
Arbitrary Timestep Video Frame Interpolation with Time-Dependent Decoding


Abstract
1. Introduction
- A new arbitrary timestep video frame interpolation framework based on an encoder–decoder is proposed, where any interpolation timestep can be fed into the decoder part.
- We propose a new data augmentation method, i.e., multi-width window sampling, to better leverage the training set for interpolating videos at any interpolation scale.
- Extensive experiments are conducted to compare our method with state-of-the-art VFI methods, showing the effectiveness of the proposed framework and data augmentation.
2. Related Work
3. Proposed Method
3.1. Arbitrary Timestep VFI Framework
3.2. Network Architecture
3.2.1. Encoder of ATVFI
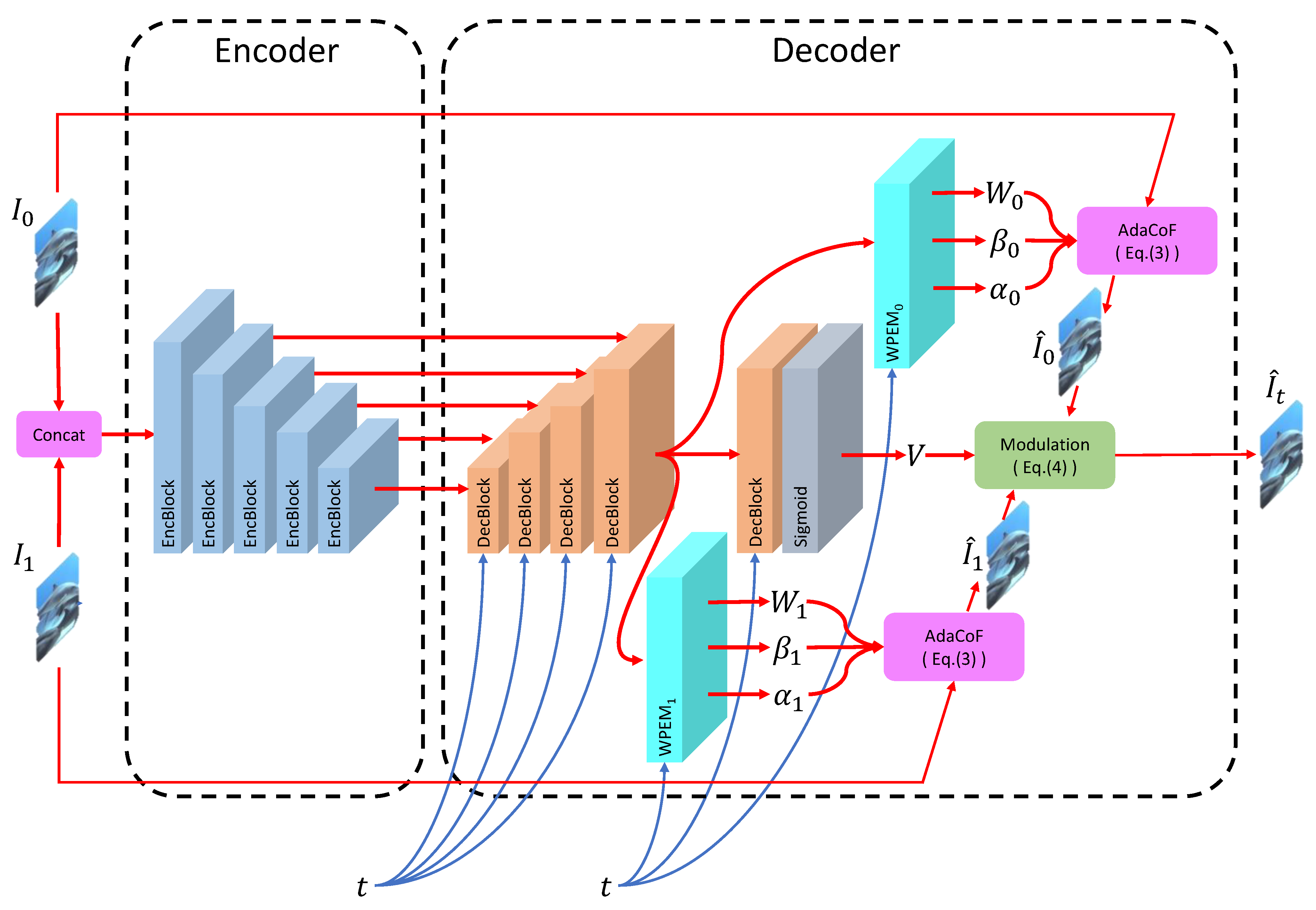
3.2.2. Decoder of ATVFI
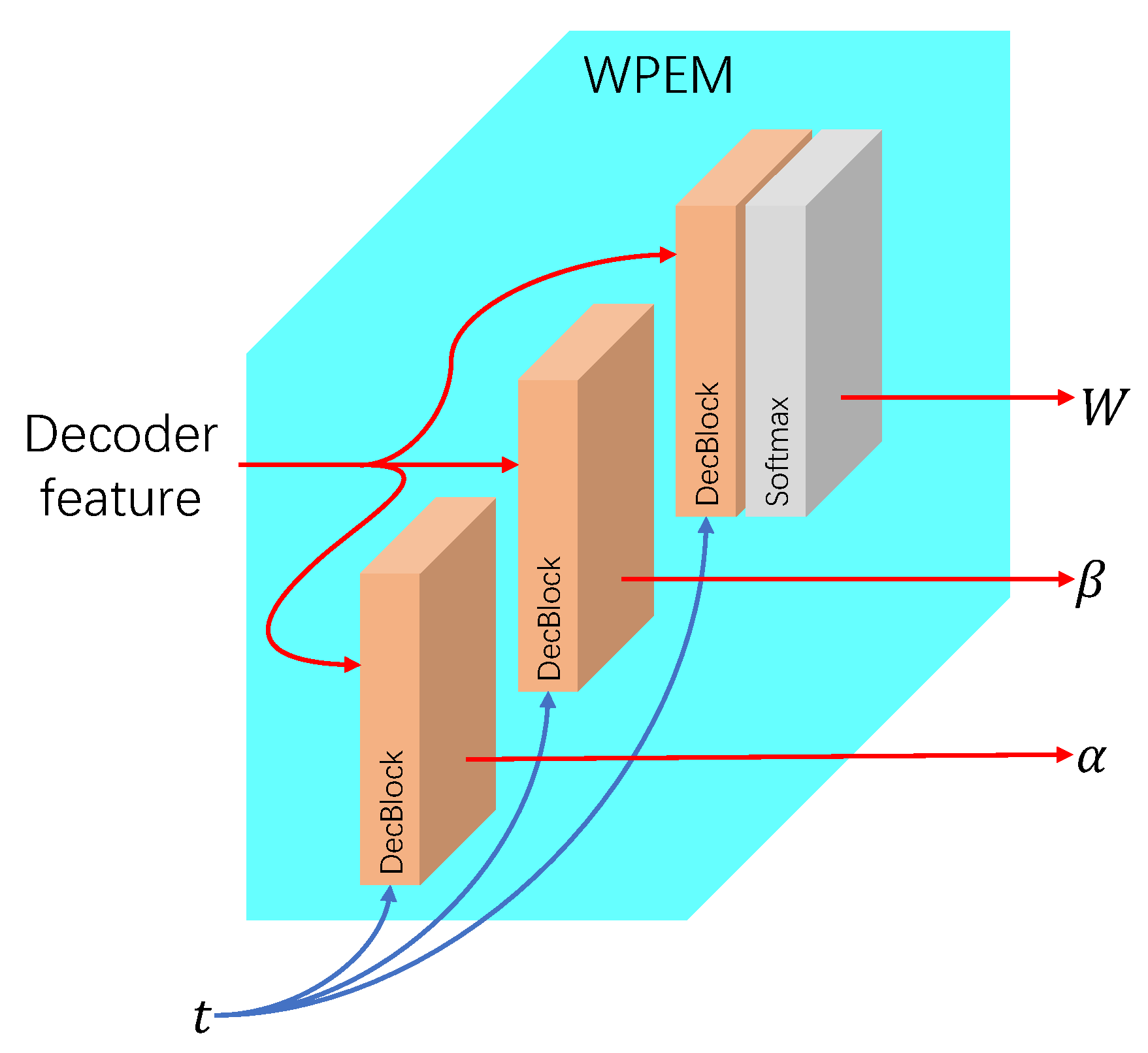
3.2.3. Algorithmic Explanation
| Algorithm 1: Pseudocode representation of ATVFI |
|
|
|
|
3.3. Multi-Width Window Sampling
4. Experiments
4.1. Basic Settings
4.2. Comparison with State-of-the-Art
4.2.1. Interpolation
4.2.2. Arbitrary-Scale Multi-Frame Interpolation
4.2.3. Comparison with Iterative Interpolation
4.2.4. Qualitative Evaluation
4.3. Ablation Study
4.3.1. Method for Adopting the Timestep as Input
- Variant “Ours-lastonly”: Only the sub-networks in the warping modules adopt t as input, while the pyramid part of the decoder network only takes encoder features and previous-level decoder features as input.
- Variant “Ours-allconv”: Apart from the first convolution layer in each level of the decoder network, all other convolution layers also adopt t as extra input in the same way.
4.3.2. Effect of Multi-Width Window Sampling
5. Discussion and Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| VFI | video frame interpolation |
| FPS | frames per second |
| ATVFI | arbitrary timestep video frame interpolation |
| MWWS | multi-width window sampling |
| WPEM | warping parameter estimation module |
References
- Niklaus, S.; Mai, L.; Liu, F. Video Frame Interpolation via Adaptive Separable Convolution. In Proceedings of the IEEE International Conference on Computer Vision, ICCV 2017, Venice, Italy, 22–29 October 2017; pp. 261–270. [Google Scholar] [CrossRef]
- Niklaus, S.; Liu, F. Context-Aware Synthesis for Video Frame Interpolation. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1701–1710. [Google Scholar] [CrossRef]
- Gui, S.; Wang, C.; Chen, Q.; Tao, D. FeatureFlow: Robust Video Interpolation via Structure-to-Texture Generation. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, 13–19 June 2020; pp. 14001–14010. [Google Scholar] [CrossRef]
- Reda, F.A.; Kontkanen, J.; Tabellion, E.; Sun, D.; Pantofaru, C.; Curless, B. FILM: Frame Interpolation for Large Motion. arXiv 2022, arXiv:2202.04901. [Google Scholar]
- Peleg, T.; Szekely, P.; Sabo, D.; Sendik, O. IM-Net for High Resolution Video Frame Interpolation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, 16–20 June 2019; pp. 2398–2407. [Google Scholar] [CrossRef]
- Bao, W.; Lai, W.; Zhang, X.; Gao, Z.; Yang, M. MEMC-Net: Motion Estimation and Motion Compensation Driven Neural Network for Video Interpolation and Enhancement. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 933–948. [Google Scholar] [CrossRef] [PubMed]
- Jiang, H.; Sun, D.; Jampani, V.; Yang, M.; Learned-Miller, E.G.; Kautz, J. Super SloMo: High Quality Estimation of Multiple Intermediate Frames for Video Interpolation. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, 18–22 June 2018; pp. 9000–9008. [Google Scholar] [CrossRef]
- Bao, W.; Lai, W.; Ma, C.; Zhang, X.; Gao, Z.; Yang, M. Depth-Aware Video Frame Interpolation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, 16–20 June 2019; pp. 3703–3712. [Google Scholar] [CrossRef]
- Sim, H.; Oh, J.; Kim, M. XVFI: eXtreme Video Frame Interpolation. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, QC, Canada, 10–17 October 2021; pp. 14469–14478. [Google Scholar] [CrossRef]
- Cheng, X.; Chen, Z. Multiple Video Frame Interpolation via Enhanced Deformable Separable Convolution. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 7029–7045. [Google Scholar] [CrossRef] [PubMed]
- Kong, L.; Jiang, B.; Luo, D.; Chu, W.; Huang, X.; Tai, Y.; Wang, C.; Yang, J. IFRNet: Intermediate Feature Refine Network for Efficient Frame Interpolation. arXiv 2022, arXiv:2205.14620. [Google Scholar] [CrossRef]
- Huang, Z.; Zhang, T.; Heng, W.; Shi, B.; Zhou, S. Real-Time Intermediate Flow Estimation for Video Frame Interpolation. In Proceedings of the 17th European Conference on Computer Vision, ECCV 2022, Tel Aviv, Israel, 23–27 October 2022; Avidan, S., Brostow, G.J., Cissé, M., Farinella, G.M., Hassner, T., Eds.; Springer: Berlin/Heidelberg, Germany, 2022; Volume 13674, pp. 624–642. [Google Scholar] [CrossRef]
- Zhang, Y.; Sung, Y. Traffic Accident Detection Using Background Subtraction and CNN Encoder–Transformer Decoder in Video Frames. Mathematics 2023, 11, 2884. [Google Scholar] [CrossRef]
- Kalluri, T.; Pathak, D.; Chandraker, M.; Tran, D. FLAVR: Flow-Agnostic Video Representations for Fast Frame Interpolation. arXiv 2020, arXiv:2012.08512. [Google Scholar]
- Liu, Z.; Yeh, R.A.; Tang, X.; Liu, Y.; Agarwala, A. Video Frame Synthesis Using Deep Voxel Flow. In Proceedings of the IEEE International Conference on Computer Vision, ICCV 2017, Venice, Italy, 22–29 October 2017; pp. 4473–4481. [Google Scholar] [CrossRef]
- Niklaus, S.; Liu, F. Softmax Splatting for Video Frame Interpolation. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, 13–19 June 2020; pp. 5436–5445. [Google Scholar] [CrossRef]
- Park, J.; Ko, K.; Lee, C.; Kim, C. BMBC: Bilateral Motion Estimation with Bilateral Cost Volume for Video Interpolation. In Proceedings of the 16th European Conference on Computer Vision, ECCV 2020, Glasgow, UK, 23–28 August 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2020; Volume 12359, pp. 109–125. [Google Scholar] [CrossRef]
- Park, J.; Lee, C.; Kim, C. Asymmetric Bilateral Motion Estimation for Video Frame Interpolation. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, QC, Canada, 10–17 October 2021; pp. 14519–14528. [Google Scholar] [CrossRef]
- Xu, X.; Si-Yao, L.; Sun, W.; Yin, Q.; Yang, M. Quadratic Video Interpolation. In Proceedings of the Annual Conference on Neural Information Processing Systems 2019—Advances in Neural Information Processing Systems 32, NeurIPS 2019, Vancouver, BC, Canada, 8–14 December 2019; Wallach, H.M., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E.B., Garnett, R., Eds.; pp. 1645–1654. [Google Scholar]
- Liu, Y.; Xie, L.; Li, S.; Sun, W.; Qiao, Y.; Dong, C. Enhanced Quadratic Video Interpolation. In Proceedings of the 2020 Workshops on Computer Vision, Glasgow, UK, 23–28 August 2020; Bartoli, A., Fusiello, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2020; Volume 12538, pp. 41–56. [Google Scholar] [CrossRef]
- Chi, Z.; Nasiri, R.M.; Liu, Z.; Lu, J.; Tang, J.; Plataniotis, K.N. All at Once: Temporally Adaptive Multi-frame Interpolation with Advanced Motion Modeling. In Proceedings of the 16th European Conference on Computer Vision, ECCV 2020, Glasgow, UK, 23–28 August 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2020; Volume 12372, pp. 107–123. [Google Scholar] [CrossRef]
- Chen, Z.; Wang, R.; Liu, H.; Wang, Y. PDWN: Pyramid Deformable Warping Network for Video Interpolation. arXiv 2021, arXiv:2104.01517. [Google Scholar] [CrossRef]
- Lu, L.; Wu, R.; Lin, H.; Lu, J.; Jia, J. Video Frame Interpolation with Transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, 18–24 June 2022; pp. 3522–3532. [Google Scholar] [CrossRef]
- Jin, X.; Wu, L.; Chen, J.; Chen, Y.; Koo, J.; Hahm, C.H. A Unified Pyramid Recurrent Network for Video Frame Interpolation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023. [Google Scholar]
- Li, Z.; Zhu, Z.L.; Han, L.H.; Hou, Q.; Guo, C.L.; Cheng, M.M. AMT: All-Pairs Multi-Field Transforms for Efficient Frame Interpolation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023. [Google Scholar]
- Heo, J.; Jeong, J. Forward Warping-Based Video Frame Interpolation Using a Motion Selective Network. Electronics 2022, 11, 2553. [Google Scholar] [CrossRef]
- Niklaus, S.; Mai, L.; Liu, F. Video Frame Interpolation via Adaptive Convolution. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 2270–2279. [Google Scholar] [CrossRef]
- Lee, H.; Kim, T.; Chung, T.; Pak, D.; Ban, Y.; Lee, S. AdaCoF: Adaptive Collaboration of Flows for Video Frame Interpolation. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, 13–19 June 2020; pp. 5315–5324. [Google Scholar] [CrossRef]
- Shi, Z.; Liu, X.; Shi, K.; Dai, L.; Chen, J. Video Frame Interpolation via Generalized Deformable Convolution. IEEE Trans. Multim. 2022, 24, 426–439. [Google Scholar] [CrossRef]
- Ding, T.; Liang, L.; Zhu, Z.; Zharkov, I. CDFI: Compression-Driven Network Design for Frame Interpolation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, Virtual, 19–25 June 2021; pp. 8001–8011. [Google Scholar]
- Meyer, S.; Djelouah, A.; McWilliams, B.; Sorkine-Hornung, A.; Gross, M.H.; Schroers, C. PhaseNet for Video Frame Interpolation. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, 18–22 June 2018; pp. 498–507. [Google Scholar] [CrossRef]
- Tran, Q.N.; Yang, S.H. Efficient Video Frame Interpolation Using Generative Adversarial Networks. Appl. Sci. 2020, 10, 6245. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.C.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; Guyon, I., von Luxburg, U., Bengio, S., Wallach, H.M., Fergus, R., Vishwanathan, S.V.N., Garnett, R., Eds.; pp. 5998–6008. [Google Scholar]
- Singh, P.; Verma, V.K.; Rai, P.; Namboodiri, V.P. HetConv: Heterogeneous Kernel-Based Convolutions for Deep CNNs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, 16–20 June 2019; pp. 4835–4844. [Google Scholar] [CrossRef]
- Liu, B.; Chen, K.; Peng, S.L.; Zhao, M. Depth Map Super-Resolution Based on Semi-Couple Deformable Convolution Networks. Mathematics 2023, 11, 4556. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the 8th International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Navab, N., Hornegger, J., III, W.M.W., Frangi, A.F., Eds.; Springer: Berlin/Heidelberg, Germany, 2015; Volume 9351, pp. 234–241. [Google Scholar] [CrossRef]
- Barbu, T. CNN-Based Temporal Video Segmentation Using a Nonlinear Hyperbolic PDE-Based Multi-Scale Analysis. Mathematics 2023, 11, 245. [Google Scholar] [CrossRef]
- Abuqaddom, I.; Mahafzah, B.A.; Faris, H. Oriented stochastic loss descent algorithm to train very deep multi-layer neural networks without vanishing gradients. Knowl.-Based Syst. 2021, 230, 107391. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Xue, T.; Chen, B.; Wu, J.; Wei, D.; Freeman, W.T. Video Enhancement with Task-Oriented Flow. Int. J. Comput. Vis. 2019, 127, 1106–1125. [Google Scholar] [CrossRef]
- Nah, S.; Kim, T.H.; Lee, K.M. Deep Multi-scale Convolutional Neural Network for Dynamic Scene Deblurring. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 257–265. [Google Scholar] [CrossRef]
- Batchuluun, G.; Koo, J.H.; Kim, Y.H.; Park, K.R. Image Region Prediction from Thermal Videos Based on Image Prediction Generative Adversarial Network. Mathematics 2021, 9, 1053. [Google Scholar] [CrossRef]
- Soomro, K.; Zamir, A.R.; Shah, M. UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild. arXiv 2012, arXiv:1212.0402. [Google Scholar]
- Baker, S.; Scharstein, D.; Lewis, J.P.; Roth, S.; Black, M.J.; Szeliski, R. A Database and Evaluation Methodology for Optical Flow. Int. J. Comput. Vis. 2011, 92, 1–31. [Google Scholar] [CrossRef]
- Su, S.; Delbracio, M.; Wang, J.; Sapiro, G.; Heidrich, W.; Wang, O. Deep Video Deblurring for Hand-Held Cameras. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 237–246. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Vimeo90k | Middlebury | UCF | Time (s) | Memory (GB) | |||
|---|---|---|---|---|---|---|---|---|
| PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | |||
| SepConv [1] | 29.76 | 0.874 | 29.60 | 0.848 | 29.18 | 0.899 | 0.011 | 0.76 |
| AdaCoF [28] | 31.98 | 0.920 | 32.40 | 0.906 | 31.56 | 0.935 | 0.011 | 0.76 |
| CAIN [2] | 30.32 | 0.885 | 29.12 | 0.830 | 28.99 | 0.892 | 0.019 | 0.97 |
| VFIformer [23] | 33.08 | 0.944 | 33.00 | 0.933 | 31.38 | 0.940 | 0.344 | 2.88 |
| Super SloMo [7] | 31.48 | 0.920 | 31.35 | 0.905 | 29.32 | 0.910 | 0.017 | 0.78 |
| DAIN [8] | 31.73 | 0.930 | 32.04 | 0.913 | 30.18 | 0.926 | 0.272 | 2.17 |
| XVFI [9] | 30.12 | 0.899 | 30.77 | 0.889 | 29.54 | 0.916 | 0.029 | 1.12 |
| EDSC [10] | 31.57 | 0.914 | 31.90 | 0.896 | 31.03 | 0.927 | 0.015 | 0.82 |
| IFRNet [11] | 32.23 | 0.927 | 32.89 | 0.925 | 31.52 | 0.935 | 0.007 | 0.79 |
| RIFE [12] | 30.41 | 0.885 | 31.66 | 0.897 | 31.48 | 0.935 | 0.006 | 0.78 |
| UPR-Net [24] | 31.73 | 0.920 | 31.95 | 0.911 | 30.98 | 0.932 | 0.021 | 0.85 |
| AMT [25] | 32.24 | 0.929 | 32.81 | 0.917 | 31.28 | 0.934 | 0.015 | 0.81 |
| Ours | 32.50 | 0.931 | 33.65 | 0.933 | 32.01 | 0.941 | 0.011 | 0.95 |
| Method | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | |
| Super SloMo [7] | 35.39 | 0.969 | 34.10 | 0.957 | 32.80 | 0.941 | 31.64 | 0.923 | 30.50 | 0.902 |
| DAIN [8] | 30.70 | 0.922 | 29.35 | 0.893 | 27.67 | 0.862 | 26.65 | 0.837 | 25.65 | 0.811 |
| EDSC [10] | 35.52 | 0.967 | 34.17 | 0.955 | 32.84 | 0.940 | 31.69 | 0.923 | 30.57 | 0.902 |
| XVFI [9] | 31.21 | 0.928 | 29.69 | 0.901 | 27.90 | 0.872 | 26.80 | 0.847 | 25.80 | 0.825 |
| IFRNet [11] | 35.61 | 0.967 | 34.37 | 0.957 | 32.97 | 0.942 | 31.86 | 0.927 | 30.84 | 0.909 |
| RIFE [12] | 31.06 | 0.919 | 29.00 | 0.880 | 27.47 | 0.846 | 26.31 | 0.817 | 25.36 | 0.791 |
| UPR-Net [24] | 35.14 | 0.9633 | 34.06 | 0.955 | 32.92 | 0.942 | 31.98 | 0.928 | 30.94 | 0.910 |
| AMT [25] | 35.03 | 0.963 | 34.33 | 0.957 | 32.82 | 0.943 | 32.01 | 0.930 | 30.94 | 0.913 |
| Ours | 36.43 | 0.972 | 34.78 | 0.960 | 33.24 | 0.943 | 31.94 | 0.925 | 30.70 | 0.903 |
| Method | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | |
| Super SloMo [7] | 33.92 | 0.962 | 33.43 | 0.957 | 32.93 | 0.952 | 32.42 | 0.946 | 31.87 | 0.938 |
| DAIN [8] | 30.76 | 0.921 | 29.87 | 0.904 | 28.90 | 0.885 | 28.24 | 0.870 | 27.56 | 0.855 |
| EDSC [10] | 34.65 | 0.961 | 34.19 | 0.957 | 33.62 | 0.951 | 33.05 | 0.945 | 32.46 | 0.937 |
| XVFI [9] | 31.75 | 0.937 | 30.63 | 0.920 | 29.49 | 0.904 | 28.71 | 0.891 | 27.96 | 0.878 |
| IFRNet [11] | 35.32 | 0.966 | 34.69 | 0.962 | 33.93 | 0.954 | 33.21 | 0.948 | 32.59 | 0.940 |
| RIFE [12] | 31.79 | 0.931 | 30.44 | 0.910 | 29.40 | 0.891 | 28.56 | 0.874 | 27.84 | 0.858 |
| UPR-Net [24] | 34.72 | 0.964 | 34.28 | 0.960 | 33.71 | 0.954 | 33.17 | 0.948 | 32.53 | 0.939 |
| AMT [25] | 34.12 | 0.961 | 33.99 | 0.960 | 33.36 | 0.954 | 32.76 | 0.948 | 32.28 | 0.941 |
| Ours | 37.00 | 0.973 | 35.98 | 0.968 | 35.05 | 0.961 | 34.20 | 0.953 | 33.37 | 0.944 |
| Method | GoPro () | Adobe240 () | ||
|---|---|---|---|---|
| PSNR | SSIM | PSNR | SSIM | |
| SepConv [1] (iterative) | 27.87 | 0.843 | 28.10 | 0.857 |
| AdaCoF [28] (iterative) | 29.34 | 0.877 | 31.27 | 0.918 |
| CAIN [2] (iterative) | 27.88 | 0.834 | 27.75 | 0.855 |
| VFIformer [23] (iterative) | 28.70 | 0.864 | 29.16 | 0.889 |
| Ours | 29.62 | 0.881 | 32.60 | 0.913 |
| Vimeo90k () | GoPro () | Adobe240 () | ||||
|---|---|---|---|---|---|---|
| PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | |
| Ours-original | 32.50 | 0.931 | 29.62 | 0.881 | 32.60 | 0.935 |
| Ours-lastonly | 32.52 | 0.932 | 29.63 | 0.881 | 32.70 | 0.938 |
| Ours-allconv | 32.60 | 0.933 | 29.67 | 0.881 | 32.72 | 0.937 |
| Vimeo90k () | GoPro () | Adobe240 () | ||||
|---|---|---|---|---|---|---|
| PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | |
| Ours | 32.50 | 0.931 | 29.62 | 0.881 | 32.60 | 0.935 |
| Ours (w/o MWWS) | 31.46 | 0.909 | 29.39 | 0.877 | 31.83 | 0.924 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, H.; Ren, D.; Yan, Z.; Zuo, W. Arbitrary Timestep Video Frame Interpolation with Time-Dependent Decoding. Mathematics 2024, 12, 303. https://doi.org/10.3390/math12020303
Zhang H, Ren D, Yan Z, Zuo W. Arbitrary Timestep Video Frame Interpolation with Time-Dependent Decoding. Mathematics. 2024; 12(2):303. https://doi.org/10.3390/math12020303
Chicago/Turabian StyleZhang, Haokai, Dongwei Ren, Zifei Yan, and Wangmeng Zuo. 2024. "Arbitrary Timestep Video Frame Interpolation with Time-Dependent Decoding" Mathematics 12, no. 2: 303. https://doi.org/10.3390/math12020303
APA StyleZhang, H., Ren, D., Yan, Z., & Zuo, W. (2024). Arbitrary Timestep Video Frame Interpolation with Time-Dependent Decoding. Mathematics, 12(2), 303. https://doi.org/10.3390/math12020303