1. Introduction
In both economic and biological research, it is a common scenario that many theories do not prescribe specific functional forms for the relationships between predictors and outcomes. For example, in biomedical studies, the influence of predictors on survival time can exhibit nonlinearity. Attempting to fit a linear model in such cases can result in biased estimates or produce misleading results. However, the functional shape of a non-parametric model is determined by the available data, eliminating the need for a linear functional form to describe the influence of a covariate. Additionally, non-parametric models offer greater flexibility in fitting data compared to parametric models. This paper delves into the in-depth study of the non-parametric accelerated failure time additive regression (NP-AFT-AR) model:
where (
) is random sample,
is the logarithm of the response variable, that is,
is the logarithm of survival time.
is a
vector of covariates,
are mutually independent and complementary subsets of
,
are regression coefficients of the covariates with indices in
, and
are unknown functions. The covariates in
have a linear relationship with the mean response, whereas the connection with the other covariates is not determined by a finite number of parameters. Parameter models require explicit assumption constraints, and they tend to overfit when there is an excessive number of model parameters. Some of these models are also based on the assumption of linearity, making them inadequate for capturing complex nonlinear relationships. However, parameter models offer the advantages of clear interpretability for explicit parameters, efficiency, and accurate parameter estimation. Hence, this paper aims to leverage these characteristics of parameter models and explores a hybrid approach that combines both parameter and non-parameter models to enhance the adaptability and performance of the model. When the emphasis is on the relationship between
and
, which can be approximated by a linear function. It provides enhanced interpretability compared to a purely non-parametric additive model. The random error term
has a mean of zero and a finite variance
. Assuming that certain components
are zero, our main objective in this research is to distinguish the nonzero components from the zero components and estimate the nonzero components accurately. A secondary objective is to elucidate the functional forms of the nonzero components, thereby suggesting a more concise model. The techniques we have established can readily be expanded to the partly linear additive AFT regression model, particularly when certain covariates may be discrete and not amenable to modeling using smoothing techniques like B-splines. We utilize the lung cancer data example to demonstrate this extension.
The structure identification method is effective in distinguishing linear variables from nonlinear ones, and numerous scholars have contributed to relevant research methods. Tibshirani [
1] combined the least square estimation technique introduced by Bireman [
2] with minimizing the residual sum of squares under constraints, transforming the solution into a continuous optimization process. This approach is known as the Lasso method, where penalties are applied to select variables, and estimated coefficients are continuously shrunk toward zero to automatically identify important explanatory variables. However, researchers such as Zhao and Yu [
3] and Zou [
4] discovered that the Lasso method may not consistently select the correct model, and the estimated regression coefficients do not exhibit asymptotic normality. To address this limitation, Fan and Li [
5] proposed the SCAD penalty, which substitutes the penalty in Lasso with a quadratic spline penalty function to reduce deviations. In the context of linear models, the SCAD method can uniformly identify the true model and possess oracle properties. Nonetheless, the non-convex nature of the SCAD penalty makes it challenging to optimize in practical applications, leading to numerical instability during the solution process. Zhang [
6] introduced the non-concave MCP (smoothly clipped absolute deviation) penalty and developed the MCP penalty likelihood procedure as an alternative approach. The MCP penalty method replaces the
penalty in Lasso with a quadratic spline penalty function to reduce bias. MCP exhibits the capability to consistently select the correct model with a probability of 1 and provides corresponding estimates with oracle properties.
Heller [
7] employed the weighted kernel smooth rank regression method to estimate the unknown parameters in the AFT model, particularly in the case of censored data. Gu [
8] introduced an empirical model selection approach for non-parametric components based on the Kullback–Leibler geometric structure. Schumaker [
9] utilized the Lasso iterative method for selecting parametric covariates, while non-parametric components were estimated using the sieve method. Johnson [
10] extended the rank-based Lasso-type estimation, which can encompass a portion of the linear AFT model. Huang and Ma [
11] applied the AFT model to analyze the relationship between gene expression and survival time, using the bridge penalty method for individual-level regularized estimation and gene selection. Long et al. [
12] established a risk prediction score through regularized rank estimation within a portion of the linear AFT model. Wei et al. [
13] explored the application extension of subgroup identification methods based on Adaptive Elastic Net and the AFT model. Wang and Gao [
14] conducted empirical likelihood inference for the AFT model under right-censored data. Cai et al. [
15] compared parametric and semiparametric AFT models in clustered survival data. Liu et al. [
16] introduced a new semiparametric approach that allows for the simultaneous selection of important variables, model structure identification, and covariate effect estimation within the AFT model.
Researchers used different methods for variable selection and parameter estimation. For instance, Fan and Li [
5] employed the Newton algorithm to estimate the penalty likelihood function. Cui et al. [
17] introduced the concept of penalty regression spline approximation and group structure identification within the additive model. However, their approach faced computational instability issues as they relied on truncated power series to approximate non-parametric truncation. Huang and Ma [
11] proposed a two-step method where, with a fixed number of predictors, nonzero variables are simultaneously selected and estimated in the additive model, using Group Lasso in the first stage and Adaptive Group Lasso in the second stage. Leng and Ma [
18] used the COSSO penalty to handle non-parametric covariate effects in the AFT model. However, due to the non-smooth nature of the penalty function at the origin, the computation can be challenging, and these methods require a significant amount of time to calculate the inverse matrix of the Hessian matrix, especially when dealing with high-dimensional covariates. Therefore, in this paper, the group coordinate descent (GCD) algorithm is employed to approximate and estimate the parameters in the non-parametric additive accelerated failure time model. GCD capitalizes on the assumption of model sparsity, and the algorithm is simple and operates at a fast pace. The GCD algorithm closely resembles the standard Newton–Raphson algorithm, but each iteration involves solving a weighted least squares problem with a penalty function.
Under the assumption that the dimensionality of covariates is allowed to diverge, this paper rigorously proves that the Group MCP penalty estimator in the non-parametric accelerated failure time model exhibits consistency and oracle properties. As the generalized cross-validation criterion is inconsistent in model selection when the sample size tends to infinity, meaning it may select irrelevant variables, the Bayesian Information Criterion (BIC) does not suffer from such issues. BIC, as shown by Golub et al. [
19], has the desirable property of selecting the true model with a probability of 1. Therefore, in the context of structure identification in the non-parametric accelerated failure time model, this study opts for tuning based on the BIC criterion.
The remaining sections of the paper are organized as follows. In
Section 2, we describe the construction of the AFT model with penalty estimation and variable selection based on Group MCP.
Section 3 introduces the algorithm and parameter tuning for the effective identification of both linear and nonlinear factors in the model. In
Section 4, we provide proof of the Group MCP’s selection consistency property, where the selected variable set asymptotically tends to include the actual predictive factors with a probability approaching 1.
Section 5 primarily focuses on numerical simulations and empirical analysis, demonstrating the method’s strong predictive performance. We also apply the method to the analysis of lung cancer data.
Section 6 provides a brief summary of the corresponding conclusions.
4. Theoretical Properties of Group MCP
Let denote the cardinality of any set , and , where is covariance matrix, . Let be the true regression coefficient and be the set of nonzero regression coefficients, Represents the number of elements in the set , and satisfies the following conditions:
(C1) and there are constants and such that the density distribution function of satisfies on [a,b] for .
(C2) is independent and identically distributed (i.i.d), and the error term is i.i.d in and exists , which is constant for all , .
(C3) The error term () is independent of the Kaplan–Meier weight (), and there is a constant satisfying that for any , there is , that is, the covariate is bounded.
(C4) The covariate matrix satisfies the SRC condition, exists , converges to 1 with probability and satisfies .
Condition (C1) can ensure that the model is sparse even when the number of covariates is large; that is, the number of covariates with nonzero coefficients can be controlled to a small number; condition (C2) can ensure the tail probability of the model under high-dimensional linear regression The assumption is still valid; according to condition (C3), the sub-Gaussian nature of the model is still guaranteed even if the data is censored; (C4) Ensure that the model meets the SRC condition, that is, ensure that the characteristic root of matrix
is always between
and
, and any model with a dimension smaller than
can be identified. Where
represents the estimated coefficient, and
represents a set of all nonzero coefficients. Denote
is the regression component of the true value,
is B-spline basis function expansion of
, and
,
. Let
be the cardinality of
, which is the number of linear components in the AFT regression model. Define
This represents the oracle estimator of
under the assumption that the identity of the linear components is known. It’s worth noting that the oracle estimator cannot be computed as
is unknown. Nevertheless, we employ it as the reference point for evaluating our proposed estimator. Similar to the actual estimates outlined in
Section 2.2, let’s define the oracle estimators as
. Denote
. Let
.The oracle estimator of the coefficients of the linear components is
. Without loss of generality, suppose that
. Write
, where
is a
-dimensional vector of zeros and
.
represents the minimal coefficient norm in the B-spline expansions of the nonlinear components. Consider a non-negative integer
and take
, such that
. Now, let’s define
as the set of functions
on
, where the
derivative
exists and adheres to a Lipschitz condition of order
: for .
Theorem 1. Suppose that , is less than the smallest eigenvalue of , and .
Then under (C1–C3), , Consequently, and . Hence, given the conditions specified in Theorem 1, the proposed estimator can effectively differentiate between linear and nonlinear components with a high probability of accuracy. Additionally, the proposed estimator exhibits the oracle property, implying that it aligns with the oracle estimator’s performance, assuming the knowledge of linear and nonlinear component identities, except for events with vanishingly low probabilities.
Theorem 2. Suppose (C1)–(C3) hold, we have
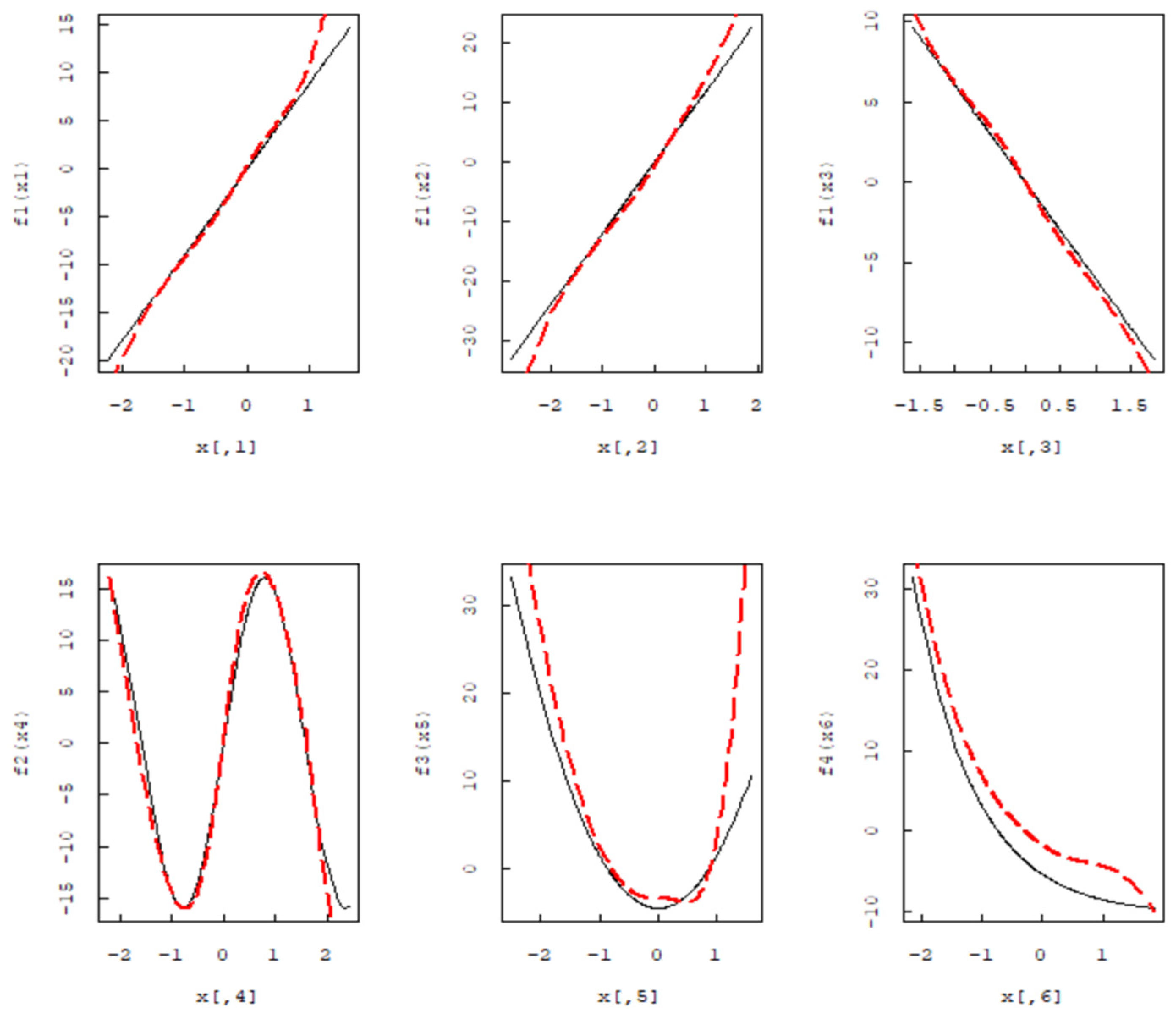
Theorem 2 provides the convergence rate of the proposed estimator within the non-parametric additive model, encompassing partially linear models as specific instances. Specifically, if we assume the second-order differentiability (d = 2) of each component and let and tend toward small , then , representing the optimal convergence rate in non-parametric regression. We will now explore the asymptotic distribution of . Denote . Each element of is a -vector of square-integrable functions with mean zero. Let the sumspace . The projection of the centered covariate vector onto the sumspace is defined to be the with that minimizes . For , denote . Therefore, the orthogonal projection onto is well-defined and unique. Additionally, each individual component is also well-defined and unique.
Theorem 3. Assuming the conditions stated in Theorem 1 and the fulfillment of (C4), and given that A is non-singular. Then, , where and .
Theorem 3 provides sufficient conditions under which the proposed estimator of the linear components in the model is asymptotically normal with the same limit normal distribution as the oracle estimator . Suppose that the first addable parts are important functions, and the remaining are non-important functions. Let be the set of non-important functions. Let , , for any , , , represents the cardinality of set A and .






{kind=link}
{kind=link}
{kind=link}