

Unmasking Deception: Empowering Deepfake Detection with Vision Transformer Network

 ,
,  , , and
, , and 
Abstract
:1. Introduction
2. Literature Review
- The fine-tuned ViT model presented in this study demonstrates superior performance compared to existing state-of-the-art models in the domain of deep-fake identification.
- A patch-wise self-attention module and global feature extraction technique considered in this study.
- Evaluating model for real-world in the deepfake detection task, with a focus on Snapchat.
- After conducting a thorough analysis of various standard data sets, our research substantiates the exceptional robustness and generalizability of the proposed method, surpassing numerous state-of-the-art techniques.
3. Materials and Methods
3.1. Data Set
3.2. ViT Architecture
3.3. Hyper-Parameters for ViT Pretrained Model
4. Experiments Results & Discussion
4.1. Evaluation Metrics
- Accuracy: The metric of accuracy assesses the comprehensive correctness of the model’s predictions by calculating the ratio of accurately classified instances to the total samples. However, in scenarios involving imbalanced data sets or situations where distinct types of errors hold differing degrees of significance, relying solely on accuracy might not suffice for a thorough evaluation.
- Precision: Precision gauges a model’s proficiency in recognizing positive samples within the set of actual positives. This metric quantifies the ratio of true positives to the sum of true positives and false positives.
- Recall: The model’s competence in precisely identifying positive samples from the pool of actual positives is measured using recall, which is alternatively known as sensitivity or the true positive rate. This metric is derived by calculating the ratio of true positives to the sum of true positives and false negatives. Essentially, recall provides an assessment of the thoroughness of positive predictions.
- F1 Score: The F1 score, determined by the harmonic mean of precision and recall, serves as a singular metric that strikes a balance between these two measures. This becomes particularly advantageous in scenarios where there is an unequal distribution among classes or when there exists an equal emphasis on both types of errors. Ranging between 0 and 1, the F1 score attains its peak performance at 1.
4.2. Results & Discussion
4.2.1. Experiment 1: Results for the Kaggle Data Set
4.2.2. Experiment 2: Real (Kaggle) + Fake (StyleGAN-Based) Data Set
4.2.3. Experiment 3: Real (Kaggle) + Fake (Kaggle + StyleGAN-Based)
4.2.4. Model Robustness
4.2.5. Theoretical and Practical Implications
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| TP | True Positive |
| FP | False Positive |
| TN | True Negative |
| FN | False Negative |
| ViT | Vision Transformer |
| (DARPA) | Defense Advanced Research Projects Agency |
| GAN | Generative Adversarial Networks |
| AI | Artificial Intelligence |
| ML | Machine Learning |
| DL | Deep Learning |
References
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. IEEE Signal Process. Mag. 2018, 10, 53–65. Available online: https://proceedings.neurips.cc/paper_files/paper/2014/hash/5ca3e9b122f61f8f06494c97b1afccf3-Abstract.html (accessed on 11 July 2023).
- Nguyen, T.T.; Nguyen QV, H.; Nguyen, D.T.; Nguyen, D.T.; Huynh-The, T.; Nahavandi, S.; Nguyen, C.M. Deep learning for deepfakes creation and detection: A survey. Comput. Vis. Image Underst. 2018, 223, 103525. Available online: https://www.sciencedirect.com/science/article/pii/S1077314222001114 (accessed on 11 July 2023). [CrossRef]
- Media Forensics. Available online: https://www.darpa.mil/program/media-forensics (accessed on 11 July 2023).
- Deepfake Detection Challenge Results: An Open Initiative to Advance AI. Available online: https://ai.facebook.com/blog/deepfake-detection-challenge-results-an-open-initiative-to-advance-ai/ (accessed on 11 July 2023).
- Akhtar, Z.; Mouree, M.R.; Dasgupta, D. Utility of Deep Learning Features for Facial Attributes Manipulation Detection. In Proceedings of the 2020 IEEE International Conference on Humanized Computing and Communication with Artificial Intelligence, HCCAI 2020, Irvine, CA, USA, 21–23 September 2020; pp. 55–60. [Google Scholar] [CrossRef]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5 MB model size. arXiv 2016, arXiv:1602.07360. Available online: https://arxiv.org/abs/1602.07360v4 (accessed on 12 July 2023).
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015—Conference Track Proceedings, San Diego, CA, USA, 7–9 May 2015; Available online: https://arxiv.org/abs/1409.1556v6 (accessed on 12 July 2023).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the—30th IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2016; pp. 2261–2269. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A.; Liu, W.; et al. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef]
- Akhtar, Z.; Dasgupta, D. A comparative evaluation of local feature descriptors for deepfakes detection. In Proceedings of the 2019 IEEE International Symposium on Technologies for Homeland Security (HST), Woburn, MA, USA, 5–6 November 2019; Available online: https://ieeexplore.ieee.org/abstract/document/9033005/ (accessed on 11 July 2023).
- Bekci, B.; Akhtar, Z.; Ekenel, H.K. Cross-Dataset Face Manipulation Detection. In Proceedings of the 2020 28th Signal Processing and Communications Applications Conference, SIU 2020—Proceedings, Gaziantep, Turkey, 5–7 October 2020. [Google Scholar] [CrossRef]
- Li, Y.; Chang, M.C.; Lyu, S. In Ictu Oculi: Exposing AI created fake videos by detecting eye blinking. In Proceedings of the 10th IEEE International Workshop on Information Forensics and Security, WIFS 2018, Delft, The Netherlands, 9–12 December 2019. [Google Scholar] [CrossRef]
- Eyebrow Recognition for Identifying Deepfake Videos. IEEE Conference Publication. Available online: https://ieeexplore.ieee.org/document/9211068/authors#authors (accessed on 12 July 2023).
- Patel, M.; Gupta, A.; Tanwar, S.; Obaidat, M.S. Trans-DF: A Transfer Learning-based end-to-end Deepfake Detector. In Proceedings of the 2020 IEEE 5th International Conference on Computing Communication and Automation, ICCCA 2020, Greater Noida, India, 30–31 October 2020; pp. 796–801. [Google Scholar] [CrossRef]
- Ciftci, U.A.; Demir, I.; Yin, L. How do the hearts of deep fakes beat? deep fake source detection via interpreting residuals with biological signals. In Proceedings of the IJCB 2020—IEEE/IAPR International Joint Conference on Biometrics, Houston, TX, USA, 28 September–1 October 2020. [Google Scholar] [CrossRef]
- Yang, J.; Xiao, S.; Li, A.; Lu, W.; Gao, X.; Li, Y. MSTA-Net: Forgery Detection by Generating Manipulation Trace Based on Multi-scale Self-texture Attention. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 4854–4866. Available online: https://ieeexplore.ieee.org/abstract/document/9643421/ (accessed on 12 July 2023). [CrossRef]
- Zhao, H.; Zhou, W.; Chen, D.; Wei, T.; Zhang, W.; Yu, N. Multi-Attentional Deepfake Detection. openaccess.thecvf.com. Available online: https://openaccess.thecvf.com/content/CVPR2021/html/Zhao_Multi-Attentional_Deepfake_Detection_CVPR_2021_paper.html?ref=https://githubhelp.com (accessed on 12 July 2023).
- Wang, J.; Wu, Z.; Ouyang, W.; Han, X.; Chen, J.; Jiang, Y.G.; Li, S.N. M2TR: Multi-modal Multi-scale Transformers for Deepfake Detection. In Proceedings of the 2022 International Conference on Multimedia Retrieval (ICMR 2022), Newark, NJ, USA, 27–30 June 2022; pp. 615–623. [Google Scholar] [CrossRef]
- Shelke, N.A.; Kasana, S.S. Multiple forgery detection and localization technique for digital video using PCT and NBAP. Multimed. Tools Appl. 2022, 81, 22731–22759. [Google Scholar] [CrossRef]
- Shelke, N.A.; Kasana, S.S. Multiple forgery detection in digital video with VGG-16-based deep neural network and KPCA. Multimed. Tools Appl. 2023. [Google Scholar] [CrossRef]
- Wang, B.; Wu, X.; Tang, Y.; Ma, Y.; Shan, Z.; Wei, F. Frequency Domain Filtered Residual Network for Deepfake Detection. Mathematics 2023, 11, 816. [Google Scholar] [CrossRef]
- Zhang, D.; Zheng, Z.; Li, M.; Liu, R. CSART: Channel and spatial attention-guided residual learning for real-time object tracking. Neurocomputing 2020, 436, 260–272. [Google Scholar] [CrossRef]
- 140 k Real and Fake Faces|Kaggle. Available online: https://www.kaggle.com/datasets/xhlulu/140k-real-and-fake-faces (accessed on 12 July 2023).
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner THoulsby, N. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. Available online: https://arxiv.org/abs/2010.11929v2 (accessed on 12 May 2023).
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Lect. Notes Comput. Sci. (including Subser. Lect. Notes Artif. Intell. Lect. Notes Bioinformatics). Volume 12346 LNCS, pp. 213–229. [Google Scholar]
- Zhang, D.; Zheng, Z.; Wang, T.; He, Y. HROM: Learning High-Resolution Representation and Object-Aware Masks for Visual Object Tracking. Sensors 2020, 20, 4807. [Google Scholar] [CrossRef] [PubMed]
- Devlin, J.; Chang, M.-W.; Lee, K.; Google, K.T.; Language, A.I. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Cordonnier, J.B.; Loukas, A.; Jaggi, M. On the relationship between self-attention and convolutional layers. In Proceedings of the 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A Style-Based Generator Architecture for Generative Adversarial Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 4217–4228. [Google Scholar] [CrossRef]
- thispersondoesnotexist.com (1024 × 1024). Available online: https://thispersondoesnotexist.com/ (accessed on 12 July 2023).
- Share the Moment|Snapchat. Available online: https://www.snapchat.com/ (accessed on 12 July 2023).
- Gandhi, A.; Jain, S. Adversarial perturbations fool deepfake detectors. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; Available online: https://ieeexplore.ieee.org/abstract/document/9207034/ (accessed on 13 July 2023).
- Hu, S.; Li, Y.; Lyu, S. Exposing GaN-generated faces using inconsistent corneal specular highlights. In Proceedings of the ICASSP, IEEE International Conference on Acoustics, Speech and Signal Processing—Proceedings, Addis Ababa, Ethiopia, 26–30 April 2021; pp. 2500–2504. [Google Scholar] [CrossRef]
- Yousaf, B.; Usama, M.; Sultani, W.; Mahmood, A.; Qadir, J. Fake visual content detection using two-stream convolutional neural networks. Neural Comput. Appl. 2022, 34, 7991–8004. [Google Scholar] [CrossRef]
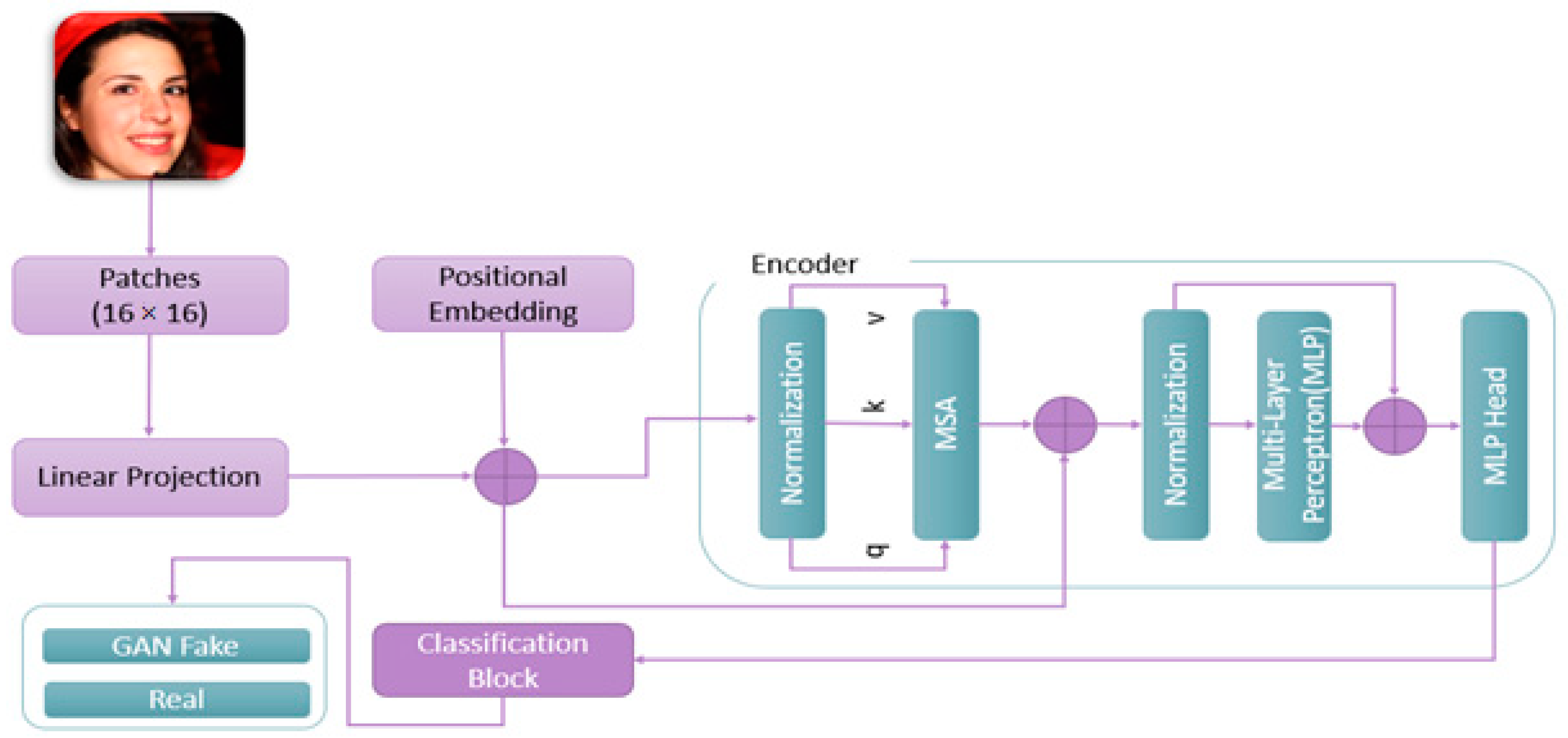


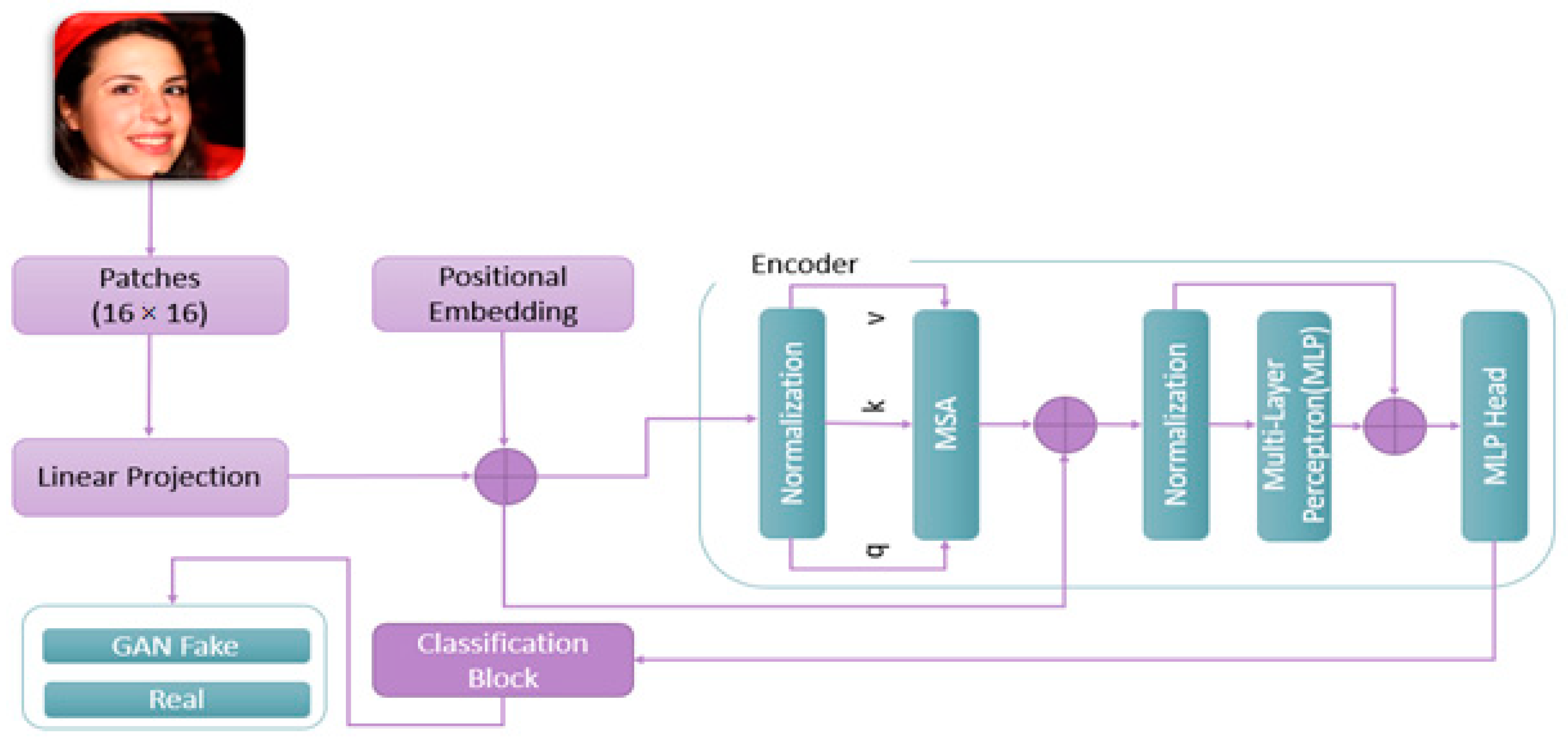{kind=link}
{kind=link}
 |  |  |  |  |  |
| Fake | Fake | Fake | Real | Real | Real |
| Parameters | Values |
|---|---|
| Encoder and Pooling Layers Dimensionality | 768 |
| Transformer Encoder Hidden Layers | 12 |
| Feed-Forward Layer Dimensionality | 3072 |
| Hidden Layers Activation | Gelu |
| Hidden Layer Dropout | 0.1 |
| Image Size | 224 × 224 |
| Channels | 3 |
| Patches | 16 × 16 |
| Balanced | True |
| Class Name | Precision | Recall | F1 | Support |
|---|---|---|---|---|
| Real | 1.0000 | 1.0000 | 1.0000 | 10,000 |
| Fake | 1.0000 | 1.0000 | 1.0000 | 10,000 |
| Accuracy | 1.0000 | 20,000 | ||
| Macro Avg | 1.0000 | 1.0000 | 1.0000 | 20,000 |
| Weighted Avg | 1.0000 | 1.0000 | 1.0000 | 20,000 |
 |  |  |  |  |  |
| Fake | Fake | Fake | Fake | Fake | Fake |
| Class Name | Precision | Recall | F1 | Support |
|---|---|---|---|---|
| Real | 1.0000 | 0.9990 | 0.9995 | 3140 |
| Fake | 0.9990 | 1.0000 | 0.9995 | 3098 |
| Accuracy | 0.9995 | 6238 | ||
| Macro Avg | 0.9995 | 0.9995 | 0.9995 | 6238 |
| Weighted Avg | 0.9995 | 0.9995 | 0.9995 | 6238 |
| Class Name | Precision | Recall | F1 | Support |
|---|---|---|---|---|
| Real | 0.9951 | 0.9980 | 0.9965 | 5917 |
| Fake | 0.9980 | 0.9952 | 0.9966 | 6083 |
| Accuracy | 0.9966 | 12,000 | ||
| Macro Avg | 0.9966 | 0.9966 | 0.9966 | 12,000 |
| Weighted Avg | 0.9966 | 0.9966 | 0.9966 | 12,000 |
 |  |  |
| Real | Real | Real |
| Authors | Method | Data Set | Evaluation Metric | Results |
|---|---|---|---|---|
| (Gandhi et al., 2020) [33] | ResNet Pretrained Architecture | 10,000 Images | Accuracy | Test 94.75% |
| (Hu et al., 2021) [34] | Corneal Specular Highlights | 1000 Images | Accuracy | Test 90.48% |
| (Yousaf et al., 2022) [35] | Two-Stream CNN | 11,982 Images | Accuracy | Test Accuracy for StyleGAN 90.65% |
| Proposed (Experiment 1) | Vision Transformer | 20,000 Test Images (Kaggle) | Accuracy | 100.0% |
| Precision | 100.0% | |||
| Recall | 100.0% | |||
| F1 | 100.0% | |||
| Proposed (Experiment 2) | Vision Transformer | 6238 Test Images (Real Images from Kaggle and Fake from StyleGAN Based website) | Accuracy | 99.95% |
| Precision | 99.95% | |||
| Recall | 99.95% | |||
| F1 | 99.95% | |||
| Proposed (Experiment 3) | Vision Transformer | 12,000 Test Images (Real Images from Kaggle and Fake from (Kaggle + StyleGAN Based website)) | Accuracy | 99.96% |
| Precision | 99.96% | |||
| Recall | 99.96% | |||
| F1 | 99.96% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Arshed, M.A.; Alwadain, A.; Faizan Ali, R.; Mumtaz, S.; Ibrahim, M.; Muneer, A. Unmasking Deception: Empowering Deepfake Detection with Vision Transformer Network. Mathematics 2023, 11, 3710. https://doi.org/10.3390/math11173710
Arshed MA, Alwadain A, Faizan Ali R, Mumtaz S, Ibrahim M, Muneer A. Unmasking Deception: Empowering Deepfake Detection with Vision Transformer Network. Mathematics. 2023; 11(17):3710. https://doi.org/10.3390/math11173710
Chicago/Turabian StyleArshed, Muhammad Asad, Ayed Alwadain, Rao Faizan Ali, Shahzad Mumtaz, Muhammad Ibrahim, and Amgad Muneer. 2023. "Unmasking Deception: Empowering Deepfake Detection with Vision Transformer Network" Mathematics 11, no. 17: 3710. https://doi.org/10.3390/math11173710
APA StyleArshed, M. A., Alwadain, A., Faizan Ali, R., Mumtaz, S., Ibrahim, M., & Muneer, A. (2023). Unmasking Deception: Empowering Deepfake Detection with Vision Transformer Network. Mathematics, 11(17), 3710. https://doi.org/10.3390/math11173710