

Generalized Penalized Constrained Regression: Sharp Guarantees in High Dimensions with Noisy Features


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
1.1. Notations and Definitions
- The generalized Moreau envelope function of a proper convex function is defined asfor , with and . The generalized Moreau envelope given above is an extended version of the well-known Moreau–Yosida envelope function [1].
- The minimizer of the above function is called the generalized proximal operator, which is given as
1.2. Motivation
- induces sparsity structure.
- encourages low-rankness structure, where is the nuclear norm of a matrix, which is defined as the sum of its singular values.
- induces block-sparsity structures, where is the mixed -norm.
- promotes finite-alphabet (i.e., constant-amplitude) signals.
- If the noise is Gaussian-distributed, then we choose or , which is related to the maximum likelihood estimation [10].
- If the noise is sparse (e.g., Laplacian distributed), then one can select .
- If the noise is bounded, then a proper choice is , and so on.
- OLS: , as in (3);
- -penalized LS or ridge regression: ;
- -penalized LS or LASSO: ;
- group LASSO: ;
- generalized least absolute deviation (LAD): .
1.3. Summary of Contributions and Related Work
- The proposed constrained G-PCR problem in (9) considers a general penalization function instead of the specific penalties used in previous works.
- This work derives a general performance measure (Theorem 1) that is more broad and useful than the particular metrics previously taken into consideration, such as the mean square error (MSE), symbol error probability, etc.
- This work generalizes these previous results, as they can be obtained as special cases of the results of this paper.
- In Appendix B, we highlight the use of the same machinery developed in this work to analyze a closely related class of problems known as Square-Root Generalized Penalized Constrained Regression.
2. Problem Setup
2.1. Dataset Model
2.2. Main Assumptions
- The unknown target vector is assumed to be a structured vector, with entries that are sampled i.i.d. from a probability distribution function , which has zero mean, and variance , where .
- The noise variance is a fixed positive constant.
- n and p grow to infinity with .
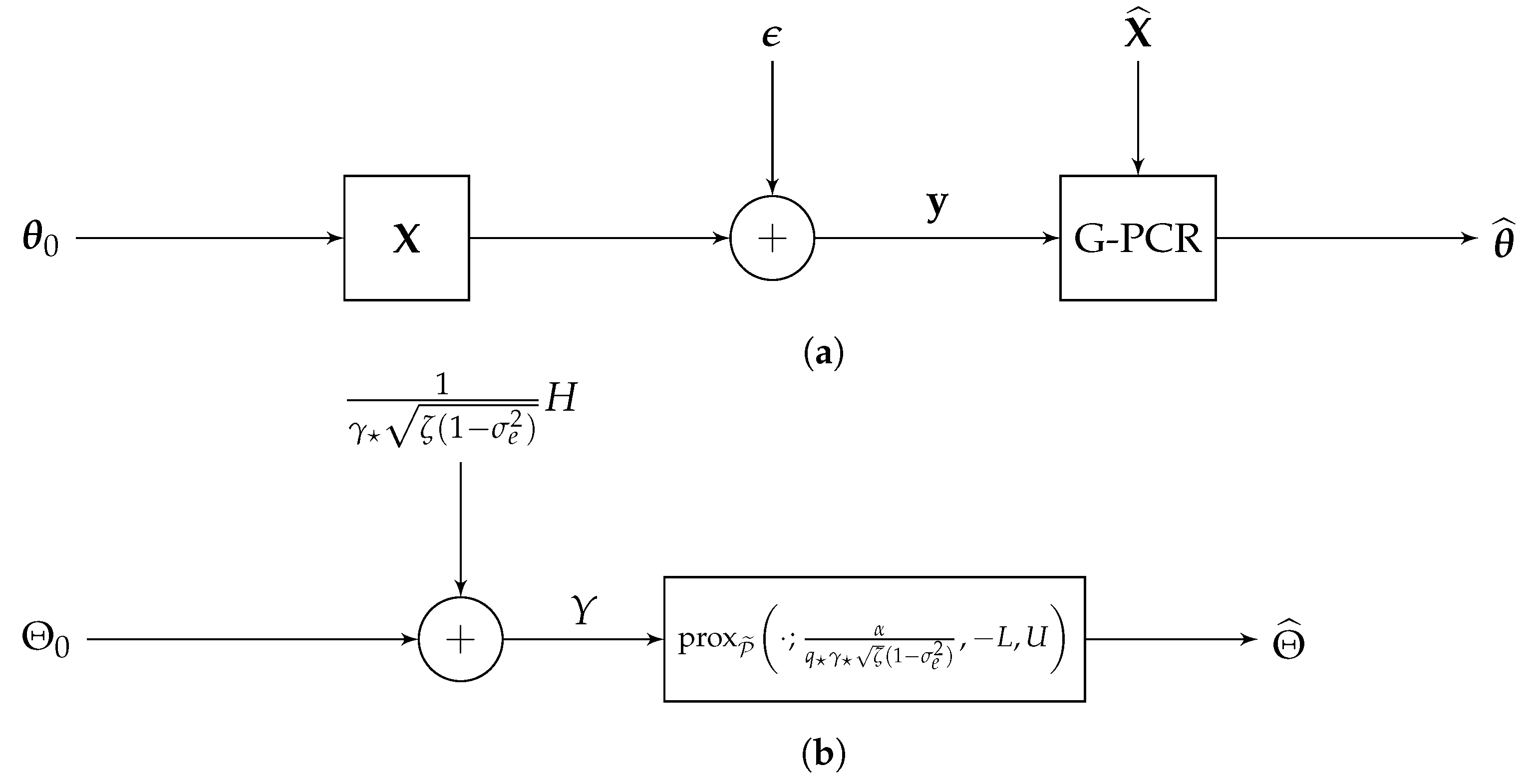
2.3. Generalized Penalized Constrained Regression (G-PCR)
3. Sharp Asymptotics
3.1. Measures of Performance
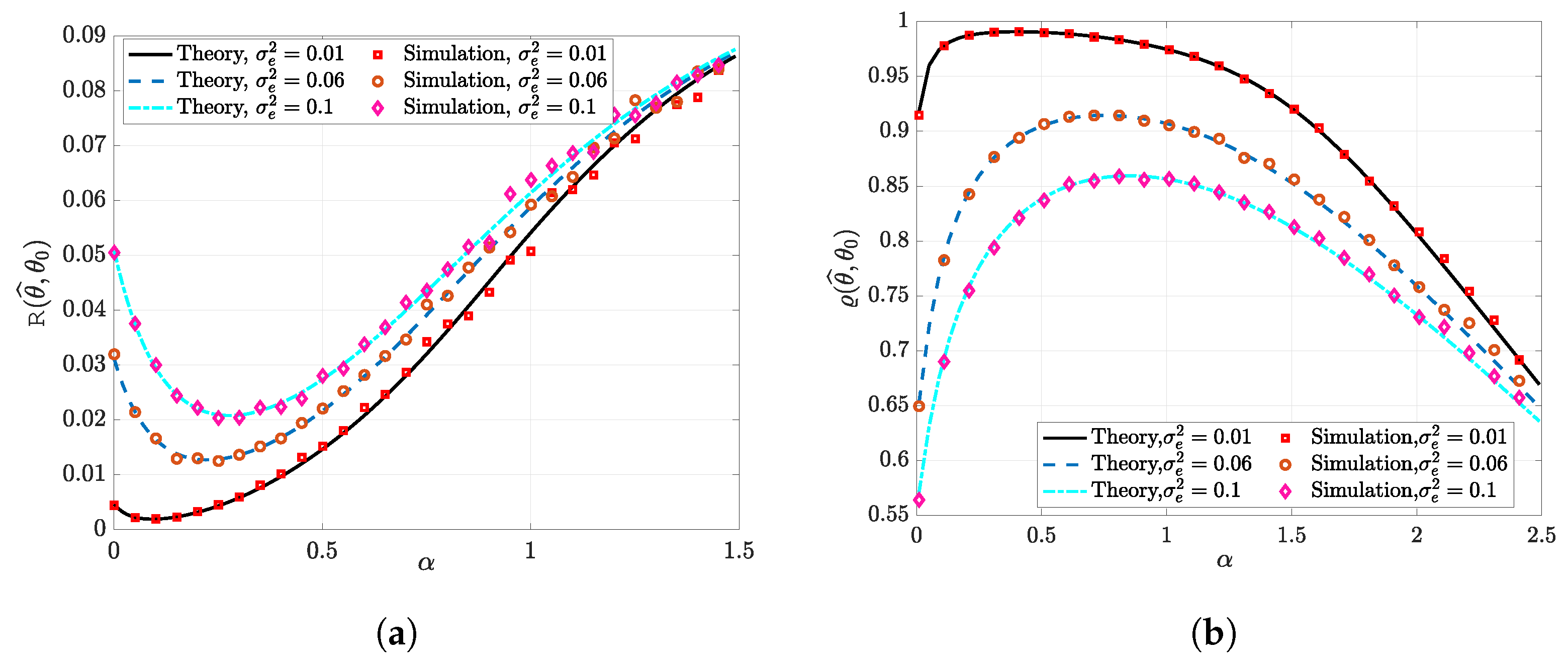
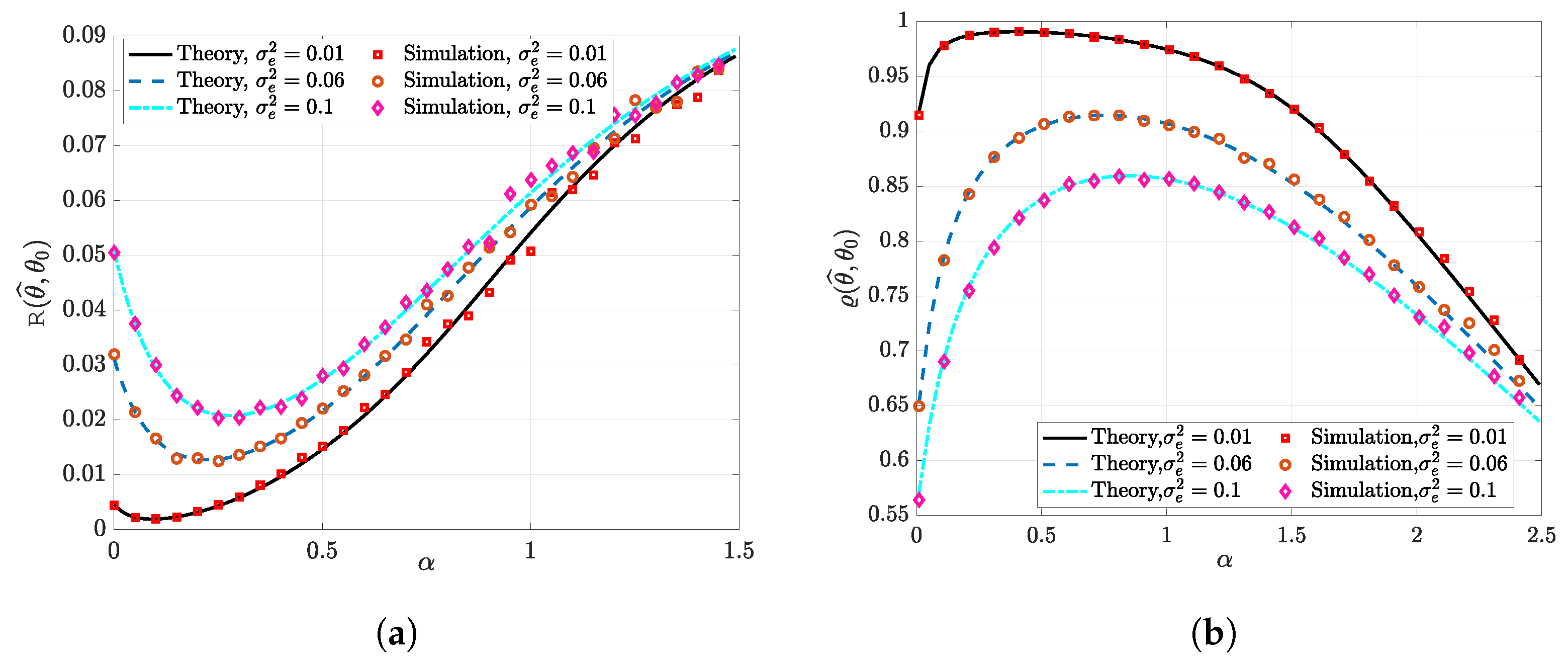
- Prediction Risk: One of the most extensively used measures of performance is the prediction risk. For a given estimator , the prediction risk is defined aswhere x and y are new test points following the linear model in (7) but are independent of the training data.
- Similarity: Another metric that is used to quantify the degree of alignment between the target vector and its estimate is the (dis)similarity. It is a measure of orientation rather than magnitude. It is defined as
3.2. High-Dimensional Performance Evaluation
4. Sparse Linear Regression
4.1. Asymptotic Behavior of Sparse G-PCR
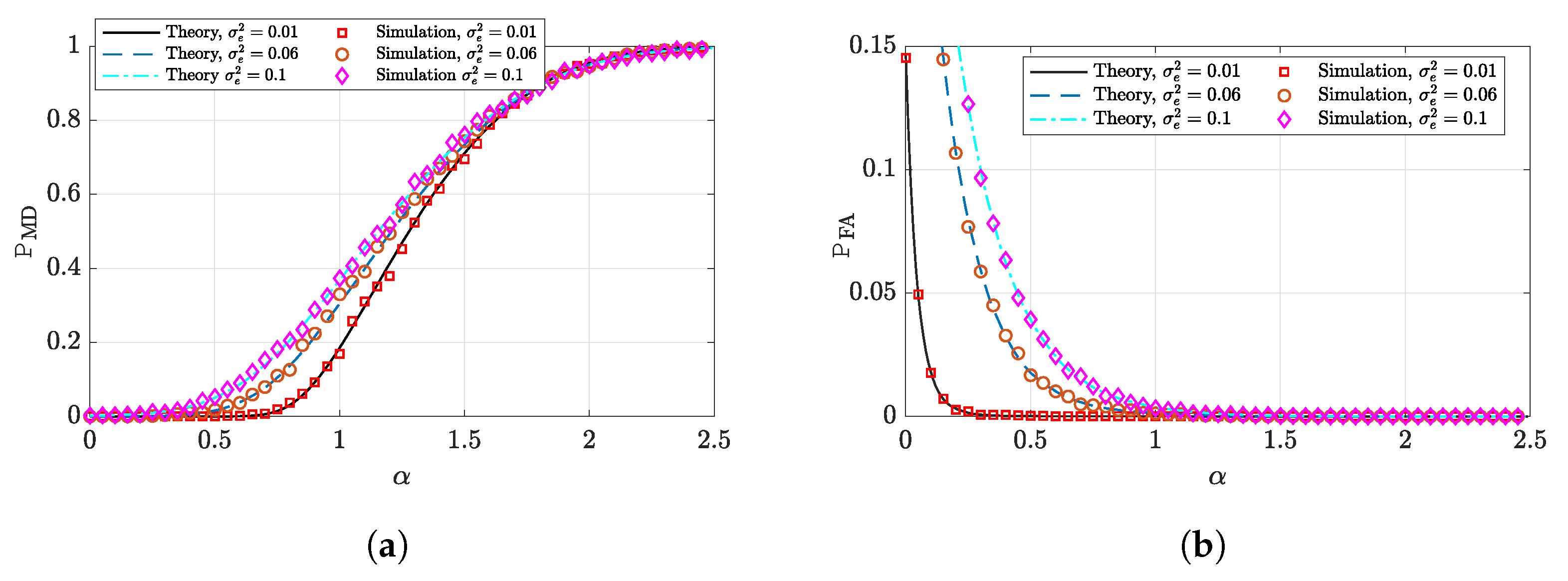
4.2. Support Recovery
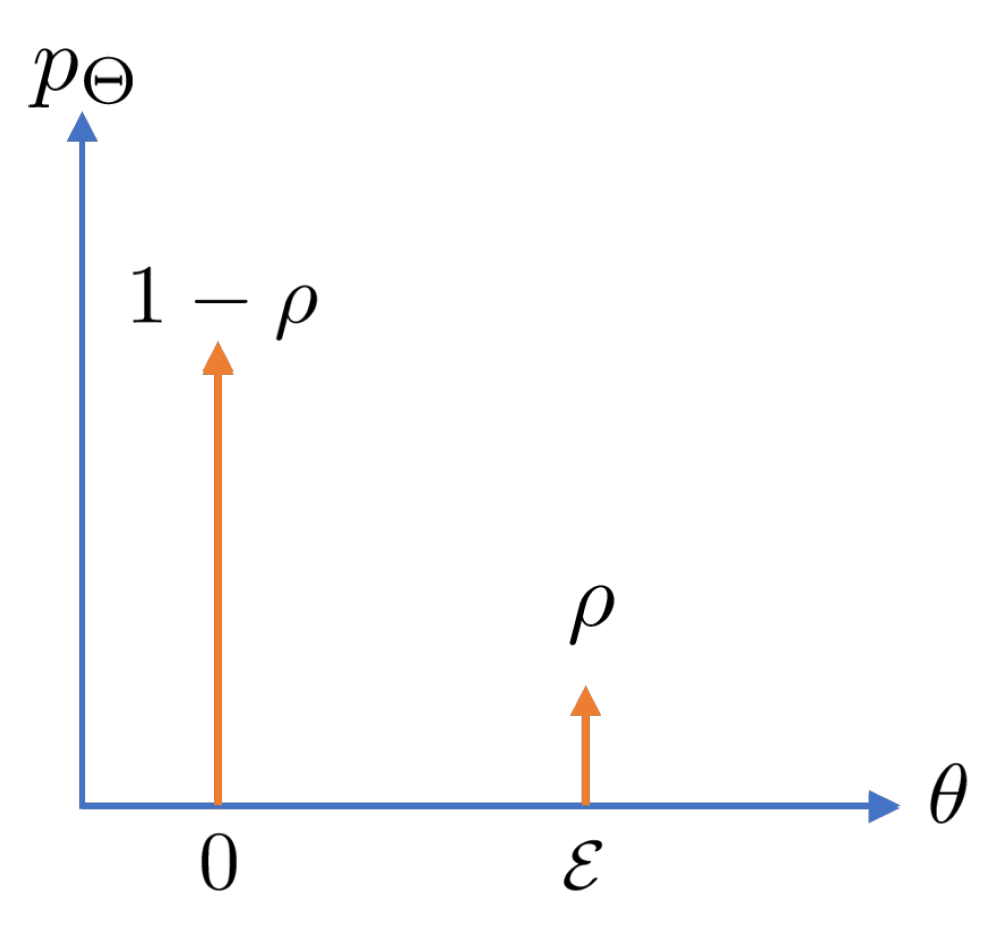
Example: Sparse-Binary Target Vectors
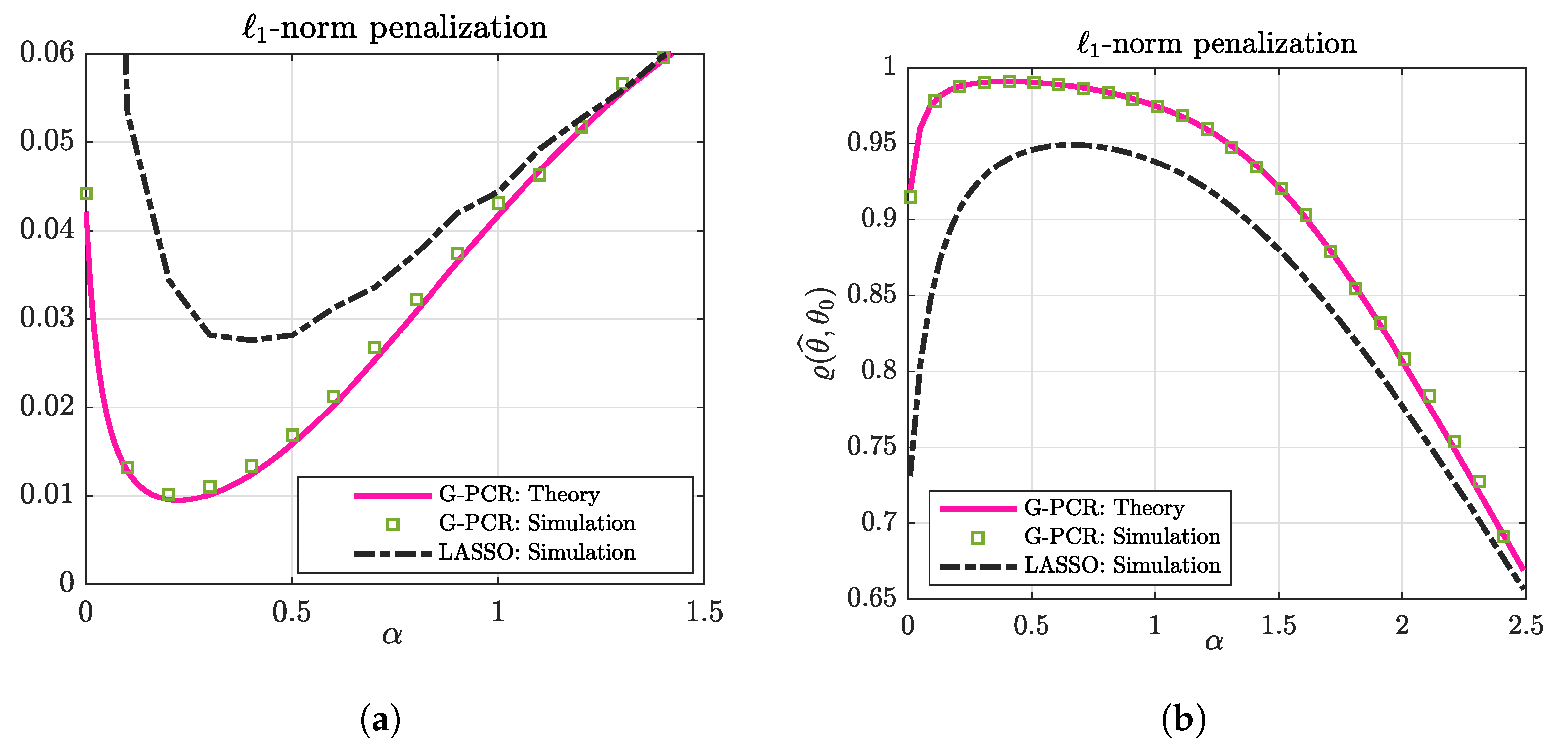
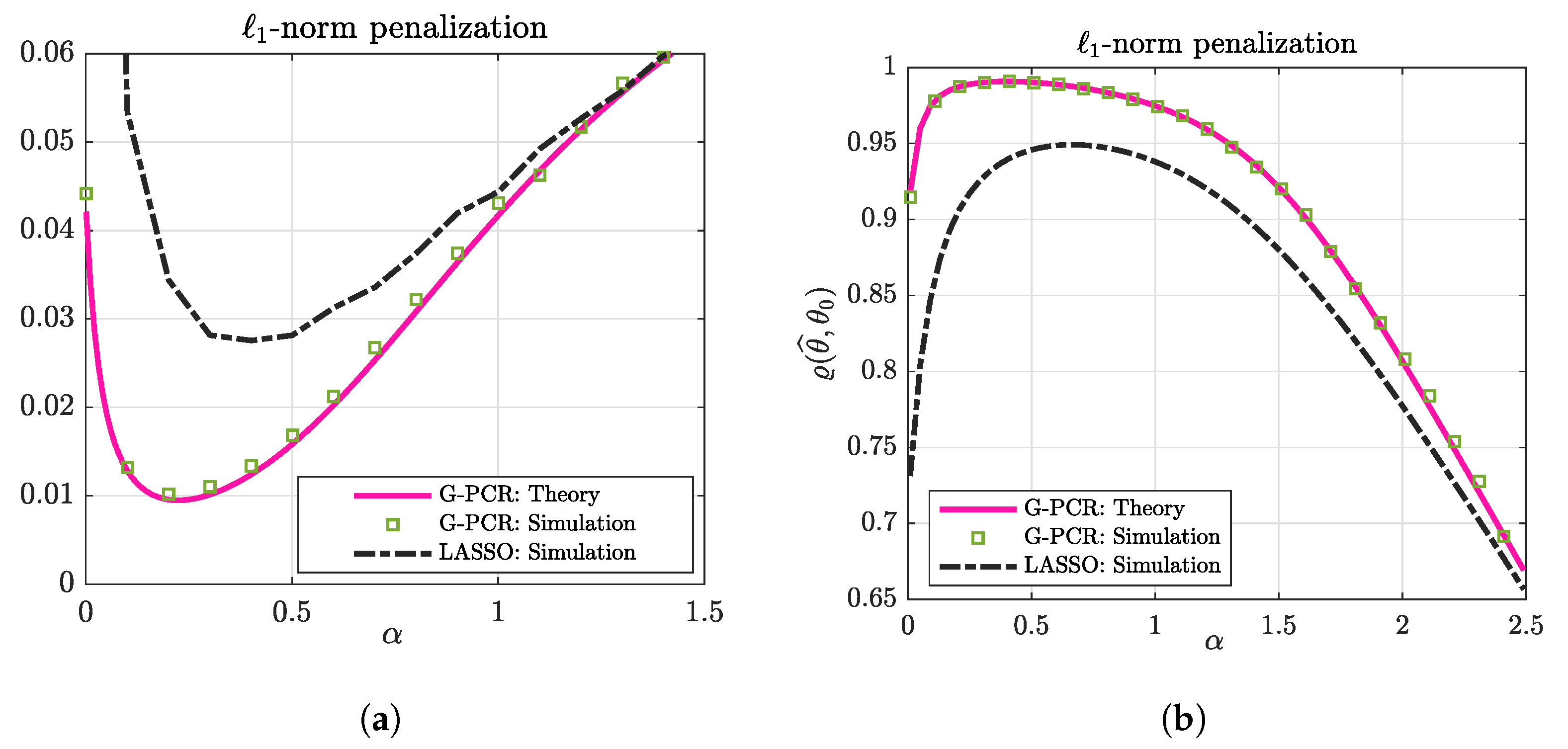
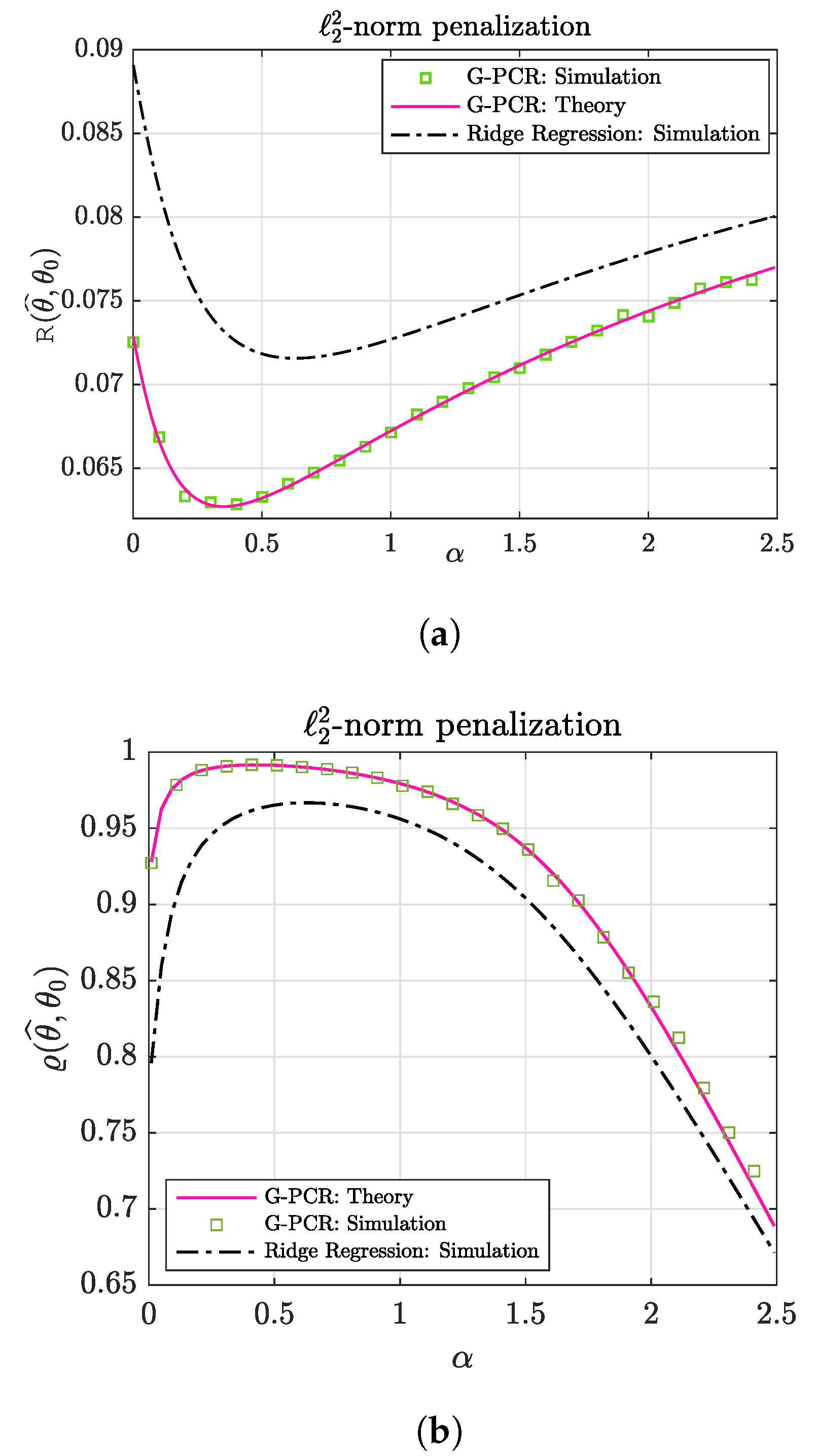
5. G-PCR with -Norm Penalization
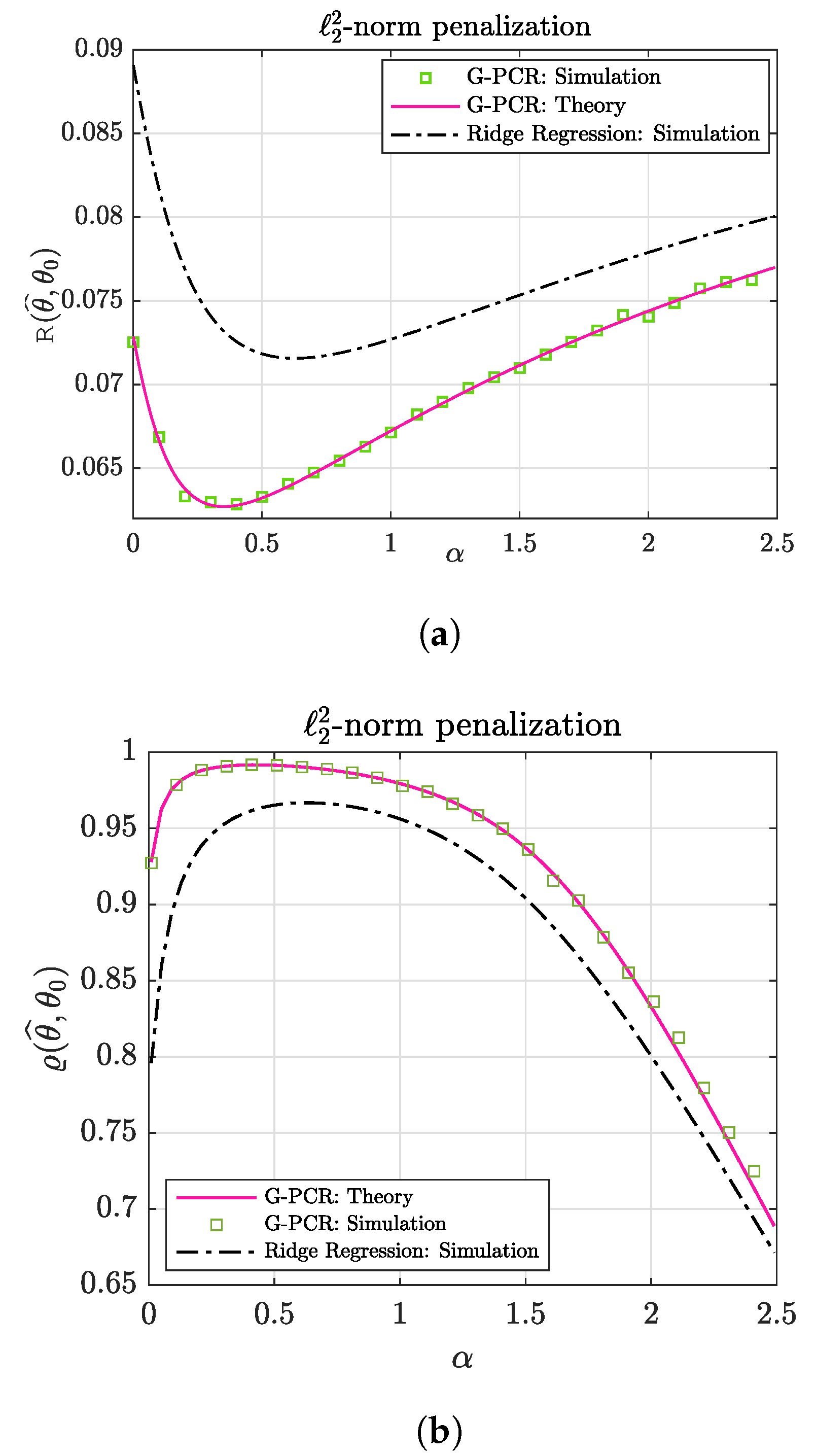
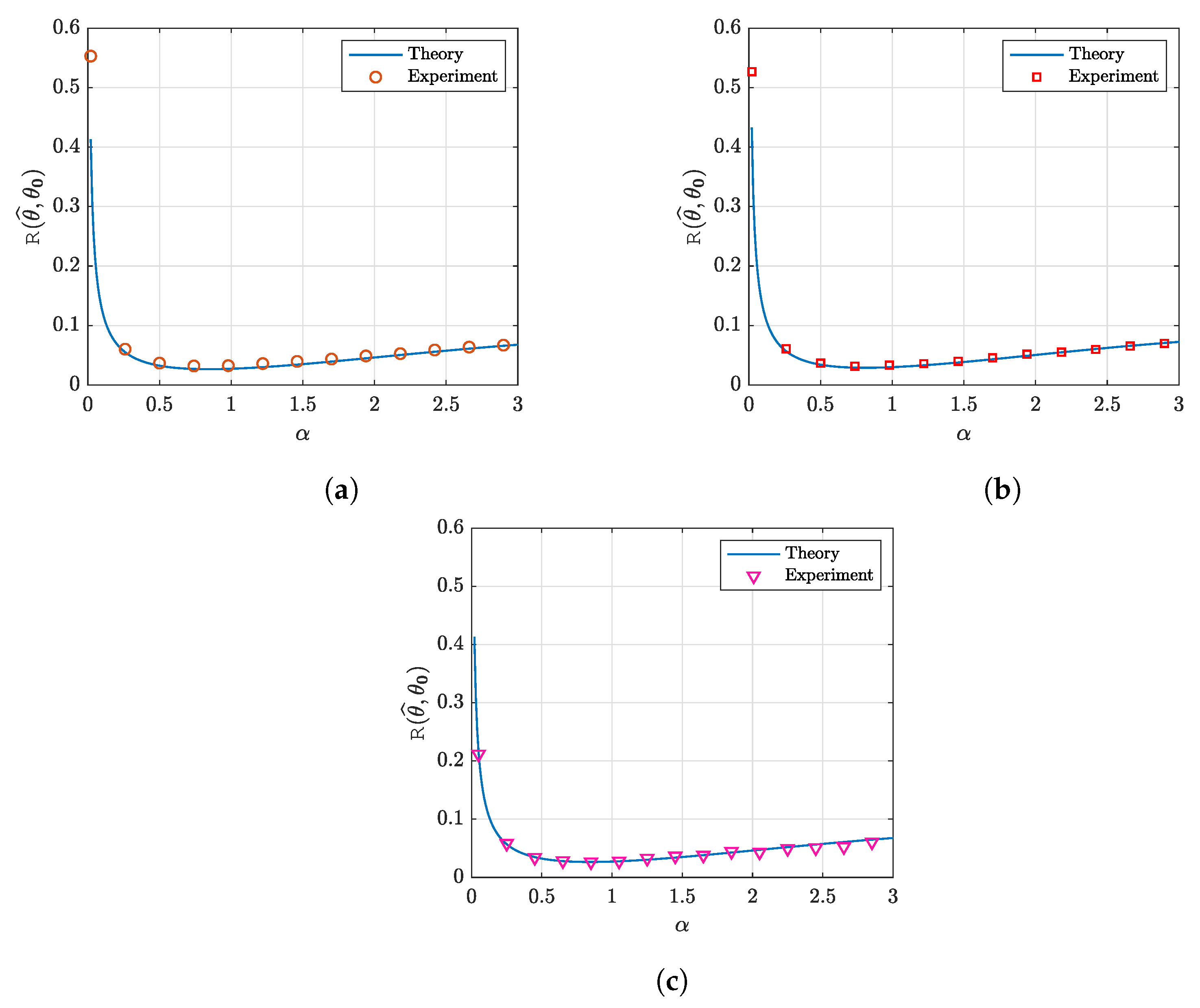
5.1. Numerical Illustration
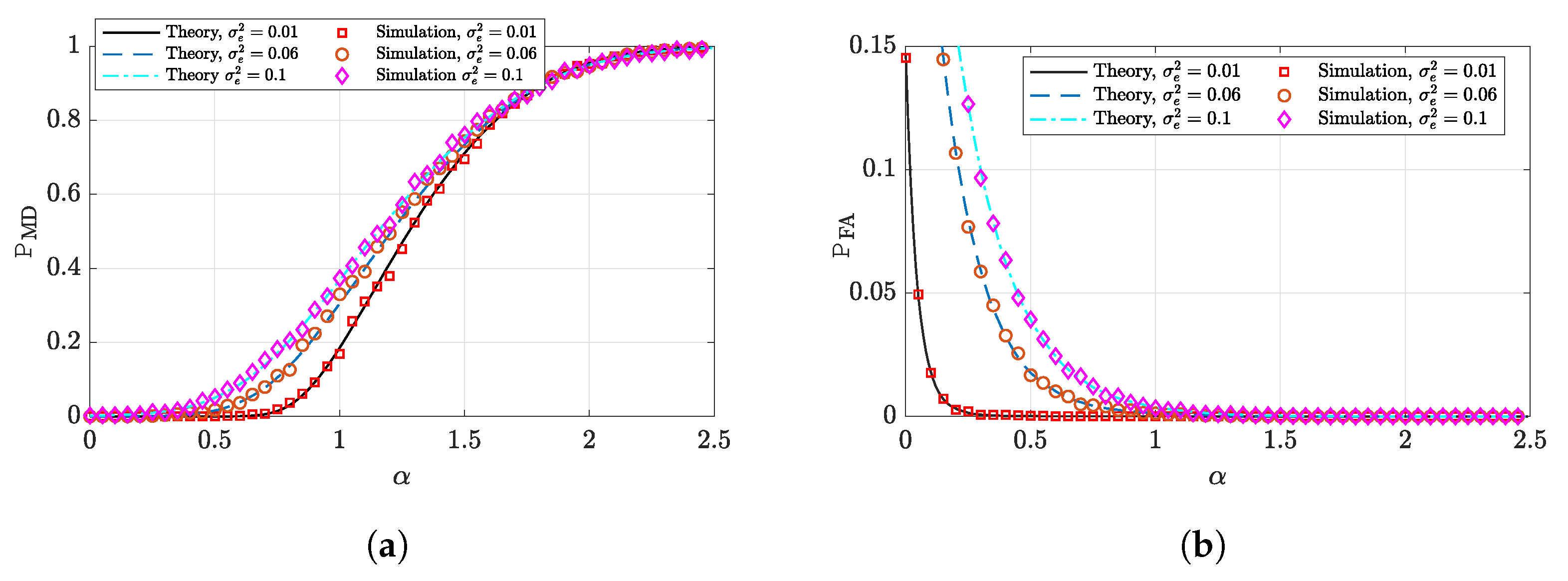
5.2. Binary Target Vector Estimation
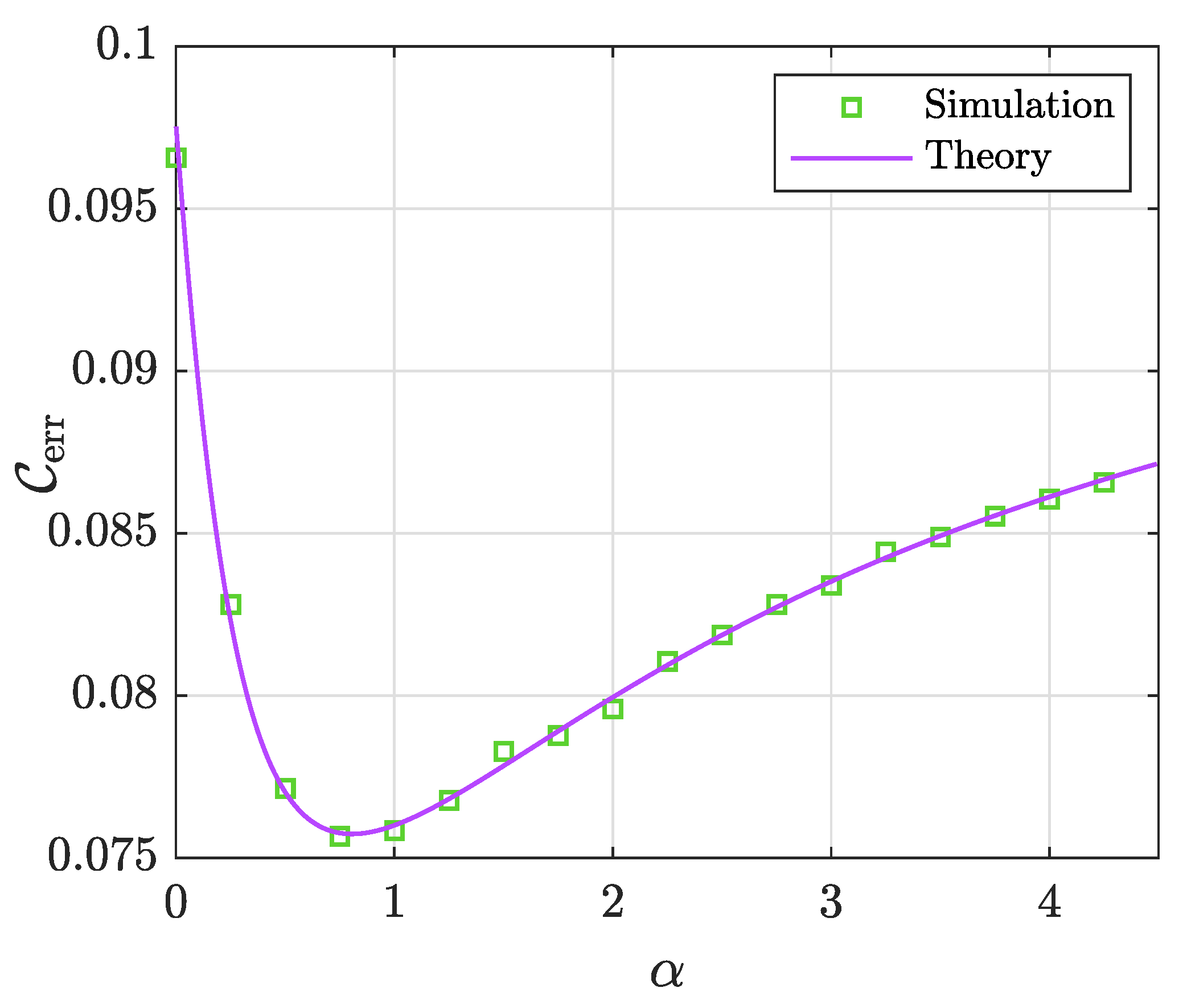
5.3. Unpenalized Regression
6. Additional Numerical Experiments
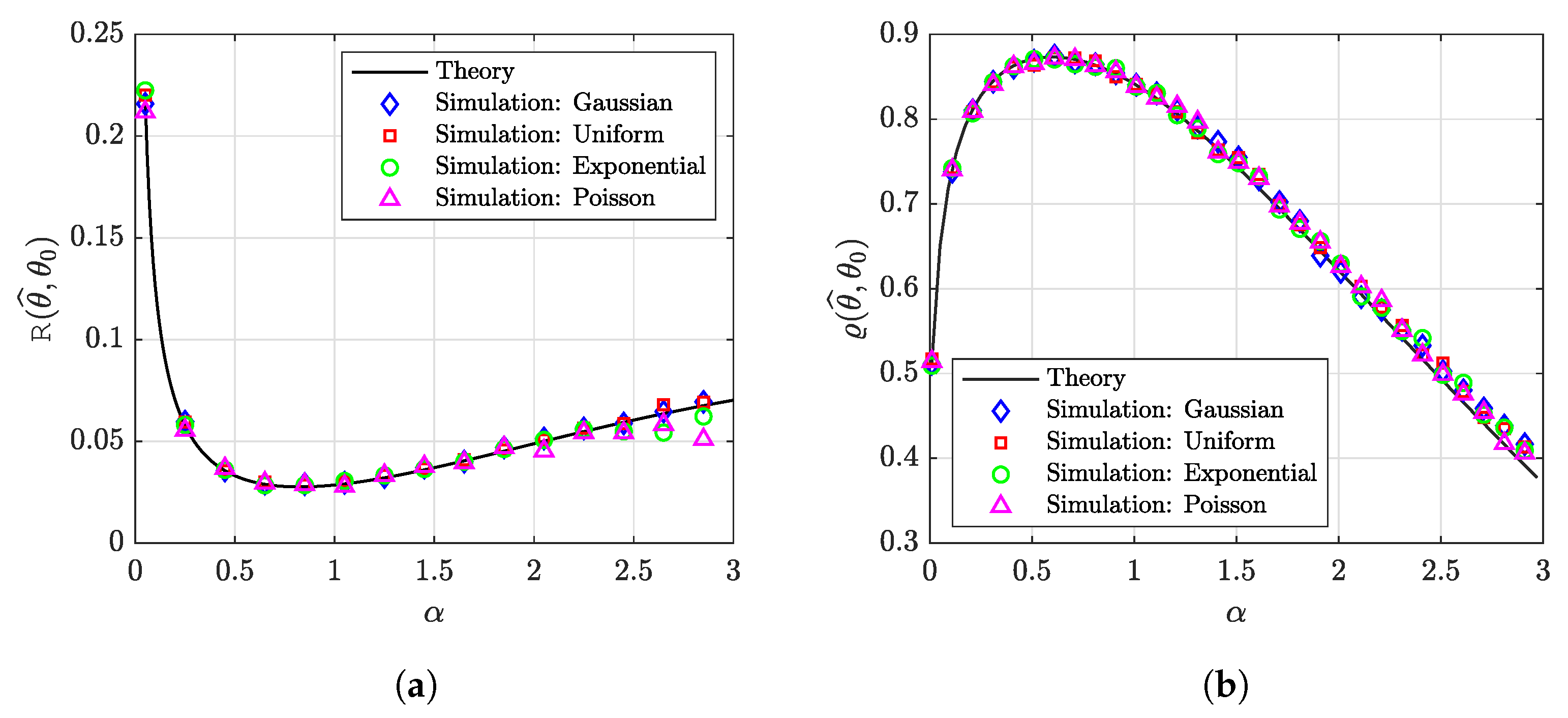
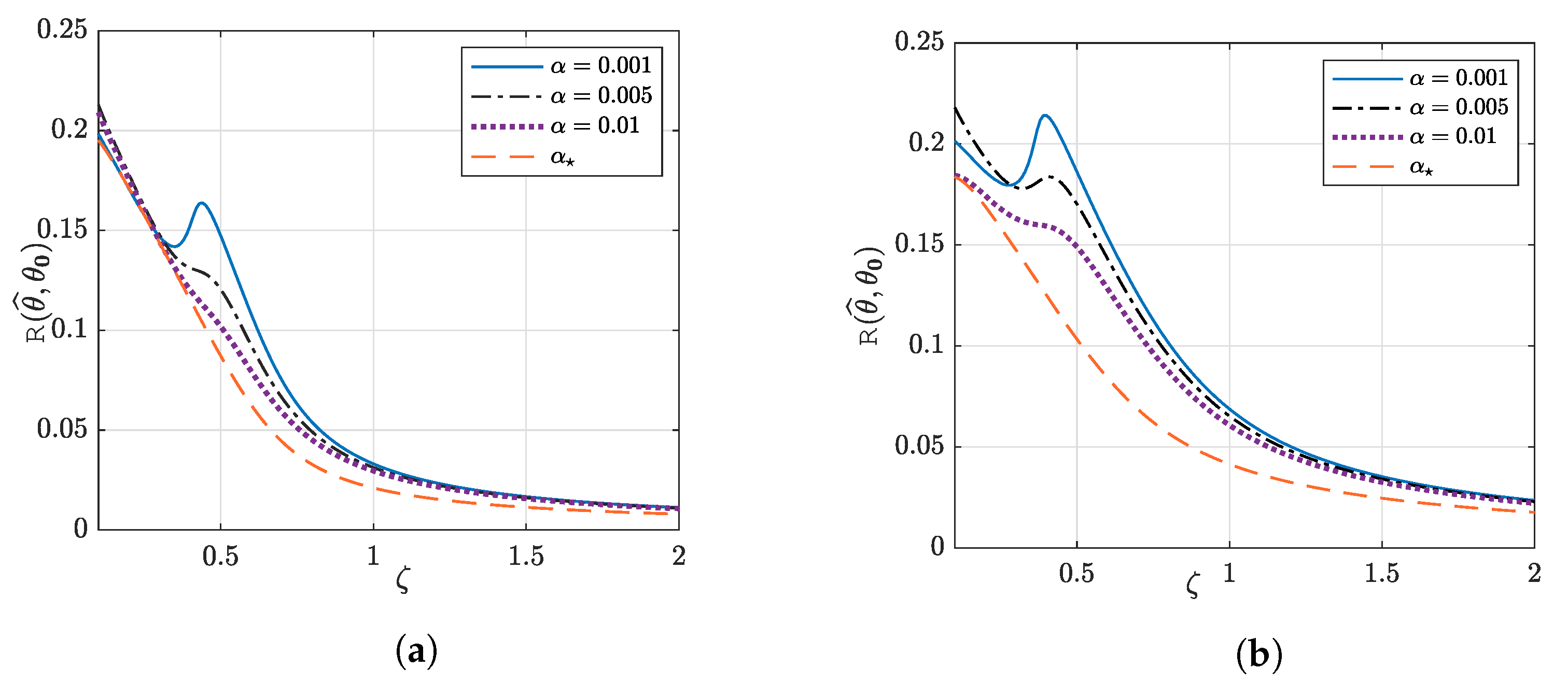
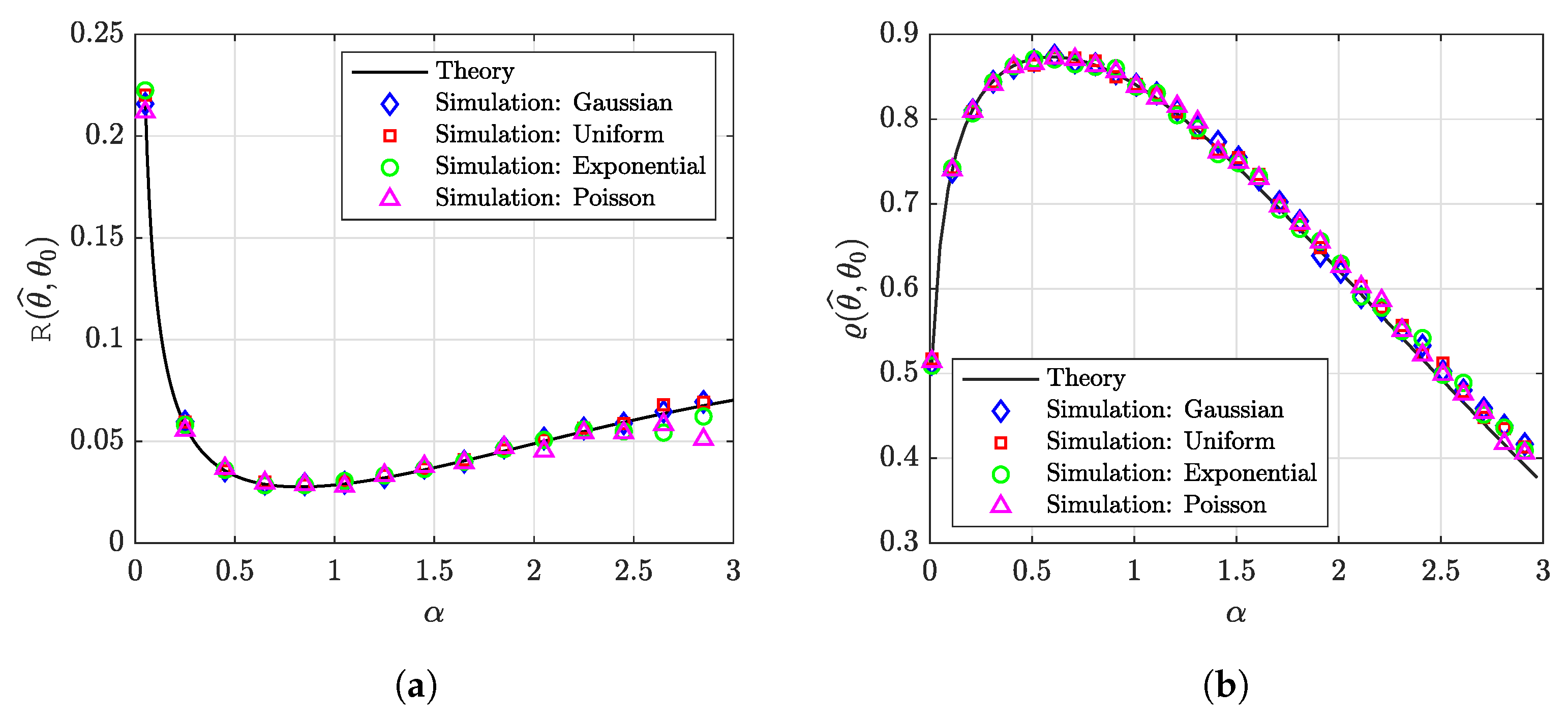
6.1. Synthetic Data: Universality of the Gaussian Design
6.2. Real-World Data
- Figure 9a: For this figure, we used breast cancer data [70] (available at: https://github.com/kivancguckiran/microarray-data (accessed on 27 May 2023)). This dataset has been used in [71] for DNA microarray gene expression classification using the LASSO. It consists of 22,215 gene expressions (features) and 118 samples. From this matrix, we took a sub-matrix X of aspect ratio . We standardized all columns of matrix X to have mean 0 and variance 1.
- Figure 9b: In this figure, glioma disease data [72] were used (available at: https://github.com/kivancguckiran/microarray-data (accessed on 27 May 2023)). This dataset includes 54,613 features and 180 samples. Similar to the breast cancer data, the sub-matrix X with the same aspect ratio was selected and standardized.
- Figure 9c: The dataset used in this figure includes colon cancer data [73] (available at: http://www.weizmann.ac.il/mcb/UriAlon/download/downloadable-data (accessed on 27 May 2023)). This dataset was used in [74] for a sparse-group LASSO model. It includes 2000 genes and 62 samples (22 normal tissues and 40 colon tumor tissues). Similar to the previous datasets, we selected a sub-matrix X with aspect ratio and standardized it.
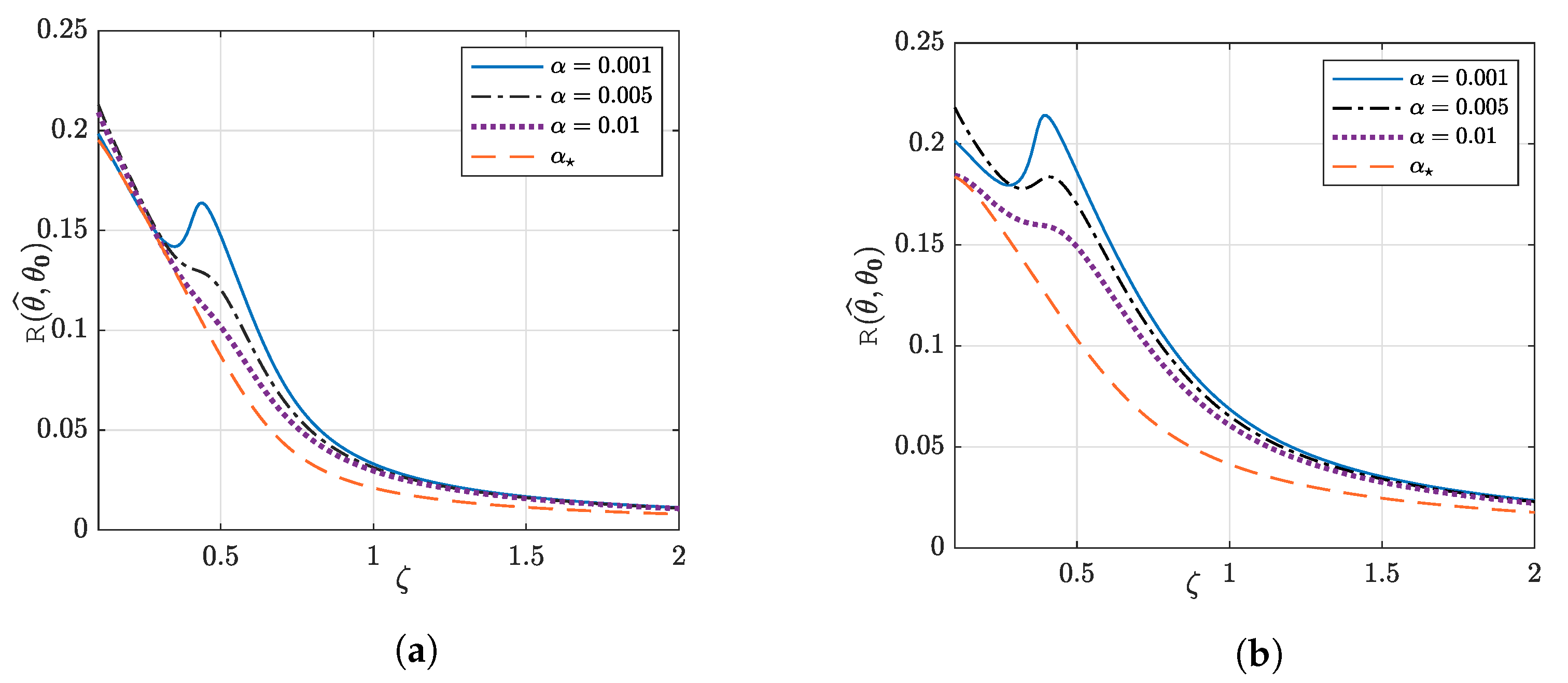
6.3. Double Descent Phenomenon
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
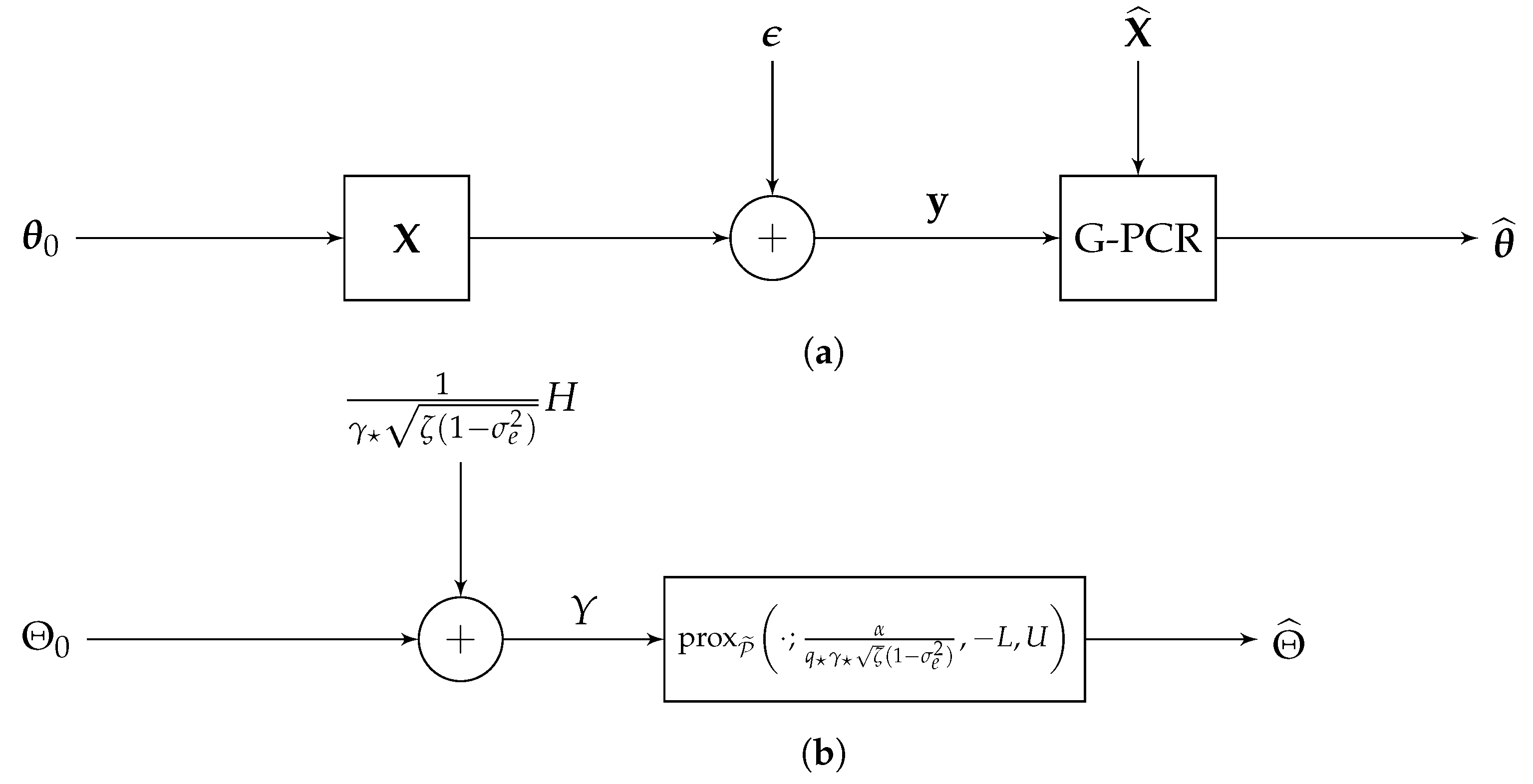
Appendix A. Proof of the Main Results
Appendix A.1. Main Analysis Framework: CGMT
Appendix A.2. Sharp Analysis of the G-PCR
Appendix A.2.1. Primal and Auxiliary Problems of the G-PCR
Appendix A.2.2. Simplifying the Auxiliary Problem
Appendix A.2.3. General Performance Metric: Proof of Theorem 1
Appendix A.2.4. Prediction Risk Analysis: Proof of Corollary 1
Appendix A.2.5. Similarity Analysis: Proof of Corollary 2
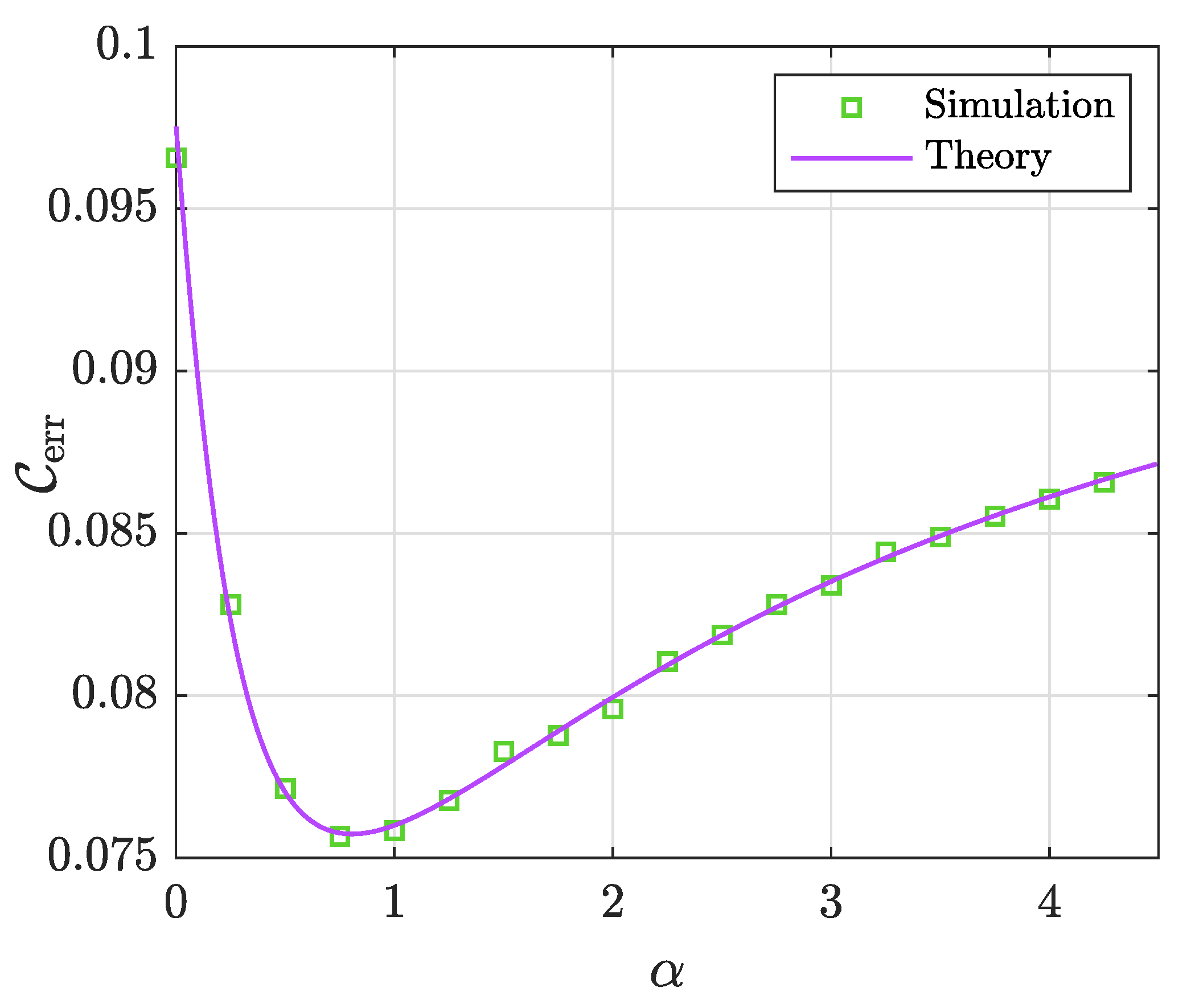
Appendix B. A Note on the Square-Root Generalized Penalized Constrained Regression
Sqrt G-PCR Learning Algorithm
References
- Parikh, N.; Boyd, S. Proximal algorithms. Found. Trends Optim. 2014, 1, 127–239. [Google Scholar] [CrossRef]
- Tarantola, A. Inverse Problem Theory and Methods for Model Parameter Estimation; SIAM: Philadelphia, PA, USA, 2005. [Google Scholar]
- Kailath, T.; Sayed, A.H.; Hassibi, B. Linear Estimation; Prentice Hall: Hoboken, NJ, USA, 2000. [Google Scholar]
- Groetsch, C.W.; Groetsch, C. Inverse Problems in the Mathematical Sciences; Springer: Berlin/Heidelberg, Germany, 1993; Volume 52. [Google Scholar]
- Bishop, C.M. Pattern recognition. Mach. Learn. 2006, 128, 1–58. [Google Scholar]
- Rencher, A.C.; Schaalje, G.B. Linear Models in Statistics; John Wiley & Sons: Hoboken, NJ, USA, 2008. [Google Scholar]
- Dhar, V. Data science and prediction. Commun. ACM 2013, 56, 64–73. [Google Scholar] [CrossRef]
- Donoho, D.L. Compressed sensing. IEEE Trans. Inf. Theory 2006, 52, 1289–1306. [Google Scholar] [CrossRef]
- Duarte, M.F.; Eldar, Y.C. Structured compressed sensing: From theory to applications. IEEE Trans. Signal Process. 2011, 59, 4053–4085. [Google Scholar] [CrossRef]
- Poor, H.V. An Introduction to Signal Detection and Estimation; Springer Science & Business Media: Berlin/Heidelberg, Germany, 1998. [Google Scholar]
- Fadili, J.M.; Bullmore, E. Penalized partially linear models using sparse representations with an application to fMRI time series. IEEE Trans. Signal Process. 2005, 53, 3436–3448. [Google Scholar] [CrossRef]
- Goldsmith, A. Wireless Communications; Cambridge University Press: Cambridge, UK, 2005. [Google Scholar]
- Marzetta, T.L.; Yang, H. Fundamentals of Massive MIMO; Cambridge University Press: Cambridge, UK, 2016. [Google Scholar]
- Candes, E.; Tao, T. The Dantzig selector: Statistical estimation when p is much larger than n. Ann. Stat. 2007, 35, 2313–2351. [Google Scholar]
- Bach, F. Structured sparsity-inducing norms through submodular functions. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 6–9 December 2010; Volume 23. [Google Scholar]
- Aster, R.C.; Borchers, B.; Thurber, C.H. Parameter Estimation and Inverse Problems; Elsevier: Amsterdam, The Netherlands, 2018. [Google Scholar]
- McDonald, G.C. Ridge regression. Wiley Interdiscip. Rev. Comput. Stat. 2009, 1, 93–100. [Google Scholar] [CrossRef]
- Tibshirani, R. Regression shrinkage and selection via the lasso. J. R. Stat. Soc. Ser. B 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Varah, J.M. Pitfalls in the numerical solution of linear ill-posed problems. SIAM J. Sci. Stat. Comput. 1983, 4, 164–176. [Google Scholar] [CrossRef]
- Thrampoulidis, C.; Abbasi, E.; Hassibi, B. Precise error analysis of regularized M-estimators in high dimensions. IEEE Trans. Inf. Theory 2018, 64, 5592–5628. [Google Scholar] [CrossRef]
- Bickel, P.J.; Ritov, Y.; Tsybakov, A.B. Simultaneous analysis of Lasso and Dantzig selector. Ann. Stat. 2009, 37, 1705–1732. [Google Scholar] [CrossRef]
- Negahban, S.; Yu, B.; Wainwright, M.J.; Ravikumar, P.K. A unified framework for high-dimensional analysis of m-estimators with decomposable regularizers. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 7–10 December 2009; pp. 1348–1356. [Google Scholar]
- Wainwright, M.J. Sharp thresholds for high-dimensional and noisy sparsity recovery using -constrained quadratic programming (Lasso). IEEE Trans. Inf. Theory 2009, 55, 2183–2202. [Google Scholar] [CrossRef]
- Belloni, A.; Chernozhukov, V.; Wang, L. Square-root lasso: Pivotal recovery of sparse signals via conic programming. Biometrika 2011, 98, 791–806. [Google Scholar] [CrossRef]
- Li, Y.H.; Hsieh, Y.P.; Zerbib, N.; Cevher, V. A geometric view on constrained M-estimators. arXiv 2015, arXiv:1506.08163. [Google Scholar]
- Bayati, M.; Montanari, A. The dynamics of message passing on dense graphs, with applications to compressed sensing. IEEE Trans. Inf. Theory 2011, 57, 764–785. [Google Scholar] [CrossRef]
- Bayati, M.; Montanari, A. The LASSO risk for Gaussian matrices. IEEE Trans. Inf. Theory 2012, 58, 1997–2017. [Google Scholar] [CrossRef]
- Donoho, D.; Montanari, A. High dimensional robust m-estimation: Asymptotic variance via approximate message passing. Probab. Theory Relat. Fields 2016, 166, 935–969. [Google Scholar] [CrossRef]
- Rangan, S.; Goyal, V.; Fletcher, A.K. Asymptotic analysis of map estimation via the replica method and compressed sensing. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 7–10 December 2009; Volume 22. [Google Scholar]
- Kabashima, Y.; Wadayama, T.; Tanaka, T. Statistical mechanical analysis of a typical reconstruction limit of compressed sensing. In Proceedings of the 2010 IEEE International Symposium on Information Theory, Austin, TX, USA, 13–18 June 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 1533–1537. [Google Scholar]
- Couillet, R.; Debbah, M. Random Matrix Methods for Wireless Communications; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar]
- Karoui, N.E. Asymptotic behavior of unregularized and ridge-regularized high-dimensional robust regression estimators: Rigorous results. arXiv 2013, arXiv:1311.2445. [Google Scholar]
- Liao, Z.; Couillet, R. Random matrices meet machine learning: A large dimensional analysis of ls-svm. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 2397–2401. [Google Scholar]
- El Karoui, N. On the impact of predictor geometry on the performance on high-dimensional ridge-regularized generalized robust regression estimators. Probab. Theory Relat. Fields 2018, 170, 95–175. [Google Scholar] [CrossRef]
- Stojnic, M. Recovery thresholds for ℓ1 optimization in binary compressed sensing. In Proceedings of the 2010 IEEE International Symposium on Information Theory, Austin, TX, USA, 13–18 June 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 1593–1597. [Google Scholar]
- Stojnic, M. A framework to characterize performance of lasso algorithms. arXiv 2013, arXiv:1303.7291. [Google Scholar]
- Thrampoulidis, C.; Oymak, S.; Hassibi, B. Regularized Linear Regression: A Precise Analysis of the Estimation Error. In Proceedings of the COLT, Paris, France, 3–6 July 2015; pp. 1683–1709. [Google Scholar]
- Thrampoulidis, C.; Panahi, A.; Guo, D.; Hassibi, B. Precise error analysis of the lasso. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, Australia, 19–24 April 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 3467–3471. [Google Scholar]
- Thrampoulidis, C.; Xu, W.; Hassibi, B. Symbol error rate performance of box-relaxation decoders in massive MIMO. IEEE Trans. Signal Process. 2018, 66, 3377–3392. [Google Scholar] [CrossRef]
- Atitallah, I.B.; Thrampoulidis, C.; Kammoun, A.; Al-Naffouri, T.Y.; Hassibi, B.; Alouini, M.S. Ber analysis of regularized least squares for bpsk recovery. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 4262–4266. [Google Scholar]
- Alrashdi, A.M.; Kammoun, A.; Muqaibel, A.H.; Al-Naffouri, T.Y. Asymptotic Performance of Box-RLS Decoders under Imperfect CSI with Optimized Resource Allocation. IEEE Open J. Commun. Soc. 2022, 3, 2051–2075. [Google Scholar] [CrossRef]
- Atitallah, I.B.; Thrampoulidis, C.; Kammoun, A.; Al-Naffouri, T.Y.; Alouini, M.S.; Hassibi, B. The BOX-LASSO with application to GSSK modulation in massive MIMO systems. In Proceedings of the 2017 IEEE International Symposium on Information Theory (ISIT), Aachen, Germany, 25–30 June 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1082–1086. [Google Scholar]
- Alrashdi, A.M.; Alrashdi, A.E.; Alghadhban, A.; Eleiwa, M.A. Optimum GSSK Transmission in Massive MIMO Systems Using the Box-LASSO Decoder. IEEE Access 2022, 10, 15845–15859. [Google Scholar] [CrossRef]
- Alrashdi, A.M.; Atitallah, I.B.; Al-Naffouri, T.Y. Precise performance analysis of the box-elastic net under matrix uncertainties. IEEE Signal Process. Lett. 2019, 26, 655–659. [Google Scholar] [CrossRef]
- Hayakawa, R.; Hayashi, K. Binary vector reconstruction via discreteness-aware approximate message passing. In Proceedings of the 2017 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Kuala Lumpur, Malaysia, 12–15 December 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1783–1789. [Google Scholar]
- Hayakawa, R.; Hayashi, K. Asymptotic Performance of Discrete-Valued Vector Reconstruction via Box-Constrained Optimization With Sum of ℓ1 Regularizers. IEEE Trans. Signal Process. 2020, 68, 4320–4335. [Google Scholar] [CrossRef]
- Deng, Z.; Kammoun, A.; Thrampoulidis, C. A model of double descent for high-dimensional binary linear classification. Inf. Inference J. IMA 2022, 11, 435–495. [Google Scholar] [CrossRef]
- Kini, G.R.; Thrampoulidis, C. Analytic study of double descent in binary classification: The impact of loss. In Proceedings of the 2020 IEEE International Symposium on Information Theory (ISIT), Los Angeles, CA, USA, 21–26 June 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 2527–2532. [Google Scholar]
- Salehi, F.; Abbasi, E.; Hassibi, B. The performance analysis of generalized margin maximizers on separable data. In Proceedings of the International Conference on Machine Learning, Virtual Online, 13–18 July 2020; PMLR: Mc Kees Rocks, PA, USA, 2020; pp. 8417–8426. [Google Scholar]
- Dhifallah, O.; Thrampoulidis, C.; Lu, Y.M. Phase retrieval via linear programming: Fundamental limits and algorithmic improvements. In Proceedings of the 2017 55th Annual Allerton Conference on Communication, Control, and Computing (Allerton), Monticello, IL, USA, 3–6 October 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1071–1077. [Google Scholar]
- Salehi, F.; Abbasi, E.; Hassibi, B. A precise analysis of phasemax in phase retrieval. In Proceedings of the 2018 IEEE International Symposium on Information Theory (ISIT), Vail, CO, USA, 17–22 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 976–980. [Google Scholar]
- Bosch, D.; Panahi, A.; Hassibi, B. Precise Asymptotic Analysis of Deep Random Feature Models. arXiv 2023, arXiv:2302.06210. [Google Scholar]
- Dhifallah, O.; Lu, Y.M. A precise performance analysis of learning with random features. arXiv 2020, arXiv:2008.11904. [Google Scholar]
- Dhifallah, O.; Lu, Y.M. Phase transitions in transfer learning for high-dimensional perceptrons. Entropy 2021, 23, 400. [Google Scholar] [CrossRef]
- Ting, M.; Raich, R.; Hero, A.O., III. Sparse image reconstruction for molecular imaging. IEEE Trans. Image Process. 2009, 18, 1215–1227. [Google Scholar] [CrossRef]
- Gui, G.; Peng, W.; Wang, L. Improved sparse channel estimation for cooperative communication systems. Int. J. Antennas Propag. 2012, 2012, 476509. [Google Scholar] [CrossRef]
- Luenberger, D.G.; Ye, Y. Linear and Nonlinear Programming; Springer: Berlin/Heidelberg, Germany, 1984; Volume 2. [Google Scholar]
- Salehi, F.; Abbasi, E.; Hassibi, B. The impact of regularization on high-dimensional logistic regression. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Donoho, D.L.; Maleki, A.; Montanari, A. Message-passing algorithms for compressed sensing. Proc. Natl. Acad. Sci. USA 2009, 106, 18914–18919. [Google Scholar] [CrossRef]
- Hayakawa, R. Noise variance estimation using asymptotic residual in compressed sensing. arXiv 2020, arXiv:2009.13678. [Google Scholar]
- Suliman, M.A.; Alrashdi, A.M.; Ballal, T.; Al-Naffouri, T.Y. SNR estimation in linear systems with Gaussian matrices. IEEE Signal Process. Lett. 2017, 24, 1867–1871. [Google Scholar] [CrossRef]
- Kobayashi, H.; Mark, B.L.; Turin, W. Probability, Random Processes, and Statistical Analysis: Applications to Communications, Signal Processing, Queueing Theory and Mathematical Finance; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar]
- Donoho, D.L.; Maleki, A.; Montanari, A. The noise-sensitivity phase transition in compressed sensing. IEEE Trans. Inf. Theory 2011, 57, 6920–6941. [Google Scholar] [CrossRef]
- Thrampoulidis, C.; Abbasi, E.; Hassibi, B. Lasso with non-linear measurements is equivalent to one with linear measurements. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, USA, 7–12 December 2015; pp. 3420–3428. [Google Scholar]
- Abbasi, E.; Salehi, F.; Hassibi, B. Universality in learning from linear measurements. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Hu, H.; Lu, Y.M. Universality laws for high-dimensional learning with random features. IEEE Trans. Inf. Theory 2022, 69, 1932–1964. [Google Scholar] [CrossRef]
- Han, Q.; Shen, Y. Universality of regularized regression estimators in high dimensions. arXiv 2022, arXiv:2206.07936. [Google Scholar]
- Dudeja, R.; Bakhshizadeh, M. Universality of linearized message passing for phase retrieval with structured sensing matrices. IEEE Trans. Inf. Theory 2022, 68, 7545–7574. [Google Scholar] [CrossRef]
- Gerace, F.; Krzakala, F.; Loureiro, B.; Stephan, L.; Zdeborová, L. Gaussian Universality of Perceptrons with Random Labels. arXiv 2023, arXiv:2205.13303. [Google Scholar]
- Chin, K.; DeVries, S.; Fridlyand, J.; Spellman, P.T.; Roydasgupta, R.; Kuo, W.L.; Lapuk, A.; Neve, R.M.; Qian, Z.; Ryder, T.; et al. Genomic and transcriptional aberrations linked to breast cancer pathophysiologies. Cancer Cell 2006, 10, 529–541. [Google Scholar] [CrossRef]
- Güçkiran, K.; Cantürk, İ.; Özyilmaz, L. DNA microarray gene expression data classification using SVM, MLP, and RF with feature selection methods relief and LASSO. Süleyman Demirel Üniv. Fen Bilim. Enstitüsü Derg. 2019, 23, 126–132. [Google Scholar] [CrossRef]
- Sun, L.; Hui, A.M.; Su, Q.; Vortmeyer, A.; Kotliarov, Y.; Pastorino, S.; Passaniti, A.; Menon, J.; Walling, J.; Bailey, R.; et al. Neuronal and glioma-derived stem cell factor induces angiogenesis within the brain. Cancer Cell 2006, 9, 287–300. [Google Scholar] [CrossRef]
- Alon, U.; Barkai, N.; Notterman, D.A.; Gish, K.; Ybarra, S.; Mack, D.; Levine, A.J. Broad patterns of gene expression revealed by clustering analysis of tumor and normal colon tissues probed by oligonucleotide arrays. Proc. Natl. Acad. Sci. USA 1999, 96, 6745–6750. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Dong, W.; Meng, D. Grouped gene selection of cancer via adaptive sparse group lasso based on conditional mutual information. IEEE/ACM Trans. Comput. Biol. Bioinform. 2017, 15, 2028–2038. [Google Scholar] [CrossRef] [PubMed]
- Belkin, M.; Hsu, D.; Ma, S.; Mandal, S. Reconciling modern machine-learning practice and the classical bias—Variance trade-off. Proc. Natl. Acad. Sci. USA 2019, 116, 15849–15854. [Google Scholar] [CrossRef] [PubMed]
- Gordon, Y. On Milman’s inequality and random subspaces which escape through a mesh in ℝn. In Geometric Aspects of Functional Analysis; Lecture Notes in Mathematics; Springer: Berlin/Heidelberg, Germany, 1988; pp. 84–106. [Google Scholar]
- Chu, H.T.; Toh, K.C.; Zhang, Y. On Regularized Square-root Regression Problems: Distributionally Robust Interpretation and Fast Computations. J. Mach. Learn. Res. 2022, 23, 13885–13923. [Google Scholar]
- Bunea, F.; Lederer, J.; She, Y. The group square-root lasso: Theoretical properties and fast algorithms. IEEE Trans. Inf. Theory 2013, 60, 1313–1325. [Google Scholar] [CrossRef]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alrashdi, A.M.; Alazmi, M.; Alrasheedi, M.A. Generalized Penalized Constrained Regression: Sharp Guarantees in High Dimensions with Noisy Features. Mathematics 2023, 11, 3706. https://doi.org/10.3390/math11173706
Alrashdi AM, Alazmi M, Alrasheedi MA. Generalized Penalized Constrained Regression: Sharp Guarantees in High Dimensions with Noisy Features. Mathematics. 2023; 11(17):3706. https://doi.org/10.3390/math11173706
Chicago/Turabian StyleAlrashdi, Ayed M., Meshari Alazmi, and Masad A. Alrasheedi. 2023. "Generalized Penalized Constrained Regression: Sharp Guarantees in High Dimensions with Noisy Features" Mathematics 11, no. 17: 3706. https://doi.org/10.3390/math11173706
APA StyleAlrashdi, A. M., Alazmi, M., & Alrasheedi, M. A. (2023). Generalized Penalized Constrained Regression: Sharp Guarantees in High Dimensions with Noisy Features. Mathematics, 11(17), 3706. https://doi.org/10.3390/math11173706