1. Introduction
With the growing application of machine learning in Earth sciences, there is an increasing need to integrate physical constraints into model optimization. This approach enhances generalization across spatiotemporal domains with limited data and improves consistency with known physical laws expressed as partial differential equations (PDEs) [
1]. The field of physics-informed machine learning addresses this through a range of applications, from purely physics-based to partially data-driven approaches [
1,
2]. Examples include fluid dynamics problems based on the incompressible Navier–Stokes equations [
3,
4,
5,
6,
7], drag force prediction [
8], advection–dispersion equations [
9], and various other flow problems [
10,
11,
12,
13,
14,
15].
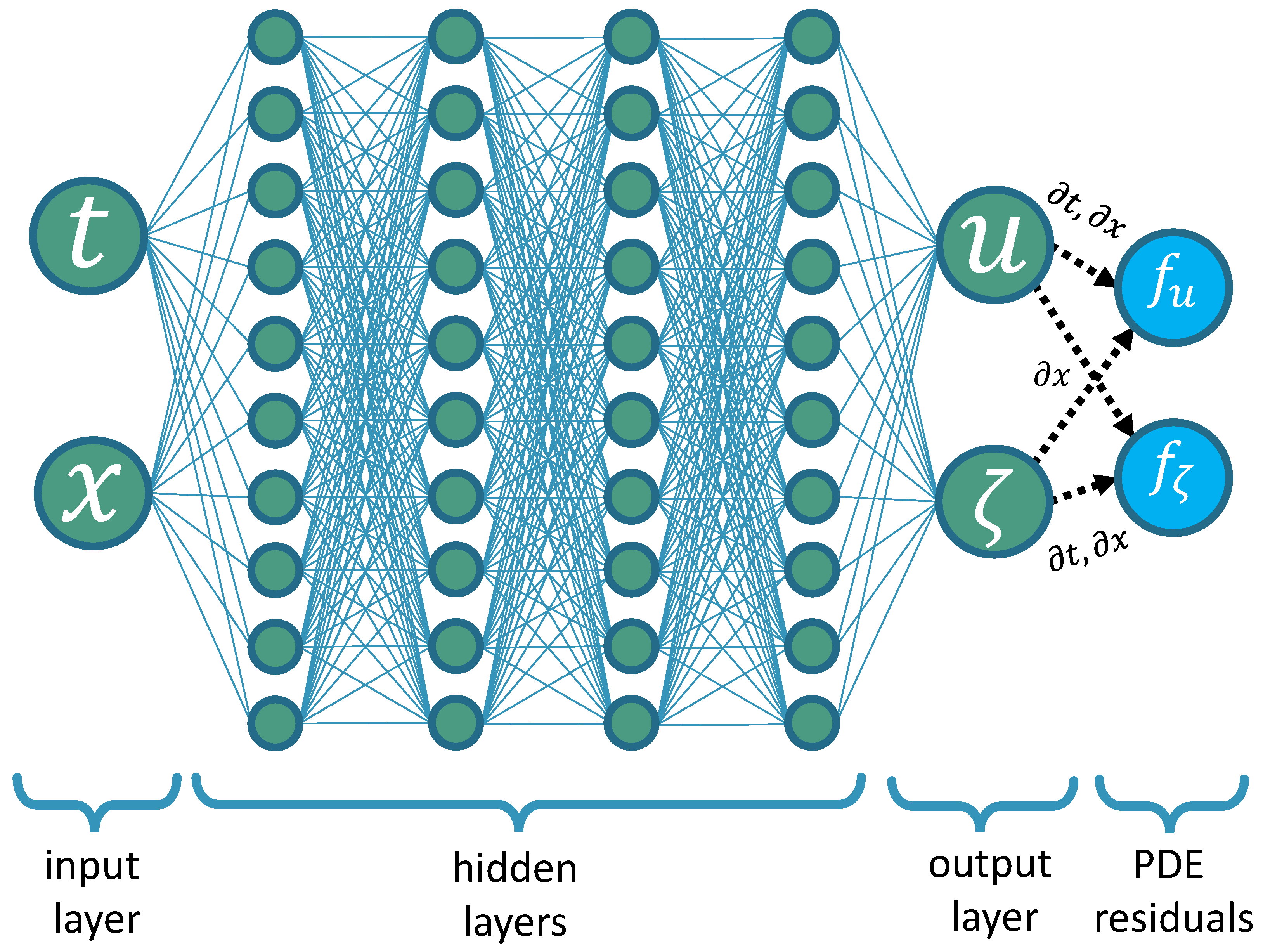
Physics-informed neural networks (PINNs) have recently gained significant attention for solving PDEs [
16,
17]. Several computational libraries now support automated PDE solutions using PINNs [
18,
19,
20,
21]. PINNs approximate PDE solutions by incorporating symbolic PDE representations as soft constraints in their loss functions, leveraging auto-differentiation for partial derivatives. This approach eliminates the need for costly simulation data, spatial gridding, or time discretization.
However, PINNs can exhibit slow or incomplete convergence, leading to long training times. Challenges include numerical stiffness, which can create obstructive loss landscapes [
22], conflicting gradients [
23,
24], and imbalances in learning objectives [
25,
26,
27,
28]. Others suggest that the causality in physical systems must be respected in order to achieve fast convergence to accurate solutions [
29]. Biases toward learning lower over higher frequencies and a missing propagation of initial and boundary conditions can also hinder PINN performance [
30,
31,
32]. To address these issues, some authors suggest moving to hybrid methods that combine conventional numerical solvers [
33,
34,
35,
36], and others focus on exploring the uncertainties in the PINN approximation [
37,
38,
39].
Numerous techniques have been developed to improve PINN convergence, including adaptive loss functions [
25,
40,
41,
42,
43,
44], domain decompositions [
22,
45,
46,
47], multi-scale models [
48], model ensembles [
49,
50], reduced-order models [
51], gradient projection [
23,
24,
52], adaptive activations [
53], adaptive sampling [
32,
54,
55], hybrid differentiation schemes [
34,
35,
36], alternative loss functions [
56], and hard constraints [
57,
58]. Given the diversity of models and problems, evaluating their effectiveness remains challenging. Thus, standardized benchmarks are needed for physics-informed machine learning [
1].
Existing PINN benchmarks focus largely on fluid dynamics [
59], including test cases for Burger’s equations [
60,
61,
62], Navier–Stokes equations [
60,
63], and shallow water equations (SWEs) [
60,
64]. SWEs are particularly useful for testing PINNs due to their ability to model diverse phenomena with relative simplicity compared to more complex systems like Navier–Stokes equations. They are particularly relevant for coastal fluid dynamics applications, such as storm surge and tsunami prediction.
Previous studies [
45,
64,
65,
66] presented accurate PINNs solutions to the 1D- and 2D-SWEs in Cartesian coordinates, as well as a test suite for atmospheric dynamics [
67] in spherical coordinates, but failed to capture a critical aspect of geophysical flows: their interaction with closed boundaries. Instead, open boundaries were chosen or periodic boundary conditions were implicitly constrained by a coordinate transformation. Moreover, test cases with Cartesian coordinates only incorporated time points before the initial wave disturbance reached the domain boundary. However, the fluid behavior near domain boundaries and the transition between wet and dry regions is of high relevance to coastal modelling applications.
The ability to model reflections at closed boundaries is critical for representing phenomena such as Kelvin waves and amphidromic systems in coastal regions. Therefore, evaluating the ability of PINNs to model wave reflections is a key criterion for their suitability in geophysical fluid flow problems. Closed boundaries introduce discontinuities, making them particularly challenging for the continuous approximation of PINNs. This study assesses their ability to handle boundary interactions and their potential to handle complicated conditions in higher-dimensional systems. As shown below, we find that closed boundaries significantly challenge the efficiency of PINNs in capturing SWE solutions.
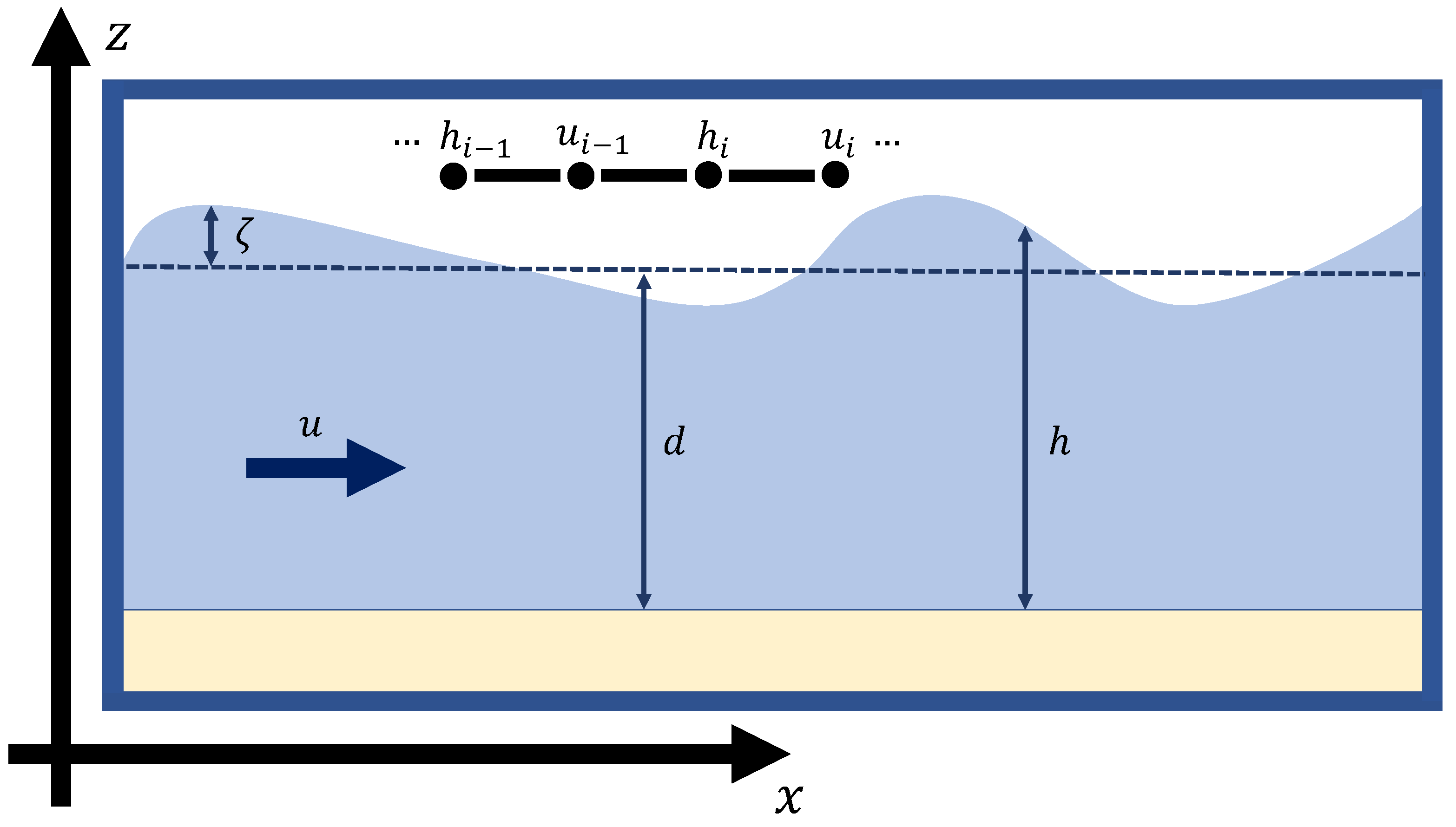
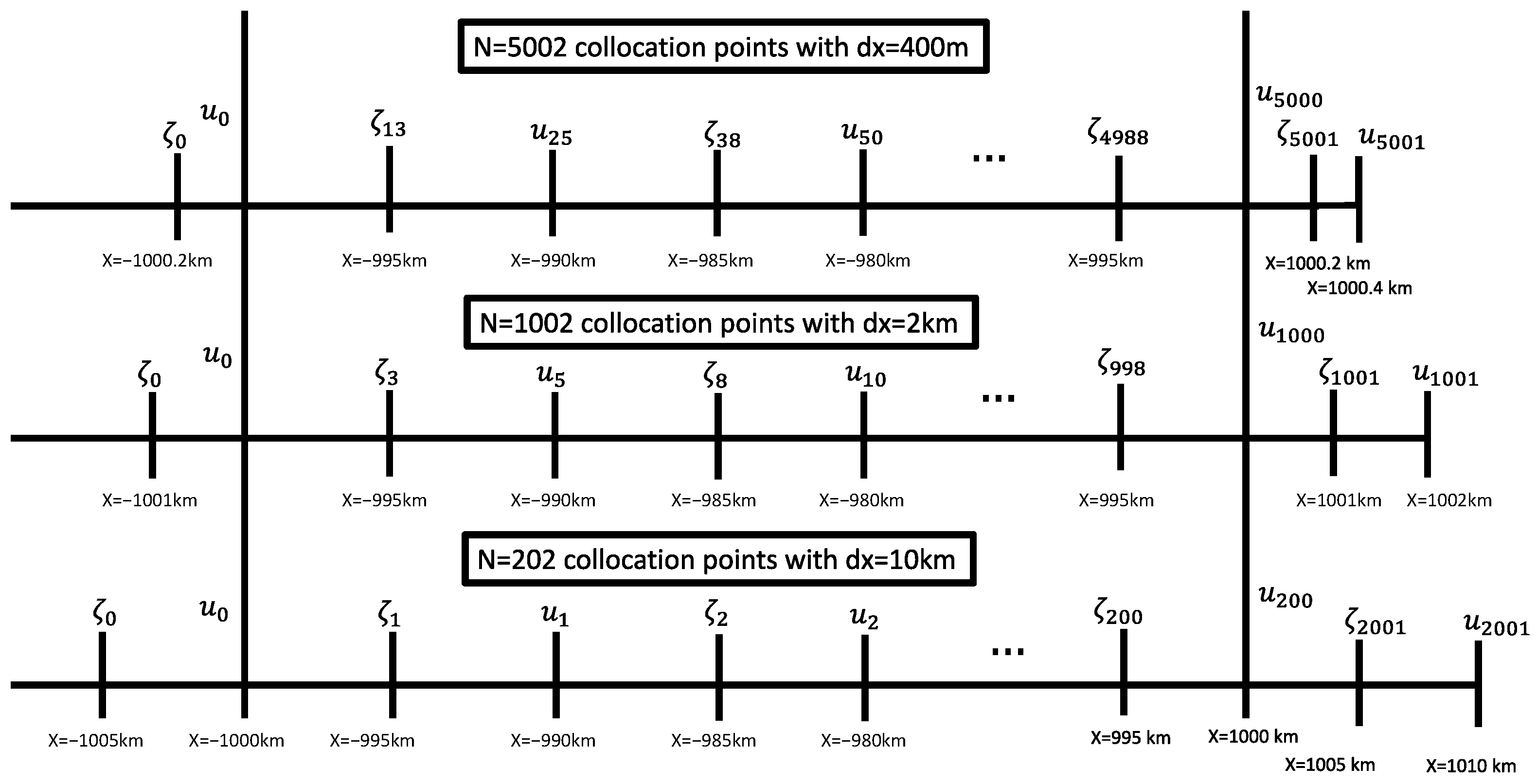
With the aim of assessing the capability of PINNs and illustrating the challenges of learning wave reflections using PINNs, we establish a new test case for physics-informed machine learning methods based on 1D shallow water equations [
68] in Cartesian coordinates with closed boundaries. We carefully constructed a numerical reference solution using a semi-implicit finite difference solver. By computing the difference between numerical solutions with decreasing spatial and temporal step sizes, we estimated the uncertainty in the final reference solution. We then used this reference solution to evaluate PINNs with various architectures, optimizers, and training techniques. We tested the efficacy of non-dimensionalization, projected conflicting gradients [
23,
24], learning rate annealing [
25], and transition functions that automatically satisfy initial and boundary conditions.
While some combinations of options and hyperparameters produced incorrect results, we found that, in several test cases, the PINNs learned the solution accurately over four wave reflections at the basin boundaries. However, the resulting trade-off between PINNs’ accuracy and the computational costs was not competitive with numerical integration. While some of the tested techniques provided minor improvements, none were able to overcome the slow convergence of PINNs. We therefore propose this problem as a suitable test case for the further development of PINNs towards Earth system modeling, specifically for coastal fluid modeling applications.
3. Results
3.1. PINNs Can Solve Closed-Boundary SWEs
We carried out initial exploratory experiments to determine a default setup for training PINNs to solve SWEs, testing a range of network, optimization, and learning configurations. We tested two implementations of the second-order LBFGS optimizer, but both produced fast convergence to inaccurate solutions, so we used ADAM optimizers in subsequent experiments. Networks that used sinusoidal activation functions [
91] or a mix of rectified linear units (ReLU) and tanh units produced similar or inferior results, so we used tanh activations exclusively. Small deviations from the default learning rate
did not affect the results, but much higher learning rates led to divergence while lower rates increased the training time. Training was successful only for non-dimensionalized SWEs. With respect to the choice of the scaling parameter
c, we found that
led to a balanced optimization of
and
u. Full-batch and mini-batch optimization led to comparable quality in the results at equal numbers of gradient steps, such that mini-batch optimization was more efficient due to the shorter computation time that was required per step. Resampling control points every epoch caused sudden peaks to appear in all loss terms afterwards, which slowed convergence. We therefore used mini-batch gradient descent with a fixed set of control points over all epochs.
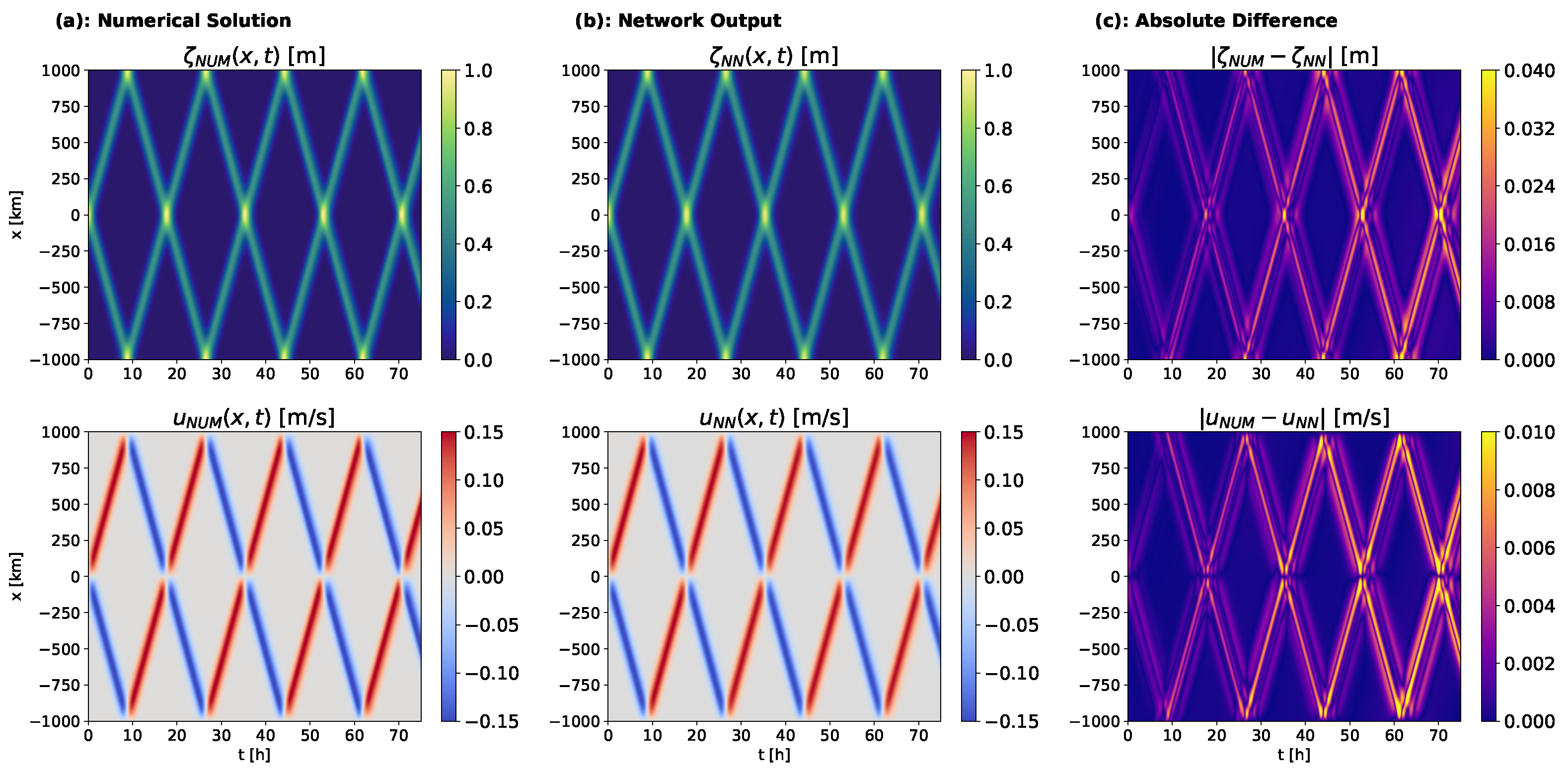
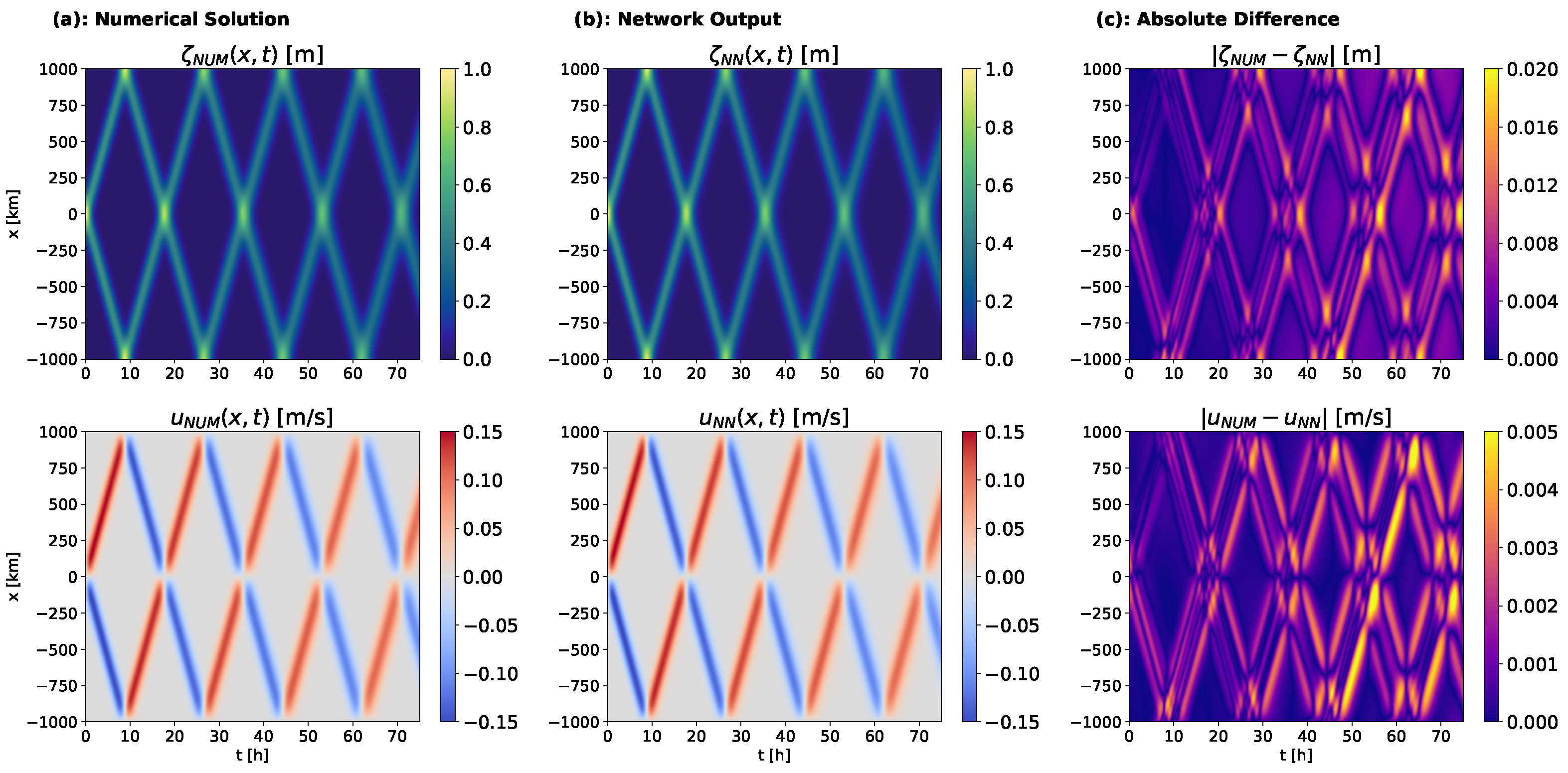
Using these default settings, we applied PINNs to solve two versions of the SWEs. In scenario A, waves propagate without the horizontal diffusion of velocity (
,
Figure 6a), while in scenario B they slowly dissipate due to the dispersive PDE term (
,
Figure 7a). In both scenarios, the initial Gaussian bell splits into to waves that reflect repeatedly from the domain boundaries. For both scenarios, training PINNs with our default settings yielded a PDE solution that closely resembled the numerical solution, with all wave reflections represented and errors 1–2 orders of magnitude smaller than the solutions (
Figure 6b,c and
Figure 7b,c). Errors tended to increase over time and were highest around the wave peaks. We quantified these errors using
- and
-norms (Equations (
29)–(
32)), averaging over five training runs with random initialization, which exhibited high consistency (
Table 3). Average errors ranged from 3 to 10% depending on the error metric and PDE variable, but were generally higher for horizontal velocity than for elevation.
These results show, to our knowledge for the first time, that PINNs can learn solutions to SWEs with closed boundaries. However, convergence for both scenarios required h over ten thousand epochs on a single GPU. Clearly, this cost–accuracy trade-off is not competitive with conventional numerical methods which required, depending on resolution, from one minute to two hours on a single central processing unit (CPU). We therefore focused our subsequent experiments on understanding how the PINNs optimization process arrives at a PDE solution, and whether the specialized techniques proposed for training PINNs could produce an accurate solution more quickly.
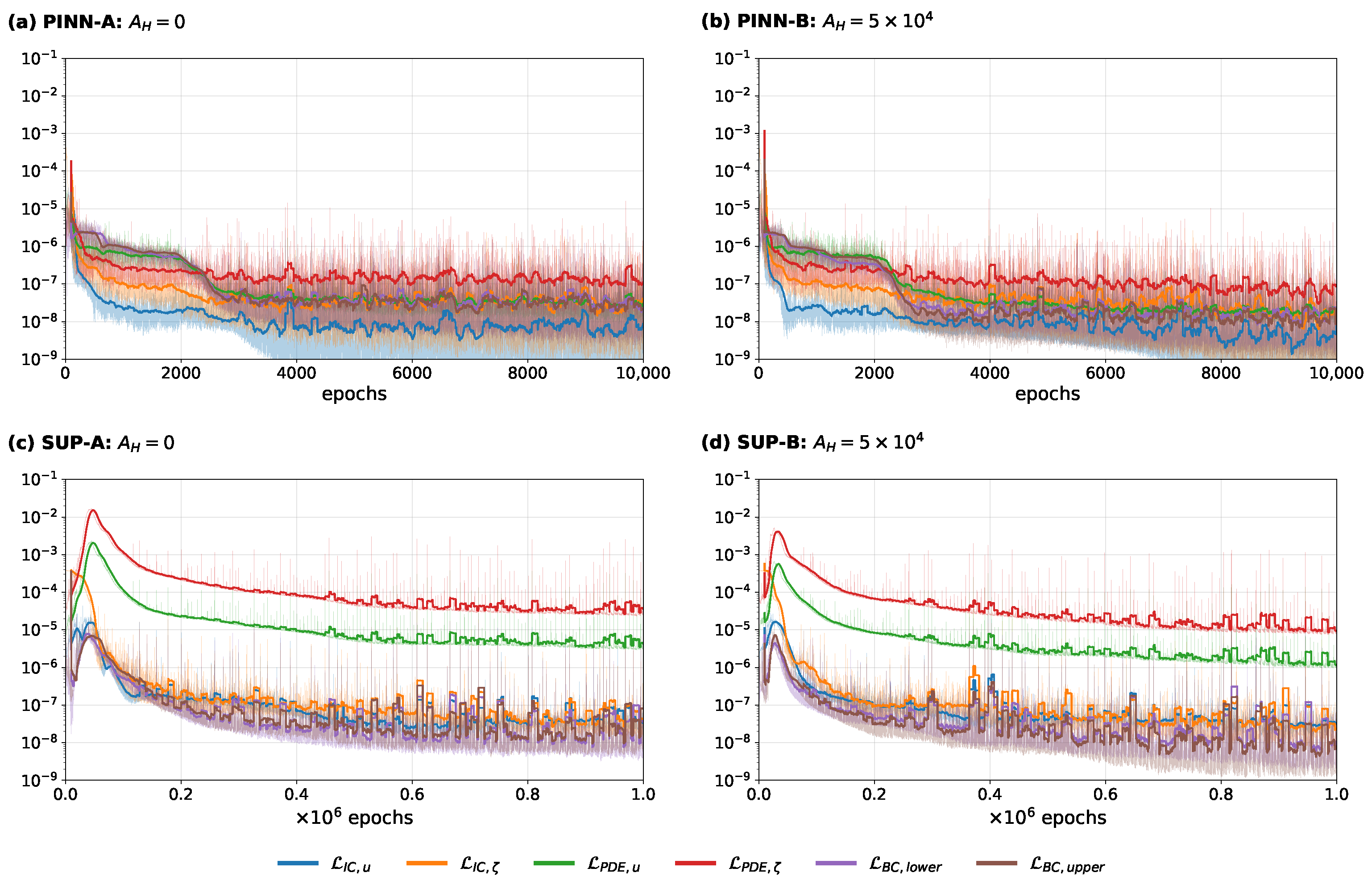
3.2. Evolution of PDE Solution and Loss Terms During Training
To investigate how PINNs converge to solutions of the SWEs, we tracked individual loss terms and differences from the reference solution over the optimization process (
Figure 8a,b). A more detailed representation of the individual contributions to the PINNs loss function is given in
Figure 9a,b, where the loss functions for the PDEs and initial conditions are shown separately for
and
u, and for both individual boundary conditions for
u as well. The relation between the changes in the difference to the reference solution and the PINNs loss can be used to determine how the physics-informed optimization contributes to higher accuracy.
In both cases, the differences between the reference solution
and
decrease slowly for up to roughly 2000 epochs. Between 2000 and 4000 epochs, they rapidly decrease by between one and two orders of magnitude and finally continue to decrease steadily at a low rate (see
Figure 8a,b). The period with the largest decline in the difference to the reference solution coincides with a steep decrease in the boundary condition loss
, whereas the initial condition and PDE losses
and
decrease more steadily. In contrast, the latter most strongly decrease within the initial 1000 epochs when the network approximation is still highly inaccurate.
This demonstrates that, to achieve fast convergence to accurate solutions, it is crucial to closely obey the no-outflow boundary conditions. This fast decline can also be seen in the momentum equation loss
, but not in the continuity equation loss
(see
Figure 9a,b), which indicates a connection to the boundary conditions, for example, at the locations of reflection. The steady late training period from 4000 to
epochs significantly improves the final model’s accuracy, but also more than doubles the amount of time required to obtain a feasible solution due to the low rate of decrease in the difference from the reference solution. Nonetheless, a reduction in the number of epochs may degrade the resulting solutions unacceptably. Overall, the difference compared to the reference solution is on the upper end of the estimated uncertainty range in the reference solution. Therefore, the network approximation can overall be said to have solved the PDE. For case B, the approximation shows even higher accuracy, which suggests that the model is adaptable to various physical settings.
3.3. Evolution of the Network Approximation over Training
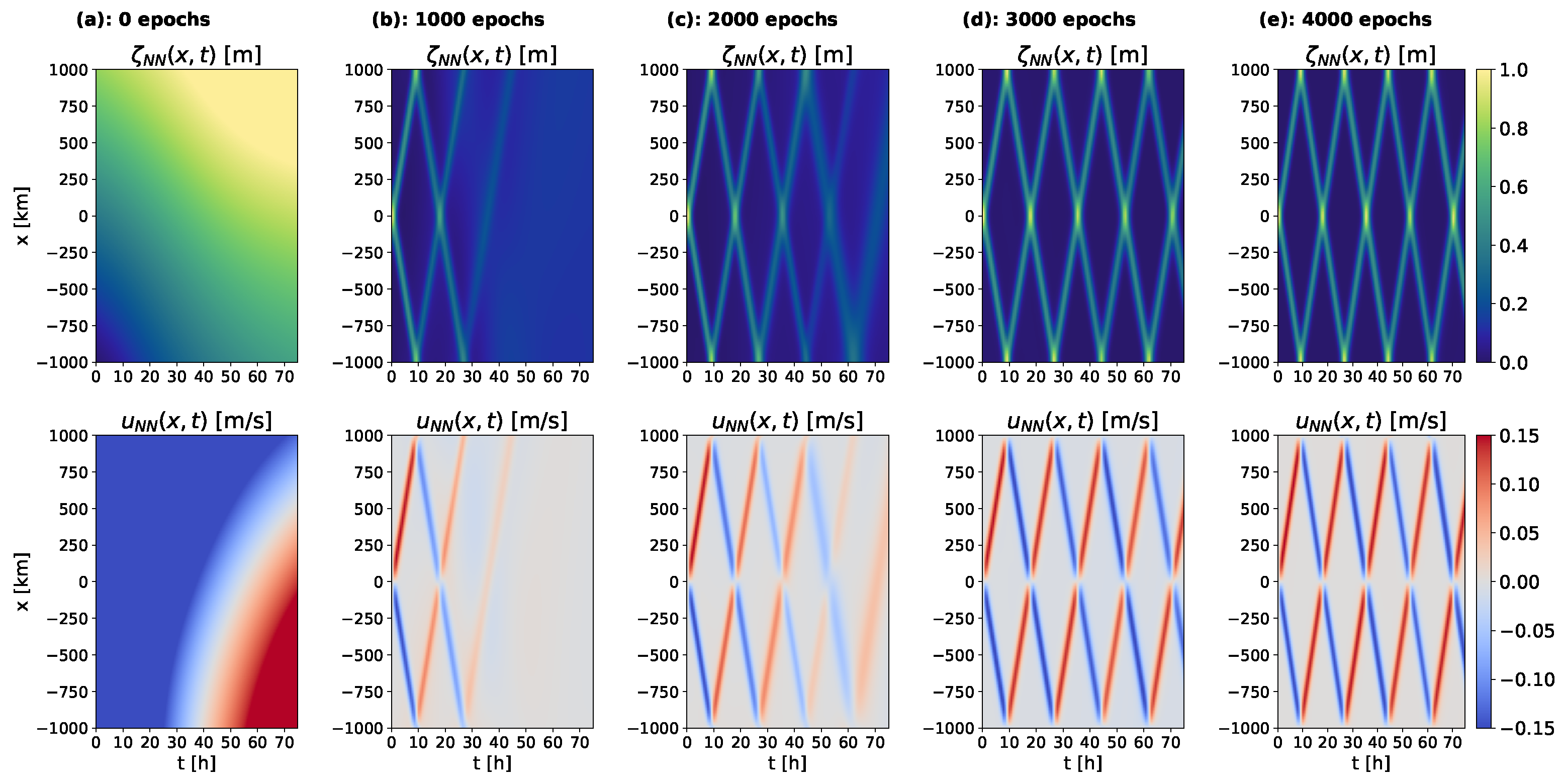
In an effort to analyze the training process and to identify the factors impeding fast convergence, we compared the network output for
and
u, and the spatiotemporal distribution of the PDE residuals
and
throughout the model optimization. The evolution of the network output and PDE residuals for case A are shown in
Figure 10 and
Figure 11, respectively, over the first 4000 epochs of training, which is consistent with other model experiments, including case B.
The change in the network approximations for
and
u (see
Figure 10) illustrates the step-wise learning process of the PINN-based model over the time interval. At each training step, the output only shows a further wave propagation after the previous propagation and reflections have been learned. This process resembles a wave propagation over time or a step-wise integration of the wave signal. Despite the minimization of the PDE loss over the entire domain at all gradient steps, the solution is learned sequentially in time, approaching the reference solution from earlier to later states.
This sequential learning of the solution is in accordance with the different rates of decrease in the difference to the reference solution over the optimization in the training curve (see
Figure 8a). Over the initial 2000 epochs, the network approximation strongly deviates from the reference solution in a large part of the domain. Between 2000 and 3000 epochs, the network completely learns the pattern of wave propagation, which causes a rapid decrease in the differences to the reference solution. In the subsequent epochs, the network makes small adjustments over the entire domain, leading to the low rate of decrease in the differences to the reference solution between 4000 and 10,000 epochs.
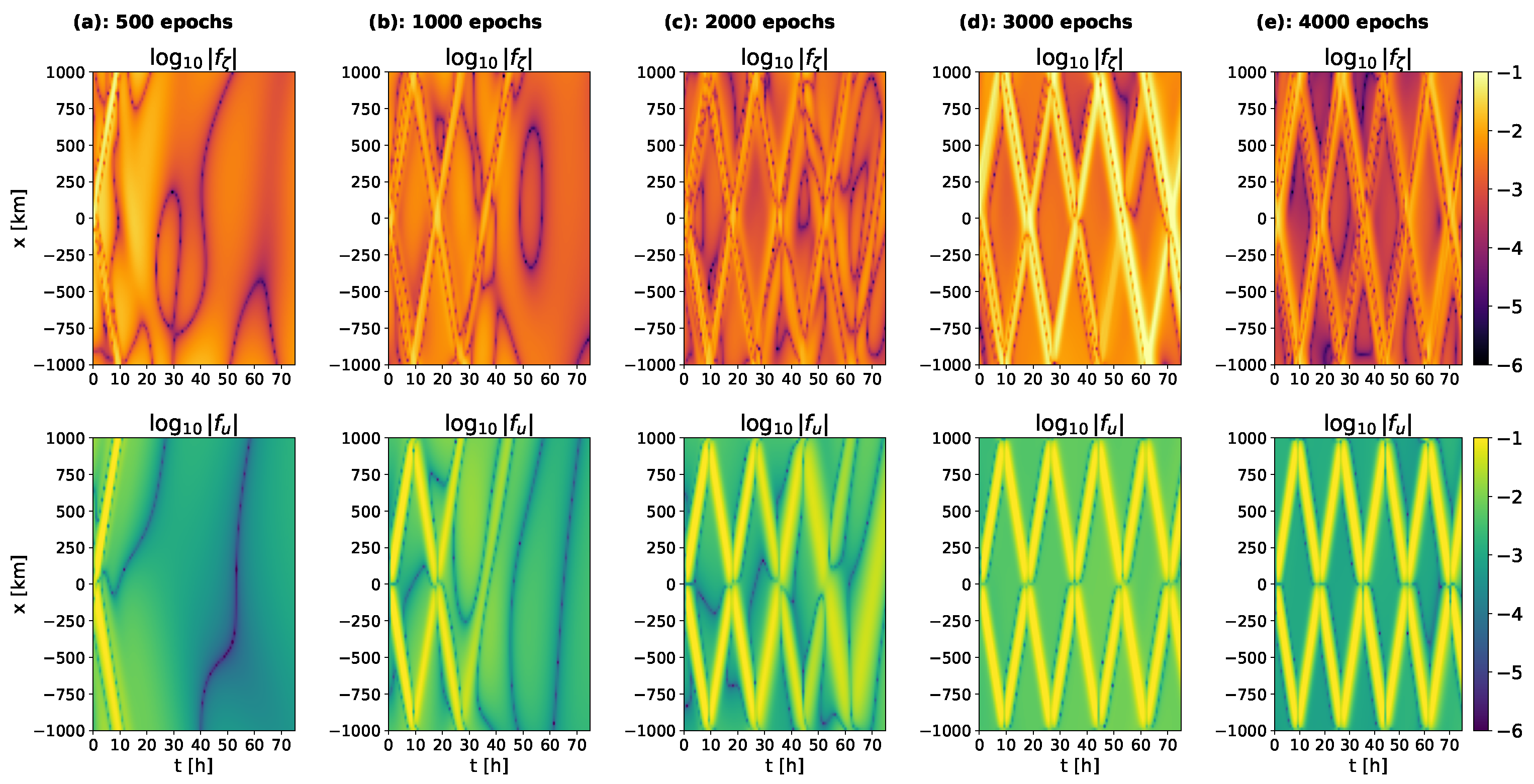
Comparing the changes in the continuity and momentum equation (see
Figure 11) residuals over training, the sequential learning of the wave propagation is apparent in both residuals. While the areas of undisturbed sea level show a steady decrease in the residuals over the first 4000 epochs, they increase by several orders of magnitude in the areas of wave propagation. This mismatch between the changes in the PDE residuals and the difference from the reference solution show that low PDE residuals do not guarantee accurate solutions, but accurate solutions do not necessarily lead to low PDE residuals.
These findings suggest that both the initial learning of the wave propagation and the slow convergence to the reference solution in the later training period contribute to long training times. The sequential learning of the individual reflections underlines the importance of the accurate representation of the boundary conditions to the ability to model all wave reflections. It is also consistent with the previously noted coincidence between the decrease in the differences from the reference solution and boundary condition losses.
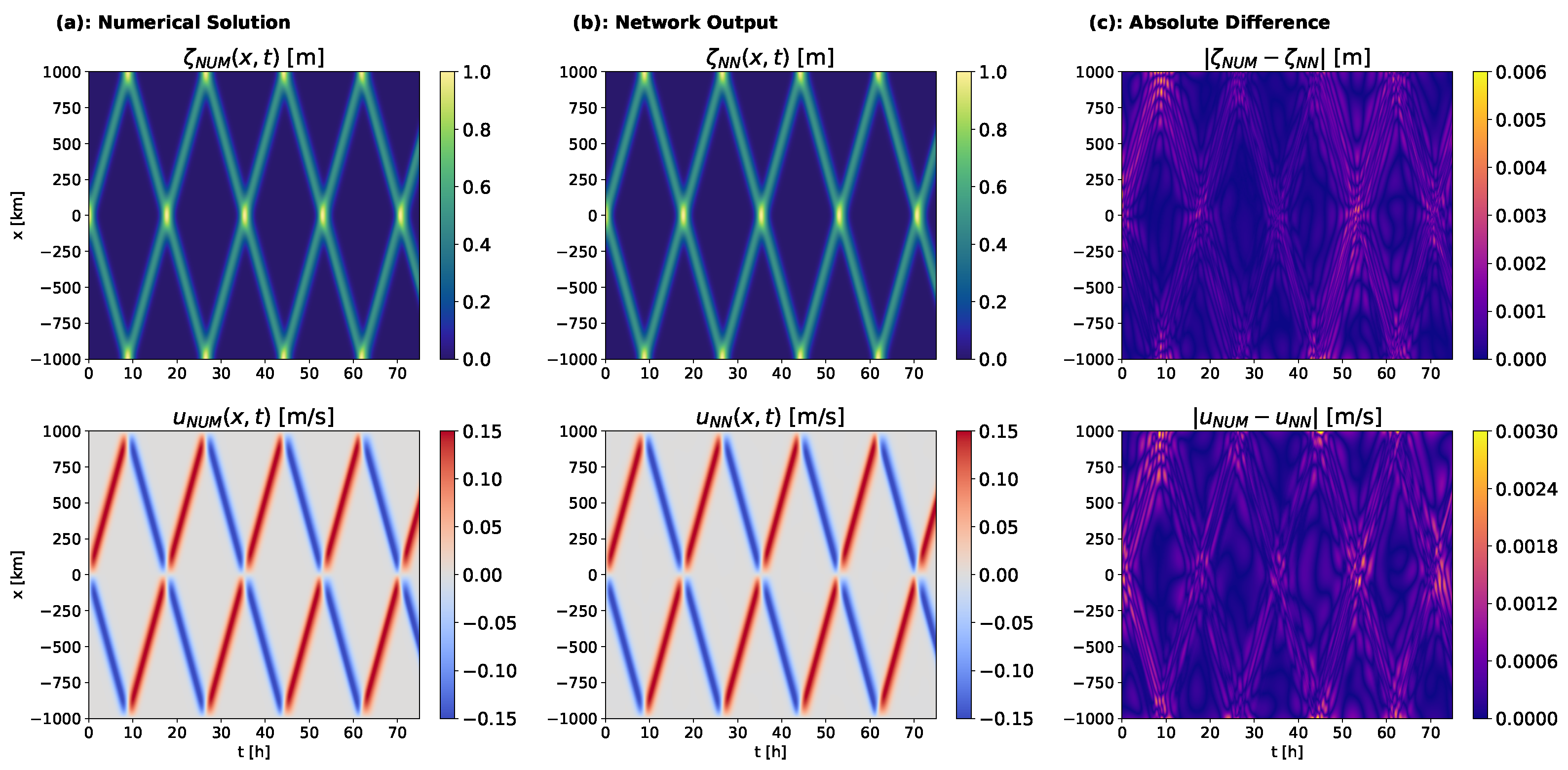
3.4. Supervised Training on the Reference Solution
To evaluate the possible limitations of the approximation ability of the neural architecture regarding the quality and speed of convergence, we trained neural networks to solve cases A and B to determine whether the network is able to learn the reference solution more accurately when trained directly on the numerical solution with a supervised least squares loss. As in the previous experiments, we show the numerical reference solution, the network approximation after training, and their absolute difference for both
and
u in
Figure 12 and
Figure 13, with the respective differences in the
- and
-norms shown in the last two columns of
Table 3.
When trained directly on the reference solution, the network approximation’s difference from the reference solution is, below
% and 1% in the
-norm, and below 1% and roughly 3% in the
-norm for
and
u, respectively, in both test cases (see
Table 3). The absolute differences compared to the reference solution do not show an increase over the time interval, as they did for the physics-informed optimization (see
Figure 12c and
Figure 13c). In comparison to the PINN-based model, the training curves show a more gradual decrease in all loss terms over the entire training period, except from some initial fluctuations in the initial and boundary condition losses (see
Figure 8c,d and
Figure 9c,d). During this initial training period, the PDE losses rapidly increase, but then continue to steadily decrease. This initial peak may be due to the absence of physical constraints in this case, allowing for physically inconsistent solutions if they lead to a better match with the reference solution. While the initial and boundary condition losses are comparable for both training modes, training on the reference solution leads to higher PDE losses in the final network output by approximately two orders of magnitude.
These results suggest that the approximation capability is not a limiting factor for the model accuracy and does not impede fast convergence. Rather, the error accumulation over time and the slow sequential learning of the wave propagation in the PINN-based model may be caused by optimization problems originating from the PDE loss function. This is also indicated by the mismatch between accurate solutions and low PDE residuals that occurs both when training on the reference solution and when using the physics-informed loss. Another possible source of the differences in the two training modes is uncertainty in the reference solution itself.
3.5. Sensitivity Study
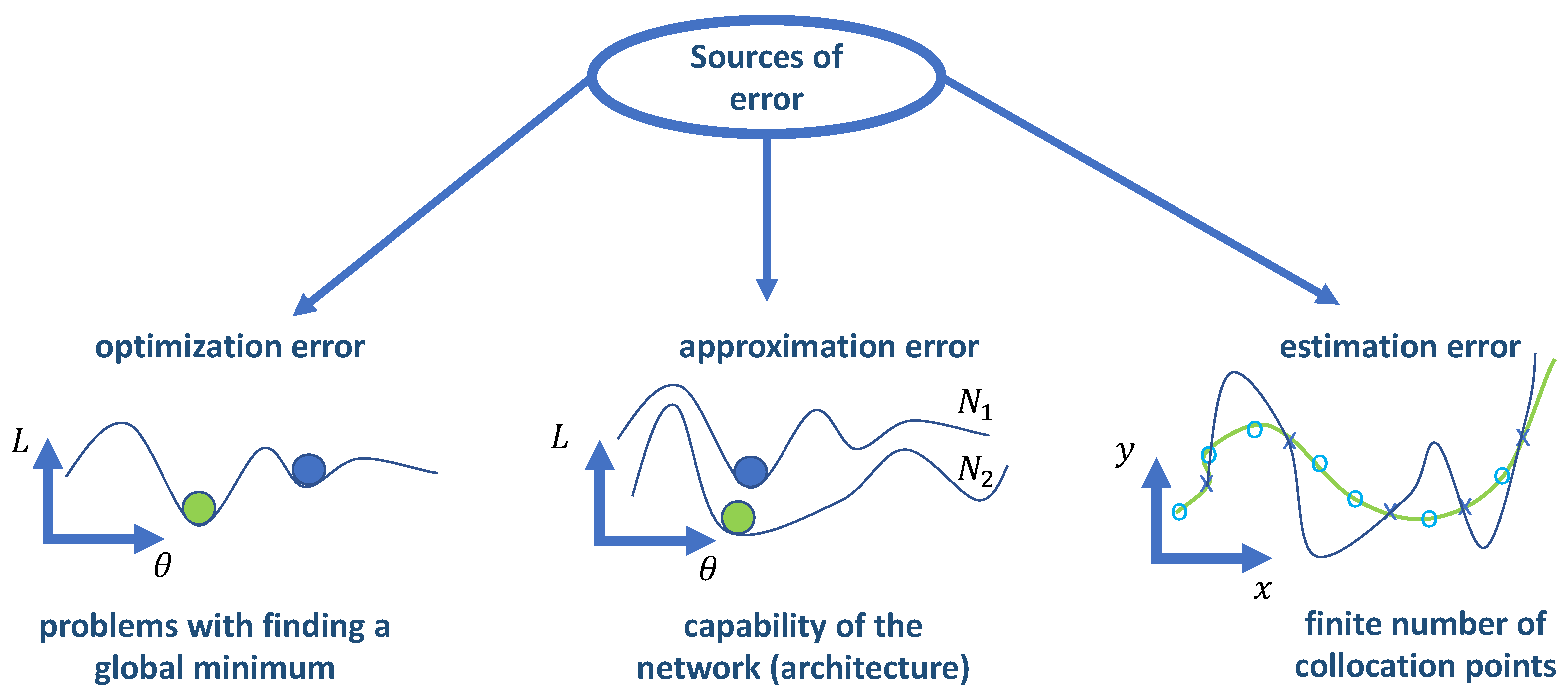
We additionally assessed how the accuracy of the PINN-based solution could depend on estimation errors arising from the finite set of control points as well as the network architecture. To this end, we performed sensitivity experiments on the total number of control points
,
and
per epoch, and on the network width and depth (i.e., the number of layers and number of activations in each layer). The accuracy reached in two additional experiments, with one half and a quarter of the control points, was compared to the default experiment of test case B in
Table 4. Similarly, for two smaller network sizes with 2 and 3 layers, with 30 and 50 activations per layer, respectively, the comparison with the default network architecture is shown in
Table 5. In these experiments, we set the number of sampling points to the lowest setting.
For all three experiments with variable numbers of sampling points, there is close to no difference in accuracy and the differences compared to the reference solution are consistently between 2 and 4% in the
- and
-norms (see
Table 4). This means that there is no considerable influence of estimation errors that would lead to the over-fitting of too-small sample sizes. Instead, when using far fewer control points, an equal accuracy can be maintained.
In contrast to this, the observed accuracy strongly depends on the network size. For both smaller network sizes, the network approximations are inaccurate, with differences compared to the reference solution of above 47% and 64% for
and above 59% and 82% for
u in both norms. Hence, network sizes much smaller than the one used in the default experiment are not feasible for this task (see
Table 5). While even larger network sizes might improve accuracy, we did not consider them here for two reasons. Firstly, we reached the limit of the memory and run time on a single GPU. Secondly, supervised training on the reference solution showed an even higher accuracy compared to the PINN solutions when using the same network architecture. For this reason, we conclude that network size was not a significant limitation for the scenarios we studied.
Together, the results of training on the reference solution and the sensitivity experiments indicate that neither approximation nor estimation errors pose a limitation to the quality and speed of convergence. As a consequence, in subsequent experiments, we focused on improving the optimization with specialized training modes.
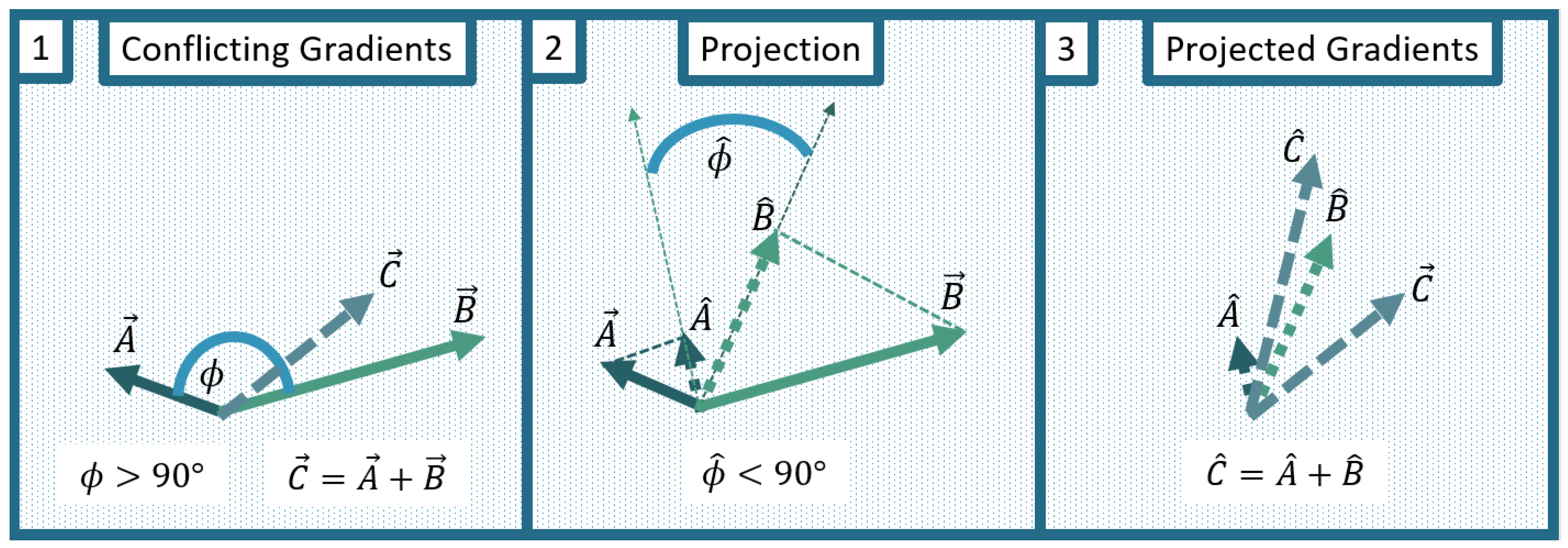
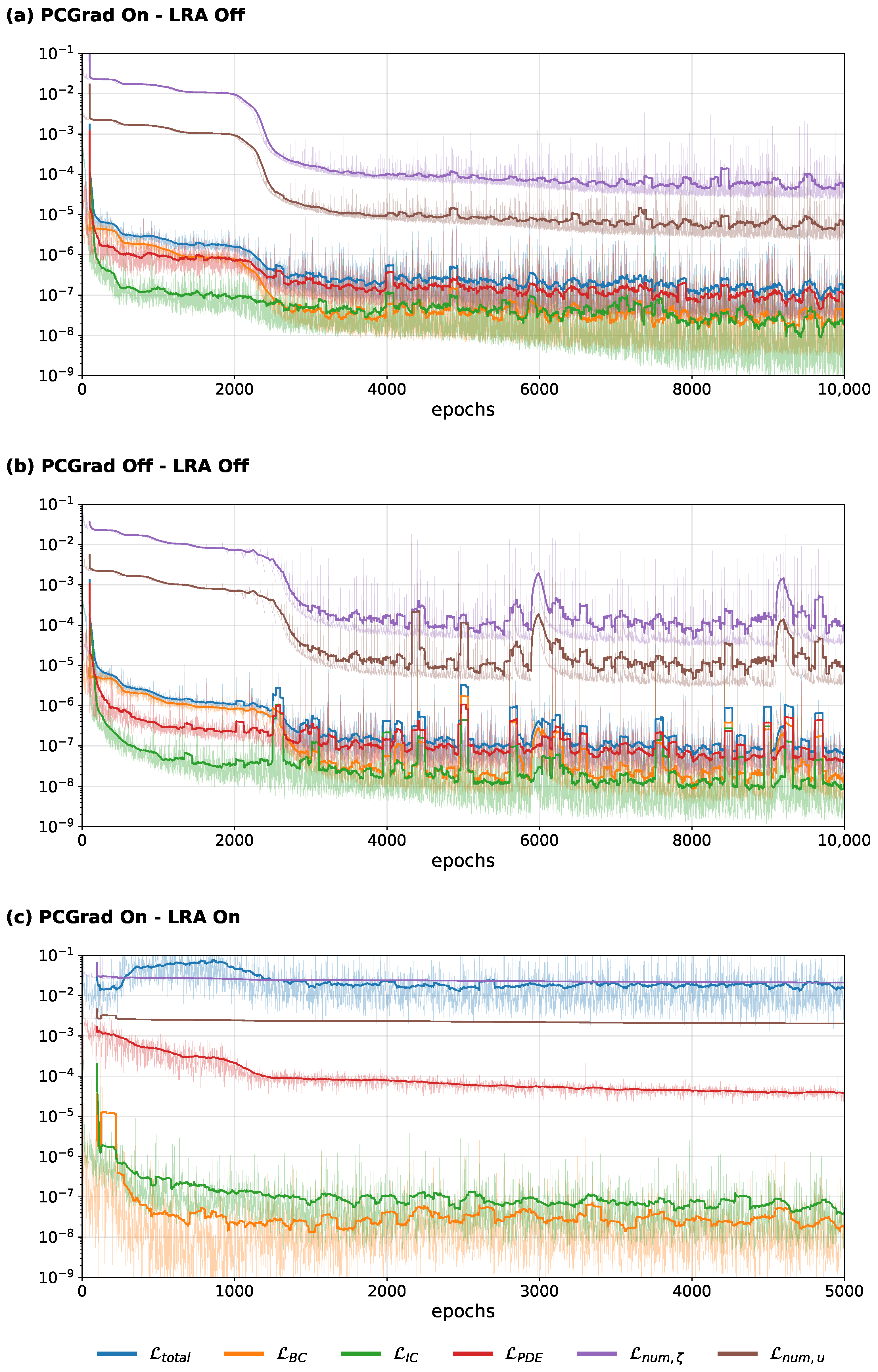
3.6. Specialized Training Modes
With the aim of improving the speed and quality of convergence, we tested two specialized training modes: the projection of conflicting gradients (PCGrad) and an adaption of the loss weights
,
and
over training, called learning rate annealing (LRA). While we had already applied PCGrad in the default setup, we here compare the optimization properties with and without this method. We compared three different experiments for case B: the first using neither of the two methods, the second only using PCGrad, and the third using both PCGrad and LRA. The differences compared to the reference solution are shown in
Table 6 and the respective training curves are shown in
Figure 14.
The use of PCGrad leads to a small but consistent improvement in the achieved accuracy, of approximately 0.5–1% in the
- and
-norms (see
Table 6). Moreover, when comparing the evolution of the difference to the reference solution as well as the individual parts of the PINNs objective function (see
Figure 14a,b), the experiment without PCGrad shows higher-amplitude oscillations, both in the running mean (solid line) and in the loss per epoch (shaded line). These high-frequency oscillations not only locally increase the difference from the reference solution, but also contribute to instabilities in the training. Specifically, at approximately 6000 and 9200 epochs, increases of about two orders of magnitude in the differences from the reference solution can be seen for the experiment without PCGrad (see
Figure 14b). The experiment using PCGrad does not show any sudden increases in the differences from the reference solution and generally contains lower oscillations with a more consistent decrease. This may improve the training efficiency and, ultimately, the accuracy. Nevertheless, no significant speedup in convergence could be achieved.
To assess if LRA could lead to an improvement in optimization, we tested it both in combination with PCGrad and on its own. As the results were equal in both cases, we here only report those obtained in combination with PCGrad. For this case, the differences compared to the reference solution remained above 70% for
and above 90% for
u (see
Table 6). Considering the minimization of the individual parts of the composite objective function (see
Figure 14c), there seems to be an imbalance in the consideration of the PDE loss term compared to the initial and boundary conditions. While the latter decrease rapidly at the beginning of training, the PDE loss only decreases at a very low pace throughout the optimization. This indicates that LRA fails to equally optimize the individual learning tasks and therefore impedes accurate solutions. Due to the additional computation time caused by the LRA algorithm, the amount of epochs was reduced to 5000 for a comparable cost of training.
Despite small improvements in the stability and accuracy of training when using the PCGrad method, none of the two methods led to a sufficient speedup that would make the cost of training feasible. A comparison of the results for both methods suggests that, in this particular case, the occurrence of conflicting gradients from individual learning tasks was more relevant than the respective weights.
3.7. Hard Constraints on Initial and Boundary Conditions
Some of the previous results indicated that, for the PINN-based model, the sequential learning of the wave propagation, and particularly learning the reflections, contributes to the slow convergence (see
Figure 8a,b and
Figure 10). Obeying the no-outflow boundary conditions was shown to be important for an accurate representation of the wave propagation, as the difference to the reference solution decreases rapidly with decreasing boundary condition losses (see
Figure 8 and
Figure 9a,b). To address this, we modified the network architecture by applying transition functions so that the network output always satisfies the boundary conditions, and in some cases also the initial conditions, regardless of the network parameters. The aim was to speed up convergence by reducing the number of learning tasks and facilitating the learning of the wave propagation and reflections. Furthermore, this could prevent local violations of the boundary conditions that could lead to inaccurate solutions. The differences between the network approximation and the reference solution for all three tested transition functions
,
and
are shown in
Table 7 and the respective training curves are shown in
Figure 15.
As a first test, we applied the transition function
to only constrain both boundary conditions. Despite reducing the amount of learning tasks and accurately representing the boundary conditions, the network approximation did not achieve any differences compared to the reference solution below 50% (see
Table 7). The change in the PDE and initial condition losses over training shows that the optimization failed to minimize both equally. While the initial condition loss rapidly decreased at the beginning of training, the PDE loss converged above a high threshold, thereby preventing accurate solutions (see
Figure 15b). To reduce the amount of learning tasks even further and additionally satisfy the initial condition implicitly, we tested two further transition functions
and
. Still, the network optimization failed to sufficiently decrease the PDE residuals and equally obstructed the convergence to accurate solutions (see
Figure 15c,d). The differences compared to the reference solution here also remained above 50%. Accordingly, no improvement in the quality or speed of convergence was reached.
4. Discussion
4.1. Main Obstacles to Accuracy and Efficiency
We demonstrated that, although PINNs can learn wave reflection scenarios based on the shallow water equations (SWE), this comes at the cost of unfeasible training times. Our experiments suggest that the primary limitations in quality and convergence speed are not due to the network architecture’s approximation capability or estimation errors (see
Table 3,
Table 4 and
Table 5). Instead, we observed systematic characteristics of the optimization process that limit the efficiency of PINNs in this task and may extend to other applications.
One key factor limiting accuracy is the rapid accumulation of errors over the time domain, reflected in the increase in the absolute differences between the reference solution and the PINN-based model’s approximation (see
Figure 6c and
Figure 7c). This error accumulation does not occur when using supervised training on the reference solution, suggesting that it stems from the physics-informed optimization process rather than the network architecture’s approximation capacity.
Regarding convergence speed, the main obstacle is the sequential learning of wave propagation, which is hindered by the challenge of learning wave reflections at the boundaries (see
Figure 10). Attempts to mitigate these limitations, such as adjustments to the optimization strategy, yielded only marginal improvements. In the following sections, we elaborate on these two aspects and discuss them in the context of the existing research.
4.2. Accumulation of Errors and Locality
To illustrate how errors accumulate over time in the PINN approximation, despite the continuous representation of the solution, we provide an upper bound for the absolute difference between the approximate solution
and the exact solution
. In this idealized setting, we assume that both
and
are continuously evaluated, with
perfectly matching the true boundary conditions. The absolute difference is then bounded by the difference in the initial states
and
, plus the time-integrated absolute difference between their time derivatives, as shown in Equation (
33).
This time-integrated difference can be expressed as the product of time t and the expected value . When the initial conditions are perfectly represented, i.e., , the upper bound reduces to a term that scales linearly with time. Thus, even with perfect initial conditions and a continuous representation of PDE residuals, small differences in the derivatives may accumulate over time. While the PINN optimization does not directly minimize the difference in the time derivatives, but rather a sum of derivatives expressed by the PDEs, we assume for this idealized comparison that low-PDE residuals would also lead to low differences in the time derivatives themselves.
Although automatic differentiation and the continuous solution representation offer advantages over traditional discrete numerical integration by reducing step-wise errors, these small discrepancies in the derivatives can grow significantly over long intervals. This is exacerbated by the discrete evaluation of all loss terms, including PDE residuals, and the imperfect representation of the initial and boundary conditions.
Firstly, PDE residuals in PINN optimization are evaluated at a finite number of points rather than continuously, which can lead to faster error accumulation in unsampled regions of the domain where larger PDE violations may go undetected. Secondly, errors in the initial and boundary conditions propagate over time. Since the unique solution of the PDEs depends on these conditions, deviations from them allow the solution to diverge from the true solution without increasing the PDE violation.
This reliance on the accuracy of earlier states has been linked to a lack of consideration for the causal structure inherent to physical systems [
29]. This stems from the evaluation of PDE residuals at point locations, which only reflect local violations at the specified time, without accounting for errors carried forward from previous states. In the absence of supervised information inside the domain, this will increase error accumulation over time. Combined, the accumulation of PDE violations over time, inaccuracies in initial and boundary conditions, and the locality of the residual evaluation present significant challenges to achieving optimal accuracy in the PINN optimization process. This is demonstrated by the increase in absolute differences over time in our experiments (
Figure 6c and
Figure 7c).
4.3. Sequential Learning
In our experiments, the evolution of the PINN approximation during optimization shows that, for the considered test cases, the PINNs learn an accurate representation of the system states sequentially over time. This means that PINN optimization requires an accurate representation of earlier states before later states can be captured (see
Figure 10). This sequential learning may be tied to the propagation hypothesis and propagation failure [
32] and the lack of physical causality [
29] described in previous work. In the context of PINNs, supervised information about the true system state is typically confined to the initial and boundary conditions at the edges of the time interval. This limitation does not apply to scenarios where additional data are provided across the domain, such as during interpolation or data assimilation applications [
3,
92,
93,
94]. Within the unsupervised regions, the accuracy of the solution depends on the propagation of information from the initial and boundary conditions through the optimization of the PDE residuals [
29,
32]. In this context, accurate solutions are generally expected to propagate from supervised to unsupervised regions, which, while sequential in time for our case, could differ in other scenarios.
In our experiments, reflections were only learned once the wave propagation in the learned solution reached the boundary, leading to a conflict between the wave propagation and the boundary conditions. A wave propagation beyond the boundary does not increase the PDE loss, as it satisfies the PDE under open boundary conditions. As a result, the physics-informed training adjusts the learned solution to reconcile both the PDEs and the closed boundary conditions only after such a conflict arises. This reliance on initial and boundary condition propagation can be explained theoretically by the properties of the initial-boundary value problems. Without specified initial and boundary conditions, no unique solution exists, but rather a family of solutions that satisfies the PDEs. This means that PDE residuals may remain low even for inaccurate solutions, provided they satisfy the PDEs within the domain.
A clear example of this is when wave heights and velocities drop to zero within a short time interval. Early in training, we observed that the network approximation (
Figure 10b) approaches zero in the second half of the time interval, corresponding to lower PDE residuals (
Figure 11b), despite the solution being closer to the reference solution at the start of the interval. Conversely, an accurate solution can have high PDE residuals if earlier states are inaccurate or if small-scale variability causes PDE violations without significantly reducing accuracy. This may explain the higher PDE residuals that were obtained for the accurate solutions when training on the reference solution (see
Figure 9c,d).
The dependence on earlier states has several implications for optimization. First, each gradient step is limited in how much it can improve the solution’s propagation based on the current approximation. Consequently, the optimization requires many training steps to propagate information through the domain. Second, localized boundary conditions or PDE violations with low total loss contributions can lead to the dissipation of the solution within a small time interval. This indicates that intermittent increases in the total loss function are essential for attaining the global optimum and achieving an accurate approximation. Furthermore, this implies that the second-order LBFGS optimizers rapidly converged to local minima, thereby preserving inaccurate solutions. This property of PINN optimization, where second-order methods converge to saddle points for non-convex loss functions due to the missing consideration of negative curvature, has been noted in previous studies, with first-order methods often showing superior results by avoiding such convergence [
95].
Recent advancements aim to address some of these challenges with various strategies. To mitigate the lack of causality between different time states, a causality parameter was introduced into the PDE loss formulation to control the weighting of PDE residuals at each location, enforcing the minimization of earlier residuals before moving to later states [
29]. Additionally, evolutionary sampling methods were developed to prioritize sampling in causally relevant regions of the domain [
32]. There has also been a shift from using the
-norm for the PDE loss to the
-norm, which can better account for the high local violations that could lead to spurious solutions [
56]. Hybrid PINN methods that incorporate discretized numerical approximations have also been explored, speeding up convergence by linking neighboring locations within the domain [
34,
35,
36]. Another promising branch of PINN development towards additional constraints is network architectures incorporating Hamiltonian mechanics [
96,
97,
98,
99], which have recently been extended from ordinary to partial differential equations [
97]. With respect to modeling ocean waves, specialized optimization algorithms such as the nature-inspired water wave optimization algorithm [
100] may also improve the accuracy and efficiency of PINN optimization.
4.4. Limitations
Our results should be viewed in the context of several limitations. First, it is challenging to assess the efficiency of training PINNs, as well as the utility and generality of specialized training approaches, across a wide variety of problems. This study provides a detailed analysis of a very specific scenario, and the results may not be directly applicable to other contexts. Furthermore, the range of optimization methods, sampling strategies, and network architectures considered was limited to maintain computational feasibility. The exploration of further hyperparameter configurations, including the choice of scaling parameters, may offer further potential for increasing efficiency. In addition, we limited the training time to 72 h using a GPU due to the practical requirements of real-world applications such as storm surge and tsunami prediction, where both accuracy and speed are critical. In these scenarios, with lead times ranging from only a few hours to a few days, the time available for computation is also limited to a few hours. Despite these limitations, our results provide valuable insights that can inform the future development of PINNs, particularly for geophysical fluid dynamics and coastal applications.
5. Conclusions
In this study, we demonstrated that physics-informed neural networks can successfully learn wave reflection scenarios based on the 1D SWE, which are relevant for geophysical fluid dynamics in coastal applications. However, optimization challenges arising from the physics-informed loss function limit both the speed and quality of convergence. These limitations are primarily due to the accumulation of errors over time and the sequential learning of the solution, both of which depend on the accuracy of earlier system states [
29,
32]. Since existing PINN-specific techniques did not yield significant improvements in training efficiency, we propose that this problem may serve as a valuable test case for future advancements in physics-informed machine learning.
To expand this application to operational forecasting systems aiming to predicting significant or maximum wave heights during storm surges or tsunamis, several development steps remain. First, PINN models must be extended to two-dimensional domains with complex features such as areas with varying topography, coastlines, and estuaries. These models would also require additional boundary conditions to account for open boundaries, tidal influences, and wind forcing. While previous attempts have explored replacing SWE-based flood models with PINNs using simplified wave equations [
101], SWE-based PINNs still need to prove their suitability for such applications.
Furthermore, the current training approach is limited to specific initial conditions, meaning that each new prediction would require retraining the model. Ongoing work on generalizing neural networks for initial and boundary conditions, such as the deep operator network (DeepONet) [
102] and multiple-input operator network (MIONet) [
103], alongside proposed extensions for physics-informed training [
104,
105,
106,
107], could resolve this issue. By eliminating the need for repeated training, PINNs could enable faster predictions for new conditions.
In the broader context of PINN development, this work highlights the need for specialized training methods that address potential failure modes and slow convergence. Recent advances, including evolutionary sampling [
32], hybrid PINNs with discretized difference approximations [
34,
35,
36], and causality-respecting PINNs [
29], show promise in improving the efficiency of PINNs. The development of efficient and scalable training methods will be crucial to making PINNs competitive with traditional numerical methods.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}