
Leveraging Searchable Encryption through Homomorphic Encryption: A Comprehensive Analysis



Abstract
1. Introduction
1.1. Related Work
1.2. Main Contributions
- To identify and classify existing SE utilizing HE. Our analysis covers several aspects of these systems, including the encryption techniques used, the structure of the search process (sequential scan or index-based), and the search capabilities offered (such as the ability to handle multiple keywords, regular expressions, wildcards, phrases, ranges, occurrences, and fuzzy keywords). Additionally, we study other functionalities like authorization and access revocation, static and dynamic approaches to SE, and correctness verification.
- To conduct an extensive analysis of the most common types of HE used in SE schemes, focusing our analysis on the identification of whether the schemes employed fall under the categories of partially homomorphic encryption, somewhat homomorphic encryption, or fully homomorphic encryption. Furthermore, we explicitly identify the HE schemes whenever possible.
- To examine how HE is used to achieve the different properties and characteristics within SE, building upon the categorization mentioned earlier. Specifically, we investigate how HE shapes the search process structure, enhances search capabilities, and enables additional functionalities in SE.
- To identify promising directions for future research and development in HE-based SE schemes, aiming to deliver more flexible and advanced solutions for SE.
1.3. Research Methodology
(searchable OR “secure search” OR “keyword search”) AND homomorphic.
1.4. Organization
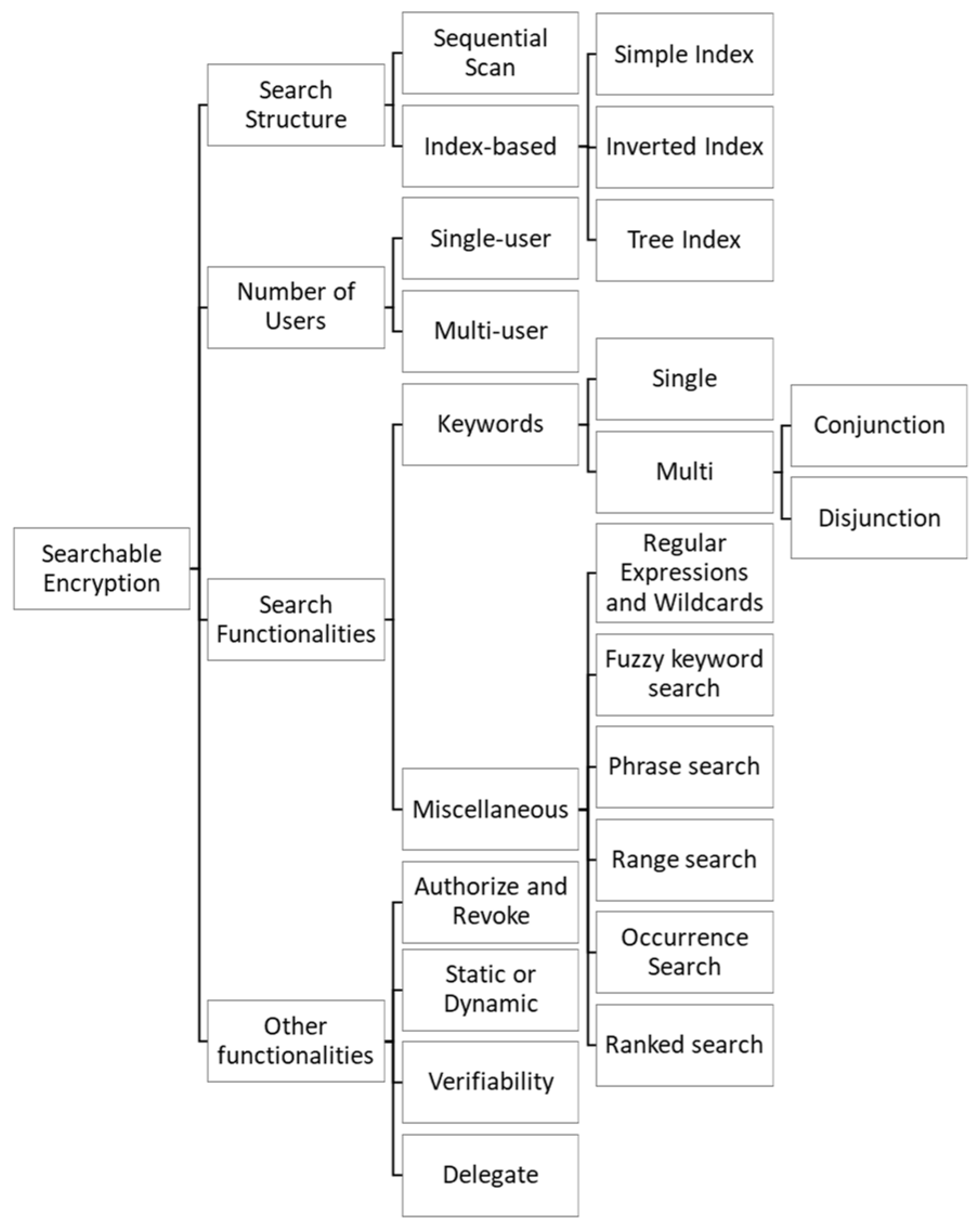
2. Searchable Encryption
- Data owner (DO) The entity in charge of data encryption and its outsourcing to the cloud server is the data owner, also known as the “client” in relevant literature [9]. Generally, the data is produced by the DO who has legitimate control and ownership over it. However, in some scenarios, another entity, known as the data provider, may be responsible for generating the data. The SE methods that use indices to aid in the search process, also known as index-based SE schemes, typically require the data provider (whether it is the data owner or not) to encrypt the index and share it with the cloud.
- Data user (DU) An entity that wants to search through the encrypted data kept by the DO is referred to as a data user. Ideally, it can only conduct the search if the DO has already given permission. The DU is, therefore, responsible for sending a search request to the cloud server which processes the request and then retrieves the results. It is worth noting that, in some systems, the DO can also act as a DU.
- Cloud server (CS) The cloud server is the entity responsible for securely storing the encrypted data and providing a SE service to authorized DUs. It performs three main tasks after receiving the DO’s encrypted documents: storing the data, searching the data, and keeping the search data structures up to date. The way the CS performs the search depends on the SE scheme being used. For an index-based SE, the CS searches by comparing the search request with the encrypted index and then sends the findings to the authorized DU. However, for SE schemes that are not index-based, the process of searching the encrypted data usually requires scanning the whole document, as will be discussed later in this section.
- Setup() The algorithm generates various system parameters (P) and the required keys (K) based on an input security parameter (). A public key and a private key must be generated for asymmetric SE, whereas only one key is required for symmetric SE. Typically, the system owner runs this algorithm.
- Encryption() An encryption algorithm encrypts the data using the key(s) generated in the previous process K, and it outputs a message obtained by encrypting the original data M using an encryption algorithm E.If the SE scheme is index-based, the input set of keywords W will also be encrypted using the input key(s) K, then it may be used to generate an index I of encrypted keywords. The DO then applies this algorithm to associate the encrypted index I with the encrypted message in order to create a searchable ciphertext (). The SC can then be uploaded to the CS.If the SE method is scan-based (meaning that the server will scan the encrypted data directly), the previous step can be skipped, and the message can be stored directly on the CS without generating an SC.
- TokenGen() The creation of search queries is done by authorized users using this algorithm, also known as Trapdoor. It takes an input encryption key K and an input query and generates a search token . The specific implementation of the algorithm depends on whether the SE scheme is index-based or scan-based. For an index-based scheme, the algorithm encrypts each keyword in the query Q using the encryption key(s) K and generates an index of encrypted keywords. The search token is then constructed from I. For a scan-based scheme, the algorithm generates a scan token . Using the chosen search query Q and the scan token , the search token is then created. Once constructed, the search token is sent to the server, which uses it to search for relevant data in the encrypted database.The DU might be the only one who can perform the query, depending on the scenario.
- Search() The search algorithm is used by the CS to search the encrypted data for matches to a search query. In an index-based scheme, the search algorithm applies the search token onto the searchable ciphertext to identify the set of encrypted keywords, and corresponding indices, that match the query. Then, it retrieves the corresponding encrypted data to the DU. In a scan-based scheme, the search algorithm applies the search token and the scan token onto the encrypted data to identify the set of searchable data segments with keywords that match the search query’s keywords. The server sends to the DU the search results once it has found any matches.
2.1. Characterization of a SE Scheme
2.1.1. Search Structure
- Simple index. In systems that employ this strategy, each document is given an index before being encrypted and uploaded to the CS. The index is composed of words that are thought to be relevant to that document. This kind of index is appropriate for applications where it is necessary to upload a small number of documents to the CS [9].
- Inverted index. The term inverted-index comes from the process of building the index backwards. This is because, instead of associating each document with a set of keywords, the index is created by coupling each keyword with the set of documents where it appears. This approach significantly reduces the time required for searching, making it the most suitable search structure for applications that involve uploading a large number of documents to the CS [9].
- Tree index. A tree index is also a very efficient method to optimize the search process. Although there are various approaches to building a tree index, the basic idea is to create a tree-like structure containing the searchable keywords, by dividing the set of keywords into smaller sets. When a DU searches for a specific keyword, the CS will search the index-tree, starting at the root and traversing every relevant node until a match is found.
2.1.2. Multiplicity of Users
2.1.3. Search Functionalities
Regular Expressions and Wildcards
Fuzzy Keyword Search
Phrase Search
Range Search
Occurrence Search
Ranked Search
2.1.4. Other Functionalities
Authorize and Revoke Users
Static or Dynamic
Verifiability
Delegate
3. Homomorphic Encryption
3.1. Partially Homomorphic Encryption
3.2. Somewhat Homomorphic Encryption
3.3. Fully Homomorphic Encryption
- Integers—The first FHE based in integers appeared in 2010 [47]. The main motivation behind these schemes lies in their conceptual simplicity. However, their lack of practicality makes them the least preferred category among researchers.
- (Rings) Learning With Error, (R)LWE—Brakerski and Vaikuntanathan [48] were the first to propose a scheme in this category. These schemes are based on the LWE problem, which is one of the most challenging problems to solve in real-time even for post-quantum algorithms. LWE has an algebraic variant called RLWE, which is more useful in practical applications;
- degree-truncated polynomial ring unit - These schemes allow computations between data that has been encrypted using various keys. López-Alt et al. [49] were the first to propose an HE scheme of this kind.
4. Analysis of SE Schemes That Utilize HE
4.1. Search Structure
4.2. Search Functionalities
4.2.1. Regular Expressions and Wildcards
4.2.2. Conjunctive Search
4.2.3. Phrase Search
4.2.4. Range Search
4.2.5. Ranked Search
4.3. Other Functionalities
4.3.1. Dynamic
4.3.2. Verifiability
5. Research Trends and Discussion
5.1. Types of HE Schemes Used in SE
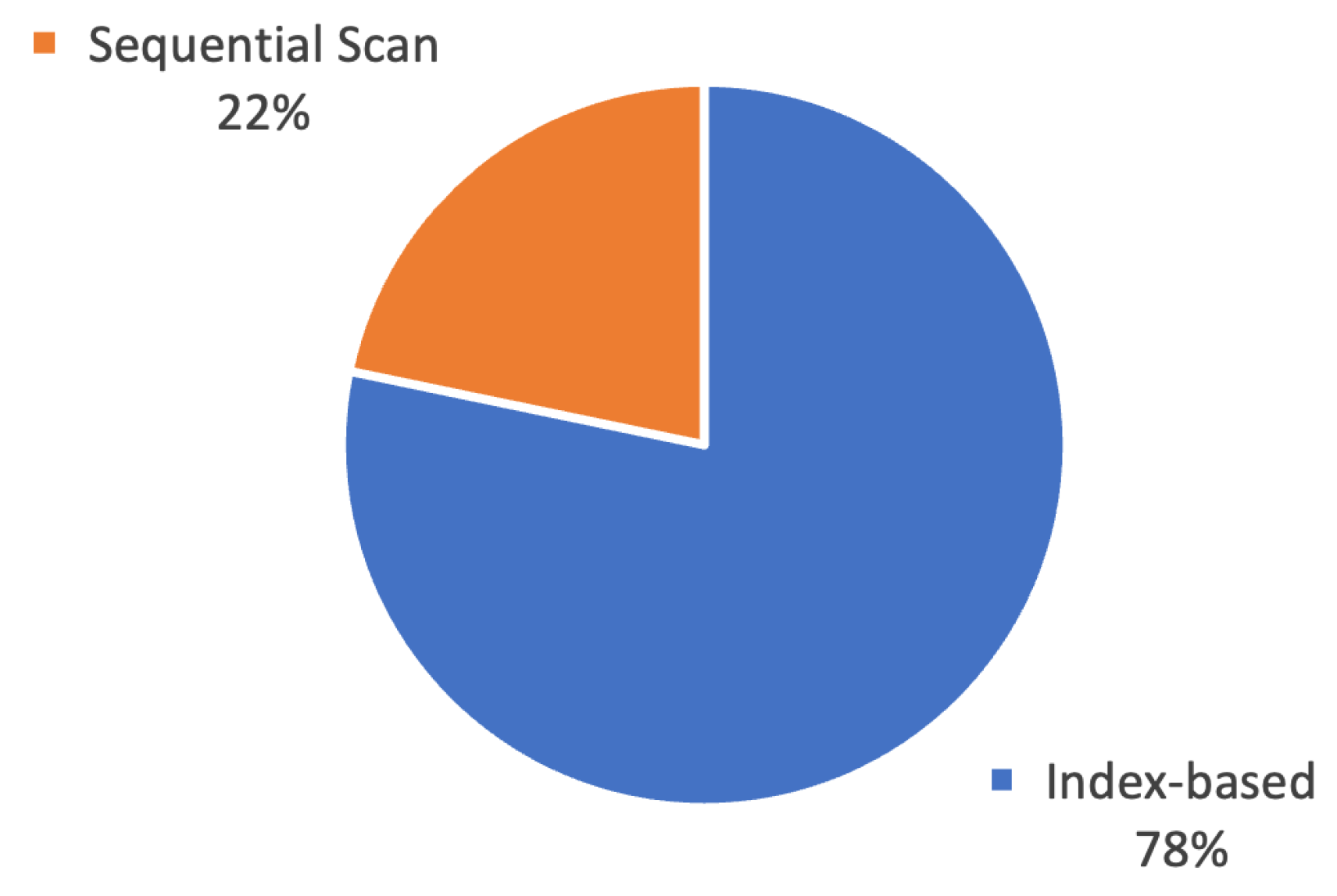
5.2. HE Usage in Search Structures
5.3. HE Usage in Search Functionalities
5.4. HE Usage in Other Functionalities
5.5. Multiplicity of Users
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AES | Advanced encryption standard |
| CP-ABE | Ciphertext-policy attribute-based encryption |
| CPA | Chosen plaintext attack |
| CS | Cloud server |
| DO | Data owner |
| DU | Data user |
| FHE | Fully homomorphic encryption |
| FHOPE | Fully homomorphic order-preserving encryption |
| FSDS | Fully secure document similarity |
| GM | Goldwasser–Micali |
| HE | Homomorphic encryption |
| IoT | Internet of Things |
| OPE | Order-preserving encryption |
| PCTD | Paillier cryptosystem with threshold decryption |
| PHE | Partially homomorphic encryption |
| PIR | Private information retrieval |
| RE | Regular expression |
| Searchable ciphertext | |
| SE | Searchable encryption |
| SIIS | Secure inverted index-based searchable encryption |
| SK-NN | Secure K nearest neighbor |
| SWHE | Somewhat homomorphic encryption |
| TF-IDF | Term frequency inverse document frequency |
References
- Suguna, M.; Ramalakshmi, M.; Cynthia, J.; Prakash, D. A Survey on Cloud and Internet of Things Based Healthcare Diagnosis. In Proceedings of the 2018 4th International Conference on Computing Communication and Automation (ICCCA), Greater Noida, India, 14–15 December 2018; pp. 1–4. [Google Scholar]
- Moumtzoglou, A.; Kastania, A.N.; Ghosh, R.; Papapanagiotou, I.; Boloor, K. A Survey on Research Initiatives for Healthcare Clouds. In Cloud Computing Applications for Quality Health Care Delivery; IGI Global: Hershey, PA, USA, 2014; pp. 1–18. [Google Scholar]
- Agrawal, S. A Survey on Recent Applications of Cloud Computing in Education: COVID-19 Perspective. J. Phys. Conf. Ser. 2021, 1828, 012076. [Google Scholar] [CrossRef]
- González-Martínez, J.A.; BoteLorenzo, M.L.; Gómez Sánchez, E.; Cano Parra, R. Cloud computing and education: A state-of-the-art survey. Comput. Educ. 2015, 80, 132–151. [Google Scholar] [CrossRef]
- Netwrix. Cloud Data Security Report; Technical Report; Netwrix: Frisco, TX, USA, 2022. [Google Scholar]
- Yang, P.; Xiong, N.N.; Ren, J. Data Security and Privacy Protection for Cloud Storage: A Survey. IEEE Access 2020, 8, 131723–131740. [Google Scholar] [CrossRef]
- Akavia, A.; Feldman, D.; Shaul, H. Secure Search on Encrypted Data via Multi-Ring Sketch. In Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security, CCS 2018, Toronto, ON, Canada, 15–19 October 2018; ACM: New York, NY, USA, 2018; pp. 985–1001. [Google Scholar]
- Xu, W.; Wang, B.; Lu, R.; Qu, Q.; Chen, Y.; Hu, Y.; Maglaras, L. Efficient Private Information Retrieval Protocol with Homomorphically Computing Univariate Polynomials. Sec. Commun. Netw. 2021, 2021, 5553256. [Google Scholar] [CrossRef]
- Sharma, D. Searchable encryption: A survey. Inf. Secur. J. 2023, 32, 76–119. [Google Scholar] [CrossRef]
- Acar, A.; Aksu, H.; Uluagac, A.; Conti, M. A survey on homomorphic encryption schemes: Theory and implementation. Acm Comput. Surv. 2018, 51, 1–35. [Google Scholar] [CrossRef]
- Choi, S.G.; Dachman-Soled, D.; Gordon, S.D.; Liu, L.; Yerukhimovich, A. Compressed Oblivious Encoding for Homomorphically Encrypted Search. In Proceedings of the 2021 ACM SIGSAC Conference on Computer and Communications Security, CCS’21, Virtual, Republic of Korea, 15–19 November 2021; ACM: New York, NY, USA, 2021; pp. 2277–2291. [Google Scholar]
- Song, D.X.; Wagner, D.; Perrig, A. Practical techniques for searches on encrypted data. In Proceedings of the Proceeding 2000 IEEE Symposium on Security and Privacy, S&P 2000, Berkeley, CA, USA, 14–17 May 2000; pp. 44–55. [Google Scholar]
- Bösch, C.; Hartel, P.; Jonker, W.; Peter, A. A Survey of Provably Secure Searchable Encryption. Acm. Comput. Surv. 2014, 47, 18:1–18:51. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, J.; Chen, X. Secure searchable encryption: A survey. J. Commun. Inf. Netw. 2016, 1, 52–65. [Google Scholar] [CrossRef]
- Han, F.; Qin, J.; Hu, J. Secure searches in the cloud: A survey. Future Gener. Comput. Syst. 2016, 62, 66–75. [Google Scholar] [CrossRef]
- Dowsley, R.; Michalas, A.; Nagel, M.; Paladi, N. A survey on design and implementation of protected searchable data in the cloud. Comput. Sci. Rev. 2017, 26, 17–30. [Google Scholar] [CrossRef]
- Poh, G.S.; Chin, J.J.; Yau, W.C.; Choo, K.K.R.; Mohamad, M.S. Searchable Symmetric Encryption: Designs and Challenges. Acm Comput. Surv. 2017, 50, 40:1–40:37. [Google Scholar] [CrossRef]
- Pham, H.; Woodworth, J.; Amini Salehi, M. Survey on secure search over encrypted data on the cloud. Concurr. Comput. Pract. Exp. 2019, 31, e5284. [Google Scholar] [CrossRef]
- Handa, R.; Krishna, C.R.; Aggarwal, N. Searchable encryption: A survey on privacy-preserving search schemes on encrypted outsourced data. Concurr. Comput. Pract. Exp. 2019, 31, e5201. [Google Scholar] [CrossRef]
- Andola, N.; Gahlot, R.; Yadav, V.; Venkatesan, S.; Verma, S. Searchable encryption on the cloud: A survey. J. Supercomput. 2022, 78, 9952–9984. [Google Scholar] [CrossRef]
- Noorallahzade, M.; Alimoradi, R.; Gholami, A. A Survey on Public Key Encryption with Keyword Search: Taxonomy and Methods. Int. J. Math. Math. Sci. 2022, 2022, 3223509. [Google Scholar] [CrossRef]
- Zhang, R.; Xue, R.; Liu, L. Searchable Encryption for Healthcare Clouds: A Survey. IEEE Trans. Serv. Comput. 2018, 11, 978–996. [Google Scholar] [CrossRef]
- Bader, J.; Michala, A. Searchable Encryption with Access Control in Industrial Internet of Things (IIoT). Wirel. Commun. Mob. Comput. 2021, 2021, 5555362. [Google Scholar] [CrossRef]
- How, H.B.; Heng, S.H. Blockchain-Enabled Searchable Encryption in Clouds: A Review. J. Inf. Secur. Appl. 2022, 67, 103183. [Google Scholar] [CrossRef]
- Pillai, B.; Lal, N. Blockchain-based Asymmetric Searchable Encryption: A Comprehensive Survey. Int. J. Eng. Trends Technol. 2022, 70, 355–365. [Google Scholar] [CrossRef]
- Boneh, D.; Kushilevitz, E.; Ostrovsky, R.; Skeith, W.E. Public Key Encryption That Allows PIR Queries. In Advances in Cryptology—CRYPTO 2007, Proceedings of the 27th Annual International Cryptology Conference, Santa Barbara, CA, USA, 19–23 August 2007; Menezes, A., Ed.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Gremany, 2007; pp. 50–67. [Google Scholar]
- Liu, J.; Zhao, B.; Qin, J.; Zhang, X.; Ma, J. Multi-Keyword Ranked Searchable Encryption with the Wildcard Keyword for Data Sharing in Cloud Computing. Comput. J. 2023, 66, 184–196. [Google Scholar] [CrossRef]
- Zheng, J.; Zhang, J.; Zhang, X.; Li, H. Symmetric searchable encryption scheme that supports phrase search. Microsyst. Technol. 2021, 27, 1721–1727. [Google Scholar] [CrossRef]
- Boneh, D.; Waters, B. Conjunctive, Subset, and Range Queries on Encrypted Data. In Theory of Cryptography, Proceedings of the Fourth Theory of Cryptography Conference, Amsterdam, The Netherlands, 21–24 February 2007; Vadhan, S.P., Ed.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Gremany, 2007; pp. 535–554. [Google Scholar]
- Rivest, R.L.; Adleman, L.; Dertouzos, M.L. On Data Banks and Privacy Homomorphisms. Found. Secur. Comput. Acad. Press 1978, 4, 169–179. [Google Scholar]
- Silva, I. Fully Homomorphic Encryption and Its Application to Private Search. Master’s Thesis, University of Porto, Porto, Portugal, 2022. [Google Scholar]
- Rivest, R.L.; Shamir, A.; Adleman, L. A method for obtaining digital signatures and public-key cryptosystems. Commun. ACM 1978, 21, 120–126. [Google Scholar] [CrossRef]
- Goldwasser, S.; Micali, S. Probabilistic encryption & how to play mental poker keeping secret all partial information. In Proceedings of the Fourteenth Annual ACM Symposium on Theory of Computing, STOC’82, New York, NY, USA, 5–7 May 1982; pp. 365–377. [Google Scholar]
- Benaloh, J. Dense probabilistic encryption. In Proceedings of the Workshop on Selected Areas of Cryptography; Clarkson University: Potsdam, NY, USA, 1994; pp. 120–128. [Google Scholar]
- Naccache, D.; Stern, J. A new public key cryptosystem based on higher residues. In Proceedings of the 5th ACM Conference on Computer and Communications Security, San Francisco, CA, USA, 2–5 November 1998; pp. 59–66. [Google Scholar]
- Elgamal, T. A public key cryptosystem and a signature scheme based on discrete logarithms. IEEE Trans. Inf. Theory 1985, 31, 469–472. [Google Scholar] [CrossRef]
- Paillier, P. Public-Key Cryptosystems Based on Composite Degree Residuosity Classes. In Proceedings of the Advances in Cryptology—EUROCRYPT ’99, Santa Barbara, CA, USA, 15–19 August 1999; Stern, J., Ed.; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 1999; pp. 223–238. [Google Scholar]
- Boneh, D.; Goh, E.J.; Nissim, K. Evaluating 2-DNF Formulas on Ciphertexts. In Proceedings of the Theory of Cryptography; Kilian, J., Ed.; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2005; pp. 325–341. [Google Scholar]
- Gentry, C. A Fully Homomorphic Encryption Scheme. Ph.D. Thesis, Stanford University, Stanford, CA, USA, 2009. [Google Scholar]
- Marcolla, C.; Sucasas, V.; Manzano, M.; Bassoli, R.; Fitzek, F.; Aaraj, N.; Marcolla, C. Survey on Fully Homomorphic Encryption, Theory, and Applications. Proc. IEEE 2022, 110, 1572–1609. [Google Scholar] [CrossRef]
- Fan, J.; Vercauteren, F. Somewhat Practical Fully Homomorphic Encryption. Paper 2012/144. Cryptol. Eprint Arch. 2012, 2012, 144. [Google Scholar]
- Brakerski, Z.; Gentry, C.; Vaikuntanathan, V. (Leveled) fully homomorphic encryption without bootstrapping. In Proceedings of the 3rd Innovations in Theoretical Computer Science Conference, ITCS’12, New York, NY, USA, 8–10 January 2012; pp. 309–325. [Google Scholar]
- Cheon, J.H.; Kim, A.; Kim, M.; Song, Y. Homomorphic Encryption for Arithmetic of Approximate Numbers. In Proceedings of the Advances in Cryptology—ASIACRYPT 2017; Takagi, T., Peyrin, T., Eds.; Lecture Notes in Computer Science. Springer: Cham, Switzerland, 2017; pp. 409–437. [Google Scholar]
- Chillotti, I.; Gama, N.; Georgieva, M.; Izabachène, M. TFHE: Fast Fully Homomorphic Encryption Over the Torus. J. Cryptol. 2020, 33, 34–91. [Google Scholar] [CrossRef]
- Scholl, P.; Smart, N.P. Improved Key Generation for Gentry’s Fully Homomorphic Encryption Scheme. In Proceedings of the Cryptography and Coding; Chen, L., Ed.; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2011; pp. 10–22. [Google Scholar]
- Gentry, C.; Halevi, S. Implementing Gentry’s Fully-Homomorphic Encryption Scheme. In Proceedings of the Advances in Cryptology—EUROCRYPT 2011; Paterson, K.G., Ed.; Lecture Notes in Computer Science. Springer: Berlin/ Heidelberg, Germany, 2011; pp. 129–148. [Google Scholar]
- van Dijk, M.; Gentry, C.; Halevi, S.; Vaikuntanathan, V. Fully Homomorphic Encryption over the Integers. In Proceedings of the Advances in Cryptology—EUROCRYPT 2010; Gilbert, H., Ed.; Lecture Notes in Computer Science. Springer: Berlin/ Heidelberg, Germany, 2010; pp. 24–43. [Google Scholar]
- Brakerski, Z.; Vaikuntanathan, V. Fully Homomorphic Encryption from Ring-LWE and Security for Key Dependent Messages. In Proceedings of the Advances in Cryptology—CRYPTO 2011; Rogaway, P., Ed.; Lecture Notes in Computer Science. Springer: Berlin/ Heidelberg, Germany, 2011; pp. 505–524. [Google Scholar]
- López-Alt, A.; Tromer, E.; Vaikuntanathan, V. On-the-fly multiparty computation on the cloud via multikey fully homomorphic encryption. In Proceedings of the Forty-First Annual ACM Symposium on Theory of Computing, New York, NY, USA, 19–22 May 2012; pp. 1219–1234. [Google Scholar]
- Challa, R. Homomorphic Encryption: Review and Applications. Lect. Notes Data Eng. Commun. Technol. 2020, 37, 273–281. [Google Scholar]
- Alloghani, M.; Alani, M.M.; Al-Jumeily, D.; Baker, T.; Mustafina, J.; Hussain, A.; Aljaaf, A.J. A systematic review on the status and progress of homomorphic encryption technologies. J. Inf. Secur. Appl. 2019, 48, 102362. [Google Scholar] [CrossRef]
- Malik, H.; Tahir, S.; Tahir, H.; Ihtasham, M.; Khan, F. A homomorphic approach for security and privacy preservation of Smart Airports. Future Gener. Comput. Syst. 2023, 141, 500–513. [Google Scholar] [CrossRef]
- Iqbal, Y.; Tahir, S.; Tahir, H.; Khan, F.; Saeed, S.; Almuhaideb, A.M.; Syed, A.M. A Novel Homomorphic Approach for Preserving Privacy of Patient Data in Telemedicine. Sensors 2022, 22, 4432. [Google Scholar] [CrossRef] [PubMed]
- Liu, G.; Yang, G.; Bai, S.; Wang, H.; Xiang, Y. FASE: A Fast and Accurate Privacy-Preserving Multi-Keyword Top-k Retrieval Scheme Over Encrypted Cloud Data. IEEE Trans. Serv. Comput. 2022, 15, 1855–1867. [Google Scholar] [CrossRef]
- Gan, Q.; Wang, X.; Huang, D.; Li, J.; Zhou, D.; Wang, C. Towards Multi-Client Forward Private Searchable Symmetric Encryption in Cloud Computing. IEEE Trans. Serv. Comput. 2022, 15, 3566–3576. [Google Scholar] [CrossRef]
- Wang, Y.; Sun, S.F.; Wang, J.; Liu, J.K.; Chen, X. Achieving Searchable Encryption Scheme With Search Pattern Hidden. IEEE Trans. Serv. Comput. 2022, 15, 1012–1025. [Google Scholar] [CrossRef]
- Andola, N.; Prakash, S.; Yadav, V.K.; Venkatesan, S.; Verma, S. A secure searchable encryption scheme for cloud using hash-based indexing. J. Comput. Syst. Sci. 2022, 126, 119–137. [Google Scholar] [CrossRef]
- Yin, F.; Lu, R.; Zheng, Y.; Tang, X.; Jiang, Q. Achieve Efficient and Privacy-Preserving Compound Substring Query over Cloud. Sec. Commun. Netw. 2021, 2021, 7941233. [Google Scholar] [CrossRef]
- Prakash, A.J.; Elizabeth, B.L. Pindex: Private multi-linked index for encrypted document retrieval. PLoS ONE 2021, 16, e0256223. [Google Scholar] [CrossRef]
- Tosun, T.; Savaş, E. FSDS: A practical and fully secure document similarity search over encrypted data with lightweight client. J. Inf. Secur. Appl. 2021, 59, 102830. [Google Scholar] [CrossRef]
- Hou, J.; Liu, Y.; Hao, R. Privacy-Preserving Phrase Search over Encrypted Data. In Proceedings of the 4th International Conference on Big Data Technologies, ICBDT’21, Beijing, China, 26–28 May 2022; Association for Computing Machinery: New York, NY, USA, 2022; pp. 154–159. [Google Scholar]
- Zhang, J.; Shen, S.; Huang, D. A Secure Ranked Search Model Over Encrypted Data in Hybrid Cloud Computing. In Cyber Security, Proceedings of the 17th China Annual Conference, CNCERT 2020, Beijing, China, 12 August 2020; Lu, W., Wen, Q., Zhang, Y., Lang, B., Wen, W., Yan, H., Li, C., Ding, L., Li, R., Zhou, Y., Eds.; Springer: Singapore, 2020; pp. 29–36. [Google Scholar]
- Elizabeth, B.; Prakash, A. Verifiable top-k searchable encryption for cloud data. Sadhana-Acad. Proc. Eng. Sci. 2020, 45, 9. [Google Scholar] [CrossRef]
- Li, Y.; Zhou, F.; Xu, Z.; Ge, Y. An Efficient Two-Server Ranked Dynamic Searchable Encryption Scheme. IEEE Access 2020, 8, 86328–86344. [Google Scholar] [CrossRef]
- Yang, Y.; Liu, X.; Deng, R.H.; Weng, J. Flexible Wildcard Searchable Encryption System. IEEE Trans. Serv. Comput. 2020, 13, 464–477. [Google Scholar] [CrossRef]
- Wen, R.; Yu, Y.; Xie, X.; Zhang, Y. LEAF: A Faster Secure Search Algorithm via Localization, Extraction, and Reconstruction. In Proceedings of the 2020 ACM SIGSAC Conference on Computer and Communications Security, CCS’20, New York, NY, USA, 9–13 November 2020; pp. 1219–1232. [Google Scholar]
- Yang, Y.; Liu, X.; Deng, R.H. Multi-User Multi-Keyword Rank Search Over Encrypted Data in Arbitrary Language. IEEE Trans. Dependable Secur. Comput. 2020, 17, 320–334. [Google Scholar] [CrossRef]
- Boucenna, F.; Nouali, O.; Kechid, S.; Tahar Kechadi, M. Secure Inverted Index Based Search over Encrypted Cloud Data with User Access Rights Management. J. Comput. Sci. Technol. 2019, 34, 133–154. [Google Scholar] [CrossRef]
- Guo, C.; Zhuang, R.; Jie, Y.; Choo, K.K.; Tang, X. Secure range search over encrypted uncertain IoT outsourced data. IEEE Internet Things J. 2019, 6, 1520–1529. [Google Scholar] [CrossRef]
- Shen, M.; Ma, B.; Zhu, L.; Du, X.; Xu, K. Secure phrase search for intelligent processing of encrypted data in cloud-based iot. IEEE Internet Things J. 2019, 6, 1998–2008. [Google Scholar] [CrossRef]
- Elizabeth, B.; Prakash, A.; Uthariaraj, V. TSED: Top-k ranked searchable encryption for secure cloud data storage. Adv. Intell. Syst. Comput. 2018, 645, 113–121. [Google Scholar]
- Wu, D.; Gan, Q.; Wang, X. Verifiable Public Key Encryption with Keyword Search Based on Homomorphic Encryption in Multi-User Setting. IEEE Access 2018, 6, 42445–42453. [Google Scholar] [CrossRef]
- Halevi, S.; Shoup, V. Algorithms in HElib. In Advances in Cryptology—CRYPTO 2014, Proceedings of the 34th Annual Cryptology Conference, Santa Barbara, CA, USA, 17–21 August 2014; Garay, J.A., Gennaro, R., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2014; pp. 554–571. [Google Scholar]
- Dworkin, M.; Barker, E.; Nechvatal, J.; Foti, J.; Bassham, L.; Roback, E.; Dray, J. Advanced Encryption Standard (AES); Federal Inf. Process. Stds. (NIST FIPS), National Institute of Standards and Technology: Gaithersburg, MD, USA, 2001.
- Bresson, E.; Catalano, D.; Pointcheval, D. A Simple Public-Key Cryptosystem with a Double Trapdoor Decryption Mechanism and Its Applications. In Advances in Cryptology—ASIACRYPT 2003, Proceedings of the 9th International Conference on the Theory and Application of Cryptology and Information Security, Taipei, Taiwan, 30 November–4 December 2003; Laih, C.S., Ed.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2003; pp. 37–54. [Google Scholar]
- Krawczyk, D.H.; Bellare, M.; Canetti, R. HMAC: Keyed-Hashing for Message Authentication; RFC 2104; RFC Editor: 1997.
- Boucenna, F.; Nouali, O.; Kechid, S. Concept-based Semantic Search over Encrypted Cloud Data. In Proceedings of the 12th International Conference on Web Information Systems and Technologies, Rome, Italy, 23–25 April 2016; pp. 235–242. [Google Scholar]
- Cao, N.; Wang, C.; Li, M.; Ren, K.; Lou, W. Privacy-Preserving Multi-Keyword Ranked Search over Encrypted Cloud Data. IEEE Trans. Parallel Distrib. Syst. 2014, 25, 222–233. [Google Scholar] [CrossRef]
- Whissell, J.S.; Clarke, C.L.A. Improving document clustering using Okapi BM25 feature weighting. Inf. Retr. 2011, 14, 466–487. [Google Scholar] [CrossRef]
- Liu, G.; Yang, G.; Wang, H.; Xiang, Y.; Dai, H. A Novel Secure Scheme for Supporting Complex SQL Queries over Encrypted Databases in Cloud Computing. Secur. Commun. Netw. 2018, 2018, e7383514. [Google Scholar] [CrossRef]
- Menezes, A.J.; Vanstone, S.A.; Oorschot, P.C.V. Handbook of Applied Cryptography, 1st ed.; CRC Press, Inc.: Boca Raton, FL, USA, 1996. [Google Scholar]
- Wan, Z.; Deng, R. VPSearch: Achieving Verifiability for Privacy-Preserving Multi-Keyword Search over Encrypted Cloud Data. IEEE Trans. Dependable Secur. Comput. 2018, 15, 1083–1095. [Google Scholar] [CrossRef]
- Dong, Q.; Guan, Z.; Wu, L.; Chen, Z. Fuzzy keyword search over encrypted data in the public key setting. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2013; Volume 7923 LNCS, pp. 729–740. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Database | N° of Results |
|---|---|
| ACM Digital Library | 186 |
| IEEE Xplore | 68 |
| Elsevier ScienceDirect | 41 |
| Scopus | 217 |
| Web of Science | 133 |
| Total | 645 |
| Type of Criterion | Criterion ID | Description |
|---|---|---|
| Inclusion | IC1 | It focus on secure search methods or SE schemes that leverage the properties of HE in the search process. |
| IC2 | It was published in peer-reviewed journals or conferences. | |
| IC3 | It was writen in English. | |
| IC4 | It was published after 2016. | |
| Exclusion | EC1 | It does not provide sufficient information on how HE is applied. |
| EC2 | It does not apply HE to improve the search method. | |
| EC3 | It was written in other languages than English. | |
| EC4 | It is not a peer-reviewed publication. |
| Article | Search Structure | Search Functionalities | Other Functionalities | User | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Index | Seq. Scan | Single Keyword | Multi Keyword | RE/ Wildcard | Conj. | Disj. | Range | Phrase | Ranked Search | Verif. | Auth./Revoke User | Dynamic | Single | Multi | ||||
| [52] | x | x | x | |||||||||||||||
| [53] | x | x | x | |||||||||||||||
| [54] | x | x | h | x | ||||||||||||||
| [55] | x | x | h | x | ||||||||||||||
| [56] | x | x | h | x | ||||||||||||||
| [57] | x | x | h | x | ||||||||||||||
| [11] | x | x | x | |||||||||||||||
| [58] | x | x | h | h | h | x | ||||||||||||
| [59] | x | x | h | x | ||||||||||||||
| [60] | x | x | h | x | ||||||||||||||
| [61] | x | x | x | h | h | x | ||||||||||||
| [62] | x | x | h | x | ||||||||||||||
| [63] | x | x | h | x | h | x | ||||||||||||
| [64] | x | x | h | h | x | |||||||||||||
| [65] | x | x | h | h | h | h | x | x | ||||||||||
| [66] | x | x | x | |||||||||||||||
| [67] | x | x | h | x | x | |||||||||||||
| [68] | x | x | h | x | ||||||||||||||
| [69] | x | h | x | |||||||||||||||
| [70] | x | x | x | h | x | |||||||||||||
| [7] | x | x | x | |||||||||||||||
| [71] | x | x | h | h | x | |||||||||||||
| [72] | x | x | h | h | x | |||||||||||||
| Article | PHE | SWHE | FHE | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Paillier | EC El Gamal | XOR | Boneh | PCTD | GM | BCP | FV | BGV | FHOPE | BFV | DGHV | |||
| [52] | x | |||||||||||||
| [53] | x | |||||||||||||
| [54] | x | |||||||||||||
| [55] | x | |||||||||||||
| [56] | x | |||||||||||||
| [57] | x | |||||||||||||
| [11] | ||||||||||||||
| [58] | x | |||||||||||||
| [59] | x | |||||||||||||
| [60] | x | |||||||||||||
| [61] | x | |||||||||||||
| [62] | ||||||||||||||
| [63] | x | x | ||||||||||||
| [64] | x | |||||||||||||
| [65] | x | |||||||||||||
| [66] | x | |||||||||||||
| [67] | x | |||||||||||||
| [68] | x | |||||||||||||
| [69] | x | |||||||||||||
| [70] | x | |||||||||||||
| [7] | x | |||||||||||||
| [71] | x | x | ||||||||||||
| [72] | x | |||||||||||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Amorim, I.; Costa, I. Leveraging Searchable Encryption through Homomorphic Encryption: A Comprehensive Analysis. Mathematics 2023, 11, 2948. https://doi.org/10.3390/math11132948
Amorim I, Costa I. Leveraging Searchable Encryption through Homomorphic Encryption: A Comprehensive Analysis. Mathematics. 2023; 11(13):2948. https://doi.org/10.3390/math11132948
Chicago/Turabian StyleAmorim, Ivone, and Ivan Costa. 2023. "Leveraging Searchable Encryption through Homomorphic Encryption: A Comprehensive Analysis" Mathematics 11, no. 13: 2948. https://doi.org/10.3390/math11132948
APA StyleAmorim, I., & Costa, I. (2023). Leveraging Searchable Encryption through Homomorphic Encryption: A Comprehensive Analysis. Mathematics, 11(13), 2948. https://doi.org/10.3390/math11132948