
A Parallel Optimization Method for Robustness Verification of Deep Neural Networks


Abstract
1. Introduction
- We introduce optimization strategies for the partition verification. Based on the analysis and improvement of key processes in this mode, the running speed is optimized.
- We design a general parallel verification framework for large batch inputs accordance with the features of DNN verification system. The verification efficiency is improved by the collaborative work between the modules and parallel task scheduling strategy.
- We combine the parallel optimization method with verification tools and conduct experiments to evaluate the effectiveness of the proposed method. The empirical results demonstrate that it has a positive impact on the efficiency of the tools.
2. Background and Related Work
2.1. Neural Networks and Robustness
2.2. Formal Verification and Parallelization
2.3. Verification Mode
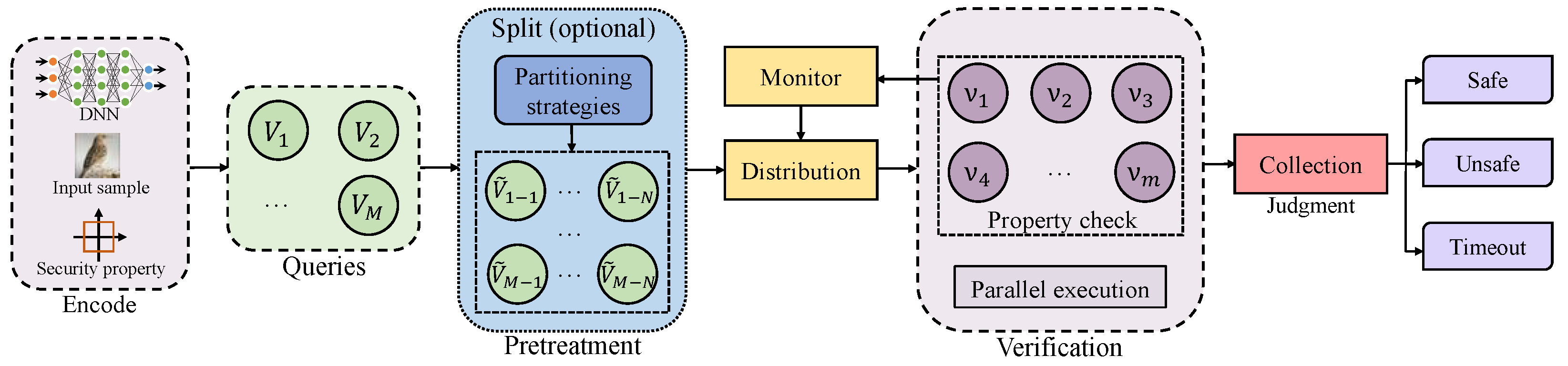
3. Parallel Optimization for Partition Verification
3.1. Partition Mode
3.2. Key Processes Analysis and Optimization
3.2.1. Split Operation
3.2.2. Target Selection
3.2.3. Timeout Strategy
3.2.4. Result Judgment
3.3. Integration Discussion
4. Parallel Verification Optimization Design
4.1. Parallel Framework
4.2. Acceleration Strategies
4.3. Verification Algorithm
| Algorithm 1 Parallel Verification | |
| Input: query , partition parameter , length threshold , timeout threshold , load threshold | |
| 1: Initialization | |
| 2: if split=true then | ▹ Stage 1: Splitting |
| 3: for do | |
| 4: pick out split targets by | |
| 5: ← split V and | |
| 6: add to verification queue Q | |
| 7: while Q is not empty do | ▹ Stage 2: Scheduling |
| 8: calculate for each | |
| 9: sort from low to high | |
| 10: distribute to in order of | |
| 11: if then | |
| 12: stop distribution to | |
| 13: result ← solve | ▹ Stage 3: Determination |
| 14: if := UNSAT then | |
| 19: return safe | |
| 16: else if := SAT then | |
| 17: return unsafe | |
| 18: else if then | |
| 19: return timeout | |
4.4. Distributed Extension
5. Experiments
5.1. Experimental Setups
5.2. Experimental Results
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 29th IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the 31st AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 4278–4284. [Google Scholar]
- Goodfellow, I.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015; pp. 1–11. [Google Scholar]
- Kurakin, A.; Goodfellow, I.; Bengio, S. Adversarial examples in the physical world. In Proceedings of the 5th International Conference on Learning Representations, Toulon, France, 24–26 April 2017; pp. 1–14. [Google Scholar]
- Yan, Z.; Guo, Y.; Zhang, C. Deepdefense: Training deep neural networks with improved robustness. arXiv 2018, arXiv:1803.00404. [Google Scholar]
- Kuper, L.; Katz, G.; Gottschlich, J.; Julian, K.; Barrett, C. Toward scalable verification for safety-critical deep networks. arXiv 2018, arXiv:1801.05950. [Google Scholar]
- Jakubovitz, D.; Giryes, R. Improving dnn robustness to adversarial attacks using jacobian regularization. In Proceedings of the 15th European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 514–529. [Google Scholar]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing properties of neural networks. In Proceedings of the 2nd International Conference on Learning Representations, Banff, AB, Canada, 14–16 April 2014; pp. 1–9. [Google Scholar]
- Pulina, L.; Tacchella, A. An abstraction-refinement approach to verification of artificial neural networks. In Proceedings of the 22nd International Conference on Computer Aided, Edinburgh, UK, 15–19 July 2010; pp. 243–257. [Google Scholar]
- Ji, S.; Du, T.; Deng, S.; Cheng, P.; Shi, J.; Yang, M.; Li, B. Robustness certification research on deep learning models: A survey. Chin. J. Comput. 2022, 45, 190–206. [Google Scholar]
- Henriksen, P.; Lomuscio, A. Deepsplit: An efficient splitting method for neural network verification via indirect effect analysis. In Proceedings of the 30th International Joint Conference on Artificial Intelligence, Montreal, QC, Canada, 19–27 August 2021; pp. 2549–2555. [Google Scholar]
- Huang, X.; Kwiatkowska, M.; Wang, S.; Wu, M. Safety verification of deep neural networks. In Proceedings of the 29th International Conference on Computer Aided, Heidelberg, Germany, 24–28 July 2017; pp. 3–29. [Google Scholar]
- Ehlers, R. Formal verification of piece-wise linear feed-forward neural networks. In Proceedings of the 15th International Symposium on Automated Technology for Verification and Analysis, Pune, India, 3–6 October 2017; pp. 269–286. [Google Scholar]
- Katz, G.; Barrett, C.; Dill, D.; Julian, K.; Kochenderfer, M. Reluplex: An efficient smt solver for verifying deep neural networks. In Proceedings of the 29th International Conference on Computer Aided, Heidelberg, Germany, 24–28 July 2017; pp. 97–117. [Google Scholar]
- Lomuscio, A.; Maganti, L. An approach to reachability analysis for feed-forward relu neural networks. arXiv 2017, arXiv:1706.07351. [Google Scholar]
- Cheng, C.; Nührenberg, G.; Ruess, H. Maximum resilience of artificial neural networks. In Proceedings of the 15th International Symposium on Automated Technology for Verification and Analysis, Pune, India, 3–6 October 2017; pp. 251–268. [Google Scholar]
- Dutta, S.; Jha, S.; Sankaranarayanan, S.; Tiwari, A. Output range analysis for deep feedforward neural networks. In Proceedings of the 10th International Symposium on NASA Formal Methods, Newport News, VA, USA, 17–19 April 2018; pp. 121–138. [Google Scholar]
- Singh, G.; Gehr, T.; Mirman, M.; Püschel, M.; Vechev, M. Fast and effective robustness certification. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; pp. 10825–10836. [Google Scholar]
- Wong, E.; Schmidt, F.; Metzen, J.; Kolter, J. Scaling provable adversarial defenses. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; pp. 8400–8409. [Google Scholar]
- Zhang, H.; Weng, T.; Chen, P.; Hsieh, C.; Daniel, L. Efficient neural network robustness certification with general activation functions. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; pp. 4939–4948. [Google Scholar]
- Weng, T.; Zhang, H.; Chen, H.; Song, Z.; Hsieh, C.; Daniel, L.; Boning, D.; Dhillon, I. Towards fast computation of certified robustness for relu networks. In Proceedings of the 35th International Conference on Machine Learning, Stockholmsmassan, Stockholm, Sweden, 10–15 July 2018; pp. 5276–5285. [Google Scholar]
- Katz, G.; Huang, D.; Ibeling, D.; Julian, K.; Lazarus, C.; Lim, R.; Shah, P.; Thakoor, S.; Wu, H.; Zeljic, A.; et al. The marabou framework for verification and analysis of deep neural networks. In Proceedings of the 31st International Conference on Computer Aided, New York, NY, USA, 15–18 July 2019; pp. 443–452. [Google Scholar]
- Singh, G.; Ganvir, R.; Püschel, M.; Vechev, M. Beyond the single neuron convex barrier for neural network certification. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 15072–15083. [Google Scholar]
- Henriksen, P.; Lomuscio, A. Efficient neural network verification via adaptive refinement and adversarial search. In Proceedings of the 24th European Conference on Artificial Intelligence, Santiago de Compostela, Spain, 29 August–8 September 2020; pp. 2513–2520. [Google Scholar]
- Wang, S.; Zhang, H.; Xu, K.; Lin, X.; Jana, S.; Hsieh, C.; Kolter, J. Beta-crown: Efficient bound propagation with per-neuron split constraints for neural network robustness verification. In Proceedings of the 34th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 6–14 December 2021; pp. 29909–29921. [Google Scholar]
- Brix, C.; Müller, M.; Bak, S.; Johnson, T.; Liu, C. First three years of the international verification of neural networks competition (VNN-COMP). Int. J. Softw. Tools Technol. Transf. 2023, 25, 329–339. [Google Scholar] [CrossRef]
- Wang, S.; Pei, K.; Whitehouse, J.; Yang, J.; Jana, S. Formal security analysis of neural networks using symbolic intervals. In Proceedings of the 27th USENIX Security Symposium, Baltimore, MD, USA, 15–17 August 2018; pp. 1599–1614. [Google Scholar]
- Katz, G.; Barrett, C.; Dill, D.; Julian, K.; Kochenderfer, M. Towards proving the adversarial robustness of deep neural networks. In Proceedings of the 1st Workshop on Formal Verification of Autonomous Vehicles, Turin, Italy, 19 September 2017; pp. 19–26. [Google Scholar]
- Tran, H.; Musau, P.; Lopez, D.; Yang, X.; Nguyen, L.; Xiang, W.; Johnson, T. Parallelizable reachability analysis algorithms for feed-forward neural networks. In Proceedings of the 7th International Conference on Formal Methods in Software Engineering, Montreal, QC, Canada, 27 May 2019; pp. 51–60. [Google Scholar]
- Müller, C.; Serre, F.; Singh, G.; Püschel, M.; Vechev, M. Scaling polyhedral neural network verification on GPUs. In Proceedings of the 4th International Conference on Machine Learning and Systems, Virtual Website, 5–9 April 2021; pp. 733–746. [Google Scholar]
- Singh, G.; Gehr, T.; Püschel, M.; Vechev, M. An abstract domain for certifying neural networks. Proc. ACM Program. Lang. 2019, 3, 1–30. [Google Scholar] [CrossRef]
- Wang, S.; Pei, K.; Whitehouse, J.; Yang, J.; Jana, S. Efficient formal safety analysis of neural networks. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; pp. 6369–6379. [Google Scholar]
- Wu, H.; Ozdemir, A.; Zeljic, A.; Julian, K.; Irfan, A.; Gopinath, D.; Fouladi, S.; Katz, G.; Pasareanu, C.; Barrett, C. Parallelization techniques for verifying neural networks. In Proceedings of the 20th International Conference on Formal Methods in Computer Aided Design, Haifa, Israel, 21–24 September 2020; pp. 128–137. [Google Scholar]
- Bassan, S.; Katz, G. Towards formal XAI: Formally approximate minimal explanations of neural networks. In Proceedings of the 29th International Conference on Tools and Algorithms for the Construction and Analysis of Systems, Paris, France, 22–27 April 2023; pp. 187–207. [Google Scholar]
- Raghunathan, A.; Steinhardt, J.; Liang, P. Certified defenses against adversarial examples. In Proceedings of the 6th International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018; pp. 1–15. [Google Scholar]
- Anderson, G.; Pailoor, S.; Dillig, I.; Chaudhuri, S. Optimization and abstraction: A synergistic approach for analyzing neural network robustness. In Proceedings of the 40th ACM SIGPLAN Conference on Programming Language Design and Implementation, Phoenix, AZ, USA, 22–26 June 2019; pp. 731–744. [Google Scholar]
- Bunel, R.; Turkaslan, I.; Torr, P.; Kohli, P.; Mudigonda, P. A unified view of piecewise linear neural network verification. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; pp. 4795–4804. [Google Scholar]
- De Palma, A.; Bunel, R.; Desmaison, A.; Dvijotham, K.; Kohli, P.; Torr, P. Improved branch and bound for neural network verification via lagrangian decomposition. arXiv 2021, arXiv:2104.06718. [Google Scholar]
- Xu, K.; Zhang, H.; Wang, S.; Wang, Y.; Jana, S.; Lin, X.; Hsieh, C. Fast and complete: Enabling complete neural network verification with rapid and massively parallel incomplete verifiers. In Proceedings of the 9th International Conference on Learning Representations, Virtual Event, Austria, 3–7 May 2021; pp. 1–15. [Google Scholar]
- Dureja, R.; Baumgartner, J.; Kanzelman, R.; Williams, M.; Rozier, K. Accelerating parallel verification via complementary property partitioning and strategy exploration. In Proceedings of the 20th International Conference on Formal Methods in Computer Aided Design, Haifa, Israel, 21–24 September 2020; pp. 16–25. [Google Scholar]
- Julian, K.; Lopez, J.; Brush, J.; Owen, M.; Kochenderfer, M. Policy compression for aircraft collision avoidance systems. In Proceedings of the 35th Digital Avionics Systems Conference, Sacramento, CA, USA, 25–29 September 2016; pp. 1–10. [Google Scholar]
- Bunel, R.; Mudigonda, P.; Turkaslan, I.; Torr, P.; Kohli, P.; Kumar, M. Branch and bound for piecewise linear neural network verification. J. Mach. Learn. Res. 2020, 21, 1–39. [Google Scholar]
- Moritz, P.; Nishihara, R.; Wang, S.; Tumanov, A.; Liaw, R.; Liang, E.; Elibol, M.; Yang, Z.; Paul, W.; Jordan, M. Ray: A distributed framework for emerging AI applications. In Proceedings of the 13th USENIX Symposium on Operating Systems Design and Implementation, Carlsbad, CA, USA, 8–10 October 2018; pp. 561–577. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Krizhevsky, A. Learning Multiple Layers of Features from Tiny Images. Master’s Thesis, University of Toronto, Toronto, ON, Canada, 2009. [Google Scholar]
- Grosse, K.; Papernot, N.; Manoharan, P.; Backes, M.; McDaniel, P. Adversarial examples for malware detection. In Proceedings of the 22nd European Symposium on Research in Computer Security, Oslo, Norway, 11–15 September 2017; pp. 62–79. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tool | Model | Dataset | Device | S Mode | |
|---|---|---|---|---|---|
| Marabou | FCN | MNIST | 0.003 | CPU | SnC |
| 0.006 | |||||
| --Crown | CNN | CIFAR10 | 0.0059 | CPU, GPU | FSB |
| 0.0078 |
| Bench. | Device | Seq | Par | Sch | Spar | Spo | |
|---|---|---|---|---|---|---|---|
| M-FCN | CPU | 0.003 | 1937.07 | 417.65 | 368.15 | 1229.90 | 1061.80 |
| 0.006 | 2192.99 | 486.24 | 402.99 | 1409.23 | 1130.03 |
| Bench. | Device | Spar | Spo | |
|---|---|---|---|---|
| C-CNN1 | CPU | 0.0059 | 91.50 | 77.46 |
| 0.0078 | 118.26 | 97.77 | ||
| C-CNN2 | CPU | 0.0059 | 732.95 | 630.96 |
| 0.0078 | 1028.22 | 869.77 | ||
| C-CNN1 | GPU | 0.0059 | 41.23 | 36.91 |
| 0.0078 | 54.02 | 46.62 | ||
| C-CNN2 | GPU | 0.0059 | 80.74 | 70.32 |
| 0.0078 | 120.59 | 103.46 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, R.; Zhou, Q.; Nan, X.; Hu, T. A Parallel Optimization Method for Robustness Verification of Deep Neural Networks. Mathematics 2024, 12, 1884. https://doi.org/10.3390/math12121884
Lin R, Zhou Q, Nan X, Hu T. A Parallel Optimization Method for Robustness Verification of Deep Neural Networks. Mathematics. 2024; 12(12):1884. https://doi.org/10.3390/math12121884
Chicago/Turabian StyleLin, Renhao, Qinglei Zhou, Xiaofei Nan, and Tianqing Hu. 2024. "A Parallel Optimization Method for Robustness Verification of Deep Neural Networks" Mathematics 12, no. 12: 1884. https://doi.org/10.3390/math12121884
APA StyleLin, R., Zhou, Q., Nan, X., & Hu, T. (2024). A Parallel Optimization Method for Robustness Verification of Deep Neural Networks. Mathematics, 12(12), 1884. https://doi.org/10.3390/math12121884