

Improving the Performance of Optimization Algorithms Using the Adaptive Fixed-Time Scheme and Reset Scheme



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- The reset scheme is utilized to improve the performance of AGDs, and a general design framework is also given, with which both the convergence performance and the stability of the optimization algorithms are significantly improved.
- A novel fixed-time optimization algorithm with an adaptive learning rate is proposed. This algorithm has fewer tuning parameters and is more robust to initial conditions compared with the existing results in [22].
- The reset scheme is applied for discrete FTGD, with which the convergence speed and stability of the discrete FTGD are both significantly improved.
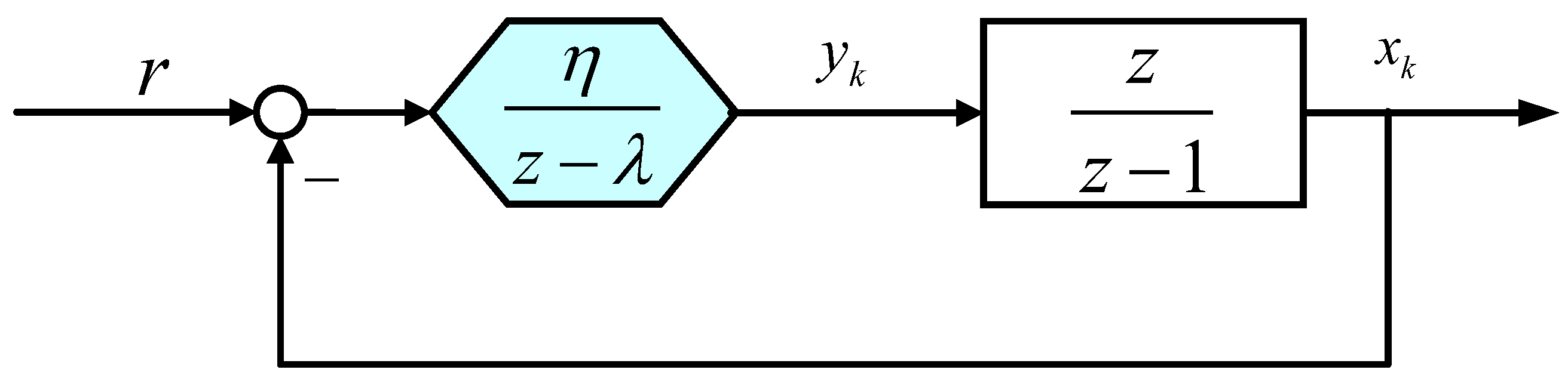
2. Systematic Representation for AGDs
3. Reset AGDs
3.1. Brief Introduction for Reset Control
3.2. Reset MGD
| Algorithm 1 Reset MGD |
|
3.3. Reset NGD
| Algorithm 2 Reset NGD |
|
3.4. Comments on Reset AGDs
- If the learning rate is set sufficiently small, may never happen, and reset AGDs will then reduce to the conventional AGDs, which indicates the same convergence speed as the conventional AGDs.
- For conventional AGDs, parameter tuning is difficult since either an excessive or insufficient learning rate will result in an inadequate performance. However, for reset AGDs, the overshoot introduced by the momentum item will be significantly attenuated, and one can tune the learning rate in the same way as the conventional GD, which simplifies the parameter tuning.
- The proposed design framework can also be applied for many other GDs/AGDs, which can be formulated as a high-order feedback system.
4. FTGD with an Adaptive Learning Rate
4.1. Continuous-Time FTGD
- Since the convergence time is determined by , one can set and tune to achieve a desirable convergence time for the practical usage. Moreover, the proposed FTGD has fewer tuning parameters compared with the results in [22].
- The parameter λ in algorithm (13) is used to attenuate the value of θ after reaching the minimum point. It is quite useful when realizing algorithm (13) in its discretization form. When , the attenuating item will disappear during the proof process of Theorem 1, and the conclusion for fixed-time convergence still holds.
- To avoid singularity, an additional positive scalar can be introduced for practical usage, and algorithm (13) can be modified aswhere is a small scalar. By using such a replacement, algorithm (18) can guarantee a fixed-time convergence to the bounded region of minimum point with .
- One can also design the following non-singular FTGDwhere , . One may refer to [24] for a more detailed proof process.
4.2. Euler Discretization of FTGD
4.3. Reset FTGD
| Algorithm 3 Reset FTGD |
|
- As known, for an l-smooth and μ-strongly convex function, the convergence speed for conventional GD can be proven to be linear. The result shown in Theorem 3 is the worst case. Generally, the reset FTGD converges to the minimum point much faster than the conventional GD since the adaptive learning rate is always greater than η.
- Compared with the results in Theorem 2, the stable region of the learning rate for reset FTGD is larger than FTGD without the reset scheme, which improves the stability of FTGD.
- The proposed reset scheme can be applied for other existing optimization algorithms with an adaptive learning rate, such as Adagrad and Adadelta algorithms.
5. Conclusive Discussion
- The reset scheme and fixed-time scheme in system control have been introduced to design high-efficiency GDs for unconstrained convex optimization problems. On the one hand, a general design framework for reset AGDs is given for the first time by using the systematic representation. On the other hand, a novel FTGD with an adaptive learning rate was designed, which has a simpler structure and fewer tuning parameters.
- The proposed algorithms could improve the performance of existing GDs in both convergence rate and stability, where the reset scheme helps attenuate the undesirable overshoot and improve the stability of AGDs, and the fixed-time scheme helps to achieve the non-asymptotic convergence and reach the optimal point in a fixed time.
- The proposed algorithms could be effectively applied for practical usages such as machine learning/deep learning problems. Some instructions for parameter tuning are also given for better practical implementations.
6. Illustrative Examples
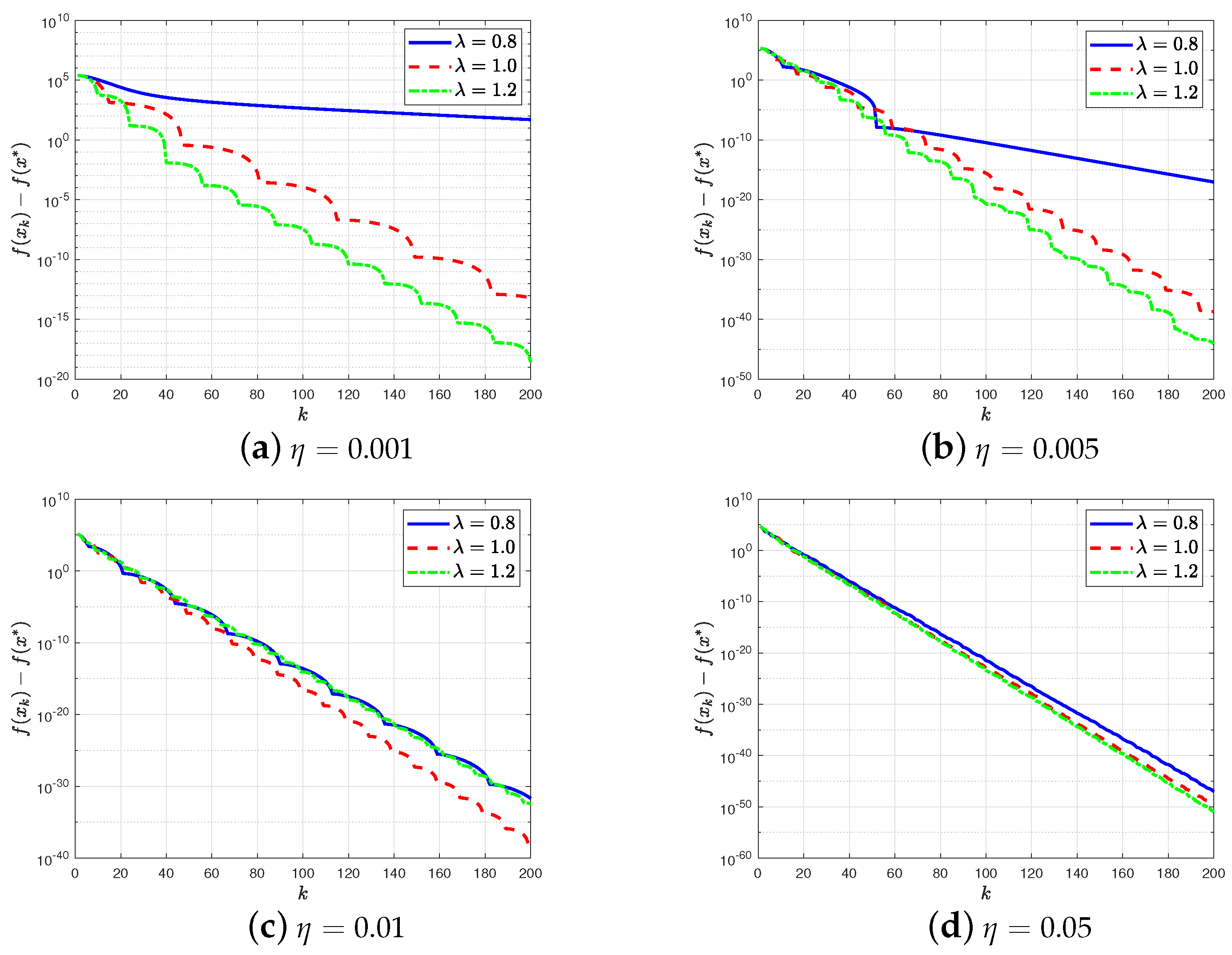
- For different initial conditions, fixed-time convergence is achieved by both FTGDs and is smaller than the estimated upper bound (1 s).
- Unlike the conventional AGDs where λ has to be between 0 and 1, the stability can still be guaranteed for . Moreover, for a different learning rate η, a larger λ always performs better, and thus is a good choice for practical usage.
- For a large learning rate ( and ), reset FTGD with different λ performs similarly since the reset condition is established almost constantly. Thus, reset FTGD totally reduces to the conventional GD.
- For different learning rates, reset FTGD always converges the fastest, while reset MGD and reset NGD perform similarly.
- For a small learning rate (), fixed-time convergence of discrete FTGD can be observed in Figure 6a (sharp decaying around ), which is similar to the result shown in Figure 3b. It is well understood since FTGD (21) has a similar simulation results to its corresponding continuous-time FTGD (20) when the learning rate is sufficiently small.
- Monotone convergence cannot be guaranteed in this example since the mentioned target function is neither l-smooth nor strongly convex, and cannot be guaranteed to be decreasing when the reset condition holds.
7. Conclusions and Future Topics
- Extending the proposed algorithms to the stochastic case;
- Applying the proposed algorithms for practical machine learning problems;
- Combining the developed gradient algorithms with artificial intelligence algorithms.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Nguyen, B.; Morell, C.; Baets, B.D. Scalable Large-Margin Distance Metric Learning Using Stochastic Gradient Descent. IEEE Trans. Cybern. 2018, 50, 1072–1083. [Google Scholar] [CrossRef] [PubMed]
- Sun, T.; Tang, K.; Li, D. Gradient Descent Learning with Floats. IEEE Trans. Cybern. 2020, 52, 1763–1771. [Google Scholar] [CrossRef] [PubMed]
- Cui, F.; Cui, Q.; Song, Y. A Survey on Learning-Based Approaches for Modeling and Classification of Human–Machine Dialog Systems. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 1418–1432. [Google Scholar] [CrossRef] [PubMed]
- Karabayir, I.; Akbilgic, O.; Tas, N. A Novel Learning Algorithm to Optimize Deep Neural Networks: Evolved Gradient Direction Optimizer (EVGO). IEEE Trans. Neural Netw. Learn. Syst. 2021, 23, 685–694. [Google Scholar] [CrossRef] [PubMed]
- Amari, S.I. Backpropagation and stochastic gradient descent method. Neurocomputing 1993, 5, 185–196. [Google Scholar] [CrossRef]
- Bottou, L. Large-Scale Machine Learning with Stochastic Gradient Descent. In Proceedings of the Computational Statistics, Pairs, France, 22–27 August 2010; pp. 177–186. [Google Scholar]
- Qian, N. On the momentum term in gradient descent learning algorithms. Neural Netw. 1999, 12, 145–151. [Google Scholar] [CrossRef]
- Nesterov, Y.; Polyak, B.T. Cubic regularization of Newton method and its global performance. Math. Program. 2006, 108, 177–205. [Google Scholar] [CrossRef]
- Yanıkoğlu, İ.; Gorissen, B.L.; den Hertog, D. A survey of adjustable robust optimization. Eur. J. Oper. Res. 2019, 277, 799–813. [Google Scholar] [CrossRef]
- Sun, X.; Teo, K.L.; Zeng, J.; Liu, L. Robust approximate optimal solutions for nonlinear semi-infinite programming with uncertainty. Optimization 2020, 69, 2109–2129. [Google Scholar] [CrossRef]
- Sun, X.; Tan, W.; Teo, K.L. Characterizing a Class of Robust Vector Polynomial Optimization via Sum of Squares Conditions. J. Optim. Theory Appl. 2023, 197, 737–764. [Google Scholar] [CrossRef]
- Kashima, K.; Yamamoto, Y. System theory for numerical analysis. Automatica 2009, 43, 231–236. [Google Scholar]
- Su, W.; Boyd, S.; Candes, E. A differential equation for modeling Nesterov’s accelerated gradient method: Theory and insights. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2510–2518. [Google Scholar]
- Wilson, A.C.; Recht, B.; Jordan, M.I. A Lyapunov analysis of momentum methods in optimization. arXiv 2016, arXiv:1611.02635. [Google Scholar]
- Wibisono, A.; Wilson, A.C.; Jordan, M.I. A variational perspective on accelerated methods in optimization. Proc. Natl. Acad. Sci. USA 2016, 113, 7351–7358. [Google Scholar] [CrossRef] [PubMed]
- Hu, B.; Lessard, L. Control interpretations for first-order optimization methods. In Proceedings of the American Control Conference, Seattle, WA, USA, 24–26 May 2017. [Google Scholar]
- Wu, W.; Jing, X.; Du, W.; Chen, G. Learning dynamics of gradient descent optimization in deep neural networks. Sci. China Inf. Sci. 2021, 64, 150102. [Google Scholar] [CrossRef]
- Dey, S.; Reich, S. A dynamical system for solving inverse quasi-variational inequalities. Optimization 2023, 1–21. [Google Scholar] [CrossRef]
- Romero, O.; Benosman, M. Finite-time convergence in continuous-time optimization. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020; pp. 8200–8209. [Google Scholar]
- Polyakov, A. Nonlinear feedback design for fixed-time stabilization of linear control systems. IEEE Trans. Autom. Control. 2011, 57, 2106–2110. [Google Scholar] [CrossRef]
- Polyakov, A.; Efimov, D.; Perruquetti, W. Finite-time and fixed-time stabilization: Implicit Lyapunov function approach. Automatica 2015, 51, 332–340. [Google Scholar] [CrossRef]
- Garg, K.; Panagou, D. Fixed-Time Stable Gradient Flows: Applications to Continuous-Time Optimization. IEEE Trans. Autom. Control. 2020, 66, 2002–2015. [Google Scholar] [CrossRef]
- Wei, Y.; Chen, Y.; Zhao, X.; Cao, J. Analysis and synthesis of gradient algorithms based on fractional-order system theory. IEEE Trans. Syst. Man Cybern. Syst. 2022, 53, 1895–1906. [Google Scholar] [CrossRef]
- Chen, Y.; Wang, F.; Wang, B. Fixed-time Convergence in Continuous-time Optimization: A Fractional Approach. IEEE Control. Syst. Lett. 2022, 7, 631–635. [Google Scholar] [CrossRef]
- Firouzbahrami, M.; Nobakhti, A. Cooperative fixed-time/finite-time distributed robust optimization of multi-agent systems. Automatica 2022, 142, 110358. [Google Scholar] [CrossRef]
- Xu, X.; Yu, Z.; Jiang, H. Fixed-Time Distributed Optimization for Multi-Agent Systems with Input Delays and External Disturbances. Mathematics 2022, 10, 4689. [Google Scholar] [CrossRef]
- Ogata, K. Discrete-Time Control Systems; Prentice Hall: Hoboken, NJ, USA, 1995. [Google Scholar]
- O’Donoghue, B.; Candes, E. Adaptive Restart for Accelerated Gradient Schemes. Found. Comput. Math. 2015, 15, 715–732. [Google Scholar] [CrossRef]
- Kizilkale, C.; Chandrasekaran, S.; Ming, G. Convergence Rate of Restarted Accelerated Gradient. 2017. Available online: https://optimization-online.org/wp-content/uploads/2017/10/6263.pdf (accessed on 16 November 2023).
- Yang, T.; Lin, Q. Restarted SGD: Beating SGD without Smoothness and/or Strong Convexity. arXiv 2015, arXiv:1512.03107v4. [Google Scholar]
- Beker, O.; Hollot, C.V.; Chait, Y.; Han, H. Fundamental properties of reset control systems. Automatica 2004, 40, 905–915. [Google Scholar] [CrossRef]
- Bisoffi, A.; Beerens, R.; Heemels, W.; Nijmeijer, H.; van de Wouw, N.; Zaccarian, L. To stick or to slip: A reset PID control perspective on positioning systems with friction. Annu. Rev. Control 2020, 49, 37–63. [Google Scholar] [CrossRef]
- Chen, Y.; Wei, Y.; Wang, Y. On 2 types of robust reaching laws. Int. J. Robust Nonlinear Control 2018, 28, 2651–2667. [Google Scholar] [CrossRef]
- Boyd, S.; Vandenberghe, L. Convex Optimization; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Karimi, H.; Nutini, J.; Schmidt, M. Linear convergence of gradient and proximal-gradient methods under the Polyak-Lojasiewicz condition. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Riva, Italy, 19–23 September 2016; Springer: Cham, Switzerland; pp. 795–811. [Google Scholar]
- Ruder, S. An overview of gradient descent optimization algorithms. arXiv 2016, arXiv:1609.04747v2. [Google Scholar]




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Y.; Sun, Y.; Wang, B. Improving the Performance of Optimization Algorithms Using the Adaptive Fixed-Time Scheme and Reset Scheme. Mathematics 2023, 11, 4704. https://doi.org/10.3390/math11224704
Chen Y, Sun Y, Wang B. Improving the Performance of Optimization Algorithms Using the Adaptive Fixed-Time Scheme and Reset Scheme. Mathematics. 2023; 11(22):4704. https://doi.org/10.3390/math11224704
Chicago/Turabian StyleChen, Yuquan, Yunkang Sun, and Bing Wang. 2023. "Improving the Performance of Optimization Algorithms Using the Adaptive Fixed-Time Scheme and Reset Scheme" Mathematics 11, no. 22: 4704. https://doi.org/10.3390/math11224704
APA StyleChen, Y., Sun, Y., & Wang, B. (2023). Improving the Performance of Optimization Algorithms Using the Adaptive Fixed-Time Scheme and Reset Scheme. Mathematics, 11(22), 4704. https://doi.org/10.3390/math11224704