

Asymptotic Properties for Cumulative Probability Models for Continuous Outcomes

Abstract
:1. Introduction
2. Method
2.1. Cumulative Probability Models
2.2. Cumulative Probability Models on Modified Data
2.3. Asymptotic Results
- 1.
- is thrice-continuously differentiable, for any x,for , where is a constant, and
- 2.
- The covariance matrix of Z is non-singular. In addition, Z and are bounded so that almost certainly for some large constant m.
- 3.
- is continuously differentiable in .
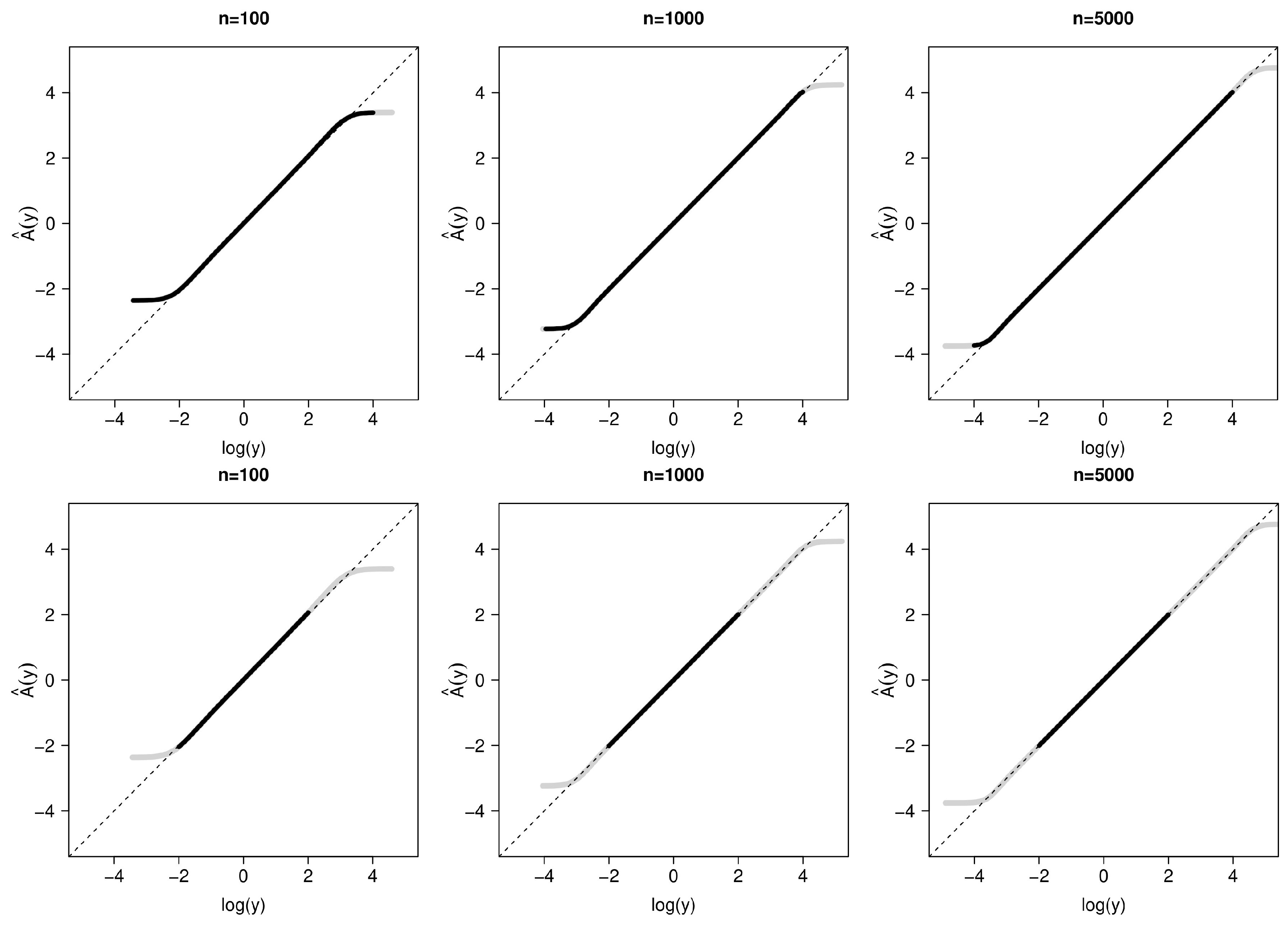
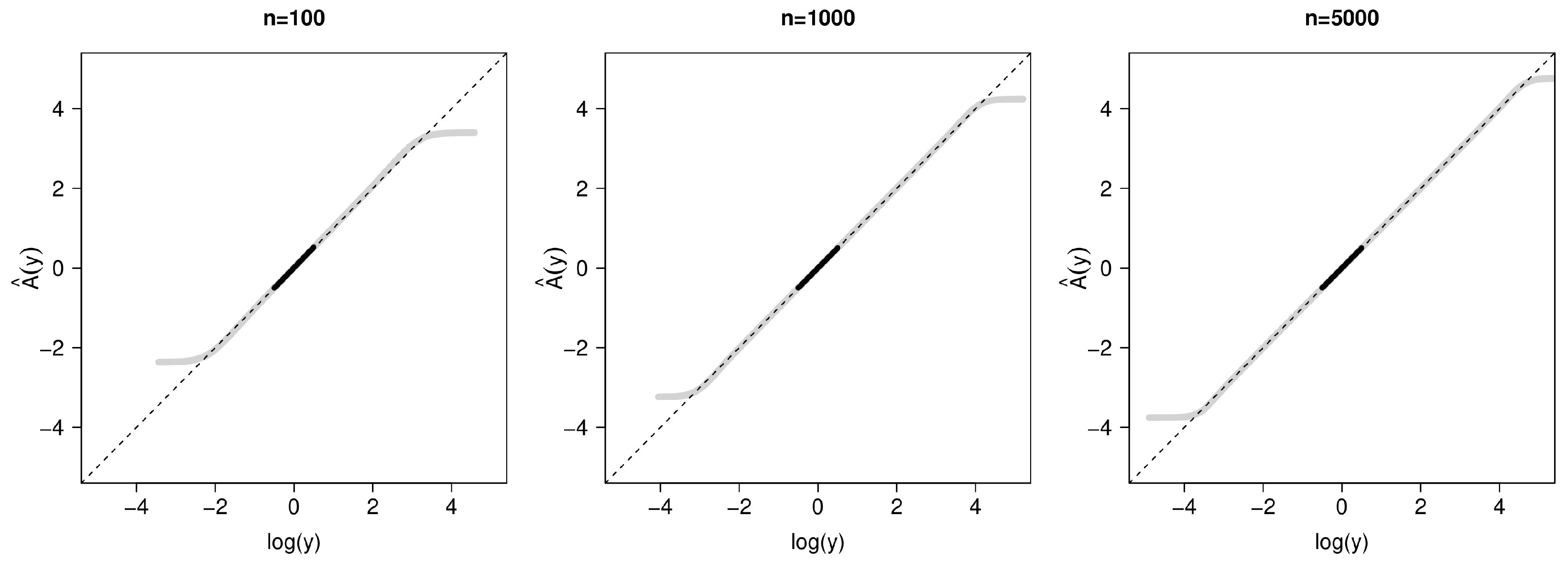
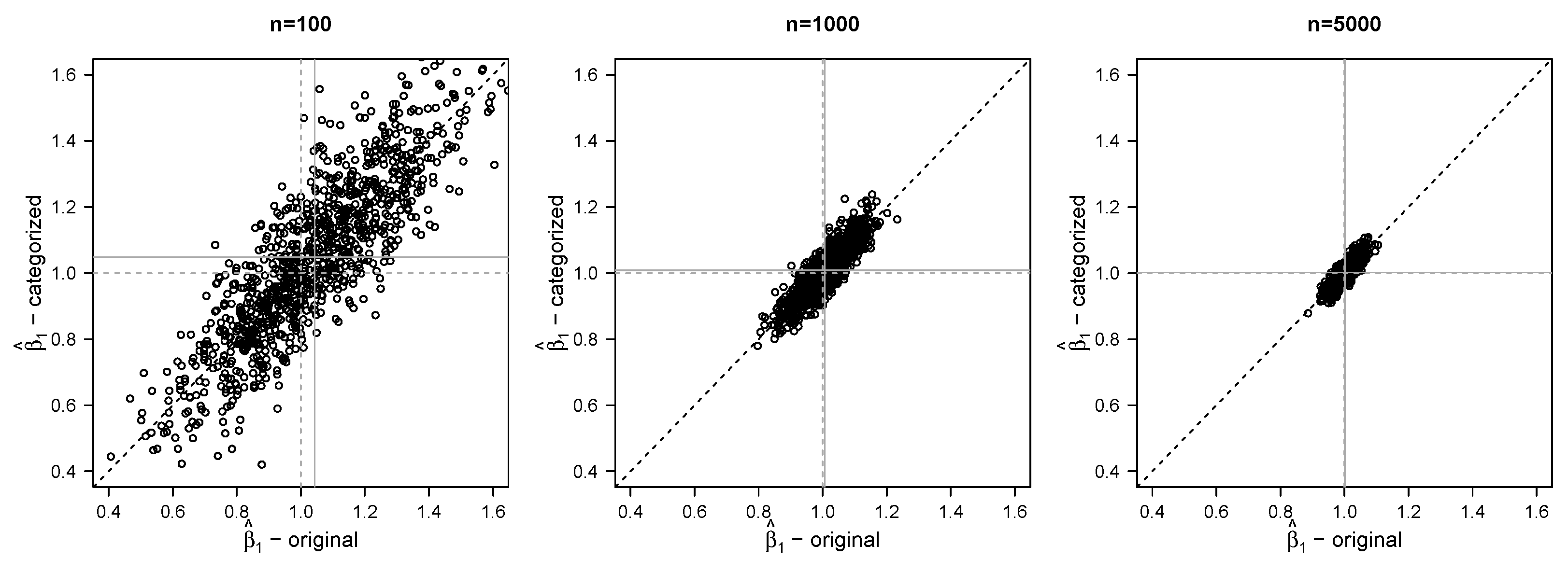
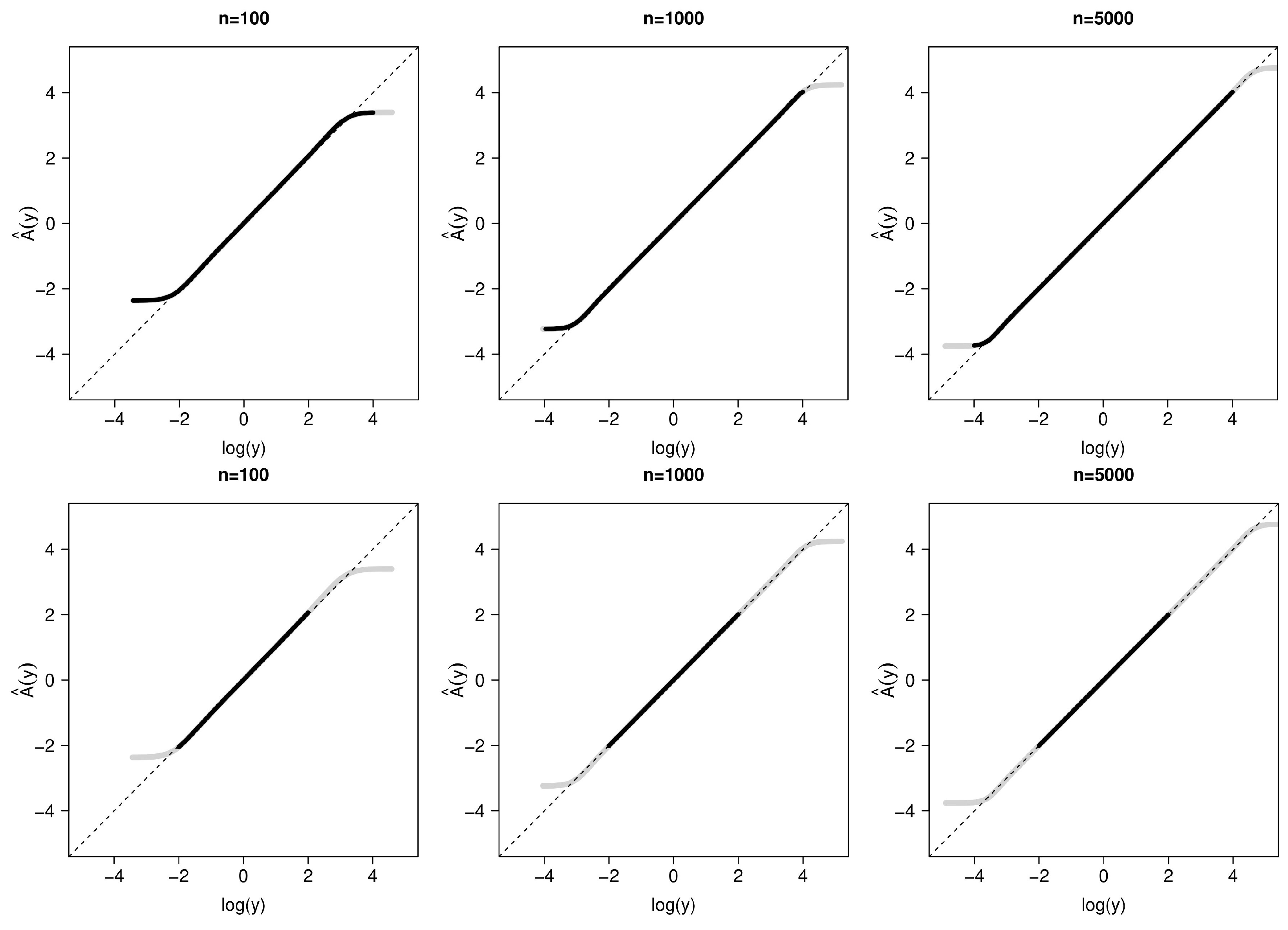
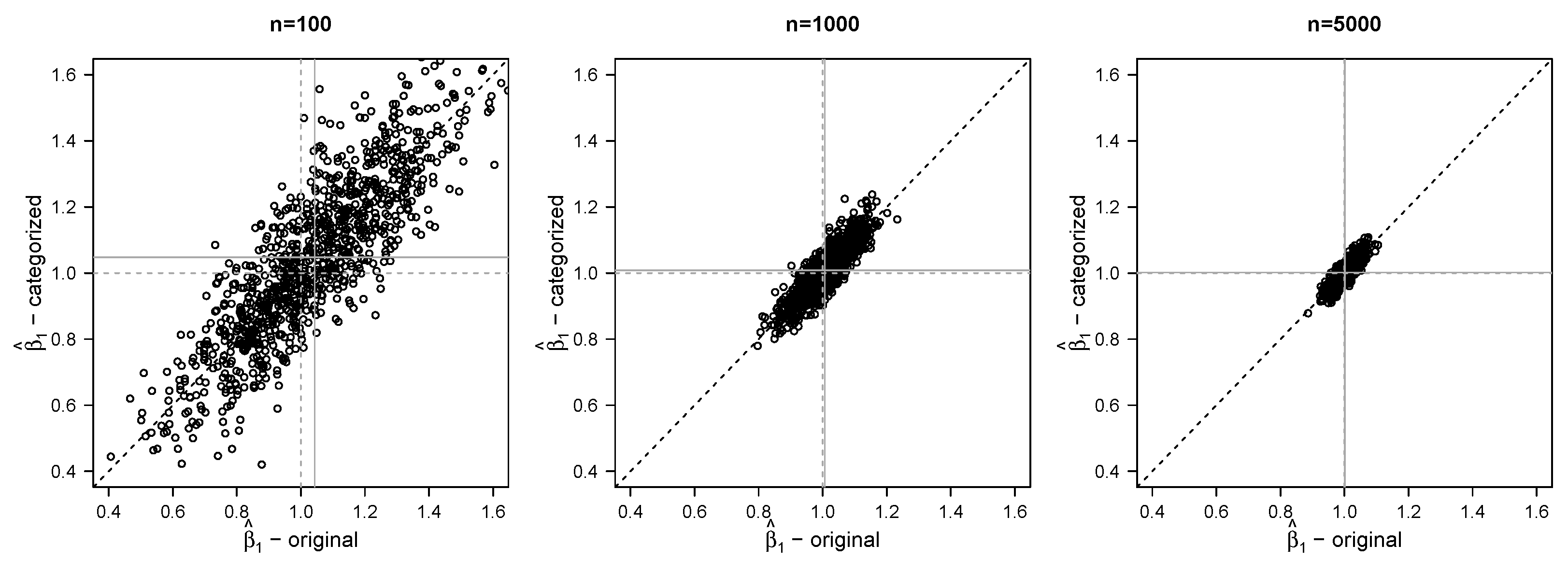
3. Simulation Study
3.1. Simulation Set-Up
3.2. Simulation Results
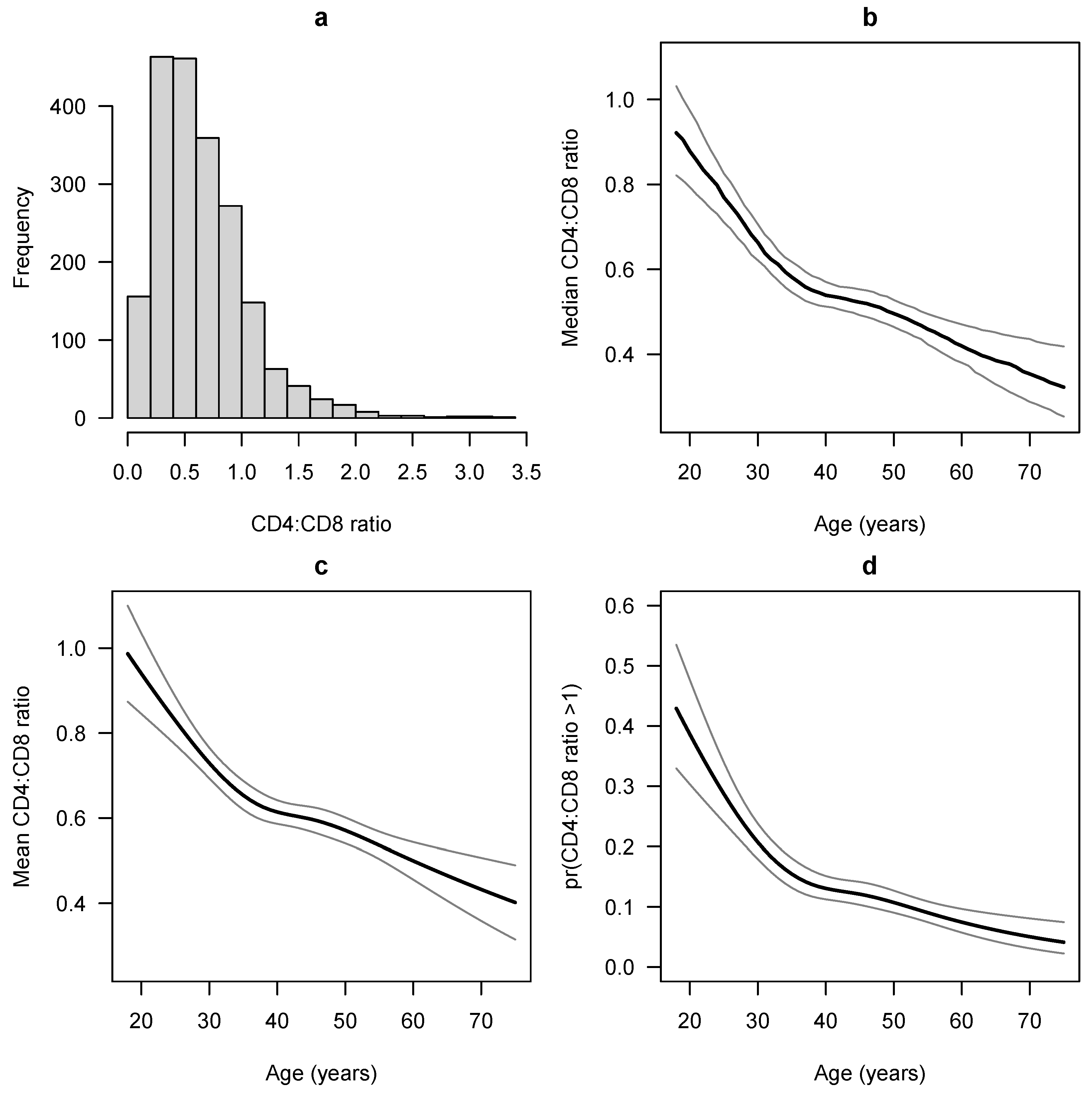
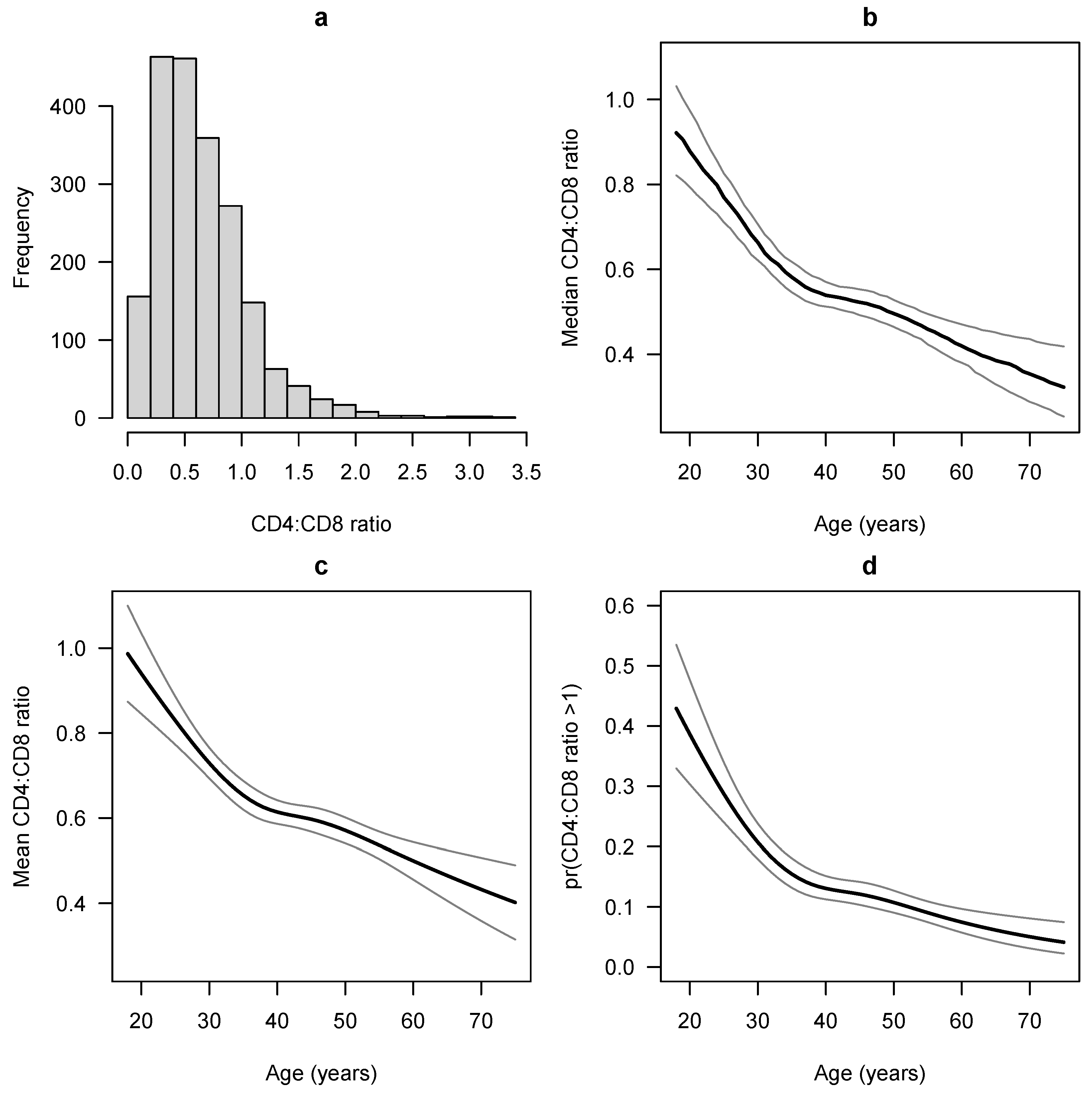
4. Example Data Analysis
5. Discussion
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Proof of Theorem 1
Appendix B. Proof of Theorem 2
References
- Box, G.E.P.; Cox, D.R. An analysis of transformations (with Discussion). J. R. Stat. Soc. Ser. B 1964, 26, 211–252. [Google Scholar]
- Doksum, K.A. An extension of partial likelihood methods for proportional hazard models to general transformation models. Ann. Statist. 1987, 15, 325–345. [Google Scholar] [CrossRef]
- Cuzick, J. Rank regression. Ann. Statist. 1988, 16, 1369–1389. [Google Scholar] [CrossRef]
- Pettitt, A.N. Inference for the linear model using a likelihood based on ranks. J. R. Statist. Soc. Ser. B 1982, 44, 234–243. [Google Scholar] [CrossRef]
- Kalbfleisch, J.D.; Prentice, R.L. Marginal likelihoods based on Cox’s regression and life model. Biometrika 1973, 60, 267–278. [Google Scholar] [CrossRef]
- Cheng, S.C.; Wei, L.J.; Ying, Z. Analysis of transformation models with censored data. Biometrika 1995, 82, 835–845. [Google Scholar] [CrossRef]
- Chen, K.; Jin, Z.; Ying, Z. Semiparametric analysis of transformation models with censored data. Biometrika 2002, 89, 659–668. [Google Scholar] [CrossRef]
- Zeng, D.; Lin, D.Y. Maximum likelihood estimation in semiparametric regression models with censored data (with Discussion). J. R. Statist. Soc. Ser. B 2007, 69, 507–564. [Google Scholar] [CrossRef]
- Manuguerra, M.; Heller, G.Z. Ordinal regression models for continuous scales. Int. J. Biostat. 2010, 6, 14. [Google Scholar] [CrossRef]
- Hothorn, T.; Möst, L.; Bühlmann, P. Most likely transformations. Scand. J. Stat. 2018, 45, 110–134. [Google Scholar] [CrossRef]
- Liu, Q.; Shepherd, B.E.; Li, C.; Harrell, F.E. Modeling continuous response variables using ordinal regression. Stat. Med. 2017, 36, 4316–4335. [Google Scholar] [CrossRef] [PubMed]
- Spertus, J.A.; Jones, P.G.; Maron, D.J.; O’Brien, S.M.; Reynolds, H.R.; Rosenberg, Y.; Stone, G.W.; Harrell, F.E.; Boden, W.E.; Weintraub, W.S.; et al. Health-status outcomes with invasive or conservative care in coronary disease. N. Engl. J. Med. 2020, 382, 1408–1419. [Google Scholar] [CrossRef] [PubMed]
- Pun, B.T.; Badenes, R.; La Calle, G.H.; Orun, O.M.; Chen, W.; Raman, R.; Simpson, B.-G.K.; Wilson-Linville, S.; Olmedillo, B.H.; de la Cueva, A.V.; et al. Prevalence and risk factors for delirium in critically ill patients with COVID-19 (COVID-D): A multicentre cohort study. Lancet 2021, 9, 239–250. [Google Scholar] [CrossRef] [PubMed]
- Pasquali, S.K.; Thibault, D.; O’Brien, S.M.; Jacobs, J.P.; Gaynor, J.W.; Romano, J.C.; Gaies, M.; Hill, K.D.; Jacobs, M.L.; Shahian, D.M.; et al. National variation in congenital heart surgery outcomes. Circulation 2020, 142, 1351–1360. [Google Scholar] [CrossRef] [PubMed]
- Williams, Z.J.; Failla, M.D.; Davis, S.L.; Heflin, B.H.; Okitondo, C.D.; Moore, D.J.; Cascio, C.J. Thermal perceptual thresholds are typical in autism spectrum disorder but strongly related to intra-individual response variability. Sci. Rep. 2019, 9, 12595. [Google Scholar] [CrossRef] [PubMed]
- Hatch, L.D.; Scott, T.A.; Slaughter, J.C.; Xu, M.; Smith, A.H.; Stark, A.R.; Patrick, S.W.; Ely, E.W. Outcomes, resource use, and financial costs of unplanned extubations in preterm infants. Pediatrics 2020, 145, e20192819. [Google Scholar] [CrossRef]
- Wang, J.-H.; Wong, R.C.B.; Liu, G.-S. Retinal transcriptome and cellular landscape in relation to the progression of diabetic retinopathy. Investig. Ophthalmol. Vis. Sci. 2022, 63, 26. [Google Scholar] [CrossRef]
- Ioannidis, J.P.A.; Kim, B.Y.S.; Trounson, A. How to design preclinical studies in nanomedicine and cell therapy to maximize the prospects of clinical translation. Nat. Biomed. Eng. 2018, 2, 797–809. [Google Scholar] [CrossRef]
- French, B.; Shotwell, M.S. Regression models for ordinal outcomes. JAMA 2022, 328, 772–773. [Google Scholar] [CrossRef]
- Billingsley, P. Probability and Measure, 3rd ed.; Wiley: New York, NY, USA, 1995. [Google Scholar]
- Van der Vaart, A.W.; Wellner, J.A. Weak Convergence and Empirical Processes; Springer: New York, NY, USA, 1996. [Google Scholar]
- Murphy, S.A.; van der Vaart, A.W. On profile likelihood. J. Am. Stat. Assoc. 2000, 95, 449–465. [Google Scholar] [CrossRef]
- Castilho, J.L.; Shepherd, B.E.; Koethe, J.R.; Turner, M.; Bebawy, S.; Logan, J.; Rogers, W.B.; Raffanti, S.; Sterling, T.R. CD4/CD8 ratio, age, and risk of serious non-communicable diseases in HIV-infected adults on antiretroviral therapy. AIDS 2016, 30, 899–908. [Google Scholar] [CrossRef]
- Sauter, R.; Huang, R.; Ledergerber, B.; Battegay, M.; Bernasconi, E.; Cavassini, M.; Furrer, H.; Hoffman, M.; Rougemont, M.; Günthard, H.F.; et al. CD4/CD8 ratio and CD8 counts predict CD4 response in HIV-1-infected drug naive and in patients on cART. Medicine 2016, 95, e5094. [Google Scholar] [CrossRef]
- Petoumenos, K.; Choi, J.Y.; Hoy, J.; Kiertiburanakul, S.; Ng, O.T.; Boyd, M.; Rajasuriar, R.; Law, M. CD4:CD8 ratio comparison between cohorts of HIV-positive Asians and Caucasians upon commencement of antiretroviral therapy. Antivir. Ther. 2017, 22, 659–668. [Google Scholar]
- Serrano-Villar, S.; Sainz, T.; Lee, S.A.; Hunt, P.W.; Sinclair, E.; Shacklett, B.L.; Ferre, A.L.; Hayes, T.L.; Somsouk, M.; Hsue, P.Y.; et al. HIV-infected individuals with low CD4/CD8 ratio despite effective antiretroviral therapy exhibit altered T cell subsets, heightened CD8+ T cell activation, and increased risk of non-AIDS morbidity and mortality. PLoS Pathog. 2014, 10, e1004078. [Google Scholar] [CrossRef]
- Silva, C.; Peder, L.; Silva, E.; Previdelli, I.; Pereira, O.; Teixeira, J.; Bertolini, D. Impact of HBV and HCV coinfection on CD4 cells among HIV-infected patients: A longitudinal retrospective study. J. Infect. Dev. Ctries. 2018, 12, 1009–1018. [Google Scholar] [CrossRef]
- Gras, L.; May, M.; Ryder, L.P.; Trickey, A.; Helleberg, M.; Obel, N.; Thiebaut, R.; Guest, J.; Gill, J.; Crane, H.; et al. Determinants of restoration of CD4 and CD8 cell counts and their ratio in HIV-1-positive individuals with sustained virological suppression on antiretroviral therapy. J. Acquir. Immune Defic. Syndr. 2019, 80, 292–300. [Google Scholar] [CrossRef]
- Serrano-Villar, S.; Perez-Elias, M.J.; Dronda, F.; Casado, J.L.; Moreno, A.; Royuela, A.; Perez-Molina, J.A.; Sainz, T.; Navas, E.; Hermida, J.M.; et al. Increased risk of serious non-AIDS-related events in HIV-infected subjects on antiretroviral therapy associated with a low CD4/CD8 ratio. PLoS ONE 2014, 9, e85798. [Google Scholar] [CrossRef]
- Harrell, F.E., Jr. Regression Modeling Strategies, 2nd ed.; Springer: Cham, Switzerland; Berlin/Heidelberg, Germany; New York, NY, USA; Dordrecht, The Netherlands; London, UK, 2015. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| n | Estimand | Original | Data Categorized Outside | |||
|---|---|---|---|---|---|---|
| Data | ||||||
| 100 | bias | 0.043 | 0.043 | 0.042 | 0.048 | |
| SD | 0.228 | 0.228 | 0.229 | 0.260 | ||
| mean SE | 0.217 | 0.217 | 0.219 | 0.251 | ||
| MSE | 0.054 | 0.054 | 0.054 | 0.070 | ||
| bias | –0.022 | –0.021 | –0.020 | –0.022 | ||
| SD | 0.119 | 0.119 | 0.120 | 0.143 | ||
| mean SE | 0.110 | 0.110 | 0.111 | 0.133 | ||
| MSE | 0.015 | 0.015 | 0.015 | 0.021 | ||
| bias | 0.019 | 0.019 | 0.019 | 0.020 | ||
| SD | 0.177 | 0.177 | 0.177 | 0.183 | ||
| mean SE | 0.174 | 0.174 | 0.175 | 0.182 | ||
| MSE | 0.032 | 0.032 | 0.032 | 0.034 | ||
| bias | 0.022 | 0.022 | 0.023 | 0.021 | ||
| SD | 0.172 | 0.172 | 0.172 | 0.176 | ||
| MSE | 0.030 | 0.030 | 0.030 | 0.031 | ||
| bias | –0.007 | - | - | - | ||
| SD | 0.266 | - | - | - | ||
| mean SE | 0.262 | - | - | - | ||
| MSE | 0.071 | - | - | - | ||
| 1000 | bias | 0.007 | 0.007 | 0.007 | 0.008 | |
| SD | 0.068 | 0.068 | 0.068 | 0.076 | ||
| mean SE | 0.067 | 0.067 | 0.068 | 0.077 | ||
| MSE | 0.005 | 0.005 | 0.005 | 0.006 | ||
| bias | –0.001 | –0.001 | –0.001 | –0.001 | ||
| SD | 0.033 | 0.033 | 0.034 | 0.040 | ||
| mean SE | 0.034 | 0.034 | 0.034 | 0.041 | ||
| MSE | 0.001 | 0.001 | 0.001 | 0.002 | ||
| bias | 0.003 | 0.003 | 0.003 | 0.003 | ||
| SD | 0.055 | 0.055 | 0.055 | 0.056 | ||
| mean SE | 0.054 | 0.054 | 0.054 | 0.057 | ||
| MSE | 0.003 | 0.003 | 0.003 | 0.003 | ||
| bias | 0.003 | 0.003 | 0.002 | 0.002 | ||
| SD | 0.054 | 0.054 | 0.054 | 0.056 | ||
| MSE | 0.003 | 0.003 | 0.003 | 0.003 | ||
| bias | –0.003 | - | - | - | ||
| SD | 0.081 | - | - | - | ||
| mean SE | 0.083 | - | - | - | ||
| MSE | 0.007 | - | - | - | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, C.; Tian, Y.; Zeng, D.; Shepherd, B.E. Asymptotic Properties for Cumulative Probability Models for Continuous Outcomes. Mathematics 2023, 11, 4896. https://doi.org/10.3390/math11244896
Li C, Tian Y, Zeng D, Shepherd BE. Asymptotic Properties for Cumulative Probability Models for Continuous Outcomes. Mathematics. 2023; 11(24):4896. https://doi.org/10.3390/math11244896
Chicago/Turabian StyleLi, Chun, Yuqi Tian, Donglin Zeng, and Bryan E. Shepherd. 2023. "Asymptotic Properties for Cumulative Probability Models for Continuous Outcomes" Mathematics 11, no. 24: 4896. https://doi.org/10.3390/math11244896
APA StyleLi, C., Tian, Y., Zeng, D., & Shepherd, B. E. (2023). Asymptotic Properties for Cumulative Probability Models for Continuous Outcomes. Mathematics, 11(24), 4896. https://doi.org/10.3390/math11244896