Abstract
In this paper, we introduce a cutting-edge system that leverages state-of-the-art deep learning methodologies to generate high-quality synthetic thermal face images. Our unique approach integrates a thermally fine-tuned Stable Diffusion Model with a Vision Transformer (ViT) classifier, augmented by a Prompt Designer and Prompt Database for precise image generation control. Through rigorous testing across various scenarios, the system demonstrates its capability in producing accurate and superior-quality thermal images. A key contribution of our work is the development of a synthetic thermal face image database, offering practical utility for training thermal detection models. The efficacy of our synthetic images was validated using a facial detection model, achieving results comparable to real thermal face images. Specifically, a detector fine-tuned with real thermal images achieved a 97% accuracy rate when tested with our synthetic images, while a detector trained exclusively on our synthetic data achieved an accuracy of 98%. This research marks a significant advancement in thermal image synthesis, paving the way for its broader application in diverse real-world scenarios.
MSC:
68T07
1. Introduction
In recent years, artificial intelligence and deep learning models have achieved significant advancements, providing robust solutions in recognition, detection, generation, and classification tasks [1,2,3]. These models predominantly rely on substantial datasets, captured using conventional visible cameras, to effectively generalize input distributions.
However, these visible cameras face inherent limitations; they cannot operate efficiently in complete darkness or discern temperature distributions. Thermal cameras, in contrast, can capture images in total darkness, detecting the infrared energy or ‘heat signatures’ emitted by objects. This unique capability of thermal cameras to record the apparent surface temperature of subjects under observation opens novel avenues in the domain of computer vision.
The evolving landscape of computer vision and deep learning has presented new challenges and opportunities. As the applications of thermal imaging grow, ranging from security surveillance to healthcare diagnostics, the need for rich and diverse datasets becomes increasingly apparent. However, the acquisition of genuine thermal images is resource-intensive, often constrained by privacy concerns, environmental conditions, and equipment costs. This gap between the potential of thermal imaging and the availability of adequate datasets to harness its full capabilities underlines the motivation for our work. By developing a system to autonomously generate high-quality synthetic thermal images, we aim to bridge this gap, providing the research community with tools and resources to push the boundaries of what is possible with thermal imaging in the realm of AI.
Merging the capabilities of thermal cameras with deep learning models can unlock impactful solutions, such as facial detection in complete darkness (see Figure 1), disease prediction based on body temperature, and machinery overheating prevention, to name but a few. Nevertheless, while deep learning models have excelled in generating and recognizing non-thermal 2D face images, applying them directly to thermal images is challenging. This is primarily because visible-light cameras capture reflected photons, whereas thermal cameras detect emitted infrared radiation, introducing unfamiliar patterns that can affect model performance.
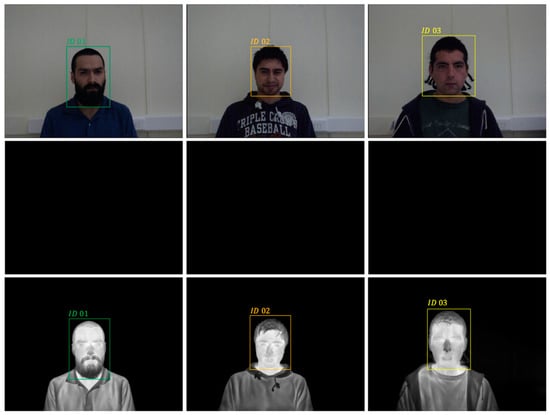
Figure 1.
Comparison of visible and thermal face detection: (top) visual detector with light, (middle) visual detector without light, and (bottom) thermal detector without light.
The dearth of extensive thermal datasets compared to visible images poses another challenge. Creating new thermal samples using thermal cameras and annotators is an option, but it is time-consuming and costly, and requires substantial human intervention. An innovative solution lies in employing deep learning-based generative models to produce these samples, circumventing these challenges.
In this context, our work introduces a novel approach: a model designed to autonomously generate high-quality thermal samples, negating the need for manual oversight or labeling. Built upon the foundation of Stable Diffusion [4] and leveraging a thermal classifier based on Vision Transformers (ViTs) [5], our model distinguishes between high- and low-quality samples. This differentiation is crucial, offering feedback that influences our prompt designer, which, in turn, modulates the input text to refine the generation process.
This model’s introduction has culminated in a comprehensive dataset, primed for training deep learning algorithms in tasks like face recognition and facial expression recognition. Importantly, each sample in this dataset is autonomously generated, ensuring a high-quality, unsupervised data creation process.
To substantiate the efficacy of our system, we utilize face detection models, gauging the quality and variability of the generated samples. The outcome is a facial detection model adept at recognizing identities in pitch-black conditions using thermal cameras, marking a pivotal contribution to computer vision.
Moreover, the adaptability of our proposed model, with its ability to generate samples that can be fine-tuned to diverse styles, signifies its versatility and its potential as a tool for various tasks, including image classification, face detection, and face recognition. In essence, our research presents an efficient, cost-effective automatic generation model, marking a significant stride in producing high-quality thermal data, while emphasizing the novelty of applying cutting-edge techniques to thermal image synthesis.
2. Related Work
In this section, we explore the current state of the art in synthetic image generation, diffusion probabilistic models, and text-to-image generation. This analysis offers a contemporary perspective on the applicability of deep learning-based models for generation purposes.
2.1. State of the Art
Image generation is a rapidly evolving and critical task in the field of computer vision. Deep learning techniques have been instrumental in revolutionizing this domain, leading to the generation of highly realistic images across various applications.
Recent research in the field of text-to-image generation has witnessed significant advancements in multimodal models and innovative approaches. Reference [6] proposes a method to fuse frozen text-only large language models (LLMs) with pre-trained image encoder and decoder models, demonstrating a wide suite of multimodal capabilities, including image retrieval, novel image generation, and multimodal dialogue. It achieves strong performance on image generation, offering an efficient mapping network to ground the LLM to an off-the-shelf text-to-image generation model. Reference [7] introduces Prompt-Free Diffusion, eliminating the need for text prompts in text-to-image generation. It relies solely on visual inputs, outperforming prior exemplar-based approaches and offering extensibility to various downstream applications. Reference [8] presents an anytime diffusion-based method that enhances image generation by allowing the process to be stopped at arbitrary times, resulting in improved intermediate generation quality and computational efficiency. Reference [9] focuses on subject-driven text-to-image generation and introduces BLIP-Diffusion, supporting multimodal control using subject images and text prompts. It enables zero-shot subject-driven generation and efficient fine-tuning for customized subjects. Reference [10] extends conditional generation capabilities by introducing DiffBlender, a multimodal text-to-image diffusion model that incorporates diverse modalities alongside text prompts, facilitating fine-grained customization and imaginative generation while retaining the knowledge of large-scale generative models.
In the domain of conditional generation, reference [11] focuses on training generation models at an unprecedented scale to achieve high-quality and diverse image synthesis. The authors introduce orthogonal regularization to improve the generator’s fidelity and variety, setting new benchmarks in class-conditional image synthesis. Reference [12] explores diffusion models, demonstrating their superior image sample quality in unconditional image synthesis. The paper further enhances sample quality with classifier guidance, achieving impressive results on ImageNet datasets with improved diversity and fidelity. SparseGNV [13] addresses the challenge of generating novel views of indoor scenes with sparse input views. This framework leverages 3D structures and generative models to efficiently create novel views, outperforming state-of-the-art methods in terms of photorealism and view consistency. The NoisyTwins method [14] introduces an augmentation strategy and decorrelation techniques to preserve intra-class diversity, establishing a new state of the art in large-scale long-tailed datasets. Implicit neural representations (INR) are the focus of reference [15], which introduces a polynomial-based approach to representing images. This innovative method eliminates the need for positional encodings and outperforms existing generative models on large datasets like ImageNet, with fewer trainable parameters. The Intra-Event Aware GAN (IEA-GAN) [16] generates correlated layer-dependent images for high-resolution detector responses, offering a cost-efficient solution for simulation-based inference and event generation. PE-GAN [17] is an on-demand PXD background generator using conditional generation with contrastive learning. This approach efficiently produces background noise for fine-grained PXD data, reducing storage requirements and enhancing image fidelity. In the context of semi-supervised generative and classification tasks, dual pseudo training DPT [18] achieves state-of-the-art performance by training a classifier on partially labeled data, training a generative model with pseudo-labels, and retraining the classifier with a mix of real and pseudo images. MaskSketch [19] is a conditional image generation method that allows spatial conditioning using guiding sketches. This method leverages self-attention maps of a masked generative transformer to achieve structure-guided image generation, outperforming existing methods in sketch-to-image translation and unpaired image-to-image translation.
In image inpainting, reference [20] introduces the T-Former, a resolution-aware network for efficient inpainting. Reference [21] focuses on Inst-Inpaint, allowing object removal with natural language input. CoPaint [22] minimizes incoherence in inpainting results. CoordFill [23] is an efficient high-resolution inpainting method. Reference [24] utilizes SDE for image restoration.
Image-to-image translation research includes UNSB [25] for unpaired tasks. Reference [26] enhances UVCGAN with modern advancements. Reference [27] explores 3D-aware generators for multi-class translation. In histopathology, image-to-image translation is used for stain transfer, as evaluated in reference [28].
The introduction of Generative Adversarial Networks (GANs) by Goodfellow et al. in 2014 [29] marked a significant milestone in image synthesis. Since then, numerous advancements have led to the development of more sophisticated GAN architectures. One such advancement is StyleGAN2 [29], which is a model that significantly improved upon its predecessor by eliminating the progressive growth technique, resulting in enhanced stability when generating high-resolution images. Unlike StyleGAN, which placed greater emphasis on lower-resolution styles, StyleGAN2 focused more on maintaining image quality throughout various resolutions. Consequently, the artifacts caused by the model’s previous inclination towards eye and mouth placement have been mitigated. As a result, StyleGAN2 ADA [30] introduces notable enhancements, which introduced adaptive discriminator augmentation techniques to enhance the stability and quality of images generated from the improved GAN model [29]. Building on the success of its predecessors, StyleGAN3 [31] further extends the capabilities of adversarial networks. It introduces novel architectural changes and optimization strategies, resulting in even more realistic and visually appealing image synthesis.
In addition to traditional image generation, the combination of GANs with other techniques has led to the development of conditional generation models. For instance, Pix2Pix [32], proposed by Isola et al., leverages paired training data to generate images conditioned on specific attributes or input images.
The field of text-to-image generation has seen significant advancements, with several pioneering approaches driving progress [4,13,33,34,35,36,37,38,39,40,41]. Among these, AlignDraw [42] played a crucial role by introducing a visionary perspective of generating images from textual descriptions. Building upon this foundation, Text-conditional GAN [43] emerged as a groundbreaking architecture, becoming the first end-to-end solution to effectively generate images from text. Recently, Diffusion models such as Stable Diffusion and Latent Diffusion have garnered significant attention in the field of image generation from text [1,4,44,45]. These models have demonstrated impressive generalization abilities, which have been further augmented through the integration of specialized techniques during the fine-tuning process. Among these techniques is DreamBooth [46].
2.2. Diffusion Models for Image Generation
Denoising diffusion probabilistic models (DDPMs) [47] are generative models that learn to generate data from noise through a process involving Markov chains. The forward process introduces noise to the data, transforming them into a Gaussian distribution. This process is defined by the transition kernel:
Noisy samples, denoted as , …, , are generated, with the step sizes being governed by a variance schedule .
The reverse process, however, is more complex. It aims to reverse the forward process by learning a reverse transition kernel that approximates the true posterior distribution. Due to the intractability of the true posterior, a variational approach is used, introducing an approximate posterior conditioned only on the current and final state of the Markov chain: .
The reverse transition kernel is parameterized by a deep neural network, such as U-NET [48], trained to minimize the Kullback–Leibler (KL) divergence between the approximate and true posterior. The reverse process is then performed by iteratively applying the reverse transition kernel, starting from a sample of noise, generating a sample from the data distribution. An example of the process of generating a thermal image using probabilistic diffusion models is shown in Figure 2.
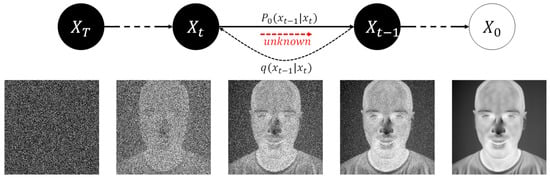
Figure 2.
Denoising diffusion probabilistic process.
2.3. Stable Diffusion
Stable Diffusion [4] is a complex, open-source system that offers a high degree of flexibility. It consists of several components and is based on a variant of the diffusion model called the Latent Diffusion Model (LDM) [4]. LDM applies the diffusion process to latent space instead of pixel space, while incorporating semantic feedback from transformers. This feedback is crucial in generating an embedded τ of the image or text that conditions the generation.
In Stable Diffusion, advanced perceptual and semantic compression techniques are used to achieve high quality in the generated images. This is achieved by combining the semantic feedback of the transformers and the application of the diffusion process in latent space. Together, these components form a highly effective system for the generation of realistic and high-quality images.
During the initial stages of the learning process, the model is tasked with translating the input data into an abstract domain known as the latent space. Rather than encapsulating unnecessary information as previously stated, this space provides a more condensed and efficient representation of the original data, achieved using an encoder trained with an autoencoder implementation [49]. On the other hand, the secondary learning process employs a generation method that captures the semantics of the input data. This process incorporates a U-Net-type denoising network in conjunction with a model that introduces generation conditionality from inputs such as text, images, or masks. The U-Net model supervises the removal of the latent space noise induced by the diffusion process. The conditionality is incorporated through transformers, which are concatenated with the internal layers of the U-Net model.
In this study, we will be utilizing Stable Diffusion as our text-to-image model for the generation of synthetic thermal images. The choice of Stable Diffusion is predicated on its ability to generate high-quality images and its flexibility in adapting to different image styles, making it ideal for our goal of creating thermal images. Furthermore, its proficiency in capturing complex semantic and visual features will enable us to generate thermal images that are both realistic and useful for our facial detection tasks.
2.4. DreamBooth
DreamBooth is a specialized technique used for fine-tuning text-to-image models, particularly those employing Stable Diffusion. DreamBooth adapts the model to new data, improving its ability to generate images that are more specific or relevant to a particular task. This process is facilitated by introducing a new key-value pair into the dictionary of the diffusion model, which allows the model to generate images of specific subjects like dogs, characters, and more.
The fine-tuning process with DreamBooth involves two main steps. The first step is to fine-tune the text-to-image model at a lower resolution using an image-text pair that contains an identified “[v]” and its corresponding class label. In parallel, a “prior preservation loss” technique is implemented. This technique makes use of the semantic content the model has learned for the corresponding class, encouraging the model to generate multiple images related to that class. Providing a brief explanation, “prior preservation loss” is a strategy that helps to retain the model’s original capabilities during the fine-tuning process, which, in turn, aids the generation of diverse images that are highly related to the class of interest. The second step involves fine-tuning the super-resolution (SR) components by blending both the low- and high-resolution images from the input set. This process enables the model to retain the fine details of the input content, resulting in a higher fidelity of the generated image’s resolution.
In the context of this work, DreamBooth becomes particularly significant as we are employing it to optimize the generation of images in our Stable Diffusion model. The combination of DreamBooth and Stable Diffusion will allow for the creation of a thermal style for the generated images. This thermal style effectively captures the aesthetic perspective of thermal images, where the visual appeal is assessed based on the clarity of temperature distributions rather than vibrant colors or composition. A high-quality thermal image, in this context, is characterized not just by its resolution but also by its accurate and coherent temperature distribution, mirroring the true thermal properties of the scene. The ‘thermal style’ essentially translates to the color palette used to denote various temperature ranges in the image, with cooler colors representing lower temperatures and warmer hues indicating higher temperatures. This combined approach is expected to significantly enhance the model’s performance in generating high-quality thermal images, thereby contributing to the advancement of thermal imaging applications.
2.5. Image Classification with Vision Transformer
Vision Transformer (ViT) was developed by Google Brain in 2020 as a variant of the original transformer architecture, which primarily finds application in natural language processing. Diverging from conventional convolutional neural networks (CNNs) employed in image classification, which process images through layers of convolution and pooling, ViT leverages a transformer-based architecture for image processing. This model has exhibited remarkable performance across various benchmark datasets, consistently achieving state-of-the-art results in image classification. This success has spurred its adoption in diverse computer vision applications, including object detection and image segmentation. The fundamental approach employed by the model involves dividing the image into fixed-size patches, treating them as input sequences, rather than processing the entire image simultaneously. These patches are then transformed into feature vectors via linear layers and fed into the transformer architecture. The transformers effectively capture the relationships between the patches, producing a final output that facilitates image classification.
In this research, we will be leveraging ViT for the classification of thermal images. The primary objective of employing ViT in our work is to verify the quality of the thermal images generated by our text-to-image model, Stable Diffusion. ViT’s exceptional performance in image classification tasks, coupled with its ability to handle high-dimensional data, makes it an ideal tool for assessing the quality of our generated thermal images. By dividing the thermal images into fixed-size patches and processing them as input sequences, ViT will enable us to capture intricate thermal patterns and subtle temperature variations. This will ensure that our generated thermal images are not only realistic but also of high quality, thereby significantly contributing to the advancement of thermal imaging applications.
3. Proposed Method
The proposed method seeks to automate the generation of high-quality thermal face images maintaining their quality throughout an unsupervised process. Our approach includes four main components: the Thermal Generator, the Thermal Classifier, the Prompt Database, and the Prompt Designer. Figure 3 illustrates the system’s scheme. The Thermal Generator is tasked with synthesizing thermal images, while the Thermal Classifier determines whether to provide model feedback or save and deliver the final image as a high-quality thermal image. The Prompt Database acts as a storage for prompts, enabling the Prompt Designer to suggest prompts from this database. The objective is to provide a diverse set of prompts that enhance the generated thermal image. The Prompt Designer plays a pivotal role in controlling the generation process by specifying the desired output characteristics. It is worth noting that the proposed system is programmed in an environment with Python 3.7 as the programming language, implemented on a local server. The training processes are executed with a Tesla T4 (16 GB VRAM) in Google Colab, thanks to its ability to access data stored on Google Drive.
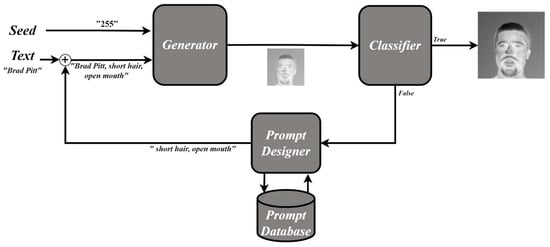
Figure 3.
Schematic diagram of the proposed thermal image generation system.
System Walkthrough:
- Process Initiation: Everything begins with a text input to the system. This text acts as a guide or a descriptor of the kind of thermal image that is intended to be generated.
- Preliminary Generation: The input text is processed by the ‘Thermal Generator’, which utilizes the Stable Diffusion model to attempt to synthesize a thermal image that matches the text specifications.
- Quality Evaluation: Once a preliminary thermal image is crafted, it is passed onto the ‘Thermal Classifier’. This component, built upon the ViT architecture, assesses the quality of the generated image. It determines if the image looks akin to a true thermal image and if it aligns with the original text specifications.
- Feedback and Adjustments: If the Thermal Classifier finds that the generated image does not meet quality standards or does not adequately match the text specifications, a feedback loop is initiated. This is where the ‘Prompt Designer’ comes into play. Utilizing the ‘Prompt Database’, the Prompt Designer suggests tweaks or variations to the original text, aiming to guide the Thermal Generator towards producing a better quality image in the subsequent attempt.
- Iterations: This generation, evaluation, and feedback process is iteratively performed until a high-quality thermal image that matches the desired specifications is crafted.
- Completion: Once a high-quality thermal image is synthesized, it is stored in a database. Over time, this automated process results in a vast database of high-quality thermal images, ready for use in various computer vision applications.
This comprehensive methodology enables the creation of expansive image databases filled with high-quality generated thermal images. Such databases are especially valuable in the fields of computer vision and machine learning, where large datasets are essential for training models. By automating the generation of high-quality thermal images, our approach offers a more efficient and effective alternative to traditional methods that rely on manual labeling or other time-consuming processes.
- Generator Module: The Thermal Generator utilizes a thermally fine-tuned Stable Diffusion, based on DreamBooth [46]. This generation model has been specifically designed to capture and emulate the distinct thermal style exhibited by thermal cameras. This module is committed to producing novel samples that genuinely reflect the thermal aesthetic. However, the generation process is not uncontrolled. Other modules work in concert with it, closely monitoring and guiding its output to ensure the creation of accurate and high-quality generative samples that adhere to the standards established by thermal imaging experts and practitioners. The system guarantees results that conform to the desired text specifications, maintaining the fidelity and reliability of the generated content. The Generator receives a text prompt and a seed, a predefined value that determines the initial state of the generation process and ensures the consistency of the generated thermal image, as inputs. The output of the Generator is a thermal image of a subject’s face, heavily influenced by the input text, ensuring that the created text perfectly matches the generated thermal image.
- Classifier Module: The Thermal Classifier is built upon the ViT architecture and fine-tuned using the methodology proposed in reference [5]. This module acts as an image classifier, specifically trained with thermal images to discriminate between accurately generated samples and those that do not match the intended thermal style. Leveraging this classification process, the module generates a flag indicating whether the image should be stored among the resulting generated samples. The primary function of the Classifier Module is to assess the quality and fidelity of the generated thermal images. It serves as a critical component in determining whether the synthetic examples align with the desired thermal style. Once an image has been generated, the Classifier provides critical feedback to the Prompt Designer, advising its decision on whether a thermal image meets the quality standards to be delivered by the system as a high-quality thermal image. This feedback is given after each image generation, allowing for iterative improvements to the generated images. By incorporating this classifier into our system, we ensure that only high-quality and visually consistent thermal images are selected for further processing.
- Prompt Designer and Prompt Database: To ensure the creation of the optimal text, we have designed a specialized text creator that allows for large variations and automatic search for the best possible text. The output text () is designed from a main text () and the flag text (). The main text contains the primary feature to be generated, such as names of celebrities, animals, or specific items. This text remains unchanged during the search process as it contains our main topic that must persist during the generation process. Conversely, the flag text is meticulously crafted by selecting a set of ‘n’ words through a comprehensive search process. During the refinement stage, this text undergoes variations in both word selection and quantity. The flag text encapsulates distinctive features and incorporates carefully chosen words to facilitate prompt engineering. If the quality of the generated image meets the required standards, it is added to the final database. However, if the image is of poor quality, the search process is initiated using the Prompt Designer until the desired category is achieved. This iterative process allows for the generation of high-quality images that match the desired category, thereby ensuring that only high-quality images are included in the final database.
4. System Module Training
In this section, we provide a comprehensive analysis of the training processes and resulting outcomes for both the generator and classifier modules. The successful implementation and evaluation of these modules are vital for the overall efficacy and reliability of the proposed system. We aim to clarify the training methodologies employed and highlight the attained results to offer a thorough understanding of each module’s performance and capabilities.
4.1. Generator Training
The training stage for the Thermal Generator aims to fine-tune the Stable Diffusion model to generate thermal images accurately, effectively learning this style. We employ DreamBooth for this process, a method for personalizing text-to-image diffusion models. The fine-tuning process using DreamBooth proceeds in two steps:
- Fine-tuning the low-resolution text-to-image model with input images paired with a text containing a unique identifier and the class name to which the subject belongs (for example, “A photo of a thermal face”). Simultaneously, a class-specific prior preservation loss is applied, leveraging the semantic prior the model possesses on the class. It encourages the generation of diverse instances belonging to the subject’s class by injecting the class name into the text prompt (e.g., “A photo of a face”).
- Fine-tuning the super-resolution components with pairs of low- and high-resolution images sourced from our input image set, ensuring the model maintains fidelity to the subject’s minute details.
Importantly, the fine-tuning process using DreamBooth does not necessitate numerous thermal images. We aim to evaluate how the Fréchet inception distance (FID) metric [50] varies with the increasing number of training images (ranging from 5 to 40 images for fine-tuning). The FID metric (Equation (2)), widely used in the evaluation of image generators, provides a quantitative measure of the quality of the generated images. The FID is a metric of differences in the density of two distributions in the high-dimensional feature space of an InceptionV3 classifier, comparing the activations of a previously trained classification network on real and generated images, using the following equation:
The parameters m and C represent the mean vectors and covariance matrices in the embedding space, respectively. The subscript ‘w’ pertains to the generated image, while the terms without subscripts refer to the real image. A low FID value implies superior generation of synthetic images.
We evaluated the FID using a total of 100 randomly generated images, post adjusting Stable Diffusion, by introducing variations in the input text to generate a more representative and varied set of images. This ensures that the Generator can generalize correctly—an essential attribute for its incorporation into the proposed system. The results are presented in Table 1 and show the FID for two versions of Stable Diffusion (V1.5 and V2.0) with different amounts of images used for fine-tuning (5, 10, 20, and 40 images). The numbers in the table represent the FID scores obtained after fine-tuning the Stable Diffusion model with different numbers of images. The FID scores provide a quantitative measure of the quality of the generated images; lower scores indicate better synthetic image quality. For Stable Diffusion version 1.5, the FID decreases when the number of images is increased from 5 to 10. However, further increasing the number of images to 20 results in an increase in the FID for both versions. Increasing the number of images to 40 again reduces the FID for both versions, but it does not reach the lowest value obtained with 10 images. The increase in FID values when fine-tuning with 20 images may be due to overfitting, where the Generator becomes too adapted to the training images and generalizes poorly to new inputs. This is mitigated when using a larger dataset of 40 images, leading to a decrease in FID values. However, the exact reasons for these trends may be complex and depend on various factors, such as the specific images used for fine-tuning and the stochastic nature of the training process. The training process has an average duration of 28 min for both versions 1.5 and 2, trained in an environment created with Google Colab using a Tesla T4 GPU (16 GB VRAM). In general, version 1.5 of Stable Diffusion outperforms version 2.0 as it produces lower FID values across all image counts.

Table 1.
Comparative FID results for fine-tuning Stable Diffusion.
4.2. Classifier Training
The Thermal Classifier utilized in this study is an implementation of the traditional ViT model [5]. It is trained using a database of 18,579 thermal images, which were sourced from reference [51]. The images are segregated into two main classes for training the ViT model: “thermal face” and “other”. The “other” class, which corresponds to poor-quality thermal face images, is determined by applying the FID on randomly generated images from the generator module. A low FID score indicates high quality of synthetic images. For our purpose, images with high FID values are classified as low quality and are included in the “other” class for training the Classifier.
To evaluate the Classifier training and the detection outcomes from Section 6, we used the accuracy (Equation (3)) and F1-score (Equation (4)) metrics. The first is a measure that considers the number of correct predictions over the total, while the second combines the precision (Equation (5)) and recall (Equation (6)) measures, which are ideal for unbalanced data, as in the case of those used for this study. Precision indicates how many of the predicted cases were true positives, while recall shows the number of true-positive cases that the model could predict correctly.
where TP—true positive; TN—true negative; FP—false positive; FN—false negative.
Training the Thermal Classifier enables the creation of a model capable of automatically distinguishing between high- and low-quality thermal samples. In our study, we experimented with classic pre-training methods such as Inceptionv3 [52], VGG16 [53], Xception [54], and InceptionresnetV2 [55]. However, only the Vision Transformer (ViT) yielded significant results suitable for further deep training. We chose not to report the results from the other models as they were significantly outperformed by ViT. The most efficient ViT Classifier was obtained after six epochs, using a batch size of 16 images and a learning rate of 0.00001, which has a training duration of 6.2 h in a Python environment created with Google Colab using a Tesla T4 GPU (16 GB VRAM). The performance achieved by the thermal ViT is displayed in Table 2, with the Classifier attaining an accuracy and F1 score of 98%.
Table 2.
Performance metrics of the ViT Thermal Classifier.
5. Results of the Proposed System
This section elucidates the results obtained from the proposed system, demonstrating its ability to generate high-quality synthetic thermal face images. The system’s efficacy is evaluated across various scenarios, including the generation of thermal images embodying different facial features and the creation of thermal images of renowned celebrities. Additionally, the influence of input text on the resultant images is also analyzed. As a consequence, this initiative led to the creation of a comprehensive dataset comprising a total of 11,828, called “PUCV-Synthetic Thermal Images (PUCV-STI)”. These images represent 2957 distinct individuals, each depicted with various degrees of kinship and different interpretations of the primary neutral individual.
- Diverse facial features: The proposed system’s functionality was evaluated by generating synthetic thermal images, each portraying unique facial features. For this assessment, four categories—neutral, smiling, angry, and bald—were identified. The goal was to generate high-quality thermal images that accurately represent these classes. Figure 4 presents examples of three subjects, each with unique facial features as generated by the system. The high quality of the images and the successful capture of the desired thermal style are particularly noteworthy.
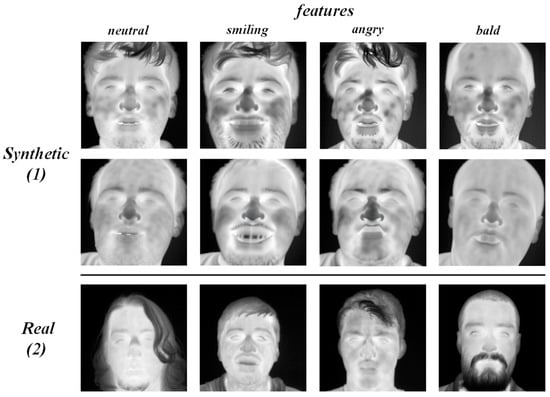 Figure 4. Synthetic thermal images compared with real thermal images. (1) Synthetic thermal images generated by the proposed system. (2) Thermal PUCV database [56].
Figure 4. Synthetic thermal images compared with real thermal images. (1) Synthetic thermal images generated by the proposed system. (2) Thermal PUCV database [56].
- Influence of text on the generated thermal image: A further examination of the system involved testing the impact of input text on the thermal image produced. For this test, famous individuals, such as celebrities, actors, and former presidents, were included with the intention of assessing the system’s capability to generate corresponding thermal images. The original textual content was maintained, and variations were introduced to the flag text, determined by the output of the Thermal Classifier. The purpose of this approach was to explore the model’s capacity to identify and represent the thermal patterns exhibited by well-known personalities. These personalities, recognizable to the model in the visible spectrum, were successfully incorporated with the desired thermal style.
The generation of celebrity faces (as shown in Figure 5) demonstrates that the impact of input text on the resulting images is a critical factor in forming the generated celebrity faces. By leveraging semantic information derived from the provided textual descriptions, the model infers and prioritizes the defining characteristics contributing to a given celebrity’s likeness. The input text guides the model’s attention towards salient attributes, allowing it to concentrate on relevant facial components and their respective configurations. The constraints imposed by the restricted variations in the target generation further underscore the role of common patterns in celebrity faces. Given that celebrities often exhibit distinctive yet recognizable facial traits, the model capitalizes on these patterns to narrow down the potential options and generate faces that align closely with the desired celebrity in the thermal spectrum.

Figure 5.
Generation of celebrity faces in the thermal spectrum.
6. System Validation via Thermal Face Detection
To evaluate the efficacy of our synthetic thermal image generation system, we embarked on a two-pronged validation approach using a facial detection model. The approach involved training two separate detectors, one with real thermal images from the thermal PUCV database [56], and the PUCV-Synthetic Thermal Images generated by our system. By comparing the performance of these two detectors, we aim to gauge the utility of our synthetic images as a substitute for real thermal images in practical applications.
We opted for Detectron2 [57] for this task, due to its excellent track record in object detection tasks. With its capabilities spanning object detection, instance segmentation, key point detection, and panoptic segmentation, Detectron2 provides a robust platform to assess the quality of our generated images.
In the training process, we employed the Faster_rcnn_R_50_FPN_3x architecture, which is specifically designed for bounding box detection. The training process, conducted separately for the real and synthetic datasets, spanned 100 epochs with a learning rate of 0.005 and a batch size of 16. Further details on the hyperparameters used can be found in Table 3.
Table 3.
Hyperparameters used in training the detection model.
Evaluation is a critical phase in the development of an object detection model, and in our case, we utilized a total of 200 automatically generated images to evaluate the model’s performance. Tests were conducted with both datasets for this facial detection application, the results of which are presented in Table 4.
Table 4.
Evaluation results of face detection application.
The results suggest that our synthetic images are fit for training a thermal detection model, achieving an accuracy and F1-score of approximately 98%. Interestingly, these performance metrics remained high even when the target face was in different positions. This underscores the feasibility of using synthetically generated images in detection processes, demonstrating low error rates and high adaptability. The model’s ability to detect faces in various positions significantly enhances its applicability in real-life situations, permitting operation even in complete darkness. The results of thermal face detection are presented in Figure 6.

Figure 6.
Results of thermal face detection.
7. Conclusions
In this study, we devised a methodological approach to synthesize synthetic thermal images using advanced deep learning techniques. The seamless integration of the thermally fine-tuned Stable Diffusion and the Vision Transformer (ViT) classifier lies at the heart of our innovative system, precisely tailoring the generation process to the unique challenges of thermal imaging.
The Stable Diffusion model, inspired by DreamBooth, expertly encapsulates the distinctive style of thermal imaging. In tandem, the ViT classifier ensures the generation of images that adhere to stringent quality standards. Our experiments showcased the pivotal role of textual prompts in shaping the image generation process, demonstrating the nuanced impact of varying levels of description specificity.
A seminal achievement of our research is the creation of a synthetic thermal face image database. This resource not only offers immense potential for training cutting-edge face detection models but also lays the groundwork for applications in face recognition and thermal pattern analysis. Such analysis might be instrumental in early disease detection or other health-related diagnostics.
In practical applications, our synthetic thermal images exhibited exceptional results in facial detection tasks. This demonstrates the real-world utility and effectiveness of our approach, further validating the quality and authenticity of our generated images.
Furthermore, while our work is rooted in thermal imaging, the methodologies and insights bear relevance to other imaging domains, such as X-ray imaging or various medical imaging techniques. Such adaptability underlines the broader applicability of our findings and methodologies.
To conclude, our research marks a pivotal advancement in the realm of synthetic thermal image generation using deep learning. It underscores the potential of these methodologies in producing high-fidelity thermal images, thereby catalyzing future explorations and potential applications in diverse imaging areas.
Author Contributions
Investigation, V.P. and G.H.; software, V.P.; supervision, G.H.; writing—original draft, V.P.; writing—review and editing, G.H., M.S. and G.F. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported in part by FONDECYT under Grant 1191188.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Ramesh, A.; Dhariwal, P.; Nichol, A.; Chu, C.; Chen, M. Hierarchical Text-Conditional Image Generation with CLIP Latents. arXiv 2022, arXiv:2204.06125. [Google Scholar]
- Radford, A.; Kim, J.W.; Xu, T.; Brockman, G.; McLeavey, C.; Sutskever, I. Robust Speech Recognition via Large-Scale Weak Supervision. In Proceedings of the 40th International Conference on Machine Learning, Honolulu, HI, USA, 23–29 July 2023. [Google Scholar]
- OpenAI. GPT-4 Technical Report. arXiv 2023, arXiv:2303.08774. [Google Scholar]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-Resolution Image Synthesis with Latent Diffusion Models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image Is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. arXiv 2021, arXiv:2010.11929. [Google Scholar]
- Koh, J.Y.; Fried, D.; Salakhutdinov, R. Generating Images with Multimodal Language Models. arXiv 2023, arXiv:2305.17216. [Google Scholar]
- Xu, X.; Guo, J.; Wang, Z.; Huang, G.; Essa, I.; Shi, H. Prompt-Free Diffusion: Taking “Text” out of Text-to-Image Diffusion Models. arXiv 2023, arXiv:2305.16223. [Google Scholar]
- Elata, N.; Kawar, B.; Michaeli, T.; Elad, M. Nested Diffusion Processes for Anytime Image Generation. arXiv 2023, arXiv:2305.19066. [Google Scholar]
- Li, D.; Li, J.; Hoi, S.C.H. BLIP-Diffusion: Pre-Trained Subject Representation for Controllable Text-to-Image Generation and Editing. arXiv 2023, arXiv:2305.14720. [Google Scholar]
- Kim, S.; Lee, J.; Hong, K.; Kim, D.; Ahn, N. DiffBlender: Scalable and Composable Multimodal Text-to-Image Diffusion Models. arXiv 2023, arXiv:2305.15194. [Google Scholar]
- Brock, A.; Donahue, J.; Simonyan, K. Large Scale GAN Training for High Fidelity Natural Image Synthesis. arXiv 2019, arXiv:1809.11096. [Google Scholar]
- Dhariwal, P.; Nichol, A. Diffusion Models Beat GANs on Image Synthesis. Adv. Neural Inf. Process. Syst. 2021, 34, 8780–8794. [Google Scholar]
- Cheng, W.; Cao, Y.-P.; Shan, Y. SparseGNV: Generating Novel Views of Indoor Scenes with Sparse Input Views. arXiv 2023, arXiv:2305.07024. [Google Scholar]
- Rangwani, H.; Bansal, L.; Sharma, K.; Karmali, T.; Jampani, V.; Babu, R.V. NoisyTwins: Class-Consistent and Diverse Image Generation through StyleGANs. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023. [Google Scholar]
- Singh, R.; Shukla, A.; Turaga, P. Polynomial Implicit Neural Representations for Large Diverse Datasets. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023. [Google Scholar]
- Hashemi, H.; Hartmann, N.; Sharifzadeh, S.; Kahn, J.; Kuhr, T. Ultra-High-Resolution Detector Simulation with Intra-Event Aware GAN and Self-Supervised Relational Reasoning. arXiv 2023, arXiv:2303.08046. [Google Scholar]
- Hashemi, H.; Hartmann, N.; Kuhr, T.; Ritter, M. PE-GAN: Prior Embedding GAN for PXD Images at Belle II. EPJ Web Conf. 2021, 251, 03031. [Google Scholar] [CrossRef]
- You, Z.; Zhong, Y.; Bao, F.; Sun, J.; Li, C.; Zhu, J. Diffusion Models and Semi-Supervised Learners Benefit Mutually with Few Labels. arXiv 2023, arXiv:2302.10586. [Google Scholar]
- Bashkirova, D.; Lezama, J.; Sohn, K.; Saenko, K.; Essa, I. MaskSketch: Unpaired Structure-Guided Masked Image Generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023. [Google Scholar]
- Deng, Y.; Hui, S.; Zhou, S.; Meng, D.; Wang, J. T-Former: An Efficient Transformer for Image Inpainting. In Proceedings of the 30th ACM International Conference on Multimedia, Lisboa, Portugal, 10–14 October 2022; pp. 6559–6568. [Google Scholar]
- Yildirim, A.B.; Baday, V.; Erdem, E.; Erdem, A.; Dundar, A. Inst-Inpaint: Instructing to Remove Objects with Diffusion Models. arXiv 2023, arXiv:2304.03246. [Google Scholar]
- Zhang, G.; Ji, J.; Zhang, Y.; Yu, M.; Jaakkola, T.; Chang, S. Towards Coherent Image Inpainting Using Denoising Diffusion Implicit Models. In Proceedings of the Fortieth International Conference on Machine Learning, Honolulu, HI, USA, 23–29 July 2023. [Google Scholar]
- Liu, W.; Cun, X.; Pun, C.-M.; Xia, M.; Zhang, Y.; Wang, J. CoordFill: Efficient High-Resolution Image Inpainting via Parameterized Coordinate Querying. arXiv 2023, arXiv:2303.08524. [Google Scholar] [CrossRef]
- Luo, Z.; Gustafsson, F.K.; Zhao, Z.; Sjölund, J.; Schön, T.B. Image Restoration with Mean-Reverting Stochastic Differential Equations. arXiv 2023, arXiv:2301.11699. [Google Scholar]
- Kim, B.; Kwon, G.; Kim, K.; Ye, J.C. Unpaired Image-to-Image Translation via Neural Schr\”odinger Bridge. arXiv 2023, arXiv:2305.15086. [Google Scholar]
- Torbunov, D.; Huang, Y.; Tseng, H.-H.; Yu, H.; Huang, J.; Yoo, S.; Lin, M.; Viren, B.; Ren, Y. Rethinking CycleGAN: Improving Quality of GANs for Unpaired Image-to-Image Translation. arXiv 2023, arXiv:2303.16280. [Google Scholar]
- Li, S.; van de Weijer, J.; Wang, Y.; Khan, F.S.; Liu, M.; Yang, J. 3D-Aware Multi-Class Image-to-Image Translation with NeRFs. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023. [Google Scholar]
- Zingman, I.; Frayle, S.; Tankoyeu, I.; Sukhanov, S.; Heinemann, F. A Comparative Evaluation of Image-to-Image Translation Methods for Stain Transfer in Histopathology. arXiv 2023, arXiv:2303.17009. [Google Scholar]
- Karras, T.; Laine, S.; Aittala, M.; Hellsten, J.; Lehtinen, J.; Aila, T. Analyzing and Improving the Image Quality of StyleGAN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Karras, T.; Aittala, M.; Hellsten, J.; Laine, S.; Lehtinen, J.; Aila, T. Training Generative Adversarial Networks with Limited Data. Adv. Neural Inf. Process. Syst. 2020, 33, 12104–12114. [Google Scholar]
- Karras, T.; Aittala, M.; Laine, S.; Härkönen, E.; Hellsten, J.; Lehtinen, J.; Aila, T. Alias-Free Generative Adversarial Networks. Adv. Neural Inf. Process. Syst. 2021, 34, 852–863. [Google Scholar]
- Isola, P.; Zhu, J.-Y.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Zhou, Y.; Zhang, R.; Sun, T.; Xu, J. Enhancing Detail Preservation for Customized Text-to-Image Generation: A Regularization-Free Approach. arXiv 2023, arXiv:2305.13579. [Google Scholar]
- Yu, Q.; Li, J.; Ye, W.; Tang, S.; Zhuang, Y. Interactive Data Synthesis for Systematic Vision Adaptation via LLMs-AIGCs Collaboration. arXiv 2023, arXiv:2305.12799. [Google Scholar]
- Yariv, G.; Gat, I.; Wolf, L.; Adi, Y.; Schwartz, I. AudioToken: Adaptation of Text-Conditioned Diffusion Models for Audio-to-Image Generation. arXiv 2023, arXiv:2305.13050. [Google Scholar]
- Liu, C.; Liu, D. Late-Constraint Diffusion Guidance for Controllable Image Synthesis. arXiv 2023, arXiv:2305.11520. [Google Scholar]
- Chen, Y.; Liu, L.; Ding, C. X-IQE: EXplainable Image Quality Evaluation for Text-to-Image Generation with Visual Large Language Models. arXiv 2023, arXiv:2305.10843. [Google Scholar]
- Xiao, G.; Yin, T.; Freeman, W.T.; Durand, F.; Han, S. FastComposer: Tuning-Free Multi-Subject Image Generation with Localized Attention. arXiv 2023, arXiv:2305.10431. [Google Scholar]
- Yarom, M.; Bitton, Y.; Changpinyo, S.; Aharoni, R.; Herzig, J.; Lang, O.; Ofek, E.; Szpektor, I. What You See Is What You Read? Improving Text-Image Alignment Evaluation. arXiv 2023, arXiv:2305.10400. [Google Scholar]
- Zhong, S.; Huang, Z.; Wen, W.; Qin, J.; Lin, L. SUR-Adapter: Enhancing Text-to-Image Pre-Trained Diffusion Models with Large Language Models. arXiv 2023, arXiv:2305.05189. [Google Scholar]
- Lu, Y.; Lu, P.; Chen, Z.; Zhu, W.; Wang, X.E.; Wang, W.Y. Multimodal Procedural Planning via Dual Text-Image Prompting. arXiv 2023, arXiv:2305.01795. [Google Scholar]
- Mansimov, E.; Parisotto, E.; Ba, J.L.; Salakhutdinov, R. Generating Images from Captions with Attention. arXiv 2016, arXiv:1511.02793. [Google Scholar]
- Reed, S.; Akata, Z.; Yan, X.; Logeswaran, L.; Schiele, B.; Lee, H. Generative Adversarial Text to Image Synthesis. In Proceedings of the 33rd International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016. [Google Scholar]
- Nichol, A.; Dhariwal, P.; Ramesh, A.; Shyam, P.; Mishkin, P.; McGrew, B.; Sutskever, I.; Chen, M. GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models. arXiv 2022, arXiv:2112.10741. [Google Scholar]
- Saharia, C.; Chan, W.; Saxena, S.; Li, L.; Whang, J.; Denton, E.; Ghasemipour, S.K.S.; Ayan, B.K.; Mahdavi, S.S.; Lopes, R.G.; et al. Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding. Adv. Neural Inf. Process. Syst. 2022, 35, 36479–36494. [Google Scholar]
- Ruiz, N.; Li, Y.; Jampani, V.; Pritch, Y.; Rubinstein, M.; Aberman, K. DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023. [Google Scholar]
- Ho, J.; Jain, A.; Abbeel, P. Denoising Diffusion Probabilistic Models. Adv. Neural Inf. Process. Syst. 2020, 33, 6840–6851. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. arXiv 2015, arXiv:1505.04597. [Google Scholar]
- Bank, D.; Koenigstein, N.; Giryes, R. Autoencoders. In Machine Learning for Data Science Handbook: Data Mining and Knowledge Discovery Handbook; Springer: Cham, Switzerland, 2021. [Google Scholar]
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium. In Advances in Neural Information Processing Systems; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Pavez, V.; Hermosilla, G.; Pizarro, F.; Fingerhuth, S.; Yunge, D. Thermal Image Generation for Robust Face Recognition. Appl. Sci. 2022, 12, 497. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; AAAI Press: San Francisco, CA, USA, 2017; pp. 4278–4284. [Google Scholar]
- Hermosilla, G.; Gallardo, F.; Farias, G.; San Martin, C. Fusion of Visible and Thermal Descriptors Using Genetic Algorithms for Face Recognition Systems. Sensors 2015, 15, 17944–17962. [Google Scholar] [CrossRef]
- Wu, Y.; Kirillov, A.; Massa, F.; Lo, W.-Y.; Girshick, R. Detectron2. 2019. Available online: https://ai.facebook.com/blog/-detectron2-a-pytorch-based-modular-object-detection-library-/ (accessed on 23 October 2023).
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).