1. Introduction
Product reliability analysis and lifetime prediction are essential in the life cycle assessment of engineering systems or components. Various types of covariate information, including external environmental conditions (e.g., temperature, humidity) and internal material properties (e.g., strength, stiffness), exert a significant impact on product lifetime prediction [
1]. In real practice, some covariates are shared within the same group, such as material variables of product units within the same production batch [
2] and working conditions of product units within the same operating region [
3]. These covariates are termed group-shared covariates in this paper. Attributed to the effects of the group-shared covariates, product units often exhibit a consistent failure mechanism within the same group, while the lifetime may vary considerably among different groups [
4].
In real-world applications, it is common that some influential group-shared covariates are missing [
5]. First, due to limited sensing resources or technical measurement restrictions, the covariate information shared within each group may not be readily available. For instance, machine settings shared within the same production batch and operating workload profiles shared within the same operational region could be unavailable due to technical limitations [
6]. Second, continuously monitoring certain covariates in a dynamic and complex environment can be expensive and time-consuming throughout the reliability assessment period, leading to missing covariate information. For example, the underground soil conditions at the stage of drainage pipe operation in the same region may not be feasible due to resource-intensive real-time monitoring [
7]. Third, due to data privacy issues or confidentiality concerns, there may be restrictions on the sharing of certain covariate information. For example, the proprietary information (e.g., design settings, quality indicators of material suppliers) and manufacturing process variables (e.g., production speed and machine settings) for a group of vehicles produced on a particular assembly line may not be accessible from warranty data [
8]. Last but not least, for many new materials or products with evolving technology, some influential covariates may not be known due to limited knowledge [
9].
Due to the above various causes of missing information, the missing covariates often demonstrate multiple types of attributes, including qualitative, quantitative, or a combination of both [
10]. For instance, the covariates may be qualitative by taking nominal values, such as various descriptors related to materials and diverse configurations pertaining to design [
8]; or ordinal levels, such as various levels of material quality and diverse usage conditions [
11]. Moreover, the covariates may also be quantitative factors that take numerical values on a continuous scale, such as manufacturing process conditions (e.g., pressure, humidity, flow rates) during the manufacturing phase [
12] or environment conditions (e.g., loading, temperature) at the operation stage [
13]. In more general and complex scenarios, the covariates may be mixed type and characterized by a blend of both qualitative and quantitative factors [
14]. These multi-type missing covariates shared within the same group significantly affect product lifetime estimation, and their influences on the product lifetime are termed
group-shared latent heterogeneity (GSLH). The GSLH quantifies the aggregate effects of group-shared missing covariates on product lifetime, which may be negative values, such as the effects of group-shared operating temperature due to the nature of chemical reactions [
15]; or positive values, such as the effects of ambient temperature shared within the same manufacturing batch [
16]. Neglecting the multi-type GSLH may result in biased estimates and inaccurate predictions of product lifetime, subsequently leading to non-optimal maintenance decisions or ineffective product design [
17].
To handle the issue of missing information in lifetime modeling when the covariate values are partially observed, some existing studies developed various imputation methods that created plausible imputations for those missing values [
6,
18]. Si et al. developed a lifetime estimation model for repairable systems when the failure counting process is partially observed [
19]. Zhou et al. used data augmentation techniques and developed an estimation approach to analyze failure time data with missing covariates at random [
20]. Nevertheless, when some specific covariates are fully unobserved, reliability analysis becomes more challenging. Some existing methods quantified the influence of missing covariates via statistical models with latent variables while maintaining data privacy [
21,
22]. Slimacek et al. developed a frailty approach to analyze wind turbine reliability and found that individual frailties could capture the effects of unobserved factors [
23]. These methods mainly focused on capturing the unit-to-unit variation based on the frailty model and its multivariate variants with different specifications, such as gamma frailty [
24], and generalized inverse Gaussian frailty [
25]. However, these existing studies typically considered single-type missing covariates, such as continuous types [
26] or discrete types [
27]. None of the aforementioned studies considered multi-type group-shared missing covariates in product lifetime prediction, and none of them examined the model robustness. When multi-type GSLH is presented, there is a critical need to develop a new lifetime prediction model with estimation algorithms that can take the influence of multi-type missing covariates shared within each group into account. Such a lifetime modeling approach can finally achieve accurate product reliability assessments and cost-effective decisions during the stages of product design, manufacturing, and field operation.
To address the research gaps, a new lifetime modeling and prediction framework is proposed, which incorporates multi-type missing information shared within each group. Specifically, we first propose a new flexible lifetime model with multi-type GSLH that simultaneously accounts for different structures of group-shared missing covariates. The proposed model is general and can incorporate several widely used model specifications in lifetime analysis, such as log-normal and Weibull models. Based on the proposed lifetime model, a Bayesian estimation algorithm is developed to jointly quantify the influence of both observed covariates and multi-type group-shared missing covariates. The developed algorithm can achieve reliable estimates under the scenarios of limited sample size and unknown subpopulation membership. On the basis of the proposed model and estimation algorithm, a tripartite method is developed to examine the existence of GSLH, identify its correct type, and further quantify its impact on product lifetime. Moreover, a comprehensive simulation study is conducted to illustrate the effectiveness of the proposed approach and investigate its robustness across various misspecification scenarios. A real case study is also presented to demonstrate the practical applicability of the proposed work. The proposed approach can unveil the underlying patterns of missing information and mitigate the impact of group-shared missing information on product reliability analysis.
The rest of this paper is organized as follows.
Section 2 presents the proposed framework for lifetime modeling and prediction in the presence of multi-type group-shared missing covariates. Within the framework, a new lifetime model which incorporates multi-type GSLH is developed and demonstrated in
Section 3. In
Section 4, the model estimation algorithm is developed and inference details are elaborated. In
Section 5, a numerical study is presented to demonstrate the effectiveness and investigate the robustness of the proposed framework. A real case study is further conducted to illustrate the practical applicability.
Section 6 draws the conclusive remarks.
3. Lifetime Modeling with Multi-Type GSLH
We propose a new lifetime model with multi-type GSLH to account for the influence of group-shared missing covariates with different structures. Considering
n groups of product units (e.g., items produced in
n manufacturing lines), each group
i,
consists of
product lifespan observations. For lifetime modeling, an accelerated failure time (AFT) model framework [
29] is adopted because of its modeling adaptability and ease of interpretation. Moreover, the AFT model is mainly used to study the reliability of industrial products and can be specified using different distributions, such as exponential, Weibull, and log-normal distributions. The AFT model can be an interesting alternative to the Cox proportional hazards model when the assumption of proportional hazards does not hold in analyzing product lifetime. The overall structure of the original AFT model can be written as
where
represents a vector of covariates for the unit
j within the group
i, and
signifies a vector of corresponding coefficients on a logarithmic scale.
symbolizes the average time to failure in the absence of the covariates on a logarithmic scale.
denotes the measurement error of the unit
j within the group
i, which is assumed to be an independent variable with a zero mean and a finite variance. By employing distinct settings of
, the AFT model can incorporate various lifetime models, such as the widely used log-normal and Weibull models in the existing literature [
13], which are also considered in this paper. In the AFT model, the covariates
are used to explain the lifetime variation.
In practice, some of the covariates
shared within the group
i become missing due to the various aforementioned reasons. The covariates
then embrace the observed covariates
(such as the measured stress factors during the operation stage) and the multi-type group-shared missing covariates (such as the design settings of product units in the same batch or the quality indicators of product material suppliers in the same region, which cannot be obtained from warranty data owing to confidential concerns). We denote such missing covariates shared within the group
i as
. The proposed lifetime model can then be formulated as
where
is a vector of the coefficients for group-shared missing covariates on a logarithmic scale.
characterizes the impact of observed covariates on the lifespan of the unit
j within the group
i on a logarithmic scale. Furthermore, we introduce
to quantify the aggregate effects of the missing covariates shared within the group
i. Herein, we can specify different covariate structures for
. As a result,
can be captured by multiple different types of random quantities as follows.
- (i)
When all instances of become qualitative random attributes with K distinct values, such as the missing K-tiered indicators of material quality from various vendors within the same region during the production stage, can then be captured by a discrete random variable which follows a categorical distribution, i.e., , where signifies a categorical distribution characterized by a parameter K for K distinct discrete values, i.e., ; and a parameter for a vector of probabilities, i.e., , such that . The discrete variant of GSLH is designated as GSLH-D.
- (ii)
When all instances of become quantitative random attributes, such as the missing ambient temperature of items produced within the same batch during the manufacturing process, the random variable then follows a continuous distribution, i.e., , where refers to an arbitrary continuous density function with hyper-parameter , whose specification can be determined via model selection methods. The continuous type of GSLH is designated as GSLH-C.
- (iii)
When comprises a blend of both qualitative and quantitative attributes, such as the missing levels of hotness along with various continuous operating conditions, the random variable then becomes a mixed type (a combination of continuous and discrete types), i.e., with probability , such that . represents a continuous density for subpopulation k with hyper-parameter . The specification of each and the number of subpopulations K can be determined via model selection methods. The mixed-type GSLH is annotated as GSLH-M.
The hierarchy of the proposed lifetime model with multi-type GSLH is illustrated in
Figure 2. When only a solitary subpopulation is present within the entire population, the model with mixed-type GSLH is equivalent to the model with continuous GSLH. On the other hand, when the whole population consists of several subpopulations and the randomness of
within each subpopulation degenerates (i.e.,
becomes close to a constant value), the model with mixed-type GSLH then approximates to the model with discrete GSLH. The proposed lifetime model, as shown in Equation (
2), is general and flexible to handle diverse structures of missing covariates shared within each group by specifying various types of
in a generic formulation. The proposed model can be viewed as encompassing several traditional models as special instances. For example, when the type of GSLH is purely continuous, the proposed lifetime model would be reduced to the frailty model [
21]. When the type of GSLH is discrete, the proposed lifetime model would be reduced to the mixture model [
27].
4. Model Estimation and Inference
The lifetime prediction performance of the proposed model depends on the parameters and all instances of as well as the hyper-parameters. We propose a Bayesian estimation approach to derive these parameter estimates and develop model inferences, given lifetime data and the observed covariates information.
Suppose there are
observations of product lifespan within group
i, along with the observed covariates
. The available data can be denoted as
, where
is a binary indicator of right-censoring for the lifespan observation of the
unit in the
group. When
takes the value of one, the lifetime
denotes the duration that elapses prior to the occurrence of a critical event (e.g., product failure) within the data collection period. Otherwise,
signifies the entire duration of the data collection period when
equals zero. The model’s unknown parameters are designated as
. The marginal likelihood
can be written as
where
represents the probability density function characterizing the lifetime distribution of the product unit
j within the group
i and
represents the reliability function.
is the probability density or mass function for GSLH. As
is the censoring indicator for the unit
j within the group
i, it equals one if the failure time is actually observed; otherwise, it is zero. In the traditional non-Bayesian estimation procedures, including the maximum likelihood estimation (MLE) method [
30],
will be integrated out and cannot be estimated, as shown in Equation (
3). Nevertheless, the instances of
all carry important information of multi-type GSLH.
To address the shortcomings of the traditional marginalized methods, the Bayesian estimation framework is employed for the development of an estimation algorithm, attributed to its enhanced estimation capability and adaptability [
31]. It becomes feasible to simultaneously estimate both the unknown parameters
and all instances of
, facilitating exact inferences for both. Specifically, the joint prior density for unknown parameters is designated as
, reflecting the prior information pertaining to all unknown parameters. Furthermore, we use
to represent the hyper-parameters for
and designate the prior density of
as
. We then derive the joint posterior as
where
is the joint likelihood function. In Equation (
4),
can be further expressed as
, where
signifies the available data for the product unit
j within the group
i.
Based on Equation (
4), the influence of multi-type GSLH on lifetime estimation can further be quantified. Herein, the GSLH is assumed to be uncorrelated among different groups. In
Section 4.1,
Section 4.2 and
Section 4.3, we will develop exact inferences of multi-type
and hyper-parameters
as well as unknown model parameters
in the presence of discrete, continuous, and mixed-type GSLH, respectively.
4.1. Discrete Type of GSLH: GSLH-D
The group-shared missing covariates with discrete structures are first investigated. The corresponding GSLH can be characterized by a discrete random quantity. Specifically, a categorical distribution can be specified for
, which involves
K discrete values
for
K mutually exclusive categories and a vector
for the probabilities associated with each category, i.e.,
, such that
. When
takes value from the support
, its probability mass function is expressed as
, where we denote
as an indicator function. Otherwise,
when
. In other words,
when
equals
, which leads to the same result when using the Dirac delta function. The advantage of this formulation lies in its simplicity for expressing the likelihood function of a set of independent identically distributed categorical variables. The density of lifetime can be represented as
. We can then derive the joint posterior density as
where
represents the index set of subpopulation
k. The size of the
index set is expressed as
, such that
, where
refers to the size operator.
represents the reliability function for all product units within the groups that pertain to the same subpopulation
k. Furthermore, when multiple independent instances of
are involved, categorical random variables constitute a multinomial likelihood, which is a generalized version of binomial likelihood on
K dimensions (
). To facilitate Bayesian estimation, the Dirichlet prior, a generalization of the beta prior, is further considered for probability quantities in the multinomial likelihood. The Dirichlet–multinomial relationship is a generalization of beta–binomial conjugate relationship in
K dimensions (
) and will foster the computational convenience of the developed Bayesian sampling algorithm. Therefore, the Dirichlet prior can be assigned to the hyper-parameter
, which is a commonly used conjugate prior for categorical distribution [
27], i.e.,
, where
refers to the parameter for Dirichlet distribution. For the hyper-parameter
, we can obtain the conditional posterior density as
Based on Equation (
6), the conditional posterior of
becomes a Dirichlet distribution with parameters
, where
. With the hyper-parameter
, we derive the conditional posterior density of all instances of
that pertain to the same subpopulation
k as
Based on Equation (
7), any
taking the value
is conditionally independent of
. Given the lower degree of correlation in the structure and the reduction in the computational complexity, all instances of
can be sampled efficiently. Moreover, the conditional posterior density of
is derived as
The derived conditional posterior densities can be used to draw the samples of and all instances of with a discrete type as well as hyper-parameter efficiently.
4.2. Continuous Type of GSLH: GSLH-C
Furthermore, we explore the continuous structure of the missing covariates shared within each group. The corresponding GSLH can be characterized by a continuous random quantity, i.e.,
, where
refers to an arbitrary continuous density function with the hyper-parameter
. The joint posterior density then becomes
The conditional posteriors of
and hyper-parameter
as well as the unknown model parameters
can further be derived as
Several distributions commonly used in reliability engineering, such as gamma and exponential densities, can be considered as potential candidates for . The final specification of can be determined via the model selection method.
4.3. Mixed-Type GSLH: GSLH-M
Moreover, we investigate a more complex structure of the missing covariates shared within each group, which is a blend of both discrete and continuous types. The mixed-type GSLH can be expressed as
with probability
, such that
. Each
signifies a continuous density function with the hyper-parameter
for all instances of
that pertain to the subpopulation
. The joint posterior is derived as
where
. As shown in Equation (
13), generating samples for all instances of
would become mathematically intractable, as the priors for all cases of
encompass
additive components. To tackle the practical challenges related to analytical complexity and boost computational efficiency, a data augmentation technique [
32] is adopted. Specifically, an augmented variable
is introduced to signify the subpopulation affiliation of each
. If group
i is a member of the subpopulation
k,
then equals
k, i.e.,
. The probability mass function for
is expressed as
, where
refers to an indicator function. The conditional density of
can then be expressed as
. We further use
to represent the index set of subpopulation
, along with
, such that
, where
is the size operator. We can then derive the joint posterior as
We can assign the Dirichlet conjugate prior for
, i.e.,
, where
refers to the parameter of the Dirichlet distribution. We can further obtain the conditional posterior of
as
The conditional posterior of
then becomes a Dirichlet distribution with parameter
, where
. The conditional posterior of the augmented variable
is then derived as
The conditional posteriors of subpopulation-specific hyper-parameter
and mixed-type GSLH
as well as unknown model parameters
can further be derived as
Based on the derived conditional posterior of hyper-parameter , the subpopulations can be obtained easily with the proportion information. For each subpopulation k, the posterior samples of hyper-parameter and subpopulation-specific cases of can be drawn efficiently based on the derived conditional posteriors.
4.4. Estimation Algorithm
Based on the derivation details in
Section 4.1,
Section 4.2 and
Section 4.3, we develop a generalized estimation algorithm under the Gibbs sampling framework [
33] for the proposed lifetime model with multi-type GSLH. The detailed procedures are summarized in Algorithm 1. Specifically,
refers to the maximum number of iterations. We employ the improved Gelman–Rubin method [
34] to ensure the convergence of the sampling procedure. The improved Gelman–Rubin method is an alternative rank-based diagnostic that addresses the issues when dealing with heavy-tailed chains or varying variances across chains.
Without any prior information about the hyper-parameter
(or
), the prior can be specified through the elicitation process from a non-informative Dirichlet conjugate prior, e.g., Jeffreys prior [
27] with parameter
(or
). In the sampling procedures of unknown parameters
, the hyper-parameters
(or
) and all instances of
, the posterior samples can be readily obtained if a conjugate prior is accessible. On the other hand, when a conjugate prior is unavailable, we can employ the Metropolis–Hasting algorithm [
35] to facilitate the generation of these posterior samples.
| Algorithm 1 Sampling algorithm for the proposed approach. |
Initialization: and
if GSLH-M then Dirichlet and
end if
procedure DrawSamples
for do
if GSLH-D then
Partition data with and set
Draw from Dirichlet
Draw from by Equation (7)
Draw from by Equation (8)
end if
if GSLH-C then
Draw from by Equation (10)
Draw from by Equation (11)
Draw from by Equation (12)
end if
if GSLH-M then
Partition data with and set
Draw from Dirichlet
Draw from by Equation (16)
Draw from by Equation (17)
Draw from by Equation (18)
Draw from by Equation (19)
end if
end for
end procedure
|
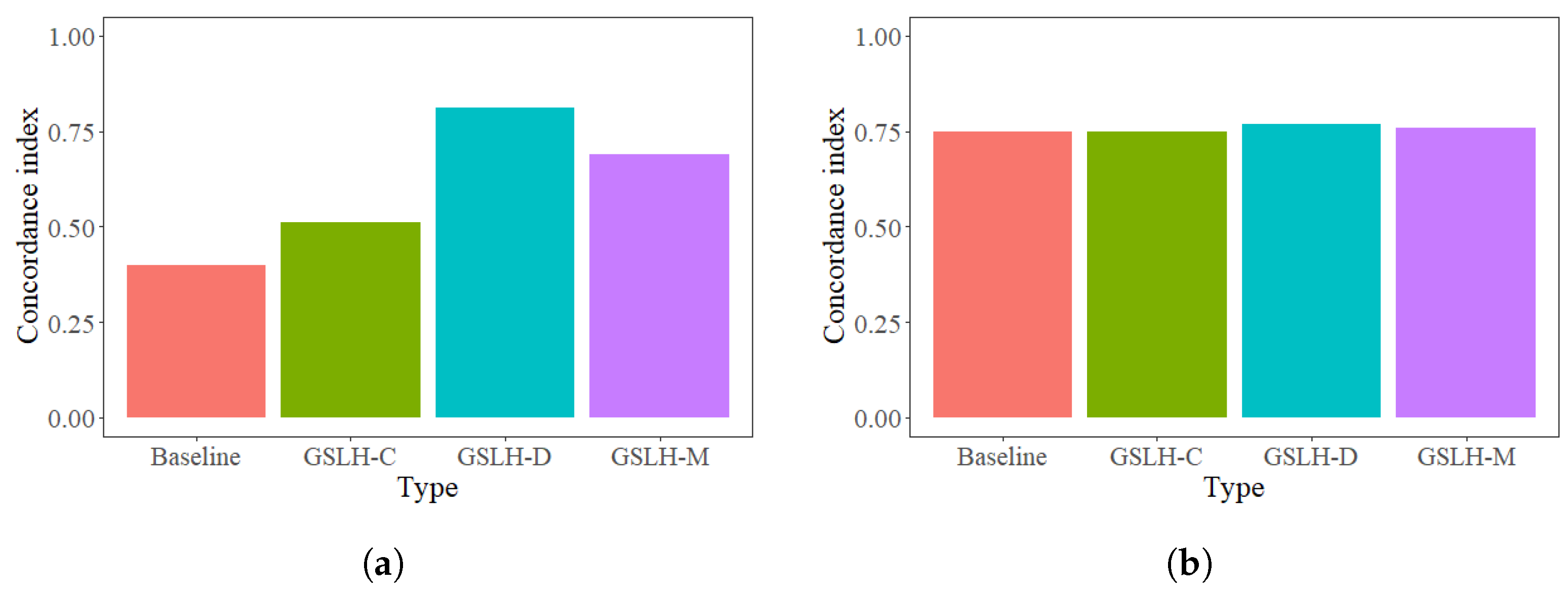
Based on the proposed formulation and estimation algorithm, the tripartite method for handling group-shared missing covariates can be further developed. The existence of GSLH is examined via comparing the DIC statistics of Markov chain Monte Carlo (MCMC) simulations between the proposed model and the baseline model which fails to consider multi-type GSLH. The DIC differences between the proposed model and the baseline model serve as the estimates of the expected loss differences in prediction. A negative value indicates that the proposed model with GSLH is more effective at capturing the underlying patterns of lifetime data; thus, the existence of GSLH should be considered. The correct type of GSLH can then be identified based on different structures of group-shared missing covariates. The proposed model with the correct type of GSLH is expected to achieve the best model-fitting performance. With the identified model, we can derive both point estimates and interval estimates of model parameters, enabling the quantification of the influence of both observed and group-shared missing covariates. With the identified missing information, we can also collaborate with the data provider to pinpoint the group-shared missing covariates with convincing interpretations based on available domain knowledge. Such a systematic process is performed iteratively until all group-shared missing information has been thoroughly explored.
With the derived estimates of unknown model parameters
and the cases of multi-type GSLH
as well as hyper-parameters, we can further calculate the reliability function. Given a test unit
l at time
, the estimated reliability function can be expressed as
, where
and
can be drawn from the derived conditional posteriors, as elaborated in
Section 4.1,
Section 4.2 and
Section 4.3.
4.5. Discussion
We can delineate various specifications for the distribution of random error
, as shown in Equation (
2). In this paper, the commonly used normal distribution and the extreme value distribution are selected for illustration purposes. By employing the reparameterization technique, the proposed model with a discrete type of GSLH is reduced to the log-normal mixture model and the Weibull mixture model, respectively [
27]. The following proposition clarifies such a model reduction.
Proposition 1. When is specified with different distributions, the GSLH-D model is reduced to the log-normal mixture model or the Weibull mixture model with specific unknown parameters for each subpopulation , i.e., , where t is the product lifetime, and represents the Weibull density function or the log-normal density function for the product lifetime of the units belonging to the subpopulation k. Specifically,
When follows a normal distribution, i.e., , where is a standard normal random variable and . Furthermore, we denote the unknown parameters related to the subpopulation k as , where and represent the mean and the variance on a logarithmic scale, respectively. Then, the GSLH-D model degenerates into the log-normal mixture model, i.e., .
When follows an extreme value distribution, i.e., , where is a random variable with standard Gumbel distribution and . Furthermore, we denote the unknown parameters related to the subpopulation k as , where and are the rate and shape parameters, respectively. Then, the GSLH-D model degenerates into the Weibull mixture model, i.e., .
Proposition 1 implies that the baseline hazard, which captures the underlying risk without considering the influence of any covariates, would become specific to each subpopulation rather than being shared across multiple different subpopulations. The discrete type of GSLH can then be captured by the subpopulation-specific model parameters
. The detailed proof can be found in
Appendix A.
Moreover, with the derived conditional posteriors of multi-type GSLH, we can obtain the following insights. First, in the GSLH-D model, all data of the same subpopulation contributes to the estimation of . The Bayesian framework enables information sharing among different product units from different groups that belong to the same subpopulation, and a large sample size is not required. On the other hand, only data within the same group is effective for the estimation of GSLH in the GSLH-C and GSLH-M models. Furthermore, the GSLH-M model with a more complex covariate structure is closely connected to the GSLH-D and GSLH-C models. When within each subpopulation approximately follows a degenerate distribution (i.e., subpopulation-specific is close to a constant value), the model with a mixed-type GSLH demonstrates similarities to the model with a discrete type of GSLH. When the entire population consists of a single subpopulation, the model with a mixed-type GSLH becomes the same as the model with continuous type of GSLH.
6. Conclusions
We proposed a flexible lifetime modeling and prediction approach with multi-type GSLH to account for the influence of complex group-shared missing covariates on product lifetime. Specifically, we first proposed a new lifetime model to comprehensively investigate multiple different structures of group-shared missing covariates. Bayesian estimation algorithms and inference procedures were further developed to simultaneously quantify the influence of both observed covariates and multi-type missing covariates shared within each group. With the generic formulation and effective estimation algorithms, a tripartite method was then developed to handle the multi-type group-shared missing covariates in a practical product lifetime analysis. The existence of multi-type group-shared missing covariates was first examined via a DIC statistics comparison. The correct type of the detected missing covariates was further identified, and finally, the influence of the group-shared missing covariates were quantified. A comprehensive simulation study was conducted under different scenarios of missing covariate information. The proposed approach showcases its effectiveness at handling multi-type group-shared missing covariates, leading to a substantial enhancement in estimation performance and prediction accuracy. Moreover, we investigated model robustness in the presence of misspecification issues. Furthermore, a real case study was presented to illustrate the applicability of the proposed work for uncovering the potential structure of multi-type group-shared missing covariates and alleviating the impact of missing covariate information on practical analysis of product lifetime. After further consultation with the data provider based on the identified information, the group-shared covariates can then be revealed with compelling interpretability.
In this paper, a novel lifetime modeling and prediction approach for a single-component system was developed. An interesting future research topic is to develop reliability analysis methods for multi-component systems with the intricate challenges posed by multi-type group-shared missing covariates. Moreover, the primary focus of this work centered on product lifetime analysis in the presence of group-shared missing covariates. Another promising direction is to develop degradation models for handling such multi-type group-shared missing information in product degradation analysis. In addition, the proposed work can be extended to semi-parametric models, such as Cox proportional hazards models for survival analysis in the future as well.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}