

Adaptive Neural Network Prescribed Time Control for Constrained Multi-Robotics Systems with Parametric Uncertainties

Abstract
1. Introduction
- To achieve the balance between rapid convergence and systems performance, a transform function was constructed, integrating the speed function into the prescribed performance function. In addition, employing this method, which merges the proposed transformation function with BLFs at every step, guarantees that all errors of the systems converge to prescribed regions during the prescribed time. Simultaneously, it effectively prevents violations of state constraints.
- Acquiring complete parameters for multi-robotic systems in actual applications is difficult, introducing complexity to control design. Based on backstepping technique, an adaptive NN method was developed to solve it. At the same time, considering that the systems have a large number of variables, it was difficult to choose an appropriate NN. Designing a suitable adaptive law to estimate the parameter boundary simplified control design while compensating for systems uncertainties.
2. Preliminaries
2.1. System Description
2.2. Graph Theory
2.3. Transform Function
2.4. Radial Basis Function Neural Networks
3. Control Design and Analysis
3.1. Adaptive NN Prescribed Time Control Design
3.2. Multi-Robotics Systems Stability Analysis
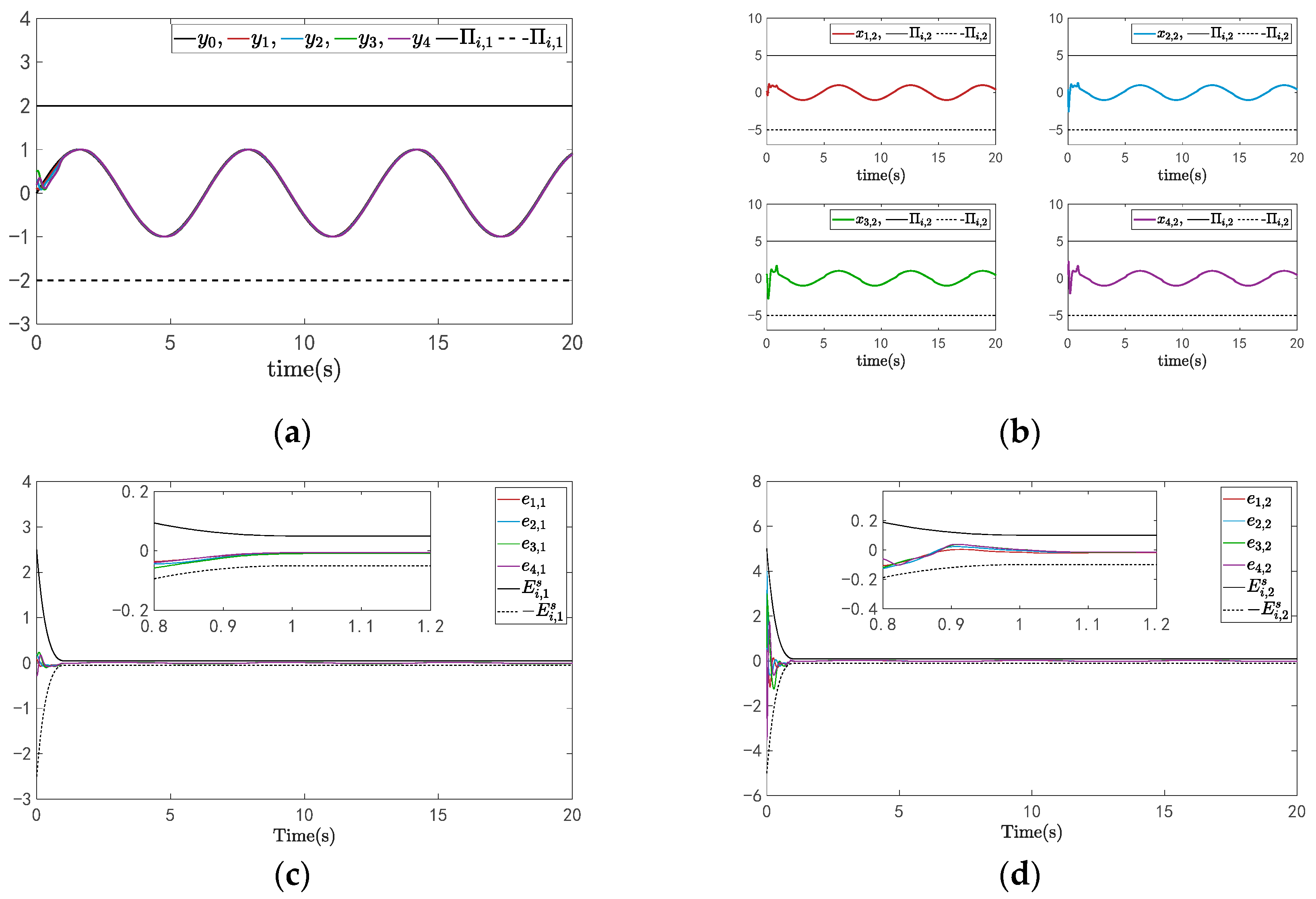
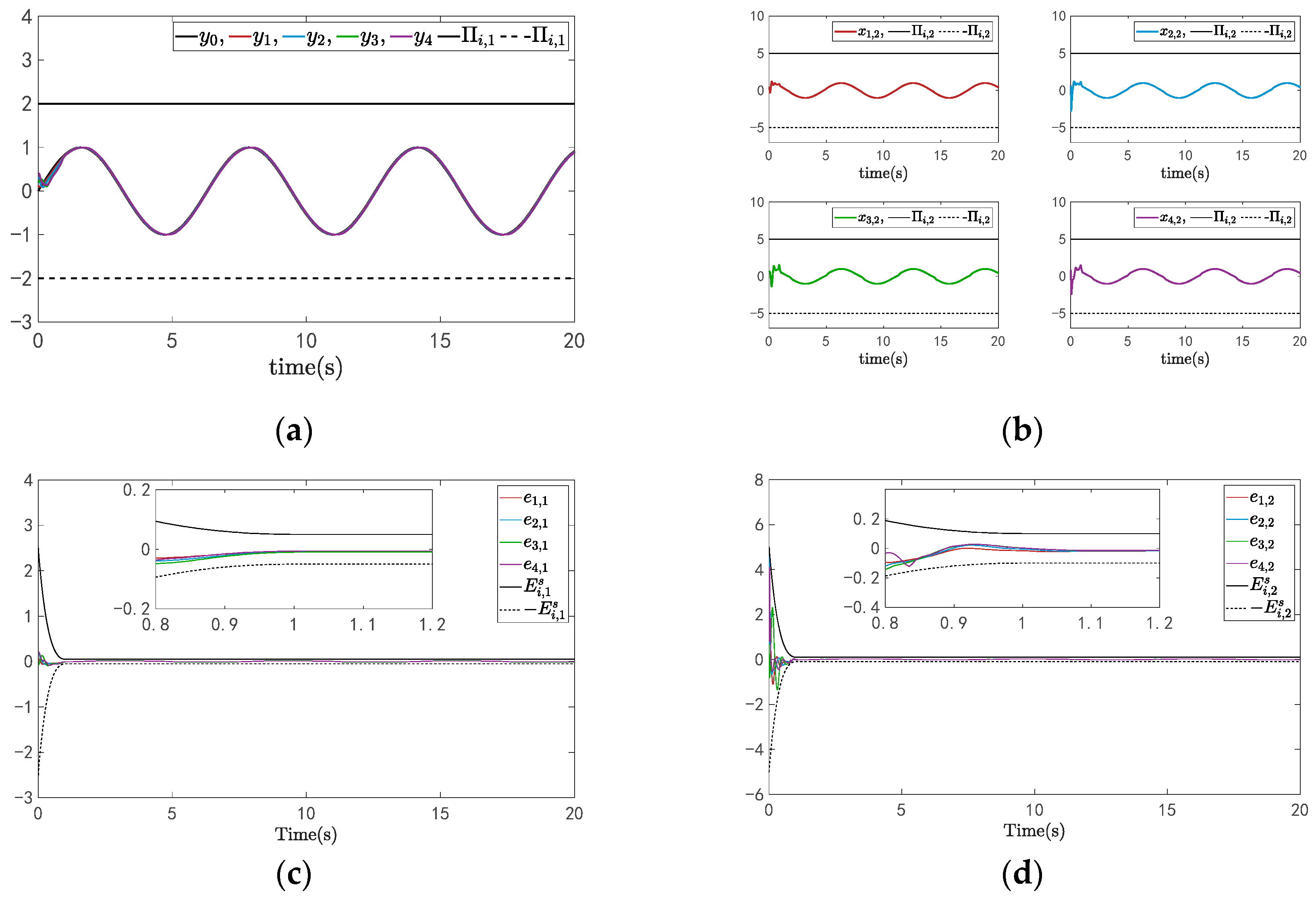
- Signals in multi-robotic systems remain within certain bounds, and systems convergence within a prescribed time , then convergence errors converge in the prescribed regions .
- The systems’ error meets the prescribed performance function , and the constraints are adhered to by the system states.
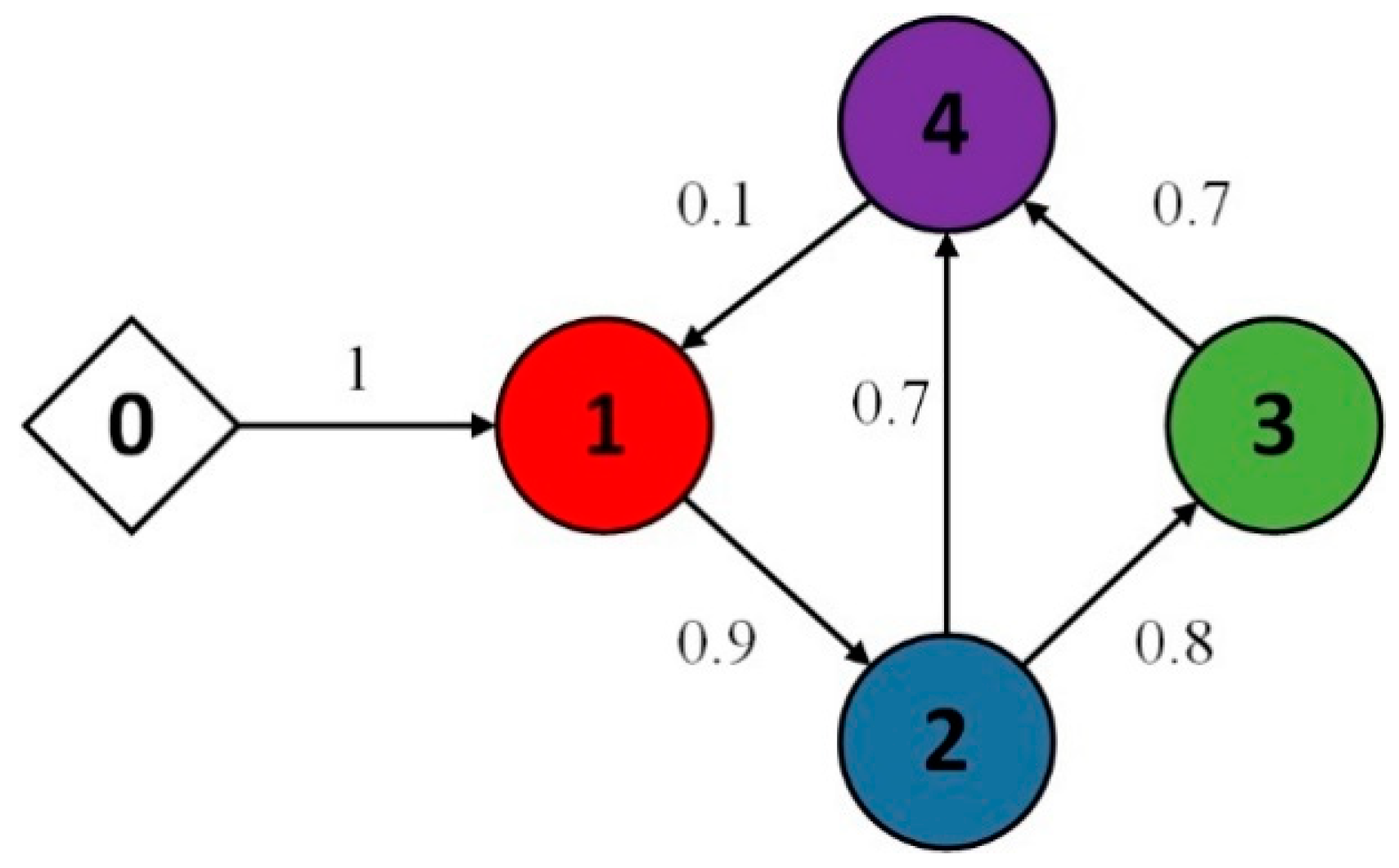
4. Simulation Example
Example
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- He, S.; Xu, Y.; Wu, Y.; Li, Y.; Zhong, W. Adaptive consensus tracking of multi-robotic systems via using integral sliding mode control. Neurocomputing 2021, 455, 154–162. [Google Scholar] [CrossRef]
- Liu, D.; Liu, Z.; Chen, C.P.; Zhang, Y. Prescribed-time containment control with prescribed performance for uncertain nonlinear multi-agent systems. J. Frankl. Inst. 2021, 358, 1782–1811. [Google Scholar] [CrossRef]
- Dai, S.; Wu, Z.; Li, S.; Wang, J.; Tan, M.; Yu, J. Model-Based Event-Triggered Dynamic Pursuing and Surrounding Control for a Multi-Robotic Fish System. IEEE Robot. Autom. Lett. 2023, 8, 3788–3795. [Google Scholar] [CrossRef]
- Behera, L.; Rybak, L.; Malyshev, D.; Gaponenko, E. Determination of workspaces and intersections of robot links in a multi-robotic system for trajectory planning. Appl. Sci. 2021, 11, 4961. [Google Scholar] [CrossRef]
- Jia, H.; Zhao, Y.; Zhai, Y.; Ding, B.; Wang, H.; Wu, Q. Crmrl: Collaborative relationship meta reinforcement learning for effectively adapting to type changes in multi-robotic system. IEEE Robot. Autom. Lett. 2022, 7, 11362–11369. [Google Scholar] [CrossRef]
- Fang, Y.; Ming, H.; Li, M.; Liu, Q.; Pham, D.T. Multi-objective evolutionary simulated annealing optimisation for mixed-model multi-robotic disassembly line balancing with interval processing time. Int. J. Prod. Res. 2020, 58, 846–862. [Google Scholar] [CrossRef]
- Sanila, P.; Pradeep, A.; Jacob, J.; Ramchand, R. Leader–follower target interception control of multi-robotic vehicles with holonomic dynamics based on unscented Kalman filter. Nonlinear Dyn. 2023, 111, 11171–11190. [Google Scholar] [CrossRef]
- Klančar, G.; Seder, M. Coordinated Multi-Robotic Vehicles Navigation and Control in Shop Floor Automation. Sensors 2022, 22, 1455. [Google Scholar] [CrossRef]
- Wang, Z.; Zhou, B.; Trentesaux, D.; Bekrar, A. Approximate optimal method for cyclic solutions in multi-robotic cell with processing time window. Robot. Auton. Syst. 2017, 98, 307–316. [Google Scholar] [CrossRef]
- Din, A.; Ismail, M.Y.; Shah, B.; Babar, M.; Ali, F.; Baig, S.U. A deep reinforcement learning-based multi-agent area coverage control for smart agriculture. Comput. Electr. Eng. 2022, 101, 108089. [Google Scholar] [CrossRef]
- Mishra, R.; Bajpai, M.K. Hybrid multiagent based adaptive genetic algorithm for limited view tomography using oppositional learning. Biomed. Signal Process. Control 2022, 75, 103610. [Google Scholar] [CrossRef]
- Nilsson, A.; Danielsson, F.; Svensson, B. Customization and flexible manufacturing capacity using a graphical method applied on a configurable multi-agent system. Robot. Comput.-Integr. Manuf. 2023, 79, 102450. [Google Scholar] [CrossRef]
- Leng, J.; Sha, W.; Lin, Z.; Jing, J.; Liu, Q.; Chen, X. Blockchained smart contract pyramid-driven multi-agent autonomous process control for resilient individualised manufacturing towards Industry 5.0. Int. J. Prod. Res. 2023, 61, 4302–4321. [Google Scholar] [CrossRef]
- Li, D.; Ge, S.S.; Lee, T.H. Fixed-time-synchronized consensus control of multiagent systems. IEEE Trans. Control Netw. Syst. 2020, 8, 89–98. [Google Scholar] [CrossRef]
- Wang, X.; Su, H. Consensus of multiagent with interaction distortions via echo control. Inf. Sci. 2022, 614, 518–533. [Google Scholar] [CrossRef]
- Wang, G.; Wang, C.; Cai, X. Consensus control of output-constrained multiagent systems with unknown control directions under a directed graph. Int. J. Robust Nonlinear Control 2020, 30, 1802–1818. [Google Scholar] [CrossRef]
- Wang, W.; Li, Y. Distributed fuzzy optimal consensus control of state-constrained nonlinear strict-feedback systems. IEEE Trans. Cybern. 2022, 53, 2914–2929. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.L.; Han, X.; Huang, T. PD and PI Control for the Lag Consensus of Nonlinear Multiagent Systems with and Without External Disturbances. IEEE Trans. Cybern. 2023, 54, 3716–3726. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Wang, G.; Li, S.; Lu, K. Composite sliding-mode consensus algorithms for higher-order multi-agent systems subject to disturbances. IET Control Theory Appl. 2020, 14, 291–303. [Google Scholar] [CrossRef]
- Xu, C.; Wu, B.; Zhang, Y. Distributed prescribed-time attitude cooperative control for multiple spacecraft. Aerosp. Sci. Technol. 2021, 113, 106699. [Google Scholar] [CrossRef]
- Ye, H.; Song, Y. Prescribed-time control for linear systems in canonical form via nonlinear feedback. IEEE Trans. Syst. Man Cybern. Syst. 2022, 53, 1126–1135. [Google Scholar] [CrossRef]
- Ren, Y.; Zhou, W.; Li, Z.; Liu, L.; Sun, Y. Prescribed-time cluster lag consensus control for second-order non-linear leader-following multiagent systems. ISA Trans. 2021, 109, 49–60. [Google Scholar] [CrossRef] [PubMed]
- Ning, B.; Han, Q.-L.; Zuo, Z.; Ding, L.; Lu, Q.; Ge, X. Fixed-time and prescribed-time consensus control of multiagent systems and its applications: A survey of recent trends and methodologies. IEEE Trans. Ind. Inform. 2022, 19, 1121–1135. [Google Scholar] [CrossRef]
- Wang, Y.; Song, Y.; Hill, D.J.; Krstic, M. Prescribed-time consensus and containment control of networked multiagent systems. IEEE Trans. Cybern. 2018, 49, 1138–1147. [Google Scholar] [CrossRef] [PubMed]
- Chen, X.; Yu, H.; Hao, F. Prescribed-time event-triggered bipartite consensus of multiagent systems. IEEE Trans. Cybern. 2020, 52, 2589–2598. [Google Scholar] [CrossRef] [PubMed]
- Dai, L.; Chen, X.; Guo, L.; Zhang, J.; Chen, J. Prescribed-time Group Consensus for Multiagent System Based on a Distributed Observer Approach. Int. J. Control Autom. Syst. 2022, 20, 3129–3137. [Google Scholar] [CrossRef]
- Zhu, P.; Hong, X.; Yang, D. Disturbance observer-based controller design for uncertain nonlinear parameter-varying systems. ISA Trans. 2022, 130, 265–276. [Google Scholar] [CrossRef] [PubMed]
- Yan, Y.; Wang, X.; Li, Y.; Zeng, L.; Li, Y.; Wang, L. Importance measure analysis of design variables and uncertain parameters in multidisciplinary systems. Appl. Math. Model. 2022, 107, 296–315. [Google Scholar] [CrossRef]
- Zhao, J.; Lin, C.M. Wavelet-TSK-type fuzzy cerebellar model neural network for uncertain nonlinear systems. IEEE Trans. Fuzzy Syst. 2018, 27, 549–558. [Google Scholar] [CrossRef]
- Zhang, Z.; Wang, Q.; Sang, Y.; Ge, S.S. Globally Adaptive Neural Network Output-Feedback Control for Uncertain Nonlinear Systems. IEEE Trans. Neural Netw. Learn. Syst. 2022, 34, 9078–9087. [Google Scholar] [CrossRef]
- Li, Y.; Min, X.; Tong, S. Adaptive fuzzy inverse optimal control for uncertain strict-feedback nonlinear systems. IEEE Trans. Fuzzy Syst. 2019, 28, 2363–2374. [Google Scholar] [CrossRef]
- Wang, Q.; Zhang, Z.; Xie, X.J. Globally adaptive neural network tracking for uncertain output-feedback systems. IEEE Trans. Neural Netw. Learn. Syst. 2021, 34, 814–823. [Google Scholar] [CrossRef] [PubMed]
- Chen, Z.; Niu, B.; Zhang, L.; Zhao, J.; Ahmad, A.M.; Alassafi, M.O. Command filtering-based adaptive neural network control for uncertain switched nonlinear systems using event-triggered communication. Int. J. Robust Nonlinear Control 2022, 32, 6507–6522. [Google Scholar] [CrossRef]
- Ding, B.; Pan, Y.; Lu, Q. Neural adaptive optimal control for nonlinear multiagent systems with full-state constraints and immeasurable states. Neurocomputing 2023, 544, 126259. [Google Scholar] [CrossRef]
- Xu, Z.; Deng, W.; Shen, H.; Yao, J. Extended-state-observer-based adaptive prescribed performance control for hydraulic systems with full-state constraints. IEEE/ASME Trans. Mechatron. 2022, 27, 5615–5625. [Google Scholar] [CrossRef]
- Duan, J.; Liu, Z.; Li, S.E.; Sun, Q.; Jia, Z.; Cheng, B. Adaptive dynamic programming for nonaffine nonlinear optimal control problem with state constraints. Neurocomputing 2022, 484, 128–141. [Google Scholar] [CrossRef]
- Ji, Q.; Chen, G.; He, Q. Neural network-based distributed finite-time tracking control of uncertain multi-agent systems with full state constraints. IEEE Access 2020, 8, 174365–174374. [Google Scholar] [CrossRef]
- Xu, Z.; Qi, G.; Liu, Q.; Yao, J. ESO-based adaptive full state constraint control of uncertain systems and its application to hydraulic servo systems. Mech. Syst. Signal Process. 2022, 167, 108560. [Google Scholar] [CrossRef]
- Liu, R.; Liu, M.; Shi, Y.; Qu, J. Adaptive Fixed-Time Fuzzy Control for Uncertain Nonlinear Systems with Asymmetric Time-Varying Full-State Constraints. Int. J. Fuzzy Syst. 2023, 25, 1597–1611. [Google Scholar] [CrossRef]
- Wang, J.; Yan, Y.; Liu, Z.; Chen, C.P.; Zhang, C.; Chen, K. Finite-time consensus control for multi-agent systems with full-state constraints and actuator failures. Neural Netw. 2023, 157, 350–363. [Google Scholar] [CrossRef]
- Li, Y.; Li, K.; Tong, S. An observer-based fuzzy adaptive consensus control method for nonlinear multiagent systems. IEEE Trans. Fuzzy Syst. 2022, 30, 4667–4678. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Case | ||||||||
|---|---|---|---|---|---|---|---|---|
| I | ||||||||
| II | ||||||||
| III |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tang, R.; Lin, H.; Liu, Z.; Zhou, X.; Gu, Y. Adaptive Neural Network Prescribed Time Control for Constrained Multi-Robotics Systems with Parametric Uncertainties. Mathematics 2024, 12, 1880. https://doi.org/10.3390/math12121880
Tang R, Lin H, Liu Z, Zhou X, Gu Y. Adaptive Neural Network Prescribed Time Control for Constrained Multi-Robotics Systems with Parametric Uncertainties. Mathematics. 2024; 12(12):1880. https://doi.org/10.3390/math12121880
Chicago/Turabian StyleTang, Ruizhi, Hai Lin, Zheng Liu, Xiaoyang Zhou, and Yixiang Gu. 2024. "Adaptive Neural Network Prescribed Time Control for Constrained Multi-Robotics Systems with Parametric Uncertainties" Mathematics 12, no. 12: 1880. https://doi.org/10.3390/math12121880
APA StyleTang, R., Lin, H., Liu, Z., Zhou, X., & Gu, Y. (2024). Adaptive Neural Network Prescribed Time Control for Constrained Multi-Robotics Systems with Parametric Uncertainties. Mathematics, 12(12), 1880. https://doi.org/10.3390/math12121880