Abstract
This paper considers a class of distributed online aggregative optimization problems over an undirected and connected network. It takes into account an unknown dynamic environment and some aggregation functions, which is different from the problem formulation of the existing approach, making the aggregative optimization problem more challenging. A distributed online optimization algorithm is designed for the considered problem via the mirror descent algorithm and the distributed average tracking method. In particular, the dynamic environment and the gradient are estimated by the averaged tracking methods, and then an online optimization algorithm is designed via a dynamic mirror descent method. It is shown that the dynamic regret is bounded in the order of . Finally, the effectiveness of the designed algorithm is verified by some simulations of cooperative control of a multi-robot system.
MSC:
68W15
1. Introduction
The distributed online optimization problem for multi-agent systems has received considerable attention in the past few decades [1,2]. The objective is to minimize a global time-varying cost function, written as the sum of local convex functions, under the constrict that each individual agent has only knowledge of the local convex functions.
Recently, some researchers have focused on distributed online aggregative optimization, which is a special class of online optimization problems. In distributed online aggregative optimization, the local cost functions include some aggregative terms motivated by many real applications. These aggregative terms make the design and analyses of the online optimization algorithm more challenging. Some tracking methods were presented to solve distributed online aggregative optimization problems. For example, a distributed aggregative gradient tracking algorithm is proposed and analyzed in [3] to solve a distributed online aggregative optimization problem. It is shown that convergence to the optimal variable is linear. Different from [3], a set constraint is considered in [4], where an online distributed gradient tracking algorithm is proposed to solve a distributed online aggregative optimization problem with exact gradient information and stochastic/noisy gradients, respectively. The upper boundary of dynamic regret is analyzed and given, and some simulations on the target surrounding problem are provided to verify the effectiveness of the designed algorithm. The authors of [5] considered the distributed online aggregative optimization without the assumption of boundedness of the gradients and the feasible sets. In particular, a projected aggregative tracking algorithm was presented in [5], and the authors showed that the dynamic regret is bounded by a constant term and a term related to time variations.
Dynamic environments are common in the real applications of online optimization [6,7,8,9,10,11]. For example, the authors of [6] showed that many online learning problems, including the dynamic texture analysis, solar flare detection, sequential compressed sensing of a dynamic scene, traffic surveillance, tracking self-exciting point processes, and network behavior in the Enron email corpus, can benefit from the incorporation of a dynamic environment. In [7], the tracking problem of a time-varying parameter with unknown dynamics was studied as an online optimization in a dynamic environment. The distributed tracking and tracking of dynamic point processes on network problems were solved in [8,9] using mirror descent methods with dynamical environments, respectively. The localization of sensor networks problem was solved in [10] by using a distributed online bandit learning algorithm over a multi-agent network with a dynamical environment. Note that the dynamic environments were assumed to be known in [6,7,8,9,10]. In contrast with [6,7,8,9,10], an unknown dynamic environment was considered in [11], where the dynamic regret was shown to be bounded.
Based on the above discussions, the distributed online aggregative optimization with a dynamic environment is motivated by many real applications. The problem has many applications, especially under the condition that the dynamic environment is unknown. Therefore, this paper considers a class of distributed online aggregative optimization problems with an unknown dynamic environment. The main contributions are as follows. Some aggregative terms and an unknown dynamic environment are simultaneously considered in this paper for an online optimization problem. The problem formulation comes from some real applications, e.g., the cooperative control problem for a multi-robot system in the simulation section. Compared with [3,4,5,6,7,8,9,10,11], the dynamic environment was not considered in [3,4,5], and the aggregative terms were not considered in [6,7,8,9,10,11], respectively. Therefore, the design and analyses of the optimization algorithm in this paper are more challenging than in [3,4,5,6,7,8,9,10,11]. In particular, some averaged tracking methods estimate the dynamic environment and the gradient. Based on the estimations, an online optimization algorithm is designed via a dynamic mirror descent method. It is shown that the dynamic regret is bounded in the order of , and some simulations are proposed to verify the effectiveness of the designed algorithm.
The remaining parts of this paper are organized as follows. In Section 2 and Section 3, some preliminaries and problem formulation are presented. The main results are proposed in Section 4. In Section 5, the performance of the designed algorithm is verified by some simulations. Section 6 concludes the paper.
2. Preliminaries
2.1. Notations
denotes the n-dimensional Euclidean space. denotes the 2-norm of a vector x. with positive integer T denotes the set . denotes the inner product of vectors and , i.e., where denotes the transpose of x. For a function , denotes the gradient of with respect to a vector x. denotes the second-largest singular value of matrix W.
2.2. Graph Theory
For a multi-agent system, we use a directed graph to describe the information exchange within it, where is the node set and is the edge set. represents that agent i can obtain information from agent j. The self-loop is unconsidered, i.e., . denotes the in-neighbor set of node i. If for every , there exists , then the graph is an undirected graph. A path between nodes i and j is a sequence of edges in the graph where are some distinct nodes. An undirected graph is connected if there is a path between each pair of nodes.
2.3. Bregman Divergence
The mirror descent algorithm based on Bregman divergence is frequently used and effective in online optimization [8]. The Bregman divergence is defined as follows. Let be a strongly convex function which satisfies
and define the Bregman divergence as
3. Problem Formulation
Considering a network system composed of N agents, and there exists a sequence of time-varying convex function over the network composed of . Considering the following optimization problem,
where , , , , and is the aggregative variable defined by . The function is convex and assigned to agent i. Supposing there exists a sequence of unknown stable non-expansive mapping , i.e., , such that
where and is an unstructured and unknown noise. Assuming that agent i independently observes the mapping , and denotes the observed value in time t. Moreover, assuming that is the optimal observed value for all agents and is the optimal solution to the following optimization problem:
It follows from (4) and (5) that
where .
Distributed Online Aggregative Optimization Problem:
The objective is to generate a sequence to minimize the following dynamic regret,
where is the optimal solution to (3) which satisfies constraint (6), i.e., while satisfies constraint (6).
Remark 1.
The online aggregative optimization problems have been studied in [4,5]. However, this paper considers an unknown dynamic environment, which is more challenging than [4,5], i.e., the mapping .
Let , and denote , and , respectively. Let be the adjacency matrix of network , and be the global step-size which will be used to design an online optimization algorithm in the next section. Let and be some convex sets which will be defined in the next section. Some necessary assumptions are as follows.
Assumption 1.
Graph is undirected and connected, and W is doubly stochastic, i.e.,
and there exists a constant such that when , and for all .
Assumption 2.
For , , and , the functions , , , , and are Lipschitz continuous, and the functions , and are bounded, i.e.,
where L is the Lipschitz constant, and .
Assumption 3.
There exists
where , is on the N-dimensional simplex, and K and are some Lipschitz constants.
Assumption 4.
There exists positive constants and M, such that , and , where is the global step sequence. Moreover, , holds for and .
Remark 2.
Assumptions 1, 3, and 4 come from [6,7,8,11]. They are common in mirror descent algorithms for distributed online optimization. Assumption 2 is also common in online aggregation optimization [4].
4. Main Result
Inspired by [11], consider the following online algorithm:
where , , , is the global step sequence, , , , and are some auxiliary variables, and is the designed sequence. In (8), the initial states are chosen such that , , and .
It follows from (8) that the states in (8) are bounded. Let sets and satisfy , , and . Let , , , and
Remark 3.

We have provided a comparative analysis of problem formulation of online optimization in Table 1, where denotes distributed average tracking. It follows that the problem considered in this paper is more challenging than [3,4,5,6,7,8,9,10,11]. Algorithms (8a)–(8d) come from [11]. In fact, algorithms (8a)–(8d) have been used in [11] to solve a class-distributed online optimization problem with an unknown mapping. However, the aggregative variable is not considered in [11]. This makes the design and analyses of the optimization algorithm more challenging. In particular, it follows from (3) that, for agent i, the gradient of the function with respect to x is . But and are unknown for agent i due to the topology constraint. Therefore, the algorithms (8e) and (8f) are added by using the distributed average tracking method to estimate and . Based on (8e) and (8f), the new gradient is introduced in algorithm (8b). Hence, algorithms (8e) and (8f) are used to achieve aggregative gradient tracking via . A strict analysis of dynamic regret of algorithm (8) will be presented as follows.
Table 1.
Comparison of problem formulation and algorithm of online optimization.
Some lemmas and the main result are presented as follows, and the proofs are given in the Appendix A, Appendix B, Appendix C, Appendix D, Appendix E, Appendix F and Appendix G.
Lemma 1.
Consider the mapping (5) and the algorithm (8a), and supposing that Assumptions 1 and 4 hold. Then for all and , there exists
where .
Lemma 2.
Considering algorithm (8f), and supposing that Assumptions 1 and 2 hold, then for all and , there exists,
where , , , and .
Lemma 3.
Considering algorithms (8a)–(8d), and supposing that Assumptions 1–4 hold, then for all and , there exists,
where .
Lemma 4.
Considering algorithm (8), and supposing that Assumptions 1–3 hold, then for all and , there exists,
where , , and .
Lemma 5.
Considering algorithm (8), and supposing that Assumptions 1, 3 and 4 hold, then for all and , there exists,
where .
Lemma 6.
Considering algorithm (8), and supposing that Assumptions 1–3 hold, then for all and , there exists,
The main result of this paper is as follows.
Theorem 1.
Considering the optimization problem (3), constraint (6), and algorithm (8), and supposing that Assumptions 1–4 hold. Let and . Then there exists
where , , and .
Remark 4.
The condition is reasonable since a sufficiently small is chosen by decreasing . It follows from the boundary in Theorem 1 that a proper step is with . In such a case, the regret is bounded in the order of for any arbitrary .
5. Simulations
Inspired by [5,8], considering a cooperative control problem for a multi-robot system in a plant , in particular, a moving target with state is modeled as
where and is the noise. Moreover, there is a multi-robot network composed of N robots aiming to protect the target, while there are N intruders aiming to capture the target. Let denote the state of the ith intruder at time t, which is assigned to robot i. Supposing that the formation of a multi-robot network is defined by a virtual leader–follower formation method, let denote the leader’s state which is unknown for all robots. In particular, let denote the estimated value of by robot i at time t, and the state of robot i is given by , where and represent an offset of robot i to the virtual leader .
The multi-robot network is used to protect the moving target by choosing an optimal virtual leader such that the average state of all the robots is close to the target. Meanwhile, each robot is simultaneously close to the associated intruder, referring to Figure 1. Let denote the averaged state of robots where . Then, the cooperative control problem can be modeled as the following optimization problem:
where
, and . In fact, the objective is to cooperate in seeking an optimal virtual leader, which is the optimal solution to the problem (13).
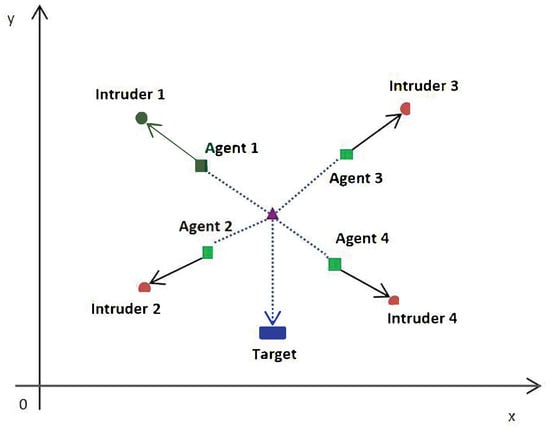
Figure 1.
The concept of the cooperative control problem for a multi-robot system.
It is worth pointing out that the estimated virtual leader should be consensus. Therefore, let be the consensus solution to problem (13). Then should be the solution to the following online optimization problem:
where and . In addition, it follows from (12) that should also have the mapping , i.e., satisfies the following constraint:
where is an unknown and unstructured noise. Note that is unknown for all robots. Hence, denotes the observed mapping of at time t for robot i. Problem (14) and constraint (15) take the form of problem (3) and constraint (6), so Algorithm 1 can be used to solve problem (14) with constraint (15).
Let , , , is a random vector chosen from a normal distribution with zero mean and standard deviation , , , , , , the unknown noise satisfies , and where is a random number chosen from a normal distribution with zero mean and standard deviation .
Choosing , and , and supposing that an arbitrary doubly stochastic W is given, it can be verified that Assumptions 1–4 and the condition hold. The simulations are performed on a computer equipped with AMD Ryzen 9 5950X 16-core CPU, 64G RAM, and Nvidia RTX 3080Ti GPU. Figure 2 shows the trajectory of robot 1 by using Algorithm 1. The dynamic regret of Algorithm 1 is indicated in Figure 3, and the regret in Figure 3 is bounded. Therefore, Theorem 1 is verified by Figure 2 and Figure 3.
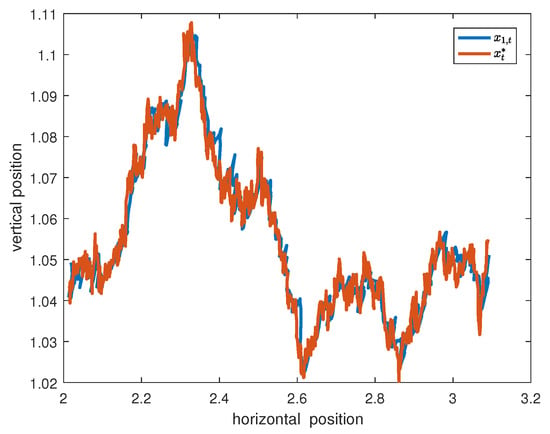
Figure 2.
Trajectories of and over .
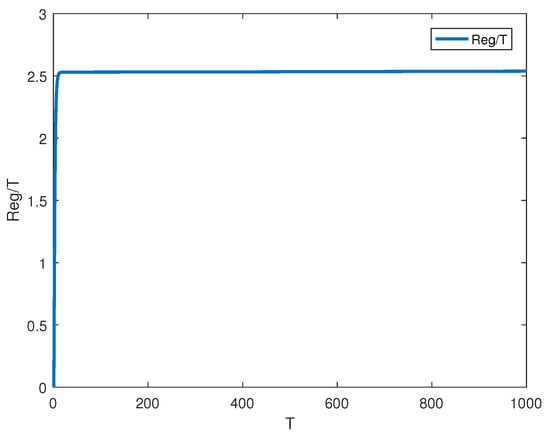
Figure 3.
The dynamic regret of Algorithm 1 for problem (14) with constraint (15).
6. Conclusions
This paper introduces an online optimization algorithm for addressing distributed online aggregative problems featuring dynamic environments. With this algorithm, the dynamic regret converges to a boundary without relying on the condition that the dynamic environment is known. Future research includes the distributed online optimization problems in the context of time-varying directed networks.
Author Contributions
Conceptualization, C.Y., S.W. and B.H.; methodology, C.Y. and S.W.; writing—original draft preparation, C.Y. and S.W.; writing—review and editing, S.Z. and S.L.; funding acquisition, B.H. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported in part by the National Key R&D Program of China under Grant 2022ZD0119601.
Data Availability Statement
No new data were created or analyzed in this study. Data sharing is not applicable to this article.
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A
Proof of Lemma 1.
The proof follows from Lemma 2.1 in [11]. □
Appendix B
Proof of Lemma 2.
Let . Then the algorithm (8f) can be rewritten as
According to Lemma 2 in [12],
It follows from Assumption 2 that . Then,
Moreover, it follows from (8f) that
By using Assumption 1,
It follows from that . Assumption 2 implies that holds. Therefore,
□
Appendix C
Proof of Lemma 3.
Let and . It follows from Lemma 2.2 in [11] that
and
By using the result in Lemma 2, (9) holds. □
Appendix D
Proof of Lemma 4.
Considering the first inequality in (10), and it follows from (A2) that
which implies that
Thus, the first inequality in (10) holds.
Consider the second inequality in (10). Note that there exists
where the last line is since the function is Lipschitz (see Assumption 2). By using (9),
Let . By using Assumption 2 and (A5),
It follows from that
According to Lemma 2 in [12], it follows that
It follows from (8e) and Assumption 1 that
According to the initial state , it follows that
It follows from (A8) and (A9) that
Combining (A6), (A7), and (A10), the second inequality in (10) holds.
Considering the third inequality in (10), and note that there exists
Similar to (A8), there exists
It follows from (A1) that
Therefore, according to (A5), (A11), and (A12), the third inequality in (10) holds. □
Appendix E
Proof of Lemma 5.
The proof is follows from Lemma 2.3 in [11]. □
Appendix F
Proof of Lemma 6.
It follows from Assumption 2 and Lemma 2 that
According to Assumption 2 and Lemma 4, we have
and
Then the proof is over by combining (A13)–(A15) and (10). □
Appendix G
Proof of Theorem 1.
Note that the function is convex. Thus, there exists
According to algorithm (8a), Lemma 4.1 in [13], and the fact that where , it follows that
By using Lemmas 2 and 3, Assumption 1, and Algorithm (8d),
It follows from Lemma 2 that
According to (A16)–(A19), we have that
Then it follows from Lemmas 5 and 6 that
Note that is fixed and satisfies . It follows from , (A20) and Assumption 2 that
Then it follows from (A21) that
Therefore, the proof is over by combining (A22) with
□
References
- Shi, Y.; Ran, L.; Tang, J.; Wu, X. Distributed optimization algorithm for composite optimization problems with non-smooth function. Mathematics 2022, 10, 3135. [Google Scholar] [CrossRef]
- Li, X.X.; Xie, L.H.; Li, N. A survey on distributed online optimization and online games. Annu. Rev. Control 2023, 56, 24. [Google Scholar] [CrossRef]
- Li, X.X.; Xie, L.H.; Hong, Y.G. Distributed aggregative optimization over multi-agent networks. IEEE Trans. Autom. Control 2022, 67, 3165–3171. [Google Scholar] [CrossRef]
- Li, X.X.; Yi, X.L.; Xie, L.H. Distributed online convex optimization with an aggregative variable. IEEE Trans. Control Netw. Syst. 2022, 9, 438–449. [Google Scholar] [CrossRef]
- Carnevale, G.; Camisa, A.; Notarstefano, G. Distributed online aggregative optimization for dynamic multirobot coordination. IEEE Trans. Autom. Control 2023, 68, 3736–3743. [Google Scholar] [CrossRef]
- Hall, E.C.; Willett, R.M. Online convex optimization in dynamic environments. IEEE J. Sel. Top. Signal Process. 2015, 9, 647–662. [Google Scholar] [CrossRef]
- Mokhtari, A.; Shahrampour, S.; Jadbabaie, A.; Ribeiro, A. Online optimization in dynamic environments: Improved regret rates for strongly convex problems. In Proceedings of the 55th IEEE Conference on Decision and Control (CDC), Las Vegas, NV, USA, 12–14 December 2016; pp. 7195–7201. [Google Scholar]
- Shahrampour, S.; Jadbabaie, A. Distributed online optimization in dynamic environments using mirror descent. IEEE Trans. Autom. Control 2018, 63, 714–725. [Google Scholar] [CrossRef]
- Nazari, P.; Khorram, E.; Tarzanagh, D.A. Adaptive online distributed optimization in dynamic environments. Optim. Method Softw. 2021, 36, 973–997. [Google Scholar] [CrossRef]
- Li, J.Y.; Li, C.J.; Yu, W.W.; Zhu, X.M.; Yu, X.H. Distributed online bandit learning in dynamic environments over unbalanced digraphs. IEEE Trans. Netw. Sci. Eng. 2021, 8, 3034–3047. [Google Scholar] [CrossRef]
- Wang, S.; Huang, B.M. Distributed online optimisation in unknown dynamic environment. Int. J. Syst. Sci. 2024, 55, 1167–1176. [Google Scholar] [CrossRef]
- Lee, S.; Zavlanos, M.M. On the sublinear regret of distributed primal-dual algorithms for online constrained optimization. arXiv 2017, arXiv:1705.11128. [Google Scholar]
- Beck, A.; Teboulle, M. Mirror descent and nonlinear projected subgradient methods for convex optimization. Oper. Res. Lett. 2003, 31, 167–175. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).