
Novel Feature-Based Difficulty Prediction Method for Mathematics Items Using XGBoost-Based SHAP Model


Abstract
1. Introduction
- Firstly, we provide a rigorous framework for assessing the difficulty of mathematics items by listing several features necessary for this task, based on the relevant literature and the features of mathematics items. In particular, the requirements of mathematics in cognition and ability and the construction of the mathematical knowledge system are taken into account. The research data are then subjected to feature extraction, followed by data analysis of the extracted features.
- Secondly, we present the XGBoost-based SHAP model, which is a prediction model for estimating item difficulty that employs classification features and is highly interpretable, based on the above framework. The features are used as a base and combined in a linear fashion. The improved XGBoost model is then applied to train and predict the feature combinations. The SHAP model is then utilized to obtain a quantitative analysis of the contribution of each feature to the difficulty of the exam, through the marginal contribution rate of each feature for each exam item and the accumulation of the marginal contributions. The hyperparameters of the model are then optimized using a grid search algorithm to improve classification accuracy.
- Finally, the model is trained and evaluated using actual test scores from millions of Chinese test takers. In order to comply with the Chinese curriculum standards, the subjective questions of the Chinese math test are divided into nine knowledge units. As a complement, we further analyze the representation of the eight features in the nine knowledge units.
2. The Related Work
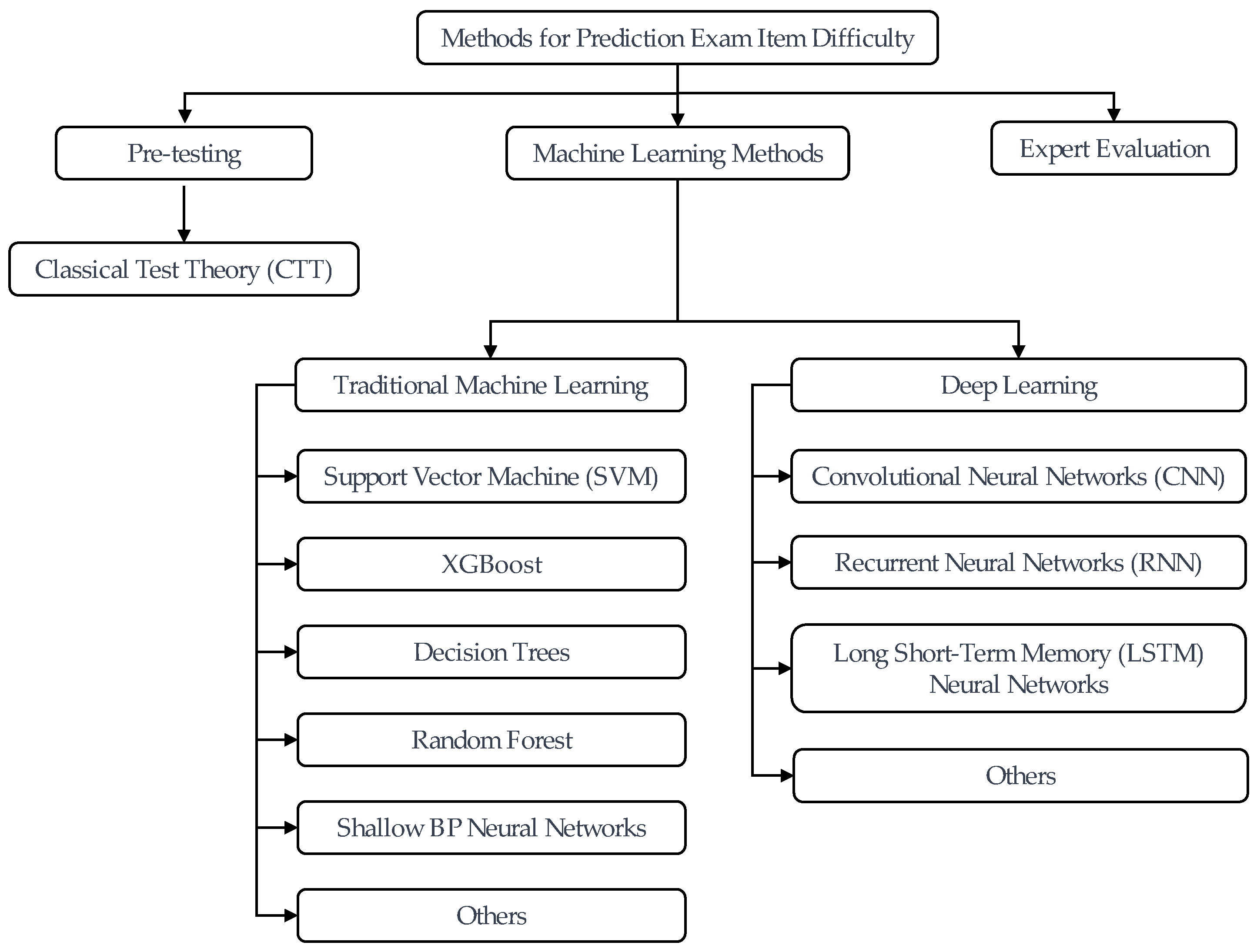
2.1. A Summary and Classification of Item Difficulty Estimation Methods
2.2. XGBoost-Based SHAP Model
3. Framework Building and Data Analysis
3.1. Feature Extraction Rules for Item Difficulty Estimation Framework
- (a)
- (b)
- Length of if .
3.2. Item Difficulty Levels
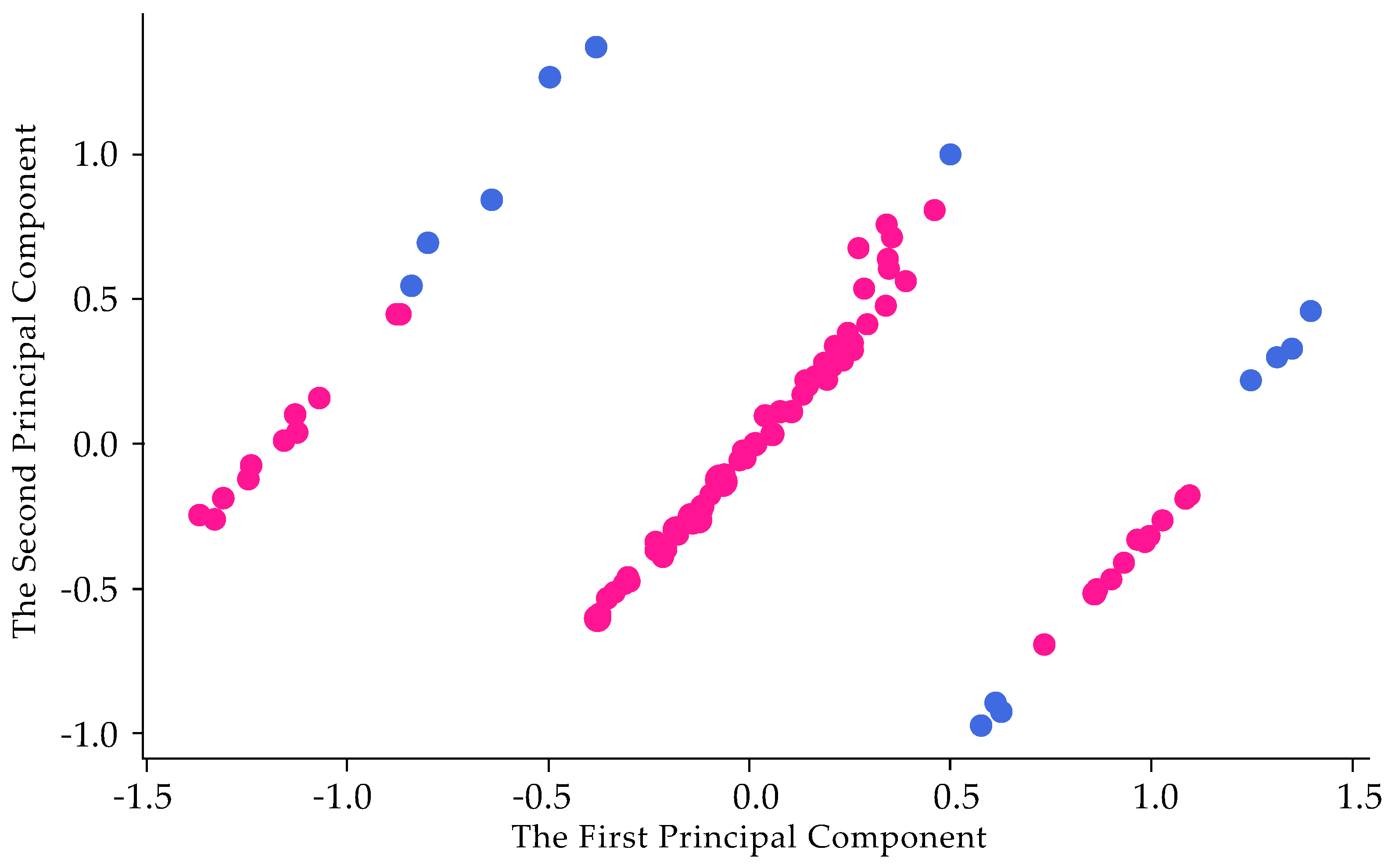
3.3. Data Analysis
4. Methodology
4.1. Model Building
4.2. Model Parameters
4.3. Model Interpretation
5. Results
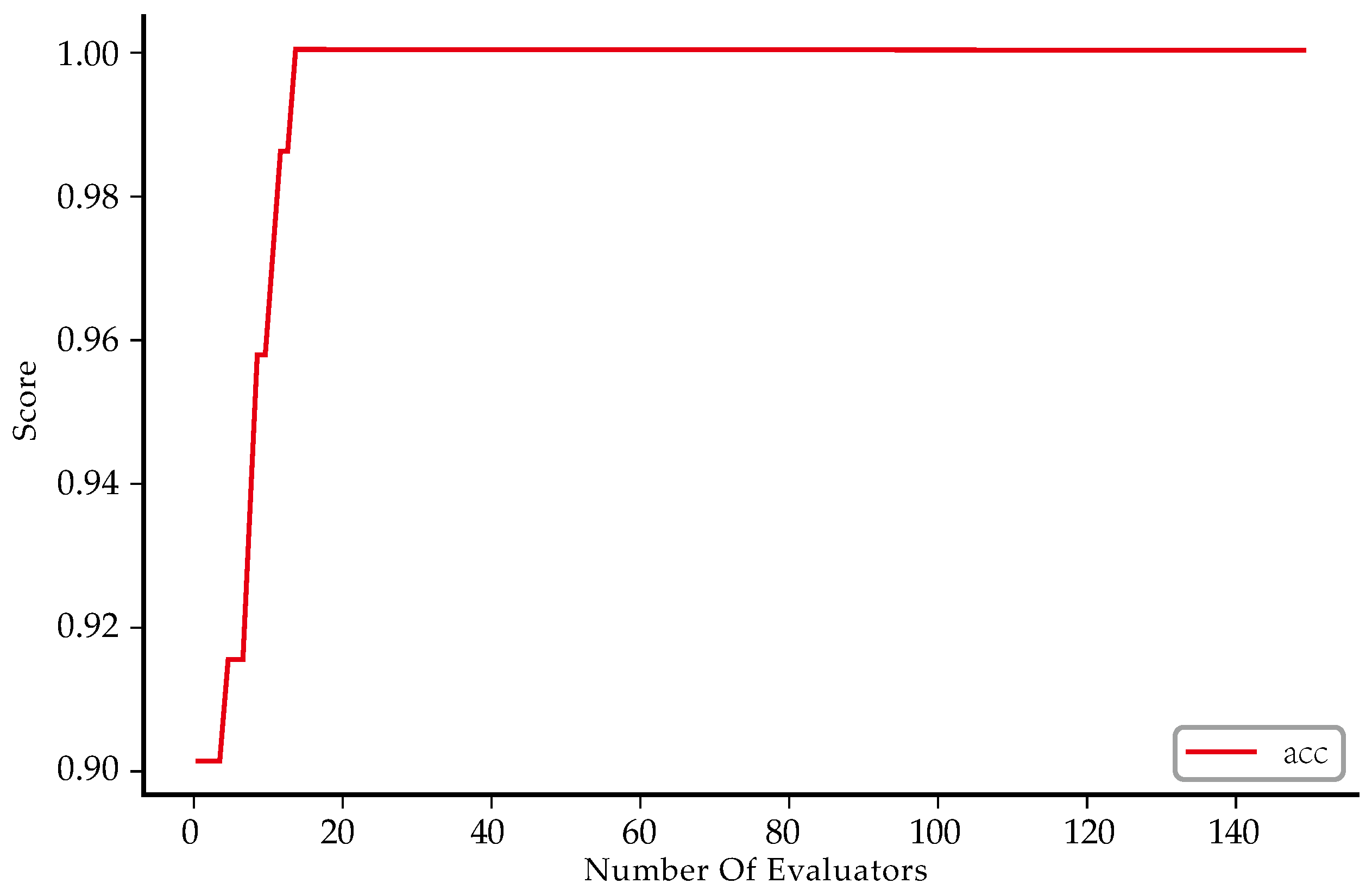
5.1. Model Evaluation
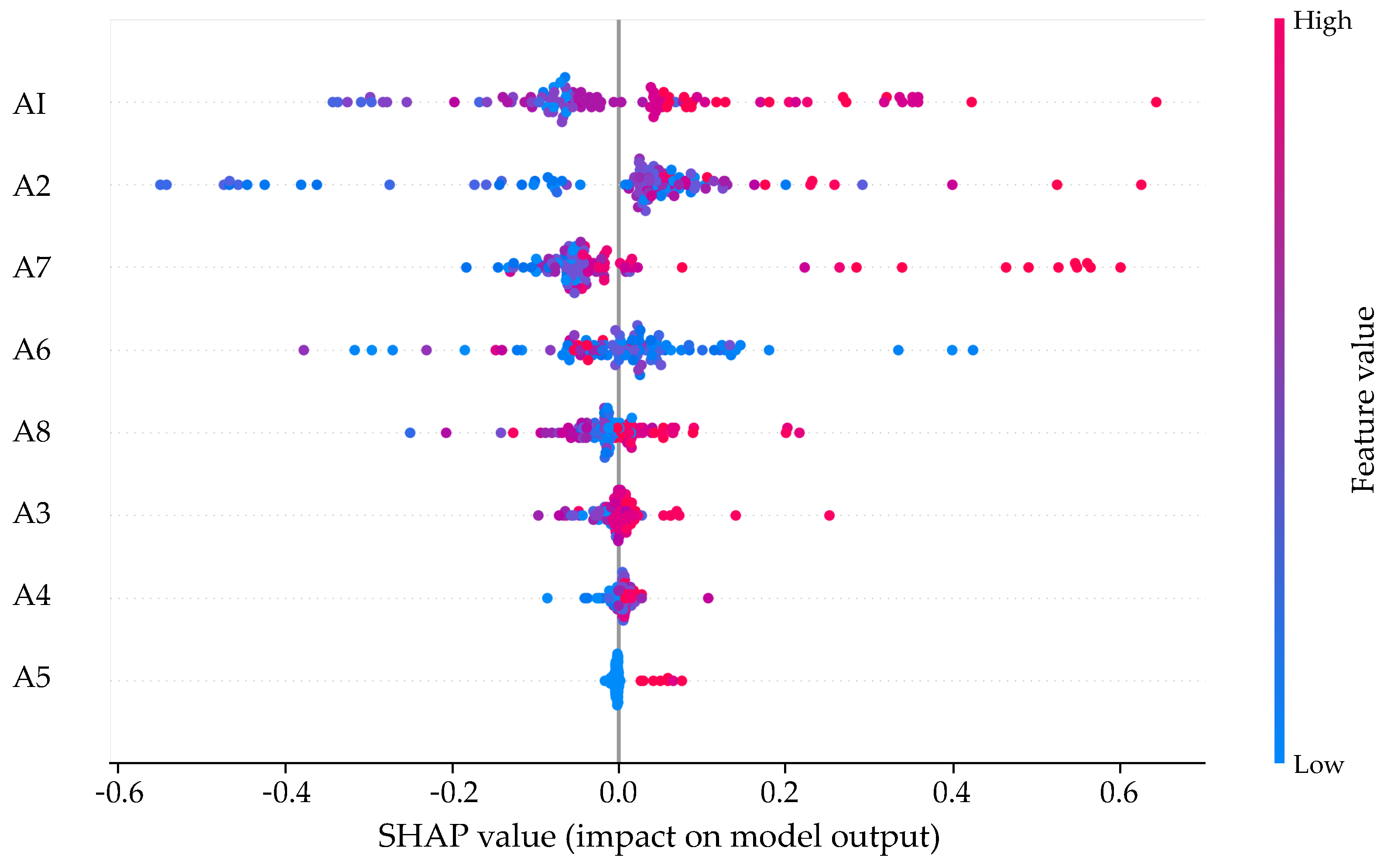
5.2. Model Interpretability
5.3. Distribution of Features in Different Knowledge Units
6. Discussion
6.1. Feature Analysis
6.2. Distribution of Features in Different Knowledge Units
6.3. Limitations and Future Directions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kurdi, G.; Leo, J.; Matentzoglu, N.; Parsia, B.; Sattler, U.; Forge, S.; Donato, G.; Dowling, W. A comparative study of methods for a priori prediction of MCQ difficulty. Semant. Web 2021, 12, 449–465. [Google Scholar] [CrossRef]
- El Masri, Y.H.; Ferrara, S.; Foltz, P.W.; Baird, J.A. Predicting item difficulty of science national curriculum tests: The case of key stage 2 assessments. Curric. J. 2017, 28, 59–82. [Google Scholar] [CrossRef]
- Choi, I.C.; Moon, Y. Predicting the Difficulty of EFL Tests Based on Corpus Linguistic Features and Expert Judgment. Lang. Assess. Q. 2020, 17, 18–42. [Google Scholar] [CrossRef]
- Sun, L.; Liu, Y.; Luo, F. Automatic Generation of Number Series Reasoning Items of High Difficulty. Front. Psychol. 2019, 10, 884. [Google Scholar] [CrossRef] [PubMed]
- Zhang, S.; Kang, B.; Zhou, L. Object Tracking by Unified Semantic Knowledge and Instance Features. IEICE Trans. Inf. Syst. 2019, E102.D, 680–683. [Google Scholar] [CrossRef]
- Gauezere, B.; Ritrovato, P.; Saggese, A.; Vento, M. Human Tracking Using a Top-Down and Knowledge Based Approach. In Proceedings of the 18th International Conference on Image Analysis and Processing (ICIAP), Genoa, Italy, 7–11 September 2015; Murino, V., Puppo, E., Eds.; Springer: Berlin/Heidelberg, Germany, 2015; Volume 9279, pp. 257–267. [Google Scholar] [CrossRef]
- Gierl, M.J.; Lai, H. Using Automatic Item Generation to Create Solutions and Rationales for Computerized Formative Testing. Appl. Psychol. Meas. 2018, 42, 42–57. [Google Scholar] [CrossRef]
- Attali, Y. Automatic Item Generation Unleashed: An Evaluation of a Large-Scale Deployment of Item Models. In Proceedings of the 19th International Conference on Artificial Intelligence in Education (AIED), London, UK, 27–30 June 2018; Rose, C., Martinez-Maldonado, R., Hoppe, H., Luckin, R., Mavrikis, M., Porayska-Pomsta, K., McLaren, B., DuBoulay, B., Eds.; Springer: Berlin/Heidelberg, Germany, 2018; Volume 10947, pp. 17–29. [Google Scholar] [CrossRef]
- Arendasy, M.E.; Sommer, M. Using automatic item generation to meet the increasing item demands of high-stakes educational and occupational assessment. Learn. Individ. Differ. 2012, 22, 112–117. [Google Scholar] [CrossRef]
- Stancheva, N.; Stoyanova-Doycheva, A.; Stoyanov, S.; Popchev, I.; Ivanova, V. An Environment for Automatic Test Generation. Cybern. Inf. Technol. 2017, 17, 183–196. [Google Scholar] [CrossRef]
- Klasnja-Milicevic, A.; Vesin, B.; Ivanovic, M.; Budimac, Z. E-Learning personalization based on hybrid recommendation strategy and learning style identification. Comput. Educ. 2011, 56, 885–899. [Google Scholar] [CrossRef]
- Tarus, J.K.; Niu, Z.; Mustafa, G. Knowledge-based recommendation: A review of ontology-based recommender systems for e-learning. Artif. Intell. Rev. 2018, 50, 21–48. [Google Scholar] [CrossRef]
- Fan, X. Item response theory and classical test theory: An empirical comparison of their item/person statistics. Educ. Psychol. Meas. 1998, 58, 357–381. [Google Scholar] [CrossRef]
- Zhan, P.; Jiao, H.; Liao, D. Cognitive diagnosis modelling incorporating item response times. Br. J. Math. Stat. Psychol. 2018, 71, 262–286. [Google Scholar] [CrossRef]
- Conejo, R.; Guzman, E.; Perez-de-la Cruz, J.L.; Barros, B. An empirical study on the quantitative notion of task difficulty. Expert Syst. Appl. 2014, 41, 594–606. [Google Scholar] [CrossRef]
- AlKhuzaey, S.; Grasso, F.; Payne, T.R.; Tamma, V. A Systematic Review of Data-Driven Approaches to Item Difficulty Prediction. In Proceedings of the 23rd International Conference, AIED 2022, Durham, UK, 27–31 July 2022; Roll, I., McNamara, D., Sosnovsky, S., Luckin, R., Dimitrova, V., Eds.; Springer: Cham, Switzerland, 2021; pp. 29–41. [Google Scholar]
- Pandarova, I.; Schmidt, T.; Hartig, J.; Boubekki, A.; Jones, R.D.; Brefeld, U. Predicting the Difficulty of Exercise Items for Dynamic Difficulty Adaptation in Adaptive Language Tutoring. Int. J. Artif. Intell. Educ. 2019, 29, 342–367. [Google Scholar] [CrossRef]
- Lim, E.C.H.; Ong, B.K.C.; Wilder-Smith, E.P.V.; Seet, R.C.S. Computer-based versus pen-and-paper testing: Students’ perception. Ann. Acad. Med. Singap. 2006, 35, 599–603. [Google Scholar] [CrossRef] [PubMed]
- Wei, T.; Fei, W.; Qi, L.; Enhong, C. Data Driven Prediction for the Difficulty of Mathematical Items. J. Comput. Res. Dev. 2019, 56, 1007–1019. [Google Scholar]
- Pollitt, A.; Marriott, C.; Ahmed, A. Language, Contextual and Cultural Constraints on Examination Performance. Presented at the International Association for Educational Assessment, Jerusalem, Israel, 14–19 May 2000. [Google Scholar]
- Kubinger, K.D.; Gottschall, C.H. Item difficulty of multiple choice tests dependant on different item response formats—An experiment in fundamental research on psychological assessment. Psychol. Sci. 2007, 49, 1–8. [Google Scholar]
- Susanti, Y.; Nishikawa, H.; Tokunaga, T.; Obari, H. Item Difficulty Analysis of English Vocabulary Questions. In Proceedings of the International Conference on Computer Supported Education (CSEDU 2016), Rome, Italy, 21–23 April 2016. [Google Scholar]
- Zhong, S.; Zhang, K.; Wang, D.; Zhang, H. Shedding light on “Black Box” machine learning models for predicting the reactivity of HO center dot radicals toward organic compounds. Chem. Eng. J. 2021, 405, 126627. [Google Scholar] [CrossRef]
- Shapley, L.S. A Value for N-Person Games; RAND Corporation: Santa Monica, CA, USA, 1952. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD), San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar] [CrossRef]
- Parsa, A.B.; Movahedi, A.; Taghipour, H.; Derrible, S.; Mohammadian, A.K. Toward safer highways, application of XGBoost and SHAP for real-time accident detection and feature analysis. Accid. Anal. Prev. 2020, 136, 105405. [Google Scholar] [CrossRef]
- Janelli, M.; Lipnevich, A.A. Effects of pre-tests and feedback on performance outcomes and persistence in Massive Open Online Courses. Comput. Educ. 2021, 161, 104076. [Google Scholar] [CrossRef]
- Sreelatha, V.K.; Manjula, V.D.; Kumar, R.S. Pre-Test as a Stimulant to Learning for Undergraduates in Medicine. J. Evol. Med. Dent. Sci. 2019, 8, 3886–3889. [Google Scholar] [CrossRef]
- Harrison, S.; Kroehne, U.; Goldhammer, F.; Luedtke, O.; Robitzsch, A. Comparing the score interpretation across modes in PISA: An investigation of how item facets affect difficulty. Large-Scale Assess. Educ. 2023, 11, 8. [Google Scholar] [CrossRef]
- DeVellis, R.F. Classical test theory. Med. Care 2006, 44, S50–S59. [Google Scholar] [CrossRef] [PubMed]
- Kohli, N.; Koran, J.; Henn, L. Relationships Among Classical Test Theory and Item Response Theory Frameworks via Factor Analytic Models. Educ. Psychol. Meas. 2015, 75, 389–405. [Google Scholar] [CrossRef] [PubMed]
- Garcia Pinzon, I.; Olivera Aguilar, M. Noncognitive factors related to academic performance. Rev. Educ. 2022, 398, 161–192. [Google Scholar] [CrossRef]
- Yaneva, V.; Ha, L.A.; Baldwin, P.; Mee, J. Predicting Item Survival for Multiple Choice Questions in a High-stakes Medical Exam. In Proceedings of the 12th International Conference on Language Resources and Evaluation (LREC), Marseille, France, 11–16 May 2020; Calzolari, N., Bechet, F., Blache, P., Choukri, K., Cieri, C., Declerck, T., Goggi, S., Isahara, H., Maegaard, B., Mariani, J., et al., Eds.; Springer: Berlin/Heidelberg, Germany, 2020; pp. 6812–6818. [Google Scholar]
- Fu-Yuan, H.; Hahn-Ming, L.; Tao-Hsing, C.; Yao-Ting, S. Automated estimation of item difficulty for multiple-choice tests: An application of word embedding techniques. Inf. Process. Manag. 2018, 54, 969–984. [Google Scholar] [CrossRef]
- Zhang, S.; Bergner, Y.; DiTrapani, J.; Jeon, M. Modeling the interaction between resilience and ability in assessments with allowances for multiple attempts. Comput. Hum. Behav. 2021, 122, 106847. [Google Scholar] [CrossRef]
- Wu, S.F.; Kao, C.H.; Lu, Y.L.; Lien, C.J. A Method Detecting Student’s Flow Construct during School Tests through Electroencephalograms (EEGs): Factors of Cognitive Load, Self-Efficacy, Difficulty, and Performance. Appl. Sci. 2022, 12, 12248. [Google Scholar] [CrossRef]
- Golino, H.F.; Gomes, C.M.A. Random forest as an imputation method for education and psychology research: Its impact on item fit and difficulty of the Rasch model. Int. J. Res. Method Educ. 2016, 39, 401–421. [Google Scholar] [CrossRef]
- Wang, C.D.; Xi, W.D.; Huang, L.; Zheng, Y.Y.; Hu, Z.Y.; Lai, J.H. A BP Neural Network Based Recommender Framework With Attention Mechanism. IEEE Trans. Knowl. Data Eng. 2022, 34, 3029–3043. [Google Scholar] [CrossRef]
- Xu, Y.; Wang, Z.; Shang, J.S. PAENL: Personalized attraction enhanced network learning for recommendation. Neural Comput. Appl. 2023, 35, 3725–3735. [Google Scholar] [CrossRef]
- von Davier, M. Automated Item Generation with Recurrent Neural Networks. Psychometrika 2018, 83, 847–857. [Google Scholar] [CrossRef]
- Hachmann, W.M.; Bogaerts, L.; Szmalec, A.; Woumans, E.; Duyck, W.; Job, R. Short-term memory for order but not for item information is impaired in developmental dyslexia. Ann. Dyslexia 2014, 64, 121–136. [Google Scholar] [CrossRef] [PubMed]
- Gorin, J.S.; Embretson, S.E. Item difficulty modeling of paragraph comprehension items. Appl. Psychol. Meas. 2006, 30, 394–411. [Google Scholar] [CrossRef]
- Stiller, J.; Hartmann, S.; Mathesius, S.; Straube, P.; Tiemann, R.; Nordmeier, V.; Krueger, D.; Belzen, A.U.Z. Assessing scientific reasoning: A comprehensive evaluation of item features that affect item difficulty. Assess. Eval. High. Educ. 2016, 41, 721–732. [Google Scholar] [CrossRef]
- Rodriguez-Perez, R.; Bajorath, J. Interpretation of machine learning models using shapley values: Application to compound potency and multi-target activity predictions. J. Comput.-Aided Mol. Des. 2020, 34, 1013–1026. [Google Scholar] [CrossRef] [PubMed]
- Wang, M.; Zheng, K.; Yang, Y.; Wang, X. An Explainable Machine Learning Framework for Intrusion Detection Systems. IEEE Access 2020, 8, 73127–73141. [Google Scholar] [CrossRef]
- Saleem, R.; Yuan, B.; Kurugollu, F.; Anjum, A.; Liu, L. Explaining deep neural networks: A survey on the global interpretation methods. Neurocomputing 2022, 513. [Google Scholar] [CrossRef]
- Sagi, O.; Rokach, L. Ensemble learning: A survey. Wiley Interdiscip.-Rev.-Data Min. Knowl. Discov. 2018, 8, e1249. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Erion, G.; Chen, H.; DeGrave, A.; Prutkin, J.M.; Nair, B.; Katz, R.; Himmelfarb, J.; Bansal, N.; Lee, S.I. From local explanations to global understanding with explainable AI for trees. Nat. Mach. Intell. 2020, 2, 56–67. [Google Scholar] [CrossRef]
- Fan, J.; Wang, X.; Wu, L.; Zhou, H.; Zhang, F.; Yu, X.; Lu, X.; Xiang, Y. Comparison of Support Vector Machine and Extreme Gradient Boosting for predicting daily global solar radiation using temperature and precipitation in humid subtropical climates: A case study in China. Energy Convers. Manag. 2018, 164, 102–111. [Google Scholar] [CrossRef]
- Abidi, S.M.R.; Hussain, M.; Xu, Y.; Zhang, W. Prediction of Confusion Attempting Algebra Homework in an Intelligent Tutoring System through Machine Learning Techniques for Educational Sustainable Development. Sustainability 2019, 11, 105. [Google Scholar] [CrossRef]
- Asselman, A.; Khaldi, M.; Aammou, S. Enhancing the prediction of student performance based on the machine learning XGBoost algorithm. Interact. Learn. Environ. 2023, 31, 3360–3379. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.I. A Unified Approach to Interpreting Model Predictions. In Proceedings of the 31st Annual Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017; Guyon, I., Luxburg, U., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Springer: Berlin/Heidelberg, Germany, 2017; Volume 30. [Google Scholar]
- Giannakas, F.; Troussas, C.; Voyiatzis, I.; Sgouropoulou, C. A deep learning classification framework for early prediction of team-based academic performance. Appl. Soft Comput. 2021, 106, 107355. [Google Scholar] [CrossRef]
- Zhai, M.; Wang, S.; Wang, Y.; Wang, D. An interpretable prediction method for university student academic crisis warning. Complex Intell. Syst. 2022, 8, 323–336. [Google Scholar] [CrossRef]
- Sahlaoui, H.; Alaoui, E.A.A.; Nayyar, A.; Agoujil, S.; Jaber, M.M. Predicting and Interpreting Student Performance Using Ensemble Models and Shapley Additive Explanations. IEEE Access 2021, 9, 152688–152703. [Google Scholar] [CrossRef]
- Kashani, H.; Movahedi, A.; Morshedi, M.A. An agent-based simulation model to evaluate the response to seismic retrofit promotion policies. Int. J. Disaster Risk Reduct. 2019, 33, 181–195. [Google Scholar] [CrossRef]
- Nohara, D. A Comparison of the National Assessment of Educational Progress (NAEP), the Third International Mathematics and Science Study Repeat (TIMSS-R), and the Programme for International Student Assessment (PISA); National Center for Education Statistics: Washington, DC, USA, 2001.
- Rasch, G. Probabilistic Models for Some Intelligence and Attainment Tests. In Achievement Tests; American Psychological Association: Washington, DC, USA, 1993; p. 199. [Google Scholar]
- Johnson, R.; Zhang, T. Learning Nonlinear Functions Using Regularized Greedy Forest. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 942–954. [Google Scholar] [CrossRef] [PubMed]
- Rubin, W. Principles of Mathematical Analysis; McGraw-Hill: New York, NY, USA, 1953. [Google Scholar]
- Xia, Y.; Liu, C.; Li, Y.; Liu, N. A boosted decision tree approach using Bayesian hyper-parameter optimization for credit scoring. Expert Syst. Appl. 2017, 78, 225–241. [Google Scholar] [CrossRef]
- Štrumbelj, E.; Kononenko, I. Explaining Prediction Models and Individual Predictions with Feature Contributions. Knowl. Inf. Syst. 2014, 41, 647–665. [Google Scholar] [CrossRef]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why Should I Trust You?”: Explaining the Predictions of Any Classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar] [CrossRef]
- Ala’raj, M.; Abbod, M.F. Classifiers consensus system approach for credit scoring. Knowl.-Based Syst. 2016, 104, 89–105. [Google Scholar] [CrossRef]
- Finlay, S. Multiple classifier architectures and their application to credit risk assessment. Eur. J. Oper. Res. 2011, 210, 368–378. [Google Scholar] [CrossRef]
- Mujahid, M.; Lee, E.; Rustam, F.; Washington, P.B.; Ullah, S.; Reshi, A.A.; Ashraf, I. Sentiment Analysis and Topic Modeling on Tweets about Online Education during COVID-19. Appl. Sci. 2021, 11, 8438. [Google Scholar] [CrossRef]
- Chicco, D.; Jurman, G. The advantages of the Matthews correlation coefficient (MCC) over F1 score and accuracy in binary classification evaluation. BMC Genom. 2020, 21, 6. [Google Scholar] [CrossRef] [PubMed]
- Sokolova, M.; Lapalme, G. A systematic analysis of performance measures for classification tasks. Inf. Process. Manag. 2009, 45, 427–437. [Google Scholar] [CrossRef]
- Hand, D.J. Classifier technology and the illusion of progress. Stat. Sci. 2006, 21, 1–14. [Google Scholar] [CrossRef]
- Ministry of Education of the People’s Republic of China. Curriculum Standard for Mathematics in Senior High School (2017 Edition, Revised 2020); China People’s Education Press: Beijing, China, 2020. [Google Scholar]
- Knight, J.K.; Wise, S.B.; Southard, K.M. Understanding Clicker Discussions: Student Reasoning and the Impact of Instructional Cues. CBE-Life Sci. Educ. 2013, 12, 645–654. [Google Scholar] [CrossRef] [PubMed]
- Lai, C.L. Trends of mobile learning: A review of the top 100 highly cited papers. Br. J. Educ. Technol. 2020, 51, 721–742. [Google Scholar] [CrossRef]
- van de Weijer-bergsma, E.; van der Ven, S.H.G. Why and for whom does personalizing math problems enhance performance? Testing the mediation of enjoyment and cognitive load at different ability levels. Learn. Individ. Differ. 2021, 87, 101982. [Google Scholar] [CrossRef]
- Grover, S.; Pea, R. Computational Thinking in K-12: A Review of the State of the Field. Educ. Res. 2013, 42, 38–43. [Google Scholar] [CrossRef]
- Wing, J.M. Computational thinking and thinking about computing. Philos. Trans. R. Soc.-Math. Phys. Eng. Sci. 2008, 366, 3717–3725. [Google Scholar] [CrossRef] [PubMed]
- Ozkan, G.; Selcuk, G.S. The effectiveness of conceptual change texts and context-based learning on students’ conceptual achievement. J. Balt. Sci. Educ. 2015, 14, 753–763. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Features | Description |
|---|---|
| PLF | Items are categorized into four levels based on the number of parameters involved: no parameters, one parameter, two parameters, and three or more parameters. |
| RLF | Items that require reasoning steps to solve are classified into four levels based on the number of steps needed. The levels are based on the intervals , , , and , respectively |
| TMF | The problem-solving process of the given items involves four types of thinking methods: forward thinking, backward thinking, primarily forward thinking (with a hint of backward thinking), and primarily backward thinking (with a hint of forward thinking). These four cases are respectively referred to as four levels of thinking. |
| CRF | Exam computation processes can fall into four categories: (1) simple symbol/numeric operations with a simple symbol and numeric value, (2) combination of simple symbol and numeric operations, (3) complex symbol/numeric operations with complex symbols and numeric values, and (4) combination of complex symbol and numeric operations. We refer to these cases as four levels for ease of description and distinction. |
| BIF | Exam’s background may fall into four categories: (1) no specific background, focusing only on mathematical knowledge; (2) real-life contexts for practical problem-solving; (3) on the background of other disciplines or mathematical culture; and (4) real-life or scientific contexts with mathematical figures and charts. |
| CCF | To standardize the quantity of printed symbols in exam items and improve problem-solving efficiency, we calculate the number of symbol units for each item and divide them into four symbol levels based on their respective ranges: , , , and |
| KCF | We extract the knowledge points covered in each exam item, using the 170 target knowledge points in the scope of Chinese high school mathematics as the knowledge units. When an exam item contains 2–3, 4, 5–6, or 7–9 knowledge units, we classify them into four knowledge levels accordingly. |
| CLF | Based on Bloom’s cognitive domain and the analysis of behavioral verbs in the three-dimensional objectives of the Chinese mathematics curriculum standards, we divide the cognitive levels into three levels of increasing complexity: Cognitive Level A (Understanding, 1 point), Cognitive Level B (Comprehension, 2 points), and Cognitive Level C (Mastery, 3 points). Next, we evaluate the cognitive level for each knowledge point in a question separately, sum them up to obtain the cognitive level score for that item, and then categorize them into four grades based on their respective ranges: , , , and . |
| Question Number | PLF | RLF | TMF | CRF | BIF | CCF | KCF | CLF |
|---|---|---|---|---|---|---|---|---|
| 17 | 2 | 2 | 1.75 | 2 | 1 | 1 | 3 | 3 |
| Question Number | PLF | RLF | TMF | CRF | BIF | CCF | KCF | CLF | TS | AS | DC | DL |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 17 | 0.563 | 0.108 | 0.250 | 0.600 | 0.000 | 0.015 | 0.429 | 0.600 | 12 | 8.5 | 0.292 | 1 |
| 18 | 0.563 | 0.242 | 0.917 | 0.400 | 0.000 | 0.085 | 0.857 | 0.850 | 12 | 8.2 | 0.317 | 1 |
| 19 | 0.375 | 0.125 | 0.583 | 0.500 | 0.000 | 0.054 | 0.571 | 0.600 | 12 | 4.49 | 0.626 | 1 |
| 20 | 0.469 | 0.300 | 0.917 | 1.000 | 0.000 | 0.020 | 1.000 | 0.950 | 12 | 1.73 | 0.856 | 2 |
| 21 | 0.469 | 0.217 | 0.417 | 0.300 | 1.000 | 0.775 | 0.286 | 0.350 | 12 | 2.22 | 0.815 | 2 |
| 22 | 0.469 | 0.075 | 0.333 | 0.700 | 0.000 | 0.165 | 0.571 | 0.650 | 10 | 3.41 | 0.659 | 1 |
| 23 | 0.563 | 0.167 | 0.750 | 0.500 | 0.000 | 0.007 | 0.143 | 0.150 | 10 | 4.23 | 0.577 | 1 |
| Model Parameter | Poptimal Value |
|---|---|
| Colsample_ bylevel | 1 |
| Colsample_ bytree | 1 |
| Learning rate | 0.4 |
| Max depth | 5 |
| N_estimators | 100 |
| Subsampl | 1 |
| Model | Training Set Fitting Accuracy | Test Set Fitting Accuracy | Score | Recall (Weighted Avg) | Precision |
|---|---|---|---|---|---|
| Proposed model | 0.9998 | 0.8064 | 0.9419 | 0.9411 | 0.9435 |
| Light GBM | 0.7875 | 0.6857 | 0.6932 | 0.6911 | 0.5600 |
| Random Forest | 0.8625 | 0.6571 | 0.6657 | 0.6603 | 0.5600 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yi, X.; Sun, J.; Wu, X. Novel Feature-Based Difficulty Prediction Method for Mathematics Items Using XGBoost-Based SHAP Model. Mathematics 2024, 12, 1455. https://doi.org/10.3390/math12101455
Yi X, Sun J, Wu X. Novel Feature-Based Difficulty Prediction Method for Mathematics Items Using XGBoost-Based SHAP Model. Mathematics. 2024; 12(10):1455. https://doi.org/10.3390/math12101455
Chicago/Turabian StyleYi, Xifan, Jianing Sun, and Xiaopeng Wu. 2024. "Novel Feature-Based Difficulty Prediction Method for Mathematics Items Using XGBoost-Based SHAP Model" Mathematics 12, no. 10: 1455. https://doi.org/10.3390/math12101455
APA StyleYi, X., Sun, J., & Wu, X. (2024). Novel Feature-Based Difficulty Prediction Method for Mathematics Items Using XGBoost-Based SHAP Model. Mathematics, 12(10), 1455. https://doi.org/10.3390/math12101455