

Generative Transformer with Knowledge-Guided Decoding for Academic Knowledge Graph Completion
Abstract
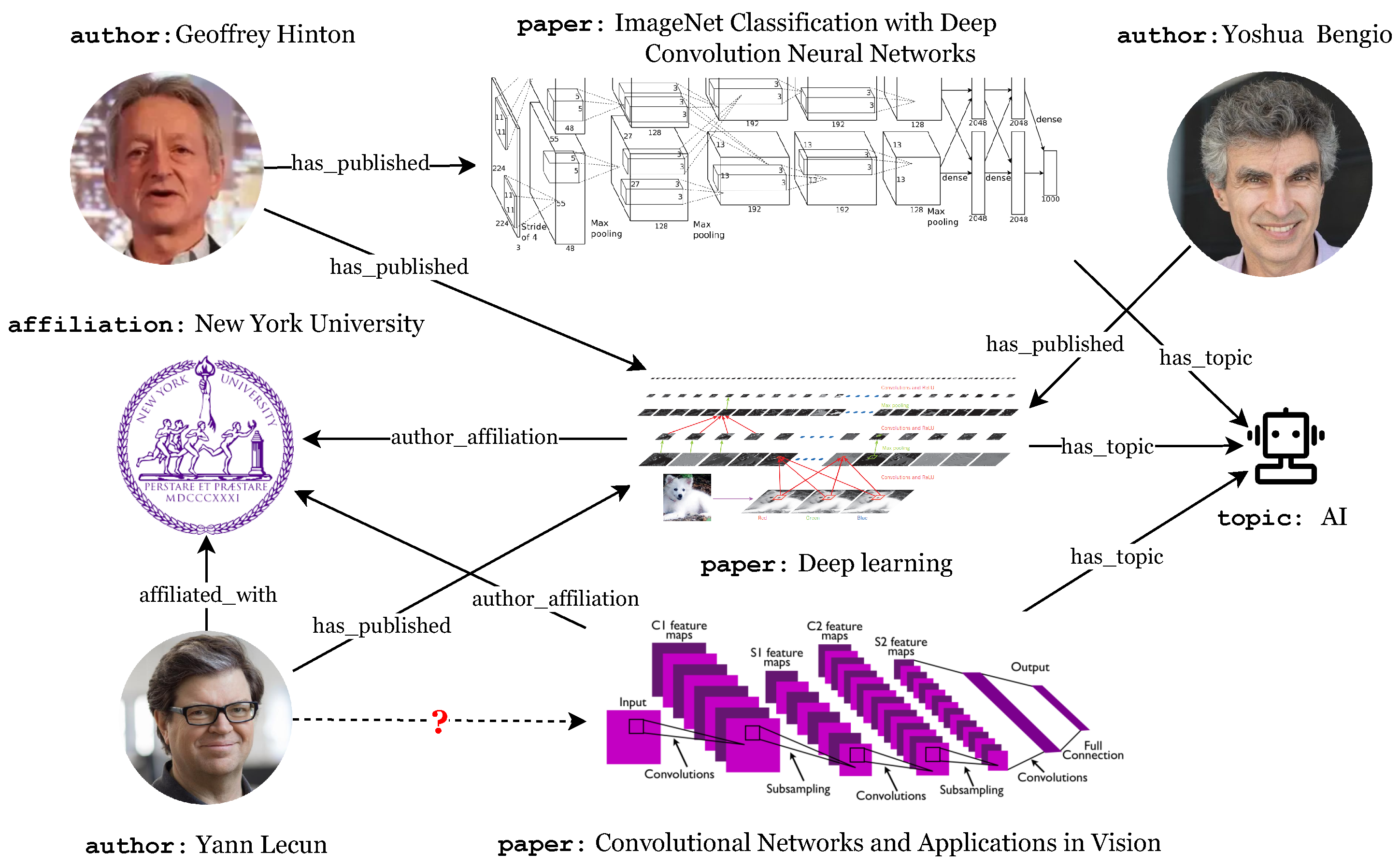
:1. Introduction
- We propose a novel model of a generative transformer with knowledge-guided decoding (GTK) for academic knowledge graph completion.
- We propose knowledge-aware demonstration and knowledge-guided decoding for knowledge graph completion.
- We evaluate the model on various benchmark datasets for knowledge graph completion, which demonstrates the effectiveness of the proposed approach.
2. Related Work
3. Background
3.1. Knowledge-Graph-Embedding-Based Methods
3.2. Pre-Trained Language-Model-Based Methods
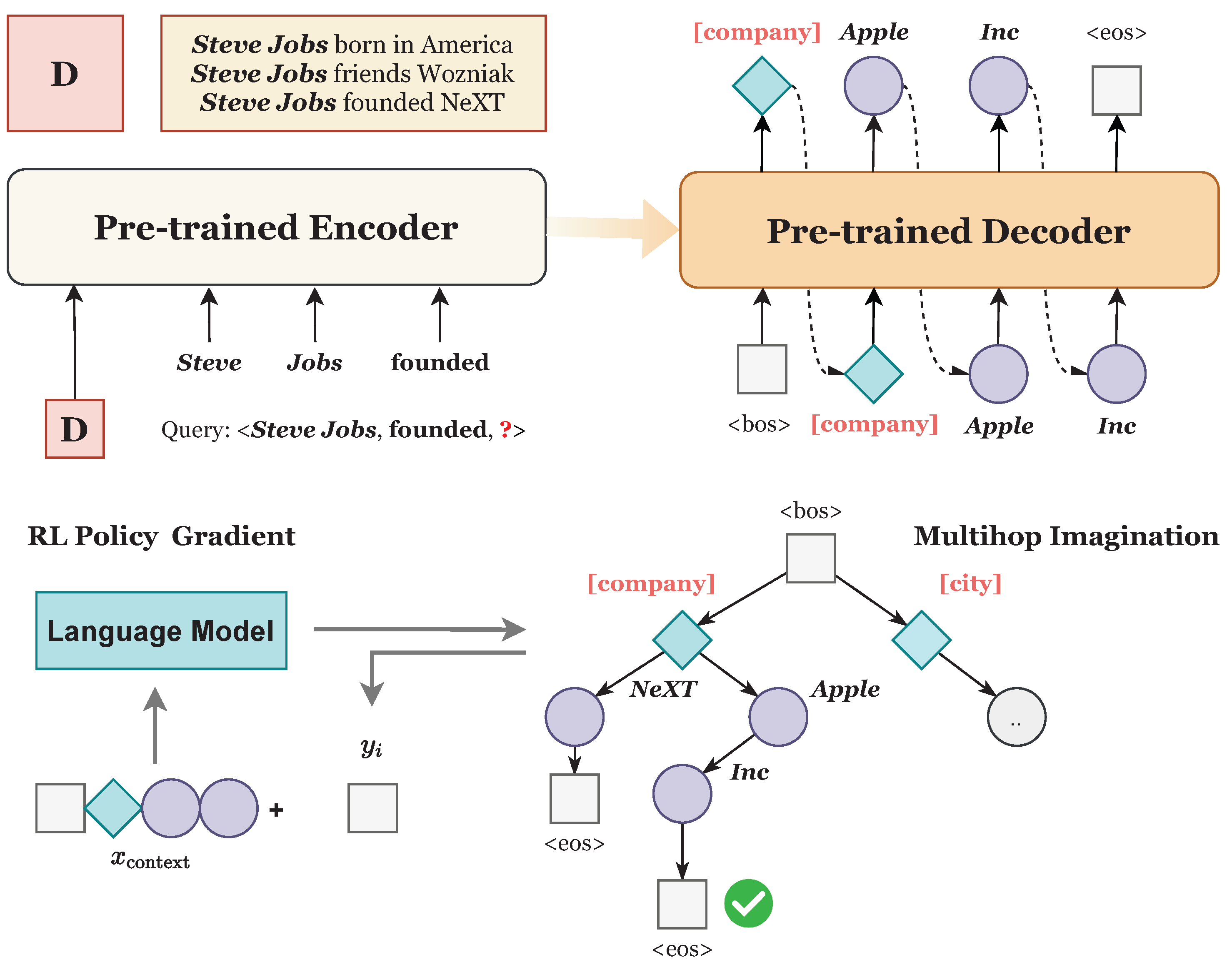
4. Approach
4.1. Link Prediction as Seq2Seq Generation
4.2. Knowledge-Aware Demonstration
4.3. Knowledge-Guided Decoding
5. Experiments
5.1. Datasets
5.2. Metrics
5.3. Settings
5.4. Results
5.5. Case Study
6. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Dong, X.; Gabrilovich, E.; Heitz, G.; Horn, W.; Lao, N.; Murphy, K.; Strohmann, T.; Sun, S.; Zhang, W. Knowledge vault: A web-scale approach to probabilistic knowledge fusion. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 601–610. [Google Scholar]
- Zhang, N.; Jia, Q.; Deng, S.; Chen, X.; Ye, H.; Chen, H.; Tou, H.; Huang, G.; Wang, Z.; Hua, N.; et al. Alicg: Fine-grained and evolvable conceptual graph construction for semantic search at alibaba. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Virtual Event, Singapore, 14–18 August 2021; pp. 3895–3905. [Google Scholar]
- Wang, X.; He, X.; Cao, Y.; Liu, M.; Chua, T.S. Kgat: Knowledge graph attention network for recommendation. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 950–958. [Google Scholar]
- Zhang, N.; Chen, M.; Bi, Z.; Liang, X.; Li, L.; Shang, X.; Yin, K.; Tan, C.; Xu, J.; Huang, F.; et al. CBLUE: A Chinese Biomedical Language Understanding Evaluation Benchmark. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics, Dublin, Ireland, 22–27 May 2022; Volume 1: Long Papers, pp. 7888–7915. [Google Scholar]
- Zhang, N.; Deng, S.; Cheng, X.; Chen, X.; Zhang, Y.; Zhang, W.; Chen, H.; Center, H.I. Drop Redundant, Shrink Irrelevant: Selective Knowledge Injection for Language Pretraining. In Proceedings of the 30th IJCAI, Virtual Event, Montreal, QC, Canada, 19–27 August 2021; pp. 4007–4014. [Google Scholar]
- Chen, X.; Zhang, N.; Xie, X.; Deng, S.; Yao, Y.; Tan, C.; Huang, F.; Si, L.; Chen, H. Knowprompt: Knowledge-aware prompt-tuning with synergistic optimization for relation extraction. In Proceedings of the ACM Web Conference 2022, Virtual Event, Lyon, France, 25–29 April 2022; pp. 2778–2788. [Google Scholar]
- Ye, H.; Zhang, N.; Deng, S.; Chen, X.; Chen, H.; Xiong, F.; Chen, X.; Chen, H. Ontology-enhanced Prompt-tuning for Few-shot Learning. In Proceedings of the ACM Web Conference 2022, Virtual Event, Lyon, France, 25–29 April 2022; pp. 778–787. [Google Scholar]
- Chen, X.; Li, L.; Zhang, N.; Liang, X.; Deng, S.; Tan, C.; Huang, F.; Si, L.; Chen, H. Decoupling Knowledge from Memorization: Retrieval-augmented Prompt Learning. arXiv 2022, arXiv:2205.14704. [Google Scholar]
- Qiao, S.; Ou, Y.; Zhang, N.; Chen, X.; Yao, Y.; Deng, S.; Tan, C.; Huang, F.; Chen, H. Reasoning with Language Model Prompting: A Survey. arXiv 2022, arXiv:2212.09597. [Google Scholar]
- Deng, S.; Zhang, N.; Zhang, W.; Chen, J.; Pan, J.Z.; Chen, H. Knowledge-driven stock trend prediction and explanation via temporal convolutional network. In Proceedings of the Companion Proceedings of The 2019 World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 678–685. [Google Scholar]
- Zhang, N.; Bi, Z.; Liang, X.; Cheng, S.; Hong, H.; Deng, S.; Zhang, Q.; Lian, J.; Chen, H. OntoProtein: Protein Pretraining with Gene Ontology Embedding. In Proceedings of the International Conference on Learning Representations, Virtual Event, 3–7 May 2021. [Google Scholar]
- Wang, Q.; Mao, Z.; Wang, B.; Guo, L. Knowledge graph embedding: A survey of approaches and applications. IEEE Trans. Knowl. Data Eng. 2017, 29, 2724–2743. [Google Scholar] [CrossRef]
- Peroni, S.; Shotton, D. OpenCitations, an infrastructure organization for open scholarship. Quant. Sci. Stud. 2020, 1, 428–444. [Google Scholar] [CrossRef]
- Knoth, P.; Zdrahal, Z. CORE: Three access levels to underpin open access. D-Lib Mag. 2012, 18, 1–13. [Google Scholar] [CrossRef]
- Wang, K.; Shen, Z.; Huang, C.; Wu, C.H.; Dong, Y.; Kanakia, A. Microsoft academic graph: When experts are not enough. Quant. Sci. Stud. 2020, 1, 396–413. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, F.; Yao, P.; Tang, J. Name Disambiguation in AMiner: Clustering, Maintenance, and Human in the Loop. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 1002–1011. [Google Scholar]
- Jaradeh, M.Y.; Oelen, A.; Farfar, K.E.; Prinz, M.; D’Souza, J.; Kismihók, G.; Stocker, M.; Auer, S. Open research knowledge graph: Next generation infrastructure for semantic scholarly knowledge. In Proceedings of the 10th International Conference on Knowledge Capture, Marina Del Rey, CA, USA, 19–21 November 2019; pp. 243–246. [Google Scholar]
- Grishman, R. Information extraction. IEEE Intell. Syst. 2015, 30, 8–15. [Google Scholar] [CrossRef]
- Zhang, N.; Ye, H.; Deng, S.; Tan, C.; Chen, M.; Huang, S.; Huang, F.; Chen, H. Contrastive Information Extraction with Generative Transformer. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 3077–3088. [Google Scholar] [CrossRef]
- Zhang, N.; Li, L.; Chen, X.; Deng, S.; Bi, Z.; Tan, C.; Huang, F.; Chen, H. Differentiable Prompt Makes Pre-trained Language Models Better Few-shot Learners. In Proceedings of the International Conference on Learning Representations, Virtual Event, 3–7 May 2021. [Google Scholar]
- Zhang, N.; Xu, X.; Tao, L.; Yu, H.; Ye, H.; Xie, X.; Chen, X.; Li, Z.; Li, L.; Liang, X.; et al. Deepke: A deep learning based knowledge extraction toolkit for knowledge base population. arXiv 2022, arXiv:2201.03335. [Google Scholar]
- Chen, X.; Li, L.; Deng, S.; Tan, C.; Xu, C.; Huang, F.; Si, L.; Chen, H.; Zhang, N. LightNER: A Lightweight Tuning Paradigm for Low-resource NER via Pluggable Prompting. In Proceedings of the 29th International Conference on Computational Linguistics, COLING 2022, Gyeongju, Republic of Korea, 12–17 October 2022; Calzolari, N., Huang, C., Kim, H., Pustejovsky, J., Wanner, L., Choi, K., Ryu, P., Chen, H., Donatelli, L., Ji, H., et al., Eds.; International Committee on Computational Linguistics: Praha, Czech Republic, 2022; pp. 2374–2387. [Google Scholar]
- Zhang, N.; Chen, X.; Xie, X.; Deng, S.; Tan, C.; Chen, M.; Huang, F.; Si, L.; Chen, H. Document-level Relation Extraction as Semantic Segmentation. In Proceedings of the 30th IJCAI, Virtual Event, Montreal, QC, Canada, 19–27 August 2021. [Google Scholar]
- Deng, S.; Zhang, N.; Kang, J.; Zhang, Y.; Zhang, W.; Chen, H. Meta-learning with dynamic-memory-based prototypical network for few-shot event detection. In Proceedings of the 13th International Conference on Web Search and Data Mining, Houston, TX, USA, 3–7 February 2020; pp. 151–159. [Google Scholar]
- Lou, D.; Liao, Z.; Deng, S.; Zhang, N.; Chen, H. MLBiNet: A Cross-Sentence Collective Event Detection Network. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Virtual Event, Bangkok, Thailand, 1–6 August 2021; Volume 1: Long Papers, pp. 4829–4839. [Google Scholar]
- Bordes, A.; Usunier, N.; Garcia-Duran, A.; Weston, J.; Yakhnenko, O. Translating embeddings for modeling multi-relational data. In Proceedings of the NeurIPS, Lake Tahoe, NV, USA, 5–8 December 2013. [Google Scholar]
- Sun, Z.; Deng, Z.H.; Nie, J.Y.; Tang, J. RotatE: Knowledge Graph Embedding by Relational Rotation in Complex Space. In Proceedings of the ICLR, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Yao, L.; Mao, C.; Luo, Y. KG-BERT: BERT for Knowledge Graph Completion. arXiv 2019, arXiv:1909.03193. [Google Scholar]
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V.; Zettlemoyer, L. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Virtual Event, 5–10 July 2020; pp. 7871–7880. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Kakade, S.M. A natural policy gradient. Adv. Neural Inf. Process. Syst. 2001, 14, 22. [Google Scholar]
- Deng, S.; Chen, H.; Li, Z.; Xiong, F.; Chen, Q.; Chen, M.; Liu, X.; Chen, J.; Pan, J.Z.; Chen, H.; et al. Construction and Applications of Open Business Knowledge Graph. arXiv 2022, arXiv:2209.15214. [Google Scholar]
- Xie, X.; Zhang, N.; Li, Z.; Deng, S.; Chen, H.; Xiong, F.; Chen, M.; Chen, H. From Discrimination to Generation: Knowledge Graph Completion with Generative Transformer. In Proceedings of the WWW, Lyon, France, 25–29 April 2022. [Google Scholar]
- Zhang, N.; Deng, S.; Sun, Z.; Chen, J.; Zhang, W.; Chen, H. Relation adversarial network for low resource knowledge graph completion. In Proceedings of the Web Conference 2020, Taipei, Taiwan, 20–24 April 2020; pp. 1–12. [Google Scholar]
- Lin, Y.; Liu, Z.; Sun, M.; Liu, Y.; Zhu, X. Learning Entity and Relation Embeddings for Knowledge Graph Completion. In Proceedings of the AAAI, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Yang, B.; Yih, W.; He, X.; Gao, J.; Deng, L. Embedding Entities and Relations for Learning and Inference in Knowledge Bases. In Proceedings of the ICLR, San Diego, CA, USA, 5–8 December 2015. [Google Scholar]
- Trouillon, T.; Welbl, J.; Riedel, S.; Gaussier, É.; Bouchard, G. Complex Embeddings for Simple Link Prediction. In Proceedings of the ICML, New York, NY, USA, 19–24 June 2016. [Google Scholar]
- Balazevic, I.; Allen, C.; Hospedales, T.M. TuckER: Tensor Factorization for Knowledge Graph Completion. In Proceedings of the EMNLP, Hong Kong, China, 3–7 November 2019. [Google Scholar]
- Nayyeri, M.; Cil, G.M.; Vahdati, S.; Osborne, F.; Rahman, M.; Angioni, S.; Salatino, A.; Recupero, D.R.; Vassilyeva, N.; Motta, E.; et al. Trans4E: Link prediction on scholarly knowledge graphs. Neurocomputing 2021, 461, 530–542. [Google Scholar] [CrossRef]
- Wang, M.; Wang, S.; Yang, H.; Zhang, Z.; Chen, X.; Qi, G. Is Visual Context Really Helpful for Knowledge Graph? A Representation Learning Perspective. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual Event, China, 20–24 October 2021; pp. 2735–2743. [Google Scholar]
- Wu, T.; Khan, A.; Yong, M.; Qi, G.; Wang, M. Efficiently embedding dynamic knowledge graphs. Knowl.-Based Syst. 2022, 250, 109124. [Google Scholar] [CrossRef]
- Zhang, N.; Xie, X.; Chen, X.; Deng, S.; Ye, H.; Chen, H. Knowledge Collaborative Fine-tuning for Low-resource Knowledge Graph Completion. J. Softw. 2022, 33, 3531. [Google Scholar] [CrossRef]
- Wang, Q.; Huang, P.; Wang, H.; Dai, S.; Jiang, W.; Liu, J.; Lyu, Y.; Zhu, Y.; Wu, H. Coke: Contextualized knowledge graph embedding. arXiv 2019, arXiv:1911.02168. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Wang, B.; Shen, T.; Long, G.; Zhou, T.; Wang, Y.; Chang, Y. Structure-Augmented Text Representation Learning for Efficient Knowledge Graph Completion. In Proceedings of the WWW, Virtual Event, Ljubljana, Slovenia, 12–23 April 2021. [Google Scholar]
- Zhang, N.; Xie, X.; Chen, X.; Deng, S.; Tan, C.; Huang, F.; Cheng, X.; Chen, H. Reasoning through memorization: Nearest neighbor knowledge graph embeddings. arXiv 2022, arXiv:2201.05575. [Google Scholar]
- Wang, L.; Zhao, W.; Wei, Z.; Liu, J. SimKGC: Simple Contrastive Knowledge Graph Completion with Pre-trained Language Models. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics, Dublin, Ireland, 22–27 May 2022. [Google Scholar]
- Wang, X.; He, Q.; Liang, J.; Xiao, Y. Language Models as Knowledge Embeddings. arXiv 2022, arXiv:2206.12617. [Google Scholar]
- Lv, X.; Lin, Y.; Cao, Y.; Hou, L.; Li, J.; Liu, Z.; Li, P.; Zhou, J. Do Pre-trained Models Benefit Knowledge Graph Completion? A Reliable Evaluation and a Reasonable Approach. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2022, Dublin, Ireland, 22–27 May 2022; pp. 3570–3581. [Google Scholar]
- Markowitz, E.; Balasubramanian, K.; Mirtaheri, M.; Annavaram, M.; Galstyan, A.; Ver Steeg, G. StATIK: Structure and Text for Inductive Knowledge Graph Completion. In Proceedings of the Findings of the Association for Computational Linguistics: NAACL 2022, Virtual Event, 10–15 July 2022; pp. 604–615. [Google Scholar]
- Shen, J.; Wang, C.; Gong, L.; Song, D. Joint language semantic and structure embedding for knowledge graph completion. arXiv 2022, arXiv:2209.08721. [Google Scholar]
- Saxena, A.; Kochsiek, A.; Gemulla, R. Sequence-to-Sequence Knowledge Graph Completion and Question Answering. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics, Dublin, Ireland, 22–27 May 2022. [Google Scholar]
- Chen, C.; Wang, Y.; Li, B.; Lam, K.Y. Knowledge Is Flat: A Seq2Seq Generative Framework for Various Knowledge Graph Completion. arXiv 2022, arXiv:2209.07299. [Google Scholar]
- Liu, R.; Zheng, G.; Gupta, S.; Gaonkar, R.; Gao, C.; Vosoughi, S.; Shokouhi, M.; Awadallah, A.H. Knowledge Infused Decoding. In Proceedings of the International Conference on Learning Representations, Virtual Event, 3–7 May 2021. [Google Scholar]
- Chami, I.; Wolf, A.; Juan, D.; Sala, F.; Ravi, S.; Ré, C. Low-Dimensional Hyperbolic Knowledge Graph Embeddings. In Proceedings of the ACL, Virtual Event, 5–10 July 2020. [Google Scholar]

{kind=link}
{kind=link}
| Dataset | # Ent | # Rel | # Train | # Dev | # Test |
|---|---|---|---|---|---|
| AIDA | 68,906 | 2 | 144,000 | 18,000 | 18,000 |
| WN18RR | 40,943 | 11 | 86,835 | 3034 | 3134 |
| FB15k-237 | 14,541 | 237 | 272,115 | 17,535 | 20,466 |
| OpenBG500 | 269,658 | 500 | 1,242,550 | 5000 | 5000 |
| Model Type | hasTopic | hasGRIDType | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| MR | MRR | Hits@1 | Hits@3 | Hits@10 | MR | MRR | Hits@1 | Hits@3 | Hits@10 | |
| TransE | 3982 | 0.400 | 0.294 | 0.462 | 0.592 | 1 | 0.968 | 0.944 | 0.990 | 1.000 |
| RotatE | 4407 | 0.433 | 0.332 | 0.492 | 0.622 | 1 | 0.953 | 0.933 | 0.975 | 0.996 |
| QuatE | 1353 | 0.426 | 0.341 | 0.472 | 0.581 | 1 | 0.957 | 0.928 | 0.983 | 0.998 |
| ComplEx | 5855 | 0.099 | 0.077 | 0.109 | 0.129 | 1566 | 0.566 | 0.531 | 0.596 | 0.609 |
| Trans4E | 3904 | 0.426 | 0.318 | 0.492 | 0.628 | 1 | 0.968 | 0.944 | 0.995 | 0.998 |
| GTK | 3835 | 0.456 | 0.355 | 0.488 | 0.650 | 1 | 0.975 | 0.967 | 0.998 | 1 |
| WN18RR | FB15k-237 | OpenBG500 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Method | Hits@1 | Hits@3 | Hits@10 | Hits@1 | Hits@3 | Hits@10 | Hits@1 | Hits@3 | Hits@10 |
| Graph-embedding approach | |||||||||
| TransE [26] ⋄ | 0.043 | 0.441 | 0.532 | 0.198 | 0.376 | 0.441 | 0.207 | 0.340 | 0.513 |
| DistMult [36] ⋄ | 0.412 | 0.470 | 0.504 | 0.199 | 0.301 | 0.446 | 0.049 | 0.088 | 0.216 |
| ComplEx [37] ⋄ | 0.409 | 0.469 | 0.530 | 0.194 | 0.297 | 0.450 | 0.053 | 0.120 | 0.266 |
| RotatE [27] | 0.428 | 0.492 | 0.571 | 0.241 | 0.375 | 0.533 | - | - | - |
| TuckER [38] | 0.443 | 0.482 | 0.526 | 0.226 | 0.394 | 0.544 | - | - | - |
| ATTH [55] | 0.443 | 0.499 | 0.486 | 0.252 | 0.384 | 0.549 | - | - | - |
| Textual encoding approach | |||||||||
| KG-BERT [28] | 0.041 | 0.302 | 0.524 | - | - | 0.420 | 0.023 | 0.049 | 0.241 |
| StAR [45] | 0.243 | 0.491 | 0.709 | 0.205 | 0.322 | 0.482 | - | - | - |
| GenKGC [33] | 0.287 | 0.403 | 0.535 | 0.192 | 0.355 | 0.439 | 0.203 | 0.280 | 0.351 |
| GTK | 0.449 | 0.501 | 0.616 | 0.291 | 0.402 | 0.550 | 0.210 | 0.366 | 0.551 |
| For One Triple | Method | Complexity | Time under A100 |
|---|---|---|---|
| Training | KG-BERT | 72 ms | |
| GTK | 2.01 ms | ||
| Inference | KG-BERT | 91,100 s | |
| GTK | 0.73 s |
| Query:(?,student, Michael Chabon) | ||
| Rank | GTK w/o hierarchical decoding | Probability |
| 1 | University of California |  |
| 5 | University of California, Santa Cruz |  |
| 2 | University of California, Irvine |  |
| 3 | University of California, San Francisco |  |
| 4 | University of California, Davis |  |
| Rank | GTK | Probability |
| 1 | University of California, Irvine |  |
| 2 | University of California, San Francisco |  |
| 5 | University of Calgary |  |
| 4 | University of California, Santa Cruz |  |
| 3 | University of California, Davis |  |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, X.; Mao, S.; Wang, X.; Bu, J. Generative Transformer with Knowledge-Guided Decoding for Academic Knowledge Graph Completion. Mathematics 2023, 11, 1073. https://doi.org/10.3390/math11051073
Liu X, Mao S, Wang X, Bu J. Generative Transformer with Knowledge-Guided Decoding for Academic Knowledge Graph Completion. Mathematics. 2023; 11(5):1073. https://doi.org/10.3390/math11051073
Chicago/Turabian StyleLiu, Xiangwen, Shengyu Mao, Xiaohan Wang, and Jiajun Bu. 2023. "Generative Transformer with Knowledge-Guided Decoding for Academic Knowledge Graph Completion" Mathematics 11, no. 5: 1073. https://doi.org/10.3390/math11051073
APA StyleLiu, X., Mao, S., Wang, X., & Bu, J. (2023). Generative Transformer with Knowledge-Guided Decoding for Academic Knowledge Graph Completion. Mathematics, 11(5), 1073. https://doi.org/10.3390/math11051073