
Action-Based Digital Characterization of a Game Player

Abstract
1. Introduction
- (a)
- To test the method in two experiments of various complexities. The first is a case study on the simple (yet powerful) game of Rock–Paper–Scissors (RPS). RPS is a game typically played between two players, in which each player simultaneously chooses one of three actions: rock, paper or scissors. A set of rules determines the winner: rock beats scissors, scissors beat paper and paper beats rock (such game relationships between rock, paper and scissors can also be found in several natural systems [8]). The second experiment is carried out in the complex environment of RTS games.
- (b)
- To perform a DC analysis and a time analysis on the DCs created using the feature and action data of five game agents while they operate in a complex RTS game environment.
- (c)
- To establish the DC method’s suitability for real-time (online/in-game) usage capabilities.
- (d)
- To discuss its possible usage in automated policy creations, in future simulation purposes or with a DC serving as a vital part in the game agent’s decision-making process.
- (a)
- To our knowledge, this is the first approach for using association rule mining in a game domain where the mined rules are not used in their entirety (e.g., for building a game knowledge database), but only as guiding factors (by utilizing rules thresholds in descending order), allowing for the discovery and extraction of actions with a higher confidence value, and, consequently, using that information for building quality abstracted player action representations.
- (b)
- The method creates explainable (interpretable) player action representations (e.g., deep-learning-based agents/models are hard to interpret [9], but this method’s action representations can be interpreted more easily).
- (c)
- The approach confirms that the output of the dcARM method shows differences in game agent action usages (i.e., which actions are used more and which are used less).
- (d)
- By comparing the differences in how agents are using actions, the (sub)patterns of comparable behavior can be established between different agents.
2. Related Work
3. Materials and Methods
3.1. Game Knowledge Acquisition
3.2. Stochastic Population-Based Nature-Inspired Algorithms for Association Rule Mining
3.2.1. Stochastic Population-Based Nature-Inspired Algorithms
3.2.2. Numeric Association Rule Mining (NARM)
3.2.3. uARMSolver Software
3.2.4. ARM-DE (Differential Evolution) Algorithm
3.2.5. Action Extraction Procedure and Action Intensity Pattern
- ARM creates the ruleset based on the feature and action dataset provided to it. If the player makes multiple actions for a given frame, the features of that game frame are duplicated, with only the actions being differing factors between such records. The dataset for ARM includes all the records for a period of maximum passed time tmpt.
- A set of actions are defined, which are extracted from the ruleset, the action counter set and the threshold at which searching for actions is stopped.
- The ruleset is traversed rule by rule in a threshold-descending manner (i.e., from rules with the highest threshold downward toward the rules with the lowest threshold) until the stopping threshold is met.
- Each rule is parsed and searched for the inclusion of any actions from the set of actions.
- The counter for that specific action is increased if any action from the set of actions is found in the rule.
- Frame number: 20 (e.g., included frames are in the interval [1, 20]).
- Extracted actions: 1, 1, 0, 0, 5, 1.
- Percentage distributions of extracted actions: 12.5%, 12.5%, 0%, 0%, 62.5%, 12.5%.
- Maximum action (62.5%): 4.
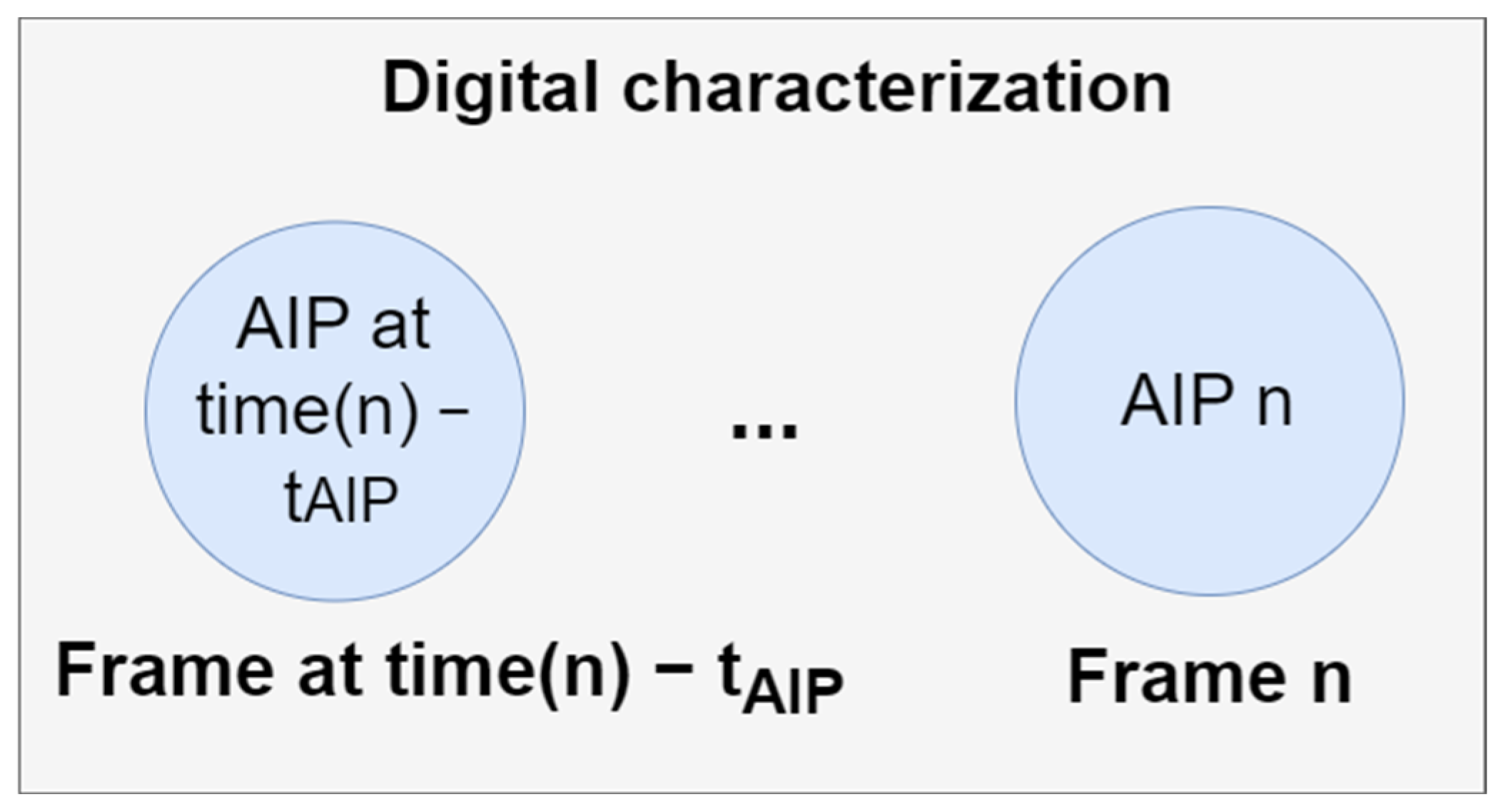
3.3. dcARM Method and the Game P layer’s Digital Characterization
| Algorithm 1: Pseudocode of the dcARM method |
| // Step 1—Define input arguments Input: names (set of names of relevant game state features and a player executed actions), θcv (rule confidence value threshold), tmpt (maximum passed time for keeping records), tAIP (maximum passed time for keeping an AIP), sampRat (sampling rate) Output: Digital Characterization (DC) of a player/game agent |
| set digChar = initializeEmpty() // init. digital characterization currentFrame = 0 do if currentFrame mod sampRat equals 0 then // Step 2—Save the feature values in the record set set playerAction = getPlayerAction(playerID, gameState) set featureValues = getFeatureValues(playerID, gameState, names) recordSet = addToRecordSet(recordSet, listOfActions(playerAction), featureValues) recordSet = removeRecordsOverTimeLimit(tmpt) // Step 3—Execute ARM and extract actions from rules setOfActions = extractActions(executeARM(recordSet), θcv) // Step 4—Create action intensity pattern AIP = createActIntPat(setOfActions) // Step 5—Digital characterization of a game agent digChar = removeOldActIntPatOverTimeLimit(playerID, tAIP) digChar = updateDigitalCharOfAgent(playerID, AIP) end if // DC can be used for automated game policy creations // DC can be used in future simulations // DC as the driver of Game Agents’ decision process // DC can be used for opponent modeling // … while gameInProgress(gameState) |
4. Case Study: Rock–Paper–Scissors Game
- (a)
- The simplicity of incorporating only three non-durative and instant actions/hands.
- (b)
- The possibility of inferring the other player’s strategy and its win rate [36].
- (c)
- The RPS cyclic game rule principles can be scaled to higher complexities (e.g., the Rock–Scissors–Paper–Lizard–Spock game [37]) and can incorporate different game mechanics/abstractions (e.g., the RPS system as an RTS game cyclic strategy selection [38]), which opens up possibilities for research in many more (game) (sub)domains.
4.1. Experimental Settings
4.2. Results of the Case Study Experiment
4.3. Short Discussion of the Results of the Case Study Experiment
5. Experiment: Real-Time Strategy Simulation Environment
5.1. Experimental Settings
- There are, in total, six game actions in microRTS to be executed by the appropriate units (all are used in the dcARM method): wait (0) (i.e., the unit takes no actions in the current frame), move (1) (i.e., the unit should move to the other cell), harvest (2) (i.e., the unit must gather resources), return (3) (i.e., the unit should return to base with the resources), produce (4) (i.e., the unit must produce another unit) and attack location (5) (i.e., the unit attacks the opponent’s unit at a specific location/cell). Due to the low number of available actions in the microRTS environment, no action abstractions are used (e.g., grouping actions based on specific criteria).
- The chosen features for this experiment, which are gathered from the microRTS game state, are shown in Table 3 (the [fr/op] part symbolizes that two distinct features are used: one for the friendly side and one for the opposing side).
- The interval of the following rule confidence thresholds θcv is used: [0.1, 1.0] (with a step of 0.1).
- The maximum passed time for keeping records is set as unlimited (i.e., all rules from the beginning of the game are included).
- The maximum passed time for keeping an AIP is set to unlimited (i.e., all AIPs from the beginning of the game are included).
- The sampling rate is set to one (i.e., the dcARM method is utilized in each game frame).
5.2. Real-Time Strategy Digital Characterization Data Results
- (a)
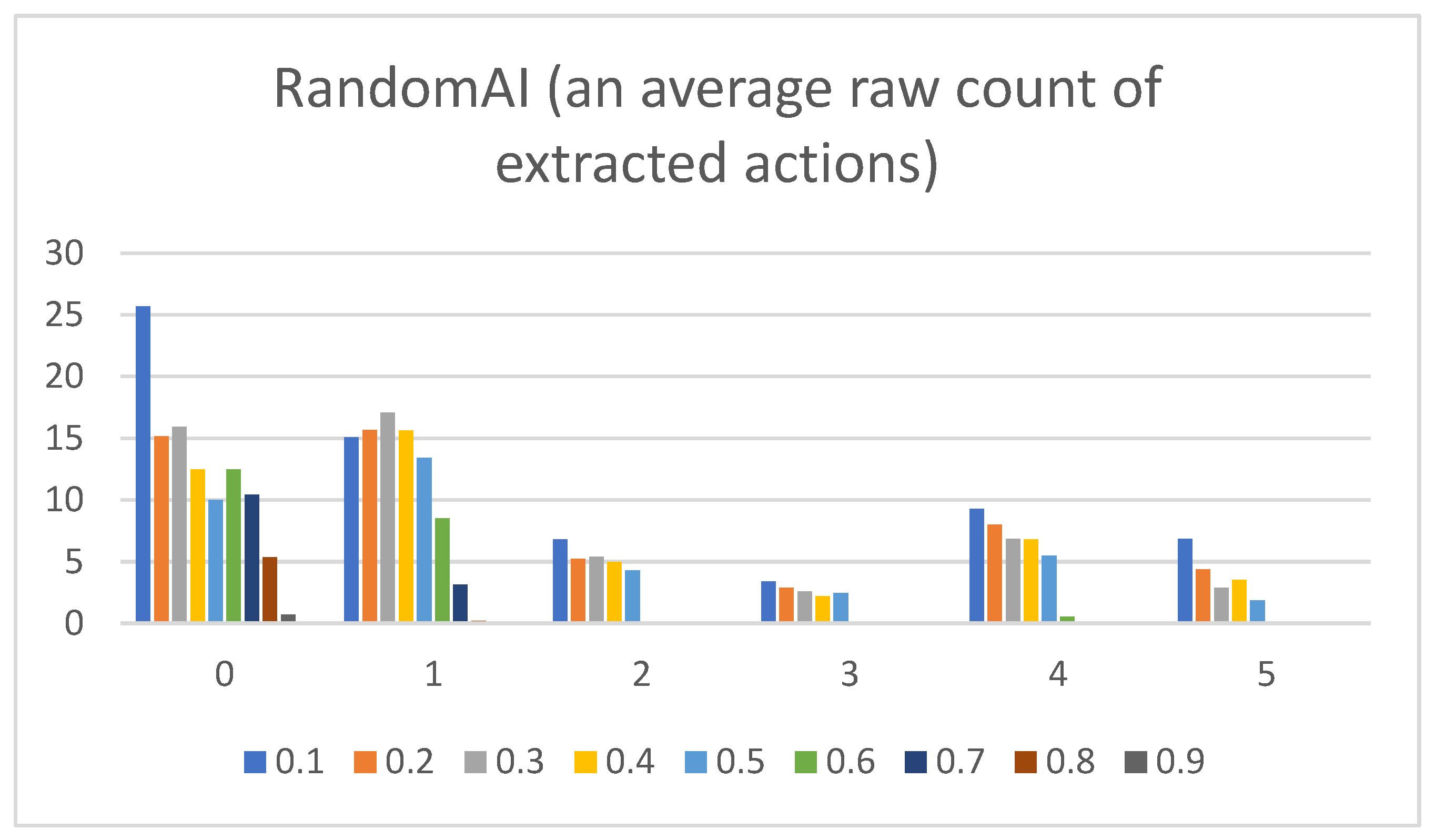
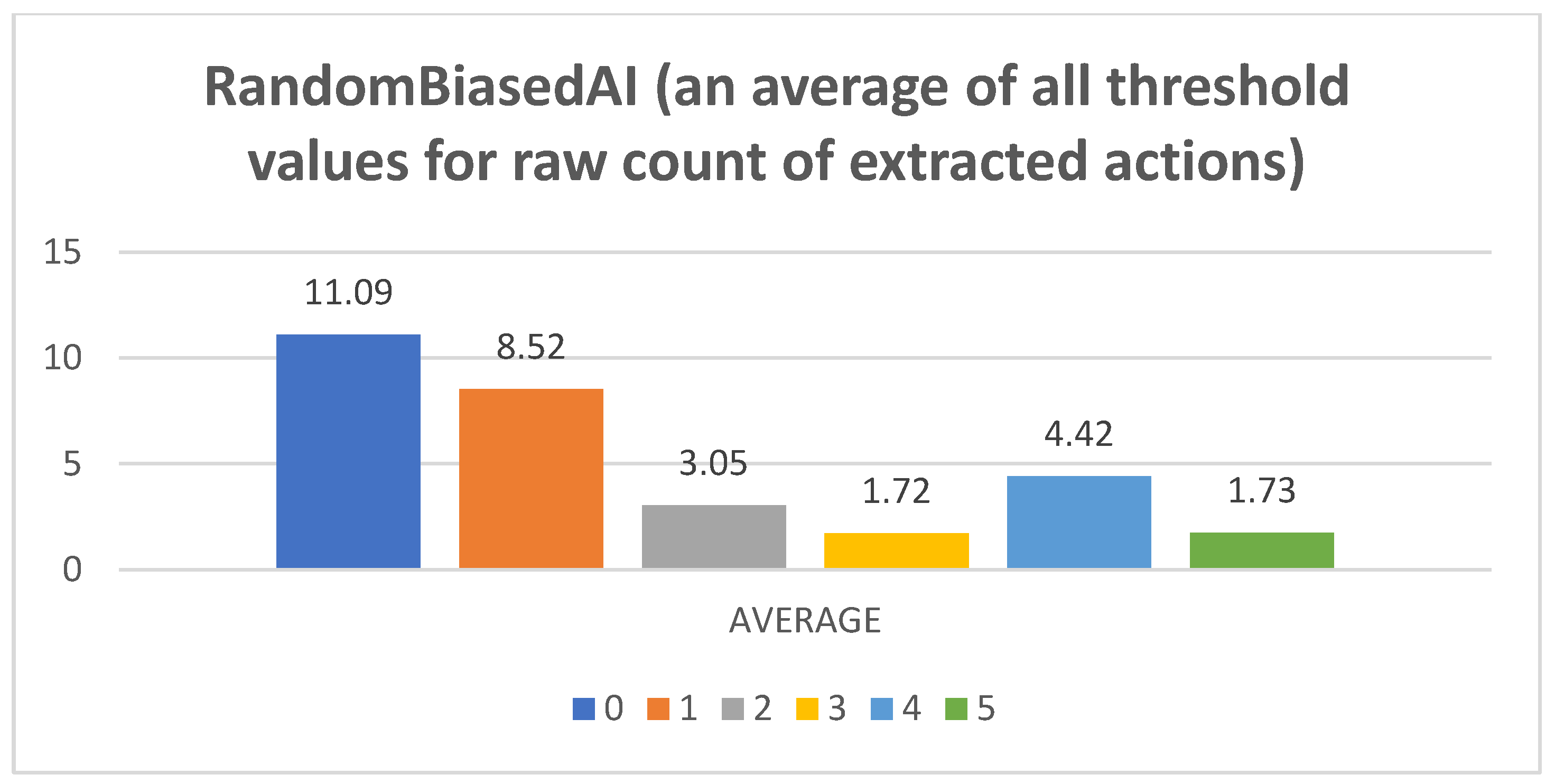
- Raw counts of extracted actions. The graphs in Figure 3, Figure 4, Figure 5, Figure 6 and Figure 7 show the raw counts of the extracted actions (i.e., the DC holds the actions averaged across all gameplay frames and also those averaged for all ten games played) (ordinate axis) for each available action (abscissa axis). The figures in Appendix B present a single value for each specific action, because discussing the differences between agents can (sometimes) be more straightforward with just one value. Therefore, the graphs shown in Figure A1, Figure A2, Figure A3, Figure A4 and Figure A5 show the average value across all thresholds (ordinate axis) for each specific action (abscissa axis). Note, however, that some thresholds with a (near) zero value can substantially lower the overall value, making interpretations with only one value more difficult due to less information.
- (b)
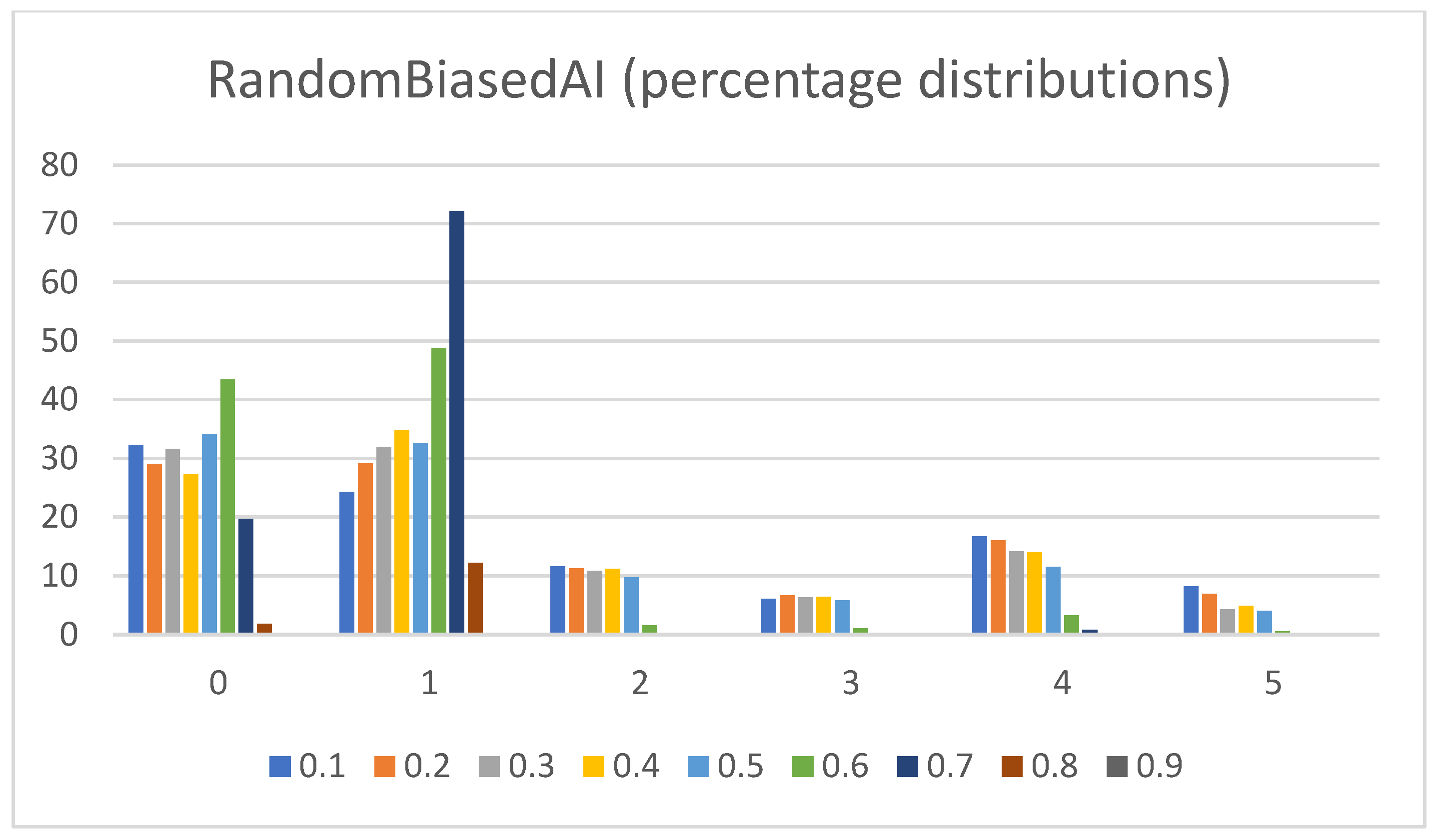
- Percentage distributions of extracted actions. The graphs in Figure 8, Figure 9, Figure 10, Figure 11 and Figure 12 show the percentage distributions of the extracted actions (i.e., the DC holds the actions averaged across all gameplay frames, and also those averaged for all ten games played) (ordinate axis) for each available action (abscissa axis).
- (c)
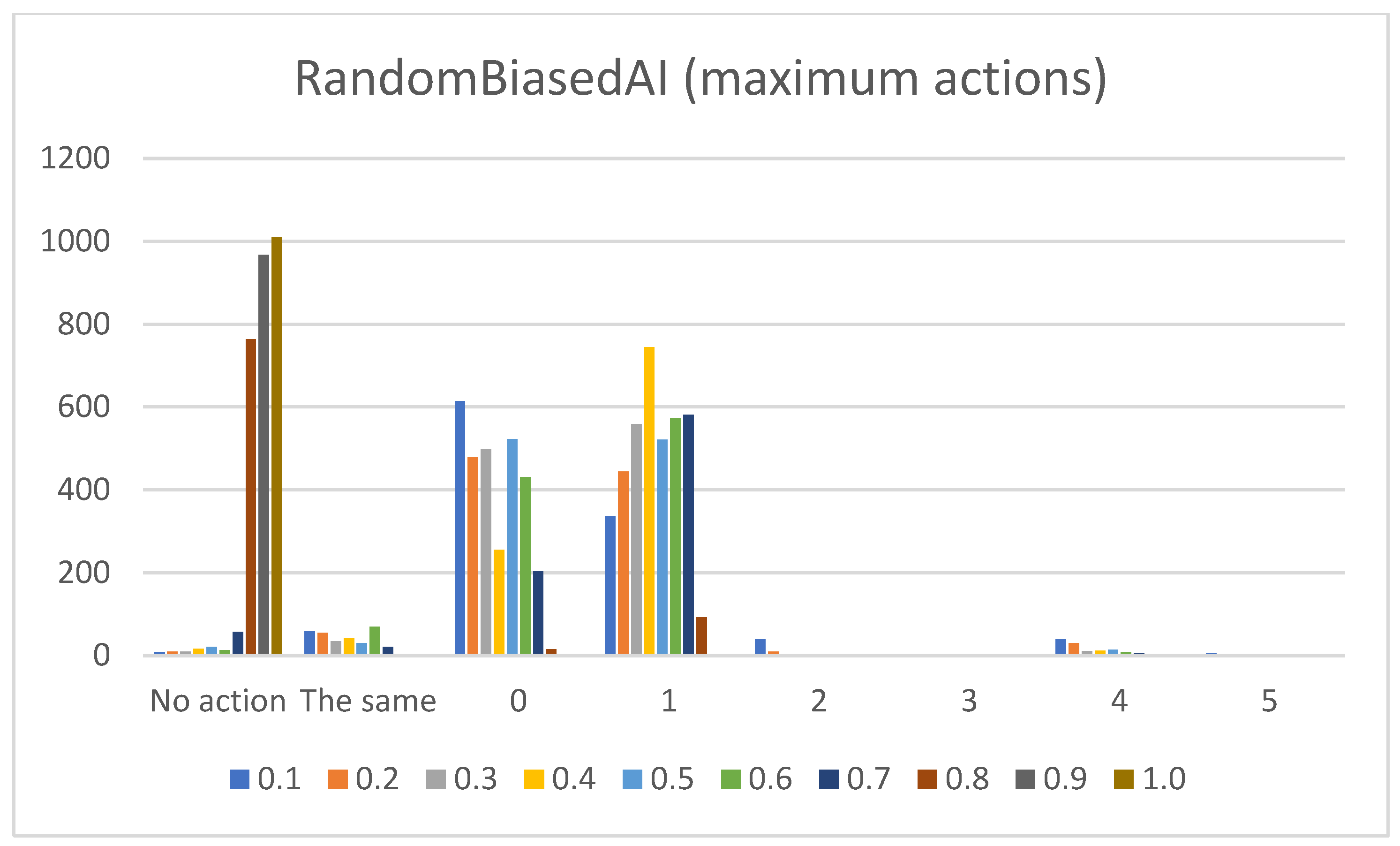
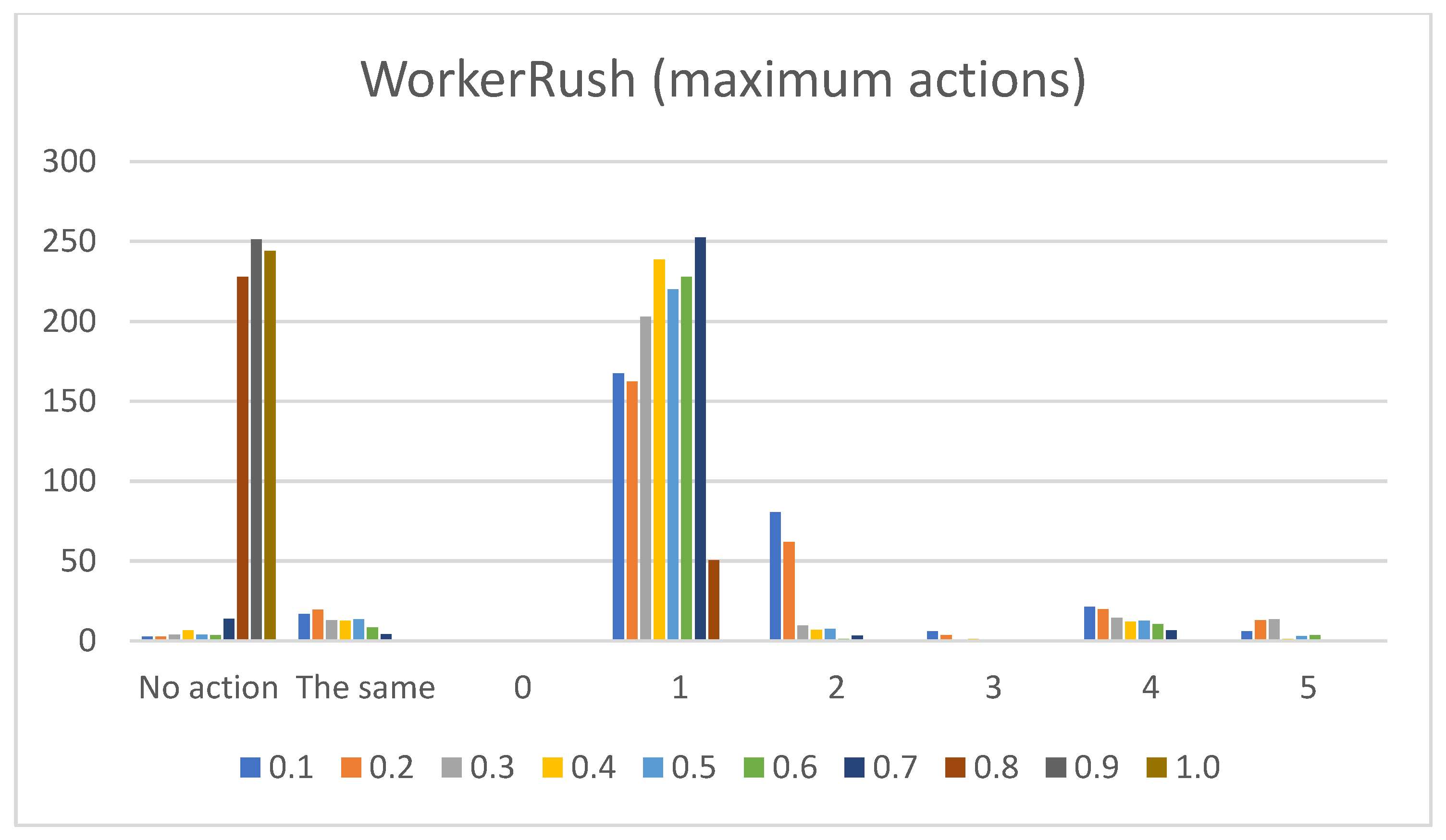
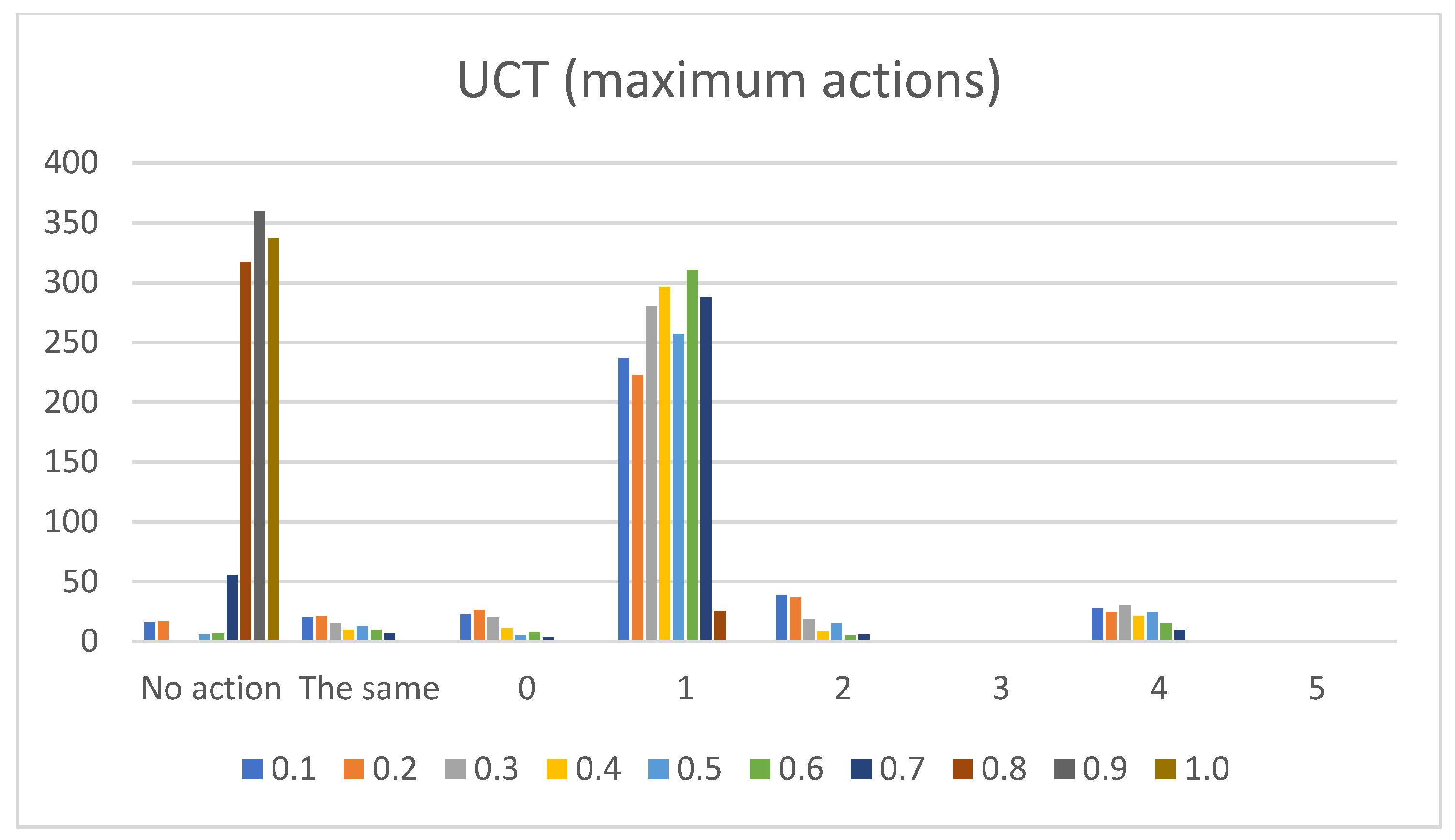
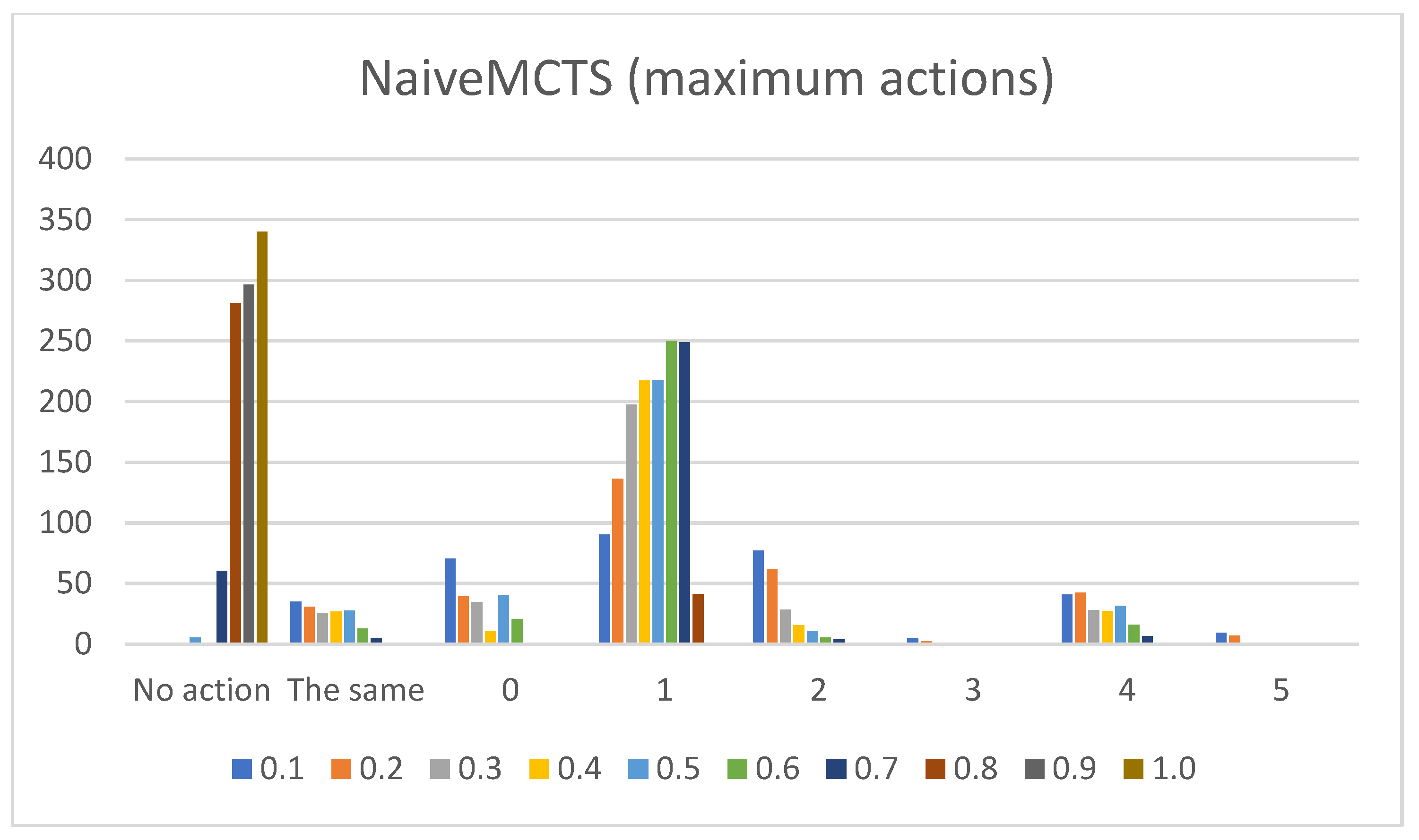
- Sum of maximum actions. The graphs shown in Figure 13, Figure 14, Figure 15, Figure 16 and Figure 17 show the counts of achieving the maximum action (i.e., the DC holds the maximum actions summed across all the gameplay frames, and also those averaged for all ten games played) (ordinate axis) for each available action (abscissa axis). Note: The graphs for the maximum actions include two additional labels named “No action” and “The same”, which stand for how many times no action is taken (i.e., if no action is taken, then there is no maximum action), and how many times two or more actions reach the same maximum action status (i.e., they havve the same maximum percentage distribution).
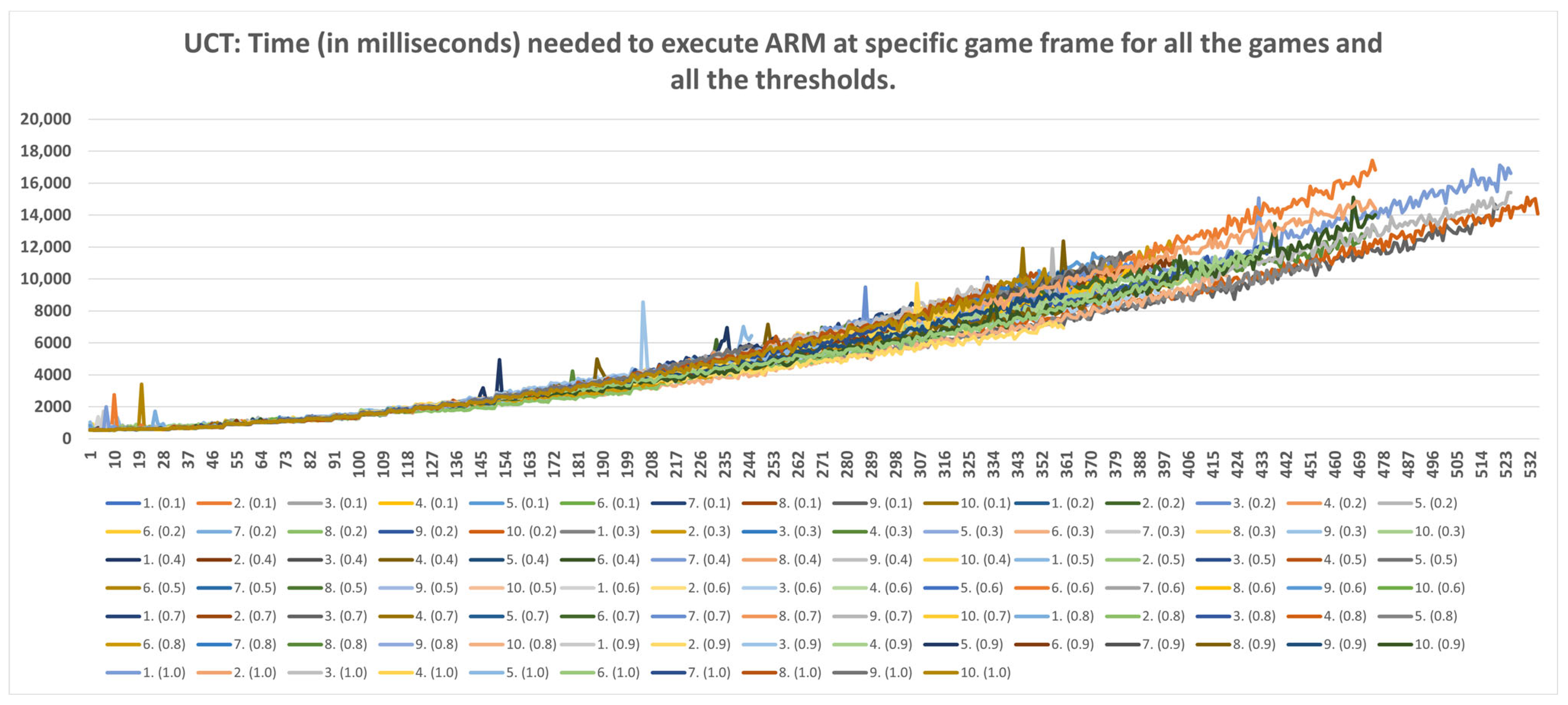
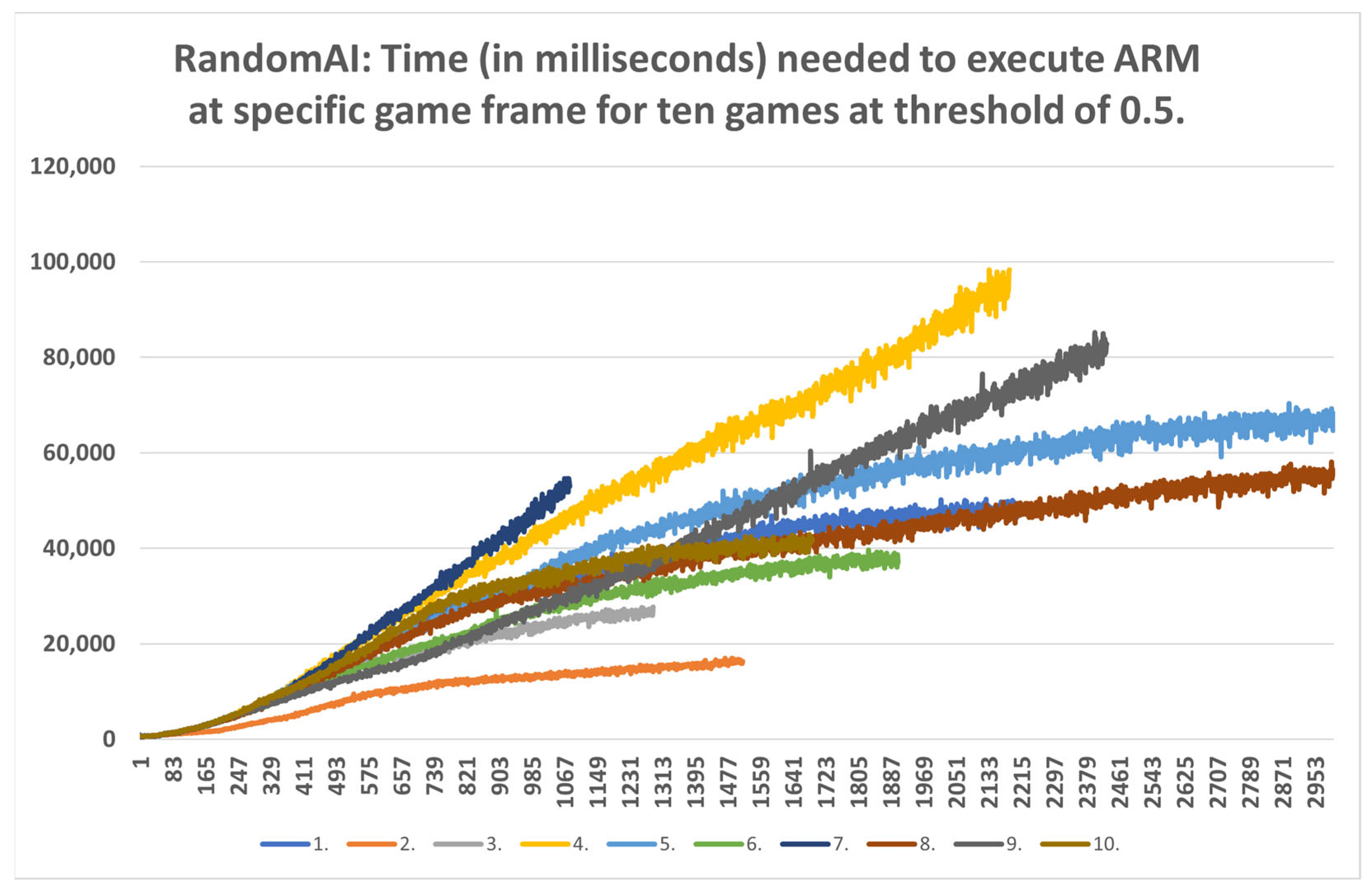
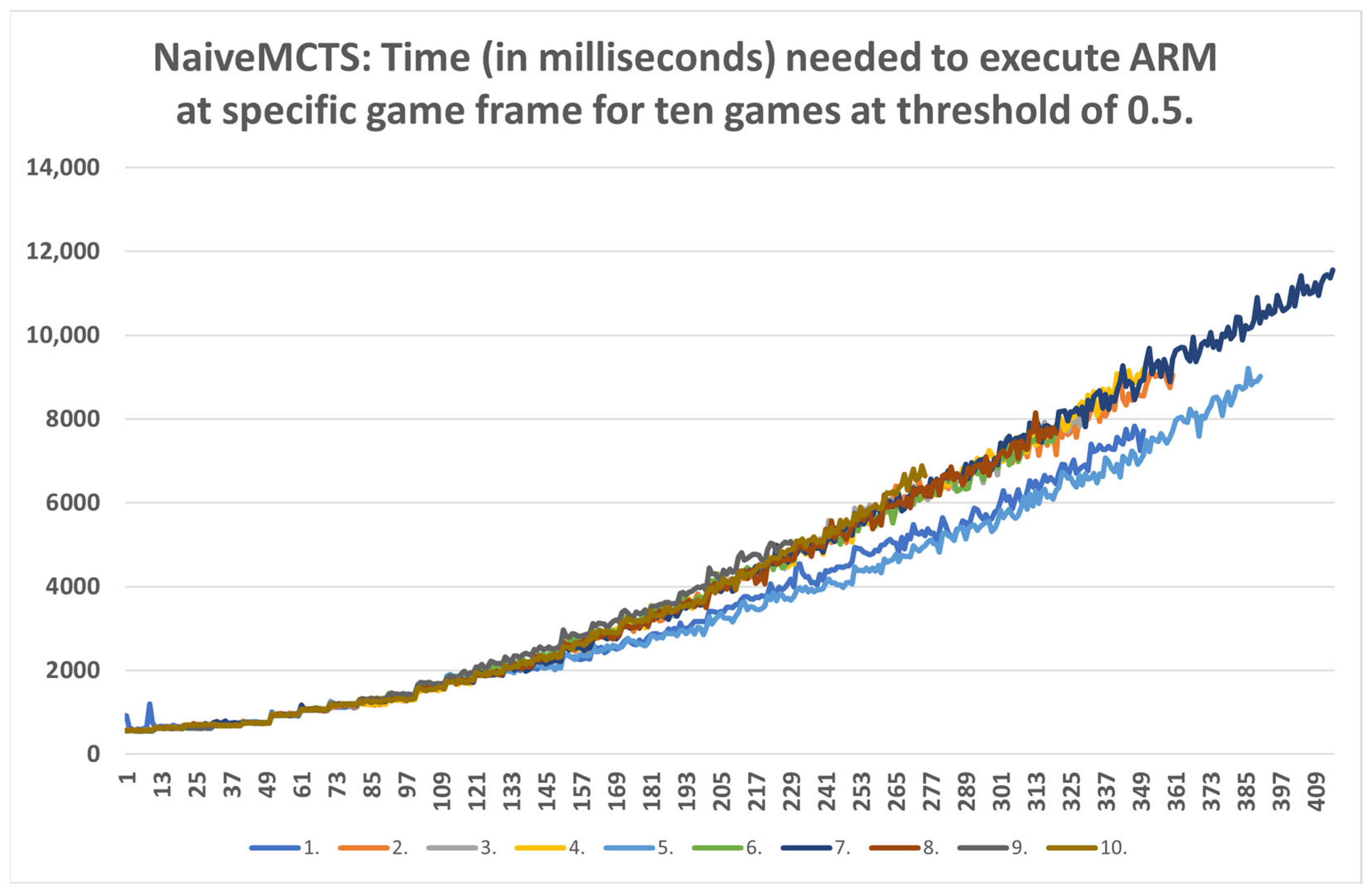
5.3. Time Data Results
6. Discussion
6.1. DC Results of Five Game Agents
- (a)
- RandomAI/RandomBiasedAI:Pretext: Both agents share the same core (i.e., random behavior), which is clearly shown on their graphs due to their similarity. Both agents are also very keen on using the wait (0) and move (1) actions.Presentation of results: The average raw count of the extracted wait (0) action for both agents shows values of around 13 to 16, whereas those of UCT and NaiveMCTS are much lower at around 8 to 10. For the move (1) action, the count is similar between the agents but with slightly lower values when compared to those of other agents (i.e., around 15, whereas other agents are a few points above this).When the percentage graphs are observed, the usage of the wait (0) action is maintained at around the 30 percent mark (with those of UCT and NaiveMCTS being much lower, at around 18 percent).In the maximum action graphs, the wait (0) and move (1) actions surpass a count of 1000 (even reaching 1500 in some cases) for the RandomAI agent, and the RandomBiasedAI has them at around 500 to 600. Every other agent has a much lower value for the maximum action count for these two actions (only that of UCT reaches the 300 mark for the move (1) action).For the remainder of the actions, only the produce (4) action is shown slightly in the graphs, and the return (3) and attack location (5) actions are not used.Summary: The wait (0) action is used less by other agents, which signals that they utilize much more intelligence- (i.e., actions with active purposes) driven behavior than these two agents do. Even the usage of “No action taken” is, for these two agents, up to three times higher than that for any other agent.
- (b)
- WorkerRush:Pretext: This rushing agent expresses the most apparent result of a clear-cut connection between the game agent’s DC and the agent’s actual modus operandi. The agent graphs show that the wait (0) action is not utilized, whereas every other agent at least considers using it.Presentation of results: The averaged raw count of the extracted move (1) action is on par with those of the other agents (even slightly higher than those of the RandomAI and RandomBiasedAI). The harvest (2) action count candles are mainly represented at around mark eight (slightly lower than those of the UCT and NaiveMCTS agents). The return (3) action is stable at mark five (somewhat higher than those for the UCT and NaiveMCTS agents). The produce (4) action is on par with that of the UCT agent (for some candles, it is even higher) at around mark eight but is lower than that of the NaiveMCTS agent. The attack location (5) action is very similar to those of the other agents.When the percentage graphs are observed, the move (1) action is the most represented action among all agents (and the graphs regarding this action are also similar), but the candles for the WorkerRush and UCT agents are around ten percent higher. The harvest (2) action is twice as high for the WorkerRush, UCT and NaiveMCTS agents compared those of the RandomAI and RandomBiasedAI agents. The produce (4) action for this agent is similar to that of NaiveMCTS at around twenty percent. This is the highest compared to the other agents, which are mainly found in the twelve to fourteen percent range. The attack location (5) action does not deviate considerably compared to those of the other agents.Regarding the maximum action graphs, the “No action taken” candles are the lowest among all the agents. The candles for other actions are similar to those of the NaiveMCTS agent. The maximum actions for the return (3) and attack location (5) actions show slightly higher behavior for this agent (i.e., in comparison to other agents, whose candles are almost non-existent).Summary: Because the primary operation of the WorkerRush agent is rushing the opponent, its DC clearly shows that the agent has no use for waiting. The agent’s harvesting behavior is twice as high as those of the random-based agents and is similar to those of the other two competent agents, signaling intelligent/scripted (i.e., non-random) behavior. The same can be stated for the utilization of returning actions (i.e., it is distinct from random behavior). Production is very high on this agent’s agenda, which is to be expected, because the agent’s primary purpose is to rush the opponent with as many units as possible.
- (c)
- UCT:Pretext: The UCT agent is quite a capable agent, and its behavior lies somewhere along the lines of NaiveMCTS but with more balanced behavior (e.g., the candle sizes do not show as much of a decline between the different thresholds in the averaged raw action count when compared to those of WorkerRush or NaiveMCTS).Presentation of results: For this agent, the presentation is kept short because most of the results are already discussed in the actions of the previous agents. To summarize, the averaged raw action counts and percentage distributions for the wait (0) action are similar to those of the NaiveMCTS agent (i.e., in the vicinity of mark eight for a raw count and around 18 percent for percentage distributions), and the maximum actions count is almost half in comparison to that of the same agent. For the move (1) and harvest (2) actions, the graphs show similar behavior to those of the WorkerRush and NaiveMCTS agents. The return (3) action is slightly less well represented than those of WorkerRush and NaiveMCTS (e.g., the percentage distributions are below ten percent, whereas these two agents have them firmly on ten percent). The produce (4) action is almost half (e.g., in terms of percentage distributions) compared to those of other agents, and is on par with RandomAI. The attack location (5) action numbers are similar to those of the NaiveMCTS agent.Summary: This agent is balanced across actions and is not too keen on production. Its actions are similar to those of NaiveMCTS but with slightly lower action counts.
- (d)
- NaiveMCTS:Pretext: It is interesting to observe how this agent’s DC comes close to the DC of the WorkerRush agent (except for the wait (0) action, which is almost non-existent in WorkerRush). This behavior could be attributed to both agents utilizing aggressive tactics against the opponent.Presentation of results: The NaiveMCTS action results are already presented when describing other agents. This agent utilizes the production (4) action quite heavily (i.e., a twenty percent distribution of choosing this output is quite intensive for an RTS game).Summary: This agent drives a very offensive-oriented game, which is quite evident when compared to the DC of the WorkerRush agent (also offensive-oriented).The data results present a comprehensive picture across specific actions and reveal the DC similarity patterns (e.g., similar offensive behaviors for NaiveMCTS and WorkerRush), as well as crucial differences (e.g., low values of wait (0) actions for non-random agents) between the agents. Such patterns are an excellent indicator of the DC being a helpful tool when researching explainable agents (e.g., agents that do not allow access to the internal code—black box concept), when trying to compare the agents with each other (e.g., possible classification of agents) or when the characterization is needed for (but not limited to) gameplay purposes (e.g., opponent modeling).The results also show the importance of different abstractions of the action data. For example, if only the maximum action usages are observed, it would seem as though the agents never use the return (3) and attack location (5) actions. However, when the averaged raw count of extracted actions and percentage distributions are taken into consideration, one can observe that they are indeed used (even up to ten percent with WorkerRush).
6.2. Suitability of dcARM Method for In-Game Usage
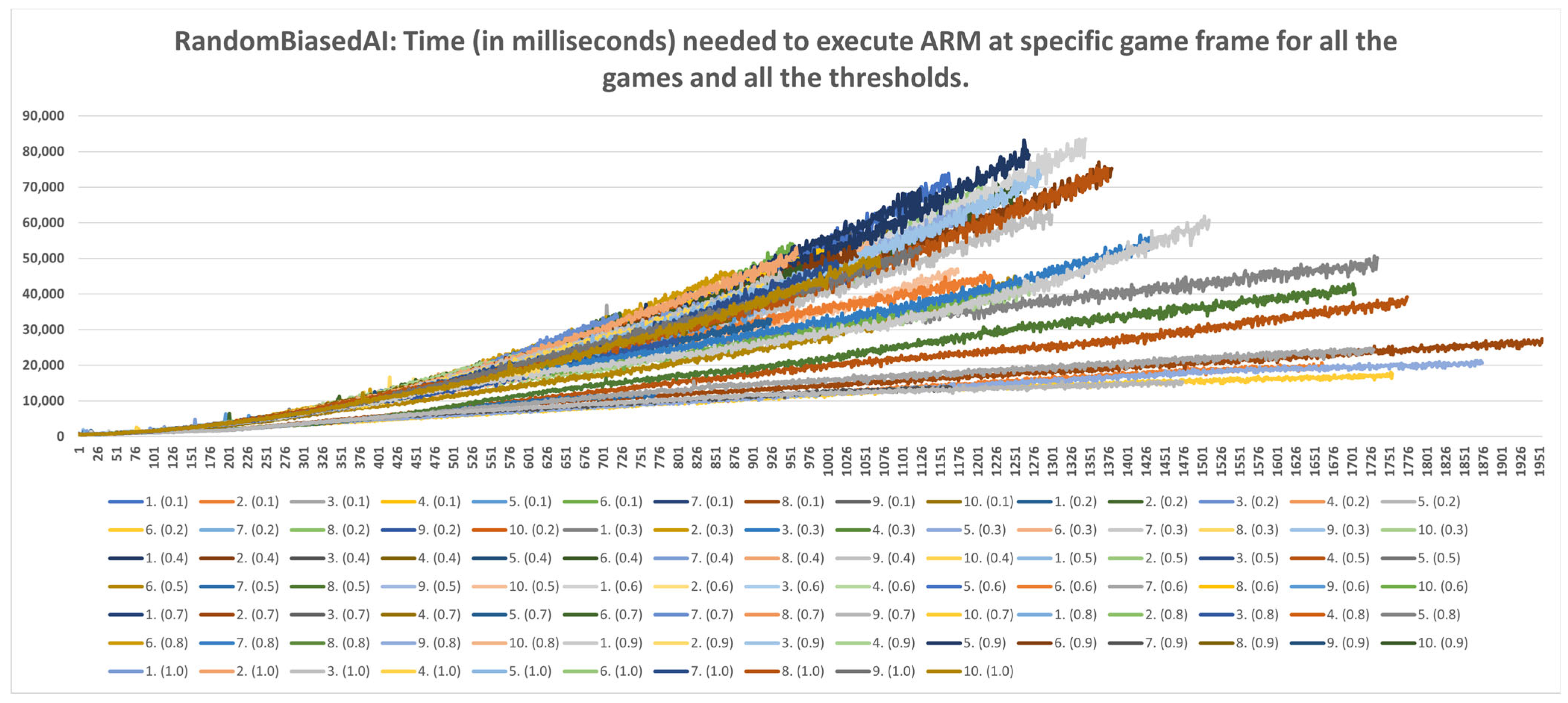
- Strategic level: This method can be used for strategic purposes, because, even with the highest time consumption of RandomAI, there is only one occurrence in which time consumption extends beyond the two-minute mark. RandomAI and RandomBiasedAI are otherwise the most time-consuming agents due to playing the longest games (i.e., measured by the overall frame count). For the other agents, the highest time consumptions are at around eighty seconds (RandomBiasedAI), nine seconds (WorkerRush), fifteen seconds (UCT) and eleven seconds (NaiveMCTS).
- Tactical operations: Regarding the timings of tactical operations, the usage of this method is also possible for every non-random agent (i.e., their measured time values are a lot lower than the sixty-second limit) and for the random agents (i.e., the method could be used to approximate the inclusion of up to a thousand frames).
- Micromanagement purposes: Some time restrictions must apply when building the DC for micromanagement purposes. For example, if non-random agents are observed, the one-second mark is passed at approximately fifty frames. Moreover, if the first fifty frames of the games are followed, the time increases almost linearly. However, later on, the time data grow in a non-linear way, and therefore the number of frames used for micromanagement should be lower. For example, in later stages of the UCT agent games, the graph in Figure A9 can easily increase by two seconds in fifty frames.
6.3. Possible Directions for Future dcARM Research
6.3.1. Automated Game Policy Creations
6.3.2. Usage of DC for Future Simulation Purposes
6.3.3. DC as the Driver of a Game Agent’s Decision Process
6.4. Drawbacks of the Method and Room for Improvement
- DC offers many different abstractions of data, which, when combined with multiple threshold possibilities, a sampling rate and a large set of actions, creates many possible DC variations (patterns). Such patterns hold subtle clues, which are sometimes only revealed when observed under the right action abstraction, or when there is knowledge of exactly what is being searched for (e.g., if the agent is frequently moving, this can be an essential clue when researching micromanagement). DC patterns can also capture the character abstraction from the macro picture (e.g., an agent is keen on production), but more refinement to the method is needed to capture the micro picture (i.e., hard-to-spot nuances). For example, one can quickly identify when the agent is keen on a specific action. However, minor differences (e.g., of one percent) in action usage can mean a different utilization of such action. For example, two agents exhibit similar patterns for some behaviors, as NaiveMCTS and WorkerRush agents do for production, but otherwise have entirely different background implementations, tactics and strategies. Such nuances are observed very nicely in the RPS case study, where even a ten percent bias toward a specific action is captured with definitive conclusions. However, RTS environments are very complex, and in-depth research on the capability of DCs is needed in the future to obtain even more definitive answers (or better resolution) regarding the (in-depth) agents’ behavior.
- Automatic feature engineering [14] is focused on in step 1 of the dcARM method. Therefore, only the features that represent the game agent correctly and contribute significantly to the relevant DC construction (i.e., the DC of the game agent is of high confidence due to the usage of quality features) should be automatically selected. This would be a substantial improvement because the dcARM method would be completely automated. To achieve this goal, the utilization of deep learning simulation environments [43] and deep learning methods [44] is on our research agenda.
- In the current work, the game is paused during the frames to allow for the uninterrupted execution of the dcARM method, and to gather all the data needed for different types of analyses. For example, lessons learned with time analysis can help enhance the method to be time-adjustable in the future, allowing it to be incorporated into the game agent’s lifecycle. In this way, part of the game agent’s time slice can be allocated to the method, helping the agent’s decision making through DC data utilization into better capabilities with which actions to play.
- Data-squashing methods [45] can be used on the dcARM method input feature datasets, which can reduce the time needed to execute the dcARM method.
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 0.1 | 0.2 | 0.3 | 0.4 | 0.5 | 0.6 | 0.7 | 0.8 | 0.9 | 1.0 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0% | 32.58/34.53/36.01 | 33.96/35.09/33.16 | 34.74/34.28/35.19 | 31.54/30.68/32.05 | 23.75/25.47/24.47 | 20.95/21.57/21.06 | 7.2/6.1/6.61 | 0/0/0 | 0/0/0 | 0/0/0 |
| 10% | 36.98/32.7/32.35 | 37.83/34/33.66 | 36.41/32.65/32.38 | 36.64/30.57/27.74 | 32.15/23.49/23.75 | 25.02/18.53/18.26 | 19.14/6.01/6.51 | 8.12/0/0 | 0/0/0 | 0/0/0 |
| 20% | 38.76/31.7/33.04 | 39.42/32.68/32.54 | 38.81/32.76/33.06 | 37.89/30.97/27.98 | 34.28/24.14/21.19 | 25.98/17.23/15.95 | 19.28/6.2/6.06 | 8.44/0/0 | 0/0/0 | 0/0/0 |
| 30% | 48.34/30.94/31.36 | 49.4/30.16/31.45 | 50.39/30.19/31.13 | 49.37/27.98/26.8 | 50.26/18.21/19 | 47.26/15.15/14.62 | 30.91/5.41/5.32 | 17.25/0/0 | 0/0/0 | 0/0/0 |
| 40% | 50.24/29.02/31.56 | 50.63/29.87/29.65 | 51.19/29.59/28.83 | 50.97/21.66/20.35 | 50.98/18.64/17.86 | 47.32/14.76/14.52 | 37.22/4.97/5.09 | 16.38/0/0 | 0/0/0 | 0/0/0 |
| 50% | 53.42/28.87/30.12 | 54.01/31.49/28.3 | 49.86/25.69/27.43 | 53.29/18.94/21.49 | 52.59/18.77/17.56 | 53.31/13.79/14.56 | 40.52/4.82/4.95 | 30.67/0/0 | 0/0/0 | 0/0/0 |
| 60% | 53.86/30.01/27.66 | 52.52/27.99/28.88 | 54.63/23.96/25.51 | 54.77/19.21/19.09 | 50.73/16.87/16.77 | 53.11/13.33/12.84 | 46.51/4.11/4.27 | 34.29/0/0 | 17.13/0/0 | 0/0/0 |
| 70% | 106.94/28.34/27.69 | 107.9/27.48/28.65 | 108.31/24.48/24.35 | 106.37/16.53/18.69 | 106.28/15.93/16.27 | 104.49/12.63/12.56 | 104.7/1.93/1.98 | 87.57/0/0 | 53.25/0/0 | 0/0/0 |
| 80% | 106.43/27.84/29.1 | 107.84/29.22/28.05 | 107.32/18.44/17.93 | 105.22/15.42/16.53 | 105.39/15.36/15.83 | 106.94/12.84/13.51 | 106.48/0/0 | 94.65/0/0 | 65.53/0/0 | 0/0/0 |
| 90% | 131.04/28.18/28.13 | 136.65/24.62/23.79 | 137.01/19.01/16.97 | 135.25/15.79/17.21 | 134.03/15.22/16.06 | 133.65/4.09/4.11 | 138.37/0/0 | 127.01/0/0 | 90.38/0/0 | 0/0/0 |
| 100% | 164.75/0/0 | 165.34/0/0 | 164.55/0/0 | 165.13/0/0 | 163.65/0/0 | 166.71/0/0 | 165.39/0/0 | 165.06/0/0 | 146.01/0/0 | 88.1/0/0 |
Appendix B





Appendix C





References
- Levy, L.; Lambeth, A.; Solomon, R.; Gandy, M. Method in the madness: The design of games as valid and reliable scientific tools. In Proceedings of the 13th International Conference on the Foundations of Digital Games, Malmö, Sweden, 7–10 August 2018; pp. 1–10. [Google Scholar] [CrossRef]
- Isaksen, A.; Gopstein, D.; Nealen, A. Exploring Game Space Using Survival Analysis. In Proceedings of the International Conference on Foundations of Digital Games, FDG 2015, Pacific Grove, CA, USA, 22–25 June 2015. [Google Scholar]
- Prensky, M. Fun, play and games: What makes games engaging. Digit. Game-Based Learn. 2001, 5, 5–31. [Google Scholar]
- Goel, A.K.; Rugaber, S. Interactive meta-reasoning: Towards a CAD-like environment for designing game-playing agents. In Computational Creativity Research: Towards Creative Machines; Atlantis Press: Paris, France, 2015; pp. 347–370. [Google Scholar] [CrossRef]
- Adil, K.; Jiang, F.; Liu, S.; Jifara, W.; Tian, Z.; Fu, Y. State-of-the-art and open challenges in RTS game-AI and Starcraft. Int. J. Adv. Comput. Sci. Appl. 2017, 8, 16–24. [Google Scholar] [CrossRef]
- Butler, S.; Demiris, Y. Partial observability during predictions of the opponent’s movements in an RTS game. In Proceedings of the 2010 IEEE Conference on Computational Intelligence and Games, IT University of Copenhagen (ITU), Copenhagen, Denmark, 18–21 August 2010; pp. 46–53. [Google Scholar] [CrossRef]
- Novak, D.; Fister, I., Jr. Adaptive Online Opponent Game Policy Modeling with Association Rule Mining. In Proceedings of the IEEE 21st International Symposium on Computational Intelligence and Informatics, Budapest, Hungary, 18–20 November 2021. [Google Scholar] [CrossRef]
- Kerr, B.; Riley, M.A.; Feldman, M.W.; Bohannan, B.J. Local dispersal promotes biodiversity in a real-life game of rock–paper–scissors. Nature 2002, 418, 171–174. [Google Scholar] [CrossRef] [PubMed]
- Dockhorn, A.; Saxton, C.; Kruse, R. Association Rule Mining for Unknown Video Games. In Fuzzy Approaches for Soft Computing and Approximate Reasoning: Theories and Applications; Springer: Cham, Switzerland, 2021; pp. 257–270. [Google Scholar] [CrossRef]
- Levine, J.; Congdon, C.B.; Ebner, M.; Kendall, G.; Lucas, S.M.; Miikkulainen, R.; Schaul, T.; Thompson, T. General video game playing. In Artificial and Computational Intelligence in Games. Dagstuhl Follow-Ups; Dagstuhl Publishing: Dagstuhl, Germany, 2013; Volume 6. [Google Scholar] [CrossRef]
- Uriarte, A.; Ontanón, S. Combat models for RTS games. IEEE Trans. Games 2017, 10, 29–41. [Google Scholar] [CrossRef]
- Dockhorn, A.; Hurtado-Grueso, J.; Jeurissen, D.; Xu, L.; Perez-Liebana, D. Game State and Action Abstracting Monte Carlo Tree Search for General Strategy Game-Playing. In Proceedings of the 2021 IEEE Conference on Games (CoG), Copenhagen, Denmark, 17–20 August 2021; pp. 1–8. [Google Scholar] [CrossRef]
- Ontanón, S.; Synnaeve, G.; Uriarte, A.; Richoux, F.; Churchill, D.; Preuss, M. A survey of real-time strategy game AI research and competition in StarCraft. IEEE Trans. Comput. Intell. AI Games 2013, 5, 293–311. [Google Scholar] [CrossRef]
- Jeerige, A.; Bein, D.; Verma, A. Comparison of deep reinforcement learning approaches for intelligent game playing. In Proceedings of the 2019 IEEE 9th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 7–9 January 2019; pp. 366–371. [Google Scholar] [CrossRef]
- Lara-Cabrera, R.; Cotta, C.; Fernández-Leiva, A.J. A review of computational intelligence in RTS games. In Proceedings of the 2013 IEEE Symposium on Foundations of Computational Intelligence (FOCI), Singapore, 16–19 April 2013; pp. 114–121. [Google Scholar] [CrossRef]
- Richoux, F.; Uriarte, A.; Baffier, J.F. Ghost: A combinatorial optimization framework for real-time problems. IEEE Trans. Comput. Intell. AI Games 2016, 8, 377–388. [Google Scholar] [CrossRef]
- Takino, H.; Hoki, K. Human-Like Build-Order Management in StarCraft to Win against Specific Opponent’s Strategies. In Proceedings of the 2015 3rd International Conference on Applied Computing and Information Technology/2nd International Conference on Computational Science and Intelligence, Okayama, Japan, 12–16 July 2015; pp. 97–102. [Google Scholar] [CrossRef]
- Stanescu, M.; Barriga, N.A.; Buro, M. Hierarchical adversarial search applied to real-time strategy games. In Proceedings of the Tenth Artificial Intelligence and Interactive Digital Entertainment Conference, North Carolina State University, Raleigh, NC, USA, 3–7 October 2014. [Google Scholar]
- Marino, J.R.; Moraes, R.O.; Toledo, C.; Lelis, L.H. Evolving action abstractions for real-time planning in extensive-form games. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January 2019–1 February 2019; Volume 33, pp. 2330–2337. [Google Scholar] [CrossRef]
- Barriga, N.A.; Stanescu, M.; Buro, M. Game tree search based on nondeterministic action scripts in real-time strategy games. IEEE Trans. Games 2017, 10, 69–77. [Google Scholar] [CrossRef]
- Churchill, D.; Buro, M. Hierarchical portfolio search: Prismata’s robust AI architecture for games with large search spaces. In Proceedings of the Eleventh Artificial Intelligence and Interactive Digital Entertainment Conference, University of California, Santa Cruz, CA, USA, 14–18 November 2015. [Google Scholar]
- Ontanón, S.; Synnaeve, G.; Uriarte, A.; Richoux, F.; Churchill, D.; Preuss, M. RTS AI Problems and Techniques. Encycl. Comput. Graph. Games 2015, 1, 1–12. [Google Scholar] [CrossRef]
- Palma, R.; Sánchez-Ruiz, A.A.; Gómez-Martín, M.A.; Gómez-Martín, P.P.; González-Calero, P.A. Combining Expert Knowledge and Learning from Demonstration in Real-Time Strategy Games. In Proceedings of the International Conference on Case-Based Reasoning, London, UK, 12–15 September 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 181–195. [Google Scholar] [CrossRef]
- Yang, P.; Roberts, D.L. Extracting human-readable knowledge rules in complex time-evolving environments. In Proceedings of the International Conference on Information and Knowledge Engineering, The Steering Committee of The World Congress in Computer Science, Computer Engineering and Applied Computing (WorldComp), Las Vegas, NV, USA, 22–25 July 2013. [Google Scholar]
- Wang, L. Discovering phase transitions with unsupervised learning. Phys. Rev. B 2016, 94, 195105. [Google Scholar] [CrossRef]
- Kantharaju, P.; Ontañón, S. Discovering meaningful labelings for RTS game replays via replay embeddings. In Proceedings of the 2020 IEEE Conference on Games (CoG), Osaka, Japan, 24–27 August 2020; pp. 160–167. [Google Scholar] [CrossRef]
- Das, S.; Suganthan, P.N. Differential evolution: A survey of the state-of-the-art. IEEE Trans. Evol. Comput. 2010, 15, 4–31. [Google Scholar] [CrossRef]
- Agrawal, R.; Srikant, R. Fast algorithms for mining association rules. In Proceedings of the 20th International Conference on Very Large Data Bases, Santiago, Chile, 12–15 September 1994; Volume 1215, pp. 487–499. [Google Scholar]
- Zaki, M.J. Scalable algorithms for association mining. IEEE Trans. Knowl. Data Eng. 2000, 12, 372–390. [Google Scholar] [CrossRef]
- Han, J.; Pei, J.; Yin, Y. Mining frequent patterns without candidate generation. ACM Sigmod Rec. 2000, 29, 1–12. [Google Scholar] [CrossRef]
- Fister, I., Jr.; Fister, I. A Brief Overview of Swarm Intelligence-Based Algorithms for Numerical Association Rule Mining. In Applied Optimization and Swarm Intelligence; Osaba, E., Yang, X.S., Eds.; Springer Tracts in Nature-Inspired Computing; Springer: Singapore, 2021; pp. 47–59. [Google Scholar] [CrossRef]
- Fister, I.; Fister, I., Jr. uARMSolver: A framework for Association Rule Mining. arXiv 2020, arXiv:2010.10884. [Google Scholar]
- Fister, I., Jr.; Iglesias, A.; Galvez, A.; Del Ser, J.; Osaba, E.; Fister, I. Differential evolution for association rule mining using categorical and numerical attributes. In Proceedings of the International Conference on Intelligent Data Engineering and Automated Learning, Madrid, Spain, 21–23 November 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 79–88. [Google Scholar] [CrossRef]
- Komai, T.; Kim, S.J.; Kousaka, T.; Kurokawa, H. A Human Behavior Strategy Estimation Method Using Homology Search for Rock-Scissors-Paper Game. J. Signal Process. 2019, 23, 177–180. [Google Scholar] [CrossRef]
- Nagatani, T.; Tainaka, K.I.; Ichinose, G. Metapopulation model of rock-scissors-paper game with subpopulation-specific victory rates stabilized by heterogeneity. J. Theor. Biol. 2018, 458, 103–110. [Google Scholar] [CrossRef] [PubMed]
- Komai, T.; Kim, S.J.; Kurokawa, H. Characteristic extraction method of human’s strategy in the Rock-Paper-Scissors game. NCSP 2018, 18, 592–595. [Google Scholar]
- Castro, S.B.; Garrido-da-Silva, L.; Ferreira, A.; Labouriau, I.S. Stability of cycles in a game of Rock-Scissors-Paper-Lizard-Spock. arXiv 2021, arXiv:2107.09383. [Google Scholar] [CrossRef]
- Tavares, A.; Azpúrua, H.; Santos, A.; Chaimowicz, L. Rock, paper, starcraft: Strategy selection in real-time strategy games. In Proceedings of the AAAI Conference on Artificial Intelligence and Interactive Digital Entertainment, Pomona, CA, USA, 8–12 October 2016; Volume 12, pp. 93–99. [Google Scholar] [CrossRef]
- Churchill, D.; Buro, M. Incorporating search algorithms into RTS game agents. In Proceedings of the AAAI Conference on Artificial Intelligence and Interactive Digital Entertainment, Online, 11–15 October 2021; Volume 8, pp. 2–7. [Google Scholar] [CrossRef]
- Ontanón, S. The combinatorial multi-armed bandit problem and its application to real-time strategy games. In Proceedings of the AAAI Conference on Artificial Intelligence and Interactive Digital Entertainment, Online, 11–15 October 2021; Volume 9, pp. 58–64. [Google Scholar] [CrossRef]
- Uriarte, A.; Ontanón, S. Game-tree search over high-level game states in RTS games. In Proceedings of the AAAI Conference on Artificial Intelligence and Interactive Digital Entertainment, Online, 11–15 October 2021; Volume 10, pp. 73–79. [Google Scholar] [CrossRef]
- Zöller, M.A.; Huber, M.F. Benchmark and survey of automated machine learning frameworks. J. Artif. Intell. Res. 2021, 70, 409–472. [Google Scholar] [CrossRef]
- Andersen, P.A.; Goodwin, M.; Granmo, O.C. Deep RTS: A game environment for deep reinforcement learning in real-time strategy games. In Proceedings of the 2018 IEEE Conference on Computational Intelligence and Games (CIG), Maastricht, The Netherlands, 14–17 August 2018; pp. 1–8. [Google Scholar] [CrossRef]
- Justesen, N.; Bontrager, P.; Togelius, J.; Risi, S. Deep learning for video game playing. IEEE Trans. Games 2019, 12, 1–20. [Google Scholar] [CrossRef]
- DuMouchel, W.; Volinsky, C.; Johnson, T.; Cortes, C.; Pregibon, D. Squashing flat files flatter. In Proceedings of the Fifth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Diego, CA, USA, 15–18 August 1999; pp. 6–15. [Google Scholar]
- Lee, J.Y. A study on metaverse hype for sustainable growth. Int. J. Adv. Smart Converg. 2021, 10, 72–80. [Google Scholar] [CrossRef]






















| 0.1 | 0.2 | 0.3 | 0.4 | 0.5 | 0.6 | 0.7 | 0.8 | 0.9 | 1.0 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0% | 0/1/28/38/33 | 0/2/29/38/31 | 0/4/27/37/32 | 0/2/30/32/36 | 0/2/29/35/34 | 0/6/31/35/28 | 0/13/36/23/28 | E: 100 | E: 100 | E: 100 |
| 10% | 0/4/39/27/30 | 0/1/40/31/28 | 0/2/35/34/29 | 0/5/50/29/16 | 0/2/63/19/16 | 0/5/51/25/19 | 0/1/96/1/2 | 43/0/57/0/0 | E: 100 | E: 100 |
| 20% | 0/3/43/25/29 | 0/2/46/27/25 | 0/2/42/24/32 | 0/11/52/19/18 | 0/3/73/17/7 | 0/4/78/8/10 | 0/2/98/0/0 | 0/0/100/0/0 | E: 100 | E: 100 |
| 30% | 0/4/74/8/14 | 0/1/81/7/11 | 0/1/86/6/7 | 0/2/89/4/5 | 0/0/99/0/1 | 0/0/100/0/0 | 0/0/100/0/0 | 0/0/100/0/0 | E: 100 | E: 100 |
| 40% | 0/2/84/6/8 | 0/4/86/4/6 | 0/2/85/7/6 | 0/1/97/1/1 | 0/0/100/0/0 | 0/0/99/1/0 | 0/0/100/0/0 | 0/0/100/0/0 | E: 100 | E: 100 |
| 50% | 0/1/89/7/3 | 0/1/89/5/5 | 0/1/89/2/8 | 0/0/99/1/0 | 0/0/100/0/0 | 0/0/100/0/0 | 0/0/100/0/0 | 0/0/100/0/0 | E: 100 | E: 100 |
| 60% | 0/0/93/5/2 | 0/2/84/6/8 | 0/2/96/2/0 | 0/0/100/0/0 | 0/0/99/0/1 | 0/0/100/0/0 | 0/0/100/0/0 | 0/0/100/0/0 | 0/0/100/0/0 | E: 100 |
| 70% | 0/0/100/0/0 | 0/0/100/0/0 | 0/0/100/0/0 | 0/0/100/0/0 | 0/0/100/0/0 | 0/0/100/0/0 | 0/0/100/0/0 | 0/0/100/0/0 | 0/0/100/0/0 | E: 100 |
| 80% | 0/0/100/0/0 | 0/0/100/0/0 | 0/0/100/0/0 | 0/0/100/0/0 | 0/0/100/0/0 | 0/0/100/0/0 | 0/0/100/0/0 | 0/0/100/0/0 | 0/0/100/0/0 | E: 100 |
| 90% | 0/0/100/0/0 | 0/0/100/0/0 | 0/0/100/0/0 | 0/0/100/0/0 | 0/0/100/0/0 | 0/0/100/0/0 | 0/0/100/0/0 | 0/0/100/0/0 | 0/0/100/0/0 | E: 100 |
| 100% | 0/0/100/0/0 | 0/0/100/0/0 | 0/0/100/0/0 | 0/0/100/0/0 | 0/0/100/0/0 | 0/0/100/0/0 | 0/0/100/0/0 | 0/0/100/0/0 | 0/0/100/0/0 | 0/0/100/0/0 |
| 0.1 | 0.2 | 0.3 | 0.4 | 0.5 | 0.6 | 0.7 | 0.8 | 0.9 | 1.0 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0% | 31.71/33.56/34.73 | 33.28/34.35/32.37 | 33.48/32.68/33.84 | 33.51/32.38/34.11 | 32.33/34.66/33.01 | 32.9/33.97/33.13 | 35.87/30.59/33.54 | 0/0/0 | 0/0/0 | 0/0/0 |
| 10% | 36.14/32/31.86 | 35.71/32.5/31.79 | 35.77/32.16/32.07 | 38.44/32.4/29.16 | 40.66/29.31/30.03 | 40.02/30.31/29.67 | 59.96/19.28/20.76 | 100/0/0 | 0/0/0 | 0/0/0 |
| 20% | 37.36/30.64/32 | 37.66/31.23/31.11 | 37.03/31.28/31.69 | 39.05/31.86/29.09 | 43.09/30.41/26.5 | 43.69/29.42/26.89 | 60.74/19.87/19.39 | 100/0/0 | 0/0/0 | 0/0/0 |
| 30% | 43.44/27.98/28.58 | 44.34/27.1/28.56 | 44.87/27.25/27.88 | 47.07/27.11/25.82 | 57.27/20.92/21.81 | 60.83/19.84/19.33 | 73.79/13.14/13.07 | 100/0/0 | 0/0/0 | 0/0/0 |
| 40% | 45.09/26.37/28.54 | 45.66/27.15/27.19 | 46.7/27.07/26.23 | 54.46/23.48/22.06 | 58.15/21.44/20.41 | 61.44/19.45/19.11 | 78.33/10.72/10.95 | 100/0/0 | 0/0/0 | 0/0/0 |
| 50% | 47.24/25.75/27.01 | 47.29/27.77/24.94 | 47.95/25.19/26.86 | 56.46/20.44/23.1 | 58.9/21.11/19.99 | 64.93/17.13/17.94 | 80.14/9.8/10.06 | 100/0/0 | 0/0/0 | 0/0/0 |
| 60% | 48.02/27.03/24.95 | 47.55/26/26.45 | 52.18/23.16/24.66 | 58.38/20.9/20.72 | 59.88/20.11/20.01 | 66.64/16.94/16.42 | 84.38/7.71/7.91 | 100/0/0 | 100/0/0 | 0/0/0 |
| 70% | 65.24/17.51/17.25 | 65.46/16.95/17.58 | 68.48/15.7/15.82 | 74.88/11.81/13.31 | 76.49/11.66/11.85 | 80.35/9.92/9.73 | 96.39/1.82/1.79 | 100/0/0 | 100/0/0 | 0/0/0 |
| 80% | 64.77/17.19/18.04 | 64.99/17.85/17.16 | 74.48/12.93/12.59 | 76.3/11.38/12.32 | 76.96/11.41/11.63 | 79.93/9.72/10.35 | 100/0/0 | 100/0/0 | 100/0/0 | 0/0/0 |
| 90% | 69.55/15.21/15.24 | 73.64/13.37/12.99 | 78.94/11.11/9.95 | 80.25/9.41/10.34 | 80.78/9.35/9.87 | 94.15/2.92/2.93 | 100/0/0 | 100/0/0 | 100/0/0 | 0/0/0 |
| 100% | 100/0/0 | 100/0/0 | 100/0/0 | 100/0/0 | 100/0/0 | 100/0/0 | 100/0/0 | 100/0/0 | 100/0/0 | 100/0/0 |
| Feature Acronym | Feature Description |
|---|---|
| [fr/op]Worker | The number of Worker units (on the map). |
| [fr/op]Light | The number of Light units. |
| [fr/op]Heavy | The number of Heavy units. |
| [fr/op]Ranged | The number of Ranged units. |
| baseThreatFriendly | Are any of the friendly bases under threat (true/false)? The base is under threat if there is an opponent unit present for two physical game map squares in either direction of the base. |
| [fr/op]ResourcesLeft | The number of resources left to spend. |
| [fr/op]Bases | The number of Bases. |
| [fr/op]Barracks | The number of Barracks. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Novak, D.; Verber, D.; Dugonik, J.; Fister, I., Jr. Action-Based Digital Characterization of a Game Player. Mathematics 2023, 11, 1243. https://doi.org/10.3390/math11051243
Novak D, Verber D, Dugonik J, Fister I Jr. Action-Based Digital Characterization of a Game Player. Mathematics. 2023; 11(5):1243. https://doi.org/10.3390/math11051243
Chicago/Turabian StyleNovak, Damijan, Domen Verber, Jani Dugonik, and Iztok Fister, Jr. 2023. "Action-Based Digital Characterization of a Game Player" Mathematics 11, no. 5: 1243. https://doi.org/10.3390/math11051243
APA StyleNovak, D., Verber, D., Dugonik, J., & Fister, I., Jr. (2023). Action-Based Digital Characterization of a Game Player. Mathematics, 11(5), 1243. https://doi.org/10.3390/math11051243