1. Introduction
Right censored data are encountered in various settings such as biomedicine, reliability, actuarial science, sociology, politics, and public health, to name a few. They are part of a class of data called survival or failure time data, which include, among others, left and right censored, left and right truncation, and interval censored data. Research with these types of data is well documented. This manuscript pertains to another aspect of failure time data, namely one where spatial modeling is incorporated via geostatistical locations of units of interest. Consider the situation where these units, located at areas described by their longitude and latitude in a two-dimensional surface, are monitored for the occurrence of some event, such as the onset of a disease, an epidemic, claims filed as a result of property losses, cancer, or migration of individuals from one area to another to seek better living conditions. There exist environmental factors, social and physical environments, population density, or weather conditions beyond the control of the investigators that can have a substantial impact on the occurrence of events between two areas via their spatial coordinates. We give one example of such data in biomedical studies that will be used in the application section. Many more examples can be found in [
1].
Example 1. Leukemia survival data: [2,3]. A total of 1043 adults were diagnosed with leukemia between 1982 and 1998, in Northeast England, which comprises 24 administrative districts boxed in . The data holds records of incidence and subsequent survival status of all leukemia cases in the region. Also recorded was the background variation in population or environmental characteristics, which could enable further epidemiologic studies. Past studies, while informal, have suggested that there could be district-to-district variation in survival rates above and beyond what might be expected to occur by chance alone.
Modeling failure time data when spatial correlation is present has emerged as an area of active research, especially with right censored data. The models of interest with these types of data are multivariate survival models that contain a parameter modeling the association between event times
and
,
of two independent units at different locations. Such models include bivariate frailty, copulas, marginal models, cluster models, and spatial correlation-type models via a covariation process using a martingale representation. For right censored data, the references are [
2,
4,
5,
6,
7,
8,
9,
10,
11,
12,
13,
14]. However, interest in spatial correlation dates back to the pioneering work of Krige and, recently, Ref. [
15]. Frailty, cluster, marginal, and copula models do not properly account for spatial correlation that is inherent with these data. As a consequence, sophisticated techniques of geostatistics coupled with modern failure time data analysis are needed. In recognition of that, Ref. [
7], with right censored data, assumed a Cox model for failure time and used a probit-type transformation of the failure times yielding a multivariate Gaussian random field. Furthermore, they imposed a spatial structure on the associated random fields that properly captures the spatial patterns among regions.
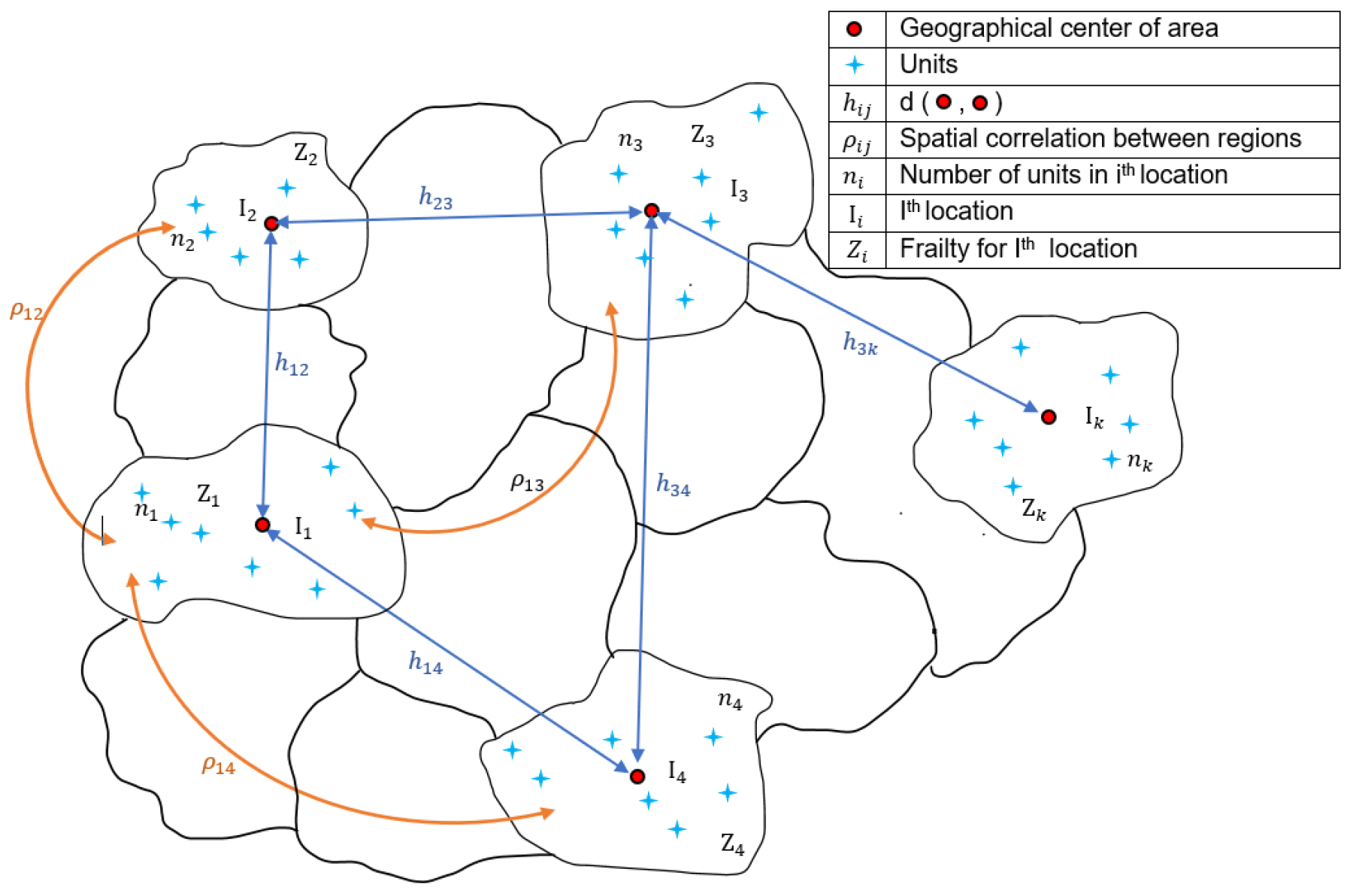
This manuscript is concerned with the development of models for estimating the regression parameters with clustered right censored data that account for spatial patterns between various locations. This is important in the sense that if the spatial impact leads to drastic consequences, local authorities could take necessary preventive actions to reduce damage. It is, therefore, of considerable importance to develop models for estimating the distribution function of time to event while accounting for spatial correlation. We consider multiple units per location in order to reflect the real life situation, and leukemia data will be used for illustration, since it fits more closely with our setting, with a pictorial representation given in
Figure 1.
In the above pictorial representation, we show that all units are assumed to be located at the geographical center. Ref. [
2] modeled spatial association via a mean random frailty per region, wherein individual frailty
within a region
j with mean frailty
was assumed to follow a gamma distribution, with parameters depending on
. The vector
is assumed to follow a multivariate normal distribution whose variance–covariance matrix is a function of the distance between regions. In this manuscript, we incorporate spatial association in the failure times via a probit transformation, leading to a multivariate Gaussian random field with the spatial correlation matrix being a function of the distance between locations. The two modeling approaches are applied to the same data, and it is shown that embedding the spatial correlation within the failure time results in improvement. Ref. [
2] did not provide large sample properties; we did so on all parameters involved in our models for the purpose of making inference and performing further investigations tailored to a specific area.
Though some work has been performed to incorporate spatial correlation in modeling, very few of the works model many units per geostatistical location while accounting for spatial patterns. The aim of this manuscript is to develop statistical models for spatially correlated right censored data for multiple units per location, where regression parameters have a region and/or area level interpretation, and in which spatial correlation is properly incorporated by transforming the original failure times.
The manuscript proceeds as follows. In
Section 2, we develop the stochastic process machinery for this type of data and motivate our model choices.
Section 3 deals with some preliminary results that will set the stage for the estimation procedures in
Section 4. In
Section 4, we propose our weighted estimating score processes and show that they are asymptotically unbiased.
Section 5 is on the existence of solutions and the infill asymptotic results of the estimators.
Section 6 presents the results of our numerical studies, which indicate good approximation to the true parameters, and an illustrative application with the leukemia dataset. The manuscript then concludes with a summary and future directions.
2. Spatially Correlated Right Censored Data and Models
The first critical step in the modeling is to identify a suitable spatial dependence model between locations. As noted earlier, we will focus on a geostatistical formulation that relies on the fitting of covariance and cross-covariance structures for Gaussian random fields for mathematical and computational convenience. This approach also facilitates incorporation of the spatial correlation parameters in the modeling via the covariation process between two locations resulting from the martingale modeling.
To facilitate reading of the manuscript, the following notation on locations and number of units per location will be adopted throughout. We have a total of k locations, with each being described by its longitude and latitude in a two-dimensional coordinate with , which represents the location. If no confusion arises, we will just write location i. The locations will be denoted by i and j, so that . Each location i has units. Units are denoted by the letters r or s. For instance, in location i, we have so that . Likewise, . For convenience, we may sometimes adopt the compact notation , similarly for .
2.1. Pairwise Right Censored Data
Consider
k geographical locations described by two-dimensional coordinates
where
and
denote longitude and latitude of the
ith geographical location, respectively. The
s represent the geographical centers. Let
be the number of subjects in the
ith geographical location. Each unit is observed until failure or censoring, whichever occurs first. At time
t, for the
unit in the
geographical location, we record failure or censoring time by
and
, respectively, and these are assumed independent. Let
,
be the usual notation with right censored data. The variable
indicates that either censoring or failure has occurred for unit
r in location
i. For
, a
p-dimensional vector
of possibly time varying covariates is recorded at time
t. Location
i is assumed to be spatially correlated with
j,
, and the spatial correlation between the two is denoted by
, where
is the Euclidean distance between
and
. The total observable entities per location at time
t are, therefore,
In the present setting of spatially correlated events, the random observables in (
1) will be taken pairwise for the purpose of accounting for the spatial correlation
. Consequently, the spatially correlated right censored data on
, on which estimation is conducted, is given by
2.2. Stochastic Process Modeling
With a view towards the multivariate Gaussian random field (MGRF), we introduce the stochastic processes needed in the following. For
, define the counting and at-risk process by
and
, respectively. Note that
indicates if an event has occurred by time
t, whereas
indicates if unit
is at risk at time
t. One may modify
to allow left truncation or other general at-risk processes. We further assume that the study ends at a time
so that the interval
is our observation window. The entire history at time
t at all geostatistical locations is contained in the
-field
with
To proceed with our modeling, we assume that the instantaneous hazard function is different from location to location. If
is the instantaneous failure rate in
for all units in location
i, from stochastic integration theory, the compensator process of
is
given by
. Hence, for each
, the process
is a zero-mean square-integrable martingale with respect to the filtration
In this manuscript, we postulate the Cox model with a different baseline per location, but the same regression parameter,
, for all locations. The model is given by
where
denotes the transpose of the vector
, and
is a
p-dimensional vector of regression parameters. The baseline hazard per location is
, and
is the set of unspecified baseline hazard functions to be estimated.
Remark 1. Our choice of same β coefficient for all locations is motivated by the fact that we are modeling the same event for all units in all locations. However, the baseline hazard is chosen to be different among the locations, see also [16,17]. The case of competing failures can also be considered, cf. [18]. 2.3. Multivariate Gaussian Random Fields
Gaussian Random Fields (GRFs) and their multivariate counterpart, MGRFs, play an important role in spatial modeling, especially in geostatistics. Estimation of parameters are facilitated if the models proposed can lead to the construction of MGRF using the resulting martingale processes. With a view towards the MGRF construction, for
, let
if ambiguity does not arise,
is the cumulative hazard function, and
is the survival function. Then,
follows a uniform distribution on
, and
follows a unit exponential distribution
. If
is the cumulative distribution function of the standard normal distribution, the probit transformation of a variable
U in
is
. Hence,
is the probit transformation of the failure time
, which follows a standard normal distribution of
. If we assume that, for each location
i, its vector of failure times
forms a Gaussian random field, then a MGRF can be constructed with
, given by
by imposing a spatial structure induced by a
spatial correlation matrix
with block matrices
,
as diagonal elements, and the off diagonal elements
depend on the spatial correlation
between two locations.
2.4. Spatial Correlation Model
As indicated earlier, the critical part in identifying significant risk factors that trigger event occurrences is to identify the best spatial correlation function. Ref. [
2] proposed a multivariate gamma frailty model incorporating spatial dependence between locations, as was performed in [
5]. Ref. [
8] extended the work of [
19] by generalizing their Multivariate Conditional Autoregressive Models. A pairwise joint distribution that depends on the distance between locations has been investigated by [
10]. Copula models, on the other hand, have been proposed by [
20,
21]. We seek a spatial correlation that is a function of distance between spatial locations, so-called
isotropic spatial covariance functions. They have received a great deal of attention recently, specifically the Matérn family [
22,
23,
24], given by
where
is the marginal variance or
sill, which is the variance if
.
is a smoothing parameter that controls the differentiability of a Gaussian process with this covariance; and
is a
range parameter that measures the correlation decay as the separation between two locations increases.
is the modified Bessel function of the second kind, and
is the gamma function. When
and
, we recover the exponential and Gaussian covariance given by
respectively. More details on sill and range can be found in Section 3 of [
25] or Section 1 of [
24]. The Matérn family turns out to be a good choice because of its flexibility in modeling various types of spatial correlation structure in many fields, and possesses a good interpretability of the parameters. The importance of this family is also highlighted in [
26], page 14. Note that in (
3), if
,
, we obtain the marginal variance, which corresponds to the case of no spatial correlation.
In what follows, we assume that the spatial correlation function depends on the q-dimensional parameter each describing various elements of the family. A Matérn-type family for spatial correlation on the transformed failure times is assumed, translating into , which is . The transformation leads to a MGRF where the marginal failure times follow the postulated Cox model with a population level interpretation for the regression parameter , and facilitates estimation of the spatial as well as regression parameters.
3. Estimation-Preliminary
The parameters arose from two models: the spatial correlation and the Cox models. The Cox models have unknown infinite dimensional baseline parameters
,
that belong to a class
of hazards on
. The regression coefficient
is in
, whereas the
q-dimensional Matérn spatial correlation parameter
is in
. Though, in the case of the Matérn family,
, we develop the theory for an unknown
q. So, the model parameter of main interest is
where
. The observable
in (
2) will be used for making an inference on
.
Remark 2. Our models have unknowns, which raises the question of identifiability. Let be the probability model on . The issue of identifiability will not arise; that is, the Kullback–Leibler information will be positive for under the assumptions that, under : (i) no two regions have the same longitude and latitude; (ii) for every region i, , that is, at least one failure occurs per region; (iii) for every i, ; and (iv) for , and (likewise defined), . The last assumption ensures estimation of the spatial correlation parameter, hence a uniquely defined spatial correlation function.
3.1. The Aalen–Breslow Estimator of and Its Properties
Following the notation in
Section 2.3, and as indicated earlier, for each
,
is a zero-mean martingale with respect to the filtration
. It then follows, via method of moments, that an Aalen–Breslow estimator for
, for
is given by
with the
k dimensional vector of baseline hazard being
Observe that
is not yet an estimator, because it still depends on the unknown regression parameter
. The expression in (
6) will later be substituted for
to estimate
and to obtain the in-probability limits of the score matrix.
In order to facilitate understanding of the asymptotic properties of the parameters in our models, it is important to go through some properties of
. The consistency of
can be shown using results in [
27].
Remark 3. An important result worth pointing out is the convergence under the infill asymptotic of the random field given byto the multivariate Gaussian random field on the space of continuous functions , and the k-fold continuous functions space, equipped with the metric Such a result can be used for making simultaneous inferences on at some fixed time points and constructing confidence bands for all the baseline or a subset of them, depending on interest, or testing equality of the baseline hazards at two different locations i and j. The latter and former could be important for epidemiologists and authorities, since the results can be used to assess severity of a certain disease or pandemic at various times of the calendar year or having an idea about which locations among the ones under investigation have higher failure rates. 3.2. Joint Modeling
For a pair of units,
and
, we define, as before, their counting, at-risk, and compensator processes by
respectively. Then,
and
are each a zero-mean martingale with respect to the filtration
and
, respectively. With a view toward joint modeling, for
, we introduce the joint counting process
by
. The covariance function
is defined by
Using stochastic integration theory, we have
The spatial correlation between the two locations implies that the covariance function depends on the spatial parameter
via the spatial correlation
by virtue of the transformation leading to the construction of the MGRF. Let
be the bivariate survival function of the transformed failure times
and
. Then, the original bivariate survivor function
for
is given by
with
and
being the marginal distribution functions of
and
respectively. Following [
28],
is given by
with the baseline joint compensator
given by
Remark 4. The covariance function in conjunction with and determines the joint distribution of and , given the covariates and . The original bivariate survivor function of and given in (7) can be taken to be of the Clayton family (cf. [29]) or the Frank family model (cf. [30]). For the Clayton model, for instance, the joint survivor function takes the form 5. Large Sample Properties
This section is devoted to the large sample properties of our estimators. Let
,
and
. Consider the vector of score processes
, such that
The in-probability limit of the variance–covariance matrix of
is given by
The next theorem is on the existence and consistency of the solution to
Theorem 3. - (a)
There exists a sequence of solutions and to the sequence of estimating equations and .
- (b)
Under Conditions I to VIII, and the infill asymptotic, and .
Before proving the theorem, a discussion on
,
is warranted, since its consistency is required for the in-probability limit of the score variance. A method of moment estimator of
is given by
and is a jump process, and will possibly loses efficiency for large
n. However, any loss of efficiency using it for the limit is minor as compared to using a more complicated smoothed estimator obtained via kernel and proposed in [
27], given by
where
is some kernel function, and
is a sequence of positive constants. Although
is smoother, both are, however, consistent for
; that is,
. We will proceed with the version
.
Proof. We apply the inverse function theorem of [
43]. Three conditions need to be satisfied: (i) the asymptotic unbiasedness of the estimating functions, (ii) the existence and continuity of the partial derivatives matrix, and (iii) the negative definiteness of the matrix of partial derivatives at the true parameter value
. Condition (i) has been already shown in Theorems 2 and 3. It remains to show (ii) and (iii). Consider
given by
Since
is unknown, we substitute it by its consistent Breslow estimator. So, the version we work with is
, given by
The gradient of
with respect to
is
Likewise, substituting the Breslow estimator in
, the gradient of
is
Taking the gradient with respect to
of the remaining two terms in
, and taking their limits according to the regularity conditions, we obtain that, at
, the first block of
, namely
, with the
element given by
Note that
is a
matrix. Obviously,
, a matrix of 0. The
block is the gradient of
with respect to
. To see how it is derived, let
be a
row vector and
be defined by
respectively. To make the notation compact, for
, let
Then, the
element of
is the
matrix given by
So that, for example, the
component of
is given by
The in-probability limit of
is
By virtue of the previous derivations, a compact notation for
is then
That limiting matrix is assumed to exist per Condition VII, and is negative definite.
We now deal with the block
. It is easy to show that the
th element,
, of the gradient of
, with respect to
, is
Note that
is a
matrix, and the in-probability limit, assuming we can interchange the integration operation and limit, is given by
Hence, the partial derivative matrix converges to a matrix
, which is negative definite at the true parameter value
. It then follows from the inverse function theorem of [
43] that there exists a unique sequence
, such that
and
as
. □
The next theorem is on the asymptotic normality of when properly standardized.
Theorem 4. Under regularity Conditions I and VIII,where Φ is a matrix given by . Proof. We apply the central limit theorem for random field given in Remark (3), page 112, of [
44]. Taylor expansion of
at
yields
where
is between
and
, and
under the infill asymptotic domain setting. Furthermore, note that
as
. The
matrix in
is the variance of the score vector which, under Conditions V and VI, is assumed to exist, and converges to a positive definite matrix. The expression of
is obtained by applying the result of multivariate central limit theorem. Finally, the theorem follows upon applying Remark (3), page 112, of [
44]. □
6. Numerical Assessment and Application
6.1. Numerical Assessment
In this subsection, we present and discuss the results of our simulation studies. This begins with the selection of the different regions that will be used. The package raster on Geographic Data Analysis and Modeling contains the geographical coordinates of many countries. We used the United States as the country.
-
Regions: The
raster package (v.3.6-26) in R contains the data on the geographical coordinates of well-defined subdivisions in many countries. We used the package to obtain the coordinates for states, counties etc. for the United States. Depending on the country, this package also allows users to select location data with several levels of depth. For the United States, we can specify either Level 1 for statewise locations or Level 2 for the countywise locations. We use Level 1 data from raster for the simulations. The geographical centers of the 48 contiguous states, excluding Hawaii and Alaska, are our
,
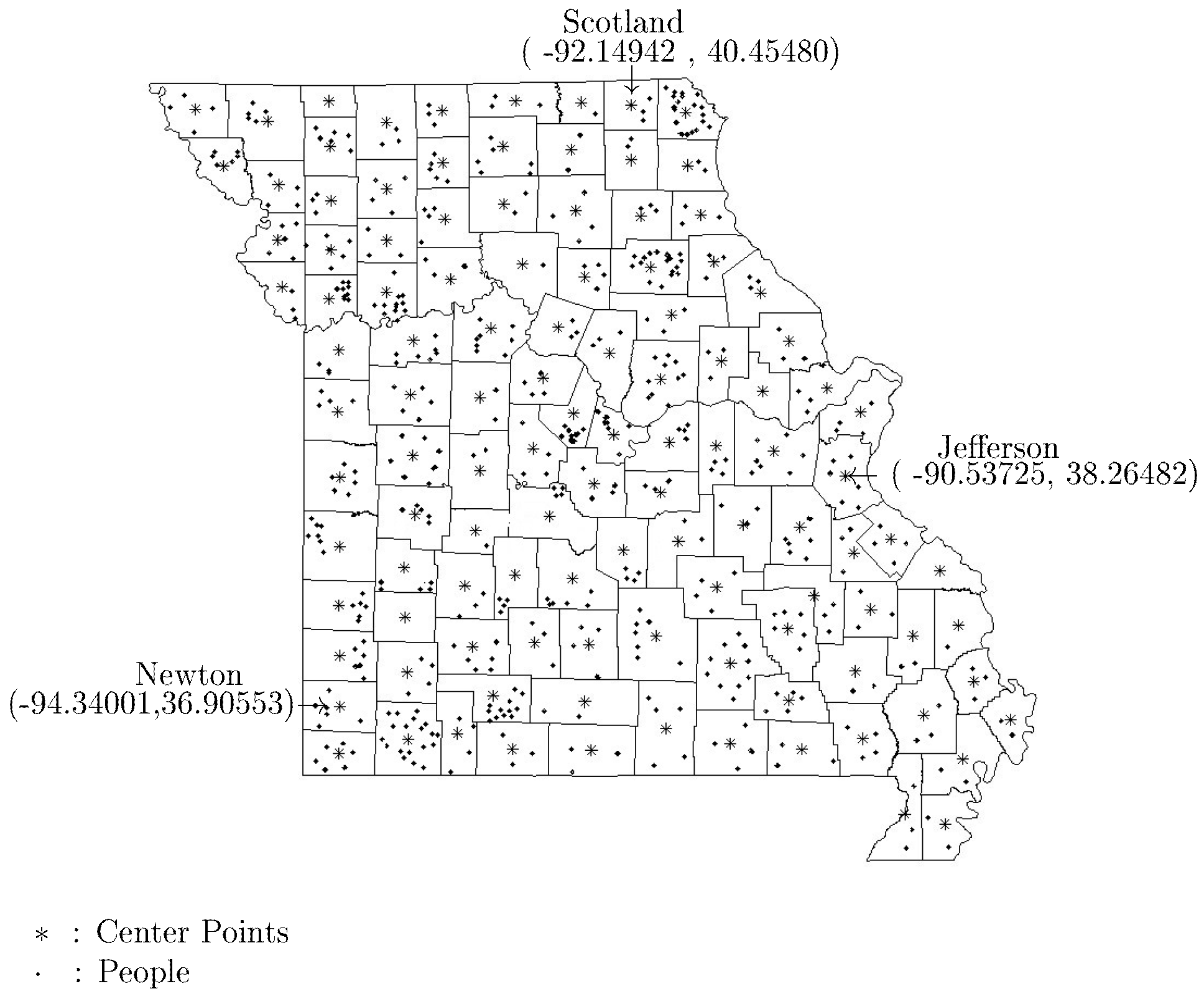
. The other alternative is to choose a state and randomly select counties within the selected state. In
Figure 2, we provide the example of the state of Missouri with the coordinates for a couple of the counties. For example, the longitude and latitude of the center of Newton county in the state of Missouri is
.
- Simulation design: We select a random sample of people from each state, where is proportional to the state population from the latest census available in R, while making sure that . We consider two covariates , where follows the binomial distribution with parameters and , and , resulting in a mixture of categorical and quantitative covariates. The spatial correlation parameter was set at . The regression coefficient vector in the Cox model is As for the proportion of censored observation, we allow from less censoring to severe censoring in order to assess its impact on the spatial correlation. The proportion of censored units was taken to be in , allowing for mild to severe censoring. For the baseline hazard, we use the Weibull hazard given by . We set , since it is the scale parameter and is irrelevant in our simulation. However, the shape parameter was taken in to allow for increasing failure over time for and decreasing for .
- Event times generation: Under the Cox model with Weibull baseline hazard, we generate failure times via the probit transformation using the following steps:
- (i)
If
denotes the probit transformation, then solving for the Cox’s model, we obtain for
Solving for
, we obtain
where
is the inverse of the Weibull cumulative hazard given by
.
- (ii)
For
, the
s are generated using the expression
where
.
-
Simulated data: For the purpose of estimating parameters, the study considers two spatial correlation models, namely the exponential and Gaussian model, as given in (
4) and (
5), and the powered spatial correlation function. For all models, 500 simulation replications were performed with each parameter specification and sample size combination. The results are given in
Table 1,
Table 2 and
Table 3. CP stands for censoring percentage.
Comments on the simulation results: The results of the simulation study indicate that the estimators of the spatial correlation , as well as regression coefficients , perform well. One thing to note here is that as the percentage of censoring increases, the biases of the increase, regardless of the sample size, whereas the biases of the remain very steady close to each other. This makes sense, since the spatial correlation parameters is the correlation between two areas, so it is not affected by large samples. However, the bias of will increase because higher censoring translates into less failure times. There is no significant difference in the results between the exponential and Gaussian spatial correlation models. The reason why this is so is both have exponential components, so the impact of the large sample will be minor. However, the standard deviations of the estimates of remain, without any noticeable pattern with the increasing sample size.
6.2. Illustrative Application
The foregoing procedures are applied to the leukemia survival data which was also analyzed in [
2]. The data contains 1043 cases of
Acute Myeloid Leukemia (AML) which were recorded between 1982 and 1998 at 24 administrative districts. It contains the time
for each unit
, and the censoring indicator
. There were 16% of censored observations. Four covariates were available; that is,
where
wbc stands for white blood cell count and
tpi for Townsend score. The Townsend score is a qualitative value in
describing quality of life in a given area. High values indicate less affluent areas. We investigate the factors affecting survival while accounting for spatial correlation.
Figure 3 shows residential locations of the AML cases during the observation window. Ref. [
2] investigated whether the survival distribution in AML in adults is homogeneous across the region after allowing for known risk factors. In their manuscript, they employ a multivariate frailty that incorporates the effects of covariates, individual heterogeneity, and spatial traits. Our approach and theirs are different. Whereas we both use the Cox model as the instantaneous failure rate, their approach in studying spatial variation is performed via the use of conditional frailty, where the conditioning random variable for all 24 districts is the vector of mean frailty
. Specifically, if
is the frailty for unit
r in location
, and
the mean frailty of all individuals in that location, they postulate that
with a
distribution on
, where
measures the spatial variation between districts. Whereas they use a conditional frailty model with a variance–covariance matrix that is a function of the distance between regions, we embed the spatial correlation in the transformed failure times, giving us a multivariate Gaussian random field with variance–covariance that is a function of the distance between regions via the Matérn spatial correlation function.
Before applying our methods, we run a set of initial data analysis.
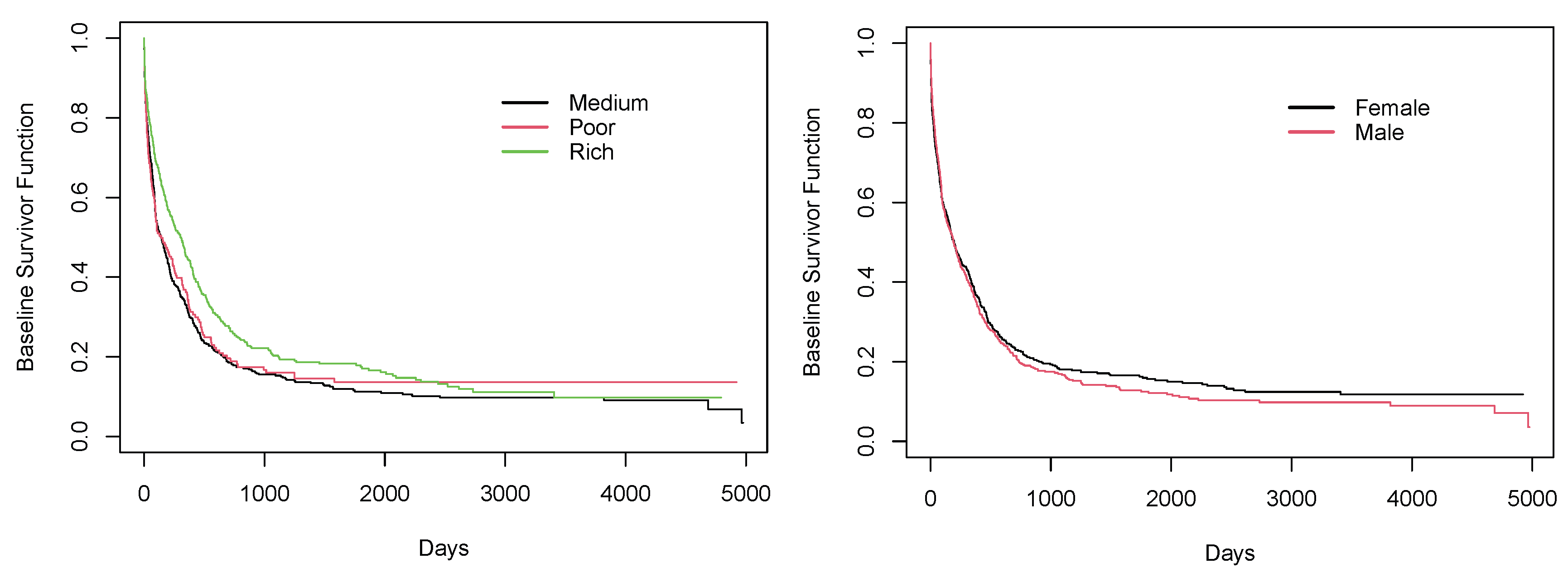
Figure 3 shows the Kaplan–Meier plots by gender. We can clearly observe that survival curve for the female group lies above that of male group. This concurs with the summary statistics in
Table 4. The variable
tpi represents the Townsend score. The higher values for
tpi indicates less affluent areas. We have grouped all individuals in the study into three categories based on
tpi. If the
tpi of a person is lower than
, he or she is categorized into the
Rich group. Likewise, if the
tpi of a person falls between
and
, the person is grouped into the
Medium category. Lastly, if a person’s
tpi is greater than
, that person is categorized into the
Poor group.
Figure 4 presents the survival curves according to these three areas. From near day 100 to 5000, the survival curve of the Medium group always lies below the survival curves of the other two groups. Moreover, when we compare the survival curves of the Poor and Rich groups, from day 0 to near day 2400, the survival curve for the Rich group is always above the Poor group. But, interestingly, we can see that from near day 2400 to 5000, the survival curve for the Poor group is above that of the Rich group.
We apply our methods to analyze the leukemia data. Factors that may increase the risk of acute myeloid leukemia include age, gender, prior cancer treatment, environmental factors, blood disorder, and genetic disorder, to name a few. We only consider available covariates in the data, and assumed that age at onset of acute myeloid leukemia (AML) on adults follows the Cox model. We used the Matérn model to account for the spatial dependence between pair of districts. The hazard function for an
rth unit in district
i is given by
We estimated the regression coefficients and the spatial correlation parameters using the estimating functions in
Section 5. We also calculated the associated standard deviations and confidence intervals. The results are presented in
Table 5. We have also presented the results of Henderson’s approach in
Table 6. The results in both tables show in both models that all regression coefficients are significant in both approaches expect that sex is not significant under the Henderson approach. So, the covariates age and wpc increase the risk of aml. In our approach, sex also increases the risk of aml, and the results concur with our preliminary analysis of the data. The estimated value of the range, which is
, indicates that the impact of environment vanishes when two units are separated by at least
units of distance. The log pseudo marginal likelihoods (LPMLs) for each model are also given. Despite the fact that our model has more parameters, it has a better LPML. However, this needs to be taken with cautious and deep investigation, such as taking into account that each unit personal geographical location would be needed to arrive at the best model in this situation. Conclusions between the two competing approaches follow.
7. Concluding Remarks
We have considered the situation where many units clustered in different geographical areas described by their longitude and latitude are monitored for the occurrence of some event. We have developed a methodology using a combination of modern survival analysis and geostatistics formulation. The parameters of our models are estimated using unbiased estimating functions, and their large sample properties were also examined using infill asymptotic approach that one encounters with spatial data. The methodology can be easily generalized to the case of recurrent events. Another generalization is to consider the geographical coordinate of each unit within a given geographical area. One can then consider both within and between areas spatial correlation. It will be of interest to develop models that account for correlation between event time via frailty when the event is allowed to recur. Another possible future direction is another model for modeling connection between failure covariates and failure times, such as the accelerated failure time model. However, other estimating approaches, such as rank-based, would need to be applied to the transformed event times. The Cox model used in the modeling may not fit the real data. Additional goodness-of-fit tests should be conducted before adopting the Cox model. The same is true for the spatial correlation function. This can be checked using the periodogram; likewise for the spatial correlation. The regularity conditions on which the asymptotic properties are obtained may also not be satisfied in practice, leading to limitations in the application of the composite likelihood. For future studies, hypotheses testing on hazard functions that account for spatial correlations need to be developed. Likewise, techniques for assessing the fit of the spatial correlation function also need to be investigated, so that practitioners will have the necessary tools at their disposal for applications to real-life data. The weak convergence result in Remark 3 also needs to be proven, so that confidence bands can be developed to identify severe areas, especially if the models are used for biomedical applications such as pandemics.




{kind=link}
{kind=link}
{kind=link}
{kind=link}