




Detection of River Floating Garbage Based on Improved YOLOv5



 and
and 
Abstract
1. Introduction
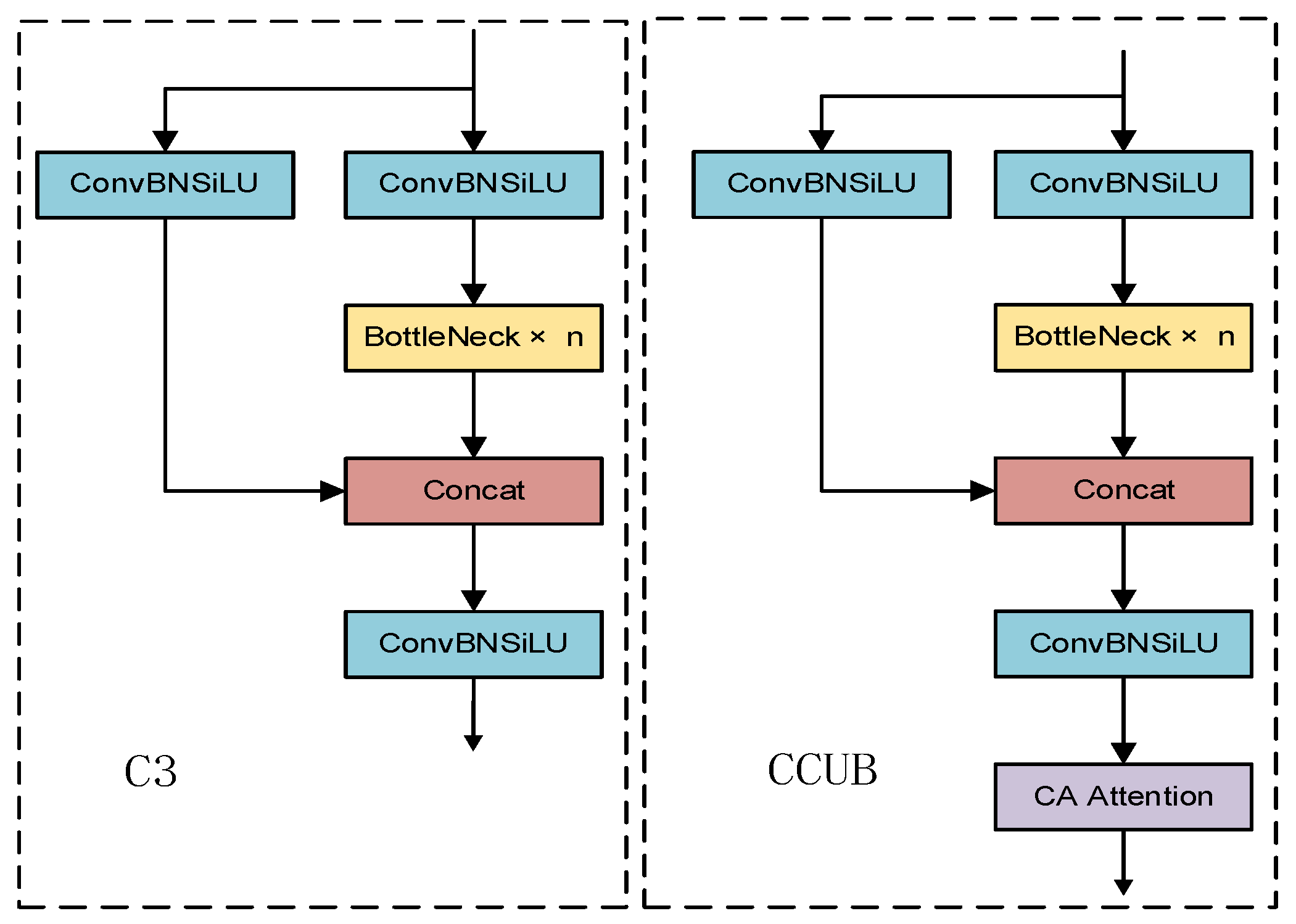
- Adding a coordinate attention (CA) [21] mechanism after the original C3 module of YOLOv5, as proposed in [22], but without compressing the number of channels in the bottleneck, which results in a new C3-CA-Uncompress Bottleneck (CCUB) module used for increasing the receptive field and allowing the model to pay more attention to important parts of the processed images;
- Verifying (by comparison with four state-of-the-art models, based on experiments conducted on two datasets—private and public) that these new elements, introduced into YOLOv5, do indeed improve the river garbage detection performance.
2. Background
2.1. Attention Mechanisms
2.2. Feature Fusion
2.3. Intersection over Union (IoU) Loss Functions
3. Related Work
3.1. Two-Stage Object Detection Models
3.1.1. R-CNN
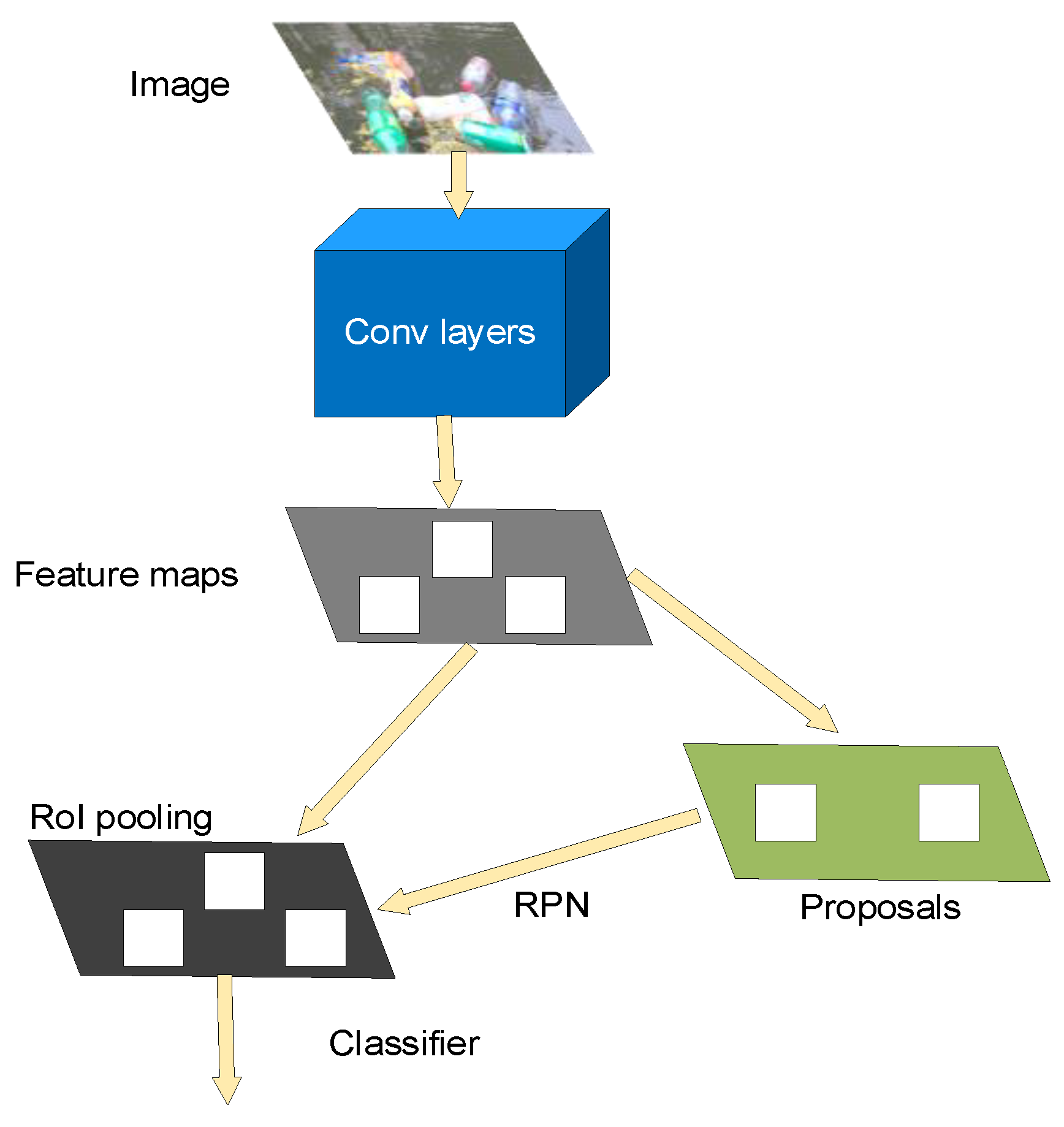
3.1.2. Faster R-CNN
3.2. Single-Stage Object Detection Models
3.2.1. Single Shot MultiBox Detector (SSD)
3.2.2. YOLO
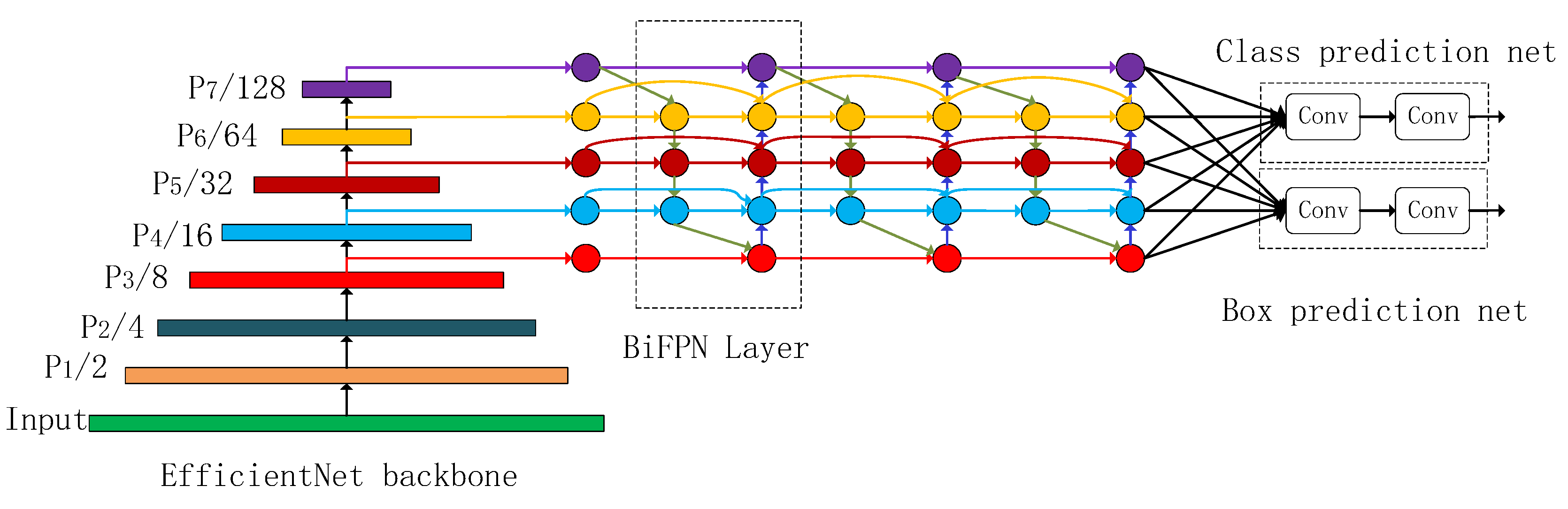
3.2.3. EfficientDet
4. Proposed YOLOv5_CBS Model
4.1. Using a SIoU Loss Function
4.2. Using a Coordinate Attention
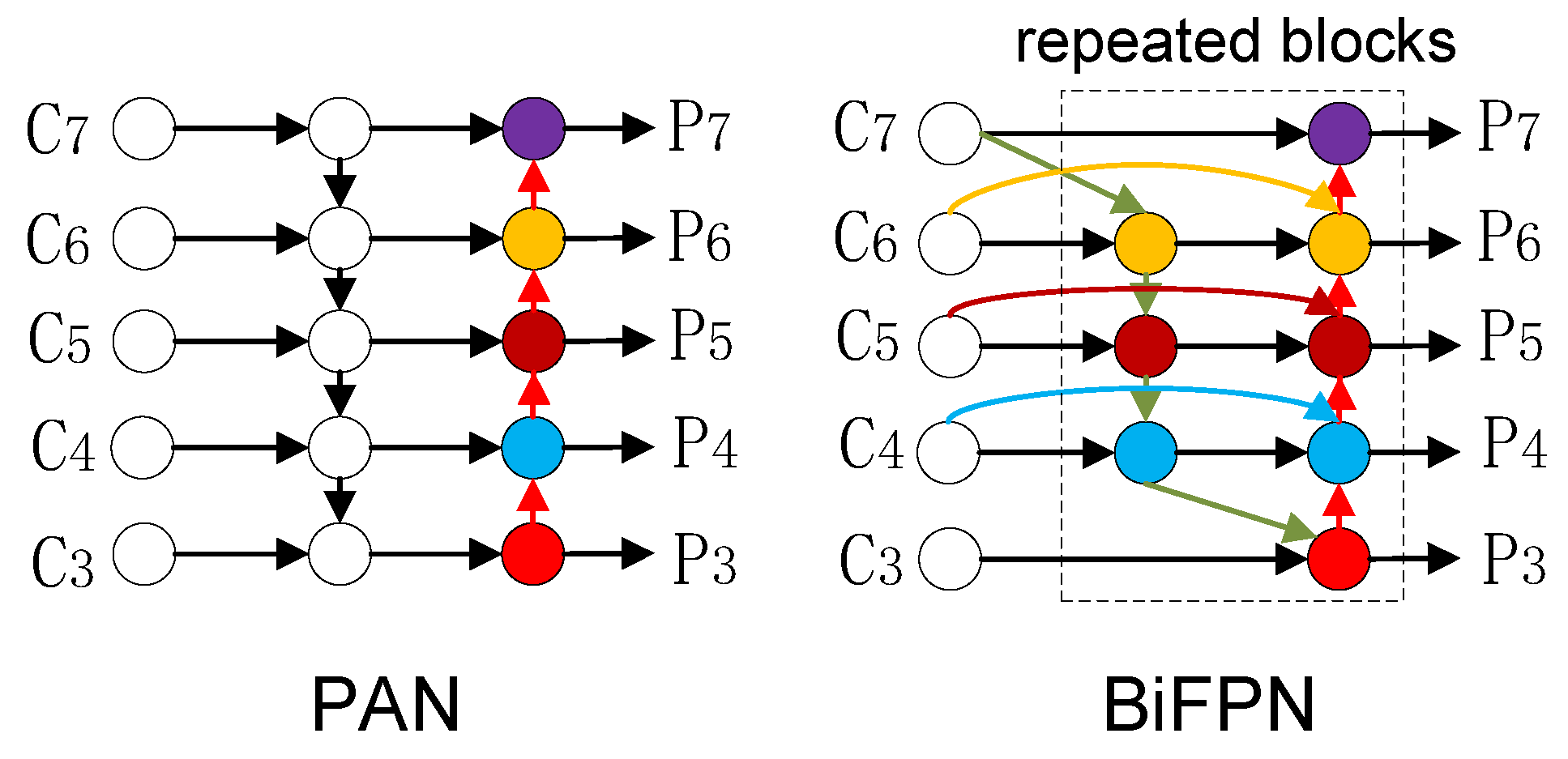
4.3. Using a BiFPN
5. Experiments and Results
5.1. Datasets
5.2. Experiments Setup
5.3. Evaluation Metrics
5.4. Results
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Huang, J.; Jiang, X.; Jin, G. Detection of River Floating Debris in UAV Images Based on Improved YOLOv5. In Proceedings of the 2022 International Joint Conference on Neural Networks (IJCNN), Padua, Italy, 18–23 July 2022; pp. 1–8. [Google Scholar]
- Viola, P.A.; Jones, M.J. Rapid Object Detection using a Boosted Cascade of Simple Features. In Proceedings of the Computer Vision and Pattern Recognition, 2001, CVPR 2001, Kauai, HI, USA, 8–14 December 2001. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE computer society conference on computer vision and pattern recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; pp. 886–893. [Google Scholar]
- Felzenszwalb, P.F.; Mcallester, D.A.; Ramanan, D. A discriminatively trained, multiscale, deformable part model. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008. [Google Scholar]
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.; Ramanan, D. Object detection with discriminatively trained part-based models. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1627–1645. [Google Scholar] [CrossRef] [PubMed]
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D. Cascade object detection with deformable part models. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2241–2248. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-fcn: Object detection via region-based fully convolutional networks. Adv. Neural Inf. Process. Syst. 2016, 29. Available online: https://arxiv.org/abs/1605.06409 (accessed on 26 July 2022).
- Li, Z.; Peng, C.; Yu, G.; Zhang, X.; Deng, Y.; Sun, J. Light-head r-cnn: In defense of two-stage object detector. arXiv 2017, arXiv:1711.07264. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. Scaled-yolov4: Scaling cross stage partial network. In Proceedings of the IEEE/cvf Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13029–13038. [Google Scholar]
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. TPH-YOLOv5: Improved YOLOv5 based on transformer prediction head for object detection on drone-captured scenarios. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 2778–2788. [Google Scholar]
- Hou, Q.B.; Zhou, D.Q.; Feng, J.S.; Ieee Comp, S.O.C. Coordinate Attention for Efficient Mobile Network Design. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR, Nashville, TN, USA, 20–25 June 2021; pp. 13708–13717. [Google Scholar]
- Li, J.; Liu, C.; Lu, X.; Wu, B. CME-YOLOv5: An Efficient Object Detection Network for Densely Spaced Fish and Small Targets. Water 2022, 14, 2412. [Google Scholar] [CrossRef]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 12993–13000. [Google Scholar]
- Gevorgyan, Z. SIoU Loss: More Powerful Learning for Bounding Box Regression. arXiv 2022, arXiv:2205.12740. [Google Scholar]
- Bello, I.; Zoph, B.; Vaswani, A.; Shlens, J.; Le, Q.V. Attention augmented convolutional networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 3286–3295. [Google Scholar]
- Choromanski, K.; Likhosherstov, V.; Dohan, D.; Song, X.; Gane, A.; Sarlos, T.; Hawkins, P.; Davis, J.; Mohiuddin, A.; Kaiser, L. Rethinking attention with performers. arXiv 2020, arXiv:2009.14794. [Google Scholar]
- Cai, Z.W.; Fan, Q.F.; Feris, R.S.; Vasconcelos, N. A Unified Multi-scale Deep Convolutional Neural Network for Fast Object Detection. In Lecture Notes in Computer Science, Proceedings of the COMPUTER VISION—ECCV 2016, PT IV, Amsterdam, The Netherlands, 11–14 October 2016; Springer Nature: Cham, Switzerland, 2016; pp. 354–370. [Google Scholar]
- Huang, L.; Wang, W.; Chen, J.; Wei, X.-Y. Attention on attention for image captioning. In Proceedings of the IEEE/CVF International Pconference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 4634–4643. [Google Scholar]
- Jie, H.; Li, S.; Gang, S.; Albanie, S. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 2011–2023. [Google Scholar] [CrossRef]
- Woo, S.H.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Lecture Notes in Computer Science, Proceedings of the COMPUTER VISION—ECCV 2018, PT VII, Munich, Germany, 8–14 September 2018; Springer Nature: Cham, Switzerland, 2018; pp. 3–19. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11531–11539. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zhai, H.; Cheng, J.; Wang, M. Rethink the IoU-based loss functions for bounding box regression. In Proceedings of the 2020 IEEE 9th Joint International Information Technology and Artificial Intelligence Conference (ITAIC), Chongqing, China, 11–13 December 2020; pp. 1522–1528. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized Intersection Over Union: A Metric and a Loss for Bounding Box Regression. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar]
- Zhang, Y.-F.; Ren, W.; Zhang, Z.; Jia, Z.; Wang, L.; Tan, T. Focal and efficient IoU loss for accurate bounding box regression. Neurocomputing 2022, 506, 146–157. [Google Scholar] [CrossRef]
- Niu, X.-X.; Suen, C.Y. A novel hybrid CNN–SVM classifier for recognizing handwritten digits. Pattern Recognit. 2012, 45, 1318–1325. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Yun, S.; Han, D.; Oh, S.J.; Chun, S.; Choe, J.; Yoo, Y. Cutmix: Regularization strategy to train strong classifiers with localizable features. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6023–6032. [Google Scholar]
- Wang, C.-Y.; Liao, H.-Y.M.; Wu, Y.-H.; Chen, P.-Y.; Hsieh, J.-W.; Yeh, I.-H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 13–19 June 2020; pp. 390–391. [Google Scholar]
- Misra, D. Mish: A self regularized non-monotonic neural activation function. arXiv 2019, arXiv:1908.08681. [Google Scholar]
- Ghiasi, G.; Lin, T.-Y.; Le, Q.V. Dropblock: A regularization method for convolutional networks. Adv. Neural Inf. Process. Syst. 2018, 31. Available online: https://proceedings.neurips.cc/paper/2018/file/7edcfb2d8f6a659ef4cd1e6c9b6d7079-Paper.pdf (accessed on 25 July 2022).
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 10778–10787. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Zhu, L.; Deng, Z.; Hu, X.; Fu, C.-W.; Xu, X.; Qin, J.; Heng, P.-A. Bidirectional feature pyramid network with recurrent attention residual modules for shadow detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 121–136. [Google Scholar]
- Du, F.-J.; Jiao, S.-J. Improvement of Lightweight Convolutional Neural Network Model Based on YOLO Algorithm and Its Research in Pavement Defect Detection. Sensors 2022, 22, 3537. [Google Scholar] [CrossRef] [PubMed]
- Cheng, Y.; Zhu, J.; Jiang, M.; Fu, J.; Pang, C.; Wang, P.; Sankaran, K.; Onabola, O.; Liu, Y.; Liu, D. FloW: A Dataset and Benchmark for Floating Waste Detection in Inland Waters. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 10953–10962. [Google Scholar]
- Liu, H.; Sun, F.; Gu, J.; Deng, L. SF-YOLOv5: A Lightweight Small Object Detection Algorithm Based on Improved Feature Fusion Mode. Sensors 2022, 22, 5817. [Google Scholar] [CrossRef] [PubMed]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Private Dataset | Flow-Img Dataset | |
|---|---|---|
| Training subset | 2106 labels | 3163 labels |
| Validation subset | 702 labels | 1054 labels |
| Test subset | 702 labels | 1054 labels |
| Component | Name/Value |
|---|---|
| Operating system | Windows 11 |
| CPU | Intel TM i5-11400F |
| GPU | GeForce RTX3060 |
| Video memory | 12 GB |
| Training acceleration | CUDA 11.3 |
| Deep learning framework for training | PyTorch 1.11 |
| Input image size | 640 × 640 |
| Initial learning rate | 0.01 |
| Final learning rate | 0.1 |
| Optimizer | SGD |
| Optimizer momentum | 0.937 |
| Training batch size | 8 |
| Model | Experiment 1 | Experiment 2 | Experiment 3 | Experiment 4 | Experiment 5 |
|---|---|---|---|---|---|
| Faster R-CNN | 76.16 | 78.63 | 75.76 | 78.11 | 75.47 |
| YOLOv3 | 80.09 | 81.34 | 79.28 | 81.46 | 82.43 |
| YOLOv4 | 80.90 | 82.73 | 80.44 | 81.83 | 82.97 |
| YOLOv5 | 85.96 | 88.37 | 87.73 | 86.44 | 88.28 |
| YOLOv5_CBS | 89.82 | 91.92 | 90.38 | 90.96 | 91.16 |
| Model | Experiment 1 | Experiment 2 | Experiment 3 | Experiment 4 | Experiment 5 |
|---|---|---|---|---|---|
| Faster R-CNN | 78.34 | 77.83 | 79.16 | 80.12 | 78.96 |
| YOLOv3 | 82.27 | 83.65 | 83.01 | 84.83 | 83.93 |
| YOLOv4 | 87.65 | 87.90 | 86.22 | 88.52 | 85.81 |
| YOLOv5 | 90.51 | 90.93 | 89.56 | 92.15 | 89.76 |
| YOLOv5_CBS | 91.68 | 92.65 | 91.46 | 93.77 | 91.34 |
| Model | Experiment 1 | Experiment 2 | Experiment 3 | Experiment 4 | Experiment 5 |
|---|---|---|---|---|---|
| Faster R-CNN | 0.7003 | 0.7198 | 0.6954 | 0.7146 | 0.6919 |
| YOLOv3 | 0.7534 | 0.7642 | 0.7379 | 0.7613 | 0.7704 |
| YOLOv4 | 0.7694 | 0.7859 | 0.7678 | 0.7805 | 0.7839 |
| YOLOv5 | 0.8049 | 0.8361 | 0.8277 | 0.8204 | 0.8314 |
| YOLOv5_CBS | 0.8564 | 0.8759 | 0.8636 | 0.8675 | 0.8712 |
| Model | Experiment 1 | Experiment 2 | Experiment 3 | Experiment 4 | Experiment 5 |
|---|---|---|---|---|---|
| Faster R-CNN | 0.7102 | 0.7118 | 0.7249 | 0.7367 | 0.7179 |
| YOLOv3 | 0.7768 | 0.7913 | 0.7880 | 0.7994 | 0.7902 |
| YOLOv4 | 0.8490 | 0.8504 | 0.8413 | 0.8572 | 0.8392 |
| YOLOv5 | 0.8763 | 0.8796 | 0.8992 | 0.8974 | 0.8637 |
| YOLOv5_CBS | 0.8935 | 0.9048 | 0.8957 | 0.9186 | 0.8904 |
| Model | Recall | F1 Score | AP (%) | Training Time (h) | FPS |
|---|---|---|---|---|---|
| Faster R-CNN | 0.604 | 0.7044 | 76.83 | 18.4 | 11.6 |
| YOLOv3 | 0.667 | 0.7574 | 80.92 | 8.6 | 30.9 |
| YOLOv4 | 0.693 | 0.7775 | 81.77 | 7.5 | 40.1 |
| YOLOv5 | 0.837 | 0.8241 | 87.36 | 2.2 | 95.2 |
| YOLOv5_CBS | 0.885 | 0.8669 | 90.85 | 2.9 | 75.2 |
| Model | Recall | F1 Score | AP (%) | Training Time (h) | FPS |
|---|---|---|---|---|---|
| Faster R-CNN | 0.621 | 0.7203 | 78.88 | 16.1 | 10.5 |
| YOLOv3 | 0.685 | 0.7891 | 83.54 | 7.5 | 31.7 |
| YOLOv4 | 0.828 | 0.8474 | 87.22 | 6.5 | 39.8 |
| YOLOv5 | 0.861 | 0.8832 | 90.58 | 1.6 | 96.2 |
| YOLOv5_CBS | 0.865 | 0.9006 | 92.18 | 2.1 | 76.9 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, X.; Zhao, J.; Zhao, L.; Zhang, H.; Li, L.; Ji, Z.; Ganchev, I. Detection of River Floating Garbage Based on Improved YOLOv5. Mathematics 2022, 10, 4366. https://doi.org/10.3390/math10224366
Yang X, Zhao J, Zhao L, Zhang H, Li L, Ji Z, Ganchev I. Detection of River Floating Garbage Based on Improved YOLOv5. Mathematics. 2022; 10(22):4366. https://doi.org/10.3390/math10224366
Chicago/Turabian StyleYang, Xingshuai, Jingyi Zhao, Li Zhao, Haiyang Zhang, Li Li, Zhanlin Ji, and Ivan Ganchev. 2022. "Detection of River Floating Garbage Based on Improved YOLOv5" Mathematics 10, no. 22: 4366. https://doi.org/10.3390/math10224366
APA StyleYang, X., Zhao, J., Zhao, L., Zhang, H., Li, L., Ji, Z., & Ganchev, I. (2022). Detection of River Floating Garbage Based on Improved YOLOv5. Mathematics, 10(22), 4366. https://doi.org/10.3390/math10224366