
Co-CrackSegment: A New Collaborative Deep Learning Framework for Pixel-Level Semantic Segmentation of Concrete Cracks

 ,
,  ,
,  ,
, 
Abstract
1. Introduction
2. Literature Review, Research Gaps, and Contributions
- Most available studies relied on individual model prediction to perform the crack semantic segmentation. Nevertheless, it is well-known that the individual model might suffer from low variance and low generalization ability in case of data alteration.
- To overcome the overfitting of crack image data, many studies focus on various hybridizations or modifications of existing models as well as transfer learning, which still do not incorporate the knowledge of multiple learning to perform the concrete semantic segmentation task.
- Crack semantic segmentation underlies several problems, particularly when dealing with complex and highly contaminated image backgrounds, blurring, shadows, etc. Therefore, it is necessary to improve the existing identification method and include novel techniques.
- The ensemble learning is a very effective method to improve the performance of individual learners through combining their knowledge using some well-established methods, such as weighted averaging, stacking, bagging, and boosting.
- For pixel-level semantic segmentation, especially in case of crack images, the abovementioned ensemble learning methods are less popular among researchers. This is mainly due to problems related to computational cost and difficulties in optimizing ensemble learning parameters.
- The traditional weighted average ensemble learning for pixel-level semantic segmentation might suffer from pixel blurring of the crack boundaries, resulting high bias of predicted crack map than the ground truth.
- It is well-known that pixel-level semantic segmentation is of high spatial correlation features which do not highly suit the independent sampling of supervised learning. Moreover, as most pixels belong to background and to crack area, class imbalance is inevitable in pixel-level crack detection. These two reasons make the use of traditional ensemble learning such as boosting and stacking difficult.
- Hence, it is of great significance to improve the existing ensemble learning methods for pixel-level semantic segmentation, especially when considering crack images that naturally include various background contaminations.
- By leveraging the ensemble deep learning philosophy, a novel collaborative semantic segmentation of concrete cracks method called Co-CrackSegment is proposed.
- Five models, namely the U-net, SegNet, DeepCrack19, and DeepLabV3 with ResNet50, and ResNet101 backbones are trained to serve as core models for the Co-CrackSegment.
- To build the collaborative model, a new iterative approach based on the best evaluation metrics, namely the Dice score, IoU, pixel accuracy, precision, and recall metrics is developed.
- Finally, detailed numerical and visual comparisons between the Co-CrackSegment and the core models as well as the weighted average ensemble learning model are presented.
3. Materials and Methods
3.1. Mathematical Background on Deep Learning-Based Semantic Segmentation
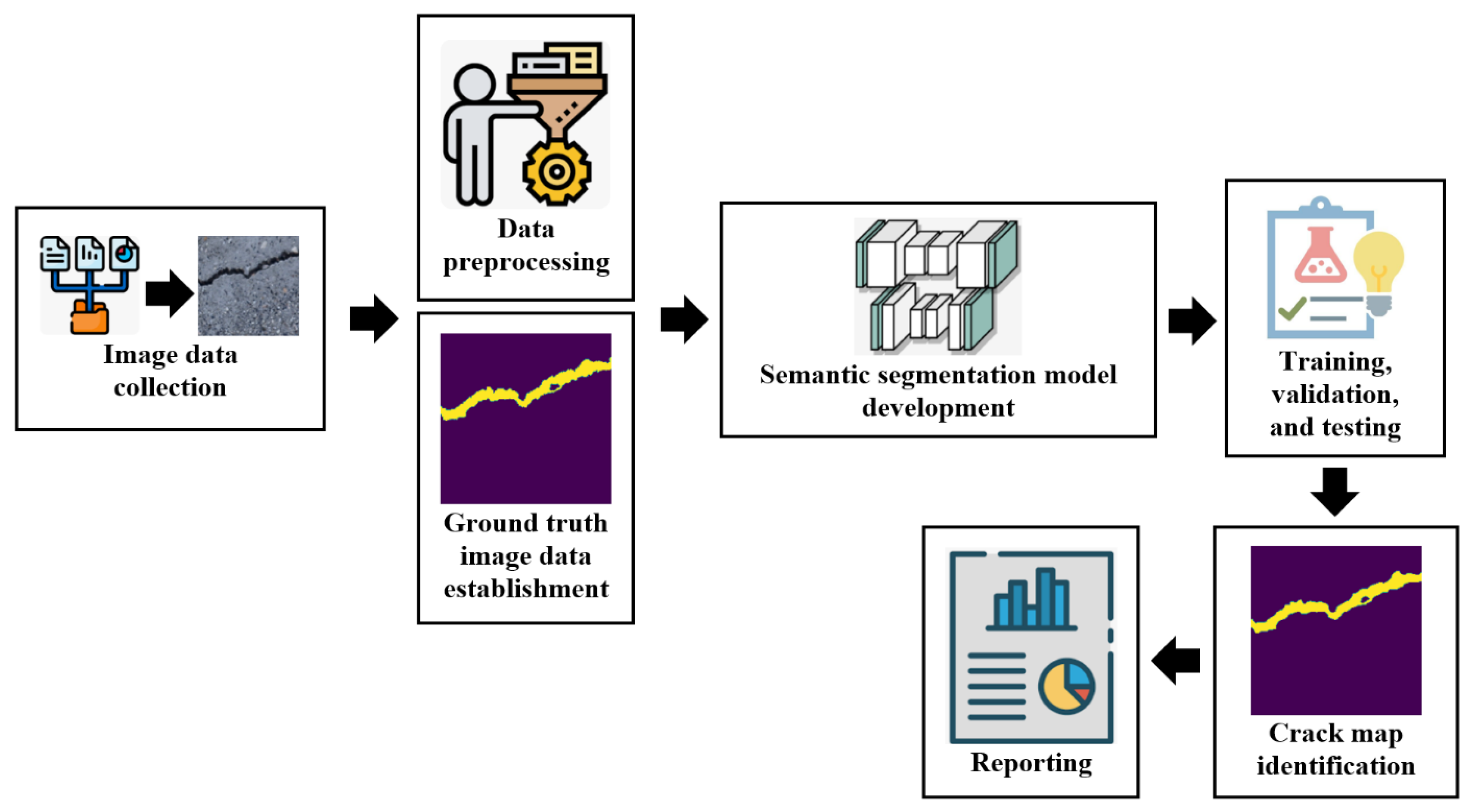
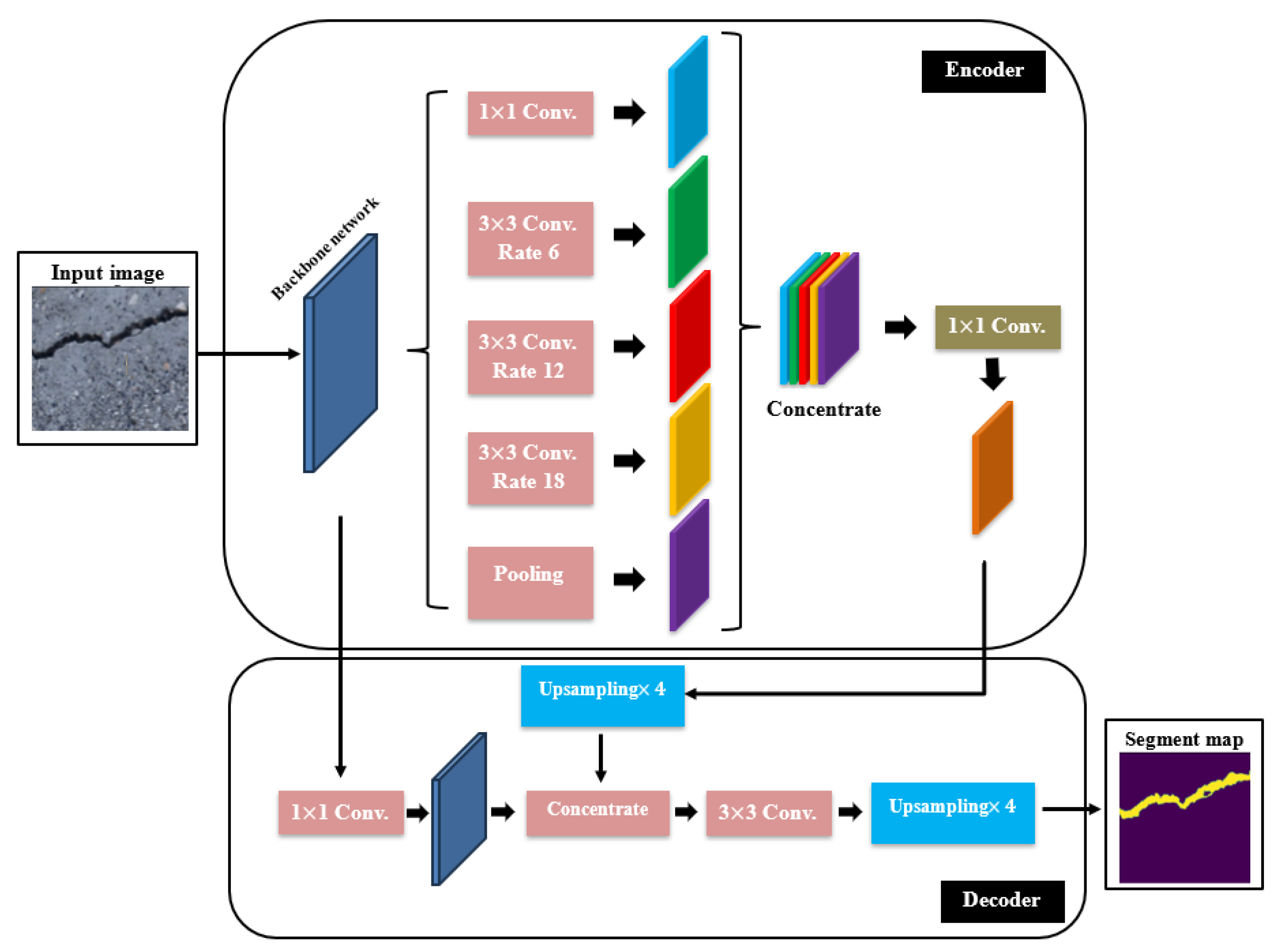
3.2. Crack Semantic Segmentation Framework
3.3. Datasets
3.4. The Core Models
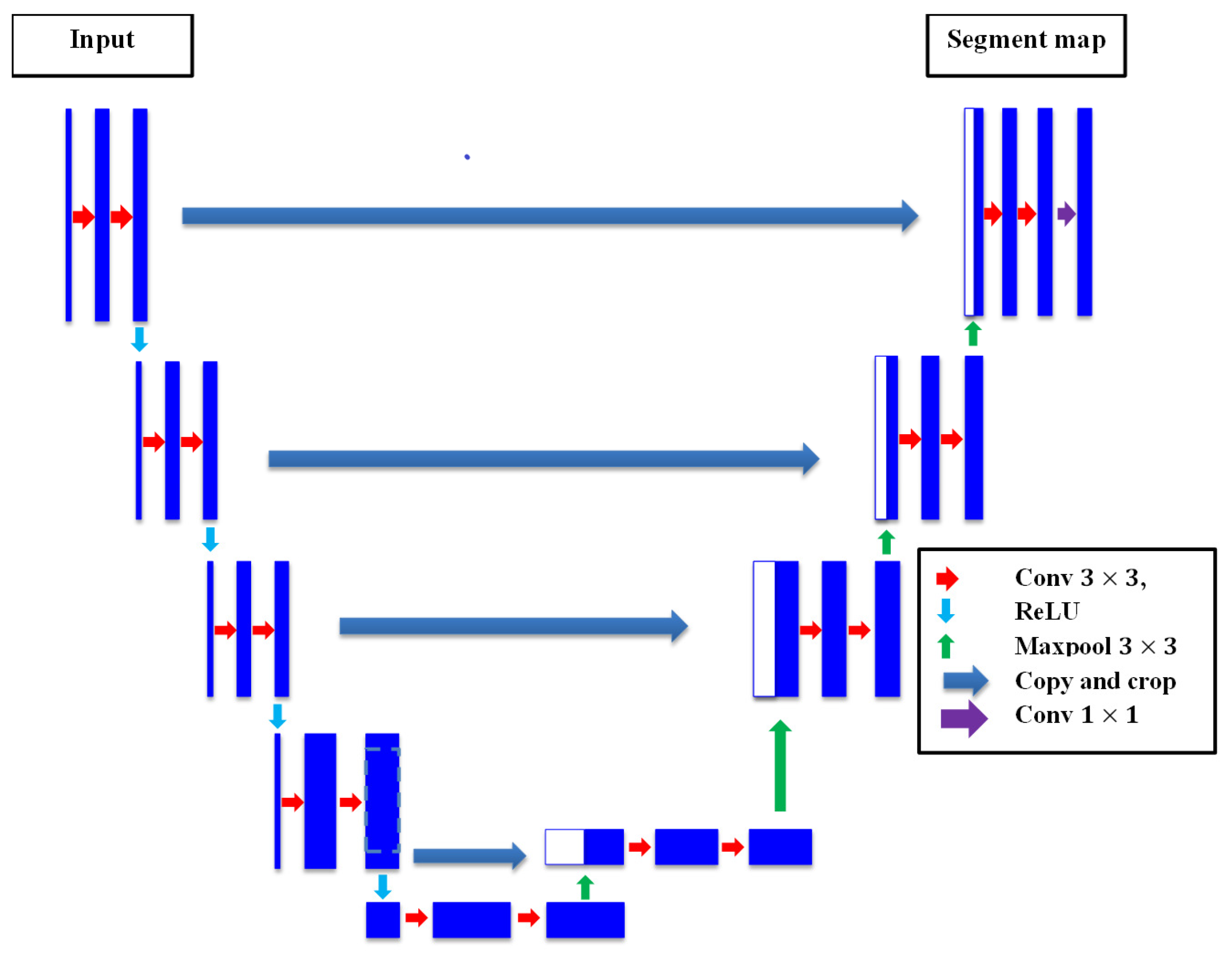
3.4.1. The U-Net
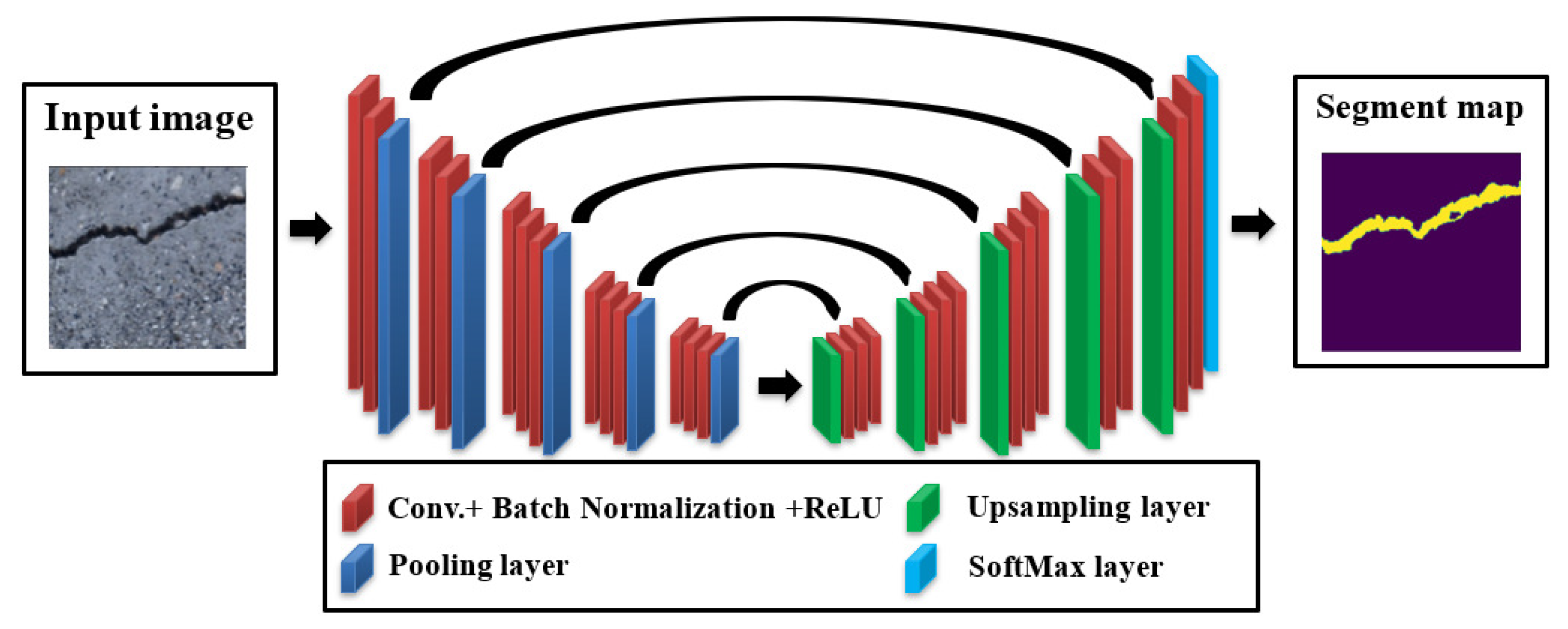
3.4.2. The SegNet
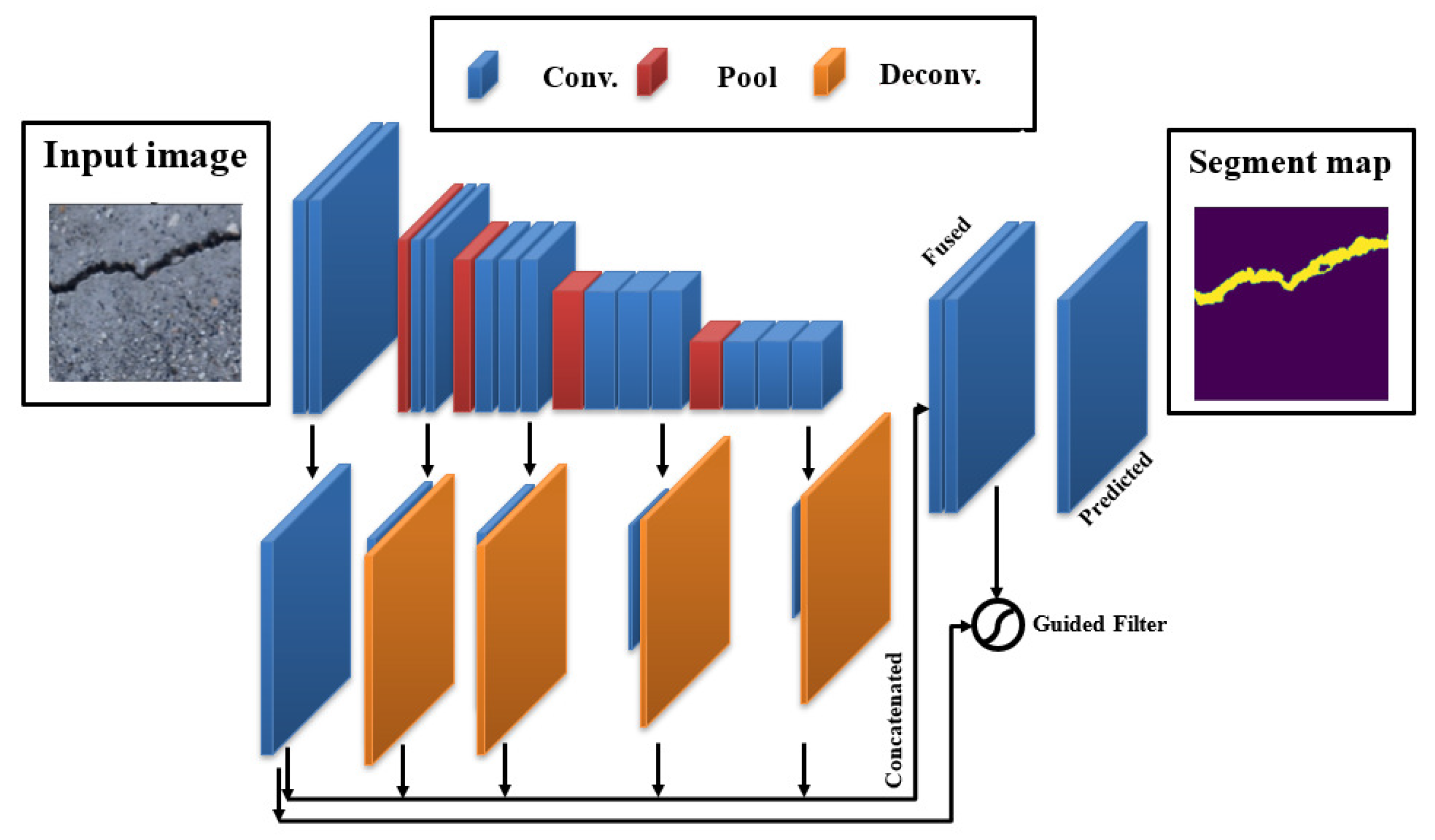
3.4.3. DeepCrack19
3.4.4. The DeepLabV3 with Backbones
3.5. Training Procedure
3.6. Evaluation Metrics
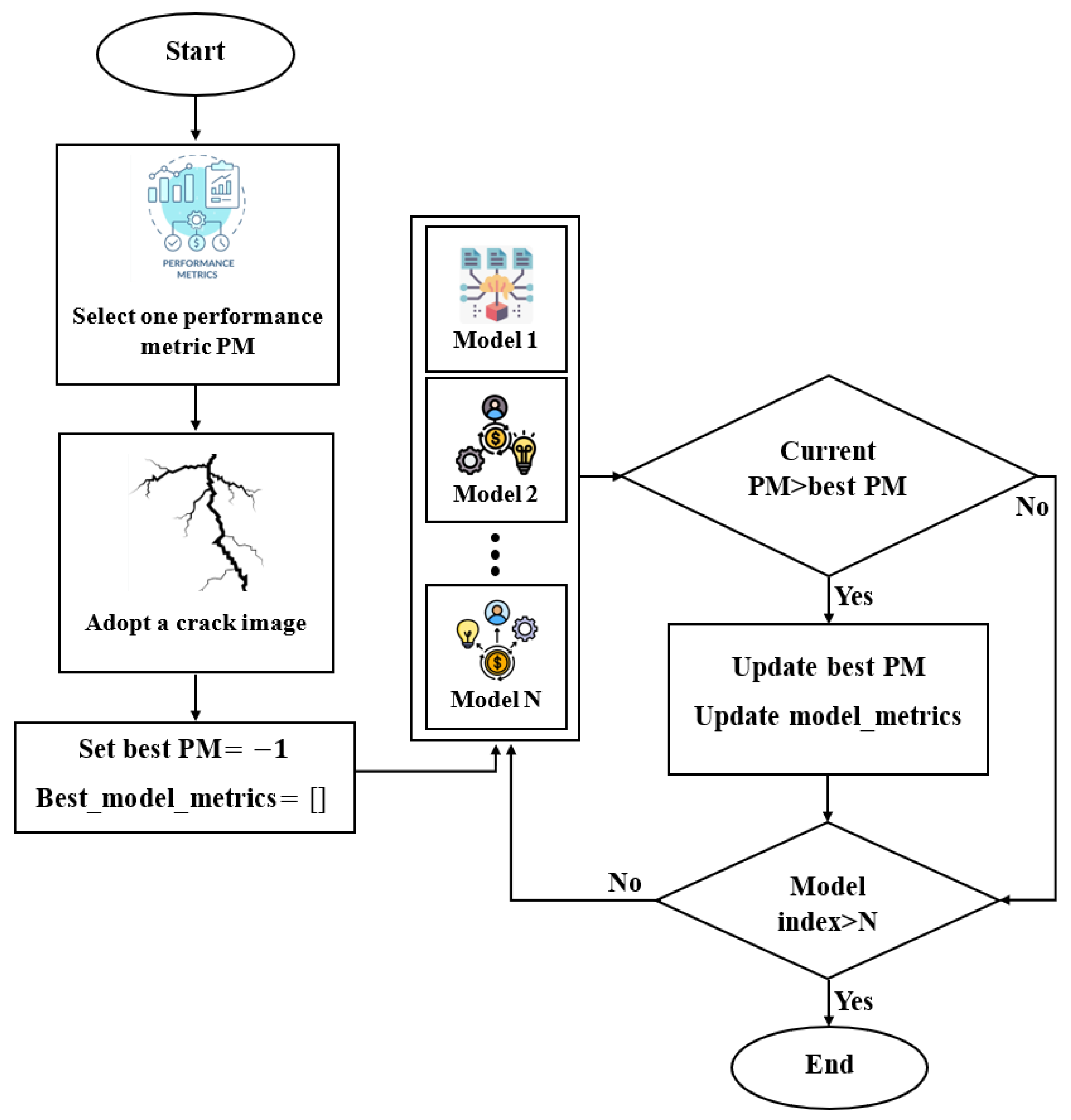
3.7. The Proposed Group Learning Method
- Load N trained semantic segmentation models in the model_list.
- Choose one Co-CrackSegment framework, namely Co-CrackSegment/Dice, Co-CrackSegment/IoU, Co-CrackSegment/Pixel_Acc, Co-CrackSegment/Precision, or Co-CrackSegment/Recall.
- Set best_evaluation_metric_score to −1, and best_model_metrics to an empty matrix.
- For each test image, conduct the following:
- (a)
- For each current_model in the model_list (N times)
- (b)
- Set the trainer.model to the current_model.
- (c)
- Evaluate current_model with test image and compute the segmentation prediction output.
- (d)
- Compute the overall evaluation metric scores including the current_evaluation_metric_score of the test image (current_model_metrics).
- (e)
- If (current_evaluation_metric_score >best_evaluation_metric_score)
- i.
- best_evaluation_metric_score = current_evaluation_metric_score
- ii.
- best_model_metrics= current_model_metrics
- iii.
- Add trainer.model to the evaluation results matrix.
- Show the results.
- Load N trained semantic segmentation models in the model_list.
- Set current_model to model1, and model_outputs to an empty matrix.
- For each test image do the following. For each current_model in the model_list do as follows:
- Compute the prediction of the current model.
- Multiply predictions by the weight of the model: weighted_predictions = predictions * weights[j].
- Add the weighted predictions to the list: model_outputs.append(weighted_predictions).
- Perform weighted average sum: ensemble_output = (sum(model_outputs) >= 0.5)
- Compute metrics for the ensemble output.
- Show the results.
4. Results and Discussion
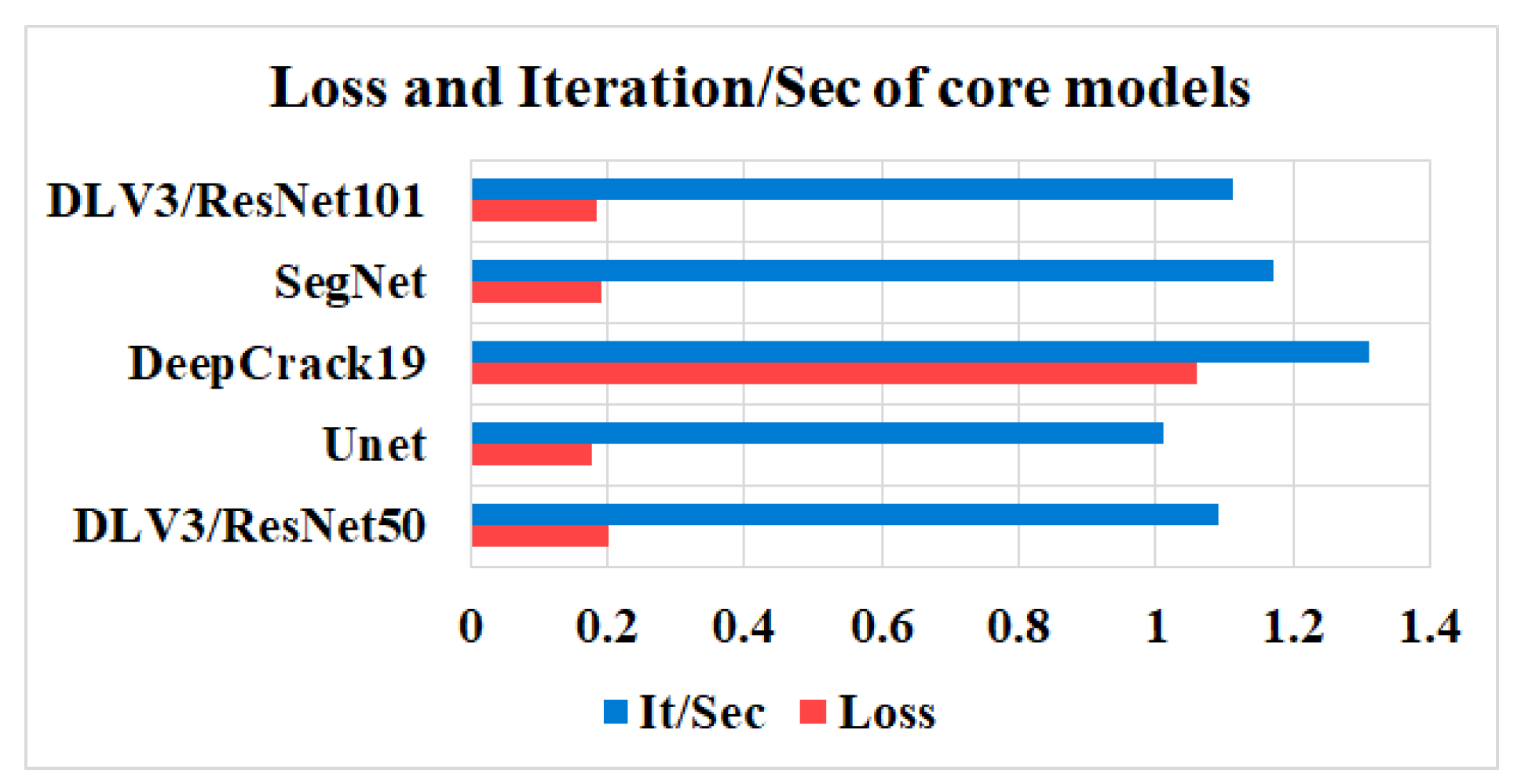
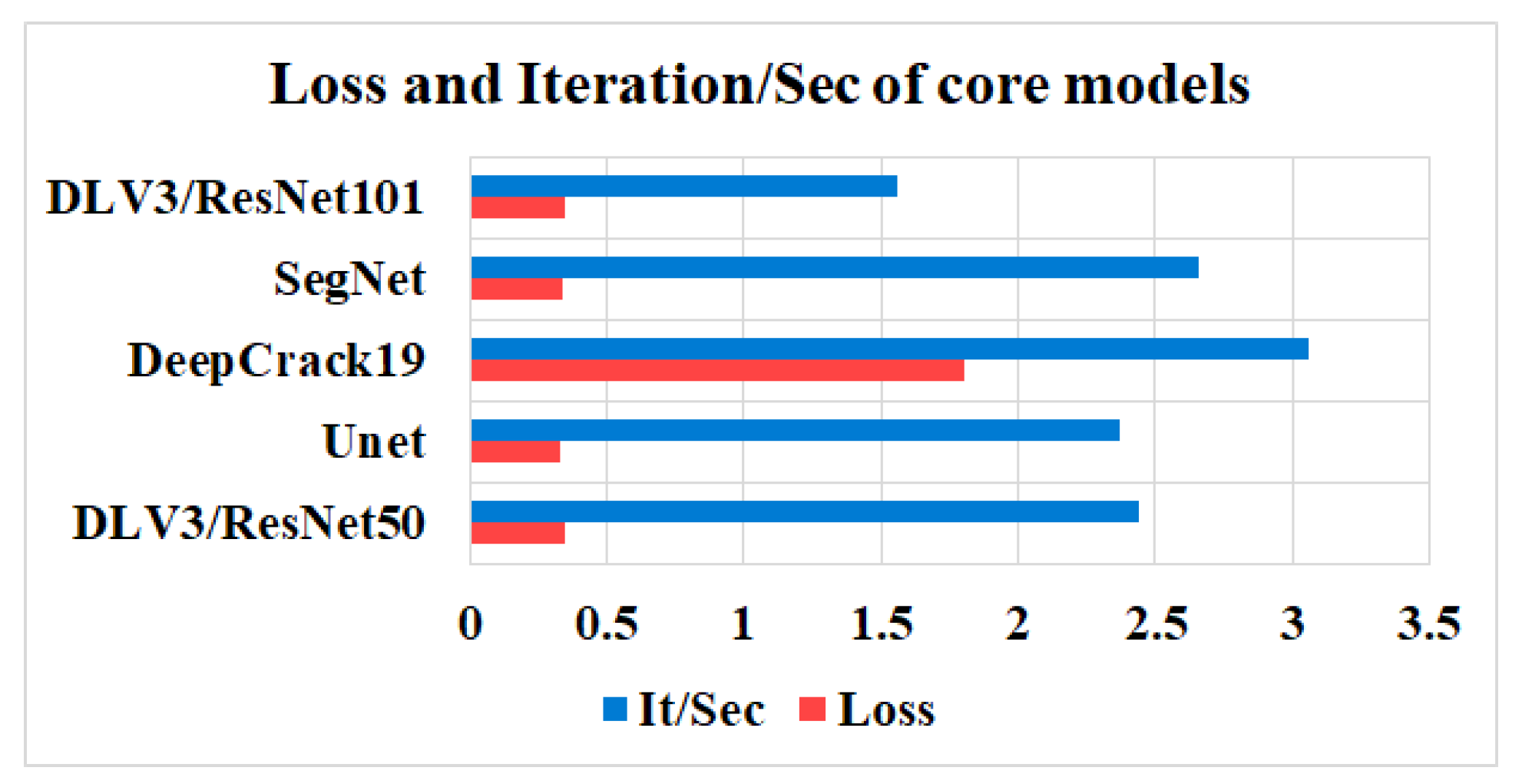
4.1. Performances of the Core Models
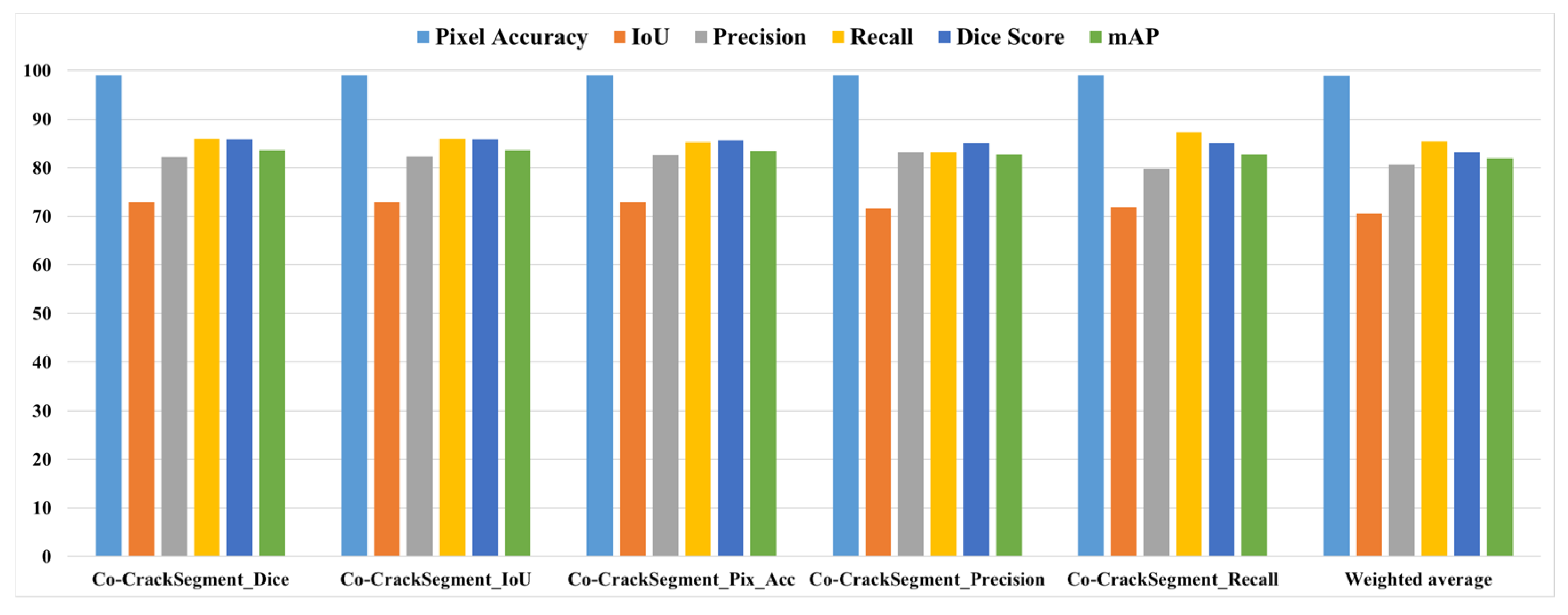
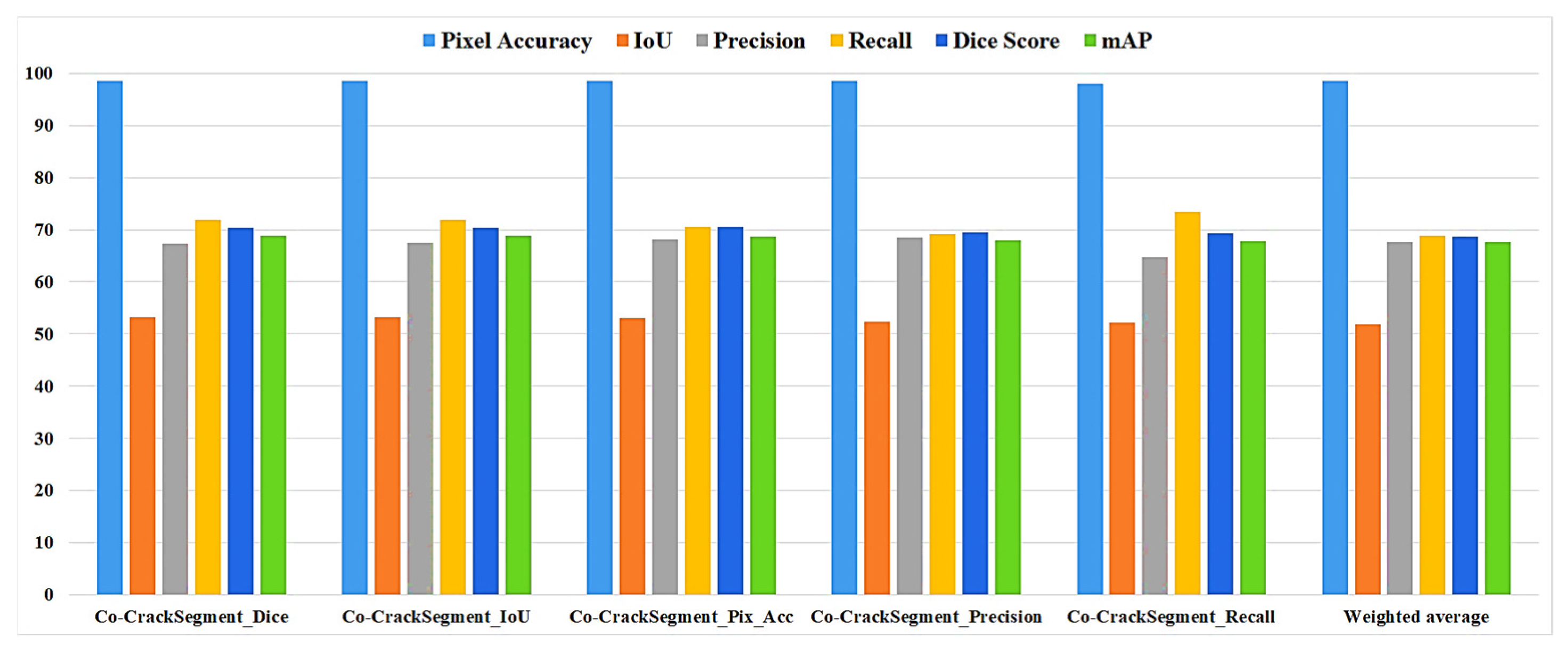
4.2. Performances of Co-CrackSegment
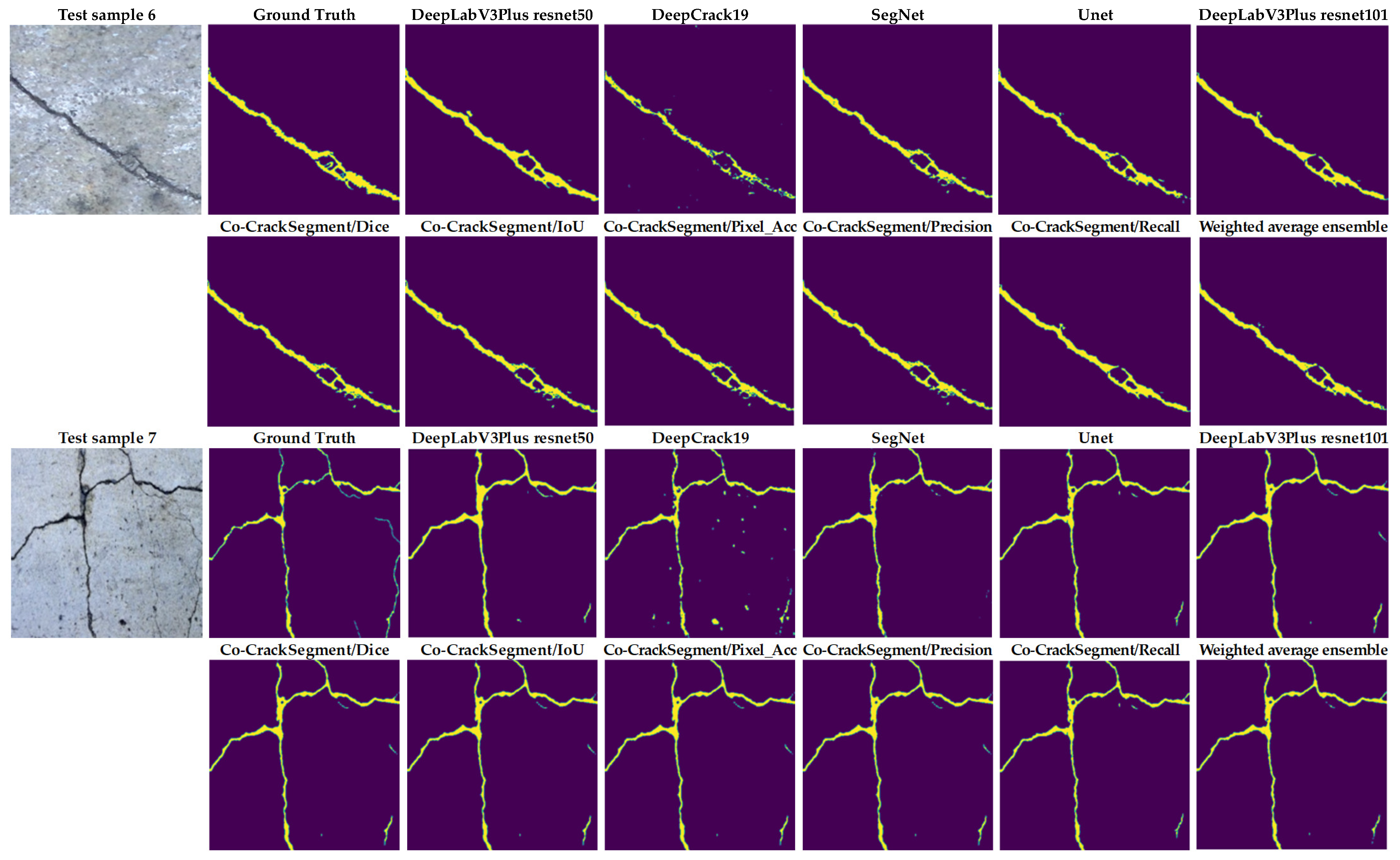
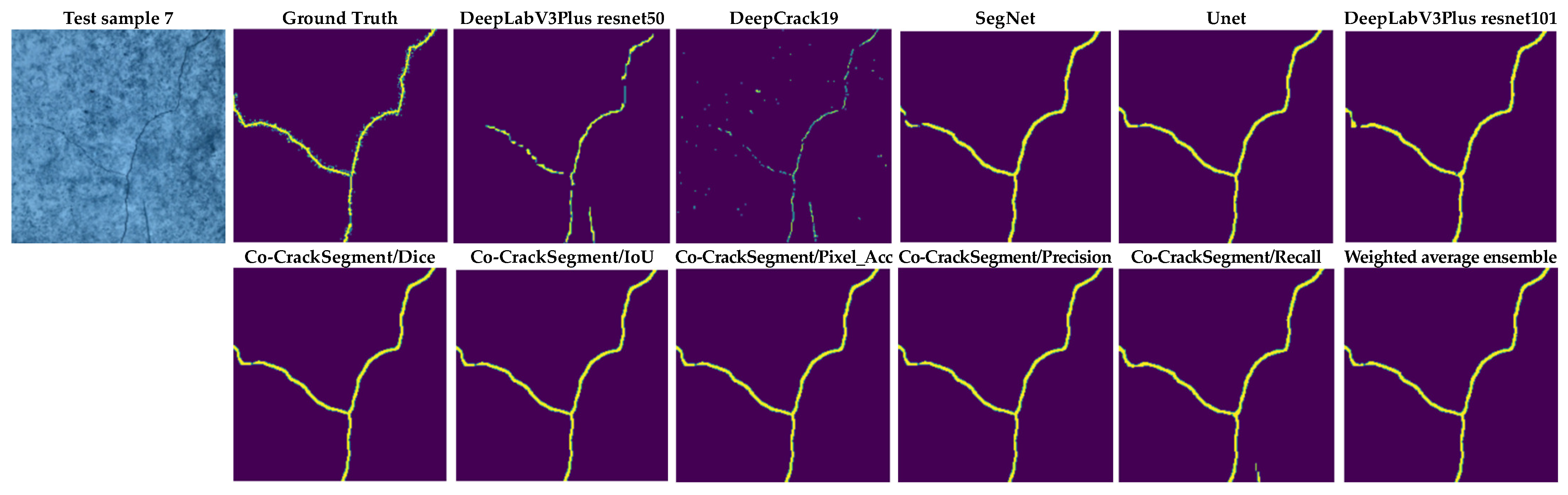
4.3. Visual Comparison and Discussion
4.4. Further Comparison and Discussion Using Image Processing and Modern Evaluation Metrics
- Mean squared error (MSE) [69] is a metric that is mainly utilized to compute the average squared difference between the original ground truth (OGT) and the semantic segmentation prediction (SSP) and is given as follows:
- Normalized cross-correlation (NCC) [70] is another metric of similarity between the OGT and SSP images. It calculates the similarity based on the displacement of one image relative to the other one. It can be formulated as in Equation (23) shows.
- Structural Similarity Index Measure (SSIM) [71,72] evaluates three main image characteristics: illumination, contrast, and structure. In terms of these three factors, SSIM calculates the similarity between SSP and OGT images in order to select the model with the highest SSIM score. SSIM is computed as follows:
- Peak signal to noise ratio (PSNR) [73] is another well-known metric to compute the similarity between the produced and the ground truth image. However, PSNR focuses only on the absolute error between corresponding pixels of the SSP and OGT images as illustrated in Equation (25).
- Hausdorff distance (HD) [74,75] originally computes the largest distance between two sets. For our mission, HD computed the similarity between different corresponding curves (edges) of the SSP and OGT images via calculating the maximum distance of a set of pixels in the first image to the nearest point (pixel) in the other image. It can be formulated as follows:
- Fréchet Distance (FD) is another similarity metric that focuses on curves similarity and takes into consideration the location and ordering of the curve’s points of both compared images.
5. Conclusions
- Under the theme of the core models, it has been reported that the U-net achieved a prominent performance by means of loss, pixel accuracy, IoU, Dice, and mAP when trained using dataset1. It was also observed that the DLV3/ResNet50 and DLV3/ResNet101 had achieved high performances when compromising the overall evaluation metrics. Moreover, the iteration per second score of the DeepCrack19 gave it competitive advantages as a computationally efficient model. Moreover, when trained using dataset2 and similar to dataset1, the U-net also achieved an outstanding performance by means of loss, accuracy, IoU, recall, Dice, and mAP. Also, the DeepCrack19 showed better computational performance than the other models when considering the number of iterations per seconds.
- When studying the proposed collaborative semantic segmentation Co-CrackSegment approach, the Co-CrackSegment/Dice and Co-CrackSegment/IoU showed the best trade-off evaluation scores compared with other Co-CrackSegment frameworks. Furthermore, when compared with the weighted average method, most Co-CrackSegment frameworks outperformed the weighted average ensemble as well as the core models by means of all evaluation metrics. This was because the traditional weighted average ensemble learning for pixel-level semantic segmentation suffered from pixel blurring of the crack boundaries due to average predictions resulting in high bias of the predicted crack map than the ground truth. Furthermore, when comparing the results of core models with the Co-CrackSegment frameworks, it was observed that the collaborative learning approach had boosted the performance of the individual models by means of all evaluation metrics. This proved the efficiency of the Co-CrackSegment approach for pixel-level semantic segmentation of surface cracks.
- When studying feeding the developed models with test samples that contained many challenges, such as crack-like scaling, foreign objects, thin cracks, bulges, voids, spalling, etc., it was reported that all the developed Co-CrackSegment approaches for pixel-level semantic segmentation of surface cracks gave very enhanced crack maps even in challenging cases. Also, the Co-CrackSegment/Dice and Co-CrackSegment/IoU frameworks achieved the best performance compared with other Co-CrackSegment frameworks and the weighted average method as well as the core models. This confirms the results presented in the previous discussion.
- It is well-known that when developing models for the pixel-level identification of concrete cracks, it is very important to realize that cracks occupy very small parts of the images, whereas the data are overwhelmed with background pixels. In other words, in an input image with a crack, the majority of pixels belong to the background class and minority of pixels belong to the crack class. Therefore, the crack image datasets are considered as highly imbalanced when conducting pixel-level classification. Hence, even minor improvements in evaluation metrics have a significant impact on effective localization of cracks within the background. In addition, the performance metrics such as pixel accuracy, precision, recall, and IoU are sensitive to such imbalanced data, and any enhancement in those metrics of the minority class of crack pixels is considered a boost to prediction performance. The use of the ensemble model, which combines the predictions of several models, helps to tackle the pixel classes’ imbalance and enhance the segmentation accuracy. To add, in practical scenarios, even a very narrow crack can be a considered as a warning sign for greater structural damage. Hence, even a slight improvement in segmentation accuracy might be very useful for early damage detection to prevent later catastrophic events.
- The practical limitations of this study can be summarized as the computational complexity, data annotation, core model selection, generalization ability, etc. When considering the ensemble learning for the pixel-level crack identification, the training of multiple models requires more computational efforts; however, the boosted prediction accuracy of the ensemble learning can offer a sort of tolerant towards computational time. Moreover, when preparing the data for training, more efforts are required to prepare ground truth feature maps, which are required in both individual model- or ensemble learning-based semantic segmentation. Furthermore, the availability of many semantic segmentation models in the literature makes the selection of best suited core models more challenging. However, the developed method solves this problem by providing the possibility of any semantic segmentation models, even if trained using other datasets. In addition, even if the ensemble learning-based semantic segmentation models aim to improve the generalization of the prediction via leveraging several core models, any bias in core models can be forwarded to the ensemble model degrading prediction accuracy. Nevertheless, the proposed Co-CrackSegment model chooses the best prediction of the core models, rather than accumulating or averaging their prediction like the traditional average weighting ensemble.
- Finally, several future improvements can be made to improve the proposed method. Firstly, the Co-CrackSegment approach can accept the insertion of any semantic segmentation model. This is mainly due to its flexibility to add core models to its main framework. Moreover, the Co-CrackSegment method can be boosted via improving the utilized performance metrics to make a better trade-off between the original performance metrics that have already been used in its framework. Furthermore, the proposed Co-CrackSegment method can be further improved for multilevel semantic segmentation of structural surface defects. Lastly, the Co-CrackSegment can be easily adapted to be used in other semantic segmentation applications.
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Alkayem, N.F.; Cao, M.; Zhang, Y.; Bayat, M.; Su, Z. Structural damage detection using finite element model updating with evolutionary algorithms: A survey. Neural Comput. Appl. 2018, 30, 389–411. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, S.D.; Tran, T.S.; Tran, V.P.; Lee, H.J.; Piran, M.J.; Le, V.P. Deep Learning-Based Crack Detection: A Survey. Int. J. Pavement Res. Technol. 2023, 16, 943–967. [Google Scholar] [CrossRef]
- Bhatt, P.M.; Malhan, R.K.; Rajendran, P.; Shah, B.C.; Thakar, S.; Yoon, Y.J.; Gupta, S.K. Image-Based Surface Defect Detection Using Deep Learning: A Review. J. Comput. Inf. Sci. Eng. 2021, 21, 040801. [Google Scholar] [CrossRef]
- Tapeh, A.T.G.; Naser, M.Z. Artificial Intelligence, Machine Learning, and Deep Learning in Structural Engineering: A Scientometrics Review of Trends and Best Practices. Arch. Comput. Methods Eng. 2022, 30, 115–159. [Google Scholar] [CrossRef]
- Thai, H.-T. Machine learning for structural engineering: A state-of-the-art review. Structures 2022, 38, 448–491. [Google Scholar] [CrossRef]
- Cao, M.; Alkayem, N.F.; Pan, L.; Novák, D. Advanced methods in neural networks-based sensitivity analysis with their applications in civil engineering. In Artificial Neural Networks: Models and Applications; IntechOpen: Rijeka, Croatia, 2016. [Google Scholar]
- Nguyen, D.H.; Wahab, M.A. Damage detection in slab structures based on two-dimensional curvature mode shape method and Faster R-CNN. Adv. Eng. Softw. 2023, 176, 103371. [Google Scholar] [CrossRef]
- Yu, L.; He, S.; Liu, X.; Jiang, S.; Xiang, S. Intelligent Crack Detection and Quantification in the Concrete Bridge: A Deep Learning-Assisted Image Processing Approach. Adv. Civ. Eng. 2022, 2022, 1813821. [Google Scholar] [CrossRef]
- Kaewniam, P.; Cao, M.; Alkayem, N.F.; Li, D.; Manoach, E. Recent advances in damage detection of wind turbine blades: A state-of-the-art review. Renew. Sustain. Energy Rev. 2022, 167, 112723. [Google Scholar] [CrossRef]
- Wang, S.-J.; Zhang, J.-K.; Lu, X.-Q. Research on Real-Time Detection Algorithm for Pavement Cracks Based on SparseInst-CDSM. Mathematics 2023, 11, 3277. [Google Scholar] [CrossRef]
- Yu, G.; Zhou, X. An Improved YOLOv5 Crack Detection Method Combined with a Bottleneck Transformer. Mathematics 2023, 11, 2377. [Google Scholar] [CrossRef]
- Tran, T.S.; Nguyen, S.D.; Lee, H.J.; Tran, V.P. Advanced crack detection and segmentation on bridge decks using deep learning. Constr. Build. Mater. 2023, 400, 132839. [Google Scholar] [CrossRef]
- Zhang, J.; Cai, Y.-Y.; Yang, D.; Yuan, Y.; He, W.-Y.; Wang, Y.-J. MobileNetV3-BLS: A broad learning approach for automatic concrete surface crack detection. Constr. Build. Mater. 2023, 392, 131941. [Google Scholar] [CrossRef]
- Alkayem, N.F.; Shen, L.; Mayya, A.; Asteris, P.G.; Fu, R.; Di Luzio, G.; Strauss, A.; Cao, M. Prediction of concrete and FRC properties at high temperature using machine and deep learning: A review of recent advances and future perspectives. J. Build. Eng. 2024, 83, 108369. [Google Scholar] [CrossRef]
- Fu, R.; Cao, M.; Novák, D.; Qian, X.; Alkayem, N.F. Extended efficient convolutional neural network for concrete crack detection with illustrated merits. Autom. Constr. 2023, 156, 105098. [Google Scholar] [CrossRef]
- Xiong, C.; Zayed, T.; Abdelkader, E.M. A novel YOLOv8-GAM-Wise-IoU model for automated detection of bridge surface cracks. Constr. Build. Mater. 2024, 414, 135025. [Google Scholar] [CrossRef]
- Alkayem, N.F.; Cao, M.; Ragulskis, M. Damage Diagnosis in 3D Structures Using a Novel Hybrid Multiobjective Optimization and FE Model Updating Framework. Complexity 2018, 2018, 3541676. [Google Scholar] [CrossRef]
- Cao, M.; Qiao, P.; Ren, Q. Improved hybrid wavelet neural network methodology for time-varying behavior prediction of engineering structures. Neural Comput. Appl. 2009, 18, 821–832. [Google Scholar] [CrossRef]
- Alkayem, N.F.; Cao, M. Damage identification in three-dimensional structures using single-objective evolutionary algorithms and finite element model updating: Evaluation and comparison. Eng. Optim. 2018, 50, 1695–1714. [Google Scholar] [CrossRef]
- Arafin, P.; Billah, A.M.; Issa, A. Deep learning-based concrete defects classification and detection using semantic segmentation. Struct. Health Monit. 2023, 23, 383–409. [Google Scholar] [CrossRef]
- Hang, J.; Wu, Y.; Li, Y.; Lai, T.; Zhang, J.; Li, Y. A deep learning semantic segmentation network with attention mechanism for concrete crack detection. Struct. Health Monit. 2023, 22, 3006–3026. [Google Scholar] [CrossRef]
- Tabernik, D.; Šuc, M.; Skočaj, D. Automated detection and segmentation of cracks in concrete surfaces using joined segmentation and classification deep neural network. Constr. Build. Mater. 2023, 408, 133582. [Google Scholar] [CrossRef]
- Shang, J.; Xu, J.; Zhang, A.A.; Liu, Y.; Wang, K.C.; Ren, D.; Zhang, H.; Dong, Z.; He, A. Automatic Pixel-level pavement sealed crack detection using Multi-fusion U-Net network. Measurement 2023, 208, 112475. [Google Scholar] [CrossRef]
- Chen, B.; Zhang, H.; Wang, G.; Huo, J.; Li, Y.; Li, L. Automatic concrete infrastructure crack semantic segmentation using deep learning. Autom. Constr. 2023, 152, 104950. [Google Scholar] [CrossRef]
- Dang, L.M.; Wang, H.; Li, Y.; Nguyen, L.Q.; Nguyen, T.N.; Song, H.-K.; Moon, H. Lightweight pixel-level semantic segmentation and analysis for sewer defects using deep learning. Constr. Build. Mater. 2023, 371, 130792. [Google Scholar] [CrossRef]
- Joshi, D.; Singh, T.P.; Sharma, G. Automatic surface crack detection using segmentation-based deep-learning approach. Eng. Fract. Mech. 2022, 268, 108467. [Google Scholar] [CrossRef]
- Mishra, M.; Jain, V.; Singh, S.K.; Maity, D. Two-stage method based on the you only look once framework and image segmentation for crack detection in concrete structures. Arch. Struct. Constr. 2022, 3, 429–446. [Google Scholar] [CrossRef]
- Shi, P.; Shao, S.; Fan, X.; Zhou, Z.; Xin, Y. MCL-CrackNet: A Concrete Crack Segmentation Network Using Multilevel Contrastive Learning. IEEE Trans. Instrum. Meas. 2023, 72, 5030415. [Google Scholar] [CrossRef]
- Savino, P.; Tondolo, F. Civil infrastructure defect assessment using pixel-wise segmentation based on deep learning. J. Civ. Struct. Health Monit. 2022, 13, 35–48. [Google Scholar] [CrossRef]
- Hadinata, P.N.; Simanta, D.; Eddy, L.; Nagai, K. Multiclass Segmentation of Concrete Surface Damages Using U-Net and DeepLabV3+. Appl. Sci. 2023, 13, 2398. [Google Scholar] [CrossRef]
- Al-Huda, Z.; Peng, B.; Algburi, R.N.A.; Al-Antari, M.A.; Al-Jarazi, R.; Zhai, D. A hybrid deep learning pavement crack semantic segmentation. Eng. Appl. Artif. Intell. 2023, 122, 106142. [Google Scholar] [CrossRef]
- Ali, R.; Chuah, J.H.; Abu Talip, M.S.; Mokhtar, N.; Shoaib, M.A. Automatic pixel-level crack segmentation in images using fully convolutional neural network based on residual blocks and pixel local weights. Eng. Appl. Artif. Intell. 2021, 104, 104391. [Google Scholar] [CrossRef]
- Kang, D.; Benipal, S.S.; Gopal, D.L.; Cha, Y.-J. Hybrid pixel-level concrete crack segmentation and quantification across complex backgrounds using deep learning. Autom. Constr. 2020, 118, 103291. [Google Scholar] [CrossRef]
- Sha, C.; Yue, C.; Wang, W. Ensemble 1D DenseNet Damage Identification Method Based on Vibration Acceleration. Struct. Durab. Health Monit. 2023, 17, 369–381. [Google Scholar] [CrossRef]
- Kailkhura, V.; Aravindh, S.; Jha, S.S.; Jayanth, N. Ensemble learning-based approach for crack detection using CNN. In Proceedings of the Fourth International Conference on Trends in Electronics and Informatics (ICOEI 2020), Tirunelveli, India, 15–17 June 2020. [Google Scholar]
- Liao, Y.; Huang, C.; Yin, Y. Segmentation of Apparent Multi-Defect Images of Concrete Bridges Based on PID Encoder and Multi-Feature Fusion. Buildings 2024, 14, 1463. [Google Scholar] [CrossRef]
- Hong, Y.; Yoo, S.B. OASIS-Net: Morphological Attention Ensemble Learning for Surface Defect Detection. Mathematics 2022, 10, 4114. [Google Scholar] [CrossRef]
- Barkhordari, M.S.; Armaghani, D.J.; Asteris, P.G. Structural Damage Identification Using Ensemble Deep Convolutional Neural Network Models. Comput. Model. Eng. Sci. 2023, 134, 835–855. [Google Scholar] [CrossRef]
- Maarouf, A.A.; Hachouf, F. Transfer Learning-based Ensemble Deep Learning for Road Cracks Detection. In Proceedings of the International Conference on Advanced Aspects of Software Engineering (ICAASE), Constantine, Algeria, 17–18 September 2022. [Google Scholar]
- Bousselham, W.; Thibault, G.; Pagano, L.; Machireddy, A. Efficient Self-Ensemble for Semantic Segmentation. arXiv 2022, arXiv:cs.CV/2111.13280. [Google Scholar]
- Nigam, I.; Huang, C.; Ramanan, D. Ensemble Knowledge Transfer for Semantic Segmentation. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Lake Tahoe, NV, USA, 12–15 March 2018. [Google Scholar]
- Zhang, L.; Slade, S.; Lim, C.P.; Asadi, H.; Nahavandi, S.; Huang, H.; Ruan, H. Semantic segmentation using Firefly Algorithm-based evolving ensemble deep neural networks. Knowl.-Based Syst. 2023, 277, 110828. [Google Scholar] [CrossRef]
- Lee, C.; Yoo, S.; Kim, S.; Lee, J. Progressive Weighted Self-Training Ensemble for Multi-Type Skin Lesion Semantic Segmentation. IEEE Access 2022, 10, 132376–132383. [Google Scholar] [CrossRef]
- Lee, T.; Kim, J.-H.; Lee, S.-J.; Ryu, S.-K.; Joo, B.-C. Improvement of Concrete Crack Segmentation Performance Using Stacking Ensemble Learning. Appl. Sci. 2023, 13, 2367. [Google Scholar] [CrossRef]
- Li, S.; Zhao, X. A Performance Improvement Strategy for Concrete Damage Detection Using Stacking Ensemble Learning of Multiple Semantic Segmentation Networks. Sensors 2022, 22, 3341. [Google Scholar] [CrossRef] [PubMed]
- Amieghemen, G.E.; Sherif, M.M. Deep convolutional neural network ensemble for pavement crack detection using high elevation UAV images. Struct. Infrastruct. Eng. 2023, 1–16. [Google Scholar] [CrossRef]
- Cyganov, G.; Rychenkov, A.; Sinitca, A.; Kaplun, D. Using the fuzzy integrals for the ensemble-based segmentation of asphalt cracks. Ind. Artif. Intell. 2023, 1, 5. [Google Scholar] [CrossRef]
- Chen, Y.; Mo, Y.; Readie, A.; Ligozio, G.; Mandal, I.; Jabbar, F.; Coroller, T.; Papież, B.W. VertXNet: An ensemble method for vertebral body segmentation and identification from cervical and lumbar spinal X-rays. Sci. Rep. 2024, 14, 3341. [Google Scholar] [CrossRef] [PubMed]
- Bao, R.; Palaniappan, K.; Zhao, Y.; Seetharaman, G. GLSNet++: Global and Local-Stream Feature Fusion for LiDAR Point Cloud Semantic Segmentation Using GNN Demixing Block. IEEE Sensors J. 2024, 24, 11610–11624. [Google Scholar] [CrossRef]
- Dais, D.; Bal, I.E.; Smyrou, E.; Sarhosis, V. Automatic crack classification and segmentation on masonry surfaces using convolutional neural networks and transfer learning. Autom. Constr. 2021, 125, 103606. [Google Scholar] [CrossRef]
- Vij, R.; Arora, S. A hybrid evolutionary weighted ensemble of deep transfer learning models for retinal vessel segmentation and diabetic retinopathy detection. Comput. Electr. Eng. 2024, 115, 109107. [Google Scholar] [CrossRef]
- Fan, Z.; Li, C.; Chen, Y.; Mascio, P.D.; Chen, X.; Zhu, G.; Loprencipe, G. Ensemble of Deep Convolutional Neural Networks for Automatic Pavement Crack Detection and Measurement. Coatings 2020, 10, 152. [Google Scholar] [CrossRef]
- Devan, K.S.; Kestler, H.A.; Read, C.; Walther, P. Weighted average ensemble-based semantic segmentation in biological electron microscopy images. Histochem. 2022, 158, 447–462. [Google Scholar] [CrossRef]
- Panella, F.; Lipani, A.; Boehm, J. Semantic segmentation of cracks: Data challenges and architecture. Autom. Constr. 2022, 135, 104110. [Google Scholar] [CrossRef]
- Munawar, H.S.; Hammad, A.W.A.; Haddad, A.; Soares, C.A.P.; Waller, S.T. Image-Based Crack Detection Methods: A Review. Infrastructures 2021, 6, 115. [Google Scholar] [CrossRef]
- Zhang, L.; Li, H.; Shen, P.; Zhu, G.; Song, J.; Shah, S.A.A.; Bennamoun, M.; Zhang, L. Improving Semantic Image Segmentation With a Probabilistic Superpixel-Based Dense Conditional Random Field. IEEE Access 2018, 6, 15297–15310. [Google Scholar] [CrossRef]
- Jadon, S. A survey of loss functions for semantic segmentation. In Proceedings of the 2020 IEEE Conference on Computational Intelligence in Bioinformatics and Computational Biology (CIBCB), Viña del Mar, Chile, 27–29 October 2020; pp. 1–7. [Google Scholar]
- Milletari, F.; Navab, N.; Ahmadi, S.-A. V-net: Fully convolutional neural networks for volumetric medical image segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 565–571. [Google Scholar]
- Bengio, Y.; Goodfellow, I.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2017; Volume 1. [Google Scholar]
- Gu, J.; Wang, Z.; Kuen, J.; Ma, L.; Shahroudy, A.; Shuai, B.; Liu, T.; Wang, X.; Wang, G.; Cai, J.; et al. Recent advances in convolutional neural networks. Pattern Recognit. 2018, 77, 354–377. [Google Scholar] [CrossRef]
- Zhu, H.; Miao, Y.; Zhang, X. Semantic Image Segmentation with Improved Position Attention and Feature Fusion. Neural Process. Lett. 2020, 52, 329–351. [Google Scholar] [CrossRef]
- Andriyanov, N. Using ArcFace Loss Function and Softmax with Temperature Activation Function for Improvement in X-ray Baggage Image Classification Quality. Mathematics 2024, 12, 2547. [Google Scholar] [CrossRef]
- Liu, Y.; Yao, J.; Lu, X.; Xie, R.; Li, L. DeepCrack: A deep hierarchical feature learning architecture for crack segmentation. Neurocomputing 2019, 338, 139–153. [Google Scholar] [CrossRef]
- Kulkarni, S.; Singh, S.; Balakrishnan, D.; Sharma, S.; Devunuri, S.; Korlapati, S.C.R. CrackSeg9k: A Collection and Benchmark for Crack Segmentation Datasets and Frameworks. In Computer Vision—ECCV 2022 Workshops; Karlinsky, L., Michaeli, T., Nishino, K., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2022; Volume 13807. [Google Scholar]
- Pak, M.; Kim, S. Crack Detection Using Fully Convolutional Network in Wall-Climbing Robot. In Advances in Computer Science and Ubiquitous Computing; Park, J.J., Fong, S.J., Pan, Y., Sung, Y., Eds.; Lecture Notes in Electrical Engineering; Springer: Singapore, 2021; Volume 715. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015; Navab, N., Hornegger, J., Wells, W., Frangi, A., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2015; Volume 9351. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Wang, Z.; Bovik, A.C. Mean squared error: Love it or leave it? A new look at Signal Fidelity Measures. IEEE Signal Process. Mag. 2009, 26, 98–117. [Google Scholar] [CrossRef]
- Almira, J.M.; Phelippeau, H.; Martinez-Sanchez, A. Fast normalized cross-correlation for template matching with rotations. J. Appl. Math. Comput. 2024, 1–33. [Google Scholar] [CrossRef]
- Setiadi, D.R.I.M. PSNR vs SSIM: Imperceptibility quality assessment for image steganography. Multimedia Tools Appl. 2020, 80, 8423–8444. [Google Scholar] [CrossRef]
- Ding, K.; Ma, K.; Wang, S.; Simoncelli, E.P. Image Quality Assessment: Unifying Structure and Texture Similarity. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 2567–2581. [Google Scholar] [CrossRef]
- Horé, A.; Ziou, D. Image Quality Metrics: PSNR vs. SSIM. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 2366–2369. [Google Scholar] [CrossRef]
- Chen, G.; Lan, H.; Yan, Y.; Peng, Y. Similarity evaluation method of single flow point energy consumption mapping based on Fréchet distance. Meas. Sci. Technol. 2023, 34, 125011. [Google Scholar] [CrossRef]
- Kwon, Y.; Moon, J.; Chung, Y. Noise-Tolerant Trajectory Distance Computation in the Presence of Inherent Noise for Video Surveillance Applications. IEEE Access 2024, 12, 92400–92418. [Google Scholar] [CrossRef]
- Buchin, K.; Löffler, M.; Ophelders, T.; Popov, A.; Urhausen, J.; Verbeek, K. Computing the Fréchet distance between uncertain curves in one dimension. Comput. Geom. 2023, 109, 101923. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Epochs | 40 |
| Loss function | Dice loss |
| Batch_size | 8 |
| Initial Learning rate | 1 × 10−3 |
| Weight_decay | 5 × 10−5 |
| Classification layer activation function | Sigmoid |
| Input image dimensions | 448 × 448 × 3 |
| Data augmentation operations | Normalization Random rotation Horizontal flip Vertical flip Random color jittering |
| Optimizer | Adam |
| Model | Loss | Pixel ACC% | IoU% | Precision% | Recall% | Dice% | mAP% | It/Sec |
|---|---|---|---|---|---|---|---|---|
| DLV3/ResNet50 | 0.201 | 98.72 | 68.41 | 73.85 | 90.92 | 80 | 84.87 | 1.09 |
| Unet | 0.178 | 98.89 | 71.15 | 81.1 | 85.58 | 82.2 | 84.9 | 1.01 |
| DeepCrack19 | 1.06 | 98.88 | 70.1 | 81.31 | 83.79 | 81.6 | 84.79 | 1.31 |
| SegNet | 0.191 | 98.78 | 69.4 | 79.23 | 85.48 | 81 | 84.522 | 1.17 |
| DLV3/ResNet101 | 0.185 | 98.9 | 70.2 | 80.38 | 84.6 | 81.7 | 84.69 | 1.11 |
| Model | Loss | Pixel ACC% | IoU% | Precision% | Recall% | Dice% | mAP% | It/Sec |
|---|---|---|---|---|---|---|---|---|
| DLV3/ResNet50 | 0.347 | 98.39 | 49.79 | 64.12 | 69.43 | 65.6 | 68.07 | 2.44 |
| Unet | 0.33 | 98.5 | 51.2 | 65.9 | 70.46 | 67.04 | 69.36 | 2.37 |
| DeepCrack19 | 1.8 | 98.4 | 51.2 | 66.24 | 69.21 | 67.1 | 68.1 | 3.06 |
| SegNet | 0.339 | 98.4 | 50.22 | 65.1 | 69.93 | 66.1 | 68.35 | 2.66 |
| DLV3/ResNet101 | 0.346 | 98.4 | 49.82 | 64.16 | 69.38 | 65.7 | 68.0 | 1.56 |
| Model | Pixel_ACC | IoU | Precision | Recall | Dice | mAP |
|---|---|---|---|---|---|---|
| Co-CrackSegment/Dice | 99.03 | 72.98 | 82.22 | 86 | 83.62 | 85.8 |
| Co-CrackSegment/IoU | 99.038 | 72.98 | 82.24 | 86 | 83.62 | 85.8 |
| Co-CrackSegment/Pixel_Acc | 99.042 | 72.88 | 82.61 | 85.3 | 83.52 | 85.57 |
| Co-CrackSegment/Precision | 98.96 | 71.67 | 83.29 | 83.22 | 82.74 | 85.1 |
| Co-CrackSegment/Recall | 98.96 | 71.85 | 79.84 | 87.31 | 82.75 | 85.12 |
| Weighted Average | 98.91 | 70.56 | 80.61 | 85.38 | 81.91 | 83.24 |
| Model | Pixel ACC | IoU | Precision | Recall | Dice | mAP |
|---|---|---|---|---|---|---|
| Co-CrackSegment/Dice | 98.52 | 53.28 | 67.37 | 71.925 | 68.9 | 70.31 |
| Co-CrackSegment/IoU | 98.52 | 53.28 | 67.41 | 71.88 | 68.9 | 70.31 |
| Co-CrackSegment/Pixel_Acc | 98.536 | 52.97 | 68.21 | 70.43 | 68.6 | 70.5 |
| Co-CrackSegment/Precision | 98.527 | 52.31 | 68.46 | 69.08 | 68.03 | 69.45 |
| Co-CrackSegment/Recall | 97.96 | 52.14 | 64.72 | 73.33 | 67.8 | 69.4 |
| Weighted Average | 98.48 | 51.84 | 67.59 | 68.89 | 67.61 | 68.62 |
| Model | MSE | NCC | SSIM | PSNR | HD | FD | |
|---|---|---|---|---|---|---|---|
| Test Sample 1 | DC19 | 5.090404 | 167.9867 | 0.89116 | 19.38638 | 41 | 65.03076 |
| Seg | 4.284303 | 156.0253 | 0.892676 | 16.9151 | 24.18677 | 67.44627 | |
| U | 2.935957 | 179.5655 | 0.960013 | 25.69829 | 41 | 65 | |
| DL50 | 3.769711 | 177.7012 | 0.952759 | 23.63699 | 12 | 64 | |
| DL100 | 3.330421 | 178.8839 | 0.959887 | 24.87016 | 9.219544 | 68.00735 | |
| CCAcc | 2.935957 | 179.5655 | 0.960013 | 25.69829 | 41 | 65 | |
| CCDice | 2.935957 | 179.5655 | 0.960013 | 25.69829 | 41 | 65 | |
| CCIoU | 2.93866 | 179.4774 | 0.958563 | 25.63876 | 17.49286 | 71.02816 | |
| CCPrec | 2.935957 | 179.5655 | 0.960013 | 25.69829 | 41 | 65 | |
| CCRec | 2.935957 | 179.5655 | 0.960013 | 25.69829 | 41 | 65 | |
| EWA | 2.935957 | 179.5655 | 0.960013 | 25.69829 | 41 | 65 | |
| Test Sample 3 | DC19 | 3.322104 | 166.2844 | 0.909039 | 19.90944 | 98.99495 | 122.9187 |
| Seg | 3.344863 | 163.8031 | 0.915298 | 19.33419 | 34 | 44.01136 | |
| U | 2.687774 | 174.2995 | 0.943509 | 22.63901 | 97.58074 | 101.0198 | |
| DL50 | 3.01243 | 168.2552 | 0.920471 | 20.1875 | 86.00581 | 103.5857 | |
| DL100 | 2.649703 | 173.5924 | 0.948537 | 22.27606 | 17.69181 | 73.00685 | |
| CCAcc | 2.687774 | 174.2995 | 0.943509 | 22.63901 | 97.58074 | 101.0198 | |
| CCDice | 2.687774 | 174.2995 | 0.943509 | 22.63901 | 97.58074 | 101.0198 | |
| CCIoU | 2.687774 | 174.2995 | 0.943509 | 22.63901 | 97.58074 | 101.0198 | |
| CCPrec | 2.687774 | 174.2995 | 0.943509 | 22.63901 | 97.58074 | 101.0198 | |
| CCRec | 2.649703 | 173.5924 | 0.948537 | 22.27606 | 17.69181 | 73.00685 | |
| EWA | 2.545727 | 174.0299 | 0.944122 | 22.52987 | 97.58074 | 101.0198 | |
| Test Sample 4 | DC19 | 6.968985 | 151.0429 | 0.88876 | 22.09238 | 98.04591 | 98.04591 |
| Seg | 7.820813 | 155.702 | 0.930462 | 22.86449 | 42.29657 | 65.80274 | |
| U | 6.510118 | 150.7105 | 0.920223 | 21.65067 | 41.04875 | 58.21512 | |
| DL50 | 7.522699 | 146.6671 | 0.916166 | 21.07367 | 42.29657 | 64.40497 | |
| DL100 | 7.046388 | 155.0674 | 0.929616 | 22.09645 | 43.28972 | 66.21933 | |
| CCAcc | 6.968985 | 151.0429 | 0.88876 | 22.09238 | 98.04591 | 98.04591 | |
| CCDice | 6.968985 | 151.0429 | 0.88876 | 22.09238 | 98.04591 | 98.04591 | |
| CCIoU | 6.968985 | 151.0429 | 0.88876 | 22.09238 | 98.04591 | 98.04591 | |
| CCPrec | 6.968985 | 151.0429 | 0.88876 | 22.09238 | 98.04591 | 98.04591 | |
| CCRec | 6.510118 | 150.7105 | 0.920223 | 21.65067 | 41.04875 | 58.21512 | |
| EWA | 6.440731 | 151.7991 | 0.922536 | 21.8441 | 41.04875 | 63.00794 | |
| Test Sample 7 | DC19 | 5.241998 | 149.5256 | 0.900443 | 22.84266 | 42.43819 | 68.06614 |
| Seg | 5.174683 | 150.1547 | 0.92168 | 22.76975 | 88.05112 | 103.5857 | |
| U | 5.022248 | 151.9687 | 0.927984 | 22.99072 | 32.06244 | 98.0051 | |
| DL50 | 5.254128 | 146.0322 | 0.919608 | 22.00982 | 39.82462 | 97.90812 | |
| DL100 | 5.41437 | 146.7453 | 0.918813 | 22.17869 | 38.60052 | 100.2846 | |
| CCAcc | 5.241998 | 149.5256 | 0.900443 | 22.84266 | 42.43819 | 68.06614 | |
| CCDice | 5.254128 | 146.0322 | 0.919608 | 22.00982 | 39.82462 | 97.90812 | |
| CCIoU | 5.254128 | 146.0322 | 0.919608 | 22.00982 | 39.82462 | 97.90812 | |
| CCPrec | 5.241998 | 149.5256 | 0.900443 | 22.84266 | 42.43819 | 68.06614 | |
| CCRec | 5.254128 | 146.0322 | 0.919608 | 22.00982 | 39.82462 | 97.90812 | |
| EWA | 5.045367 | 151.2616 | 0.927378 | 22.91473 | 32.06244 | 98.15294 |
| Model | MSE | NCC | SSIM | PSNR | HD | FD | |
|---|---|---|---|---|---|---|---|
| Test Sample 1 | DC19 | 6.832252 | 48.4373 | 0.863592 | 19.25924 | 26.24881 | 36.12478 |
| Seg | 4.355582 | 162.5278 | 0.972308 | 26.47704 | 1.414214 | 24.59675 | |
| U | 5.178737 | 129.0308 | 0.955406 | 21.846 | 70.61161 | 73 | |
| DL50 | 4.221642 | 163.9014 | 0.972118 | 26.78918 | 23.02173 | 35.12834 | |
| DL100 | 1.409566 | 170.4413 | 0.982088 | 28.46795 | 23.02173 | 36.12478 | |
| CCAcc | 1.441632 | 170.2985 | 0.979723 | 28.50447 | 9.055385 | 33.52611 | |
| CCDice | 1.409566 | 170.4413 | 0.982088 | 28.46795 | 23.02173 | 36.12478 | |
| CCIoU | 1.409566 | 170.4413 | 0.982088 | 28.46795 | 23.02173 | 36.12478 | |
| CCPrec | 1.441632 | 170.2985 | 0.979723 | 28.50447 | 9.055385 | 33.52611 | |
| CCRec | 4.274815 | 164.6856 | 0.972295 | 26.98574 | 23.02173 | 36.22154 | |
| EWA | 0.965682 | 174.2385 | 0.98686 | 30.03775 | 18.02776 | 33.52611 | |
| Test Sample 2 | DC19 | 6.072239 | 90.54725 | 0.848512 | 21.69663 | 65.06919 | 120 |
| Seg | 5.375188 | 142.2985 | 0.918754 | 22.74978 | 60.60528 | 63.07139 | |
| U | 5.150934 | 147.3639 | 0.933801 | 23.17458 | 15.81139 | 26 | |
| DL50 | 5.541824 | 134.3218 | 0.913235 | 23.47934 | 67.6757 | 69.33974 | |
| DL100 | 5.114214 | 146.4902 | 0.931999 | 23.22485 | 55.17246 | 56.63921 | |
| CCAcc | 5.114214 | 146.4902 | 0.931999 | 23.22485 | 55.17246 | 56.63921 | |
| CCDice | 5.150934 | 147.3639 | 0.933801 | 23.17458 | 15.81139 | 26 | |
| CCIoU | 5.150934 | 147.3639 | 0.933801 | 23.17458 | 15.81139 | 26 | |
| CCPrec | 5.114214 | 146.4902 | 0.931999 | 23.22485 | 55.17246 | 56.63921 | |
| CCRec | 5.150934 | 147.3639 | 0.933801 | 23.17458 | 15.81139 | 26 | |
| EWA | 5.2925 | 145.2522 | 0.925752 | 23.14277 | 60.60528 | 63.03174 | |
| Test Sample 4 | DC19 | 3.120879 | 60.42887 | 0.919145 | 23.94023 | 168.5853 | 168.5853 |
| Seg | 1.416261 | 130.9994 | 0.985554 | 27.93816 | 4.242641 | 4.242641 | |
| U | 1.637453 | 103.4132 | 0.978663 | 26.34464 | 5.830952 | 5.830952 | |
| DL50 | 1.925599 | 89.42068 | 0.963906 | 25.24646 | 85.58621 | 85.58621 | |
| DL100 | 2.252687 | 85.10124 | 0.950184 | 22.36086 | 128.316 | 128.316 | |
| CCAcc | 1.416261 | 130.9994 | 0.985554 | 27.93816 | 4.242641 | 4.242641 | |
| CCDice | 1.416261 | 130.9994 | 0.985554 | 27.93816 | 4.242641 | 4.242641 | |
| CCIoU | 1.416261 | 130.9994 | 0.985554 | 27.93816 | 4.242641 | 4.242641 | |
| CCPrec | 1.416261 | 130.9994 | 0.985554 | 27.93816 | 4.242641 | 4.242641 | |
| CCRec | 1.416261 | 130.9994 | 0.985554 | 27.93816 | 4.242641 | 4.242641 | |
| EWA | 1.797154 | 116.5731 | 0.963911 | 26.29038 | 128.316 | 128.316 | |
| Test Sample 5 | DC19 | 7.181078 | 103.493 | 0.875115 | 20.66885 | 78.64477 | 78.64477 |
| Seg | 5.029394 | 145.7196 | 0.928192 | 22.97278 | 22.02272 | 105.1713 | |
| U | 6.573891 | 106.5596 | 0.907852 | 18.53504 | 89.82205 | 90.60905 | |
| DL50 | 5.752867 | 145.4219 | 0.927931 | 23.24723 | 17.08801 | 67 | |
| DL100 | 4.725365 | 148.3228 | 0.936244 | 22.83153 | 15 | 53.33854 | |
| CCAcc | 5.999159 | 150.4845 | 0.938444 | 23.59179 | 13.41641 | 52.34501 | |
| CCDice | 4.837807 | 150.5741 | 0.938416 | 23.43016 | 13.89244 | 51.35173 | |
| CCIoU | 4.837807 | 150.5741 | 0.938416 | 23.43016 | 13.89244 | 51.35173 | |
| CCPrec | 5.619378 | 148.1263 | 0.932509 | 23.50203 | 42.42641 | 43.28972 | |
| CCRec | 5.515253 | 149.5283 | 0.936773 | 23.06961 | 14.42221 | 53.23533 | |
| EWA | 6.505735 | 150.2057 | 0.936753 | 23.61027 | 13.0384 | 53.23533 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alkayem, N.F.; Mayya, A.; Shen, L.; Zhang, X.; Asteris, P.G.; Wang, Q.; Cao, M. Co-CrackSegment: A New Collaborative Deep Learning Framework for Pixel-Level Semantic Segmentation of Concrete Cracks. Mathematics 2024, 12, 3105. https://doi.org/10.3390/math12193105
Alkayem NF, Mayya A, Shen L, Zhang X, Asteris PG, Wang Q, Cao M. Co-CrackSegment: A New Collaborative Deep Learning Framework for Pixel-Level Semantic Segmentation of Concrete Cracks. Mathematics. 2024; 12(19):3105. https://doi.org/10.3390/math12193105
Chicago/Turabian StyleAlkayem, Nizar Faisal, Ali Mayya, Lei Shen, Xin Zhang, Panagiotis G. Asteris, Qiang Wang, and Maosen Cao. 2024. "Co-CrackSegment: A New Collaborative Deep Learning Framework for Pixel-Level Semantic Segmentation of Concrete Cracks" Mathematics 12, no. 19: 3105. https://doi.org/10.3390/math12193105
APA StyleAlkayem, N. F., Mayya, A., Shen, L., Zhang, X., Asteris, P. G., Wang, Q., & Cao, M. (2024). Co-CrackSegment: A New Collaborative Deep Learning Framework for Pixel-Level Semantic Segmentation of Concrete Cracks. Mathematics, 12(19), 3105. https://doi.org/10.3390/math12193105