


Evaluation and Analysis of Heuristic Intelligent Optimization Algorithms for PSO, WDO, GWO and OOBO
Abstract
:1. Introduction
2. Algorithm Description
2.1. Particle Swarm Optimization
- Particles maintain a safe distance from the nearest individual to prevent collisions between particles.
- Each particle aims to approach the target value as closely as possible.
- The particles strive to converge toward the center of the target population.
2.1.1. Parameter Setting for Particle Swarm Optimization Algorithm
2.1.2. Physical Model Building and Particle Swarm Updating Method
2.1.3. Algorithm for Particle Swarm Optimization: Fitness Function Selection
2.1.4. Identify the Particle Swarm Optimization Algorithm’s Border Range
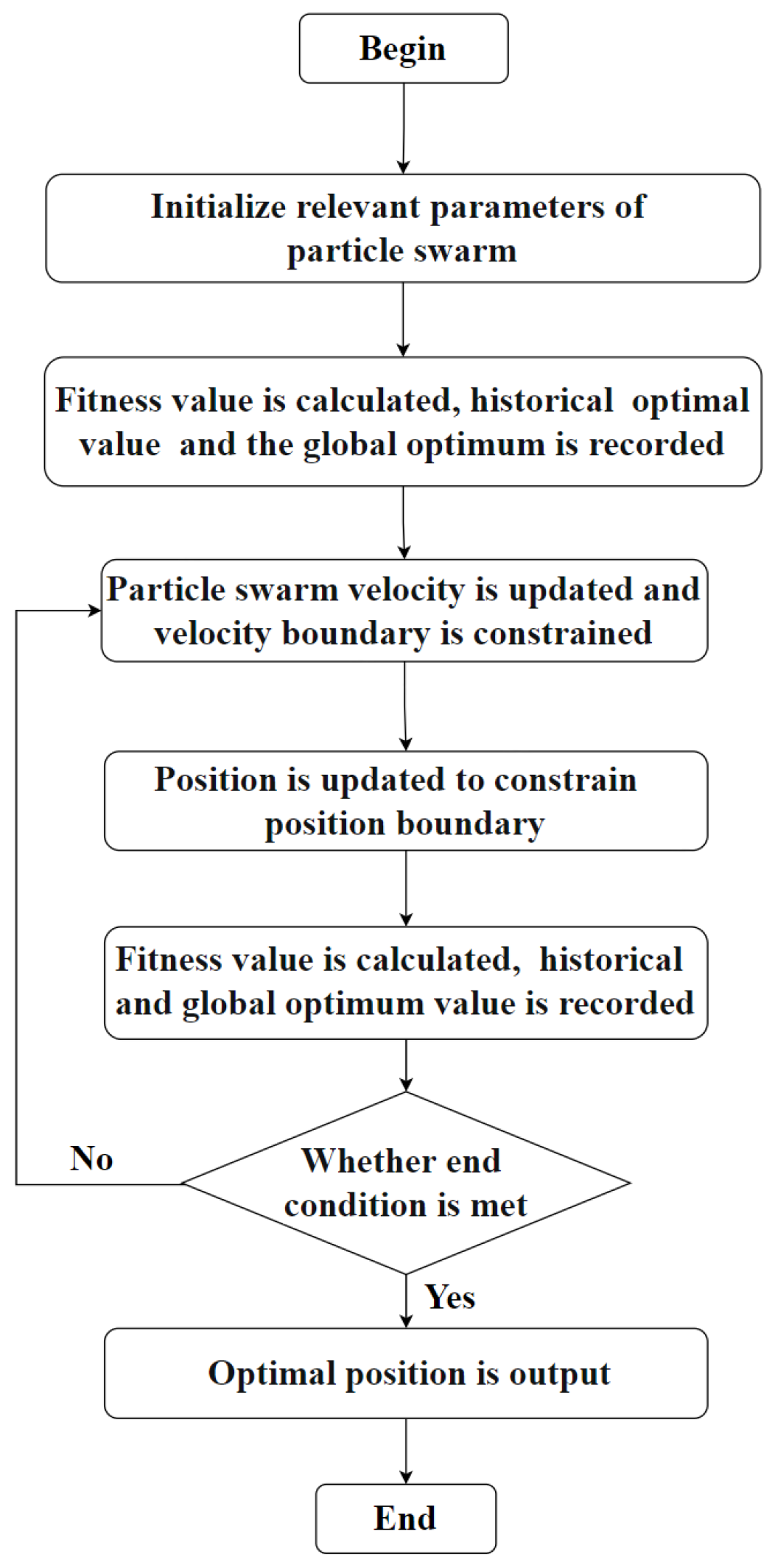
2.1.5. The Particle Swarm Optimization Algorithm’s Process
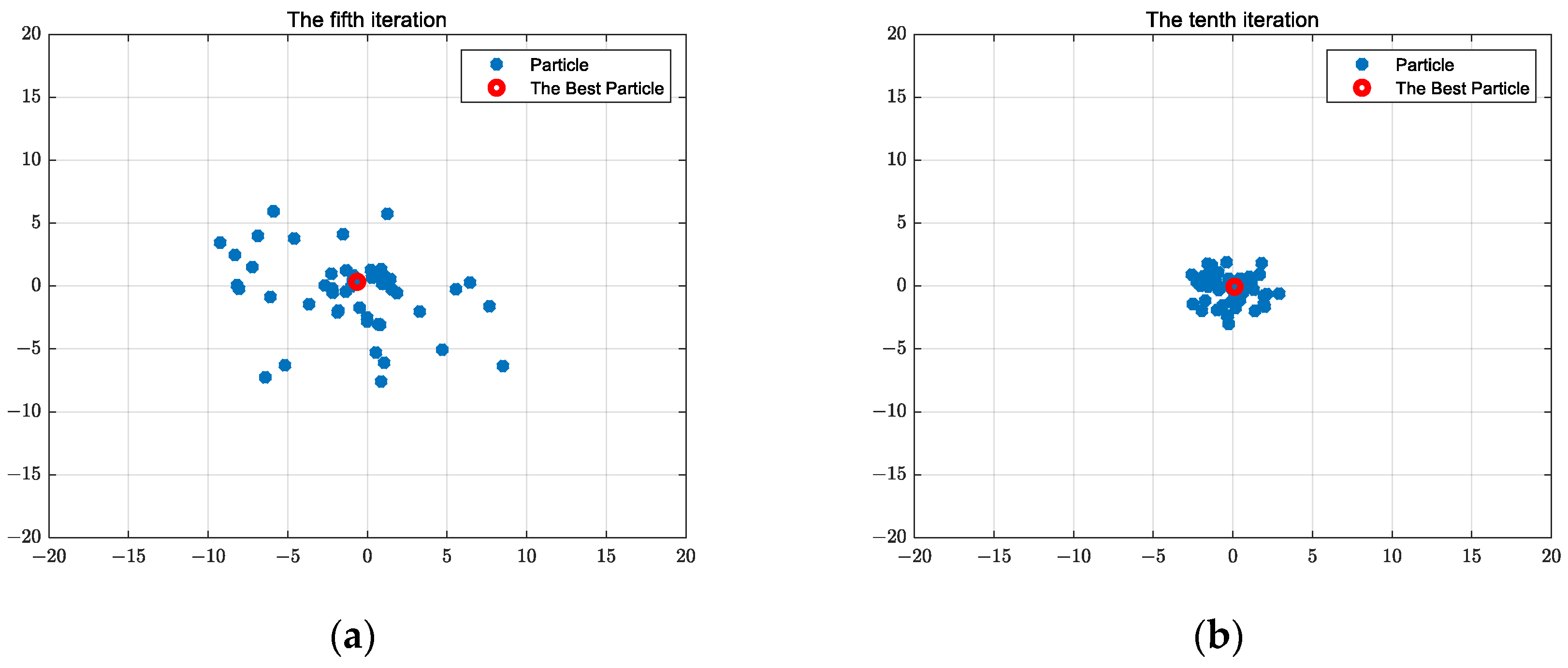
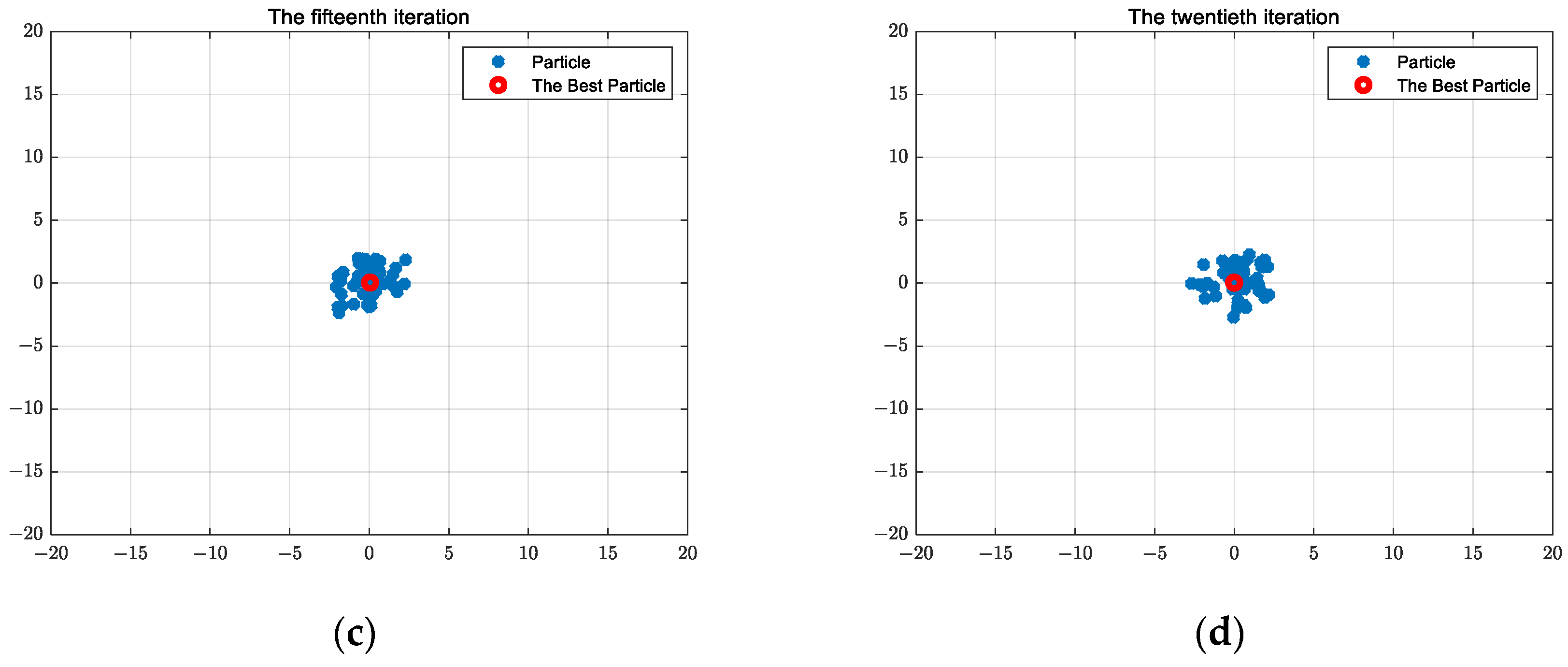
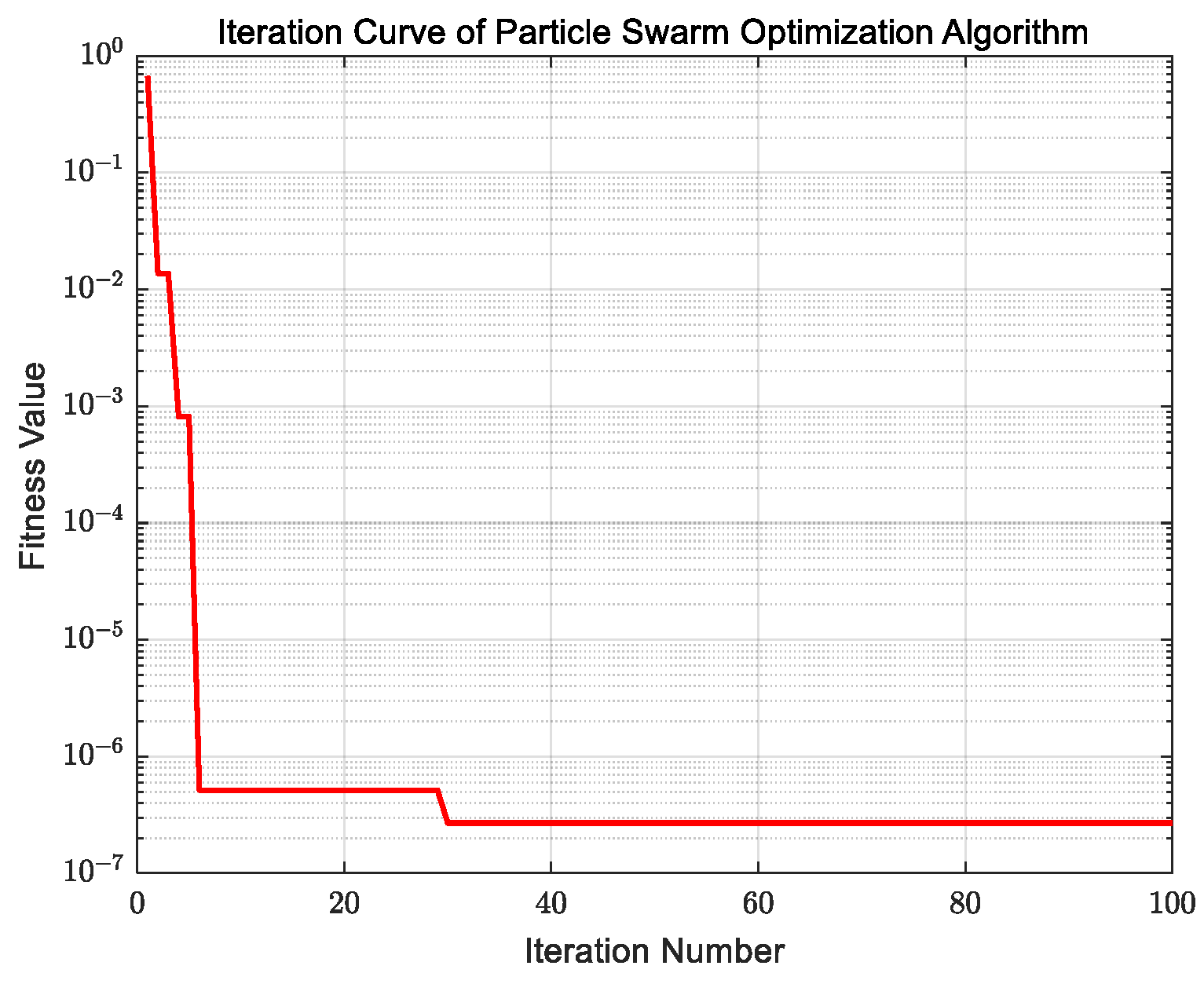
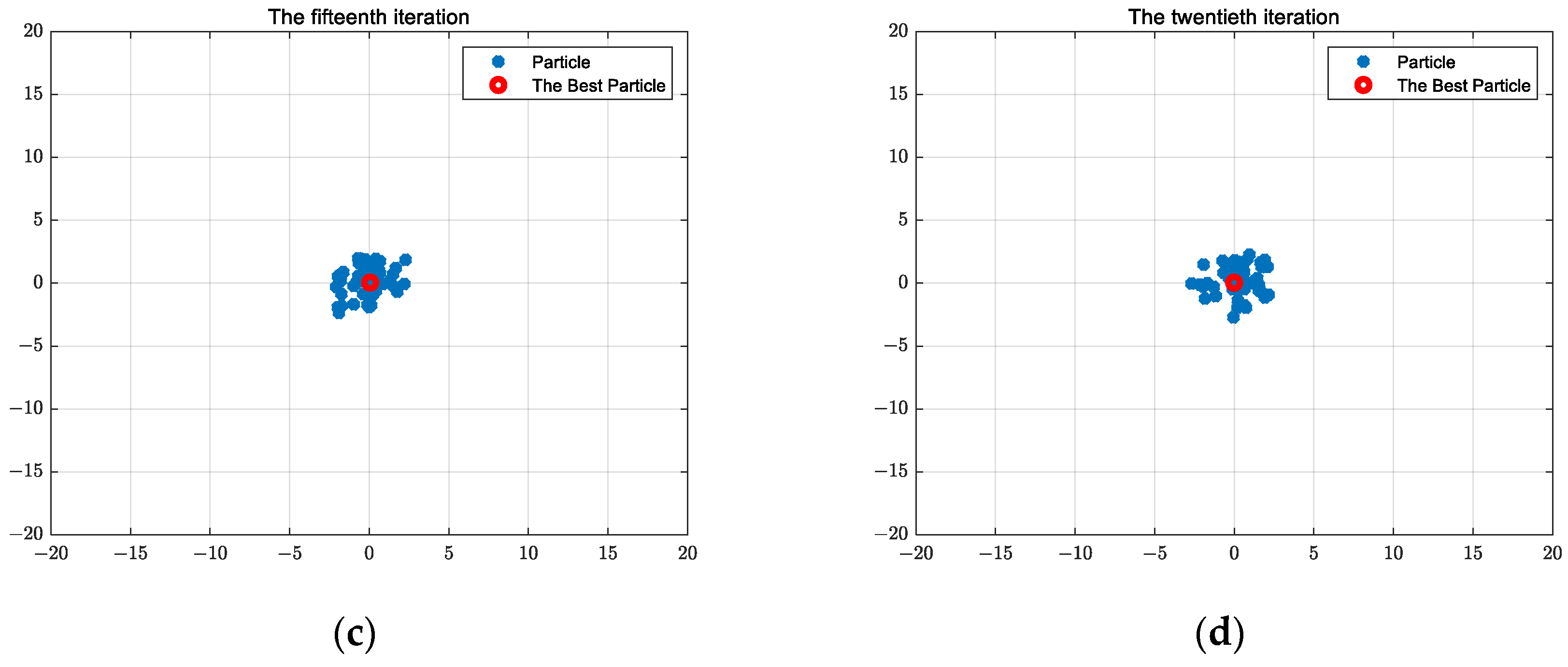
2.1.6. Particle Swarm Optimization Algorithm Calculation Results
2.2. Wind Driven Optimization Algorithm
2.2.1. Parameterization of the Wind Driven Optimization Algorithm
2.2.2. Method for Establishing Physical Models and Updating Air Units
2.2.3. Algorithm for the Wind Driven Optimization: Fitness Function Selection
2.2.4. Identify the Wind Driven Optimization Algorithm’s Boundary Range
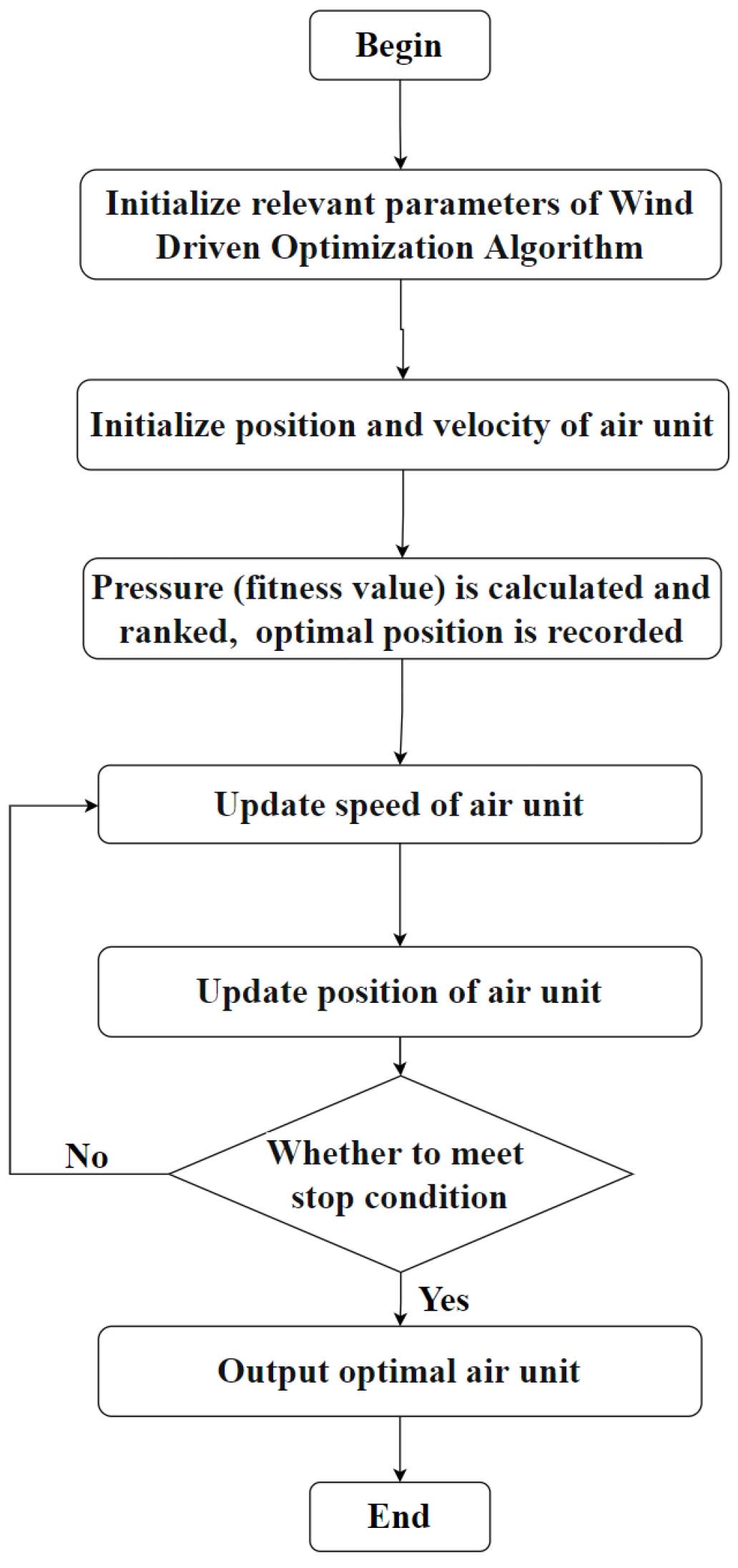
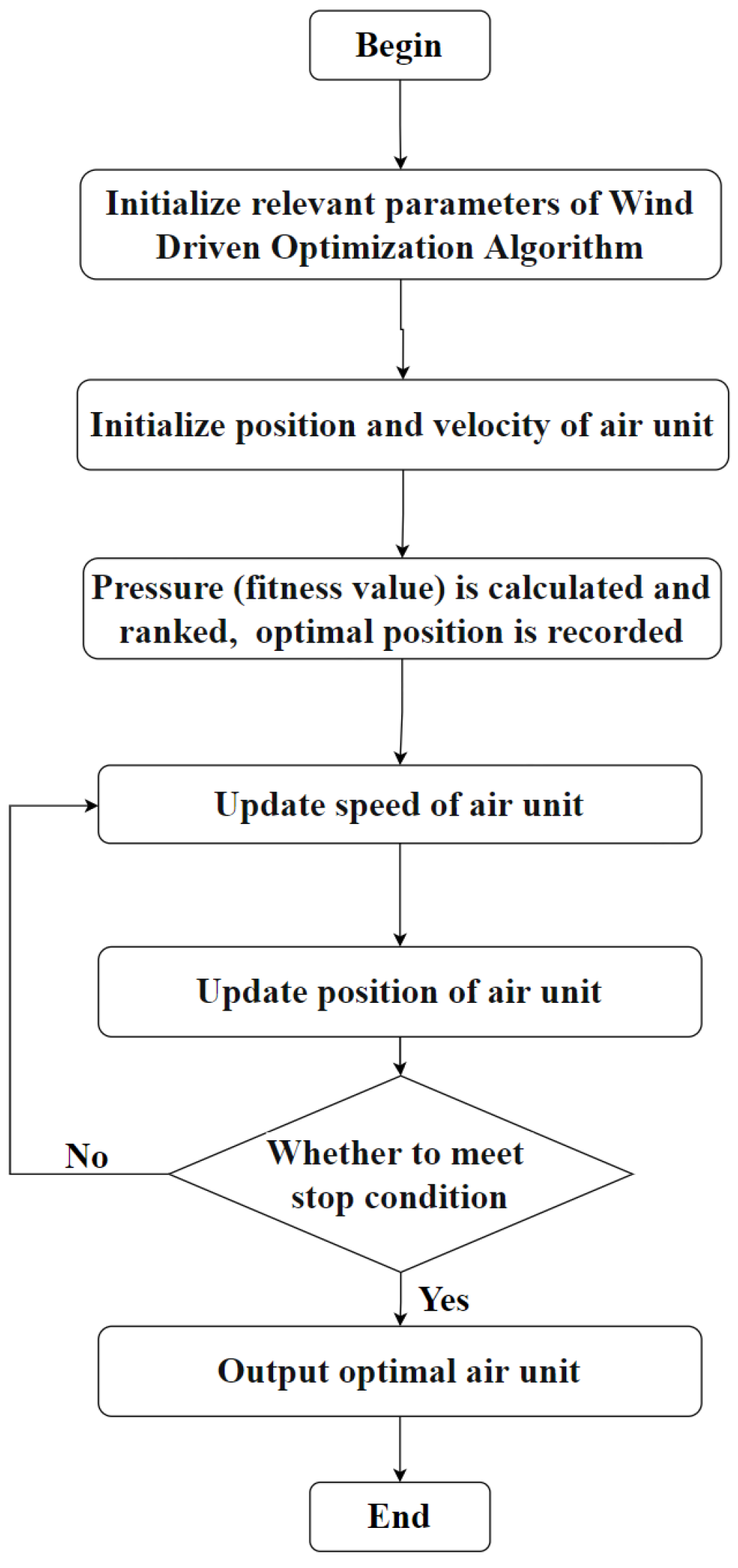
2.2.5. The Wind Driven Optimization Algorithm’s Process
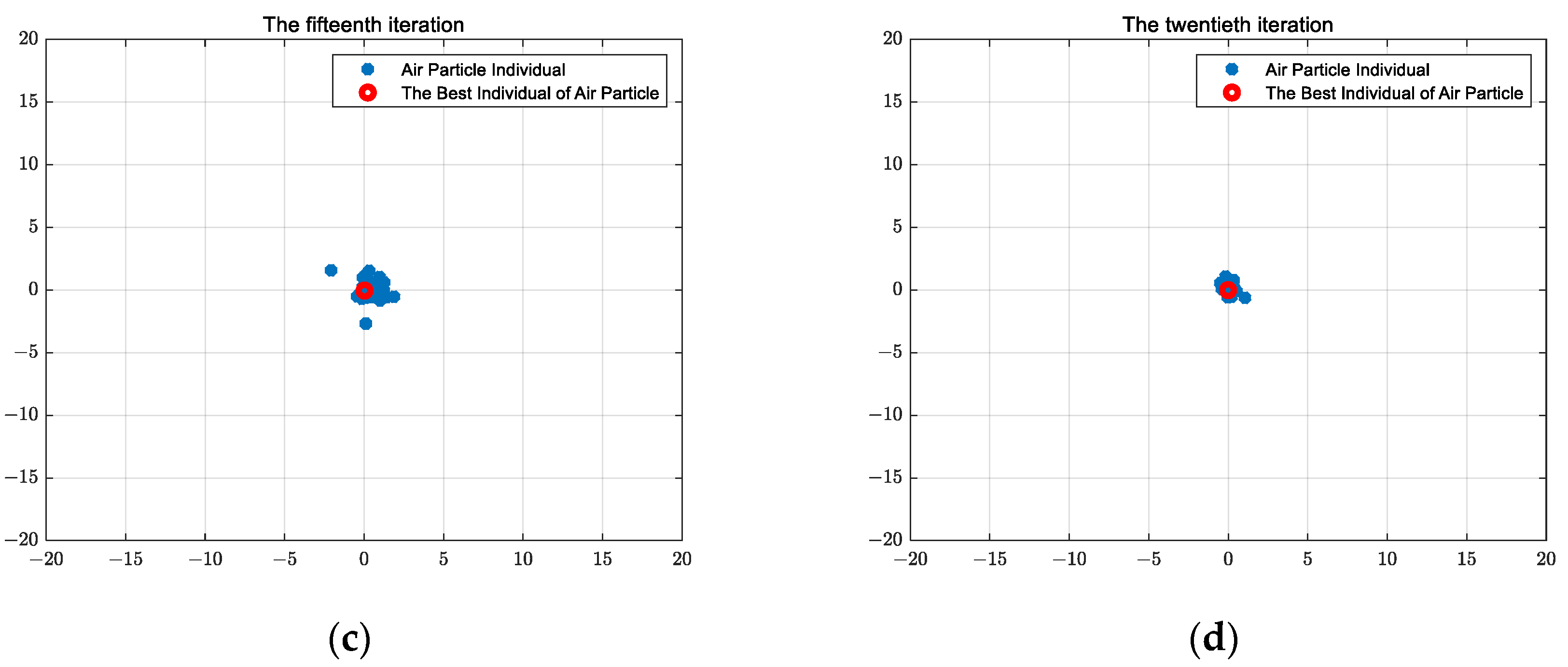
2.2.6. Wind Driven Optimization Algorithm Calculation Results
2.3. Grey Wolf Optimization Algorithm
2.3.1. Trapping Prey
2.3.2. Hunting Prey
2.3.3. Attacking Prey
2.3.4. Searching Prey
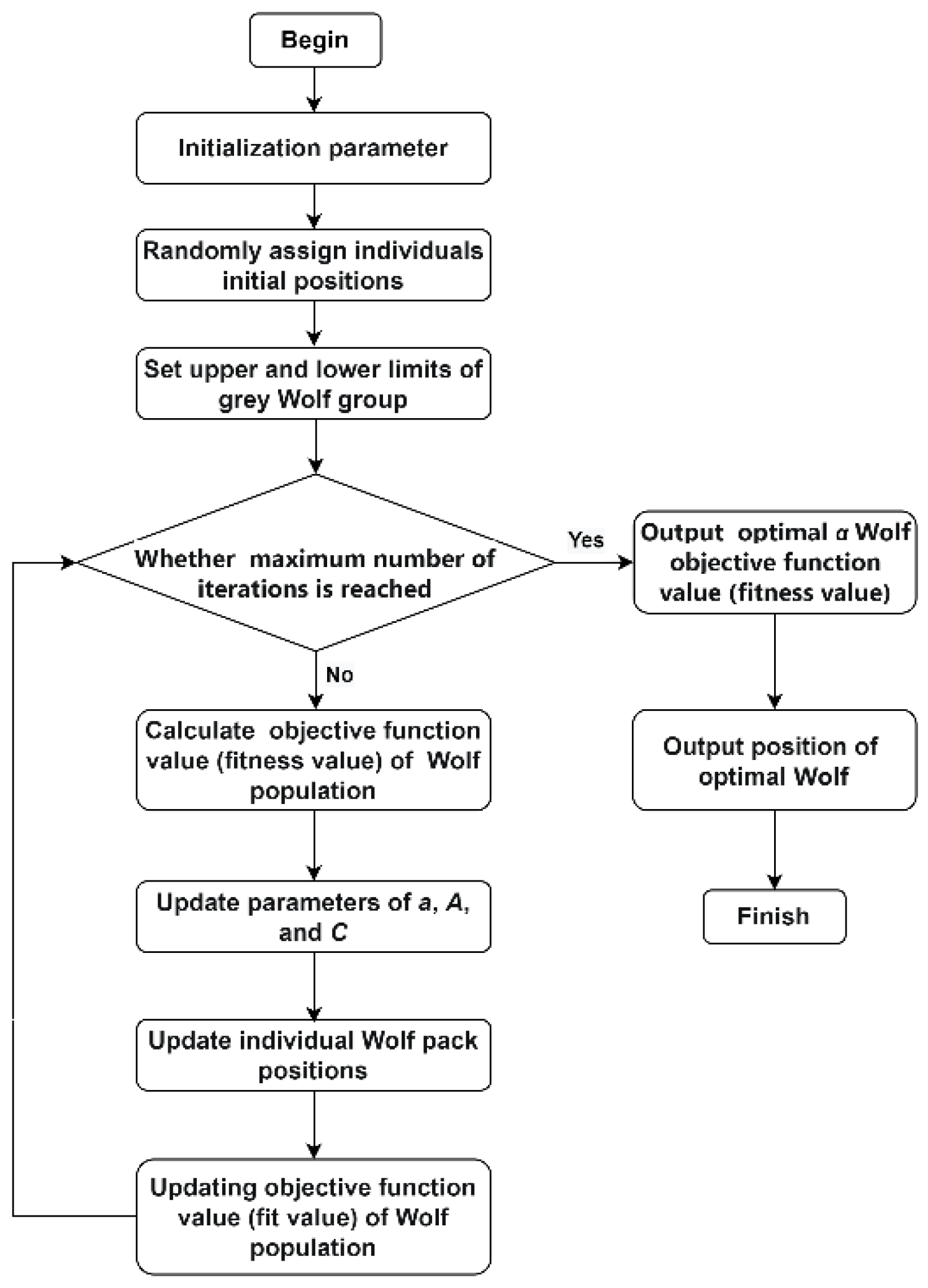
2.3.5. Application of the Grey Wolf Optimization Algorithm
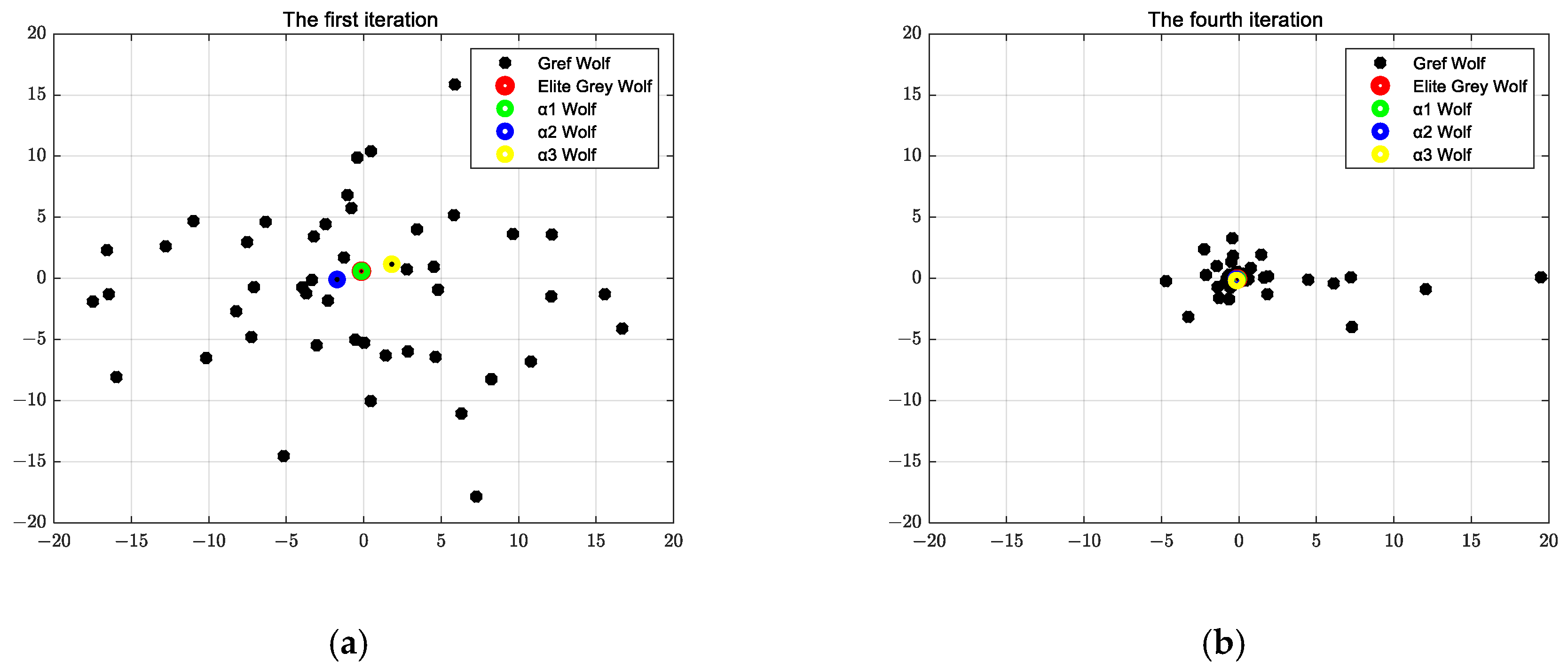
2.3.6. Grey Wolf Optimization Algorithm Calculation Results
2.4. One-to-One-Based Optimizer Algorithm
2.4.1. Boundary Range of OOBO Algorithm
2.4.2. Initialization of Parameters of OOBO Algorithm
2.4.3. Physical Modeling and Population Updating Methods
- (1)
- Each individual is a positive integer from 1 to N and is chosen randomly.
- (2)
- Individuals are not duplicated.
- (3)
- No member has a value equal to its position in the N tuple.
2.4.4. Selection of Fitness Function for One-to-One-Based Optimizer
2.4.5. Calculation Results of One-to-One-Based Optimizer Algorithm
3. Performance Comparison and Study of Various Algorithms
3.1. Descriptive Statistical Analysis
- (1)
- The optimal value [31]
- (2)
- The worst value [32]
- (3)
- The average value [33]
- (4)
- The standard deviation [34]
3.2. Complexity Analysis of Algorithms
3.3. Nonparametric Test Evaluation of Algorithms
3.4. Algorithmic Control Parameters Effect on Results
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yu, J.; Zhou, X.; Chen, M. Research on Representative Algorithms of Swarm Intelligence. Comput. Eng. Appl. 2010, 46, 1–4+74. [Google Scholar]
- Xie, L.; Zheng, Y.; Chen, J. Enabling Technologies in the Problem Solving Environment HED. Commun. Comput. Phys. 2008, 4, 1170–1193. [Google Scholar]
- Kennedy, J.; Eberhart, R. Particle Swarm Optimization. In Proceedings of the ICNN ‘95—International Conference on Neural Networks, Perth, WA, Australia, 27 November–1 December 1995. [Google Scholar]
- Shi, Y.; Eberhart, R. A Modified Particle Swarm Optimizer. In Proceedings of the 1998 IEEE Congress on Evolutionary Computation, Anchorage, AK, USA, 4–9 May 1998; pp. 69–73. [Google Scholar]
- Shi, Y.; Eberhart, R. Empirical Study of Particle Swarm Optimization. In Proceedings of the 1999 IEEE Congress on Evolutionary Computation, Washington, DC, USA, 6–9 July 1999; pp. 1945–1950. [Google Scholar]
- Chen, W.; Wu, X. Improved Wind Driven Optimization Algorithm Based on Multi-Strategy Fusion. J. Chongqing Univ. Sci. Technol. (Nat. Sci. Ed.) 2022, 24, 44–52. [Google Scholar]
- Gu, Q.; Zhang, S.; Liu, S. Application of an Improved Wind Driven Optimization Algorithm in Reservoir Operation. J. China Inst. Water Resour. Hydropower Res. 2022, 20, 237–243+250. [Google Scholar]
- Zhang, S.; Luo, Q.; Zhou, Y. Hybrid Grey Wolf Optimizer Using Elite Opposition-Based Learning Strategy and Simplex Method. Int. J. Comput. Intell. Appl. 2017, 16, 1750012. [Google Scholar] [CrossRef]
- Kong, X.; Yao, Y.; Yang, W.; Yang, Z.; Su, J. Solving the Flexible Job Shop Scheduling Problem Using a Discrete Improved Grey Wolf Optimization Algorithm. Machines 2022, 10, 1100. [Google Scholar] [CrossRef]
- Chen, M.; Chen, J.; Zeng, G. An Improved Artificial Bee Colony Algorithm Combined with Extremal Optimization and Boltzmann Selection Probability. Swarm Evol. Comput. 2019, 49, 158–177. [Google Scholar] [CrossRef]
- Lee, K. Modern Heuristic Optimization Techniques with Applications to Power Systems; John Wiley & Sons: Hoboken, NJ, USA, 2005. [Google Scholar]
- Yang, W.; Li, Q. Survey on PSO Algorithm. Eng. Sci. 2004, 6, 87–94. [Google Scholar]
- Bergh, F.; Engelbrecht, A. A Study of PSO Particle Trajectories. Inf. Sci. 2006, 176, 937–971. [Google Scholar]
- Chen, Q.; Zheng, Y.; Jiang, H. Improved Particle Swarm Optimization Algorithm Based on Neural Network for Dynamic Path Planning. J. Huazhong Univ. Sci. Technol. (Nat. Sci. Ed.) 2021, 49, 51–55. [Google Scholar]
- Liu, H.; Zeng, H.; Zhou, W. Optimization of Job Shop Scheduling Based on Improved Particle Swarm Optimization Algorithm. J. Shandong Univ. (Eng. Sci.) 2019, 49, 75–82. [Google Scholar]
- Chatterjee, A.; Siarry, P. Nonlinear Inertia Weight Variation for Dynamic Adaptation in Particle Swarm Optimization. Comput. Oper. Res. 2006, 33, 859–871. [Google Scholar] [CrossRef]
- Spavieri, G.; Cavalca, D.; Fernandes, R. An Adaptive Individual Inertia Weight Based on Best, Worst and Individual Particle Performances for the PSO Algorithm. In Proceedings of the 17th International Conference on Artificial Intelligence and Soft Computing, ICAISC 2018, Zakopane, Poland, 3–7 June 2018; pp. 536–547. [Google Scholar]
- An, P. Particle Swarm Optimization Algorithm Based on Chaotic Theory and Adaptive Inertia Weight. J. Nanoelectron. Optoelectron. 2017, 12, 404–408. [Google Scholar]
- Bayraktar, Z.; Komurcu, M.; Werner, D. Wind Driven Optimization (WDO): A Novel Nature-inspired Optimization Algorithm and Its Application to Electromagnetic. In Proceedings of the Antennas and Propagation Society International Symposium (APSURSI), Toronto, ON, Canada, 11–17 July 2010; pp. 1–4. [Google Scholar]
- Ren, Z.; Zhang, R.; Tian, Y. Wind Driven Optimization Algorithm. J. Jiangsu Univ. Sci. Technol. (Nat. Sci. Ed.) 2015, 29, 153–158. [Google Scholar]
- Yanxia, S.; Chikomborero, S.; OdunAyo, I. OFDM Network Optimization Using a QPSK Based on a Wind-Driven Genetic Algorithm. Sensors 2022, 22, 6174. [Google Scholar]
- Ranjan, P. The Synthesis of a Pixelated Metamaterial Cross-polarizer Using the Binary Wind-driven Optimization Algorithm. J. Comput. Electron. 2022, 21, 453–470. [Google Scholar] [CrossRef]
- Seyedali, M.; Seyed, M.; Andrew, L. Grey Wolf Optimizer. Adv. Eng. Softw. 2014, 69, 46–61. [Google Scholar]
- Zhang, X.; Wang, X. Comprehensive Review of Grey Wolf Optimization Algorithm. Comput. Sci. 2019, 46, 30–38. [Google Scholar]
- Ahmed, H.; Youssef, B.; Eikorany, A. Hybrid Grey Wolf Optimizer-artificial Neural Network Classification Approach for Magnetic Resonance Brain Images. Appl. Opt. 2018, 57, 25. [Google Scholar] [CrossRef]
- Li, S.; Ye, C. Improved Grey Wolf Optimizer Algorithm Using Nonlinear Convergence Factor and Elite Re-election Strategy. Comput. Eng. Appl. 2021, 57, 62–68. [Google Scholar]
- Dehghani, M.; Trojovská, E.; Trojovský, P.; Malik, O.P. OOBO: A New Metaheuristic Algorithm for Solving Optimization Problems. Biomimetics 2023, 8, 468. [Google Scholar] [CrossRef] [PubMed]
- Yao, X.; Liu, Y.; Lin, G. Evolutionary Programming Made Faster. IEEE Trans. Evol. Comput. 1999, 3, 82–102. [Google Scholar]
- Digalakisi, J.; Margaritis, K. On Benchmarking Functions for Genetic Algorithms. Int. J. Comput. Math. 2001, 77, 481–506. [Google Scholar] [CrossRef]
- Yang, X. Firefly Algorithm, Stochastic Test Functions and Design Optimization. Int. J. Bio-Inspired Comput. 2010, 2, 78–84. [Google Scholar] [CrossRef]
- Sun, Y. Research on PSO Algorithms and Applications for Some Optimization Problem. Ph.D. Thesis, Hefei University of Technology, Hefei, China, 2020. [Google Scholar]
- Su, W. Research on Theory and Method of Multi-index Comprehensive Evaluation. Ph.D. Thesis, Xiamen University, Xiamen, China, 2000. [Google Scholar]
- Dang, D.; Zhang, S.; Ge, P.; Tian, X. Transformer Fault Diagnosis Method Based on Support Vector Machine Optimized by Improved Quantum-behaved PSO. J. Electr. Power Sci. Technol. 2019, 34, 108–113. [Google Scholar]
- Bi, X.; Li, Y.; Chen, C. A Self-Adaptive Teaching-and-Learning-Based Optimization Algorithm with a Mixed Strategy. J. Harbin Eng. Univ. 2016, 37, 842–848. [Google Scholar]
- Li, Y.; Wang, S.; Chen, Q.; Wang, X. Comparative Study of Several New Swarm Intelligence Optimization Algorithms. Comput. Eng. Appl. 2020, 56, 1853–1869. [Google Scholar]
- Zhang, H.; Chen, M. Improved Harris Hawks Optimization Algorithm Based on Hybrid Strategy. Comput. Syst. Appl. 2023, 32, 166–178. [Google Scholar]
- Li, N. Self-adaptive Bacterial Foraging Algorithm Based on Estimation of Distribution. J. Intell. Fuzzy Syst. 2021, 40, 5595–5607. [Google Scholar]
- Zhang, J.; Zhang, J. Signal Detection and Fault Diagnosis Based on Improved Particle Swarm Optimization Algorithm. J. Shandong Univ. (Nat. Sci.) 2023, 58, 63–75+83. [Google Scholar]
- Shi, Y. Particle Swarm Optimization: Developments, Applications and Resources. In Proceedings of the 2001 Congress on Evolutionary Computation, Seoul, Republic of Korea, 27–30 May 2001. [Google Scholar]
- Trelea, I.C. The Particle Swarm Optimization Algorithm: Convergence Analysis and Parameter Selection. Inf. Process. Lett. 2003, 85, 317–325. [Google Scholar] [CrossRef]
- Clerc, M.; Kennedy, J. The Particle Swarm-Explosion, Stability, and Convergence in a Multidimensional Complex Space. IEEE Trans. Evol. Comput. 2002, 6, 58–73. [Google Scholar] [CrossRef]
- Zhao, N.; Deng, J. A Survey of Particle Swarm Optimization. Sci. Technol. Innov. Her. 2015, 12, 216–217. [Google Scholar]
- Yang, B.; Qian, W. Summary on Improved Inertia Weight Strategies for Particle Swarm Optimization Algorithm. J. Bohai Univ. (Nat. Sci. Ed.) 2019, 40, 274–288. [Google Scholar]
- Feng, Q.; Li, Q.; Quan, W. Overview of Multiobjective Particle Swarm Optimization Algorithm. Chin. J. Eng. 2021, 43, 745–753. [Google Scholar]
- Liu, X.; Wang, H.; Lei, X.; Liao, W.; Wang, M.; Wang, W.; Zhang, P. Influence of Parameter Settings in PSO Algorithm on Simulation Results of Xin’anjiang Model. S.–N. Water Transf. Water Sci. Technol. 2018, 16, 69–74, 208. [Google Scholar]
- Liu, Z.; Liang, H. Parameter Setting and Experimental Analysis of the Random Number in Particle Swarm Optimization Algorithm. Control Theory Appl. 2010, 27, 1489–1496. [Google Scholar]









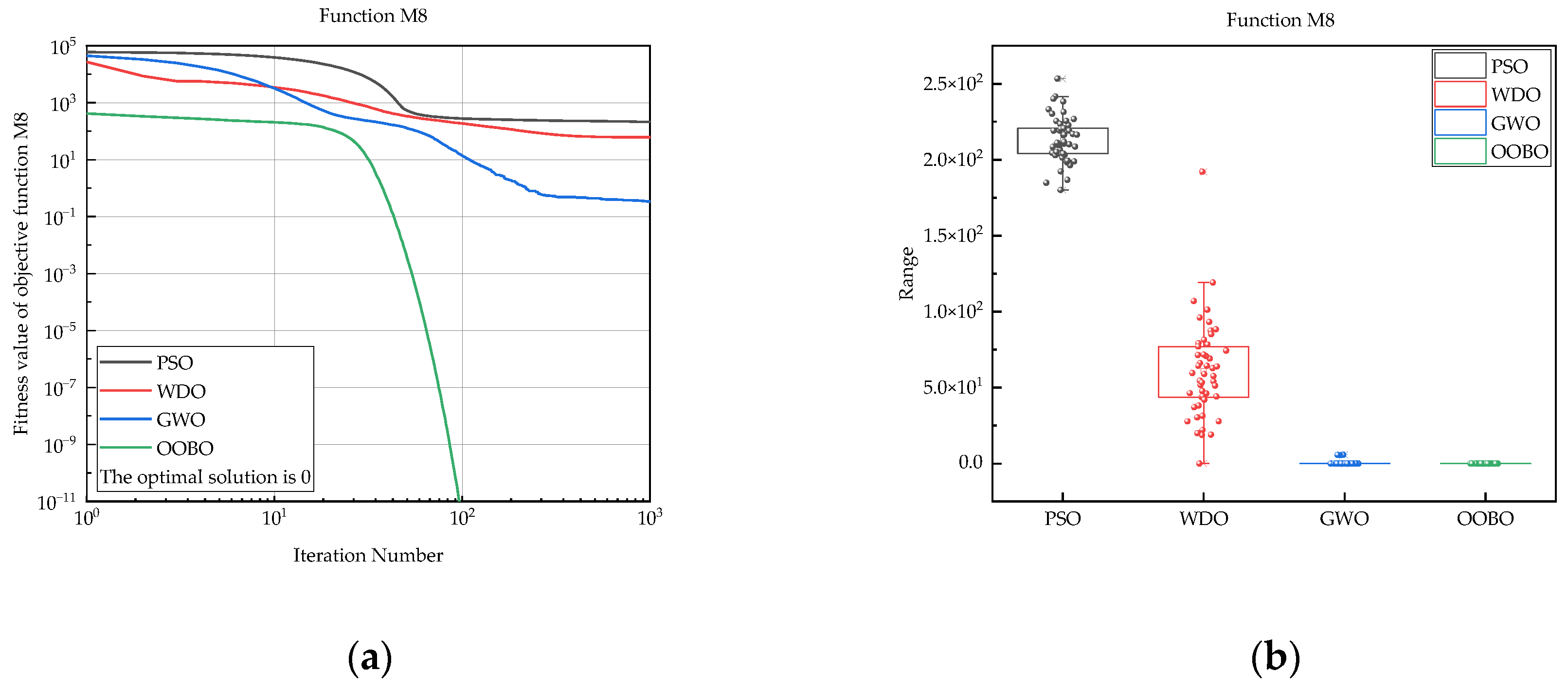










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
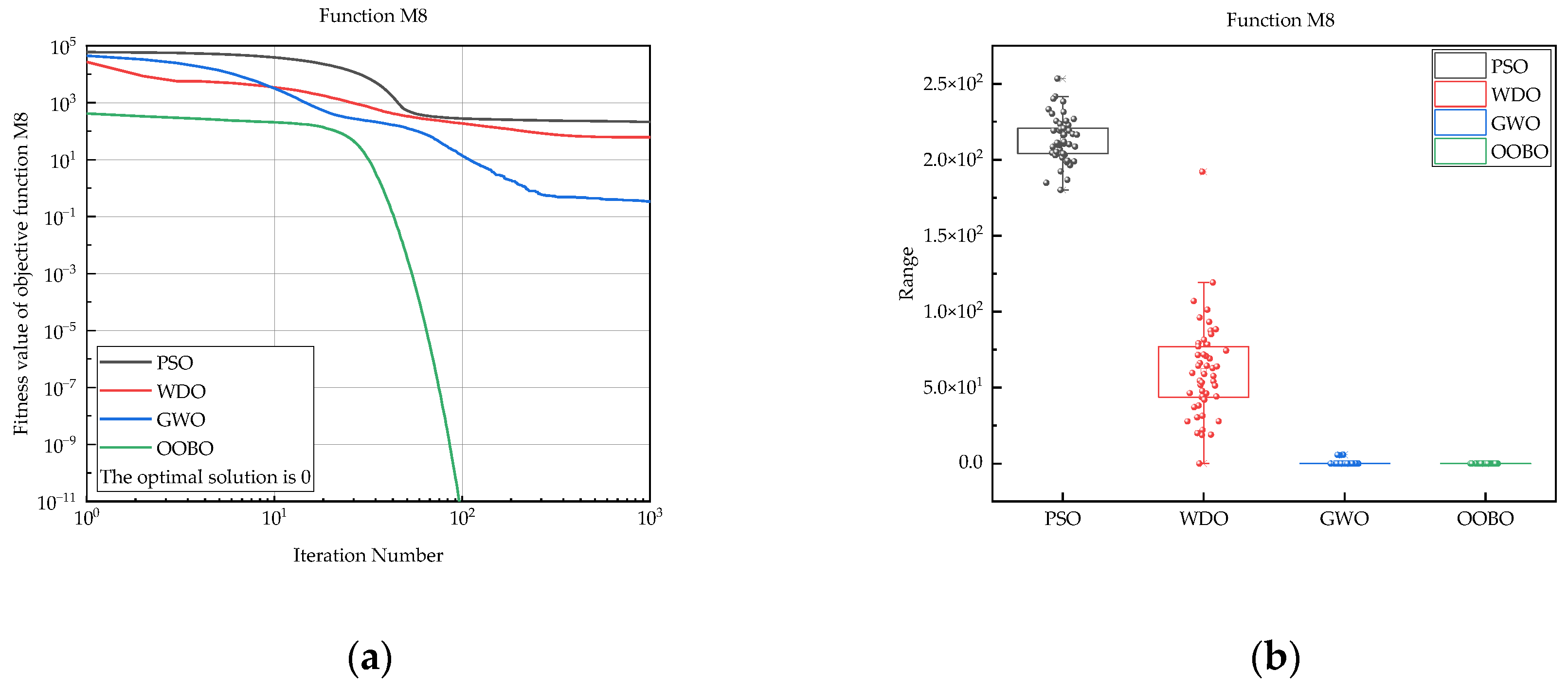{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm Name | Set Value of the Algorithm Parameters |
|---|---|
| Particle Swarm Optimization (PSO) | The population size was set to 100 individuals, the maximum number of iterations was 1000, and the speed range was confined to the interval [−2, 2]. |
| Wind Driven Optimization (WDO) | The population size was set to 100 individuals, the maximum number of iterations was 1000. |
| Grey Wolf Optimization (GWO) | The population size was set to 100 individuals, the maximum number of iterations was 1000. |
| One-to-One-Based Optimizer (OOBO) | The population size was set to 100 individuals, the maximum number of iterations was 1000. |
| Test Function | Dimension n | Variables Range | Optimal Solution |
|---|---|---|---|
| 30 | [−100, 100] | 0 | |
| 30 | [−10, 10] | 0 | |
| 30 | [−100, 100] | 0 | |
| 30 | [−10, 10] | 0 | |
| 30 | [−30, 30] | 0 | |
| 30 | [−100, 100] | 0 | |
| 30 | [−1.28, 1.28] | 0 | |
| 30 | [−5.12, 5.12] | 0 | |
| 30 | [−32, 32] | 0 | |
| 30 | [−600, 600] | 0 | |
| 30 | [−50, 50] | 0 | |
| 30 | [−50, 50] | 0 |
| Test Function | Dimension n | Variables Range | Optimal Solution |
|---|---|---|---|
| 2 | [−65, 65] | 1 | |
| 4 | [−5, 5] | 0.0003 | |
| 2 | [−5, 5] | −1.0316 | |
| 2 | [−5, 5] | 0.398 | |
| 2 | [−2, 2] | 3 | |
| 3 | [0, 1] | −3.86 | |
| 6 | [0, 1] | -3.32 | |
| 4 | [0, 10] | −10.1532 | |
| 4 | [0, 10] | −10.4028 | |
| 4 | [0, 10] | −10.5363 |
| Test Function | Algorithm Name | Optimal Value | Worst Value | Average Value | Standard Deviation |
|---|---|---|---|---|---|
| M1 | PSO | 8.80 × 100 | 1.49 × 101 | 1.19 × 101 | 1.42 × 100 |
| WDO | 5.67 × 10−47 | 1.66 × 10−37 | 3.42 × 10−39 | 2.35 × 10−38 | |
| GWO | 9.22 × 10−88 | 2.81 × 10−84 | 3.11 × 10−85 | 5.64 × 10−85 | |
| OOBO | 1.91 × 10−185 | 3.01 × 10−183 | 4.53 × 10−184 | 0 | |
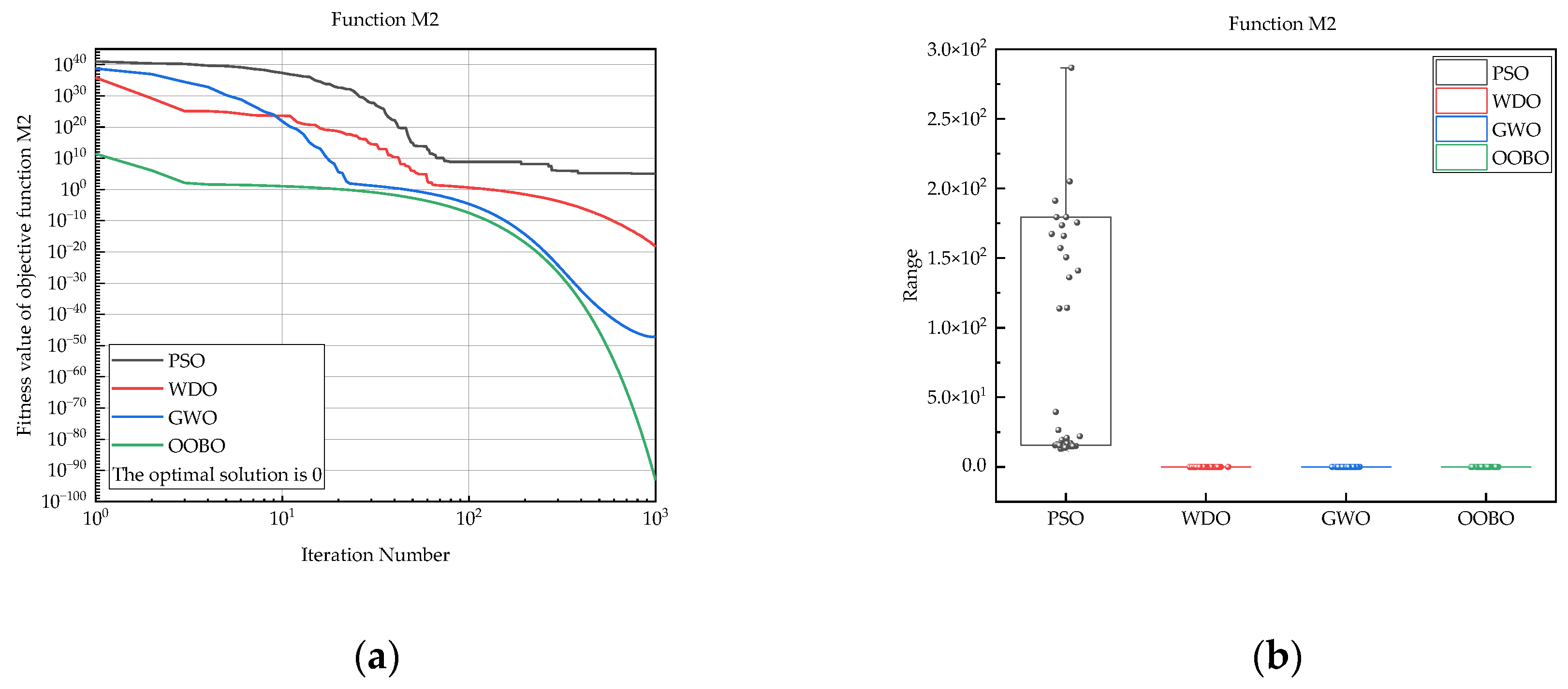
| M2 | PSO | 1.31 × 101 | 4.57 × 106 | 1.05 × 105 | 6.47 × 105 |
| WDO | 4.08 × 10−22 | 2.45 × 10−17 | 6.50 × 10−19 | 3.48 × 10−18 | |
| GWO | 4.00 × 10−49 | 1.90 × 10−47 | 5.09 × 10−48 | 4.29 × 10−48 | |
| OOBO | 1.49 × 10−94 | 2.84 × 10−93 | 7.47 × 10−94 | 5.19 × 10−94 | |
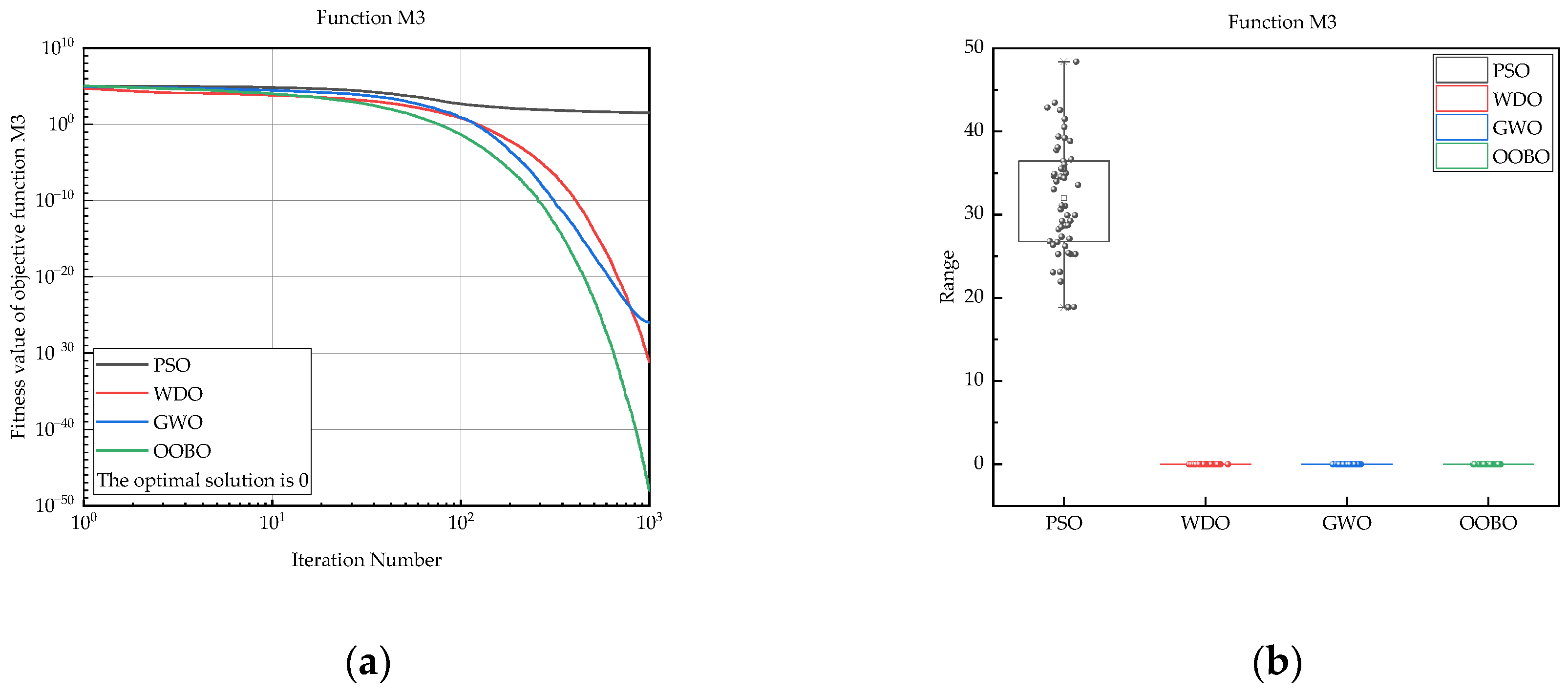
| M3 | PSO | 1.89 × 101 | 4.84 × 101 | 3.20 × 101 | 6.65 × 100 |
| WDO | 9.65 × 10−38 | 1.84 × 10−30 | 7.09 × 10−32 | 2.67 × 10−31 | |
| GWO | 4.02 × 10−33 | 2.57 × 10−25 | 1.10 × 10−26 | 4.18 × 10−26 | |
| OOBO | 1.45 × 10−57 | 4.77 × 10−47 | 9.62 × 10−49 | 6.74 × 10−48 | |
| M4 | PSO | 1.18 × 100 | 1.52 × 100 | 1.36 × 100 | 7.98 × 10−2 |
| WDO | 1.80 × 10−22 | 6.05 × 10−18 | 2.98 × 10−19 | 9.13 × 10−19 | |
| GWO | 2.98 × 10−23 | 3.53 × 10−21 | 7.11 × 10−22 | 7.30 × 10−22 | |
| OOBO | 6.04 × 10−79 | 1.23 × 10−77 | 5.03 × 10−78 | 2.99 × 10−78 | |
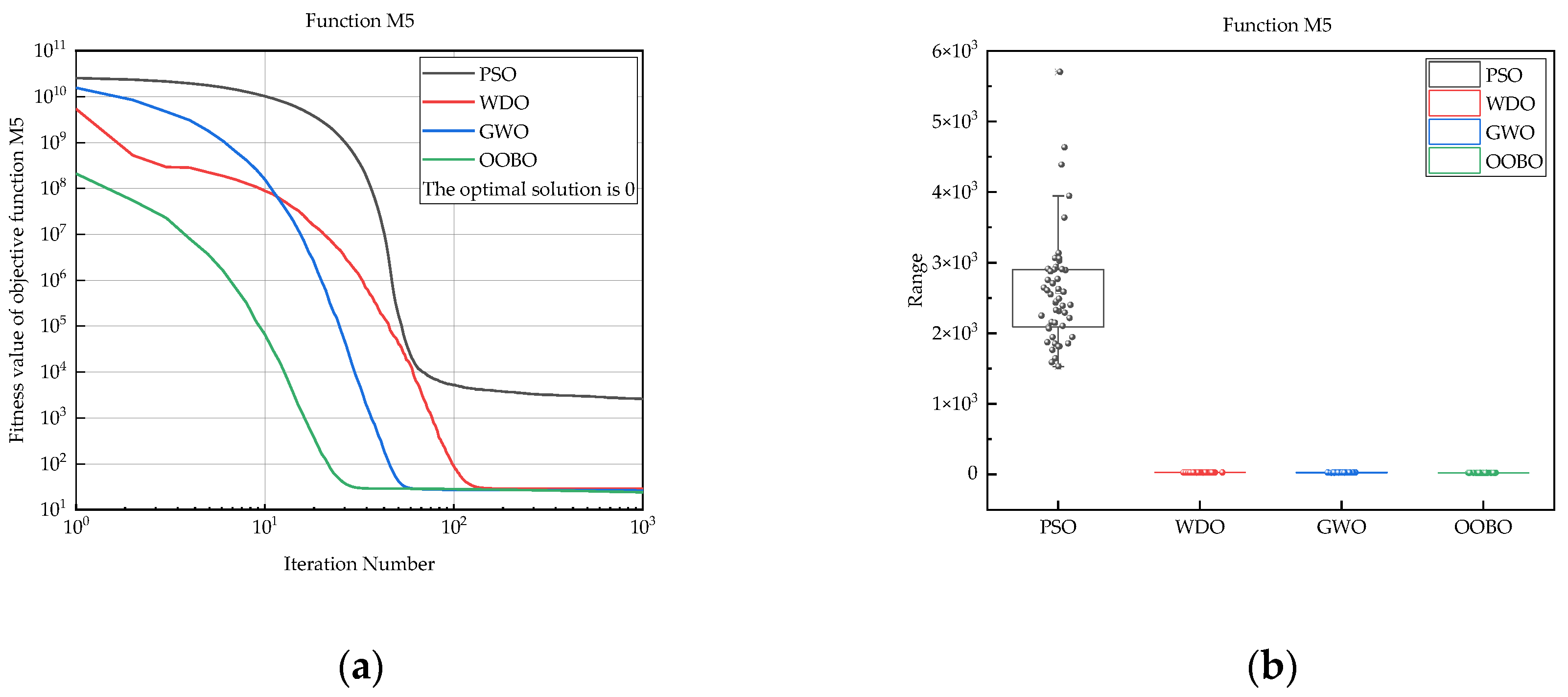
| M5 | PSO | 1.53 × 103 | 5.70 × 103 | 2.60 × 103 | 7.93 × 102 |
| WDO | 2.79 × 101 | 2.87 × 101 | 2.84 × 101 | 3.17 × 10−1 | |
| GWO | 2.48 × 101 | 2.79 × 101 | 2.63 × 101 | 7.58 × 10−1 | |
| OOBO | 2.30 × 101 | 2.47 × 101 | 2.40 × 101 | 2.17 × 10−1 | |
| M6 | PSO | 7.49 × 100 | 1.53 × 101 | 1.19 × 101 | 1.65 × 100 |
| WDO | 5.41 × 10−2 | 3.12 × 10−1 | 1.53 × 10−1 | 5.77 × 10−2 | |
| GWO | 2.05 × 10−6 | 7.11 × 10−1 | 1.74 × 10−1 | 2.01 × 10−1 | |
| OOBO | 2.54 × 10−10 | 1.77 × 10−8 | 3.65 × 10−9 | 3.99 × 10−9 | |
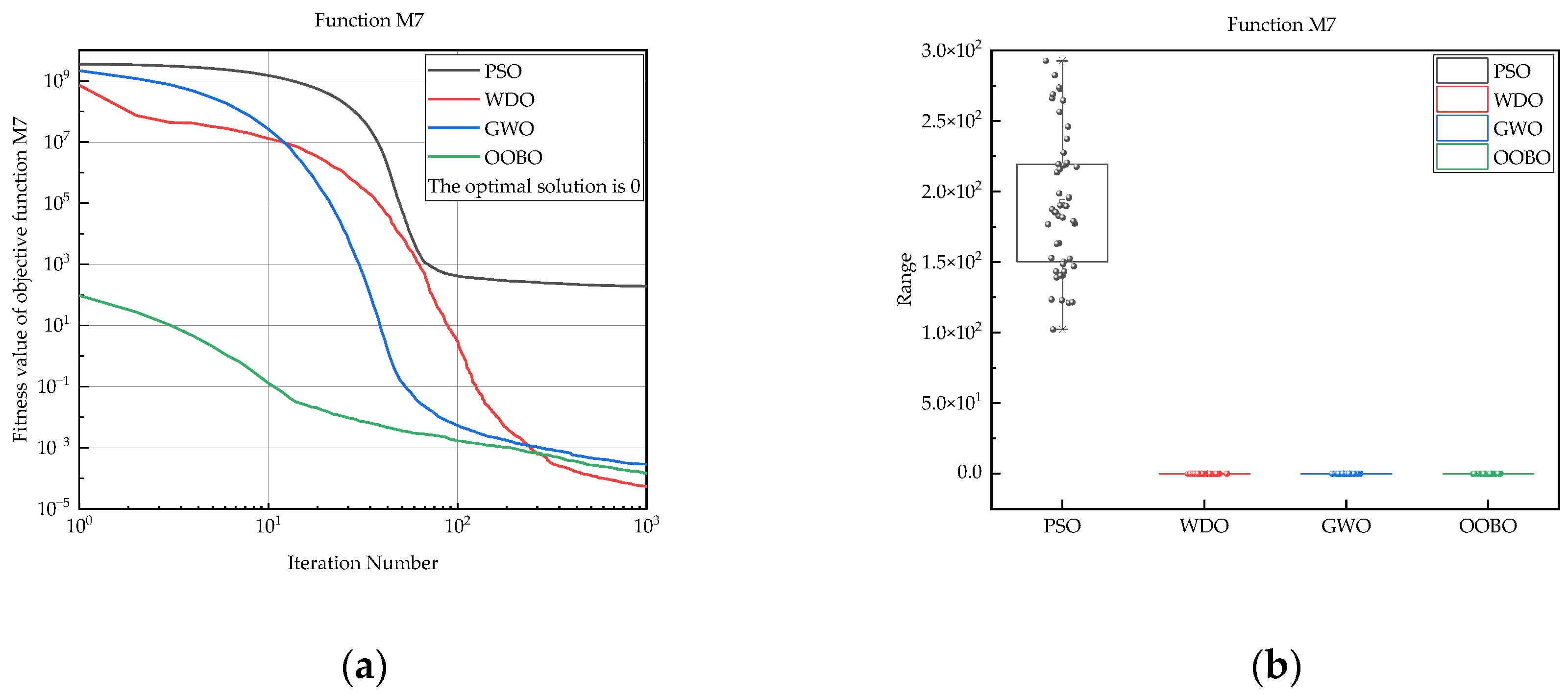
| M7 | PSO | 1.02 × 102 | 2.93 × 102 | 1.92 × 102 | 4.86 × 101 |
| WDO | 9.14 × 10−6 | 1.50 × 10−4 | 5.44 × 10−5 | 3.69 × 10−5 | |
| GWO | 4.70 × 10−5 | 1.10 × 10−3 | 2.89 × 10−4 | 1.94 × 10−4 | |
| OOBO | 1.95 × 10−5 | 2.72 × 10−4 | 1.44 × 10−4 | 6.59 × 10−5 | |
| M8 | PSO | 1.80 × 102 | 2.53 × 102 | 2.13 × 102 | 1.48 × 101 |
| WDO | 0 | 1.92 × 102 | 6.07 × 101 | 3.15 × 101 | |
| GWO | 0 | 5.70 × 100 | 3.39 × 10−1 | 1.36 × 100 | |
| OOBO | 0 | 0 | 0 | 0 | |
| M9 | PSO | 3.81 × 100 | 2.10 × 101 | 1.35 × 101 | 8.41 × 100 |
| WDO | 0 | 2.09 × 101 | 4.19 × 10−1 | 2.96 × 100 | |
| GWO | 2.06 × 101 | 2.09 × 101 | 2.08 × 101 | 7.97 × 10−2 | |
| OOBO | 4.00 × 10−15 | 7.55 × 10−15 | 4.85 × 10−15 | 1.53 × 10−15 | |
| M10 | PSO | 3.12 × 10−1 | 5.87 × 10−1 | 4.74 × 10−1 | 4.52 × 10−2 |
| WDO | 0 | 6.91 × 10−2 | 2.70 × 10−3 | 1.04 × 10−2 | |
| GWO | 0 | 1.29 × 10−2 | 9.00 × 10−4 | 3.10 × 10−3 | |
| OOBO | 0 | 0 | 0 | 0 | |
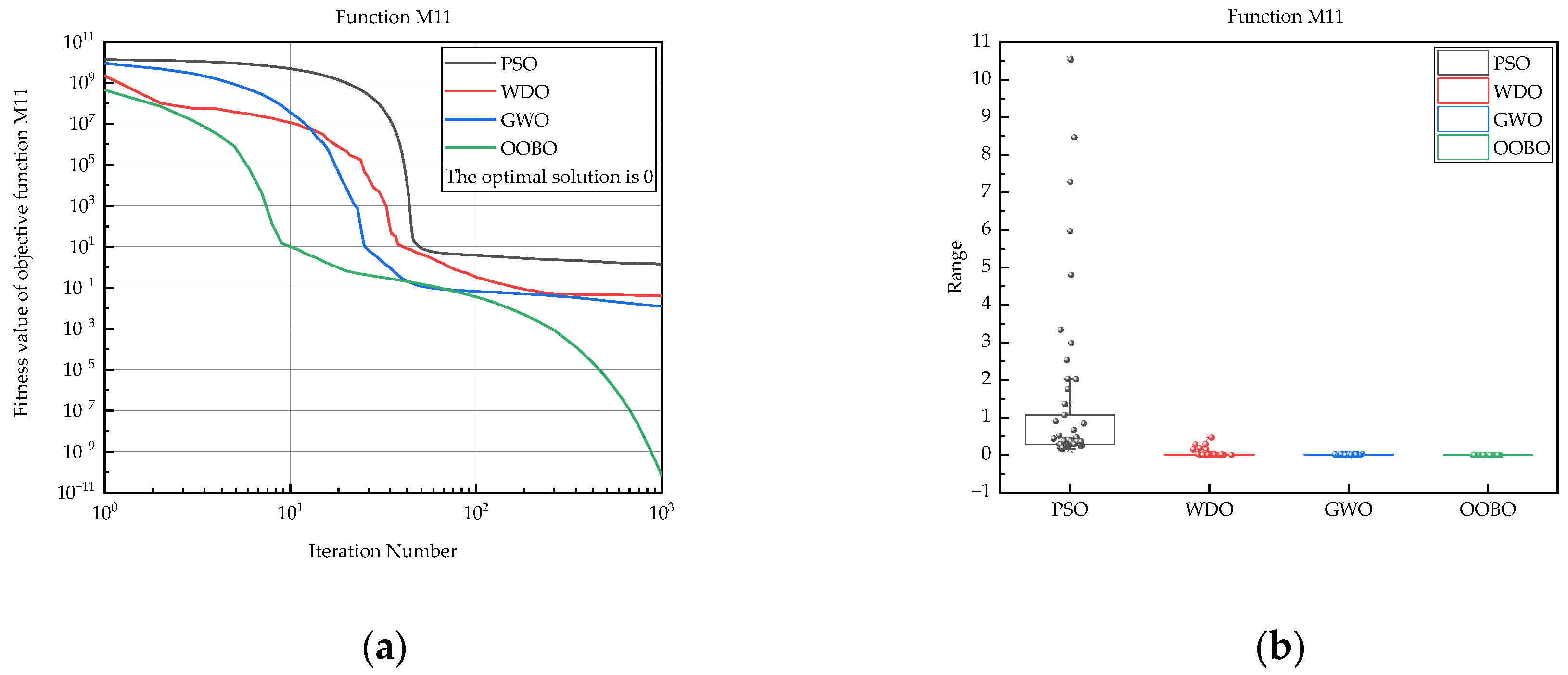
| M11 | PSO | 1.55 × 10−1 | 1.05 × 101 | 1.35 × 100 | 2.26 × 100 |
| WDO | 2.80 × 10−3 | 4.66 × 10−1 | 4.03 × 10−2 | 8.85 × 10−2 | |
| GWO | 2.64 × 10−7 | 3.32 × 10−2 | 1.27 × 10−2 | 9.06 × 10−3 | |
| OOBO | 1.32 × 10−11 | 4.44 × 10−10 | 6.61 × 10−11 | 6.56 × 10−11 | |
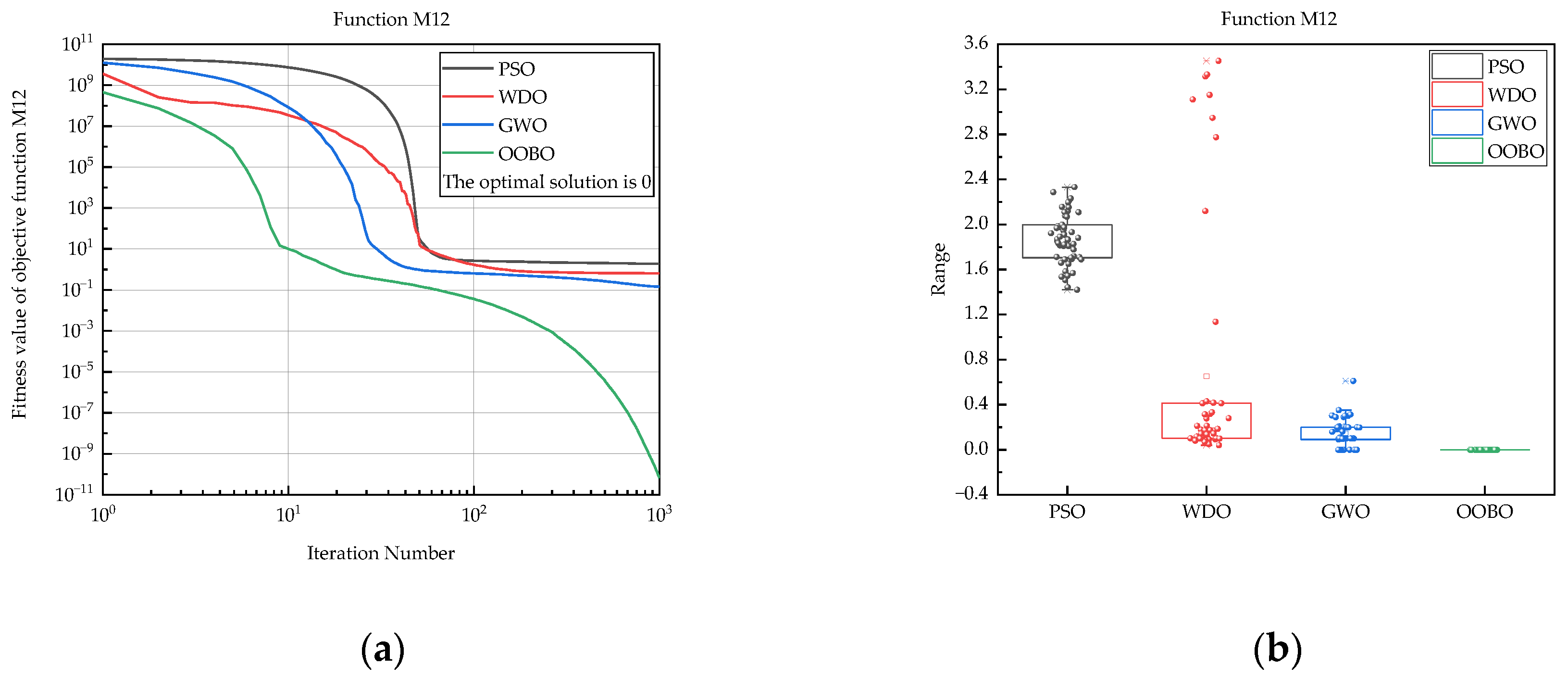
| M12 | PSO | 1.42 × 100 | 2.33 × 100 | 1.87 × 100 | 2.24 × 10−1 |
| WDO | 3.99 × 10−2 | 3.45 × 100 | 6.51 × 10−1 | 1.07 × 100 | |
| GWO | 4.18 × 10−6 | 6.10 × 10−1 | 1.43 × 10−1 | 1.22 × 10−1 | |
| OOBO | 1.32 × 10−11 | 4.44 × 10−10 | 6.61 × 10−11 | 6.56 × 10−11 | |
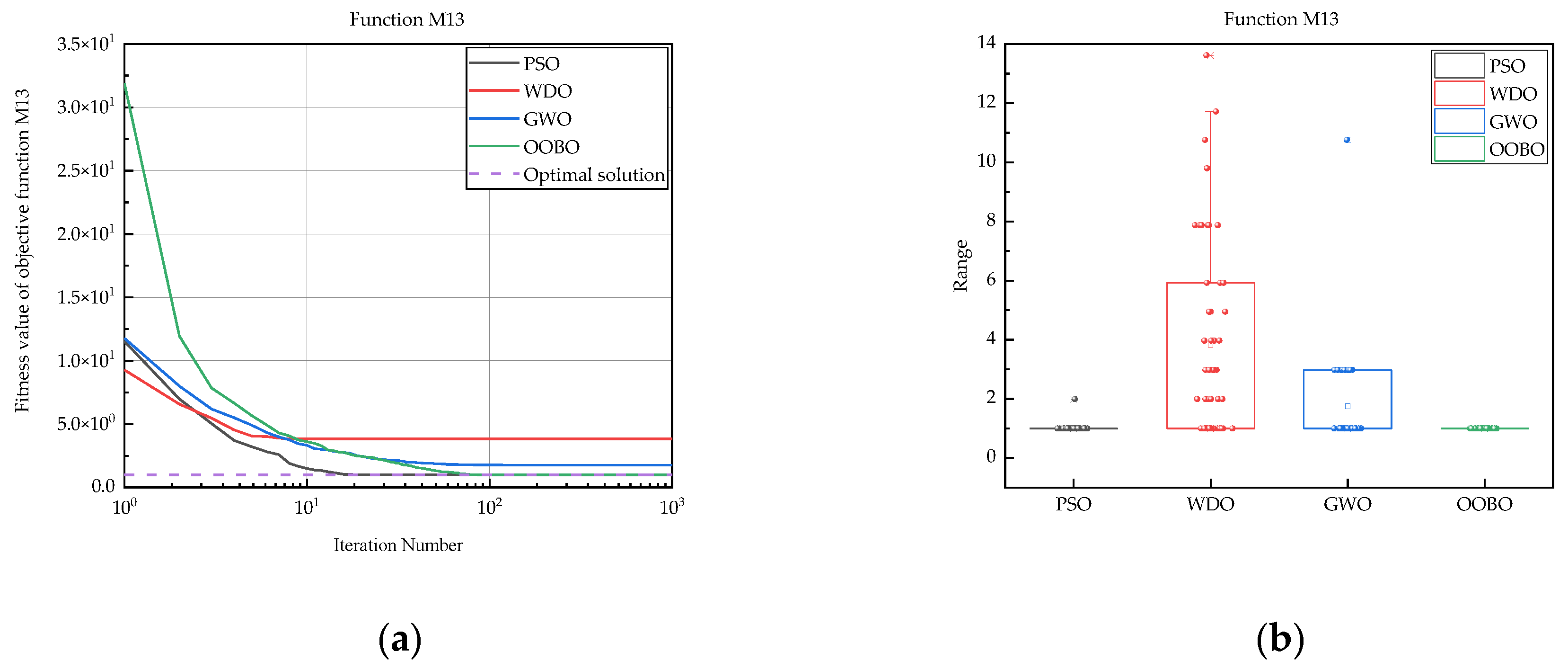
| M13 | PSO | 9.98 × 10−1 | 1.99 × 100 | 1.02 × 100 | 1.41 × 10−1 |
| WDO | 9.98 × 10−1 | 1.36 × 101 | 3.83 × 100 | 3.25 × 100 | |
| GWO | 9.98 × 10−1 | 1.08 × 101 | 1.75 × 100 | 1.58 × 100 | |
| OOBO | 9.98 × 10−1 | 9.98 × 10−1 | 9.98 × 10−1 | 0 | |
| M14 | PSO | 5.03 × 10−4 | 1.23 × 10−3 | 7.89 × 10−4 | 1.33 × 10−4 |
| WDO | 3.08 × 10−4 | 2.04 × 10−2 | 1.20 × 10−3 | 3.96 × 10−3 | |
| GWO | 3.07 × 10−4 | 5.65 × 10−2 | 2.25 × 10−3 | 8.78 × 10−3 | |
| OOBO | 3.07 × 10−4 | 3.07 × 10−4 | 3.07 × 10−4 | 4.16 × 10−18 | |
| M15 | PSO | −1.03 × 100 | −1.03 × 100 | −1.03 × 100 | 8.04 × 10−5 |
| WDO | −1.03 × 100 | −1.03 × 100 | −1.03 × 100 | 2.39 × 10−5 | |
| GWO | −1.03 × 100 | −1.03 × 100 | −1.03 × 100 | 4.31 × 10−10 | |
| OOBO | −1.03 × 100 | −1.03 × 100 | −1.03 × 100 | 2.56 × 10−16 | |
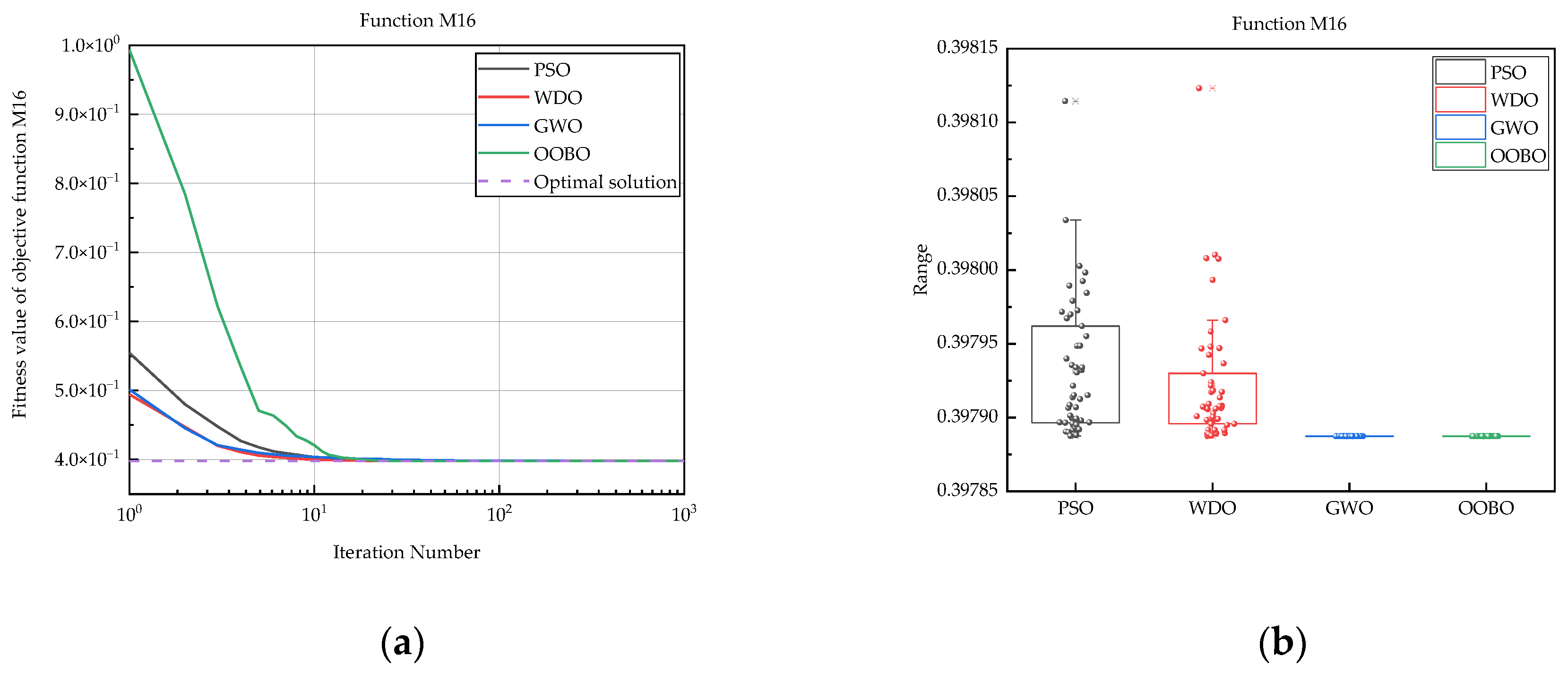
| M16 | PSO | 3.98 × 10−1 | 3.98 × 10−1 | 3.98 × 10−1 | 4.63 × 10−5 |
| WDO | 3.98 × 10−1 | 3.98 × 10−1 | 3.98 × 10−1 | 4.36 × 10−5 | |
| GWO | 3.98 × 10−1 | 3.98 × 10−1 | 3.98 × 10−1 | 2.04 × 10−8 | |
| OOBO | 3.98 × 10−1 | 3.98 × 10−1 | 3.98 × 10−1 | 0 | |
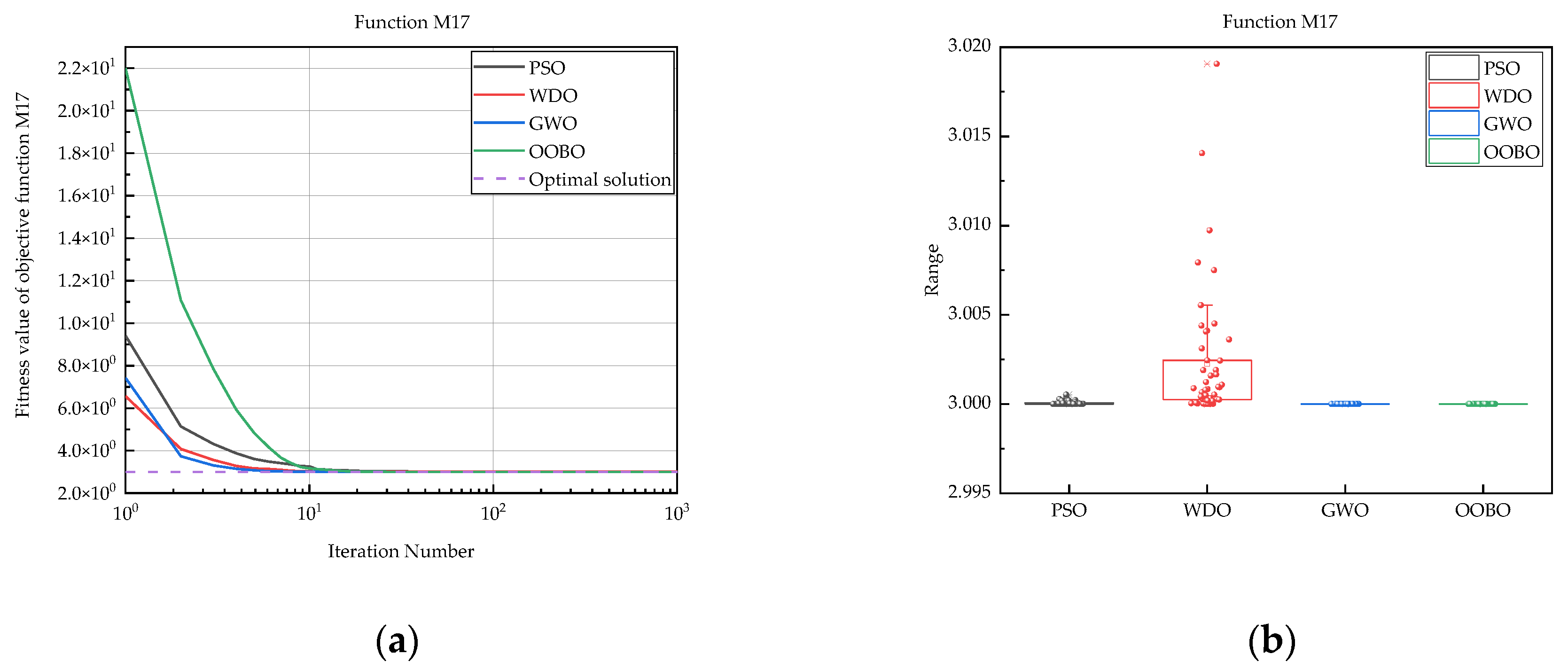
| M17 | PSO | 3.00 × 100 | 3.00 × 100 | 3.00 × 100 | 1.05 × 10−4 |
| WDO | 3.00 × 100 | 3.02 × 100 | 3.00 × 100 | 3.73 × 10−3 | |
| GWO | 3.00 × 100 | 3.00 × 100 | 3.00 × 100 | 8.14 × 10−7 | |
| OOBO | 3.00 × 100 | 3.00 × 100 | 3.00 × 100 | 5.46 × 10−16 | |
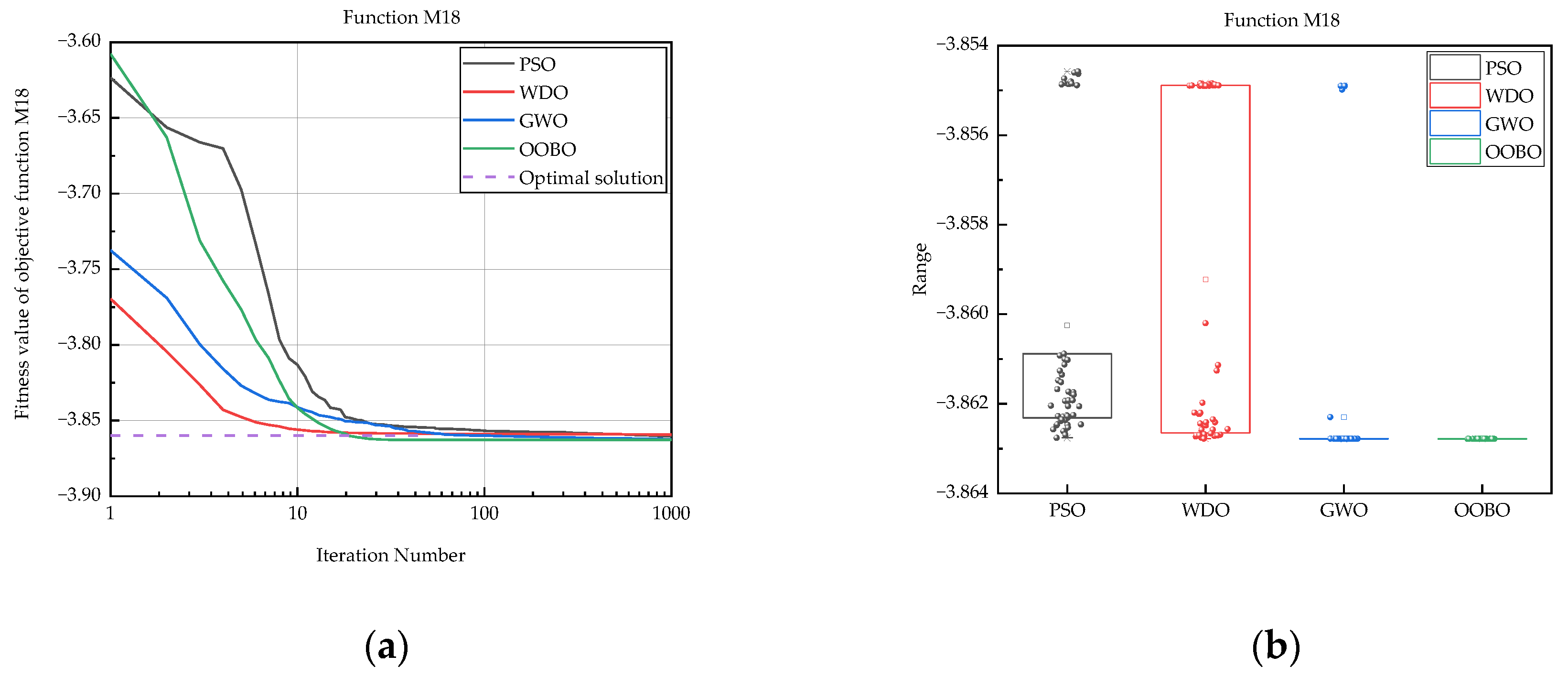
| M18 | PSO | −3.86 × 100 | −3.85 × 100 | −3.86 × 100 | 3.14 × 10−3 |
| WDO | −3.86 × 100 | −3.85 × 100 | −3.86 × 100 | 3.76 × 10−3 | |
| GWO | −3.86 × 100 | −3.85 × 100 | −3.86 × 100 | 1.88 × 10−3 | |
| OOBO | −3.86 × 100 | −3.86 × 100 | −3.86 × 100 | 1.28 × 10−15 | |
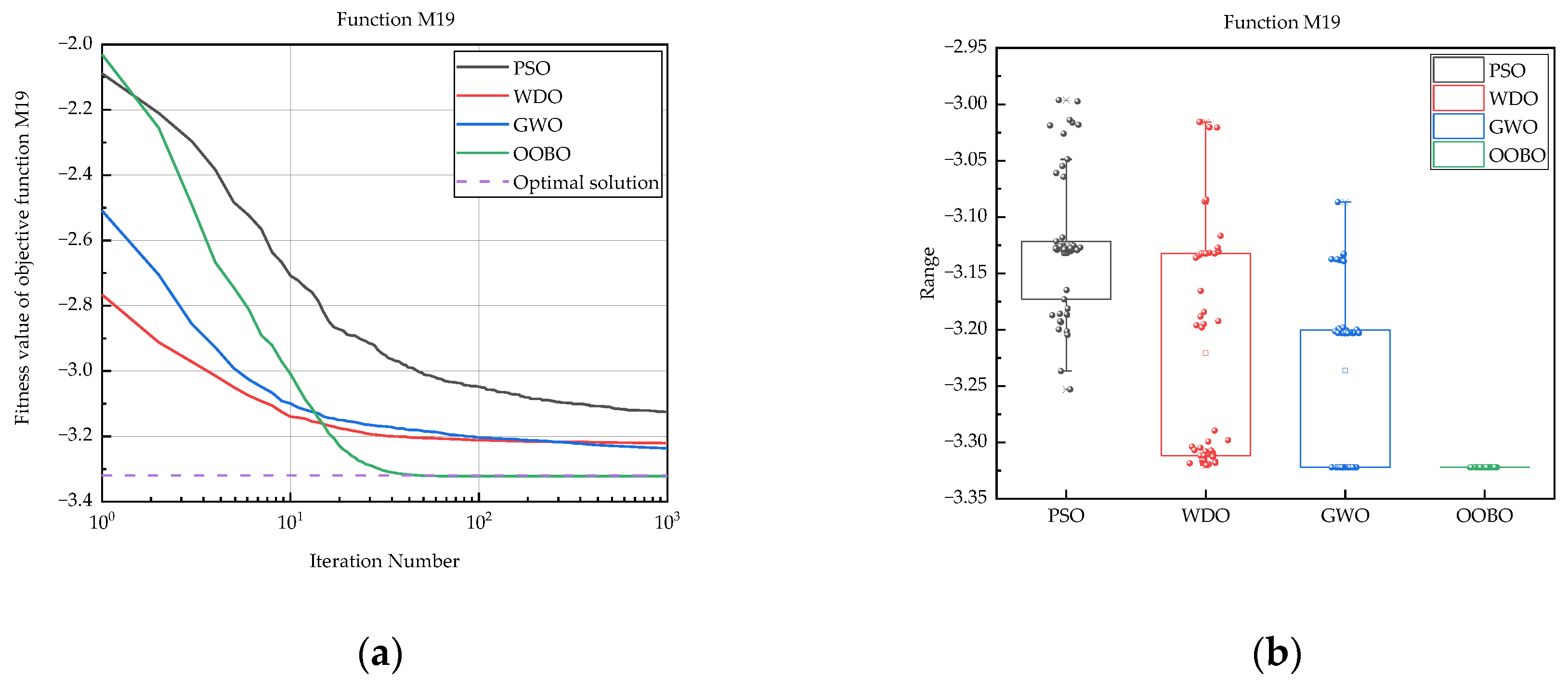
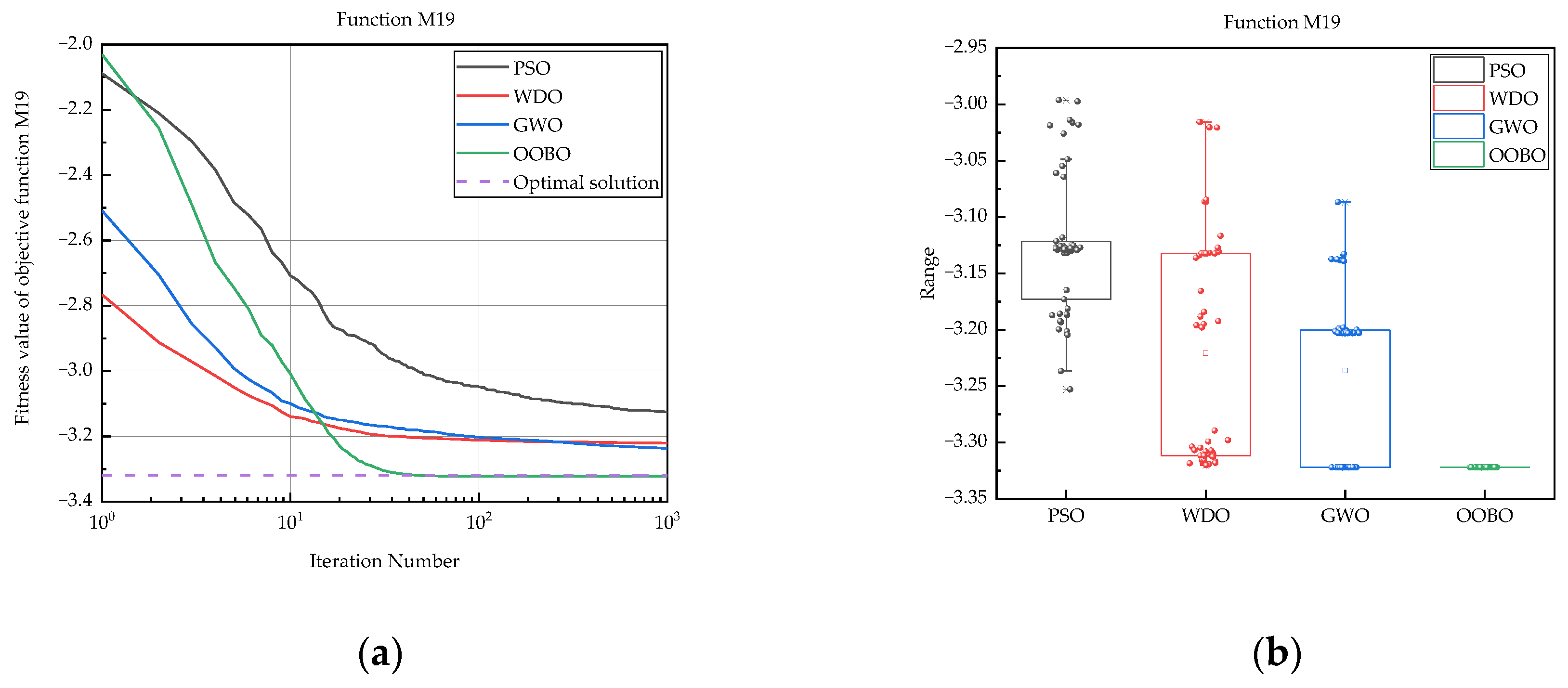
| M19 | PSO | −3.25 × 100 | −3.00 × 100 | −3.13 × 100 | 6.17 × 10−2 |
| WDO | −3.32 × 100 | −3.02 × 100 | −3.22 × 100 | 1.03 × 10−1 | |
| GWO | −3.32 × 100 | −3.09 × 100 | −3.24 × 100 | 7.27 × 10−2 | |
| OOBO | −3.32 × 100 | −3.32 × 100 | −3.32 × 100 | 9.19 × 10−16 | |
| M20 | PSO | −1.00 × 101 | −2.57 × 100 | −7.83 × 100 | 2.32 × 100 |
| WDO | −1.00 × 101 | −2.43 × 100 | −6.78 × 100 | 2.25 × 100 | |
| GWO | −1.02 × 101 | −5.10 × 100 | −9.75 × 100 | 1.38 × 100 | |
| OOBO | −1.02 × 101 | −1.02 × 101 | −1.02 × 101 | 3.31 × 10−15 | |
| M21 | PSO | −1.03 × 101 | −2.69 × 100 | −8.91 × 100 | 1.93 × 100 |
| WDO | −1.02 × 101 | −2.73 × 100 | −7.21 × 100 | 2.28 × 100 | |
| GWO | −1.04 × 101 | −5.09 × 100 | −9.98 × 100 | 1.46 × 100 | |
| OOBO | −1.04 × 101 | −1.04 × 101 | −1.04 × 101 | 1.32 × 10−15 | |
| M22 | PSO | −1.05 × 101 | −5.05 × 100 | −9.71 × 100 | 1.01 × 100 |
| WDO | −1.04 × 101 | −2.24 × 100 | −7.66 × 100 | 2.28 × 100 | |
| GWO | −1.05 × 101 | −1.05 × 101 | −1.05 × 101 | 2.30 × 10−5 | |
| OOBO | −1.05 × 101 | −1.05 × 101 | −1.05 × 101 | 1.78 × 10−15 |
| Test Function | PSO | WDO | GWO | OOBO |
|---|---|---|---|---|
| M1 | 124.84 | 141.64 | 252.19 | 18.21 |
| M2 | 164.82 | 189.57 | 288.32 | 19.24 |
| M3 | 83.69 | 88.55 | 359.98 | 46.03 |
| M4 | 67.19 | 75.68 | 252.44 | 50.33 |
| M5 | 152.42 | 170.51 | 239.31 | 19.78 |
| M6 | 52.03 | 58.68 | 248.02 | 39.56 |
| M7 | 65.53 | 70.62 | 295.72 | 32.71 |
| M8 | 55.89 | 61.67 | 283.99 | 40.12 |
| M9 | 54.09 | 58.45 | 189.70 | 17.11 |
| M10 | 55.59 | 59.49 | 286.42 | 179.16 |
| M11 | 56.51 | 61.22 | 404.10 | 193.20 |
| M12 | 301.68 | 328.69 | 429.65 | 377.48 |
| M13 | 94.61 | 99.99 | 88.67 | 130.31 |
| M14 | 58.38 | 70.73 | 51.73 | 17.83 |
| M15 | 27.21 | 31.41 | 27.01 | 17.90 |
| M16 | 84.24 | 108.38 | 63.63 | 62.39 |
| M17 | 19.14 | 22.58 | 16.75 | 52.94 |
| M18 | 50.07 | 62.08 | 41.34 | 18.46 |
| M19 | 89.01 | 104.55 | 83.23 | 18.73 |
| M20 | 37.61 | 42.93 | 36.26 | 26.64 |
| M21 | 27.77 | 33.27 | 28.82 | 23.18 |
| M22 | 30.88 | 35.25 | 32.29 | 23.83 |
| Test Function | Five Dimensions | Ten Dimensions | Fifteen Dimensions | Twenty Dimensions | Twenty-Five Dimensions | Thirty Dimensions |
|---|---|---|---|---|---|---|
| M1 | 74.64 | 132.27 | 169.67 | 193.74 | 212.27 | 252.19 |
| M2 | 83.31 | 140.04 | 151.74 | 140.8 | 247.75 | 288.32 |
| M3 | 107.39 | 154.49 | 175.64 | 224.92 | 312.99 | 359.98 |
| M4 | 78.59 | 120.41 | 150.56 | 186.84 | 250.18 | 252.44 |
| M5 | 86.99 | 144.78 | 160.22 | 164.93 | 172.09 | 239.31 |
| M6 | 41.44 | 129.24 | 139.13 | 185.97 | 190.61 | 248.02 |
| M7 | 87.47 | 87.81 | 135.67 | 195.84 | 204.18 | 295.72 |
| M8 | 79.57 | 97.59 | 120.83 | 151.63 | 236.02 | 283.99 |
| M9 | 87.28 | 94.01 | 109.18 | 109.40 | 184.07 | 189.70 |
| M10 | 112.66 | 140.00 | 165.53 | 176.59 | 270.12 | 286.42 |
| M11 | 153.39 | 176.45 | 195.9 | 265.19 | 324.81 | 404.10 |
| M12 | 157.78 | 214.7 | 245.1 | 302.79 | 393.51 | 429.65 |
| Average Value | Standard Deviation Value | ||||||
|---|---|---|---|---|---|---|---|
| Test Function | PSO | WDO | GWO | PSO | WDO | GWO | |
| rij | M1 | 4 | 3 | 2 | 1 | 4 | 3 |
| M2 | 4 | 3 | 2 | 1 | 4 | 3 | |
| M3 | 4 | 2 | 3 | 1 | 4 | 2 | |
| M4 | 4 | 3 | 2 | 1 | 4 | 3 | |
| M5 | 4 | 3 | 2 | 1 | 4 | 2 | |
| M6 | 4 | 2 | 3 | 1 | 4 | 2 | |
| M7 | 4 | 1 | 3 | 2 | 4 | 1 | |
| M8 | 4 | 3 | 2 | 1 | 4 | 3 | |
| M9 | 2 | 4 | 3 | 1 | 4 | 3 | |
| M10 | 4 | 3 | 2 | 1 | 4 | 3 | |
| M11 | 4 | 3 | 2 | 1 | 4 | 3 | |
| M12 | 4 | 3 | 2 | 1 | 3 | 4 | |
| M13 | 2 | 4 | 3 | 1 | 2 | 4 | |
| M14 | 2 | 3 | 4 | 1 | 2 | 3 | |
| M15 | 4 | 3 | 2 | 1 | 4 | 3 | |
| M16 | 4 | 3 | 2 | 1 | 4 | 3 | |
| M17 | 4 | 3 | 2 | 1 | 3 | 4 | |
| M18 | 4 | 3 | 2 | 1 | 3 | 4 | |
| M19 | 4 | 3 | 2 | 1 | 2 | 4 | |
| M20 | 4 | 3 | 2 | 1 | 4 | 3 | |
| M21 | 3 | 4 | 2 | 1 | 3 | 4 | |
| M22 | 3 | 4 | 2 | 1 | 3 | 4 | |
| Rj | 35 | 21 | 16 | 34 | 23 | 15 | |
| Algorithm Name | Sample Size k | Freedom Degree n | Significance Level Set θ | F-Test Critical Value Fθ (n, k) | Statistics Calculated Value |
|---|---|---|---|---|---|
| Friedman test result (Average value) | 4 | 22 | 0.05 | 5.79 | 48.71 |
| Friedman test result (Standard deviation value) | 4 | 22 | 43.04 |
| PSO | WDO | GWO | OOBO | |
|---|---|---|---|---|
| Mean-rank ordering (Mean) | 3.64 | 3.00 | 2.32 | 1.04 |
| Mean-rank ordering (Standard deviation) | 3.50 | 3.09 | 2.27 | 1.14 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, X.; Xu, R.; Yu, W.; Wu, S. Evaluation and Analysis of Heuristic Intelligent Optimization Algorithms for PSO, WDO, GWO and OOBO. Mathematics 2023, 11, 4531. https://doi.org/10.3390/math11214531
Huang X, Xu R, Yu W, Wu S. Evaluation and Analysis of Heuristic Intelligent Optimization Algorithms for PSO, WDO, GWO and OOBO. Mathematics. 2023; 11(21):4531. https://doi.org/10.3390/math11214531
Chicago/Turabian StyleHuang, Xiufeng, Rongwu Xu, Wenjing Yu, and Shiji Wu. 2023. "Evaluation and Analysis of Heuristic Intelligent Optimization Algorithms for PSO, WDO, GWO and OOBO" Mathematics 11, no. 21: 4531. https://doi.org/10.3390/math11214531
APA StyleHuang, X., Xu, R., Yu, W., & Wu, S. (2023). Evaluation and Analysis of Heuristic Intelligent Optimization Algorithms for PSO, WDO, GWO and OOBO. Mathematics, 11(21), 4531. https://doi.org/10.3390/math11214531