1. Introduction
In the realm of recommendation systems, sequential recommendation plays a pivotal role in deducing user preferences from historical interactions such as clicks, reviews, and purchases. Its primary objective is to predict the next item that a user might find appealing, therefore enhancing user engagement and satisfaction. For example, if an online shopping mall recommends popular products based solely on overall purchase data, it might suggest items that are not relevant to the user’s recent searches or purchase history. On the other hand, by considering sequential purchase history and recent searches, it can make more effective recommendations, such as suggesting suitable phone accessories to a user who has just purchased a smartphone. Therefore, sequential recommendations that can reflect the evolving preferences and current interests of users over time can provide personalized recommendations that enhance user satisfaction.
Since the introduction of the Transformer [
1], a groundbreaking architecture for natural language processing, Transformer-based recommender models such as Bert4Rec [
2] and SASRec [
3] have garnered attention in a sequential recommendation. However, in the face of noisy interactions stemming from random events or sparse data scenarios, these models can yield biased outcomes, including false positives and false negatives [
4]. Put differently, recommender systems that overlook noise may have adverse effects and could impede the accurate learning of user preferences [
5]. Furthermore, drawing inferences from highly sparse user behavioral data can limit the representation capacity of sequential pattern encoding and pose a risk of inherent popularity bias [
6].
To address these issues, there has been a surge in research on generative recommender models that can learn the underlying data distributions and uncertainties [
7]. Generative models can infer the underlying distribution of the data through learning and generate probabilities based on this inferred distribution. This allows them to produce reliable data even in noisy scenarios, as they are less affected by noise. Therefore, generative models can be effectively used in recommendation tasks where there is a lack of user–item interaction information or in cases where noise, such as incorrect clicks unrelated to user preferences, is present. Specifically, generative recommendation models can generate probabilities for items with no interactions in situations where interaction information is lacking and can derive useful information by learning latent features in noisy data scenarios. They are broadly categorized into two types: those leveraging Generative Adversarial Networks (GAN) [
8] and those based on Variational AutoEncoders (VAE) [
9]. However, GAN-based models often grapple with optimization instability, leading to degraded performance, while VAE-based models face issues such as posterior collapse [
10].
Recently, the Diffusion model (DM) has garnered acclaim across diverse domains [
11,
12]. By operating via forward and reverse processes, the DM gradually introduces noise into the original data during the forward process and then reconstructs the original input by iteratively removing noise in the reverse process. This multi-step generation approach offers stable and efficient optimization, addressing challenges such as posterior collapse. In other words, generative models infer the underlying distribution of data through learning and generate new data. In recommendation systems, they can learn the latent distribution of data and handle noise, therefore deriving useful information for personalized recommendations. Specifically, diffusion models, which progressively add and remove noise, can model the sequential interaction process of users and predict preference changes over time, making them effectively applicable to sequential recommendations. Consequently, there is growing interest in leveraging the DM to more accurately model complex interaction generation in recommendation systems [
13,
14]. Although most DM-based sequential recommendation models have employed Gaussian distribution noise, there is potential for performance enhancement by exploring distributions with higher degrees of freedom [
15].
In this paper, we present a novel approach to address these challenges. We introduce a new noise distribution based on the Weibull distribution, which can derive various distributions with just two parameters. Additionally, we suggest a modified Transformer structure based on Macaron Net [
16], along with normalized loss and a warmup strategy [
17]. Ultimately, we propose a new Diffusion model-based sequential recommender model that integrates these approaches. Our research focuses on four datasets from life-related online commerce [
18], closely associated with real-world recommendation scenarios. Through experiments, we validate that the proposed model outperforms the existing Diffusion model-based sequential recommender model [
19] and provides insights into the effectiveness of methodologies for enhancing sequential recommender systems.
2. Related Work
Recommendation systems have evolved from traditional methods, such as collaborative filtering, to approaches using deep learning. However, they often struggle with limited generalization performance in scenarios with weak collaborative signals, inappropriate latent representations, and noisy data. To address these challenges, methods utilizing generative models such as VAEs [
20] and GANs [
21] have emerged. However, VAEs often fail to effectively capture personalized user preferences, and GANs suffer from training instability. To overcome these limitations, Walker et al. [
22] were the first to apply the DM to recommender systems, offering superior representational capabilities and training stability. Through the DM, they leveraged robust collaborative signals and latent representations of user–item interactions, resulting in improved performance compared to previous VAE-based models. However, their approach still had limitations in handling sequential scenarios due to a lack of consideration for temporal information.
Considering the temporal changes in user preferences, Wang et al. [
13] proposed DiffRec, which integrates the DM into recommender systems, and introduced its extensions, L-DiffRec and T-DiffRec. L-DiffRec clusters items and compresses interactions, then performs diffusion processes in the latent space to generate top-K recommendations. T-DiffRec employs a time-aware reweighting mechanism, assuming that recent interactions can better capture user preferences. By giving more weight to recent interactions compared to earlier ones, it enhances the model’s adaptability and performance regarding user behavior. These results demonstrate the impact of considering temporal information on improving recommendation performance.
Recently, Li et al. [
19] proposed a new DM for sequential recommendation. They defined sequences in the preprocessing stage of the dataset, organizing interactions in chronological order and treating the most recent interaction as the target data for training. This preprocessing allows for the direct reflection of users’ temporal information. Moreover, they utilized the DM’s ability to generate distributions to represent the latent features of items and the multi-level interests of users. The introduction of noise in the DM acted as a factor inducing a more robust learning process. Instead of the Mean Squared Error (MSE) used in the previous DDPM, they employed cross-entropy loss for relevance calculation in the reverse process due to the static nature of item embeddings. Additionally, they used transformers as an approximation for reconstructing item representations.
The characteristics of the aforementioned representative DM-based recommender systems are summarized in
Table 1.
3. Methodology
In sequential recommendation, the set of users is denoted as U, and the set of items as I. User–item interactions are sorted in chronological order according to timestamp t to construct a sequence , where and . The goal is to predict the next item of interest for the user based on previous interactions. In other words, based on sequence S, we can summarize it as . Each item is also transformed into its corresponding embedding vector e. Consequently, the interaction sequence can be represented as .
3.1. Model Architecture
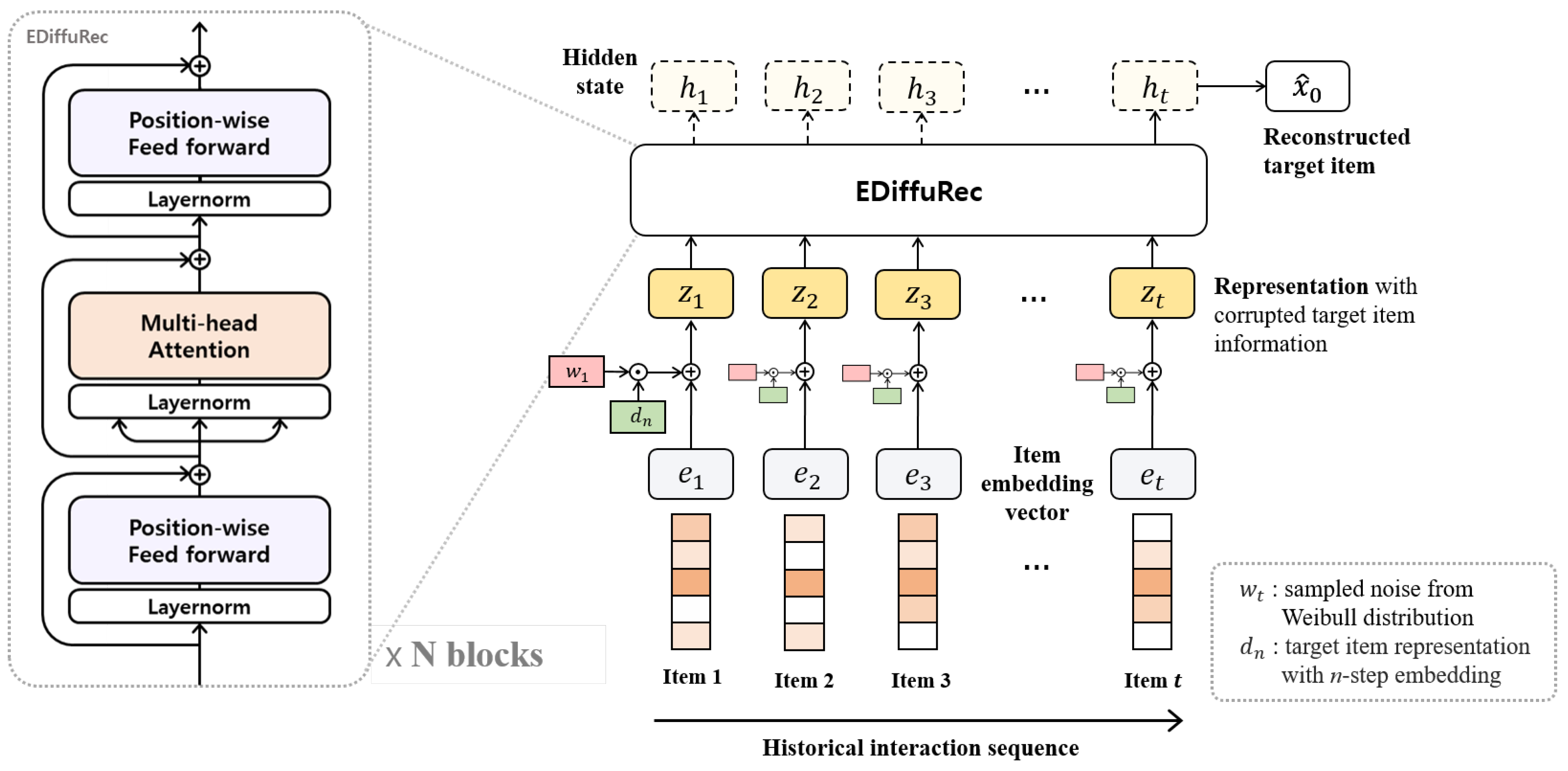
We utilize a model inspired by the Macaron Net [
16], a Transformer-based model, as the approximator for the proposed EDiffuRec. Unlike the basic Transformer, which consists of a multi-head attention block and an FFN block, the existing Macaron Net positions two FFN layers before and after the multi-head attention block and multiplies the FFN outputs by 0.5. The proposed model uses the Macaron Net structure but uses the FFN outputs without multiplying by 0.5, thus enhancing the model’s representation capability. EDiffuRec is illustrated in
Figure 1. The right side of the figure illustrates the training process of the approximator, where
represents the embedded item vector and
denotes the noise sampled from the Weibull distribution.
indicates the value obtained by adding positional embeddings to
at step
n. By element-wise multiplying
and
and adding them to
, a representation
is created, which serves as the input to the approximator. The output of the approximator yields the reconstructed target item representation
through training. In the training process, a sampled step
n is used, while the test process involves a reverse process over the total step
T.
3.2. Diffusion Model
The DM, as established by the DDPM [
23] framework, has demonstrated considerable effectiveness in various domains such as image generation [
11], text generation [
24], and audio generation [
12]. As a likelihood-based generative model, the DM shares similarities and differences with VAEs. One of the main differences is that while VAEs utilize a single latent variable, the DM utilizes multiple latent variables for degradation and restoration. In terms of the learning objectives of the model, both models are similar in optimizing the Evidence Lower Bound (ELBO) by minimizing negative log-likelihood. Generally, the DM consists of a forward process and a reverse process. In the forward process, noise is gradually added to the original data to corrupt the sample, and in the reverse process, the model learns to recover the corrupted data.
In the forward process, given a data sample
, Gaussian noise is incrementally added at each step according to a Markov chain, corrupting the original data. The scale of the noise added at each step is determined by the variance schedule
. This is formalized as follows:
where
t in
represents the diffusion step to add noise, and
I denotes the identity matrix. Furthermore, according to the reparameterization trick [
23],
can be directly derived from
. This is formalized as follows:
In the reverse process, the DM learns to remove the added noise from
to restore
in the reverse direction, iteratively approximating the original
. Since
cannot be directly estimated, it is commonly approximated using an approximator such as Transformer [
1] or U-Net [
25]. This process is formalized as follows:
where
and
represent the mean and variance parameterized by
, respectively. Through parameterization [
23],
can be set as a constant.
Additionally,
can be approximated by the tractable distribution
, and rewritten as follows using Bayes’ rule [
26]:
The optimization process minimizes the KL divergence between the posterior distribution in the forward process and the prior distribution in the reverse process to optimize the parameter
. Therefore, the objective function is formalized as follows through simplification [
23]:
where
represents the noise sampled from the Gaussian distribution
, and
denotes the approximator.
In this paper, based on the DM structure in [
19] for sequential recommendation, the forward process initially adds noise to each item in the sequence, which is transformed into embedding vectors, to obtain the distribution representation
, where
n is determined through step sampling. The added noise is sampled from the specified noise distribution. Subsequently, the obtained
serves as the input to the approximator, which is trained to predict
. In the reverse process, the approximator trained through the forward process is utilized to predict the target item. The reverse process is performed through the
T step without step sampling. In summary, the process can be described as follows:
Forward process:
According to Equation (
2),
can be expressed as
.
Reverse process:
According to Equation (
5),
can be expressed as
.
3.3. Noise Distribution
The DM essentially adds Gaussian noise, based on the Gaussian distribution
, to data samples in the forward process. In the reverse process, it removes noise from data samples containing Gaussian noise, generating data samples during the inference process. The Gaussian distribution has a fixed mean of 0 and a degree of freedom of 1. Using distributions with more degrees of freedom can potentially improve the performance of generative models [
15].
We propose using the Weibull distribution with shape and scale parameters as a new noise distribution. The Weibull distribution can derive various distributions, including asymmetric shapes, by using two parameters. Examples of the Weibull distribution and Gaussian distribution are shown in
Figure 2. To define the DM process using the Weibull distribution, we can rewrite the equation obtained when using the Gaussian distribution, as shown in Equation (
1), as follows:
where
represents the noise from the Gaussian distribution at step
t. We define the Weibull distribution as
, with
k as the shape parameter and
as the scale parameter. Taking this into account, Equation (
9) can be rewritten as follows:
where
, and since the typical Weibull distribution only takes non-negative values to reflect noise across various ranges, we introduce a location parameter
c allowing for variation across different ranges. Therefore, the probability density function of the proposed distribution is as follows:
To summarize, the Weibull distribution can derive various distributions using two parameters that determine shape and scale, enabling more precise modeling by accounting for different types of noise. Additionally, while the traditional Gaussian distribution is affected by extreme values or outliers that influence the mean, the Weibull distribution, being asymmetric, can mitigate the impact of noise or outliers. Therefore, utilizing the Weibull distribution allows for more accurate modeling of user behavior characteristics, providing personalized recommendations, and proving useful in real-world data that is noisy or asymmetric.
3.4. Normalized Loss
The loss function commonly used to train the approximator of the DM is MSE. However, this is more suitable for continuous distribution problems and is not suitable for sequential recommendation mapping in a discrete item space. Furthermore, sequential recommendation, inferring the target item from multiple items, can be viewed as a multi-class classification problem, and the goal is to minimize the difference between the predicted distribution and the actual distribution. Hence, we utilize cross-entropy loss as follows:
where
I denotes a set of items, and
U denotes a set of users. The symbol · represents the inner product, and
denotes the target item representation reconstructed through the approximator. In this scenario, by applying L2 normalization to
, denoted as
, the vectors have the same range, making the comparison easier as the recommendation scores reflect a more consistent comparison based on the directionality of the embedding values. This approach enhances the stability and performance of the model.
3.5. Learning Rate Warmup
Typically, at the beginning of training, all parameters are initialized with random values. However, using a learning rate (LR) that is too large in such a state can potentially lead to numerical instability. To prevent this, LR warmup [
17] is a strategy that starts with a small LR initially and transitions to the initially set LR value when the training process achieves stability. LR warmup involves slowly increasing the LR, and adjusting the LR during this process is referred to as LR scheduling. This strategy can also contribute to improving the performance of deep learning models [
27].
The initial LR for warmup is set to with a duration of 20 epochs, gradually increasing the LR during the first 20 epochs of training. Subsequently, the LR transitions to the model’s initial LR value of , allowing for stable LR maintenance and continued optimization.
3.6. Experimental Datasets
In this paper, we conduct experiments on publicly available product review datasets [
18] for Beauty, Toys, Tools, and Video sourced from Amazon, one of the real-life-oriented online commerce platforms. The dataset consists of user review data for products in each category collected from May 1996 to July 2014.
We preprocess the dataset in accordance with the prior research [
3]. We treat all interactions as implicit feedback and exclude users and items associated with interactions of fewer than five. Subsequently, we arrange interactions following the chronological order of timestamps. Given a sequence of interactions,
, we designate the most recent interaction
as the test item. The preceding interaction,
is assigned as the validation item. All interactions prior to these two, excluding
and
, are considered to be training items. In summary, all datasets are divided into train, validation, and test items based on the order of interaction sequences.
Table 2 below presents the statistics of the dataset.
3.7. Evaluation Metrics
We evaluate the performance of our sequential recommender using commonly employed metrics: Hit Rate (HR@K) and Normalized Discounted Cumulative Gain (NDCG@K), following the top-
K protocol as established in related research [
28]. We consider
, where HR@K denotes the proportion of correctly recommended items within the top-
K list. NDCG@K assesses recommendations by factoring in the order of recommended items and assigning weights accordingly. NDCG@K is calculated as follows:
where DCG@K represents the sum of relevance scores
considered up to rank
K, and
denotes the relevance scores between users and items. Additionally, Ideal DCG@K (IDCG@K) signifies the ideal recommendation ranking, indicating the maximum value of DCG@K. To sum up, the Hit Rate represents the proportion of recommendations that contain the actual correct answer, while NDCG measures how good the model’s recommendations are compared to the ideal recommendations, with values ranging from 0 to 1. For both metrics, higher values indicate better performance. Scores are computed by calculating the inner product between the sequence representation and candidate items, with all items in the dataset serving as candidate items. To mitigate potential biases resulting from a small number of negative items [
29], we rank all candidate items to predict the target item.
3.8. Compared Methods
We conduct comparative experiments between the proposed EDiffuRec and the previous DM-based sequential recommendation model. Additionally, to comprehensively analyze the efficacy of EDiffuRec, we evaluate its performance by partially integrating it into the model.
DiffuRec [
19] is a pioneering work that applies the DM to a sequential recommendation. It utilizes the diffusion distribution to adaptively reflect users’ multiple interests. A Transformer backbone model is employed as an approximator for reconstructing the target item representation.
Ablation 1 is a comparative model that applies a proposed structure, a variation of Macaron Net, to the approximator.
Ablation 2 is a comparative model that applies L2 normalization to reconstructed through the approximator in cross-entropy during training.
Ablation 3 is a comparative model that utilizes noise sampled from the Weibull distribution in the DM process.
EDiffuRec denotes our proposed model, which uses a modified Transformer structure based on Macaron Net, normalization, Weibull distribution, and LR warmup.
3.9. Implementation Details
All experiments are conducted on a single Nvidia GeForce RTX 4070 Ti GPU, using Python 3.8.11 and PyTorch 1.8.0. We utilize Adam [
30] for optimization, with a batch size of 512, a dropout rate of
, and dimensions of embeddings and hidden layers set to 128. We limit the maximum sequence length to 50. The initial LR for warmup is set to
, and after a duration of 20, it is set to
. Additionally, the parameters
k and
for the Weibull distribution are set to 2 and
, respectively.
4. Results
We present the overall performance of our model and the contributions of each component in
Table 3. When using the modified Transformer structure based on the Macaron Net alone, we observe slightly improved performance in the NDCG metric for the Toys dataset. However, it degrades performance in other metrics. Utilizing normalization in the loss generally leads to improvements, notably enhancing performance across all metrics for the Tools and Video datasets. The model using noise sampled from the Weibull distribution shows enhanced improvements in the NDCG metric for the Beauty dataset and all metrics for the Tools dataset. Additionally, it exhibits particular performance improvements at
in the Toys and Video datasets. EDiffuRec, combining these components, outperforms across all datasets and metrics.
Specifically, it achieves performance improvements ranging from to for the Beauty dataset, from to 13.52% for the Toys dataset, from to for the Tools dataset, and from to for the Video dataset.
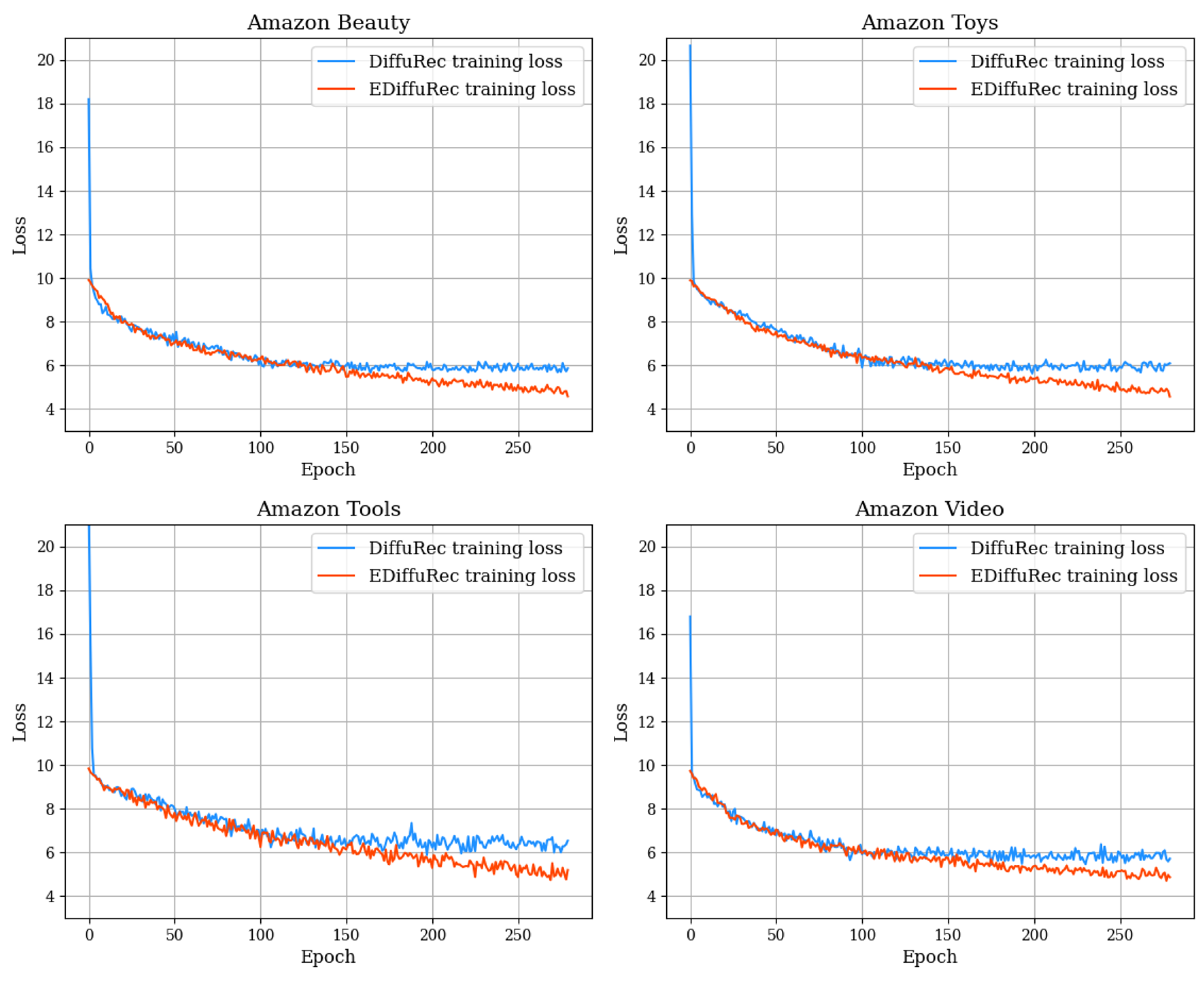
We illustrate the comparison of training losses between EDiffuRec and the baseline in
Figure 3. Our proposed model, incorporating the L2 norm in the loss, starts with a significantly lower loss from the beginning of training. Moreover, using a warmup strategy to enhance the stability of the model, we observe even lower loss after 150 epochs.
We compare our proposed Weibull distribution with different noise assumptions in
Table 4. In the Gaussian distribution as in DDPM [
23], the mean is set to 0 and the variance to 1. The log-normal distribution utilizes parameters that determine the shape and scale, similar to the Weibull distribution. In this comparison experiment, we set the shape to 0 and the scale to
. The Gaussian mixture distribution combines two Gaussian distributions, both with a mean of 0 and variances of
and
, respectively, with a weight of
. Comparing the results, the performance of the Gaussian distribution is superior in terms of HR@10 and NDCG@10 on the Beauty dataset, while on the Toys dataset, the log-normal distribution in HR@5 performs better than other methods, and the Gaussian mixture outperforms in NDCG@5. However, in all other metrics, our proposed Weibull distribution achieves the most superior performance. It proves that using a distribution with higher degrees of freedom, such as the noise distribution, could be helpful for performance improvement. In this sense, there is still the possibility of deriving a more suitable distribution for both the log-normal and Gaussian mixture distributions through parameter adjustments.
To further investigate the impact of warmup duration settings, we conducted performance comparison experiments on all datasets. The results are depicted in
Figure 4. In the case of the Beauty dataset, there is not a significant difference in performance according to the HR metric, while a longer duration correlates with improved performance in the NDCG metric. In the Toys dataset, similarly, there is no significant performance difference in terms of HR metrics. However, in contrast to the Beauty dataset, performance improves with shorter durations. This difference is most pronounced in the Tools dataset, where it is evident that as the duration increases, performance remains notably low. For the Video dataset, a relatively shorter duration yields higher performance in both HR and NDCG at
and
. These findings indicate that performance could fluctuate based on the duration, emphasizing the importance of selecting an appropriate duration that suits the characteristics of the data.
5. Discussion and Limitations
This study aimed to propose a model that better reflects personalized preferences through an improved Diffusion model in sequential recommendation systems. As shown in
Table 3, EDiffuRec demonstrates enhanced performance compared to the existing Diffusion model-based sequential recommender model. We hypothesize that the addition of an extra FFN layer, unlike the traditional Transformer encoder structure, significantly contributes to the comprehensive learning of user behavior patterns embedded in sequential information.
Furthermore, the results presented in
Table 4 align with previous research [
15], which suggested that using distributions with higher degrees of freedom can positively impact the performance of generative models. This underscores the meaningful application of such distributions in generative recommendation models. The strategy of applying warmup, as demonstrated in
Figure 3, enhances both performance and stability, corroborating the proposal of [
17]. By starting with a sufficiently low learning rate during the initial stages of training, the numerical instability of the training weights is mitigated, allowing the model to avoid local optima and converge towards a global optimum, therefore achieving a lower loss.
As shown in
Table 5, adding an additional FFN layer increased both the training and testing time compared to DiffuRec due to the increase in parameters. Nonetheless, EDiffuRec converges in fewer epochs due to stable learning, resulting in a comparable total training time and improved final performance. However, considering time efficiency, it is necessary to explore strategies to reduce the number of parameters or decrease training time in future work. Additionally, since this study did not separately investigate learning rate scheduling from learning rate warmup, there remains potential for more efficient and stable learning and consequent performance improvements.
6. Conclusions
In this paper, we have introduced a novel diffusion sequential recommendation model tailored for real-life-oriented online commerce. Our proposed model, EDiffuRec, integrates several key enhancements, including a modified Transformer structure inspired by the Macaron Net, a normalized loss function, a novel noise assumption following the Weibull distribution, and the incorporation of warmup techniques.
Specifically, we leverage a modified Transformer structure based on the Macaron Net to bolster the model’s information representation capacity. Furthermore, we introduce a Weibull distribution for generating noise tailored to the generative model’s requirements. Additionally, the adoption of a normalized loss function and warmup strategy contributes to the model’s overall stability. Extensive experiments, including ablation studies, were conducted to assess the effectiveness of each major design component.
Comparative experiments were carried out on four datasets, consistent with prior research in the field of diffusion sequential recommender models. Our experimental results demonstrate performance enhancements ranging from a minimum of to a maximum of across all evaluation metrics. Based on these findings, we anticipate that our EDiffuRec model will significantly elevate user satisfaction and marketing efficiency within the online commerce domain through enhanced personalization.
In today’s digital landscape, characterized by ubiquitous online and streaming services, personalized recommendations play a pivotal role in enhancing user satisfaction. Advancements in this research domain, focused on modeling human preferences, facilitate profound insights into human behavior from a machine-learning perspective.
Author Contributions
Conceptualization, H.L. and J.K.; methodology, H.L.; software, H.L.; validation, H.L.; formal analysis, H.L.; investigation, H.L.; writing—original draft, H.L.; writing—review and editing, J.K.; visualization, H.L.; supervision, J.K. All authors have read and agreed to the published version of the manuscript.
Funding
This work was partly supported by the Institute of Information and Communications Technology Planning and Evaluation (IITP) under the metaverse support program to nurture the best talents (IITP-2023-RS-2023-00254529) grant funded by the Korea government (MSIT). This work was also supported by the Basic Science Research Program through the National Research Foundation of Korea (NRF), funded by the Ministry of Education (RS-2023-00271991).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 6000–6010. [Google Scholar]
- Sun, F.; Liu, J.; Wu, J.; Pei, C.; Lin, X.; Ou, W.; Jiang, P. BERT4Rec: Sequential recommendation with bidirectional encoder representations from transformer. In Proceedings of the ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; pp. 1441–1450. [Google Scholar]
- Kang, W.C.; McAuley, J. Self-attentive sequential recommendation. In Proceedings of the IEEE International Conference on Data Mining, Singapore, 17–20 November 2018; pp. 197–206. Available online: https://github.com/kang205/SASRec.git (accessed on 11 May 2024).
- Wang, Y.; Zhang, H.; Liu, Z.; Yang, L.; Yu, P.S. Contrastvae: Contrastive variational autoencoder for sequential recommendation. In Proceedings of the ACM International Conference on Information & Knowledge Management, Atlanta, GA, USA, 17–21 October 2022; pp. 2056–2066. [Google Scholar]
- Wang, W.; Feng, F.; He, X.; Nie, L.; Chua, T.S. Denoising implicit feedback for recommendation. In Proceedings of the ACM International Conference on Web Search and Data Mining, Virtual Event, Israel, 8–12 March 2021; pp. 373–381. [Google Scholar]
- Yang, Y.; Huang, C.; Xia, L.; Huang, C.; Luo, D.; Lin, K. Debiased contrastive learning for sequential recommendation. In Proceedings of the ACM Web Conference, Austin, TX, USA, 30 April–4 May 2023; pp. 1063–1073. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Liang, D.; Krishnan, R.G.; Hoffman, M.D.; Jebara, T. Variational autoencoders for collaborative filtering. In Proceedings of the World Wide Web Conference, Lyon, France, 23–27 April 2018; pp. 689–698. [Google Scholar]
- Lucas, J.; Tucker, G.; Grosse, R.; Norouzi, M. Understanding Posterior Collapse in Generative Latent Variable Models. 2019. Available online: https://openreview.net/forum?id=r1xaVLUYuE (accessed on 11 May 2024).
- Dhariwal, P.; Nichol, A. Diffusion models beat gans on image synthesis. Adv. Neural Inf. Process. Syst. 2021, 34, 8780–8794. [Google Scholar]
- Kong, Z.; Ping, W.; Huang, J.; Zhao, K.; Catanzaro, B. Diffwave: A versatile diffusion model for audio synthesis. arXiv 2020, arXiv:2009.09761. [Google Scholar]
- Wang, W.; Xu, Y.; Feng, F.; Lin, X.; He, X.; Chua, T.S. Diffusion recommender model. In Proceedings of the International ACM SIGIR Conference on Research and Development in Information Retrieval, Taipei, Taiwan, 23–27 July 2023; pp. 832–841. [Google Scholar]
- Yang, Z.; Wu, J.; Wang, Z.; Wang, X.; Yuan, Y.; He, X. Generate What You Prefer: Reshaping sequential recommendation via guided diffusion. arXiv 2024, arXiv:2310.20453. [Google Scholar]
- Nachmani, E.; Roman, R.S.; Wolf, L. Denoising diffusion gamma models. arXiv 2021, arXiv:2110.05948. [Google Scholar]
- Lu, Y.; Li, Z.; He, D.; Sun, Z.; Dong, B.; Qin, T.; Wang, L.; Liu, T.Y. Understanding and improving transformer from a multi-particle dynamic system point of view. arXiv 2019, arXiv:1906.02762. [Google Scholar]
- He, T.; Zhang, Z.; Zhang, H.; Zhang, Z.; Xie, J.; Li, M. Bag of tricks for image classification with convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 558–567. [Google Scholar]
- Amazon Product Data. Available online: https://cseweb.ucsd.edu/~jmcauley/datasets/amazon/links.html (accessed on 11 May 2024).
- Li, Z.; Sun, A.; Li, C. Diffurec: A diffusion model for sequential recommendation. ACM Trans. Inf. Syst. 2023, 42, 1–28. [Google Scholar] [CrossRef]
- Ma, J.; Zhou, C.; Cui, P.; Yang, H.; Zhu, W. Learning disentangled representations for recommendation. Adv. Neural Inf. Process. Syst. 2019, 32, 5711–5722. [Google Scholar]
- Guo, G.; Zhou, H.; Chen, B.; Liu, Z.; Xu, X.; Chen, X.; Dong, Z.; He, X. IPGAN: Generating informative item pairs by adversarial sampling. IEEE Trans. Neural Netw. Learn. Syst. 2020, 33, 694–706. [Google Scholar] [CrossRef]
- Walker, J.; Zhong, T.; Zhang, F.; Gao, Q.; Zhou, F. Recommendation via collaborative diffusion generative model. In Proceedings of the International Conference on Knowledge Science, Engineering and Management, Singapore, 6–8 August 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 593–605. [Google Scholar]
- Ho, J.; Jain, A.; Abbeel, P. Denoising diffusion probabilistic models. Adv. Neural Inf. Process. Syst. 2020, 33, 6840–6851. [Google Scholar]
- Gong, S.; Li, M.; Feng, J.; Wu, Z.; Kong, L. Diffuseq: Sequence to sequence text generation with diffusion models. arXiv 2022, arXiv:2210.08933. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Iage Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Luo, C. Understanding diffusion models: A unified perspective. arXiv 2022, arXiv:2208.11970. [Google Scholar]
- Smith, L.N. A disciplined approach to neural network hyper-parameters: Part 1—Learning rate, batch size, momentum, and weight decay. arXiv 2018, arXiv:1803.09820. [Google Scholar]
- Hidasi, B.; Karatzoglou, A. Recurrent neural networks with top-k gains for session-based recommendations. In Proceedings of the ACM International Conference on Information and Knowledge Management, Torino, Italy, 22–26 October 2018; pp. 843–852. [Google Scholar]
- Krichene, W.; Rendle, S. On sampled metrics for item recommendation. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual Event, CA, USA, 6–10 July 2020; pp. 1748–1757. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).







{kind=link}
{kind=link}
{kind=link}
{kind=link}