1. Introduction
This paper investigates methods for optimizing experimental designs in clinical trials, focusing on maximizing the information needed to predict responses to various treatments while considering ethical constraints relevant to personalized medicine. We extend existing approaches by addressing the challenge of patient allocation to treatments, aiming to balance statistical efficiency with the ethical imperative of minimizing the risk of administering suboptimal treatments to new patients. Our interest in personalized medicine leads to the modeling of patient–treatment interactions. Consequently, there is generally no single best treatment; the optimal choice depends on the patient’s covariates. Common patient covariates, also known as prognostic factors, include age, sex, prior illnesses, and baseline status on various indicators such as depression and susceptibility to certain conditions. These covariates may be represented by continuous metrics or discrete scales. Despite the differences in their nature, the challenge of optimally allocating patients remains a general problem, regardless of the type of covariates involved.
The main challenges in optimally allocating patients to effective treatments in clinical trials are (i) patient heterogeneity: variability among patients makes it difficult to predict individual responses to different treatments; (ii) ethical considerations: ensuring equitable access to potentially effective treatments for all participants while maintaining scientific rigor; (iii) bias and randomization: proper randomization is essential to avoid skewed results and the effects of uncontrolled factors, so as to ensure accurate assessments of treatment effectiveness; (iv) treatment effectiveness: identifying the most effective treatment for various patient subgroups can be challenging; (v) sample size and power: determining appropriate sample sizes is crucial for detecting meaningful differences between treatments; and (vi) dynamic changes in patient status: variations in patients’ conditions over time can affect treatment effectiveness and influence trial conclusions [
1]. In this study, we focus on points (ii) through (vi) and examine methods to address these challenges.
The problem of prescribing optimal designs in clinical trials is formalized as the maximization of a compound optimal design criterion that balances the information gained from the trial with the goal of maximizing patient outcomes by allocating them to the most effective treatments. While the first component of the objective function, related to statistical information, was discussed in Duarte and Atkinson [
2], the second component addresses ethical concerns.
Typically, clinical trials are designed to either (i) maximize the information that enhances statistical inference about the response models; or (ii) satisfy ethical requirements by ensuring each patient is allocated to the most effective treatment as that becomes evident. These objectives often conflict with each other, leading to the formulation of an optimal allocation problem that may (i) maximize the information gained while imposing an upper limit on regret arising from allocation of patients to treatments which are not the best for them; or (ii) minimize regret while constraining the amount of information obtained, typically measured by a suitable convex function of the Fisher information matrix (FIM). When both objectives are convex (or concave), they can be combined using a linear combination with a Lagrange coefficient. This approach facilitates a balanced compromise between the incremental gain in information and the ethical considerations associated with treatment allocation [
3,
4].
In this paper, we consider the standard model commonly used in clinical trials, as described by Rosenberger and Lachin [
5]. This model for the expected response to a given treatment includes a linear component to account for the effects of prognostic factors, or covariates, along with an additive constant representing the treatment effect [
6]. The coefficients that link the covariates to the response for each treatment are either known a priori or can be sequentially estimated by fitting previous responses using least-squares methods. The response is assumed to follow a normal distribution, with each treatment associated with a distinct level of observational noise variance, which may be known beforehand or estimated from trial data. Such dependence of response variance on treatment is an extension of the standard model of Rosenberger and Lachin [
5]. A second extension of the standard model is the existence of patient–treatment interactions.
Hu et al. [
7] proposed a general family of covariate-adaptive, response-adaptive designs and derived the asymptotic properties of optimal allocation schemes. Additionally, Atkinson [
8] presented optimal experimental designs for regression models—those with covariates—specifically when there are two treatments with differing variances. In this setup, a single normal response model is applied to all subjects. An up-to-date review of this topic can be found in Sverdlov et al. [
9].
The use of compound criteria to identify sequential optimal designs is an area of active research, with the primary goal of reconciling the two key objectives of maximizing information and addressing ethical considerations. To incorporate ethical concerns into the optimal design criterion, a method based on randomly reinforced urn designs was applied, as detailed in May and Flournoy [
10]. In a similar vein, Antognini and Giovagnoli [
11] explored problems without covariates, integrating standardized information and ethical measures into the optimality criterion. Their approach dynamically adjusts the weight on the two components based on the observed outcomes. Sverdlov et al. [
12] examined responses related to time-to-event data, also without covariates. Furthermore, Metelkina and Pronzato [
13] proposed a covariate-adaptive sequential allocation strategy that converges to the optimum, demonstrating the equivalence of this approach to penalized designs.
The numerical computation of compound designs that incorporate ethical considerations poses significant challenges, often hindering their practical application. In many cases, the computational complexity of these designs makes their implementation in real-world settings challenging. Consequently, decision makers (such as physicians and other agents) often opt for simpler methods that offer greater interpretability and can be more easily integrated into suitable information systems [
14]. This paper addresses this issue by introducing a semidefinite programming formulation to derive asymptotic designs, along with a sequential allocation algorithm suited for real-world scenarios where prior knowledge is limited and the model parameters and response variance are extracted from individuals’ responses.
Our approach automates the computation of standardized compound designs by using the D-optimality criterion to measure information and quantifying rewards based on the expected response. The framework assumes known treatment variances and determines the optimal (continuous) designs for patient allocation across treatments. The information component in our compound designs is grounded in the Neyman allocation method, incorporating covariates as previously explored in Duarte and Atkinson [
2]. The ethics-based component is represented by the reward of the response, which is determined by the expectation calculated over a finitely large patient sample. When employing sequential designs, this expectation can also be iteratively approximated using a finite sample with known response values.
Further, we also address the more common scenario where treatment response variances and coefficients are initially unknown. In this case, we propose a sequential optimal design framework that updates the model after each patient response is obtained, subsequently allocating the next patient to the treatment that maximizes the compound objective.
This paper introduces three key innovations: (i) the development of a framework that enables the computation of compound designs incorporating standardized information measures and regret components; (ii) the formulation of semidefinite programming (SDP) methods to generalize the numerical computation of these designs; and (iii) the creation of an adaptive optimal allocation scheme that updates both the models for the responses and response variances in real time.
The paper is organized as follows.
Section 2 provides the background and introduces the notation used for the problem formulation.
Section 3 outlines the problem of optimal allocation using the compound-standardized information–regret (I-R) criterion.
Section 4 presents the semidefinite programming (SDP) formulations designed to systematically address the problem; the construction of normalization values for computing normalized regret is detailed in
Appendix A.
Section 5 describes the algorithm for determining optimal sequential allocation designs, which is illustrated with an example. In
Section 6, we apply the proposed methodologies to a real-world case, specifically focusing on the optimal allocation of Parkinson’s disease patients to two alternative care treatments. Finally, in
Section 7, we conclude with a brief discussion of our results.
2. Notation and Background
This section establishes the nomenclature and fundamental background used in the subsequent sections.
In our notation, boldface lowercase letters represent vectors, boldface capital letters represent continuous domains, blackboard bold capital letters denote discrete domains, and capital letters are used for matrices. Finite sets with elements are compactly represented by . The transpose operation of a matrix or vector is denoted by ”. The determinant of a matrix is represented by , and the trace is denoted by . The nomenclature used throughout the paper is provided at the end.
Let denote the covariates in the linear response model, represent the treatments, and indicate the levels each factor can have in the experiment. Here, K, I, and J denote the number of covariates, treatments, and factor levels in the response model, respectively.
When
(indicating two treatments) and there are
k covariates, the response model is given by
where
is the vector of covariates,
denotes the design space which contains all possible values of
,
represents the set of parameters to be estimated (including all
’s and
’s), and
is the domain of these parameters, with
being the total number of parameters across all treatment models. The models
, for
, represent the expected responses, each characterized by an error term with variance
. The
pth realization of
characterizing the
pth patient is represented as
.
The allocation is optimized to maximize the information extracted from patients’ responses while considering the predictions from the model. Our goal is to determine the allocation of individuals to treatment 1 for estimating the parameters
, and to treatment 2 for estimating the parameters of the second treatment model. In approximate optimal designs,
w represents the fraction of individuals allocated to treatment 1, while
denotes the fraction allocated to treatment 2. This yields the design matrix
Here, the upper row of
indicates the fraction allocated to each treatment, while the lower row denotes the treatment number itself. In cases where the number of individuals is small and an exact design is required, rounding procedures can be used to determine the allocation, as described in Pukelsheim and Rieder [
15].
Let
, and without loss of generality, let
. Consequently, the Fisher information matrix (FIM) for the experimental design
is a
diagonal matrix given by Atkinson [
8]:
3. Standardized Compound Designs
In this section, we formulate standardized compound designs that balance information measurement criteria with regret. The response models for all treatments are continuous and exhibit linear dependence on K covariates. Moreover, the variances of the treatment responses are known a priori. Our goal is to establish a general conceptual framework for determining continuous optimal information–regret (I-R) designs, characterized by the fraction of patients allocated to each treatment.
We focus on the computation of I-R designs, which aim to reconcile the objectives of allocating individuals to the most promising treatments while optimizing parameter estimation efficiency across different response groups; see Hu et al. [
7], Antognini and Giovagnoli [
11], Metelkina and Pronzato [
13]. In most applications, responses are either binary or follow a standard linear model. For both types, it is rational to evaluate allocation procedures based on the proportion of patients receiving the most effective treatment. However, in the presence of patient–treatment interactions, there is generally no single best treatment; the optimal choice depends on the patient’s covariates. If the responses are significantly different, the choice of treatment is crucial. Conversely, if the responses are similar, the advantage of one treatment over another is minimal. Thus, we use the expected response value based on previous allocations as our indicator for correct allocation. This approach represents an innovation compared to earlier methods.
This problem is particularly relevant as it mirrors the sequential allocation of individuals in clinical trials. It exploits prior information—characterized by both continuous and discrete covariates known a priori—to refine allocation strategies in later stages. Practically, optimization strategies offer significant advantages over pure randomization techniques, as discussed in Bertsimas et al. [
16], Kallus [
17].
In this context, we integrate standardized D-optimality, which quantifies the information content, with standardized regret, which measures the expected loss associated with not selecting the optimal treatment—the one corresponding to the highest response.
We first consider the information criterion. Assume the covariates
for
are discrete, taking values in
. Consequently, the design space is defined as
. Let
denote the set of parameters to be estimated, including the vectors
and
in Equation (1). In this simplified configuration, we consider categorical covariates with two levels:
(lower) and
(upper). According to the bound on the determinant of a Hadamard matrix [
18,
19], extreme observations provide the most information for the D-optimality criterion in first-order models.
We emphasize that using these limited support points for the designs helps reduce the computational burden when demonstrating the properties of our designs in a non-sequential context and provides valuable asymptotic allocations. In the application to constructing sequential clinical trials discussed in
Section 5, covariate values are sampled from continuous distributions.
The criterion used for information-theoretical analysis in this work is D-optimality. This approach aims to maximize the determinant of the matrix
, or equivalently, the
power of the determinant, which represents the geometric mean of the diagonal elements of matrix
B, as described in Duarte and Atkinson [
2] (Equation 3.d).
To address our objective of integrating criteria that measure different aspects—specifically, the information content in the allocation and the regret associated with individual treatment assignments—we use standardized criteria, as detailed by Dette [
20]. Hence, the information criterion we seek to maximize is given by
where
represents the Fisher information matrix (FIM) for treatment
i, and
denotes the optimal allocation when D-optimality is the sole criterion. For simplicity, we assume the models
are linear in parameters, which makes the matrices
independent of
. The explicit inclusion of
in the definition of
serves two main purposes: (i) it clarifies the dependency on the number of parameters; and (ii) it aligns the functional with the regret representation, which does depend on
.
We now introduce the regret criterion. The objective is to assign an individual, denoted as individual , who is characterized by covariate values , to the treatment that maximizes the expected response. For simplicity, we assume that higher response values are preferred, although the opposite preference could also be applied.
To align this criterion with the information criterion, it is necessary to normalize the responses to fall within the range
. To achieve this normalization, we need to evaluate all
I treatments and, for each treatment, consider all possible covariate values in
. Here,
includes the
m previous vectors of covariates that have already been allocated. Assuming perfect knowledge of the parameters
for all models, let
denote the maximum response value achieved by the treatment that yields the highest response. Specifically,
represents the highest value of the response over all models
and covariate values
, obtained using model (1).
Conversely, the minimum response is denoted by
, which satisfies
Let
denote the difference in response expectations between the “optimal” and “least favorable” treatments for
. Each of these values can be computed using the mixed-integer linear programming (MILP) procedure detailed in
Appendix A. The parameter
ensures compatibility between the standardized regret and the standardized information criteria. To complete the scaling, we also need to determine the minimum response achieved (i.e., the baseline), denoted as
These problems determine the maximum (or minimum) response of a set of discrete points, considering the full set of response models. This approach is used to systematically find the extrema of possibly nonlinear or even discontinuous response models. We rely on a branch-and-cut large-scale solver [
21], which ensures solvability even for larger numbers of discrete points and response models.
We now turn to the design of experiments. In the clinical trials motivating our work, the choice of covariate vector is not under our control. Each patient p arrives with a predetermined covariate vector. The central design question is determining the most suitable treatment for each patient.
The optimal treatment allocation for the
individual is given by the treatment
, which is defined as
where
represents the response of treatment
i given the covariate vector
and the parameter vector
.
In this context, regret measures the cost associated with not selecting the most effective treatment, as described by Rosenberger and Sverdlov [
22]. When comparing different allocation strategies for
I treatments across
m individuals with known covariate information, regret is quantified as the average difference between the expected outcomes of the optimal allocation policy and those of an alternative policy.
Specifically, the non-standardized average regret, denoted as
, is defined as
where
is the maximum expected response achievable across all treatments given the covariate information available, and
is the response of the treatment actually assigned to the
individual. Here,
ℓ denotes a vector, where
specifies the treatment assigned to the
individual.
The scale factor used to normalize the average regret to the unit interval,
, remains constant for optimal designs when the model coefficients of treatments are known. However, it must be re-estimated in sequential allocation schemes as new data become available. Given that
the standardized average regret, referred to as “regret” (without superscript) in the following sections, is given by
Alternatively,
can be expressed as
where
represents the response of the treatment assigned to the
individual.
Minimizing regret in the allocation process corresponds to selecting the treatment that maximizes the following objective function (up to constant terms):
where
denotes the vector of proportions of patients allocated to each treatment, subject to the constraint
.
Let
(with
) denote the number of subjects previously assigned to treatment
i. Consequently, we have
where
represents the expectation of the standardized loss for the
individuals previously allocated to treatment
i. For a detailed derivation of Equation (7), refer to
Appendix B.
The I-R-optimality criterion is formulated by integrating the information-theoretic criterion from Equation (3) with the regret criterion from Equation (7). The I-R-optimal design seeks to address the following optimization problem:
which is equivalently expressed as
where
represents the relative weight assigned to the regret criterion, which is determined in advance. In practice, the decision maker selects this parameter to reflect the relative importance of ethical considerations versus inferential accuracy when developing response models for both groups. For instance, if
is set to 0.95, it suggests that ethical concerns are given 19 times more significance than the information criterion. This high value of
is typically used in scenarios where patients are well-informed, and the priority is to minimize regret by allocating them to the treatment with the least potential regret.
Problem (8) is formulated similarly to (Metelkina and Pronzato [
13], Equation 2.9) and can also be represented as a semidefinite program. However, it is important to note that the multiplicative compound criterion proposed by Hu et al. [
7] cannot be expressed in semidefinite form due to the lack of semidefinite representability of the functions involved. Additionally, when
, the I-R-optimality criterion simplifies to D-optimality, as discussed in (Duarte and Atkinson [
2], §4). On the other hand, when
, the criterion aligns with concepts from multi-armed bandit theory, such as those explored by Villar et al. [
23].
4. Optimal I-R Designs via SDP
We now present a formulation to address problem (8) using semidefinite programming. Solving this problem via SDP involves several key steps: (i) determining the value of
in Equation (3a), which can be precomputed using the procedure outlined in (Duarte and Atkinson [
2], A1.a–A1.e). This corresponds to calculating the determinant for the optimal design when the objective is the D-optimality criterion. (ii) Estimating the average response of each treatment, a process that relies on the parameter vector
derived from previous allocations and is inherently subject to noise. (iii) Computing the quantities
,
,
, and
, as obtained from Equations (4), (A1) and (A2). (iv) Incorporating the weight
, as specified by the user.
In practical terms, this design can be interpreted as an approximate, infinite-size local design intended to estimate a specific parameter vector
. The primary goal of this formulation is to establish an asymptotic framework for resolving local designs within sequential procedures, as outlined by Pocock [
24]. The formulation is presented below.
Here,
B is a lower triangular matrix of size
,
the diagonal elements of
B, and
t the hypograph of the determinant function.
To illustrate the application of Problem (9), consider a scenario similar to the one presented in Section 4 of Duarte and Atkinson [
2]. In this setup, there are two treatments and two covariates (denoted as
and
), each with two levels. The design space is defined as
. The local parameter values
for treatment 1 are
, and for treatment 2 they are
. By solving programs (A1) and (A2), we obtain the following values:
,
, and
. The expected values for each model are
and
, respectively. This setup demonstrates that the second treatment has a significantly higher expected value, making it the preferable choice to minimize regret. However, it is crucial to recognize that decision making is also influenced by the uncertainty in the responses, as quantified by
, which in turn impacts the information-based criterion.
We systematically vary the parameter
to conduct a comparative analysis between I-R-optimal designs and purely information-theoretical designs, as presented in Duarte and Atkinson [
2]. For each value of
, we use the optimal
values from Table 1 in Duarte and Atkinson [
2], which were derived for the case
. Additionally, we explore different values of
in the set
to assess the impact of the weighting parameter, where a higher
emphasizes the importance of regret in the allocation process.
The performance of these designs depends on the values of
. In our calculations, we assume an equal occurrence of each
value, resulting in balanced
experiments for each treatment. The corresponding results are presented in
Table 1 (the third and fifth columns) and align well with our expected trends. To simplify the interpretation of the results, we denote
as the proportion of individuals allocated to the first treatment, with
representing the proportion allocated to the second treatment. “Opt” refers to the objective function value at convergence. As anticipated, for treatment 1, which has a lower expected response, a smaller fraction of individuals is allocated. The weights consistently remain below a half, reflecting the allocations observed in purely information-theoretical designs, specifically those based on the D-optimality criterion, as shown in Table 1 of Duarte and Atkinson [
2]. As expected, the fraction of patients allocated to treatment 1 decreases with increasing
, illustrating the growing influence of the ethical component in decision making. The optimum decreases as
increases, with this effect being more pronounced for smaller values of
. This reduction in the optimum with increasing
results from heightened uncertainty, which consequently diminishes the amount of information gathered from the experimental plan (see Table 1 in Duarte and Atkinson [
2] for an analysis based solely on information-based allocation). To evaluate the influence of
on the optimum, we must first consider the allocation driven purely by regret minimization. In this case, the allocation is minimally affected by
, as individuals are primarily assigned to the treatment with the higher expected response (treatment 2), regardless of its variance. As
decreases, the standardized information component in
(see Equation (8a)) becomes more critical, and its reduction less pronounced than the decrease in the standardized regret.
To apply the results presented in
Table 1 effectively in practical scenarios, researchers should follow these steps:
- (i)
Use the given values of and to compute ;
- (ii)
Set the value of ;
- (iii)
Find the corresponding value of w for the compound optimality criterion based on from step (i);
- (iv)
Allocate individuals to each treatment i.
5. Sequential Optimal Design Based on the I-R Rule
We now investigate the optimal sequential design based on the I-R rule, as represented by (9). Our approach is consistent with sequential allocation algorithms similar to those used by Atkinson [
6] and Atkinson [
25]. Specifically, (i) the values of the variances and coefficients within the response models for all treatments, denoted as
, are unknown; (ii) the value of
is determined in advance by solving the D-optimal design problem; (iii) the weighting parameter
remains fixed throughout the analysis; and (iv) we have information about the underlying distributions of the covariates.
Without loss of generality, we assume that the covariates are uniformly distributed within the range (i.e., for ). Additionally, the response noise is modeled as a normal distribution with mean zero and standard deviation for treatment . While these values are initially unknown, estimates of them are updated iteratively as each patient is allocated and their response is recorded. The updated estimates, denoted as for , represent the residual mean square errors from the fitted models for the I treatments and reflect the effectiveness of the iterative fitting procedure in capturing the noise in the responses. For , the estimate is given by . As in previous sections, I represents the number of treatments, and indexes the patients enrolled in the trial. The covariate denotes an individual covariate, and represents the vector of covariates for patient p.
In the context of sequential treatment allocation, we have access to the covariates and allocations for the initial p patients, forming a matrix that includes both allocations and explanatory variables. For patient , who has a vector of covariates, when treatment i is assigned, the combined vector of allocation and explanatory variables for this patient is represented as for .
Previous work on optimal experimental designs, particularly those focusing on information criteria (e.g., Atkinson [
6] and (Smith [
26], §10)), has shown that minimizing the variance of the estimate after
observations can be achieved by selecting the treatment for which the sensitivity function reaches its maximum value. This approach corresponds to a specific case of optimal design theory aimed at reducing the variance of a single parameter estimate within a model with multiple nuisance parameters, known as
-optimality. For more details, refer to (Atkinson et al. [
27], §10.3) for the case with
. However, in our approach, which uses a compound (convex) criterion, we take a different approach. Specifically, we compute the value of Equation (8) for each available treatment for patient
. We then allocate the patient to the treatment that maximizes the overall performance according to this criterion.
In the sequential development of designs, especially when employing linear response models and information criteria, calculating the sensitivity function is a straightforward task as it directly depends on the information matrix and can be readily computed for each proposed treatment allocation. However, for I-R-optimal designs, this process requires an alternative approach due to the complexity of establishing the sensitivity function for the regret component. To circumvent this challenge, we adopt a different strategy. We compute the metric that represents the compound criterion for
I distinct scenarios, each one constructed by considering the allocation of patient
to a different treatment
. In other words, we evaluate
given by
which represents the I-R performance of the design
constructed after treatments have been allocated to
p individuals (with the superscript denoting the number of individuals with available information), and treatment
i is assigned to patient
. Here, the subscript aids in tracking the provisional treatment allocation for subject
.
To calculate the design , several steps are required. First, we need to update the weights, , and their corresponding Fisher information matrices (FIMs) following the tentative allocation of treatment i to subject . Additionally, we must compute the metrics for each treatment i. The updates involve the following:
Parameter estimates: Recalculate , the estimates of and , and so , based on the available data;
Updated metrics: Reconstruct and using the responses from the p individuals, whose treatment allocations and responses are known;
Weights vector: Recalculate the vector of weights, where represents the fraction of individuals allocated to each treatment.
Once these updates are complete, we compute the normalized ratios as follows:
To determine the allocation, we use the following rule:
This rule dictates that patient
will be allocated to treatment 1 if the ratio
is greater than or equal to
, and to treatment 2 otherwise.
In the context of tentatively allocating treatment i to subject , we predict the response of this subject using the treatment model from Equation (1), denoted as . Here, is estimated based on data from the first individuals who were allocated to this specific treatment. The predicted response is then used to update two key elements:
Additionally, the experimental design itself is updated. This involves recalculating the weights using the formula
where
represents the number of patients previously allocated to treatment
i. The updated design is denoted as
. The treatment for subject
is then selected based on the one that maximizes the objective function.
This procedure is repeated iteratively for a total of P individuals, where P can be predetermined or adjusted based on ongoing trial results using a specified criterion. To assess the properties of our procedure for a given value of P, we use simulations. To minimize the impact of randomness, we replicate the entire procedure times. Algorithm 1 outlines the treatment allocation process.
Initially, individuals are allocated to each treatment to ensure a non-singular Fisher information matrix (FIM). Parameter estimates for the model are derived from the responses of these individuals. The procedure is then systematically repeated until the allocation of the individual. After each new patient is admitted, their covariates are considered in the decision-making process to optimize treatment allocation. Once the response is available, it is integrated into the dataset, prompting updates to the model parameters, the FIM, and the expectation estimates. In the algorithm is an indicator variable with value 1 if the individual is allocated to treatment i and 0 otherwise.
Algorithm 2 systematically outlines the procedure for sequential allocation based on the proposed I-R criterion. To illustrate the mechanics of the procedure, we consider the allocation of the individual. The implementation requires the following quantities:
- (i)
The number of competing treatments, denoted as I;
- (ii)
The number of covariates, denoted as K;
- (iii)
The vector of covariates for the individual, denoted as ;
- (iv)
The Fisher information matrices (FIMs) for each treatment, and the global FIM after allocating the individual, denoted as ;
- (v)
The estimates of ;
- (vi)
The values of , , , and ;
- (vii)
The estimated error variances for all treatments, denoted as , obtained after allocating the individual.
This iterative process is applied to all individuals,
, as they enter the trial.
| Algorithm 1 Algorithm to randomize the allocation (). |
| procedure RandomizeAllocation() |
|
Allocate individuals to both treatments () |
| |
| Construct |
| for to do ▹ sampling loop |
| for to Pdo ▹ individuals loop |
| for to kdo ▹ treatments loop |
| Allocate j individual to treatment i |
| Update , from and |
|
Update |
| Update |
| Compute with using (10) |
| end for |
| |
| Allocate j applying rule (12) |
| Update the set of responses obtained from treatment i |
| Update and via LS |
| Update and |
| Update () |
| |
| end for |
| end for |
| |
| end procedure |
| Algorithm 2 Allocation of the individual. |
| procedure AllocateIndividual(Input: I, K, , , , , , , , ) |
| Construct the vector |
| for i in do |
| Compute the function for |
| end for |
| Allocate the individual to the treatment prescribed by rules (11–12) |
| Update , , , , , , |
| end procedure |
To evaluate the algorithm, we consider a scenario with two treatments (
), two covariates (
),
simulations, and
individuals. The parameter values used to generate the response data for the treatments are
for treatment 1 and
for treatment 2, as detailed in
Section 4. We set
, with corresponding variances of
and
, and examine two different values of
, specifically
. Additionally, we use the value of
, which was found by (Duarte and Atkinson [
2], Table 1, line 7) for
and
. The table gives properties of D- (and other) optimal designs for the information component of our compound design.
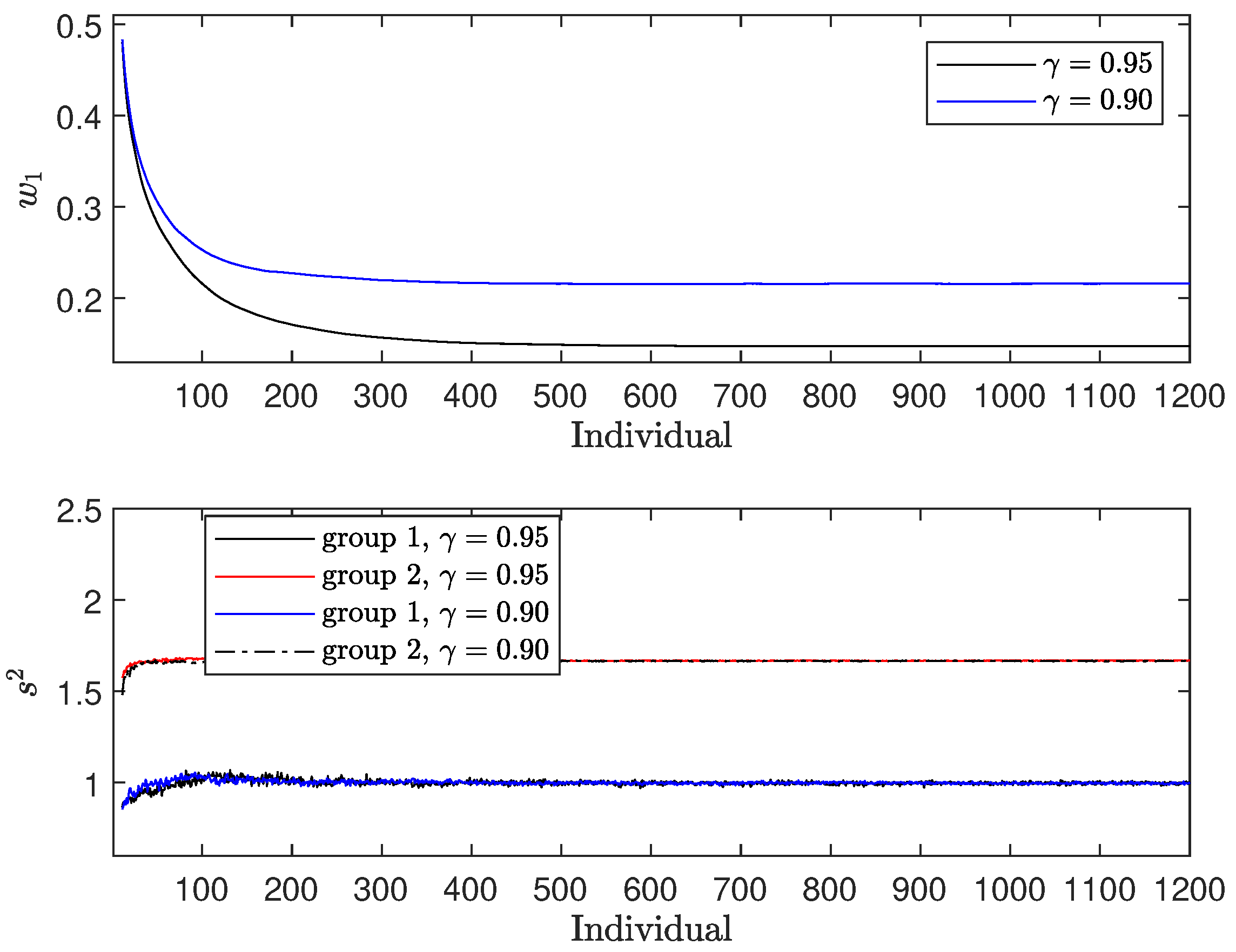
In the upper panel of
Figure 1, we observe the fraction
, which represents the proportion of individuals allocated to treatment 1. Two distinct patterns emerge:
It is also observed that
decreases as
increases, reflecting the increased weight given to the regret term. As a result, more individuals are allocated to the treatment with a higher expectation (treatment 2), despite its larger variance. The difference in allocation between the two treatments at convergence is 0.0728. In the lower panel of
Figure 1, we examine the variance estimates
for both treatments (
). Both estimates converge to the actual variance of the responses. Notably,
shows more pronounced fluctuations, mainly because it is estimated from a smaller fraction of patients, whereas
is estimated from the larger remaining fraction.
Figure 1.
Results for : (i) upper panel—; (ii) lower panel—.
Figure 1.
Results for : (i) upper panel—; (ii) lower panel—.
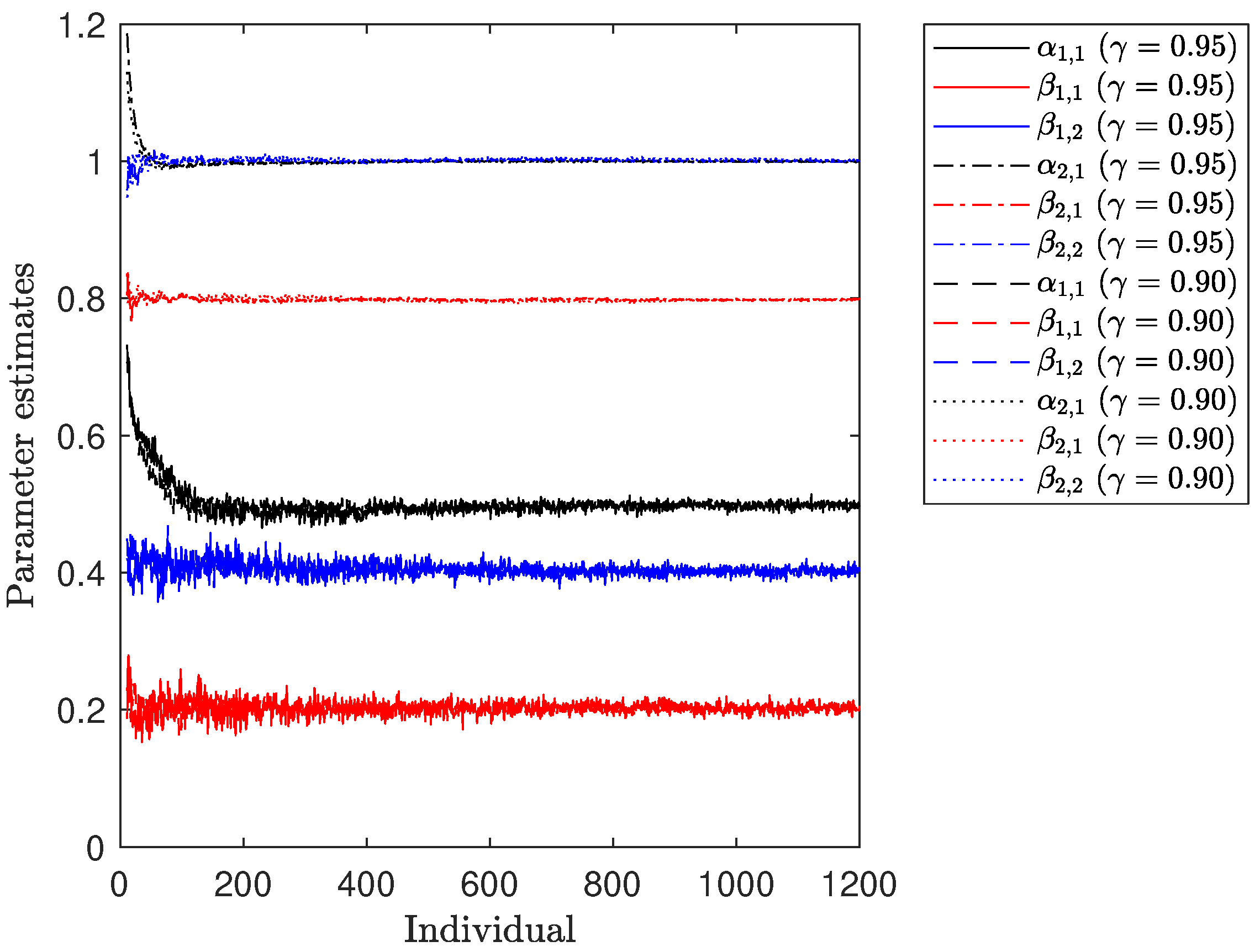
Figure 2 illustrates the progression of parameter estimates for both treatments over the course of the numerical experiment. It is noticeable that all of them converge towards the true values of
. However, a pattern resembling that observed for the variance estimates
is also evident. Specifically, the estimation of the parameters for
relies on a relatively small number of individuals, causing any new data point to have a more pronounced impact on the existing estimates. In contrast, the parameter estimates for
exhibit smoother trajectories due to the larger number of responses considered in the fitting process.
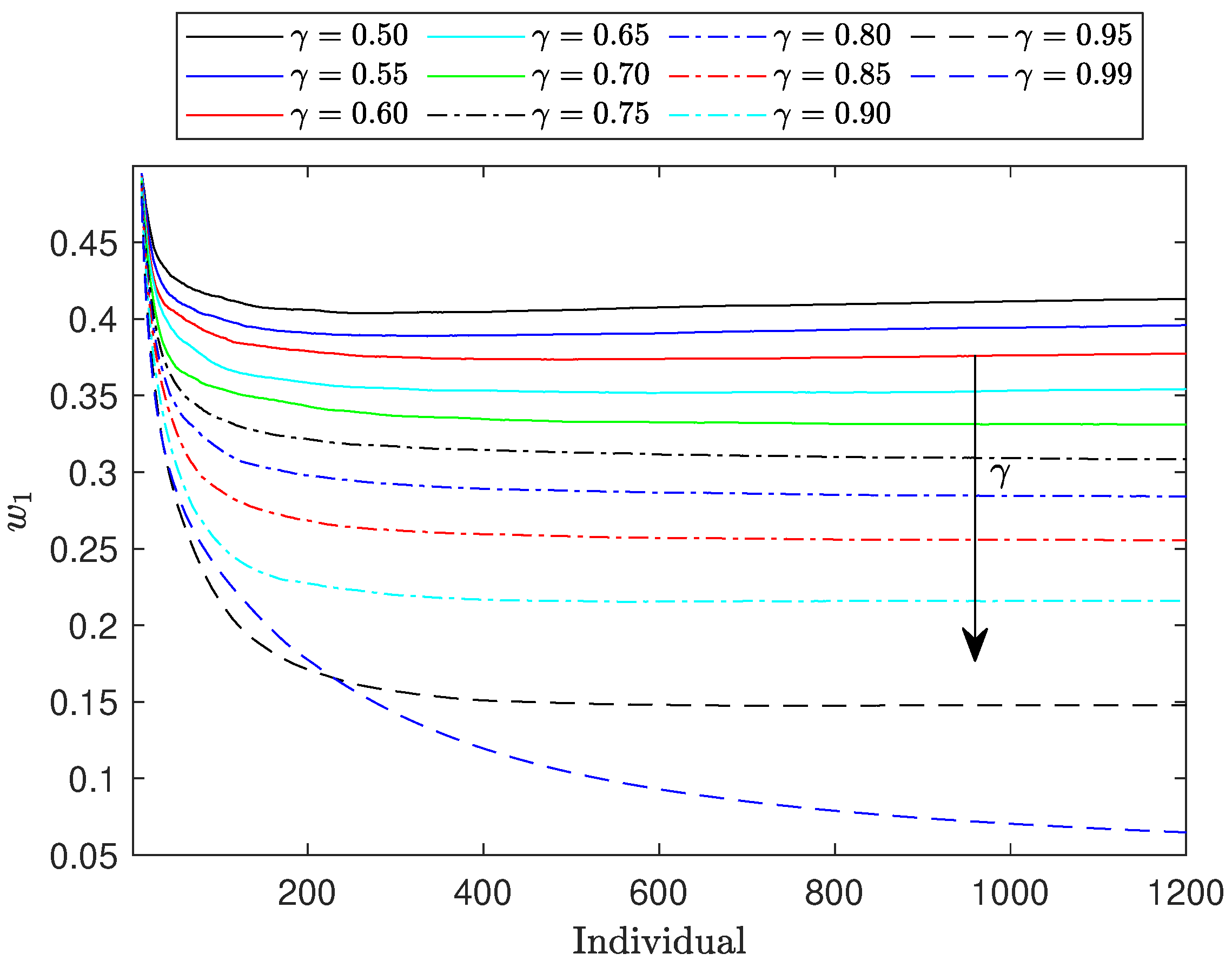
Figure 3 illustrates the evolution of
across a range of
values from 0.50 to 0.99. The observed trends align with our expectations: as the weight assigned to the regret component increases, the values of
decrease, and the corresponding curves become flatter. This downward trend in
continues as
increases. Notably, when
reaches 1.0, corresponding to an allocation based solely on regret,
approaches zero. Consequently, the Fisher information matrix (FIM) becomes nearly singular, and
approaches zero. This suggests that the information component of the objective function in Equation (8) becomes prone to numerical instability. This phenomenon occurs because when the FIM approaches singularity it becomes ill-conditioned, meaning its condition number increases significantly. This leads to numerical instability in the computation of its determinant, as small errors in the input data or round-off errors during calculations can result in large inaccuracies in the output.
To address these challenges while still evaluating the algorithm’s performance at extreme values, we conducted tests with . The results remained consistent with the broader trends observed for other values.
6. A Real Case Application
In this section, we apply the methodologies developed in
Section 4 and
Section 5 to a real-world case study. Specifically, we investigate the clinical trial described by Atkinson et al. [
28], which focuses on the randomization of Parkinson’s disease patients. The primary aim of this study was to devise a randomization protocol for assigning patients to one of two treatment groups:
To evaluate treatment efficacy, we use the quality of life (QoL) as the response variable. This is measured by the Parkinson’s Disease Questionnaire with 8 items (PDQ-8) [
29], with QoL, denoted as
, quantified as a percentage (ranging from 0% to 100%), where higher values indicate a lower quality of life. Several prognostic factors are known to influence QoL, with two demonstrating particularly strong correlations: (i) disease duration and stage, represented as
, and measured on the Hoehn and Yahr scale [
30,
31]; and (ii) psychological well-being and neuropsychiatric symptoms (e.g., depression and anxiety), denoted as
, and assessed using Beck’s Depression Inventory (BDI) [
32], based on responses to a structured questionnaire.
The models used for preliminary results for both treatments follow the structure outlined in Equation (1). The first prognostic factor, , corresponds to , while the second, , represents . In the dataset used for modeling the two responses to these two variables and are constrained to integer values. Specifically, ranges from 1 to 5 (i.e., ), and ranges from 1 to 35 (i.e., ). Consequently, the design space considered is denoted as , with covariate values randomly, but not uniformly, drawn from this space.
To mimic the empirical distribution of covariates we simulated from continuous distributions, which were then discretized. The variable was generated by sampling from a normal distribution with a mean of 2.3837 and a standard deviation of 0.2857. Additionally, was sampled from a Gamma distribution with a shape parameter of 1.7678 and a scale parameter of 6.8145. These parameters were estimated from historical data. The model parameters for each treatment are specified as follows:
For treatment 1: , with .
For treatment 2: , with .
The expected values for each model are (i) ; and (ii) . Additionally, the values for , , and are (i) ; (ii) ; and (iii) .
The D-optimal design is uniformly distributed, with . The normalization factor for the D-optimal design used, , is 0.4203. It is important to note that given the characteristics of the response variable our objective is to minimize the second term in Equation (10), which is equivalent to maximizing its negative. Consequently, treatment 1 should be preferred due to its lower expectation, despite having a higher level of uncertainty. Visual inspection of the graphical representations of both models shows that in a specific region of the design space, defined as , where both and are low, treatment 2 becomes the preferred choice.
The compound designs derived from the SDP formulation (9) for
are summarized in
Table 2. These results align with the key trends identified in
Section 4. Specifically, the treatment with the higher expectation is assigned to more than half of the individuals, despite also having a larger variance. This approach is consistent with our goal of maximizing the normalized regret. Notably, treatment 1 emerges as the most favorable option across almost the entire design domain. Moreover, as the weight of the regret component increases, the proportion of individuals allocated to treatment 1 also rises.
We now apply the treatment allocation algorithm discussed in
Section 5 using the I-R rule. For this simulation, we set
and
(i.e., 1200 individuals). The values for
and
are generated randomly from a uniform distribution over the ranges
and
, respectively.
The upper panel of
Figure 4 presents the weights
for the two values of
. These weights closely match the results obtained using SDP, as shown in
Table 2. The difference in
at convergence between
and
is approximately 0.0699. As expected, the weight assigned to treatment 1, which has the higher expectation, exceeds 0.5 in both cases, reaching around 0.80. This indicates that the allocation favors the treatment with the higher expectation.
The lower panel of
Figure 4 displays the estimated variances of the response models for both treatment groups. The variances converge to a stable value, consistent with the test case. Notably, the group with the larger weight shows less variability in its variance estimate.
7. Conclusions
This paper demonstrates the application of compound design criteria for patient allocation in personalized medicine. Building upon the framework proposed in Duarte and Atkinson [
2], which focused on patient allocation without considering ethical aspects, this study integrates ethical considerations into the allocation process. Specifically, the aim is to balance the acquisition of information for parametric response models with ethical considerations to ensure that each patient is assigned to the most effective available treatment.
The proposed approach is designed for response models that are linearly dependent on prognostic factors and characterized by continuous responses with distinct noise variances. A concave compound design criterion is developed that combines D-optimality with regret minimization, as detailed in
Section 3. This dual criterion reflects the necessity of both maximizing the precision of parameter estimates and minimizing patient harm or regret, emphasizing the importance of fairness in clinical decision making, considering a weighted sum objective function.
To compute continuous optimal designs for the I-R criterion within a discrete design space, semidefinite programming is considered, as outlined in
Section 4. Previous work in Duarte and Atkinson [
2] addressed the numerical computation of designs maximizing information about parameters in a similar setup, and this paper builds upon those formulations. This work assumes that the variances of the treatments and model parameters are known, facilitating the construction of the expectation of each treatment response.
In scenarios where information about variances and model parameters is unavailable, a sequential adaptive optimal design algorithm is presented in
Section 5. This algorithm iteratively updates estimates of parameters and variances as responses are collected. A systematic method for computing sequential adaptive optimal allocation schemes is proposed, and its application is illustrated with a concrete example. Although the approach aligns with reinforcement learning algorithms described in studies such as Zhao et al. [
33] and Matsuura et al. [
34], it differs by utilizing a known parametric structure a priori rather than a model-free representation.
The proposed computational methods are evaluated through two distinct scenarios: first, using a simplified illustrative example; and second, applying them to a real-world problem involving Parkinson’s disease patients. The treatments considered are (i) treatment 1, which employs a cutting-edge digital technology-centered procedure; and (ii) treatment 2, encompassing a traditional treatment and monitoring protocol.
Beyond computational efficiency, the proposed methods thoughtfully integrate ethical considerations into traditionally information-based designs in personalized medicine. This helps mitigate the ethical dilemma of balancing data collection in experimental settings with ensuring patients receive the best possible care. By incorporating regret minimization, the approach ensures that even patients not initially assigned to the optimal treatment experience reduced harm during the early stages of the experiment.
Moreover, this approach could be extended to non-medical domains such as marketing, economics, or policy-making, where optimal allocation strategies must balance information acquisition with fairness or ethical considerations. The framework’s flexibility also opens up the potential for application to treatments with binary or categorical outcomes, further broadening its relevance as well as models of linear and nonlinear classes.
The computational methods proposed are robust and versatile, offering practical insights into the allocation process. Future research could explore alternative randomization techniques, as discussed in Atkinson [
25], which address trade-offs between efficiency losses due to randomization and bias reduction. Additionally, developing theoretical results to support the convergence of these methods would be beneficial. The approach introduced could also be adapted to models beyond the linear regression framework considered here, with careful attention to selecting appropriate regret measures and scaling for these alternative models.
Finally, while this study centers on known model parameters and variances, exploring scenarios with more complex model structures or unknown variance assumptions remains a promising direction. Introducing Bayesian methods or robust optimization techniques could offer a means of addressing the uncertainties inherent in patient responses or treatment variabilities. In particular, incorporating patient heterogeneity more explicitly into the model could further enhance the framework’s applicability to real-world clinical trials where patient responses may not follow identical parametric structures. The inclusion of such considerations could lead to even more refined and ethically sound allocation strategies, reinforcing the value of this approach in personalized medicine.






{kind=link}
{kind=link}
{kind=link}
{kind=link}