1. Introduction
Many machine-learning tasks solved by means of neural networks, for example, solvers of optimization problems, models generating images in a predefined region, control problems with actions in some interval, require the restriction of the neural network outputs by certain constraints. The restrictions imply that outputs of a neural network have to satisfy specified constraints.
The most existing approaches to construct a neural network with the output constraints are based on adding regularization terms to a loss function of the network to penalize constraint violations. However, the corresponding
soft constraints only penalize their possible violation, but they do not guarantee that the constraints will be satisfied for a new example [
1]. Another interesting approach is to modify the neural network to provide predictions within a set formed by the constraints. In this case, we have
hard constraints which are satisfied for any input example during training and inference [
2].
There are several approaches to impose hard constraints on the neural network outputs, for example, [
2,
3,
4,
5,
6,
7]. Most approaches consider the linear and convex hard constraints. One of the approaches to impose convex constraints was proposed in [
8]. The key idea behind the method is to add a neural network layer which maps a latent vector to a point that is guaranteed to be inside a feasible set defined by the constraints. Following this method, we propose its extension, which allows us to consider the well-known type of non-convex constraints called the star-shaped constraints [
9]. At that, the convex constraints can be regarded as a special case of constraints that can be used in the proposed method. To the best of our knowledge, at the moment, no approach is known that allows building layers of neural networks implementing the non-convex star-shaped constraints such that the optimization problem is not solved during the forward pass of the neural network.
The proposed method can be applied to solving optimization problems with arbitrary differentiable loss functions and with star-shaped constraints, to implementing generative models with constraints. It can be used when constraints are imposed on a predefined points or a subsets of points.
Our contributions can be summarized as follows:
A problem of building a neural network with non-convex hard constraints on output vectors is formulated. The neural network consists of two parts. The first part is an arbitrary neural network that processes input data. The second part is a layer that implements the proposed method for restricting predictions by star-shape constraints.
A method for non-convex constraints specification, inspired by constructive solid geometry in computer graphics, is proposed.
A new neural network layer for implementing the hard constraints on star-shape domains is introduced.
The proposed method is evaluated, confirming experimentally its properties.
The paper is organized as follows. Related work can be found in
Section 2. The problem statement for constructing a neural network with outputs satisfying certain constraints for an arbitrary input vector is given in
Section 3.
Section 4 describes how to represent the star-shaped region as a combination of the set operations. The signed distance function used to represent non-convex sets is introduced in the same section. The general method for constructing a neural network with restricted output and its modification is provided in
Section 5. An approach for applying the ray casting method for solving the stated problem is considered in
Section 6. Numerical experiments illustrating the proposed method are provided in
Section 7. Concluding remarks can be found in
Section 8.
2. Related Work
It should be noted that a few machine-learning models implement hard constraints. Brosowsky et al. [
5] proposed a neural network architecture which imposes linear hard constraints on the network output by using a linear combination of vertices of a polyhedron produced by the constraints with coefficients in the form of the softmax operation results. A limitation of the method is that only linear constraints are considered. Another limitation is that the method requires the enumeration of all vertices of a polyhedron produced by the linear constraints, whose number may be very large. Frerix et al. [
2] proposed an approach for solving problems with conical constraints of the form
. According to the approach, points are generated in the set produced by linear constraints
by means of a set of rays. It is important to point out that the authors of [
2] claim that the approach does not allow for efficient incorporation of constraints in some cases. Moreover, if the method is applied to non-conical constraints, then all vertices of the set have to be considered. Another approach specifically designed for solving constrained optimization problems is provided by Donti et al. [
6]. The approach tries to incorporate equality and inequality constraints into the learning-based optimization algorithms. However, its performance heavily relies on the training process and the chosen model architecture. A method for solving optimization problem with linear constraints is also presented in [
10]. The method allows solving the optimization problems only with linear constraints and may also require significant computational resources. An RL algorithm designed to enforce affine hard constraints in a task of the robot policy learning was proposed in [
11]. An outstanding framework to impose hard convex constraints on the neural network outputs called RAYEN was presented in [
7]. It supports any combination of linear and convex quadratic inequality constraints. An interesting approach for solving quadratic optimization problems with linear constraints posed on the neural network outputs was proposed in [
4]. Agrawal et al. [
3] presented a similar approach based on adding a differentiable optimization layer to a neural network, which implements a projection operator to guarantee that the neural network output satisfies constraints. However, according to this approach, convex optimization problems have to be solved for each forward pass. In [
1], the authors show that imposing hard constraints can in fact be done in a computationally feasible way by using a Krylov subspace approach. Liu et al. [
12] proposed a differentiable layer, named the differentiable Frank-Wolfe layer, using the well-known Frank-Wolfe method for solving constrained optimization problems without projections and Hessian matrix computations. Sun et al. [
13] developed a new framework, named alternating differentiation, that differentiates convex optimization problems with polyhedral constraints in a fast and recursive way.
A number of approaches partially addressing the task of solving constrained optimization problems were considered in [
14,
15,
16,
17,
18,
19,
20,
21]. They are analyzed in survey papers [
22,
23]. At the same time, the aforementioned approaches solve optimization problems with linear or convex constraints, but they do not consider the non-convex star-shaped constraints.
3. The Problem Statement
A connected region is called
star-shaped when it contains a point from which every boundary point is visible. Formally, if the feasible set
is the star-shaped region, then there exists a point
such that every point
can be represented as
where
r is a vector or a ray,
;
is a scale factor, and
.
The condition
is fulfilled for all
such that
, i.e., the entire segment belongs to the region:
The point
p is called the origin. Let
be a star-shaped region specified by a set of constraints. The first goal is to construct a differentiable neural network layer with outputs, satisfying constraints for an arbitrary input vector:
such that
is surjective.
The second goal is to build a surjective mapping
to the boundary of
denoted as
, i.e.,:
It should be noted that, in practice, the precise mapping to the boundary cannot be constructed due to numerical errors, and, therefore, the second goal is to find an
-accurate mapping to the boundary such that
4. Region Definition as a Signed Distance Function
In the case of convex constraints, the natural region definition can be formulated as a system of inequality constraints, which is equivalent to an intersection of convex regions. For star-shaped non-convex regions, not only can the intersection operation be used, but also union, subtraction, and so on. It is worth mentioning that the star-shape property is not closed under union and even intersection operations, meaning that an intersection of two star-shaped regions can be not star-shaped. Therefore, we use a general scheme for defining non-convex constraints, because no specific scheme for star-shaped regions can be implemented.
For defining a non-convex domain, we follow the principle of constructive solid geometry, where a complex object is defined as a combination of set operators and geometric primitives, such as cuboids, spheres, hyperplanes, etc. The whole object can be seen as a tree, where internal nodes represent operators, edges connect operators with arguments to which they apply, and the leaf nodes are primitives.
We define a constraint tree as a graph whose nodes represent n-ary operators and edges connect the operators to their arguments. Leaf nodes in the tree correspond to primitives, and can be considered as 0-ary operators.
Basically, the non-convex region
can be represented as a composition of the union and intersection operations over some sets, recursively represented in the same way, and convex primitives. For example:
or in another form:
However, some more complex scenarios require additional operators, such as the set difference “∖”, especially, when the set of primitives is limited to convex primitives. Therefore, we consider different sets of operators, starting from the simplest one to the general case:
Only the intersection operator “∩” can be considered, which is equivalent to the system of constraints:
where each constraint
represents a primitive, e.g., a plane. In the case of convex primitives, it leads to a convex domain.
The intersection “∩” and union “∪” operators can be studied. A computationally simple algorithm for constructing non-convex sets with the above operators is described below in detail.
The complete set of operators includes the intersection and union operators as well as the set difference “∖” operator.
A connected non-convex region can be defined in one of three ways described above. Intuitively, the simpler the definition is, the more effective the algorithm that can be implemented. For example, for the first above case and linear constraints, the algorithm is linear and can be reduced to the ray-hyperplane intersection and to the minimum calculations [
8]. For other cases, two different methods are considered further.
In a general case, a constraint tree for the region
can be associated with a
signed distance function (SDF) considered in [
24]. Formally, it is defined as a function
that measures a distance to the set boundary
multiplied by
in a case when an input point lies inside the
:
If
, then the SDF value is positive and coincides with the distance to
, i.e., the following holds
Each set operator in a constraint tree can be translated into the SDF operator:
where • represents a set operator which is defined for different values as:
;
;
.
A unary inverse operator is
It can be seen from the above that the SDF can be used to represent non-convex sets and to implement the set operations. The sign of the SDF can be used to check whether a point belongs to the region ot not.
The idea behind the SDF usage is to represent both convex and non-convex regions in the form of a function in a computationally simple way because the set operations are rather simple.
5. General Method
We propose a neural network consisting of two parts. The first part is an arbitrary neural network, which processes input data that is specific to a concrete application problem, for example, it can be a convolutional neural network for the image inputs. The second part is a layer whose outputs are guaranteed to satisfy star-shape constraints (see
Figure 1). Let us describe this layer in detail.
Suppose that
is the origin of
, which is star-shaped, closed, and has a non-zero volume. Then, by definition, every point
can be parameterized by a pair
, such that
. The main idea behind the method is to use this parameterization to construct points inside
, so the corresponding output of the neural network layer (see
Section 3) is calculated as:
where
, and
and
are outputs of neural networks with parameters
, which map an input to the step size and the ray direction, respectively. The step size
should not violate constraints along the ray
:
Obviously, the upper boundary of
depends on the ray direction
. Let us denote the above supremum as
. The second goal can be achieved by constructing the neural network layer as:
The function can be regarded as a neural network with parameters .
The mapping to the boundary can be used to construct the neural network with parameters in two ways described below.
5.1. Ray and Scale Approach
First, a point inside the region
can be represented as a convex combination of the origin
and some point on the boundary. Hence, we can write the following expression for
in terms of the neural networks described above:
Therefore, can be used to generate points in the region interior. The mapping should be surjective, so necessarily should be a function of z. For example, in the implementation, can be the output of a neural network with the sigmoid activation function at the last layer.
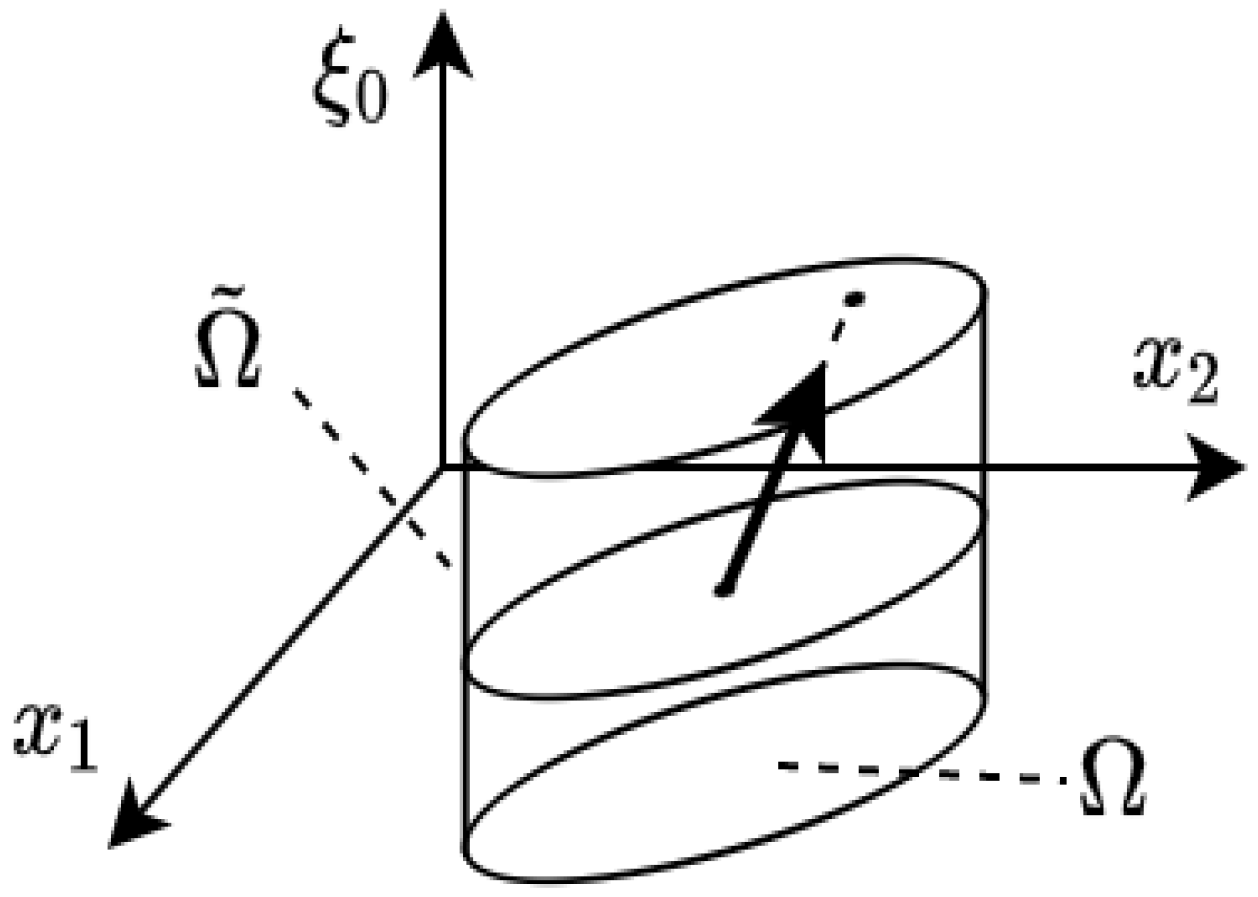
5.2. Extended Space Approach
The second way to construct
by using
is to increase the output space dimensionality by one, obtaining the region
, which is described below, and then to find a boundary point and a project back to the original space
. We can use an arbitrary definition of
, when two conditions are satisfied. First, the region
can be projected to the original region
, i.e., the 0-th component represents the extra dimension:
Second, the region
should be also star-shaped, closed, and with a non-zero volume. A straightforward example (see
Figure 2), satisfying the above two conditions, is a closed cylinder defined as:
where
and
.
Using the set
, the mapping to the region
interior can be constructed from
in the following way:
where the projection
is carried out by discarding 0-th component:
Since
can be represented as an intersection of linear constraints on
and the original domain
then SDF for
can be inferred from
by applying the intersection operator on SDF:
Therefore, an extended space does not have to be explicitly defined for estimating the SDF-based intersection point calculated as such that .
When the value of
is large, the first term in the maximum (
21),
, will dominate, and points will concentrate at the boundary. This problem can be solved by taking
as a function of
i.e.,
. A special case is when
, which allows avoiding manual tuning of
. The SDF with such values of
is
and it can be interpreted as a SDF of the union of spheres of radius
around every point of
.
The main remaining question for implementing and is how to estimate the maximum allowable step size in a differentiable way.
5.3. Iterative Approach for Finding
The most general approach of finding the maximum allowable step size
, which can be applied to an arbitrary constraint tree, is based on optimization of the SDF absolute value along the ray, and is usually called the ray marching algorithm. This algorithm was initially proposed in [
25] for applying to the computer graphics field. It is not limited to the specific constraint tree structures or a narrow set of the set operations, and allows us to decide on the quality–performance trade-off. The algorithm is based on using the SDF value as a step size along the ray direction, which guarantees that the tracing path will not pass through the object boundary. It iteratively updates the intersection point estimate by moving it along the ray until
. The iterative process can be described as follows:
The SDF function is computed by combining operators in accordance with the constraint tree.
Gradient Estimation
Since depends on the ray direction, which is calculated as an output of the neural network , then we have to calculate gradient of to optimize parameters of the neural network. We consider two approaches to compute the partial derivative with respect to the ray direction vector:
The first approach is natural for neural networks. It is based on an automated differentiation algorithm and requires the calculation of the derivative of the SDF
M times. The second approach, based on the implicit function, is much more computationally effective because it allows us to estimate the gradient at the intersection point in a single pass. The only limitation is that it assumes that the intersection point estimation is precise. Let us consider the second approach in detail. The step size
is a function of
r, such that there holds for all
r:
where
is the layer that maps inputs onto
:
We have to find the derivative of
with respect to
r, for which partial derivatives
are needed because of
where
.
Let us define
. If
, then we can apply the implicit function theorem [
26]: there is a small neighborhood around
, where the function
exists such that
, and
The partial derivative of
g at point
can be found analytically:
and the gradient of
g at point
, where
is constant, is:
Therefore, the desired gradient is a scaled normal of the decision boundary:
When the denominator is zero, the decision boundary normal is orthogonal to the ray direction, and
can be set to zero too. Finally, a neural network with the proposed layer at the end is suitable for the gradient-based optimization or training. Indeed, if the ray direction function
r is implemented as a neural network with the parameters
:
, and some loss functional
is defined, where
, then the loss gradient over the vector of parameters can be found as:
where the loss function gradient
is known,
is found via automatic differentiation, and the Jacobian matrix of
at
r is of the form:
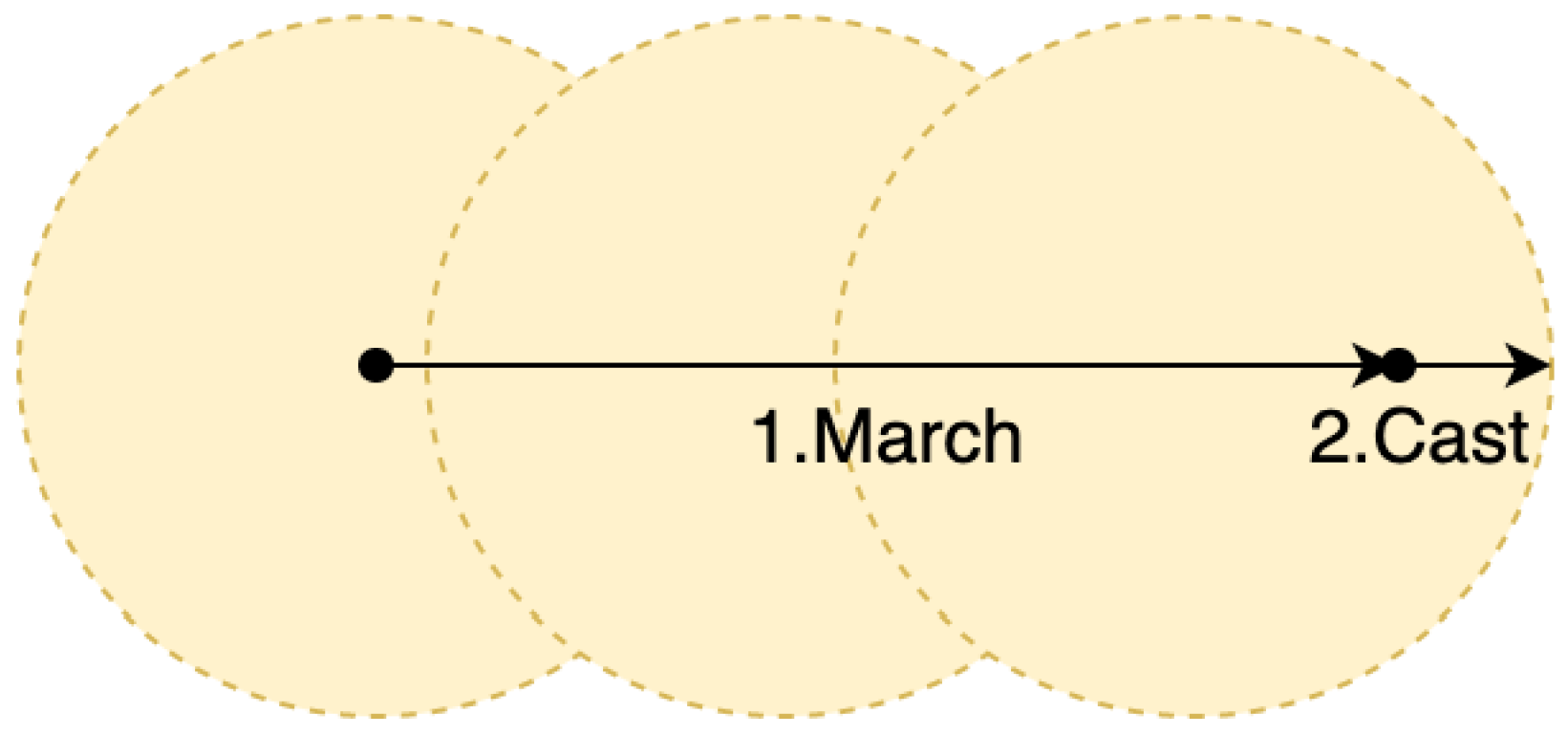
5.4. Modification
The above gradient estimation is exact when the iterative marching process converges exactly to the boundary point. It takes place in some cases, for example, when
is a sphere, or a hyperplane, and the ray direction is collinear with the hyperplane normal. In general, the iterative process with a finite number of steps can converge to a point which is
-close to the boundary. Hence, the proposed gradient estimation becomes less accurate. To increase the accuracy, a two-stage modification can be used (see
Figure 3). At the first stage, the iterative marching process is used to find an intersection point approximation, which is
-close to the boundary, but is not exactly at it. At the second stage, the ray casting is applied from the approximate point to the closest primitive, determined at the SDF calculation. The required number of steps can be found in advance to guarantee
-accurate approximation, for which the ray casting produces correct results on the boundary.
If we define a set of the ray points that belong to the domain
as:
then the function
determines a distance to the domain boundary along the ray:
Formally, the modified algorithm has one additional step:
where
is the distance to the boundary obtained with the ray casting from the point
x along the ray direction
r, and
are the closest primitives (the constraint tree leaves).
6. Ray Casting
The idea of the general ray casting method is that, for each node of a constraint tree, the list of segments which intersect the given ray can be computed. It means that the intersection of a ray and some region, determined by a constraint tree node, can be represented as a union of line segments which are stored as a list of these segments. The intersection point searching process starts from the bottom of the tree by computing segments by means of intersecting the primitive of the ray. For example, for a sphere primitive, an intersection segment can be in case the ray intersects the sphere twice: when going inside and outside, otherwise, the intersection may be an empty set, or in a limiting case of a tangent ray: ; for a plane primitive, there will be one intersection or an empty set. Then, the operators that take only bare primitives as an input are computed resulting in lists of segments and so on.
First, we consider the simple case of using only the intersection and union operators, also assuming that the origin is outside the domain. We can associate each node of the constraint tree with its own distance function
, and calculate operators based on the distance function values of the arguments. For the union, the distance function can be easily defined:
Unfortunately, for the intersection operator, all intervals have to be considered, not only distance functions, and cannot be written in a concise recursive form. For 0-ary operators or primitives, distances are calculated analytically.
We assume that primitives are convex and propose the following algorithm. First, we convert the set formula to a representation like the disjunctive normal form:
where each component is an intersection of primitives or negated primitives
:
We need to find a point of the intersection of the ray and the domain closest to its origin:
where
R is the ray, i.e., there holds
Let us consider the intersection with the ray:
Since the ray is one-dimensional, we encode these sets by intersections of one-dimensional segments in coordinates. Each is a primitive or a negated primitive. In the former case, we can easily compute the intersection , which can be encoded as:
In implementation, we always encode the intersection with the ray in the same way as a segment, where ends are equal to when the intersection is empty.
The next step is to find the intersection of all such segments
by iteratively applying the interval intersection operation, which is defined as following:
It is interesting to note that the disjunctive normal form representation of the domain is better than the conjunctive normal form because components in the latter consist of interval unions that are harder to store and process. Although, this advantage takes place only when primitives are convex.
In the case of negated primitives, e.g.,
the algorithm can also be applied, but more than one interval can appear for each such primitive. In this case, all intervals must be intersected with other primitives. In the worst case, when all the primitives are negated (non-convex)
the total number of
intervals have to be found for the union, making this algorithm inappropriate.
7. Numerical Experiments
7.1. An Example of Independent Random Variables
To illustrate the ability of the proposed method to deal with non-convex constraints, we consider a simple problem of point generation on a surface. Let us consider two independent binary random variables
A and
B. The goal is to predict probabilities of elementary events:
under the condition that random variables
A and
B are independent, i.e., the following equality is valid:
This constraint cannot be formulated as a system of linear inequalities. Indeed, if we denote probabilities
, the independency property can be expressed as
and thus the constraint set is:
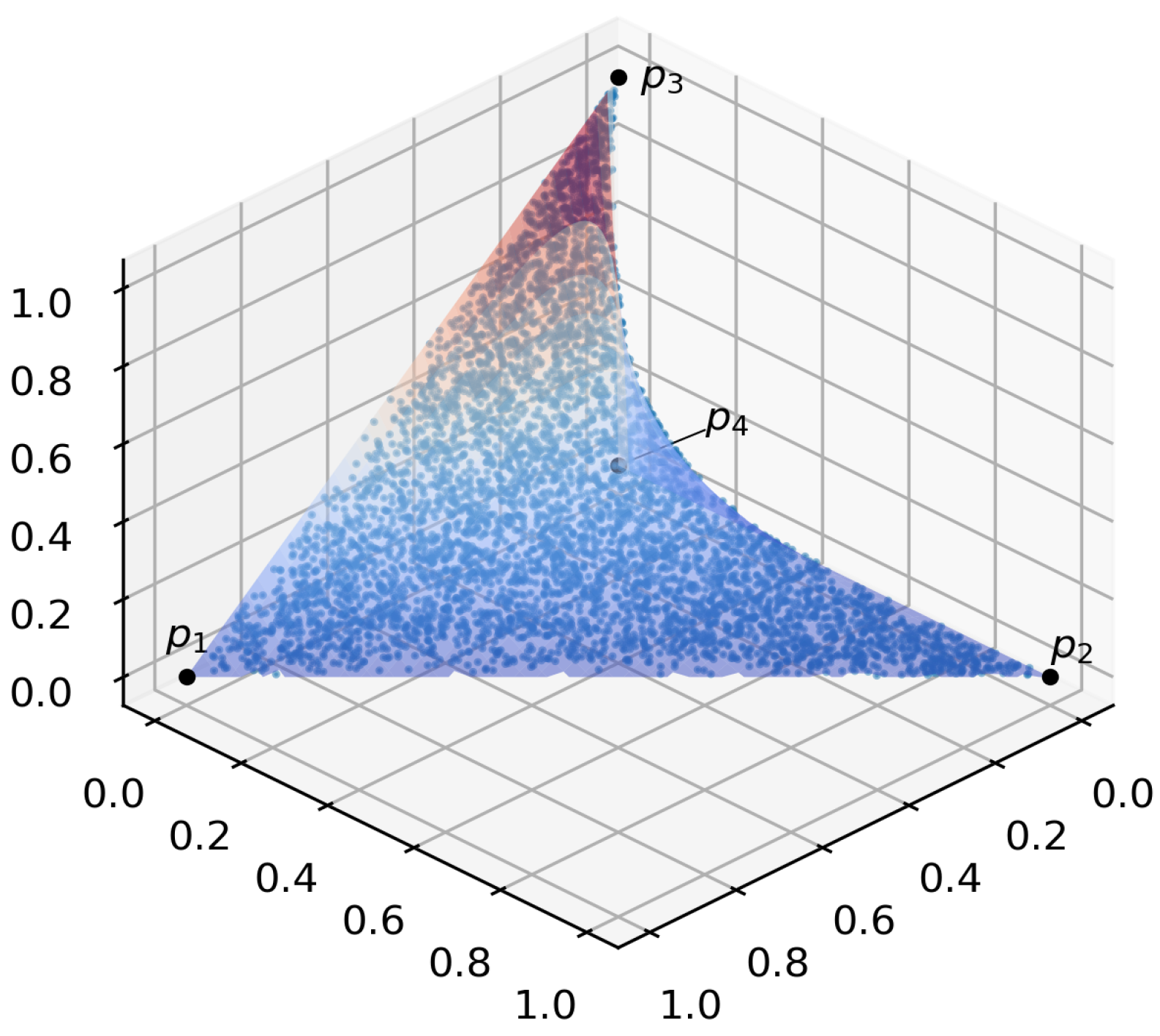
The solution space is 3-dimensional, because the variable
can be replaced with
, adding one extra inequality constraint
:
We aim to generate discrete probability distributions with components
that satisfy the above constraints for an arbitrary input vector. The basic neural network is represented as one softmax layer, and the additional differentiable layer with output satisfying these constraints. The admissible points belong to a surface in the 3-dimensional space, which is shown at
Figure 4. The probability simplex extreme points or vertices are denoted as
.
We define the SDF as follows:
and try to generate points on the surface, i.e., where
.
7.2. Personalized Treatment Under Dose Constraints
As an example of the neural network training with the proposed constrained layer, we consider a problem of choosing doses of chemotherapy (
) and radiation (
) based on patient feature vector with synthetically generated data [
27,
28]. In this problem, it is important that no dose ratio is acceptable. The constraints are defined as a union of multiple rectangles, obtained by intersection of axis-parallel hyperplanes, and the admissible set has a ladder-like shape. The patient vector
z in the example consists of three features, where only the first feature is significant. Each feature is sampled from the uniform distribution in the interval
. The neural network takes the patient feature vector
z as an input and predicts the dose estimation
, satisfying the constraints. The loss function depending on the input vector
z and the estimated dose
is determined as follows:
The neural network parameters are optimized to minimize the loss over elements of the dataset:
We use the following hyperparameters of the neural network: 3 layers having 8 units with SiLU activations, trained with Adam with the learning rate
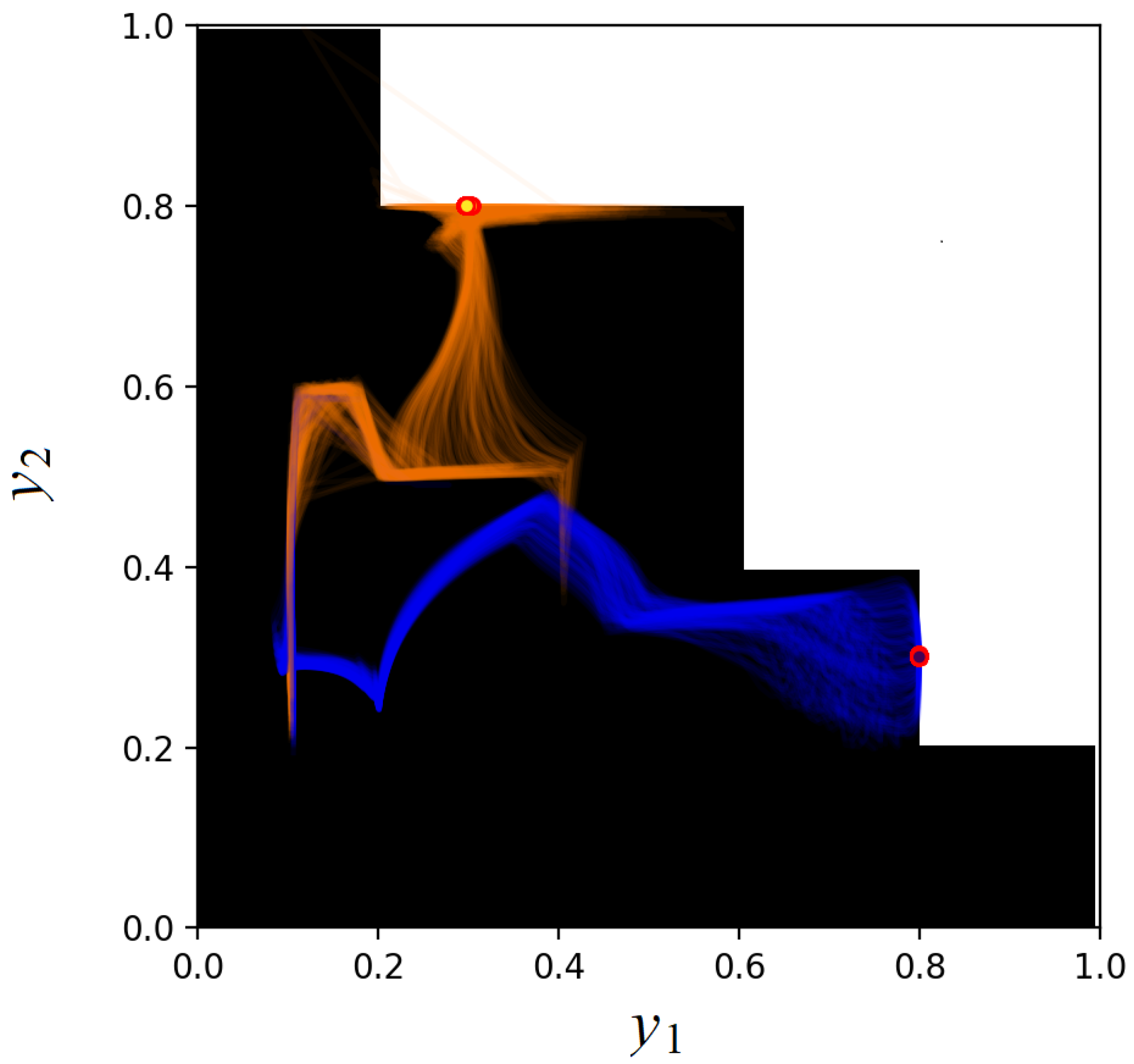
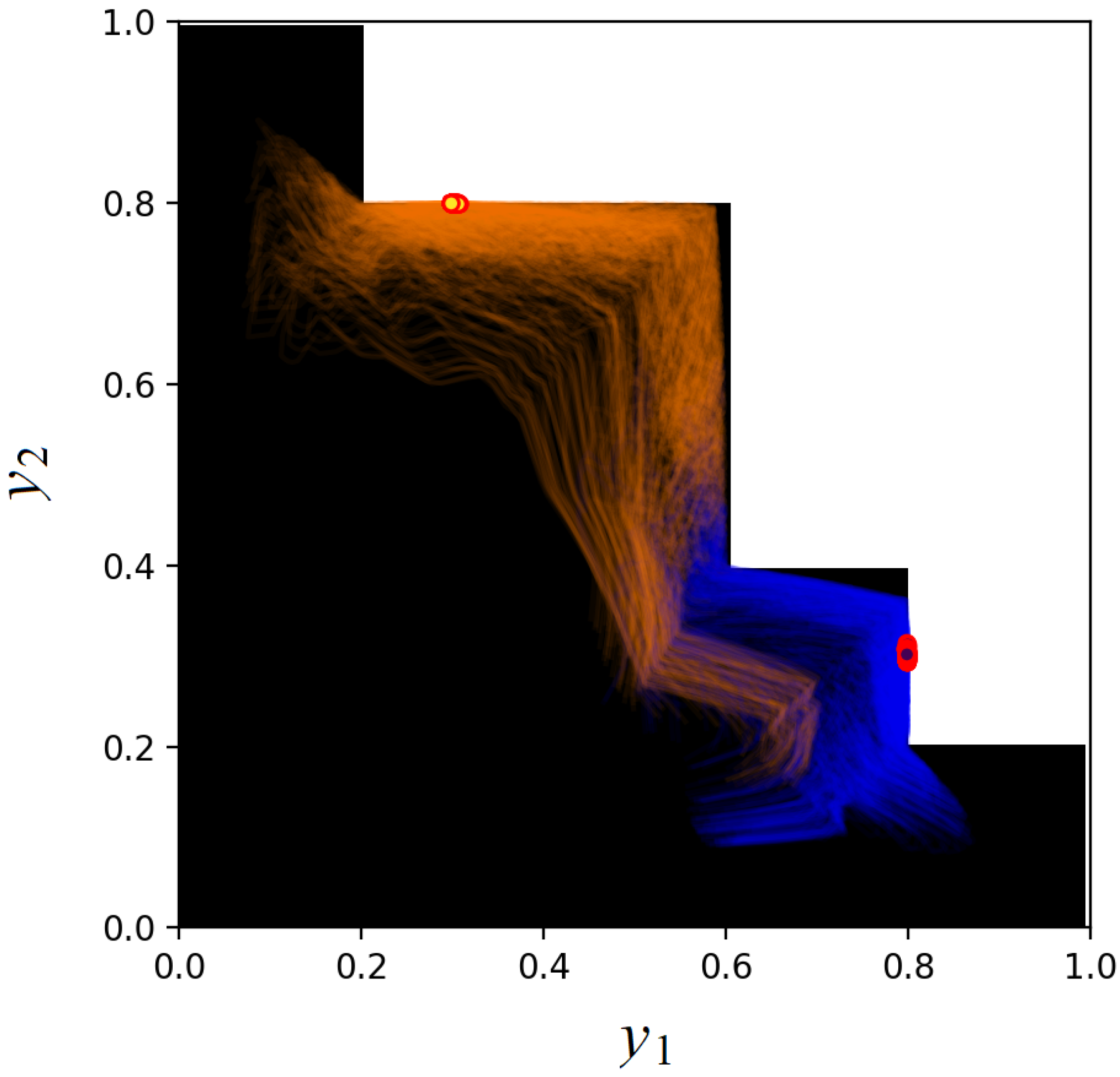
, a batch size of 16 for 1000 epochs on the dataset consisting of 500 synthetically generated patient vectors. Also, we limit the number of ray marching iterations to 5. The dataset consists of 500 points. The semi-transparent blue and orange curves in
Figure 5 and
Figure 6 represent trajectories of estimated doses
for every dataset point over training iterations, for negative and positive values of
, respectively.
Figure 5 illustrates the ray and scale approach, whereas
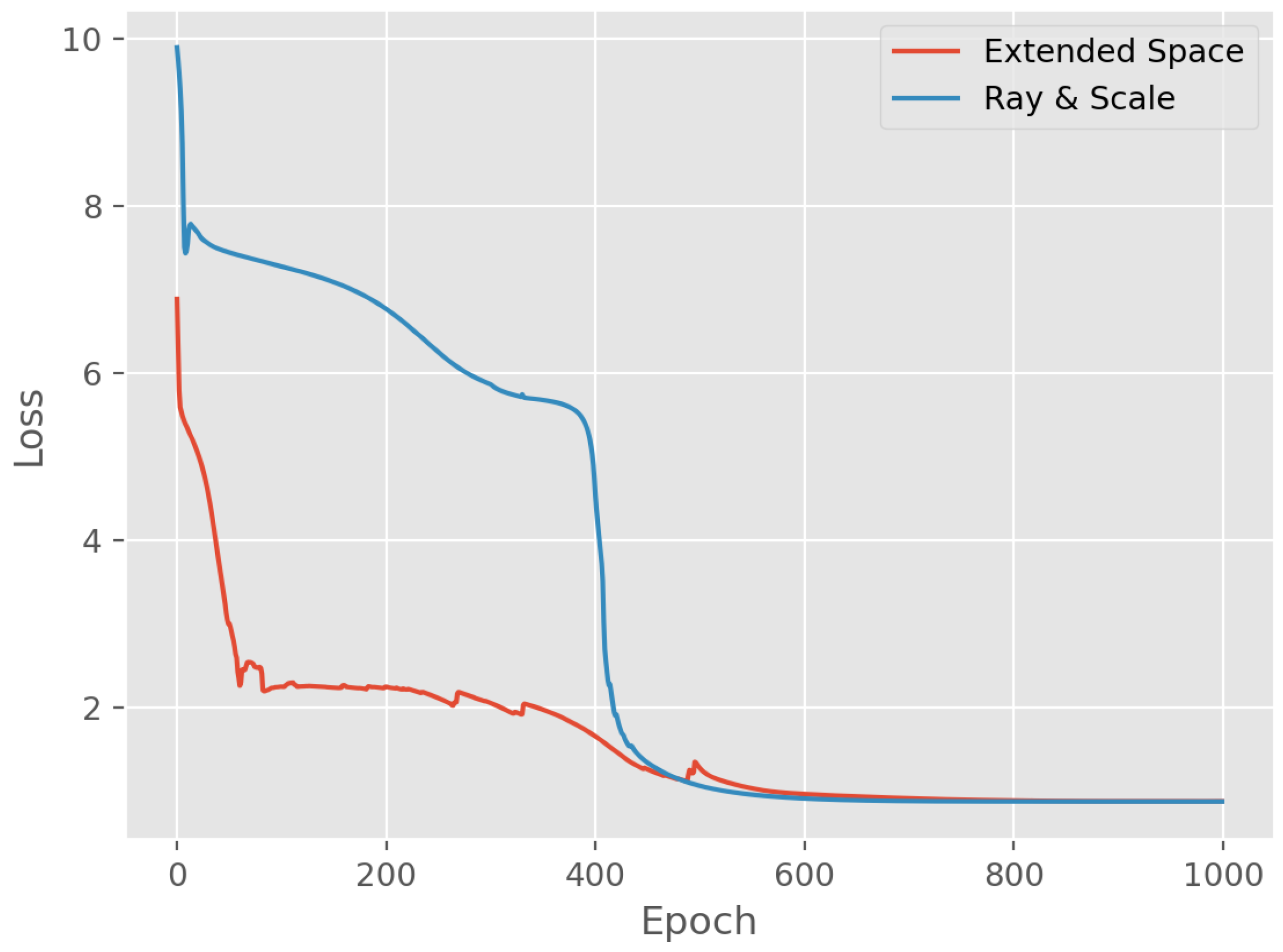
Figure 6 shows results of the extended space approach. The final predictions are shown as blue and orange circles with red boundary. The loss functions are shown in
Figure 7. It can be seen from
Figure 5 and
Figure 6 that trajectories resemble the shape of the admissible set when a separate value is used for determining the point inside the admissible ray segment. This is because the ray direction and the scale are calculated and optimized as separate variables. The extended state approach does not have such a peculiarity. Also, due to different parameterization, trajectories in the extended space approach are much more diverse. Interestingly, both approaches, even with different outputs before training, converge almost identically starting from 500 iteration.
Let us consider the second example of the personalized treatment problem, where the loss function partially depends on the second feature
of the input:
It can be seen from the above that the optimal solution in the case
without constraints is
,
.
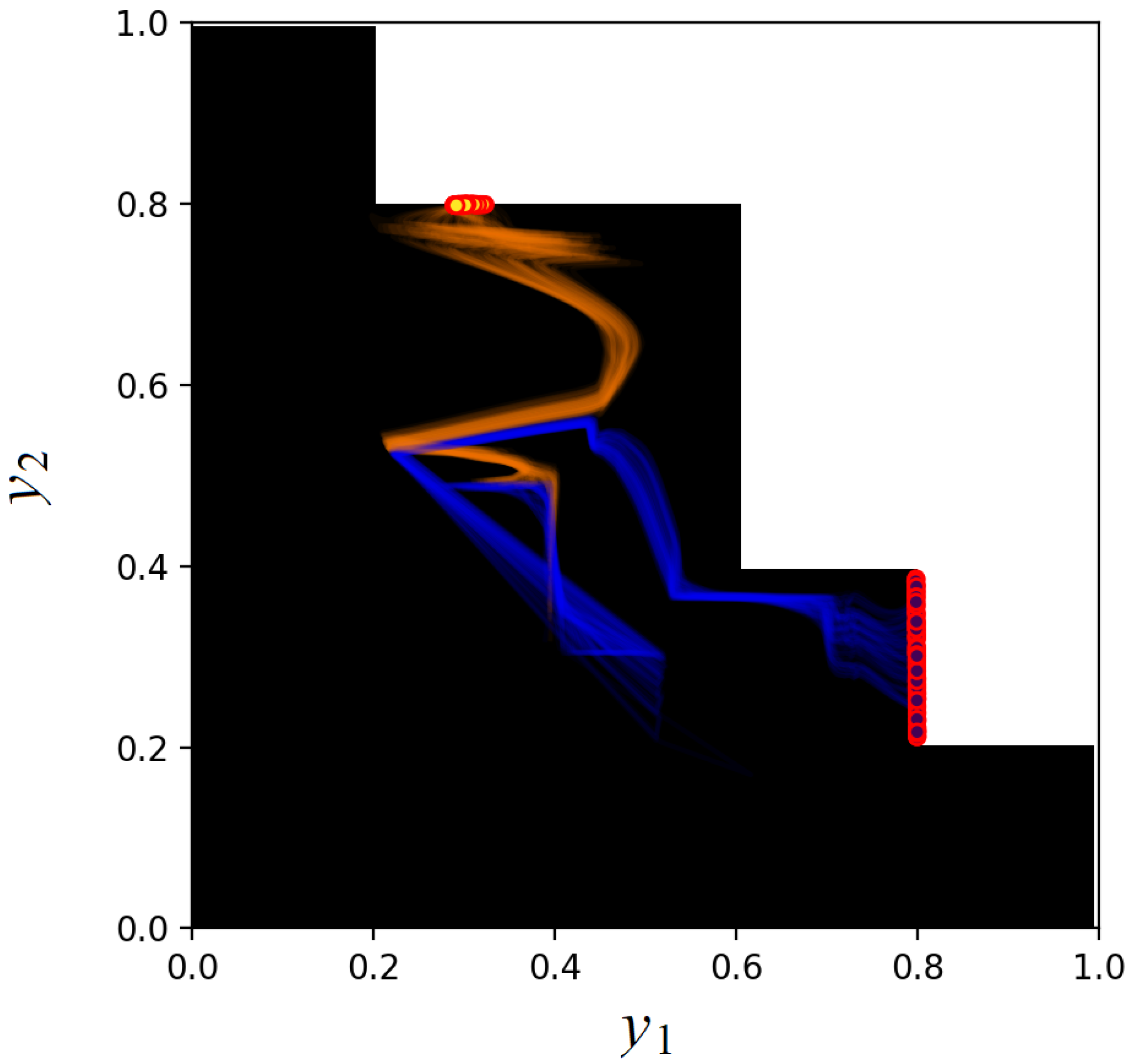
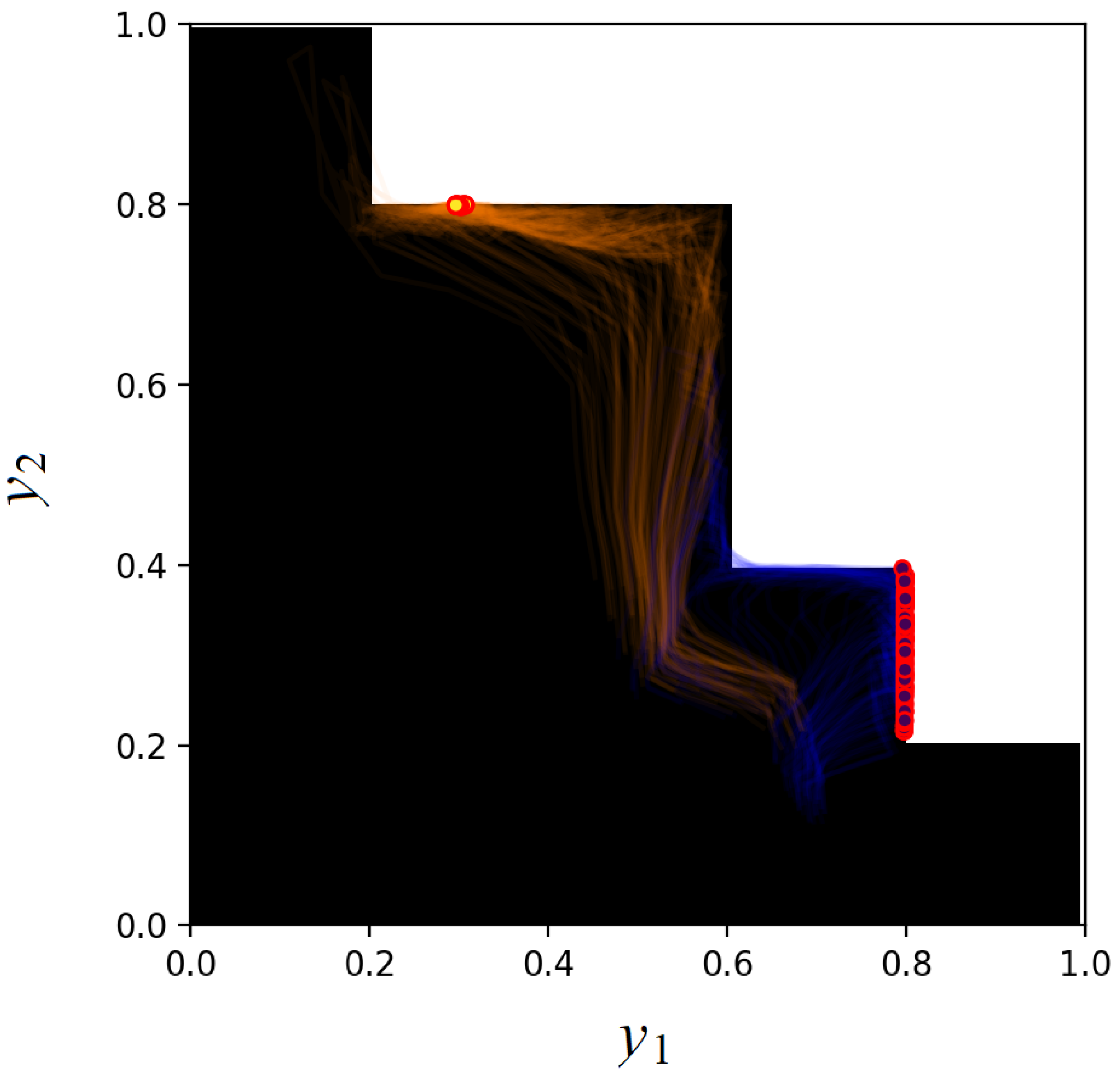
Figure 8 and
Figure 9 represent the same trajectories of estimated doses
by using the ray and scale approach (
Figure 8) and the extended space approach (
Figure 9).
Figure 10 shows how the predicted value
depends on the second feature
of the input for cases of using the ray and scale and the extended space approaches. It is interesting to point out that, in contrast to the previous example, the optimal solution is not concentrated at one point, it is spread out in the interval of
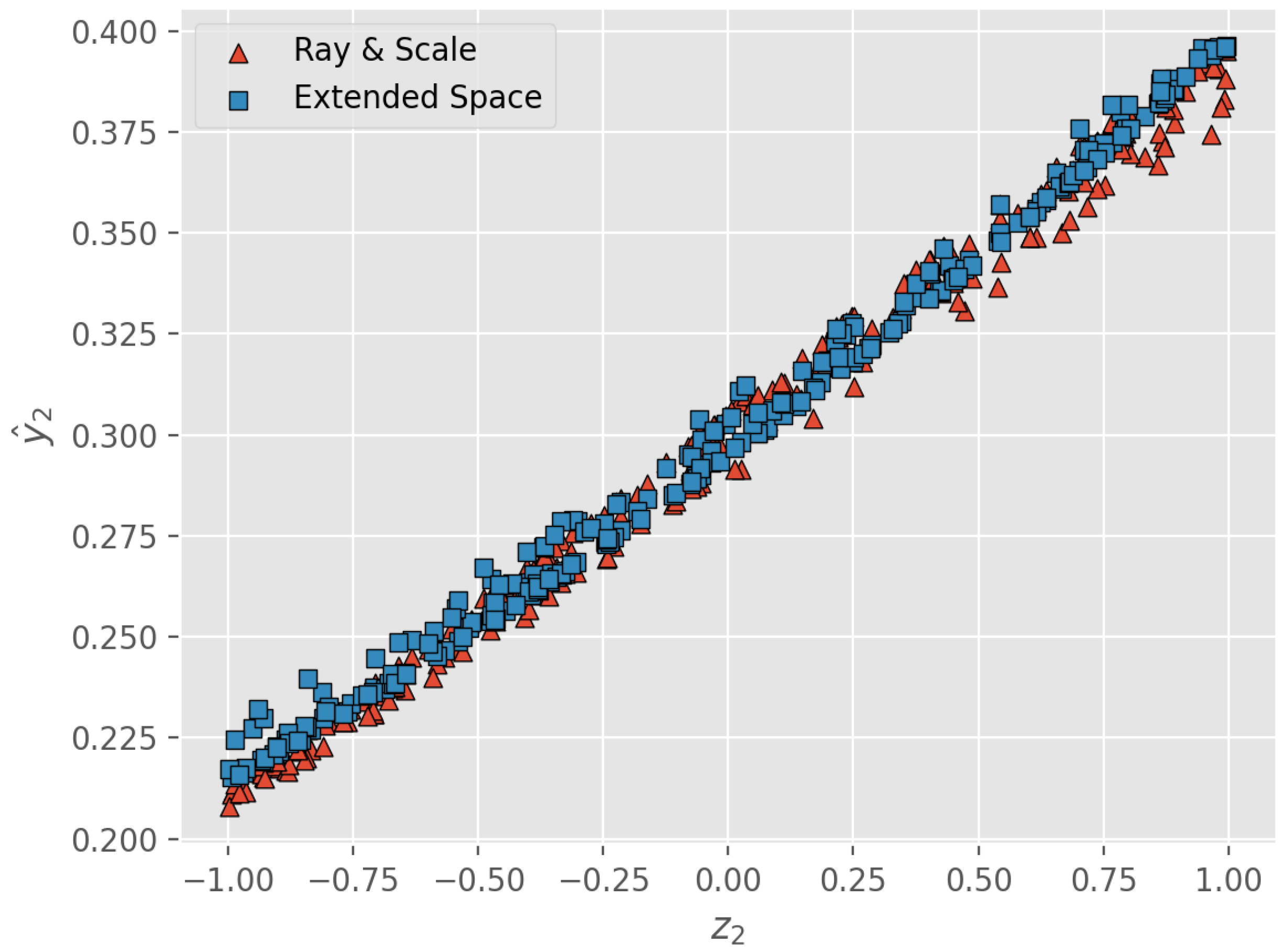
. It can be seen from
Figure 10 that the neural network has learned the linear dependence on
in case of
correctly (the Pearson correlation coefficient is larger than
in both cases), while in the other case
, the learned solutions are concentrated around one point
.
Trajectories of estimated doses obtained in accordance with the Ray & Scale and the extended space approaches when the loss function partially depends on the second feature .
8. Conclusions
A method imposing hard constraints in the form of a star-shaped region on the neural network output values has been presented. It is implemented by adding a layer to the neural network, which generates a parameterized shift of the origin towards a ray. The method can be applied to various problems which require the restriction of the neural network output by certain constraints, for example, constrained optimization problems and physics-informed neural networks.
The main limitation of the proposed method is that should be star-shaped. Approaches to handle more complex cases is a problem whose solution meets many obstacles. Therefore, this important problem can be regarded as a direction for further research.
Results presented in the paper can be viewed as a general approach to constructing neural networks with the star-shaped constraints imposed on the network output. Specific applications of the approach to certain real problems could significantly simplify it by means of its adaptation to a the problem peculiarities. The implementation of the approach to various real problems forms a set of other interesting directions for further study.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}