
Data-Driven Prescribed Performance Platooning Control Under Aperiodic Denial-of- Service Attacks

Abstract
1. Introduction
- (1)
- For nonlinear connected automated vehicle system (CAVs) under state constraint and aperiodic DoS attacks, the nonlinear CAV is converted into an equivalent linear data model by using the dynamic linearization technique (DLT). Moreover, to reduce the adverse effect of aperiodic DoS attacks, an attack compensation mechanism based on the latest received data is proposed, which greatly ensures the safe driving of nonlinear CAVs.
- (2)
- The existing data-driven prescribed performance platooning control methods [29,30,31,32] are based on the sliding mode control framework, which may cause chattering problems. Differently from them, a novel prescribed performance transformation strategy for nonlinear CAVs under aperiodic DoS attacks is developed to complete the vehicular tracking control task.
2. Preliminaries and Data-Driven Control Algorithm Design
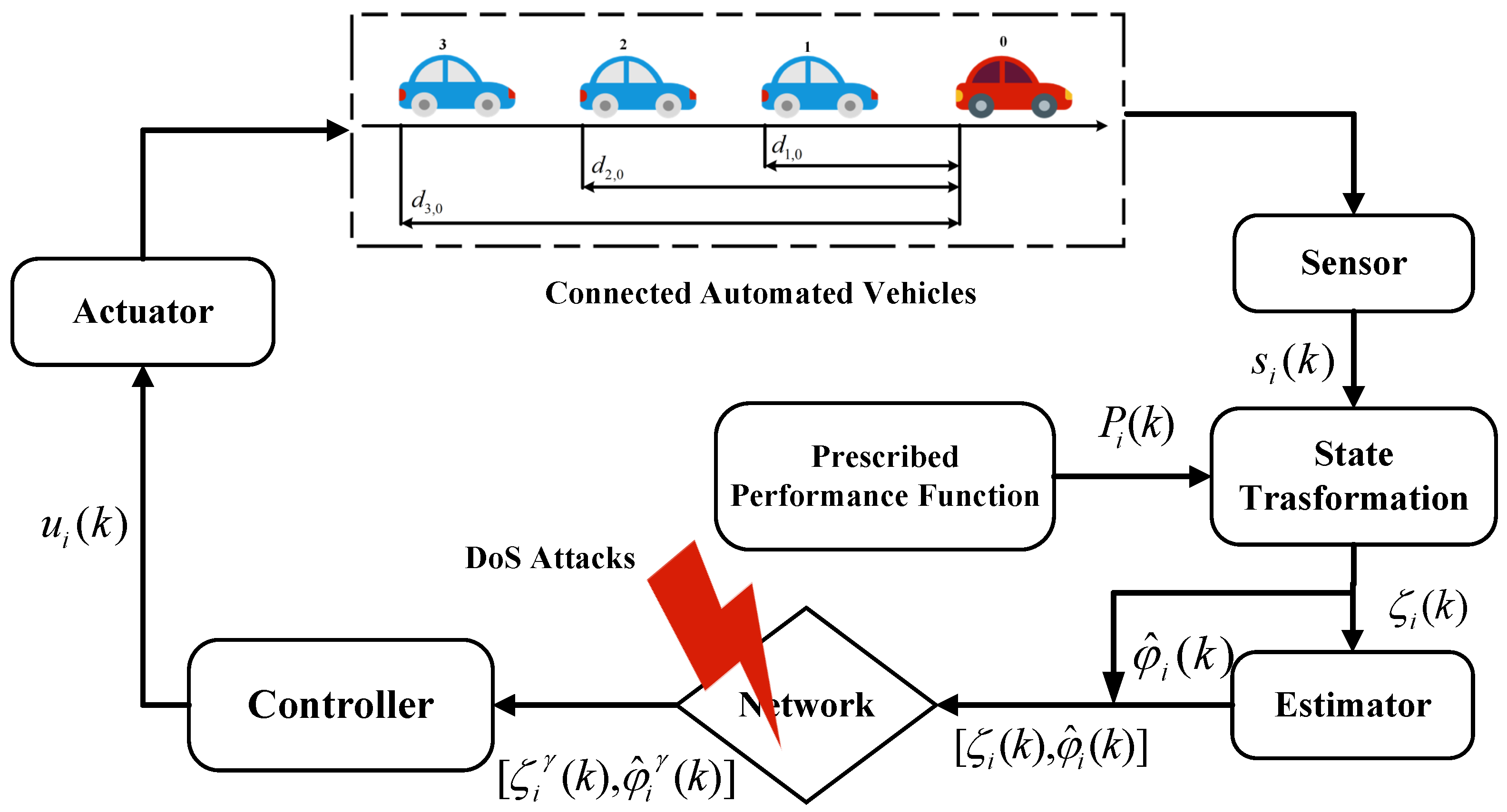
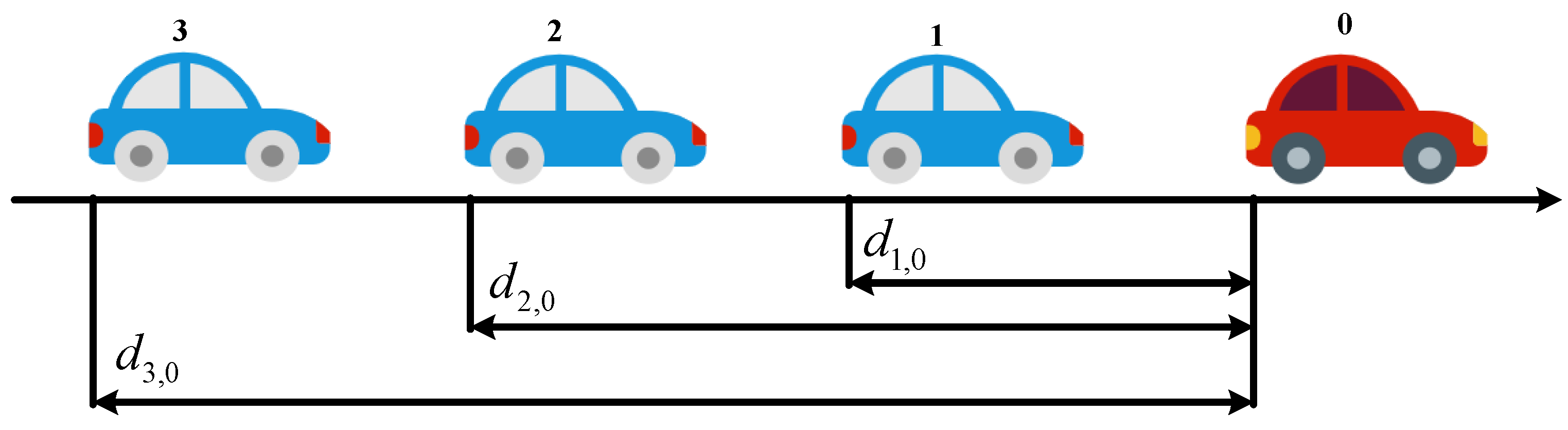
2.1. Connected Automated Vehicle System Model
2.2. Prescribed Performance Control Scheme Design
- (i)
- for any ;
- (ii)
- , and .
2.3. Data-Driven Prescribed Performance Platooning Control Under Aperiodic DoS Attacks
3. Stability Analysis
| Algorithm 1 Data-Driven Prescribed Performance Resilient Control Algorithm. |
| 1: Select suitable parameters , , , , , and . 2: The system’s state is constrained within the prescribed region (7). 3: The constrained state is converted into the unconstrained one (12). 4: The attack compensation mechanism (23) is designed to reduce the impact of attacks. 5: Updating by using estimation algorithm (24a) and (24b). 6: Verify the reset conditions: if , then . 7: Input leader , safety distance , and compensation mechanism and . 8: Update the control input with (25) and output it. |
- (1)
- (2)
- When and , namely, there exist DoS attacks.
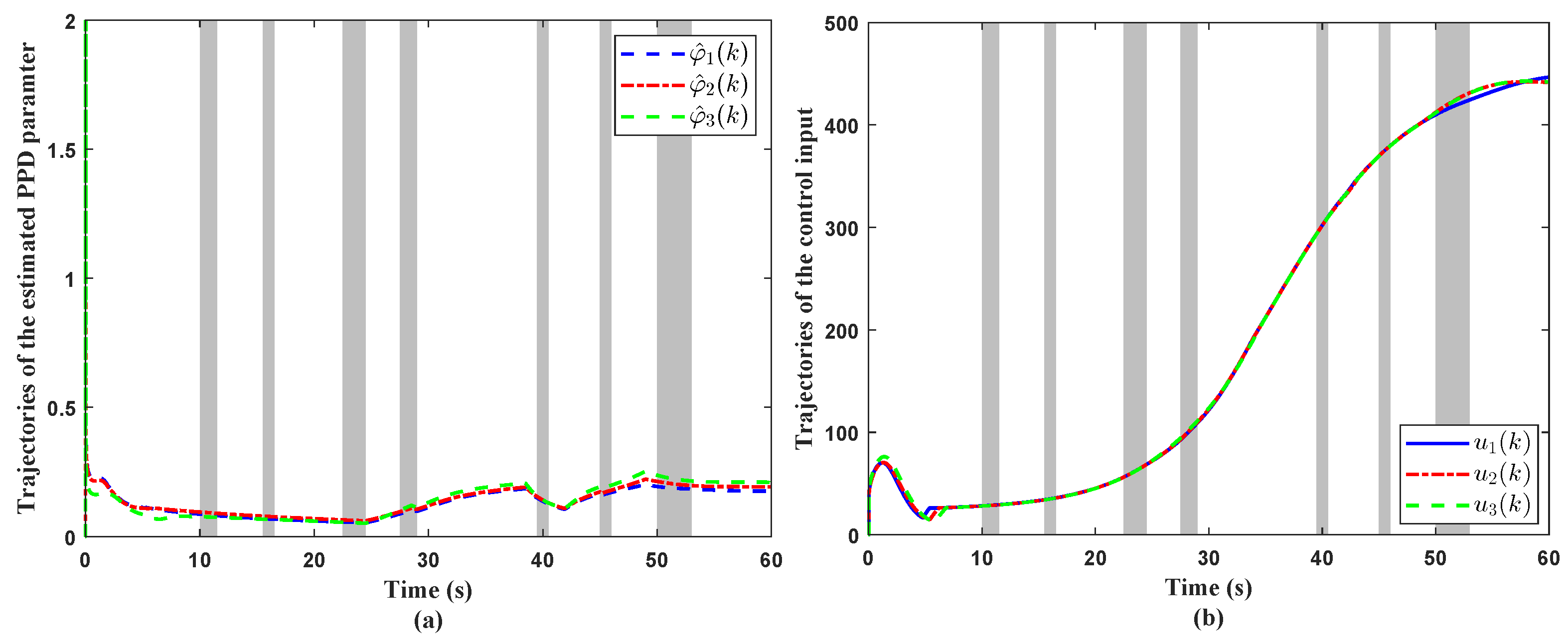
4. Simulation
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhao, N.; Zhao, X.; Xu, N.; Zhang, L. Resilient event-triggered control of connected automated vehicles under cyber attacks. IEEE/CAA J. Autom. Sin. 2023, 10, 2300–2302. [Google Scholar] [CrossRef]
- Zhang, X.; Fang, S.; Shen, Y.; Yuan, X.; Lu, Z. Hierarchical velocity optimization for connected automated vehicles with cellular vehicle-to-everything communication at continuous signalized intersections. IEEE Trans. Intell. Transp. Syst. 2023, 25, 2944–2955. [Google Scholar] [CrossRef]
- Liu, H.; Zhuang, W.; Yin, G.; Li, Z.; Cao, D. Safety-critical and flexible cooperative on-ramp merging control of connected and automated vehicles in mixed traffic. IEEE Trans. Intell. Transp. 2023, 24, 2920–2934. [Google Scholar] [CrossRef]
- Ge, X.; Han, Q.-L.; Zhang, X.-M.; Ding, D. Communication resource-efficient vehicle platooning control with various spacing policies. IEEE/CAA J. Autom. Sin. 2023, 11, 362–376. [Google Scholar] [CrossRef]
- Husain, S.S.; Al-Dujaili, A.Q.; Jaber, A.A.; Humaidi, A.J.; Al-Azzawi, R.S. Design of a Robust Controller Based on Barrier Function for Vehicle Steer-by-Wire Systems. World Electr. Veh. J. 2024, 15, 17. [Google Scholar] [CrossRef]
- Li, Y.; Zhao, Y.; Tong, S. Adaptive fuzzy control for heterogeneous vehicular platoon systems with collision avoidance and connectivity preservation. IEEE Trans. Fuzzy Syst. 2023, 31, 3934–3943. [Google Scholar] [CrossRef]
- Abbas, S.; Husain, S.; Al-Wais, S.; Humaidi, A. Adaptive Integral Sliding Mode Controller (SMC) Design for Vehicle Steer-by-Wire System. SAE Int. J. Veh. Dyn. Stab. NVH 2024, 8, 383–396. [Google Scholar] [CrossRef]
- Che, W.-W.; Zhang, L.; Deng, C.; Wu, Z.-G. Hierarchical lane-changing control for vehicle platoons in prescribed performance. Automatica 2025, 171, 111972. [Google Scholar] [CrossRef]
- Zhang, S.-Q.; Che, W.-W.; Deng, C. Observer-based event-triggered control for linear mass under a directed graph and dos attacks. J. Control Decis. 2022, 9, 384–396. [Google Scholar] [CrossRef]
- Hong, Y.; Su, Y.; Cai, H. Internal Model Based Cooperative Robust Resilient Control Under DoS Attacks With Application to Vehicles Formation. IEEE Trans. Ind. Inform. 2024, 1–11. [Google Scholar] [CrossRef]
- Ren, Y.; Xie, X.; Nguyen, A.-T. Security control of autonomous ground vehicles under dos attacks via a novel controller with the switching mechanism. IEEE Trans. Fuzzy Syst. 2024, 32, 3669–3681. [Google Scholar] [CrossRef]
- Zhao, N.; Zhang, H.; Shi, P. Observer-based sampled-data adaptive tracking control for heterogeneous nonlinear multi-agent systems under denial-of-service attacks. IEEE Trans. Autom. Sci. Eng. 2024. early access. [Google Scholar] [CrossRef]
- Luo, X.; Zhu, M.; Wang, X.; Guan, X. Detection and isolation of false data injection attack via adaptive kalman filter bank. J. Control Decis. 2024, 11, 60–72. [Google Scholar] [CrossRef]
- Wang, Y.-M.; Li, Y.-X. Adaptive security control of time-varying constraints nonlinear cyber-physical systems with false data injection attacks. J. Control Decis. 2024, 11, 50–59. [Google Scholar] [CrossRef]
- Yan, B.; Ni, J.; Zhong, Y.; Yu, D.; Wang, Z. Collision-Free Formation Control for Heterogeneous Multiagent Systems Under DoS Attacks. IEEE Trans. Cybern. 2024, 54, 6244–6255. [Google Scholar] [CrossRef]
- Hou, Z.; Jin, S. Data-driven model-free adaptive control for a class of mimo nonlinear discrete-time systems. IEEE Trans. Neural Netw. 2011, 22, 2173–2188. [Google Scholar]
- Bu, X.; Hou, Z.; Zhang, H. Data-driven multiagent systems consensus tracking using model free adaptive control. IEEE Trans. Neural Netw. Learn. Syst. 2017, 29, 1514–1524. [Google Scholar] [CrossRef]
- Hou, Z.; Zhu, Y. Controller-dynamic-linearization-based model free adaptive control for discrete-time nonlinear systems. IEEE Trans. Industrial Inform. 2013, 9, 2301–2309. [Google Scholar] [CrossRef]
- Hou, Z.; Jin, S. A novel data-driven control approach for a class of discrete-time nonlinear systems. IEEE Trans. Control Syst. 2010, 19, 1549–1558. [Google Scholar] [CrossRef]
- Chen, R.Z.; Li, Y.X.; Hou, Z.S. Distributed model-free adaptive control for multi-agent systems with external disturbances and DoS attacks. Inf. Sci. 2022, 613, 309–323. [Google Scholar] [CrossRef]
- Deng, C.; Jin, X.-Z.; Wu, Z.-G.; Che, W.-W. Data-driven-based cooperative resilient learning method for nonlinear mass under dos attacks. IEEE Trans. Neural Netw. Learn. Syst. 2023, 35, 12107–12116. [Google Scholar] [CrossRef] [PubMed]
- Zhu, P.; Jin, S.; Bu, X.; Hou, Z. Distributed Data-Driven Control for a Connected Autonomous Vehicle Platoon Subjected to False Data Injection Attacks. IEEE Trans. Autom. Sci. Eng. 2023, 21, 7527–7538. [Google Scholar] [CrossRef]
- Zhang, P.; Che, W.-W. Data-driven prescribed performance platooning sliding mode control under dos attacks. Int. J. Robust Nonlinear Control 2024, 34, 11581–11603. [Google Scholar] [CrossRef]
- Zhou, Q.; Ren, Q.; Ma, H.; Chen, G.; Li, H. Model-Free Adaptive Control for Nonlinear Systems Under Dynamic Sparse Attacks and Measurement Disturbances. IEEE Trans. Circuits Syst. I Regul. Pap. 2024, 71, 4731–4741. [Google Scholar] [CrossRef]
- Bechlioulis, C.P.; Rovithakis, G.A. Robust adaptive control of feedback linearizable mimo nonlinear systems with prescribed performance. IEEE Trans. Autom. Control 2008, 53, 2090–2099. [Google Scholar] [CrossRef]
- Zhang, L.; Che, W.-W.; Chen, B.; Lin, C. Adaptive fuzzy output-feedback consensus tracking control of nonlinear multiagent systems in prescribed performance. IEEE Trans. Cybern. 2022, 53, 1932–1943. [Google Scholar] [CrossRef]
- Shi, S.-N.; Li, Y.-X. Event-based adaptive asymptotic tracking control of nonlinear time-varying systems with prescribed performance. J. Control Decis. 2023, 10, 355–364. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, X.; Chen, Z.; Li, L. Adaptive Event-Triggered Path Tracking Control with Proximate Appointed-Time Prescribed Performance for Autonomous Ground Vehicles. IEEE Trans. Ind. Electron. 2024, 1–11. [Google Scholar] [CrossRef]
- Liu, D.; Yang, G.-H. Data-driven adaptive sliding mode control of nonlinear discrete-time systems with prescribed performance. IEEE Trans. Syst. Man Cybern. Syst. 2017, 49, 2598–2604. [Google Scholar] [CrossRef]
- Hou, M.; Wang, Y. Data-driven adaptive terminal sliding mode control with prescribed performance. Asian J. Control 2021, 23, 774–785. [Google Scholar] [CrossRef]
- Liu, D.; Zhou, Z.-P.; Li, T.-S. Data-driven bipartite consensus tracking for nonlinear multiagent systems with prescribed performance. IEEE Trans. Syst. Man Cybern. Syst. 2023, 53, 3666–3674. [Google Scholar] [CrossRef]
- Esmaeili, B.; Salim, M.; Baradarannia, M. Predefined performance-based model-free adaptive fractional-order fast terminal sliding-mode control of MIMO nonlinear systems. ISA Trans. 2022, 131, 108–123. [Google Scholar] [CrossRef] [PubMed]
- Feng, S.; Tesi, P. Resilient control under denial-of-service: Robust design. Automatica 2017, 79, 42–51. [Google Scholar] [CrossRef]
- Xu, D.; Jiang, B.; Shi, P. A novel model-free adaptive control design for multivariable industrial processes. IEEE Trans. Ind. 2014, 61, 6391–6398. [Google Scholar] [CrossRef]
- Sharma, N.K.; Roy, S.; Janardhanan, S. New design methodology for adaptive switching gain based discrete-time sliding mode control. Int. J. Control 2021, 94, 1081–1088. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Comparative Parameters | Our Method | Method in [23] | Unit |
|---|---|---|---|
| Tracking error | m | ||
| Starting convergence time | 10 | 38 | second (s) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, P.; Wang, Z.; Che, W. Data-Driven Prescribed Performance Platooning Control Under Aperiodic Denial-of- Service Attacks. Mathematics 2024, 12, 3313. https://doi.org/10.3390/math12213313
Zhang P, Wang Z, Che W. Data-Driven Prescribed Performance Platooning Control Under Aperiodic Denial-of- Service Attacks. Mathematics. 2024; 12(21):3313. https://doi.org/10.3390/math12213313
Chicago/Turabian StyleZhang, Peng, Zhenling Wang, and Weiwei Che. 2024. "Data-Driven Prescribed Performance Platooning Control Under Aperiodic Denial-of- Service Attacks" Mathematics 12, no. 21: 3313. https://doi.org/10.3390/math12213313
APA StyleZhang, P., Wang, Z., & Che, W. (2024). Data-Driven Prescribed Performance Platooning Control Under Aperiodic Denial-of- Service Attacks. Mathematics, 12(21), 3313. https://doi.org/10.3390/math12213313