
Dual Elite Groups-Guided Differential Evolution for Global Numerical Optimization


Abstract
:1. Introduction
2. Related Work
2.1. Differential Evolution
| Algorithm 1: The pseudocode of DE (DE/rand/1/bin) |
| Input: Population size PS, Scaling factor F, Crossover rate CR, Maximum fitness evaluations FESmax; |
|
| Output: f(x) and x |
2.2. Research on DE
2.2.1. Research on Mutation
2.2.2. Research on Parameter Adaptation
3. Proposed DEGGDE
3.1. DE/Current-to-Duelite/1
3.2. Difference between “DE/Current-to-Duelite/1” and Existing Similar Mutation Strategies
3.3. The Complete DEGGDE
| Algorithm 2: The pseudocode of DEGGDE |
| Input: Population size PS, Maximum fitness evaluations FESmax; |
|
| Output: f(gbest) and gbest |
4. Experiments
4.1. Experimental Setup
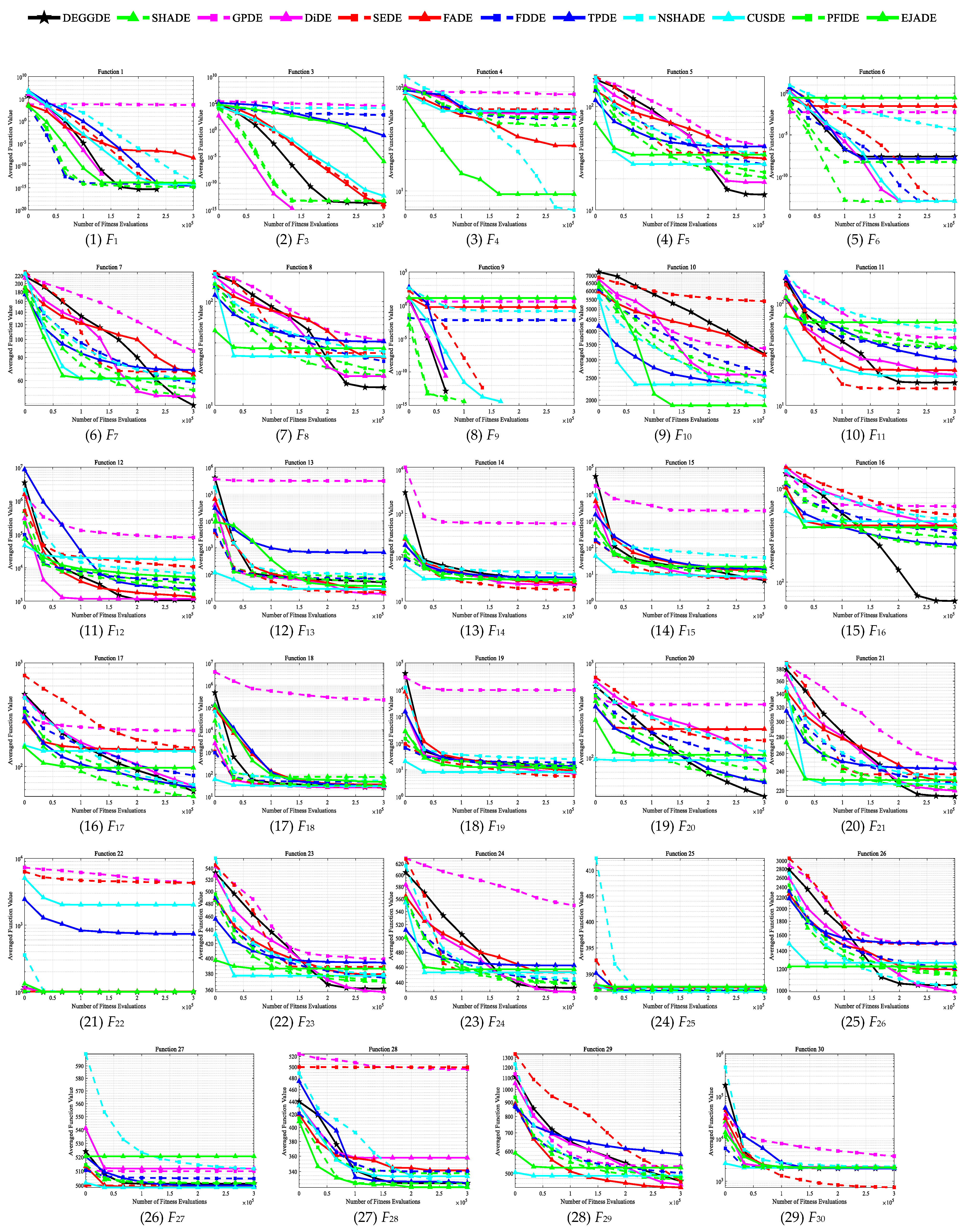
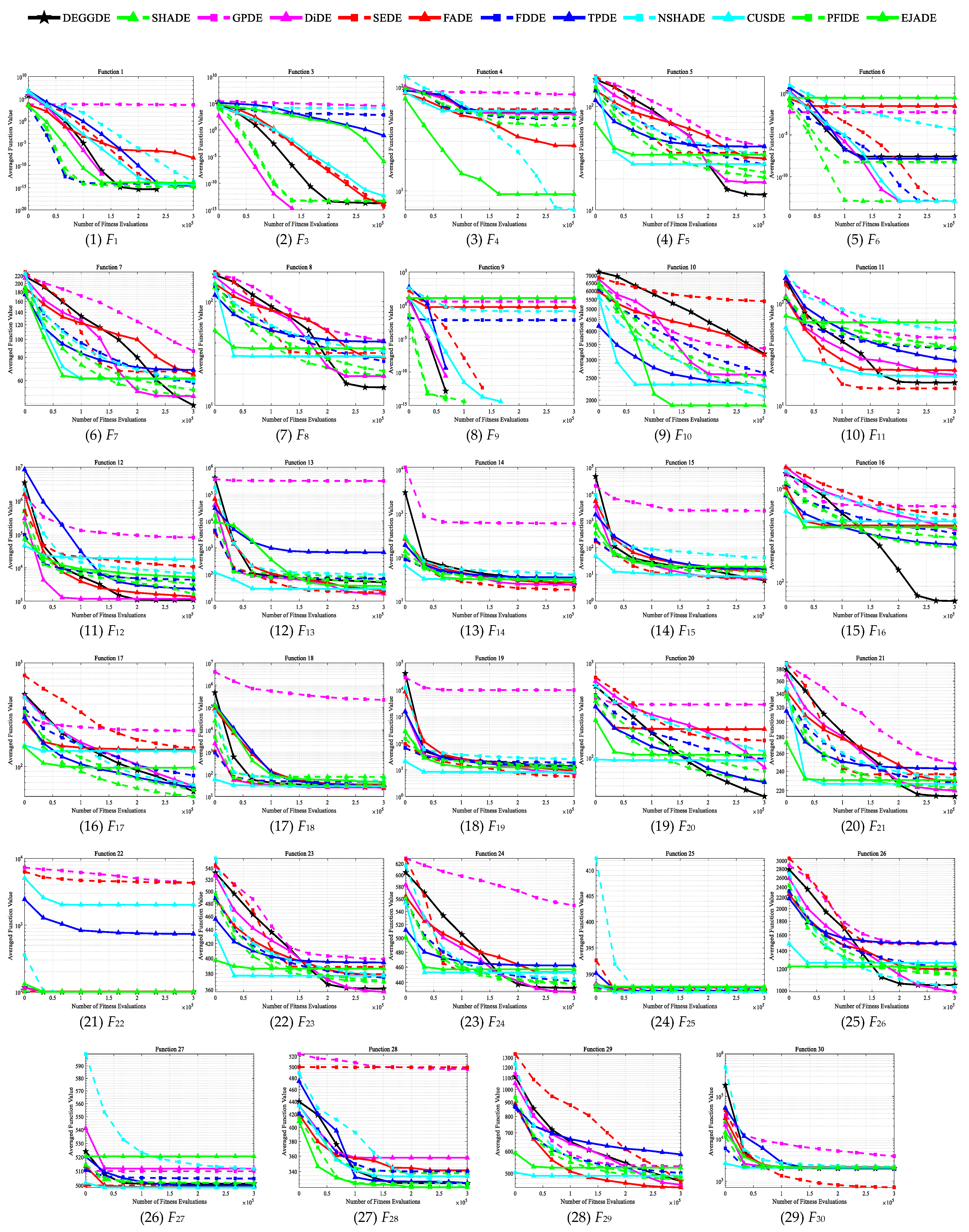
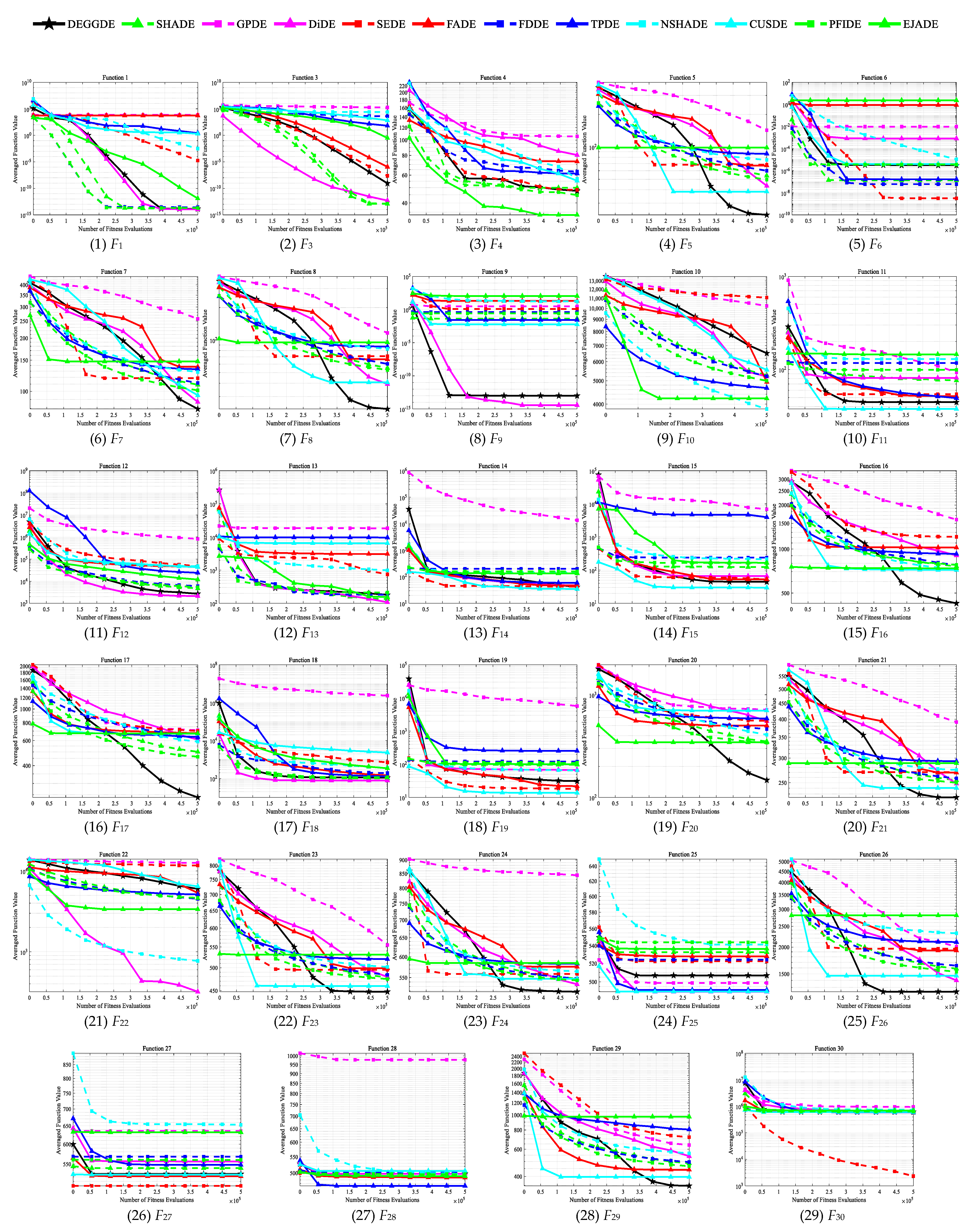
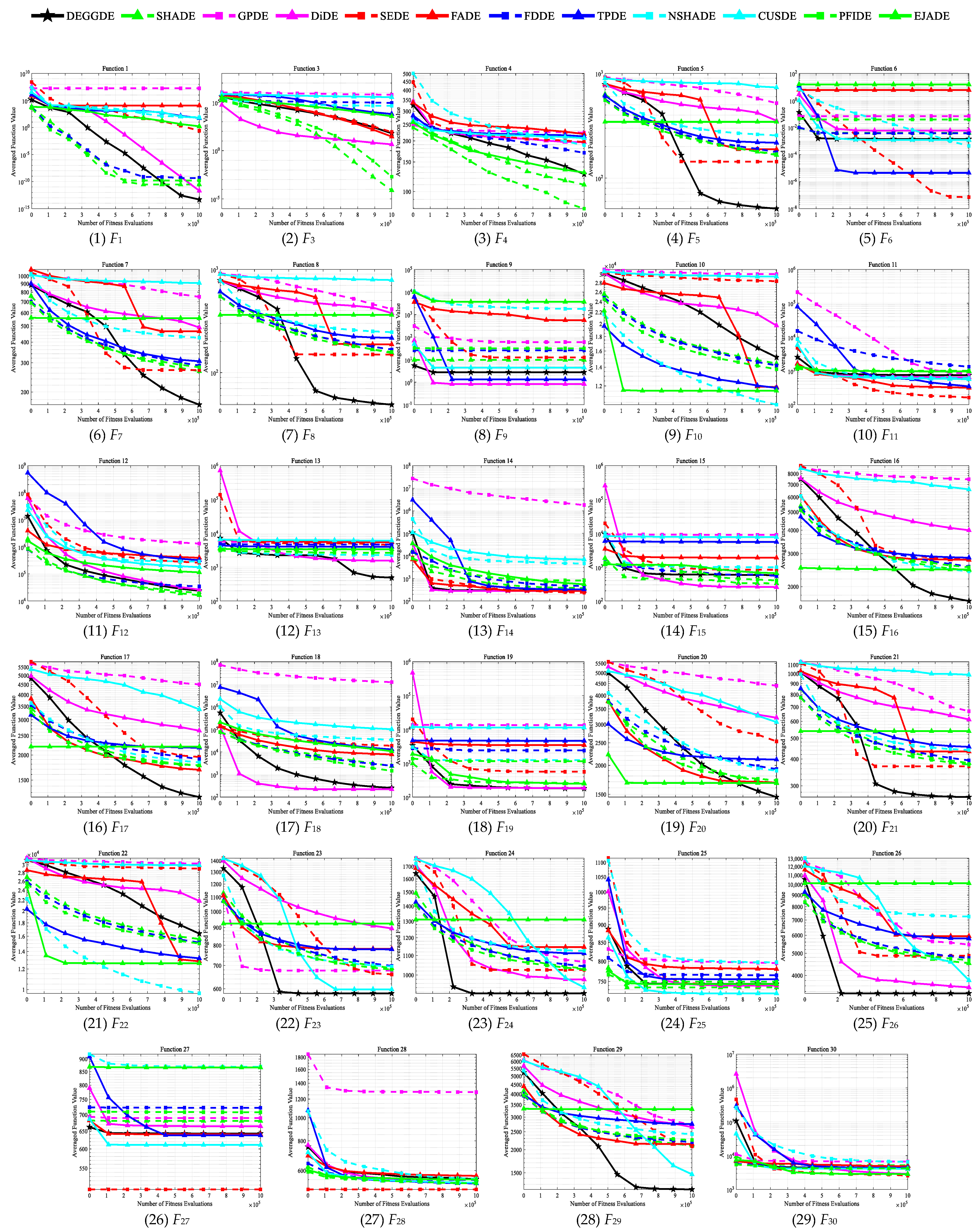
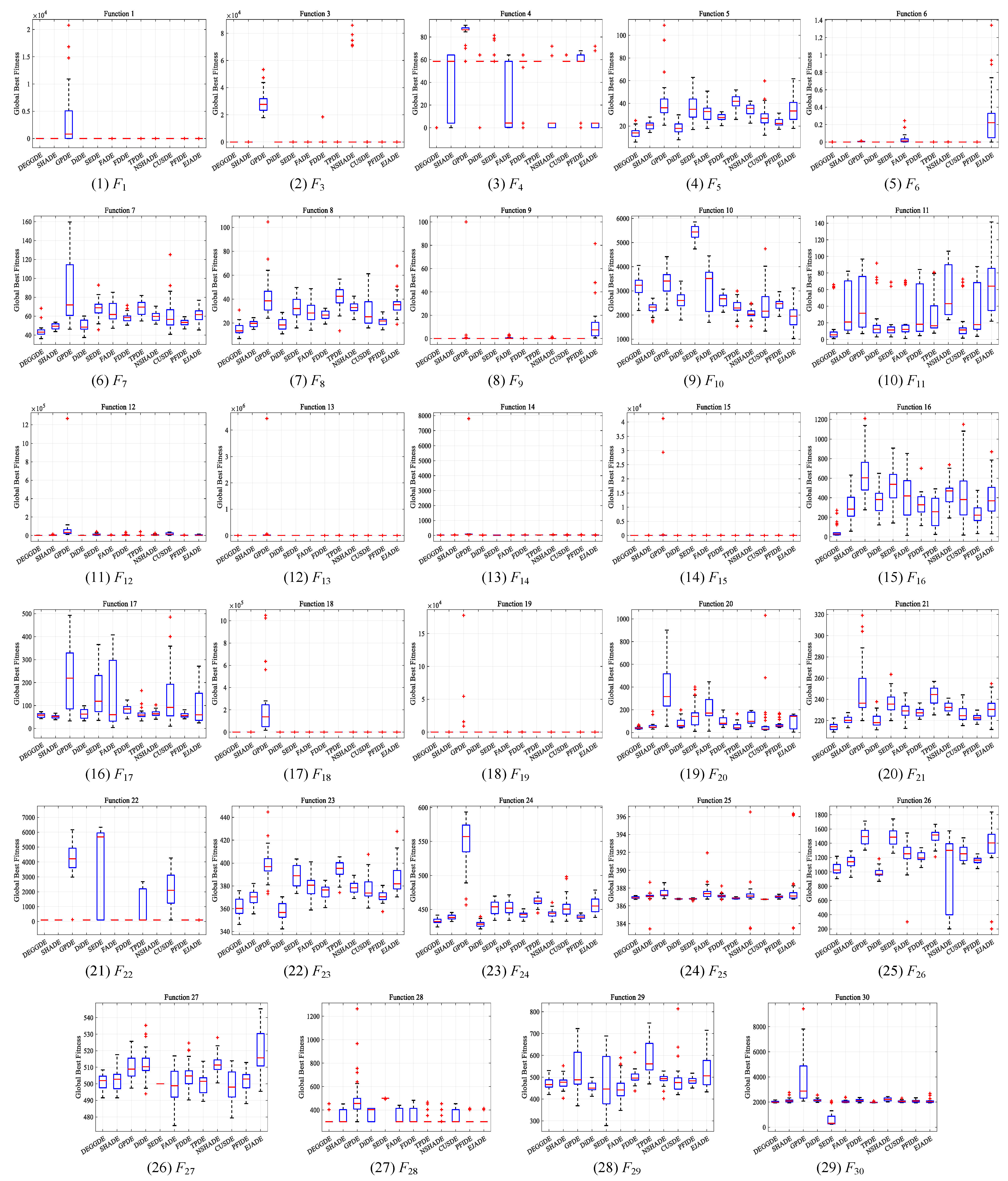
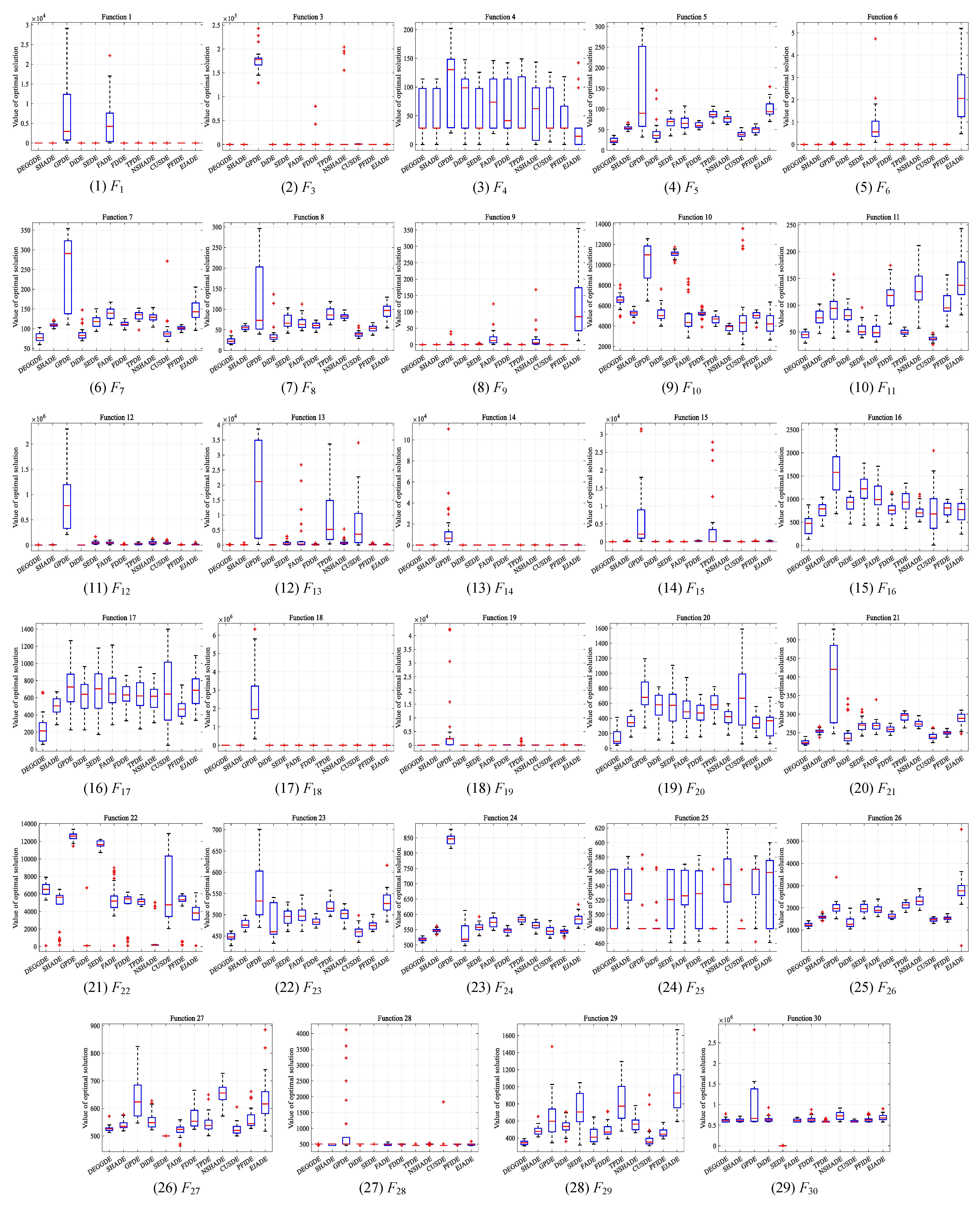
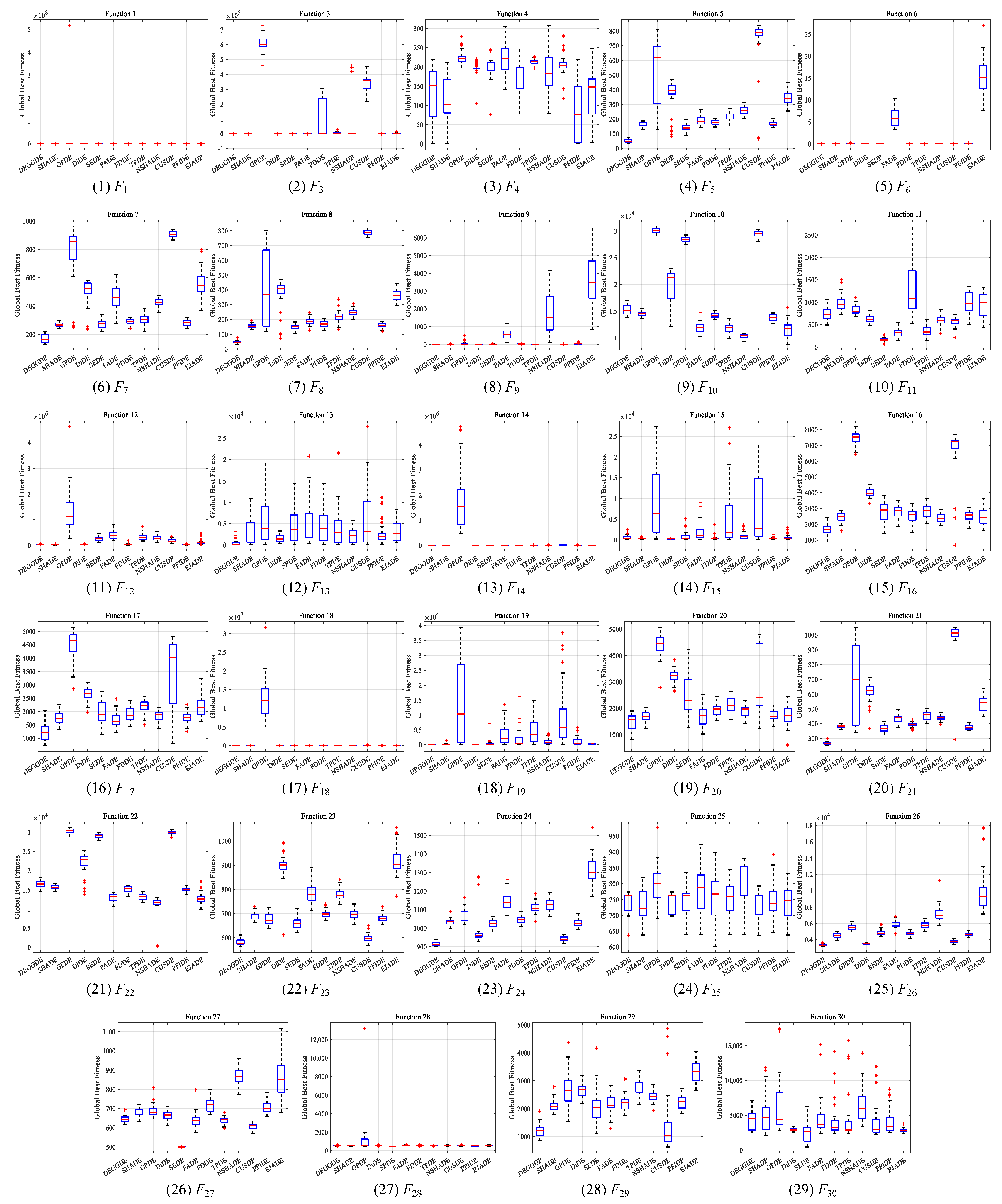
4.2. Comparisons between DEGGDE and State-of-the-Art DE Methods on the CEC’2017 Set
4.3. Deep Investigation on the Effectiveness of “DE/Current-to-Duelite/1”
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Storn, R.; Price, K. Differential evolution—A simple and efficient heuristic for global optimization over continuous spaces. J. Glob. Optim. 1997, 11, 341–359. [Google Scholar] [CrossRef]
- Zhang, J.; Chen, D.; Yang, Q.; Wang, Y.; Liu, D.; Jeon, S.-W.; Zhang, J. Proximity ranking-based multimodal differential evolution. Swarm Evol. Comput. 2023, 78, 101277. [Google Scholar] [CrossRef]
- Liu, D.; He, H.; Yang, Q.; Wang, Y.; Jeon, S.-W.; Zhang, J. Function value ranking aware differential evolution for global numerical optimization. Swarm Evol. Comput. 2023, 78, 101282. [Google Scholar] [CrossRef]
- Yang, Q.; Yan, J.-Q.; Gao, X.-D.; Xu, D.-D.; Lu, Z.-Y.; Zhang, J. Random neighbor elite guided differential evolution for global numerical optimization. Inf. Sci. 2022, 607, 1408–1438. [Google Scholar] [CrossRef]
- Zhou, S.; Xing, L.; Zheng, X.; Du, N.; Wang, L.; Zhang, Q. A self-adaptive differential evolution algorithm for scheduling a single batch-processing machine with arbitrary job sizes and release times. IEEE Trans. Cybern. 2021, 51, 1430–1442. [Google Scholar] [CrossRef]
- Xu, Y.; Pi, D.; Wu, Z.; Chen, J.; Zio, E. Hybrid discrete differential evolution and deep q-network for multimission selective maintenance. IEEE Trans. Reliab. 2022, 71, 1501–1512. [Google Scholar] [CrossRef]
- Liu, H.; Chen, Q.; Pan, N.; Sun, Y.; An, Y.; Pan, D. Uav stocktaking task-planning for industrial warehouses based on the improved hybrid differential evolution algorithm. IEEE Trans. Ind. Inform. 2022, 18, 582–591. [Google Scholar] [CrossRef]
- Brest, J.; Maučec, M.S.; Bošković, B. Single objective real-parameter optimization: Algorithm jso. In Proceedings of the IEEE Congress on Evolutionary Computation, Donostia, Spain, 5–8 June 2017; pp. 1311–1318. [Google Scholar]
- Awad, N.H.; Ali, M.Z.; Suganthan, P.N. Ensemble sinusoidal differential covariance matrix adaptation with euclidean neighborhood for solving cec2017 benchmark problems. In Proceedings of the IEEE Congress on Evolutionary Computation, Donostia, Spain, 5–8 June 2017; pp. 372–379. [Google Scholar]
- Tanabe, R.; Fukunaga, A.S. Improving the search performance of shade using linear population size reduction. In Proceedings of the IEEE Congress on Evolutionary Computation, Beijing, China, 6–11 July 2014; pp. 1658–1665. [Google Scholar]
- Liao, J.; Cai, Y.; Wang, T.; Tian, H.; Chen, Y. Cellular direction information based differential evolution for numerical optimization: An empirical study. Soft Comput. 2016, 20, 2801–2827. [Google Scholar] [CrossRef]
- Mohamed, A.W. An improved differential evolution algorithm with triangular mutation for global numerical optimization. Comput. Ind. Eng. 2015, 85, 359–375. [Google Scholar] [CrossRef]
- Opara, K.; Arabas, J. Comparison of mutation strategies in differential evolution—A probabilistic perspective. Swarm Evol. Comput. 2018, 39, 53–69. [Google Scholar] [CrossRef]
- Sun, G.; Cai, Y.; Wang, T.; Tian, H.; Wang, C.; Chen, Y. Differential evolution with individual-dependent topology adaptation. Inf. Sci. 2018, 450, 1–38. [Google Scholar] [CrossRef]
- Tian, M.; Gao, X.; Yan, X. Performance-driven adaptive differential evolution with neighborhood topology for numerical optimization. Knowl.-Based Syst. 2020, 188, 105008. [Google Scholar] [CrossRef]
- Ghosh, A.; Das, S.; Das, A.K.; Gao, L. Reusing the past difference vectors in differential evolution—A simple but significant improvement. IEEE Trans. Cybern. 2020, 50, 4821–4834. [Google Scholar] [CrossRef]
- Gong, W.; Cai, Z. Differential evolution with ranking-based mutation operators. IEEE Trans. Cybern. 2013, 43, 2066–2081. [Google Scholar] [CrossRef]
- Wang, C.; Gao, J. High-dimensional waveform inversion with cooperative coevolutionary differential evolution algorithm. IEEE Geosci. Remote Sens. Lett. 2012, 9, 297–301. [Google Scholar] [CrossRef]
- Wang, J.; Liao, J.; Zhou, Y.; Cai, Y. Differential evolution enhanced with multiobjective sorting-based mutation operators. IEEE Trans. Cybern. 2014, 44, 2792–2805. [Google Scholar] [CrossRef]
- Wang, K.; Gong, W.; Liao, Z.; Wang, L. Hybrid niching-based differential evolution with two archives for nonlinear equation system. IEEE Trans. Syst. Man Cybern. Syst. 2022, 52, 7469–7481. [Google Scholar] [CrossRef]
- Ji, W.X.; Yang, Q.; Gao, X.D. Gaussian sampling guided differential evolution based on elites for global optimization. IEEE Access 2023, 11, 80915–80944. [Google Scholar] [CrossRef]
- Hamza, N.M.; Essam, D.L.; Sarker, R.A. Constraint consensus mutation-based differential evolution for constrained optimization. IEEE Trans. Evol. Comput. 2016, 20, 447–459. [Google Scholar] [CrossRef]
- Xia, X.; Tong, L.; Zhang, Y.; Xu, X.; Yang, H.; Gui, L.; Li, Y.; Li, K. Nfdde: A novelty-hybrid-fitness driving differential evolution algorithm. Inf. Sci. 2021, 579, 33–54. [Google Scholar] [CrossRef]
- Zhao, X.; Xu, G.; Rui, L.; Liu, D.; Liu, H.; Yuan, J. A failure remember-driven self-adaptive differential evolution with top-bottom strategy. Swarm Evol. Comput. 2019, 45, 1–14. [Google Scholar] [CrossRef]
- Zou, L.; Pan, Z.; Gao, Z.; Gao, J. Improving the search accuracy of differential evolution by using the number of consecutive unsuccessful updates. Knowl.-Based Syst. 2022, 250, 109005. [Google Scholar] [CrossRef]
- Cai, Y.; Wu, D.; Zhou, Y.; Fu, S.; Tian, H.; Du, Y. Self-organizing neighborhood-based differential evolution for global optimization. Swarm Evol. Comput. 2020, 56, 100699. [Google Scholar] [CrossRef]
- Cheng, J.; Pan, Z.; Liang, H.; Gao, Z.; Gao, J. Differential evolution algorithm with fitness and diversity ranking-based mutation operator. Swarm Evol. Comput. 2021, 61, 100816. [Google Scholar] [CrossRef]
- Cai, Y.; Wang, J.; Yin, J. Learning-enhanced differential evolution for numerical optimization. Soft Comput. 2012, 16, 303–330. [Google Scholar] [CrossRef]
- Gao, Z.; Pan, Z.; Gao, J. Multimutation differential evolution algorithm and its application to seismic inversion. IEEE Trans. Geosci. Remote Sens. 2016, 54, 3626–3636. [Google Scholar] [CrossRef]
- Nadimi-Shahraki, M.H.; Taghian, S.; Mirjalili, S.; Faris, H. Mtde: An effective multi-trial vector-based differential evolution algorithm and its applications for engineering design problems. Appl. Soft Comput. 2020, 97, 106761. [Google Scholar] [CrossRef]
- Tan, Z.; Li, K.; Wang, Y. Differential evolution with adaptive mutation strategy based on fitness landscape analysis. Inf. Sci. 2021, 549, 142–163. [Google Scholar] [CrossRef]
- Xia, X.; Gui, L.; Zhang, Y.; Xu, X.; Yu, F.; Wu, H.; Wei, B.; He, G.; Li, Y.; Li, K. A fitness-based adaptive differential evolution algorithm. Inf. Sci. 2021, 549, 116–141. [Google Scholar] [CrossRef]
- Piotrowski, A.P. Adaptive memetic differential evolution with global and local neighborhood-based mutation operators. Inf. Sci. 2013, 241, 164–194. [Google Scholar] [CrossRef]
- Das, S.; Abraham, A.; Chakraborty, U.K.; Konar, A. Differential evolution using a neighborhood-based mutation operator. IEEE Trans. Evol. Comput. 2009, 13, 526–553. [Google Scholar] [CrossRef]
- Liu, X.f.; Zhan, Z.H.; Lin, Y.; Chen, W.N.; Gong, Y.J.; Gu, T.L.; Yuan, H.Q.; Zhang, J. Historical and heuristic-based adaptive differential evolution. IEEE Trans. Syst. Man Cybern. Syst. 2019, 49, 2623–2635. [Google Scholar] [CrossRef]
- Zhou, X.G.; Zhang, G.J. Differential evolution with underestimation-based multimutation strategy. IEEE Trans. Cybern. 2019, 49, 1353–1364. [Google Scholar] [CrossRef] [PubMed]
- Das, S.; Mandal, A.; Mukherjee, R. An adaptive differential evolution algorithm for global optimization in dynamic environments. IEEE Trans. Cybern. 2014, 44, 966–978. [Google Scholar] [CrossRef]
- Wang, Y.; Liu, Z.-Z.; Li, J.; Li, H.-X.; Yen, G.G. Utilizing cumulative population distribution information in differential evolution. Appl. Soft Comput. 2016, 48, 329–346. [Google Scholar] [CrossRef]
- Abbass, H.A. The self-adaptive pareto differential evolution algorithm. In Proceedings of the Congress on Evolutionary Computation, Honolulu, HI, USA, 12–17 May 2002; Volume 1, pp. 831–836. [Google Scholar]
- Das, S.; Konar, A.; Chakraborty, U. Two improved differential evolution schemes for faster global search. In Proceedings of the Annual Conference on Genetic and Evolutionary Computation, Washington, DC, USA, 25–29 June 2005; pp. 991–998. [Google Scholar]
- Qin, A.K.; Huang, V.L.; Suganthan, P.N. Differential evolution algorithm with strategy adaptation for global numerical optimization. IEEE Trans. Evol. Comput. 2009, 13, 398–417. [Google Scholar] [CrossRef]
- Draa, A.; Bouzoubia, S.; Boukhalfa, I. A sinusoidal differential evolution algorithm for numerical optimisation. Appl. Soft Comput. 2015, 27, 99–126. [Google Scholar] [CrossRef]
- Tang, L.; Dong, Y.; Liu, J. Differential evolution with an individual-dependent mechanism. IEEE Trans. Evol. Comput. 2015, 19, 560–574. [Google Scholar] [CrossRef]
- Zhou, Y.Z.; Yi, W.C.; Gao, L.; Li, X.Y. Adaptive differential evolution with sorting crossover rate for continuous optimization problems. IEEE Trans. Cybern. 2017, 47, 2742–2753. [Google Scholar] [CrossRef]
- Tanabe, R.; Fukunaga, A. Success-history based parameter adaptation for differential evolution. In Proceedings of the IEEE Congress on Evolutionary Computation, Cancun, Mexico, 20–23 June 2013; pp. 71–78. [Google Scholar]
- Zhang, J.; Sanderson, A.C. Jade: Adaptive differential evolution with optional external archive. IEEE Trans. Evol. Comput. 2009, 13, 945–958. [Google Scholar] [CrossRef]
- Cheng, S.; Liu, B.; Shi, Y.; Jin, Y.; Li, B. Evolutionary computation and big data: Key challenges and future directions. In Proceedings of the Data Mining and Big Data, Bali, Indonesia, 25–30 June 2016; pp. 3–14. [Google Scholar]
- Yang, Q.; Song, G.W.; Chen, W.N.; Jia, Y.H.; Gao, X.D.; Lu, Z.Y.; Jeon, S.W.; Zhang, J. Random contrastive interaction for particle swarm optimization in high-dimensional environment. IEEE Trans. Evol. Comput. 2023, 1. [Google Scholar] [CrossRef]
- Yang, Q.; Chen, W.N.; Gu, T.; Jin, H.; Mao, W.; Zhang, J. An adaptive stochastic dominant learning swarm optimizer for high-dimensional optimization. IEEE Trans. Cybern. 2022, 52, 1960–1976. [Google Scholar] [CrossRef]
- Bhattacharya, M.; Islam, R.; Abawajy, J. Evolutionary optimization: A big data perspective. J. Netw. Comput. Appl. 2016, 59, 416–426. [Google Scholar] [CrossRef]
- Yang, Q.; Song, G.-W.; Gao, X.-D.; Lu, Z.-Y.; Jeon, S.-W.; Zhang, J. A random elite ensemble learning swarm optimizer for high-dimensional optimization. Complex Intell. Syst. 2023, 1–34. [Google Scholar] [CrossRef]
- Price, K.V. An introduction to differential evolution. In New Ideas in Optimization; McGraw-Hill Inc.: New York, NY, USA, 1999. [Google Scholar]
- Ghosh, A.; Das, S.; Das, A.K.; Senkerik, R.; Viktorin, A.; Zelinka, I.; Masegosa, A.D. Using spatial neighborhoods for parameter adaptation: An improved success history based differential evolution. Swarm Evol. Comput. 2022, 71, 101057. [Google Scholar] [CrossRef]
- Yi, W.; Chen, Y.; Pei, Z.; Lu, J. Adaptive differential evolution with ensembling operators for continuous optimization problems. Swarm Evol. Comput. 2022, 69, 100994. [Google Scholar] [CrossRef]
- Awad, N.; Ali, M.; Liang, J.; Qu, B.; Suganthan, P. Problem definitions and evaluation criteria for the cec 2017 special session and competition on single objective bound constrained real-parameter numerical optimization. In Technical Report; Nanyang Technological University Singapore: Singapore, 2016; pp. 1–34. [Google Scholar]
- Storn, R.; Price, K. Minimizing the real functions of the icec’96 contest by differential evolution. In Proceedings of the IEEE International Conference on Evolutionary Computation, Nayoya, Japan, 20–22 May 1996; pp. 842–844. [Google Scholar]
- Price, K.V.; Storn, R.; Lampinen, J. Differential Evolution: A Practical Approach to Global Optimization; Springer Science & Business Media: Berlin, Germany, 2005. [Google Scholar]
- Baatar, N.; Zhang, D.; Koh, C.S. An improved differential evolution algorithm adopting λ -best mutation strategy for global optimization of electromagnetic devices. IEEE Trans. Magn. 2013, 49, 2097–2100. [Google Scholar] [CrossRef]
- Chen, S.; He, Q.; Zheng, C.; Sun, L.; Wang, X.; Ma, L.; Cai, Y. Differential evolution based simulated annealing method for vaccination optimization problem. IEEE Trans. Netw. Sci. Eng. 2022, 9, 4403–4415. [Google Scholar] [CrossRef]
- Das, S.; Suganthan, P.N. Differential evolution: A survey of the state-of-the-art. IEEE Trans. Evol. Comput. 2011, 15, 4–31. [Google Scholar] [CrossRef]
- Deng, W.; Xu, J.; Gao, X.Z.; Zhao, H. An enhanced msiqde algorithm with novel multiple strategies for global optimization problems. IEEE Trans. Syst. Man Cybern. Syst. 2022, 52, 1578–1587. [Google Scholar] [CrossRef]
- Eiben, A.E.; Hinterding, R.; Michalewicz, Z. Parameter control in evolutionary algorithms. IEEE Trans. Evol. Comput. 1999, 3, 124–141. [Google Scholar] [CrossRef]
- Fan, Q.; Yan, X. Self-adaptive differential evolution algorithm with zoning evolution of control parameters and adaptive mutation strategies. IEEE Trans. Cybern. 2016, 46, 219–232. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Gong, M.; Wang, C.; Miao, Q. Pareto self-paced learning based on differential evolution. IEEE Trans. Cybern. 2021, 51, 4187–4200. [Google Scholar] [CrossRef]
- Yang, Q.; Chen, W.N.; Deng, J.D.; Li, Y.; Gu, T.; Zhang, J. A level-based learning swarm optimizer for large-scale optimization. IEEE Trans. Evol. Comput. 2018, 22, 578–594. [Google Scholar] [CrossRef]
- Yang, Q.; Zhu, Y.; Gao, X.; Xu, D.; Lu, Z. Elite directed particle swarm optimization with historical information for high-dimensional problems. Mathematics 2022, 10, 1384. [Google Scholar] [CrossRef]
- Yang, Q.; Zhang, K.-X.; Gao, X.-D.; Xu, D.-D.; Lu, Z.-Y.; Jeon, S.-W.; Zhang, J. A dimension group-based comprehensive elite learning swarm optimizer for large-scale optimization. Mathematics 2022, 10, 1072. [Google Scholar] [CrossRef]
- Li, Y.; Wang, S.; Yang, B. An improved differential evolution algorithm with dual mutation strategies collaboration. Expert Syst. Appl. 2020, 153, 113451. [Google Scholar] [CrossRef]
- Deng, L.; Li, C.; Han, R.; Zhang, L.; Qiao, L. Tpde: A tri-population differential evolution based on zonal-constraint stepped division mechanism and multiple adaptive guided mutation strategies. Inf. Sci. 2021, 575, 22–40. [Google Scholar] [CrossRef]
- Cao, Z.; Wang, Z.; Fu, Y.; Jia, H.; Tian, F. An adaptive differential evolution framework based on population feature information. Inf. Sci. 2022, 608, 1416–1440. [Google Scholar] [CrossRef]
- Yang, Q.; Chen, W.N.; Li, Y.; Chen, C.L.P.; Xu, X.M.; Zhang, J. Multimodal estimation of distribution algorithms. IEEE Trans. Cybern. 2017, 47, 636–650. [Google Scholar] [CrossRef]
- Yang, Q.; Li, Y.; Gao, X.; Ma, Y.-Y.; Lu, Z.-Y.; Jeon, S.-W.; Zhang, J. An adaptive covariance scaling estimation of distribution algorithm. Mathematics 2021, 9, 3207. [Google Scholar] [CrossRef]
- Sun, J.; Gao, S.; Dai, H.; Cheng, J.; Zhou, M.; Wang, J. Bi-objective elite differential evolution algorithm for multivalued logic networks. IEEE Trans. Cybern. 2020, 50, 233–246. [Google Scholar] [CrossRef]
- Zhang, G.; Ma, X.; Wang, L.; Xing, K. Elite archive-assisted adaptive memetic algorithm for a realistic hybrid differentiation flowshop scheduling problem. IEEE Trans. Evol. Comput. 2022, 26, 100–114. [Google Scholar] [CrossRef]
- Yang, Q.; Hua, L.K.; Gao, X.; Xu, D.; Lu, Z.; Jeon, S.-W.; Zhang, J. Stochastic cognitive dominance leading particle swarm optimization for multimodal problems. Mathematics 2022, 10, 761. [Google Scholar] [CrossRef]
- Yang, Q.; Bian, Y.-W.; Gao, X.; Xu, D.; Lu, Z.; Jeon, S.-W.; Zhang, J. Stochastic triad topology based particle swarm optimization for global numerical optimization. Mathematics 2022, 10, 1032. [Google Scholar] [CrossRef]
- Yang, Q.; Guo, X.; Gao, X.; Xu, D.; Lu, Z. Differential elite learning particle swarm optimization for global numerical optimization. Mathematics 2022, 10, 1261. [Google Scholar] [CrossRef]
- Yang, Q.; Jing, Y.; Gao, X.; Xu, D.; Lu, Z.; Jeon, S.-W.; Zhang, J. Predominant cognitive learning particle swarm optimization for global numerical optimization. Mathematics 2022, 10, 1620. [Google Scholar] [CrossRef]
- Sun, G.; Lan, Y.; Zhao, R. Differential evolution with gaussian mutation and dynamic parameter adjustment. Soft Comput. 2019, 23, 1615–1642. [Google Scholar] [CrossRef]
- Meng, Z.; Yang, C.; Li, X.; Chen, Y. Di-de: Depth information-based differential evolution with adaptive parameter control for numerical optimization. IEEE Access 2020, 8, 40809–40827. [Google Scholar] [CrossRef]
- Liang, J.; Qiao, K.; Yu, K.; Ge, S.; Qu, B.; Xu, R.; Li, K. Parameters estimation of solar photovoltaic models via a self-adaptive ensemble-based differential evolution. Sol. Energy 2020, 207, 336–346. [Google Scholar] [CrossRef]
- Wang, Y.; Gao, S.; Yu, Y.; Cai, Z.; Wang, Z. A gravitational search algorithm with hierarchy and distributed framework. Knowl.-Based Syst. 2021, 218, 106877. [Google Scholar] [CrossRef]
- Xiao, T.-L.; Yang, Q.; Gao, X.-D.; Ma, Y.-Y.; Lu, Z.-Y.; Jeon, S.-W.; Zhang, J. Variation encoded large-scale swarm optimizers for path planning of unmanned aerial vehicle. In Proceedings of the Genetic and Evolutionary Computation Conference, Lisbon, Portugal, 15–19 July 2023; pp. 102–110. [Google Scholar]
- Lu, Z.; Liang, S.; Yang, Q.; Du, B. Evolving block-based convolutional neural network for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5525921. [Google Scholar] [CrossRef]
- Gao, X.; Cao, W.; Yang, Q.; Wang, H.; Wang, X.; Jin, G.; Zhang, J. Parameter optimization of control system design for uncertain wireless power transfer systems using modified genetic algorithm. CAAI Trans. Intell. Technol. 2022, 7, 582–593. [Google Scholar] [CrossRef]
- Wei, F.F.; Chen, W.N.; Yang, Q.; Deng, J.; Luo, X.N.; Jin, H.; Zhang, J. A classifier-assisted level-based learning swarm optimizer for expensive optimization. IEEE Trans. Evol. Comput. 2021, 25, 219–233. [Google Scholar] [CrossRef]
- Chen, W.N.; Tan, D.Z.; Yang, Q.; Gu, T.; Zhang, J. Ant colony optimization for the control of pollutant spreading on social networks. IEEE Trans. Cybern. 2020, 50, 4053–4065. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Problem Type | Index | Problem Name | Optimum |
|---|---|---|---|
| Unimodal Problems | 1 | Shifted and Rotated Bent Cigar Problem | 100 |
| 3 | Shifted and Rotated Zakharov Problem | 300 | |
| Simple Multimodal Problems | 4 | Shifted and Rotated Rosenbrock’s Problem | 400 |
| 5 | Shifted and Rotated Rastrigin’s Problem | 500 | |
| 6 | Shifted and Rotated Expanded Scaffer’s F6 Problem | 600 | |
| 7 | Shifted and Rotated Lunacek Bi_Rastrigin Problem | 700 | |
| 8 | Shifted and Rotated Non-Continuous Rastrigin’s Problem | 800 | |
| 9 | Shifted and Rotated Levy Problem | 900 | |
| 10 | Shifted and Rotated Schwefel’s Problem | 1000 | |
| Hybrid Problems | 11 | Hybrid Problem 1 (N = 3) | 1100 |
| 12 | Hybrid Problem 2 (N = 3) | 1200 | |
| 13 | Hybrid Problem 3 (N = 3) | 1300 | |
| 14 | Hybrid Problem 4 (N = 4) | 1400 | |
| 15 | Hybrid Problem 5 (N = 4) | 1500 | |
| 16 | Hybrid Problem 6 (N = 4) | 1600 | |
| 17 | Hybrid Problem 6 (N = 5) | 1700 | |
| 18 | Hybrid Problem 6 (N = 5) | 1800 | |
| 19 | Hybrid Problem 6 (N = 5) | 1900 | |
| 20 | Hybrid Problem 6 (N = 6) | 2000 | |
| Composition Problems | 21 | Composition Problem 1 (N = 3) | 2100 |
| 22 | Composition Problem 2 (N = 3) | 2200 | |
| 23 | Composition Problem 3 (N = 4) | 2300 | |
| 24 | Composition Problem 4 (N = 4) | 2400 | |
| 25 | Composition Problem 5 (N = 5) | 2500 | |
| 26 | Composition Problem 6 (N = 5) | 2600 | |
| 27 | Composition Problem 7 (N = 6) | 2700 | |
| 28 | Composition Problem 8 (N = 6) | 2800 | |
| 29 | Composition Problem 9 (N = 3) | 2900 | |
| 30 | Composition Problem 10 (N = 3) | 3000 | |
| Search Range: | |||
| D | Parameter | DEGGDE | SHADE (2013) | GPDE (2019) | DiDE (2020) | SEDE (2020) | FADE (2021) | FDDE (2021) | TPDE (2021) | NSHADE (2022) | CUSDE (2022) | PFIDE (2022) | EJADE (2022) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 30 | PS | 230 | 110 | 30 | 300 | 50 | Initialized as 3 × 25 Adaptively Adjusted | 150 | 100 | 180 | 100 | 140 | 100 |
| 50 | 300 | 170 | 40 | 500 | 50 | 150 | 100 | 180 | 100 | 140 | 100 | ||
| 100 | 410 | 170 | 40 | 1000 | 80 | 150 | 100 | 190 | 100 | 140 | 100 |
| F | Category | Quality | DEGGDE | SHADE | GPDE | DiDE | SEDE | FADE | FDDE | TPDE | NSHADE | CUSDE | PFIDE | EJADE |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| F1 | Unimodal Functions | Mean | 0.00 × 100 | 5.60 × 10−15 | 4.13 × 103 | 0.00 × 100 | 0.00 × 100 | 5.22 × 10−9 | 8.05 × 10−15 | 2.84 × 10−15 | 2.58 × 10−14 | 4.26 × 10−15 | 1.42 × 10−15 | 1.47 × 10−14 |
| Std | 0.00 × 100 | 6.98 × 10−15 | 6.02 × 103 | 0.00 × 100 | 0.00 × 100 | 2.86 × 10−8 | 7.16 × 10−15 | 5.78 × 10−15 | 1.55 × 10−14 | 6.62 × 10−15 | 4.34 × 10−15 | 5.88 × 10−15 | ||
| p-value | – | 1.28 × 10−4 + | 1.21 × 10−12 + | NaN = | NaN = | 8.27 × 10−7 + | 1.43 × 10−6 + | 1.09 × 10−2 + | 6.59 × 10−13 + | 1.31 × 10−3 + | 8.14 × 10−2 = | 1.92 × 10−12 + | ||
| F3 | Mean | 1.71 × 10−14 | 5.70 × 10−14 | 2.94 × 104 | 0.00 × 100 | 3.80 × 10−15 | 1.14 × 10−14 | 6.15 × 102 | 8.72 × 10−2 | 1.27 × 104 | 4.26 × 10−13 | 5.12 × 10−14 | 1.24 × 10−6 | |
| Std | 2.66 × 10−14 | 1.50 × 10−14 | 8.09 × 103 | 0.00 × 100 | 1.45 × 10−14 | 2.32 × 10−14 | 3.37 × 103 | 2.06 × 10−1 | 2.90 × 104 | 2.08 × 10−13 | 1.73 × 10−14 | 6.80 × 10−6 | ||
| p-value | – | 1.10 × 10−7 + | 1.01 × 10−11 + | 1.31 × 10−3 − | 2.12 × 10−2 − | 3.80 × 10−1 = | 4.07 × 10−4 + | 1.01 × 10−11 + | 1.01 × 10−11 + | 9.70 × 10−12 + | 1.71 × 10−2 + | 9.21 × 10−5 + | ||
| F1–3 | w/t/l | – | 2/0/0 | 2/0/0 | 0/1/1 | 0/1/1 | 1/1/0 | 2/0/0 | 2/0/0 | 2/0/0 | 2/0/0 | 1/1/0 | 2/0/0 | |
| F4 | Simple Multimodal Functions | Mean | 5.66 × 101 | 4.30 × 101 | 8.51 × 101 | 5.50 × 101 | 6.10 × 101 | 2.73 × 101 | 5.00 × 101 | 5.86 × 101 | 6.55 × 100 | 5.87 × 101 | 5.12 × 101 | 9.31 × 100 |
| Std | 1.07 × 101 | 2.76 × 101 | 6.60 × 100 | 1.50 × 101 | 6.35 × 100 | 2.88 × 101 | 2.22 × 101 | 3.61 × 10−14 | 1.68 × 101 | 1.01 × 100 | 2.28 × 101 | 2.09 × 101 | ||
| p-value | – | 6.09 × 10−1 = | 1.70 × 10−12 + | 2.75 × 10−7 − | 1.64 × 10−5 + | 3.06 × 10−3 − | 1.11 × 10−5 − | 2.71 × 10−14 + | 1.39 × 10−8 − | 4.29 × 10−14 + | 1.39 × 10−6 − | 1.24 × 10−7 − | ||
| F5 | Mean | 1.41 × 101 | 2.07 × 101 | 4.13 × 101 | 1.85 × 101 | 3.57 × 101 | 3.16 × 101 | 2.76 × 101 | 4.11 × 101 | 3.45 × 101 | 2.78 × 101 | 2.31 × 101 | 3.42 × 101 | |
| Std | 4.17 × 100 | 3.61 × 100 | 1.95 × 101 | 5.75 × 100 | 1.21 × 101 | 7.89 × 100 | 2.87 × 100 | 6.58 × 100 | 5.09 × 100 | 9.08 × 100 | 3.43 × 100 | 1.01 × 101 | ||
| p-value | – | 2.78 × 10−7 + | 4.95 × 10−11 + | 1.27 × 10−3 + | 1.85 × 10−10 + | 1.14 × 10−10 + | 6.68 × 10−11 + | 3.01 × 10−11 + | 3.68 × 10−11 + | 2.42 × 10−9 + | 2.03 × 10−9 + | 7.34 × 10−11 + | ||
| F6 | Mean | 2.51 × 10−8 | 1.14 × 10−13 | 5.31 × 10−3 | 1.14 × 10−13 | 1.14 × 10−13 | 2.92 × 10−2 | 1.14 × 10−13 | 1.37 × 10−8 | 4.42 × 10−5 | 1.14 × 10−13 | 5.70 × 10−9 | 2.86 × 10−1 | |
| Std | 1.02 × 10−7 | 5.14 × 10−29 | 2.42 × 10−3 | 5.14 × 10−29 | 5.14 × 10−29 | 5.28 × 10−2 | 0.00 × 100 | 4.18 × 10−8 | 6.74 × 10−5 | 0.00 × 100 | 2.55 × 10−8 | 3.18 × 10−1 | ||
| p-value | – | 1.70 × 10−1 = | 5.22 × 10−12 + | 1.70 × 10−1 = | 1.70 × 10−1 = | 5.22 × 10−12 + | 4.46 × 10−12 − | 4.46 × 10−8 − | 5.22 × 10−12 + | 4.46 × 10−12 − | 2.77 × 10−9 − | 5.22 × 10−12 + | ||
| F7 | Mean | 4.41 × 101 | 4.94 × 101 | 8.66 × 101 | 4.95 × 101 | 6.72 × 101 | 6.46 × 101 | 5.85 × 101 | 6.85 × 101 | 5.97 × 101 | 6.13 × 101 | 5.33 × 101 | 6.18 × 101 | |
| Std | 6.14 × 100 | 2.86 × 100 | 3.80 × 101 | 6.23 × 100 | 1.00 × 101 | 1.01 × 101 | 4.73 × 100 | 8.05 × 100 | 5.19 × 100 | 1.71 × 101 | 3.14 × 100 | 7.45 × 100 | ||
| p-value | 1.00 × 100 = | 4.11 × 10−7 + | 2.87 × 10−10 + | 3.77 × 10−4 + | 3.82 × 10−10 + | 8.10 × 10−10 + | 2.03 × 10−9 + | 1.78 × 10−10 + | 1.29 × 10−9 + | 7.69 × 10−8 + | 1.01 × 10−8 + | 1.86 × 10−9 + | ||
| F8 | Mean | 1.49 × 101 | 1.95 × 101 | 4.21 × 101 | 1.91 × 101 | 3.19 × 101 | 2.92 × 101 | 2.67 × 101 | 4.12 × 101 | 3.30 × 101 | 2.97 × 101 | 2.14 × 101 | 3.55 × 101 | |
| Std | 5.17 × 100 | 2.79 × 100 | 1.67 × 101 | 5.00 × 100 | 8.59 × 100 | 8.01 × 100 | 3.43 × 100 | 9.31 × 100 | 4.25 × 100 | 1.27 × 101 | 3.54 × 100 | 9.40 × 100 | ||
| p-value | – | 9.18 × 10−5 + | 5.43 × 10−11 + | 1.80 × 10−3 + | 1.16 × 10−9 + | 3.96 × 10−9 + | 1.06 × 10−9 + | 1.94 × 10−10 + | 7.33 × 10−11 + | 5.05 × 10−8 + | 1.10 × 10−6 + | 1.19 × 10−10 + | ||
| F9 | Mean | 0.00 × 100 | 0.00 × 100 | 3.56 × 100 | 0.00 × 100 | 0.00 × 100 | 5.45 × 10−1 | 5.97 × 10−3 | 0.00 × 100 | 1.31 × 10−1 | 0.00 × 100 | 0.00 × 100 | 1.24 × 101 | |
| Std | 0.00 × 100 | 0.00 × 100 | 1.82 × 101 | 0.00 × 100 | 0.00 × 100 | 8.39 × 10−1 | 2.27 × 10−2 | 0.00 × 100 | 3.12 × 10−1 | 0.00 × 100 | 0.00 × 100 | 1.68 × 101 | ||
| p-value | – | NaN = | 1.20 × 10−12 + | NaN = | NaN = | 1.29 × 10−7 + | 1.61 × 10−1 = | NaN = | 4.31 × 10−11 + | NaN = | NaN = | 1.21 × 10−12 + | ||
| F10 | Mean | 3.19 × 103 | 2.29 × 103 | 3.37 × 103 | 2.58 × 103 | 5.41 × 103 | 3.15 × 103 | 2.63 × 103 | 2.33 × 103 | 2.08 × 103 | 2.34 × 103 | 2.44 × 103 | 1.90 × 103 | |
| Std | 4.03 × 102 | 2.35 × 102 | 5.67 × 102 | 3.86 × 102 | 2.89 × 102 | 8.19 × 102 | 2.66 × 102 | 3.22 × 102 | 2.13 × 102 | 7.55 × 102 | 2.10 × 102 | 5.11 × 102 | ||
| p-value | – | 7.38 × 10−10 − | 9.33 × 10−2 = | 8.84 × 10−7 − | 3.02 × 10−11 + | 3.26 × 10−1 = | 3.26 × 10−7 − | 3.20 × 10−9 − | 8.99 × 10−11 − | 6.05 × 10−7 − | 5.00 × 10−9 − | 3.82 × 10−10 − | ||
| F4–10 | w/t/l | – | 3/3/1 | 6/1/0 | 3/2/2 | 5/2/0 | 5/1/1 | 3/1/3 | 4/1/2 | 5/0/2 | 4/1/2 | 3/1/3 | 5/0/2 | |
| F11 | Hybrid Functions | Mean | 1.67 × 101 | 3.71 × 101 | 4.61 × 101 | 2.00 × 101 | 1.47 × 101 | 2.21 × 101 | 3.55 × 101 | 2.74 × 101 | 5.46 × 101 | 1.93 × 101 | 3.63 × 101 | 6.55 × 101 |
| Std | 2.40 × 101 | 2.91 × 101 | 3.25 × 101 | 2.33 × 101 | 1.46 × 101 | 2.36 × 101 | 2.94 × 101 | 2.06 × 101 | 2.94 × 101 | 2.25 × 101 | 2.91 × 101 | 3.18 × 101 | ||
| p-value | – | 3.81 × 10−6 + | 4.09 × 10−7 + | 1.23 × 10−3 + | 2.55 × 10−3 − | 4.96 × 10−4 + | 3.58 × 10−5 + | 5.58 × 10−5 + | 1.72 × 10−6 + | 5.31 × 10−3 + | 1.24 × 10−5 + | 8.29 × 10−8 + | ||
| F12 | Mean | 1.08 × 103 | 3.14 × 103 | 8.01 × 104 | 1.17 × 103 | 1.07 × 104 | 1.37 × 103 | 4.37 × 103 | 2.35 × 103 | 6.75 × 103 | 1.76 × 104 | 1.60 × 103 | 5.17 × 103 | |
| Std | 3.08 × 102 | 2.88 × 103 | 2.26 × 105 | 3.73 × 102 | 9.86 × 103 | 1.55 × 103 | 6.63 × 103 | 7.38 × 103 | 6.10 × 103 | 1.11 × 104 | 8.18 × 102 | 3.98 × 103 | ||
| p-value | – | 6.53 × 10−8 + | 3.02 × 10−11 + | 3.87 × 10−1 = | 3.08 × 10−8 + | 2.34 × 10−1 = | 5.27 × 10−5 + | 1.09 × 10−1 = | 4.20 × 10−10 + | 3.02 × 10−11 + | 1.24 × 10−3 + | 7.12 × 10−9 + | ||
| F13 | Mean | 4.96 × 101 | 6.59 × 101 | 3.08 × 105 | 1.88 × 101 | 2.13 × 101 | 2.45 × 101 | 6.73 × 101 | 6.69 × 102 | 9.96 × 101 | 2.82 × 101 | 5.32 × 101 | 3.65 × 101 | |
| Std | 4.22 × 101 | 3.83 × 101 | 1.12 × 106 | 7.17 × 100 | 6.15 × 100 | 9.74 × 100 | 4.37 × 101 | 1.52 × 103 | 4.32 × 101 | 6.03 × 100 | 4.53 × 101 | 2.16 × 101 | ||
| p-value | – | 3.15 × 10−2 + | 3.34 × 10−11 + | 9.83 × 10−8 − | 3.52 × 10−7 − | 4.08 × 10−5 − | 6.97 × 10−3 + | 1.22 × 10−2 + | 1.39 × 10−6 + | 2.53 × 10−4 − | 5.89 × 10−1 = | 1.62 × 10−1 = | ||
| F14 | Mean | 2.32 × 101 | 3.00 × 101 | 5.91 × 102 | 2.38 × 101 | 1.81 × 101 | 2.68 × 101 | 3.27 × 101 | 3.47 × 101 | 4.02 × 101 | 3.17 × 101 | 2.81 × 101 | 3.09 × 101 | |
| Std | 4.20 × 100 | 4.53 × 100 | 1.96 × 103 | 4.22 × 100 | 1.17 × 101 | 7.80 × 100 | 6.02 × 100 | 2.60 × 100 | 8.59 × 100 | 1.02 × 101 | 6.75 × 100 | 8.18 × 100 | ||
| p-value | – | 1.70 × 10−8 + | 3.02 × 10−11 + | 9.33 × 10−2 = | 6.31 × 10−1 = | 1.00 × 10−3 + | 2.92 × 10−9 + | 5.49 × 10−11 + | 6.07 × 10−11 + | 3.26 × 10−7 + | 7.60 × 10−7 + | 4.80 × 10−7 + | ||
| F15 | Mean | 5.95 × 100 | 1.67 × 101 | 2.43 × 103 | 7.11 × 100 | 6.69 × 100 | 1.29 × 101 | 1.67 × 101 | 1.58 × 101 | 4.18 × 101 | 8.16 × 100 | 1.27 × 101 | 1.90 × 101 | |
| Std | 2.29 × 100 | 1.43 × 101 | 9.07 × 103 | 4.10 × 100 | 3.65 × 100 | 5.49 × 100 | 1.30 × 101 | 2.76 × 100 | 3.17 × 101 | 5.27 × 100 | 9.68 × 100 | 1.34 × 101 | ||
| p-value | – | 1.87 × 10−5 + | 3.02 × 10−11 + | 5.01 × 10−1 = | 8.42 × 10−1 = | 3.20 × 10−9 + | 1.39 × 10−6 + | 3.34 × 10−11 + | 1.29 × 10−9 + | 4.21 × 10−2 + | 1.60 × 10−7 + | 5.46 × 10−9 + | ||
| F16 | Mean | 6.26 × 101 | 3.00 × 102 | 6.46 × 102 | 3.67 × 102 | 5.23 × 102 | 4.03 × 102 | 3.31 × 102 | 2.53 × 102 | 4.57 × 102 | 4.47 × 102 | 2.36 × 102 | 3.86 × 102 | |
| Std | 7.53 × 101 | 1.44 × 102 | 2.44 × 102 | 1.32 × 102 | 1.94 × 102 | 2.39 × 102 | 1.23 × 102 | 1.50 × 102 | 1.22 × 102 | 3.33 × 102 | 1.17 × 102 | 1.90 × 102 | ||
| p-value | – | 2.23 × 10−9 + | 3.02 × 10−11 + | 2.87 × 10−10 + | 8.15 × 10−11 + | 1.60 × 10−7 + | 8.10 × 10−10 + | 2.38 × 10−7 + | 4.08 × 10−11 + | 7.09 × 10−8 + | 3.65 × 10−8 + | 5.07 × 10−10 + | ||
| F17 | Hybrid Functions | Mean | 5.77 × 101 | 5.15 × 101 | 2.23 × 102 | 6.46 × 101 | 1.51 × 102 | 1.46 × 102 | 8.20 × 101 | 6.27 × 101 | 6.67 × 101 | 1.41 × 102 | 5.96 × 101 | 9.73 × 101 |
| Std | 9.41 × 100 | 6.83 × 100 | 1.45 × 102 | 1.92 × 101 | 9.82 × 101 | 1.40 × 102 | 2.00 × 101 | 2.48 × 101 | 1.44 × 101 | 1.21 × 102 | 1.13 × 101 | 6.69 × 101 | ||
| p-value | – | 1.44 × 10−2 − | 3.81 × 10−7 + | 2.90 × 10−1 = | 1.64 × 10−5 + | 3.95 × 10−1 = | 2.49 × 10−6 + | 7.84 × 10−1 = | 1.44 × 10−2 + | 4.03 × 10−3 + | 5.89 × 10−1 = | 4.29 × 10−1 = | ||
| F18 | Mean | 2.55 × 101 | 7.57 × 101 | 2.19 × 105 | 2.49 × 101 | 2.64 × 101 | 3.43 × 101 | 4.54 × 101 | 3.03 × 101 | 5.13 × 101 | 2.88 × 101 | 3.13 × 101 | 4.56 × 101 | |
| Std | 3.04 × 100 | 5.70 × 101 | 2.66 × 105 | 3.67 × 100 | 5.28 × 100 | 1.07 × 101 | 2.74 × 101 | 2.52 × 100 | 2.19 × 101 | 9.32 × 100 | 9.61 × 100 | 3.16 × 101 | ||
| p-value | – | 3.65 × 10−8 + | 3.02 × 10−11 + | 4.12 × 10−1 = | 9.05 × 10−2 = | 7.69 × 10−8 + | 7.22 × 10−6 + | 8.20 × 10−7 + | 1.78 × 10−10 + | 9.33 × 10−2 = | 6.97 × 10−3 + | 1.25 × 10−5 + | ||
| F19 | Mean | 1.09 × 101 | 1.59 × 101 | 9.63 × 103 | 7.41 × 100 | 5.67 × 100 | 9.24 × 100 | 1.86 × 101 | 1.39 × 101 | 2.47 × 101 | 8.24 × 100 | 1.27 × 101 | 1.18 × 101 | |
| Std | 3.04 × 100 | 7.18 × 100 | 3.35 × 104 | 2.73 × 100 | 2.12 × 100 | 3.86 × 100 | 1.34 × 101 | 1.85 × 100 | 5.40 × 100 | 2.29 × 100 | 3.86 × 100 | 5.70 × 100 | ||
| p-value | – | 2.50 × 10−3 + | 1.61 × 10−10 + | 4.35 × 10−5 − | 5.09 × 10−8 − | 3.18 × 10−3 − | 1.17 × 10−5 + | 7.20 × 10−5 + | 1.21 × 10−10 + | 2.39 × 10−4 − | 8.24 × 10−2 = | 9.23 × 10−1 = | ||
| F20 | Mean | 3.88 × 101 | 5.67 × 101 | 3.63 × 102 | 7.86 × 101 | 1.51 × 102 | 2.00 × 102 | 9.64 × 101 | 5.48 × 101 | 1.16 × 102 | 9.38 × 101 | 7.21 × 101 | 1.07 × 102 | |
| Std | 9.42 × 100 | 3.32 × 101 | 1.97 × 102 | 4.12 × 101 | 1.08 × 102 | 1.21 × 102 | 4.27 × 101 | 3.25 × 101 | 4.75 × 101 | 1.98 × 102 | 3.65 × 101 | 5.82 × 101 | ||
| p-value | – | 8.66 × 10−5 + | 3.69 × 10−11 + | 6.53 × 10−8 + | 1.17 × 10−5 + | 1.61 × 10−6 + | 9.92 × 10−11 + | 1.91 × 10−1 = | 6.70 × 10−11 + | 9.93 × 10−2 = | 5.00 × 10−9 + | 2.62 × 10−3 + | ||
| F11–20 | w/t/l | – | 9/0/1 | 10/0/0 | 3/5/2 | 4/3/3 | 6/2/2 | 10/0/0 | 7/3/0 | 10/0/0 | 6/2/2 | 7/3/0 | 7/3/0 | |
| F21 | Composition Functions | Mean | 2.14 × 102 | 2.21 × 102 | 2.48 × 102 | 2.20 × 102 | 2.37 × 102 | 2.29 × 102 | 2.28 × 102 | 2.43 × 102 | 2.33 × 102 | 2.27 × 102 | 2.23 × 102 | 2.31 × 102 |
| Std | 3.50 × 100 | 3.42 × 100 | 2.69 × 101 | 6.32 × 100 | 1.02 × 101 | 7.36 × 100 | 4.17 × 100 | 8.38 × 100 | 4.55 × 100 | 7.43 × 100 | 3.31 × 100 | 9.75 × 100 | ||
| p-value | – | 5.53 × 10−8 + | 4.08 × 10−11 + | 8.15 × 10−5 + | 5.49 × 10−11 + | 9.76 × 10−10 + | 4.50 × 10−11 + | 3.02 × 10−11 + | 3.02 × 10−11 + | 1.07 × 10−9 + | 1.41 × 10−9 + | 1.29 × 10−9 + | ||
| F22 | Mean | 1.00 × 102 | 1.00 × 102 | 4.29 × 103 | 1.00 × 102 | 4.28 × 103 | 1.01 × 102 | 1.00 × 102 | 7.38 × 102 | 1.00 × 102 | 2.02 × 103 | 1.00 × 102 | 1.00 × 102 | |
| Std | 0.00 × 100 | 0.00 × 100 | 1.19 × 103 | 0.00 × 100 | 2.58 × 103 | 1.78 × 100 | 0.00 × 100 | 1.08 × 103 | 2.23 × 10−13 | 1.32 × 103 | 0.00 × 100 | 7.54 × 10−1 | ||
| p-value | – | NaN = | 1.21 × 10−12 + | NaN = | 1.70 × 10−8 + | 1.37 × 10−3 + | 1.69 × 10−14 − | 6.54 × 10−4 + | 1.79 × 10−7 + | 1.52 × 10−4 + | 1.69 × 10−14 − | 1.94 × 10−9 + | ||
| F23 | Mean | 3.61 × 102 | 3.70 × 102 | 3.99 × 102 | 3.58 × 102 | 3.89 × 102 | 3.80 × 102 | 3.75 × 102 | 3.94 × 102 | 3.79 × 102 | 3.77 × 102 | 3.71 × 102 | 3.87 × 102 | |
| Std | 7.76 × 100 | 6.12 × 100 | 1.42 × 101 | 7.48 × 100 | 9.36 × 100 | 1.04 × 101 | 5.81 × 100 | 7.26 × 100 | 5.09 × 100 | 1.06 × 101 | 5.20 × 100 | 1.39 × 101 | ||
| p-value | – | 7.20 × 10−5 + | 4.08 × 10−11 + | 7.48 × 10−2 = | 4.50 × 10−11 + | 2.60 × 10−8 + | 2.83 × 10−8 + | 3.34 × 10−11 + | 2.37 × 10−10 + | 6.01 × 10−8 + | 1.17 × 10−5 + | 1.46 × 10−10 + | ||
| F24 | Mean | 4.33 × 102 | 4.38 × 102 | 5.50 × 102 | 4.28 × 102 | 4.53 × 102 | 4.53 × 102 | 4.42 × 102 | 4.62 × 102 | 4.45 × 102 | 4.53 × 102 | 4.39 × 102 | 4.57 × 102 | |
| Std | 4.06 × 100 | 3.62 × 100 | 3.53 × 101 | 4.21 × 100 | 9.65 × 100 | 9.26 × 100 | 4.56 × 100 | 6.85 × 100 | 5.69 × 100 | 1.55 × 101 | 3.05 × 100 | 1.22 × 101 | ||
| p-value | – | 8.29 × 10−6 + | 3.02 × 10−11 + | 4.35 × 10−5 − | 1.61 × 10−10 + | 1.21 × 10−10 + | 2.39 × 10−8 + | 3.02 × 10−11 + | 1.86 × 10−9 + | 1.17 × 10−9 + | 1.03 × 10−6 + | 6.70 × 10−11 + | ||
| F25 | Mean | 3.87 × 102 | 3.87 × 102 | 3.87 × 102 | 3.87 × 102 | 3.87 × 102 | 3.88 × 102 | 3.87 × 102 | 3.87 × 102 | 3.87 × 102 | 3.87 × 102 | 3.87 × 102 | 3.88 × 102 | |
| Std | 1.09 × 10−1 | 7.64 × 10−1 | 5.24 × 10−1 | 3.59 × 10−2 | 5.88 × 10−2 | 9.47 × 10−1 | 2.70 × 10−1 | 7.33 × 10−2 | 2.02 × 100 | 1.94 × 10−2 | 1.43 × 10−1 | 3.22 × 100 | ||
| p-value | – | 9.79 × 10−5 + | 2.01 × 10−8 + | 3.80 × 10−7 − | 8.83 × 10−7 − | 2.32 × 10−6 + | 7.66 × 10−5 + | 1.03 × 10−2 − | 5.87 × 10−4 + | 5.03 × 10−10 − | 2.05 × 10−3 + | 2.32 × 10−2 + | ||
| F26 | Mean | 1.05 × 103 | 1.14 × 103 | 1.50 × 103 | 9.89 × 102 | 1.49 × 103 | 1.20 × 103 | 1.21 × 103 | 1.49 × 103 | 1.03 × 103 | 1.26 × 103 | 1.16 × 103 | 1.23 × 103 | |
| Std | 7.94 × 101 | 8.30 × 101 | 1.11 × 102 | 6.85 × 101 | 1.18 × 102 | 2.68 × 102 | 7.11 × 101 | 1.01 × 102 | 4.93 × 102 | 1.11 × 102 | 5.22 × 101 | 5.24 × 102 | ||
| p-value | – | 5.61 × 10−5 + | 3.02 × 10−11 + | 3.50 × 10−3 − | 3.02 × 10−11 + | 5.60 × 10−7 + | 1.43 × 10−8 + | 3.34 × 10−11 + | 1.03 × 10−2 − | 2.23 × 10−9 + | 7.60 × 10−7 + | 7.64 × 10−5 + | ||
| F27 | Mean | 5.01 × 102 | 5.02 × 102 | 5.10 × 102 | 5.12 × 102 | 5.00 × 102 | 4.99 × 102 | 5.05 × 102 | 5.00 × 102 | 5.12 × 102 | 4.99 × 102 | 5.02 × 102 | 5.21 × 102 | |
| Std | 4.37 × 100 | 6.42 × 100 | 7.28 × 100 | 9.01 × 100 | 7.49 × 10−5 | 9.79 × 100 | 8.40 × 100 | 5.76 × 100 | 5.42 × 100 | 8.86 × 100 | 6.03 × 100 | 1.35 × 101 | ||
| p-value | – | 9.12 × 10−1 = | 2.00 × 10−6 + | 1.73 × 10−7 + | 7.73 × 10−2 = | 3.11 × 10−1 = | 7.24 × 10−2 = | 3.79 × 10−1 = | 1.41 × 10−9 + | 4.20 × 10−1 = | 8.42 × 10−1 = | 1.01 × 10−8 + | ||
| F28 | Mean | 3.26 × 102 | 3.38 × 102 | 4.96 × 102 | 3.58 × 102 | 4.99 × 102 | 3.42 × 102 | 3.40 × 102 | 3.26 × 102 | 3.21 × 102 | 3.34 × 102 | 3.26 × 102 | 3.21 × 102 | |
| Std | 5.36 × 101 | 5.55 × 101 | 2.07 × 102 | 5.53 × 101 | 1.87 × 100 | 5.59 × 101 | 5.97 × 101 | 5.11 × 101 | 4.41 × 101 | 5.94 × 101 | 4.71 × 101 | 4.28 × 101 | ||
| p-value | – | 3.22 × 10−1 = | 4.62 × 10−5 + | 2.08 × 10−2 + | 6.44 × 10−12 + | 8.09 × 10−1 = | 5.89 × 10−3 + | 4.01 × 10−5 + | 1.11 × 10−5 − | 2.45 × 10−4 + | 4.00 × 10−5 − | 5.28 × 10−6 − | ||
| F29 | Mean | 4.69 × 102 | 4.75 × 102 | 5.31 × 102 | 4.56 × 102 | 4.67 × 102 | 4.46 × 102 | 5.02 × 102 | 5.85 × 102 | 4.90 × 102 | 4.91 × 102 | 4.84 × 102 | 5.25 × 102 | |
| Std | 2.66 × 101 | 2.81 × 101 | 9.33 × 101 | 2.31 × 101 | 1.19 × 102 | 5.80 × 101 | 2.96 × 101 | 7.03 × 101 | 2.47 × 101 | 7.62 × 101 | 1.63 × 101 | 7.48 × 101 | ||
| p-value | – | 3.26 × 10−1 = | 4.64 × 10−3 + | 4.36 × 10−2 − | 1.86 × 10−1 = | 1.38 × 10−2 − | 5.27 × 10−5 + | 4.62 × 10−10 + | 1.30 × 10−3 + | 4.83 × 10−1 = | 9.07 × 10−3 + | 4.43 × 10−3 + | ||
| F30 | Mean | 2.01 × 103 | 2.12 × 103 | 3.87 × 103 | 2.14 × 103 | 7.08 × 102 | 2.03 × 103 | 2.11 × 103 | 1.99 × 103 | 2.23 × 103 | 2.06 × 103 | 2.09 × 103 | 2.09 × 103 | |
| Std | 6.81 × 101 | 1.77 × 102 | 2.10 × 103 | 1.12 × 102 | 6.99 × 102 | 8.80 × 101 | 1.08 × 102 | 5.02 × 101 | 1.28 × 102 | 7.74 × 101 | 1.06 × 102 | 1.71 × 102 | ||
| p-value | – | 1.06 × 10−3 + | 2.15 × 10−10 + | 1.61 × 10−6 + | 2.83 × 10−8 − | 4.38 × 10−1 = | 2.53 × 10−4 + | 1.58 × 10−1 = | 7.77 × 10−9 + | 6.67 × 10−3 + | 2.62 × 10−3 + | 4.06 × 10−2 + | ||
| F21–30 | w/t/l | – | 6/4/0 | 10/0/0 | 4/2/4 | 6/2/2 | 6/3/1 | 8/1/1 | 7/2/1 | 8/0/2 | 7/2/1 | 7/1/2 | 9/0/1 | |
| w/t/l | – | 20/7/2 | 28/1/0 | 10/10/9 | 15/8/6 | 18/7/4 | 23/2/4 | 20/6/3 | 25/0/4 | 19/5/5 | 18/6/5 | 23/3/3 | ||
| Rank | 3.28 | 5.28 | 11.55 | 3.72 | 6.38 | 6.72 | 6.83 | 7.31 | 8.00 | 5.98 | 4.84 | 8.10 | ||
| F | Category | Quality | DEGGDE | SHADE | GPDE | DiDE | SEDE | FADE | FDDE | TPDE | NSHADE | CUSDE | PFIDE | EJADE |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| F1 | Unimodal Functions | Mean | 1.40 × 10−14 | 1.63 × 10−14 | 7.14 × 103 | 1.07 × 10−14 | 1.82 × 10−5 | 5.38 × 103 | 2.79 × 10−14 | 2.62 × 100 | 3.18 × 10−3 | 1.91 × 100 | 2.08 × 10−14 | 1.26 × 10−12 |
| Std | 6.42 × 10−30 | 5.31 × 10−15 | 8.07 × 103 | 6.02 × 10−15 | 5.18 × 10−5 | 5.97 × 103 | 1.26 × 10−14 | 1.43 × 101 | 1.17 × 10−2 | 4.05 × 100 | 7.21 × 10−15 | 3.73 × 10−12 | ||
| p-value | – | 2.14 × 10−2 + | 1.21 × 10−12 + | 5.47 × 10−3 − | 1.21 × 10−12 + | 1.21 × 10−12 + | 4.98 × 10−13 + | 1.21 × 10−12 + | 1.21 × 10−12 + | 1.21 × 10−12 + | 4.63 × 10−13 + | 1.16 × 10−12 + | ||
| F3 | Mean | 8.74 × 10−10 | 1.22 × 10−13 | 1.76 × 105 | 5.04 × 10−13 | 2.39 × 10−8 | 1.14 × 10−6 | 4.09 × 103 | 6.61 × 101 | 2.49 × 104 | 6.07 × 102 | 1.33 × 10−13 | 3.20 × 10−1 | |
| Std | 1.68 × 10−9 | 3.87 × 10−14 | 2.26 × 104 | 2.02 × 10−12 | 3.70 × 10−8 | 1.78 × 10−6 | 1.63 × 104 | 5.67 × 101 | 6.48 × 104 | 4.38 × 102 | 3.76 × 10−14 | 1.73 × 100 | ||
| p-value | – | 9.34 × 10−12 − | 3.02 × 10−11 + | 1.77 × 10−11 − | 1.56 × 10−8 + | 3.02 × 10−11 + | 1.01 × 10−7 + | 3.02 × 10−11 + | 3.02 × 10−11 + | 3.02 × 10−11 + | 1.60 × 10−11 − | 2.61 × 10−2 + | ||
| F1–3 | w/t/l | – | 1/0/1 | 2/0/0 | 0/0/2 | 2/0/0 | 2/0/0 | 2/0/0 | 2/0/0 | 2/0/0 | 2/0/0 | 1/0/1 | 2/0/0 | |
| F4 | Simple Multimodal Functions | Mean | 4.77 × 101 | 4.98 × 101 | 1.05 × 102 | 8.05 × 101 | 4.84 × 101 | 7.32 × 101 | 6.31 × 101 | 6.13 × 101 | 5.69 × 101 | 5.48 × 101 | 4.48 × 101 | 3.36 × 101 |
| Std | 3.33 × 101 | 3.82 × 101 | 5.88 × 101 | 4.88 × 101 | 3.45 × 101 | 4.07 × 101 | 4.41 × 101 | 4.81 × 101 | 4.83 × 101 | 4.28 × 101 | 3.56 × 101 | 4.59 × 101 | ||
| p-value | – | 6.32 × 10−1 = | 8.50 × 10−5 + | 3.84 × 10−3 + | 9.55 × 10−2 = | 4.00 × 10−3 + | 8.62 × 10−1 = | 1.82 × 10−1 = | 1.74 × 10−1 = | 2.55 × 10−1 = | 1.53 × 10−2 − | 1.01 × 10−3 − | ||
| F5 | Mean | 2.34 × 101 | 5.39 × 101 | 1.43 × 102 | 4.35 × 101 | 6.82 × 101 | 6.72 × 101 | 6.00 × 101 | 8.63 × 101 | 7.56 × 101 | 3.84 × 101 | 4.96 × 101 | 9.84 × 101 | |
| Std | 5.66 × 100 | 5.10 × 100 | 9.61 × 101 | 2.77 × 101 | 1.39 × 101 | 1.53 × 101 | 6.66 × 100 | 1.02 × 101 | 8.67 × 100 | 6.54 × 100 | 7.77 × 100 | 1.95 × 101 | ||
| p-value | – | 3.01 × 10−11 + | 3.68 × 10−11 + | 5.18 × 10−7 + | 3.33 × 10−11 + | 3.01 × 10−11 + | 3.01 × 10−11 + | 3.01 × 10−11 + | 3.01 × 10−11 + | 9.68 × 10−10 + | 3.01 × 10−11 + | 3.00 × 10−11 + | ||
| F6 | Mean | 3.12 × 10−6 | 1.32 × 10−7 | 9.72 × 10−3 | 8.20 × 10−4 | 3.20 × 10−9 | 8.85 × 10−1 | 6.07 × 10−8 | 1.66 × 10−7 | 1.07 × 10−5 | 4.03 × 10−6 | 3.58 × 10−6 | 2.34 × 100 | |
| Std | 3.58 × 10−6 | 3.47 × 10−7 | 1.41 × 10−2 | 3.11 × 10−3 | 1.22 × 10−8 | 9.02 × 10−1 | 1.63 × 10−7 | 3.30 × 10−7 | 1.20 × 10−5 | 6.98 × 10−6 | 4.97 × 10−6 | 1.36 × 100 | ||
| p-value | – | 2.33 × 10−9 − | 3.01 × 10−11 + | 2.03 × 10−4 + | 2.62 × 10−12 − | 3.01 × 10−11 + | 9.78 × 10−11 − | 9.25 × 10−9 − | 2.05 × 10−3 + | 5.39 × 10−1 = | 4.55 × 10−1 = | 3.01 × 10−11 + | ||
| F7 | Mean | 7.95 × 101 | 1.09 × 102 | 2.57 × 102 | 8.70 × 101 | 1.19 × 102 | 1.38 × 102 | 1.11 × 102 | 1.33 × 102 | 1.29 × 102 | 9.43 × 101 | 1.01 × 102 | 1.48 × 102 | |
| Std | 1.22 × 101 | 4.85 × 100 | 8.76 × 101 | 1.74 × 101 | 1.54 × 101 | 1.53 × 101 | 7.12 × 100 | 1.11 × 101 | 1.08 × 101 | 3.55 × 101 | 4.99 × 100 | 2.48 × 101 | ||
| p-value | – | 8.15 × 10−11 + | 3.02 × 10−11 + | 5.55 × 10−2 = | 1.78 × 10−10 + | 3.02 × 10−11 + | 7.39 × 10−11 + | 4.50 × 10−11 + | 3.02 × 10−11 + | 4.03 × 10−3 + | 1.31 × 10−8 + | 4.50 × 10−11 + | ||
| F8 | Mean | 2.31 × 101 | 5.52 × 101 | 1.17 × 102 | 3.92 × 101 | 7.10 × 101 | 6.65 × 101 | 6.02 × 101 | 8.70 × 101 | 8.30 × 101 | 4.06 × 101 | 5.29 × 101 | 9.52 × 101 | |
| Std | 7.51 × 100 | 5.06 × 100 | 8.89 × 101 | 2.50 × 101 | 1.58 × 101 | 1.53 × 101 | 7.72 × 100 | 1.46 × 101 | 6.17 × 100 | 8.14 × 100 | 7.31 × 100 | 1.71 × 101 | ||
| p-value | – | 3.01 × 10−11 + | 4.06 × 10−11 + | 4.73 × 10−6 + | 3.32 × 10−11 + | 3.01 × 10−11 + | 3.32 × 10−11 + | 3.01 × 10−11 + | 3.01 × 10−11 + | 2.41 × 10−9 + | 4.95 × 10−11 + | 3.00 × 10−11 + | ||
| F9 | Mean | 9.88 × 10−14 | 4.20 × 10−2 | 2.96 × 100 | 3.80 × 10−15 | 1.19 × 100 | 1.98 × 101 | 4.19 × 10−1 | 2.71 × 10−2 | 1.70 × 101 | 5.97 × 10−3 | 2.63 × 10−1 | 1.12 × 102 | |
| Std | 3.94 × 10−14 | 8.82 × 10−2 | 9.17 × 100 | 2.08 × 10−14 | 1.27 × 100 | 2.45 × 101 | 4.98 × 10−1 | 1.01 × 10−1 | 3.31 × 101 | 2.27 × 10−2 | 2.62 × 10−1 | 8.79 × 101 | ||
| p-value | – | 6.63 × 10−4 + | 3.93 × 10−12 + | 1.32 × 10−10 − | 1.84 × 10−7 + | 4.08 × 10−12 + | 8.61 × 10−4 + | 7.70 × 10−6 + | 4.08 × 10−12 + | 5.35 × 10−6 + | 1.87 × 10−4 + | 4.08 × 10−12 + | ||
| F10 | Mean | 6.51 × 103 | 5.28 × 103 | 1.02 × 104 | 5.21 × 103 | 1.11 × 104 | 4.95 × 103 | 5.22 × 103 | 4.67 × 103 | 3.82 × 103 | 5.52 × 103 | 5.00 × 103 | 4.22 × 103 | |
| Std | 7.20 × 102 | 3.27 × 102 | 1.96 × 103 | 7.44 × 102 | 3.17 × 102 | 1.67 × 103 | 3.89 × 102 | 4.11 × 102 | 2.91 × 102 | 3.49 × 103 | 4.03 × 102 | 1.01 × 103 | ||
| p-value | – | 6.01 × 10−8 − | 1.29 × 10−9 + | 1.47 × 10−7 − | 3.02 × 10−11 + | 9.21 × 10−5 − | 6.01 × 10−8 − | 2.61 × 10−10 − | 3.02 × 10−11 − | 1.32 × 10−4 − | 5.00 × 10−9 − | 8.10 × 10−10 − | ||
| F4–10 | w/t/l | – | 4/1/2 | 7/0/0 | 4/1/2 | 5/1/1 | 6/0/1 | 4/1/2 | 4/1/2 | 5/1/1 | 4/2/1 | 4/1/2 | 5/0/2 | |
| F11 | Hybrid Functions | Mean | 4.46 × 101 | 7.65 × 101 | 9.30 × 101 | 8.14 × 101 | 5.43 × 101 | 5.18 × 101 | 1.18 × 102 | 4.94 × 101 | 1.30 × 102 | 3.77 × 101 | 9.93 × 101 | 1.46 × 102 |
| Std | 6.47 × 100 | 1.51 × 101 | 2.93 × 101 | 1.52 × 101 | 1.32 × 101 | 1.28 × 101 | 2.63 × 101 | 4.93 × 100 | 3.33 × 101 | 4.86 × 100 | 2.26 × 101 | 4.40 × 101 | ||
| p-value | – | 3.81 × 10−10 + | 1.20 × 10−8 + | 6.68 × 10−11 + | 2.75 × 10−3 + | 3.78 × 10−2 + | 3.01 × 10−11 + | 7.29 × 10−3 + | 3.01 × 10−11 + | 2.75 × 10−5 − | 3.01 × 10−11 + | 3.01 × 10−11 + | ||
| F12 | Mean | 2.71 × 103 | 4.77 × 103 | 8.21 × 105 | 2.15 × 103 | 4.81 × 104 | 4.50 × 104 | 5.93 × 103 | 2.40 × 104 | 4.82 × 104 | 4.33 × 104 | 5.38 × 103 | 1.19 × 104 | |
| Std | 1.43 × 103 | 2.42 × 103 | 5.48 × 105 | 5.98 × 102 | 3.08 × 104 | 2.25 × 104 | 6.25 × 103 | 1.54 × 104 | 3.28 × 104 | 2.23 × 104 | 3.14 × 103 | 1.10 × 104 | ||
| p-value | – | 5.09 × 10−6 + | 3.02 × 10−11 + | 9.05 × 10−2 = | 3.02 × 10−11 + | 3.69 × 10−11 + | 3.83 × 10−5 + | 8.15 × 10−11 + | 5.49 × 10−11 + | 3.02 × 10−11 + | 2.43 × 10−5 + | 4.20 × 10−10 + | ||
| F13 | Mean | 1.81 × 102 | 1.34 × 102 | 1.83 × 104 | 1.08 × 102 | 7.47 × 102 | 3.08 × 103 | 1.81 × 102 | 9.64 × 103 | 9.90 × 102 | 6.50 × 103 | 2.11 × 102 | 1.54 × 102 | |
| Std | 5.23 × 101 | 1.38 × 102 | 1.50 × 104 | 5.60 × 101 | 8.43 × 102 | 6.56 × 103 | 1.39 × 102 | 1.02 × 104 | 1.00 × 103 | 8.10 × 103 | 1.98 × 102 | 7.44 × 101 | ||
| p-value | – | 5.61 × 10−5 − | 6.70 × 10−11 + | 1.25 × 10−5 − | 3.18 × 10−4 + | 1.95 × 10−3 + | 9.63 × 10−2 = | 3.02 × 10−11 + | 9.92 × 10−11 + | 8.20 × 10−7 + | 1.37 × 10−1 = | 5.55 × 10−2 = | ||
| F14 | Mean | 4.16 × 101 | 1.39 × 102 | 1.36 × 104 | 4.78 × 101 | 4.26 × 101 | 4.69 × 101 | 2.00 × 102 | 5.91 × 101 | 1.51 × 102 | 3.49 × 101 | 1.58 × 102 | 1.35 × 102 | |
| Std | 7.91 × 100 | 4.62 × 101 | 2.18 × 104 | 1.34 × 101 | 6.56 × 100 | 1.00 × 101 | 4.91 × 101 | 1.19 × 101 | 4.11 × 101 | 9.81 × 100 | 4.65 × 101 | 8.11 × 101 | ||
| p-value | – | 3.34 × 10−11 + | 3.02 × 10−11 + | 1.09 × 10−1 = | 5.20 × 10−1 = | 4.21 × 10−2 + | 3.02 × 10−11 + | 3.65 × 10−8 + | 4.08 × 10−11 + | 4.22 × 10−4 − | 3.02 × 10−11 + | 2.61 × 10−10 + | ||
| F15 | Mean | 4.48 × 101 | 1.25 × 102 | 6.91 × 103 | 6.63 × 101 | 5.29 × 101 | 5.30 × 101 | 2.40 × 102 | 3.96 × 103 | 2.14 × 102 | 2.97 × 101 | 1.65 × 102 | 1.67 × 102 | |
| Std | 1.22 × 101 | 6.85 × 101 | 8.75 × 103 | 2.47 × 101 | 4.54 × 101 | 2.77 × 101 | 1.19 × 102 | 7.98 × 103 | 8.67 × 101 | 1.45 × 101 | 8.32 × 101 | 1.20 × 102 | ||
| p-value | – | 3.20 × 10−9 + | 3.02 × 10−11 + | 8.66 × 10−5 + | 7.51 × 10−1 = | 8.07 × 10−1 = | 1.33 × 10−10 + | 8.15 × 10−5 + | 3.02 × 10−11 + | 2.83 × 10−8 − | 8.99 × 10−11 + | 1.69 × 10−9 + | ||
| F16 | Mean | 4.26 × 102 | 7.62 × 102 | 1.59 × 103 | 9.06 × 102 | 1.21 × 103 | 1.02 × 103 | 7.78 × 102 | 9.26 × 102 | 7.25 × 102 | 7.21 × 102 | 7.78 × 102 | 7.39 × 102 | |
| Std | 1.98 × 102 | 1.55 × 102 | 4.83 × 102 | 1.83 × 102 | 3.09 × 102 | 3.14 × 102 | 1.53 × 102 | 2.52 × 102 | 1.53 × 102 | 5.23 × 102 | 1.42 × 102 | 2.51 × 102 | ||
| p-value | – | 4.69 × 10−8 + | 5.49 × 10−11 + | 1.29 × 10−9 + | 1.78 × 10−10 + | 2.67 × 10−9 + | 1.56 × 10−8 + | 1.31 × 10−8 + | 1.60 × 10−7 + | 1.84 × 10−2 + | 1.70 × 10−8 + | 1.53 × 10−5 + | ||
| F17 | Hybrid Functions | Mean | 2.39 × 102 | 5.00 × 102 | 7.09 × 102 | 6.10 × 102 | 7.01 × 102 | 6.77 × 102 | 6.30 × 102 | 6.36 × 102 | 5.90 × 102 | 6.69 × 102 | 4.62 × 102 | 6.74 × 102 |
| Std | 1.58 × 102 | 1.00 × 102 | 2.34 × 102 | 1.83 × 102 | 2.66 × 102 | 2.48 × 102 | 1.22 × 102 | 1.67 × 102 | 1.43 × 102 | 3.95 × 102 | 1.10 × 102 | 1.83 × 102 | ||
| p-value | – | 5.09 × 10−8 + | 2.67 × 10−9 + | 6.52 × 10−9 + | 1.20 × 10−8 + | 3.82 × 10−9 + | 2.03 × 10−9 + | 5.00 × 10−9 + | 6.52 × 10−9 + | 4.35 × 10−5 + | 3.01 × 10−7 + | 8.10 × 10−10 + | ||
| F18 | Mean | 1.12 × 102 | 1.02 × 102 | 2.36 × 106 | 7.85 × 101 | 7.05 × 102 | 1.47 × 102 | 1.91 × 102 | 1.29 × 102 | 3.63 × 102 | 2.31 × 103 | 1.15 × 102 | 3.45 × 102 | |
| Std | 5.32 × 101 | 6.61 × 101 | 1.42 × 106 | 3.95 × 101 | 7.80 × 102 | 1.10 × 102 | 1.22 × 102 | 4.42 × 101 | 4.12 × 102 | 2.65 × 103 | 7.84 × 101 | 4.16 × 102 | ||
| p-value | – | 2.97 × 10−1 = | 3.02 × 10−11 + | 1.63 × 10−2 − | 5.97 × 10−9 + | 2.46 × 10−1 = | 1.77 × 10−3 + | 1.54 × 10−1 = | 4.08 × 10−5 + | 1.78 × 10−10 + | 7.06 × 10−1 = | 7.66 × 10−5 + | ||
| F19 | Mean | 3.11 × 101 | 9.70 × 101 | 5.73 × 103 | 6.78 × 101 | 1.79 × 101 | 2.18 × 101 | 1.21 × 102 | 2.53 × 102 | 6.51 × 101 | 1.38 × 101 | 1.11 × 102 | 1.00 × 102 | |
| Std | 8.92 × 100 | 3.58 × 101 | 1.16 × 104 | 2.16 × 101 | 1.03 × 101 | 4.86 × 100 | 3.74 × 101 | 5.99 × 102 | 1.81 × 101 | 3.87 × 100 | 4.39 × 101 | 5.85 × 101 | ||
| p-value | – | 9.92 × 10−11 + | 3.02 × 10−11 + | 1.85 × 10−8 + | 4.11 × 10−7 − | 3.37 × 10−5 − | 3.34 × 10−11 + | 3.48 × 10−1 = | 1.17 × 10−9 + | 2.37 × 10−10 − | 3.02 × 10−11 + | 1.25 × 10−7 + | ||
| F20 | Mean | 1.47 × 102 | 3.51 × 102 | 7.14 × 102 | 5.52 × 102 | 5.57 × 102 | 5.01 × 102 | 4.63 × 102 | 5.87 × 102 | 4.07 × 102 | 7.01 × 102 | 3.41 × 102 | 3.44 × 102 | |
| Std | 1.03 × 102 | 9.30 × 101 | 2.16 × 102 | 1.84 × 102 | 2.58 × 102 | 2.05 × 102 | 1.43 × 102 | 1.24 × 102 | 1.13 × 102 | 3.89 × 102 | 9.93 × 101 | 1.89 × 102 | ||
| p-value | – | 2.60 × 10−8 + | 5.49 × 10−11 + | 8.10 × 10−10 + | 1.56 × 10−8 + | 6.52 × 10−9 + | 1.17 × 10−9 + | 4.50 × 10−11 + | 3.82 × 10−9 + | 1.31 × 10−8 + | 9.83 × 10−8 + | 4.08 × 10−5 + | ||
| F11–20 | w/t/l | – | 8/1/1 | 10/0/0 | 6/2/2 | 7/2/1 | 7/2/1 | 9/1/0 | 8/2/0 | 10/0/0 | 6/0/4 | 8/2/0 | 9/1/0 | |
| F21 | Composition Functions | Mean | 2.24 × 102 | 2.55 × 102 | 3.92 × 102 | 2.48 × 102 | 2.70 × 102 | 2.69 × 102 | 2.58 × 102 | 2.93 × 102 | 2.75 × 102 | 2.41 × 102 | 2.50 × 102 | 2.89 × 102 |
| Std | 6.22 × 100 | 6.13 × 100 | 9.85 × 101 | 3.46 × 101 | 1.87 × 101 | 1.68 × 101 | 8.43 × 100 | 1.16 × 101 | 8.62 × 100 | 1.02 × 101 | 5.60 × 100 | 1.58 × 101 | ||
| p-value | – | 3.69 × 10−11 + | 3.02 × 10−11 + | 8.88 × 10−6 + | 3.02 × 10−11 + | 3.02 × 10−11 + | 3.02 × 10−11 + | 3.02 × 10−11 + | 3.02 × 10−11 + | 1.43 × 10−8 + | 4.50 × 10−11 + | 3.02 × 10−11 + | ||
| F22 | Mean | 6.01 × 103 | 4.57 × 103 | 1.26 × 104 | 3.20 × 102 | 1.17 × 104 | 5.35 × 103 | 4.53 × 103 | 5.13 × 103 | 7.71 × 102 | 6.34 × 103 | 4.65 × 103 | 3.36 × 103 | |
| Std | 2.10 × 103 | 2.14 × 103 | 4.21 × 102 | 1.21 × 103 | 3.67 × 102 | 2.13 × 103 | 1.97 × 103 | 3.56 × 102 | 1.55 × 103 | 3.89 × 103 | 1.96 × 103 | 1.97 × 103 | ||
| p-value | – | 1.43 × 10−5 − | 3.02 × 10−11 + | 1.81 × 10−8 − | 3.02 × 10−11 + | 1.33 × 10−2 − | 1.73 × 10−6 − | 4.44 × 10−7 − | 1.07 × 10−7 − | 1.09 × 10−1 = | 2.88 × 10−6 − | 7.63 × 10−8 − | ||
| F23 | Mean | 4.48 × 102 | 4.78 × 102 | 5.55 × 102 | 4.79 × 102 | 4.95 × 102 | 4.99 × 102 | 4.84 × 102 | 5.20 × 102 | 5.02 × 102 | 4.60 × 102 | 4.75 × 102 | 5.31 × 102 | |
| Std | 8.48 × 100 | 9.83 × 100 | 7.25 × 101 | 3.75 × 101 | 1.81 × 101 | 2.18 × 101 | 8.54 × 100 | 1.53 × 101 | 1.38 × 101 | 1.45 × 101 | 1.02 × 101 | 2.67 × 101 | ||
| p-value | – | 4.08 × 10−11 + | 3.02 × 10−11 + | 6.77 × 10−5 + | 3.69 × 10−11 + | 3.69 × 10−11 + | 3.02 × 10−11 + | 3.02 × 10−11 + | 3.02 × 10−11 + | 4.46 × 10−4 + | 3.69 × 10−11 + | 3.02 × 10−11 + | ||
| F24 | Mean | 5.18 × 102 | 5.47 × 102 | 8.44 × 102 | 5.35 × 102 | 5.59 × 102 | 5.75 × 102 | 5.48 × 102 | 5.83 × 102 | 5.65 × 102 | 5.47 × 102 | 5.44 × 102 | 5.85 × 102 | |
| Std | 6.23 × 100 | 6.57 × 100 | 1.57 × 101 | 3.27 × 101 | 1.36 × 101 | 1.70 × 101 | 8.36 × 100 | 8.74 × 100 | 1.20 × 101 | 1.46 × 101 | 7.53 × 100 | 1.84 × 101 | ||
| p-value | – | 3.02 × 10−11 + | 3.02 × 10−11 + | 5.69 × 10−1 = | 3.02 × 10−11 + | 3.02 × 10−11 + | 3.34 × 10−11 + | 3.02 × 10−11 + | 3.02 × 10−11 + | 1.61 × 10−10 + | 6.07 × 10−11 + | 3.02 × 10−11 + | ||
| F25 | Mean | 5.07 × 102 | 5.33 × 102 | 4.99 × 102 | 4.90 × 102 | 5.22 × 102 | 5.28 × 102 | 5.24 × 102 | 4.91 × 102 | 5.41 × 102 | 4.90 × 102 | 5.44 × 102 | 5.36 × 102 | |
| Std | 3.69 × 101 | 3.28 × 101 | 3.53 × 101 | 2.24 × 101 | 3.66 × 101 | 3.42 × 101 | 3.51 × 101 | 2.86 × 101 | 4.46 × 101 | 2.50 × 101 | 3.24 × 101 | 4.52 × 101 | ||
| p-value | – | 4.33 × 10−4 + | 4.06 × 10−2 − | 9.06 × 10−1 = | 2.84 × 10−1 = | 6.97 × 10−3 + | 2.07 × 10−2 + | 7.01 × 10−2 = | 7.62 × 10−3 + | 5.69 × 10−1 = | 4.35 × 10−5 + | 6.10 × 10−3 + | ||
| F26 | Mean | 1.24 × 103 | 1.59 × 103 | 2.01 × 103 | 1.40 × 103 | 1.96 × 103 | 1.93 × 103 | 1.64 × 103 | 2.11 × 103 | 2.32 × 103 | 1.47 × 103 | 1.54 × 103 | 2.81 × 103 | |
| Std | 8.99 × 101 | 8.59 × 101 | 3.21 × 102 | 3.02 × 102 | 2.06 × 102 | 2.02 × 102 | 1.05 × 102 | 1.45 × 102 | 2.40 × 102 | 7.58 × 101 | 8.94 × 101 | 7.55 × 102 | ||
| p-value | – | 3.34 × 10−11 + | 3.02 × 10−11 + | 1.22 × 10−1 = | 3.02 × 10−11 + | 3.02 × 10−11 + | 3.02 × 10−11 + | 3.02 × 10−11 + | 3.02 × 10−11 + | 3.82 × 10−10 + | 6.70 × 10−11 + | 5.57 × 10−10 + | ||
| F27 | Mean | 5.26 × 102 | 5.40 × 102 | 6.36 × 102 | 5.56 × 102 | 5.00 × 102 | 5.21 × 102 | 5.68 × 102 | 5.48 × 102 | 6.53 × 102 | 5.25 × 102 | 5.60 × 102 | 6.32 × 102 | |
| Std | 1.12 × 101 | 1.59 × 101 | 7.26 × 101 | 2.90 × 101 | 9.63 × 10−5 | 2.15 × 101 | 4.22 × 101 | 3.53 × 101 | 3.18 × 101 | 2.10 × 101 | 3.54 × 101 | 8.37 × 101 | ||
| p-value | – | 3.59 × 10−5 + | 6.07 × 10−11 + | 1.36 × 10−7 + | 3.02 × 10−11 − | 3.26 × 10−1 = | 3.96 × 10−8 + | 3.03 × 10−3 + | 3.02 × 10−11 + | 3.95 × 10−1 = | 2.02 × 10−8 + | 2.23 × 10−9 + | ||
| F28 | Mean | 4.98 × 102 | 4.92 × 102 | 9.77 × 102 | 4.98 × 102 | 5.00 × 102 | 4.86 × 102 | 5.01 × 102 | 4.63 × 102 | 4.97 × 102 | 5.06 × 102 | 4.97 × 102 | 4.91 × 102 | |
| Std | 1.98 × 101 | 2.14 × 101 | 1.02 × 103 | 1.99 × 101 | 9.72 × 10−5 | 2.84 × 101 | 1.50 × 101 | 1.41 × 101 | 1.82 × 101 | 2.51 × 102 | 1.78 × 101 | 2.62 × 101 | ||
| p-value | – | 7.32 × 10−1 = | 8.59 × 10−5 + | 2.45 × 10−1 = | 3.30 × 10−4 + | 7.52 × 10−1 = | 3.56 × 10−4 + | 1.72 × 10−9 − | 4.40 × 10−1 = | 4.51 × 10−4 + | 3.56 × 10−2 − | 9.72 × 10−2 = | ||
| F29 | Mean | 3.48 × 102 | 4.87 × 102 | 6.40 × 102 | 5.41 × 102 | 7.18 × 102 | 4.42 × 102 | 4.96 × 102 | 8.06 × 102 | 5.64 × 102 | 3.97 × 102 | 4.66 × 102 | 9.76 × 102 | |
| Std | 2.22 × 101 | 5.20 × 101 | 2.37 × 102 | 8.17 × 101 | 2.07 × 102 | 9.57 × 101 | 7.86 × 101 | 2.24 × 102 | 7.97 × 101 | 1.32 × 102 | 6.00 × 101 | 2.78 × 102 | ||
| p-value | – | 3.02 × 10−11 + | 5.57 × 10−10 + | 8.15 × 10−11 + | 1.17 × 10−9 + | 9.51 × 10−6 + | 3.34 × 10−11 + | 3.02 × 10−11 + | 3.02 × 10−11 + | 2.17 × 10−1 = | 3.69 × 10−11 + | 3.02 × 10−11 + | ||
| F30 | Mean | 6.19 × 105 | 6.24 × 105 | 9.44 × 105 | 6.48 × 105 | 2.33 × 103 | 6.19 × 105 | 6.51 × 105 | 5.95 × 105 | 7.35 × 105 | 5.99 × 105 | 6.41 × 105 | 6.90 × 105 | |
| Std | 4.59 × 104 | 4.11 × 104 | 6.07 × 105 | 7.13 × 104 | 2.51 × 103 | 3.65 × 104 | 7.44 × 104 | 2.29 × 104 | 8.98 × 104 | 2.45 × 104 | 6.08 × 104 | 7.35 × 104 | ||
| p-value | – | 6.20 × 10−1 = | 2.38 × 10−3 + | 2.81 × 10−2 + | 3.02 × 10−11 − | 8.30 × 10−1 = | 1.05 × 10−1 = | 3.04 × 10−1 = | 3.01 × 10−7 + | 7.91 × 10−3 − | 1.76 × 10−1 = | 9.21 × 10−5 + | ||
| F21–30 | w/t/l | – | 7/2/1 | 9/0/1 | 5/4/1 | 7/1/2 | 6/3/1 | 8/1/1 | 6/2/2 | 8/1/1 | 5/4/1 | 7/1/2 | 8/1/1 | |
| w/t/l | – | 20/4/5 | 28/0/1 | 15/7/7 | 21/4/4 | 21/5/3 | 23/3/3 | 20/5/4 | 25/2/2 | 17/6/6 | 20/4/5 | 24/2/3 | ||
| Rank | 2.93 | 4.79 | 11.14 | 4.45 | 6.86 | 6.97 | 7.00 | 7.48 | 8.00 | 5.07 | 5.28 | 8.03 | ||
| F | Category | Quality | DEGGDE | SHADE | GPDE | DiDE | SEDE | FADE | FDDE | TPDE | NSHADE | CUSDE | PFIDE | EJADE |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| F1 | Unimodal Functions | Mean | 4.87 × 10−14 | 2.80 × 10−11 | 1.72 × 107 | 2.04 × 10−12 | 2.51 × 10−1 | 1.15 × 104 | 4.62 × 10−10 | 5.42 × 101 | 7.40 × 101 | 6.12 × 101 | 1.57 × 10−10 | 1.65 × 100 |
| Std | 5.27 × 10−14 | 6.94 × 10−11 | 9.42 × 107 | 1.69 × 10−12 | 5.67 × 10−1 | 1.44 × 104 | 1.00 × 10−9 | 1.42 × 102 | 1.08 × 102 | 2.06 × 102 | 2.97 × 10−10 | 2.74 × 100 | ||
| p-value | – | 1.87 × 10−7 + | 1.83 × 10−11 + | 2.49 × 10−11 + | 1.83 × 10−11 + | 1.83 × 10−11 + | 2.22 × 10−10 + | 1.83 × 10−11 + | 1.83 × 10−11 + | 1.83 × 10−11 + | 5.05 × 10−11 + | 1.83 × 10−11 + | ||
| F3 | Mean | 6.25 × 101 | 7.80 × 10−5 | 6.07 × 105 | 4.52 × 100 | 8.46 × 101 | 2.89 × 101 | 8.82 × 104 | 6.20 × 103 | 4.46 × 104 | 3.43 × 105 | 2.00 × 10−3 | 3.64 × 103 | |
| Std | 4.90 × 101 | 2.12 × 10−4 | 4.95 × 104 | 7.44 × 100 | 8.52 × 101 | 3.80 × 101 | 1.28 × 105 | 4.93 × 103 | 1.34 × 105 | 5.12 × 104 | 1.03 × 10−2 | 4.02 × 103 | ||
| p-value | – | 3.02 × 10−11 − | 3.02 × 10−11 + | 5.57 × 10−10 − | 6.73 × 10−1 = | 1.11 × 10−4 − | 2.71 × 10−2 + | 3.02 × 10−11 + | 4.50 × 10−11 + | 3.02 × 10−11 + | 3.02 × 10−11 − | 7.38 × 10−10 + | ||
| F1–3 | w/t/l | – | 1/0/1 | 2/0/0 | 1/0/1 | 1/1/0 | 1/0/1 | 2/0/0 | 2/0/0 | 2/0/0 | 2/0/0 | 1/0/1 | 2/0/0 | |
| F4 | Simple Multimodal Functions | Mean | 1.27 × 102 | 1.10 × 102 | 2.24 × 102 | 1.96 × 102 | 1.97 × 102 | 2.20 × 102 | 1.70 × 102 | 2.13 × 102 | 1.89 × 102 | 2.08 × 102 | 7.92 × 101 | 1.30 × 102 |
| Std | 7.43 × 101 | 6.39 × 101 | 1.98 × 101 | 1.88 × 101 | 2.79 × 101 | 4.68 × 101 | 3.86 × 101 | 6.87 × 100 | 5.65 × 101 | 3.14 × 101 | 6.51 × 101 | 6.49 × 101 | ||
| p-value | – | 1.49 × 10−1 = | 8.10 × 10−10 + | 1.53 × 10−5 + | 1.34 × 10−5 + | 2.15 × 10−6 + | 5.37 × 10−2 = | 1.69 × 10−8 + | 3.50 × 10−3 + | 1.46 × 10−6 + | 8.68 × 10−3 − | 8.88 × 10−1 = | ||
| F5 | Mean | 5.11 × 101 | 1.66 × 102 | 5.20 × 102 | 3.54 × 102 | 1.43 × 102 | 1.89 × 102 | 1.77 × 102 | 2.18 × 102 | 2.56 × 102 | 7.31 × 102 | 1.69 × 102 | 3.44 × 102 | |
| Std | 1.14 × 101 | 1.61 × 101 | 2.34 × 102 | 1.20 × 102 | 2.36 × 101 | 2.95 × 101 | 1.65 × 101 | 2.52 × 101 | 2.97 × 101 | 1.91 × 102 | 1.55 × 101 | 4.54 × 101 | ||
| p-value | – | 3.02 × 10−11 + | 3.02 × 10−11 + | 3.02 × 10−11 + | 3.02 × 10−11 + | 3.02 × 10−11 + | 3.02 × 10−11 + | 3.02 × 10−11 + | 3.02 × 10−11 + | 4.07 × 10−11 + | 3.02 × 10−11 + | 3.01 × 10−11 + | ||
| F6 | Mean | 1.41 × 10−3 | 3.95 × 10−3 | 6.92 × 10−2 | 5.89 × 10−3 | 7.10 × 10−8 | 5.85 × 100 | 3.73 × 10−3 | 4.43 × 10−6 | 4.38 × 10−4 | 1.21 × 10−3 | 3.86 × 10−2 | 1.53 × 101 | |
| Std | 1.08 × 10−3 | 4.55 × 10−3 | 5.47 × 10−2 | 6.17 × 10−3 | 1.60 × 10−7 | 1.90 × 100 | 5.82 × 10−3 | 3.94 × 10−6 | 1.21 × 10−3 | 2.36 × 10−3 | 3.82 × 10−2 | 4.19 × 100 | ||
| p-value | – | 1.44 × 10−2 + | 3.02 × 10−11 + | 1.03 × 10−2 + | 3.01 × 10−11 − | 3.02 × 10−11 + | 7.84 × 10−1 = | 3.02 × 10−11 − | 8.48 × 10−9 − | 4.71 × 10−4 − | 5.49 × 10−11 + | 3.02 × 10−11 + | ||
| F7 | Mean | 1.68 × 102 | 2.67 × 102 | 7.50 × 102 | 4.90 × 102 | 2.72 × 102 | 4.65 × 102 | 2.89 × 102 | 3.07 × 102 | 4.25 × 102 | 9.08 × 102 | 2.82 × 102 | 5.58 × 102 | |
| Std | 3.00 × 101 | 1.60 × 101 | 2.33 × 102 | 1.07 × 102 | 2.60 × 101 | 8.74 × 101 | 1.96 × 101 | 3.17 × 101 | 3.01 × 101 | 1.96 × 101 | 1.98 × 101 | 9.51 × 101 | ||
| p-value | – | 3.02 × 10−11 + | 3.02 × 10−11 + | 3.02 × 10−11 + | 3.02 × 10−11 + | 3.02 × 10−11 + | 3.02 × 10−11 + | 3.02 × 10−11 + | 3.02 × 10−11 + | 3.02 × 10−11 + | 3.02 × 10−11 + | 3.02 × 10−11 + | ||
| F8 | Mean | 4.89 × 101 | 1.55 × 102 | 4.13 × 102 | 3.77 × 102 | 1.50 × 102 | 1.88 × 102 | 1.68 × 102 | 2.17 × 102 | 2.46 × 102 | 7.89 × 102 | 1.58 × 102 | 3.62 × 102 | |
| Std | 1.16 × 101 | 1.35 × 101 | 2.65 × 102 | 9.70 × 101 | 1.85 × 101 | 2.45 × 101 | 2.13 × 101 | 4.03 × 101 | 2.34 × 101 | 1.96 × 101 | 1.64 × 101 | 3.86 × 101 | ||
| p-value | – | 3.02 × 10−11 + | 3.02 × 10−11 + | 4.07 × 10−11 + | 3.02 × 10−11 + | 3.02 × 10−11 + | 3.02 × 10−11 + | 3.02 × 10−11 + | 3.02 × 10−11 + | 3.02 × 10−11 + | 3.02 × 10−11 + | 3.01 × 10−11 + | ||
| F9 | Mean | 2.75 × 100 | 9.67 × 100 | 6.01 × 101 | 8.27 × 10−1 | 1.25 × 101 | 5.63 × 102 | 2.59 × 101 | 1.33 × 100 | 1.76 × 103 | 4.42 × 100 | 3.18 × 101 | 3.66 × 103 | |
| Std | 1.44 × 100 | 7.08 × 100 | 1.04 × 102 | 6.19 × 10−1 | 1.23 × 101 | 2.73 × 102 | 9.15 × 100 | 1.11 × 100 | 1.16 × 103 | 3.96 × 100 | 2.56 × 101 | 1.47 × 103 | ||
| p-value | – | 3.64 × 10−8 + | 1.31 × 10−8 + | 9.14 × 10−9 − | 1.63 × 10−5 + | 3.02 × 10−11 + | 3.02 × 10−11 + | 4.91 × 10−5 − | 3.02 × 10−11 + | 2.46 × 10−1 = | 3.69 × 10−11 + | 3.02 × 10−11 + | ||
| F10 | Mean | 1.52 × 104 | 1.44 × 104 | 3.01 × 104 | 1.97 × 104 | 2.84 × 104 | 1.19 × 104 | 1.42 × 104 | 1.18 × 104 | 1.03 × 104 | 2.94 × 104 | 1.38 × 104 | 1.15 × 104 | |
| Std | 9.57 × 102 | 4.40 × 102 | 4.55 × 102 | 3.08 × 103 | 4.63 × 102 | 9.87 × 102 | 4.20 × 102 | 8.89 × 102 | 4.37 × 102 | 5.82 × 102 | 5.61 × 102 | 1.60 × 103 | ||
| p-value | – | 1.60 × 10−3 − | 3.02 × 10−11 + | 2.20 × 10−7 + | 3.02 × 10−11 + | 9.92 × 10−11 − | 3.83 × 10−5 − | 3.02 × 10−11 − | 3.02 × 10−11 − | 3.02 × 10−11 + | 7.69 × 10−8 − | 2.87 × 10−10 − | ||
| F4–10 | w/t/l | – | 5/1/1 | 7/0/0 | 6/0/1 | 6/0/1 | 6/0/1 | 4/2/1 | 4/0/3 | 5/0/2 | 5/1/1 | 5/0/2 | 5/1/1 | |
| F11 | Hybrid Functions | Mean | 7.50 × 102 | 9.95 × 102 | 8.32 × 102 | 6.39 × 102 | 1.62 × 102 | 3.17 × 102 | 1.33 × 103 | 3.48 × 102 | 6.08 × 102 | 5.65 × 102 | 1.01 × 103 | 9.64 × 102 |
| Std | 1.49 × 102 | 1.94 × 102 | 1.04 × 102 | 8.87 × 101 | 4.92 × 101 | 7.84 × 101 | 6.06 × 102 | 1.16 × 102 | 1.29 × 102 | 1.00 × 102 | 2.14 × 102 | 2.41 × 102 | ||
| p-value | – | 3.09 × 10−6 + | 1.76 × 10−2 + | 1.11 × 10−3 − | 3.02 × 10−11 − | 3.69 × 10−11 − | 3.83 × 10−6 + | 9.92 × 10−11 − | 4.98 × 10−4 − | 1.49 × 10−6 − | 8.88 × 10−6 + | 4.22 × 10−4 + | ||
| F12 | Mean | 2.39 × 104 | 1.63 × 104 | 1.33 × 106 | 2.63 × 104 | 2.61 × 105 | 3.96 × 105 | 3.47 × 104 | 3.23 × 105 | 2.87 × 105 | 1.75 × 105 | 1.96 × 104 | 1.15 × 105 | |
| Std | 9.49 × 103 | 7.67 × 103 | 8.38 × 105 | 9.77 × 103 | 9.23 × 104 | 1.59 × 105 | 3.55 × 104 | 1.31 × 105 | 1.06 × 105 | 6.68 × 104 | 1.24 × 104 | 9.64 × 104 | ||
| p-value | – | 8.12 × 10−4 − | 3.02 × 10−11 + | 3.11 × 10−1 = | 3.02 × 10−11 + | 3.02 × 10−11 + | 8.65 × 10−1 = | 3.02 × 10−11 + | 3.02 × 10−11 + | 3.34 × 10−11 + | 1.76 × 10−2 − | 1.69 × 10−9 + | ||
| F13 | Mean | 4.91 × 102 | 3.39 × 103 | 5.43 × 103 | 1.56 × 103 | 4.50 × 103 | 5.52 × 103 | 4.63 × 103 | 4.00 × 103 | 2.29 × 103 | 6.07 × 103 | 2.66 × 103 | 3.37 × 103 | |
| Std | 8.17 × 102 | 3.07 × 103 | 5.23 × 103 | 8.75 × 102 | 4.14 × 103 | 5.15 × 103 | 4.12 × 103 | 4.59 × 103 | 1.75 × 103 | 6.75 × 103 | 2.57 × 103 | 2.51 × 103 | ||
| p-value | – | 8.35 × 10−8 + | 4.31 × 10−8 + | 2.00 × 10−6 + | 3.65 × 10−8 + | 5.97 × 10−9 + | 4.31 × 10−8 + | 2.20 × 10−7 + | 2.78 × 10−7 + | 1.25 × 10−7 + | 3.01 × 10−7 + | 2.60 × 10−8 + | ||
| F14 | Mean | 3.00 × 102 | 3.72 × 102 | 1.80 × 106 | 2.80 × 102 | 2.33 × 102 | 2.78 × 102 | 4.61 × 102 | 3.26 × 102 | 4.61 × 103 | 6.91 × 103 | 8.15 × 102 | 5.51 × 102 | |
| Std | 4.83 × 101 | 1.61 × 102 | 1.24 × 106 | 4.33 × 101 | 1.36 × 102 | 6.86 × 101 | 1.50 × 102 | 6.38 × 101 | 6.92 × 103 | 4.49 × 103 | 1.80 × 103 | 2.44 × 102 | ||
| p-value | – | 1.62 × 10−1 = | 3.02 × 10−11 + | 7.48 × 10−2 = | 8.66 × 10−5 − | 8.50 × 10−2 = | 3.57 × 10−6 + | 5.37 × 10−2 = | 6.01 × 10−8 + | 3.02 × 10−11 + | 5.09 × 10−6 + | 2.78 × 10−7 + | ||
| F15 | Mean | 5.78 × 102 | 3.33 × 102 | 9.00 × 103 | 2.58 × 102 | 8.38 × 102 | 1.90 × 103 | 5.51 × 102 | 5.60 × 103 | 9.98 × 102 | 7.73 × 103 | 4.06 × 102 | 6.65 × 102 | |
| Std | 4.86 × 102 | 1.20 × 102 | 8.92 × 103 | 4.64 × 101 | 1.04 × 103 | 2.17 × 103 | 6.43 × 102 | 7.38 × 103 | 8.54 × 102 | 8.20 × 103 | 1.88 × 102 | 6.62 × 102 | ||
| p-value | – | 4.36 × 10−2 − | 7.69 × 10−8 + | 3.37 × 10−4 − | 6.95 × 10−1 = | 7.66 × 10−5 + | 9.94 × 10−1 = | 1.60 × 10−3 + | 7.62 × 10−3 + | 9.79 × 10−5 + | 3.79 × 10−1 = | 7.17 × 10−1 = | ||
| F16 | Mean | 1.68 × 103 | 2.44 × 103 | 7.47 × 103 | 4.00 × 103 | 2.80 × 103 | 2.78 × 103 | 2.56 × 103 | 2.85 × 103 | 2.41 × 103 | 6.60 × 103 | 2.54 × 103 | 2.47 × 103 | |
| Std | 3.70 × 102 | 3.29 × 102 | 4.23 × 102 | 2.64 × 102 | 6.35 × 102 | 3.87 × 102 | 3.75 × 102 | 4.09 × 102 | 2.73 × 102 | 1.63 × 103 | 3.59 × 102 | 5.69 × 102 | ||
| p-value | – | 7.77 × 10−9 + | 3.02 × 10−11 + | 3.02 × 10−11 + | 1.20 × 10−8 + | 3.16 × 10−10 + | 2.92 × 10−9 + | 8.99 × 10−11 + | 5.46 × 10−9 + | 6.12 × 10−10 + | 2.44 × 10−9 + | 4.44 × 10−7 + | ||
| F17 | Hybrid Functions | Mean | 1.23 × 103 | 1.78 × 103 | 4.51 × 103 | 2.65 × 103 | 1.96 × 103 | 1.69 × 103 | 1.91 × 103 | 2.17 × 103 | 1.84 × 103 | 3.37 × 103 | 1.77 × 103 | 2.20 × 103 |
| Std | 3.26 × 102 | 2.22 × 102 | 5.25 × 102 | 2.51 × 102 | 4.47 × 102 | 2.79 × 102 | 2.43 × 102 | 2.59 × 102 | 2.03 × 102 | 1.33 × 103 | 2.10 × 102 | 4.03 × 102 | ||
| p-value | – | 7.09 × 10−8 + | 3.02 × 10−11 + | 3.34 × 10−11 + | 5.53 × 10−8 + | 2.49 × 10−6 + | 2.23 × 10−9 + | 1.21 × 10−10 + | 6.52 × 10−9 + | 5.09 × 10−8 + | 3.35 × 10−8 + | 1.46 × 10−10 + | ||
| F18 | Mean | 2.55 × 102 | 2.38 × 103 | 1.25 × 107 | 2.22 × 102 | 1.89 × 104 | 7.75 × 103 | 2.46 × 103 | 1.30 × 104 | 3.47 × 104 | 1.01 × 105 | 1.46 × 103 | 1.08 × 104 | |
| Std | 9.24 × 101 | 2.08 × 103 | 5.55 × 106 | 5.31 × 101 | 1.62 × 104 | 5.12 × 103 | 2.15 × 103 | 7.38 × 103 | 1.86 × 104 | 4.38 × 104 | 9.16 × 102 | 7.07 × 103 | ||
| p-value | – | 1.21 × 10−10 + | 3.02 × 10−11 + | 1.12 × 10−1 = | 3.02 × 10−11 + | 3.02 × 10−11 + | 4.50 × 10−11 + | 3.02 × 10−11 + | 3.02 × 10−11 + | 3.02 × 10−11 + | 4.08 × 10−11 + | 3.02 × 10−11 + | ||
| F19 | Mean | 1.81 × 102 | 2.61 × 102 | 1.34 × 104 | 1.85 × 102 | 5.60 × 102 | 3.46 × 103 | 2.39 × 103 | 4.62 × 103 | 1.24 × 103 | 1.13 × 104 | 1.15 × 103 | 2.49 × 102 | |
| Std | 3.46 × 101 | 2.24 × 102 | 1.36 × 104 | 3.17 × 101 | 1.31 × 103 | 3.61 × 103 | 4.34 × 103 | 4.24 × 103 | 1.16 × 103 | 1.24 × 104 | 1.48 × 103 | 6.73 × 101 | ||
| p-value | – | 1.11 × 10−4 + | 1.69 × 10−9 + | 5.89 × 10−1 = | 7.28 × 10−1 = | 4.08 × 10−11 + | 8.15 × 10−11 + | 6.52 × 10−9 + | 1.55 × 10−9 + | 8.48 × 10−9 + | 3.09 × 10−6 + | 1.64 × 10−5 + | ||
| F20 | Mean | 1.46 × 103 | 1.68 × 103 | 4.40 × 103 | 3.21 × 103 | 2.54 × 103 | 1.68 × 103 | 1.93 × 103 | 2.12 × 103 | 1.90 × 103 | 3.07 × 103 | 1.72 × 103 | 1.68 × 103 | |
| Std | 3.19 × 102 | 2.01 × 102 | 4.37 × 102 | 2.66 × 102 | 8.77 × 102 | 3.43 × 102 | 2.12 × 102 | 2.88 × 102 | 2.33 × 102 | 1.27 × 103 | 1.84 × 102 | 4.26 × 102 | ||
| p-value | – | 1.27 × 10−2 + | 3.02 × 10−11 + | 3.02 × 10−11 + | 3.25 × 10−7 + | 2.24 × 10−2 + | 1.36 × 10−7 + | 1.69 × 10−9 + | 1.11 × 10−6 + | 4.31 × 10−8 + | 2.62 × 10−3 + | 1.56 × 10−2 + | ||
| F11–20 | w/t/l | – | 7/1/2 | 10/0/0 | 4/4/2 | 6/2/2 | 8/1/1 | 8/2/0 | 8/1/1 | 9/0/1 | 9/0/1 | 8/1/1 | 9/1/0 | |
| F21 | Composition Functions | Mean | 2.66 × 102 | 3.83 × 102 | 6.68 × 102 | 6.12 × 102 | 3.70 × 102 | 4.33 × 102 | 3.94 × 102 | 4.56 × 102 | 4.41 × 102 | 9.89 × 102 | 3.76 × 102 | 5.39 × 102 |
| Std | 9.89 × 100 | 1.09 × 101 | 2.73 × 102 | 6.73 × 101 | 2.39 × 101 | 2.93 × 101 | 1.50 × 101 | 2.87 × 101 | 1.80 × 101 | 1.34 × 102 | 1.51 × 101 | 5.23 × 101 | ||
| p-value | – | 3.02 × 10−11 + | 3.02 × 10−11 + | 3.02 × 10−11 + | 3.02 × 10−11 + | 3.02 × 10−11 + | 3.02 × 10−11 + | 3.02 × 10−11 + | 3.02 × 10−11 + | 3.34 × 10−11 + | 3.02 × 10−11 + | 3.02 × 10−11 + | ||
| F22 | Mean | 1.64 × 104 | 1.56 × 104 | 3.04 × 104 | 2.18 × 104 | 2.90 × 104 | 1.28 × 104 | 1.51 × 104 | 1.32 × 104 | 9.68 × 103 | 2.99 × 104 | 1.50 × 104 | 1.26 × 104 | |
| Std | 9.55 × 102 | 5.87 × 102 | 5.70 × 102 | 3.07 × 103 | 5.37 × 102 | 1.09 × 103 | 7.79 × 102 | 7.00 × 102 | 4.82 × 103 | 5.43 × 102 | 5.73 × 102 | 1.49 × 103 | ||
| p-value | – | 1.00 × 10−3 − | 3.02 × 10−11 + | 1.87 × 10−7 + | 3.02 × 10−11 + | 3.02 × 10−11 − | 5.86 × 10−6 − | 3.69 × 10−11 − | 3.02 × 10−11 − | 3.02 × 10−11 + | 4.11 × 10−7 − | 8.10 × 10−10 − | ||
| F23 | Mean | 5.82 × 102 | 6.88 × 102 | 6.77 × 102 | 8.95 × 102 | 6.60 × 102 | 7.82 × 102 | 6.98 × 102 | 7.79 × 102 | 6.95 × 102 | 5.98 × 102 | 6.81 × 102 | 9.24 × 102 | |
| Std | 1.26 × 101 | 1.59 × 101 | 2.49 × 101 | 6.37 × 101 | 2.59 × 101 | 4.11 × 101 | 1.66 × 101 | 2.41 × 101 | 1.90 × 101 | 1.78 × 101 | 1.63 × 101 | 6.51 × 101 | ||
| p-value | – | 3.02 × 10−11 + | 3.02 × 10−11 + | 3.02 × 10−11 + | 3.02 × 10−11 + | 3.02 × 10−11 + | 3.02 × 10−11 + | 3.02 × 10−11 + | 3.02 × 10−11 + | 3.01 × 10−4 + | 3.02 × 10−11 + | 3.02 × 10−11 + | ||
| F24 | Mean | 9.14 × 102 | 1.03 × 103 | 1.07 × 103 | 9.79 × 102 | 1.03 × 103 | 1.15 × 103 | 1.04 × 103 | 1.11 × 103 | 1.13 × 103 | 9.41 × 102 | 1.03 × 103 | 1.31 × 103 | |
| Std | 1.03 × 101 | 1.85 × 101 | 3.48 × 101 | 7.68 × 101 | 2.15 × 101 | 4.51 × 101 | 2.10 × 101 | 2.83 × 101 | 3.05 × 101 | 1.32 × 101 | 1.98 × 101 | 8.06 × 101 | ||
| p-value | – | 3.02 × 10−11 + | 3.02 × 10−11 + | 4.98 × 10−11 + | 3.02 × 10−11 + | 3.02 × 10−11 + | 3.02 × 10−11 + | 3.02 × 10−11 + | 3.02 × 10−11 + | 4.57 × 10−9 + | 3.02 × 10−11 + | 3.02 × 10−11 + | ||
| F25 | Mean | 7.44 × 102 | 7.35 × 102 | 7.95 × 102 | 7.39 × 102 | 7.43 × 102 | 7.80 × 102 | 7.65 × 102 | 7.55 × 102 | 7.97 × 102 | 7.22 × 102 | 7.49 × 102 | 7.44 × 102 | |
| Std | 3.39 × 101 | 5.31 × 101 | 6.07 × 101 | 3.16 × 101 | 4.22 × 101 | 7.11 × 101 | 7.66 × 101 | 4.75 × 101 | 6.56 × 101 | 4.36 × 101 | 5.83 × 101 | 5.51 × 101 | ||
| p-value | – | 8.88 × 10−1 = | 1.11 × 10−4 + | 7.17 × 10−1 = | 5.79 × 10−1 = | 1.03 × 10−2 + | 5.75 × 10−2 = | 1.76 × 10−1 = | 9.21 × 10−5 + | 1.54 × 10−1 = | 8.30 × 10−1 = | 8.88 × 10−1 = | ||
| F26 | Mean | 3.34 × 103 | 4.53 × 103 | 5.46 × 103 | 3.55 × 103 | 4.88 × 103 | 5.95 × 103 | 4.77 × 103 | 5.80 × 103 | 7.24 × 103 | 3.81 × 103 | 4.66 × 103 | 1.01 × 104 | |
| Std | 9.87 × 101 | 2.34 × 102 | 3.26 × 102 | 8.94 × 101 | 3.53 × 102 | 4.16 × 102 | 2.52 × 102 | 4.03 × 102 | 9.90 × 102 | 1.96 × 102 | 1.95 × 102 | 3.00 × 103 | ||
| p-value | – | 3.02 × 10−11 + | 3.02 × 10−11 + | 7.77 × 10−9 + | 3.02 × 10−11 + | 3.02 × 10−11 + | 3.02 × 10−11 + | 3.02 × 10−11 + | 3.02 × 10−11 + | 9.92 × 10−11 + | 3.02 × 10−11 + | 3.02 × 10−11 + | ||
| F27 | Mean | 6.43 × 102 | 6.81 × 102 | 6.90 × 102 | 6.64 × 102 | 5.00 × 102 | 6.41 × 102 | 7.22 × 102 | 6.38 × 102 | 8.69 × 102 | 6.11 × 102 | 7.08 × 102 | 8.66 × 102 | |
| Std | 1.63 × 101 | 2.25 × 101 | 3.11 × 101 | 2.08 × 101 | 9.87 × 10−5 | 3.93 × 101 | 3.56 × 101 | 1.81 × 101 | 4.72 × 101 | 1.90 × 101 | 3.32 × 101 | 1.12 × 102 | ||
| p-value | – | 6.53 × 10−8 + | 7.38 × 10−10 + | 4.35 × 10−5 + | 3.02 × 10−11 − | 2.64 × 10−1 = | 7.39 × 10−11 + | 4.20 × 10−1 = | 3.02 × 10−11 + | 5.53 × 10−8 − | 1.46 × 10−10 + | 3.69 × 10−11 + | ||
| F28 | Mean | 5.52 × 102 | 5.31 × 102 | 1.28 × 103 | 5.34 × 102 | 5.00 × 102 | 5.70 × 102 | 5.48 × 102 | 5.30 × 102 | 5.55 × 102 | 5.34 × 102 | 5.31 × 102 | 5.50 × 102 | |
| Std | 3.41 × 101 | 2.98 × 101 | 2.30 × 103 | 3.77 × 101 | 8.10 × 10−5 | 3.31 × 101 | 2.51 × 101 | 1.94 × 101 | 3.50 × 101 | 2.78 × 101 | 2.99 × 101 | 3.42 × 101 | ||
| p-value | – | 3.27 × 10−2 − | 9.52 × 10−4 + | 4.23 × 10−3 − | 8.48 × 10−9 − | 1.27 × 10−2 + | 7.06 × 10−1 = | 1.89 × 10−4 − | 1.33 × 10−1 = | 1.50 × 10−2 − | 3.51 × 10−2 − | 7.51 × 10−1 = | ||
| F29 | Mean | 1.22 × 103 | 2.11 × 103 | 2.72 × 103 | 2.65 × 103 | 2.09 × 103 | 2.15 × 103 | 2.20 × 103 | 2.75 × 103 | 2.43 × 103 | 1.47 × 103 | 2.26 × 103 | 3.31 × 103 | |
| Std | 2.40 × 102 | 2.23 × 102 | 6.39 × 102 | 2.86 × 102 | 6.19 × 102 | 3.55 × 102 | 2.68 × 102 | 2.74 × 102 | 2.01 × 102 | 1.11 × 103 | 2.65 × 102 | 3.71 × 102 | ||
| p-value | – | 4.98 × 10−11 + | 4.98 × 10−11 + | 3.02 × 10−11 + | 6.52 × 10−9 + | 1.78 × 10−10 + | 4.98 × 10−11 + | 3.02 × 10−11 + | 3.02 × 10−11 + | 3.40 × 10−1 = | 4.08 × 10−11 + | 3.02 × 10−11 + | ||
| F30 | Mean | 4.27 × 103 | 5.14 × 103 | 6.69 × 103 | 2.89 × 103 | 2.55 × 103 | 4.86 × 103 | 4.42 × 103 | 4.34 × 103 | 6.51 × 103 | 4.03 × 103 | 4.19 × 103 | 2.85 × 103 | |
| Std | 1.48 × 103 | 2.70 × 103 | 4.74 × 103 | 2.04 × 102 | 1.35 × 103 | 3.00 × 103 | 2.80 × 103 | 3.51 × 103 | 2.54 × 103 | 2.54 × 103 | 1.86 × 103 | 2.82 × 102 | ||
| p-value | – | 4.12 × 10−1 = | 5.94 × 10−2 = | 1.95 × 10−3 − | 6.36 × 10−5 − | 6.00 × 10−1 = | 5.11 × 10−1 = | 7.24 × 10−2 = | 2.25 × 10−4 + | 7.48 × 10−2 = | 5.40 × 10−1 = | 6.55 × 10−4 − | ||
| F21–30 | w/t/l | – | 6/2/2 | 9/1/0 | 7/1/2 | 6/1/3 | 7/2/1 | 6/3/1 | 5/3/2 | 8/1/1 | 5/3/2 | 6/2/2 | 6/2/2 | |
| w/t/l | – | 19/4/6 | 28/1/0 | 18/5/6 | 19/4/6 | 22/3/4 | 20/7/2 | 19/4/6 | 24/1/4 | 21/4/4 | 20/3/6 | 22/4/3 | ||
| Rank | 3.21 | 4.45 | 10.69 | 5.90 | 4.93 | 7.34 | 6.72 | 6.93 | 7.48 | 7.83 | 5.03 | 7.48 | ||
| Problem Set | Problem Property | Index | DEGGDE | SHADE | GPDE | DiDE | SEDE | FADE | FDDE | TPDE | NSHADE | CUSDE | PFIDE | EJADE |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CEC’2017-30D | Unimodal Problems | w/t/l | – | 2/0/0 | 2/0/0 | 0/1/1 | 0/1/1 | 1/1/0 | 2/0/0 | 2/0/0 | 2/0/0 | 2/0/0 | 1/1/0 | 2/0/0 |
| Simple Multimodal Problems | – | 3/3/1 | 6/1/0 | 3/2/2 | 5/2/0 | 5/1/1 | 3/1/3 | 4/1/2 | 5/0/2 | 4/1/2 | 3/1/3 | 5/0/2 | ||
| Hybrid Problems | – | 9/0/1 | 10/0/0 | 3/5/2 | 4/3/3 | 6/2/2 | 10/0/0 | 7/3/0 | 10/0/0 | 6/2/2 | 7/3/0 | 7/3/0 | ||
| Composition Problems | – | 6/4/0 | 10/0/0 | 4/2/4 | 6/2/2 | 6/3/1 | 8/1/1 | 7/2/1 | 8/0/2 | 7/2/1 | 7/1/2 | 9/0/1 | ||
| Overall | – | 20/7/2 | 28/1/0 | 10/10/9 | 15/8/6 | 18/7/4 | 23/2/4 | 20/6/3 | 25/0/4 | 19/5/5 | 18/6/5 | 23/3/3 | ||
| Overall | Rank | 3.28 | 5.28 | 11.55 | 3.72 | 6.38 | 6.72 | 6.83 | 7.31 | 8.00 | 5.98 | 4.84 | 8.10 | |
| CEC’2017-50D | Unimodal Problems | w/t/l | – | 1/0/1 | 2/0/0 | 0/0/2 | 2/0/0 | 2/0/0 | 2/0/0 | 2/0/0 | 2/0/0 | 2/0/0 | 1/0/1 | 2/0/0 |
| Simple Multimodal Problems | – | 4/1/2 | 7/0/0 | 4/1/2 | 5/1/1 | 6/0/1 | 4/1/2 | 4/1/2 | 5/1/1 | 4/2/1 | 4/1/2 | 5/0/2 | ||
| Hybrid Problems | – | 8/1/1 | 10/0/0 | 6/2/2 | 7/2/1 | 7/2/1 | 9/1/0 | 8/2/0 | 10/0/0 | 6/0/4 | 8/2/0 | 9/1/0 | ||
| Composition Problems | – | 7/2/1 | 9/0/1 | 5/4/1 | 7/1/2 | 6/3/1 | 8/1/1 | 6/2/2 | 8/1/1 | 5/4/1 | 7/1/2 | 8/1/1 | ||
| Overall | – | 20/4/5 | 28/0/1 | 15/7/7 | 21/4/4 | 21/5/3 | 23/3/3 | 20/5/4 | 25/2/2 | 17/6/6 | 20/4/5 | 24/2/3 | ||
| Overall | Rank | 2.93 | 4.79 | 11.14 | 4.45 | 6.86 | 6.97 | 7.00 | 7.48 | 8.00 | 5.07 | 5.28 | 8.03 | |
| CEC’2017-100D | Unimodal Problems | w/t/l | – | 1/0/1 | 2/0/0 | 1/0/1 | 1/1/0 | 1/0/1 | 2/0/0 | 2/0/0 | 2/0/0 | 2/0/0 | 1/0/1 | 2/0/0 |
| Simple Multimodal Problems | – | 5/1/1 | 7/0/0 | 6/0/1 | 6/0/1 | 6/0/1 | 4/2/1 | 4/0/3 | 5/0/2 | 5/1/1 | 5/0/2 | 5/1/1 | ||
| Hybrid Problems | – | 7/1/2 | 10/0/0 | 4/4/2 | 6/2/2 | 8/1/1 | 8/2/0 | 8/1/1 | 9/0/1 | 9/0/1 | 8/1/1 | 9/1/0 | ||
| Composition Problems | – | 6/2/2 | 9/1/0 | 7/1/2 | 6/1/3 | 7/2/1 | 6/3/1 | 5/3/2 | 8/1/1 | 5/3/2 | 6/2/2 | 6/2/2 | ||
| Overall | – | 19/4/6 | 28/1/0 | 18/5/6 | 19/4/6 | 22/3/4 | 20/7/2 | 19/4/6 | 24/1/4 | 21/4/4 | 20/3/6 | 22/4/3 | ||
| Overall | Rank | 3.21 | 4.45 | 10.69 | 5.90 | 4.93 | 7.34 | 6.72 | 6.93 | 7.48 | 7.83 | 5.03 | 7.48 |
| F | Category | Quality | DE/Current- to-duelite/1 | DE/Current- to-Pelite/1 | DE/Current- to-Aelite/1 | DE/Current-to- duelite/1-WD | DE/Current-to- duelite/1-PD | DE/Current-to- duelite/1-PWD |
|---|---|---|---|---|---|---|---|---|
| F1 | Unimodal Functions | Mean | 1.40 × 10−14 | 1.40 × 10−14 | 6.83 × 10−1 | 1.37 × 10−11 | 1.40 × 10−14 | 1.49 × 10−14 |
| p-value | – | NAN = | 1.21 × 10−12 + | 1.21 × 10−12 + | 1.00 × 100 = | 1.61 × 10−1 = | ||
| F3 | Mean | 8.74 × 10−10 | 1.78 × 10−5 | 5.37 × 103 | 9.94 × 10−3 | 4.34 × 10−10 | 2.00 × 10−7 | |
| p-value | – | 3.02 × 10−11 + | 3.02 × 10−11 + | 3.02 × 10−11 + | 1.26 × 10−1 = | 3.34 × 10−11 + | ||
| F1–3 | w/t/l | – | 1/1/0 | 2/0/0 | 2/0/0 | 0/2/0 | 1/1/0 | |
| F4 | Simple Multimodal Functions | Mean | 4.77 × 101 | 4.99 × 101 | 6.12 × 101 | 6.30 × 101 | 4.69 × 101 | 6.44 × 101 |
| p-value | – | 7.63 × 10−1 = | 1.30 × 10−4 + | 1.23 × 10−1 = | 4.37 × 10−1 = | 3.59 × 10−2 + | ||
| F5 | Mean | 2.34 × 101 | 3.18 × 101 | 3.59 × 101 | 2.69 × 101 | 4.17 × 101 | 4.15 × 101 | |
| p-value | – | 8.13 × 10−3 + | 5.68 × 10−9 + | 1.66 × 10−2 + | 8.08 × 10−10 + | 5.59 × 10−7 + | ||
| F6 | Mean | 3.12 × 10−6 | 9.36 × 10−6 | 1.65 × 10−4 | 2.71 × 10−5 | 2.24 × 10−6 | 8.74 × 10−6 | |
| p-value | – | 4.34 × 10−5 + | 3.01 × 10−11 + | 2.71 × 10−8 + | 9.41 × 10−1 = | 1.27 × 10−3 + | ||
| F7 | Mean | 7.95 × 101 | 1.01 × 102 | 7.42 × 101 | 7.46 × 101 | 1.08 × 102 | 1.12 × 102 | |
| p-value | – | 2.53 × 10−4 + | 1.49 × 10−1 = | 8.24 × 10−2 = | 4.18 × 10−9 + | 6.72 × 10−10 + | ||
| F8 | Mean | 2.31 × 101 | 3.83 × 101 | 3.46 × 101 | 3.01 × 101 | 4.20 × 101 | 5.15 × 101 | |
| p-value | – | 2.43 × 10−5 + | 4.09 × 10−7 + | 1.26 × 10−3 + | 4.25 × 10−7 + | 2.60 × 10−10 + | ||
| F9 | Mean | 9.88 × 10−14 | 6.63 × 10−2 | 2.10 × 10−1 | 8.74 × 10−2 | 2.98 × 10−3 | 6.01 × 10−2 | |
| p-value | – | 5.36 × 10−4 + | 2.86 × 10−10 + | 3.62 × 10−4 + | 7.65 × 10−1 = | 1.23 × 10−2 + | ||
| F10 | Mean | 6.51 × 103 | 6.97 × 103 | 5.26 × 103 | 6.55 × 103 | 6.84 × 103 | 6.75 × 103 | |
| p-value | – | 4.86 × 10−3 + | 1.25 × 10−5 − | 1.00 × 100 = | 1.30 × 10−1 = | 2.06 × 10−1 = | ||
| F4–10 | w/t/l | – | 6/1/0 | 5/1/1 | 4/3/0 | 3/4/0 | 6/1/0 | |
| F11 | Hybrid Functions | Mean | 4.46 × 101 | 5.38 × 101 | 7.32 × 101 | 5.74 × 101 | 3.95 × 101 | 4.48 × 101 |
| p-value | – | 1.90 × 10−3 + | 1.95 × 10−10 + | 4.41 × 10−6 + | 3.58 × 10−3 − | 8.24 × 10−1 = | ||
| F12 | Mean | 2.71 × 103 | 2.69 × 103 | 2.19 × 10+04 | 3.86 × 103 | 2.34 × 103 | 2.26 × 103 | |
| p-value | – | 2.28 × 10−1 = | 6.07 × 10−11 + | 2.51 × 10−2 + | 1.86 × 10−1 = | 1.33 × 10−1 = | ||
| F13 | Mean | 1.81 × 102 | 2.00 × 102 | 6.80 × 102 | 1.92 × 102 | 1.89 × 102 | 2.01 × 102 | |
| p-value | – | 3.39 × 10−2 + | 3.01 × 10−7 + | 6.79 × 10−2 = | 4.38 × 10−1 = | 3.64 × 10−2 + | ||
| F14 | Mean | 4.16 × 101 | 6.14 × 101 | 6.11 × 101 | 5.66 × 101 | 5.26 × 101 | 5.45 × 101 | |
| p-value | – | 4.80 × 10−7 + | 7.09 × 10−8 + | 2.49 × 10−6 + | 1.02 × 10−5 + | 1.61 × 10−6 + | ||
| F15 | Mean | 4.48 × 101 | 4.56 × 101 | 1.01 × 102 | 4.76 × 101 | 4.02 × 101 | 4.20 × 101 | |
| p-value | – | 7.17 × 10−1 = | 5.46 × 10−9 + | 4.29 × 10−1 = | 1.71 × 10−1 = | 4.20 × 10−1 = | ||
| F16 | Mean | 4.26 × 102 | 4.83 × 102 | 6.08 × 102 | 5.18 × 102 | 5.68 × 102 | 5.38 × 102 | |
| p-value | – | 2.52 × 10−1 = | 2.27 × 10−3 + | 7.73 × 10−2 = | 6.38 × 10−3 + | 2.81 × 10−2 + | ||
| F17 | Mean | 2.39 × 102 | 2.93 × 102 | 3.03 × 102 | 3.14 × 102 | 3.96 × 102 | 3.81 × 102 | |
| p-value | – | 3.64 × 10−2 + | 5.01 × 10−2 = | 4.86 × 10−3 + | 1.75 × 10−5 + | 3.01 × 10−4 + | ||
| F18 | Mean | 1.12 × 102 | 6.26 × 101 | 9.21 × 101 | 6.97 × 101 | 5.67 × 101 | 5.53 × 101 | |
| p-value | – | 1.11 × 10−4 − | 1.71 × 10−1 = | 1.06 × 10−3 − | 1.09 × 10−5 − | 1.34 × 10−5 − | ||
| F19 | Mean | 3.11 × 101 | 3.59 × 101 | 4.19 × 101 | 3.52 × 101 | 3.16 × 101 | 3.84 × 101 | |
| p-value | – | 7.98 × 10−2 = | 2.25 × 10−4 + | 1.15 × 10−1 = | 7.62 × 10−1 = | 6.97 × 10−3 + | ||
| F20 | Mean | 1.47 × 102 | 1.58 × 102 | 1.90 × 102 | 1.49 × 102 | 3.16 × 102 | 2.80 × 102 | |
| p-value | – | 3.11 × 10−1 = | 3.63 × 10−1 = | 6.31 × 10−1 = | 5.19 × 10−7 + | 2.96 × 10−5 + | ||
| F11–20 | w/t/l | – | 4/5/1 | 7/3/0 | 4/5/1 | 4/4/2 | 6/3/1 | |
| F21 | Composition Functions | Mean | 2.24 × 102 | 2.27 × 102 | 2.32 × 102 | 2.25 × 102 | 2.38 × 102 | 2.43 × 102 |
| p-value | – | 7.73 × 10−1 = | 6.36 × 10−5 + | 6.84 × 10−1 = | 6.53 × 10−7 + | 3.01 × 10−7 + | ||
| F22 | Mean | 6.01 × 103 | 6.33 × 103 | 5.44 × 103 | 6.09 × 103 | 6.59 × 103 | 6.61 × 103 | |
| p-value | – | 3.45 × 10−2 + | 8.31 × 10−3 − | 2.01 × 10−1 = | 5.01 × 10−2 = | 1.27 × 10−2 + | ||
| F23 | Mean | 4.48 × 102 | 4.48 × 102 | 4.57 × 102 | 4.49 × 102 | 4.56 × 102 | 4.59 × 102 | |
| p-value | – | 8.19 × 10−1 = | 3.85 × 10−3 + | 4.12 × 10−1 = | 9.47 × 10−3 + | 2.92 × 10−2 + | ||
| F24 | Mean | 5.18 × 102 | 5.18 × 102 | 5.27 × 102 | 5.21 × 102 | 5.19 × 102 | 5.20 × 102 | |
| p-value | – | 2.12 × 10−1 = | 1.86 × 10−3 + | 1.41 × 10−1 = | 9.59 × 10−1 = | 8.19 × 10−1 = | ||
| F25 | Mean | 5.07 × 102 | 5.35 × 102 | 5.35 × 102 | 5.36 × 102 | 5.17 × 102 | 5.37 × 102 | |
| p-value | – | 7.96 × 10−3 + | 4.22 × 10−3 + | 3.76 × 10−3 + | 8.10 × 10−2 = | 1.03 × 10−2 + | ||
| F26 | Mean | 1.24 × 103 | 1.27 × 103 | 1.37 × 103 | 1.28 × 103 | 1.18 × 103 | 1.29 × 103 | |
| p-value | – | 1.15 × 10−1 = | 4.74 × 10−6 + | 7.73 × 10−2 = | 5.08 × 10−3 − | 9.47 × 10−3 + | ||
| F27 | Mean | 5.26 × 102 | 5.26 × 102 | 5.39 × 102 | 5.31 × 102 | 5.29 × 102 | 5.26 × 102 | |
| p-value | – | 8.42 × 10−1 = | 6.10 × 10−3 + | 9.33 × 10−2 = | 8.42 × 10−1 = | 7.51 × 10−1 = | ||
| F28 | Mean | 4.98 × 102 | 5.05 × 102 | 4.97 × 102 | 4.99 × 102 | 5.02 × 102 | 5.05 × 102 | |
| p-value | – | 1.09 × 10−2 + | 3.15 × 10−2 − | 2.64 × 10−1 = | 8.08 × 10−1 = | 5.71 × 10−1 = | ||
| F29 | Mean | 3.48 × 102 | 3.78 × 102 | 3.90 × 102 | 3.56 × 102 | 3.82 × 102 | 3.99 × 102 | |
| p-value | – | 9.63 × 10−2 = | 3.16 × 10−5 + | 2.58 × 10−1 = | 1.03 × 10−2 + | 1.91 × 10−2 + | ||
| F30 | Mean | 6.19 × 105 | 6.16 × 105 | 6.01 × 105 | 6.08 × 105 | 6.04 × 105 | 6.02 × 105 | |
| p-value | – | 5.11 × 10−1 = | 8.65 × 10−1 = | 8.53 × 10−1 = | 1.81 × 10−1 = | 4.73 × 10−1 = | ||
| F21–30 | w/t/l | – | 3/7/0 | 7/1/2 | 1/9/0 | 3/6/1 | 6/4/0 | |
| w/t/l | – | 14/14/1 | 21/5/3 | 11/17/1 | 10/16/3 | 19/9/1 | ||
| Rank | 2.00 | 3.52 | 4.41 | 3.72 | 3.17 | 4.17 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, T.-T.; Yang, Q.; Gao, X.-D. Dual Elite Groups-Guided Differential Evolution for Global Numerical Optimization. Mathematics 2023, 11, 3681. https://doi.org/10.3390/math11173681
Wang T-T, Yang Q, Gao X-D. Dual Elite Groups-Guided Differential Evolution for Global Numerical Optimization. Mathematics. 2023; 11(17):3681. https://doi.org/10.3390/math11173681
Chicago/Turabian StyleWang, Tian-Tian, Qiang Yang, and Xu-Dong Gao. 2023. "Dual Elite Groups-Guided Differential Evolution for Global Numerical Optimization" Mathematics 11, no. 17: 3681. https://doi.org/10.3390/math11173681
APA StyleWang, T.-T., Yang, Q., & Gao, X.-D. (2023). Dual Elite Groups-Guided Differential Evolution for Global Numerical Optimization. Mathematics, 11(17), 3681. https://doi.org/10.3390/math11173681