
Heterogeneous Information Network-Based Recommendation with Metapath Search and Memory Network Architecture Search

Abstract
:1. Introduction
- We propose a novel neural network architecture search algorithm for recommendation tasks on heterogeneous information networks, which can automatically search for the number of layers of neural networks, the number of neurons in each layer, the number of dimensions of the node embedding, and the type of graph neural networks used in the recommendation process. It can significantly reduce the time and computational resources compared with the manually searching way.
- We propose a metagraph search method for heterogeneous information networks based on a micro-neural network architecture search, which can automatically search for metagraphs which are more suitable for different heterogeneous information networks and recommendation tasks.
- We conducted experiments on Amazon and Yelp datasets, comparing the architecture settings obtained from the automatic search with the manually set recommendation structure and verified the recommendation effectiveness of the algorithm.
2. Related Works
2.1. Heterogeneous Information Network Recommendation Model
2.2. Network Architecture Search
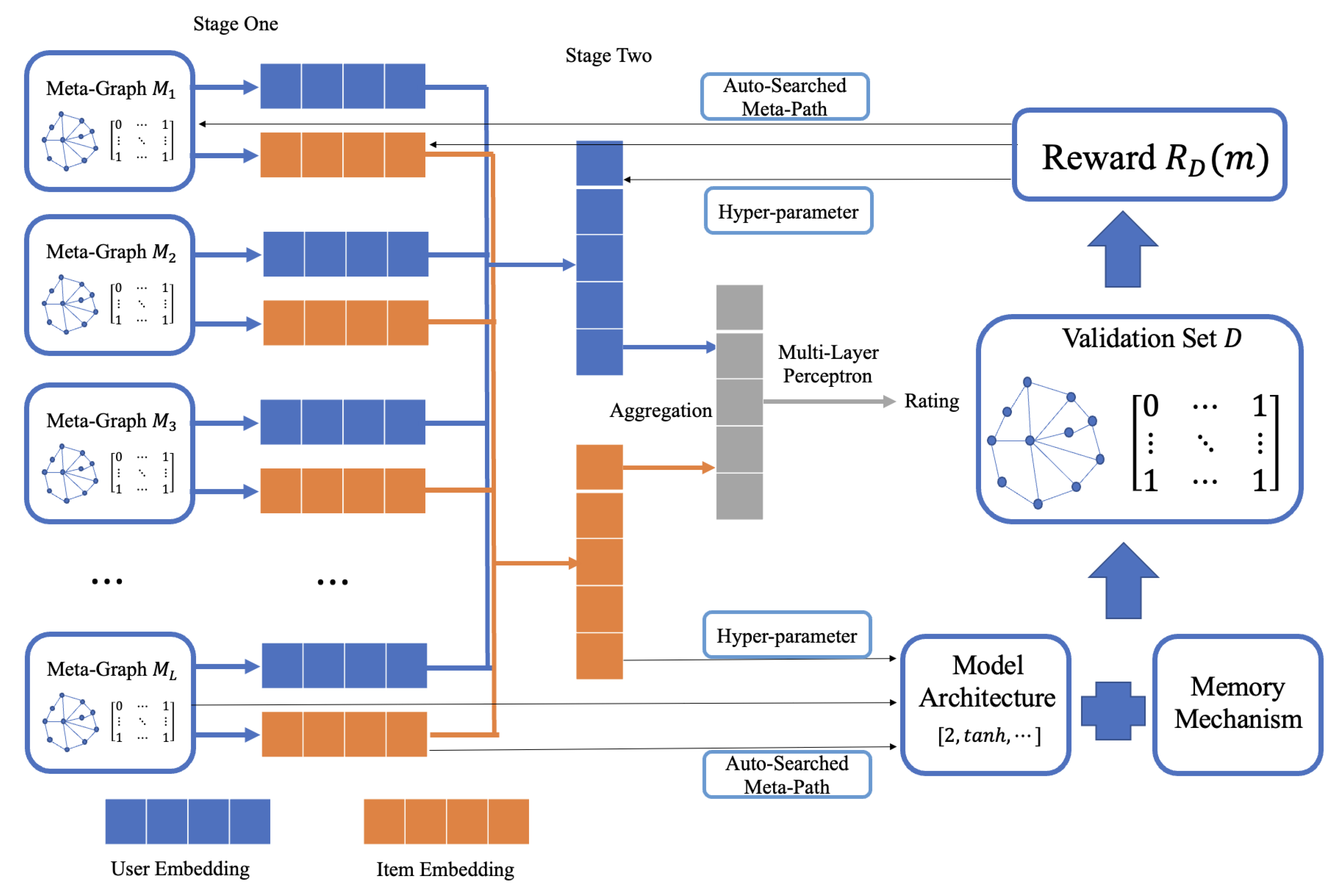
3. Methods
3.1. ANAS-HIN Algorithm
3.1.1. Neural Network Architecture Search Problem Formalization
3.1.2. Neural Network Architecture Search Space
- Graph convolutional layer: The graph convolutional layer is mainly used to aggregate the adjacent node features in the network by convolution to obtain the node embedding in the next layer.where denotes the connection matrix under the metagraph, M the connection matrix after regularization under D is the connection matrix of the degree matrix with diagonal elements , and the non-diagonal elements are 0. W is the weight matrix.
- Graph attention layer: The graph attention layer is a variation of the graph convolutional layer. When node aggregation is performed in the graph convolutional layer, the relationship between node features is not considered; however, in the network, the influence between nodes with different features is often different. Therefore, the graph attention layer employs an attention mechanism to perform node aggregation. Suppose the set of neighbor nodes of node ; then, when performing node aggregation, the graph attention layer uses the attention mechanism to calculate the weights of node on node as follows.where W is the learnable weight matrix and is the attention mechanism. In our experiments, we use a feedforward neural network as the attention mechanism. Then, the graph attention layer regularizes the weights of all neighboring nodes using softmax as follows.Finally, the graph attention layer uses a weighting approach to obtain the output of the next layer.
- Graph sage layer: The graph sage layer is another class of variants of the graph convolutional layer. To ensure symmetry in node aggregation, the graph sage layer uses maximization pooling to aggregate the neighboring nodes of node .where denotes the element-wise max pooling.
- Concatenation: For user embedding and product embedding , we directly stitch the embeddings obtained under different metagraphs to obtain the final user embedding and product embedding.where represents the splicing operation. However, the stitching operation increases the dimensionality of the embedding and therefore requires more computational power of the computer.
- Mean: To avoid the increase in embedding dimensions, the user embedding and the commodity embedding under different metagraphs are averaged.where denotes the averaging operation. In contrast, averaging can ensure that the dimensionality of the aggregated vectors does not change, but it does not take into account the difference between different metagraphs, while averaging directly will make the aggregated vectors lose some information.
- Attention: The attention mechanism [40] can effectively avoid the disadvantages of these two methods. The attention mechanism can weight the user and product embeddings according to the input of different metagraphs, and the weight will be changed by the impact of the embeddings on the recommendation effect obtained from different original maps. The specific computation process is as follows.For the metagraph derived from M, the user embedding obtained from the and the product embedding , we use a two-layer perceptron for users and items, respectively, to obtain the attention scores of the corresponding users and items and .where denotes the weight matrix, and is the bias term. is the nonlinear activation function. After obtaining the attention scores, we regularize the attention scores of different metapaths using the softmax function as follows.where L denotes the set of all metagraph compositions. Finally, we obtain the embedding of end users and items by weighting as Equations (10) and (11).Finally, we use the embedding of users and products to obtain the user ratings for the products. For user and product pairs , we first stitch together the embeddings of the user and the item , and we use a multilayer feed forward neural network to predict the user’s rating of the item. The specific prediction process is shown below. The specific prediction process is shown as Equation (12).where W denotes the weight matrix, and b is the bias term. is the function of the composite composition of the multilayer feedforward nonlinear neural network.
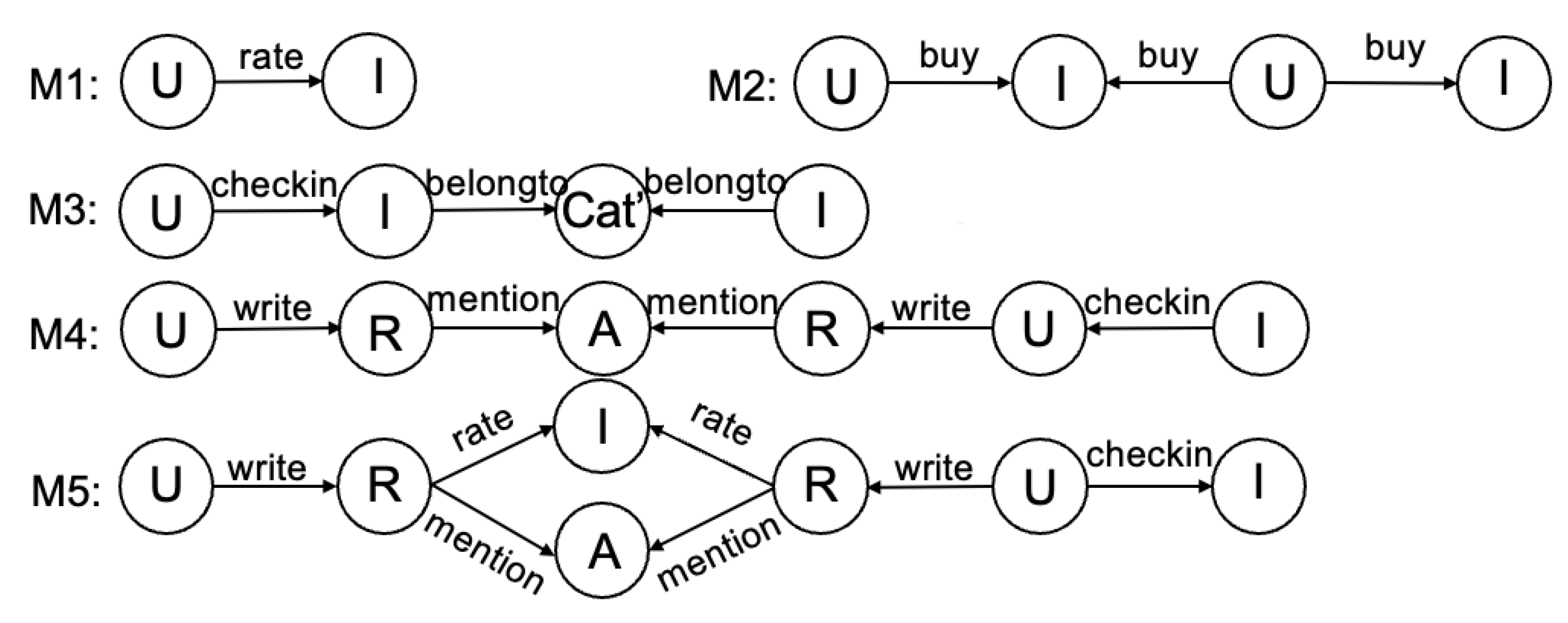
3.2. Metapaths Auto-Search
3.3. Recurrent Neural Network with Memory Mechanism
- The controller predicts the number of layers of the graph neural network in 1, 2, 3, placed at position 0 of the list of predicted model frames, calculated as:
- The controller predicts the nonlinear activation function of the graphical neural network in Sigmoid, tanh, relu, ⋯, elu, placed at the 1st position in the list of predicted model frames, calculated as:where are the learnable parameter matrices in recurrent neural networks and M is the learnable parameter matrix in the memory mechanism. Then, the controller sequentially predicts the graph neural network type, the number of graph neural network attention mechanism heads, the number of graph neural network output dimensions, the number of metagraph node embedding dimensions, the multivariate graph embedding aggregation method, and the number of scoring multilayer feedforward neural network layers. After that we will experimentally verify the effect of the memory mechanism on the effect of the model.
3.4. Optimization
4. Experiment
4.1. Dataset
4.2. Evaluation Indicators
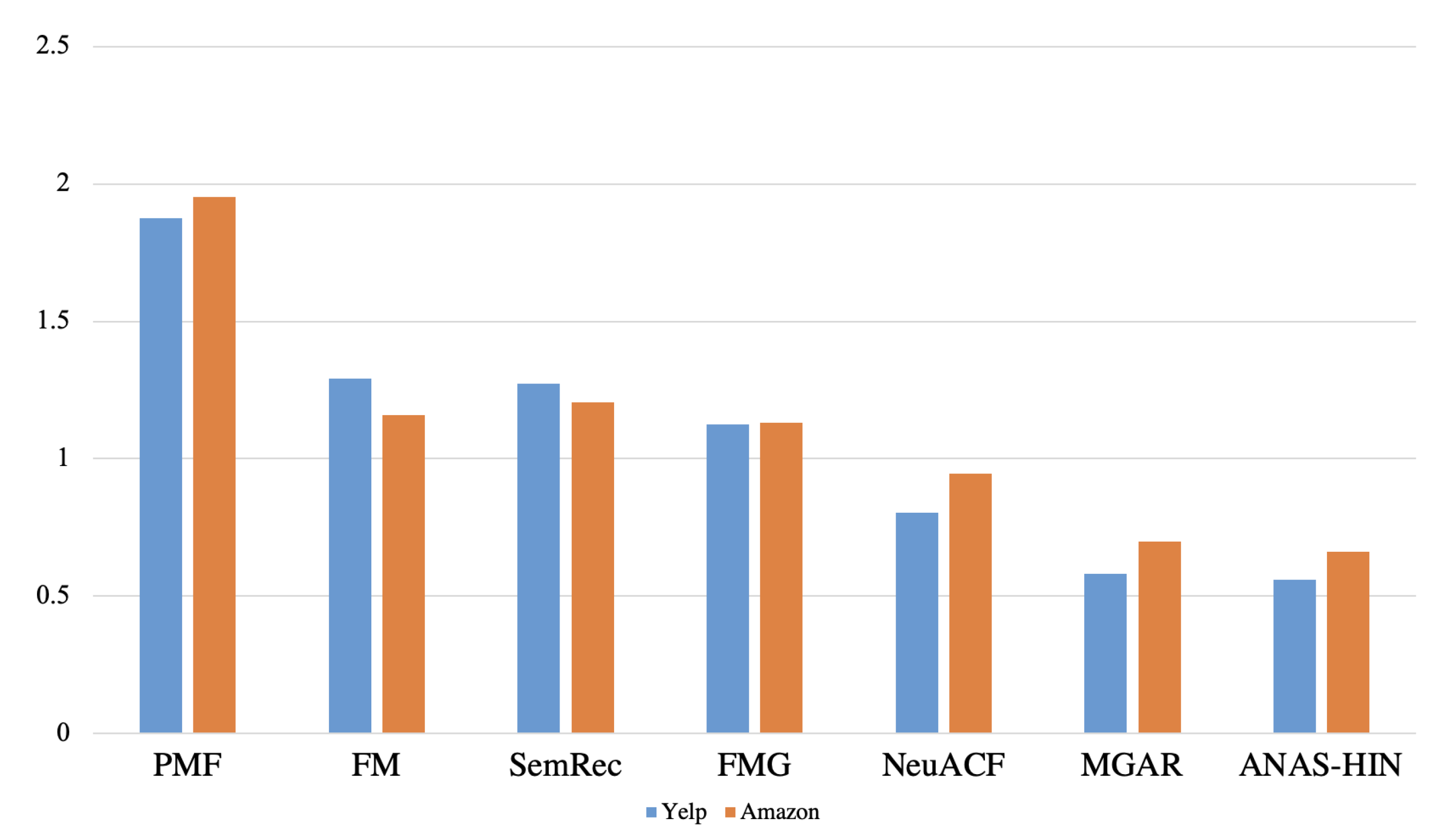
4.3. Baseline Algorithms
- NeuACF [1]: The NeuACF model makes recommendations from two aspects. On the one hand, it uses human-defined metapaths for similarity between users and items; on the other hand, it uses matrix decomposition methods to obtain the embedding of users and items, uses inner product to obtain the similarity between users and items, and finally, it combines the similarity of both aspects to predict users’ ratings of items.
- MGAR [6]: Similar to the FMG model, the MGAR model is also a two-stage model. In the first stage, the MGAR model performs matrix decomposition through the connection matrix of metagraphs to obtain the embedding of users and products, and then in the second stage, the FMG weights the different metagraphs through the attention model to obtain the users’ ratings of products.
- SemRec [14]: The SemRec model is mainly for weighted heterogeneous information network for recommendation, which uses human-defined weighted metapaths to calculate the similarity between users and products, and finally uses this similarity to predict users’ ratings of products.
- FMG [24]: The FMG model is similar to the recommendation model framework we introduced. In the first stage, it uses a method based on metagraph and metapath matrix decomposition to obtain the embeddings of users and items; then, it uses the embeddings of users and items as their features, followed by a factor machine model to predict the users’ ratings of items.
- FM [25]: Factorization machine (FM) mainly uses linear combinations of users and items to predict users’ ratings of items. Unlike the PMF model, the factor machine model considers not only the first-order similarity between users and items but also the second-order similarity between users and items, and finally, the factor machine model combines this order similarity and the second-order similarity to predict users’ ratings of items.
- PMF [42]: Probabilistic Matrix Factorization (PMF) model transforms the interaction between users and items into an interaction matrix between users and items, and uses matrix decomposition to obtain the embeddings of users and items, and finally uses the inner product between the embeddings of users and items to predict the users’ ratings of items.
4.4. Experimental Results
4.5. Ablation Study
4.6. Impact of Different Metagraphs on the Model
5. Summary
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Han, X.; Shi, C.; Wang, S.; Yu, P.S.; Song, L. Aspect-Level Deep Collaborative Filtering via Heterogeneous Information Networks. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, IJCAI 2018, Stockholm, Sweden, 13–19 July 2018; pp. 3393–3399. [Google Scholar] [CrossRef]
- Sun, Y.; Han, J.; Yan, X.; Yu, P.S.; Wu, T. PathSim: Meta Path-Based Top-K Similarity Search in Heterogeneous Information Networks. Proc. VLDB Endow. 2011, 4, 992–1003. [Google Scholar] [CrossRef]
- Kong, X.; Zhang, J.; Yu, P.S. Inferring anchor links across multiple heterogeneous social networks. In Proceedings of the 22nd ACM International Conference on Information and Knowledge Management, CIKM’13, San Francisco, CA, USA, 27 October–1 November 2013; pp. 179–188. [Google Scholar] [CrossRef]
- Ji, M.; Sun, Y.; Danilevsky, M.; Han, J.; Gao, J. Graph Regularized Transductive Classification on Heterogeneous Information Networks. In Proceedings of the Machine Learning and Knowledge Discovery in Databases, European Conference, ECML PKDD 2010, Barcelona, Spain, 20–24 September 2010; Balcázar, J.L., Bonchi, F., Gionis, A., Sebag, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; Volume 6321, pp. 570–586. [Google Scholar] [CrossRef]
- Yu, X.; Ren, X.; Sun, Y.; Gu, Q.; Sturt, B.; Khandelwal, U.; Norick, B.; Han, J. Personalized entity recommendation: A heterogeneous information network approach. In Proceedings of the Seventh ACM International Conference on Web Search and Data Mining, WSDM 2014, New York, NY, USA, 24–28 February 2014; pp. 283–292. [Google Scholar] [CrossRef]
- Zhao, C.; Wang, H.; Li, Y.; Mu, K. Combining Meta-Graph and Attention for Recommendation over Heterogenous Information Network. In Proceedings of the Database Systems for Advanced Applications—24th International Conference, DASFAA 2019, Chiang Mai, Thailand, 22–25 April 2019; Li, G., Yang, J., Gama, J., Natwichai, J., Tong, Y., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; Volume 6321, pp. 570–586. [Google Scholar] [CrossRef]
- Zhou, K.; Song, Q.; Huang, X.; Hu, X. Auto-GNN: Neural Architecture Search of Graph Neural Networks. arXiv 2019, arXiv:1909.03184. [Google Scholar]
- Cai, S.; Li, L.; Han, X.; Zha, Z.; Huang, Q. Edge-featured Graph Neural Architecture Search. arXiv 2021, arXiv:2109.01356. [Google Scholar]
- Kyriakides, G.; Margaritis, K.G. Evolving graph convolutional networks for neural architecture search. Neural Comput. Appl. 2022, 34, 899–909. [Google Scholar] [CrossRef]
- Chatzianastasis, M.; Dasoulas, G.; Siolas, G.; Vazirgiannis, M. Graph-based Neural Architecture Search with Operation Embeddings. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, ICCVW 2021, Montreal, QC, Canada, 11–17 October 2021; pp. 393–402. [Google Scholar] [CrossRef]
- Xue, Y.; Wang, Y.; Liang, J.; Slowik, A. A Self-Adaptive Mutation Neural Architecture Search Algorithm Based on Blocks. IEEE Comput. Intell. Mag. 2021, 16, 67–78. [Google Scholar] [CrossRef]
- Xue, Y.; Jiang, P.; Neri, F.; Liang, J. A Multi-Objective Evolutionary Approach Based on Graph-in-Graph for Neural Architecture Search of Convolutional Neural Networks. Int. J. Neural Syst. 2021, 31, 2150035. [Google Scholar] [CrossRef] [PubMed]
- Liu, H.; Simonyan, K.; Yang, Y. DARTS: Differentiable Architecture Search. arXiv 2018, arXiv:1806.09055. [Google Scholar]
- Shi, C.; Zhang, Z.; Luo, P.; Yu, P.S.; Yue, Y.; Wu, B. Semantic Path based Personalized Recommendation on Weighted Heterogeneous Information Networks. In Proceedings of the 24th ACM International Conference on Information and Knowledge Management, CIKM 2015, Melbourne, VIC, Australia, 19–23 October 2015; pp. 453–462. [Google Scholar] [CrossRef]
- Sun, Y.; Norick, B.; Han, J.; Yan, X.; Yu, P.S.; Yu, X. Integrating meta-path selection with user-guided object clustering in heterogeneous information networks. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’12, Beijing, China, 12–16 August 2012; pp. 1348–1356. [Google Scholar] [CrossRef]
- Wang, S.; Cao, L.; Wang, Y.; Sheng, Q.Z.; Orgun, M.A.; Lian, D. A Survey on Session-based Recommender Systems. ACM Comput. Surv. 2022, 54, 154:1–154:38. [Google Scholar] [CrossRef]
- Cho, J.; Kang, S.; Hyun, D.; Yu, H. Unsupervised Proxy Selection for Session-based Recommender Systems. In Proceedings of the SIGIR ’21: The 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, 11–15 July 2021; pp. 327–336. [Google Scholar] [CrossRef]
- Raza, S.; Ding, C. News recommender system: A review of recent progress, challenges, and opportunities. Artif. Intell. Rev. 2022, 55, 749–800. [Google Scholar] [CrossRef] [PubMed]
- Raza, S.; Ding, C. Fake news detection based on news content and social contexts: A transformer-based approach. Int. J. Data Sci. Anal. 2022, 13, 335–362. [Google Scholar] [CrossRef] [PubMed]
- Raza, S.; Ding, C. Deep Neural Network to Tradeoff between Accuracy and Diversity in a News Recommender System. In Proceedings of the 2021 IEEE International Conference on Big Data (Big Data), Orlando, FL, USA, 15–18 December 2021; pp. 5246–5256. [Google Scholar] [CrossRef]
- Yang, C.; Zhao, C.; Wang, H.; Qiu, R.; Li, Y.; Mu, K. A Semantic Path-Based Similarity Measure for Weighted Heterogeneous Information Networks. In Proceedings of the Knowledge Science, Engineering and Management—11th International Conference, KSEM 2018, Changchun, China, 17–19 August 2018; Liu, W., Giunchiglia, F., Yang, B., Eds.; Springer: Berlin/Heidelberg, Germany, 2018; Volume 11061, pp. 311–323. [Google Scholar] [CrossRef]
- Shi, C.; Han, X.; Song, L.; Wang, X.; Wang, S.; Du, J.; Yu, P.S. Deep Collaborative Filtering with Multi-Aspect Information in Heterogeneous Networks. IEEE Trans. Knowl. Data Eng. 2021, 33, 1413–1425. [Google Scholar] [CrossRef]
- Huang, Z.; Zheng, Y.; Cheng, R.; Sun, Y.; Mamoulis, N.; Li, X. Meta Structure: Computing Relevance in Large Heterogeneous Information Networks. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1595–1604. [Google Scholar] [CrossRef]
- Zhao, H.; Yao, Q.; Li, J.; Song, Y.; Lee, D.L. Meta-Graph Based Recommendation Fusion over Heterogeneous Information Networks. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 635–644. [Google Scholar] [CrossRef]
- Rendle, S. Factorization Machines. In Proceedings of the ICDM 2010, The 10th IEEE International Conference on Data Mining, Sydney, Australia, 14–17 December 2010; pp. 995–1000. [Google Scholar] [CrossRef]
- Gao, Y.; Yang, H.; Zhang, P.; Zhou, C.; Hu, Y. GraphNAS: Graph Neural Architecture Search with Reinforcement Learning. arXiv 2019, arXiv:1904.09981. [Google Scholar]
- Zoph, B.; Vasudevan, V.; Shlens, J.; Le, Q.V. Learning Transferable Architectures for Scalable Image Recognition. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8697–8710. [Google Scholar] [CrossRef]
- Cai, H.; Chen, T.; Zhang, W.; Yu, Y.; Wang, J. Reinforcement Learning for Architecture Search by Network Transformation. arXiv 2017, arXiv:1707.04873. [Google Scholar]
- Baker, B.; Gupta, O.; Naik, N.; Raskar, R. Designing Neural Network Architectures using Reinforcement Learning. In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, 24–26 April 2017. [Google Scholar]
- Li, W.; Gong, S.; Zhu, X. Neural Graph Embedding for Neural Architecture Search. In Proceedings of the The Thirty-Fourth AAAI Conference on Artificial Intelligence, AAAI 2020, The Thirty-Second Innovative Applications of Artificial Intelligence Conference, IAAI 2020, The Tenth AAAI Symposium on Educational Advances in Artificial Intelligence, EAAI 2020, New York, NY, USA, 7–12 February 2020; pp. 4707–4714. [Google Scholar]
- Chen, J.; Gao, J.; Chen, Y.; Oloulade, M.B.; Lyu, T.; Li, Z. GraphPAS: Parallel Architecture Search for Graph Neural Networks. In Proceedings of the SIGIR ’21: The 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, 11–15 July 2021; pp. 2182–2186. [Google Scholar] [CrossRef]
- Gao, Y.; Zhang, P.; Li, Z.; Zhou, C.; Liu, Y.; Hu, Y. Heterogeneous Graph Neural Architecture Search. In Proceedings of the IEEE International Conference on Data Mining, ICDM 2021, Auckland, New Zealand, 7–10 December 2021; pp. 1066–1071. [Google Scholar] [CrossRef]
- Liu, H.; Simonyan, K.; Vinyals, O.; Fernando, C.; Kavukcuoglu, K. Hierarchical Representations for Efficient Architecture Search. In Proceedings of the 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Real, E.; Moore, S.; Selle, A.; Saxena, S.; Suematsu, Y.L.; Tan, J.; Le, Q.V.; Kurakin, A. Large-Scale Evolution of Image Classifiers. In Proceedings of the 34th International Conference on Machine Learning, ICML 2017, Sydney, NSW, Australia, 6–11 August 2017; pp. 2902–2911. [Google Scholar]
- Miikkulainen, R.; Liang, J.Z.; Meyerson, E.; Rawal, A.; Fink, D.; Francon, O.; Raju, B.; Shahrzad, H.; Navruzyan, A.; Duffy, N.; et al. Evolving Deep Neural Networks. arXiv 2017, arXiv:1703.00548. [Google Scholar]
- Xie, L.; Yuille, A.L. Genetic CNN. In Proceedings of the IEEE International Conference on Computer Vision, ICCV 2017, Venice, Italy, 22–29 October 2017; pp. 1388–1397. [Google Scholar] [CrossRef]
- Chen, Y.; Meng, G.; Zhang, Q.; Xiang, S.; Huang, C.; Mu, L.; Wang, X. RENAS: Reinforced Evolutionary Neural Architecture Search. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, 16–20 June 2019; pp. 4787–4796. [Google Scholar] [CrossRef]
- Pham, H.; Guan, M.Y.; Zoph, B.; Le, Q.V.; Dean, J. Efficient Neural Architecture Search via Parameter Sharing. In Proceedings of the 35th International Conference on Machine Learning, ICML 2018, Stockholmsmässan, Stockholm, Sweden, 10–15 July 2018; Volume 80, pp. 4092–4101. [Google Scholar]
- Wu, Z.; Pan, S.; Chen, F.; Long, G.; Zhang, C.; Yu, P.S. A Comprehensive Survey on Graph Neural Networks. arXiv 2019, arXiv:1901.00596. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- He, R.; McAuley, J.J. Ups and Downs: Modeling the Visual Evolution of Fashion Trends with One-Class Collaborative Filtering. In Proceedings of the 25th International Conference on World Wide Web, WWW 2016, Montreal, QC, Canada, 11–15 April 2016; pp. 507–517. [Google Scholar] [CrossRef]
- Salakhutdinov, R.; Mnih, A. Probabilistic Matrix Factorization. In Proceedings of the Advances in Neural Information Processing Systems 20, Proceedings of the Twenty-First Annual Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 3–6 December 2007; pp. 1257–1264. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Description |
|---|---|
| G | Heterogeneous information network |
| E | Edge set of G |
| V | Node set of G |
| A | Adjacency matrix |
| X | Node feature matrix |
| Neighbor nodes of node | |
| P | Metapath of G |
| M | Metagraph of G |
| Connection matrix of metapath P or metagraph M | |
| m | Neural network architecture |
| Reward of m on the validation set D |
| Hyperparameters | Search Space |
|---|---|
| Number of layers of the graph neural network | 1, 2, 3 |
| Nonlinear activation functions for graphical neural networks | Sigmoid, tanh, relu, identity, softplus, leaky_relu, elu |
| Graph neural network type | Graph sage layer, graph attention layer, graph convolutional layer |
| Figure neural network attention mechanism head count | 1, 2, 4, 8 |
| Figure neural network output dimension | 128, 256, 512 |
| Metaplot node embedding dimension | 128, 256 |
| Multiple metagraph embedding aggregation method | Splicing, averaging, attention mechanism aggregation |
| Scoring multilayer feedforward neural network layers | 1, 2, 3 |
| Relations (A-B) | Number of A | Number of B | Number of (A-B) | |
|---|---|---|---|---|
| Yelp | User-User | 18,454 | 18,454 | 125,223 |
| User-Business | 18,454 | 576 | 20,000 | |
| User-Review | 18,454 | 20,000 | 20,000 | |
| Business-Star | 576 | 9 | 576 | |
| Business-State | 576 | 51 | 576 | |
| Business-Category | 576 | 1237 | 1827 | |
| Business-City | 576 | 1010 | 576 | |
| Review-Business | 20,000 | 576 | 20,000 | |
| Review-Aspect | 20,000 | 10 | 172,349 | |
| Amazon | User-Business | 16,970 | 336 | 19,287 |
| User-Review | 16,970 | 18,331 | 18,198 | |
| Business-Category | 336 | 16 | 323 | |
| Review-Business | 18,331 | 336 | 20,000 | |
| Review-Aspect | 18,331 | 10 | 162,407 |
| ANAS-HIN-M | ANAS-HIN | |
|---|---|---|
| Yelp | 0.5701 | 0.5607 |
| Amazon | 0.6743 | 0.6632 |
| M1 | M2 | M3 | M4 | M5 | M6 | M7 | M8 | M9 | M-Auto | M-A-All |
|---|---|---|---|---|---|---|---|---|---|---|
| 1.2539 | 1.3064 | 1.3374 | 1.3738 | 1.3628 | 1.1953 | 1.3821 | 1.3705 | 1.3792 | 1.1345 | 0.5607 |
| M1 | M2 | M3 | M4 | M5 | M-Auto | M-A-All |
|---|---|---|---|---|---|---|
| 1.1309 | 1.1356 | 1.1429 | 1.1763 | 1.149 | 1.0856 | 0.6632 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yuan, P.; Sun, Y.; Wang, H. Heterogeneous Information Network-Based Recommendation with Metapath Search and Memory Network Architecture Search. Mathematics 2022, 10, 2895. https://doi.org/10.3390/math10162895
Yuan P, Sun Y, Wang H. Heterogeneous Information Network-Based Recommendation with Metapath Search and Memory Network Architecture Search. Mathematics. 2022; 10(16):2895. https://doi.org/10.3390/math10162895
Chicago/Turabian StyleYuan, Peisen, Yi Sun, and Hengliang Wang. 2022. "Heterogeneous Information Network-Based Recommendation with Metapath Search and Memory Network Architecture Search" Mathematics 10, no. 16: 2895. https://doi.org/10.3390/math10162895
APA StyleYuan, P., Sun, Y., & Wang, H. (2022). Heterogeneous Information Network-Based Recommendation with Metapath Search and Memory Network Architecture Search. Mathematics, 10(16), 2895. https://doi.org/10.3390/math10162895