4.2. Results and Discussion
In this study, a large number of experiments were conducted, and the suggested approach was assessed using the aforementioned standards. The first criterion was the average branch coverage by the generated test data, as was previously described. Each test production method was run ten times to acquire the average values of the branch coverage. The results show that most benchmark programs provide test data with better branch coverage. The ability to detect bugs increases with the degree of coverage of the data. One could argue that the test results produced by the recommended method are more beneficial.
The program’s source code is divided into classes and functions; huge programs are made up of classes and functions towards the end. Contrarily, according to programming best practices, a function contains between 20 and 100 lines of code. The benchmarks utilized in this paper are extremely established and popular. Additionally, any programming constructions that can be applied to complicated software in the actual world are included in these benchmarks. These benchmarks employ every possible conditional, loop, arithmetic, logical, and jump operator and instruction. The same results can be produced by the suggested technique in real-world programs. The produced test data by the suggested methods in the
triangleType,
Cal, and
Reminder benchmarks is 100%, as shown in
Table 5. The suggested approach generates test data that has approximately 99.99% coverage. The suggested approach achieves 99.93% coverage in
calDay, whereas PSO and ACO algorithms produce 100% coverage for this program. In terms of average coverage, the suggested strategy works better overall.
As previously indicated, another factor utilized to compare the proposed technique to other algorithms in the creation of test data was convergence speed. This criterion shows the typical rate of delivering effective test results. An algorithm’s rate of convergence is determined by the average number of iterations needed to generate test data (AG). The algorithm’s rate of convergence is shown by the average number of iterations.
The average number of iterations indicates the convergence speed of the algorithm. Fewer numbers of iterations indicate a higher convergence speed of the related algorithm.
Table 6 gives the average number of iterations for each algorithm concerning test data production. The obtained results reveal that the convergence speed of the BOA method is, on average, better than that of the GA. That is, when compared with the GA, in
triangleType,
isValidDate,
Cal,
Reminder, and
printCalender, the proposed method can achieve maximum convergence speed.
Another assessment factor that was taken into account was the amount of time needed to produce the test data with the greatest possible coverage. A related algorithm’s fast speed is shown by less time spent producing test data.
Table 7 displays the AET required to produce test data using various techniques. The suggested approach outperforms the GA and the PSO algorithm in terms of speed, as shown by the results collected and shown in
Table 7. In
triangleType, calDay, isValidDate, Cal, and
Reminder benchmarks, the BOA method as well as the ACO method have higher speeds (lower time consumption) than the other methods. Indeed, can generate effective test data in less time and cost.
The success rate is another evaluation criterion that was used in this study for comparing different methods. This criterion reflects the chance that the test data generated will cover every software branch. Higher numbers for the output in this criterion suggest more efficacy. Each method was run ten times on each benchmark to calculate this criterion. The likelihood that each method would completely cover all program branches was then calculated. The likelihood that various algorithms will achieve 100% coverage is shown in
Table 8. Except for the
printCalender benchmark program, the suggested technique achieved a high percentage of success.
Another factor for assessing the results was the stability of the outcomes. It should be emphasized that the heuristic methods randomly produce the starting population. Hence, the results provided by different executions of each algorithm may be different. Accordingly, the results of only one execution may not demonstrate the capability of an algorithm; each algorithm should be executed more than once. Furthermore, the average standard deviation of the results should be computed and taken into consideration. In this study, 10 different executions (each execution includes 200 iterations) were investigated. The results from 10 executions of the benchmark programs showed that the average objective function of the BOA performed better than GA and ACO.
Table 9 gives standard deviation values for 10 exactions of the different algorithms.
Figure 5 illustrates the coverage of the produced test data for all programs. In the experiments, the overall coverage of the test data is 99.95%. ACO and BOA generate test data with the most coverage. The average required time of the proposed method to achieve 99.95% coverage is 1.77 s. None of the existing methods generate test data with a coverage rate of 99.95% in 1.7 s. Regarding the average results shown in
Figure 6,
Figure 7 and
Figure 8, the ACO achieves 99.97% code coverage in 26.15 s. Indeed, the time spent by the ACO algorithm is almost 14 times the time required by the BOA method. In real-world large software products, the required time of ACO is not acceptable compared to the time required by the BOA.
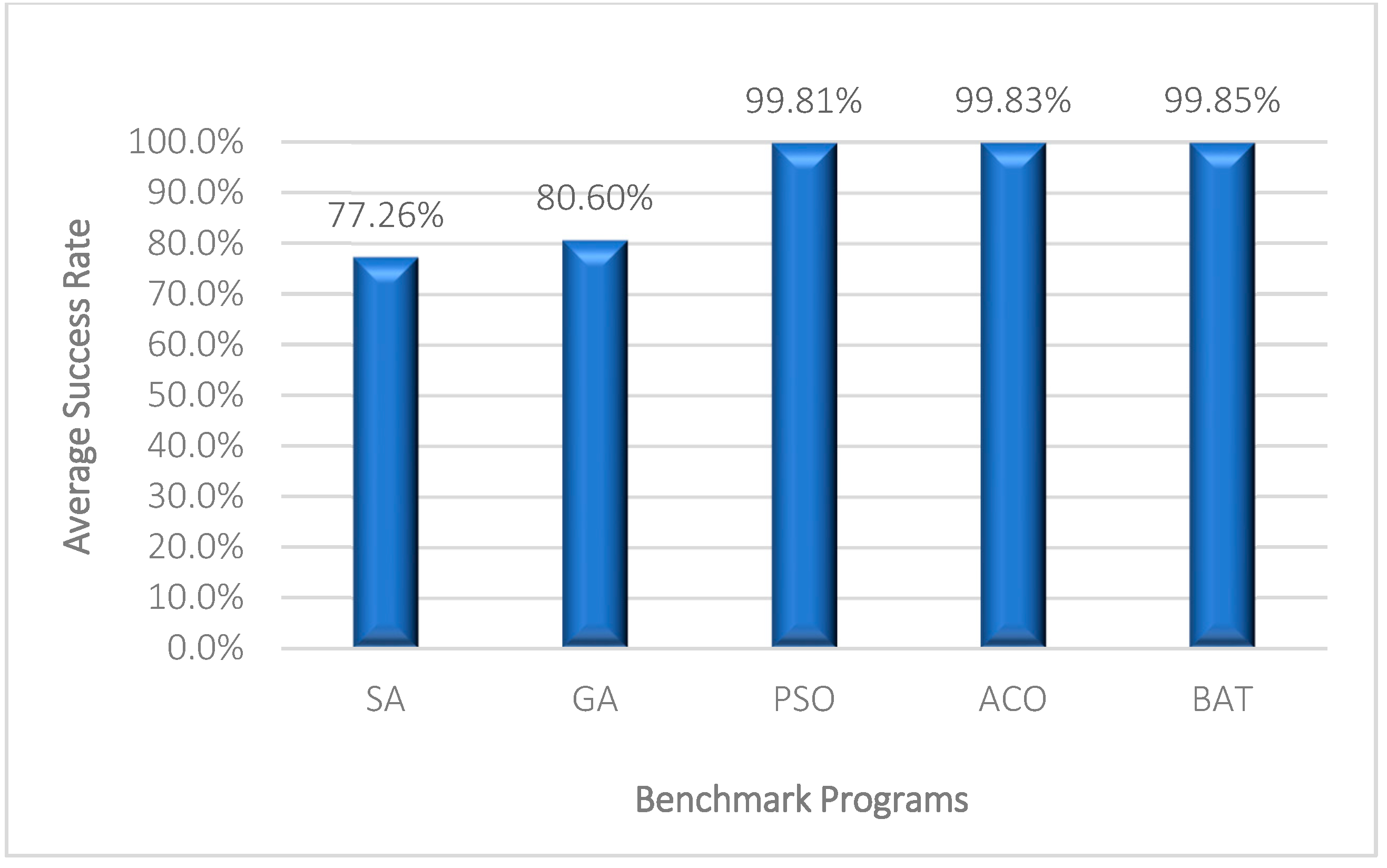
Figure 6 shows the success rate of algorithms in generating maximum-coverage test data. Significantly, 99.85% of the generated test data can achieve maximum coverage.
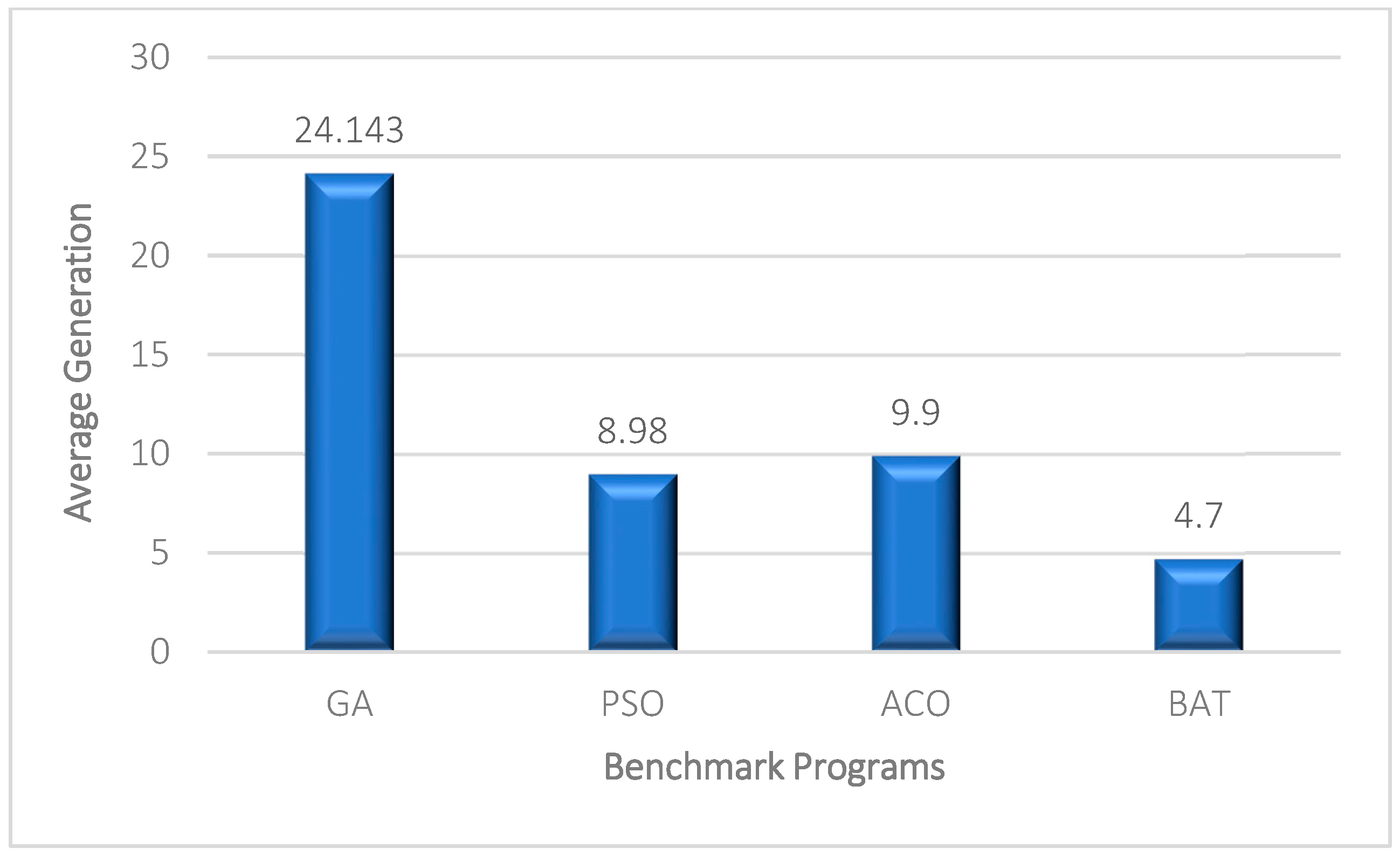
Figure 7 shows the average number of iterations required by each algorithm to generate maximum-coverage test data.
Figure 8 also illustrates the average required time of the test generation algorithms. The proposed method generates the maximum-coverage test data after about 4.7 iterations on average. Indeed, the proposed method has a higher convergence speed than the other test generation algorithms. Generating test data with 99.95% coverage after 4.7 iterations (on average) and 1.7 s by the proposed method is a superior result in the field. ACO can generate test data with a higher amount of coverage, but its speed is considerably lower than the proposed method. On the other hand, the stability of the proposed method is higher than the other algorithm. The stability of a heuristic-based algorithm indicates its reliability during different executions. The same or very similar results during different executions indicate the reliability of heuristic-based test generation algorithms. The standard deviation among the obtained results of the proposed method is 0.09 which is lower than the other algorithms. All in all, the proposed method can be used as an effective test generation method to test real-world large software products. Generating test data with 99.95% with a negligible amount of time and the lowest standard deviation (higher reliability) are the main advantages of the method.
4.3. Parameter Calibration and Statistical Analysis
Finding the best values for each method’s parameters is one of the downsides of heuristic algorithms. In most cases, parameters are crucial in advancing an algorithm toward the best outcome. The six parameters that make up the BOA can be modified depending on the software and the application in question. Like all the other algorithms, adjusting the parameters of the BOA is carried out via trial and error. These parameters are first given in
Table 10; then, the optimal adjusted values for the BOA are shown in
Table 11.
To analyze the significance of the results, a statistical test has been performed on the results. ANOVA was used to evaluate the significance of the difference in the coverage of the generated test data. The outcomes of the ANOVA test are shown in
Table 12. The significance of the variance in the results is shown by the values of f and p. The null hypothesis in the ANOVA test indicates that the coverage of the test data produced by various algorithms does not differ significantly. The ANOVA results show that the null hypothesis was not accepted, and they also show that the suggested approach and the other methods significantly differ in how well they cover the given program branches. The suggested strategy provides much more coverage of the test data generated.
In this study, BOA was modified and discretized, and adopted to the test generation problem. Furthermore, a mutation operator was embedded into the BOA to create local diversity in the population. The modified and discretized BOA, as a swarm-based heuristic algorithm, has higher performance in the software test generation problem. Software test data generation is formally a combinatorial optimization problem. BOA was used to find the optimal combination of the test data to attain the highest branch coverage. The movement operator in the BOA was implemented based on sound loudness and frequency; in the test data generation problem, the developed BOA had a higher success rate and performance than the SA, GA, PSO, and ACO.
The mutation test was carried out to assess the efficacy of the generated test data using the suggested technique. The Mujava tool was used to automatically introduce a set of faults (bugs) into the program’s source code. The provided test data were used to identify the injected faults. Mujava evaluates the mutation score of the test data. The ability of each test set to find the implanted bugs is represented by the mutation score.
Table 13 displays the mutation score (fault detection capabilities) of test data for each program. The findings validate the suggested method’s usefulness in generating bug detection data.
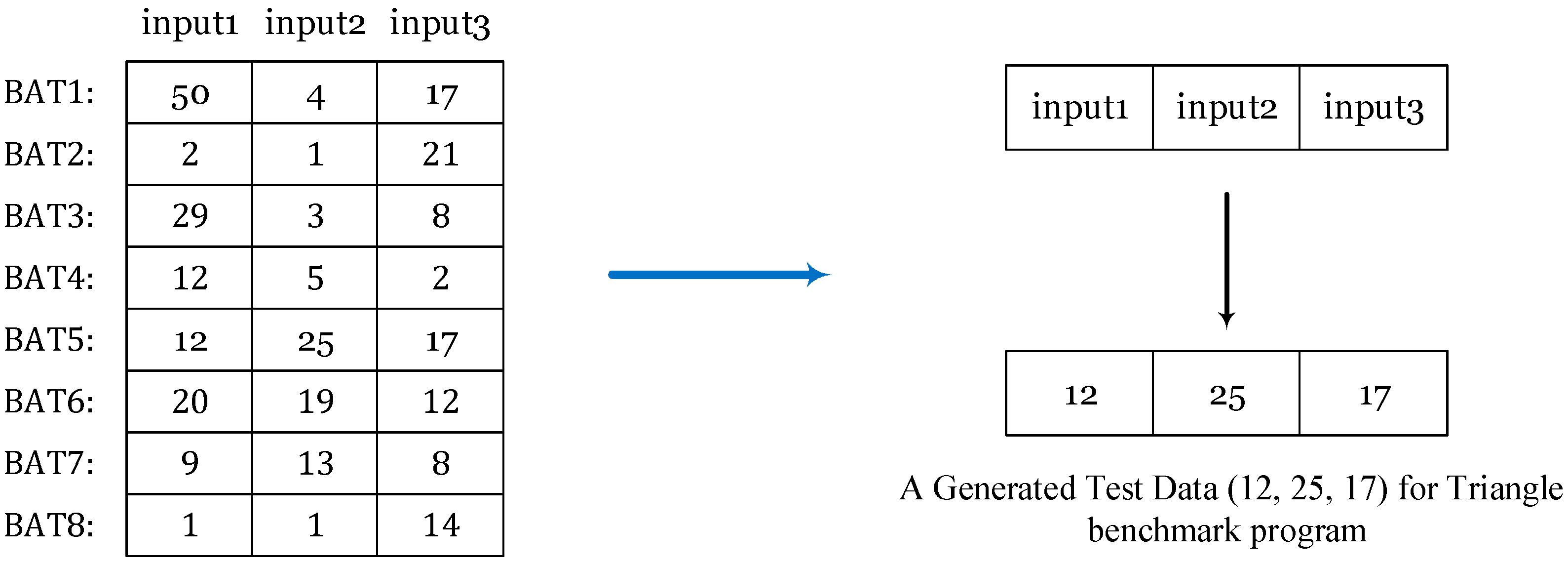
Table 14 shows the generated test data for the
triangletype program.


 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}