4.1. Establishment of Recommendation Algorithm Evaluation Indicators
The model evaluation indicators that we propose are mainly from an economic perspective. The (click through rate) and ( is the hit ratio) are the main indicators; the indicator is an indicator that is directly related to commercial realization, and is an evaluation index of user stickiness. These indicators can reflect the health status of the whole system and the effectiveness of the model and can provide more effective training data for subsequent model optimization.
The
indicator, that is, the click through rate indicator, is an important indicator with which to measure the recommendation effect in the field of Internet advertising and recommendation systems. In actual operation, this indicator is an important measure of the platform economy. If an interaction process is defined as a tuple, where the options are is action, is context, and is return, then the
value can be calculated from Equation (13) to determine the logging policy:
The
(abbreviated as
) indicator is a commonly used evaluation indicator of the recommendation system. It is defined as the ratio of the number of users and the total number of users whose products appear in the Top-K recommendation list in the test set.
is used to measure how accurate the model is at predicting user behavior. Its value can be calculated by using Equation (14):
4.2. Validation Experiment of Static Features
The purpose of conducting the effectiveness verification experiment on the user’s static features was to verify the effectiveness of the user’s feature engineering. Because the feature engineering contains nonlinear information, the preconditions of most statistical testing methods were not satisfied. Here, the experiment was verified by conducting a comparative experiment under the same environmental conditions.
The commonly used random forest model was selected as the baseline test model for the experimental model. The data input into the model were processed by using different feature engineering methods, and different feature engineering processing methods were used as variables. The results output from the model were horizontally compared. The feature processing methods were as follows:
- (1)
A feature engineering method based on counting, which simply counted the data to calculate the browse and interaction quantity of each product as the baseline method for comparison.
- (2)
A feature engineering method based on SVD decomposition: the hidden code length level of the SVD was set at 5, 20, and 50 levels, and the codes were svd-5, -20, and -50, respectively.
- (3)
A feature engineering method based on simple sublinear coding: the levels of the number of users (M) were 50, 150, 500, and 5000, and the codes were SubLinEmb-50, -150, -500, and -5 k, respectively.
- (4)
A systematic design based on the user’s static characteristic data: When processing the data, the information contained within the data was cleaned, converted, and processed. After the processing was completed, the data were cached in the memory system until the near-line and online applications. The code name was Entirety-Plan.
The environmental parameters of the experiments were constructed and presented in
Table 2, by using two indicators in CTR, i.e., HR@5 and HR@2, to measure the performance of the model algorithm.
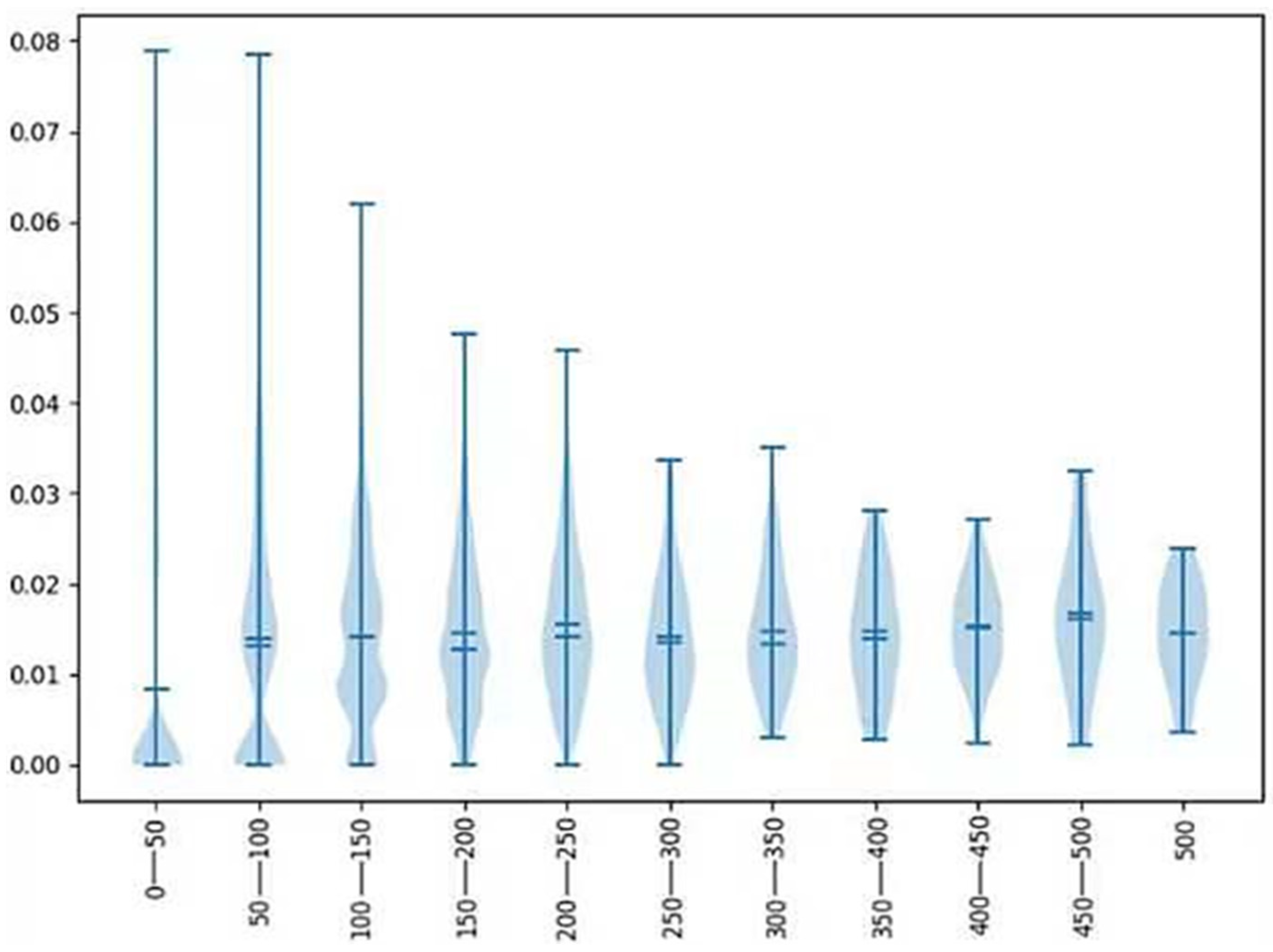
The comparison results are shown in
Figure 4, where the middle dot represents the mean value and the line segment represents the standard error. The general information level included in the feature engineering process can be seen. The following conclusions can be drawn from the results:
First, the increase in the hidden variables of feature engineering based on SVD can enhance the effect of HR@5. When 200 dimensions were present, the indicator was enhanced, but the enhancement was limited.
Second, sublinear coding was more accurate than feature engineering was based on SVD. More neighbor samples will not enhance the effects, and too many neighbors will introduce redundant data, which will have the opposite effect.
Third, for many product recommendations, the effect of popular product recommendations and random recommendations was almost zero.
Fourth, the scheme that combined linear and sublinear and sequential patterns was optimal, which was not unexpected because the scheme was based on the most comprehensive information.
Regarding HR@5 and, correspondingly, HR@2, the result was very similar to that in
Figure 3. At the same time, compared with the HR@5 data, the HR@2 value was slightly worse.
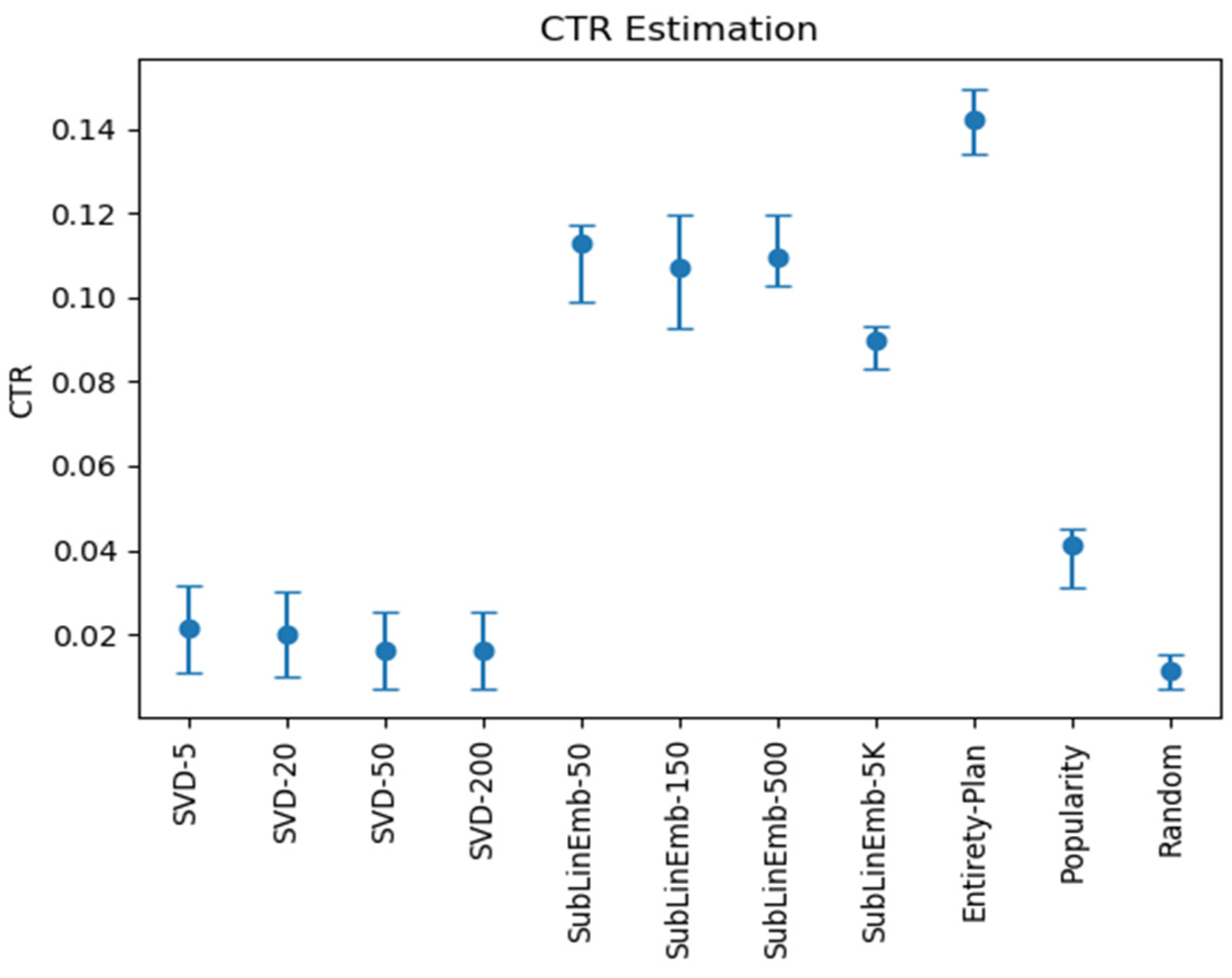
The control results of the CTR are shown in
Figure 5. From the CTR indicators, we found the following:
- (1)
Increasing the number of implicit variables will not enhance the index, but it will decrease the performance of the index.
- (2)
As a baseline model, the effect of the popularity recommendation was stronger than that of SVD, but the effect was not very strong overall. The random recommendations were the worst, which we were expecting.
- (3)
The feature engineering method using sublinear coding was much more effective than the linear SVD correlation method was because it considered this situation in theory.
- (4)
The scheme that combined the linear and sublinear and sequential patterns as a whole was optimal, which was not unexpected because it had the most comprehensive information.
From the results of the above experiments, we found that introducing a method to add nonlinear expectations into the recommendation system is beneficial, and the scheme whereby the data of various modes are combined resulted in the strongest effect. The reasons are as follows.
First, when processing the data, a variety of mode information such as information on the linear and nonlinear data and lists is included, and the information types are more comprehensive.
Second, the information of multiple modes can output more information when combined, which reduces the impact of data sparsity.
Third, through some metric learning enhancement methods, the preference estimation is additionally introduced, which is more robust and an effective supplement to the information.
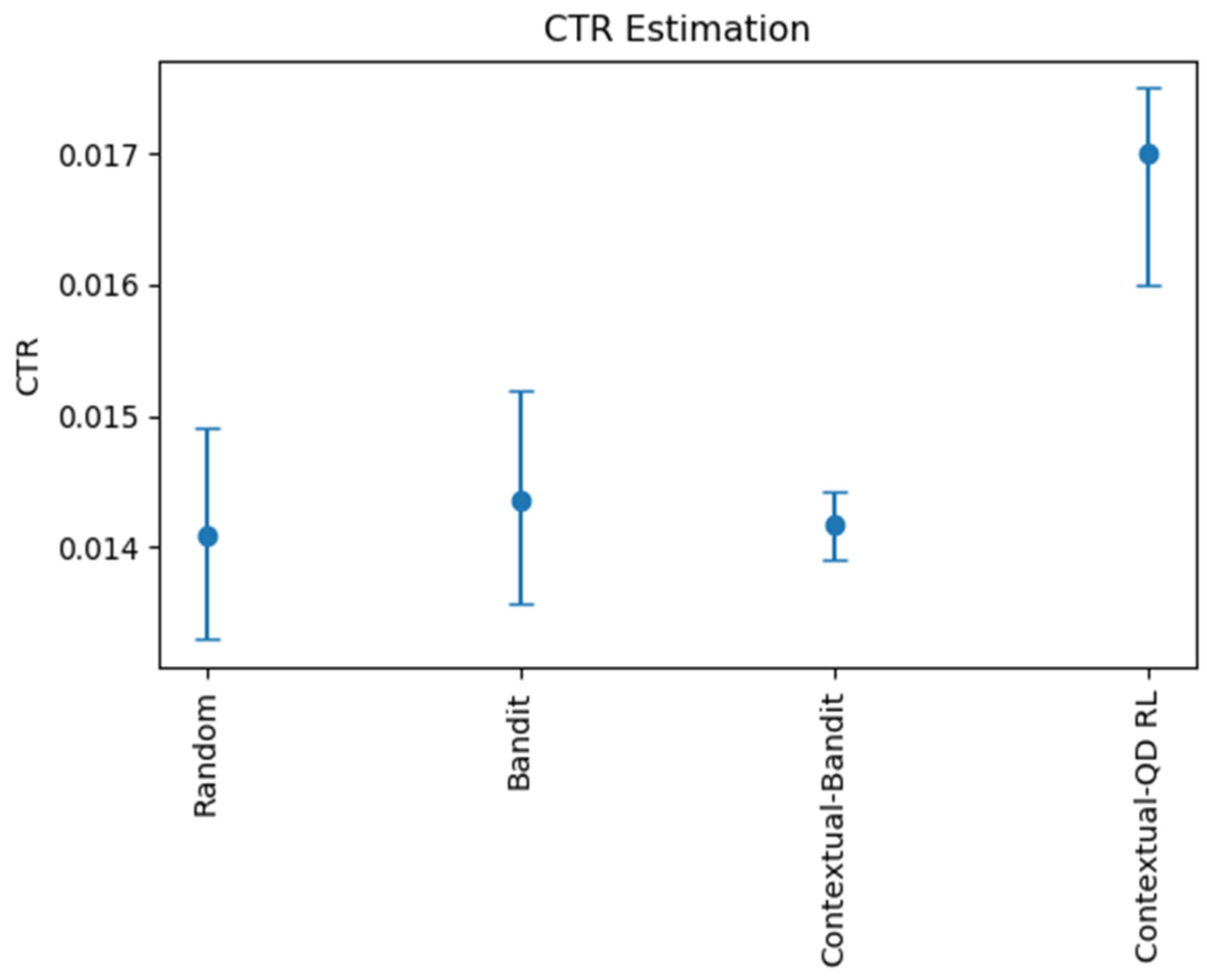
4.3. Model Comparison Experiment of Interactive Data
The same experimental logic was used to test the model by using interactive data. The purpose of this experiment was to verify that the enhancement of the contextual–quantile regression reinforcement learning model was effective. Logical regression and bandit, as well as a contextual bandit and the random recommendation algorithm, were used for this experiment. Each algorithm required different parameters; therefore, the parameters of each algorithm were the approximate optimal parameters obtained by conducting a random search. Because the statistical caliber of the interactive data was different from that of the static data, no mutual comparison was made with the static data. The results are shown in
Figure 6.
Few differences existed between the bandit model and random recommendation because many goods were involved and the pure interactive data were too sparse for goods to be recommended. Moreover, the bandit model does not consider context. Regarding the context-based reinforcement learning model, its effect was far stronger than the first two because it introduced the information contained in the context. However, because the bandit algorithm is linear, it can still be enhanced. Compared with the other models, the contextual–quantile regression reinforcement learning model was more accurate because it fit more nonlinear information, and the data buffer could alleviate the sparse data problem. From the results, we concluded that the enhancement of the contextual–quantile regression reinforcement learning model was stronger than that of the traditional reinforcement learning method.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}