
Dynamic Regimes for Corporate Human Capital Development Used Reinforcement Learning Methods


Abstract
:1. Introduction
2. Literature Review
2.1. Methods for Corporate HC Management
2.2. Modern Trends for the Personnel Professional Development
- Guaranteed job retention;
- Acquisition of new knowledge, skills, abilities, disclosure of abilities;
- Growth in labor market value;
- Expanding opportunities for professional and career growth;
- Expansion of social networks and connections;
- Growth in self-esteem and self-confidence.
- Growth in productivity and quality of work, income and profits;
- Reducing staff turnover;
- Increasing employee motivation;
- Increasing the contribution of each employee to the achievement of goals;
- Facilitating the delegation of authority;
- Improvement in corporate culture;
- Reducing the adaptation period;
- Improving the moral and psychological climate in the team and project teams;
- Positive impact on labor discipline.
- Development of the labor potential of society;
- The growth of social labor productivity.
2.3. Applications of RL in Organizational Systems
- In industry and management, RL is used across the entire spectrum of resource management tasks [33,34,35,36,37,38], the development of production scheduling principles [39], development of restocking plans that set the timing and volume of restocking, and the development of logistics routes and supply chains [40,41];
- In designing education and e-learning systems, RL can increase their effectiveness by selecting curricula [56].
3. Research Methodology
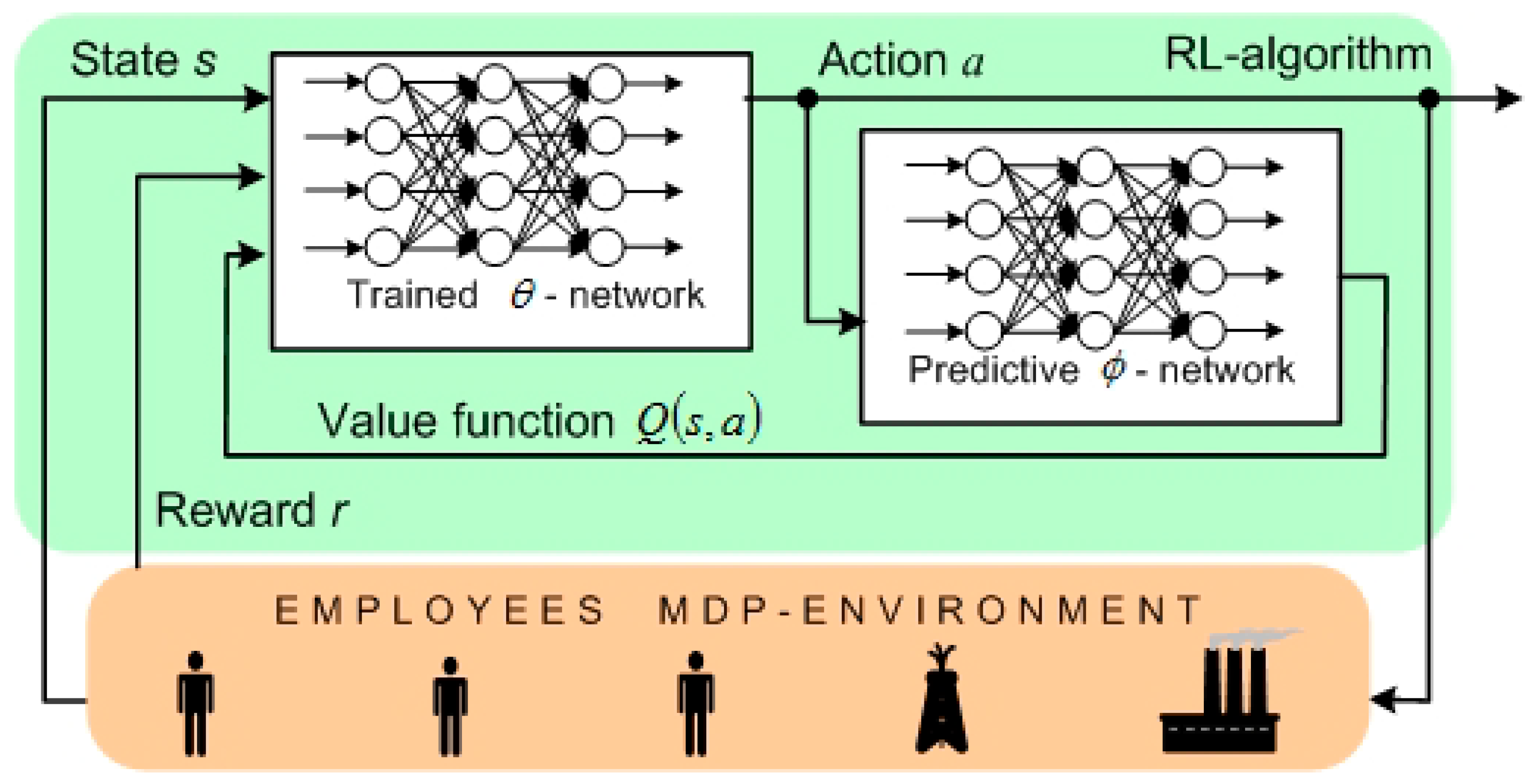
3.1. Concept Description
- RL makes the best decision over time for each employee at any given time, taking into account the diversity of the employees’ characteristics. This can be achieved without an exact mathematical model of an employee, and without data on the cause–effect relationships between the decision (impact) and the result (return);
- RL and its solutions improves the long-term results, taking into account the distribution over time and the delayed effect of the impact;
- RL allows for the design of a reward function that is adaptive and based on domain expertise;
- RL provides multi-criteria optimization in terms of efficiency and risk criteria (for example, for a company to lose a competitive employee who may go to another employer).
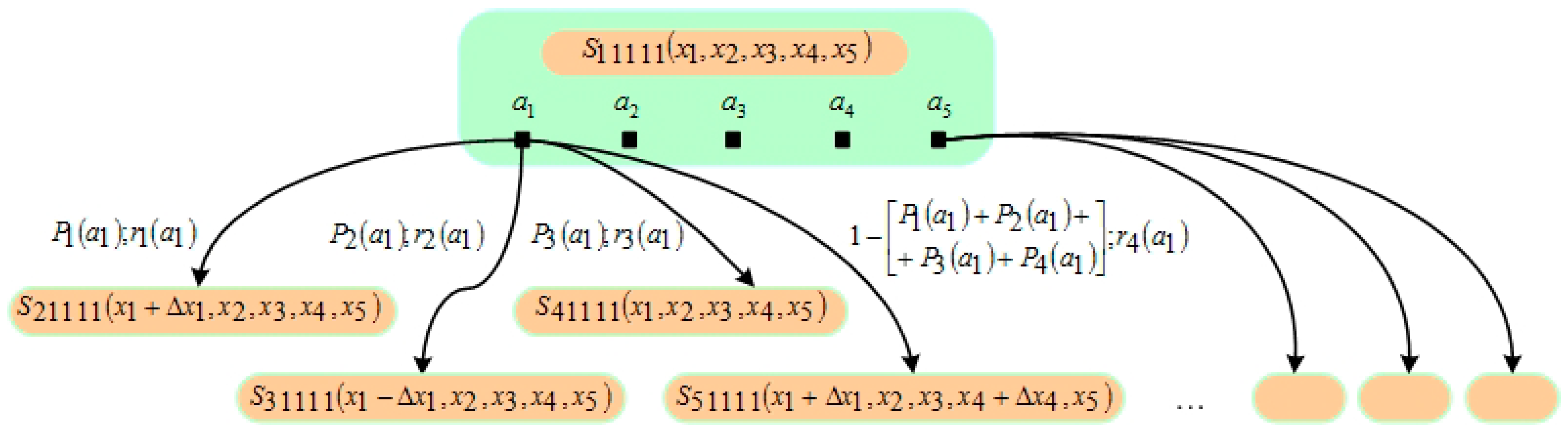
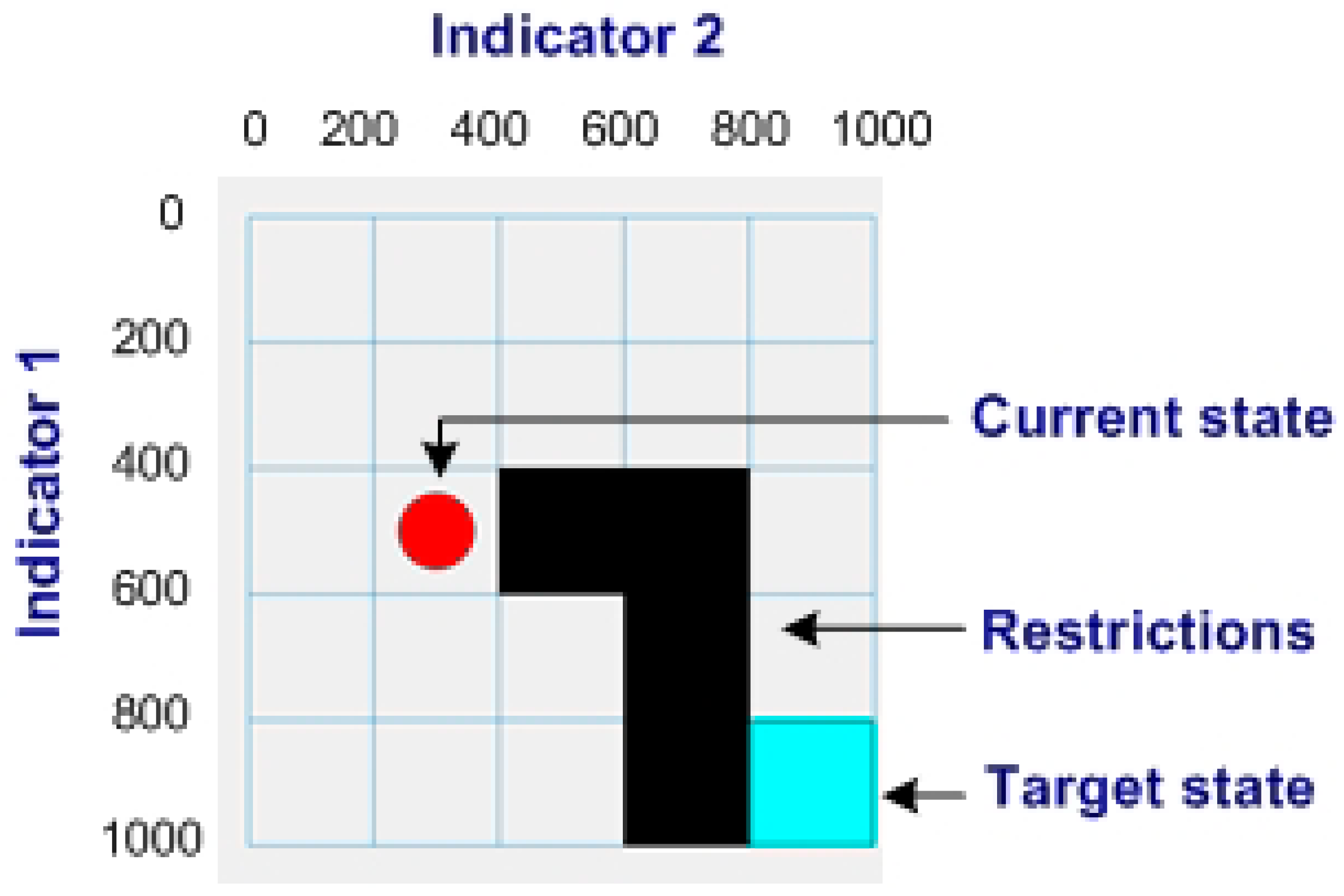
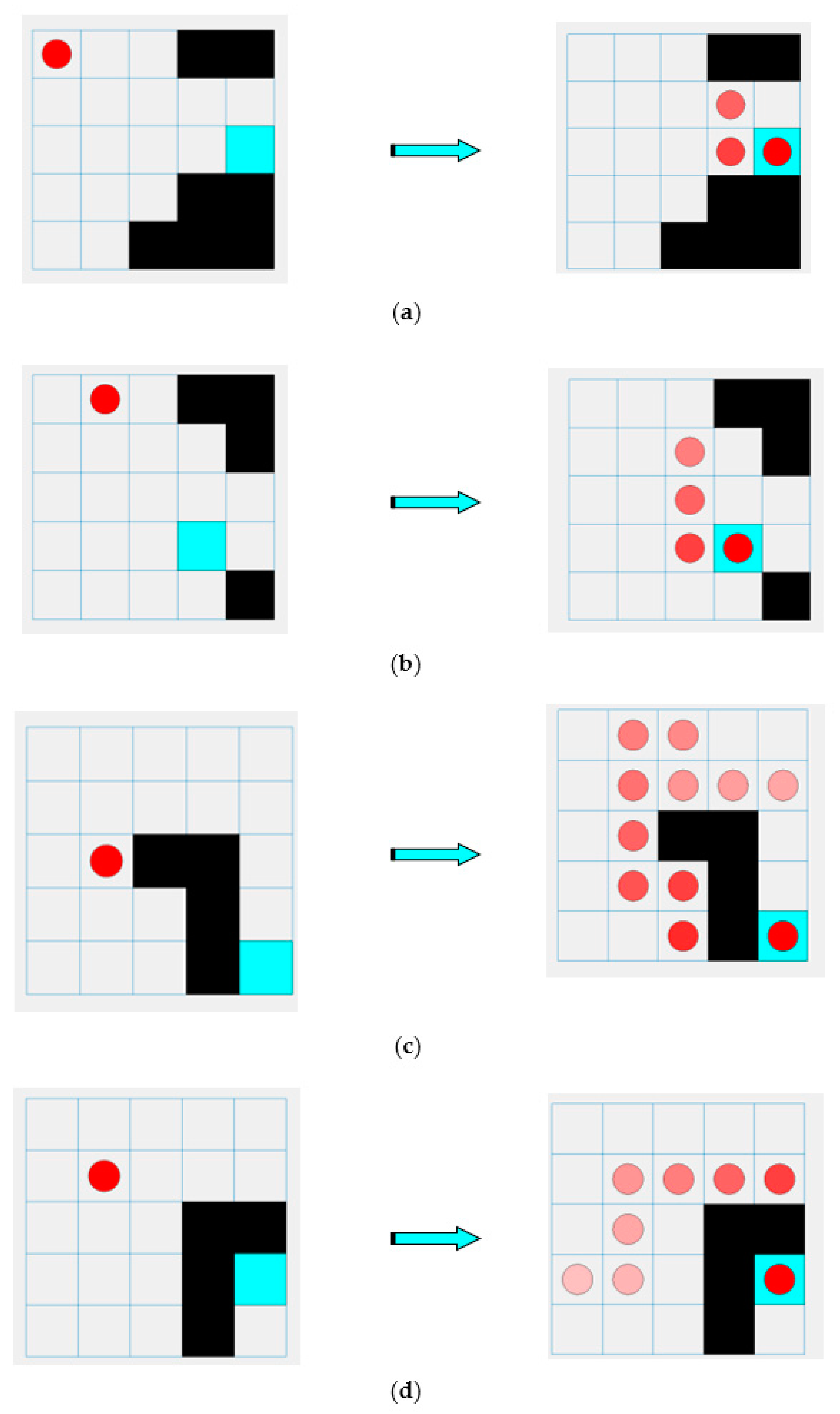
3.2. Statement of the Problem
3.3. Agent Learning Algorithms
| Algorithm 1: Estimation of the agent’s utility function based on double deep Q-networks. |
| 1. Initialization of hyperparameters: learning rate ; discount coefficient ; update rate of the trained network ; predictive network update rate 2. Initialization of the number of use cases per training step, B; number of updates per package, U; data packet size, P; case memories with a maximum size of K; number of steps in episode T; initialization of network parameters with random values; initialization of predictive network parameters For each episode 3. for m := 1 to T do 4. Accumulate and save h cases , using the current strategy 5. for b := 1 to B do 6. select the b-th package of cases from memory 7. for u := 1 to U do 8. for i := 1 to P do 9. calculate target Q-values for each case 10. , where , if -final state otherwise 11. end for 12. Calculate the loss function 13. 14. Update trained network parameters 15. 16. end for 17. end for 18. decrease 19. if (m mod F) = 0 then 20. Updating predictive network parameters 21. 22. end if 23. end for |
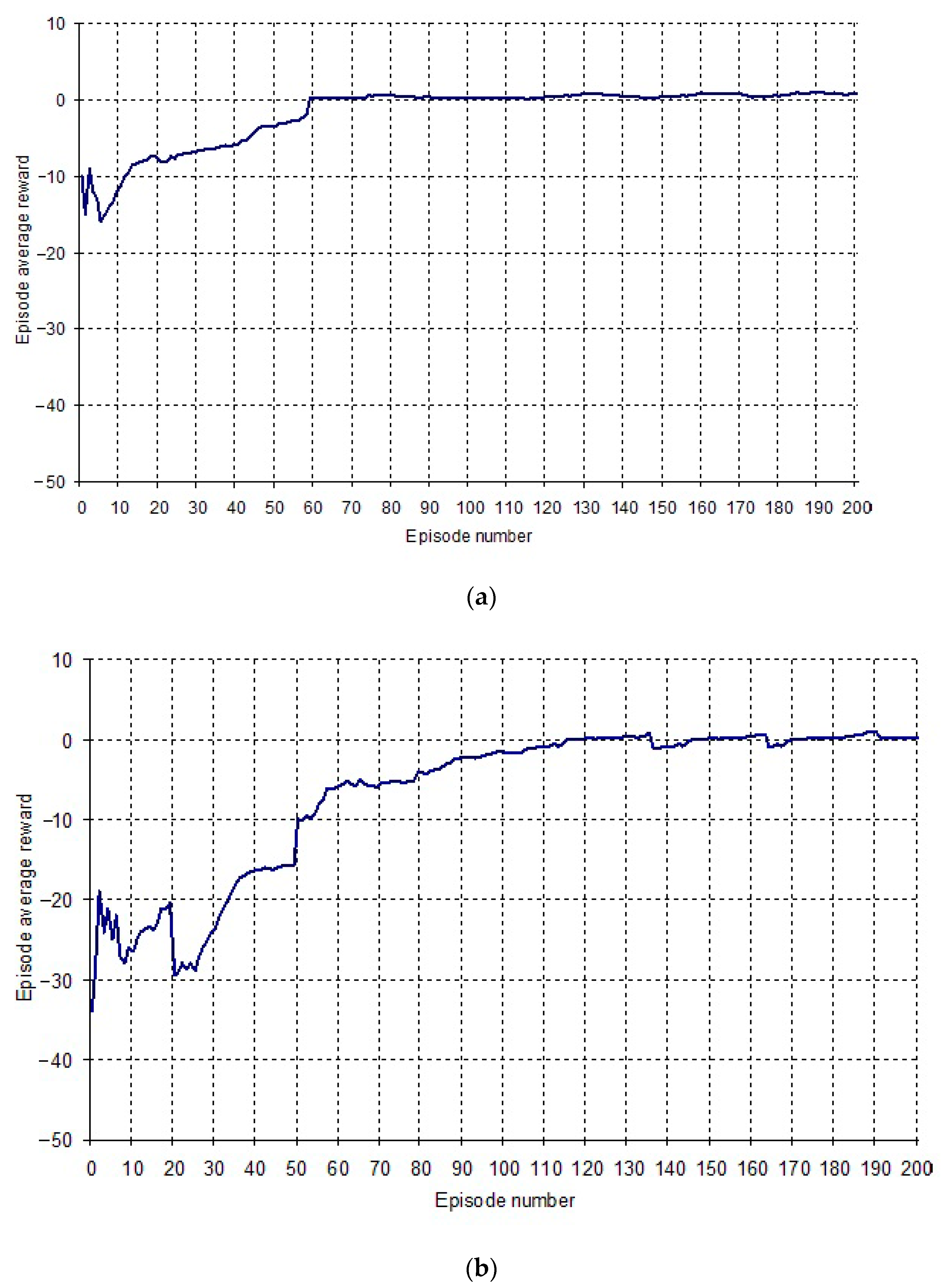
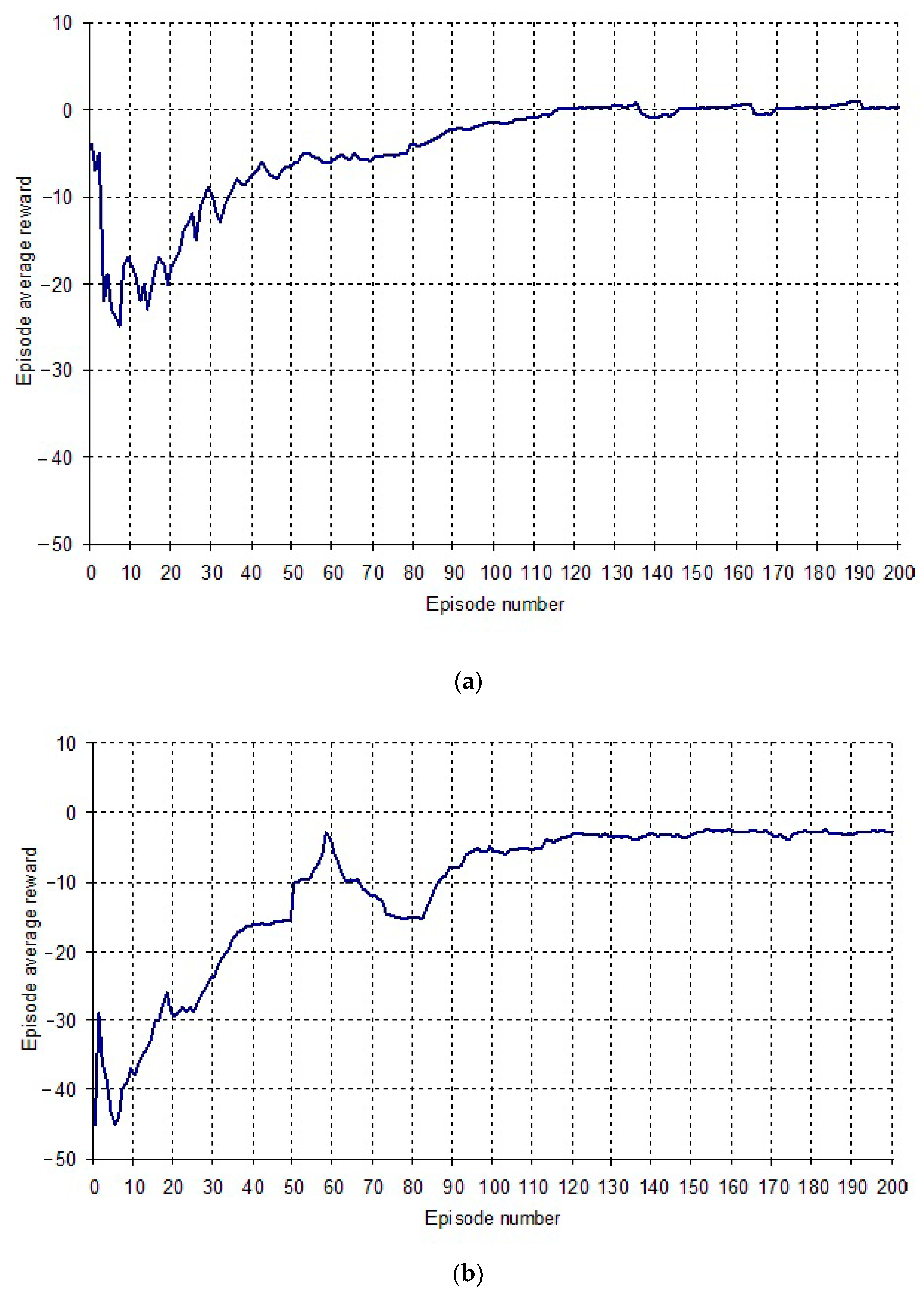
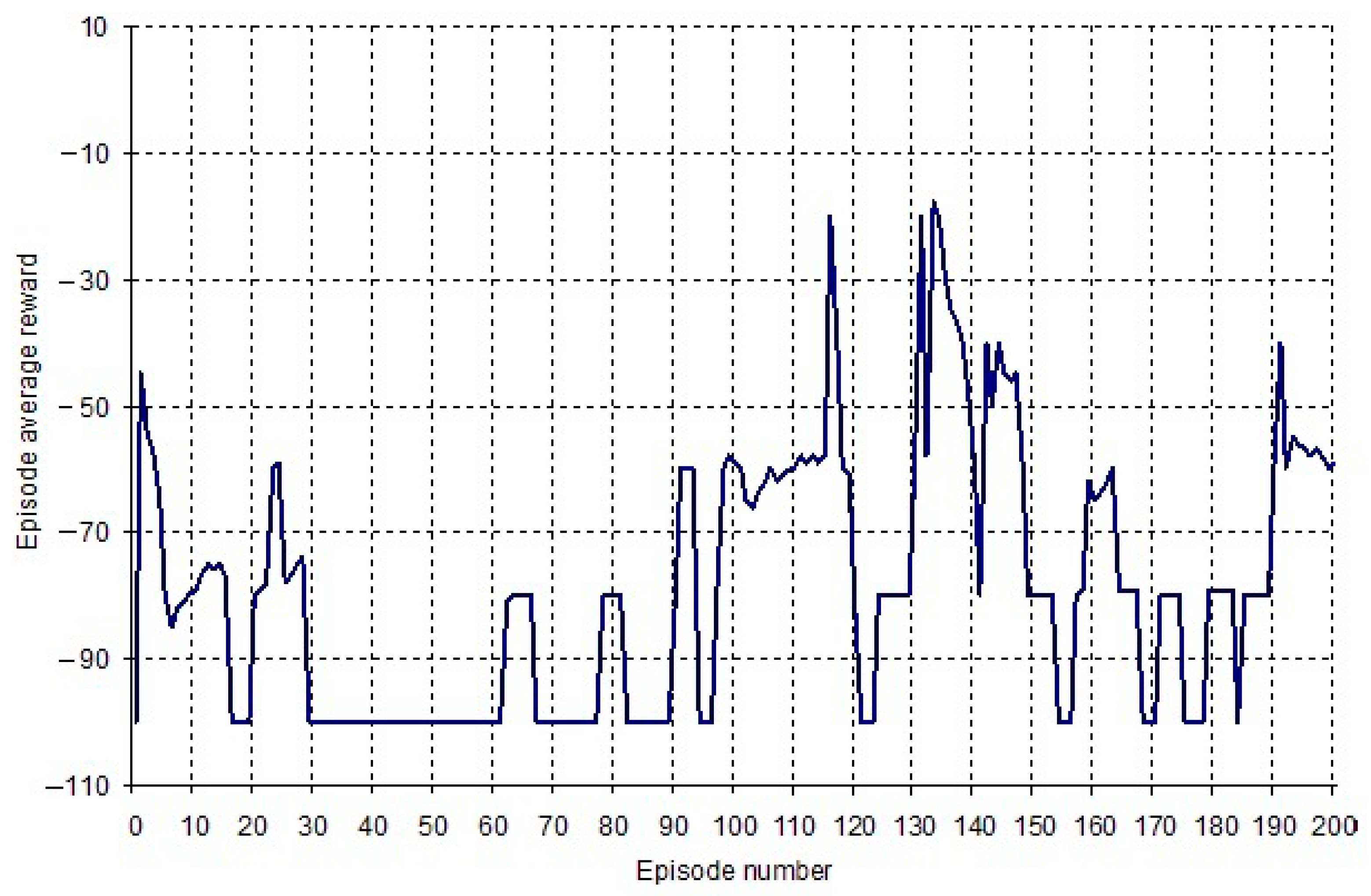
4. Empirical Results and Discussion
5. Conclusions
- The control object is characterized by the stochastic dynamics of its indicators, and management decisions are not determined. To describe an object, a Markov decision process (MDP) model is used as a set of requirements for determining and changing system states when sequences of actions are stochastic. When describing the control object, the Markov property is used, which proposes that the current state of the object and the projected impact at the current period contain sufficient information to determine the transition probability of the object to the next state at the next period. The MDP formalism is an important abstraction in solving the problem of learning a purposeful agent in the process of interacting with the environment.
- The control problem has a strategic nature. RL methods allow for the study of long-term strategies. Solutions that are effective in the current period do not always show high efficiency in the long-term. Other decisions, in contrast, may have a delayed effect and be in demand when planning for the medium-term.
- The control problem is presented in the form of sequential decision making. RL methods are applicable when decisions are made sequentially and actions are related to the study of the environment. The trained model provides optimal long-term multi-stage results in the form of rewards. The optimal control regime or a sequential set of actions allows for the maximization of the average expected rewards for the entire period of the implementation of management decisions. Classical algorithms of dynamic programming and Bellman’s principle of optimality are used as a theoretical basis. The basic concept of dynamic programming when used in RL problems is to use value functions to organize and structure the search for good strategies.
Funding
Data Availability Statement
Conflicts of Interest
References
- Church, A.H.; Bracken, D.W.; Fleeno, J.W.; Rose, D.S. Handbook of Strategic 360 Feedback; Oxford University Press: New York, NY, USA, 2019; p. 637. [Google Scholar]
- Steelman, L.A.; Williams, J.R. Feedback at Work; Springer Nature: Berlin, Germany, 2019; p. 280. [Google Scholar]
- Zhang, L.; Guo, X.; Lei, Z.; Lim, M.K. Social Network Analysis of Sustainable Human Resource Management from the Employee Training’s Perspective. Sustainability 2019, 11, 380. [Google Scholar] [CrossRef]
- Hernaus, T.; Pavlovic, D.; Klindzic, M. Organizational career management practices: The role of the relationship between HRM and trade unions. Empl. Relat. Int. J. 2019, 41, 84–100. [Google Scholar] [CrossRef]
- Alzyoud, A.A.Y. The Influence of Human Resource Management Practices on Employee Work Engagement. Found. Manag. 2018, 10, 251–256. [Google Scholar] [CrossRef]
- Hitka, M.; Kucharčíková, A.; Štarchoň, P.; Balážová, Ћ.; Lukáč, M.; Stacho, Z. Knowledge and Human Capital as Sustainable Competitive Advantage in Human Resource Management. Sustainability 2019, 11, 4985. [Google Scholar] [CrossRef]
- Stokowski, S.; Li, B.; Goss, B.D.; Hutchens, S.; Turk, M. Work Motivation and Job Satisfaction of Sport Management Faculty Members. Sport Manag. Educ. J. 2018, 12, 80–89. [Google Scholar] [CrossRef]
- Fang, W.; Zhang, Y.; Mei, J.; Chai, X.; Fan, X. Relationships between optimism, educational environment, career adaptability and career motivation in nursing undergraduates: A cross-sectional study. Nurse Educ. Today 2018, 68, 33–39. [Google Scholar] [CrossRef]
- Dickmann, M.; Cerdin, J.-L. Boundaryless career drivers—Exploring macro-contextual factors in location decisions. J. Glob. Mobil. Home Expatr. Manag. Res. 2014, 2, 26–52. [Google Scholar] [CrossRef]
- Jung, Y.; Takeuchi, N. A lifespan perspective for understanding career self-management and satisfaction: The role of developmental human resource practices and organizational support. Hum. Relat. 2018, 71, 73–102. [Google Scholar] [CrossRef]
- Zsigmond, T.; Mura, L. Emotional intelligence and knowledge sharing as key factors in business management—Evidence from Slovak SMEs. Econ. Sociol. 2023, 16, 248–264. [Google Scholar] [CrossRef]
- Osranek, R.; Zink, K.J. Corporate Human Capital and Social Sustainability of Human Resources. In Sustainability and Human Resource Management; CSR, Sustainability, Ethics & Governance; Ehnert, I., Harry, W., Zink, K., Eds.; Springer: Berlin/Heidelberg, Germany, 2014. [Google Scholar]
- Orlova, E.V. Design of Personal Trajectories for Employees’ Professional Development in the Knowledge Society under Industry 5.0. Soc. Sci. 2021, 10, 427. [Google Scholar] [CrossRef]
- Flores, E.; Xu, X.; Lu, Y. Human Capital 4.0: A workforce competence typology for Industry 4.0. J. Manuf. Technol. Manag. 2020, 31, 687–703. [Google Scholar] [CrossRef]
- Flores, E.; Xu, X.; Lu, Y. A Reference Human-centric Architecture Model: A skill-based approach for education of future workforce. Procedia Manuf. 2020, 48, 1094–1101. [Google Scholar] [CrossRef]
- Demartini, P.; Paoloni, P. Human Capital Assessment: A Labor Accounting or a Management Control Perspective? In Management, Valuation, and Risk for Human Capital and Human Assets; Palgrave Macmillan: New York, NY, USA, 2014. [Google Scholar] [CrossRef]
- Bassi, L.; Mcmurrer, D. Developing Measurement Systems for Managing in the Knowledge Era. Organ. Dyn. 2005, 34, 185–196. [Google Scholar] [CrossRef]
- Martinez, J.B.; Fernandez, M.L.; Fernandez, P.M.R. Research proposal on the relationship between corporate social responsibility and strategic human resource management. Int. J. Manag. Enterp. Dev. 2011, 10, 173. [Google Scholar] [CrossRef]
- Hasan, I.; Hoi, C.K.; Wu, Q.; Zhang, H. Social Capital and Debt Contracting: Evidence from Bank Loans and Public Bonds. J. Financ. Quant. Anal. 2017, 52, 1017–1047. [Google Scholar] [CrossRef]
- Lins, K.V.; Servaes, H.; Tamayo, A. Social Capital, Trust, and Firm Performance: The Value of Corporate Social Responsibility during the Financial Crisis. J. Financ. 2016, 72, 1785–1824. [Google Scholar] [CrossRef]
- Massingham, P.; Nguyet, T.; Nguyen, Q.; Massingham, R. Using 360-degree peer review to validate self-reporting in human capital measurement. J. Intellect. Cap. 2011, 12, 43–74. [Google Scholar] [CrossRef]
- Scott, H.; Cheese, P.; Cantrell, S. Focusing HR on growth at Harley-Davidson: Sustaining widespread success by prioritizing employee development. Strat. HR Rev. 2006, 5, 28–31. [Google Scholar] [CrossRef]
- Boudreau, J.W.; Jesuthasan, R. Transformative HR: How Great Companies Use Evidence-Based Change for Sustainable Advantage; Jossey Bass: San Francisco, CA, USA, 2011. [Google Scholar]
- Chynoweth, C. Stop doing dumb things with data. People Management, 23 November 2015. [Google Scholar]
- Lengnick-hall, M.; Lengnick-hall, C. Human Resource Management in the Knowledge Economy; Barrett Koehler Publishers: San Francisco, CA, USA, 2003. [Google Scholar]
- Douthit, S.; Mondore, S. Creating a business-focused HR function with analytics and integrated talent management. People Strategy 2014, 36, 16–21. [Google Scholar]
- Mouritsen, J.; Bukh, P.N.; Marr, B. Reporting on intellectual capital: Why, what and how? Meas. Bus. Excell. 2014, 8, 46–54. [Google Scholar] [CrossRef]
- Haube, J. HR Analytics: A Look Inside Walmart’s HR ‘Test and Learn’ Model. HR Daily. 2015. Available online: http://community.hrdaily.com.au/profiles/blogs/hr-analytics-a-look-insidewalmart-s-hr-test-learn-model (accessed on 21 August 2021).
- HCMI (Human Capital Management Institute). Imperial Services Sales Training ROI Case Study. 2016. Available online: http://www.hcminst.com/thought-leadership/workforce-analyticscase-studies/ (accessed on 21 July 2023).
- Smith, T. HR Analytics: The What, Why and How; CreateSpace Independent Publishing Platform: Scotts Valley, CA, USA, 2013. [Google Scholar]
- Fuller, R. The Paradox of Workplace Productivity. Harvard Business Review. 2016. Available online: https://hbr.org/2016/04/the-paradox-of-workplace-productivity (accessed on 21 July 2023).
- Hesketh, A. Case Study: Xerox; Chartered Institute of Personnel and Development: London, UK, 2014; Available online: http://www.valuingyourtalent.com/media/Case%20study%20-%20Xerox%20-%20PDF_tcm1044-5905.pdf (accessed on 21 July 2023).
- Liu, Z.; Zhang, H.; Rao, B.; Wang, L. A Reinforcement Learning Based Resource Management Approach for Time-critical Workloads in Distributed Computing Environment. In Proceedings of the IEEE International Conference on Big Data, Seattle, WA, USA, 10–13 December 2018; pp. 252–261. [Google Scholar] [CrossRef]
- Munaye, Y.Y.; Juang, R.-T.; Lin, H.-P.; Tarekegn, G.B.; Lin, D.-B. Deep Reinforcement Learning Based Resource Management in UAV-Assisted IoT Networks. Appl. Sci. 2021, 11, 2163. [Google Scholar] [CrossRef]
- Ding, Q.; Jahanshahi, H.; Wang, Y.; Bekiros, S.; Alassafi, M.O. Optimal Reinforcement Learning-Based Control Algorithm for a Class of Nonlinear Macroeconomic Systems. Mathematics 2022, 10, 499. [Google Scholar] [CrossRef]
- Pinheiro, G.G.; Defoin-Platel, M.; Regin, J.-C. Outsmarting Human Design in Airline Revenue Management. Algorithms 2022, 15, 142. [Google Scholar] [CrossRef]
- Qiu, H.; Mao, W.; Patke, A.; Wang, C.; Franke, H.; Kalbarczyk, Z.T.; Başar, T.; Iyer, R.K. Reinforcement learning for resource management in multi-tenant serverless platforms. In Proceedings of the EuroMLSys ’22: Proceedings of the 2nd European Workshop on Machine Learning and Systems, Rennes, France, 5–8 April 2022; pp. 20–28. [Google Scholar] [CrossRef]
- Li, Q.; Lin, T.; Yu, Q.; Du, H.; Li, J.; Fu, X. Review of Deep Reinforcement Learning and Its Application in Modern Renewable Power System Control. Energies 2023, 16, 4143. [Google Scholar] [CrossRef]
- Wang, R.; Chen, Z.; Xing, Q.; Zhang, Z.; Zhang, T. A Modified Rainbow-Based Deep Reinforcement Learning Method for Optimal Scheduling of Charging Station. Sustainability 2022, 14, 1884. [Google Scholar] [CrossRef]
- Abideen, A.Z.; Sundram, V.P.K.; Pyeman, J.; Othman, A.K.; Sorooshian, S. Digital Twin Integrated Reinforced Learning in Supply Chain and Logistics. Logistics 2021, 5, 84. [Google Scholar] [CrossRef]
- Yan, Y.; Chow, A.H.; Ho, C.P.; Kuo, Y.-H.; Wu, Q.; Ying, C. Reinforcement learning for logistics and supply chain management: Methodologies, state of the art, and future opportunities. Transp. Res. Part E Logist. Transp. Rev. 2022, 162, 102712. [Google Scholar] [CrossRef]
- Han, D.; Mulyana, B.; Stankovic, V.; Cheng, S. A Survey on Deep Reinforcement Learning Algorithms for Robotic Manipulation. Sensors 2023, 23, 3762. [Google Scholar] [CrossRef]
- Orr, J.; Dutta, A. Multi-Agent Deep Reinforcement Learning for Multi-Robot Applications: A Survey. Sensors 2023, 23, 3625. [Google Scholar] [CrossRef]
- Dutreilh, Х. Using reinforcement leaming for autonomic resource allocation in clouds: Towards а fully automated work-flow. In Proceedings of the ICAS 2011, The Seventh International Conference on Autonomic and Autonomous Systems, Venice, Italy, 22–27 May 2011; pp. 67–74. [Google Scholar]
- Littman, М.; Boyan, J. A Distributed reinforcement leaming scheme for network routing. In Proceedings of the International Workshop on Applications of Neural Networks to Telecommunications, Halkidiki, Greece, 13–16 September 2013; pp. 1–7. [Google Scholar]
- Das, A.; Shafik, R.A.; Merrett, G.V.; Al-Hashimi, B.M.; Kumar, A.; Veeravalli, B. Reinforcement Learning-Based Inter- and Intra-Application Thermal Optimization for Lifetime Improvement of Multicore Systems. In Proceedings of the DAC’14: Proceedings of the 51st Annual Design Automation Conference, San Francisco, CA, USA, 1–5 June 2014; pp. 1–6. [Google Scholar] [CrossRef]
- Rolnick, D.; Donti, P.L.; Kaack, L.H.; Kochanski, K.; Lacoste, A.; Sankaran, K.; Bengio, Y. Tackling climate change with machine leaming. arXiv 2019, arXiv:1906.05433. [Google Scholar]
- Chen, T.; Bu, S.; Liu, X.; Kang, J.; Yu, F.R.; Han, Z. Peer-to-Peer Energy Trading and Energy Conversion in Interconnected Multi-Energy Microgrids Using Multi-Agent Deep Reinforcement Learning. IEEE Trans. Smart Grid 2022, 13, 715–727. [Google Scholar] [CrossRef]
- Kumari, A.; Kakkar, R.; Gupta, R.; Agrawal, S.; Tanwar, S.; Alqahtani, F.; Tolba, A.; Raboaca, M.S.; Manea, D.L. Blockchain-Driven Real-Time Incentive Approach for Energy Management System. Mathematics 2023, 11, 928. [Google Scholar] [CrossRef]
- La, Р.; Bhatnagar, S. Reinforcement leaming with function approximation for traffic signal control. IEEE Trans. Intell. Transp. Syst. 2011, 12, 412–421. [Google Scholar] [CrossRef]
- Rezaee, К.; Abdulhai, В.; Abdelgawad, Н. Application of reinforcement leaming with continuous state space to ramp metering in real-world conditions. In Proceedings of the 2012 15th International IEEE Confeгence on Intelligent Transportation Systems, Anchorage, AK, USA, 16–19 September 2012; pp. 1590–1595. [Google Scholar]
- Mohammadi, М.; Al-Fuqaha, А.; Guizani, М.; Oh, J. Semisupervised deep reinforcement leaming in support of IoT and smart city services. IEEE Internet Things J. 2018, 5, 624–635. [Google Scholar] [CrossRef]
- Zhao, Y.; Kosorok, M.R.; Zeng, D. Reinforcement learning design for cancer clinical trials. Stat. Med. 2009, 28, 3294–3315. [Google Scholar] [CrossRef]
- Laber, E.B.; Lizotte, D.J.; Qian, M.; Pelham, W.E.; Murphy, S.A. Dynamic treatment regimes: Technical challenges and applications. Electron. J. Stat. 2014, 8, 1225–1272. [Google Scholar] [CrossRef]
- Yu, C.; Liu, J.; Nemati, S. Reinforcement Learning in Healthcare: A Survey. arXiv 2019, arXiv:1908.08796. [Google Scholar] [CrossRef]
- Chi, M.; VanLehn, K.; Litman, D.; Jordan, P. Empirically evaluating the application of reinforcement learning to the induction of effective and adaptive pedagogical strategies. User Model. User-Adapt. Interact. 2011, 21, 137–180. [Google Scholar] [CrossRef]
- Xiong, Z.; Liu, X.-Y.; Zhong, S.; Yang, H.; Walid, A. Practical deep reinforcement learning approach for stock trading. arXiv 2018, arXiv:1811.07522. [Google Scholar]
- Li, X.; Li, Y.; Zhan, Y.; Liu, X.-Y. Optimistic bull or pessimistic bear: Adaptive deep reinforcement learning for stock portfolio allocation. arXiv 2019, arXiv:1907.01503. [Google Scholar]
- Li, Y.; Ni, P.; Chang, V. An Empirical Research on the Investment Strategy of Stock Market based on Deep Reinforcement Learning model. In Proceedings of the 4th International Conference on Complexity, Future Information Systems and Risk, Crete, Greece, 2–4 May 2019; pp. 52–58. [Google Scholar] [CrossRef]
- Azhikodan, A.R.; Bhat, A.G.; Jadhav, M.V. Stock Trading Bot Using Deep Reinforcement Learning. In Innovations in Computer Science and Engineering; Springer: Berlin/Heidelberg, Germany, 2019; pp. 41–49. [Google Scholar]
- Moody, J.; Wu, L.; Liao, Y.; Saffell, M. Performance functions and reinforcement learning for trading systems and portfolios. J. Forecast. 1998, 17, 441–470. [Google Scholar] [CrossRef]
- Liang, Z.; Chen, H.; Zhu, J.; Jiang, K.; Li, Y. Adversarial deep reinforcement learning in portfolio management. arXiv 2018, arXiv:1808.09940. [Google Scholar]
- Jiang, Z.; Liang, J. Cryptocurrency portfolio management with deep reinforcement learning. In Proceedings of the 2017 Intelligent Systems Conference (IntelliSys), London, UK, 7–8 September 2017; pp. 905–913. [Google Scholar]
- Yu, P.; Lee, J.S.; Kulyatin, I.; Shi, Z.; Dasgupta, S. Model-based Deep Reinforcement Learning for Dynamic Portfolio Optimization. arXiv 2019, arXiv:1901.08740. [Google Scholar]
- Amirzadeh, R.; Nazari, A.; Thiruvady, D. Applying Artificial Intelligence in Cryptocurrency Markets: A Survey. Algorithms 2022, 15, 428. [Google Scholar] [CrossRef]
- Feng, L.; Tang, R.; Li, X.; Zhang, W.; Ye, Y.; Chen, H.; Guo, H.; Zhang, Y. Deep reinforcement learning based recommendation with explicit user-item interactions modeling. arXiv 2018, arXiv:1810.12027. [Google Scholar]
- Liu, J.; Zhang, Y.; Wang, X.; Deng, Y.; Wu, X. Dynamic Pricing on E-commerce Platform with Deep Reinforcement Learning. arXiv 2019, arXiv:1912.02572. [Google Scholar]
- Zheng, G.; Zhang, F.; Zheng, Z.; Xiang, Y.; Yuan, N.J.; Xie, X.; Li, Z. DRN: A deep reinforcement learning framework for news recommendation. In Proceedings of the 2018 Worldwide Web Conference, Lyon, France, 23–27 April 2018; pp. 167–176. [Google Scholar]
- Lake, B.M.; Ullman, T.D.; Tenenbaum, J.B.; Gershman, S.J. Building machines that learn and think like people. Behav. Brain Sci. 2017, 40, e253. [Google Scholar] [CrossRef]
- Gershman, S.J. Reinforcement learning and causal models. Oxf. Handb. Causal Reason. 2017, 1, 295. [Google Scholar]
- Liu, Y.; Dolan, R.J.; Kurth-Nelson, Z.; Behrens, T.E. Human Replay Spontaneously Reorganizes Experience. Cell 2019, 178, 640–652.e14. [Google Scholar] [CrossRef]
- Feliciano-Avelino, I.; Méndez-Molina, A.; Morales, E.F.; Sucar, L.E. Causal Based Action Selection Policy for Reinforcement Learning. In Advances in Computational Intelligence; MICAI 2021; Lecture Notes in Computer Science; Batyrshin, I., Gelbukh, A., Sidorov, G., Eds.; Springer: Cham, Switzerland, 2021; Volume 13067. [Google Scholar] [CrossRef]
- Bornstein, A.M.; Khaw, M.W.; Shohamy, D.; Daw, N.D. Reminders of past choices bias decisions for reward in humans. Nat. Commun. 2017, 8, 15958. [Google Scholar] [CrossRef]
- Orlova, E.V. Innovation in Company Labor Productivity Management: Data Science Methods Application. Appl. Syst. Innov. 2021, 4, 68. [Google Scholar] [CrossRef]
- Orlova, E.V. Assessment of the Human Capital of an Enterprise and its Management in the Context of the Digital Transformation of the Economy. J. Appl. Econ. Res. 2021, 20, 666–700. [Google Scholar] [CrossRef]
- Orlova, E.V. Inference of Factors for Labor Productivity Growth Used Randomized Experiment and Statistical Causality. Mathematics 2023, 11, 863. [Google Scholar] [CrossRef]
- Orlova, E.V. Methodology and Statistical Modeling of Social Capital Influence on Employees’ Individual Innovativeness in a Company. Mathematics 2022, 10, 1809. [Google Scholar] [CrossRef]
- Orlova, E.V. Technique for Data Analysis and Modeling in Economics, Finance and Business Using Machine Learning Methods. In Proceedings of the IEEE 4th International Conference on Control Systems, Mathematical Modeling, Automation and Energy Efficiency (SUMMA), Lipetsk, Russia, 9–11 November 2022; pp. 369–374. [Google Scholar] [CrossRef]
- Orlova, E.V. Data Science Methods for Modeling and Decision Support in Companies’ Labor Productivity Management. In Proceedings of the IEEE Proceedings of 3rd International Conference on Control Systems, Mathematical Modeling, Automation and Energy Efficiency (SUMMA), Lipetsk, Russia, 10–12 November 2021; pp. 202–207. [Google Scholar] [CrossRef]
- Markov, A.A. The Theory of Algorithms. J. Symb. Log. 1953, 18, 340–341. [Google Scholar]
- Bellman, R. A Markovian decision process. J. Math. Mech. 1957, 6, 679–684. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Subject of Study and Highlights | Methods of Study | References |
|---|---|---|
| Propose human-centered architecture and a human-centered architectural model. HC is based on competencies, human life cycle, and scenarios of the external environment | Information system development | [14,15] |
| Examines the features of corporate HC and its management using generations theory | Expert measures | [16] |
| Shows that factors of the company’s HC are not independent, but often have a close correlation. Points out on the complexity of building specific mechanisms for career management | Correlation analysis | [3,4,5,6,7,8] |
| Propose subjective self-ratings of employees as to their individual HC and its conversion to objective measurements | Expert measures | [17] |
| Development of a HC strategy of a company. Description of the relationship between corporate social responsibility and strategic HRM. Focuses on social capital, economic performance, and society wealth | Strategic analysis | [10,18,19,20,21] |
| Measurement of the effectiveness of leadership development programs. HR analysis as a driver and a measuring tool to support organizational change | HC metrics (indices analysis) | [22,23] |
| Using times series to build up data about HC and its comparison over time | Times series analysis | [24] |
| Cause–effect relationships between HR processes and product shrink | Structural equations modeling | [25] |
| HC-related measurements within the company’s intellectual capital relating to the company strategy: product development, improvement of personal skills, creating knowledge and competences within current and future technologies | HC metrics (indexes analysis) | [26] |
| Explore HR quantitative and qualitative data across the organization and its analysis as “capability metrics” to the business unit leader | HC metrics | [27] |
| Model for support decision making. Analysis of the relations of the HC data and its impact on managerial effectiveness and engagement. Using HC measures for the diagnosis of business problems and sales effectiveness | Descriptive measures | [28,29,30,31] |
| Corporate performance dashboard with greater emphasis on HR data in decision making | Information system development/use/support | [32] |
| Problem | Algorithm | References |
|---|---|---|
| Stock trading Development of a decision-making strategy | DDPG (deep deterministic policy gradient) Adaptive DDPG DQN (deep Q-networks) RCNN (recurrent convolutional neural networks) | [57,58,59,60] |
| Portfolio management Algorithmic trading Portfolio optimization | DDPG Model-free CNN Model-based CNN | [61,62,63,64,65,66] |
| Online services and retail Development of recommender systems Development of dynamic pricing algorithms (in real-time) | Actor-critic method SS-RTB (sponsored search real-time bidding) DDPG DQN | [66,67,68] |
| Algorithm | Policy Effectiveness-Average Reward | Learning Efficiency-Convergence Rate (Number of Episodes) |
|---|---|---|
| DQN | −0.15 | 0.27 (53) |
| DDQN | 0.2 | 0.29 (58) |
| SARSA | −3.1 | 0.59 (117) |
| PRO | −52 | - |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Orlova, E.V. Dynamic Regimes for Corporate Human Capital Development Used Reinforcement Learning Methods. Mathematics 2023, 11, 3916. https://doi.org/10.3390/math11183916
Orlova EV. Dynamic Regimes for Corporate Human Capital Development Used Reinforcement Learning Methods. Mathematics. 2023; 11(18):3916. https://doi.org/10.3390/math11183916
Chicago/Turabian StyleOrlova, Ekaterina V. 2023. "Dynamic Regimes for Corporate Human Capital Development Used Reinforcement Learning Methods" Mathematics 11, no. 18: 3916. https://doi.org/10.3390/math11183916
APA StyleOrlova, E. V. (2023). Dynamic Regimes for Corporate Human Capital Development Used Reinforcement Learning Methods. Mathematics, 11(18), 3916. https://doi.org/10.3390/math11183916