
The Algorithm That Maximizes the Accuracy of k-Classification on the Set of Representatives of the k Equivalence Classes


Abstract
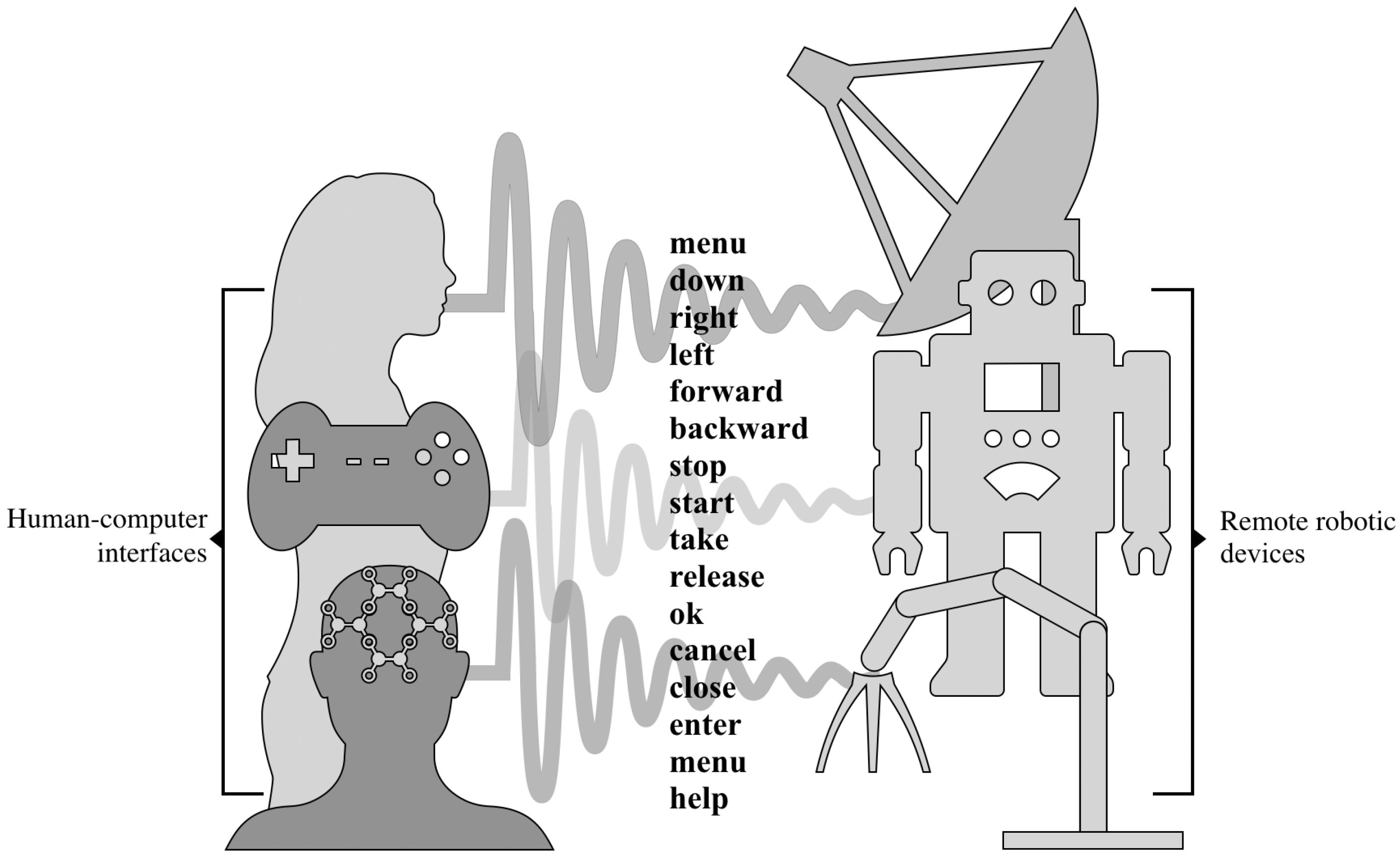
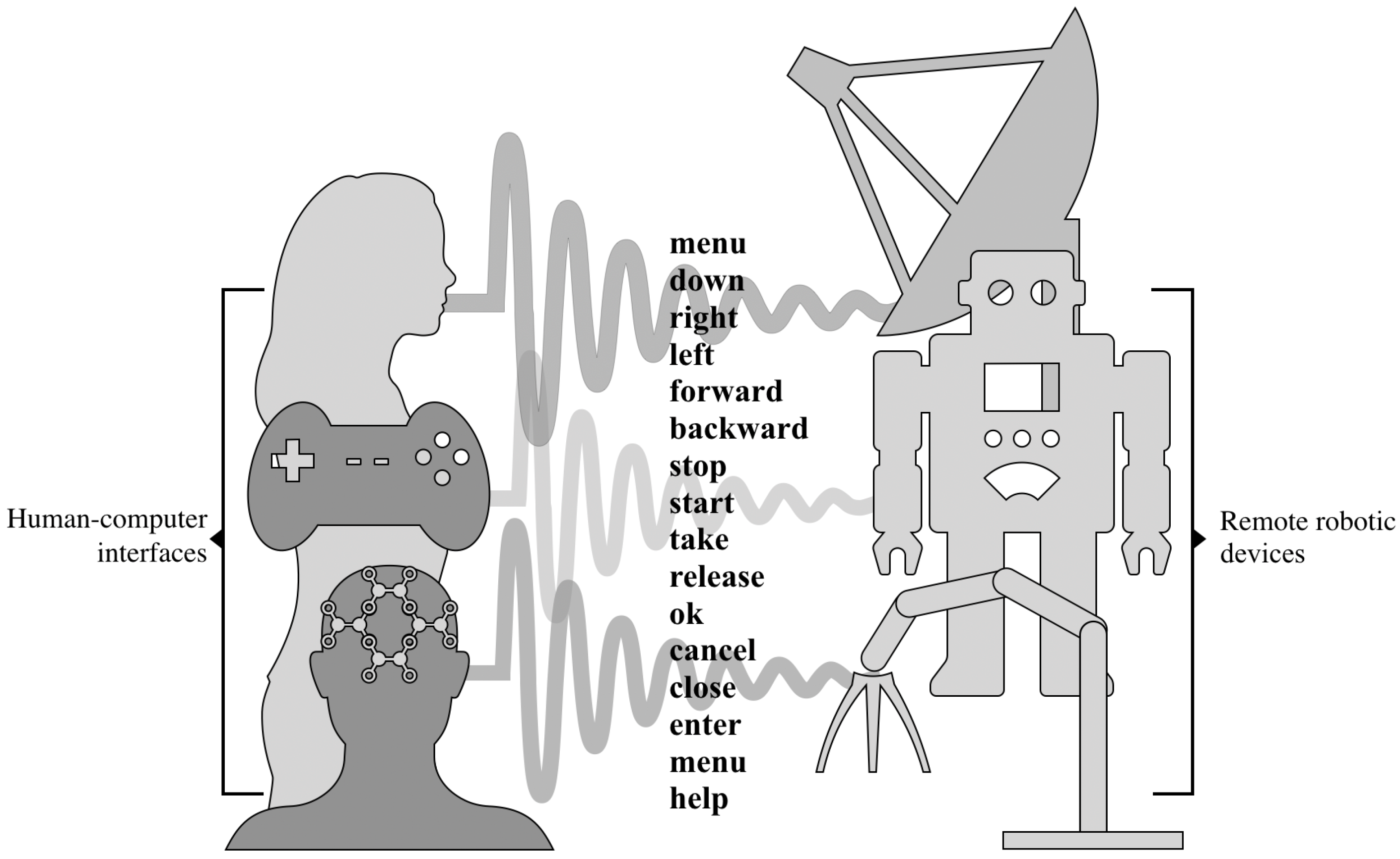
:1. Introduction
2. Theoretical Section
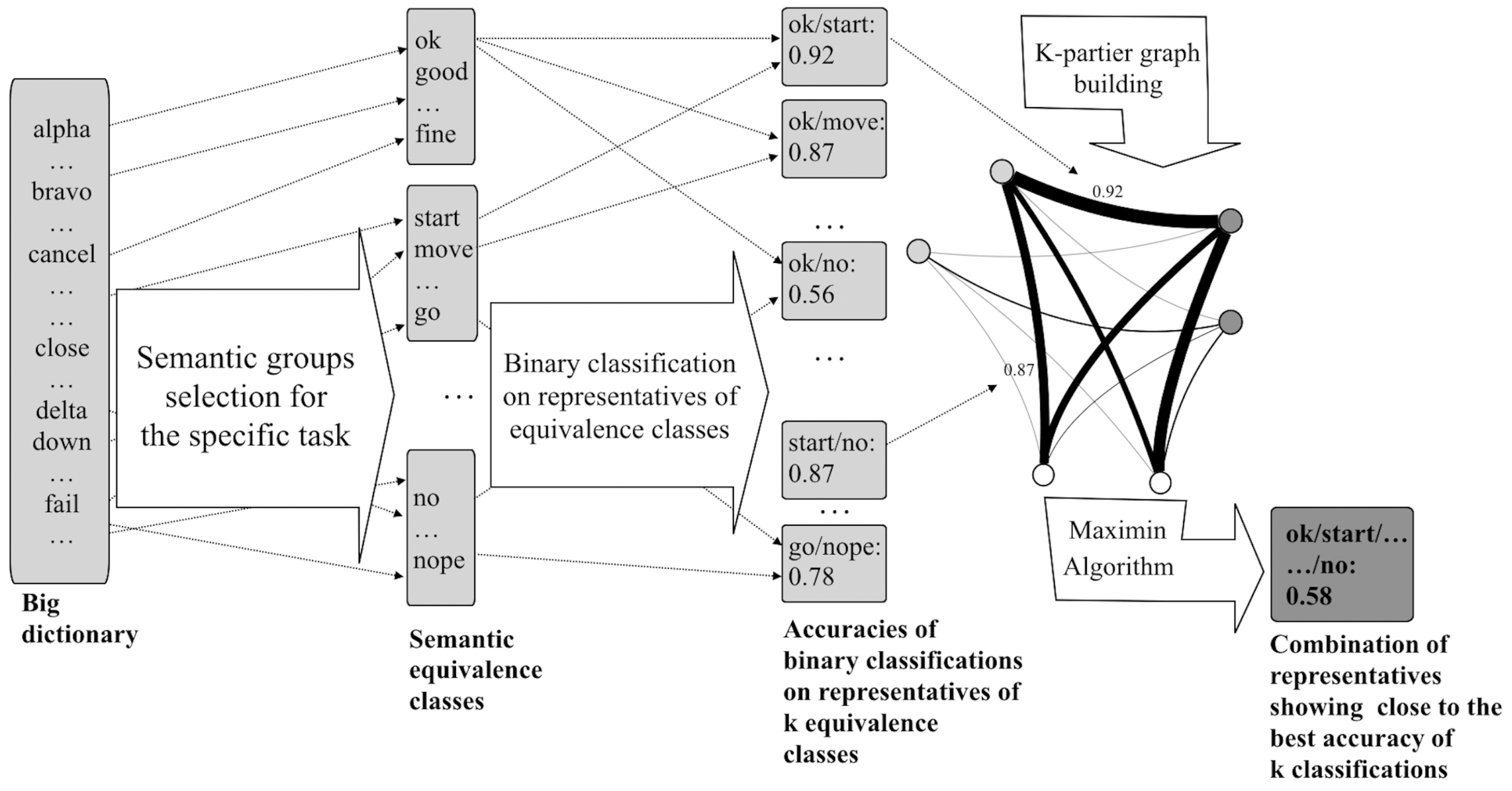
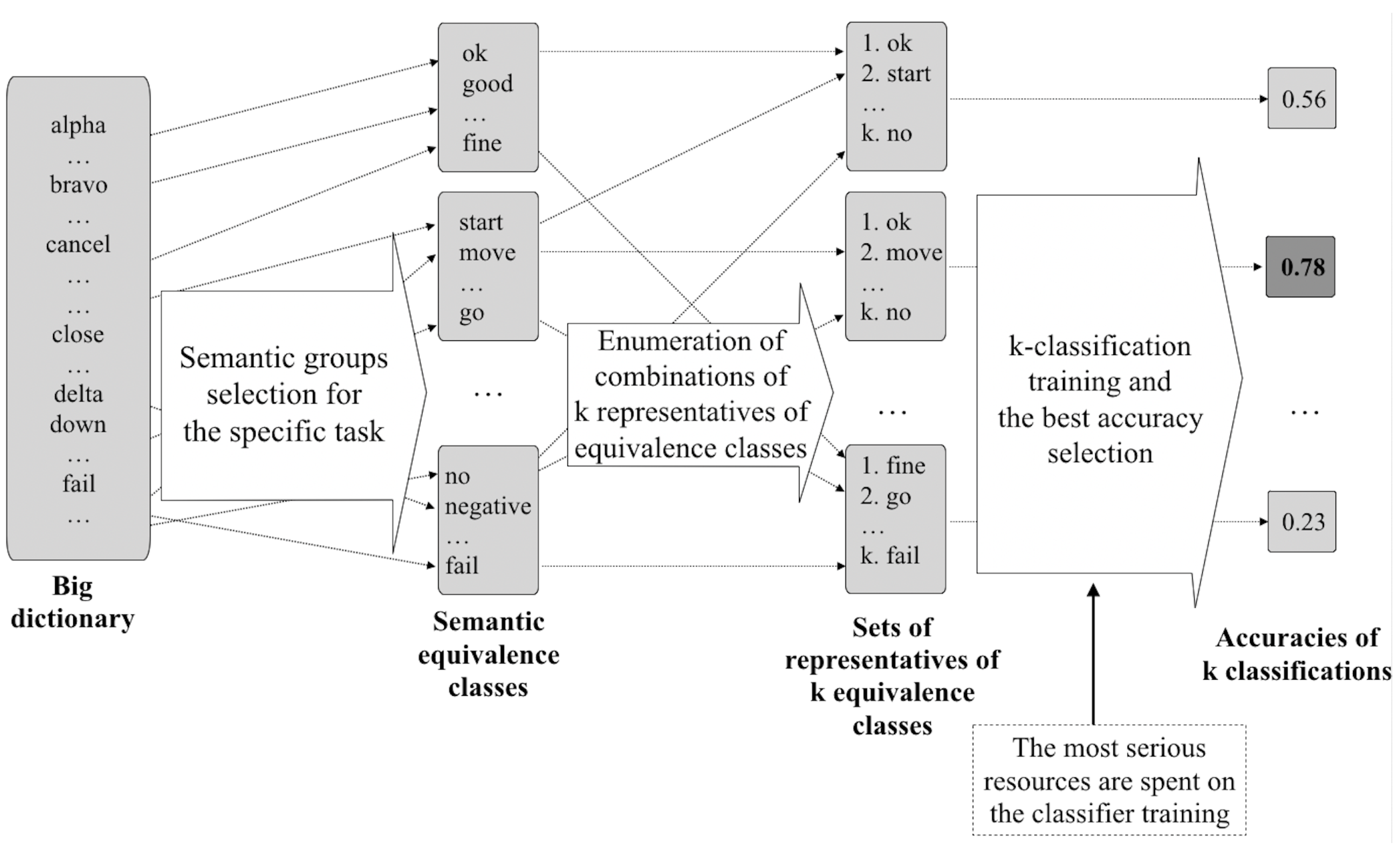
2.1. Formulation of the Problem and Proposed Idea
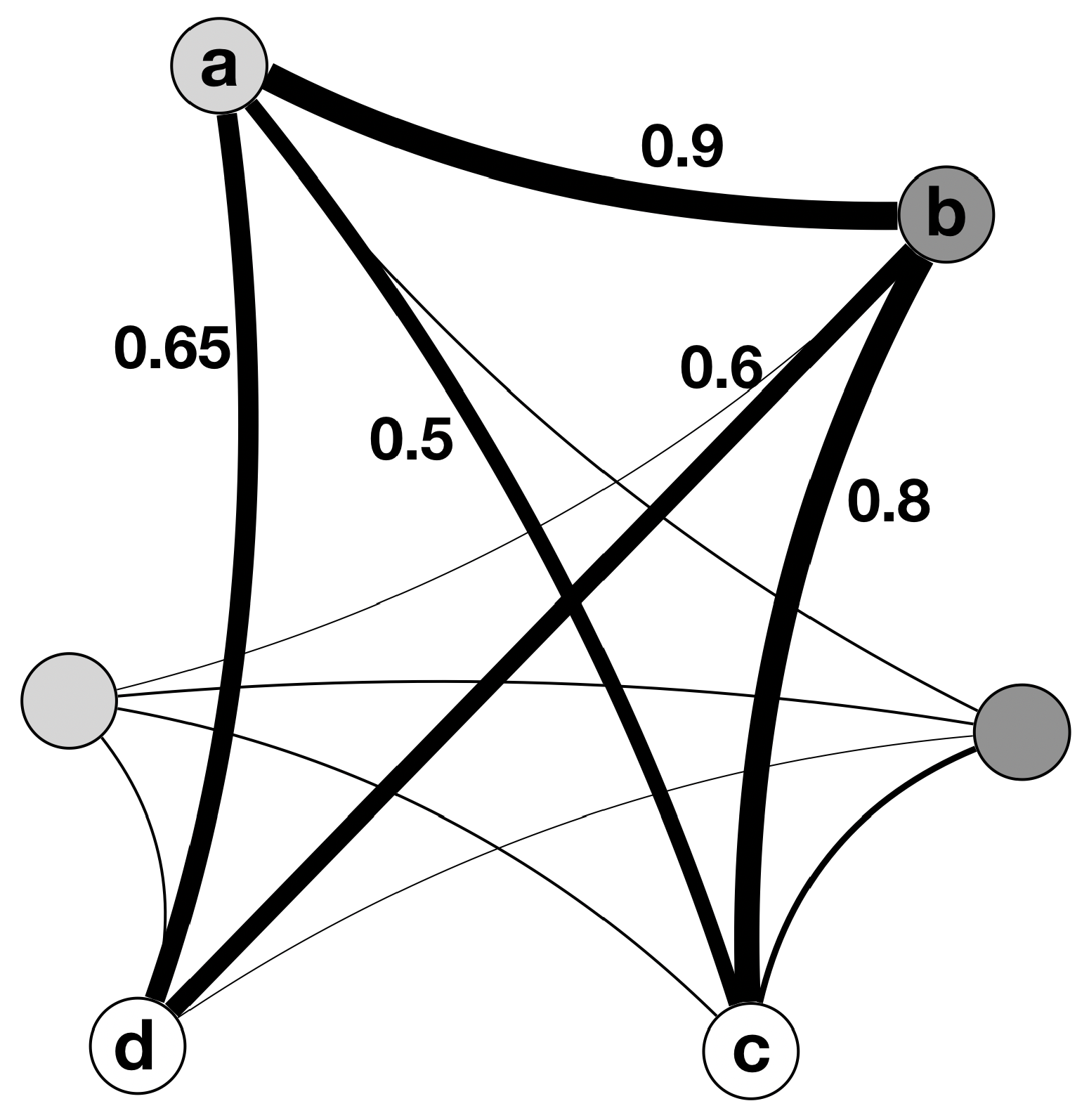
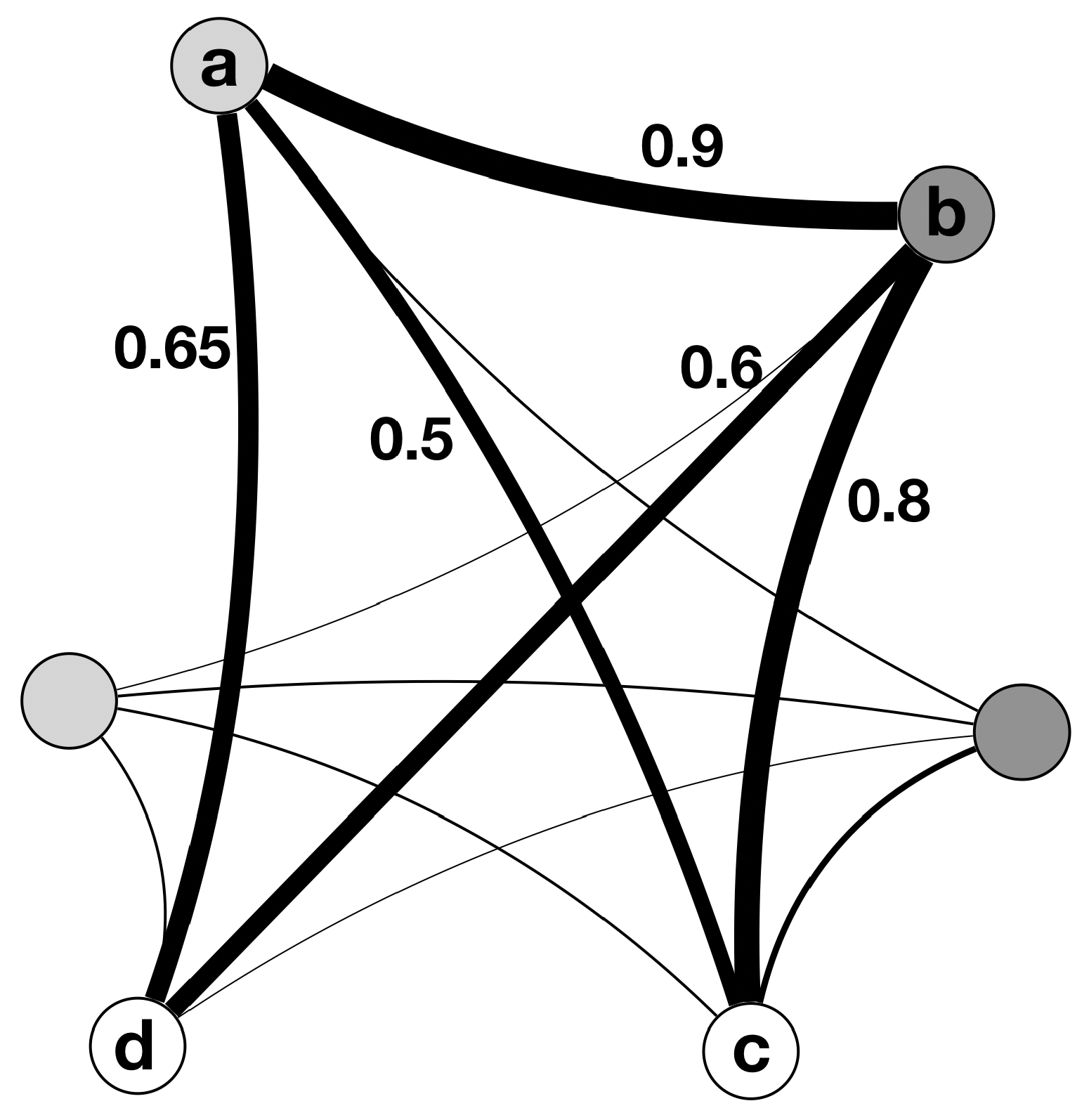
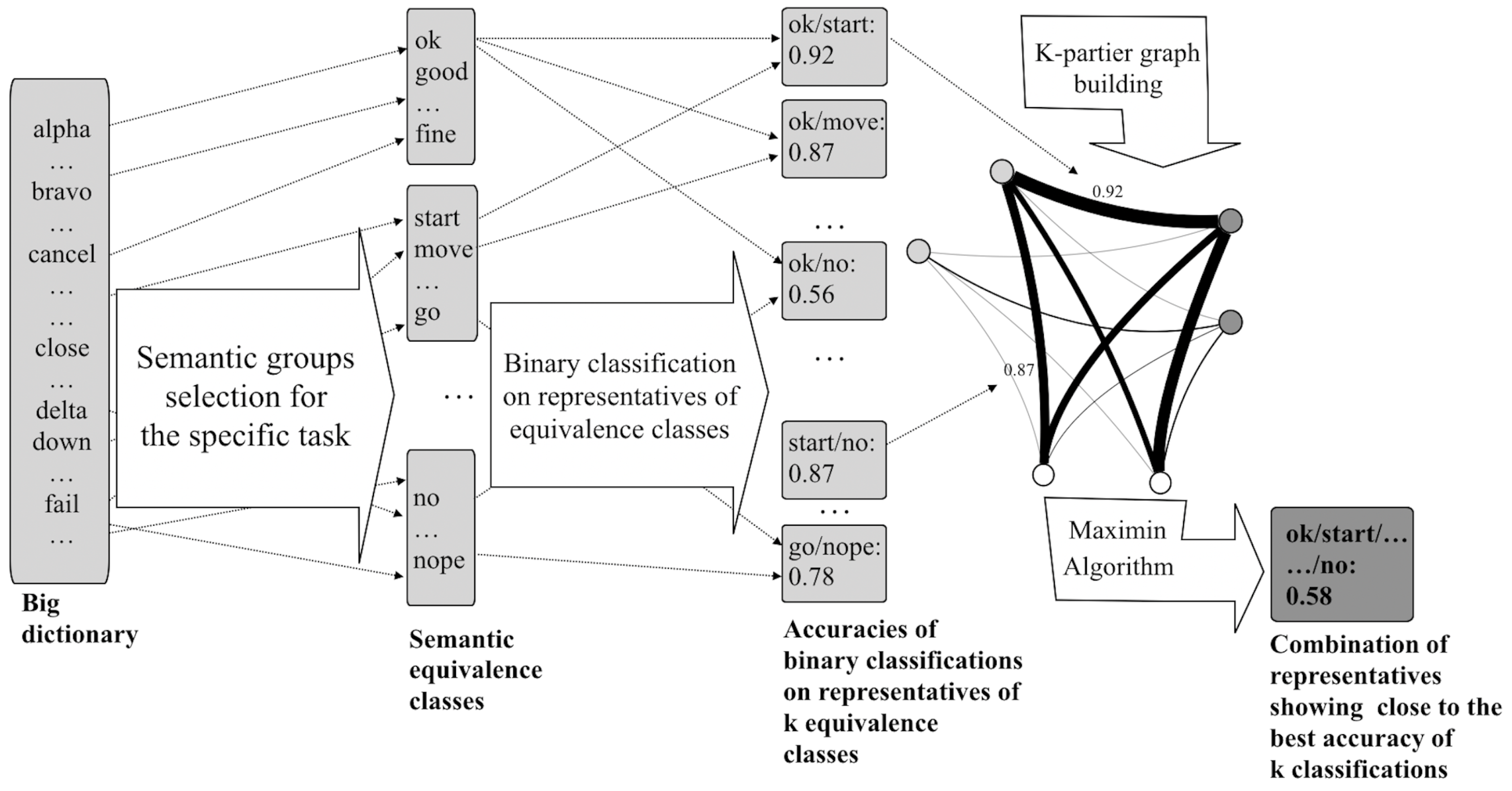
2.2. The Proposed Graph Algorithms
2.2.1. Maximin Algorithm
| Algorithm 1 The Maximin Algorithm. |
|
2.2.2. Maximal Algorithm
| Algorithm 2 Maximal Algorithm. |
|
2.2.3. Complexity of the Proposed Maximin and Maximal Algorithms
3. Materials and Methods
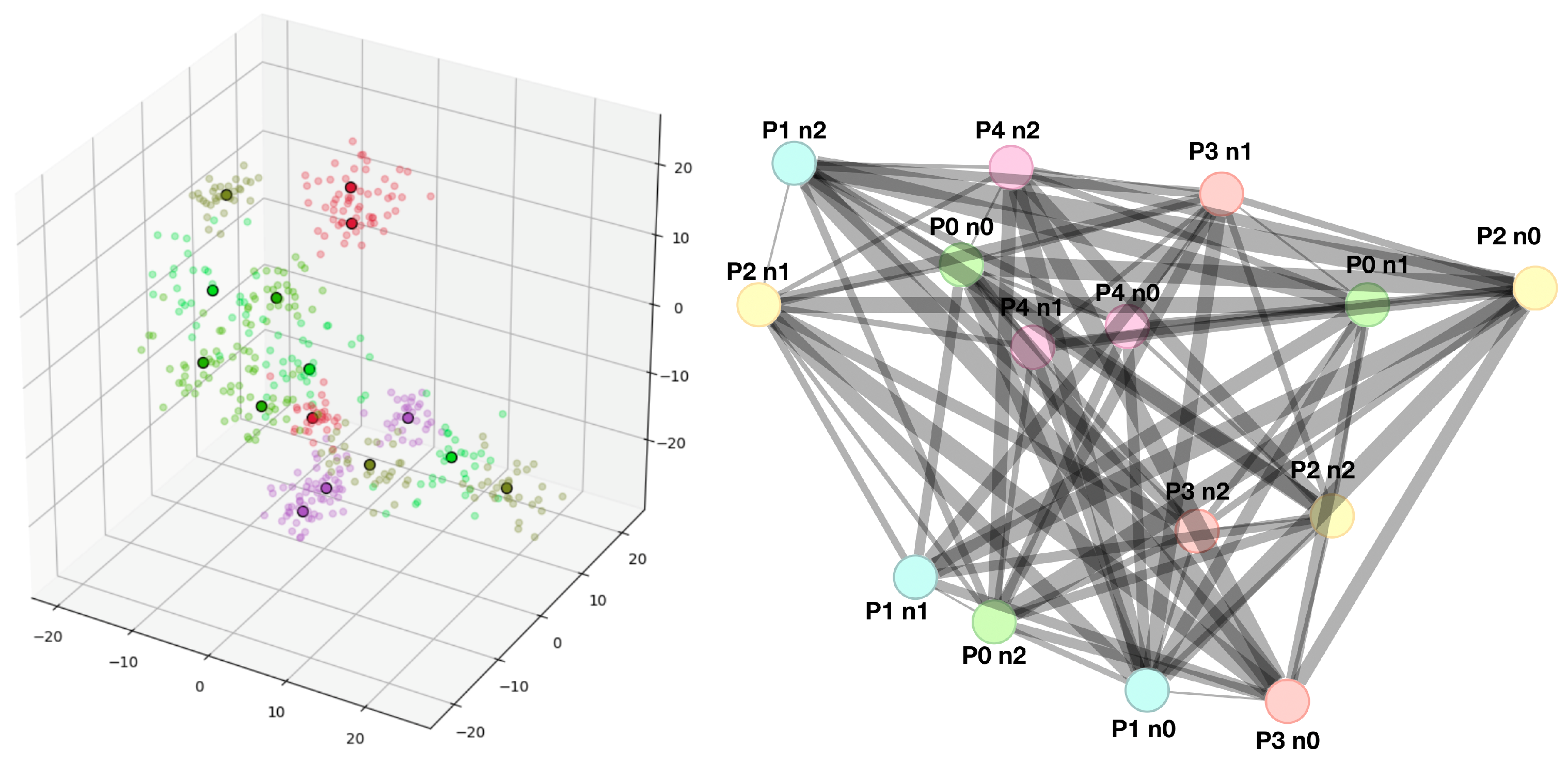
3.1. Data Simulation
3.2. Data Classification
- Linear: ;
- RBF: , where must be greater than 0.
3.3. Proposed Algorithms’ Application and k-Classification Accuracy Comparison
- k-classification based on the result of the combination obtained by the Maximin Algorithm (Algorithm 1)—corresponds to a k-clique with the highest lowest weight of the clique edge (the highest worst accuracy of the binary classification);
- k-classification based on the result of the combination obtained by the Maximal Algorithm (Algorithm 2)—the obtained representatives’ combinations based on the k-clique with a maximum total weight;
- The best k-classification accuracy from all possible combinations of representatives for a given simulation—the result of a complete enumeration (the brute-force algorithm).
3.4. Runtime of Maximin and Maximal Algorithms and Brute-Force Algorithm
4. Results
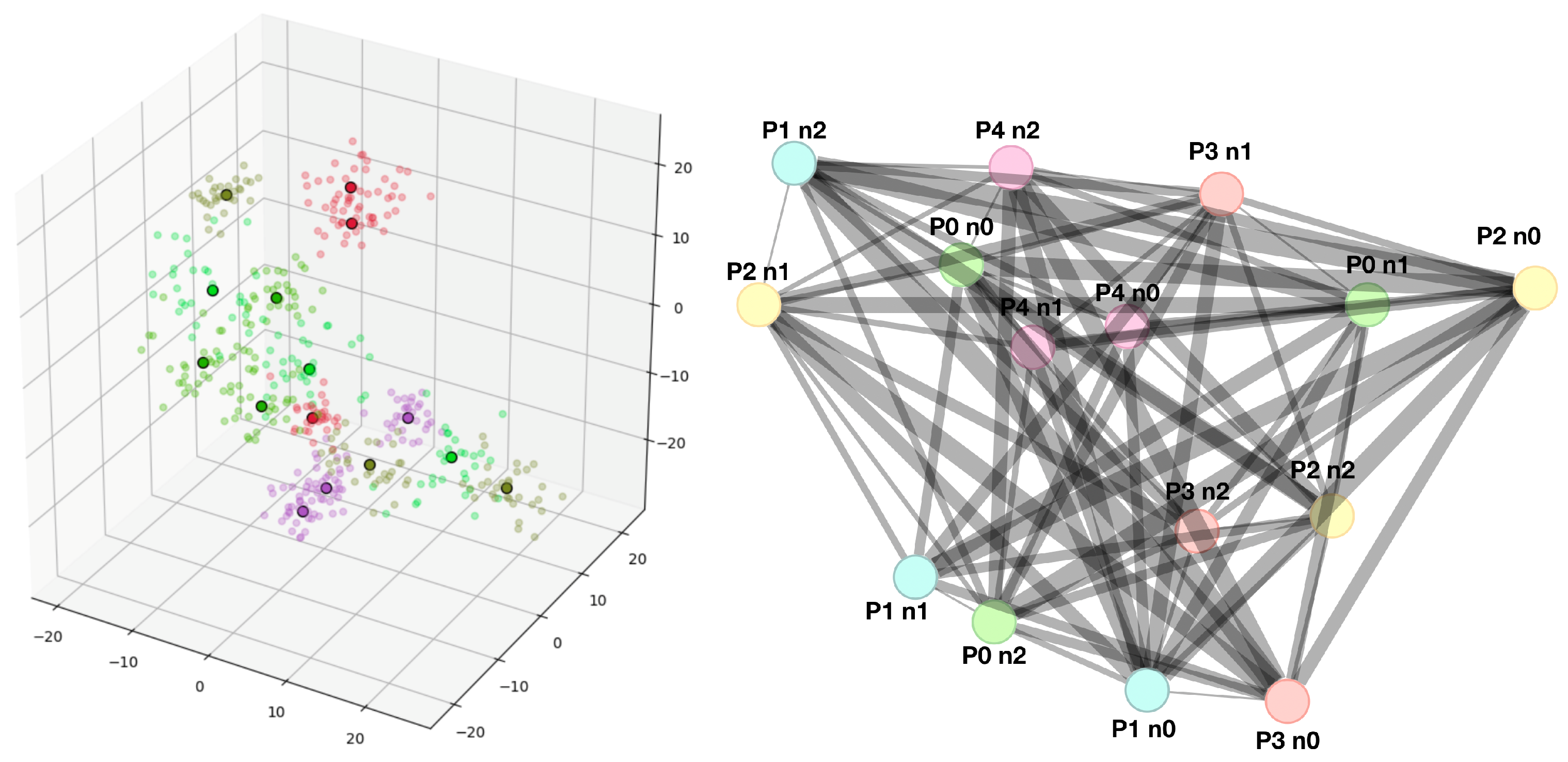
4.1. Data Simulation and Graph Representation
4.2. k-Classification Accuracy on Simulated Data Using the Maximin and Maximal Algorithms and the Best k-Classification Accuracy Obtained by the Brute-Force Algorithm
4.3. Runtime on Simulated Data Using the Maximin and Maximal Algorithms and Complete Enumeration of the Brute-Force Algorithm
5. Discussion
6. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| BCI | brain–computer interface |
| EEG | electroencephalogram |
| SVM | support vector machine |
| RVM | relevance vector machine |
| k-NN | k-nearest-neighbors algorithm |
| LDA | linear discriminant analysis |
| NP-complete | nondeterministic polynomial-time complete |
References
- Vorontsova, D.; Menshikov, I.; Zubov, A.; Orlov, K.; Rikunov, P.; Zvereva, E.; Flitman, L.; Lanikin, A.; Sokolova, A.; Markov, S.; et al. Silent EEG-Speech Recognition Using Convolutional and Recurrent Neural Network with 85% Accuracy of 9 Words Classification. Sensors 2021, 21, 6744. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, C.H.; Karavas, G.K.; Artemiadis, P. Inferring imagined speech using EEG signals: A new approach using Riemannian manifold features. J. Neural Eng. 2018, 15, 016002. [Google Scholar] [CrossRef] [PubMed]
- Cooney, C.; Folli, R.; Coyle, D. Mel Frequency Cepstral Coefficients Enhance Imagined Speech Decoding Accuracy from EEG. In Proceedings of the 2018 29th Irish Signals and Systems Conference (ISSC), Belfast, UK, 21–22 June 2018. [Google Scholar]
- Panachakel, J.T.; Ramakrishnan, A.G.; Ananthapadmanabha, T.V. Decoding Imagined Speech using Wavelet Features and Deep Neural Networks. In Proceedings of the 2019 IEEE 16th India Council International Conference (INDICON), Rajkot, India, 13–15 December 2019. [Google Scholar]
- Pramit, S.; Muhammad, A.; Sidney, F. SPEAK YOUR MIND! Towards Imagined Speech Recognition with Hierarchical Deep Learning. arXiv 2019, arXiv:1904.04358. [Google Scholar]
- Tseng, P.; Urpi, N.; Lebedev, M.; Nicolelis, M. Decoding Movements from Cortical Ensemble Activity Using a Long Short-Term Memory Recurrent Network. Neural Comput. 2019, 31, 1085–1113. [Google Scholar] [CrossRef] [PubMed]
- Minsky, M. Steps toward Artificial Intelligence. Proc. IRE 1961, 49, 8–30. [Google Scholar] [CrossRef]
- Statnikov, A.; Aliferis, C.F.; Hardin, D.P. A Gentle Introduction to Support Vector Machines in Biomedicine: Theory and Methods; World Scientific: Singapore, 2011. [Google Scholar]
- Tipping, M.E. Sparse Bayesian Learning and the Relevance Vector Machine. J. Mach. Learn. Res. 2001, 1, 211–244. [Google Scholar]
- Fix, E.; Hodges, J. Discriminatory Analysis. Nonparametric Discrimination: Consistency Properties; USAF School of Aviation Medicine: Randolph Field, TX, USA, 1951. [Google Scholar]
- Fisher, R.A. The Use of Multiple Measurements in Taxonomic Problems. Ann. Eugen. 1936, 7, 179–188. [Google Scholar] [CrossRef]
- Karp, R. Reducibility among combinatorial problems. In Complexity of Computer Computations; Miller, R., Thatcher, J., Eds.; Plenum Press: Berkeley, CA, USA, 1972; pp. 85–103. [Google Scholar]
- Phillips, C.A. Multipartite Graph Algorithms for the Analysis of Heterogeneous Data; University of Tennessee: Knoxville, TN, USA, 2015. [Google Scholar]
- Downey, R.G.; Fellows, M.R. Parameterized Complexity; Springer: New York, NY, USA, 1999. [Google Scholar]
- Corinna, C.; Vladimir, V. Support-vector networks. Mach. Learn. 2015, 20, 273–297. [Google Scholar]
- Bron, C.; Kerbosch, J. Algorithm 457: Finding all cliques of an undirected graph. Proc. ACM 1973, 16, 575–577. [Google Scholar] [CrossRef]
- Tomita, E.; Tanaka, A.; Takahashi, H. The Worst-Case Time Complexity for Generating all Maximal Cliques and Computational Experiments. Theor. Comput. Sci. 2006, 363, 28–42. [Google Scholar] [CrossRef] [Green Version]
- Moon, J.; Moser, L. On Cliques in Graphs. Israel J. Math. 1965, 3, 23–28. [Google Scholar] [CrossRef]
- Mazurin, A.; Bernadotte, A. Clustering quality criterion based on the features extraction of a tagged sample with an application in the field of brain–computer interface development. Intell. Syst. Theory Appl. 2021, 25, 323–330. [Google Scholar]
- Zubov, A.; Isaeva, M.; Bernadotte, A. Neural network classifier for EEG data from people who have undergone COVID-19 and have not. Intell. Syst. Theory Appl. 2021, 25, 319–322. [Google Scholar]
- DaSalla, C.S.; Kambara, H.; Sato, M.; Koike, Y. Single-trial classification of vowel speech imagery using common spatial patterns. Neural Netw. 2009, 22, 1334–1339. [Google Scholar] [CrossRef] [PubMed]
- Balaji, A.; Haldar, A.; Patil, K.; Ruthvik, T.S.; Valliappan, C.A.; Jartarkar, M.; Baths, V. EEG-based classification of bilingual unspoken speech using ANN. In Proceedings of the 2017 39th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Jeju, Korea, 11–15 July 2017. [Google Scholar]
- Sun, S.; Huang, R. An adaptive k-nearest neighbor algorithm. In Proceedings of the 2010 Seventh International Conference on Fuzzy Systems and Knowledge Discovery, Yantai, China, 11–12 August 2010. [Google Scholar]
- Zhang, D.; Li, Y.; Zhang, Z. Deep Metric Learning with Spherical Embedding. arXiv 2020, arXiv:2011.02785. [Google Scholar]
- Sereshkeh, A.R.; Trott, R.; Bricout, A.; Chau, T. EEG Classification of Covert Speech Using Regularized Neural Networks IEEE/ACM Transactions on Audio, Speech, and Language Processing. IEEE J. Sel. Top. Signal Process. 2017, 15, 37–50. [Google Scholar]
- Brigham, K.; Kumar, B. Imagined Speech Classification with EEG Signals for Silent Communication: A Preliminary Investigation into Synthetic Telepathy. In Proceedings of the 2010 4th International Conference on Bioinformatics and Biomedical Engineering (iCBBE 2010), Chengdu, China, 10–12 June 2010. [Google Scholar]
- Chengaiyan, S.; Retnapandian, A.S.; Anandan, K. Identification of vowels in consonant-vowel-consonant words from speech imagery based EEG signals. Cogn. Neurodyn. 2020, 14, 1–19. [Google Scholar] [CrossRef] [PubMed]
- Pawar, D.; Dhage, S. Multiclass covert speech classification using extreme learning machine. Biomed. Eng. Lett. 2020, 10, 217–226. [Google Scholar] [CrossRef] [PubMed]
- Min, B.; Kim, J.; Park, H.J.; Lee, B. Vowel Imagery Decoding toward Silent Speech BCI Using Extreme Learning Machine with Electroencephalogram. BioMed Res. Int. 2016, 2016, 2618265. [Google Scholar] [CrossRef] [PubMed]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of Classes | A Set of Distributions Corresponds to the k-Clique from the Maximin Algorithm | A Set of Distributions Corresponds to a Maximal k-Clique from the Maximal Algorithm | The Best k-Classification Accuracy from the Brute-Force Algorithm | Median k-Classification Accuracy | Minimal k-Classification Accuracy |
|---|---|---|---|---|---|
| k-classification accuracy (SVM with linear kernel) | |||||
| 0.93 | 0.93 | 0.93 | 0.72 | 0.5 | |
| 0.98 | 0.98 | 0.98 | 0.75 | 0.34 | |
| 4 | 0.93 | 0.98 | 0.98 | 0.81 | 0.53 |
| 0.97 | 0.97 | 0.97 | 0.75 | 0.5 | |
| 0.87 | 0.87 | 0.97 | 0.75 | 0.46 | |
| 0.83 | 0.85 | 0.89 | 0.59 | 0.3 | |
| 0.92 | 0.92 | 0.92 | 0.58 | 0.25 | |
| 8 | 0.89 | 0.85 | 0.9 | 0.59 | 035 |
| 0.68 | 0.68 | 0.75 | 0.54 | 0.32 | |
| 0.76 | 0.78 | 0.82 | 0.55 | 0.26 | |
| 0.64 | 0.63 | 0.64 | 0.50 | 0.19 | |
| 16 | 0.54 | 0.48 | 0.54 | 0.27 | 0.13 |
| 0.48 | 0.47 | 0.50 | 0.29 | 0.09 | |
| 0.49 | 0.49 | 0.49 | 0.28 | 0.15 | |
| 0.64 | 0.65 | 0.66 | 0.30 | 0.22 | |
| k-classification accuracy (SVM with RBF kernel) | |||||
| 0.98 | 0.98 | 0.98 | 0.73 | 0.33 | |
| 0.87 | 0.89 | 0.92 | 0.75 | 0.48 | |
| 4 | 0.87 | 0.87 | 0.87 | 0.67 | 0.42 |
| 0.95 | 0.95 | 0.95 | 0.78 | 0.48 | |
| 0.87 | 0.87 | 0.94 | 0.68 | 0.41 | |
| 0.81 | 0.78 | 0.88 | 0.59 | 0.33 | |
| 0.82 | 0.88 | 0.88 | 0.58 | 0.33 | |
| 8 | 0.9 | 0.9 | 0.9 | 0.6 | 03 |
| 0.68 | 0.79 | 0.8 | 0.55 | 0.28 | |
| 0.69 | 0.7 | 0.75 | 0.53 | 0.25 | |
| 0.63 | 0.65 | 0.66 | 0.51 | 0.23 | |
| 16 | 0.48 | 0.48 | 0.48 | 0.29 | 0.14 |
| 0.53 | 0.47 | 0.53 | 0.28 | 0.12 | |
| 0.48 | 0.47 | 0.50 | 0.29 | 0.09 | |
| 0.62 | 0.64 | 0.65 | 0.31 | 0.23 | |
| Runtime | |||
|---|---|---|---|
| Number of Classes | Maximin Algorithm | Maximal Algorithm | Brute-Force Algorithm |
| 4 | 3 ms | 10 ms | 700 ms |
| 8 | 30 ms | 300 ms | 10 min |
| 16 | 1200 ms | 10 h | 160 h |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bernadotte, A. The Algorithm That Maximizes the Accuracy of k-Classification on the Set of Representatives of the k Equivalence Classes. Mathematics 2022, 10, 2810. https://doi.org/10.3390/math10152810
Bernadotte A. The Algorithm That Maximizes the Accuracy of k-Classification on the Set of Representatives of the k Equivalence Classes. Mathematics. 2022; 10(15):2810. https://doi.org/10.3390/math10152810
Chicago/Turabian StyleBernadotte, Alexandra. 2022. "The Algorithm That Maximizes the Accuracy of k-Classification on the Set of Representatives of the k Equivalence Classes" Mathematics 10, no. 15: 2810. https://doi.org/10.3390/math10152810
APA StyleBernadotte, A. (2022). The Algorithm That Maximizes the Accuracy of k-Classification on the Set of Representatives of the k Equivalence Classes. Mathematics, 10(15), 2810. https://doi.org/10.3390/math10152810