1. Introduction
Sketching is a fundamental and essential form of artwork that has been used in traditional art production for centuries [
1,
2,
3,
4,
5,
6]. Recently, sketching has become a crucial element in producing digital artworks, including webtoons and illustrations. Furthermore, sketching has evolved into an independent form of art. Among the various types of sketches, portrait sketching is an essential process for producing visually pleasing characters in digital content creation. In portrait sketching, line sketches that depict the important shape of a character by using lines of various widths are more commonly and widely utilized than tonal sketches that describe shape by using both lines and tones.
In the fields of image processing, computer vision, and computer graphics, many authors have presented line extraction studies that express the shape of objects by using lines [
7,
8,
9,
10,
11]. Recently, line extraction studies have been accelerated on a large scale, due to the progress of deep learning technology. Convincing results from these deep learning technologies necessitate high-quality data, ideally line sketch images drawn by professional human artists. However, the use of artist-created line sketch images as training data has been limited, due to artist-specific distortions or deformations that cause misalignment in the training process.
We present a deep-learning-based model that generates line-based portrait sketches from portrait photos. In order to achieve this, high-quality datasets were created, by hiring a group of professional artists, and a method was devised that resolves the misalignment between the artist-created Ground Truth (GT) sketches and the faces in the photograph. A sketch production strategy that mimics the artist’s sketching process is also proposed.
The misalignment problem is addressed, by proposing a new loss term that considers the distance from the line segments of the sketch. This term contributes to sketch generation in a form that allows misalignment between GT sketch and generated results, unlike conventional losses based on matching between GT and generated results.
The strategy that artists use—applying short strokes to depict detailed shapes, such as eyes and nose, while longer strokes are used to express smooth shapes, such as hair—is mimicked, by separating the portrait into face and hair regions. These regions are segmented and trained independently, and the line sketch from the portraits is finally completed by combining the results produced by the independently trained models.
The following two contributions are claimed:
Related works are described in
Section 2, and an overview of the proposed method is introduced in
Section 3. Our generative model is illustrated in
Section 4, and the proposed loss function is introduced in
Section 5. The implementation details and results are presented in
Section 6, and a comparison between our results and the existing techniques is provided in
Section 7. Conclusions and future research are presented in
Section 8.
2. Related Work
The conversion techniques of images into sketch styles are divided into two categories: the general style generative framework and the sketch-oriented portrait generative framework. The general style generative framework is a flexible approach that not only transforms images into sketches but also allows the creation of various target styles. By contrast, the sketch-oriented portrait generative framework specializes in converting images into sketch line styles, focusing particularly on portrait sketches.
2.1. General Style GENERATIVE Framework
General style generative frameworks can be classified based on the types of underlying neural network: Neural Style Transfer and image-to-image translation.
2.1.1. Neural Style Transfer
Neural Style Transfer (NST) is a technique where a neural network is used to apply the texture of a target style image to the shape of a content image [
12]. Feature maps for shape information are extracted from the content image, using a backbone network, such as VGGNet or ResNet [
13,
14]. Then, a Gram matrix, which represents the correlations between feature map texture information computed from the style image, is constructed. Result images are finally produced by applying an iterative optimization technique, allowing the initial random noise image to evolve and reflect the extracted shape and texture information. However, several artifacts are produced in the result images by the NST, which has prompted many researchers to strive for improved style transfer quality [
15,
16]. These optimization-based methods are deemed inefficient, as the optimization process takes significant time to generate the result images. Moreover, since the NST technique defines style as texture, it is almost impossible to generate a sketch where texture is rare.
2.1.2. Image-to-Image Translation
A Generative Adversarial Network (GAN) is a method of synthesizing images from latent vectors [
17]. Among GAN-based style transfer techniques, the image-to-image translation method transforms images from a specific domain with the styles of another domain [
18,
19,
20,
21,
22,
23]. Several GAN-based models that allow style transfer between unpaired datasets [
20,
21,
24] have gained attention since they addressed the constraint of paired data. The cycle consistency loss of CycleGAN [
21] plays a key role in style transfer between unpaired datasets. A model structure containing two pairings of generator and discriminator was designed, where the two generators synthesized images of each domain. The difference between the Ground Truth image domain and the reconstructed image domain was included in their loss functions. Meanwhile, the features were separated into content and style space, to generate visually pleasing results by Huang et al. [
22].
Remarkable results in synthesizing artwork styles expressed in texture information, such as painting, have been presented by these GAN-based image-to-image translation studies. For our aim to synthesize line-based portrait sketches from portrait photos, models that execute style transfer between independent domains, like portrait photos and line-based portrait sketches, could be a solution. However, due to the target style line-based sketches possessing little texture information, these techniques show limitations in fulfilling the desired purpose. Images similar to sketches can be synthesized, but the quality of the synthesized images is unsatisfactory.
2.2. Sketch-Oriented Portrait Generative Framework
Most sketch-oriented portrait generative frameworks convert an input portrait photo into a sketch image. The synthesized sketch styles can be classified into two types: tonal sketch and line sketch.
2.2.1. Tonal Sketch Generation
Tonal sketch is a drawing technique where the shape of a character is described using lines and tones. A GAN-based model comprised of a hierarchical discriminator and generator, to synthesize tonal portrait images according to face photos, was proposed by Yi et al. [
25]. Several regions were segmented from the face image, and were processed in a hierarchical strategy. Their model, targeted to process face photos, successfully generated tonal sketches of portraits of visually reasonable quality.
A method of generating sketches in a particular cartoon style, by matching portrait photos and cartoon-style faces geometrically, was proposed by Su et al. [
26]. The shape of the input face was deformed, to fit the shape of the cartoon style. However, most of the input face photos tended to excessively converge into the target cartoon style, making it difficult to identify different input face photos’ synthesized sketches. Important limitations were revealed when applying the tonal sketch generation frameworks for line sketching, as the results of these techniques exhibited several artifacts not permissible in line sketching.
2.2.2. Line Sketch Generation
Line sketching is a drawing technique where the shape of a character is depicted using only lines of various lengths and widths. Before deep-learning-based techniques, various techniques for detecting edges and lines, based on the high-frequency components of images, had been proposed [
7,
8,
9]. However, these techniques were limited, as they did not consider the content information of the image. Recently, CNN or GAN-based methods, specialized for line sketching, have been proposed.
A photo–contour-drawing-paired dataset was constructed and a GAN-based model designed to generate contour drawing images from the corresponding photos was proposed by Li et al. [
10]. Although this model was proficient at describing objects of a wide range, the quality of the lines extracted from the face images was not visually pleasing.
A technique that generates line sketch images from portrait photos was proposed by Kim et al. [
11]. Due to the high cost of artist-handcrafted line sketches for portrait photos, they built a large number of synthesized pseudo line sketch images as an alternative to artist-handcrafted line sketches. Although their results were visually more pleasing than previous works, they remained vulnerable to noise, and they showed a lack of coherence.
3. Overview
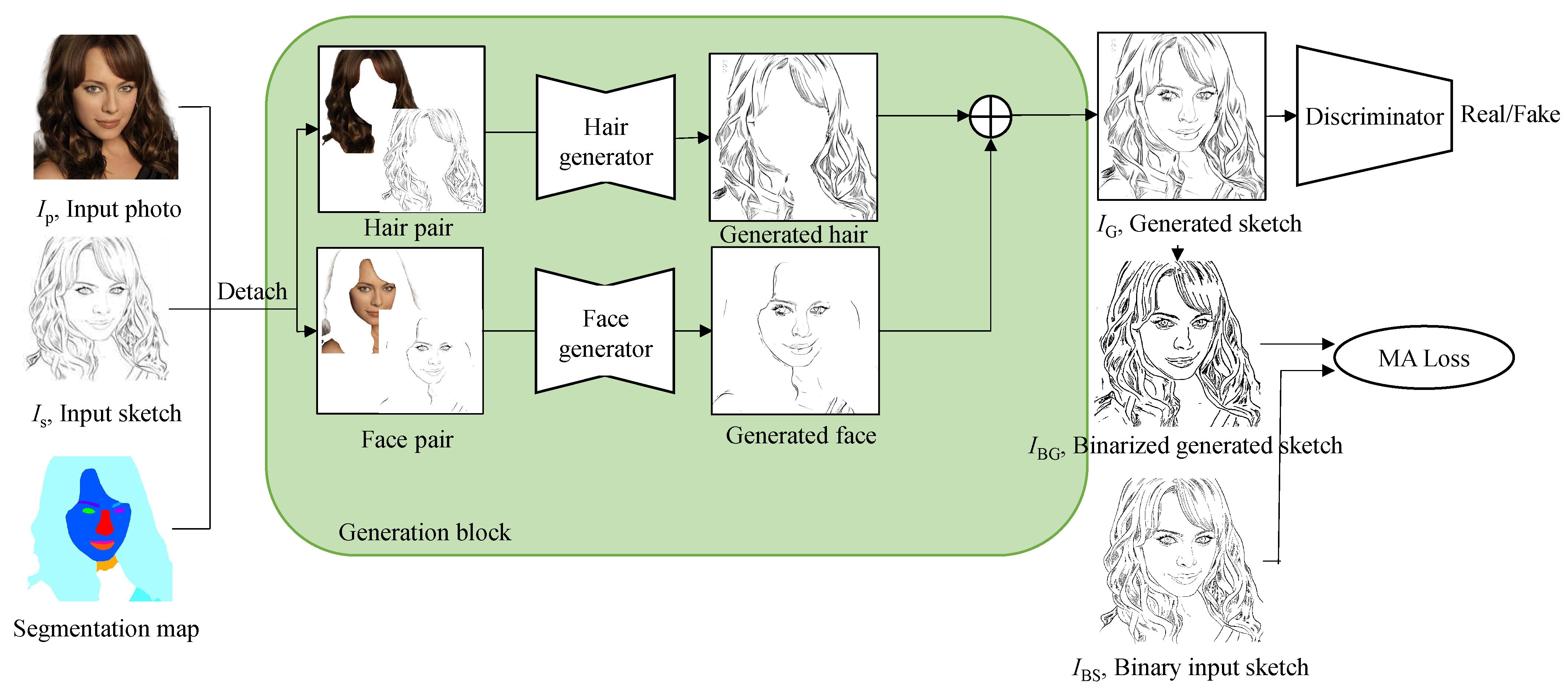
An overview of our proposed framework, which consists of a generation block, a discriminator, and our proposed misalignment loss, is presented in
Figure 1. The generation block takes an input photo (
) and generates a corresponding sketch (
) that is fed into the discriminator and is used to compute the loss simultaneously.
During the training phase, the generation block requires three inputs: an input photo
, an input sketch
, and a segmentation map extracted from (
). The input photo (
) and the input sketch
are obtained from our portrait photo-and-sketch-paired dataset (
Section 6.1). A semantic segmentation technique is employed, to compute the segmentation map from the input photo [
27], where the semantic labels include hair, lips, eyebrows, eyes, and skin.
The segmentation map separates and into hair and face regions, respectively, and forms two photo–sketch-paired datasets for hair and face regions. Generators for hair and face regions are trained with their respective paired datasets, producing hair and face sketches, which are then combined to generate the final sketch image, referred to as . The discriminator distinguishes whether is a real or fake sketch, and is binarized, to compute the misalignment loss. After training, our generation block generates the sketch image () from the input photo ().
4. Generation Block
The generation block consists of two stages for generating line sketches of portraits. One stage processes hair while the other processes the face, excluding hair. Photo–sketch-paired datasets for hair and face are used as the training data for the generation block. Each paired dataset is used to train two partial generators for hair and face.
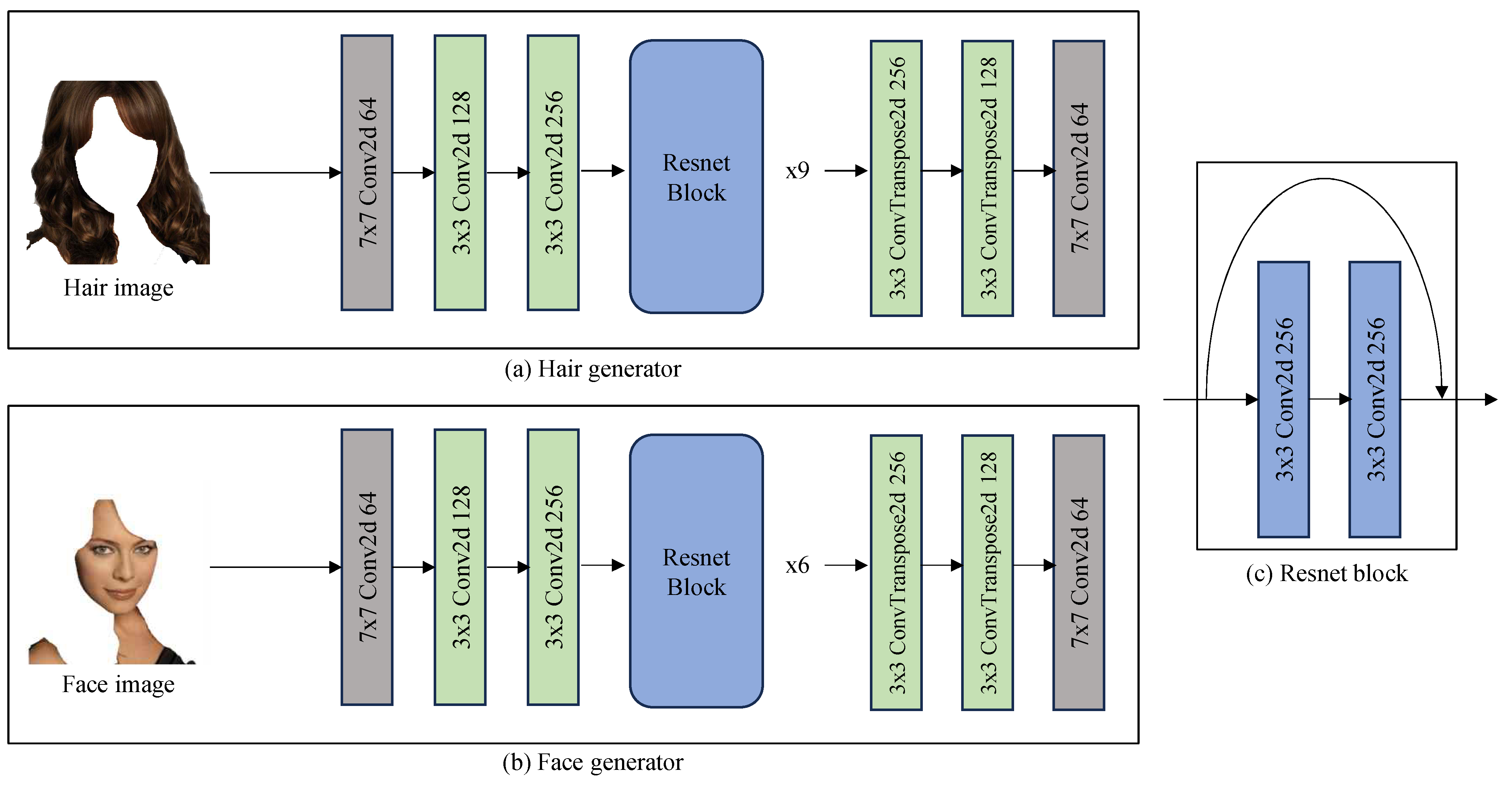
To achieve our purpose, we design our generator. Generally, deep network models have higher capacity, but the information learned in the earlier layers tends to be lost in the later layers. To address this information loss, the skip connection structure of ResNet [
14] is employed as the backbone structure of our generator.
Differently designed hair and face generators are utilized, taking into account the characteristics of each region (
Figure 2). Hair sketches necessitate a longer and more detailed flow than other regions, whereas face sketches require less texture but a more global feature representation. Deep-structure generators are typically suitable for representing local features, while generators with less deep structure are appropriate for representing global shapes. As such, the hair generator is designed to have a deeper structure than the face generator. ResNet 9 blocks are experimentally used for the hair generator (
Figure 2a), and ResNet 6 blocks are utilized for the face generator (
Figure 2b).
Hair and face sketch images are generated, using the hair and face generators. These images are then combined to generate the sketch image
. The improvement in sketch generation performance, due to the use of two separate generators, is illustrated in
Figure 3d,e. Notably, in the result using the generators (e), a clearer flow in the hair region and a suppression of artifacts in the face region can be observed.
5. Misalignment Loss for Addressing Misalignment
Misalignments are often found in paired datasets of photos and artist-created sketches, including our own data (Sketchy [
28], QMUL-Shoe-Chair-V2 [
29], Apdrawing [
25]). This is due to the natural occurrence of hand-drawn sketches that may not align perfectly with reference photos. Furthermore, the degree of misalignment varies across data examples.
Figure 4 illustrates the misalignments present in our data, where the facial contours match, but misalignments occur in detailed areas, such as the eyes. The third example in
Figure 4 demonstrates severe misalignments, especially in the contour of the hair, as well as the eyes and eyebrows.
These misalignments pose challenges to training generative models on photo and artist-created sketch data, and significantly reduce the quality of the generated sketches. Unclear short strokes are exhibited by sketches generated by models trained on such datasets (
Figure 3c).
The L1 loss, commonly used in generative models, is notably affected by these misalignments. In black-and-white pixel-based line sketch images without gray values, a large loss value is observed if a black pixel in the GT sketch ((
,
) in
Figure 5a) does not match a black pixel in the same location in the generated sketch ((
,
) in
Figure 5b). In other words, the
loss becomes small only when the corresponding pixel components of GT and generated sketches at the same location match.
As generated sketches are heavily reliant on brightness differences from photos, they are naturally prone to differences from the GT sketch. Instead of finding the exact edges of the photo, our generative model is aimed at learning the unique artistic style inherent in the GT sketch. Therefore, in our study, the allowance of small misalignments, such as those illustrated in
Figure 5, is reasonable.
To counteract the generated-sketch quality degradation caused by these misalignments, a novel misalignment loss is proposed. The misalignment loss measures misalignment distance (
Section 5.1) and incorporates it into the model (
Section 5.2). Unlike the
loss, which does not tolerate differences caused by a misalignment of even one pixel, our misalignment loss tolerates misalignments greater than the
loss, as it considers the degree of the misalignment. The visual impact of the misalignment loss can be observed by comparing sketches before (
Figure 3c) and after (
Figure 3e) the application of the misalignment loss.
5.1. Misalignment Distance Map for Black-and-White Pixels
The Misalignment Distance (MD) between the GT sketch and the generated sketch is stored in the MD map. Two separate MD maps are computed, one each for black and for white pixels.
The calculation process of the MD for black pixels is illustrated below. Initially, the GT sketch and the generated sketch, denoted as
and
, respectively, are binarized. For a black pixel (
) in
(yellow box in
Figure 5a), the distance to the closest black pixel from the corresponding position (
) in
is determined, yielding
(between the yellow box and the green box in
Figure 5b). As a result, the value
is stored at the (
) position within the MD map (yellow box in
Figure 5c). The MD map for black pixels is denoted as
. The MD map for white pixels,
, follows the same calculation process.
5.2. Misalignment Loss
The misalignment loss is calculated by incorporating the MD map, as follows:
where
is the binary GT sketch,
denotes the black pixels of
, and
signifies the white pixels of
. In addition,
is the MD value at position
for
. In other words, the first term of the equation above represents the sum of the MD map values calculated at all positions
of the black pixels
in the binary GT sketch
. Moreover, all the MD map values denoted as
, calculated for the white pixels (
), are summed (right term). The misalignment loss is obtained by combining these two terms. A comparison between the results before applying the misalignment loss (
Figure 3c) and after applying the misalignment loss (
Figure 3e) reveals that the latter exhibits a clearer flow and fewer artifacts, indicating improved quality.
5.3. Total Loss
The total loss function
of the proposed model consists of three terms, and is defined by the following equation:
where
,
, and
denote adversarial loss, L1 loss, and misalignment loss, respectively. Furthermore,
,
, and
are the weights assigned to each loss term, which are hyperparameters.
Adversarial loss.
is the adversarial loss commonly used in GAN-based models [
17]. This loss improves the discriminator’s ability to distinguish the generated sketch
and the GT sketch
from the input photo
. Moreover, the generator’s sketch generation capability is enhanced. The mathematical expression for this loss is as follows:
Pixel-wise L1 loss.
signifies the pixel-wise
loss, which is frequently employed in GAN-based style transfer studies [
10,
25]. It measures the difference between the generated sketch
and the GT sketch
, encouraging the generator to produce images resembling the GT sketch. This loss is computed at the pixel level and is represented by the following equation:
The weight of the adversarial loss, , is set to 1. Appropriate values for and are determined by adjusting their ratio. The degree to which the generated sketch closely mimics the GT sketch at the pixel level is influenced by . A higher value leads to the generated sketch becoming more similar to the GT sketch, in terms of pixel-wise alignment. Conversely, governs the degree to which the generated sketch replicates the relatively global shape of the GT sketch, thereby preserving local invariance. A higher value results in the generated sketch more closely resembling the shape of the GT sketch lines. The values of , , and are determined by experimentation, and are set to 1, 10, and 0.1, respectively.
6. Implementation and Results
This section illustrates the construction process of our training dataset, the details of our implementation, and our results.
6.1. Dataset
A multitude of sketch datasets were reviewed for this study. Datasets comprising solely sketches devoid of paired images (e.g., TU-Berlin [
30], QuickDraw [
31], MangaGAN-BL [
26]), along with photo-to-sketch datasets for non-facial objects (BSDS500 [
32], Sketchy [
28], QMUL-Shoe-Chair-V2 [
29], Contour Drawing [
10]), were deemed unsuitable. Apdrawing [
25], a photo–sketch-paired dataset with good sketch quality, was also excluded, as it contains shaded representations instead of line drawings.
Consequently, a new dataset was constructed. Two artists were hired to draw visually pleasing and high-quality line-drawing sketches. The sketches produced by the artists inherently exhibited misalignment between the photo and the sketch. Instead of tolerating misalignment during dataset construction, we provided precise instructions to the artists to maintain the identification and pose of the characters in the sketch with the corresponding photo. This method permitted a degree of misalignment between the photo and the sketch, while maintaining consistency in identification and pose, thereby constituting a semi-paired photo-to-sketch dataset. This dataset comprised 90 pairs of photos and sketches.
6.2. Implementation Details
Hyperparameters, including the learning rate and the decay rate, were established through experimentation. The learning rate was fixed at 0.0002, and decay was initiated after 80% of the total epochs. The model was trained for 10,000 epochs, taking approximately five days. The implementation was carried out in Python, using PyTorch on a computer system equipped with a single Intel Pentium I7 CPU and dual nVidia GTX 3090Ti GPUs. The Linux Ubuntu operating system was deployed.
6.3. Results
Figure 6 shows the sketch results generated from various facial photos by applying our trained sketch generation model. The quality of our results is comparable to the GT sketch. Noteworthy was the tendency of our model to replicate the aspects emphasized by the artists when depicting characters, instead of solely tracing edges based on brightness discrepancies. The sketches demonstrate distinct and coherent stroke flows. In particular, strokes in the hair regions appear long and coherent, while those in the facial contours and lips are semantically consistent. Moreover, the results exhibit detailed representation in regions such as teeth, mouth, and eyebrows.
7. Analysis and Evaluation
For the evaluation of our generated sketch images, a quantitative metric was required. This section introduces the metric employed and compares our resulting images to those from State-of-the-Art research.
7.1. Metric
As our dataset included GT sketches, it was possible to measure the difference between GT sketches and generated sketches in pixel-level alignment, which is accuracy. Accuracy denotes the pixel-wise similarity between two images, and it is a reasonable metric when generating sketch images that align pixel-by-pixel with the GT sketch [
11].
However, an exact pixel-level match with the GT sketch was not the intended goal of our generated sketches. Misalignment between the photo and the GT sketch was assumed. As a result, the sketch lines generated from the photo naturally fit the boundaries of the photo, while misalignment occurred with the GT sketch lines. This was the reason why we devised the misalignment loss in
Section 5. Even if the generated sketch did not match the GT sketch precisely, our aim was to preserve the identity of the photo and to reflect the style of the GT sketch. Therefore, we needed an alternative metric, to capture this goal.
The Frechet Inception Distance (FID) [
33] is a widely accepted metric for assessing the quality of synthesized images. The FID quantifies the distance between the distributions of generated and real images, where a smaller FID value indicates a higher similarity between the two image sets. Hence, a low FID value denotes well-generated images. The FID is prevalently used in GAN-based image generation research [
25,
34,
35], comparing the distribution of generated images to GT images, to assess their similarity.
The FID is calculated between the generated sketch and the GT sketch. Additionally, to assess the preservation of the input photo’s identity in the generated sketch, the FID between the generated sketch and the input photo is computed. These metrics facilitate a comparison of the results from various sketch generation models to our own. Specifically, a comparison is exclusively made to line-based sketch generation models, as tonal sketch images, despite potentially displaying lower sketch quality, are deemed similar to input photos, in terms of the FID, due to their tonal expressions. The exclusion of tonal sketch generation models ensures a fair comparison.
In summary, our results were compared to line-based sketch generation models using the FID between the generated sketch and the GT sketch, as well as the FID between the generated sketch and the input photo.
7.2. Comparison to Related Work
Experiments were conducted using portrait photos of individuals of varied ages and genders.
Table 1a presents the FID values between the generated sketches and the GT sketches. Our proposed method achieved the lowest value, indicating that our results closely resemble the GT sketches among the line-based sketches.
Table 1b shows the FID values between the generated sketches and the input photos. Our proposed method obtained the lowest value, implying that our results closely resemble the input photos among the line-based sketches. Therefore, our results quantitatively express a style similar to GT sketches, while preserving the identity of the input photo.
A visual comparison of our proposed method to tonal sketch generation techniques [
21,
22,
24], as well as to line-based sketch generation techniques [
8,
10,
11], was also conducted. As depicted in
Figure 7, our results present reduced noise and clearly portray various elements, such as facial contours and hair, resulting in a better representation of the input photo’s identity. The sketch lines are coherent and visually pleasing. Furthermore, our results better capture the artist’s expression, similar to GT sketches.
7.3. Comparison to Diffusion Model
Our results were compared to the recently acclaimed diffusion model [
36]. Among the different variants of diffusion models, Stable Diffusion [
37] is widely adopted as a backbone network, due to its ability to generate stable results. However, in the universal framework where diffusion models generate images solely from input prompts, a direct comparison to our method was deemed unsuitable. Therefore, the application of ControlNet [
38] was chosen, as it integrates additional conditions, such as edges, poses, and semantic maps, to generate images that adhere to the specified conditions. Hence, both edges of a photo and prompts were incorporated as inputs, to generate sketch images in the framework we employed.
To compare our generated sketch images, there are three methods for generating sketches using the diffusion model: Vanilla SD (Stable Diffusion), LoRA (Low-Rank Adaptation of large language models), and Dreambooth (
Figure 8 3rd–5th columns). Firstly, ’Vanilla SD’ is the term ascribed to the utilization of Stable Diffusion and ControlNet without fine-tuning with our sketch dataset.
The remaining two methods involve fine-tuning with our sketch train dataset without the corresponding photo. Unique instance tokens (trigger words) are assigned to this sketch data. Two types of training methods for fine-tuning diffusion models—LoRA [
39] and Dreambooth [
40]—are followed. These methods are known for their effectiveness in training diffusion models on specific objects or styles, achieving impressive fine-tuning results with only a limited number of training samples.
During the inference phase subsequent to model training, a variety of results can be generated by adjusting the combination of prompts and random seed values. The prompt “<instance token> sketch, line, without tone” and the edge information of the input photo are employed as inputs. However, in Vanilla SD, the <instance token> is omitted. Additionally, both positive prompts, such as “best quality, high quality”, and negative prompts, such as “deformed, worst quality, low resolution”, can be utilized. Various prompt combinations for the same input photo are trialed, to attain the best quality. Furthermore, by varying the random seed value of the diffusion model, the outcomes yielding the highest quality are presented.
Figure 8 exhibits a comparison of the sketches generated using our proposed method to those produced by the diffusion model. Due to the use of large-scale and high-quality training images prior to fine-tuning with our data, the results of the diffusion model are visually pleasing. However, Vanilla SD and LoRA tended to generate gray-scale tonal sketches rather than line sketches (
Figure 8, 3rd and 4th columns). Dreambooth, by contrast, produced line sketches, but failed to maintain the identity and consistency of the input photo. For instance, excessive beards were added to a man’s face (
Figure 8, 3rd row), or lower teeth were depicted for Obama (
Figure 8, 6th row). Irrelevant elements or distorted shapes not present in the input photo tended to be generated by all three types of diffusion models. By contrast, the identity of the input photo is effectively preserved in our results.
8. Conclusions and Future Work
In this paper, a generative model for generating line-based portrait sketches from portrait photos is presented. The approach involves collaboration with professional artists for the creation of high-quality datasets, and addresses the misalignment problem emerging from the differences between the Ground Truth sketches and the portrait photos. A novel loss term that considers the distance between the Ground Truth sketches and the generated sketches is introduced to resolve this issue, facilitating the generation of sketches with reduced artifacts and unclear short strokes.
An artistic strategy is further incorporated that delineates the image into distinct regions, each expressed uniquely. In particular, the portrait photo is segmented into facial and hair regions, and separate models are trained for each respective region. The results are subsequently combined, to produce the final line sketch.
A reduction in artifacts and unclear short strokes is visually demonstrated in our results. Moreover, when compared to the State-of-the-Art results, a better preservation of the identity inherent in the input portrait photo is numerically indicated by our results.
Nevertheless, our method as presented was confined to portrait photos. Thus, the application of our proposed technique to non-portrait subjects may not yield optimal results. As a future avenue of work, the scope of the approach could be expanded, to cover a more diverse range of subjects, including animals, still lives, and landscapes.
Potential is also envisaged in extending the approach to the video domain, where preserving temporal coherence between frames holds paramount importance. Given that line-based sketches, in contrast to natural images or tonal sketches, comprise discrete elements (specifically black or white pixels), mitigating the issue of flickering artifacts presents a noteworthy avenue for future work.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}