3.1. The Objective Space Decomposition Strategy
MaOEAs based on an objective space decomposition strategy are an important branch of decomposition-based MaOEAs. In this paper, the objective space decomposition strategy proposed by Liu et al. [
17] is adopted to divide the whole objective space into a set of subspaces using a set of predefined reference vectors.
In the objective space decomposition strategy, a set of uniformly distributed reference vectors, termed as , are predefined to decompose an MOEA or MaOEA into a set of MOEAs or MaOEAs. The objective space is decomposed into N subspaces, termed as , according to the acute angles between the candidate solutions and the reference vectors. Here, , where is the ith subspace and means the acute angle between p and .
According to the definition of subspace, a solution belongs to if and only if the solution has the smallest angle to among all unit vectors. In the optimization process, each solution will be arranged into a subspace during the optimization process. In this paper, is the corresponding reference vector of the solutions in .
To more vividly explain the definition of a subspace, an example is shown in
Figure 3. In the example, five reference vectors (including two axes) divide the bidimensional objective space into five subspaces, and the population is partitioned into five subpopulations in five subspaces. Clearly, no solution lies in
and
; thus,
and
are inactive reference vectors.
3.3. The Main Framework of the ART-DMaOEA
According to the classic definition of reference vectors [
11], the initial point of the reference vectors used in this paper is always the coordinate origin. To be consistent with this definition, the objective values of the individuals need to be translated as follows:
where
,
and
are the objective vectors before and after translation, respectively, and
represents the minimal objective values calculated in the population.
The role of the translation operation is twofold: (1) to guarantee that all the translated objective values are inside the first quadrant, where the extreme point of each objective function is on the corresponding coordinate axis, thereby maximizing the coverage of the reference vectors, and (2) to set the ideal point to be the origin of the coordinate system, which simplifies the formulations presented later on.
The main framework of the proposed ART-DMaOEA is listed in Algorithm 1, from which we can see that a classic elitism strategy is adopted in ART-DMaOEA. As shown in Algorithm 1, three parameters are first initialized: (1) reference vectors
V (line 1); (2) an initial population with
N individuals
P (line 2); (3) the number of used function evaluations
(line 3). Then, the main loop of the proposed algorithm is presented (lines 4–14). During each iteration, the algorithm performs three main steps: (1) offspring generation (lines 5–9); (2) reference vectors processing (lines 10–14); and (3) environmental selection (line 15). In lines 5–9, an offspring population
is generated using the simulated binary crossover and polynomial mutation. Here,
Q is the combined population of
P and
, used in preparation for the later selection procedure. In line 8, the parent population
P is an empty set, and the individuals surviving to the next iteration in the following selection procedure are included in
P. In line 10, the active reference vectors in the current generation are filtered out as
. It should be noted that
V is not changed in this procedure. In lines 11–12, if the number of active reference vectors exceeds half the original
V, the method for the first state of the optimization process runs to deal with the active reference vectors. In this function, individuals are selected into
P and excluded from
Q; therefore,
P and
Q are listed in the output in line 11. If half of the original reference vectors
V tend to be inactive (line 13), the method prepared for the second state is applied (line 14). The methods used in the two states have the same input and output; the difference lies in the specific calculation process. In line 15, based on the newly processed
, environmental selection is performed to maintain a sound balance between convergence and diversity. The main contribution of this paper is in lines 9–14, i.e., dealing with active reference and the environmental selection method.
| Algorithm 1: Main Framework of the proposed ART-DMaOEA |
 |
In each ART-DMaOEA generation, the active reference vectors are selected from the original reference vectors V according to the spatial distribution relationship between Q and V. The predefined V are unchanged throughout the optimization process. In addition, apart from dealing with active reference vectors, the function Strategy for the first state() and Strategy for the second state() act as components of the environmental selection method. After the two functions are performed, solutions with good diversity performance are be absorbed into P and excluded from Q.
3.4. Strategies for the Two States
In this section, the two states during the optimization process of the proposed algorithm on MaOEA and the tailored two strategies are described in detail.
First, in Algorithm 2 all the inactive reference vectors and corresponding inactive subspaces are removed. As can be seen in Algorithm 2,
is initialized as
V in line 1; then, each individual is associated with a reference vector in
V according to the definition of subspace described in
Section 3.1.
In lines 3–7, reference vectors with no individual associated are deleted from , and the corresponding subspaces are deleted from S. In line 8, the remaining reference vectors in and subspaces in S are renumbered as and , respectively. Note that in Algorithm 2, no change in the original set of reference vectors V is performed.
In the proposed ART-DMaOEA, we set two optimization states: (1) over half of the original reference vectors are active and can work to maintain diversity in the generation; and (2) half of the original reference vectors are inactive. In the first state, we can roughly judge that the difference between the shape of the predefined reference vectors and the obtained population (which can be seen as an approximation of the true PF of the MaOP) is not very large; therefore, we only need a slight adjustment. The second state means that there is a huge difference between the predefined reference vectors and the true PF of the MaOP, causing a strong adjustment of the reference vectors is needed.
| Algorithm 2: Delete Inactive Reference Vectors |
 |
Not each MaOP experiences both states during optimization by decomposition-based MaOEAs; whether it does is determined by the difference between the shape of the true PF of the problem and the predefined reference vectors. Certain problems may be in the first state during the whole optimization process, while others may continue to fall into the second state, and still others experience both states. The strategies developed for dealing with the two states are described in Algorithm 3 and Algorithm 4, respectively.
| Algorithm 3: Strategy for the first state |
 |
As shown in Algorithm 3, P and Q serve as both input and output, which is to say that the two parameters are edited by Algorithm 3. A new solution (or solutions) is admitted into P and excluded from Q. In line 1, the subspace with the largest population size among all the active subspaces is found, and its index is referred to as k. In lines 2–3, the acute angle between each individual in and the corresponding reference vector is calculated. The index of the individual with the largest acute angle among is denoted as (line 4). In lines 5–7, is absorbed into P from Q and the a reference vector is constructed using . In line 8, the newly constructed reference vector is added to the set of active reference vectors for later environmental selection.
In Algorithm 3, the individual with the best diversity performance among the subspace with the largest population size is selected into the next generation and constructed as a new reference vector. The new active reference vectors (updated in line 8) tend to be more suitable for the current population. For further explanation, an example is shown in
Figure 4. In
Figure 4,
Figure 4a provides the distribution of the original reference vectors and the obtained population, while
Figure 4b shows the deletion of inactive reference vectors. The solution pointed to by the yellow arrow in
Figure 4c can be seen as
, the corresponding subspace of
can be seen as
, and
represents the newly constructed reference vectors. Obviously, the new set of active reference vectors in
Figure 4c can be more evenly distributed in the region where the true PF is located, making it more efficient in maintaining diversity performance for the population.
| Algorithm 4: Strategy for the second state |
 |
In the second state, over half of the original reference vectors do not work, and adding only one vector in Algorithm 3 seems to be an exhausting approach to achieve the same effect as in the first state. As a result, a tailored strategy for the second state is developed, with the main steps shown in Algorithm 4. Apart from having the same input and output, the goals to be achieved by the two algorithms are similar; that is, they each seek to construct new reference vectors while selecting individuals to survive to the next generation. Unlike from the first state, in the second state more than one reference vector is constructed.
As can be seen in Algorithm 4, subspaces with two or more individuals are entered into (lines 1–4). Then, each subspace in is further divided only once (lines 5–17). In line 6, the first reference vectors and corresponding subspaces are recorded as and , respectively. In line 7, the acute angle between each individual in and each active reference vector in is calculated, and the minimal acute angles of each individual in are recorded. In line 8, the individual with the maximum minimal acute angle is selected and denoted as . Then, is absorbed into P (line 9) and excluded from Q (line 10). In lines 11–12, a new reference vector is constructed using and added to . Then, is removed from (line 13). In lines 14–17, because the active reference vectors changes, the number of individuals in certain subspaces in may be less than two; therefore, they must be removed from . Generally, the construction of a new reference vector means that the original subspace is divided; this distribution of active reference vectors is more suitable for the optimized MaOP. The loop (lines 5–17) terminates when all of the subspaces in are divided by newly constructed reference vectors.
In Algorithm 4, there are three parameters with a high similarity: (1) the original reference vectors V; (2) the active reference vectors ; and (3) the active reference vector with two or more solutions . While Algorithm 4 is being run, V is an invariant and and are variants. Here, is selected from V in Algorithm 2 and serves as input and output parameter of Algorithm 4, while is a temporary parameter of Algorithm 2 and works for the updating of .
The key step of the strategy for the second state is selecting candidate solutions to construct new solutions, i.e., lines 6-8 in Algorithm 4. In line 7, the minimum acute angle of a solution to the existing reference vectors indicates the degree of the difference between the solution and reference vectors. The solution with the maximal minimum acute angle has the largest difference compared with the existing reference vectors in and is suitable for construction as a reference vector. Because changes when a new reference vector is added, and the maximal minimum acute angle changes as well, The loop (lines 5–17) adopts a one-by-one method instead of a one-off method, i.e., only one reference vector is selected in each iteration of the loop. Apart from selecting the individual with the best diversity performance against the active reference vectors in , because the newly constructed reference vectors is added to the method of maximum minimum acute angle ensures that at most one new reference vector is added between any two adjacent active reference vectors of derived from V.
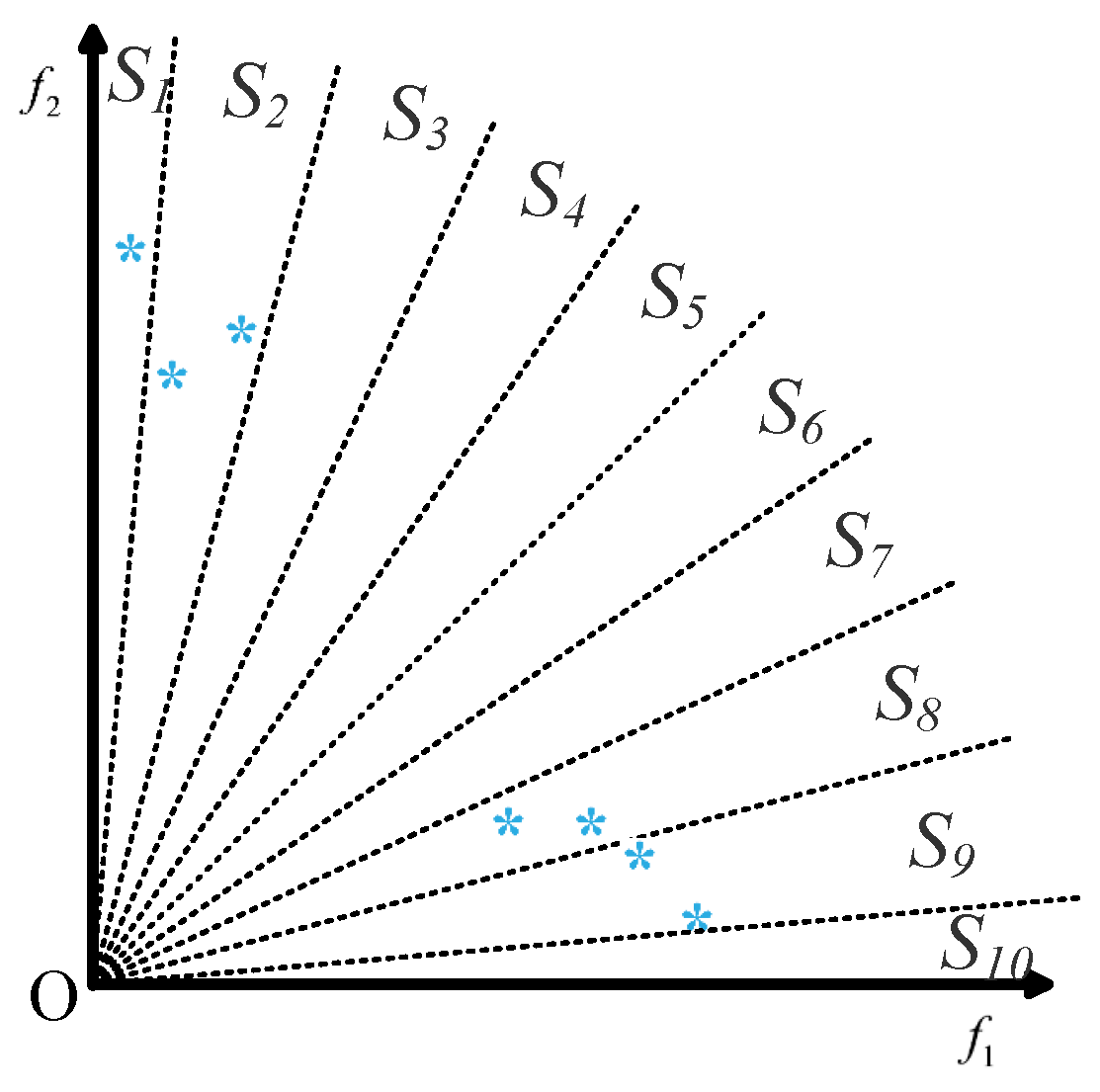
Here, we use the example shown in
Figure 5 to illustrate the main steps of the strategy described in Algorithm 4. In
Figure 5a,
are ten predefined reference vectors and the red points are candidate solutions. Clearly,
are inactive reference vectors and the other five are active reference vectors. In
Figure 5b, the five inactive reference vectors are deleted and the remaining five are active reference vectors. Furthermore, the corresponding subspaces of
each have two or more solutions. Then, following Algorithm 4, the solution in the subspace of
is selected and constructed as a new reference vector in
Figure 5b, indicated by the yellow arrow. The blue vector is the newly constructed reference vector.
Figure 5c–e shows the constructed reference vectors from the corresponding subspaces of
,
, and
, respectively. Finally, the final
output from Algorithm 4 is shown in
Figure 5f.
From this example, we can easily see the core idea of the strategy developed for the second state, that is, if the predefined reference vectors are substantially different from an MaOP, the strategy can obtain a set of active reference vectors that are distributed as uniformly as possible in the region where the true PF of the optimization problem is located.
3.6. Time Complexity Analysis
The main time complexity of the proposed ART-DMaOEA mainly lies in lines 5–10 of Algorithms 1, 3, 4, and 5. In each generation, only one of Algorithm 3 and Algorithm 4 runs, and Algorithm 4 costs more than Algorithm 3; thus, we only need to calculate the time cost of Algorithm 4.
In Algorithm 1, line 5, it costs to generate a new population, where D denotes the number of the decision variables in an MaOP. Algorithm 1, line 9, takes to clean up the dominated solutions for all subspaces.
In Algorithm 2, it costs to associate each individual with a subspace and to delete inactive reference vectors.
In Algorithm 4, it costs N to obtain (lines 1–4). Then, the time complexity cost of calculating the cosines among the solutions is . Next, constructing a new reference vector costs . As a result, the time complexity of the loop (lines 6–17) is .
In Algorithm 5, it costs to calculate the summation of the objective values (lines 1–6). Then, is used to select solutions using the maximum minimum acute angle method.
To summarize, the worst-case overall computational complexity of ART-DMaOEA within one generation is .

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}