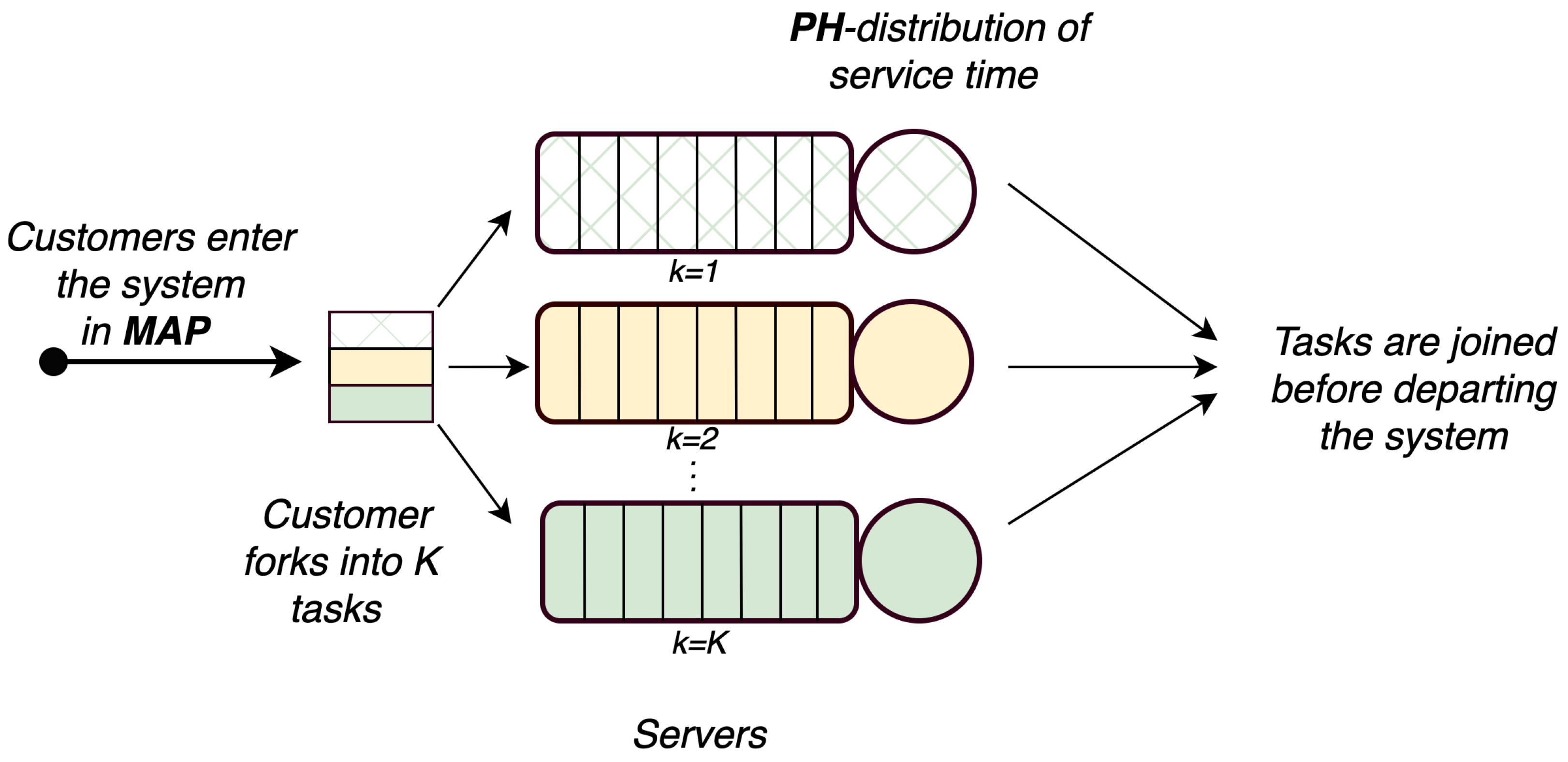
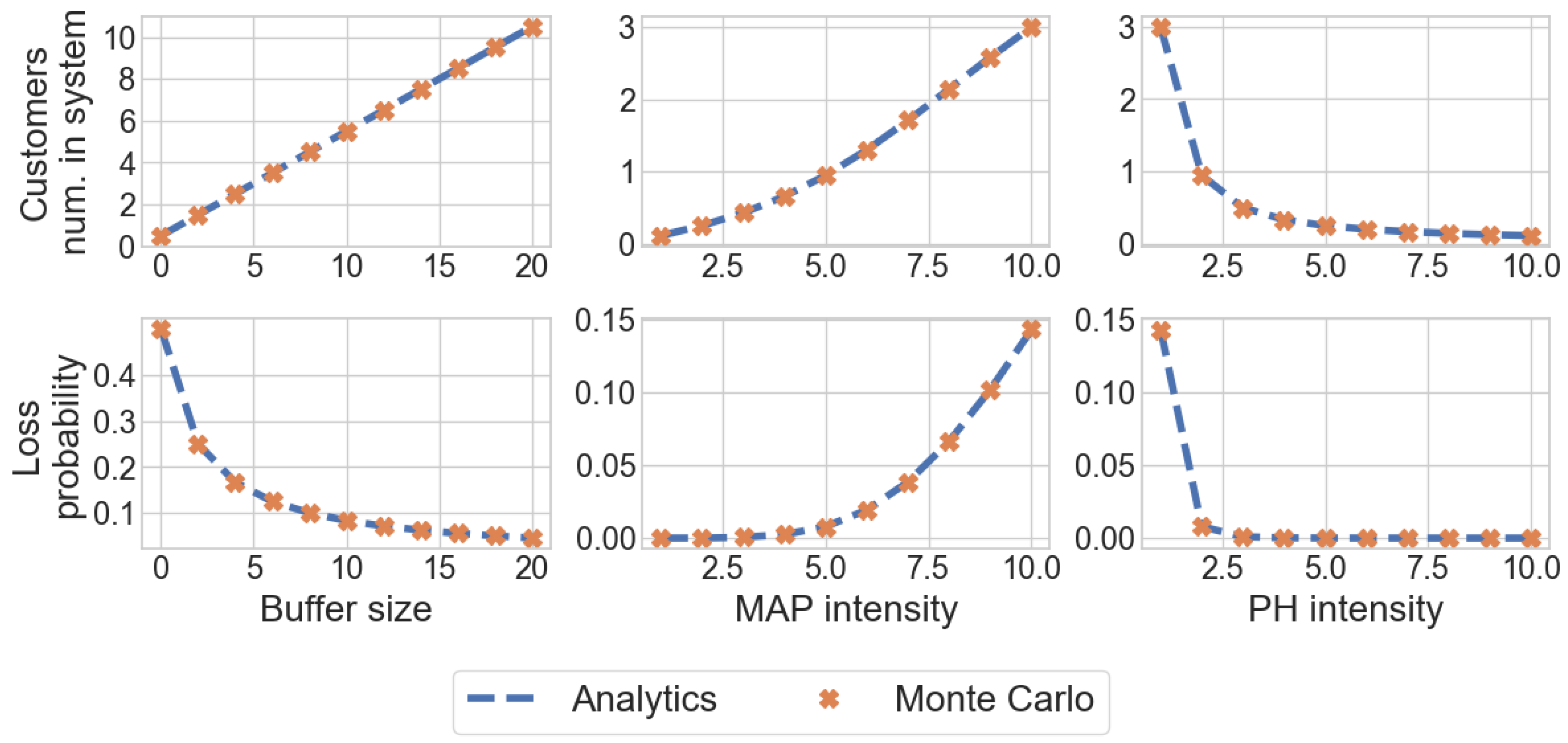
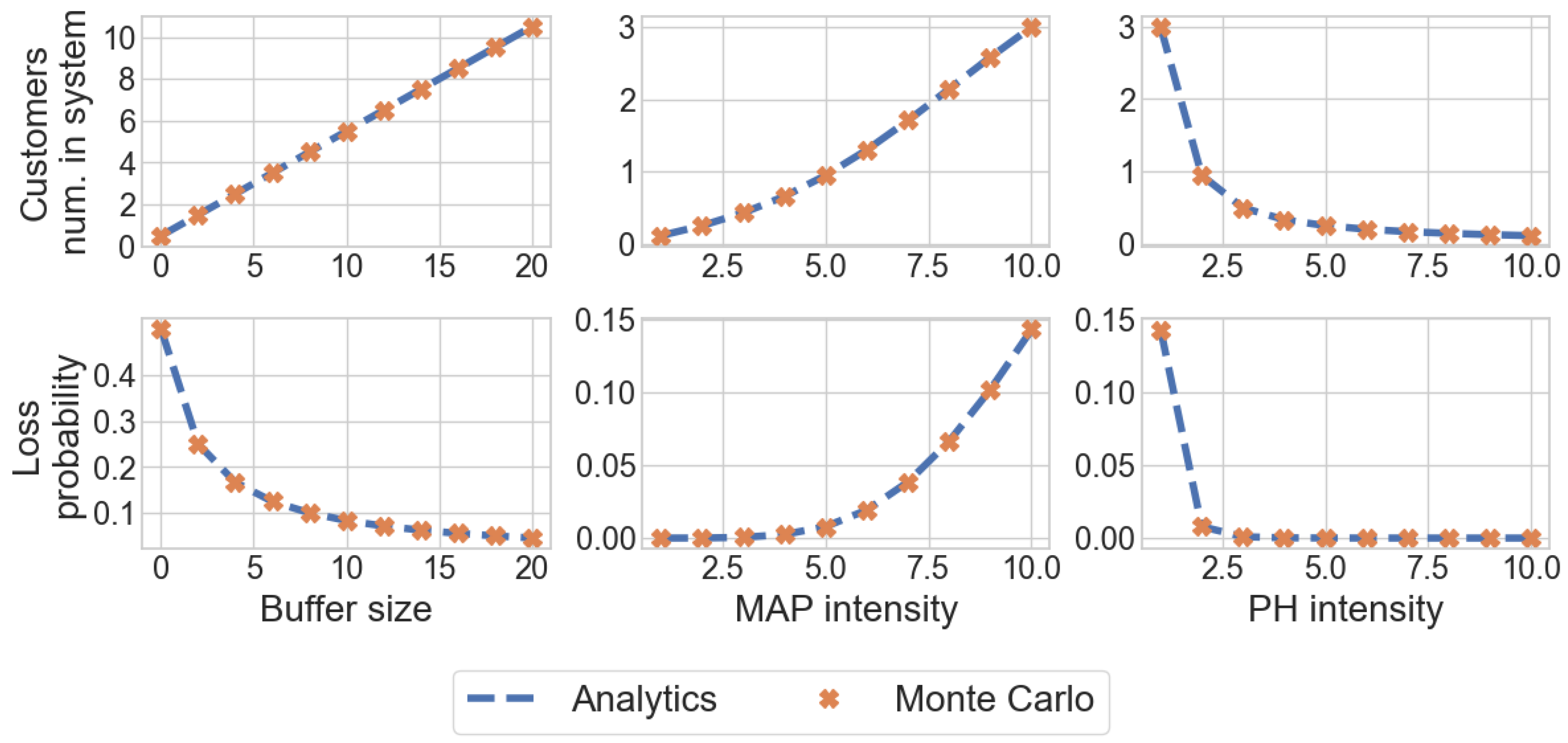
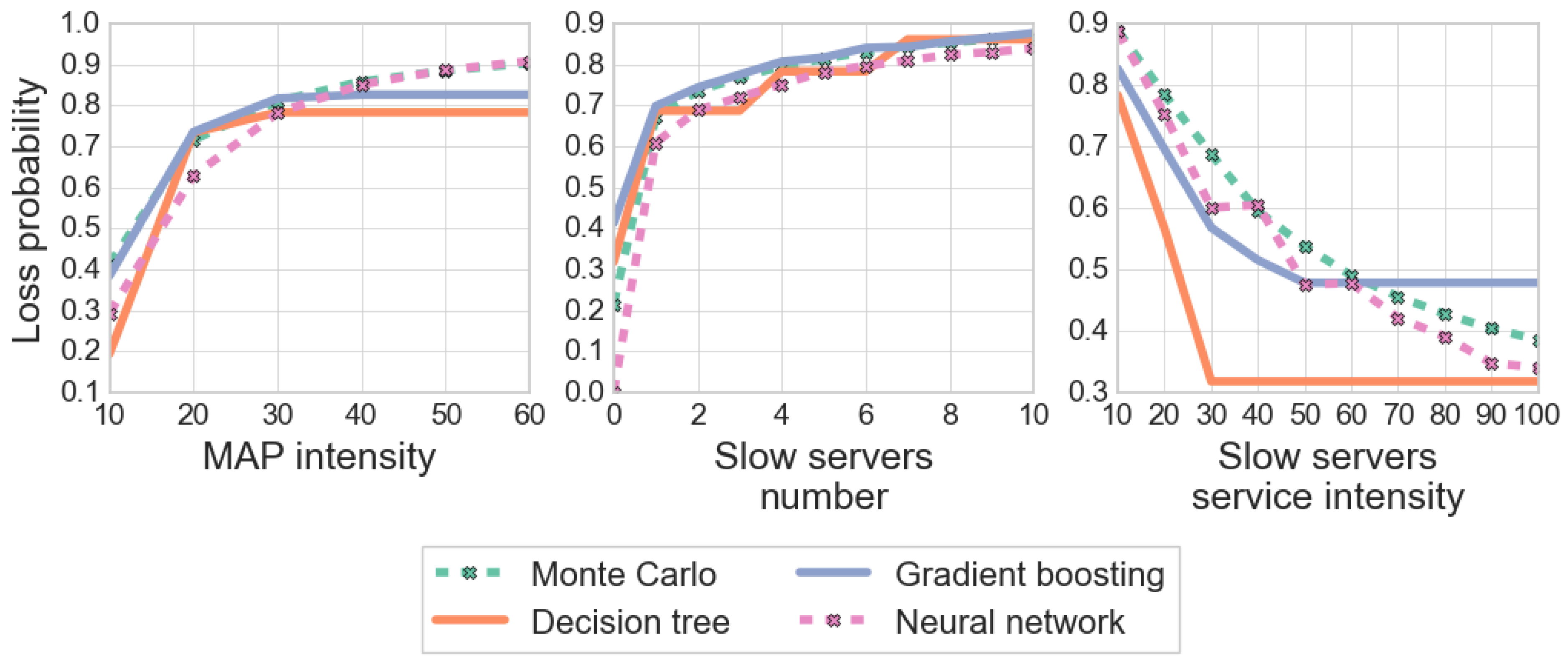
The analysis of this particular case is of theoretical interest, because the study of such a system under the assumption of an incoming flow and a distribution of service time has not been previously considered in the literature. In addition, the numerical results of this section will be used to validate a simulation model that describes the functioning of the general fork–join system () considered in this article.
3.1. Markov Chain Describing the Process of System Functioning
Assume that the first service device () has infinite buffer, and the capacity of the second () is limited.
At time t, let the following:
denotes the number of tasks in the subsystem , ;
denotes the number of tasks in the subsystem , ;
denotes the states of the underlying process of the , ;
denotes the states of underlying process of the service process on the kth server,
The operation of the system is described by a regular irreducible Markov chain
with the state space
Let us arrange the states of the chain in the lexicographic order and denote by the matrix of transition rates of the chain from the states with the value i of the first component to the states with the value of this component. We also denote by the matrix that is defined as
To proceed to writing the infinitesimal generator Q of the Markov chain we introduce the following notations:
I (O) is an identity (zero) matrix;
is a symbol of the Kronecker product (sum) of matrices;
is a diagonal matrix with diagonal blocks ;
is a sub-diagonal matrix with sub-diagonal blocks
is an over-diagonal matrix with over-diagonal blocks
Lemma 1. The infinitesimal generator Q of the Markov chain , has a block tridiagonal structurewhere non-zero blocks have the following form: is a square matrix of size is a matrix of size is a matrix of size is a square matrix of size is a square matrix of size is a square matrix of size
Proof. We represent each of the matrices in the block form and explain the probabilistic meaning of their blocks.
The matrix describes the rates of transitions of the Markov chain that do not lead to an increase in the number of tasks in the subsystems and . In this matrix and the others blocks are described as follows:
contains the rates of transitions of the chain caused by the idle transitions of the (the rates are described by the matrix );
contains the rates of transitions of the chain accompanied by the end of servicing on server 2 (the rates describe the matrix if and the matrix if );
contains the rates of transitions of the chain that do not lead to the arrival of a customer in the or the completion of the service on server 2. Such transitions are made during idle transitions of the underlying process or the underlying process of the service on server 2 (the rates are described by the matrix );
contains the rates of transitions of the chain that are caused by a change in the state of the underlying process of the (accompanied or not accompanied by the arrival of a customer) or idle transitions of the underlying process of the service on server 2 (the rates are described by the matrix );
The matrix describes the rates of transitions of the Markov chain which entail the arrival of a customer in the . It has a block over-diagonal structure, where, for , the over-diagonal blocks describe the transitions of the underlying process of the accompanied by the establishment of the initial phase of the service processes on the first and on the second servers (the matrix ) or, for transitions of the underlying process of the accompanied by the establishment of the initial phase of the service process on the first server and an increase in the queue in the system by one (the matrix ).
The matrix describes the rates of transitions of the Markov chain that lead to the completion of the service on the second server ((the rates are described by the matrix if and by the matrix if );
The blocks of the generator are described similarly to the blocks but taking into account the fact that, at the time of the chain transition, the system is not empty. □
Corollary 1. The process belongs to the class of quasi- birth-and-death () processes. Proof of the corollary follows from the structure of the infinitesimal generator and the definition of a quasi- birth-and-death process given in [32]. 3.2. Ergodicity Condition
The criterion for the existence of a stationary regime in the system under consideration coincides with the necessary and sufficient condition for the ergodicity of the Markov chain . This condition is defined in the following theorem.
Theorem 1. The necessary and sufficient condition for the ergodicity of the Markov chain is the fulfillment of the inequalitywhere Proof. According to [
33], a necessary and sufficient condition for ergodicity is the fulfillment of the inequality
where the stochastic vector
is a solution to a system of linear algebraic equations
Let us represent the vector
in the form
, where the vector
has order an of
and vectors
have orders
Then, taking into account the expressions for the blocks
, specified in Lemma 1, the system (4) will be written as
where
Let us now represent the vectors in the form where is the stationary vector of , is a stationary vector i.e., is the only solution to the system , and vectors of order satisfy the normalization equation We use these expressions in the equations of system (5), having previously multiplied the first equation by , and each of the subsequent equations on
Taking into account the relations
,
, we reduce system (5) to the following system for vectors
:
Next, we multiply the equations of system (6) on the right by . As a result, we are convinced that the probabilities satisfy the system of equilibrium equations for the process of death and reproduction with death rates and reproduction rates Having added the normalization equation, we come to the conclusion that the probability present on the left side of (8) has the form (2).
Now, consider inequality (3), which specifies the ergodicity condition. Our goal in this inequality is to move from vectors to vectors , whose order is times smaller, and to simplify this inequality as much as possible.
We use the representation
and substitute the vectors
, in this form, into the inequality (3). Then, taking into account the form of the blocks
of the generator specified in Lemma 1, we reduce inequality (3) to the form
Taking into account the relations
, let us transform inequality (7) into the form
Then, taking into account the notation
, inequality (8) is reduced to form (1). □
Remark 1. The left-hand side of inequality (1) is a rate of the flow of customers accepted into the system, and the right-hand side is a rate of the output flow from the first server (serving an infinite buffer) under overload conditions. It is clear that, for the existence of a stationary regime in the system, it is necessary and sufficient that the first of the mentioned rates is less than the second one. Inequality (1) can be rewritten in terms of the system load factor, 3.5. Sojourn Time of a Customer in the System
In this section, we consider the average sojourn time of a customer in the system from the moment it arrives to the moment when tasks corresponding to the same customer are joined before departing the system. Denote this average as Below, we derive the lower and upper bounds for In doing so, we take into account the following considerations.
(1). The average is not less than the average value of the maximum service times, of tasks belonging to the same customer.
(2). The average is not greater than the average value of the maximum sojourn times of tasks belonging to the same customer, if we assume that the subsystems and are independent.
(3). The average sojourn time in the subsystem , is not greater than the average sojourn time in the similar subsystem having an infinite buffer, .
(4). The average sojourn time in the subsystem where the original is thinned out due to the finite buffer in the subsystem is no more than the average sojourn time in the similar subsystem with an infinite buffer and the original .
From point 1, it follows that
Let us calculate the right-hand side of inequality (10).
Let
be a random variable equal to the service time on the first server,
Then, the average
is equal to the average value of the random variable
Taking into account that the service times on the servers of subsystems
and
are independent random variables, it is easy to see that the distribution function
of the random variable
is found as
Let us now calculate the mean value of the random variable
Furthermore, from points 2–4, the following inequalities follow
The systems
introduced above are
systems that differ only in the parameters of the service time distribution. The distribution of the service time in the system
is described by an irreducible representation
Let us find an upper bound,
of the desired average,
as the average of the maximum of sojourn times in the systems
and
It is known, as can be seen in [
33], that the sojourn time in the system
has a
distribution. Denote the irreducible representation of this distribution for the system
as
. To calculate the upper bound
, we will use the proof similar to that for formula (12). As a result, we obtain the following relations:
Next, it is necessary to obtain expressions for the parameters
of the sojourn time distributions in the systems
and
. These expressions were obtained in [
33] and will be given below for the convenience of the reader. Since all further results on finding the sojourn time are valid for any system
, including the systems
and
in order to avoid cumbersome expressions, we will omit the index
k in the notation
That is, we will consider the distribution of the sojourn time in the
system with
given by the matrices
and
, and the service time distribution given by the
Mth-order representation
According to [
33], when deriving expressions for the parameters
, the blocks of the Markov chain generator describing the operation of the system
are used. This generator looks like
where
Denote by
the vectors of the stationary distribution of the system states at an arbitrary time. The vectors
are calculated using an algorithm similar to Algorithm 1 with minimal changes. For the convenience of the reader, we present this algorithm below (Algorithm 2).
| Algorithm 2 The vectors of the stationary state probabilities of the system. |
|
| where the matrix R is the minimal non-negative solution of the matrix equation |
|
| and the vector is the unique solution of the following system of linear algebraic equations |
|
Next, we use the results of [
33] for the sojourn time in the queueing system, the operation of which is described by the general
process. According to these results, the indicated sojourn time has a
distribution, the parameters of which are defined in [
33]. In our case, we modify these results to the case of the
system, which is a special case of the system considered in [
33]. Taking into account this difference, we derive the following statement.
Statement 1. The sojourn time in the system under consideration has a distribution with an irreducible representation , where the row vector τ and the square matrix T have orders and are calculated by the following formulas:where is a column vector of order whose lth entry is equal to one and the remaining entries are equal to zero, -diagonal matrix of order , whose diagonal entries are equal to the corresponding entries of the vectorwhere the matrix is calculated as Corollary 2. The upper bound is calculated by formula (13), where the vectors and the matrices , are defined by formulas (14)–(17) in which all occurring notations (except ) are provided with the index k.
Thus, it follows from formulas (10)–(13) that the lower and upper bounds for mean sojourn time, in the fork–join queue under consideration are defined from the following inequalities:where the vectors and the matrices , are defined by Statement 1 and Corollary 2. 


 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}