
Symmetric ADMM-Based Federated Learning with a Relaxed Step

Abstract
1. Introduction
1.1. Related Work
1.2. Our Contribution
1.3. Organization
2. Preliminaries
2.1. Notations
- (I)
- The Frechet subdifferential of f at is denoted asand when , .
- (II)
- The limiting subdifferential of f at is denoted asand assuming that is a minimal-value point of f, then . If , then x is said to be a stable point of f, and the set of stable points of f is denoted as .
2.2. Loss Function
2.3. Symmetric ADMM
2.4. Federated Learning
| Algorithm 1 Federated Learning |
|
2.5. Stationary Points
3. Symmetric ADMM-Based Federated Learning with a Relaxed Step and Convergence
3.1. Fed-RSADMM
| Algorithm 2 Fed-RSADMM |
|
3.2. FedAvg-RSADMM
| Algorithm 3 FedAvg-RSADMM |
|
3.3. Convergence
- (a)
- The function is lower semi-continuous.
- (b)
- The function , is continuous and has the same L-Lipschitz continuous gradient.
- (c)
- The parameters in the algorithm satisfy the following:The penalty parameter () complies with the following:where , .
- (d)
- The datasets of all devices are independently and identically distributed (i.i.d).
- (1)
- Ω is a non-empty compact set, and as ;
- (2)
- .
3.4. Linear Convergence Rate
- (1)
- ;
- (2)
- For any given and , there exists a positive integer () such that
- (3)
- The {} sequence is Q-linearly convergent.
4. Numerical Experiment
4.1. Testing Examples
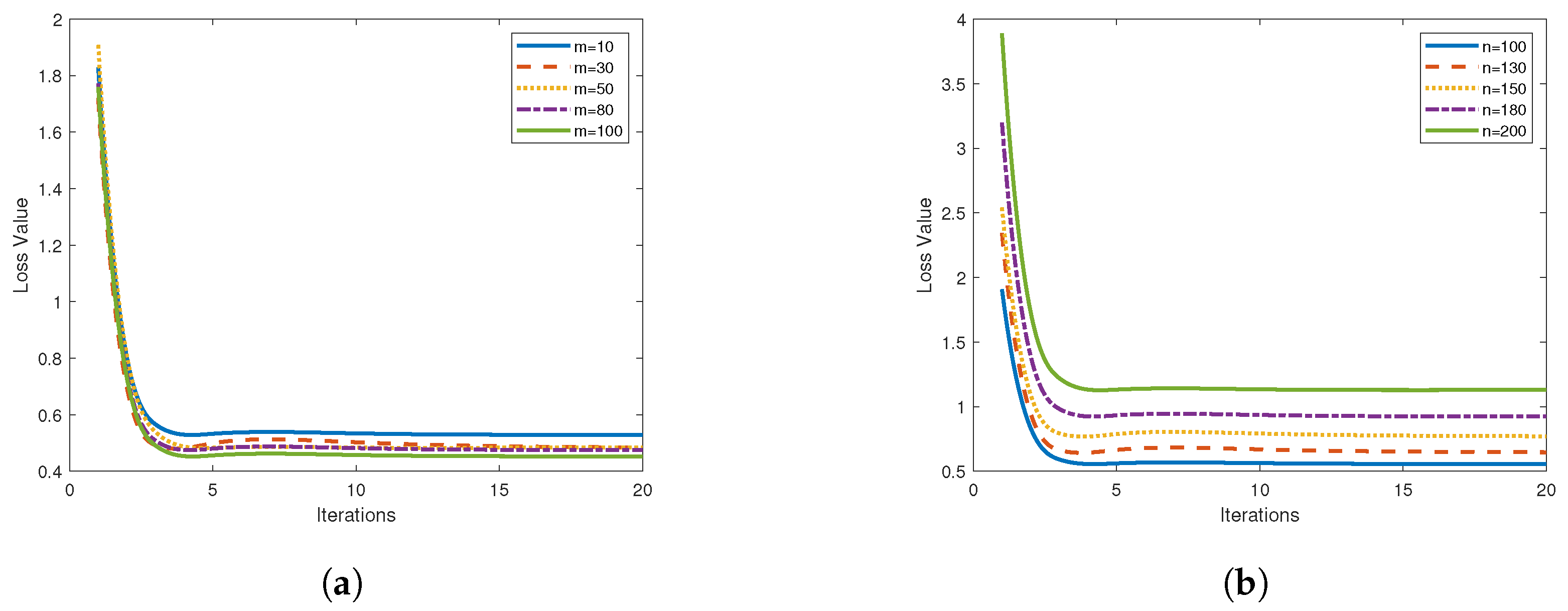
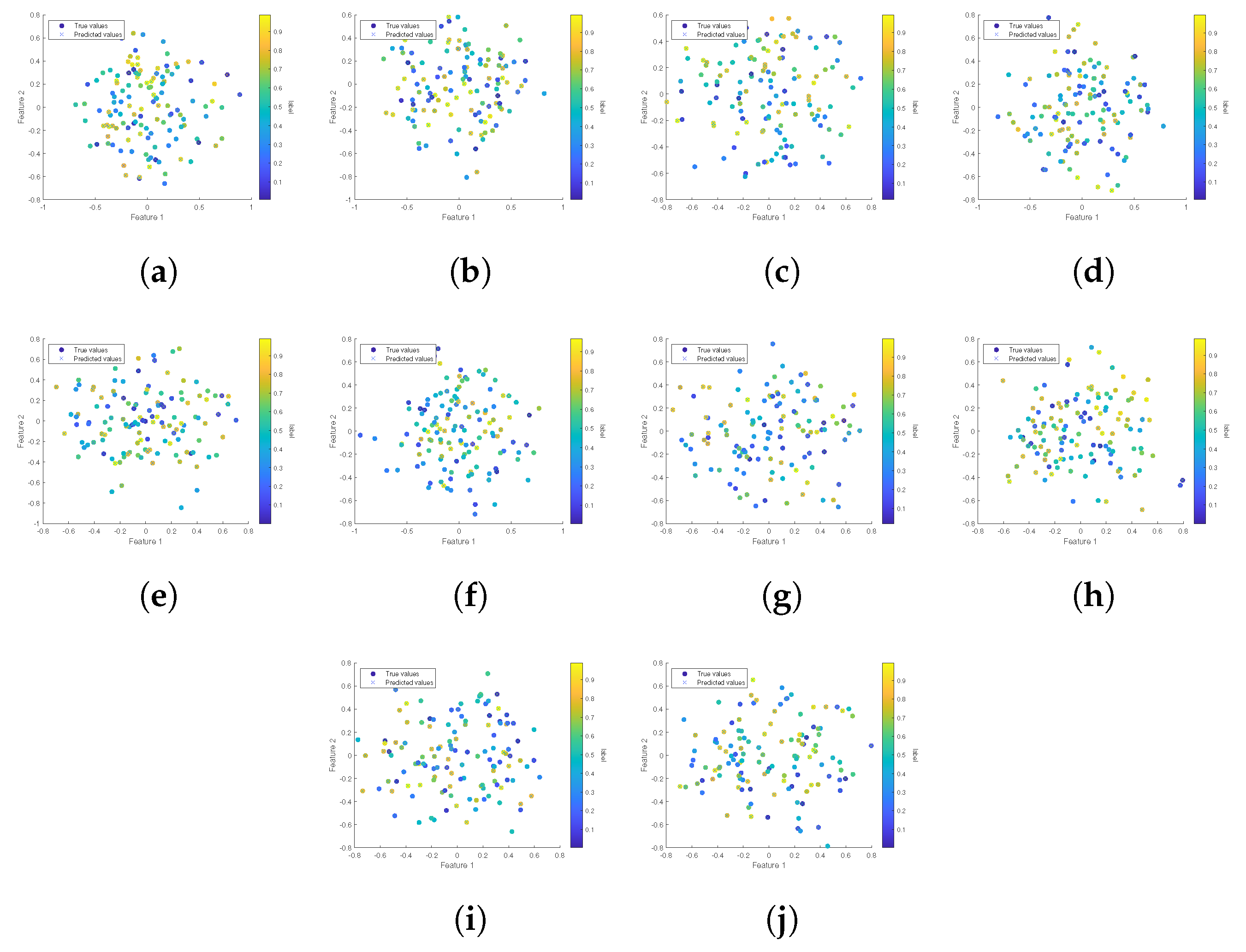
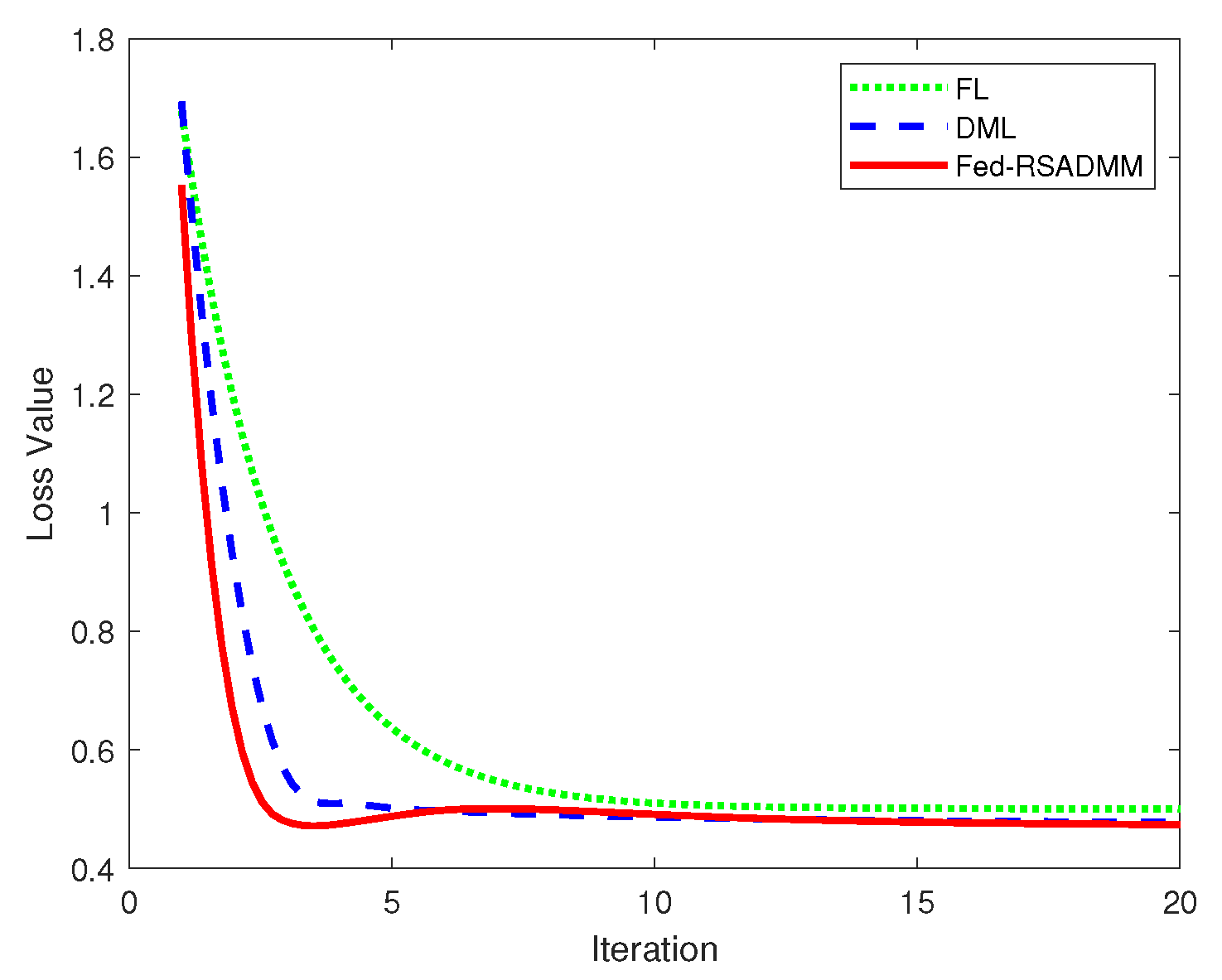
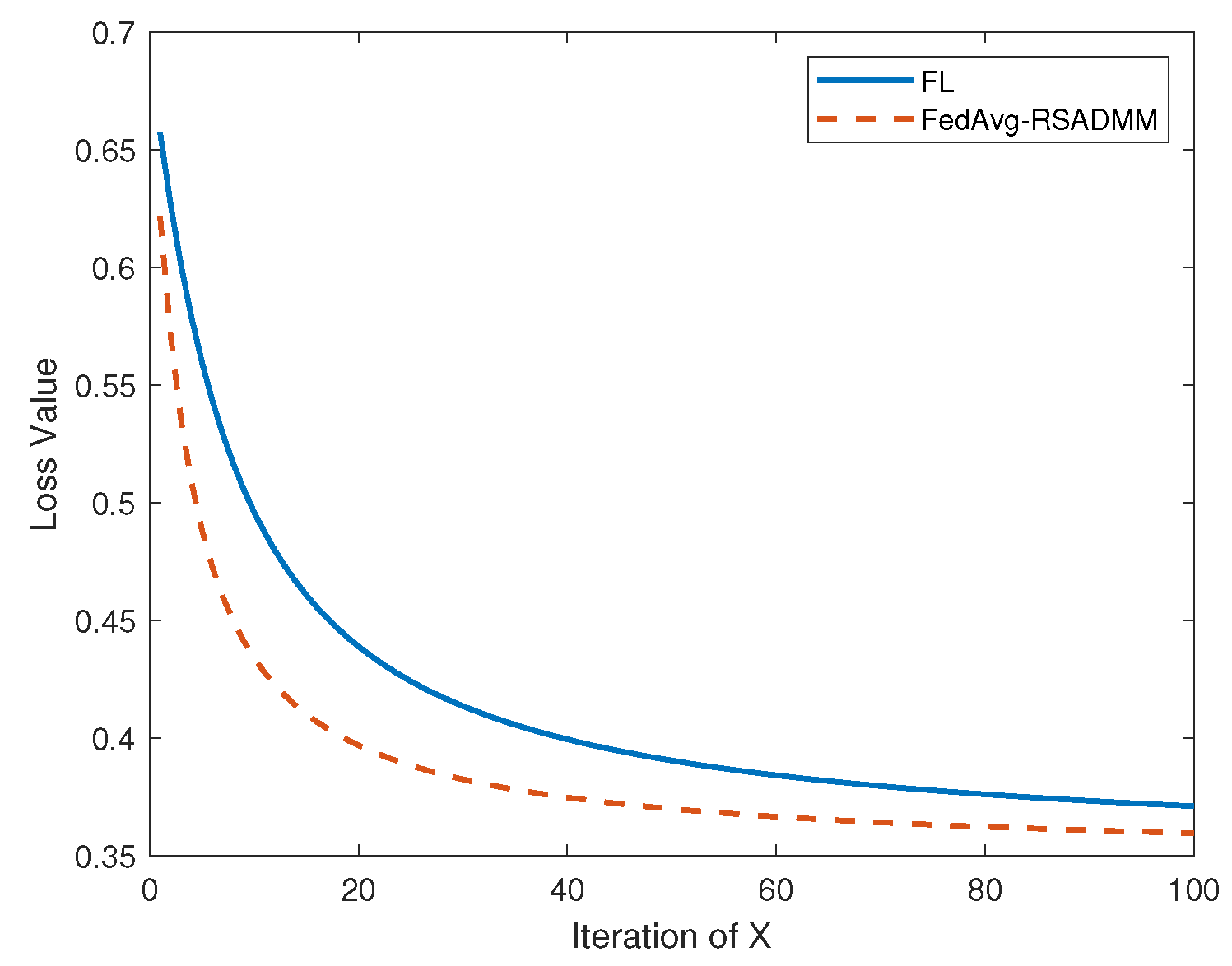
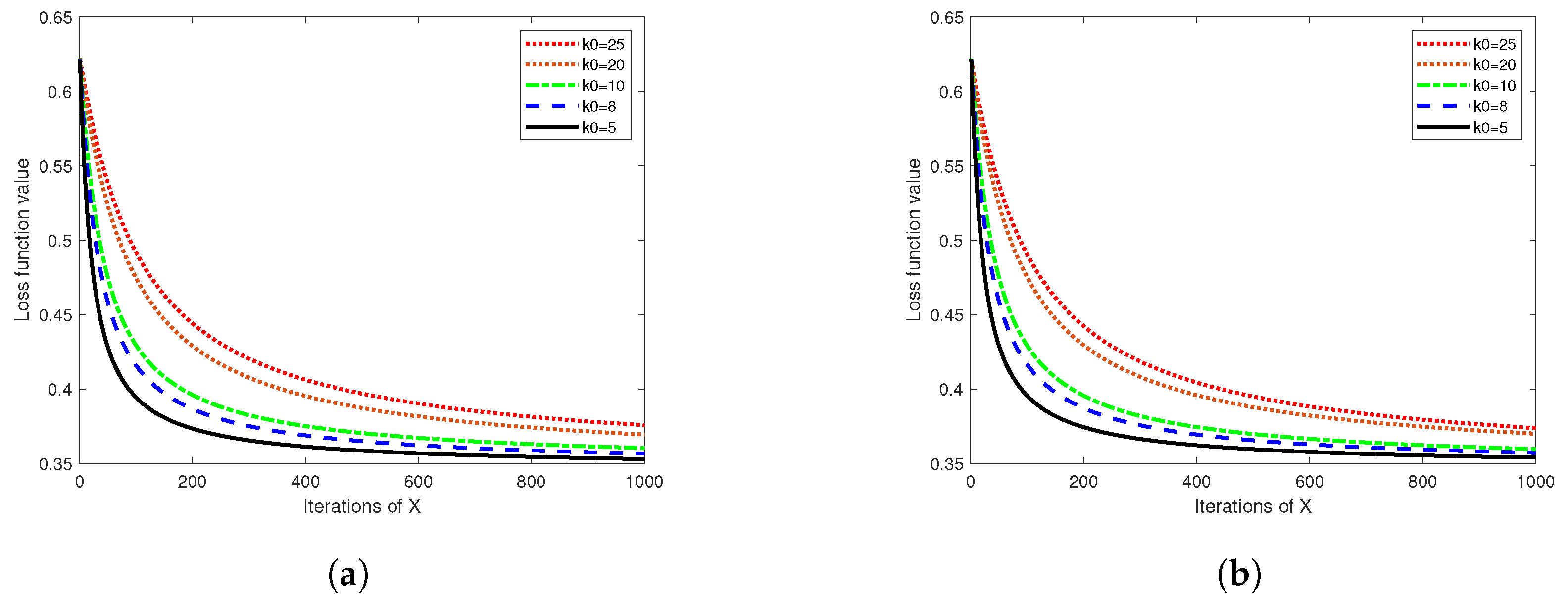
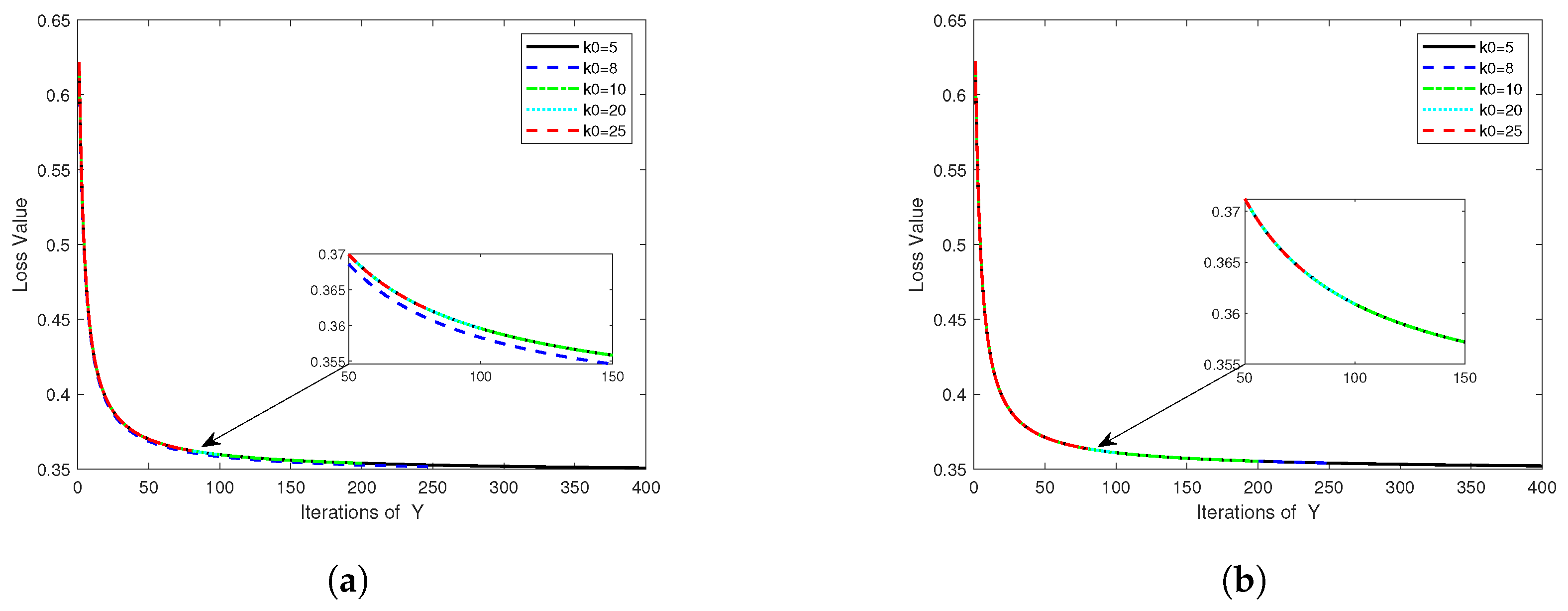
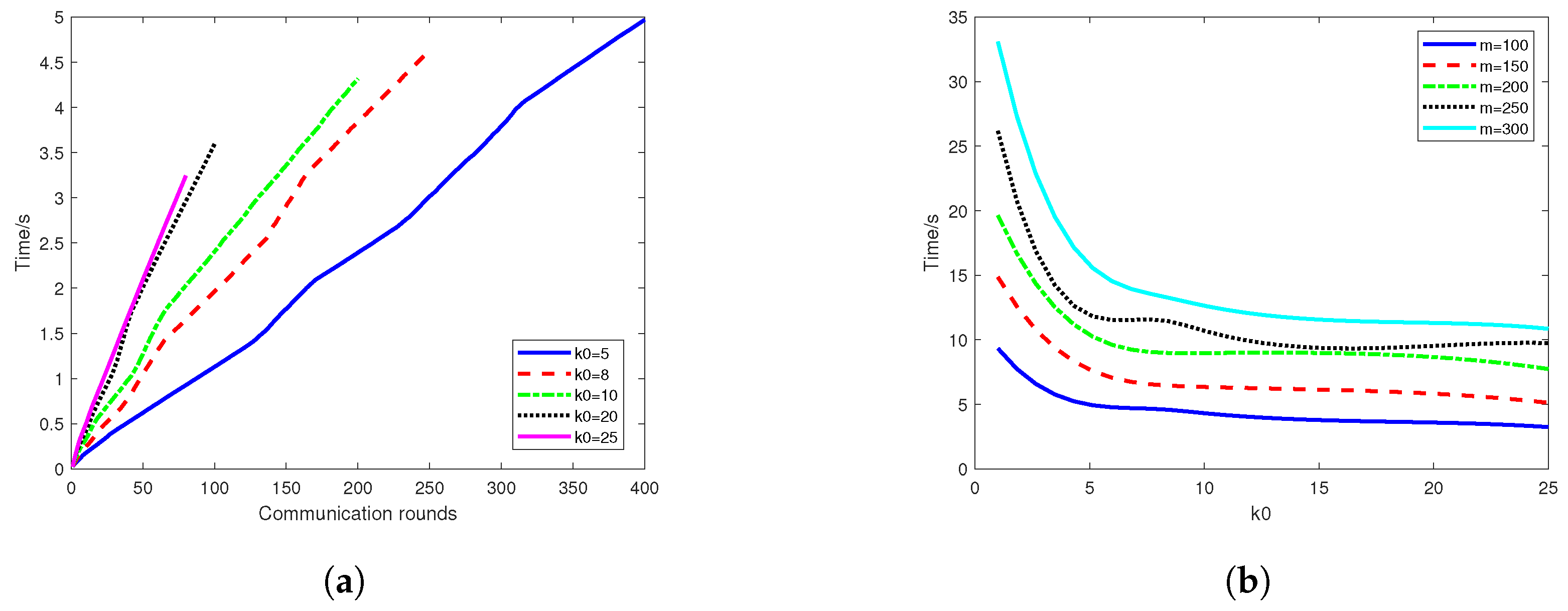
4.2. Numerical Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
Appendix A.1. Proof of Lemma 3
Appendix A.2. Proof of Lemma 4
Appendix A.3. Proof of Theorem 1
Appendix A.4. Proof of Lemma 5
Appendix A.5. Proof of Theorem 2
Appendix A.6. Proof of Theorem 3
References
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; Arcas, B.A.y. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, PMLR, Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- Li, T.; Sahu, A.K.; Zaheer, M.; Sanjabi, M.; Talwalkar, A.; Smith, V. Federated optimization in heterogeneous networks. Proc. Mach. Learn. Syst. 2020, 2, 429–450. [Google Scholar]
- Zhang, X.; Hong, M.; Dhople, S.; Yin, W.; Liu, Y. Fedpd: A federated learning framework with adaptivity to non-iid data. IEEE Trans. Signal Process. 2021, 69, 6055–6070. [Google Scholar] [CrossRef]
- Yang, Q.; Liu, Y.; Chen, T.; Tong, Y. Federated machine learning: Concept and applications. Acm Trans. Intell. Syst. Technol. (TIST) 2019, 10, 1–19. [Google Scholar] [CrossRef]
- Liu, T.; Wang, Z.; He, H.; Shi, W.; Lin, L.; An, R.; Li, C. Efficient and secure federated learning for financial applications. Appl. Sci. 2023, 13, 5877. [Google Scholar] [CrossRef]
- Zeng, Q.; Lv, Z.; Li, C.; Shi, Y.; Lin, Z.; Liu, C.; Song, G. FedProLs: Federated learning for IoT perception data prediction. Appl. Intell. 2023, 53, 3563–3575. [Google Scholar] [CrossRef]
- Manias, D.M.; Shami, A. Making a case for federated learning in the internet of vehicles and intelligent transportation systems. IEEE Netw. 2021, 35, 88–94. [Google Scholar] [CrossRef]
- Posner, J.; Tseng, L.; Aloqaily, M.; Jararweh, Y. Federated learning in vehicular networks: Opportunities and solutions. IEEE Netw. 2021, 35, 152–159. [Google Scholar] [CrossRef]
- Konečný, J.; McMahan, B.; Ramage, D. Federated optimization: Distributed optimization beyond the datacenter. arXiv 2015, arXiv:1511.03575. [Google Scholar]
- Satish, S.; Nadella, G.S.; Meduri, K.; Gonaygunta, H. Collaborative Machine Learning without Centralized Training Data for Federated Learning. Int. Mach. Learn. J. Comput. Eng. 2022, 5, 1–14. [Google Scholar]
- Zhou, S.; Li, G.Y. Federated learning via inexact ADMM. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 9699–9708. [Google Scholar] [CrossRef]
- Elgabli, A.; Park, J.; Ahmed, S.; Bennis, M. L-FGADMM: Layer-wise federated group ADMM for communication efficient decentralized deep learning. In Proceedings of the 2020 IEEE Wireless Communications and Networking Conference (WCNC), Seoul, Republic of Korea, 25–28 May 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–6. [Google Scholar]
- Zhang, X.; Khalili, M.M.; Liu, M. Improving the privacy and accuracy of ADMM-based distributed algorithms. In Proceedings of the International Conference on Machine Learning, PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 5796–5805. [Google Scholar]
- Guo, Y.; Gong, Y. Practical collaborative learning for crowdsensing in the internet of things with differential privacy. In Proceedings of the 2018 IEEE Conference on Communications and Network Security (CNS), Beijing, China, 30 May–1 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–9. [Google Scholar]
- Zhang, X.; Khalili, M.M.; Liu, M. Recycled ADMM: Improve privacy and accuracy with less computation in distributed algorithms. In Proceedings of the 2018 56th Annual Allerton Conference on Communication, Control, and Computing (Allerton), Monticello, IL, USA, 2–5 October 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 959–965. [Google Scholar]
- Huang, Z.; Hu, R.; Guo, Y.; Chan-Tin, E.; Gong, Y. DP-ADMM: ADMM-based distributed learning with differential privacy. IEEE Trans. Inf. Forensics Secur. 2019, 15, 1002–1012. [Google Scholar] [CrossRef]
- He, S.; Zheng, J.; Feng, M.; Chen, Y. Communication-efficient federated learning with adaptive consensus admm. Appl. Sci. 2023, 13, 5270. [Google Scholar] [CrossRef]
- Ding, J.; Errapotu, S.M.; Zhang, H.; Gong, Y.; Pan, M. Stochastic ADMM based distributed machine learning with differential privacy. In Proceedings of the Security and Privacy in Communication Networks: 15th EAI International Conference, SecureComm 2019, Orlando, FL, USA, 23–25 October 2019; Proceedings, Part I 15. Springer International Publishing: Berlin/Heidelberg, Germany, 2019; pp. 257–277. [Google Scholar]
- Hager, W.W.; Zhang, H. Convergence rates for an inexact ADMM applied to separable convex optimization. Comput. Optim. Appl. 2020, 77, 729–754. [Google Scholar] [CrossRef]
- Yue, S.; Ren, J.; Xin, J.; Lin, S.; Zhang, J. Inexact-ADMM based federated meta-learning for fast and continual edge learning. In Proceedings of the Twenty-Second International Symposium on Theory, Algorithmic Foundations, and Protocol Design for Mobile Networks and Mobile Computing, Shanghai, China, 26–29 July 2021; pp. 91–100. [Google Scholar]
- Ryu, M.; Kim, K. Differentially private federated learning via inexact ADMM with multiple local updates. arXiv 2022, arXiv:2202.09409. [Google Scholar]
- Zhang, S.; Choromanska, A.E.; LeCun, Y. Deep learning with elastic averaging SGD. In Proceedings of the Advances in Neural Information Processing Systems 28, Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Koloskova, A.; Stich, S.U.; Jaggi, M. Sharper convergence guarantees for asynchronous SGD for distributed and federated learning. In Proceedings of the Advances in Neural Information Processing Systems 35, New Orleans, LA, USA, 28 November–9 December2022; pp. 17202–17215. [Google Scholar]
- Yu, H.; Yang, S.; Zhu, S. Parallel restarted SGD with faster convergence and less communication: Demystifying why model averaging works for deep learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January 27–1 February 2019; Volume 33, pp. 5693–5700. [Google Scholar]
- Dai, S.; Meng, F. Addressing modern and practical challenges in machine learning: A survey of online federated and transfer learning. Appl. Intell. 2023, 53, 11045–11072. [Google Scholar] [CrossRef]
- Wang, J.; Joshi, G. Cooperative SGD: A unified framework for the design and analysis of local-update SGD algorithms. J. Mach. Learn. Res. 2021, 22, 1–50. [Google Scholar]
- Smith, V.; Forte, S.; Ma, C.; Takac, M.; Jordan, M.I.; Jaggi, M. CoCoA: A general framework for communication-efficient distributed optimization. J. Mach. Learn. Res. 2018, 18, 1–49. [Google Scholar]
- Konečný, J.; McMahan, H.B.; Ramage, D.; Richtárik, P. Federated optimization: Distributed machine learning for on-device intelligence. arXiv 2016, arXiv:1610.02527. [Google Scholar]
- Konečný, J.; McMahan, H.B.; Yu, F.X.; Richtárik, P.; Suresh, A.T.; Bacon, D. Federated learning: Strategies for improving communication efficiency. arXiv 2016, arXiv:1610.05492. [Google Scholar]
- Li, T.; Sahu, A.K.; Sanjabi, M.; Zaheer, M.; Talwalkar, A.; Smith, V. On the convergence of federated optimization in heterogeneous networks. arXiv 2018, arXiv:1812.06127. [Google Scholar]
- Rockafellar, R.T.; Wets RJ, B. Variational Analysis; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Parikh, N.; Boyd, S. Proximal algorithms. Found. Trends® Optim. 2014, 1, 127–239. [Google Scholar] [CrossRef]
- Shalev-Shwartz, S.; Ben-David, S. Understanding Machine Learning: From Theory to Algorithms; Cambridge University Press: Cambridge, UK, 2014. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Bottou, L. Large-scale machine learning with stochastic gradient descent. In Proceedings of the COMPSTAT’2010: 19th International Conference on Computational Statistics, Paris, France, 22–27 August 2010; Keynote, Invited and Contributed Papers. Physica-Verlag HD: Heidelberg, Germany, 2010; pp. 177–186. [Google Scholar]
- Wang, S.; Tuor, T.; Salonidis, T.; Leung, K.K.; Makaya, C.; He, T.; Chan, K. Adaptive federated learning in resource constrained edge computing systems. IEEE J. Sel. Areas Commun. 2019, 37, 1205–1221. [Google Scholar] [CrossRef]
- Zhu, Y. An augmented ADMM algorithm with application to the generalized lasso problem. J. Comput. Graph. Stat. 2017, 26, 195–204. [Google Scholar] [CrossRef]
- Yang, K.; Jiang, T.; Shi, Y.; Ding, Z. Federated learning via over-the-air computation. IEEE Trans. Wirel. Commun. 2020, 19, 2022–2035. [Google Scholar] [CrossRef]
- Jia, Z.; Gao, X.; Cai, X.; Han, D. Local linear convergence of the alternating direction method of multipliers for nonconvex separable optimization problems. J. Optim. Theory Appl. 2021, 188, 1–25. [Google Scholar] [CrossRef]
- Jia, Z.; Gao, X.; Cai, X.; Han, D. The convergence rate analysis of the symmetric ADMM for the nonconvex separable optimization problems. J. Ind. Manag. Optim. 2021, 17, 1943–1971. [Google Scholar] [CrossRef]
- Kadu, A.; Kumar, R. Decentralized full-waveform inversion. In Proceedings of the 80th EAGE Conference and Exhibition 2018, Copenhagen, Denmark, 11–14 June 2018; European Association of 1Geoscientists and Engineers: Utrecht, The Netherlands, 2018; Volume 2018, pp. 1–5. [Google Scholar]
- Yin, Z.; Orozco, R.; Herrmann, F.J. WISER: Multimodal variational inference for full-waveform inversion without dimensionality reduction. arXiv 2024, arXiv:2405.10327. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Loss Function |
|---|---|
| Linear regression | |
| Squared-SVM | |
| K-means |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, J.; Zhu, Y.; Dang, Y. Symmetric ADMM-Based Federated Learning with a Relaxed Step. Mathematics 2024, 12, 2661. https://doi.org/10.3390/math12172661
Lu J, Zhu Y, Dang Y. Symmetric ADMM-Based Federated Learning with a Relaxed Step. Mathematics. 2024; 12(17):2661. https://doi.org/10.3390/math12172661
Chicago/Turabian StyleLu, Jinglei, Ya Zhu, and Yazheng Dang. 2024. "Symmetric ADMM-Based Federated Learning with a Relaxed Step" Mathematics 12, no. 17: 2661. https://doi.org/10.3390/math12172661
APA StyleLu, J., Zhu, Y., & Dang, Y. (2024). Symmetric ADMM-Based Federated Learning with a Relaxed Step. Mathematics, 12(17), 2661. https://doi.org/10.3390/math12172661