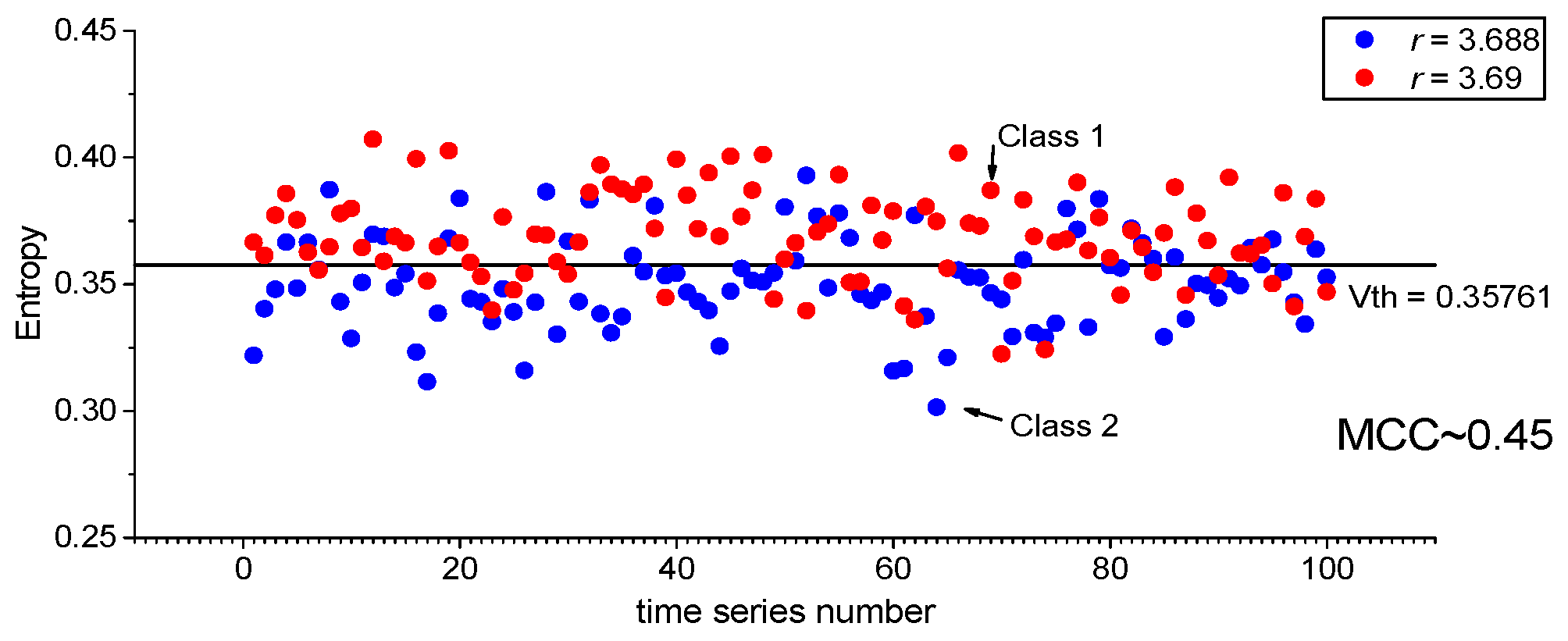
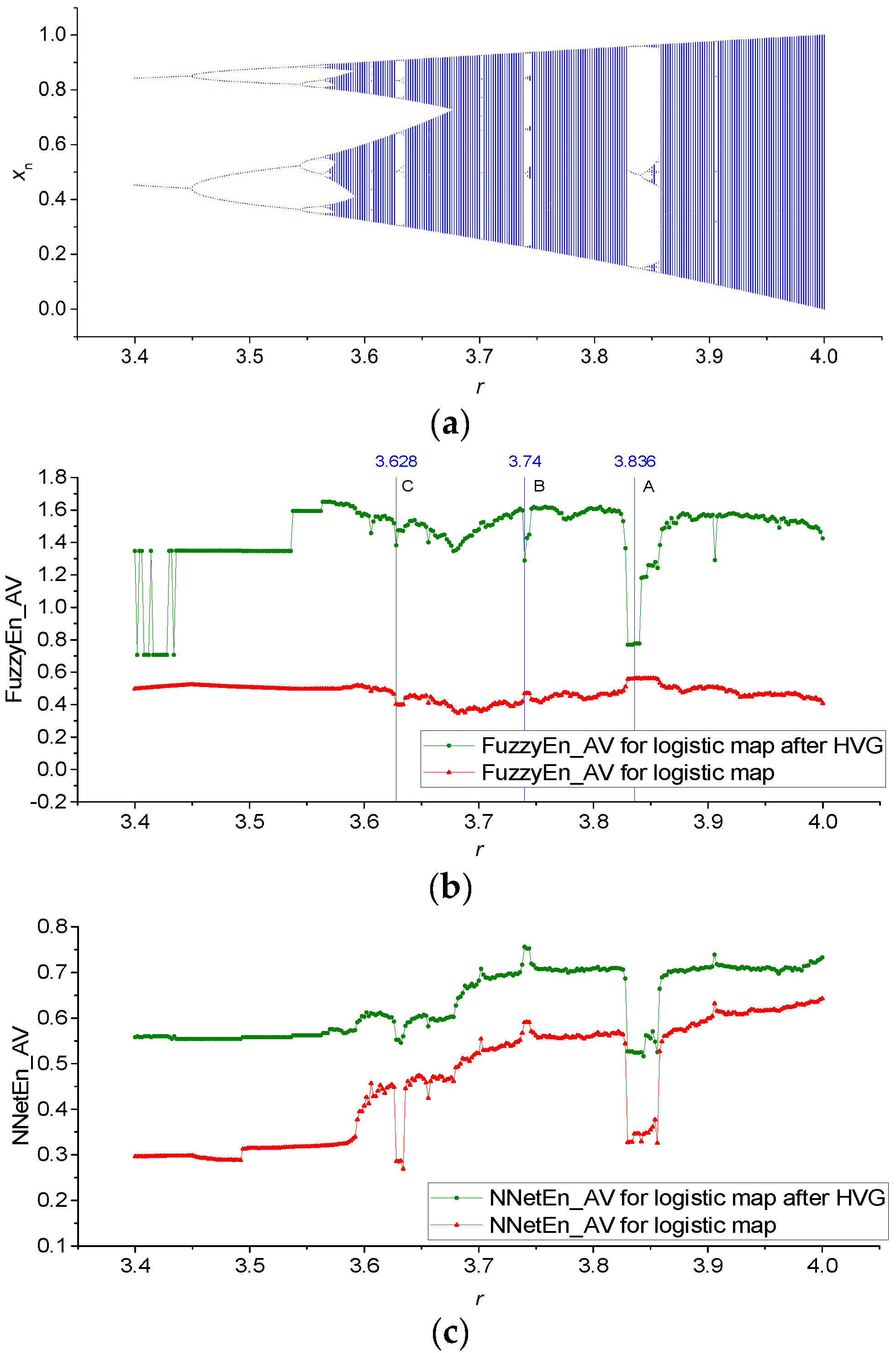
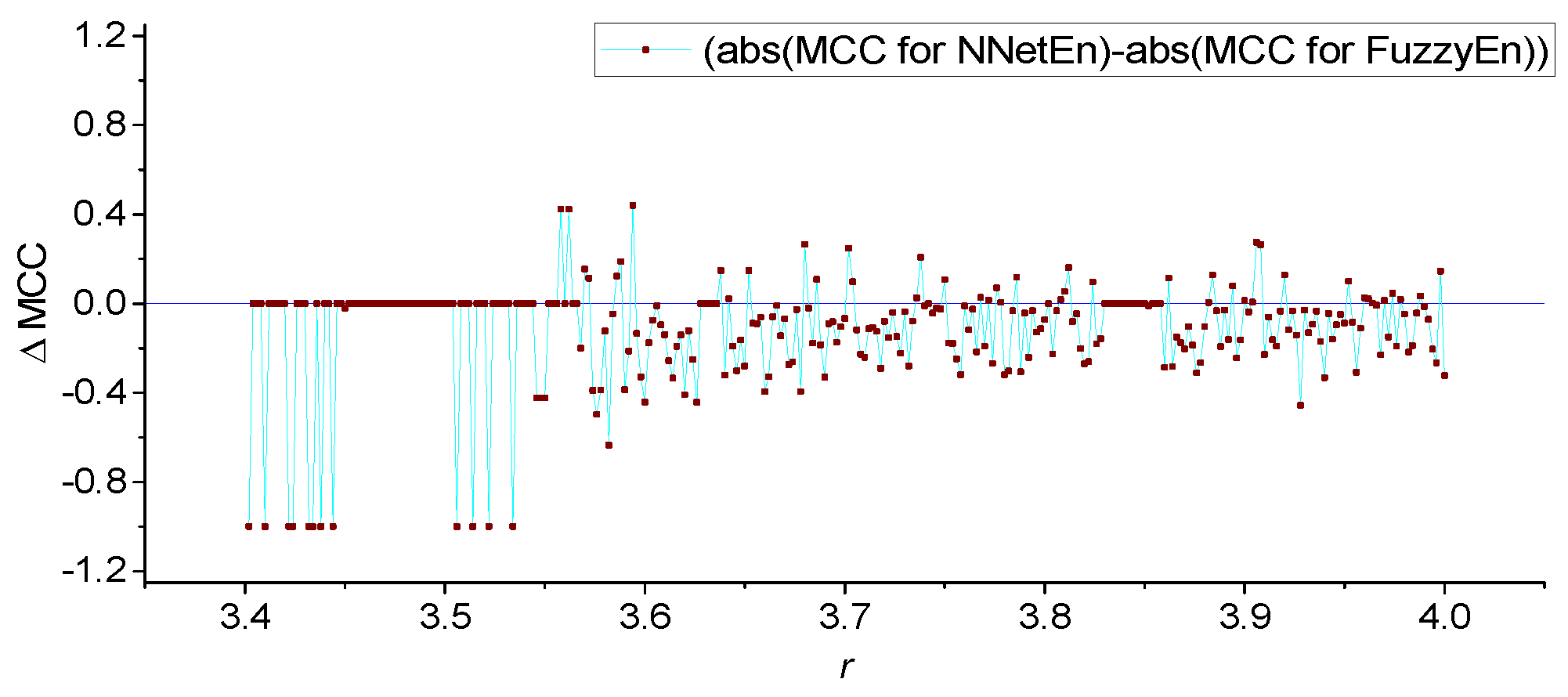
3. Results
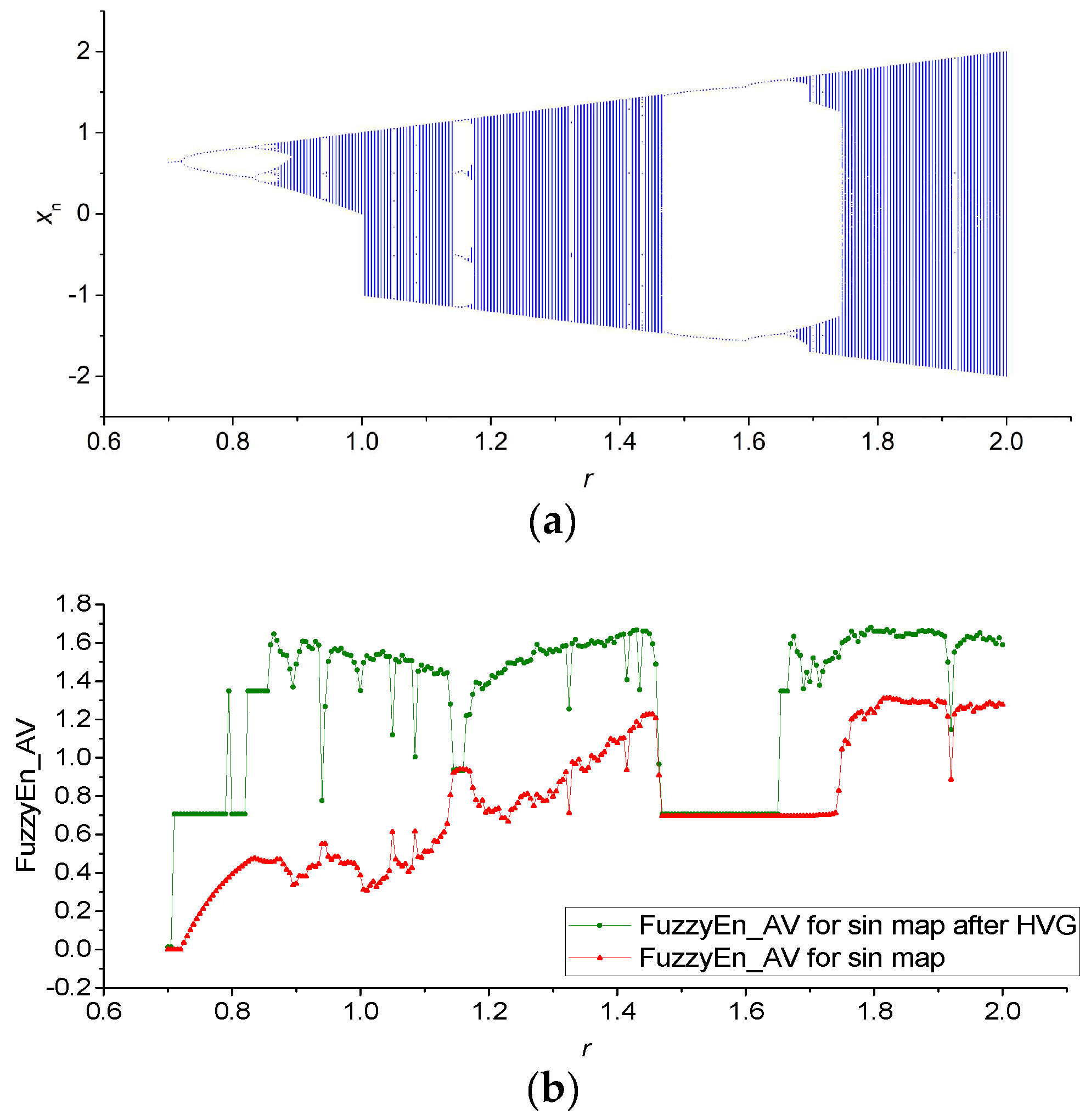
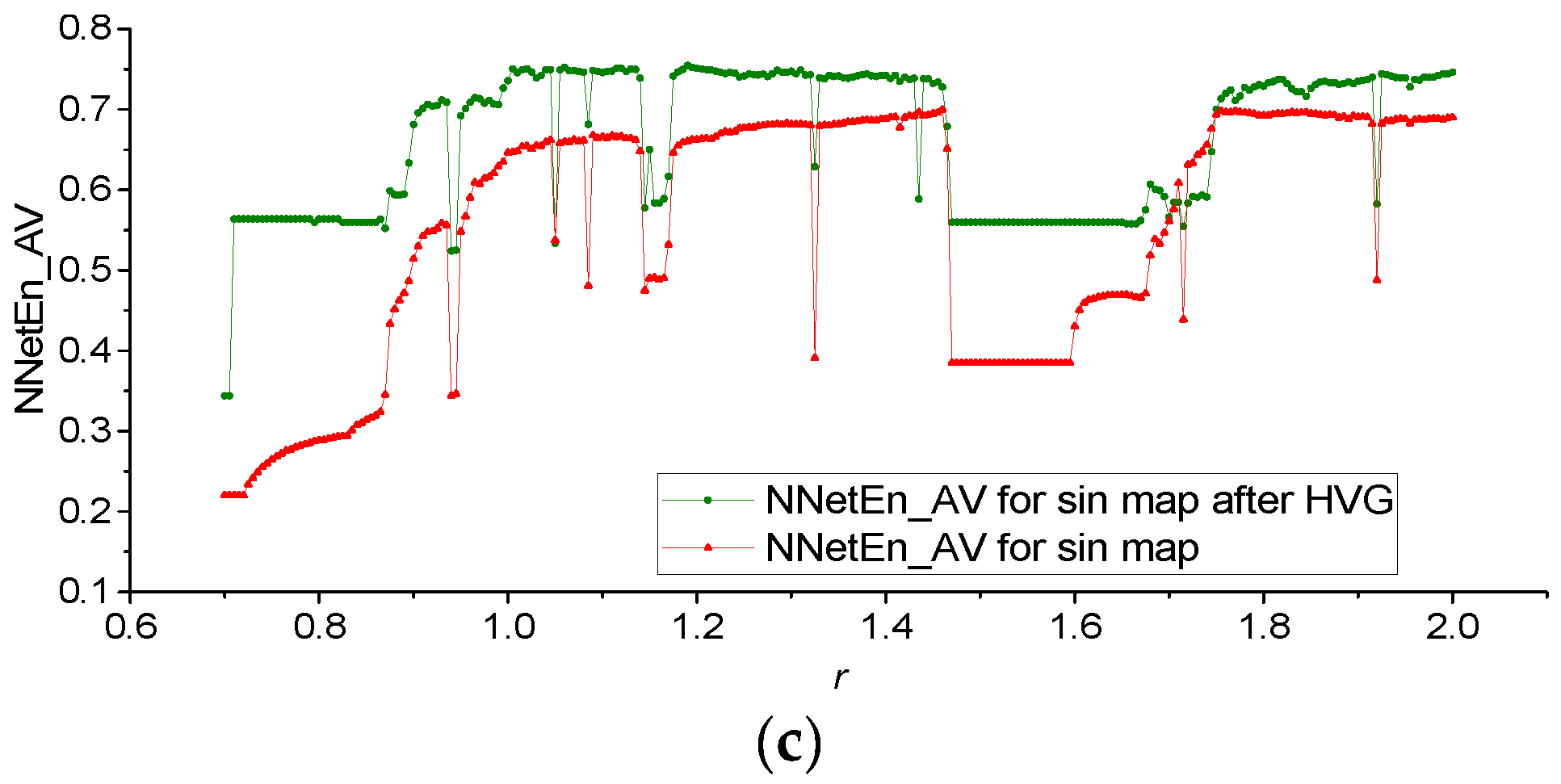
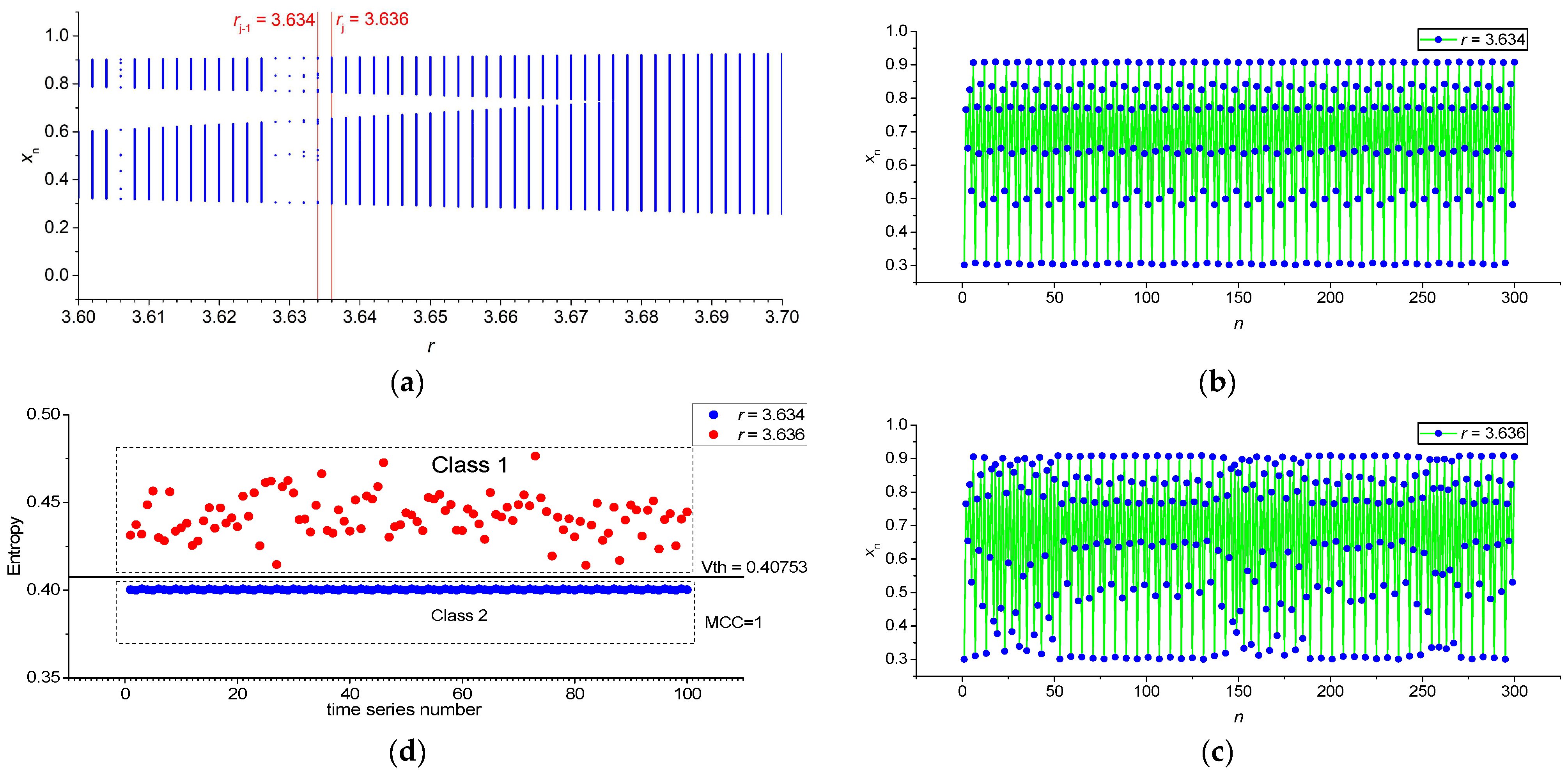
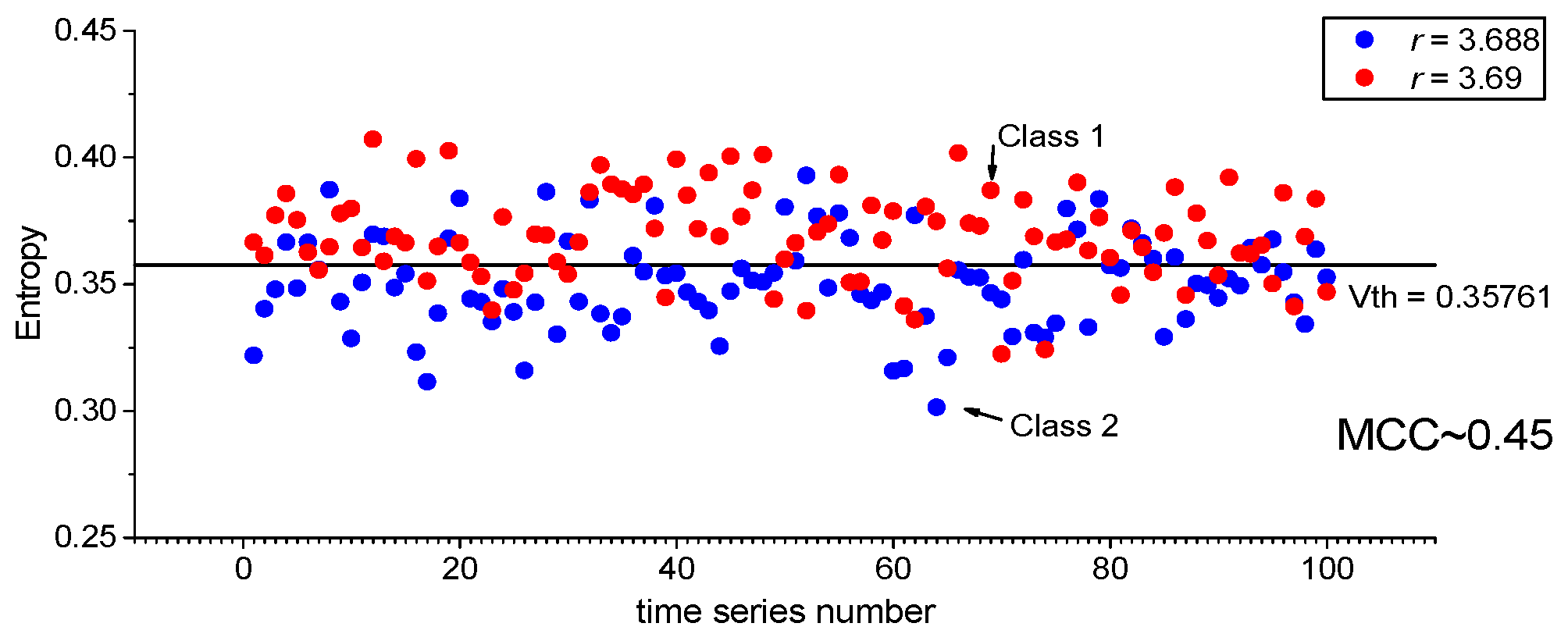
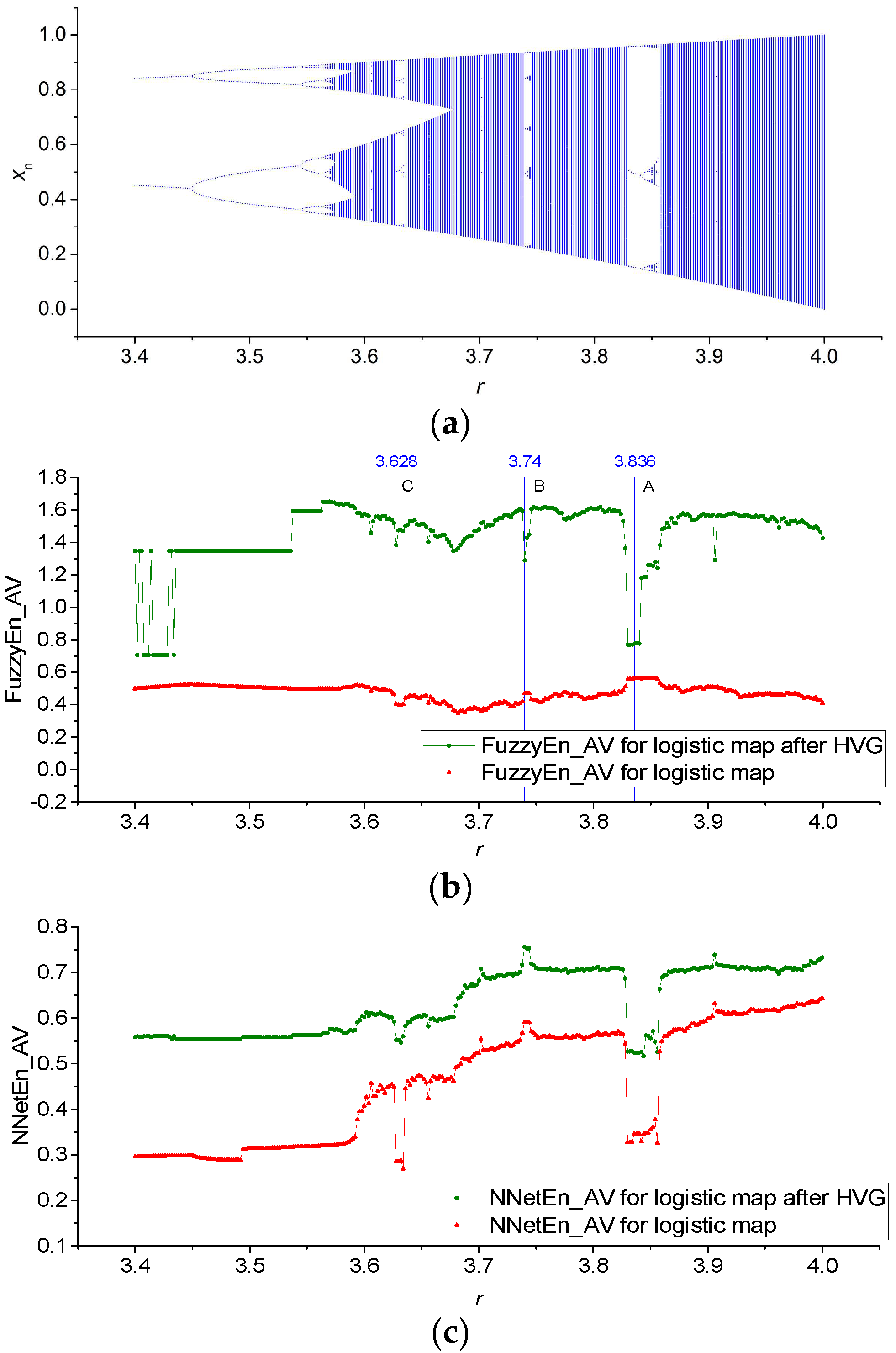
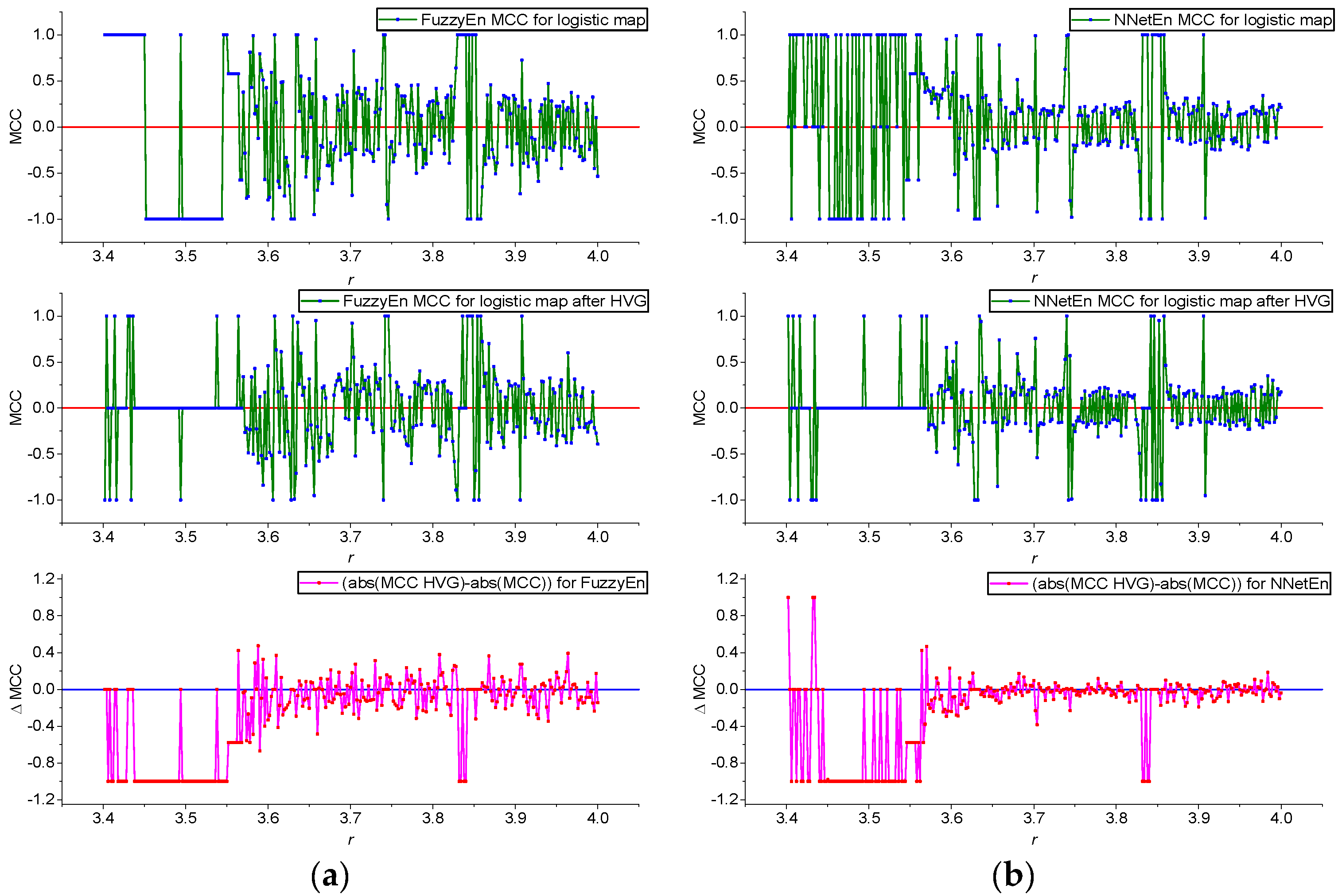
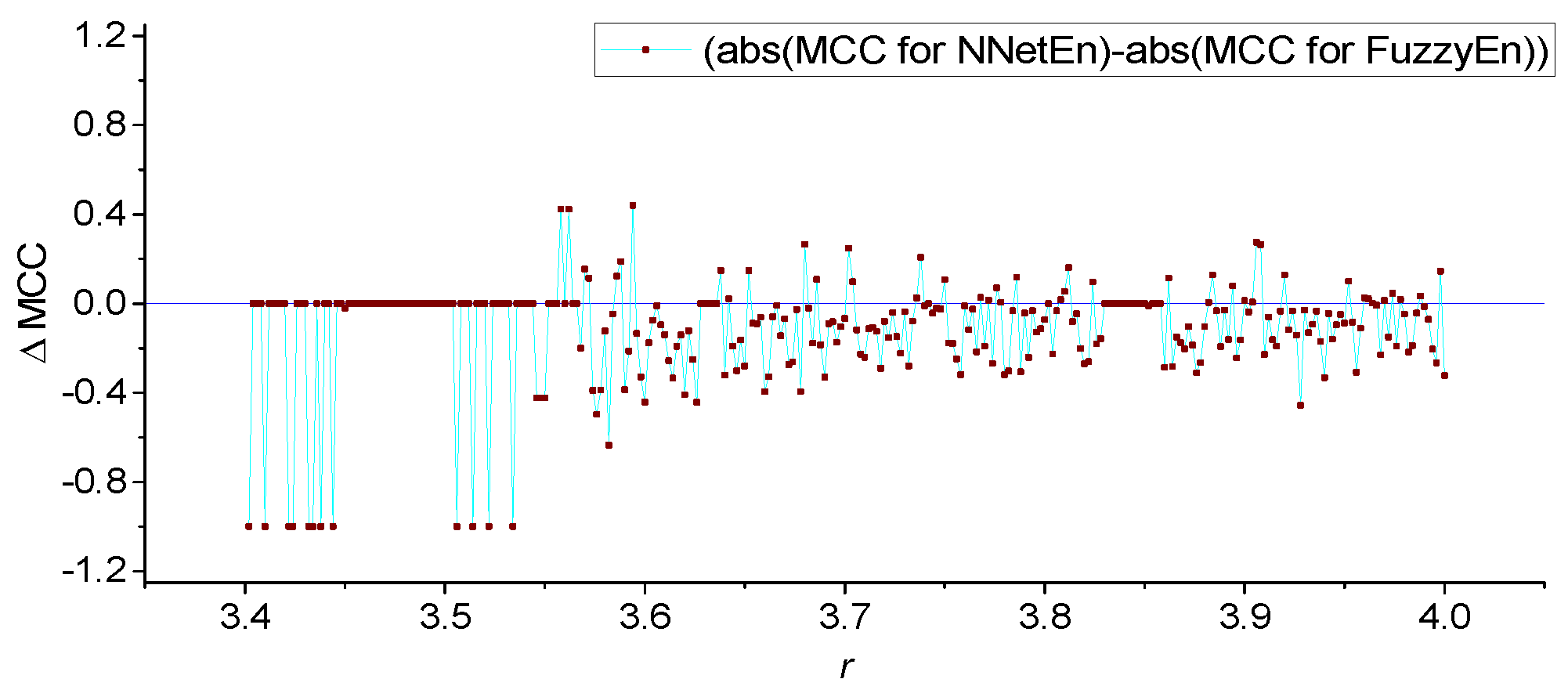
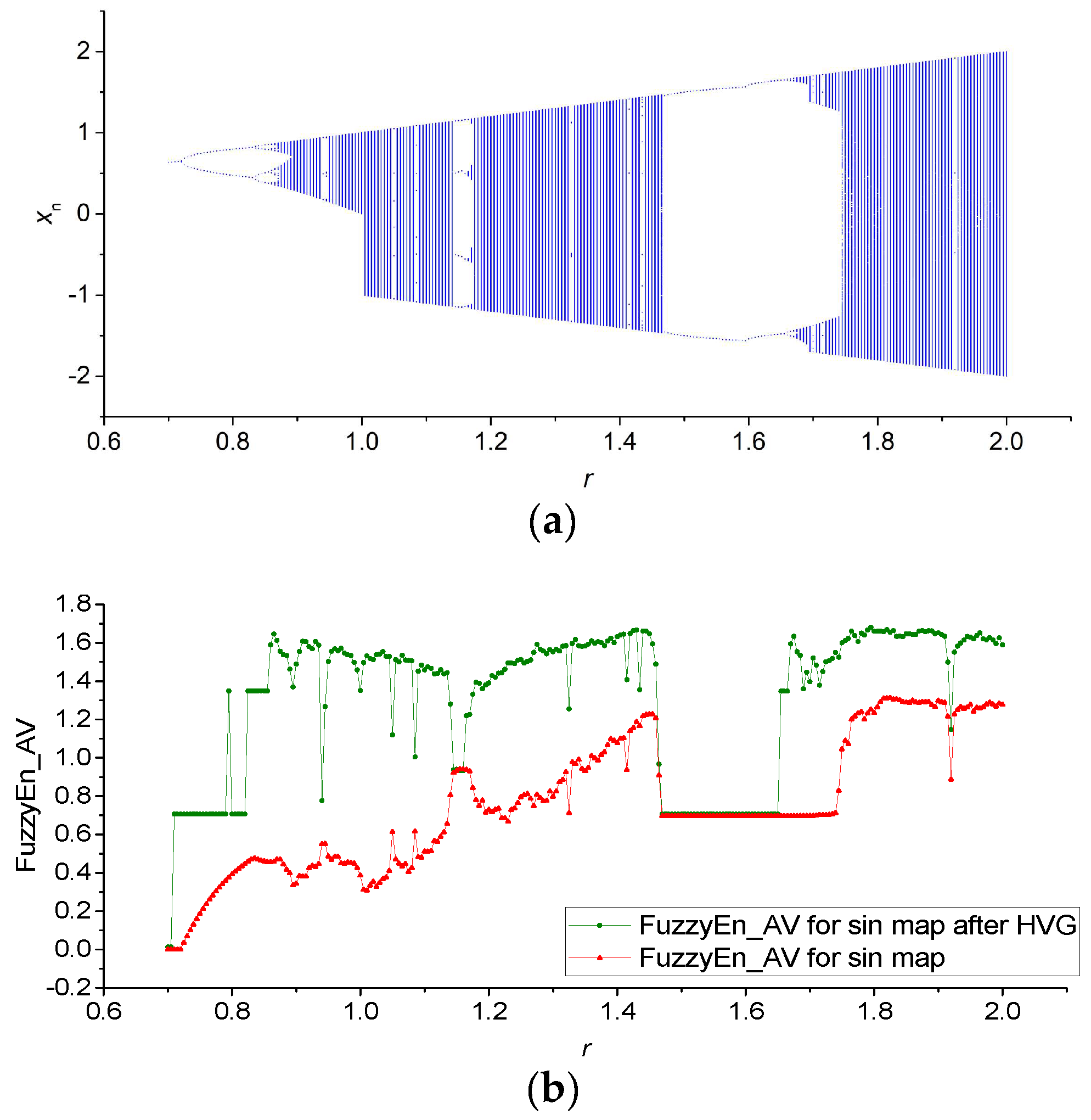
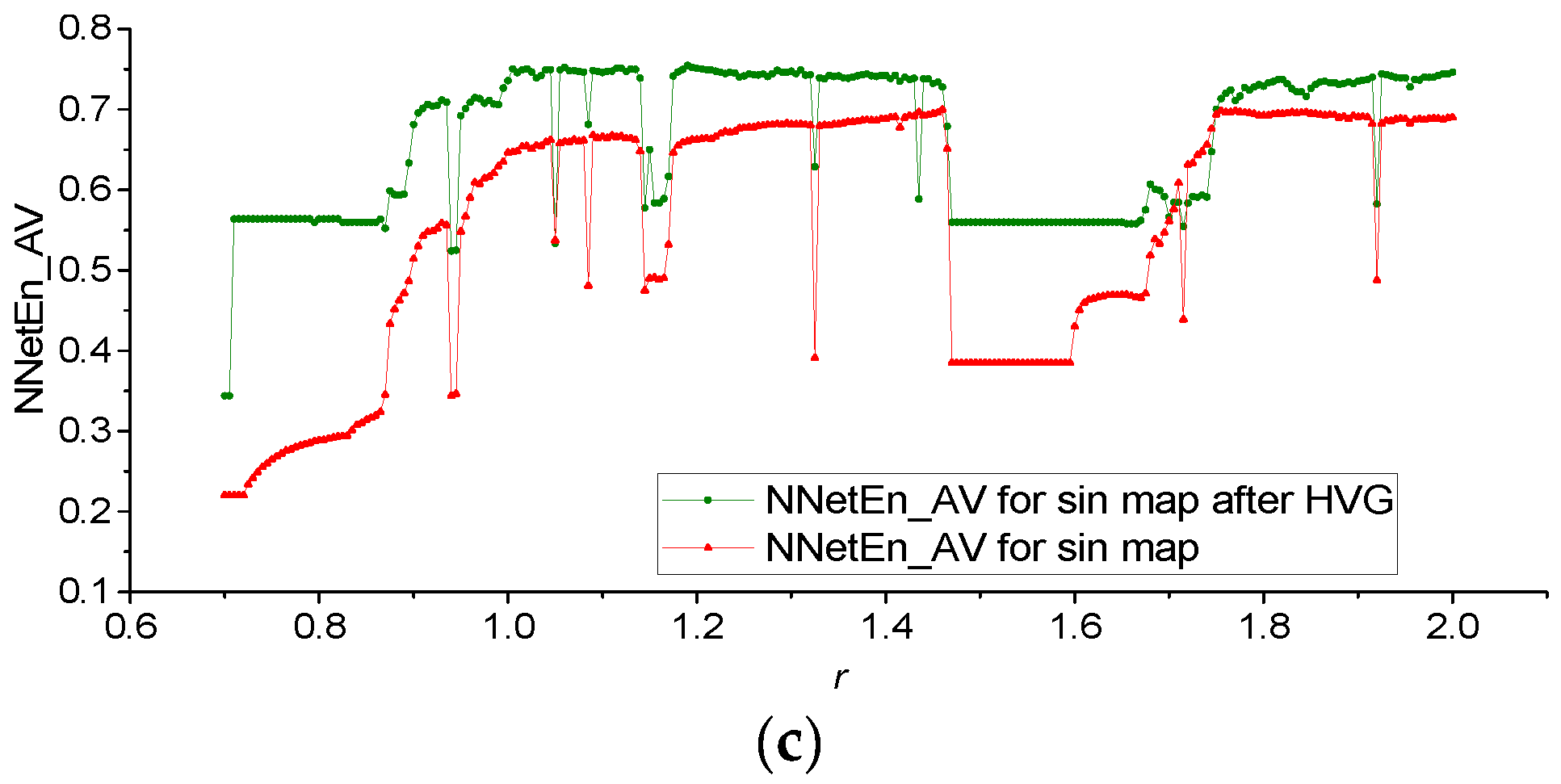
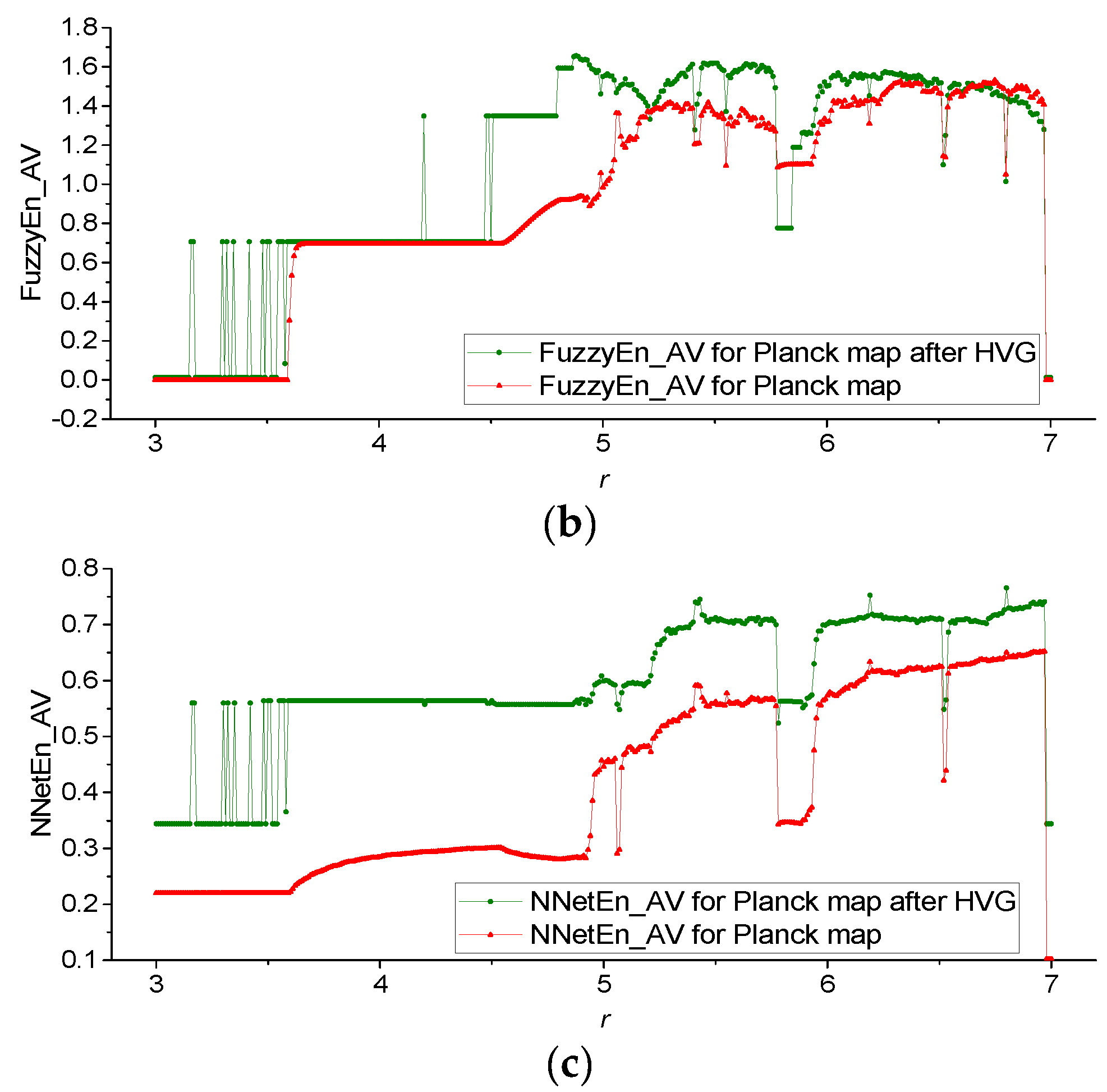
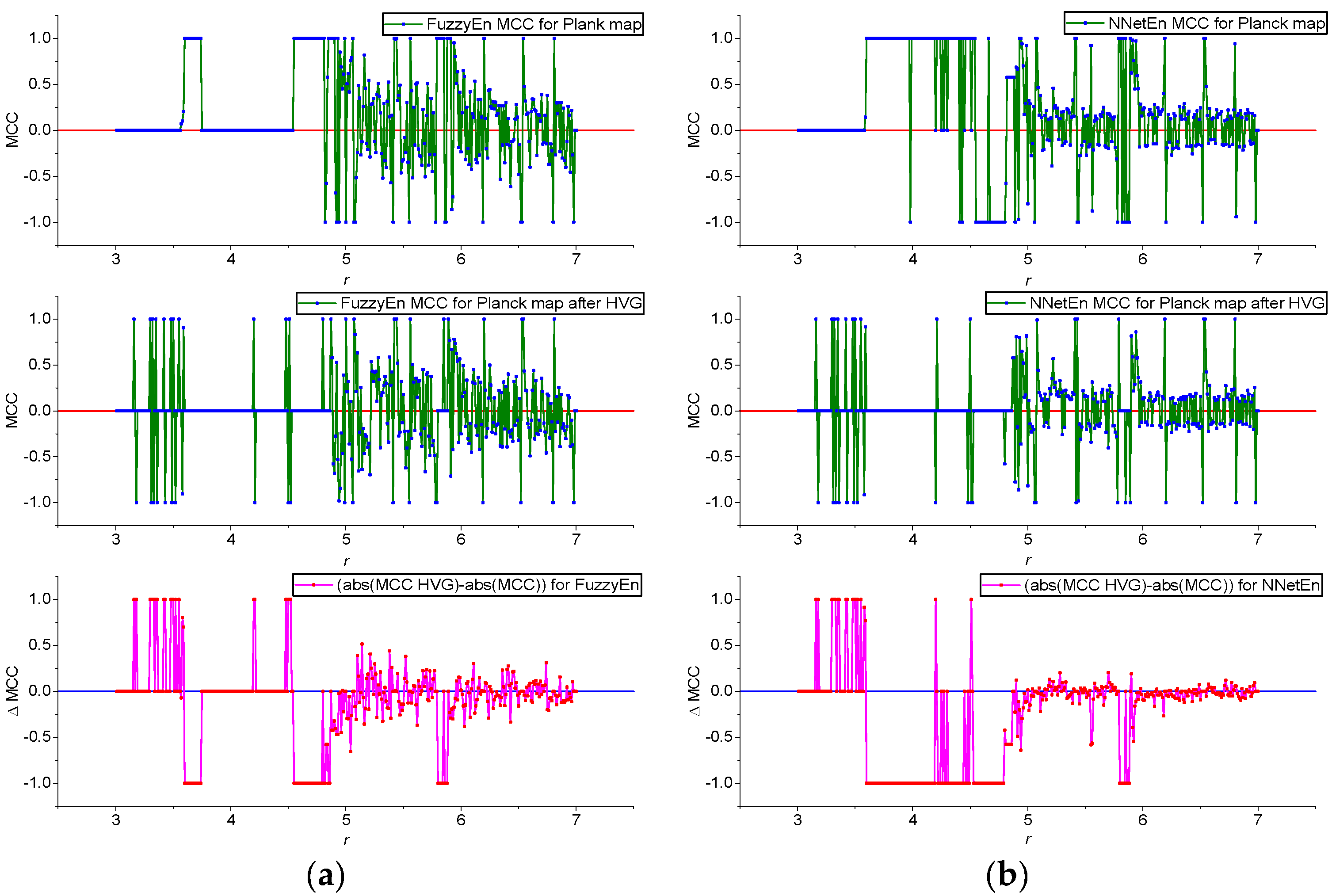
3.1. Results for Logistic, Sine, and Planck Maps
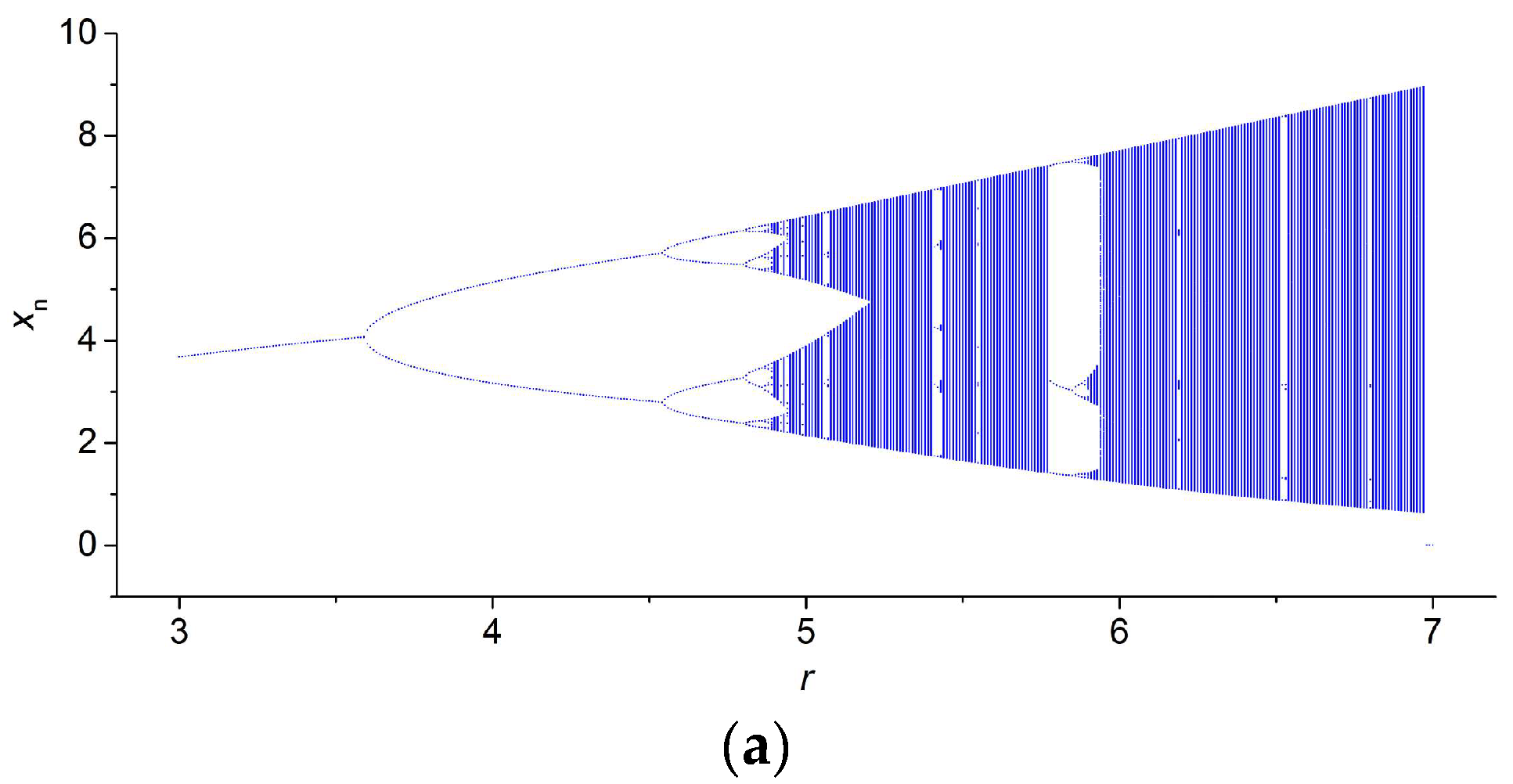
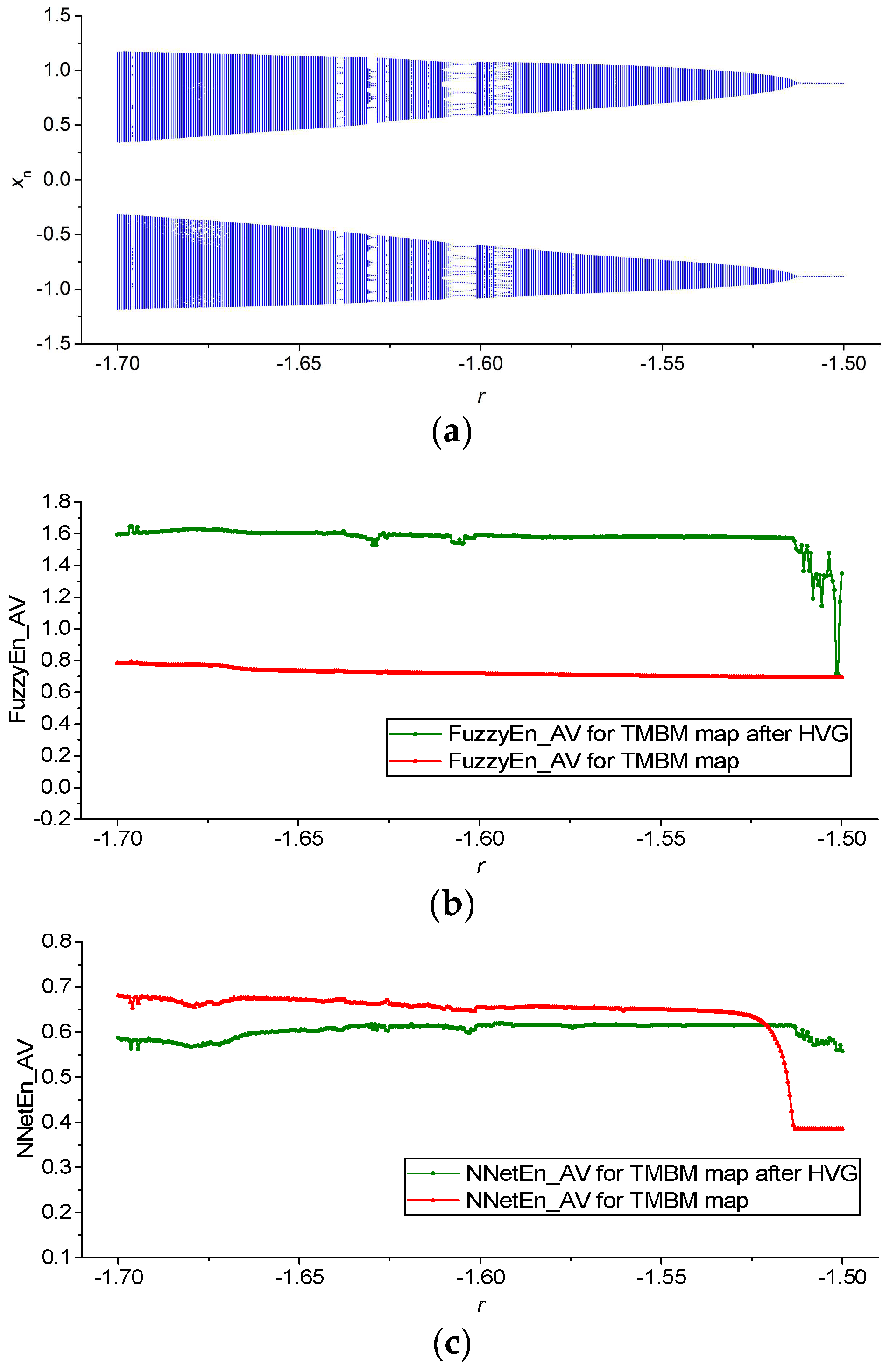
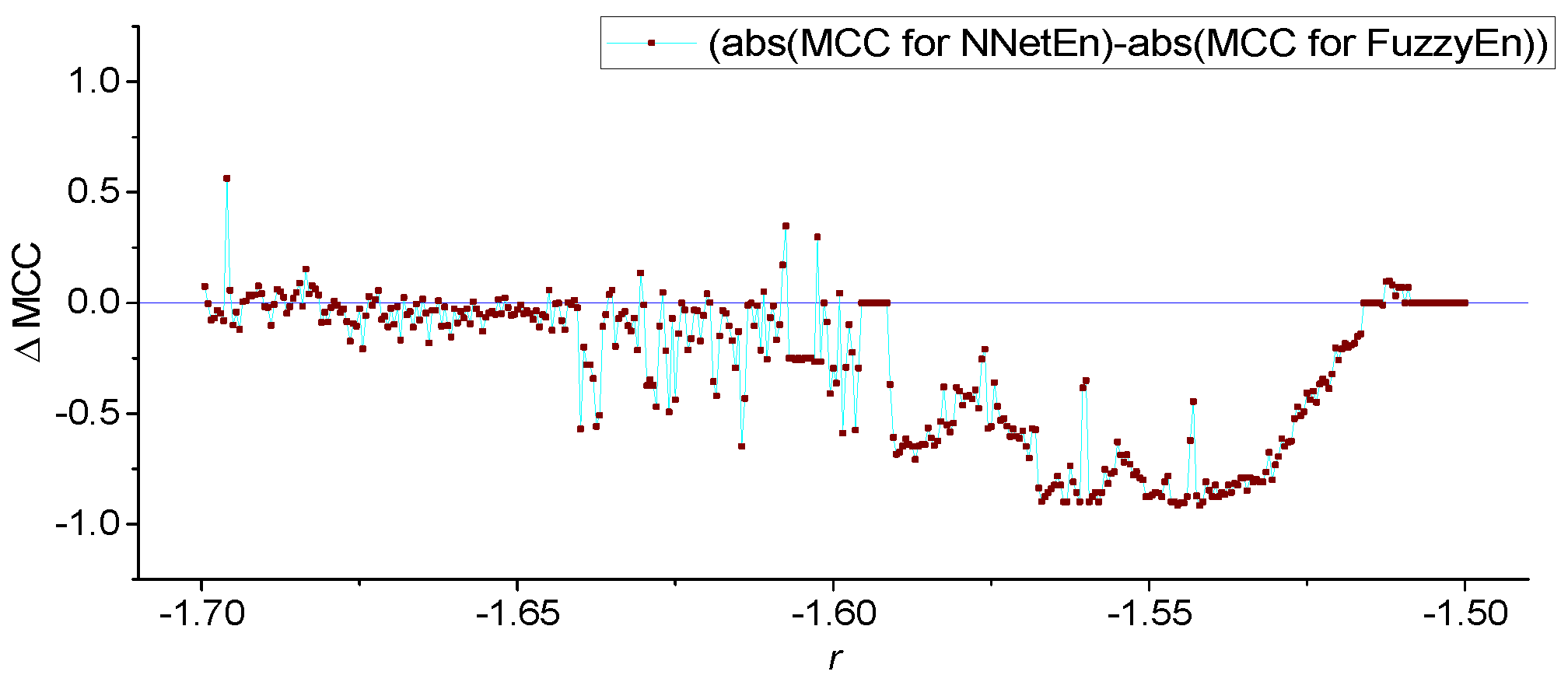
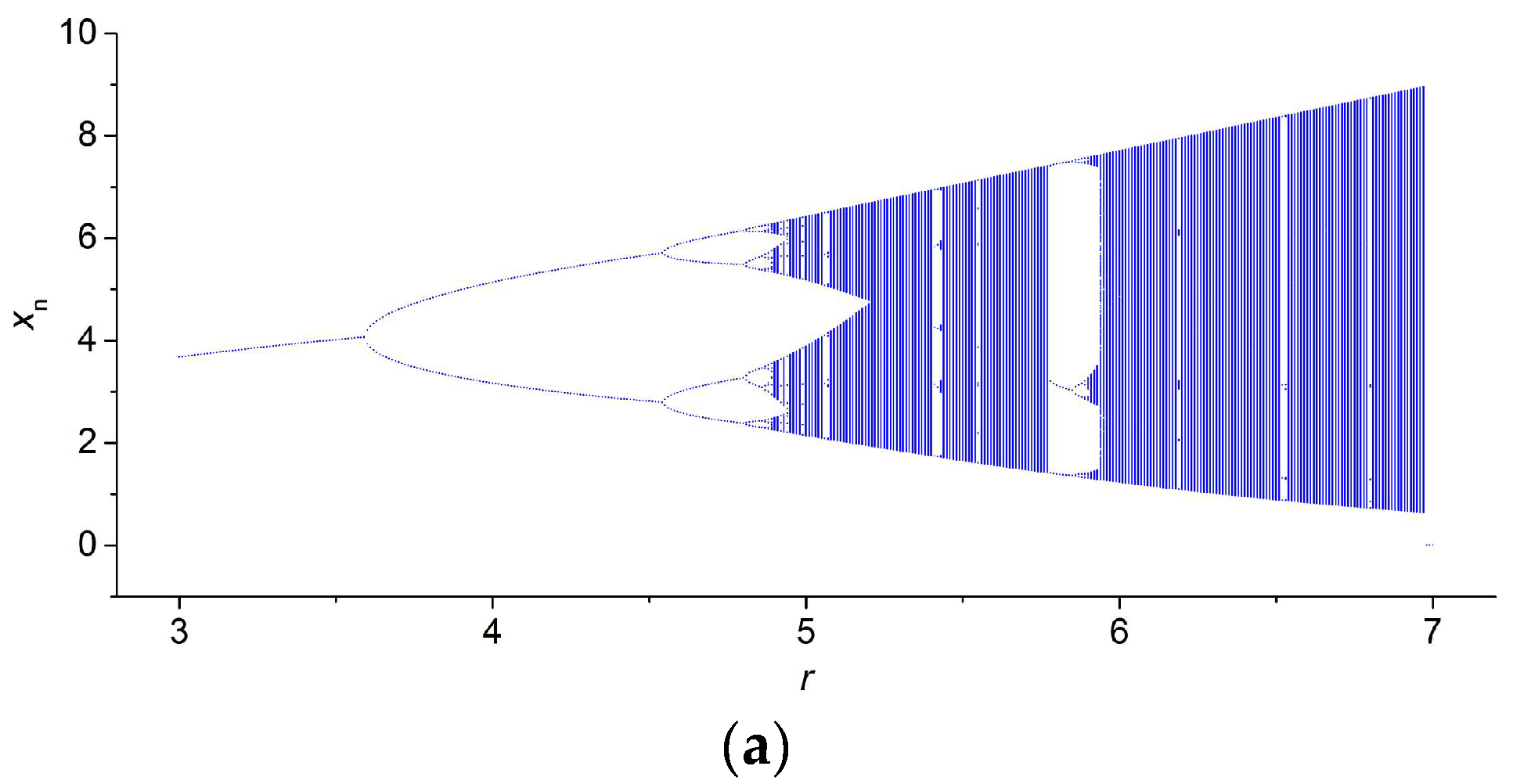
3.2. Results for TMBM Map
4. Discussion and Conclusions
- (1)
- Selecting measurement duration and sampling frequency of the EEG signal.
- (2)
- Experimenting to obtain a set of time series data.
- (3)
- Cutting time series using a specific length N. The value of N is often selected intuitively or through the repetition of similar work.
- (4)
- Selecting methods for processing time series, filter parameters, or wavelet transformations.
- (5)
- Selecting entropy characteristics, entropies, and their parameters, often intuitively, through the repetition of values from other works or by brute force.
- (1)
- Finding the type of entropy and its parameters with the highest average GEFMCC value for four chaotic mappings (Table 1, last column). The search for the type of entropy and its parameters was carried out by enumeration or optimization using the particle swarm method. Optimize GEFMCC(N) for several values of time series length N. Select the minimum length N to correspond to the expected classification accuracy and the capabilities of the experiment.
- (2)
- Selecting the duration of measurements and sampling frequency of the EEG signal based on the analysis of the results of point 1.
- (3)
- Experimenting to obtain a set of time series data.
- (4)
- Cutting time series at a specific length N, based on the results of point 1.
- (5)
- Selecting methods for processing time series, filter parameters, or wavelet transformations.
- (6)
- Selecting entropy features, entropies, and their parameters, based on the results of point 1.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations and Acronyms
| Acc | Accuracy |
| AHVG-DGPE | Discrete Generalized Past Entropy based on the Amplitude difference distribution of the Horizontal Visibility Graph |
| ApEn | Approximate Entropy |
| BCI | Brain–Computer Interfacing |
| CoSiEn | Cosine Similarity Entropy |
| EEG | Electroencephalogram |
| Ep | Number of Epochs |
| FN | False Negative |
| FP | False Positive |
| FuzzyEn | Fuzzy Entropy |
| GEFMCC | Global Efficiency of entropy calculated using Matthews Correlation Coefficient |
| HVG | Horizontal Visibility Graph |
| LogNNet | Logistic Neural Network |
| MCC | Matthews Correlation Coefficient |
| ML | Machine Learning |
| NNetEn | Neural Network Entropy |
| NVG | Natural Visibility Graph |
| PermEn | Permutation Entropy |
| SampEn | Sample Entropy |
| SVDEn | Singular Value Decomposition Entropy |
| TMBM | Two-Memristor-Based Map |
| TN | True Negative |
| TP | True Positive |
| VG | Visibility Graphs |
| VIU | Valencian International University |
Appendix A

References
- Velichko, A.; Belyaev, M.; Izotov, Y.; Murugappan, M.; Heidari, H. Neural Network Entropy (NNetEn): Entropy-Based EEG Signal and Chaotic Time Series Classification, Python Package for NNetEn Calculation. Algorithms 2023, 16, 255. [Google Scholar] [CrossRef]
- Aoki, Y.; Takahashi, R.; Suzuki, Y.; Pascual-Marqui, R.D.; Kito, Y.; Hikida, S.; Maruyama, K.; Hata, M.; Ishii, R.; Iwase, M.; et al. EEG Resting-State Networks in Alzheimer’s Disease Associated with Clinical Symptoms. Sci. Rep. 2023, 13, 3964. [Google Scholar] [CrossRef]
- Belyaev, M.; Murugappan, M.; Velichko, A.; Korzun, D. Entropy-Based Machine Learning Model for Fast Diagnosis and Monitoring of Parkinsons Disease. Sensors 2023, 23, 8609. [Google Scholar] [CrossRef]
- Yuvaraj, R.; Rajendra Acharya, U.; Hagiwara, Y. A Novel Parkinson’s Disease Diagnosis Index Using Higher-Order Spectra Features in EEG Signals. Neural Comput. Appl. 2018, 30, 1225–1235. [Google Scholar] [CrossRef]
- Aljalal, M.; Aldosari, S.A.; Molinas, M.; AlSharabi, K.; Alturki, F.A. Detection of Parkinson’s Disease from EEG Signals Using Discrete Wavelet Transform, Different Entropy Measures, and Machine Learning Techniques. Sci. Rep. 2022, 12, 22547. [Google Scholar] [CrossRef]
- Han, C.-X.; Wang, J.; Yi, G.-S.; Che, Y.-Q. Investigation of EEG Abnormalities in the Early Stage of Parkinson’s Disease. Cogn. Neurodyn. 2013, 7, 351–359. [Google Scholar] [CrossRef]
- Roy, G.; Bhoi, A.K.; Bhaumik, S. A Comparative Approach for MI-Based EEG Signals Classification Using Energy, Power and Entropy. IRBM 2022, 43, 434–446. [Google Scholar] [CrossRef]
- Cuesta-Frau, D.; Miró-Martínez, P.; Oltra-Crespo, S.; Jordán-Núñez, J.; Vargas, B.; González, P.; Varela-Entrecanales, M. Model Selection for Body Temperature Signal Classification Using Both Amplitude and Ordinality-Based Entropy Measures. Entropy 2018, 20, 853. [Google Scholar] [CrossRef]
- Vallejo, M.; Gallego, C.J.; Duque-Muñoz, L.; Delgado-Trejos, E. Neuromuscular Disease Detection by Neural Networks and Fuzzy Entropy on Time-Frequency Analysis of Electromyography Signals. Expert Syst. 2018, 35, e12274. [Google Scholar] [CrossRef]
- Nalband, S.; Prince, A.; Agrawal, A. Entropy-Based Feature Extraction and Classification of Vibroarthographic Signal Using Complete Ensemble Empirical Mode Decomposition with Adaptive Noise. IET Sci. Meas. Technol. 2018, 12, 350–359. [Google Scholar] [CrossRef]
- Wu, D.; Wang, X.; Su, J.; Tang, B.; Wu, S. A Labeling Method for Financial Time Series Prediction Based on Trends. Entropy 2020, 22, 1162. [Google Scholar] [CrossRef]
- Richman, J.S.; Moorman, J.R. Physiological Time-Series Analysis Using Approximate Entropy and Sample Entropy. Am. J. Physiol. Circ. Physiol. 2000, 278, H2039–H2049. [Google Scholar] [CrossRef]
- Chanwimalueang, T.; Mandic, D. Cosine Similarity Entropy: Self-Correlation-Based Complexity Analysis of Dynamical Systems. Entropy 2017, 19, 652. [Google Scholar] [CrossRef]
- Li, S.; Yang, M.; Li, C.; Cai, P. Analysis of Heart Rate Variability Based on Singular Value Decomposition Entropy. J. Shanghai Univ. 2008, 12, 433–437. [Google Scholar] [CrossRef]
- Xie, H.-B.; Chen, W.-T.; He, W.-X.; Liu, H. Complexity Analysis of the Biomedical Signal Using Fuzzy Entropy Measurement. Appl. Soft Comput. 2011, 11, 2871–2879. [Google Scholar] [CrossRef]
- Simons, S.; Espino, P.; Abásolo, D. Fuzzy Entropy Analysis of the Electroencephalogram in Patients with Alzheimer’s Disease: Is the Method Superior to Sample Entropy? Entropy 2018, 20, 21. [Google Scholar] [CrossRef]
- Mu, Z.; Hu, J.; Min, J. EEG-Based Person Authentication Using a Fuzzy Entropy-Related Approach with Two Electrodes. Entropy 2016, 18, 432. [Google Scholar] [CrossRef]
- Kumar, P.; Ganesan, R.A.; Sharma, K. Fuzzy Entropy as a Measure of EEG Complexity during Rajayoga Practice in Long-Term Meditators. In Proceedings of the 2020 IEEE 17th India Council International Conference (INDICON), New Delhi, India, 10–13 December 2020; pp. 1–5. [Google Scholar]
- Bandt, C.; Pompe, B. Permutation Entropy: A Natural Complexity Measure for Time Series. Phys. Rev. Lett. 2002, 88, 174102. [Google Scholar] [CrossRef]
- Chakraborty, S.; Paul, D.; Das, S. t-Entropy: A New Measure of Uncertainty with Some Applications. In Proceedings of the 2021 IEEE International Symposium on Information Theory (ISIT), Melbourne, Australia, 12–20 July 2021; pp. 1475–1480. [Google Scholar]
- Chen, Z.; Ma, X.; Fu, J.; Li, Y. Ensemble Improved Permutation Entropy: A New Approach for Time Series Analysis. Entropy 2023, 25, 1175. [Google Scholar] [CrossRef]
- LogNNet Neural Network|Encyclopedia MDPI. Available online: https://encyclopedia.pub/entry/2884 (accessed on 27 February 2024).
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-Based Learning Applied to Document Recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Xiong, J.; Liang, X.; Zhu, T.; Zhao, L.; Li, J.; Liu, C. A New Physically Meaningful Threshold of Sample Entropy for Detecting Cardiovascular Diseases. Entropy 2019, 21, 830. [Google Scholar] [CrossRef]
- Zhao, L.; Wei, S.; Zhang, C.; Zhang, Y.; Jiang, X.; Liu, F.; Liu, C. Determination of Sample Entropy and Fuzzy Measure Entropy Parameters for Distinguishing Congestive Heart Failure from Normal Sinus Rhythm Subjects. Entropy 2015, 17, 6270–6288. [Google Scholar] [CrossRef]
- Udhayakumar, R.K.; Karmakar, C.; Li, P.; Palaniswami, M. Effect of Embedding Dimension on Complexity Measures in Identifying Arrhythmia. In Proceedings of the 2016 38th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Orlando, FL, USA, 16–20 August 2016; pp. 6230–6233. [Google Scholar]
- Myers, A.; Khasawneh, F.A. On the Automatic Parameter Selection for Permutation Entropy. Chaos Interdiscip. J. Nonlinear Sci. 2020, 30, 33130. [Google Scholar] [CrossRef]
- Cuesta-Frau, D.; Murillo-Escobar, J.P.; Orrego, D.A.; Delgado-Trejos, E. Embedded Dimension and Time Series Length. Practical Influence on Permutation Entropy and Its Applications. Entropy 2019, 21, 385. [Google Scholar] [CrossRef]
- EntropyHub/EntropyHub Guide.Pdf at Main MattWillFlood/EntropyHub GitHub. Available online: https://github.com/MattWillFlood/EntropyHub/blob/main/EntropyHubGuide.pdf (accessed on 14 March 2024).
- Flood, M.W.; Grimm, B. EntropyHub: An Open-Source Toolkit for Entropic Time Series Analysis. PLoS ONE 2021, 16, e0259448. [Google Scholar] [CrossRef]
- Ribeiro, M.; Henriques, T.; Castro, L.; Souto, A.; Antunes, L.; Costa-Santos, C.; Teixeira, A. The Entropy Universe. Entropy 2021, 23, 222. [Google Scholar] [CrossRef]
- Lacasa, L.; Luque, B.; Ballesteros, F.; Luque, J.; Nuño, J.C. From Time Series to Complex Networks: The Visibility Graph. Proc. Natl. Acad. Sci. USA 2008, 105, 4972–4975. [Google Scholar] [CrossRef]
- Lacasa, L.; Toral, R. Description of Stochastic and Chaotic Series Using Visibility Graphs. Phys. Rev. E 2010, 82, 36120. [Google Scholar] [CrossRef]
- Luque, B.; Lacasa, L.; Ballesteros, F.J.; Robledo, A. Feigenbaum Graphs: A Complex Network Perspective of Chaos. PLoS ONE 2011, 6, e22411. [Google Scholar] [CrossRef]
- Flanagan, R.; Lacasa, L.; Nicosia, V. On the Spectral Properties of Feigenbaum Graphs. J. Phys. A Math. Theor. 2019, 53, 025702. [Google Scholar] [CrossRef]
- Requena, B.; Cassani, G.; Tagliabue, J.; Greco, C.; Lacasa, L. Shopper Intent Prediction from Clickstream E-Commerce Data with Minimal Browsing Information. Sci. Rep. 2020, 10, 16983. [Google Scholar] [CrossRef]
- Casado Vara, R.; Li, L.; Iglesias Perez, S.; Criado, R. Increasing the Effectiveness of Network Intrusion Detection Systems (NIDSs) by Using Multiplex Networks and Visibility Graphs. Mathematics 2022, 11, 107. [Google Scholar] [CrossRef]
- Akgüller, Ö.; Balcı, M.A.; Batrancea, L.M.; Gaban, L. Path-Based Visibility Graph Kernel and Application for the Borsa Istanbul Stock Network. Mathematics 2023, 11, 1528. [Google Scholar] [CrossRef]
- Li, S.; Shang, P. Analysis of Nonlinear Time Series Using Discrete Generalized Past Entropy Based on Amplitude Difference Distribution of Horizontal Visibility Graph. Chaos Solitons Fractals 2021, 144, 110687. [Google Scholar] [CrossRef]
- Hu, X.; Niu, M. Degree Distributions and Motif Profiles of Thue–Morse Complex Network. Chaos Solitons Fractals 2023, 176, 114141. [Google Scholar] [CrossRef]
- Gao, M.; Ge, R. Mapping Time Series into Signed Networks via Horizontal Visibility Graph. Phys. A Stat. Mech. Its Appl. 2024, 633, 129404. [Google Scholar] [CrossRef]
- Li, S.; Shang, P. A New Complexity Measure: Modified Discrete Generalized Past Entropy Based on Grain Exponent. Chaos Solitons Fractals 2022, 157, 111928. [Google Scholar] [CrossRef]
- May, R.M. Simple Mathematical Models with Very Complicated Dynamics. Nature 1976, 261, 459–467. [Google Scholar] [CrossRef]
- Sedik, A.; El-Latif, A.A.A.; Wani, M.A.; El-Samie, F.E.A.; Bauomy, N.A.; Hashad, F.G. Efficient Multi-Biometric Secure-Storage Scheme Based on Deep Learning and Crypto-Mapping Techniques. Mathematics 2023, 11, 703. [Google Scholar] [CrossRef]
- Velichko, A.; Heidari, H. A Method for Estimating the Entropy of Time Series Using Artificial Neural Networks. Entropy 2021, 23, 1432. [Google Scholar] [CrossRef]
- Pham, V.-T.; Velichko, A.; Van Huynh, V.; Radogna, A.V.; Grassi, G.; Boulaaras, S.M.; Momani, S. Analysis of Memristive Maps with Asymmetry. Integration 2024, 94, 102110. [Google Scholar] [CrossRef]
- Carlos Bergillos Varela Ts2vg. Available online: https://pypi.org/project/ts2vg/ (accessed on 27 February 2024).
- Chen, W.; Wang, Z.; Xie, H.; Yu, W. Characterization of Surface EMG Signal Based on Fuzzy Entropy. IEEE Trans. Neural Syst. Rehabil. Eng. 2007, 15, 266–272. [Google Scholar] [CrossRef]
- EntropyHub. An Open-Source Toolkit for Entropic Time Series Analysis. Available online: https://www.entropyhub.xyz/ (accessed on 27 February 2024).
- NNetEn Entropy|Encyclopedia MDPI. Available online: https://encyclopedia.pub/entry/18173 (accessed on 27 February 2024).
- MNIST Handwritten Digit Database, Yann LeCun, Corinna Cortes and Chris Burges. Available online: http://yann.lecun.com/exdb/mnist/ (accessed on 16 August 2020).
- GitHub—Izotov93/NNetEn: Python Package for NNetEn Calculation. Available online: https://github.com/izotov93/NNetEn (accessed on 15 February 2024).
- Chicco, D.; Warrens, M.J.; Jurman, G. The Matthews Correlation Coefficient (MCC) Is More Informative than Cohen’s Kappa and Brier Score in Binary Classification Assessment. IEEE Access 2021, 9, 78368–78381. [Google Scholar] [CrossRef]
- Wu, G.C.; Baleanu, D. Discrete Fractional Logistic Map and Its Chaos. Nonlinear Dyn. 2014, 75, 283–287. [Google Scholar] [CrossRef]
- Wu, G.C.; Niyazi Cankaya, M.; Banerjee, S. Fractional Q-Deformed Chaotic Maps: A Weight Function Approach. Chaos 2020, 30, 121106. [Google Scholar] [CrossRef] [PubMed]
- Wu, G.C.; Baleanu, D.; Zeng, S. Da Discrete Chaos in Fractional Sine and Standard Maps. Phys. Lett. A 2014, 378, 484–487. [Google Scholar] [CrossRef]
- Conejero, J.A.; Lizama, C.; Mira-Iglesias, A.; Rodero, C. Visibility Graphs of Fractional Wu–Baleanu Time Series. J. Differ. Equations Appl. 2019, 25, 1321–1331. [Google Scholar] [CrossRef]
- Xiao, H.; Mandic, D.P. Variational Embedding Multiscale Sample Entropy: A Tool for Complexity Analysis of Multichannel Systems. Entropy 2022, 24, 26. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| GEFMCC | Average | ||||
|---|---|---|---|---|---|
| Logistic Map | Sine Map | Planck Map | TMBM Map | GEFMCC | |
| FuzzyEn no HVG | 0.572 | 0.524 | 0.360 | 0.539 | 0.499 |
| FuzzyEn after HVG | 0.334 | 0.362 | 0.355 | 0.2271 | 0.331 |
| NNetEn no HVG | 0.461 | 0.439 | 0.485 | 0.253 | 0.409 |
| NNetEn after HVG | 0.273 | 0.268 | 0.288 | 0.216 | 0.261 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Conejero, J.A.; Velichko, A.; Garibo-i-Orts, Ò.; Izotov, Y.; Pham, V.-T. Exploring the Entropy-Based Classification of Time Series Using Visibility Graphs from Chaotic Maps. Mathematics 2024, 12, 938. https://doi.org/10.3390/math12070938
Conejero JA, Velichko A, Garibo-i-Orts Ò, Izotov Y, Pham V-T. Exploring the Entropy-Based Classification of Time Series Using Visibility Graphs from Chaotic Maps. Mathematics. 2024; 12(7):938. https://doi.org/10.3390/math12070938
Chicago/Turabian StyleConejero, J. Alberto, Andrei Velichko, Òscar Garibo-i-Orts, Yuriy Izotov, and Viet-Thanh Pham. 2024. "Exploring the Entropy-Based Classification of Time Series Using Visibility Graphs from Chaotic Maps" Mathematics 12, no. 7: 938. https://doi.org/10.3390/math12070938
APA StyleConejero, J. A., Velichko, A., Garibo-i-Orts, Ò., Izotov, Y., & Pham, V.-T. (2024). Exploring the Entropy-Based Classification of Time Series Using Visibility Graphs from Chaotic Maps. Mathematics, 12(7), 938. https://doi.org/10.3390/math12070938