1. Introduction
One of the basic principles of electrical power systems (EPS) management is to ensure standard static stability (SSS) and dynamic stability (TS) margins under normal and post-emergency operating conditions. Ensuring SSS and TS by introducing restrictions on the amount of active power flows, on the one hand, is an effective measure, and on the other hand, leads to a significant impact on the functioning of the electricity market [
1]. The economic distribution of active load power between EPS synchronous generators (SG) is based on the optimization problem [
2], which affects the total cost of electricity generation and transmission. Considering additional restrictions on the flow of active capacities inevitably leads to an increase in the cost of electricity for the end consumer. An alternative way to ensure EPS SSS and TS is to use emergency control (EC), which allows one to select and implement the necessary amount of control actions (CA) to maintain the stability of the EPS [
3]. The most common CAs for storing TS include the following:
Use of fast valving (FV) in a steam turbine (ST) [
6].
The above-mentioned ways are generally used and have proven effective in EPS with traditional high-inertia SGs.
Today, the general development of EPS is the transition to low-carbon electricity production with flexible digital control systems and the monitoring of the processes of production, transmission, and consumption of active and reactive power [
7]. The introduction of renewable energy sources (RES) is a global practice to reduce the level of fossil fuel generation sources [
8]. A wide use of RES in EPS allows us to reduce the total inertia and increases the stochasticity of the electricity generation process. Thus, in modern EPS there is a fundamental change in the characteristics of transient processes [
9,
10]. A decrease in the total inertia of the EPS leads to an increase in the speed of transient processes and increased requirements for the speed of EC systems. In addition, the current stage of development of EPS includes the development of systems for measuring electrical mode parameters based on synchronized phasor measurement units (PMU) [
11,
12], the development of digital signal processing (DSP) methods [
13], increasing the productivity and speed of computing systems, and accumulating large volumes of data characterizing the operation of EPS.
In EPS EC practice, the CA selection for maintaining SSS and TS is typically divided into local and centralized categories. The former ensures the stability of individual power plants, load nodes, or selected energy districts, while the latter secures the stability of large energy networks. Algorithms for local EPS EC complexes often use a method involving the creation of a logical matrix to correlate anticipated accidents with the required CA values. This compliance matrix is formed through a series of calculations of steady-state and transient electrical modes using a pre-prepared mathematical model of EPS, considering the most likely emergency scenarios. To develop centralized EPS EC systems, a method is employed that involves calculating a compliance matrix in a cyclic mode for the current EPS mode, also considering the most likely emergency processes.
For existing local and centralized EPS EC complexes, the following features exist:
CA selection is performed for predefined emergency processes, i.e., EPS stability may not be ensured in the event of an unplanned disturbance or cascading accident;
When choosing CA, mathematical EPS models are used, the parameters of which may differ from the actual ones, which helps to reduce the accuracy of emergency control;
The use of a pre-prepared matrix of correspondence between an accident and the required CA value leads to an increase in the likelihood of the implementation of unnecessary CAs due to the consideration of the worst scenarios for the development of the emergency process.
The disadvantages of traditional EPS EC systems are compensated by means of using redundancy and echelon construction of the emergency control structure [
14]. However, as the speed of transient processes increases, existing EPS EC systems may become ineffective or contribute to the development of cascading accidents.
Considering the characteristics of modern EPS, including developed monitoring systems, large data volumes, and the need to significantly enhance the speed and adaptability of EPS EC systems, a promising approach is the use of machine learning (ML) algorithms [
15,
16,
17,
18] for EPS EC. ML algorithms offer high performance and adaptability, owing to their lack of procedural logic, which is typical of deterministic approaches to transient analysis in EPS. This study explores the use of ML algorithms for tuning ST FV parameters. This CA is employed to maintain the TS of both individual SGs and the entire EPS [
19].
This study proposes an adaptive methodology for determining the parameters of the ST FV characteristic for emergency control of the power system to maintain EPS TS. The main contribution of the article is the development of a comprehensive methodology for determining the parameters of the ST FV process based on ML algorithms to ensure the adaptability and speed of the EPS EC process. The adaptability of the proposed methodology ensures the selection of the optimal ST FV law for any emergency process leading to the loss of EPS TS.
The article is organized as follows:
Section 2 provides an overview of the research involved in the development of adaptive algorithms for selecting EPS TS performance parameters. It discusses the advantages and disadvantages of existing algorithms, as well as the main benefits for research in the subject area.
Section 3 provides a methodology for setting the ST FV process parameters based on ML algorithms.
Section 4 presents the results of a numerical experiment on the mathematical model of the IEEE39 EPS test system. In the conclusion the results of the proposed methodology and directions for future research are indicated.
2. Related Research
ST FV is an effective method for maintaining EPS TS by rapidly reducing the mechanical power of ST in the short term and increasing the braking area of SG [
20].
Figure 1 shows a schematic diagram of a power unit with a shut-off valve (IV).
Figure 1 illustrates a single-shaft ST configuration with an IV positioned between the superheater (RH) and the medium pressure cylinder (IP). Superheated steam from the boiler enters the high-pressure cylinder (HP) through a control valve, enhancing the power unit’s efficiency. The steam then flows into the RH, and the recovered steam passes through a shut-off valve into the IP. Subsequently, the steam moves into a low-pressure cylinder (LP), the final stage in the cycle of converting steam energy into mechanical work, culminating in a condenser [
21].
In ST, FV is achieved by temporarily closing the shut-off valve, which leads to a reduction in steam pressure on the turbine blades and a decrease in the torque transmitted to the SG rotor. ST FV is an effective and economical TS measure that preserves EPS inertia and avoids prolonged SG startups.
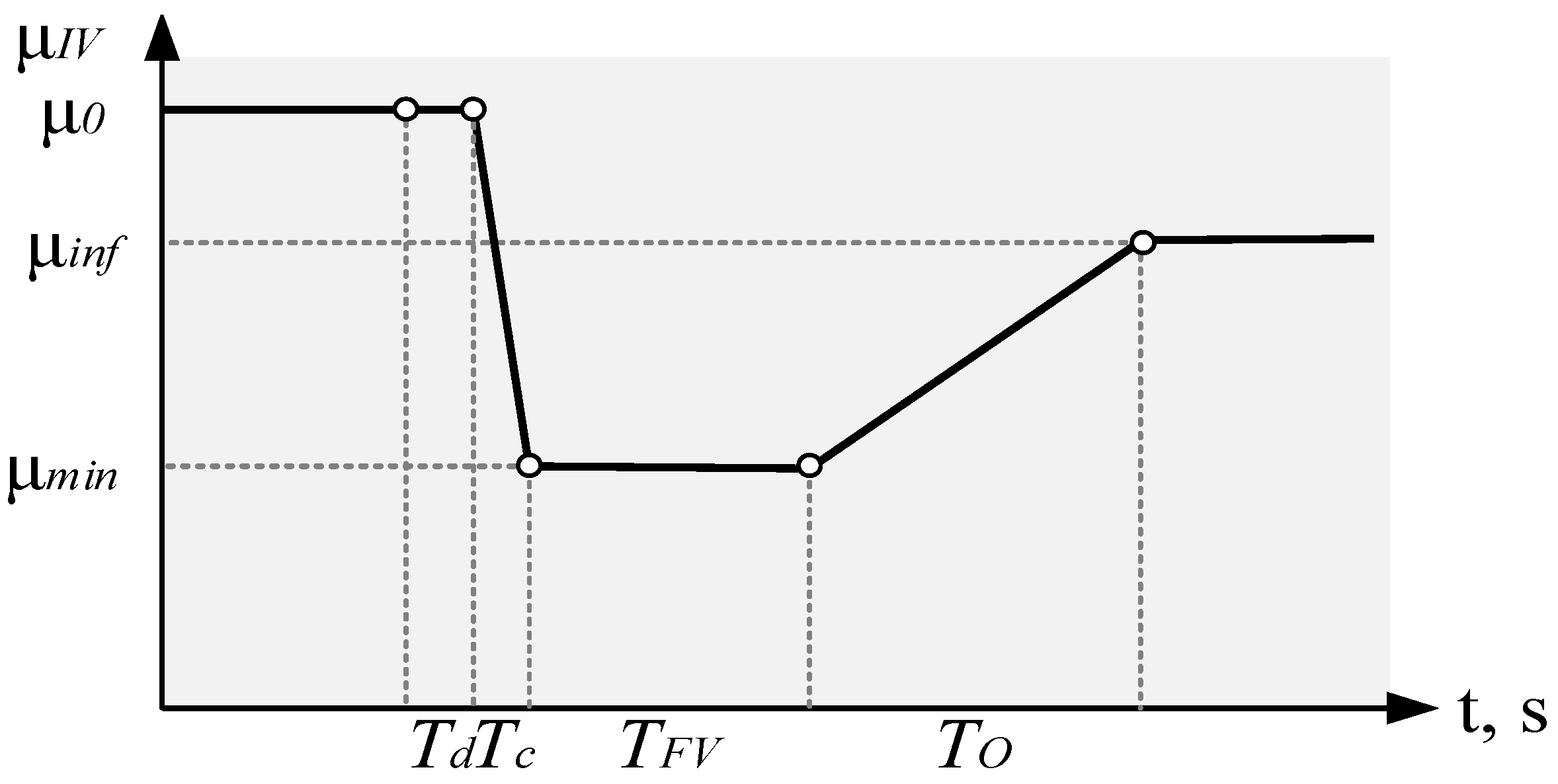
Figure 2 depicts the process of changing IV in the ST FV. The x-axis indicates the time in seconds, the y-axis indicates the position of IV. In particular,
Figure 2 shows the following: μ
IV—position IV, μ
0—initial position IV, μ
inf—position IV after ST FV, μ
min—minimum position IV at ST FV,
Td—delay in the start of the IV movement process at ST FV,
Tc—closing time IV at ST FV,
TFV—time of holding the minimum position IV at ST FV, and
To—time of transition from position IV μ
min to position μ
inf.
In determining the characteristics of the IV position change process, the following variables are calculated: μ
inf, μ
min,
Tc,
TFV, and
To. The shut-off valve closes as quickly as possible. To prevent low frequency oscillation (LFO) of the SG active power when the turbine power increases after ST FV, the opening of the shut-off valve is performed at a limited speed [
22]. To prevent LFO caused by the actions of the power unit regulators after the ST FV, the IV is opened with a time delay
To. The time during which the shut-off valve is closed is limited by the technological protections of the steam boiler and individually for each power unit. The depth of turbine ramping and turbine power after ST FV also have limitations due to the permissible operating conditions of the steam boiler and turbine.
Figure 2 shows the following sections of the ST FV process: open position IV, closing process IV, the delay of a closed position IV for the time
TFV, opening the IV for time
To, and open position IV.
In 1973, R.H. Park published a paper [
23] that provides a detailed description of using ST FV to maintain EPS stability. Historically, the initial studies exploring the use of ST FV date back to 1925 [
24] and 1928 [
25]. Subsequently, the paper [
26] highlights the advantages of using ST FV with a delayed opening of the IV:
The delay when opening IV increases the magnitude of the first swing cycle in the post-emergency operating mode of SG, which increases the probability of maintaining stability;
When opening IV without delay, the probability of LFO groups of oscillators occurring with a subsequent loss of TS increases.
The study [
27] discussed the problem of maintaining superheater pressure when using ST FV. Since the 1980s, active implementation of ST FV began. In the study [
28], an expert system was proposed to determine the following parameters of the IV motion in the ST FV process: μ
inf and μ
min. To implement a certain ST FV law in real time, a pre-prepared lookup table was used. However, this approach did not assume sufficient adaptability and considered only a certain set of disturbances for which the values μ
inf and μ
min were prepared in advance. The study did not consider the probability of loss of SG stability in the second and subsequent swing cycles after the implementation of ST FV.
In the study [
29], mathematical models of ST in various configurations and methods for modeling ST FV are presented. The effectiveness of ST FV in enhancing EPS sustainability is also demonstrated. The theoretical basis for the effectiveness of ST FV is supported by applying the rule of area (EAC). For numerical modeling, a fragment of the Brazilian EPS consisting of 13 nodes with a voltage class of 345 kV was used. The authors note that the use of ST FV can lead to increased pressure in the ST superheater; therefore, the motion characteristics of the IV should consider the overall technical condition of the superheater. To improve the efficiency and reliability of ST FV, the authors suggest supplementing the ST with a bypass device that diverts part of the steam to the condenser during ST FV implementation.
The authors of [
30] propose a technique based on the use of artificial neural networks (ANN) to determine the parameters of the law of IV position change during ST FV. The parameters to be determined were μ
inf, μ
min, and
TFV. The initial power SG, the post-accident power reduction SG, and the rotor acceleration magnitude SG were used as inputs to the ANN algorithm. The general algorithm for using ST FV is as follows: identification of disturbance; within 0.08 s, the input data used for ANN is saved; and the parameters μ
min and
TFV are determined. After 0.65 the parameter μ
inf is determined. Mathematical and physical models were used for testing.
In [
31] the ANN algorithm was also used to synthesize the law of IV position change during the ST FV process. The change in active power SG during the disturbance process and the change in rotor speed SG were used as input parameters for the ANN. The output parameters are μ
min, μ
inf, and
TFV. For the numerical experiment, an EPS mathematical model consisting of a 600 MW SG and an IB was used. The performance of the trained ANN algorithm ranged from 60 to 80 ms.
In the study [
32] a multi-agent approach (MAS) was used to synthesize the law of IV position change in the ST FV process. The attached algorithm consists of two agents: a tracking agent and a managing agent. The tracking agent models the load angle of each protected SG to track buckling. The control agent determines the values μ
min, μ
inf, and
TFV of the IV position change law during the ST FV process. The input parameters for the developed methodology are pre-emergency active power SG, post-emergency active power SG, and predicted value of the load angle SG. The proposed methodology was tested using mathematical data. The study [
33] used the Lyapunov stability theory (LST) to synthesize the ST FV law. To test the methodology, a mathematical model of EPS consisting of three nodes and two SGs was used. The authors of the study [
34] used the radial basis function network (RBFNN) algorithm to determine the values of μ
min, μ
inf, and
TFV of the IV position change law during the ST FV process. To determine the required parameters, a system of input and output data similar to [
30] was used. The Gaussian function was used as the activation function. The study [
35] is devoted to the use of the maximum principle (MP) to synthesize the ST FV law. Testing was performed on a standard IEEE39 model. To synthesize the ST FV law in [
36], the transition energy function (TEF) method was used, which is determined by the sum of kinetic and potential energy SG EPS. Testing was performed on the IEEE24 model. In the study [
37], the feedback linearization (FL) method was used to select the parameters of the ST FV law. The authors of [
38] used the optimization method and the equal area criterion (EAC) with testing on the IEEE 39 model to determine the values of μ
min and
TFV. Also, the direction of studying ST FV contains the following: the analysis of the results of testing on a real-time modeling complex [
39], real EPS [
40,
41], as well as the influence of ST FV on the protection systems of electrical network elements [
42].
Table 1 provides an analysis of the methods considered for synthesizing the ST FV law.
Among the studies reviewed, two groups of methods used to synthesize the optimal ST FV law can be distinguished: ML algorithms and classical algorithms for transient analysis in EPS [
43,
44,
45,
46,
47].
Today, due to the development of computer technology the availability of large volumes of data on transient processes in EPS and the development of systems for collecting and transmitting information, ML algorithms are actively used for analyzing and managing EPS. Developing and implementing adaptive EPS EC systems based on ML and ST FV becomes possible. Also, for the problem of synthesizing the ST FV law, to use new ML algorithms that eliminate the disadvantages of ANN-based algorithms is possible [
48].
3. Methodology
The methodology for introducing ML algorithm into the EPS management process to ensure sustainability can be described as follows:
Data collection. In this stage, physical or synthetic data obtained during the modeling of transient processes on a mathematical model of the EPS under consideration can be used;
Data pre-processing. This stage includes the elimination of gaps, noise, and outliers in the data, correlation analysis, processing of features, and identification of the main components in the data;
Training several ML algorithms to analyze the accuracy, time efficiency, and fault tolerance;
Testing of algorithms. During this stage the ML algorithm that provides optimal results in terms of accuracy and speed is determined;
Testing the selected ML algorithm in real time;
Development and implementation of digital infrastructure that ensures the correct operation of the trained algorithm;
Monitoring and possible correction of parameters of ML algorithm during use in the EPS control loop.
Figure 3 shows a graphical interpretation of the proposed methodology.
This article covers steps 1–4. The study of steps 5–7 is a task for future research; this work discusses the complete list of stages of the methodology to provide a complete picture of the study.
3.1. Dataset Generation
The data collection stage is a key component when developing an EPS management methodology based on ML algorithms [
49]. Sources of input data can include physical changes and synthetic data obtained from modeling a series of transients in EPS. Each data source has its advantages and disadvantages associated with the presence of noise, gaps in the data, inaccuracy in the representation of EPS parameters in the mathematical model, the impossibility of considering the entire list of accidents, etc. [
50]. As a result, the most optimal way to generate a data sample is a combination of physical and synthetic data.
When using synthetic data, an important issue is the modeling of changes in the parameters of the EPS electrical mode and the list of considered disturbances. The loads in the nodes are considered as variable parameters when changing the EPS operating mode. Voltages, flows of active and reactive powers, current loads of the electrical network, and SG loads are dependent parameters determined by the requirement to ensure a balance of active power in the EPS. EPS load variations can be modeled considering intra-daily and seasonal variations [
51]. In the simplest cases, load changes are modeled using a probabilistic approach.
In this study, a probabilistic approach of load deviation from the base value with a normal distribution was used to model the load change of the test EPS. To obtain the reference laws of IV position change during the ST FV process, the algorithm given in [
38] was used. Voltage values at the nodes of the EPS model flow of active and reactive powers across the elements of the electrical network, active and reactive powers of SG, and load angles of SG are used as features.
3.2. Dataset Preparation
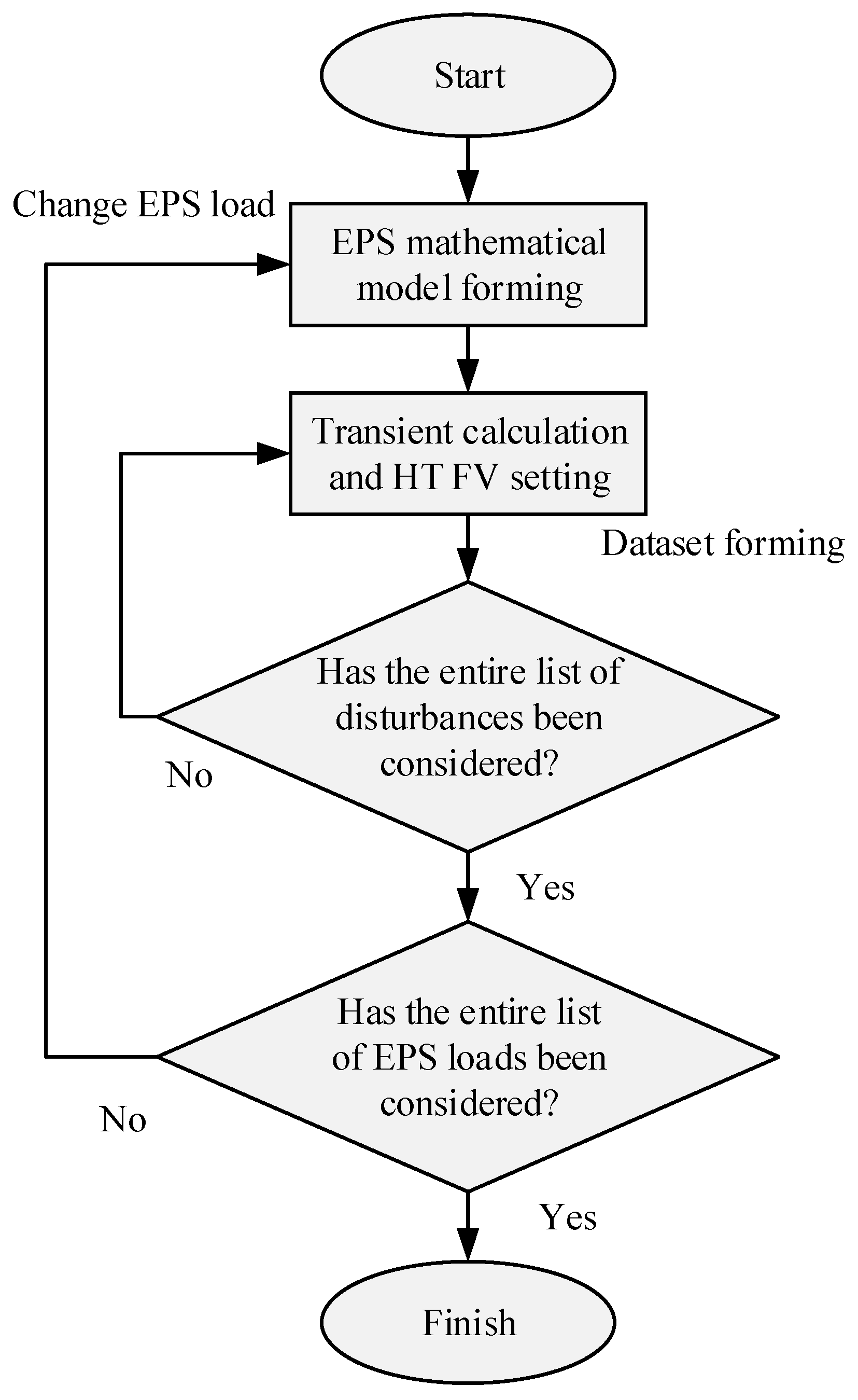
One of the key stages of using ML algorithms is collecting and preparing source data. In this study, the results of mathematical modeling were used to generate a data sample. The loads in the nodes of the EPS test model, the node, and the type of simulated disturbance was selected as varied parameters during modeling. The data generation technique used in this article is as follows:
Formation of a dynamic model of the test EPS in Python3 free software in consideration of the SG parameters, electrical network elements, and loads;
Specifying a list of accidents to be considered in the form of three-phase, two-phase, and single-phase short circuits (SC) in electrical network nodes;
For the selected SG, the optimal law of IV variation is calculated to maintain TS;
The loads in the test EPS nodes are changed by adding a random variable with a normal distribution to the basic load values;
The calculation of the optimal law of change of IV for maintaining TS is performed;
A cyclic calculation is performed until the end of the load search in the EPS nodes.
Figure 4 shows a flowchart for generating data samples.
The features in the sample are active and reactive powers SG, load angles SG, flows of active and reactive power through the elements of the electrical network, voltage modules, and phases in the nodes of the electrical network. The target indicator is the law of IV position change in the ST FV process.
3.3. ML Algorithm Selection
The problem of synthesizing the law of IV position change in the ST FV process is a multidimensional classification problem in which various combinations of parameters μmin, μinf, and TFV act as classes. In this study, the parameters μmin and TFV are used to form classes, the value of μinf is taken equal to 1.
In this work, to synthesize the ST FV law, classification algorithms were used that are actively used for problems of process analysis in EPS [
52]: k-nearest neighbors (KNN), support vector machine (SVM), decision tree (DT), random forest (RF), extreme gradient boosting (XGBoost), and ANN. The choice of these algorithms is determined by a combination of their performance, accuracy, and ease of use. These algorithms are widely used to solve problems in EPS control, analysis, and diagnostics.
The KNN algorithm is one of the simplest classification algorithms, which simply consists of sequentially performing the following operations [
53]:
Calculation of the distance to each of the objects in the training sample;
Determination of k objects of the training set with the smallest distance;
Calculate the most frequently encountered class for k objects, which will be the result of the classification.
The algorithm parameter is n_neighbors—the number of objects with a minimum distance. The advantages of the algorithm include resistance to outliers in the data, interpretability of the results, and ease of implementation of the algorithm.
The SVM algorithm [
54] uses the technique of constructing a separating hyperplane, which is determined because of training, to classify data. The parameters of the algorithm are
C—soft constraint weight,
kernel—kernel function, in this work the radial basis function (RBF) kernel is used, and
gamma—kernel coefficient. The advantages of the algorithm include a high accuracy, the ability to efficiently process high-dimensional data, and a small number of hyperparameters.
DT [
55] is a flexible classification algorithm based on the construction of logical rules. The DT algorithm can be represented as a hierarchical structure, the purpose of which is to split the data sample in order to optimize a pre-determined criterion (Gini coefficient, entropy value, or logistic error function). Training the DT algorithm consists of sequentially performing the following steps:
Enumerate all the features, and search for the feature with the best separation;
Dividing the sample into two parts, enumerating the features, and dividing each of the resulting subsamples;
The division of subsamples continues until subsamples of unit dimension are obtained, which are called DT leaves.
The parameters of the algorithm are as follows:
criterion—a function for assessing the quality of data splitting,
splitter—a strategy used to select a split at each node, and
max_depth—the maximum depth of DT. The advantages of the algorithm include interpretability due to the visual representation capabilities of a trained DT, and efficiency of work on untrained data. As a way to improve the DT algorithm, the RF algorithm [
56], which is an ensemble ML algorithm, is used. During the training process of the ensemble algorithm, several DTs are created, which reduces the probability of overfitting.
The classification result of the RF algorithm is an aggregation of the classification of each of the RFs included in the ensemble. Each RF algorithm is trained independently, allowing efficient use of parallel computing. The parameters of the algorithm are as follows: n_estimators—the number of trees in the algorithm, criterion—a function for assessing the quality of data partitioning, and max_depth—the maximum depth of DT. The advantages of the algorithm include a high degree of use of parallel calculations when training and testing the algorithm, high resistance to overtraining, and to assess the importance of each feature for classification.
Further development of the RF algorithm led to the development of the XGBoost algorithm [
57]. This algorithm uses gradient boosting to iteratively train weak classifiers. The parameters of the algorithm are as follows:
criterion—the function for assessing the quality of data dividing,
learning_rate,
n_estimators—the number of iterations in boosting,
max_depth—the maximum depth of the tree, and
max_features—the number of features considered by the algorithm to construct splitting in the tree. The advantages of the algorithm include resistance to overtraining due to the use of L1 and L2 regularizes, a high degree of parallelization, and a high optimization in the use of computing resources.
The following configurable parameters for the ANN algorithm are used: batch_size—the number of records processed together before updating the model parameters, learning_rate—the learning rate, and epochs—the number of epochs. For this study, the ANN is built using a series of fully connected linear layers followed by rectified linear unit (ReLU) activation functions. The input dimension corresponds to the number of features in the processed data set, and the output dimension equals the number of classes in the classification problem.
3.4. ML Algorithm Training and Testing
After generating a data sample, it is processed using statistical analysis methods, a detailed description of which is given in the study [
58].
Table 2 summarizes the methods used to determine the hyperparameters in the used ML algorithms. For the SVM, DT, RF and XGBoost algorithms, the main training method is stochastic gradient descent (SGD). For the KNN algorithm, the training is the procedure for calculating the distance between classes.
To estimate the performance of the trained algorithm the following metrics are used: accuracy, precision, recall, F1 score, and the area under the receiver operating characteristic (AUC) [
59].
5. Conclusions
The development of modern EPS significantly impacts the accuracy and adaptability of EPS EC algorithms. With the introduction of a considerable amount of RES, the nature of the transition processes in EPS is undergoing radical changes. An increase in the speed of transient processes, along with a rise in the stochasticity of EPS operation, necessitates a revision of the operating principles in EPS EC devices. The advantages of the proposed method include high adaptability and performance. One of the difficulties of the technique is the process of matting the data sample and re-training the model when the configuration in the protected EPS is changed. However, this feature can be mitigated by developing an automatic approach for generating data during the operation of the EPS.
The problem of implementing an adaptive selection of the ST FV law based on an ML algorithm has been considered in the study. To form a data sample, the EPS IEEE39 mathematical model was used. A total of 300 transient processes were considered, of which 196 features were identified. After statistical analysis, the number of features was reduced to 109.
Next, the procedures for training and testing the KNN, SVM, DT, RF, XGBoost, and ANN algorithms were performed on the generated data samples. The highest accuracy on the training and test samples corresponds to the XGBoost algorithm (98.17% on the training set and 97.14% on the test set). The smallest computational delay for classifying one transient process also corresponds to the XGBoost algorithm (4.2 ms on the training set and 3.8 ms on the test set).
The following can be considered as directions for further research on the topics discussed in this article: development of a methodology for selecting CAs based on ML algorithms for storing TS and SSS in combined EPS; CA selection based on ML algorithms to maintain voltage stability and maintain a required frequency level; testing the developed methods on a real-time modeling complex; and development of an architecture for implementing the ESP EC methodology based on ML algorithms in the operational control loop of an EPS operation.

 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}