1. Introduction
Statistical process control (SPC) is one of the methods most used in manufacturing industries to evaluate, monitor, and identify changes for process improvements. Thus, it is key to improving product quality and ensuring statistical process control [
1,
2]. The Shewhart control chart is a well-known, powerful method to examine the steadiness of a process. The control chart is a procedure to study a process from a sequence of random samples taken from the process. Data presented in the form of a control chart basis, patterns of runs, presence of outliers in the data will often suggest areas of opportunity for process improvement. Troubleshooting is successful when providing information about when the trouble began and what may be the cause. The process capability is independent of any specification; it represents the natural behavior of the process after the unnatural interferences are eliminated. It is a natural occurrence and is measured by the in-control chart variation. For these purposes, the traditional control technique introduced in 1924 by Walter Shewhart has been widely used in the manufacturing and service industries [
3,
4,
5,
6,
7].
Monitoring whether the process is in statistical control has been the primary function of the control charts. They are based on data representing one or several products or service quality characteristics [
2]. The variable control charts must be used if these characteristics are measured based on numerical scales. On the other hand, attribute control charts must be used if the quality characteristic cannot be easily represented in numerical form. However, for at least three decades, trends in research have dealt with the issue of control charts based on the fuzzy set theory [
8,
9,
10,
11], and this approach is still widely used [
12,
13,
14,
15,
16].
Process capability analysis is another SPC tool, where process capability is very well defined as the capacity of a process to meet customer expectations defined as specification limits [
17]. Process capability indices are summary statistics that measure the process characteristics overall or potential performance (variables or attributes) relative to the target and specification limits [
18]. This approach helps define a relationship between the process capability and the specification limits. This correspondence is made by forming the width ratio between the specification limits and the natural width tolerance set as six process standard deviation units [
19].
The main outputs for any process capability analysis will define whether a process can produce items within the specification limits predetermined by the customer. A larger value of the process capability index implies a high process yield; a lower one implies a low process yield. This process only expresses its capability at the moment and should never be considered capability in the future [
20]. The typical process capability indices in the literature are
,
,
, and
[
21]. In this research, the
and
are only analyzed.
The
index, called in literature as precision index [
22], is defined as the ratio between specifications limits over the process spread (
) [
17]. The index represents how well the process fits upper and lower specifications limits, describing the customer product requirements. When the process variation is considerable, the
value is small, which means a poor process capability. Since this index never considers any process shift, if the process average is not centered near the midpoint of specification width, then the
index could give misleading process performance. So, a new process capability index called
was introduced by Kane in 1986 [
22]. The main use of the
index is to indicate the variability associated with a process. This index is widely used to relate the natural tolerances (3
) to the customer requirements by considering the location of the process mean. Like to
index, a greater value for
index is desired. A
index value greater or equal to 1.33 is recommended [
23]. However, the
and
indices are not related to the cost of failing to meet the customer’s target requirement. On the other hand, the
index introduced by Hsiang and Taguchi (1985) measures a process’s ability to cluster around the target and reflects the degree of process targeting [
24]. However, the information provided by
index could be taken when the
and
indices values are the same [
19].
Because the fuzzy set theory introduced by Zadeh (1965) [
25] has demonstrated to deal with imprecise information, its capability to determine flexible parameters and to analyze the results shows more sensitiveness [
26], the fuzzy approach has received attention for the last two decades. Several studies that include the fuzzy set theory to calculate process capability indices can be found in the literature [
1,
2,
26,
27,
28,
29,
30,
31,
32,
33,
34,
35,
36,
37,
38,
39,
40,
41,
42,
43,
44,
45,
46,
47,
48]. Since the introduction of neutrosophic logic (an extension of fuzzy logic), it has also been used to calculate process capability indices [
49,
50,
51].
It is common to use a dataset collected from quality control laboratories or directly from automated measuring instruments that are part of the process to evaluate process performance. The process capability indices are the typical approach to deal with this task. Note that these standard methods use data taken on the final product.
However, for complex processes where it is challenging to have enough data to calculate process capability indices (under a traditional or fuzzy approach), an alternative method to gather the required data is based on developing models with sufficient predictive capability. This alternative is the use of neural networks-based predictive models that could work as a source of data when a reasonable accuracy has been reached. A wide range of these kinds of models can be found in the literature with application in different fields of science [
52,
53,
54,
55,
56,
57,
58,
59,
60,
61,
62].
An alternative to the artificial neural network models is the neural structures based on the Geometric Transformation Model as a universal approximator. This approach uses a single methodological framework for various tasks. A fast non-iterative study with a predefined number of computation steps provides repeatability for large and small training samples [
63]. Additionally, the neuro-fuzzy models are becoming more widespread in several industries. Tkachenko et al. (2021) [
64] present a new neuro-fuzzy diagnostic system based on non-iterative ANN and a new fuzzy model, a T-controller.
Because the desired results for process capability indices are of the “bigger is better” type and considering that the process location and variability are two critical parameters in any process performance analysis. The traditional experimental designs are a powerful tool to overcome this problem. This approach has been widely exploited in different fields of science to define optimal process conditions [
65,
66,
67,
68,
69,
70,
71,
72]. However, although the traditional design of experiments is very common, for almost two decades, the design of experiments approach has also been applied via couple with neural networks models [
73,
74,
75,
76,
77,
78,
79,
80,
81,
82].
This research presents a novelty method to evaluate process performance by a non-invasive approach to calculate the fuzzy process capability indices. The proposed method uses the significative process variables data records that influence the response. The data collected is used to develop an artificial neural network model. This model is now being employed as a data source, firstly applying it to the design of experiments approach to identify the optimal conditions for the process performance. Once the optimal variables operating values have been obtained, these new operating conditions are re-introduced to the neural network model to calculate the output measures. Measures that are being used to calculate the fuzzy process capability indices. Currently, an integral method like the one presented is not found in the literature. The main contributions of this study are described below.
Artificial neural network-based modeling with reasonable accuracy has been reached in a papermaking process. Hence, this model can be used to measure a critical quality characteristic.
The fuzzy set theory has been incorporated to overcome the vagueness and uncertainty in the generated data commonly presented in soft sensors.
Via coupled applications of artificial neural network based-modeling + experimental designs, data for process performance evaluation can be generated by engineers instead of taking measurements directly on the product. Hence, the method can be considered as non-invasive.
This paper is organized as follows:
Section 2 briefly reviews the traditional and fuzzy methods to calculate process capability indices.
Section 3 presents the proposed methodology by defining a framework. Meanwhile,
Section 4 presents an actual case application presenting data from a papermaking process to validate the proposed method. Finally, the last section presents the conclusions and recommendations.
4. Real Case Application
The process capability analysis has been held for a papermaking process in a paper grade of 200 g (basis weight named “L-200”). These capability indices have been calculated using a fuzzy environment to get more reliable information about the process capability.
Firstly, the model proposed in [
83] is used as an alternative method to collect data on paper’s basis weight. This model is advantageous since it can predict the basis weight with reasonable accuracy (greater than 90%) for new operating conditions or data not included in the training and validation process. Mainly for the grades from 180 to 250 g/m
2, reaching an error from 4.8 to 6.7%. In the modeling process, the input array size was 182,834 rows by 24 columns, while the output array size was 182,834 rows by one column. This amount of data samples was enough to develop a robust neural network model. Additionally, the 24 columns correspond to all the independent variables affecting the basis weight in the paper. Hence, these variables must be continuously monitored and controlled by process engineers.
For the training and validation process, the input array size was 164,550 rows by 24 columns, while the output array size was 164,550 rows by one column. In the testing process, the input array size was 18,284 rows by 24 columns, while the output array size was 18,284 rows by one column. The following is a more detailed description of the process of obtaining the neural network model proposed in [
83].
The best-found architecture and structure of the neural network model are shown in
Table 1. The activation functions and the number of neurons per layer were moved by trial and error for the neural network architecture design. Meanwhile, the rest of the hyperparameters were: the loss and metric functions, a learning rate of 0.001 for the RMSprop optimizer, a batch size of 32, and 1000 epochs for each of the training and test process.
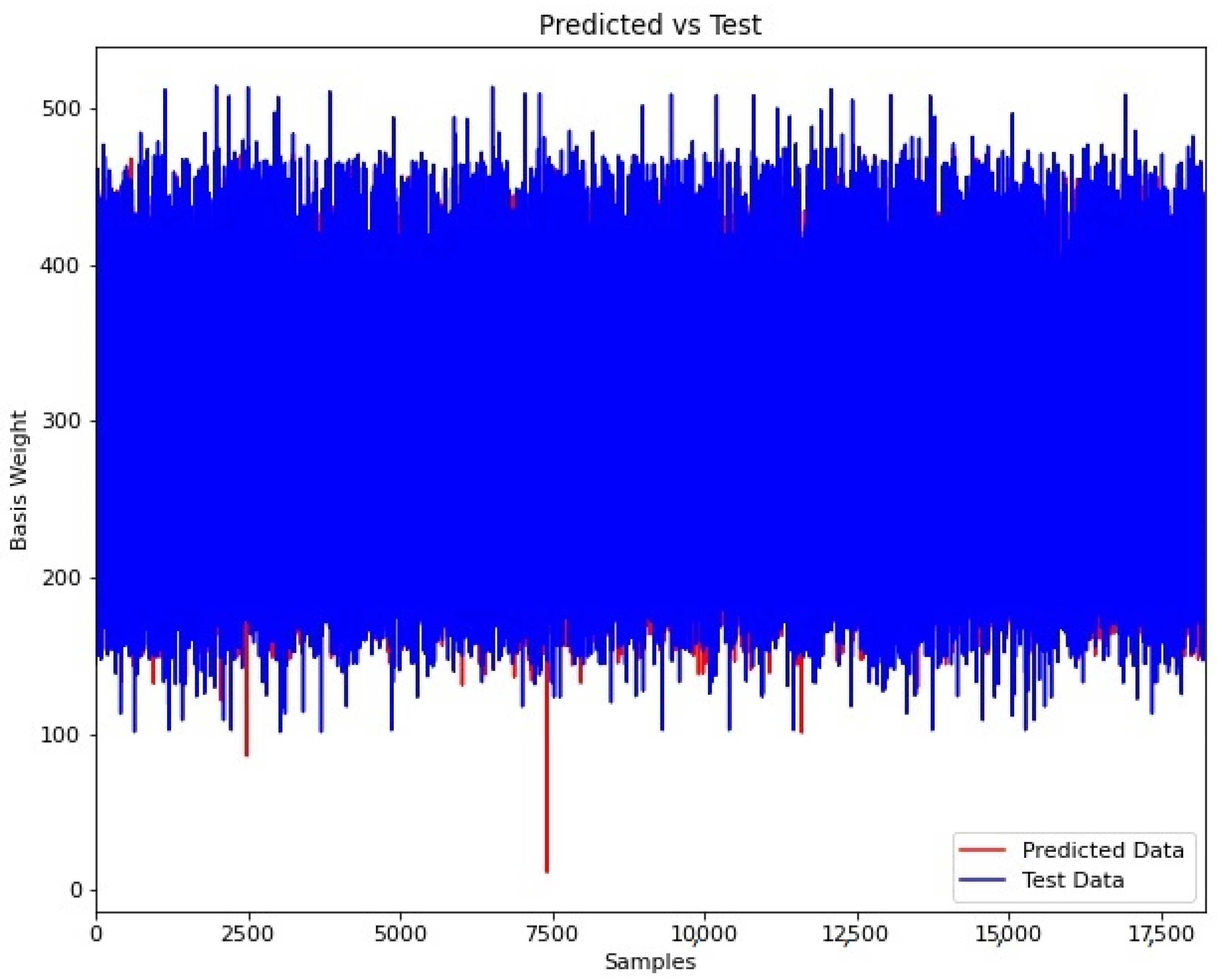
Figure 2 presents a training summary for the model loss level. Meanwhile, in
Figure 3 is shown the predicted vs. test data to evaluate the model performance in the building process. Finally, in
Figure 4 is shown in detail the predicted vs. test data for a random range selected from 12,000 to 12,200. As shown in graphical results, the model developed can determine the basis weight with reasonable precision.
The resulting mean absolute error (MAE) was 12.40 g. In addition, an external dataset not included in the process building of the model was used to validate the model performance. The resulting mean absolute error (MAE) was 12.10 g by using the external dataset.
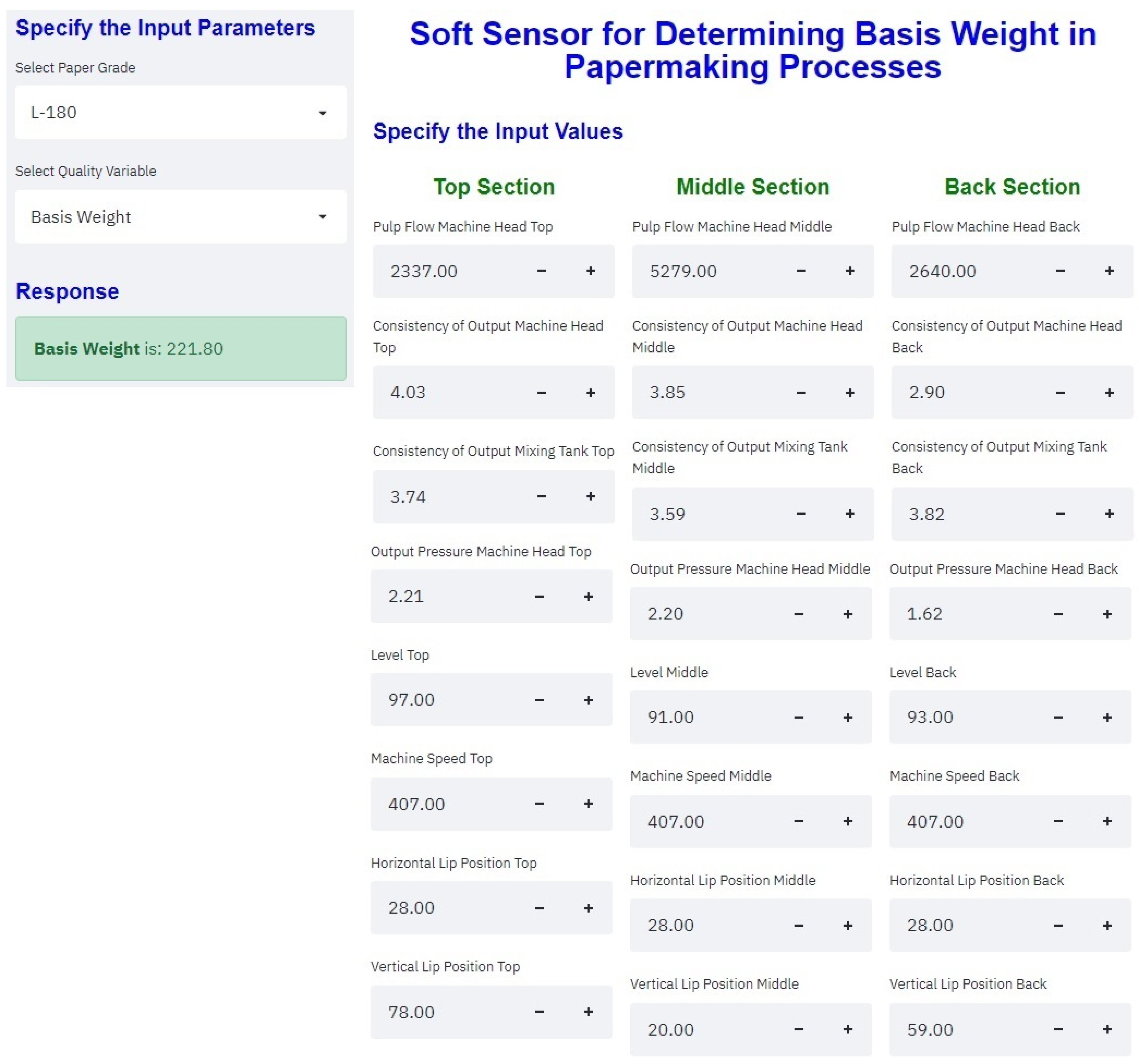
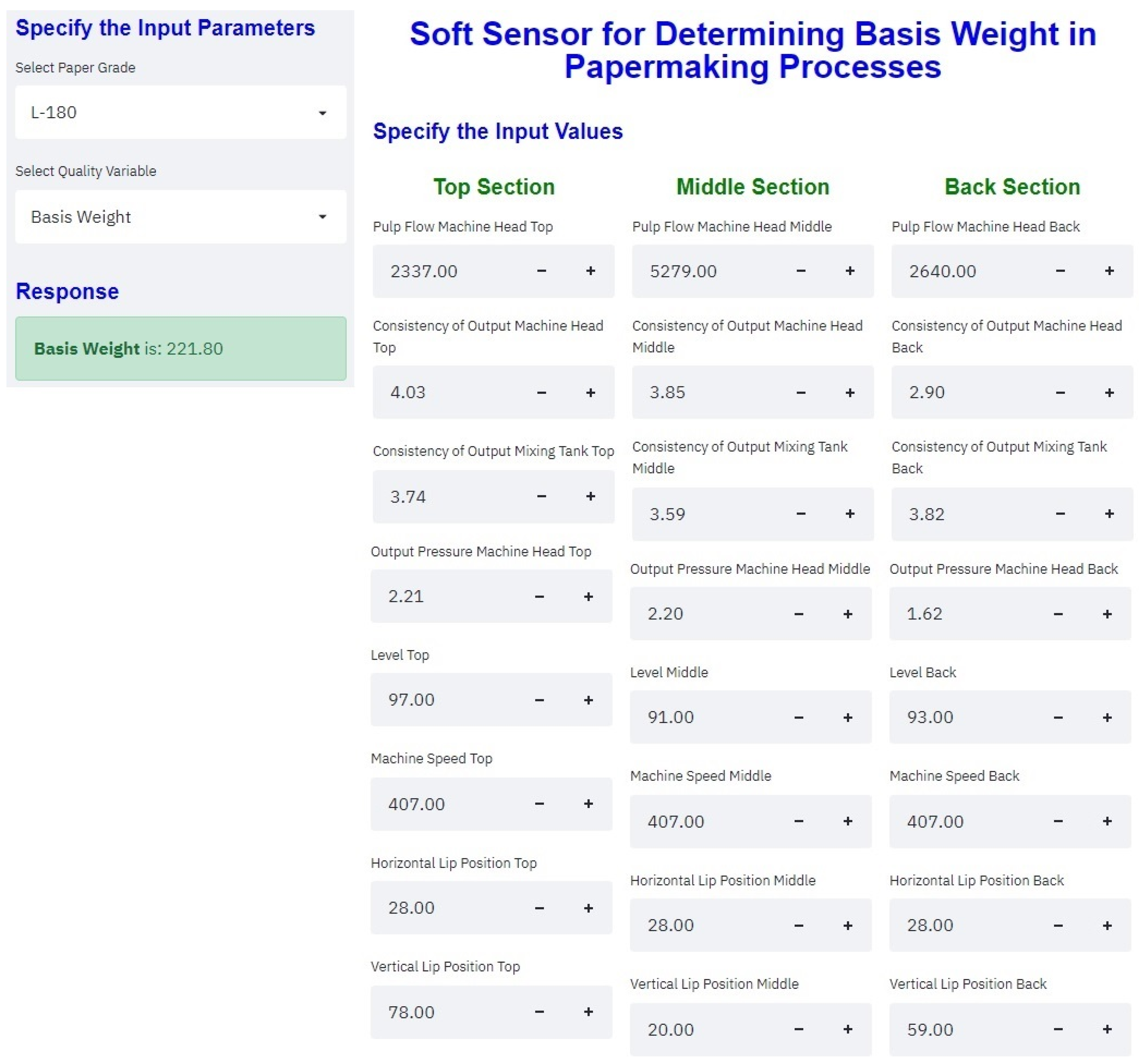
The graphic user interface was developed using the streamlit library in the Python programming language. So, the model was embedded in the user interface. The generated package can work well in any local host. Moreover, the model can also work in a web environment, allowing the process engineers to calculate basis weight offline.
Figure 5 shows the framework of the graphic user interface proposed by Rodríguez et al. [
83]. To present the graphical user interface from a terminal on your computer, you must add the path where the GUI source code is located and then enter the following instruction:
run streamlit name.py.
The GUI will automatically display the average value of each independent variable; however, as mentioned above, the user can manually manipulate each variable.
Given the excellent performance shown by the neural network model to predict the basis weight, it was used to evaluate the response in the experimental design step. In addition, due to the large number of independent variables involved in the papermaking process, the Placket-Burman factorial experimental design was selected. Before carrying out the experimental design analysis, all independent variables were coded. The high and low levels of each independent variable were defined in collaboration with process engineers according to the parameters commonly used to manufacture the different grades of paper.
Table 2 shows the entire list of independent variables and their levels included in the experiment.
Notice that the developed model is deterministic since the response will always be the same under the same operating conditions. However, in a real situation, the response must show variability. So, a first experimental design must be carried out to know the variability and include it in the model response. Therefore, Minitab-19
® was used to generate the fully randomized design table. This table contains one replicate per experiment, with 48 runs without blocks. Each experiment’s response (basis weight) was the predicted value using the neural network model inserted in the graphic user interface. Notice that each run of the experimental design can be entered manually in the graphical user interface or enter all runs as a matrix array in the source code that generated the neural network model in Python using the
model.predict(x) function. The coded data are presented in the
Appendix A.
The results in
Figure 6 show that the model’s assumptions are met: normality, constant variance, and independence. Meanwhile,
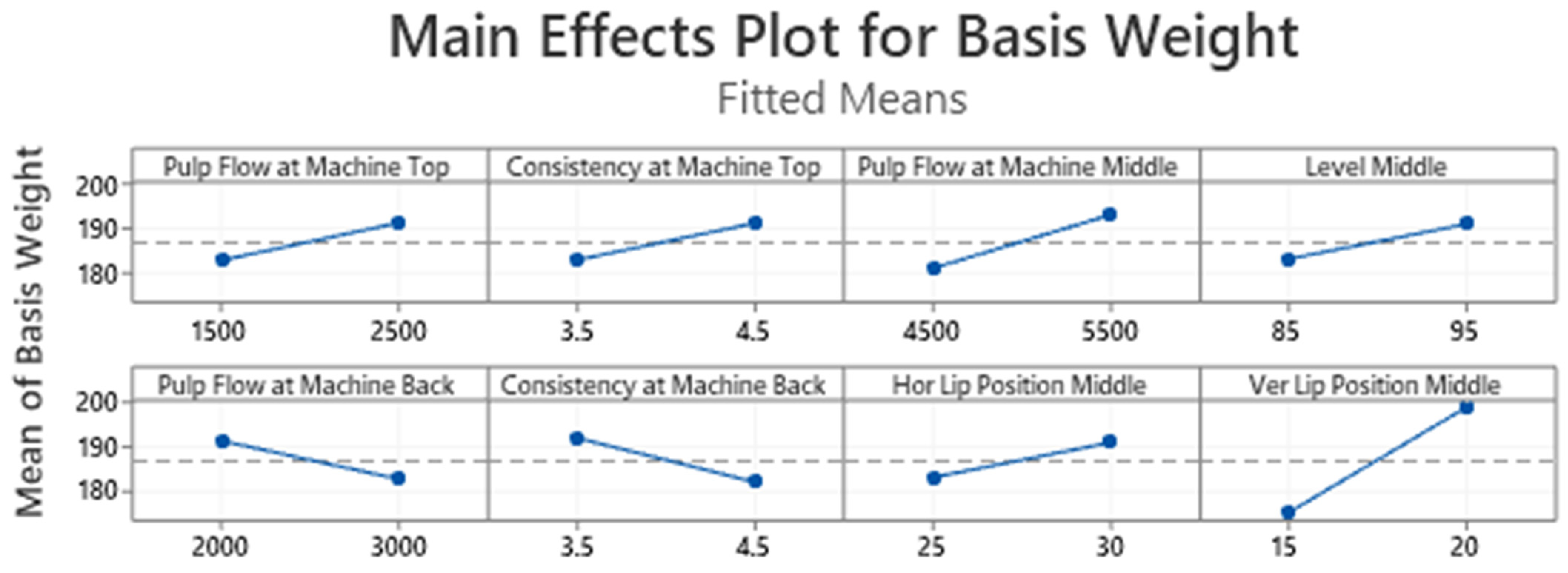
Table 3 summarizes the analysis of variance. The stepwise selection method uses an α risk value to enter 0.15 and an α risk value to remove 0.15. The results indicate that the process variables, Pulp Flow at Machine Top, Pulp Flow at Machine Middle, Pulp Flow at Machine Back, Consistency at Machine Back, and Vertical Lip Position, were significant at 5%. On the other hand, Consistency at Machine Top, Level Middle, and Horizontal Lip Position Middle showed
p-values of 0.051, 0.064, and 0.067, respectively. These variables were also considered significant. The main effects plot for each variable mentioned above is shown in
Figure 7.
Note the main experimental design results are shown, such as the graphs validating the model assumptions, the analysis of variance, and the main effects plot. However, in the present work, the experimental design approach is used to obtain the optimal operating parameters (for a 200 g paper) for all 24 independent variables and not to quantify the effects on the response variable (basis weight).
Finally, the first optimal operating conditions were determined by using the response optimizer. The results show a desirability index of 1.000 and the optimal values are summarized in
Table 4. Although these variables considerably affect the basis weight, defining the values (in advance, which are called set points) for the other independent variables is necessary. Therefore,
Table 4 also presents the recommended values.
The next step is generating the data to know the expected fuzzy process variability. Thus, the variability for all independent variables is determined. This variability is shown in
Table 4. This variability is included in a random dataset generated around the set point for each independent variable. Since the cycle time of a paper roll is about forty minutes, and because the papermaking process can generate data in the interval time of one minute; hence, a total of forty random data were generated for each independent variable. The resulting array size of 40 rows by 24 columns was introduced in the GUI to predict the basis weight. The predicted values (basis weight) used to calculate the fuzzy process variability are illustrated in
Table 5. Finally, using Equation (8), the membership function of
has been calculated and illustrated in
Figure 8. The results show that the standard deviation ranges from 1.39 to 4.55. This variability was included in the developed model. So, the predicted values are now affected by any random value taken from this data range.
Because the developed model is capable to provide different basis weight values for the same provided operating conditions; therefore, it is possible to perform replicated experimental designs, which allow knowing the variability, magnitude, and direction of the effects for each independent variable. Thus, by following the same method mentioned above, Minitab-19® is used again to carry out a replicated experimental design. Firstly, a fully randomized design table is generated. This table contains five replicates per experiment; so, there are 240 runs without blocks. The generated matrix size is 240 rows and 24 columns (due to the table size, these data are not included in the paper). This matrix is used to estimate the basis weight for each experiment (operating condition).
The results in
Figure 9 show that the model’s assumptions are again met: normality, constant variance, and independence. As mentioned above, the experimental design approach is used to obtain the optimal operating parameters; however, the tables shown in
Appendix B and
Appendix C summarize the coefficients and the analysis of variance, respectively. The results indicate that the process variables significant at a level of 5% were: Pulp Flow at Machine Top, Consistency at Machine Top, Pulp Flow at Machine Middle, Output Pressure at Machine Middle, Level Middle, Pulp Flow at Machine Back, Consistency at Machine Back, Consistency at Tank Back, Output Pressure at Machine Back, Level Back, Machine Speed Top, Ver Lip Position Top, Hor Lip Position Middle, and Ver Lip Position Middle. These variables have a significative effect on the basis weight. However, variables such as Pulp Flow at Machine Top, Consistency at Machine Top, Pulp Flow at Machine Middle, Level Middle, Consistency at Tank Back, Level Back, Machine Speed Top, Ver Lip Position Top, Hor Lip Position Middle, and Ver Lip Position Middle must be changed from low to a high level to reduce variability.
Meanwhile, the rest of the significative variables must change from high to low. The main effects plot for each variable mentioned above is shown in
Figure 10. Finally, the optimal operating conditions were determined using the response optimizer in Minitab-19
®. The results show a desirability index of 1.000 for the optimal values summarized in
Table 6.
The following step is generating the data to carry out the fuzzy process capability analysis. Again, the expected variability for each independent variable (presented in
Table 4) must be considered. Therefore, using this variability, a new random dataset is generated around the set point defined in
Table 6. Note that the operating conditions shown in
Table 6 differ from those in
Table 4. This difference is because the model includes the previously calculated variation and will present variation in the output data similar to the shown by the measurement systems. Hence, the resulting array size was 40 rows by 24 columns in the step where the variability range was estimated. This matrix was introduced in the graphic user interface to predict the basis weight. The predicted values (basis weight) used to apply the fuzzy process capability analysis are illustrated in
Table 7. Note that these values include the expected variation for each independent variable and the variability included in the model.
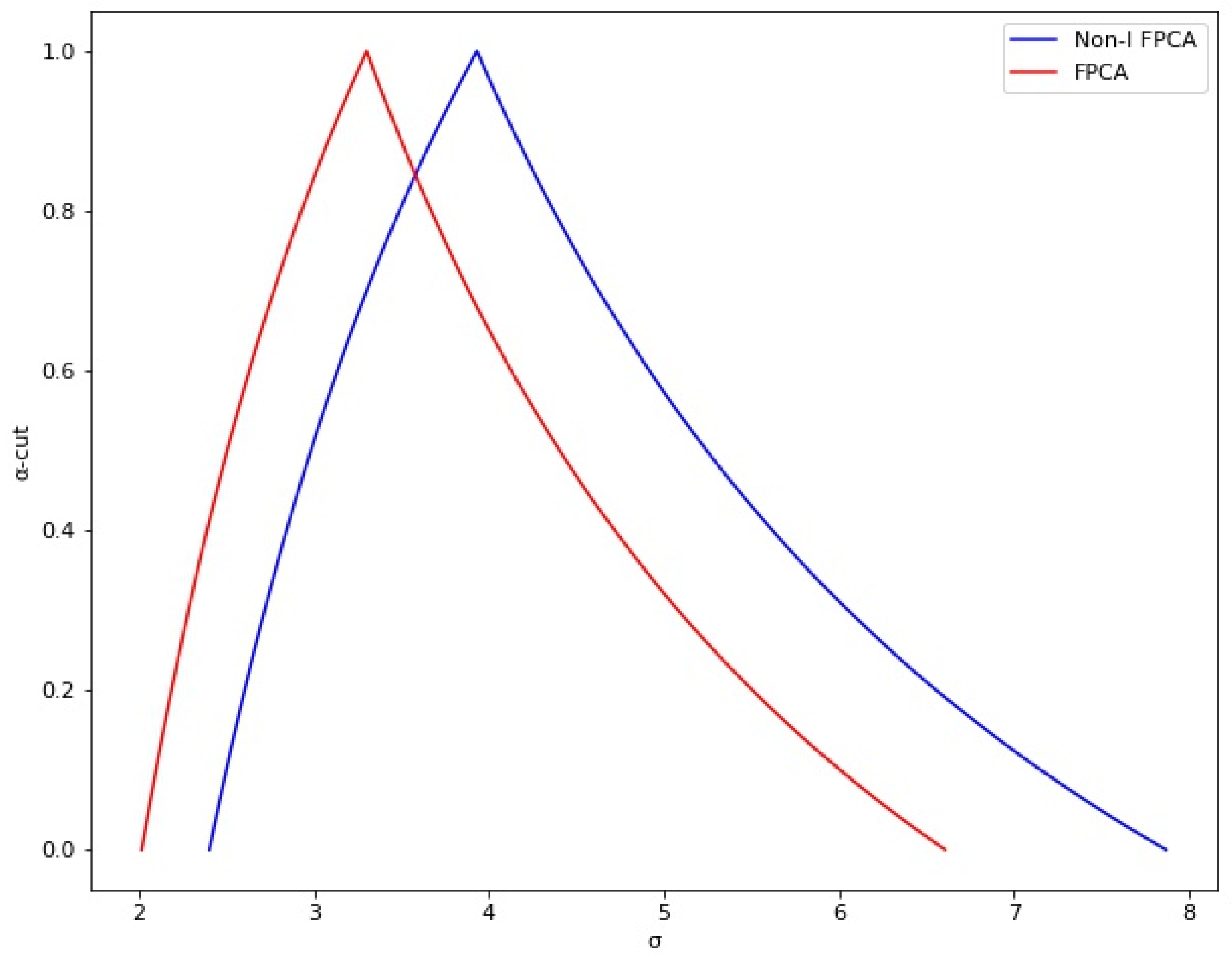
The fuzzy process capability indices are calculated in the proposed method’s last step. Firstly, using Equation (8), the membership function of
has been calculated and illustrated in
Figure 11. The standard deviation goes from 2.40 to 7.87 for different
-cut values. Notice that this variability is greater than estimated at the beginning because this variability includes the variability shown by all independent variables. This variability could be larger; however, by defining the optimal parameters, the variability was reduced in the predicted values of the basis weight. In addition, if the process engineers can have a better control for each of the significant critical variables identified in the experimental design step; then, the standard deviation would be reduced.
With calculated, now it is possible to calculate the fuzzy process capability indices. Because the method used to estimate included all data; therefore, and must be changed to and . The specification limits are defined by using the triangular fuzzy numbers to achieve this aim. Since the upper and lower specification limits for a paper grade of 200 g are 210 and 190 g, respectively; therefore, the specification limits are defined as follows: and .
Now, by using the Equations (9) and (10) the
-cut values for the upper and lower specification limits are obtained as follows:
, and
. And by using Equation (11), the membership function of
is calculated and depicted in
Figure 12. The range for
goes from 0.54 to 1.19 with different
-cut values.
Equations (12) and (13) are used to calculate the membership functions of
and
.
changes between 0.27 to 0.92 with different α-cut values. Meanwhile,
changed between 0.69 to 1.68 with different
-cut values. Therefore, using Equation (14), the range for
goes from 0.27 to 0.92, as shown in
Figure 13.
The membership functions of
-level were also calculated using the following equation:
. The
-level change between 0.81 to 2.77, as shown in
Figure 14.
Finally, a dataset of 200
g of paper grade randomly selected from the quality control system (QCS) is collected to compare the proposed method against the traditional and fuzzy approaches. For this purpose, forty continued basis weight readings between 190 to 210
g were taken. The
and
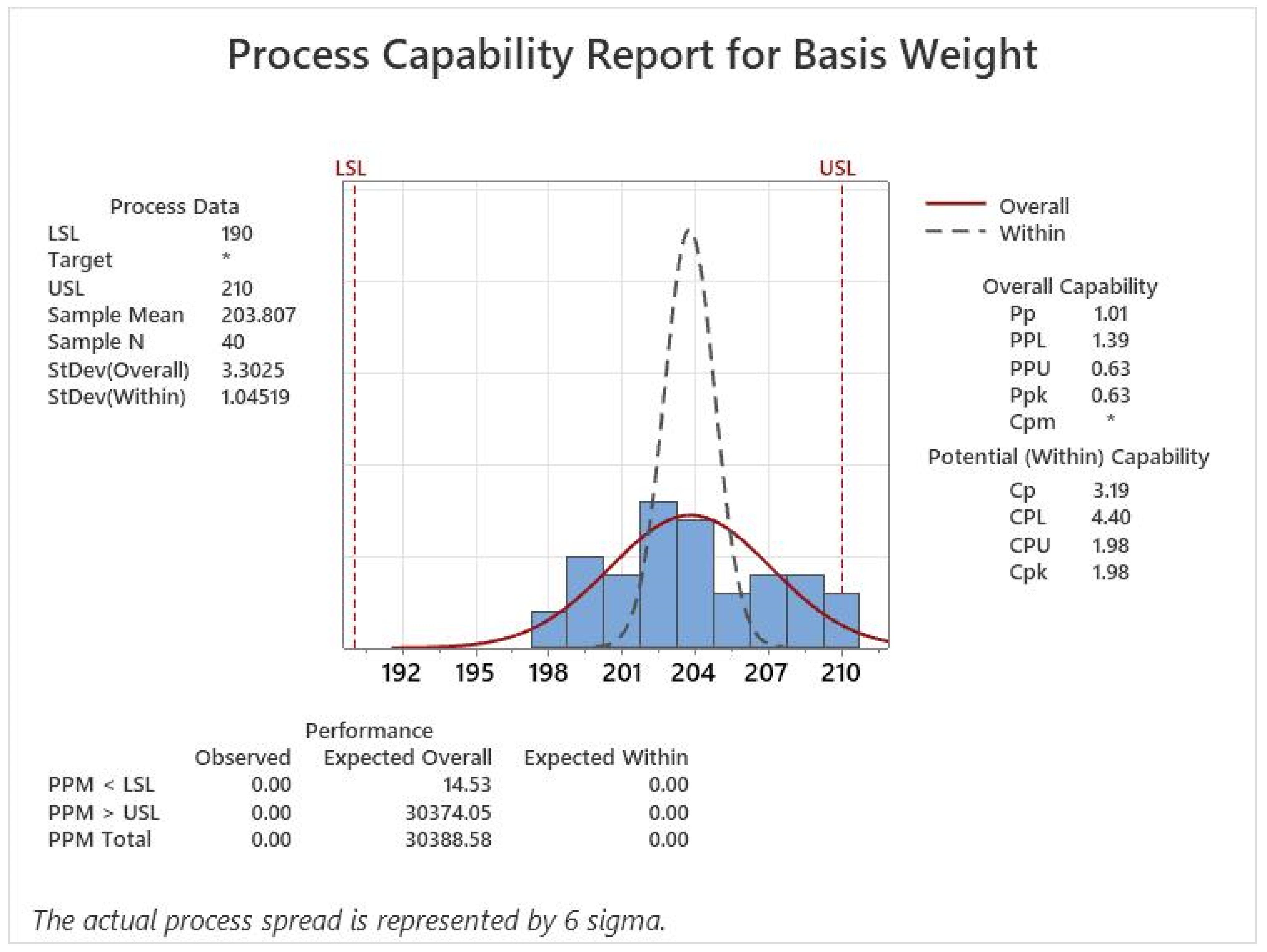
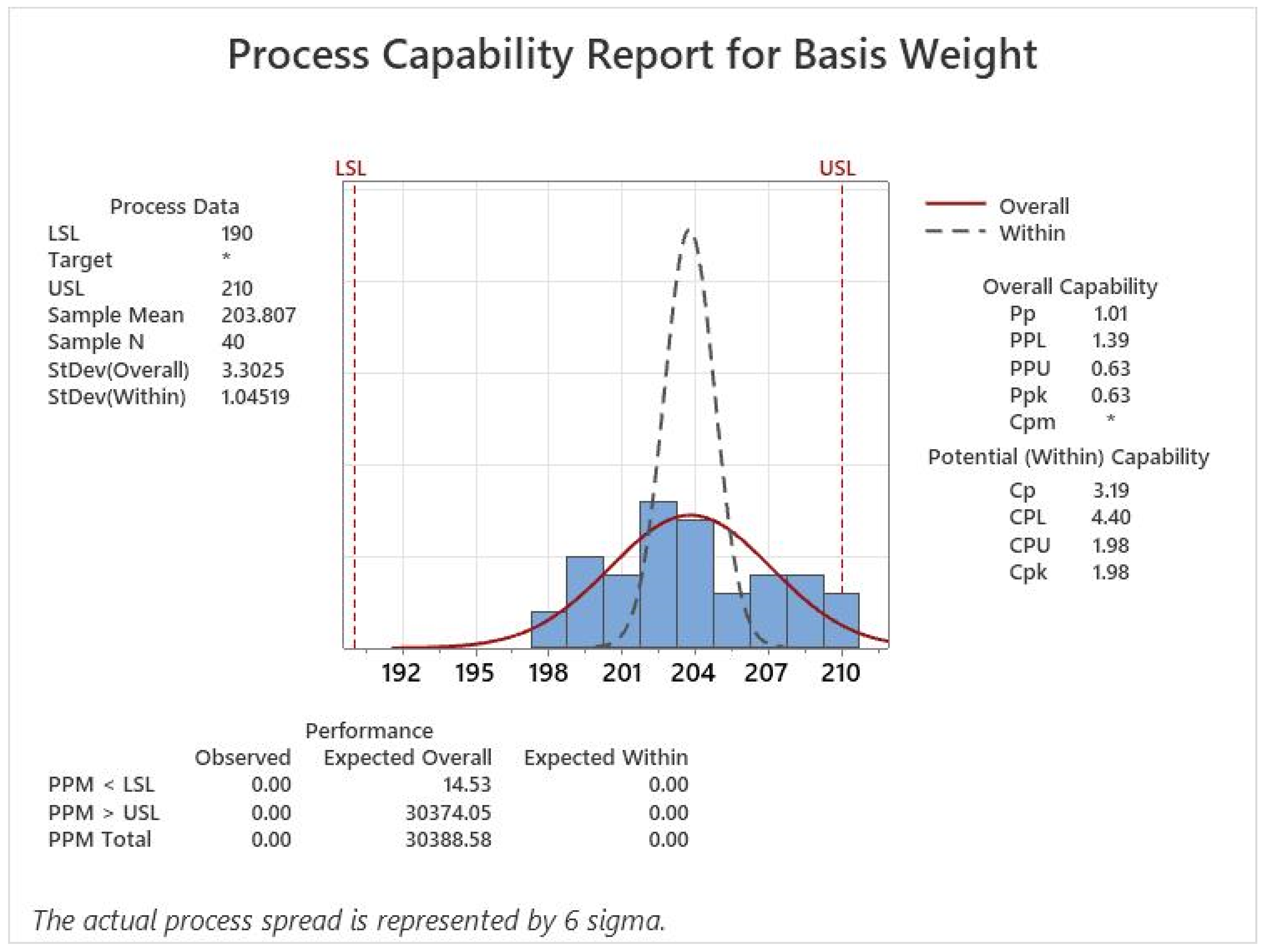
indices were calculated using the traditional process capability analysis. The used dataset is illustrated in
Table 8. The analysis was carried out in Minitab-19
®. The results show a
of 1.01 and a
of 0.63, as shown in
Figure 15. In addition, the fuzzy process capability indices were calculated for different
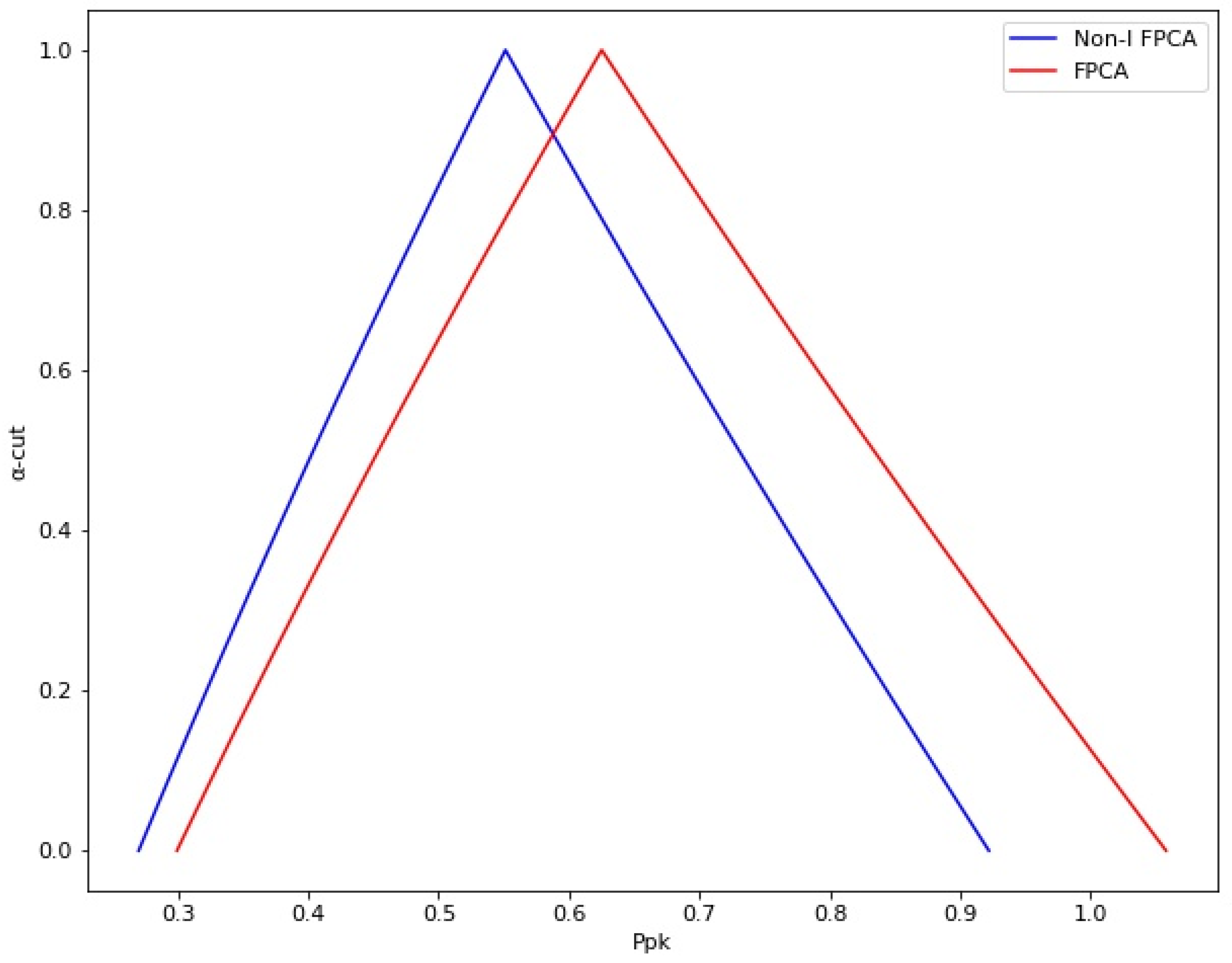
-cut values using the same dataset. The results show that the standard deviation goes from 2.02 to 6.61. The
ranges go from 0.64 to 1.42, while the
goes from 0.30 to 1.06. Finally, the
-level changes between 0.90 to 3.17. These values are presented from
Figure 11,
Figure 12,
Figure 13 and
Figure 14, respectively.
5. Conclusions
Unlike the existing methods, the proposed method does not use final product/service measures. Instead, the used dataset corresponds to predicted values made by the trained model. Therefore, the fuzzy process capability indices are determined by using data directly from each independent variable that affects the response, including its variability.
In the traditional approach to evaluating process capability indices, the response variable values are usually close to the target value because the data come from a normal process. In the proposed method, the experimental designs were used first to know the membership function of the process variability. The standard deviation ranges from 1.39 to 4.55. The model included this variability to carry out a replicated experimental design to define the optimal operating conditions that will bring the response variable closer to a target value.
The
and
capability indices estimated using the traditional approach are within the range of values calculated with the proposed method for these same indices. The results showed a
of 1.01, and
of 0.63. When the minimum and maximum values are calculated with the proposed and existing fuzzy methods, the standard deviation with the proposed method will always be larger than the existing fuzzy methods. This difference is because the model includes the natural variation of the process and the variation shown by each independent variable. As shown in
Figure 11, the proposed method showed a larger standard deviation than the fuzzy method. For this parameter, the proposed method showed values from 2.40 to 7.87, while the fuzzy method results showed values from 2.02 to 6.61. For the
index, the proposed method showed a
from 0.54 to 1.19, while the fuzzy method showed a
from 0.64 to 1.42. Meanwhile, the proposed method showed a
from 0.27 to 0.92, compared with the fuzzy method showing a
from 0.30 to 1.06. On the other hand, the proposed method showed a
-level from 0.81 to 2.77, while the fuzzy method showed values from 0.90 to 3.17.
Since most of the processes tend to maintain or even decrease their performance, and because the variability of the independent variables was included; therefore, the results indicate that the proposed method gives us a better overview than the traditional and fuzzy approaches related to the true potential of the process performance. The proposed method’s observed advantages come from finding the optimal operating conditions of the process parameters to obtain the desired result of the paper basis weight and reduce its variability.
An essential benefit of using the proposed method is that it allows us to know the impact on performance and variability of the significant variables of the paper manufacturing process; thus, this information should guide us in the product and process improvements.
Furthermore, this method is helpful for slow processes where cycle times are very long and collecting enough data to perform a process capability analysis is complicated. In addition, if data can be collected for each process variable, then the process capability indices can be calculated for each manufactured product/service.
On the other hand, since a variability factor is added around an optimal value defined in the experimental design step, the proposed method’s performance results will always present a different value even when using the same data collected for each independent variable. Therefore, this disadvantage will affect the variation of the intersection point probability. Finally, although the model can estimate the basis weight reasonably, general assumptions must be verified and this technology could be susceptible to measurement drift from long-term usage. Additionally, since the neural network model performance relies heavily on the historian data for specific paper grades. If there is a significant change in the paper included during the design, rebuilding the neural network model will be recommended.
Because the fuzzy process capability indices were estimated using the triangular membership function, the proposed method will use other fuzzy membership functions in future research to compare their results with reality. In addition, a sensitivity analysis could be performed in order to compare the results of the proposed model with other approaches such as the neuro-fuzzy systems and neural-like structures based on geometric data transformations.


 ,
, 













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}