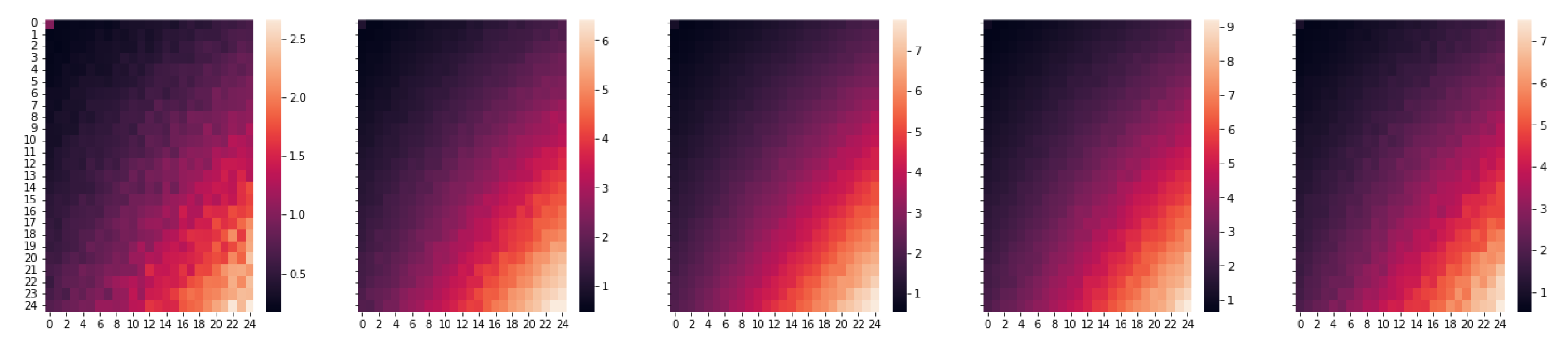
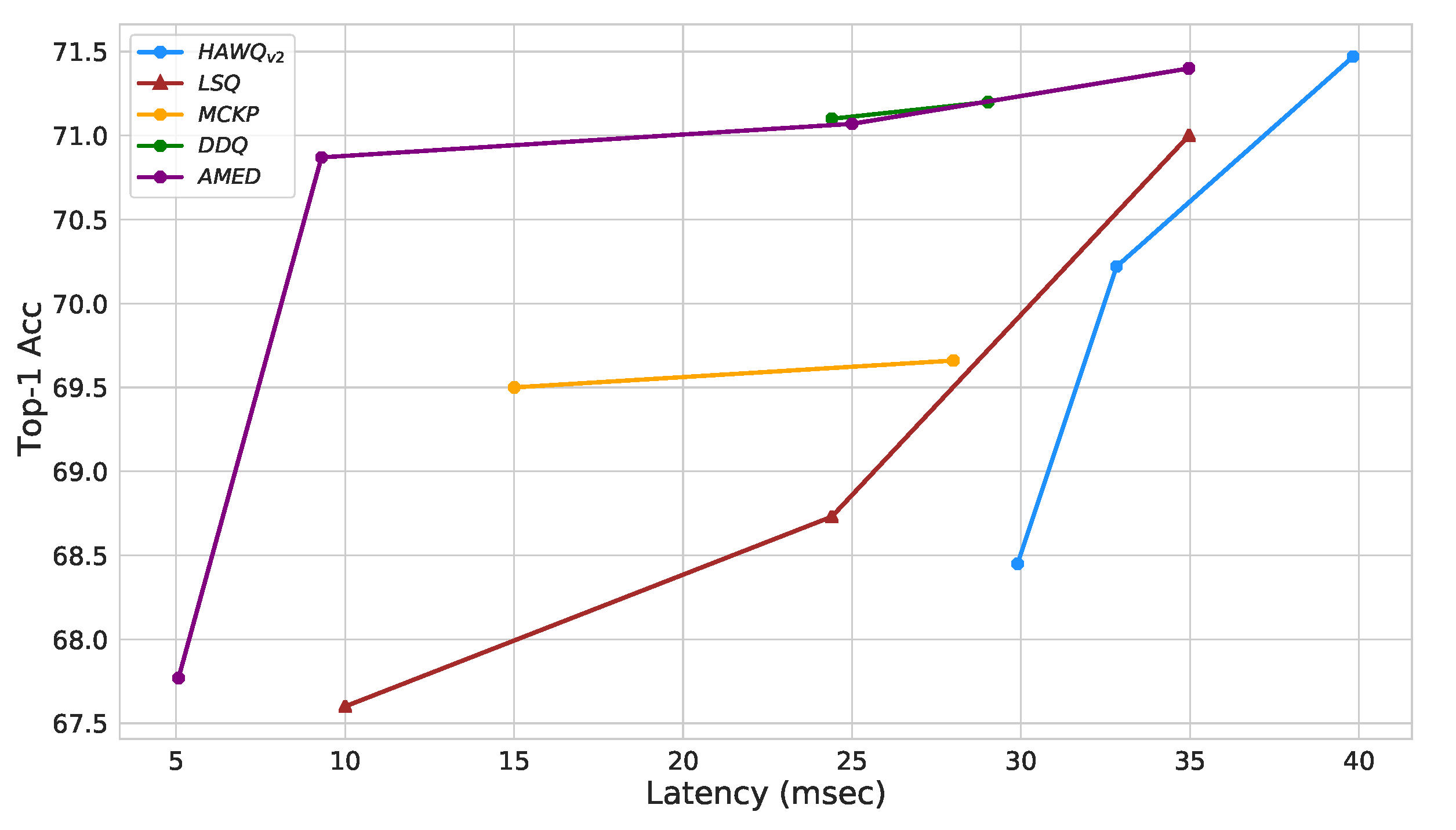
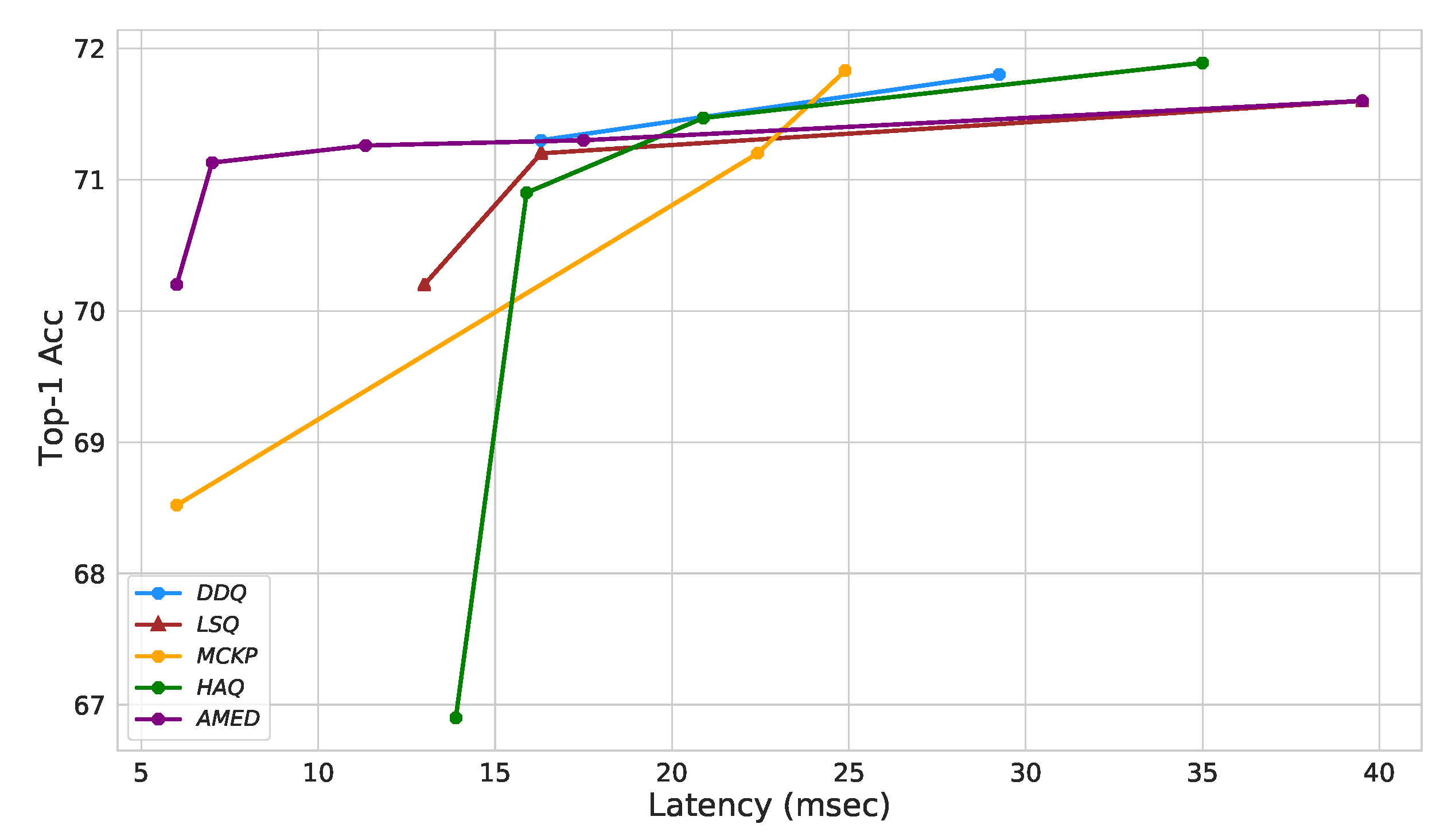
This section introduces our proposed technique for mixed-precision quantization. It leverages the strengths of both approaches described in
Section 2. We achieve this by first combining the desired properties of the model into a single, unified objective function. Then, we employ the Pareto optimization approach to efficiently sample solutions that achieve a desirable trade-off between these properties. We define the problem (
Section 4.1) and describe our perspective of the quantization process of neural networks (
Section 4.2), following which, we describe our MP quantizer (
Section 4.3) and our MP simulator (
Section 4.4). Finally, we introduce the technique of AMED (
Section 4.5).
4.1. Problem Definition
The DNN architecture parameters grouped into
layers are denoted by
(
Figure 2). The bit-allocation vector is denoted by
, where
is the number of possible bit allocations. Additionally, a quantized set of model parameters is denoted by
.
is a temporal vector, denoted by
at time
t, and the
l-th layer bitwidth at time
t is denoted by
.
Due to the dependence on specific accelerator properties, a differentiable form of the hardware objective (e.g., latency) cannot be directly measured in advance. This renders traditional optimization techniques relying on gradient descent inapplicable. Furthermore, the non-i.i.d. nature of latency across layers adds another layer of complexity. Quantization choices for one layer (e.g., ) can influence the cache behavior of subsequent layers (e.g., l), leading to unpredictable changes in the overall latency. This makes individual layer optimization ineffective.
Motivated by multi-objective optimization approaches that can handle trade-offs between competing goals, we propose encoding user-specified properties of the DNN model (e.g., accuracy, memory footprint, and latency) into a single, non-differentiable objective function. By doing so, we aim to avoid introducing relaxations that might not accurately capture the true behavior of the hardware platform, potentially leading to suboptimal solutions.
Since the objective function is non-differentiable with respect to the model parameters, we employ a nested optimization approach. This approach involves optimizing the inner loop (minimizing ) before tackling the outer loop (minimizing ).
To identify a set of solutions that best balance the trade-off between model performance and hardware constraints, we introduce two modifications to our objective function:
We introduce a penalty term that becomes increasingly negative as the quantized model’s accuracy falls below a user-specified threshold. This ensures that solutions prioritize models meeting the desired accuracy level.
We incorporate a hard constraint on the model size. This constraint acts as a filter, preventing the algorithm from exploring solutions that exceed a user-defined maximum size for the quantized model.
With respect to the above and by using a maximization problem, our objective is defined as follows:
where:
and
would be the baseline performance. We used a uniform 8-bit quantized network performance as
.
4.2. Multivariate Markov Chain
Quantization error contributes to the overall approximation error. These errors can be conceptualized as non-orthogonal signals within the error space. Crucially, the error vectors may not always point in the same direction.
Simply quantizing the model’s weight matrices and adding the resulting error to predictions is insufficient. Furthermore, quantized models without a subsequent fine-tuning step often underperform.
Nahshan et al. [
41] demonstrates that the quantization error signals of models with similar bitwidths exhibit smaller angles in the error space, indicating higher similarity. This suggests that, even for models destined for very low precision, an intermediate quantization step (e.g., 8 bits) can be beneficial.
To the best of our knowledge, the optimal approach for progressively quantizing deep learning models, especially those with mixed precision and complex architectures, remains an open question. The high dimensionality of such a process makes traditional ablation studies challenging.
While it is well known that optimization of DNNs is not an MDP nor canonical for each precision [
42,
43], Nahshan observations motivate our exploration of temporal precision in the quantization process. We propose modeling the network’s state as a function of its previous mixed-precision configuration, akin to a multivariate Markov chain.
Formally, we define the bit allocation as a multivariate Markov chain, as defined in [
44].
Let
be the bit allocation of the
i-th layer at time t, defined as:
where:
and
is a one-step transition probability matrix for the
i-th layer precision as a Markov chain.
In the context of this work, every layer of the neural network
i has a precision at time
t, and the transition for it to a new precision at
is given by Equation (
3).
We denote the multivariate transition matrix of all layers as
:
and thus, the bit-allocation multivariate Markov chain update rule is:
Modeling
explicitly is challenging, since we would like to model it so close minima of the loss will have the highest probability. As an alternative to explicit modeling, we suggest using sampling techniques over
where
. In this study, we use random walk Metropolis–Hastings [
45], a Markov chain Monte Carlo (MCMC) method. For
, we construct a distribution from Objective
2.
We use an exponential moving average (EMA), denoted by
, to avoid cases of diverged samples of quantized models:
where
empirically reduces the number of required samples.
The update of new samples
is by applying a logarithmic scale over Equation (
2):
where
is the update step of the transition matrix
, which is simply updating the probability of transitioning to a different precision based on the scaled loss.
is defined in Equation (
1) by the weighted sum of losses. Note that the only difference here from Equation (
2) is the monotonic logarithm function, as well as taking the mask out of the log. since the mask operated elementwise (Hadamard product) with the objective.
We employ the random walk Metropolis–Hastings algorithm (Algorithm 1) to determine whether to accept a new bit-allocation vector
or retain the current one.
| Algorithm 1 Random walk Metropolis–Hastings step. |
| Input: , |
| = ▹ Axis 2 |
| ▹ is the layerwise acceptance ratio; |
| if 0 then ▹ Element-wise |
| |
| |
| else |
|
|
| end if |
The algorithm proceeds in the following steps:
- 1.
Candidate Generation: A candidate vector, denoted by , is proposed for the next allocation.
- 2.
Layerwise acceptance ratio: A layerwise acceptance ratio, , is calculated.
- 3.
Bernoulli-Based Acceptance:
If , a Bernoulli distribution with probability is used for acceptance:
- −
If the Bernoulli trial succeeds, is accepted.
- −
Otherwise, the current allocation is retained.
If , is automatically accepted.
This acceptance scheme adaptively balances exploration and exploitation:
Exploration Phase: Accepts a higher proportion of new candidates, encouraging broad space exploration. Exploitation Phase: Preferentially accepts candidates that leverage knowledge from previously discovered samples.
4.4. Simulator
To enable direct sampling of signals from emulated hardware, we developed a hardware accelerator simulator. This simulator allows us to model various aspects of an accelerator, including the inference time for different architectures, and generate signals usable within our algorithm. These signals can extend beyond latency to encompass memory utilization, energy consumption, or other relevant metrics.
4.4.1. Underlying Architecture Modeled
Our simulator draws heavily on SCALE-Sim v2 [
17], a Systolic Accelerator Simulator (SAS) capable of cycle-accurate timing analysis. A SAS is ideal for DNN computations due to its efficient operand movement and high compute density. This setup minimizes global data movement, largely keeping data transfer local (neighbor to neighbor within the array), which improves both energy efficiency and speed. Our SAS can additionally provide power/energy consumption, memory bandwidth usage, and trace results, all tailored to a specific accelerator configuration and neural network architecture. We extended its capabilities by incorporating support for diverse bitwidths and convolutional neural network (CNN) architectures not originally supported, such as Inverted Residuals (described in [
47]).
4.4.2. Simulator Approximations
1. Optimal Data Flow Assumptions: The simulator models specific types of dataflows—Output Stationary (OS), Weight Stationary (WS), or Input Stationary (IS)—and assumes an ideal scenario where outputs can be transferred out of the compute array without stalling the compute operations. In real-world implementations, such smooth operations might not always be feasible, potentially leading to a higher actual runtime.
2. Memory Interaction: This simplistically models the memory hierarchy, assuming a double-buffered setup to hide memory access latencies. This model may not fully capture the complex interactions and potential bottlenecks of real memory systems.
The original
ScaleSim simulator was validated against real hardware setups using a detailed in-house RTL model [
17].
4.4.3. Using the Simulator
The simulator operates on two key inputs:
1. Network Architecture Topology File: This file specifies the structure of the neural network, including the arrangement of layers and their connections.
2. Accelerator Properties Descriptor: This descriptor defines the characteristics of the target hardware accelerator, such as its memory configuration and processing capabilities.
We evaluated the simulator using various network architectures: ResNet-18, ResNet-50 [
48], and MobileNetV2 [
47]. While MobileNetV3 could potentially be explored in future work, it is not included in the current set of experiments. The specific accelerator properties used are detailed in
Table 1.
SRAM Utilization Estimation:
The current simulator estimates SRAM utilization based on bandwidth limitations. Incorporating a more accurate calculation of SRAM utilization within the simulator is a potential area for future improvement. This would provide a more precise signal for the algorithm.
Simulator Output:
The simulator generates a report for each layer, containing various metrics such as the following:
- -
Compute cycles;
- -
Average bandwidths for DRAM accesses (input feature map, filters, output feature map);
- -
Stall cycles;
- -
Memory utilization (potentially improved in future work);
- -
Extracting Latency Metrics:
From the reported compute cycles and clock speed (
f), we calculate the computation latency as
. Similarly, the memory latency for each SRAM is estimated using:
where
- -
C denotes the compute cycles;
- -
f denotes the clock speed;
- -
b denotes the number of bits required for the specific SRAM;
- -
denotes the memory bandwidth;
- -
Word size is assumed to be 16 bits.
The total latency of the quantized model is determined by the maximum latency value obtained from these calculations (computation and memory latencies for each layer).
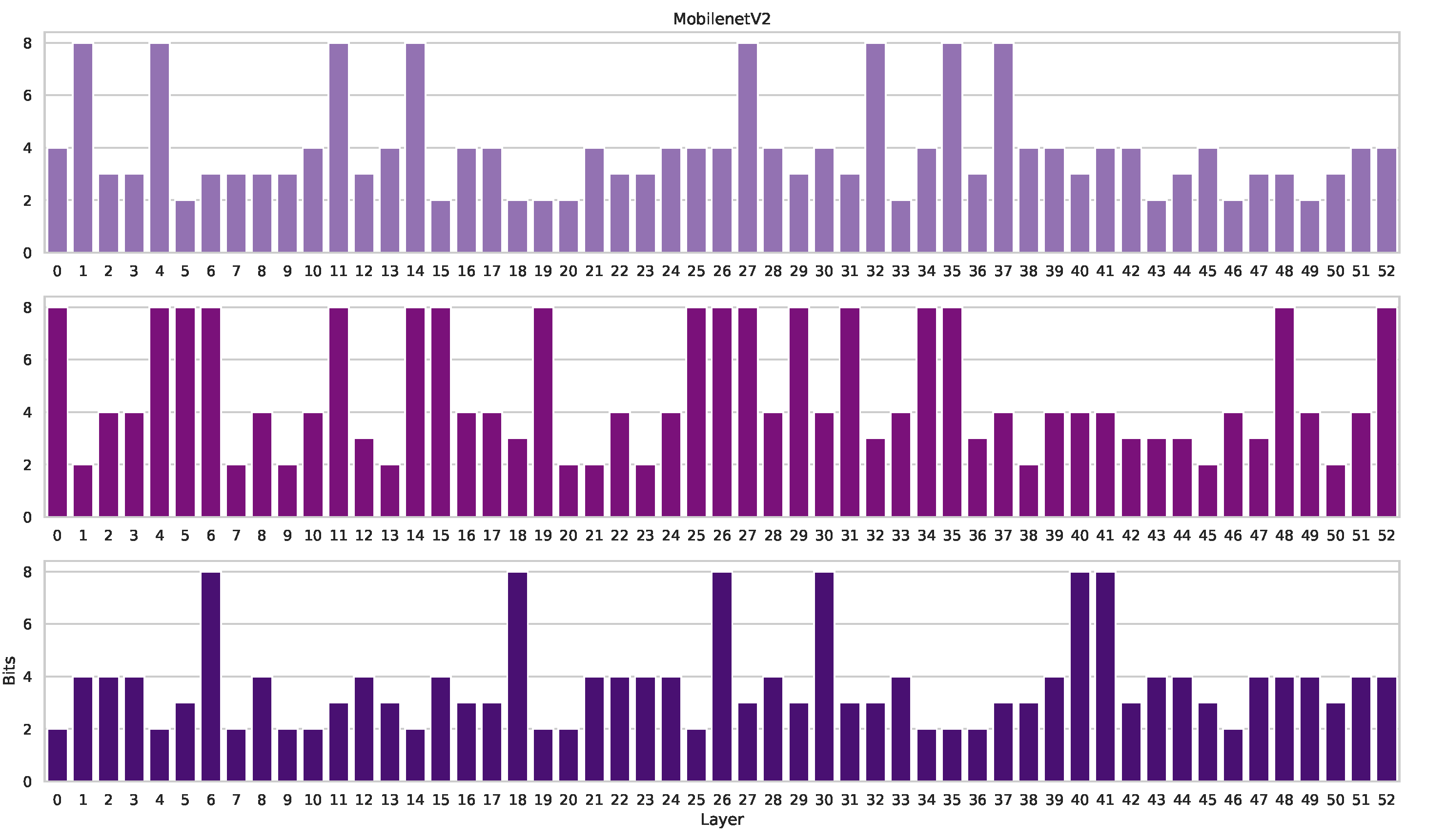
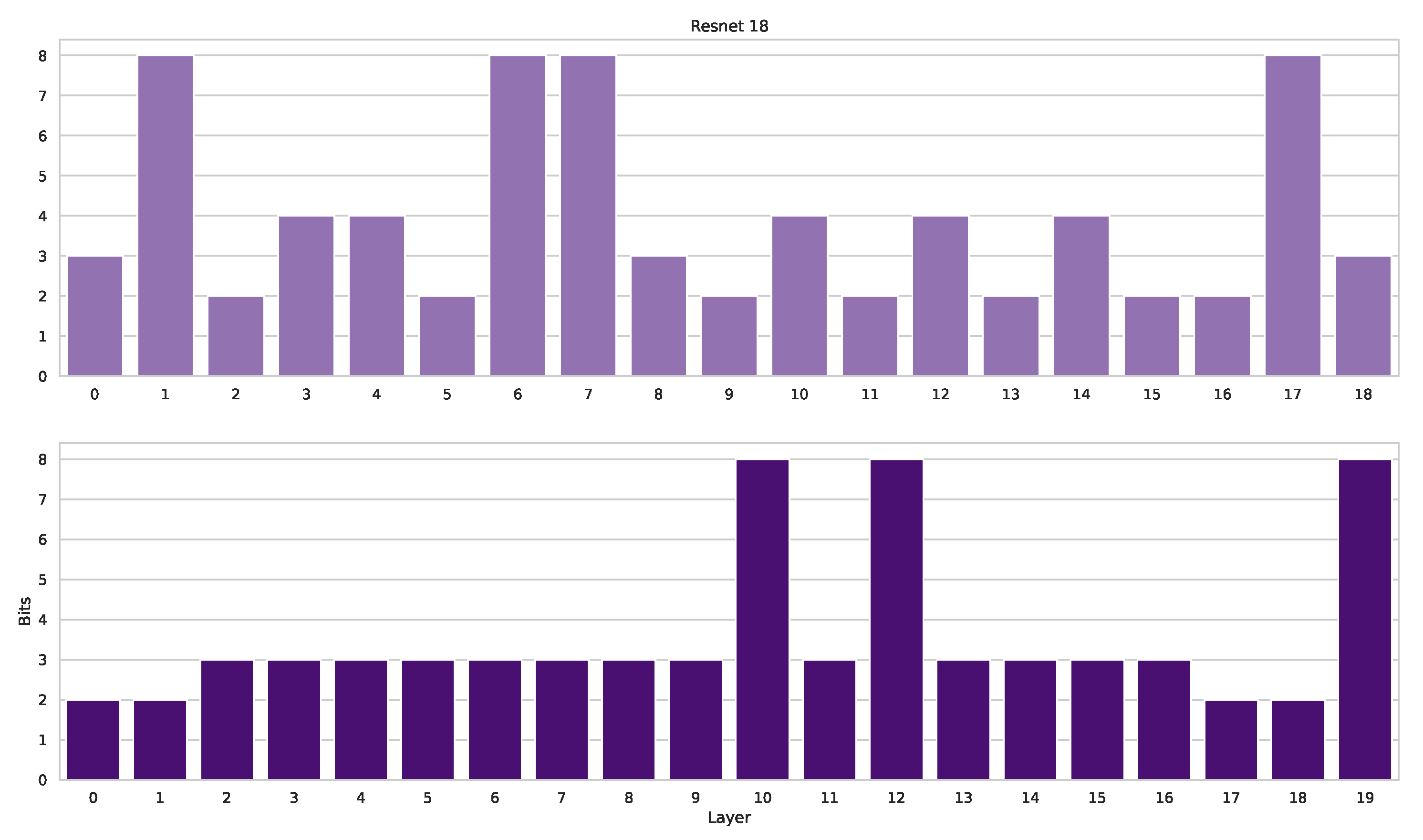
4.5. Training and Quantizing with AMED
AMED employs a Metropolis–Hastings algorithm (Algorithm 1) to sample precision vectors
. These precision vectors guide the quantization process, resulting in a mixed-precision model
. Details on the quantization procedure, including activation quantization matching weight precision, can be found in
Section 4.3.
Following quantization, we perform a two-epoch optimization step using stochastic gradient descent (SGD) to fine-tune both the quantized model parameters and the scaling factors and associated with the weights and activations, respectively.
The quantized model’s performance is evaluated on the validation set using the cross-entropy loss
and on a simulated inference scenario detailed in
Section 4.4, using the latency loss
. Both loss values contribute to updating the estimated expected utility
(Equation (
7)) and guide the sampling of a new precision vector
.
Figure 4 illustrates the quantization process, while Algorithm 2 details the complete workflow.
| Algorithm 2 Training procedure of AMED. |
| Input: dataset: , model: , params: , simulator |
|
|
| ▹ between all bit representations
|
| Fit |
| Compute reference , |
| for i in epoch do |
| Evaluate , |
| Update ▹ from (7)
|
| Update ▹ by Algorithm 1
|
| Quantize the model |
| Fit |
| end for |
The algorithm described in Algorithm 2 is agnostic to the quantizer and to the hardware specification and simulation. This means that one can use any quantization technique that relies on the statistics of the weights and activations in a single layer and any hardware or hardware simulator and use AMED to choose the best mixed-precision bit allocation for the hardware.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}