
Ocular Biometrics with Low-Resolution Images Based on Ocular Super-Resolution CycleGAN


Abstract
1. Introduction
Background of Biometrics
- -
- Different from a conventional CycleGAN, our proposed OSRCycleGAN reduces the number of weight filters by half in generator and discriminator. Consequently, it can decrease system complexity and memory usage while increasing the processing speed.
- -
- The proposed OSRCycleGAN does not use identity loss compared to conventional CycleGAN loss while using cycle consistent and perceptual losses. When calculating the perceptual loss in particular, it calculates authentic and imposter matching dissimilarities between mini-batch unit images in order to reflect them in cycle consistent and discriminator losses.
- -
- For a fair performance evaluation by other researchers, the trained OSRCycleGAN model and algorithms are publicly available on request.
2. Related Work
2.1. Iris and Ocular Recognition without SRR
2.2. Iris and Ocular Recognition with SRR
2.2.1. Conventional Image Processing-Based Method
2.2.2. Learning-Based Method
2.2.3. Deep Feature-Based Method
3. Proposed Method
3.1. Overview of Proposed Method
3.2. SRR by OSRCycleGAN
3.2.1. Architecture of CycleGAN
3.2.2. Architecture of OSRCycleGAN
3.2.3. Loss of OSRCycleGAN
3.2.4. Difference between OSRCycleGAN and Original CycleGAN
- -
- Different from a conventional CycleGAN, our proposed OSRCycleGAN reduces the number of weight filters by half in generator and discriminator. Consequently, it can decrease system complexity and memory usage while increasing the processing speed.
- -
- The proposed OSRCycleGAN does not use identity loss compared to conventional CycleGAN loss while using cycle consistent and perceptual losses. When calculating the perceptual loss in particular, it calculates authentic and imposter matching dissimilarities between mini-batch unit images in order to reflect them in cycle consistent and discriminator losses.
3.3. Ocular Recognition
4. Experimental Results
4.1. Dataset and Experimental Environments
4.2. Training of the Proposed Model
Training of OSRCycleGAN
4.3. Testing of the Proposed Method
4.3.1. Ablation Studies
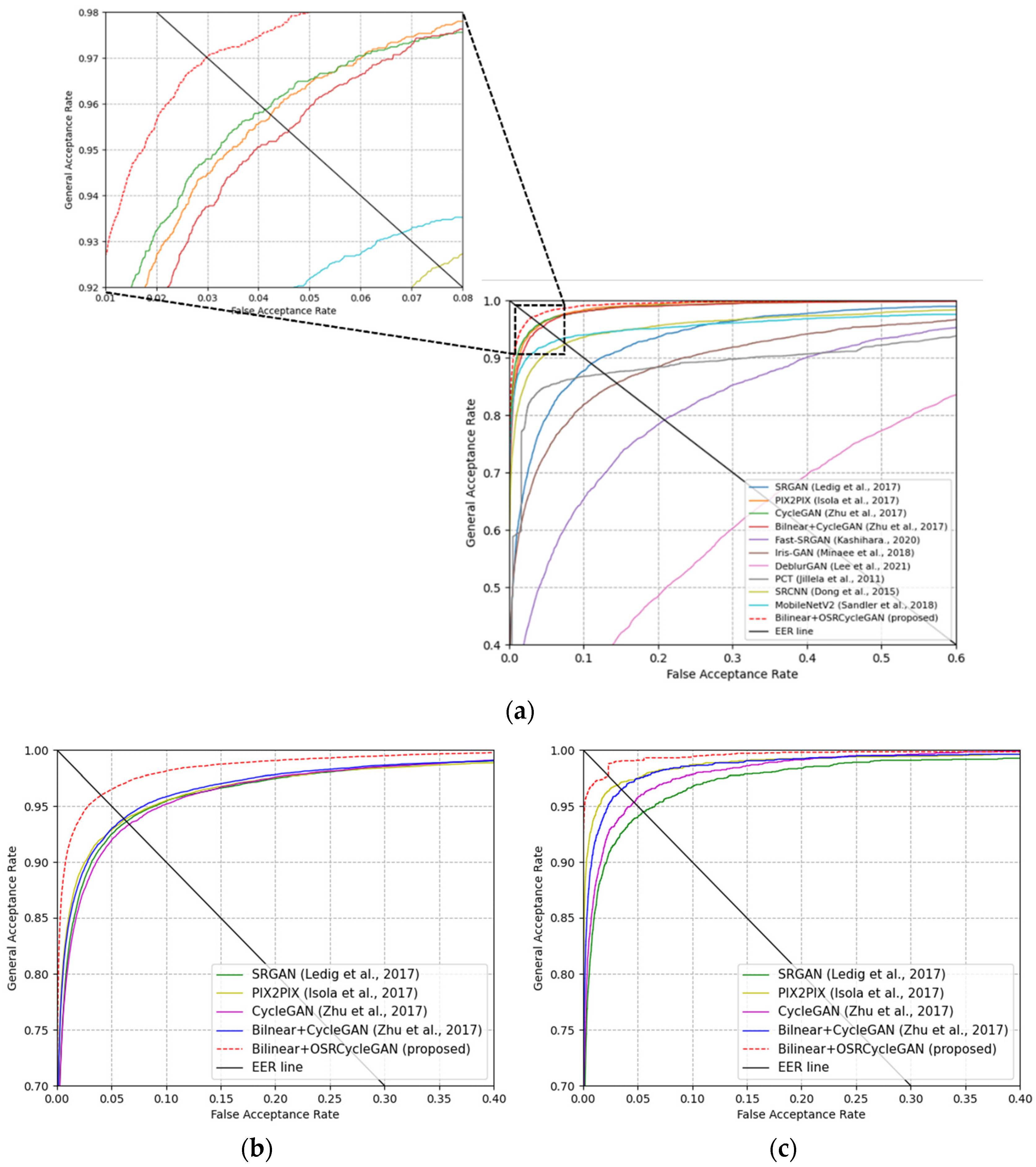
4.3.2. Comparisons with the State-of-the-Art Methods

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| High-Resolution Image Obtained by | Recognizer Input | Loss for GAN | EER (%) | |
|---|---|---|---|---|
| Traditional image processing-based | PCT [71] | Reconstruction image (three channels) | Null | 13.23 |
| Learning-based | SRCNN [16] | Mean Squared Error loss | 7.54 | |
| Deep learning-based | MobileNetV2 [72] | Mean Squared Error loss | 6.78 | |
| SRGAN [19] | Original SRGAN loss | 11.18 | ||
| Pix2Pix [66] | Original Pix2pix loss | 4.21 | ||
| CycleGAN [50] | Original CycleGAN loss | 4.19 | ||
| Bilinear interpolation + CycleGAN [50] | Interpolated image (two channels) + reconstruction image (one channel) | Original CycleGAN loss | 4.41 | |
| Fast-SRGAN [68] | Reconstruction image (three channel) | Original Fast-SRGAN loss + VGG content loss | 20.86 | |
| Iris-GAN [69] | Original Iris-GAN loss | 14.43 | ||
| DeblurGAN [70] | Original DeblurGAN loss | 34.86 | ||
| Bilinear interpolation +OSRCycleGAN (proposed) | Interpolated image (two channels) + reconstruction image (one channel) | Cycle consistent loss + Perceptual loss | 3.02 | |
| High-Resolution Image Obtained by | Recognizer Input | Loss for GAN | EER (%) |
|---|---|---|---|
| SRGAN [19] | Reconstruction image (three channels) | Original SRGAN loss | 6.39 |
| Pix2Pix [66] | Reconstruction image (three channels) | Original Pix2pix loss | 6.24 |
| CycleGAN [50] | Reconstruction image (three channels) | Original CycleGAN loss | 6.65 |
| Bilinear interpolation + CycleGAN [50] | Interpolated image (two channels) + reconstruction image (one channel) | Original CycleGAN loss | 6.11 |
| Bilinear interpolation + OSRCycleGAN (proposed) | Interpolated image (two channels) + reconstruction image (one channel) | Cycle consistent loss + Perceptual loss | 4.06 |
| High-Resolution Image Obtained by | Recognizer Input | Loss for GAN | EER (%) |
|---|---|---|---|
| SRGAN [19] | Reconstruction image (three channels) | Original SRGAN loss | 5.57 |
| Pix2Pix [66] | Reconstruction image (three channels) | Original Pix2pix loss | 3.09 |
| CycleGAN [50] | Reconstruction image (three channels) | Original CycleGAN loss | 4.46 |
| Bilinear interpolation + CycleGAN [50] | Interpolated image (two channels) + reconstruction image (one channel) | Original CycleGAN loss | 3.35 |
| Bilinear interpolation + OSRCycleGAN (proposed) | Interpolated image (two channels) + reconstruction image (one channel) | Cycle consistent loss + Perceptual loss | 2.13 |
4.3.3. Evaluation Based on Cross-Database Matching Performance
4.3.4. Processing Time and System Complexity
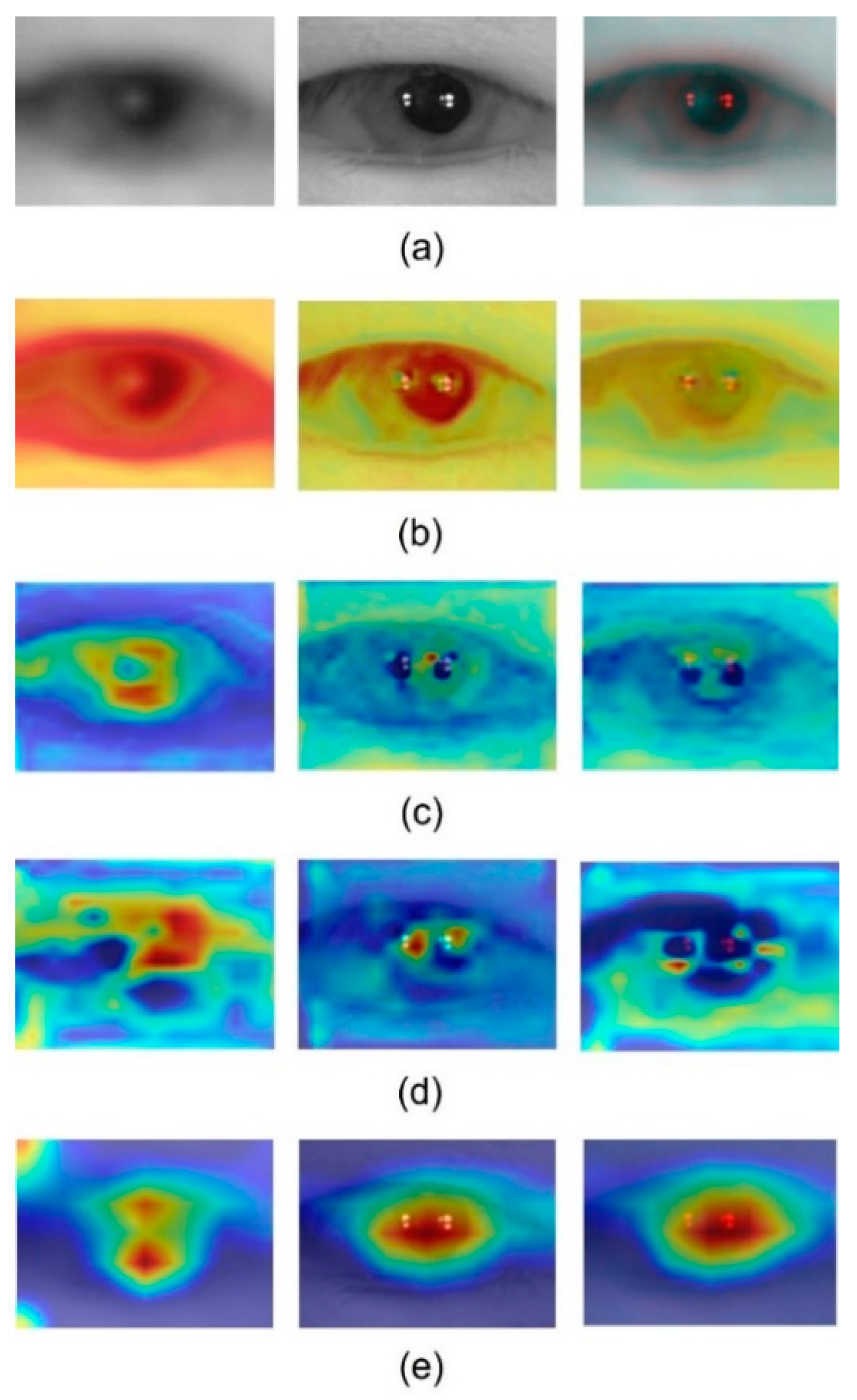
4.4. Analysis with Class Activation Maps
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Proenca, H.; Neves, J.C. Deep-PRWIS: Periocular recognition without the iris and sclera using deep learning frameworks. IEEE Trans. Inf. Forensics Secur. 2017, 13, 888–896. [Google Scholar] [CrossRef]
- Noh, K.J.; Choi, J.; Hong, J.S.; Park, K.R. Finger-vein recognition based on densely connected convolutional network using score-level fusion with shape and texture images. IEEE Access 2020, 8, 96748–96766. [Google Scholar] [CrossRef]
- Daugman, J.G. High confidence visual recognition of persons by a test of statistical independence. IEEE Trans. Pattern Anal. Mach. Intell. 1993, 15, 1148–1161. [Google Scholar] [CrossRef]
- Daugman, J.G. Biometric Personal Identification System Based on Iris Analysis. U.S. Patent 5291560, 1 March 1994. [Google Scholar]
- Daugman, J.G. Statistical richness of visual phase information: Update on recognizing persons by iris patterns. Int. J. Comput. Vis. 2001, 45, 25–38. [Google Scholar] [CrossRef]
- Daugman, J.G. The importance of being random: Statistical principles of iris recognition. Pattern Recognit. 2003, 36, 279–291. [Google Scholar] [CrossRef]
- Daugman, J.G. How iris recognition works. IEEE Trans. Circuits Syst. Video Technol. 2004, 14, 21–30. [Google Scholar] [CrossRef]
- Daugman, J.G. New methods in iris recognition. IEEE Trans. Syst. Man, Cybern. Part B (Cybern.) 2007, 37, 1167–1175. [Google Scholar] [CrossRef]
- Nguyen, K.; Fookes, C.; Jillela, R.; Sridharan, S.; Ross, A. Long range iris recognition: A survey. Pattern Recognit. 2017, 72, 123–143. [Google Scholar] [CrossRef]
- Verma, S.; Mittal, P.; Vatsa, M.; Singh, R. At-a-distance person recognition via combining ocular features. In Proceedings of the IEEE International Conference on Image Processing, Phoenix, AZ, USA, 25–28 September 2016; pp. 3131–3135. [Google Scholar]
- Bharadwaj, S.; Bhatt, H.S.; Vasta, M.; Singh, R. Periocular biometrics: When iris recognition fails. In Proceedings of the 4th IEEE International Conference on Biometrics: Theory, Application, and Systems, Washington, DC, USA, 27–29 September 2010; pp. 1–6. [Google Scholar]
- Su, H.; Tang, L.; Wu, Y.; Tretter, D.; Zhou, J. Spatially adaptive block-based super-resolution. IEEE Trans. Image Process. 2011, 21, 1031–1045. [Google Scholar] [CrossRef]
- Babacan, S.D.; Molina, R.; Katsaggelos, A.K. Variational Bayesian super resolution. IEEE Trans. Image Process. 2011, 20, 984–999. [Google Scholar] [CrossRef]
- Hu, J.; Wu, X.; Zhou, J. Noise robust single image super-resolution using a multiscale image pyramid. Signal Process. 2018, 148, 157–171. [Google Scholar] [CrossRef]
- Taniguchi, K.; Ohashi, M.; Han, X.-H.; Iwamoto, Y.; Sasatani, S.; Chen, Y.-W. Example-based super-resolution using locally linear embedding. In Proceedings of the 6th International Conference on Computer Sciences and Convergence Information Technology, Jeju Island, Korea, 29 November 2011–1 December 2011; pp. 861–865. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 295–307. [Google Scholar] [CrossRef] [PubMed]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27-30 June 2016; pp. 1646–1654. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the 28th Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.P.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Tan, C.-W.; Kumar, A. Accurate iris recognition at a distance using stabilized iris encoding and Zernike moments phase features. IEEE Trans. Image Process. 2014, 23, 3962–3974. [Google Scholar] [CrossRef]
- Nguyen, K.; Fookes, C.; Sridharan, S.; Denman, S. Quality-driven super-resolution for less constrained iris recognition at a distance and on the move. IEEE Trans. Inf. Forensics Secur. 2011, 6, 1248–1258. [Google Scholar] [CrossRef]
- Rodriguez, A.; Panza, J.; Kumar, B.V.K.V. Segmentation-free ocular detection and recognition. In Proceedings of the SPIE Defense, Security, and Sensing, Orlando, FL, USA, 25–29 April 2011; p. 8029. [Google Scholar] [CrossRef]
- Cho, S.R.; Nam, G.P.; Shin, K.Y.; Nguyen, D.T.; Pham, T.D.; Lee, E.C.; Park, K.R. Periocular-based biometrics robust to eye rotation based on polar coordinates. Multimedia Tools Appl. 2015, 76, 11177–11197. [Google Scholar] [CrossRef]
- Oishi, S.; Ichino, M.; Yoshiura, H. Fusion of iris and periocular user authentication by AdaBoost for mobile devices. In Proceedings of the IEEE International Conference on Consumer Electronics, Las Vegas, NV, USA, 9–12 January 2015; pp. 428–429. [Google Scholar] [CrossRef]
- Tan, C.-W.; Kumar, A. Towards online iris and periocular recognition under relaxed imaging constraints. IEEE Trans. Image Process. 2013, 22, 3751–3765. [Google Scholar] [CrossRef]
- Gangwar, A.; Joshi, A. DeepIrisNet: Deep iris representation with applications in iris recognition and cross-sensor iris recognition. In Proceedings of the IEEE International Conference on Image Processing, Phoenix, AZ, USA, 25–28 September 2016; pp. 2301–2305. [Google Scholar] [CrossRef]
- Lee, M.B.; Gil Hong, H.; Park, K.R. Noisy ocular recognition based on three convolutional neural networks. Sensors 2017, 17, 2933. [Google Scholar] [CrossRef]
- Liu, M.; Zhou, Z.; Shang, P.; Xu, D. Fuzzified image enhancement for deep learning in iris recognition. IEEE Trans. Fuzzy Syst. 2019, 28, 92–99. [Google Scholar] [CrossRef]
- Vizoni, M.V.; Marana, A.N. Ocular recognition using deep features for identity authentication. In Proceedings of the International Conference on System, Signals and Image Processing, Niteroi, Brazil, 1–3 July 2020; pp. 155–160. [Google Scholar]
- Lee, Y.W.; Kim, K.W.; Hoang, T.M.; Arsalan, M.; Park, K.R. Deep residual CNN-based ocular recognition based on rough pupil detection in the images by NIR camera sensor. Sensors 2019, 19, 842. [Google Scholar] [CrossRef]
- Nguyen, K.; Fookes, C.; Sridharan, S.; Denman, S. Feature-domain super-resolution for iris recognition. Comput. Vis. Image Underst. 2013, 117, 1526–1535. [Google Scholar] [CrossRef]
- Deshpande, A.; Patavardhan, P.P.; Rao, D.H. Super-resolution for iris feature extraction. In Proceedings of the IEEE Inter-national Conference on Computational Intelligence and Computing Research, Coimbatore, India, 18–20 December 2014; pp. 1–4. [Google Scholar]
- Nguyen, K.; Fookes, C.; Sridharan, S.; Denman, S. Focus-score weighted super-resolution for uncooperative iris recognition at a distance and on the move. In Proceedings of the 25th International Conference of Image and Vision Computing New Zealand, Queenstown, New Zealand, 8–9 November 2010; pp. 1–8. [Google Scholar] [CrossRef]
- Fahmy, G. Super-resolution construction of iris images from a visual low resolution face video. In Proceedings of the 9th International Symposium on Signal Processing and Its Applications, Sharjah, United Arab Emirates, 12–15 February 2007; pp. 1–4. [Google Scholar]
- Shirke, S.D.; Rajabhushnam, C. Biometric personal iris recognition from an image at long distance. In Proceedings of the 3rd International Conference on Trends in Electronics and Informatics, Tirunelveli, India, 23–25 April 2019; pp. 560–565. [Google Scholar]
- Cui, J.; Wang, Y.; Huang, J.Z.; Tan, T.; Sun, Z. An iris image synthesis method based on PCA and super-resolution. In Proceedings of the 17th International Conference on Pattern Recognition, Cambridge, UK, 26 August 2004; pp. 471–474. [Google Scholar]
- Shin, K.Y.; Park, K.R.; Kang, B.J.; Park, S.J. Super-resolution method based on multiple multi-layer perceptrons for iris recognition. In Proceedings of the 4th International Conference on Ubiquitous Information Technologies & Applications, Fukuoka, Japan, 20–22 December 2009; pp. 1–5. [Google Scholar]
- Shin, K.Y.; Kang, B.J.; Park, K.R.; Shin, J.-h. A Study on the restoration of a low-resolution iris image into a high-resolution one based on multiple multi-layered perceptrons. J. Korea Multimed. Soc. 2010, 13, 1581–1592. [Google Scholar]
- Shin, K.Y.; Kang, B.J.; Park, K.R. Super-resolution iris image restoration based on multiple MLPs and CLS filter. J. Internet Technol. 2012, 13, 233–244. [Google Scholar]
- Alonso-Fernandez, F.; Farrugia, R.A.; Bigun, J. Eigen-patch iris super-resolution for iris recognition improvement. In Proceedings of the 23rd European Signal Processing Conference (EUSIPCO), Nice, France, 31 August–4 September 2015; pp. 76–80. [Google Scholar] [CrossRef]
- Ribeiro, E.; Uhl, A.; Alonso-Fernandez, F.; Farrugia, R.A. Exploring deep learning image super-resolution for iris recognition. In Proceedings of the 25th European Signal Processing Conference (EUSIPCO), Kos, Greece, 28 August 2017–2 September 2017. [Google Scholar] [CrossRef]
- Reddy, N.; Noor, D.F.; Li, Z.; Derakhshani, R. Multi-frame super resolution for ocular biometrics. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 566–574. [Google Scholar]
- Ribeiro, E.; Uhl, A. Exploring Texture Transfer Learning via Convolutional Neural Networks for Iris Super Resolution. In Proceedings of the International Conference of the Biometrics Special Interest Group (BIOSIG), Darmstadt, Germany, 20–22 September 2017. [Google Scholar] [CrossRef]
- Tan, J.; Liao, X.; Liu, J.; Cao, Y.; Jiang, H. Channel attention image steganography with generative adversarial networks. IEEE Trans. Netw. Sci. Eng. 2021, 9, 888–903. [Google Scholar] [CrossRef]
- Liao, X.; Yu, Y.; Li, B.; Li, Z.; Qin, Z. A new payload partition strategy in color image steganography. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 685–696. [Google Scholar] [CrossRef]
- Liao, X.; Yin, J.; Chen, M.; Qin, Z. Adaptive payload distribution in multiple images steganography based on image texture features. IEEE Trans. Dependable Secur. Comput. 2022, 19, 897–911. [Google Scholar] [CrossRef]
- Yin, G.; Wang, W.; Yuand, Z.; Ji, W.; Yue, D.; Sun, S.; Chua, T.-S.; Wang, C. Conditional hyper-network for blind super-resolution with multiple degradations. IEEE Trans. Image Process. 2022, 31, 3949–3960. [Google Scholar] [CrossRef]
- Martins, A.L.D.; Homem, M.R.P.; Mascarenhas, N.D.A. Super-resolution Image reconstruction using the ICM Algorithm. In Proceedings of the IEEE International Conference on Image Processing, San Antonio, TX, USA, 16–19 September 2007; pp. 1–4. [Google Scholar]
- Han, Y.; Shu, F.; Zhang, Q. Image super-resolution reconstruction based on adaptive interpolation norm regularization. In Proceedings of the International Symposium on Intelligent Signal Processing and Communication Systems, Xiamen, China, 28 November–1 December 2007; pp. 1–4. [Google Scholar]
- Zhu, J.-Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2242–2251. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June 2016; pp. 770–778. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted Boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Multinomial Logistic Loss. Available online: http://caffe.berkeleyvision.org/doxygen/classcaffe_1_1MultinomialLogisticLossLayer.html (accessed on 1 July 2022).
- CASIA-iris Version 4. Available online: http://biometrics.idealtest.org/dbDetailForUser.do?id=4#/datasetDetail/4 (accessed on 3 July 2022).
- Kumar, A.; Passi, A. Comparison and combination of iris matchers for reliable personal authentication. Pattern Recognit. 2010, 43, 1016–1026. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–8 December 2012; pp. 1097–1105. [Google Scholar]
- NVIDIA GeForce GTX 1070. Available online: https://www.nvidia.com/en-us/geforce/products/10series/geforce-gtx-1070/ (accessed on 3 July 2022).
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. 2015. Available online: https://www.tensorflow.org (accessed on 10 July 2022).
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional architecture for fast feature embedding. In Proceedings of the 22nd ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 675–678. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the International Conference on Learning Representation, San Diego, CA, USA, 7–9 May 2015; pp. 1–15. [Google Scholar]
- Bottou, L. Stochastic Gradient Descent Tricks. In Neural Networks: Tricks of the Trade; Montavon, G., Orr, G.B., Müller, K.R., Eds.; Lecture Notes in Computer Science; Springer: Berlin, Heidelberg, 2012; p. 7700. [Google Scholar]
- Stathaki, T. Image Fusion: Algorithms and Applications; Academic Press: Cambridge, MA, USA, 2008. [Google Scholar]
- Salomon, D. Data Compression: The Complete Reference, 4th ed.; Springer: New York, NY, USA, 2006. [Google Scholar]
- Wang, Z.; Bovik, A.; Sheikh, H.; Simoncelli, E. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Isola, P.; Zhu, J.-Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Gonzalez, R.C.; Woods, R.E. Digital Image Processing; Prentice Hall: Upper Saddle River, NJ, USA, 2010. [Google Scholar]
- Kashihara, K. Iris recognition for biometrics based on CNN with super-resolution GAN. In Proceedings of the IEEE Conference on Evolving and Adaptive Intelligent Systems, Bari, Italy, 27–29 May 2020; pp. 1–6. [Google Scholar]
- Minaee, S.; Abdolrashidi, A. Iris-GAN: Learning to Generate Realistic Iris Images Using Convolutional GAN. arXiv 2018, arXiv:1812.04822. Available online: https://arxiv.org/abs/1812.04822 (accessed on 10 July 2022).
- Lee, M.B.; Kang, J.K.; Yoon, H.S.; Park, K.R. Enhanced Iris Recognition Method by Generative Adversarial Network-Based Image Reconstruction. IEEE Access 2021, 9, 10120–10135. [Google Scholar] [CrossRef]
- Jillela, R.; Ross, A.; Flynn, P.J. Information fusion in low-resolution iris videos using Principal Components Transform. In Proceedings of the IEEE Workshop on Applications of Computer Vision (WACV), Kona, HI, USA, 5–7 January 2011; pp. 262–269. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Student’s T-Test. Available online: https://en.wikipedia.org/wiki/Student%27s_t-test (accessed on 3 October 2022).
- Cohen, J. A power primer. Psychol. Bull. 1992, 112, 155. [Google Scholar] [CrossRef]
- Jetson TX2 Module. Available online: https://www.nvidia.com/en-us/autonomous-machines/embedded-systems/ (accessed on 15 July 2022).
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar] [CrossRef]












| Category | Method(s) | Strength | Weakness | ||
|---|---|---|---|---|---|
| Without SRR | Handcrafted feature-based | Iris | Daugman’s method [5,8] | Does not require an additional graphics processing unit | Does not consider the performance degradation for low-resolution iris images |
| Stabilized iris encoding and Zernike moments phase features [20] | |||||
| Noisy image captured at a distance [39] | |||||
| Iris + ocular | Used ocular region including iris and periocular [10,22,23,24,25] | High recognition performance in various environments as both iris and periocular region information are used | Poorer recognition performance than the deep-feature-based method | ||
| Deep feature-based | Iris | DeepIrisNet [26] | Improved recognition performance for noisy iris images as multiple CNNs are used | Training time for each model is increased as multiple CNNs are used | |
| Ocular | Multiple CNN-based noisy ocular recognition [27] | Solves existing iris segmentation accuracy problem and low-quality image issue by using both iris and ocular regions | - Training time increases because of multiple CNNs - Does not consider the performance degradation for low-resolution images | ||
| With SRR | Image processing-based | Iris | SRR for captured image at a distance [21,33], MAP [31], PG + POCS [32], FCM [35] | SRR was applied to prevent performance degradation due to low-resolution image captured from a long distance | Limitations in resolution restoration because of existing image processing technique |
| Learning-based | PCA + ICA [34], PCA [36,40], MLP [37,38,39] | Better restoration results than traditional image processing methods | Limited improvement of SRR performance in various environments | ||
| Deep feature-based | Iris | Stacked auto-encoder [41], SRCNN + VDCNN [43] | Higher SRR performance than image processing-based or learning-based methods | Limited recognition and SRR accuracies in various environments as a general CNN or encoder are used | |
| Ocular | Multi-frame SRR + CNN-based deblurring [42] | Improved performance by separating SRR and deblurring processes | |||
| OSRCycleGAN (proposed method) | Generator and discriminator improve SRR performance through competitive learning | Requires intensive training procedure | |||
| Layers | Feature Map Size (Width × Height × Channels) | Filter Size | Number of Filters | Stride |
|---|---|---|---|---|
| Input layer | 380 × 280 × 3 | |||
| Conv-1 * | 380 × 280 × 32 | 7 × 7 × 3 | 32 | 1 |
| Conv-2 * | 190 × 140 × 64 | 3 × 3 × 32 | 64 | 2 |
| Conv-3 * | 95 × 70 × 128 | 3 × 3 × 64 | 128 | 2 |
| Residual 1–6 ** | 95 × 70 × 128 | 3 × 3 × 128 | 128 | 1 |
| Deconv1 * | 190 × 140 × 64 | 4 × 4 × 128 | 64 | 2 |
| Deconv2 * | 380 × 280 × 32 | 4 × 4 × 64 | 32 | 2 |
| Output * | 380 × 280 × 3 | 7 × 7 × 32 | 3 | 1 |
| Layers | Feature Map Size | Filter Size | Number of Filters | Stride |
|---|---|---|---|---|
| Input layer | 380 × 280 × 3 | |||
| Conv-1 * | 190 × 140 × 32 | 4 × 4 × 3 | 32 | 2 |
| Conv-2 ** | 95 × 70 × 64 | 4 × 4 × 32 | 64 | 2 |
| Conv-3 ** | 48 × 35 × 128 | 4 × 4 × 64 | 128 | 2 |
| Conv-4 ** | 24 × 18 × 256 | 4 × 4 × 128 | 256 | 1 |
| Conv-5 (Output) | 24 × 18 × 1 | 4 × 4 × 256 | 1 | 1 |
| Category | Number of Classes | Number of Images | ||||
|---|---|---|---|---|---|---|
| Before Augmentation | After Augmentation | |||||
| DB1 | DB2 | DB1 | DB2 | DB1 | DB2 | |
| CASIA-Iris-Distance | 142 | 140 | 2080 | 2056 | 351,520 | 347,464 |
| CASIA-Iris-Lamp | 408 | 408 | 8054 | 8036 | 1,361,126 | 1,358,084 |
| IIT Delhi iris database | 210 | 223 | 1120 | 1120 | 189,280 | 189,280 |
| Methods | PSNR | SNR | SSIM |
|---|---|---|---|
| SRGAN [19] | 15.64 | 1.15 | 0.68 |
| Pix2Pix [66] | 27.2 | 5.91 | 0.78 |
| CycleGAN [50] | 18.4 | 1.74 | 0.71 |
| OSRCycleGAN | 22.66 | 2.03 | 0.74 |
| High-Resolution Image Obtained by | Recognizer Input | Recognizer Training Method | Loss for OSRCycleGAN | EER (%) |
|---|---|---|---|---|
| Bilinear interpolation | Interpolated image (three channels) | Without training (only testing) | Loss is not used | 11.41 |
| Fine-tuning * | 4.58 | |||
| OSRCycleGAN | Reconstruction image (three channels) | Without training (only testing) | Cycle consistent loss | 8.55 |
| Cycle consistent loss + Perceptual loss | 11.68 | |||
| Fine-tuning * | Cycle consistent loss | 13.98 | ||
| Cycle consistent loss + Perceptual loss | 4.28 | |||
| Bilinear interpolation + OSRCycleGAN (proposed) | Interpolated image (two channels) + reconstruction image(one channel) | Fine-tuning * | Cycle consistent loss | 9.26 |
| Cycle consistent loss + Perceptual loss | 7.01 | |||
| Fine-tuning ** | Cycle consistent loss | 13.25 | ||
| Cycle consistent loss + Perceptual loss | 3.28 | |||
| Train from scratch | Cycle consistent loss | 4.23 | ||
| Cycle consistent loss + Perceptual loss | 3.93 |
| High-Resolution Image Obtained by | Recognizer Input | Recognizer Training Method | Loss for OSRCycleGAN | EER (%) |
|---|---|---|---|---|
| Bilinear interpolation + Gaussian Blurring | Interpolated image (three channels) | Without training (only testing) | Loss is not used | 13.99 |
| Fine-tuning * | 4.82 | |||
| OSRCycleGAN | Reconstruction image (three channels) | Without training (only testing) | Cycle consistent loss | 10.84 |
| Cycle consistent loss + Perceptual loss | 6.15 | |||
| Fine-tuning * | Cycle consistent loss | 13.26 | ||
| Cycle consistent loss + Perceptual loss | 5.41 | |||
| Bilinear interpolation + OSRCycleGAN (proposed) | Interpolated image (two channels) + reconstruction image(one channel) | Fine-tuning * | Cycle consistent loss | 4.42 |
| Cycle consistent loss + Perceptual loss | 3.80 | |||
| Fine-tuning ** | Cycle consistent loss | 5.56 | ||
| Cycle consistent loss + Perceptual loss | 10.69 | |||
| Train from scratch | Cycle consistent loss | 6.95 | ||
| Cycle consistent loss + Perceptual loss | 3.02 | |||
| Cycle consistent loss + Perceptual loss + Identity loss | 6.26 | |||
| Cycle consistent loss + Perceptual loss + Identity loss + Focal loss | 5.88 |
| Cases | EER (%) |
|---|---|
| Case 1 | 3.68 |
| Case 2 | 6.46 |
| Environments | OSRCycleGAN | ResNet-101 | Total |
|---|---|---|---|
| Desktop computer | 6.89 | 47 | 53.89 |
| Jetson TX2 embedded system | 110 | 313 | 423 |
| Environments | Pix2Pix [66] | CycleGAN [50] | OSRCycleGAN |
|---|---|---|---|
| Desktop computer | 25.53 | 22.22 | 6.89 |
| Jetson TX2 embedded system | 273 | 177 | 110 |
| Pix2Pix [66] | CycleGAN [50] | OSRCycleGAN |
|---|---|---|
| 111.6 × 106 | 24.07 × 106 | 3.69 × 106 |
| CycleGAN [50] | 4.11 |
| OSRCycleGAN | 2.04 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, Y.W.; Kim, J.S.; Park, K.R. Ocular Biometrics with Low-Resolution Images Based on Ocular Super-Resolution CycleGAN. Mathematics 2022, 10, 3818. https://doi.org/10.3390/math10203818
Lee YW, Kim JS, Park KR. Ocular Biometrics with Low-Resolution Images Based on Ocular Super-Resolution CycleGAN. Mathematics. 2022; 10(20):3818. https://doi.org/10.3390/math10203818
Chicago/Turabian StyleLee, Young Won, Jung Soo Kim, and Kang Ryoung Park. 2022. "Ocular Biometrics with Low-Resolution Images Based on Ocular Super-Resolution CycleGAN" Mathematics 10, no. 20: 3818. https://doi.org/10.3390/math10203818
APA StyleLee, Y. W., Kim, J. S., & Park, K. R. (2022). Ocular Biometrics with Low-Resolution Images Based on Ocular Super-Resolution CycleGAN. Mathematics, 10(20), 3818. https://doi.org/10.3390/math10203818